CVE-2026-22769 affects Dell RecoverPoint for Virtual Machines (RP4VM) and is described by Dell/NVD as a hardcoded credential vulnerability. NVD states that versions prior to 6.0.3.1 HF1 are affected, and that an unauthenticated remote attacker with knowledge of the credential could potentially gain unauthorized access to the underlying operating system and achieve root-level persistence. (NVD)
This is not just a patch-note problem. Google Mandiant and Google Threat Intelligence Group (GTIG) publicly reported zero-day exploitation by a suspected PRC-nexus threat cluster (UNC6201), with activity observed since at least mid-2024. Their reporting also includes concrete post-exploitation details and forensic clues that defenders can actually use. (Google Cloud)
The reason this CVE matters so much is where it lives: backup and disaster recovery infrastructure. These systems often sit deep inside trusted network zones, hold privileged access paths, and are frequently less instrumented than standard servers. If a backup appliance is compromised, the risk is not only data theft or persistence. It is also potential disruption of recovery operations and loss of confidence in your resilience layer.
This article is written for security engineers, IR teams, platform owners, and technical leaders who need a practical, evidence-driven response—not just “patch now” headlines.
What CVE-2026-22769 is, in plain technical terms
At the core, this is a hardcoded credential issue (CWE-798) in Dell RecoverPoint for Virtual Machines. NVD records the CNA (Dell) CVSS v3.1 vector as 10.0 Critical with AV:N/AC:L/PR:N/UI:N/S:C/C:H/I:H/A:H, which means the vulnerability is network-reachable, low complexity, requires no privileges and no user interaction, and has high impact across confidentiality, integrity, and availability. (NVD)
The NVD description is explicit:
- affected product: Dell RecoverPoint for Virtual Machines
- affected range: versions prior to 6.0.3.1 HF1
- consequence: unauthorized OS access and possible root-level persistence
- action: upgrade or apply remediations ASAP (NVD)
Dell’s advisory (DSA-2026-079) provides the authoritative remediation matrix and notes multiple affected versions, including older 5.3 branches and “potentially earlier versions,” with upgrade/script-based paths depending on the branch. (Dell)
This is important because many organizations still have long-lived DR and replication appliances that lag behind application patch cycles. In practice, “we don’t think we run an old version” is not a control. You need version evidence.
Why this CVE is more dangerous than a typical appliance bug
Some vulnerabilities are severe on paper but hard to weaponize. Some are easy to exploit but affect low-value systems. CVE-2026-22769 is neither of those.
This vulnerability hits a category of infrastructure that is often:
- deeply connected to production virtualization environments,
- trusted by admins and automation,
- expected to operate quietly inside segmented networks,
- and sometimes lightly monitored compared with general-purpose Linux servers.
Dell itself recommends that RP4VM be deployed only in a trusted, access-controlled internal network with appropriate firewalls and segmentation, and that it is not intended for untrusted or public networks. That guidance is operationally sensible, but it also highlights the trust assumptions around the product. (Dell)
In other words, if this appliance is compromised, the attacker is not landing in a random low-privilege web app. They may land in a place designed to interact with critical systems and recovery workflows.
That changes incident response priorities.
What the Mandiant and GTIG reporting adds that defenders actually need
Dell and NVD tell you what the vulnerability is and how to remediate it. Mandiant/GTIG tells you how this looked in real intrusions.
In the Google Cloud / Mandiant / GTIG writeup, the researchers report:
- active zero-day exploitation of CVE-2026-22769,
- exploitation since at least mid-2024,
- UNC6201 use of the flaw for lateral movement and persistence,
- malware deployment including SLAYSTYLE, BRICKSTORM, and GRIMBOLT. (Google Cloud)
That alone would make the article worth reading. But the real value for defenders is the technical depth in the incident observations (including Tomcat Manager abuse, WAR deployment behavior, and persistence on the appliance), which helps teams move from abstract risk to concrete triage and validation.
If your team patches without reviewing artifacts consistent with the published tradecraft, you may reduce exposure while missing evidence of prior compromise.
That is the central operational lesson of this CVE.

The search intent behind “CVE-2026-22769” and what engineers really need from an article
For this keyword, the highest-value content is not a reworded CVE entry. It is a page that answers the full response workflow:
- What is confirmed?
- Which versions are affected?
- What is the vendor-approved fix?
- Is exploitation real and current?
- What logs/files should I check?
- How do I prove remediation, not just claim it?
Public web results around this CVE reinforce that pattern. The most authoritative sources in the current SERP are the Dell advisory, the NVD record, the CVE record, and the Mandiant/GTIG analysis, each serving a different user intent (remediation, standard record, canonical ID, and incident tradecraft respectively). (Dell)
If you are building content for serious security readers, satisfying this search intent is what improves both user trust and long-term performance. Engineers return to pages that help them do the work.
Affected versions and remediation paths you should use as your source of truth
Dell’s DSA-2026-079 should be your source of truth for remediation planning.
From Dell’s advisory:
- 6.0 / 6.0 SP1 / 6.0 SP1 P1 / 6.0 SP1 P2 / 6.0 SP2 / 6.0 SP2 P1 / 6.0 SP3 / 6.0 SP3 P1 are listed with remediation options including upgrade to 6.0.3.1 HF1 or following the remediation script KB article.
- 5.3 SP4 P1 has a specific path that includes migration to 6.0 SP3 and upgrade to 6.0.3.1 HF1, or the remediation script path.
- Dell further states that 5.3 SP4, 5.3 SP3, 5.3 SP2, and potentially earlier versions are also impacted and recommends upgrading to 5.3 SP4 P1 or a 6.x version before applying remediation steps. (Dell)
Dell also provides a remediation-script KB article, which includes practical deployment notes such as:
- no reboot required,
- script is nondisruptive to main RecoverPoint operations,
- runtime is around 10 seconds per RPA,
- the Installation menu on that appliance may be unavailable for about 5 minutes after the script runs. (Dell)
Those details matter for change-window planning. They help reduce resistance from operations teams because you can describe the impact precisely instead of vaguely.
Important operational nuance
A vulnerability ticket should not be marked “fixed” simply because someone says “we ran the script” or “we upgraded.” A defensible closure should include:
- appliance ID / hostname,
- previous version,
- remediation method used,
- timestamp,
- change ticket reference,
- output or evidence of completion,
- and a compromise triage result.
That is how you avoid “green dashboards, red incidents” later.
The KEV signal and why it changes patch governance
NVD’s change history for CVE-2026-22769 includes KEV-related entries and shows a due date of 2026-02-21 for the known exploited vulnerability action reflected there. (NVD)
Even if you are not a U.S. federal agency, that signal matters. In practice, KEV inclusion (and KEV-related references reflected in NVD) helps security teams justify emergency remediation windows and exception escalations because it distinguishes this from a speculative or low-likelihood risk.
For internal communication, this is a useful message:
“This is not a theoretical appliance issue. It is a critical hardcoded credential vulnerability with public reporting of active exploitation and KEV-priority response signals. We need both remediation and compromise assessment.”
That framing is accurate, actionable, and easier for stakeholders to support.
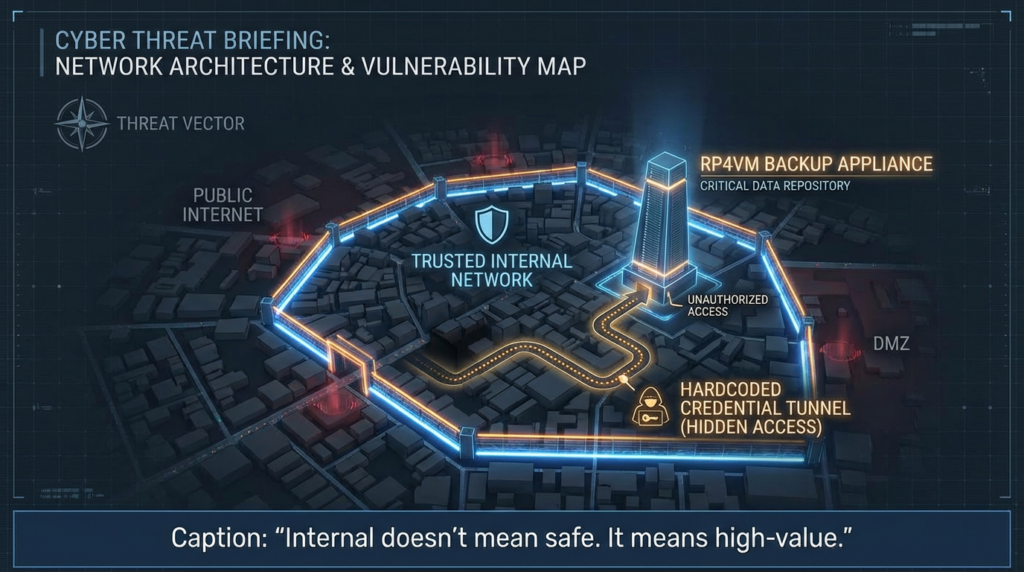
Why hardcoded credentials remain an enterprise-grade failure mode
It is tempting to talk about hardcoded credentials as an “old” class of vulnerability. That is the wrong mental model.
MITRE classifies this as CWE-798: Use of Hard-coded Credentials, and the weakness remains dangerous precisely because it breaks the trust model across deployments. If the credential is shared, known, or recoverable, the authentication boundary collapses in a way that can scale across installations. (NVD)
In appliance-heavy environments, the risk is amplified because:
- appliances often have admin interfaces and service credentials by design,
- they may be “trusted by network placement” more than by continuous inspection,
- and they are frequently excluded from standard endpoint telemetry pipelines.
That combination is exactly why a CVE like 2026-22769 can produce outsized impact relative to the simplicity of the root cause.
Compromise assessment: what to check after you remediate
This is the most important section for practitioners.
Patching/remediating exposure is not the same as proving no compromise occurred. Because Mandiant/GTIG reported real-world exploitation, you should assume compromise triage is part of the response, not an optional add-on. (Google Cloud)
Defensive triage goals
Your goals are to answer three questions per appliance:
- Was this instance affected?
- Was there evidence of suspicious management-interface activity?
- Is there evidence of persistence or payload deployment consistent with published reporting?
Practical triage workflow
Start with scope and evidence preservation:
- Identify all RP4VM appliances (prod, DR, lab, forgotten secondaries).
- Record version/build before any change.
- Capture relevant logs and file metadata before aggressive cleanup.
- Apply vendor remediation.
- Perform artifact review.
- Document findings centrally.
This sequence matters. If you patch first and investigate later without collecting baseline artifacts, you may erase useful evidence.
High-value artifact categories to review
Based on publicly reported behavior and product architecture, prioritize:
- Tomcat Manager access patterns (especially suspicious administrative endpoints),
- deployment artifacts (e.g., unexpected WAR files),
- Tomcat logs and cache/compiled outputs,
- unexpected modifications to startup or boot-executed scripts,
- new userland processes / persistence anchors,
- network connections originating from the appliance that do not match normal operations.
The exact paths and indicators should be aligned with the Mandiant/GTIG technical writeup and your internal appliance baselines. (Google Cloud)
Defensive command examples for investigation and evidence collection
The following examples are defensive triage examples only. They are intended to help incident responders review logs and file integrity on suspected appliances. They are not exploitation steps.
Review appliance logs for suspicious management endpoint access
# Example: search for suspicious Tomcat Manager access/deploy patterns
grep -E '/manager|/manager/text/deploy|PUT /manager/text/deploy' \\
/home/kos/auditlog/fapi_cl_audit_log.log 2>/dev/null | tail -200
Check for unexpected WAR files and Tomcat artifacts
# List WAR files that may indicate deployed web applications
find /var/lib/tomcat9 -type f -name '*.war' -ls 2>/dev/null
# Inspect Tomcat cache/compiled directories for recently created content
find /var/cache/tomcat9/Catalina -type f -printf '%TY-%Tm-%Td %TH:%TM %p\\n' 2>/dev/null | sort
Review possible persistence-related script modifications
# Inspect a high-value script for unexpected changes
ls -l /home/kos/kbox/src/installation/distribution/convert_hosts.sh 2>/dev/null
sha256sum /home/kos/kbox/src/installation/distribution/convert_hosts.sh 2>/dev/null
grep -nE 'rc\\.local|nohup|/tmp|/var/tmp|curl|wget|base64' \\
/home/kos/kbox/src/installation/distribution/convert_hosts.sh 2>/dev/null
Quick Python parser for suspicious /manager requests in audit logs
import re
from pathlib import Path
LOG_PATH = Path("/home/kos/auditlog/fapi_cl_audit_log.log")
PATTERNS = [
re.compile(r"/manager"),
re.compile(r"/manager/text/deploy"),
re.compile(r"PUT\\s+/manager/text/deploy"),
]
def scan_log(path: Path):
if not path.exists():
print(f"[!] Not found: {path}")
return
with path.open("r", errors="ignore") as f:
for i, line in enumerate(f, 1):
if any(p.search(line) for p in PATTERNS):
print(f"{i}: {line.rstrip()}")
if __name__ == "__main__":
scan_log(LOG_PATH)
These commands are useful because they produce reviewable evidence. Save outputs with timestamps, attach them to the ticket, and summarize the result in plain language.

What a “proof of remediation” package should contain
For CVE-2026-22769, a mature response program should produce a small, auditable evidence bundle per appliance.
Minimum evidence set
| Evidence Type | Why it matters | Example |
|---|---|---|
| Asset identification | Proves you assessed the correct system | hostname, site, cluster, owner |
| Pre-remediation version | Confirms exposure status | screenshot / CLI output |
| Remediation action | Proves what was actually done | upgrade record or script execution evidence |
| Post-remediation validation | Confirms change took effect | new version/build output |
| Compromise triage summary | Distinguishes “patched” from “investigated” | log review + file checks + result |
| Ticket linkage | Enables audit traceability | change/incident IDs |
| Exception note (if any) | Prevents silent risk acceptance | why delayed, compensating controls |
Example internal tracker row
| RP4VM Appliance | Site | Pre-Fix Version | Remediation Method | Post-Fix Verification | Compromise Triage | Owner | Status |
|---|---|---|---|---|---|---|---|
| rp4vm-prod-01 | DC-East | 6.0 SP3 P1 | Upgrade to 6.0.3.1 HF1 | Version screenshot + CLI captured | Log review completed, no suspicious /manager deploy events found | Platform Sec | Complete |
This kind of tracker saves time later when leadership asks “Are we done?” and the honest answer is “We are remediated on X appliances; triage is complete on Y; Z remain in progress.”
Communication guidance for security leaders and incident commanders
Technical teams often understand the urgency quickly. The harder part is getting aligned action across infrastructure, operations, and management.
A useful communication pattern for this CVE is:
- What it is: Critical hardcoded credential vulnerability in RP4VM.
- Why now: Public reporting of active exploitation; high-priority remediation signal reflected in NVD.
- What we’re doing: Vendor remediation + compromise triage + evidence collection.
- What we need: Change approval, access to appliance owners, and temporary prioritization over noncritical maintenance.
This avoids three common mistakes:
- treating it as a “routine patch,”
- overhyping unverified details,
- declaring closure based only on upgrade completion.
Staying anchored to Dell, NVD, and Mandiant/GTIG keeps the message credible. (Dell)
In a vulnerability response like CVE-2026-22769, teams usually know what the vendor says to do. The hard part is making sure that across multiple appliances and teams, the remediation is:
- applied consistently,
- verified consistently,
- and documented in a way that survives audit and post-incident review.
An AI-assisted security validation platform like Penligent can support that by helping teams orchestrate repeatable validation tasks, preserve outputs, and turn fragmented checks into structured evidence. That is especially useful when incident pressure is high and different operators are touching different systems.
A second useful angle is the distinction between remediation intent and remediation proof. Vendor guidance tells you the intended fix path. Validation workflows help confirm that the exposure and reachable attack path have actually been reduced in your environment as deployed.
That framing is practical, defensible, and aligned with how serious teams already operate.
Related vulnerability context that is actually relevant
You asked to include related CVEs where appropriate. The best way to do that here is not to force unrelated browser or endpoint CVEs into the same story just because they are recent.
A more useful pattern for readers is to connect by weakness class and asset class:
- Weakness class: hardcoded credentials / authentication boundary collapse (CWE-798)
- Asset class: backup, replication, virtualization, and management appliances
- Response pattern: treat “critical + exploited + high-trust appliance” as an incident-class workflow, not just patching
This helps readers generalize the lesson without blurring facts about CVE-2026-22769 itself.
A practical response plan your team can execute this week
First 24 hours
- Inventory all RP4VM appliances (production, DR, secondary sites, test environments).
- Confirm versions against Dell’s advisory.
- Restrict management-plane access paths as tightly as possible.
- Start change windows for 6.0.3.1 HF1 upgrade or Dell’s remediation script path.
- Open an incident/IR task for compromise assessment on affected systems. (Dell)
24–72 hours
- Execute remediation and collect evidence per appliance.
- Review logs for suspicious management-interface activity and deployment patterns.
- Inspect Tomcat-related artifacts and persistence-relevant files.
- Escalate any suspicious findings for deeper IR.
- Track completion status in a central evidence-backed dashboard. (Google Cloud)
First week
- Validate network segmentation around backup/DR appliances.
- Update vulnerability prioritization criteria to elevate high-trust appliances with exploitation signals.
- Add detection content / hunt checks for appliance management abuse patterns.
- Review your exception process: did any systems get marked “done” without evidence?
A CVE like this should improve your response process, not just your patch count.
Final take
CVE-2026-22769 is not just another “critical CVE” headline. It is a trust-boundary failure in backup and recovery infrastructure, with public reporting of active exploitation and enough technical detail available to justify a full remediation-plus-triage response.
The right way to handle it is:
- follow Dell’s remediation guidance,
- prioritize based on exploitation-backed signals,
- investigate for possible prior compromise,
- and document the response with real evidence.
That combination is what turns urgency into defensible security work.
References and further reading
Authoritative external references
- Dell DSA-2026-079: Security Update for RecoverPoint for Virtual Machines Hardcoded Credential Vulnerability (remediation matrix, deployment guidance) (Dell)
- NVD: CVE-2026-22769 (description, CVSS/CWE, change history, KEV-related details reflected in NVD) (NVD)
- CVE.org Record: CVE-2026-22769 (canonical CVE record) (CVE)
- Google Cloud / Mandiant / GTIG: UNC6201 Exploiting a Dell RecoverPoint for Virtual Machines Zero-Day (technical reporting and exploitation context) (Google Cloud)
- Dell KB: Apply the remediation script for DSA-2026-079 (operational notes such as no reboot and nondisruptive runtime) (Dell)

