An AI product can tell users they are private, anonymous, temporary, or incognito. None of those words proves where prompt data went after the user hit submit. A proposed class action filed on March 31, 2026, against Perplexity made that gap impossible to ignore. The complaint alleges that Perplexity used tracking technologies including Meta Pixel, Google Ads, Google DoubleClick, and Meta’s Conversions API to share users’ conversational data and identifiers with Meta and Google, including when a subscribed user was in Incognito mode. Perplexity, through its chief communications officer, reportedly said it had not been served with a matching lawsuit and could not verify the allegations. The legal merits will take time. The control questions are already here.
That is the real lesson for AI builders, security engineers, and technical buyers. A privacy label in a UI is a statement about one user-facing behavior. It is not proof about browser instrumentation, server-side event pipelines, analytics sinks, internal logging, provider retention, support tooling, or the way data is linked back to accounts. The complaint is useful because it forces a boring but important question: if a product says private, what technical and organizational evidence would show that the claim is actually true across the full path of the data.
For compliance teams, that question lands directly in the territory of SOC 2 and ISO/IEC 27001. The AICPA defines a SOC 2 examination as a report on controls at a service organization relevant to security, availability, processing integrity, confidentiality, or privacy. ISO says ISO/IEC 27001 defines the requirements an information security management system must meet and is about establishing, implementing, maintaining, and continually improving that system. Neither framework treats a feature label as sufficient evidence by itself. Both care about system boundaries, controls, risk handling, and proof that the controls are not just described but actually operating. (AICPA & CIMA)
The mistake many AI companies make is small but costly. They assume a retention claim is the same thing as a privacy claim. It is not. Deleting a thread after 24 hours addresses one question. It does not answer whether prompt content was copied into telemetry, whether a third-party script saw the submission event, whether an API provider retained anything, whether an administrator could inspect the exchange, or whether an experimentation pipeline used derived data later. In AI systems, privacy is never one bit. It is a chain of decisions across collection, transmission, storage, access, and secondary use. (Perplexity AI)
The lawsuit is not the verdict, but the control questions are already clear
The Perplexity complaint is worth reading closely because it is more specific than the headlines. It alleges that tracking technologies were present as soon as a user landed on the homepage, before the user entered a prompt. It further alleges that once users began interacting with the AI system, those technologies shared conversational data with Meta and Google, and that subscribed users in Incognito mode still had prompts and identifiers disclosed. The complaint also points to email addresses, cookies, geolocation data, and conversation URLs as part of the shared data picture. These are allegations in a filed complaint, not findings by a court, but they are detailed enough to frame a serious engineering review.
The complaint matters because it does not describe privacy failure as a mysterious AI problem. It describes an ordinary web and data-flow problem sitting inside an AI product. A user opens a page. Scripts run. Cookies are set. Requests go out. Events get enriched. Identifiers link one system to another. That is how modern growth and analytics stacks often work. The risk is not that pixels exist at all. The risk is that a product marketed for intimate, free-form questioning can accidentally or deliberately let highly sensitive prompt data cross into systems built for attribution, audience creation, optimization, or profiling.
That difference matters for legal and technical reasons. A finance calculator leaking event labels is one class of problem. An AI system that invites questions about cancer treatment, pregnancy, taxes, job loss, or debt and then lets those prompts touch ad-tech plumbing is a different class of problem because the user’s expectation of confidentiality is materially different. The complaint leans heavily on that distinction with health and financial examples. Whether the court ultimately agrees with every allegation, the design lesson is already obvious: AI products collect unusually rich user intent, and that raises the cost of any sloppy data boundary.
There is also a subtle but important nuance in the Perplexity materials themselves. Perplexity’s help center says Incognito threads expire within 24 hours and are not recoverable, and another help article says searches in Incognito mode are never stored. At the same time, Perplexity’s developer documentation says the Sonar API operates under a strict zero-data-retention policy and collects only billing metadata, while Enterprise documentation describes audit logs that record end-to-end queries, agent steps, answers, timestamps, user details such as email and IP address, and settings changes, delivered to a webhook. The point is not to call any of those statements false. The point is that privacy promises differ by surface, and a buyer who treats “the product” as one uniform data policy is already thinking too loosely. (Perplexity AI)
That is why the right response to a story like this is not brand tribalism. It is control decomposition. What exactly does Incognito mean. Does it mean not stored in history. Not retained anywhere. Not used for training. Not shared with third parties. Not linked to an account. Not accessible to admins. Different organizations mean different things by “private,” and some product teams ship the label before they finish deciding which of those meanings they are willing to guarantee. A serious security review breaks that ambiguity apart and tests each piece. (Perplexity AI)
What an AI privacy claim actually covers, and what it usually does not
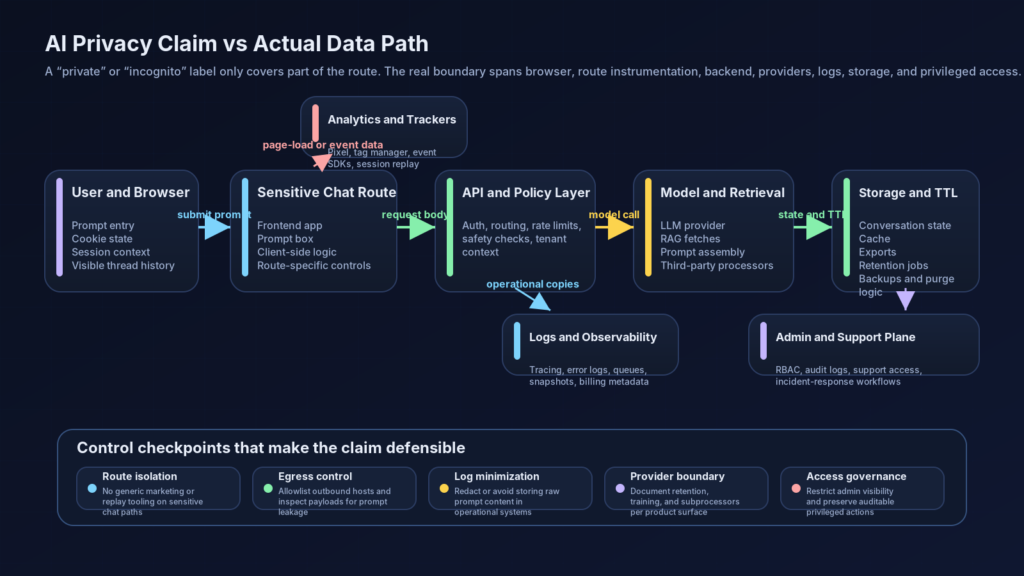
When a product says a thread is private, there are at least six different questions hidden inside that sentence. The first is history visibility. Will the conversation appear in the ordinary sidebar or user history. The second is retention. If it disappears from the UI, is it actually deleted from active storage, backups, caches, and observability systems. The third is disclosure. Was any part of the prompt, URL, title, payload, or identifier sent to a third party during processing. The fourth is linkage. Even if the content was partially redacted, can an email address, cookie, IP, or account ID reconnect it to a known person. The fifth is secondary use. Can the content still be used for model training, evaluation, product improvement, abuse analysis, or ad targeting. The sixth is access scope. Which employees, systems, or enterprise administrators can still see some version of the interaction. (NIST)
A privacy mode typically addresses only one or two of those dimensions. A product may honestly implement “do not keep this in the visible user history” while still routing request metadata to standard observability tooling. A product may promise “anonymous threads” while continuing to accept browser cookies or same-session identifiers that make the interaction linkable. A provider may say “we do not train on your API data” while still keeping billing metadata, timing, and model selection telemetry. None of those states is automatically deceptive. They become dangerous when the public label encourages a broader user expectation than the system actually earns. (docs.perplexity.ai)
The web tracking stack makes this even more complicated. Meta describes Meta Pixel as a JavaScript snippet that tracks visitor activity on a website. Meta’s Conversions API is designed to connect advertiser marketing data, including website events and app events, directly to Meta. Google Ads documentation says the Google tag captures information about the pages viewed by visitors, including page URL and title, and that optional event snippets can pass specific user actions such as purchases, form fills, or registrations. Google Analytics documentation says automatically collected events are triggered by basic interactions as long as the Google tag or Firebase SDK is in place. Those tools were built for measurement and marketing workflows, not for handling sensitive free-text conversations with an AI assistant unless they are extremely carefully scoped. (Facebook Developers)
That scoping problem is the hinge of modern AI privacy engineering. A chat surface is not just another landing page. It is a place where users externalize uncertainty, fear, money problems, legal exposure, medical questions, hiring decisions, source code, internal documents, architecture diagrams, and incident details. In practice, an AI prompt box is often closer to a support escalation form, a medical question box, and a confidential note field than to a product search bar. If the surrounding telemetry stack does not recognize that, the company can end up treating the most sensitive part of the product like a normal conversion funnel. (OWASP Gen AI Security Project)
This is where the NIST Privacy Framework is useful. NIST describes it as a voluntary tool to help organizations identify and manage privacy risk through enterprise risk management. That phrasing matters. Privacy risk is not handled by one switch. It is handled by deciding what a system can predictably do, what users can manage, and how well data can be separated or disassociated when full identity is not required. The moment an AI product mixes rich free-text inputs with general-purpose growth instrumentation, the privacy problem becomes an enterprise design problem, not a copywriting problem. (NIST)
OWASP makes the same point from the LLM side. Its LLM risk project flags sensitive information disclosure as a major class of risk and warns that LLM applications can expose personal information, confidential business data, proprietary details, and credentials. It also recommends sanitization, strong input validation, and strict access controls, while noting that policy language alone may fail under prompt injection or other bypasses. In other words, even a well-worded privacy promise is fragile if it is not backed by defensive design and technical enforcement. (OWASP Gen AI Security Project)
What SOC 2 asks about an AI system
A SOC 2 report is not a stamp saying “trust us.” The AICPA describes it as a report on controls relevant to security, availability, processing integrity, confidentiality, or privacy. Its publicly available Trust Services Criteria material frames those criteria as control criteria used to evaluate and report on controls over information and systems used to provide services. An illustrative SOC 2 Type II report from the AICPA includes management’s assertion, a description of the system, the service auditor’s report, and tests of controls with the results of those tests. That is a much more demanding shape than a help-center article or a settings toggle. (AICPA & CIMA)
For AI products, that has a practical consequence. If a company says an interaction is private, a SOC 2-oriented reviewer will not stop at the wording. They will want to understand the system that makes the claim meaningful. Which components process the interaction. Which data stores hold transient or durable copies. Which subprocessors receive anything derived from the interaction. How access is restricted. How logging is configured. How deletion works. How exceptions are handled. How the company knows the control kept working last month, not just on the day someone wrote the policy. Those are not exotic AI questions. They are classic control questions applied to an AI-shaped system. (AICPA & CIMA)
This is also where people misuse the phrase “SOC 2 compliant.” Strictly speaking, SOC 2 is an attestation framework and reporting regime, not a product feature and not a law. The question is whether a service organization can describe its system and demonstrate relevant controls in a way an independent auditor can examine. If your AI chat product says private but you cannot produce evidence for script governance, vendor boundaries, prompt logging rules, access reviews, and exception handling, the label may still sound good in product copy, but it is weak in a control environment. (AICPA & CIMA)
The distinction between design and operation matters too. Google Cloud’s SOC 2 compliance page explains the conventional difference between Type I and Type II by saying a Type I report covers the design of controls at a point in time, while a Type II report covers design and operating effectiveness over a period of time. That matters for AI privacy because almost every bad outcome in this area comes from drift. A growth team adds a tag. A product manager turns on a new event. A support integration expands scope. A model provider changes retention defaults. A redaction layer breaks after a release. Type II thinking forces teams to care about whether the controls kept working, not whether they once existed. (Google Cloud)
In AI systems, the most useful way to read SOC 2 is as a demand for system clarity. If a company cannot explain how a prompt moves through browser, backend, provider, logging, and admin surfaces, then every privacy promise is underspecified. If the company can explain the path but cannot show tests and evidence, the promise is still weak. If the company can show the path and the tests but the evidence only exists for one tier, such as the API while the consumer app behaves differently, the promise needs to be narrowly scoped. This is why product labels, trust-center claims, API docs, and actual instrumentation must all line up. (Perplexity AI)
What ISO 27001 asks that a feature label never can
ISO says ISO/IEC 27001 is the best-known standard for information security management systems and defines the requirements an ISMS must meet. It says the standard helps organizations establish, implement, maintain, and continually improve an information security management system and manage risks related to the security of data they own or handle. That wording is important because it frames security and privacy-adjacent governance as a management system, not a collection of one-off features. (ISO)
A private-thread button cannot satisfy that by itself. What matters is whether the organization has identified the risk of sensitive prompt data entering analytics, vendor, logging, or support pathways; assigned owners; implemented controls; checked whether the controls operate; and improved them when gaps are found. That is the difference between a UI claim and a system of control. One is a message to users. The other is a repeatable internal capability. (ISO)
For AI products, ISO/IEC 27001 should push teams to ask broader questions than “do we store the thread.” Which engineering teams can add third-party scripts to sensitive routes. Is there a separate change approval path for chat surfaces that may handle confidential data. Are prompt logs redacted before entering observability systems. Are vendor retention settings reviewed at procurement and during renewal. Do access reviews cover support personnel and debugging tooling. Does incident response include accidental disclosure through analytics or model-output channels. These are the kinds of questions that turn vague privacy language into auditable process. (ISO)
NIST’s AI Risk Management Framework makes the same point from another angle. NIST says the framework is meant to help manage risks to individuals, organizations, and society associated with AI, and the Generative AI profile is intended for voluntary use to incorporate trustworthiness considerations into design, development, use, and evaluation. That language matters because it discourages a shallow view of AI compliance. A serious AI assurance program does not just ask whether the model is accurate. It asks whether the end-to-end system handles identity, telemetry, content, and human operations in a way that aligns with the organization’s stated commitments. (NIST)
An ISO 27001-minded team therefore treats “Incognito” as a risk statement that needs decomposition. What exact assets are in scope. Which threat scenarios apply. Which controls are intended to reduce the risk. What evidence proves those controls exist and operate. What residual risk remains. Where are the exceptions documented. That is the mindset that separates a good trust page from a real control environment. (ISO)
The real AI data flow auditors and attackers both care about
Most AI privacy mistakes happen because teams reason about the visible UI instead of the invisible path. A better mental model is to treat an AI interaction as a bundle of distinct data elements moving through multiple planes: the browser plane, the application plane, the provider plane, the observability plane, the storage plane, and the operations plane. Every plane can create copies, derivatives, or new identifiers. Every plane can be governed well or badly. (NIST)
Browser-side instrumentation
The browser plane includes everything loaded into the user’s session: first-party scripts, tag managers, analytics libraries, A/B testing SDKs, chat widgets, session replay tools, consent managers, and custom telemetry hooks. The reason this plane is dangerous is simple. It sees the interaction before the backend has a chance to classify or redact it. Google Ads says the Google tag captures page URL and title, and event snippets can pass specific actions. Google Analytics says basic interactions can automatically generate events when the tag is present. Meta Pixel tracks visitor activity, and Meta’s Conversions API supports sending website or app events. On an AI chat route, those ordinary mechanisms can become a privacy problem if prompt content or linked identifiers bleed into the payload. (Aide Google)
The hard part is that this can happen without a single malicious actor. A frontend engineer adds instrumentation to improve conversion tracking on a signup flow. The same component gets reused on a chat page. A URL reflects part of the prompt for sharing or recovery. A title updates with the prompt for convenience. An event captures text fields to improve form analytics. Each decision sounds locally reasonable. Together, they create an outbound trail no one intended. That is why sensitive AI routes should be handled more like payment pages or medical intake forms than like generic marketing pages. (Aide Google)
Application and API processing
Once the prompt leaves the browser, the application plane takes over. API gateways authenticate the request. Middleware attaches session identifiers, tenant information, or experimentation flags. Prompt-routing layers decide which model or tool to call. Retrieval components may fetch documents. Safety systems may score content. Rate-limiting and abuse systems may hash or sample input. Response assemblers may store context windows or thread state. By the time the user receives an answer, the system may have generated several internal artifacts even if the UI later says the thread expired. (docs.perplexity.ai)
This is where many teams accidentally over-promise. They define privacy in terms of the conversation table in the primary database. But prompt fragments may also exist in reverse proxies, application logs, tracing spans, failed-job payloads, dead-letter queues, debugging snapshots, vector-store caches, abuse-review tickets, or analytics warehouses. A defensible privacy claim needs to say which of those paths are excluded, which are retained for operational reasons, and which are technically impossible because of architecture and egress rules. If you do not know, the promise is not yet mature. (NIST)
Provider boundaries and product tiers
The provider plane adds another layer. Consumer AI products, enterprise workspaces, and APIs often have different retention and monitoring behavior. Perplexity’s own public material illustrates this clearly: the help center frames Incognito mode around temporary private threads, the API docs say Sonar has zero data retention and only retains billing metadata, and Enterprise offers audit logs that intentionally record user and admin actions. Those are not contradictory statements. They are different data contracts for different surfaces. The compliance mistake is to collapse them into one brand-level privacy sentence. (Perplexity AI)
A serious review therefore scopes by surface. Logged-out public chat is one system. Consumer authenticated chat is another. Enterprise workspace is another. API calls are another. Mobile clients can be another. Browser extension or agentic browsing features can be another. If your trust material does not distinguish those surfaces, buyers are forced to infer, and those inferences will usually be broader than your lawyers or engineers intended. (Perplexity AI)
Storage, deletion, and recovery behavior
Deletion claims are only credible when they describe the storage model. If threads expire after 24 hours, does that mean soft delete, hard delete, tombstone plus asynchronous purge, or UI suppression. Are backups in scope. Are shared links invalidated. Are embeddings or derived summaries also deleted. Are audit logs exempt. Can support staff restore data. What happens in legal hold or abuse investigations. Most user-facing privacy language does not answer these questions, but auditors, security reviewers, and sophisticated enterprise buyers eventually will. (Perplexity AI)
Human and administrative access
The operations plane is often forgotten because it sits behind the product. But it is one of the most important compliance boundaries. Who can inspect a prompt when debugging an outage. Which support workflows allow screenshot or transcript access. Which admin actions are logged. How are privileged actions reviewed. Perplexity’s enterprise audit-logs documentation is instructive here because it explicitly frames visibility into user activities and settings changes as a compliance and incident-response feature. A privacy promise that ignores the admin plane is incomplete by definition. (Perplexity AI)
How to test an AI privacy claim like a security engineer
A privacy claim should be treated the same way a pentester treats an authz claim. Not as an insult, and not as a compliment. As a testable assertion. The right workflow is evidence first: collect the promise, enumerate the surfaces, observe the traffic, compare behavior across account states, and preserve artifacts another person can replay. This is not only useful for offensive testing. It is exactly the kind of disciplined verification that improves compliance evidence later. (AICPA & CIMA)
Start with promise collection. Save the exact UI text, help-center language, API docs, trust-center claims, privacy-policy statements, and enterprise documentation that describe the behavior. If the product says “not stored,” “anonymous,” “private,” “incognito,” or “zero retention,” copy the exact context in which the promise appears. Many disputes arise because a team quietly changes the meaning of a phrase across surfaces without changing the phrase itself. Promise collection gives you a stable baseline before any technical testing begins. (Perplexity AI)
Then map the surfaces you will test. At minimum, separate logged-out web, logged-in free or paid web, enterprise workspace, public API, mobile app, and any browser or agent feature. Do not assume behavior transfers between them. The Perplexity public materials are a good reminder that retention and logging semantics can differ substantially by interface. Your evidence needs to say which surface you actually examined. (Perplexity AI)
Next, inventory the instrumentation before you even submit a prompt. Sensitive-route privacy failures often start with scripts and tags already present on page load. The simplest first pass is static inventory from source code or built assets.
rg -n --hidden -S \
'fbq\(|gtag\(|google_tag_manager|googletagmanager|doubleclick|analytics|segment|mixpanel|amplitude|posthog|sentry|hotjar|fullstory|datadog' \
.
This is not proof of disclosure. It is only a map of what deserves closer review. False positives are expected. What matters is whether any of these libraries run on routes where users may enter sensitive prompts, and whether their configuration can capture prompt text, route titles, custom event parameters, or account-linked identifiers.
Static inventory should be followed by live network capture. Use browser DevTools, Burp, mitmproxy, or Playwright to record all outbound requests on the target route before and after prompt submission. You are looking for three classes of issues: prompt text or paraphrases appearing in URLs, JSON bodies, or form payloads; identifiers such as email, cookie IDs, or user IDs riding with the event; and differences between public and “private” modes that are smaller than the UI language implies. The complaint against Perplexity is so instructive precisely because it frames the problem this way: not as a magical AI leak, but as outbound request behavior.
A lightweight automated check is often enough to catch bad surprises in CI. The example below records outbound requests while a Playwright test submits a prompt, then fails if any hostname outside a small allowlist sees traffic after the submit action.
import { test, expect } from '@playwright/test';
const ALLOWLIST = new Set([
'app.example.ai',
'api.example.ai',
'cdn.example.ai',
'logs.example.ai'
]);
test('sensitive chat route does not egress to unapproved hosts', async ({ page }) => {
const seen = [];
page.on('request', req => {
const url = new URL(req.url());
seen.push({
host: url.hostname,
method: req.method(),
resourceType: req.resourceType(),
url: req.url()
});
});
await page.goto('https://app.example.ai/chat');
await page.getByPlaceholder('Ask anything').fill(
'I need legal advice about a separation agreement and my tax exposure'
);
await page.keyboard.press('Enter');
await page.waitForTimeout(3000);
const suspicious = seen.filter(r => !ALLOWLIST.has(r.host));
expect(suspicious, JSON.stringify(suspicious, null, 2)).toEqual([]);
});
This kind of test does not replace manual analysis. It gives you regression coverage. If a tag manager change suddenly introduces a new outbound domain on the chat surface, you want to know during rollout, not from a complaint.
On the browser side, a good defensive baseline is to sharply restrict where the sensitive route may connect at all. A Content-Security-Policy in Report-Only mode can help teams learn what a route is trying to contact before they enforce a block.
Content-Security-Policy-Report-Only:
default-src 'self';
script-src 'self' https://static.example.ai;
connect-src 'self' https://api.example.ai https://logs.example.ai;
img-src 'self' data:;
style-src 'self' 'unsafe-inline';
report-to default-endpoint;
CSP is not a silver bullet. Same-origin applications can still exfiltrate data to their own backend, and server-side forwarding can still happen later. But on sensitive chat routes it is a strong forcing function. It makes accidental third-party dependencies visible and limits the chance that a generic marketing integration quietly reaches into the most sensitive part of the product.
The next step is payload analysis. If you find outbound events, inspect them for direct prompt content, reflected titles, conversation URLs, account-linked identifiers, or high-cardinality custom parameters. AI products often generate secondary data that looks harmless until it is linked back to a person: thread IDs, experiment cohort IDs, device fingerprints, billing account IDs, tenant names, or email hashes. In privacy reviews, linkage often matters as much as raw content. A prompt fragment plus a stable account marker can be enough to create a serious issue.
After network behavior, test retention honestly. Create a thread in the claimed private mode. Verify whether it disappears from the visible UI. Then test what else still persists: browser history, direct-link access, export endpoints, admin views, audit logs, support flows, or delayed deletion windows. If the product offers an API surface with a stronger retention claim than the consumer surface, test both and keep the evidence separate. Many privacy misunderstandings happen because teams conflate short-lived UI visibility with actual deletion. (Perplexity AI)
Finally, document the results in a format that survives retest. Save the promise you tested, the account state, timestamps, route, browser build, relevant headers, request samples, screenshots, and the exact reproduction sequence. This is where privacy testing stops looking like a one-off red-team stunt and starts becoming audit-useful evidence. Compliance programs do not need theatrical findings. They need traceable artifacts and clear scope. (AICPA & CIMA)
The practical mapping below is an engineering interpretation of what these promises mean when translated into control testing. It is not a substitute for legal review or audit scoping, but it is a far better starting point than trusting the feature name. (AICPA & CIMA)
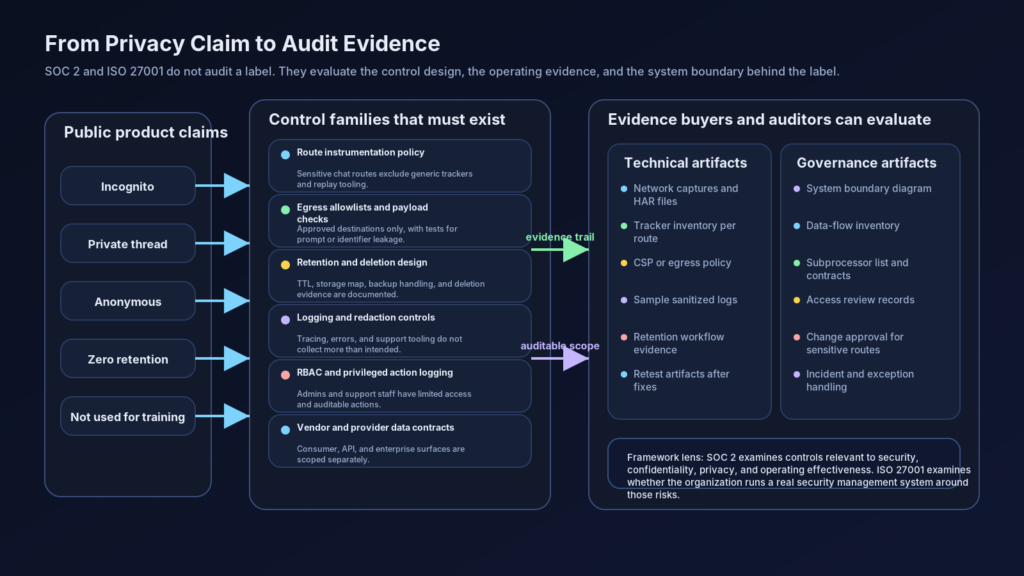
| Product claim | What must be verified | Evidence that matters | Failure mode |
|---|---|---|---|
| Private thread | Access scope, storage, sharing, admin visibility | ACL tests, storage model, shared-link behavior, admin-view evidence | UI hides history but backend or support path still exposes content |
| Incognito | History retention, third-party disclosure, identifier linkage | Network captures, tag inventory, cookie analysis, deletion tests | Thread disappears from sidebar but event payloads still leave the route |
| Anonymous thread | Identity binding, cookie behavior, session continuity | Logged-out tests, cookie correlation, account association review | No account login, but stable identifiers still link behavior |
| Zero retention | Provider contract, request logging, debugging exceptions | Provider docs, packet captures, backend log policy, exception handling | Content not trained on, but still retained in logs or support tooling |
| Not used for training | Data lineage and model-improvement controls | Opt-out behavior, training pipeline exclusions, vendor settings | Operational retention or evaluation use still occurs even without formal training |
| Enterprise audit logs | Log coverage, retention, privacy boundaries | Sample logs, webhook configs, admin RBAC, redaction rules | Logs intended for governance over-collect sensitive content |

What recent AI-related CVEs teach about the same problem
Privacy claims in AI systems are not challenged only by analytics and policy language. They are also challenged by ordinary software flaws in the surrounding product. Three recent CVEs are especially useful because each highlights a different way that surface-level expectations can diverge from actual system behavior. (Mozilla)
CVE-2025-3035 shows that even context glue can leak
Mozilla’s advisory for CVE-2025-3035 says that in Firefox versions before 137, if a user first used the AI chatbot in one tab and later activated it in another, the document title of the previous tab could leak into the chat prompt. NVD classifies it under CWE-359, exposure of private personal information. This is a clean example of why AI privacy cannot be reduced to server retention alone. Even the browser-side context glue around an assistant can leak information across boundaries a user did not intend to join. (Mozilla)
Why is that relevant here. Because many AI products aggressively integrate browser state, open tabs, file context, or workspace metadata to make the assistant feel helpful. The more helpful the assistant, the more careful the context-binding logic must be. A product may never send anything to Meta or Google and still have a serious privacy bug if context from one surface bleeds into another. The fix, in this case, was browser-side, but the design lesson generalizes to AI copilots, browser agents, enterprise assistants, and productivity overlays. (Mozilla)
CVE-2025-43862 shows that hidden UI is not the same as authorization
NVD says Dify versions prior to 0.6.12 allowed a normal user to access and modify APP orchestration even though the web UI did not present APP orchestration to that user. NVD explicitly describes it as an access control flaw and recommends stricter user-role permissions and RBAC. That is deeply relevant to AI compliance because it mirrors a common mental error: if the user cannot see the control, the capability must not exist. In security, that is never enough. Real authorization lives in the backend, not in the menu layout. (nvd.nist.gov)
The analogy to privacy claims should be obvious. A private-thread icon or a missing history entry tells you what the UI chose to expose. It does not prove what the backend accepted, stored, or forwarded. In the Dify case, the hidden capability still existed. In privacy cases, the hidden data path can still exist. That is why serious control testing must inspect role checks, API endpoints, storage models, and egress behavior directly. Surface disappearance is not a control objective. Backend enforcement is. (nvd.nist.gov)
CVE-2025-3248 and the later Langflow advisory show that AI platforms still need standard appsec discipline
GitHub’s reviewed advisory and NVD say Langflow versions prior to 1.3.0 were vulnerable to unauthenticated code injection in the /api/v1/validate/code endpoint, allowing remote code execution. CISA later added CVE-2025-3248 to its Known Exploited Vulnerabilities catalog. A separate Langflow GitHub security advisory later described a distinct unauthenticated remote code execution path in the public flow build endpoint where attacker-controlled flow data reached exec() without sandboxing. (GitHub)
This is not a privacy-mode story, but it belongs in the same article because it corrects another widespread misconception. AI compliance does not sit on top of application security. It depends on it. If your AI platform exposes unsafe execution paths, weak auth, or backend code injection, your privacy and audit story will collapse under much more basic pressure. The Langflow examples are useful because they show how quickly AI-specific infrastructure becomes standard exploit territory. Once that happens, “we have a private mode” is almost irrelevant unless the ordinary application security baseline is also solid. (GitHub)
Taken together, these CVEs describe a broad lesson. AI privacy and AI compliance are not separate disciplines floating above the stack. They are the product of browser correctness, authorization correctness, vendor scoping, logging discipline, secure coding, and careful data governance. If any of those layers is immature, the trust promise will be weaker than the product copy suggests. (Mozilla)
Building evidence that can actually support SOC 2 and ISO 27001 work
The phrase “audit-ready” is often abused. In practice, an auditor or assessor is rarely impressed by a PDF full of broad claims. What they need is a coherent evidence pack that ties system description, policy intent, technical configuration, and operating proof together. AI privacy reviews are strongest when they preserve both the governance side and the packet-level side. (AICPA & CIMA)
At minimum, that evidence pack should include a current system boundary for the AI feature. The boundary should show user entry points, browsers or clients, the application layer, model routing or provider dependencies, logging and analytics systems, storage layers, admin or support surfaces, and any third-party subprocessors that may touch interaction data. This is not architecture-diagram theater. Without boundary clarity, it is almost impossible to test or explain what a privacy promise is supposed to cover. (ISO)
The second essential artifact is a data flow inventory specific to the sensitive route. A generic privacy policy is not enough. You need route-level or feature-level clarity for what enters the page, which scripts execute, where requests go, what identifiers are attached, what the backend stores, what the provider sees, what logs retain, and how deletion works. The Perplexity public materials are useful here because they show how different surfaces can honestly have different contracts. Your evidence pack must be equally specific. (Perplexity AI)
Third, you need proof of change control around sensitive instrumentation. If a product route can accept intimate prompt data, adding a new tag, SDK, session-replay tool, or server-side event forwarder should not be treated like a routine marketing tweak. There should be an owner, a review path, a rationale, and ideally an automated regression check to ensure no newly introduced endpoint sees sensitive traffic without approval. This is where mature privacy engineering starts to look a lot like mature application security. (NIST)
Fourth, you need access-control and logging evidence. Who can view prompts or derived artifacts internally. Are support tools redacted. Are enterprise audit logs intentionally more verbose, and if so, how are they secured. Are admin actions logged and reviewed. Is the log sink itself scoped and protected. Perplexity’s Enterprise audit-log documentation is a good example of explicit admin-side visibility. Any team selling into compliance-sensitive customers needs equivalent clarity for its own privileged plane. (Perplexity AI)
Fifth, you need deletion and retention evidence. It is not enough to say a thread expires. Show the deletion job, the retention schedule, any exceptions, and the behavior of backups, logs, and linked artifacts. If your API has zero data retention but your consumer surface does not, say so. If abuse-detection or billing metadata is retained, say so. Precise scoping is always stronger than broad language that cannot survive a follow-up question. (docs.perplexity.ai)
Sixth, you need independent validation. For sensitive AI surfaces, that can include privacy-focused red-team exercises, pentests that explicitly test telemetry and egress, route-specific tag audits, tabletop reviews of accidental disclosure scenarios, and retests after remediation. This is the narrow place where an evidence-first security workflow becomes directly useful to compliance work. The value is not that a tool can write prose quickly. The value is that it can preserve what was tested, what was observed, and whether the same issue stayed fixed after a change. (AICPA & CIMA)
Public Penligent materials are helpful here for one reason only: they describe reporting in the right direction. Penligent’s homepage says it offers one-click reports aligned with SOC 2 and ISO 27001, and its pricing page says even the free tier can export PDF or Markdown reports with evidence and reproduction steps. Its reporting article makes the more important point explicitly: the problem is not “how do I make AI write a PDF,” but how to turn evidence into something another human can verify. That is exactly the bar privacy testing and audit preparation should use. The phrase aligned only means something when the artifact behind it is traceable and replayable. (Penligent)
In practical terms, that means a security report becomes useful to SOC 2 or ISO 27001 work when it preserves scope, timestamps, environment, reproduction steps, network observations, screenshots, remediation status, and retest status. If those details are present, the report can support vulnerability management evidence, remediation tracking, and control improvement discussions. If those details are absent, the report may still look polished, but it is weak evidence. (Penligent)
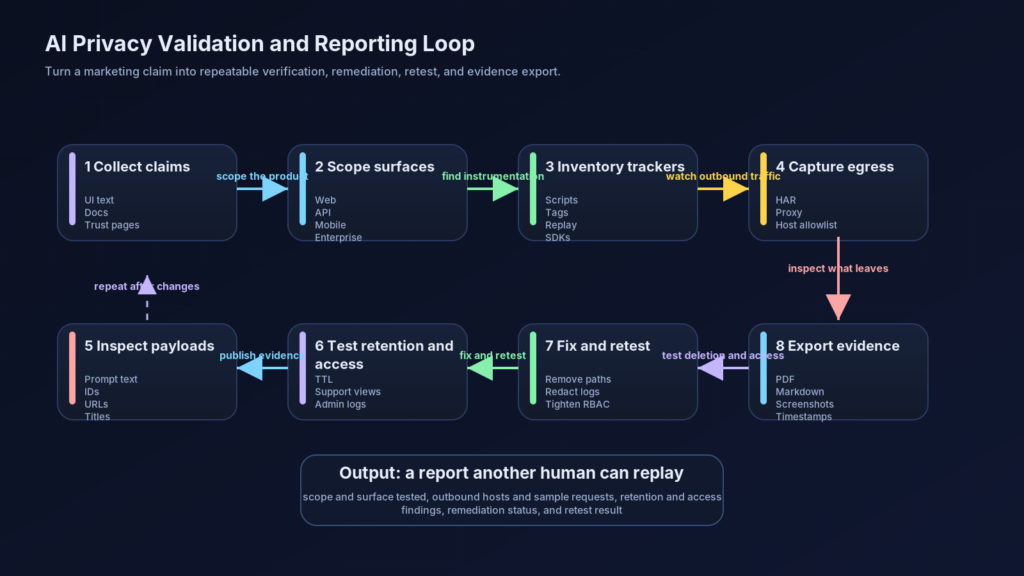
The matrix below is an operational synthesis of the kinds of artifacts that tend to matter most when AI privacy claims must survive security review and audit scrutiny. (AICPA & CIMA)
| Evidence area | What good evidence looks like | Why it matters |
|---|---|---|
| System boundary | Diagram of chat routes, provider calls, logs, analytics, admin surfaces, and subprocessors | Prevents overbroad or misleading privacy claims |
| Promise inventory | Screenshots and text of UI, help docs, privacy policy, API docs, trust pages | Fixes the baseline of what users were told |
| Tracker inventory | Code search results, tag-manager export, route-by-route dependency list | Shows whether sensitive routes carry generic telemetry |
| Egress testing | HAR files, proxy traces, Playwright captures, hostname allowlists | Validates whether prompts or identifiers leave approved boundaries |
| Retention model | Data-store map, TTL jobs, deletion workflow, backup exceptions | Turns “expires” into a concrete storage claim |
| Access control | RBAC matrix, admin-view tests, support access logs, review records | Proves that hidden UI is not the only line of defense |
| Logging controls | Redaction rules, sample sanitized logs, log retention schedule | Prevents privacy failure through observability systems |
| Vendor scoping | Provider retention docs, contract settings, DPA references, opt-out settings | Distinguishes API, enterprise, and consumer data contracts |
| Independent validation | Pentest findings, retests, remediation tickets, evidence exports | Demonstrates control effectiveness beyond policy text |
| Continuous assurance | CI checks for trackers, CSP reports, change approvals, review cadence | Shows the controls are maintained over time |
The mistakes that break AI compliance programs
The first mistake is treating user history as the whole privacy story. A team sees that a thread disappears from the sidebar and concludes the system is private. That is the same category error Dify illustrated from the authorization side: what the UI no longer shows is not the same as what the backend can still do. Privacy claims that stop at visible history are shallow. (nvd.nist.gov)
The second mistake is collapsing all product surfaces into one promise. Consumer web, mobile, API, enterprise workspace, browser agent, and admin console are rarely governed identically. Perplexity’s public documents are useful precisely because they reveal different commitments across consumer, API, and enterprise interfaces. Any AI vendor that sells into technical buyers should be equally specific. (Perplexity AI)
The third mistake is assuming a vendor opt-out or a “not used for training” setting resolves the full privacy problem. OWASP’s LLM guidance is a good corrective here. Sensitive information disclosure can happen through output, routing, or processing even when training is not the issue. Training is one path. Logging, debugging, replay, analytics, and unsafe integrations are others. (OWASP Gen AI Security Project)
The fourth mistake is ignoring ordinary application security because the team believes the main risk is model behavior. The Langflow advisories and the Dify access-control flaw show why that is naive. AI products still fail through missing auth, unsafe execution, access-control bugs, and context leakage. A privacy or compliance program that overlooks standard appsec will inherit those failures whether or not the privacy policy is well written. (nvd.nist.gov)
The fifth mistake is building evidence only after a customer questionnaire arrives. That almost guarantees weak artifacts and imprecise claims. The better pattern is continuous evidence capture: tag inventories as code, route-level egress tests in CI, deletion behavior documented by design, privileged access logged by default, and privacy assertions reviewed when product changes land. That is not only good engineering. It is also what makes a SOC 2 or ISO 27001 conversation less painful later. (ISO)
What a strong AI privacy posture actually looks like
A strong AI privacy posture is not a single badge, and it is not a marketing phrase. It is a stack. The public promise is narrow and accurate. The route instrumentation is intentionally limited. The provider boundary is documented. The logging plane is redacted or strongly scoped. The privileged plane is visible and controlled. The retention model is specific. The tests are repeatable. The exceptions are written down. The evidence is current. That is what turns “private” from a vibe into a control statement. (AICPA & CIMA)
That stack should also be honest about limits. Temporary threads may still be observable to enterprise administrators. APIs may have stronger retention controls than consumer interfaces. Abuse-prevention workflows may justify narrow operational metadata collection. Support incidents may create limited exception windows. Buyers do not need perfection theater. They need precision. A narrow claim that survives scrutiny is worth much more than a broad one that collapses on the first technical follow-up. (Perplexity AI)
The Perplexity lawsuit, whatever its outcome, has already done the market a favor. It exposed how casually the industry uses words like private and incognito in products built to absorb the most revealing kind of human input. The right takeaway is not panic. It is higher standards. If your AI system asks users to trust it with sensitive prompts, the burden is on you to prove what happens to those prompts across browser, backend, provider, logs, storage, and people. That proof is what security teams want. It is what enterprise buyers want. And it is what frameworks like SOC 2 and ISO/IEC 27001 are really pushing organizations to build.
Further reading and reference links
AICPA, SOC 2 Trust Services Criteria overview and related resources. (AICPA & CIMA)
ISO, ISO/IEC 27001 overview for information security management systems. (ISO)
NIST Privacy Framework. (NIST)
NIST AI Risk Management Framework and the Generative AI profile. (NIST)
OWASP Top 10 for LLM Applications and OWASP guidance on sensitive information disclosure. (OWASP)
Mozilla advisory and NVD entry for CVE-2025-3035. (Mozilla)
NVD entry for Dify CVE-2025-43862. (nvd.nist.gov)
GitHub advisory, NVD entry, and CISA KEV notice for Langflow CVE-2025-3248, plus the later public-flow advisory. (GitHub)
Perplexity help-center and developer pages on Incognito mode, API privacy, and Enterprise audit logs. (Perplexity AI)
Penligent homepage. (Penligent)
Penligent pricing, including evidence and reproduction-step exports. (Penligent)
How to Get an AI Pentest Report. (Penligent)
AI SOC, ISO 27001, SOC 2, and the Security Stack Real AI Teams Need in 2026. (Penligent)
How to Use AI for SOC 2 and ISO 27001 Compliance While Reducing Costs. (Penligent)

