The correct spelling is PentAGI. That is how the project identifies itself on its official website and its official GitHub repository. Getting the name right matters, but the larger mistake is comparing PentAGI and Penligent as if they were trying to optimize for exactly the same thing. Publicly documented PentAGI materials describe a fully autonomous, self-hosted, multi-agent penetration testing system with a Docker-based execution layer, integrated tooling, observability, and programmable APIs. Publicly documented Penligent materials describe an AI pentest product that foregrounds verified findings, reproducible proof, customizable reports, prompt editing, scope locking, and operator-controlled actions. Those are related categories, but they are not identical product centers of gravity. (PentAGI)
That distinction matters because a security team is not buying a slogan. It is choosing how offensive work is going to be planned, supervised, validated, replayed, reported, and defended when something goes wrong. If your main question is whether PentAGI is “just a scanner,” the public record does not support that. PentAGI is far more ambitious than a classic scanner. If your main question is whether PentAGI publicly presents the same kind of front-and-center human-in-the-loop control surface that Penligent does, the answer is much less favorable to PentAGI. The fairest reading is this: PentAGI looks like a serious autonomous execution system, while Penligent publicly looks more like an operator-centric, evidence-first offensive workflow. (GitHub)
PentAGI is the official spelling, and the branding already signals the product category
PentAGI’s official website titles the product “PentAGI – Advanced AI-Powered Penetration Testing.” Its GitHub repository is likewise named “PentAGI” and expands the acronym as “Penetration testing Artificial General Intelligence.” The official site describes it as a fully autonomous AI agent for complex penetration testing tasks, while the repository README describes a fully autonomous AI agents system capable of performing complex penetration testing tasks. That shared language is important because it places PentAGI squarely in the autonomous-agent end of the market, not in the narrower category of scanner augmentation. (PentAGI)
That branding choice does more than settle capitalization. It tells you how the project wants to be judged. PentAGI is not asking to be evaluated as a better dashboard for vulnerability summaries. It is asking to be evaluated as an autonomous offensive system. That raises the bar. Once a tool claims autonomy rather than assistance, the comparison has to move beyond “Does it run tools?” and toward “What happens when state changes, when authorization matters, when the agent gets stuck, when scope needs to be narrowed, or when a human has to explain exactly what happened?” (GitHub)
The wrong way to compare PentAGI and Penligent
NIST SP 800-115 still gives the cleanest frame for this discussion. Technical security testing is not merely about finding issues. NIST describes the work as planning and conducting technical tests, analyzing findings, and developing mitigation strategies. OWASP’s Web Security Testing Guide describes a similarly broad discipline that spans threat modeling, manual inspection, authentication, authorization, input handling, testing methodology, and reporting. In other words, the standard frame for penetration testing is workflow-shaped, not alert-shaped. (NIST Computer Security Resource Center)
That is why “Which tool is more autonomous?” is usually the wrong first question. The better first questions are whether the system preserves state, whether it can be supervised without friction, whether it produces evidence another engineer can replay, whether it helps with business logic and authorization flaws instead of only noisy signatures, and whether the reporting output is usable by humans who were not present during execution. Once you use that frame, many apparently similar “AI pentest” tools stop looking interchangeable. (OWASP)
The current OWASP API Security guidance makes this point even sharper. API1 remains Broken Object Level Authorization, and OWASP explains why object identifiers across paths, headers, query strings, and payloads create an authorization problem that simple discovery tools routinely miss. API3, Broken Object Property Level Authorization, emphasizes that exposure often happens at the property level, not just the endpoint level. A product that cannot survive authenticated flows, role changes, object switching, and replay validation may still be useful, but it is not solving the hardest part of modern web testing. (OWASP)
The table below is the comparison frame that actually matters.
| What to compare | Why it matters | What shallow comparisons miss |
|---|---|---|
| Target modeling | Real tests depend on roles, assets, frameworks, trust boundaries | Autonomy claims hide weak context handling |
| Auth and session resilience | Stateful applications break brittle agents quickly | A tool may look good on unauthenticated demos |
| Authorization testing | BOLA, tenant isolation, and property exposure are high-value findings | Scanner-style output overstates coverage |
| Operator control | Humans need to redirect, constrain, and verify critical steps | “Autonomous” can mean hard to steer |
| Evidence and replay | Findings need artifacts, steps, and retest paths | Internal logs are not the same as deliverable proof |
| Reporting | Stakeholders need something they can read, edit, and act on | Tool output is not the same as a report |
| Deployment trust boundary | Agent stacks execute commands, hold keys, and touch infrastructure | Setup details decide real risk |
| Governance | Scope, approvals, and auditability determine whether teams can trust the system | Demos rarely reveal operational friction |
The table is not abstract theory. It is the practical consequence of reading product pages through the lens NIST and OWASP already give us. (NIST Computer Security Resource Center)
What PentAGI publicly documents
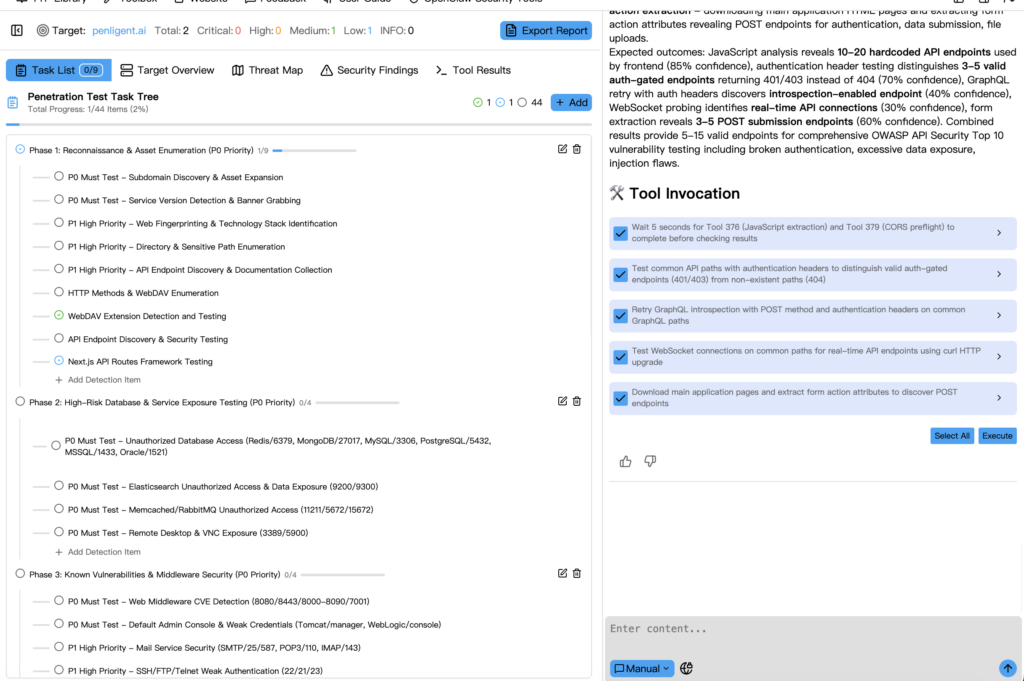
PentAGI’s GitHub README documents a substantial stack. It describes sandboxed Docker execution, more than 20 professional pentesting tools, long-term memory, knowledge graph integration using Graphiti and Neo4j, external search integrations, a delegation model with specialized agents, detailed reporting, REST and GraphQL APIs, persistent storage of commands and outputs in PostgreSQL with pgvector, and a microservices architecture designed for scaling. That is not the profile of a thin wrapper over an existing scanner. It is the profile of a system built to orchestrate tools, context, and execution at the platform level. (GitHub)
Public setup materials reinforce the same impression. PentAGI’s Quick Start lists Docker and Docker Compose or Podman, a minimum of 2 vCPU, 4 GB of RAM, 20 GB of free disk, and internet access for images and updates. The stack can be brought up through Docker Compose, and the project says at least one language model provider must be configured to use PentAGI. Optional search engine keys improve results, but the core point is clear: PentAGI expects to live as a self-hosted, configurable, infrastructure-aware system, not as a lightweight assistant layered over a browser tab. (GitHub)
The trust boundary is equally explicit. The repository states that the default docker-compose.yml runs the PentAGI service as root because it needs access to docker.sock for container management, though it notes that a TCP/IP Docker connection can remove that root requirement. That is not, by itself, a condemnation. Many powerful infrastructure tools impose real privilege tradeoffs. But it is precisely the kind of design detail mature teams must evaluate, because the agent is not only reasoning about offensive steps. It is anchored to an execution environment with meaningful permissions and outward integrations. (GitHub)
PentAGI’s public materials also show that the project understands autonomy needs supervision. The README documents an execution monitoring feature in beta, with automatic mentor intervention, pattern detection, progress analysis, alternative strategy suggestions, and configurable thresholds. It documents task planning, tool call limits, and a reflector mechanism for failure recovery. It also documents that when a flow gets stuck, an operator can pause the flow, inspect the current task and subtask, directly invoke the relevant agent functions, and resume the flow or intervene manually. Those are important capabilities. They show PentAGI is not pretending autonomous systems never need human rescue. (GitHub)
Public development materials extend that supervision model further. PentAGI documents an ftester utility that lets users directly invoke agent functions, terminal commands, browser actions, and flows from the command line, as well as test different prompts and observe detailed outputs. It also documents that Langfuse and observability services can capture full traces of AI interactions and function calls. This is technically serious work. It means PentAGI’s public posture toward transparency is not empty. The nuance is that the transparency it foregrounds is largely system observability and agent debugging, not front-line operator editing as a core day-to-day product promise. (GitHub)
What Penligent publicly documents
Penligent’s homepage tells a different story from the very first claims it chooses to foreground. The page emphasizes “Find Vulnerabilities. Verify Findings. Execute Exploits.” It separately emphasizes “One-click reports with fully customizable editing.” It claims “Evidence-First Results You Can Reproduce,” and explains that every finding comes with artifacts, steps, and traceable proof. Most importantly for this comparison, it explicitly says “Edit prompts, lock scope, and customize actions for your environment.” Those phrases do not merely advertise features. They reveal the interaction model Penligent wants buyers to picture. (Penligent)
The homepage also claims support for more than 200 industry tools and markets “Real-Time CVE Exploits for Always-On Red Teaming,” including one-click PoC exploit scripts. Those are public claims from Penligent’s own site, so they should be read as vendor positioning rather than independently verified benchmark outcomes. Still, they matter because they show what Penligent is visibly asking to be judged on: verification, reproducibility, action control, report shaping, and workflow continuity from discovery into proof. (Penligent)
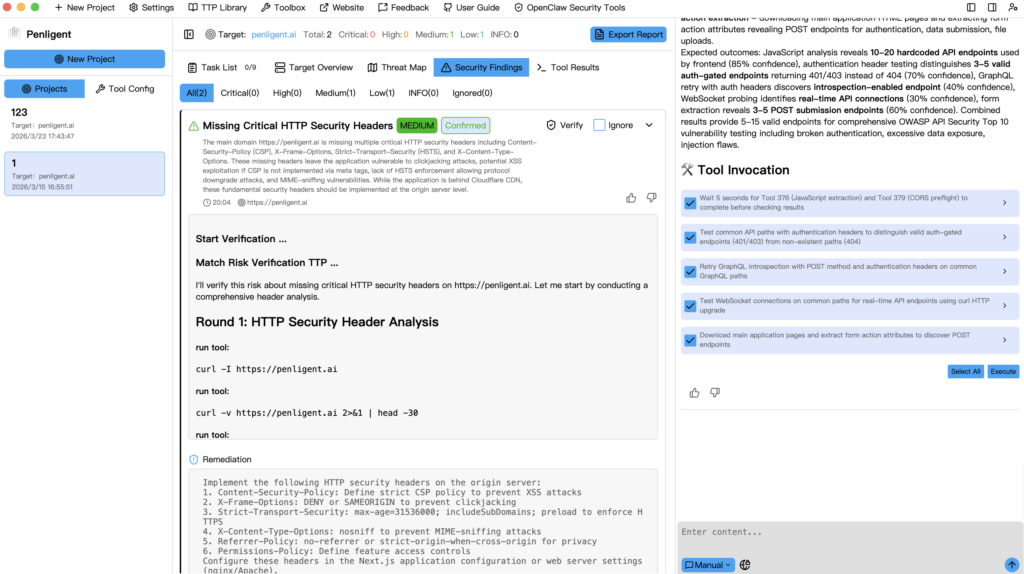
Penligent’s documentation adds practical detail that strengthens the operator-control reading. The public docs include a Kali quick start, installation via a Debian package, explicit configuration of AI-generated script paths, Python interpreter paths, and Bash interpreter paths, and a tool management flow where users can add a tool path or command. The same docs recommend validating tools from the CLI and assessing the impact of noisy scans or exploit modules before running them in production. That is the language of a product designed to let a human operator manage execution boundaries directly, not just observe what an autonomous stack decided to do. (Penligent)
The most important difference is not that Penligent has control and PentAGI has none. The difference is where each product places that control in its public story. Penligent puts it on the front stage. PentAGI puts it deeper in the supervision, debugging, and platform-operations layer. For many real buyers, that distinction matters more than another headline about multi-agent orchestration. (Penligent)

PentAGI vs Penligent at a glance
The comparison below stays inside publicly documented claims and visible product materials.
| Dimension | PentAGI, public materials | Penligent, public materials |
|---|---|---|
| Official positioning | Fully autonomous AI agents system for complex pentesting tasks | AI pentest tool emphasizing verification, reproducible proof, and editable workflow |
| Deployment style | Self-hosted stack with Docker Compose, model/provider configuration, optional observability services | Packaged product with public install docs and UI-driven workflow configuration |
| Tooling claim | 20+ professional security tools | 200+ industry tools |
| Control emphasis | Execution monitoring, planner, flow pause, manual intervention, function testing | Edit prompts, lock scope, customize actions |
| Evidence emphasis | Commands and outputs stored, observability through Langfuse and Grafana, detailed reports | Artifacts, steps, traceable proof, customizable report editing |
| Reporting emphasis | Detailed vulnerability reports with exploitation guides | One-click reports with fully customizable editing |
| Likely strongest fit | Research, self-hosting, stack control, agent experimentation, internal platform engineering | Operator-led testing, evidence packaging, reproducibility, stakeholder-ready delivery |
All of those cells are drawn from what the products publicly say about themselves. That matters because a fair comparison must separate documented evidence from speculation about hidden features or roadmap promises. (GitHub)
Deployment and trust boundary are not side issues
PentAGI’s public Quick Start immediately tells you that deployment is part of the evaluation. The project expects container orchestration, resource planning, model-provider configuration, and in many cases optional supporting stacks such as Langfuse, Graphiti, or Grafana. That can be a major strength for a team that wants stack ownership and architectural freedom. It also means the product experience is inseparable from infrastructure work. You are not only evaluating a pentesting workflow. You are evaluating a self-hosted execution environment that will hold credentials, interact with models, use search systems, and run offensive tooling. (GitHub)
By contrast, Penligent’s public materials present a more packaged operational surface. The homepage promises faster onboarding and fewer setup burdens. The docs still show real configuration work, including runtime paths and installed tool integration, so the honest claim is not “zero effort.” The honest claim is that Penligent’s public posture exposes less infrastructure assembly to the end user than PentAGI’s public Quick Start does. That is an important distinction for teams that want an offensive workflow, not an autonomous-agent platform engineering project. (Penligent)
That difference becomes more important as soon as you think about repeated engagements. Many security teams do not lose time because they lack tools. They lose time because every engagement requires rebuilding context, checking which commands ran, remembering why the agent took a certain branch, turning traces into a report, and rebuilding evidence for retesting. A product that reduces those transitions without forcing the operator to become the maintainer of a whole autonomous stack will often win in practice, even if a self-hosted system looks more flexible on paper. Public Penligent materials are clearly designed to appeal to exactly that concern. (Penligent)
Here is what the public setup experience looks like at a glance.
# PentAGI public quick start, simplified from the official README
curl -O https://raw.githubusercontent.com/vxcontrol/pentagi/master/docker-compose.yml
docker compose up -d
# Then visit https://localhost:8443
# The official docs say you must configure at least one LLM provider
# Penligent public Kali install path, simplified from the public docs
sudo dpkg -i penligent.kali_amd64_1.0.4.deb
# Then configure the AI script path, Python runtime, Bash runtime,
# and add tool paths or commands inside the product UI if needed
Those snippets are not presented as a benchmark. They are presented because setup posture is part of product character. A self-hosted autonomous stack and an operator-facing packaged workflow do not impose the same kind of friction, and that friction changes what teams actually adopt. (GitHub)
Autonomy is not the same as human in the loop
This is where many comparisons become sloppy. PentAGI absolutely has public supervision mechanisms. It documents execution monitoring, mentor intervention, task planning, hard limits, recovery flows, and direct testing utilities. It also explicitly documents pause-and-intervene behavior when a flow gets stuck. So the simplistic claim that PentAGI has no human oversight is false. Public evidence shows the opposite. (GitHub)
But that still does not make PentAGI and Penligent equivalent on human-in-the-loop design. PentAGI’s public supervision features look like the control surface of a sophisticated autonomous system that expects failure handling, tuning, and platform-level debugging. Penligent’s homepage language looks like the control surface of a product that expects the operator to edit prompts, lock scope, and customize actions as a normal part of usage. That is a different relationship between human and system. One is “the human supervises and repairs the autonomous stack.” The other is “the human co-directs the workflow as it runs.” (GitHub)
For many real engagements, the second model is easier to trust. A tester investigating business logic, tenant boundaries, or authenticated state changes often needs to override assumptions quickly. That means changing a hypothesis, narrowing a scope, freezing a tool choice, or repeating a request chain with only one variable changed. If those edits are first-class and visible, the product feels like a controllable cockpit. If they are possible but mostly exposed through debugging and supervisor layers, the product feels more like an autonomous engine with a service hatch. Publicly, Penligent is closer to the cockpit model. Publicly, PentAGI is closer to the engine model. (Penligent)
That does not mean the engine model is inferior. In research labs, self-hosted environments, or teams that want deep autonomy with internal tuning, the engine model may be exactly right. It does mean buyers should stop treating “human in the loop” as a checkbox. The real question is where the human enters the loop, with what cost, at what layer, and with how much context preserved. (NIST Computer Security Resource Center)
Recent agent-tool CVEs changed the stakes of this comparison
The reason this issue matters more in 2026 than it did a year ago is that adjacent agent ecosystems have already shown what goes wrong when control surfaces look stronger than they really are. CVE-2026-24887 documented a Claude Code issue in which a confirmation prompt could be bypassed through command parsing, allowing untrusted commands to execute if the attacker could insert untrusted content into context. That is the exact kind of failure that turns “the human has approval” into a false sense of safety. (NVD)
CVE-2025-68433 documented a Zed issue in which malicious MCP configuration inside project settings could run arbitrary shell commands on the host when the project was opened. The fix involved a worktree trust mechanism, and the published workaround was to review project settings before opening new projects. That is not a distant curiosity. It is a reminder that agent workflows do not only have runtime risk. They also have configuration trust risk. A tool that executes commands, loads settings, or inherits agent context needs explicit boundaries and operator-visible trust decisions. (NVD)
CVE-2026-23882 documented an MCP server creation flaw in Blinko where arbitrary commands and arguments could be specified and then executed while “testing the connection.” That detail matters because it collapses a common assumption. Engineers often think the dangerous step is actual production execution, while setup or connectivity tests are safe. In agent tooling, setup paths are often execution paths. That is exactly why scope locking, command visibility, configuration review, and audit trails are not “nice to have.” They are part of the security model. (NVD)
None of those CVEs accuse PentAGI or Penligent of the same bugs. That would be inaccurate. Their value here is different. They raise the standard for every AI-assisted execution workflow. When a product asks you to trust autonomous or semi-autonomous command execution, you should demand clearer answers about approvals, scope, replayability, configuration trust, and forensic visibility than you would have demanded from a passive scanning tool. (NVD)
The table below shows why these CVEs matter to pentest workflow evaluation.
| CVE | What broke | Why it matters here | What buyers should ask |
|---|---|---|---|
| CVE-2026-24887 | Confirmation prompt bypass in an agentic coding tool | “Human approval” can fail at command parsing boundaries | Is approval enforced at the right layer, and can commands be reviewed clearly |
| CVE-2025-68433 | Project-level MCP config could trigger arbitrary shell commands | Configuration files can become execution surfaces | How does the tool treat imported context, project trust, and settings |
| CVE-2026-23882 | Testing an MCP connection executed arbitrary commands | Setup and diagnostics can become command execution paths | What runs during setup, testing, and plugin configuration, and how visible is it |
This is why the strongest comparison questions now sound less like marketing and more like engineering review. (NVD)
Traceability is not one thing
PentAGI and Penligent both present traceability, but they foreground different forms of it. PentAGI’s public documentation is strongest on system observability. Commands and outputs are stored persistently. Langfuse, OpenTelemetry, Grafana, and related services can capture traces, metrics, logs, and function-call histories. That is excellent for platform operators, researchers, and teams optimizing agent behavior over time. (GitHub)
Penligent’s public messaging is strongest on analyst-consumable traceability. The homepage says every finding comes with artifacts, steps, and traceable proof. It shows a report editor with customizable editing and a workflow narrative that ends in evidence the user can reproduce. That kind of traceability is less about deep platform telemetry and more about preserving the chain a tester, reviewer, client, or remediation owner needs to follow. (Penligent)
Those are not substitutes for each other. A platform team may love PentAGI’s trace stack and still struggle when a delivery team needs a fast, editable, stakeholder-readable proof package. An analyst may love Penligent’s evidence packaging and still want more backend observability for tuning or model debugging. The point is not that one type of trace is real and the other is fake. The point is that the public materials suggest different primary users for the trace layer. PentAGI appears to prioritize the platform side. Penligent appears to prioritize the operator and report-consumer side. (GitHub)
The distinction is useful enough to make explicit.
| Trace layer | Main question answered | Typical user | PentAGI public strength | Penligent public strength |
|---|---|---|---|---|
| System observability | What did the agent and infrastructure do internally | Platform engineer, researcher, operator debugging the stack | Strong, with persistent command/output storage and observability services | Public materials are lighter here |
| Analyst evidence chain | What happened, how to replay it, and what to hand off | Pentester, reviewer, client, remediation owner | Present, but less foregrounded in public messaging | Strong, with artifacts, steps, traceable proof, and editable reports |
Once that difference is visible, many product decisions become easier to explain. (GitHub)
Reporting is where many AI pentest products lose credibility
Security tools often look strongest at the moment of discovery and weakest at the moment of explanation. PentAGI publicly promises detailed vulnerability reports with exploitation guides. That is a meaningful capability and one that many research-grade tools never turn into a usable feature. Penligent publicly goes one step further in its outward messaging by showing report-generation UI and emphasizing fully customizable editing. That is not a cosmetic distinction. It changes whether the output feels like a machine artifact or a deliverable a human can own. (GitHub)
This matters because reports are not passive paperwork. They are where offensive testing gets translated into remediation, ticketing, risk acceptance, executive briefing, and retest planning. If a finding cannot be rewritten, clarified, narrowed, expanded, or organized without leaving the original system context behind, teams end up rebuilding the report manually. The promised time savings from AI then disappear in the least glamorous part of the workflow. Penligent’s public emphasis on customizable editing is compelling precisely because it attacks that failure mode directly. (Penligent)
That is also where a product like Penligent fits naturally into real work without taking over the article. When a team needs to preserve proof, revise language for different stakeholders, and lock the exact steps that should be repeated after remediation, a workflow built around visible artifacts and editable reporting reduces friction in a way that raw autonomy does not. The value there is not marketing gloss. It is continuity between execution and delivery. (Penligent)
Business logic and authorization are the real dividing line
OWASP’s API guidance remains one of the best reality checks in this market. Broken Object Level Authorization is still API1, and Broken Object Property Level Authorization remains central because modern applications expose risk through object references, fields, and state transitions that generic discovery cannot interpret on its own. A tool that shines in blind tool orchestration but cannot help an operator reason through role boundaries, request variations, and replay conditions will struggle exactly where the highest-value application flaws live. (OWASP)
This is why the phrase “more like a scanner” has to be used carefully. PentAGI’s public materials show far more than scanning. It supports autonomous tool execution, browser access, external search, specialist agents, reporting, and supervision. Calling it a traditional scanner would be misleading. The sharper critique is different: PentAGI’s public materials center autonomy and agent infrastructure more than they center the low-friction, operator-directed handling of nuanced application logic. Penligent’s public messaging, by contrast, explicitly leans into business-logic focus, verified impact, and controlled action surfaces. That makes it easier to picture Penligent in the middle of a messy authenticated engagement. (GitHub)
A useful way to make that concrete is to look at what an operator actually has to do during a BOLA check. No serious tester trusts a single machine-generated conclusion here. The operator has to preserve two identities, compare object access patterns, verify side effects, and collect evidence that survives retest. That is exactly the kind of stepwise control surface Penligent’s public messaging appears designed to support. (OWASP)
# User A can access object 8472
curl -s -H "Authorization: Bearer $TOKEN_A" \
https://target.example/api/orders/8472 | jq .
# Replay the exact same request as User B
curl -s -H "Authorization: Bearer $TOKEN_B" \
https://target.example/api/orders/8472 | jq .
# Save both responses and diff them
curl -s -H "Authorization: Bearer $TOKEN_A" \
https://target.example/api/orders/8472 > a.json
curl -s -H "Authorization: Bearer $TOKEN_B" \
https://target.example/api/orders/8472 > b.json
diff -u a.json b.json
That snippet is simple on purpose. The important part is not command complexity. It is the workflow requirement: preserve state, replay exactly, vary only the relevant identity, and collect reproducible evidence. Any AI pentest tool worth trusting has to make that cycle easier, not more theatrical. (OWASP)
What strong human-in-the-loop design actually looks like
A strong human-in-the-loop offensive workflow does not mean a human manually approves every trivial command. That collapses into fatigue. It means the human can intervene where judgment changes outcome. In practice, those moments are hypothesis changes, scope changes, destructive-step approvals, ambiguous authorization findings, and evidence finalization. NIST’s emphasis on planning, analysis, and mitigation already implies that human judgment remains part of the work even when execution is accelerated. (NIST Computer Security Resource Center)
That is why the best public Penligent signal is not “AI-powered pentest tool.” Everyone says something like that now. The stronger signal is that the homepage explicitly surfaces prompt editing, scope locking, action customization, reproducible proof, and customizable reports. Each of those is a concrete answer to a real pentest failure mode: wrong assumptions, wandering scope, unreplayable action chains, or unusable reports. (Penligent)
PentAGI’s public supervision model answers a different set of questions. How do you stop loops. How do you improve weak models. How do you resume a stuck flow. How do you inspect function calls. How do you wire the system into observability. Those are valuable answers, especially for teams building and running autonomous infrastructure. They simply do not describe the same front-of-house interaction model. (GitHub)
For teams that care most about proof, retest discipline, and stakeholder handoff, that difference is not subtle. It is operational. When the human is visibly inside the path from prompt to scope to action to report, the system is easier to trust under scrutiny. When the human mainly appears as the debugger, supervisor, or stack maintainer, the system may still be impressive, but it feels different in a real engagement. (Penligent)
Where PentAGI is genuinely strong
A fair comparison should say this plainly: PentAGI’s public materials are impressive. The project is open source, MIT licensed, self-hosted, API-accessible, multi-agent, search-aware, browser-aware, tool-rich, and observability-aware. It stores command and output data persistently, provides detailed supervision features, and gives advanced users ways to inspect, test, and tune agent behavior. For security teams that want to own the stack, modify the workflows, integrate with internal systems, and run offensive automation in controlled environments, PentAGI presents a serious platform story. (GitHub)
It is also the stronger public fit for users who think like platform engineers. If you want to experiment with model providers, agent roles, flow recovery, knowledge graphs, observability pipelines, or direct API integration, PentAGI’s public documentation offers more visible depth than many products in the category. That matters. Plenty of glossy AI pentest pages collapse as soon as you ask what happens beneath the demo layer. PentAGI does not look like that. (GitHub)
Even the supervision story, while not my preferred model for everyday operator control, shows engineering seriousness. Execution monitoring, planner support, hard tool-call limits, reflector recovery, ftester utilities, and pause-and-resume flows are all signs that the project treats long-horizon agent failure as an engineering problem rather than pretending the model will simply reason its way through it. That is a mature design instinct. (GitHub)
Where Penligent is publicly stronger
Penligent’s public edge is not that it sounds more futuristic. It is that its public materials sound more grounded in the actual bottlenecks of operator work. Verified findings. Reproducible proof. Customizable report editing. Prompt editing. Scope locking. Action customization. Tool integration through explicit paths and commands. Those are not abstract platform virtues. They are workflow virtues. They speak to what an engineer needs when the test stops being a demo and starts becoming a deliverable. (Penligent)
That is especially relevant for black-box web and API work. The highest-friction part of these engagements is rarely the first scan. It is the middle: preserving context, validating impact without drifting scope, capturing evidence at the right moment, and turning all of that into a report another human can trust. Penligent’s public materials are more explicit about that middle than PentAGI’s are. That is why Penligent reads less like a raw autonomous execution system and more like a practical operator cockpit. (Penligent)
That difference also shows up in retesting and delivery. When a team needs to move from an initial finding to a fixed, reproducible before-and-after proof package, the value is not merely that an agent ran commands. The value is that the chain remains visible, editable, and communicable. In that narrow but important sense, Penligent’s public route looks better aligned with how many professional teams actually ship offensive results. (Penligent)
A fair answer to the scanner question
The strongest honest conclusion is not that PentAGI is a scanner. It is not. Publicly, it is a self-hosted autonomous multi-agent pentesting system with real tool execution, context systems, reporting, observability, and supervision. Reducing it to “traditional scanning” would weaken the article because the public record does not support that claim. (GitHub)
The sharper and more credible conclusion is that PentAGI’s public product identity is centered on autonomous execution and stack sophistication, while Penligent’s public product identity is centered on operator-visible control, evidence, reproducibility, and editable outputs. That is where the real wedge is. One looks more like an offensive automation platform you build around. The other looks more like an offensive workflow product you operate through. (GitHub)
For buyers, that means the right question is not “Which one is more AI?” The right question is “Where do I need the human to stay, and what kind of artifact do I need at the end?” If the answer is “deep self-hosting, stack ownership, agent tuning, and platform-level observability,” PentAGI is a strong public candidate. If the answer is “transparent control, reproducible proof, scope discipline, editable reports, and a workflow another engineer can pick up tomorrow,” the public case for Penligent is stronger. (GitHub)
Which teams should choose PentAGI
Choose PentAGI when your team wants to own the offensive automation stack as infrastructure. That usually means you are comfortable with Docker, model-provider setup, key management, observability services, internal API integration, and the reality that agent behavior tuning may be part of adoption. PentAGI’s public materials make the most sense in research-heavy environments, internal security platforms, air-gapped or self-hosted settings, and teams that value open-source transparency at the architecture level. (GitHub)
Choose PentAGI when you see autonomy not as a convenience layer but as a system you want to inspect, extend, and adapt. Its public documentation gives advanced users more to work with than most glossy AI security pages do. That alone will make it attractive to a certain class of engineer. (GitHub)
Which teams should choose Penligent
Choose Penligent when your team cares more about visible control surfaces than about running a self-hosted autonomous agent stack. Its public materials are more persuasive for black-box testing, bug bounty style workflows, repeated customer engagements, and environments where evidence packaging and stakeholder-ready reporting are part of the daily job rather than an afterthought. (Penligent)
Choose Penligent when human judgment needs to stay close to the action path. The strongest public case for Penligent is not “more AI.” It is that the operator appears to remain legible inside the workflow, with more explicit control over prompts, scope, actions, and final evidence. For many teams, that is the difference between a system they admire and a system they actually adopt. (Penligent)
Further reading
- NIST, Technical Guide to Information Security Testing and Assessment. (NIST Computer Security Resource Center)
- OWASP, Web Security Testing Guide. (OWASP)
- OWASP, API1:2023 Broken Object Level Authorization. (OWASP)
- USENIX Security 2024, PentestGPT: Evaluating and Harnessing Large Language Models for Penetration Testing. (USENIX)
- NVD, CVE-2026-24887. (NVD)
- NVD, CVE-2026-23882. (NVD)
- NVD, CVE-2025-68433. (NVD)
- Penligent official homepage. (Penligent)
- AI Pentest Tool, What Real Automated Offense Looks Like in 2026. (Penligent)
- Pentest AI Tools in 2026, What Actually Works, What Breaks. (Penligent)
- Human-in-the-loop agent AI pentest tool Penligent, A Cohesive Engineer-first Guide. (Penligent)
- Penligent public documentation. (Penligent)