
Teams search for outsourced penetration testing when they need expertise, coverage, or independent validation faster than their internal staff can provide it. That search does not mean they want to surrender judgment. It usually means they want three things at once: an adversarial view of their systems, a deliverable that engineering and leadership can act on, and a testing model that does not collapse the moment software changes a week later. NIST still frames penetration testing as a specialized activity that uses real-world attack techniques and requires careful planning, notification, and rules. Adobe’s public writeup on outsourced penetration testing makes the same point in a more modern way: outside specialists bring fresh perspectives and product-specific skills, but the engagement still needs structure, bounded access, and clear objectives. (منشورات NIST)
That is why the phrase outsource penetration testing with AI needs to be handled carefully. The useful promise is not that a model replaces every external pentester. The useful promise is that AI can absorb the slowest, most repetitive, and most operationally frustrating parts of the outsourced pentest workflow: asset mapping, authenticated replay, hypothesis tracking, evidence capture, retesting after fixes, and converting raw findings into repeatable proof. Done well, that does not weaken control. It strengthens it, because the organization keeps the scope definition, approval boundaries, evidence trail, and decision-making in-house while still choosing when to bring in external specialists for fresh eyes or deep niche work. That operating model also fits what public guidance already says about penetration testing: it is iterative, evidence-driven, and inseparable from rules of engagement and reporting. (منشورات NIST)
A second reason this topic matters now is staffing pressure. ISC2’s 2025 Cybersecurity Workforce Study describes persistent skills and staff shortages, continuing budget constraints, and heavy interest in AI as support for time-consuming, repetitive tasks rather than as a total replacement for practitioners. In other words, the market conditions around pentesting have shifted in exactly the direction that makes an evidence-first AI workflow attractive: security teams are under-resourced, still need specialist coverage, and are looking for ways to automate operational grind without pretending that automation eliminates the need for human expertise. (ISC2)
What outsourced penetration testing actually buys
The modern buyer is not only purchasing a test. The buyer is purchasing perspective, process, and proof. Adobe describes outsourced penetration testing as valuable because external testers bring diverse experience from other environments and can approach a system with a fresh set of eyes. Adobe also says it uses outsourcing to match specialized skills to product needs, including AI-specific testing for products like Firefly. That matters because many organizations do not need generic scanner output. They need somebody who can think like an attacker with the right domain context, whether the target is a SaaS app, an internal network, an API estate, or an AI-enabled workflow. (Adobe Blog)
NIST’s service procurement guidance adds a quieter but equally important layer. When organizations acquire IT security services, NIST recommends building a business case, defining strong service agreements with measurable outcomes and remedies, using metrics throughout the service lifecycle, and maintaining enough technical expertise internally to understand and manage the service being provided. That is the opposite of blind outsourcing. The customer is still expected to know what is being bought, how success is measured, what counts as non-compliance, and how the result will be overseen. Outsourcing a pentest never outsourced accountability in the first place. (منشورات NIST)
This is also where many security buyers confuse three different products that look similar from the outside. A traditional consultant-led pentest is usually a time-boxed project with a scoping call, testing window, report, and maybe a retest. PTaaS vendors describe a more platformized operating model: manual testing plus a delivery platform, continuous testing, faster launch, collaborative reporting, and integrations into engineering workflows. An AI-assisted internal workflow is something else again. It can borrow from both models, but the center of gravity moves inward: the organization keeps the engagement control plane and uses AI to drive authorized testing, preserve state, structure evidence, and shorten the path between patch and verified closure. Cobalt’s and HackerOne’s official PTaaS pages are vendor materials, not neutral academic reviews, but both independently emphasize the same operational pain points: repeated procurement, delayed launches, static reporting, and the need for ongoing or on-demand testing. (كوبالت)
Why the old outsourced pentest model frustrates modern teams
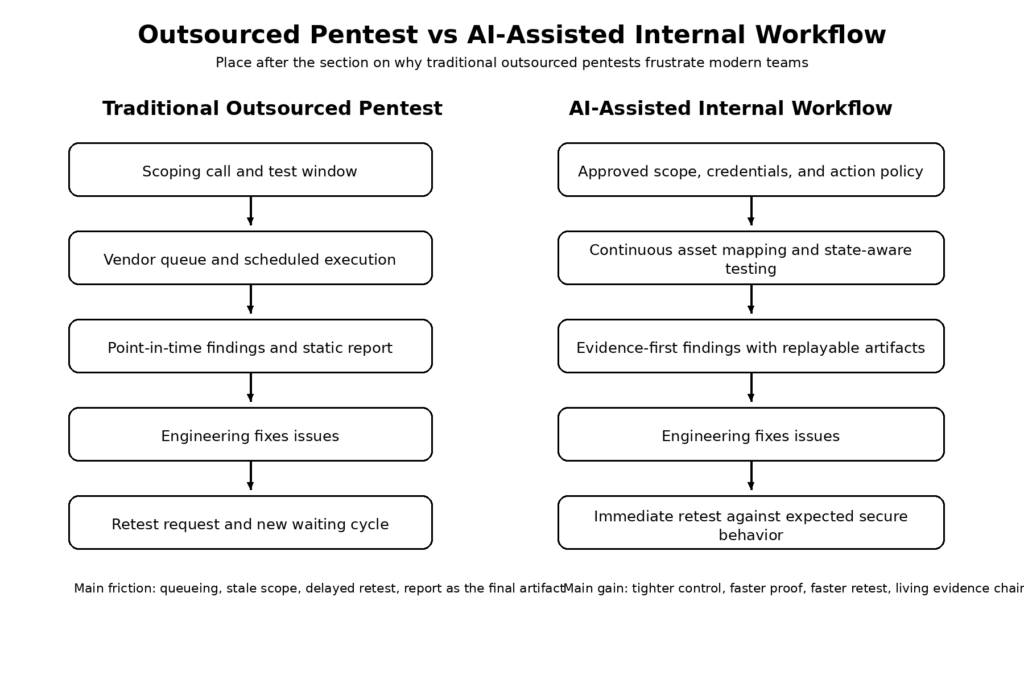
The core problem with the old outsourced model is not that outside testers are ineffective. The problem is that software changed faster than the delivery mechanics around pentesting. A product team can deploy three meaningful changes between kickoff and final report. Meanwhile, the application under test has new routes, new auth behavior, new third-party dependencies, and new configuration drift that the original scope did not anticipate. What looked like a clean annual test in procurement language turns into a stale snapshot in engineering reality. That is why vendor PTaaS pages keep attacking the same enemy: one-off testing that does not fit modern SDLC rhythm. Cobalt explicitly positions PTaaS against “legacy penetration testing” that does not integrate into a modern development lifecycle and describes continuous programs of testing, fix validation, and strategic guidance. HackerOne markets on-demand launch speed and faster actionable outcomes. Even if those claims are commercial, the problem definition is consistent across providers. (كوبالت)
The second frustration is retesting. A traditional pentest often discovers an issue, delivers a finding, and stops. Engineering fixes the bug. Then everyone asks the operationally expensive question: who proves the fix, with what evidence, against which exact reproduction steps, and on what timeline? NIST’s testing guidance is already explicit that reporting is not the end of the work. Findings should lead to mitigation recommendations and to documented actions that track remediation. Bug bounty guidance makes the same point from a different angle: a useful report needs clear steps to reproduce, URLs, parameters, roles, screenshots, and proof-of-concept evidence so another human can replay the issue. If reproduction and evidence are weak, retest becomes guesswork. (منشورات NIST)
The third frustration is audience mismatch. NIST notes that penetration testing reports may have multiple audiences and that multiple report formats may be required. Engineering wants exact requests, artifacts, affected components, and retest criteria. Security leadership wants risk, business context, and remediation priority. Auditors may want scope, methodology, date, and proof that remediation was tracked. If the outsourced test produces a polished executive PDF but not a replayable evidence object, engineering pays the price. If it produces raw notes without management context, the security program pays the price. The more often teams ship, the more costly this mismatch becomes. (منشورات NIST)
The fourth frustration is operational control. Adobe’s guidance on authenticated black-box testing stresses well-defined rules of engagement, especially in production-like environments, so testers can explore freely but within structured limits that protect system integrity and data. That is a practical reminder that pentesting is not just “go break stuff.” It is controlled pressure on real systems. When the testing model is too externalized, the organization often feels that control only at the kickoff stage, not throughout execution. That is exactly the gap an internal AI-assisted workflow can close. (Adobe Blog)
Penetration testing is not vulnerability scanning
This distinction is the hinge point for the entire conversation. NIST defines penetration testing as security testing in which assessors mimic real-world attacks to identify methods for circumventing security features in an application, system, or network. It often involves launching real attacks on real systems and data. NIST separately describes vulnerability scanning as identifying hosts, host attributes, missing patches, misconfigurations, and known vulnerabilities by matching discovered software against vulnerability data. In plain English, a scanner can tell you that a door looks weak. A pentest asks whether the door opens, what is behind it, whether the attacker can move farther once inside, and what evidence proves that path is real. (منشورات NIST)
That gap matters even more in APIs and web applications. OWASP’s Web Security Testing Guide remains one of the best public references because it treats web testing as a broad discipline that includes information gathering, authentication, authorization, session management, business logic, and more. The guide’s business logic section is especially important here: it says business logic flaws often cannot be detected by scanners, are usually application-specific, and remain a manual art. If your “AI pentest” only summarizes scanner results in better English, it never reaches the terrain where a large share of meaningful application risk lives. (مؤسسة OWASP)
OWASP’s API Security Top 10 sharpens the point. The API1:2023 category, Broken Object Level Authorization, explains that attackers exploit endpoints by manipulating object identifiers in paths, query strings, headers, or payloads. Every endpoint receiving an object identifier should perform object-level authorization checks. That is not a pattern a simple version scan can settle. It requires state, identity, behavioral comparison, and replay. In practice, it often requires logging in as one user, learning how the API expresses object identity, then intentionally testing whether the same function grants access to another user’s object. AI can help orchestrate and preserve those comparisons, but only if the workflow is built around authorization boundaries and evidence rather than generic CVE matching. (مؤسسة OWASP)
NIST also emphasizes that penetration testing is labor-intensive, requires expertise, and carries real risk because it uses actual exploits and attacks against real systems and data. That is an argument against ungoverned automation, not against AI. The right lesson is that automation belongs inside a control framework. The wrong lesson is that anything with an LLM and a scanner becomes “a pentest platform.” (منشورات NIST)
Control is the first requirement
The title phrase “without losing control” is not rhetorical. It is the governing requirement. NIST SP 800-115 includes a Rules of Engagement template that starts with purpose, scope, assumptions and limitations, risks, personnel, and schedule. The same document says penetration testing should occur only after careful consideration, notification, and planning. That is the baseline. AI should live downstream of those decisions, not replace them. (منشورات NIST)
In practice, control means at least seven things.
It means explicit authorization. You are not testing “the internet.” You are testing named assets, during named windows, under named approvals, with named contacts who can halt the engagement. NIST’s ROE template and PTES’s pre-engagement material both treat scope, communication lines, start and end dates, emergency contacts, and rules of engagement as first-class elements of the job. (منشورات NIST)
It means action boundaries. Passive collection, low-impact probing, authenticated navigation, state-changing actions, and exploit-like validation are not morally or operationally equivalent. Production systems often require different gates for each. Adobe says authenticated black-box testing depends on well-defined rules of engagement to maintain stability and prevent inadvertent harm, especially in production environments. (Adobe Blog)
It means credential boundaries. Test identities are not generic “logins.” They represent specific roles, permission levels, and trust assumptions. Business logic and authorization testing collapse when identity context is sloppy. OWASP’s API guidance makes that obvious: the whole difference between authorized and unauthorized object access depends on knowing exactly which identity is making the request. (مؤسسة OWASP)
It means evidence retention. If the workflow cannot preserve requests, responses, captures, logs, screenshots, preconditions, and postconditions, then every later dispute becomes subjective. Bugcrowd’s researcher documentation explicitly encourages screenshots and proof-of-concept videos because they provide clear replication steps, and HackerOne’s quality report guidance emphasizes clear reproduction steps with URLs, parameters, and user roles. Those are not just bug bounty niceties. They are the same evidence principles a serious AI pentest workflow needs. (HackerOne Help Center)
It means reporting discipline. NIST says multiple audiences may require multiple report formats. The workflow therefore needs both an evidence object for engineers and a prioritization and risk layer for managers. (منشورات NIST)
It means operator override. An AI-assisted test that cannot be redirected, paused, constrained, or forced into human review is not mature. It is merely automated.
It means post-test verification. A pentest without retest criteria is an unfinished job. NIST’s remediation language, bug bounty reproduction guidance, and the real-world behavior of incident-driven patch cycles all point in the same direction: the closure loop matters as much as initial discovery. (منشورات NIST)
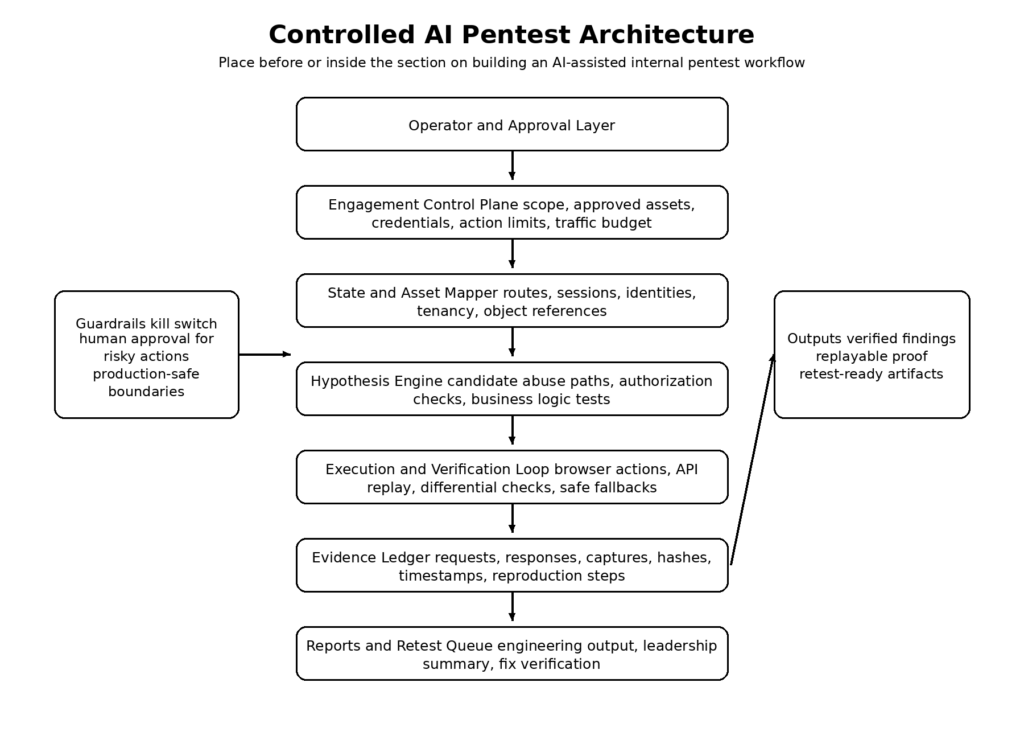
Building an AI-assisted internal pentest workflow
A useful way to think about AI in this space is not “autonomous hacker” first. Think “control plane plus evidence loop.” The practical architecture has five layers: engagement control, asset and state mapping, hypothesis management, proof generation, and structured reporting. That architecture aligns more cleanly with NIST and PTES than with most marketing language. NIST describes planning, discovery, attack, additional discovery, and reporting phases; PTES lays out pre-engagement interactions, intelligence gathering, threat modeling, vulnerability analysis, exploitation, post exploitation, and reporting. AI can make each of those phases faster and more durable, but only if it is attached to the right artifacts. (منشورات NIST)
The first layer is the engagement control plane. This is where scope, risk, and authority live. It is not glamorous, but it is the difference between a security workflow and a liability generator. The model should never be free to discover a hostname and silently decide that it is in scope. The operator should define target sets, credential classes, allowed action families, time windows, concurrency limits, and kill switches before any testing begins. NIST’s ROE template is a good starting point because it encodes exactly the details most AI demos skip: purpose, boundaries, assumptions, risks, personnel, and schedule. (منشورات NIST)
A simple policy object might look like this:
engagement:
ticket_id: ENG-2026-041
owner: appsec@example.com
emergency_contact: incident-bridge@example.com
authorized_targets:
- api.staging.example.com
- web.staging.example.com
authorized_window:
start_utc: "2026-04-10T01:00:00Z"
end_utc: "2026-04-10T05:00:00Z"
credential_profiles:
- role: user_basic
- role: user_premium
- role: support_admin
action_policy:
passive_allowed: true
low_impact_active_allowed: true
state_change_requires_human_approval: true
exploit_modules_blocked_by_default: true
social_engineering_allowed: false
file_upload_tests_allowed: true
safety_limits:
max_requests_per_minute: 120
max_parallel_sessions: 4
stop_on_data_modification_outside_test_accounts: true
evidence_policy:
save_request_response_pairs: true
save_browser_captures: true
hash_artifacts: true
retain_days: 90
This is not bureaucracy for its own sake. It is how you preserve authority while gaining speed. It also makes AI auditable. If an action was not permitted in policy, it should not occur. If a finding cannot be traced to an allowed target, an allowed identity, and an allowed window, it should not survive review. That is what “without losing control” looks like in a system, not just in a tagline. The shape of this policy follows the same concerns NIST and PTES put into pre-engagement and rules-of-engagement planning. (منشورات NIST)
The second layer is asset and state mapping. Modern web apps and APIs are not flat targets. They have account roles, tenancy boundaries, feature flags, rate limits, session transitions, anti-CSRF behavior, reverse proxies, and object identifiers that mean different things depending on which route or account reaches them. OWASP’s WSTG keeps information gathering and business logic testing up front for a reason. A test can only be intelligent if it understands the workflow it is pressuring. (مؤسسة OWASP)
The third layer is hypothesis management. This is where AI actually becomes valuable. A good system does not jump from “I saw a suspicious parameter” to “critical vulnerability confirmed.” It should track the distinction between observation, candidate hypothesis, partial proof, confirmed finding, and retest closure. Example hypotheses might include: “support_admin can access invoices outside assigned tenant by changing invoice_id,” “checkout discount logic can be applied out of sequence,” or “password reset workflow accepts reused intermediate state.” Business logic testing is hard precisely because these are stateful ideas, not static signatures. AI is useful here because it can preserve context, sequence alternate test paths, compare outcomes across identities, and keep a ledger of what has or has not been proven. OWASP’s business logic guidance is blunt that this class of issue remains manual and creative. AI should enhance that creative workflow, not pretend to replace it with signatures. (مؤسسة OWASP)
The fourth layer is proof generation. This is where many AI security products quietly fail. Proof is not a clever explanation. Proof is reproducible evidence that another engineer or tester can replay. HackerOne’s documentation emphasizes clear numbered steps with URLs, parameters, and roles. Bugcrowd emphasizes screenshots and POC media because they make exact replication easier. NIST’s reporting guidance connects results to corrective action and mitigation. The implication is straightforward: an AI system that cannot produce replayable evidence should not be trusted to produce final findings. (HackerOne Help Center)
A structured evidence record can be simple but powerful:
{
"finding_id": "F-2026-0042",
"engagement_id": "ENG-2026-041",
"target": "api.staging.example.com",
"category": "Broken Object Level Authorization",
"hypothesis": "user_basic can read another tenant invoice by changing invoice_id",
"accounts_used": ["user_basic_a", "user_basic_b"],
"preconditions": [
"Both accounts are active",
"Each account owns at least one invoice",
"No admin roles were used"
],
"evidence": {
"request_1_hash": "sha256:...",
"response_1_hash": "sha256:...",
"request_2_hash": "sha256:...",
"response_2_hash": "sha256:...",
"browser_capture_ids": ["cap-009", "cap-010"],
"server_log_reference": "logref-8811"
},
"impact_summary": "Unauthorized cross-tenant invoice disclosure",
"reproduction_steps": [
"Log in as user_basic_a",
"Capture an invoice request for account A",
"Replace invoice_id with an invoice owned by account B",
"Replay request without changing role or tenant context",
"Observe 200 response and invoice content for account B"
],
"retest_status": {
"state": "open",
"expected_fix_behavior": "403 or 404 with no object data returned"
}
}
A finding object like this solves three common problems at once. It gives engineering a replay path. It gives security a consistent evidence model. It gives retest a fixed comparison target. It also forces the AI layer to operate like a disciplined assistant instead of a free-form narrator. That is the real value of structure. (HackerOne Help Center)
A short note about Penligent belongs here because its public material is unusually explicit about exactly these properties. The home page emphasizes evidence-first results with artifacts, steps, and traceable proof, plus scope-locking controls. Its recent article on AI pentest reports makes the burden of proof even clearer: a report is only useful if it can survive retest, and the workflow must preserve evidence another human can verify. Those are healthy design choices because they push the product definition closer to NIST-style testing and away from “chatbot as pentester” theatrics. (penligent.ai)
The fifth layer is reporting. NIST notes that testing results may be used for corrective action, mitigation planning, benchmarking progress, assessing security implementation status, cost-benefit analysis, and other lifecycle activities, and that multiple audiences may require multiple report formats. The best AI-assisted workflow therefore produces at least three outputs from the same evidence base: a concise leadership summary, an engineering-facing technical finding set, and a remediation and retest queue. One evidence chain, multiple readers. That is how you get speed without turning reporting into fiction. (منشورات NIST)

Business logic testing and API authorization are the proving ground
If you want to know whether an AI pentesting workflow is serious, ask how it handles business logic and authorization testing. Do not start with its copywriting. Start with the hardest tests.
OWASP’s business logic guidance says these flaws require unconventional thinking, are often among the hardest to detect, and usually cannot be automated away as a scanner problem. That observation is more important now than when it was first written because the modern application surface has become even more stateful. Shopping flows, identity recovery, invitation systems, usage metering, approval workflows, tenancy rules, and step-based onboarding all create security boundaries that exist in application behavior rather than in package versions. (مؤسسة OWASP)
OWASP’s API guidance says something similarly important from the authorization side. API1:2023 Broken Object Level Authorization exists because APIs routinely expose object identifiers and rely heavily on client-provided IDs to decide which objects to access. The issue is not merely whether the endpoint is authenticated. It is whether the server verifies that this identity may touch this object through this action. That nuance is precisely why so many “AI security” tools remain shallow. They can read a Swagger file. They can summarize route lists. But they cannot reliably preserve identity and compare authorization behavior across sessions, accounts, tenants, and object types unless the workflow was designed for that from the start. (مؤسسة OWASP)
A safe and useful test pattern for your own staging environment looks like this:
# Authorized testing only, using dedicated staging accounts.
# Baseline request as the legitimate owner.
curl -s -H "Authorization: Bearer ${TOKEN_USER_A}" \
https://api.staging.example.com/v1/invoices/1001 | jq .
# Negative test, same role, different user's object.
curl -i -s -H "Authorization: Bearer ${TOKEN_USER_A}" \
https://api.staging.example.com/v1/invoices/2009
# Expected secure behavior:
# HTTP 403 or 404, and no object data from invoice 2009.
# Repeat with a second identity to confirm ownership assumptions.
curl -i -s -H "Authorization: Bearer ${TOKEN_USER_B}" \
https://api.staging.example.com/v1/invoices/2009
On its own, this does not prove a vulnerability. It proves a test shape. The real work is in what surrounds the request: how the object IDs were learned, whether the token actually represents the claimed role, whether tenant context is encoded elsewhere, whether caching or stale state distorted the result, and whether the same logic breaks on write actions as well as reads. That is where AI can materially help. It can keep the object lineage straight, track which assumptions have already been validated, suggest adjacent authorization checks, and assemble the result into a replayable evidence package. What it should not do is skip the validation burden because the pattern “looks like” BOLA. OWASP’s own language makes the risk and the verification criteria clear. (مؤسسة OWASP)
A second place AI earns its keep is sequence testing. A business workflow often depends on order: create invite, accept invite, activate tenant, assign role, initiate password reset, confirm token, set secret, finalize session. Bugs appear when one state transition can be skipped, reused, or replayed. A good AI workflow can model the sequence, generate misuse cases, and remember which step mutations have already been tested. That does not convert business logic testing into a solved automation problem. It converts it into a more systematic and less forgetful manual problem. That is the right ambition. (مؤسسة OWASP)
Another short Penligent paragraph is natural here. Its recent public blog material consistently distinguishes smart suggestions from verified findings, and frames an AI pentest copilot as useful only when it narrows the gap between signal and proof without hiding the evidence trail. That is a better standard than “the model sounds convincing.” It mirrors the same divide you see in OWASP and bug bounty reporting guidance: suggestions are easy, proof is the job. (penligent.ai)
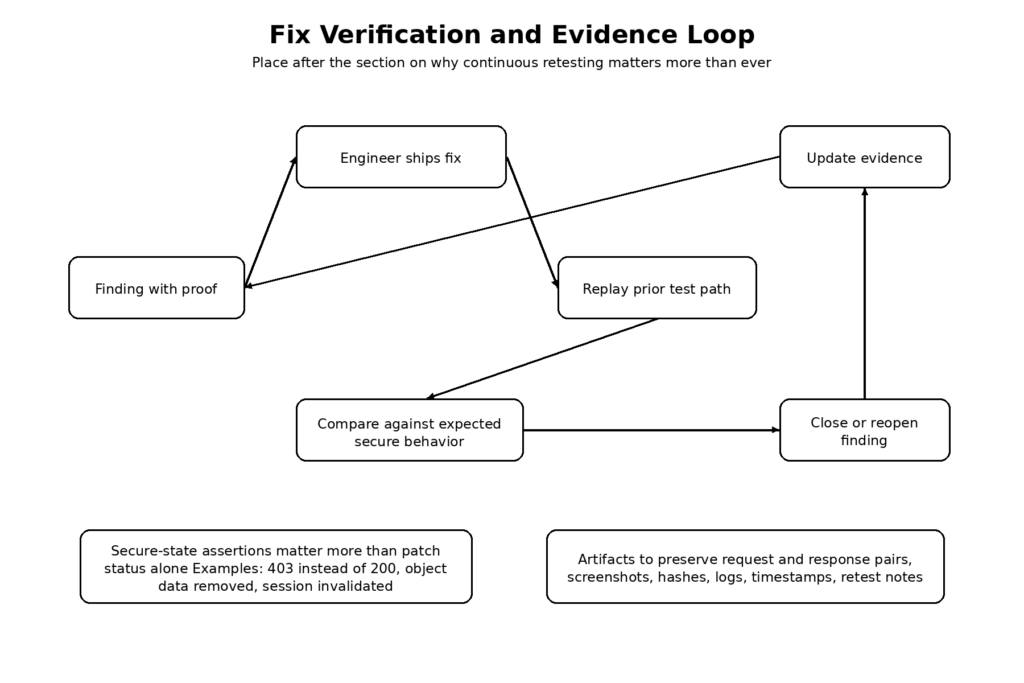
Why continuous retesting matters more than ever
The strongest case for internalizing part of outsourced penetration testing is not novelty. It is retest velocity.
Consider Log4Shell, CVE-2021-44228. NVD describes the issue as attacker-controlled JNDI lookups that can lead to remote code execution when message lookup substitution is enabled. NVD also notes that 2.15.0 disabled the dangerous behavior by default and 2.16.0 removed it. CISA later warned that multiple threat actor groups continued exploiting Log4Shell on unpatched public-facing systems. The operational lesson was brutal and simple: once the world knows a class of weakness is everywhere, you do not merely need one pentest finding. You need rapid exposure identification, environment-aware validation, patch verification, and repeatable evidence that the vulnerable behavior is actually gone. (NVD)
Now consider MOVEit Transfer, CVE-2023-34362. NVD describes it as a SQL injection vulnerability in the MOVEit Transfer web application that could allow an unauthenticated attacker to gain access to the database. The entry further notes that, depending on the database engine, attackers may infer structure, alter or delete database elements, and that exploitation of unpatched systems occurred in May and June 2023 over HTTP or HTTPS. CISA and the FBI publicly tied the incident wave to exploitation by the CL0P ransomware operation, while Progress’s advisory described the issue as capable of escalated privileges and unauthorized access. That is exactly the kind of defect that exposes the weakness of static pentesting. The hard part is not discovering that SQLi exists in theory. The hard part is quickly determining whether your exposed instance is affected, whether interim mitigations worked, what evidence confirms closure, and how soon you can re-verify the internet-facing surface after changes. (NVD)
CitrixBleed, CVE-2023-4966, shows another retest pattern: sometimes patching is necessary but not sufficient. NVD describes the issue as sensitive information disclosure in NetScaler ADC and Gateway when configured in specific gateway or AAA roles, and notes that the CVE is in CISA’s Known Exploited Vulnerabilities Catalog. NetScaler’s own blog says the issue was associated with targeted attacks and session hijacking behavior, states that no workaround existed beyond updating, and recommends not only installing the fixed builds but also killing all active and persistent sessions. This is the operational reality that static annual pentests miss. A serious security program needs the ability to turn a vendor advisory into an internal verification checklist: identify affected builds, confirm exposure mode, apply the fix, clear sessions where required, and re-run targeted checks to confirm the vulnerable state no longer exists. (NVD)
ConnectWise ScreenConnect, CVE-2024-1709, is a fourth example with a slightly different lesson. NVD describes it as an authentication bypass affecting ScreenConnect 23.9.7 and prior, and the NVD record references CISA’s KEV catalog. ConnectWise’s own bulletin repeatedly urges on-prem customers to upgrade immediately, explains which versions remediate the flaw, and says it is critical to assess systems for signs of impact while upgrading and before bringing them back online. That is not a side note. It means the remediation workflow itself is a security task: patch, inspect, review logs and file system activity, verify no compromise indicators remain, then re-enable operations. In a workflow like that, a retest-capable internal evidence system is not a nice-to-have. It is the difference between closure and hope. (NVD)
These cases share a pattern. They are not primarily arguments that outsourced pentesting is bad. They are arguments that point-in-time validation is too brittle on its own. When the threat changes, when a vendor ships a fix, when your application deploys a new auth path, or when a compensating control is introduced under pressure, the organization needs a fast way to re-run bounded tests and regenerate proof. That is the part AI can internalize exceptionally well. (NVD)
A practical retest loop
A retest loop should be smaller and more deterministic than the original discovery run. It is not a second full pentest every time. It is a replay of the hypotheses and artifacts that led to the finding, plus a few adjacent checks for partial fixes.
A minimal retest harness can be as simple as this:
#!/usr/bin/env bash
# Authorized use only in owned or approved environments.
BASE_URL="https://api.staging.example.com"
TOKEN="${TOKEN_USER_A}"
check_blocked() {
local path="$1"
local expected="$2"
code=$(curl -s -o /tmp/retest.out -w "%{http_code}" \
-H "Authorization: Bearer ${TOKEN}" \
"${BASE_URL}${path}")
if [[ "${code}" == "${expected}" ]]; then
echo "[PASS] ${path} returned ${code}"
else
echo "[FAIL] ${path} returned ${code}, expected ${expected}"
echo "----- body -----"
cat /tmp/retest.out
echo
fi
}
check_blocked "/v1/invoices/2009" "403"
check_blocked "/v1/invoices/2010" "403"
check_blocked "/v1/invoices/2011/export" "403"
The important part is not the shell. The important part is that the retest is anchored to previously captured evidence and expected secure behavior. If the original finding proved that cross-tenant invoice access returned 200 with leaked data, the retest should explicitly assert the post-fix secure state, preserve new artifacts, and update the finding object from open to closed only when the evidence supports it. That is how you stop security programs from mistaking “patch applied” for “risk verified as closed.” NIST’s post-testing guidance, Bugcrowd’s evidence expectations, and the structure of real incident response advisories all support this mindset. (منشورات NIST)
Choosing what to keep external and what to internalize
The most credible operating model is hybrid, not absolutist. Adobe’s public example is explicit about hybrid methodology, combining authenticated black-box testing and source-code-assisted testing. That is a strong clue for buyers. The right question is not “Should AI replace all external pentesters?” The right question is “Which parts of the pentest lifecycle benefit from being internal, continuous, and evidence-driven, and which parts benefit from truly external perspective or specialist depth?” (Adobe Blog)
The following comparison helps make that boundary concrete.
| Decision area | Traditional outsourced pentest | PTaaS model | AI-assisted internal workflow |
|---|---|---|---|
| Launch model | Project-based kickoff and testing window | Platform-backed, faster launch, ongoing engagement | Immediate on approved targets once policy and credentials exist |
| Scope flexibility | Often fixed early | More flexible than project-only work | Highest flexibility inside authorized boundaries |
| Retesting | Frequently delayed or treated as add-on | Usually improved through platform workflows | Can be continuous and tied directly to patch verification |
| Business logic and API state | Depends heavily on individual tester depth | Still human-led, often better collaboration | Strong when state, identity, and evidence are modeled well |
| External perspective | Strong | Strong | Weaker unless paired with outside review |
| Specialist niche work | Strong | Strong | متغير |
| Evidence preservation | Highly variable by vendor | Usually better than static PDFs | Best when evidence ledger is built into workflow |
| Control over credentials and boundaries | Shared with vendor | Shared with vendor and platform | Highest internal control |
| Best use case | Independent assessment, compliance, specialist reviews | Ongoing human testing with platform support | High-frequency validation, retest, regression, evidence generation |
This table is a synthesis of NIST’s testing and service-management guidance, Adobe’s hybrid outsourced testing model, PTaaS vendor descriptions from Cobalt and HackerOne, and OWASP’s emphasis on stateful web and API testing. The point is not that one column wins universally. The point is that each model solves a different operational problem. (منشورات NIST)
The internalize-first category is fairly clear. Keep high-frequency authenticated regression testing, authorization checks, fix verification, repeated business logic hypotheses, evidence collection, and engineering-facing reporting close to the application team. These are the places where latency kills value and where every additional retest request makes static outsourcing look expensive.
The keep-external category is also clear. Bring in outside experts when you need an unfamiliar perspective, a formal independent assessment, a niche specialty, code-assisted deep review, red teaming beyond the application layer, social engineering under formal approvals, or environments where a third-party attestation or recognized outside specialist carries institutional weight. NIST’s service guidance never said not to use external providers. It said to define outcomes, keep oversight, and retain internal expertise. That remains the sane approach. (منشورات NIST)
Common ways teams get this wrong
The first failure mode is treating the model as a source of truth. A convincing paragraph is not a finding. A classification label is not proof. Public report-quality guidance from both HackerOne and Bugcrowd assumes that a finding must be reproducible and supported by concrete evidence. If an AI system cannot show the request, response, artifact, and reproduction path, it has not earned trust. (HackerOne Help Center)
The second failure mode is skipping the control plane. Teams get excited about tool use, browser automation, or multi-step reasoning and forget the boring essentials: approved targets, exact window, credential boundaries, blocked actions, incident contact, and evidence retention. NIST’s ROE template exists because these details are not optional. (منشورات NIST)
The third failure mode is flattening identity. Business logic and authorization testing demand exact account context. If your AI agent does not know which role it is using, which tenant it belongs to, and which object lineage it is testing, it will produce noisy or misleading results. OWASP’s API and business logic guidance both make that problem obvious. (مؤسسة OWASP)
The fourth failure mode is overvaluing novelty and undervaluing closure. Real teams are not rewarded because the AI found a poetic vulnerability title. They are rewarded when a verified risk becomes a verified fix. That is why retesting, evidence hashes, screenshots, replayable requests, and final secure-state assertions matter so much. NIST’s post-testing guidance and the real-world instructions in vendor incident bulletins point to the same operational truth. (منشورات NIST)
The fifth failure mode is assuming that replacing vendors automatically reduces risk. It may reduce spend or delay, but it can also remove the fresh perspective that Adobe specifically values in its outsourced program. Internal AI workflows are powerful. They are not immune to local blind spots. The mature answer is to use them to reduce dependency on repeated outsourced labor, not to eliminate the value of independent external testing where it genuinely matters. (Adobe Blog)
A buyer checklist for outsourcing penetration testing with AI
Before adopting any AI-assisted pentest workflow, ask these questions.
Can the system enforce explicit scope, schedule, and action rules, or does it only document them after the fact. NIST and PTES both place pre-engagement rules at the foundation of the work. (منشورات NIST)
Can it preserve authenticated state and identity context across multi-step tests, especially for API authorization and business logic cases. OWASP makes clear that these are core risk areas and that they do not reduce cleanly to scanner signatures. (مؤسسة OWASP)
Can it produce replayable evidence, not just summaries. HackerOne and Bugcrowd say the answer must include steps, roles, URLs, parameters, screenshots, or POC media. (HackerOne Help Center)
Can it retest against expected secure behavior after a fix. The advisory patterns from NetScaler and ConnectWise show why post-fix validation matters operationally, not just theoretically. (NetScaler)
Can it generate outputs for multiple audiences from one evidence base. NIST says good reporting often needs multiple formats for different stakeholders. (منشورات NIST)
Can operators override, pause, or constrain the workflow mid-run. If not, the system is automating risk transfer, not security validation.
Can your team still bring in an external specialist or a formal outsourced pentest when independent perspective is the actual requirement. Hybrid beats ideology. Adobe’s own model is proof of that. (Adobe Blog)
What changes when you stop buying a PDF
The real shift is not “manual versus AI.” The real shift is document versus system.
A traditional outsourced pentest often ends in a report. A strong AI-assisted workflow begins with a policy, accumulates state, produces evidence, creates a report, and then continues into retest. That does not make the report less important. It makes the report a view over a living evidence chain instead of a terminal artifact. NIST’s post-testing guidance, bug bounty reporting practice, and current PTaaS marketing all converge on versions of this idea, even though they come from very different contexts. (منشورات NIST)
That is also why the best use of AI here is surprisingly conservative. Use it to narrow the distance between observation and proof. Use it to preserve context across long, stateful tests. Use it to turn raw execution into evidence another human can review. Use it to speed retest after patches or configuration changes. Use it to keep the control plane and the evidence model inside the organization. Do not use it as an excuse to skip scope discipline, evidence standards, or outside expertise when independent judgment is part of the requirement. (منشورات NIST)
The phrase outsource penetration testing with AI without losing control is therefore not about giving the job to a machine. It is about reclaiming the parts of the job that should have been internal operating capability all along: scope governance, authenticated regression, proof capture, engineering-facing retest, and fast validation after change. External specialists still matter. But they become a sharper tool used for the right work, not a queue you must re-enter every time you need to verify that a patch actually closed the hole. (منشورات NIST)
مزيد من القراءة
For external references, start with NIST SP 800-115, which remains the clearest public baseline for how technical security testing, penetration testing phases, rules of engagement, reporting, and remediation fit together. Pair it with NIST SP 800-35 for the procurement and service-management side of security testing services. Then read the OWASP Web Security Testing Guide for application testing depth, the OWASP API Security Top 10 entry on API1:2023 Broken Object Level Authorization for API-specific authorization risk, and the OWASP Top Ten project page for the current released web risk baseline. Adobe’s outsourced penetration testing blog is also worth reading because it is one of the better public descriptions of why a mature security team still values external testing while keeping structure and objectives internal. (منشورات NIST)
For incident-driven validation examples, the NVD entries and vendor advisories for CVE-2021-44228 Log4Shell, CVE-2023-34362 MOVEit Transfer, CVE-2023-4966 CitrixBleed, and CVE-2024-1709 ConnectWise ScreenConnect are useful because they show how real flaws force teams to think about exposure, mitigation, and retest instead of treating a pentest as a one-time event. (NVD)
For related Penligent material, the most relevant English pages are the Penligent home page, which publicly describes scope control and evidence-oriented outputs, the article كيفية الحصول على تقرير اختبار الذكاء الاصطناعي الخماسي, the article AI Pentest Copilot, From Smart Suggestions to Verified Findingsو أداة اختبار الذكاء الاصطناعي الخماسي، كيف تبدو الهجمات الآلية الحقيقية في عام 2026. Those pages are useful because they focus on proof, retest, and workflow design rather than reducing pentesting to AI-generated prose. (penligent.ai)

