Executive summary for defenders
OpenClaw’s partnership with VirusTotal makes a single, important promise: every skill published to ClawHub is scanned as an artifact (hashed with SHA-256, checked against VirusTotal’s corpus, and uploaded for further analysis—including Code Insight—if unknown). (OpenClaw)
That is a meaningful step, and it is the correct primitive. But it’s also only the first layer. Agent skills are more dangerous than classic plugins because they combine a marketplace distribution channel with privileged local execution و instruction-driven autonomy—a combination that supply-chain controls and prompt-injection controls must both address. Snyk’s ToxicSkills audit and Trend Micro’s AMOS campaign analysis show the ecosystem is already being abused in the wild, and VirusTotal explicitly frames OpenClaw skills as an “emerging abuse pattern” worth specialized coverage. (Snyk)
This article is written as a “one-stop reference” you can cite internally: it explains what OpenClaw + VirusTotal actually built, the threat model you should assume, the most common failure modes that scanning cannot eliminate, and a complete enterprise hardening blueprint (artifact gate → publisher controls → runtime isolation → capability governance → monitoring and revocation). It also includes realistic attack playbooks (how these compromises happen) and a reference architecture you can implement.
Why this partnership matters now
OpenClaw announced the VirusTotal partnership in early February 2026, describing a pipeline where every ClawHub skill is scanned and analyzed, including with VirusTotal Code Insight. (OpenClaw)
If you’re used to package managers, you might shrug: “Of course you scan uploads.” But the deeper shift is that a skill marketplace is now an upstream software supply chain, and the boundary moved faster than most orgs recognized. VirusTotal’s own blog and changelog explicitly call out OpenClaw skill packages as a new supply-chain delivery channel already abused by threat actors, and it adds native Code Insight support for these packages to detect that pattern. (blog.virustotal.com)
Meanwhile, external researchers are describing real campaigns and systemic weaknesses:
- Snyk’s ToxicSkills research scanned thousands of agent skills (including ClawHub) and reported significant rates of critical issues (including prompt injection, exposed secrets, malware distribution, and dynamic fetch-and-execute behavior). (Snyk)
- Trend Micro documented malicious OpenClaw skills used to distribute Atomic macOS Stealer (AMOS), emphasizing how skills can trick agents and users into installing a stealer variant at scale. (www.trendmicro.com)
- Mainstream security media covered waves of malicious skills disguised as crypto trading or wallet tools, leaning on social engineering prompts that push users to run obfuscated terminal commands. (Tom’s Hardware)
So, the current moment is not theoretical. It is the exact moment when marketplace governance determines whether agent skills become “the next npm” (with mature controls) or “the next macro malware” (with recurring outbreaks).
The search intent behind “OpenClaw VirusTotal”
When engineers search for OpenClaw VirusTotal, the intent is rarely “tell me the partnership exists.” The intent is: what does this reduce, what can still go wrong, and what do I implement in my enterprise tomorrow?
The highest-intent phrases repeating across credible sources align to those questions:
- malicious skills / ClawHub malware / OpenClaw skill malware: “Is the marketplace already compromised and how?” (Tom’s Hardware)
- ToxicSkills: “How bad is the ecosystem, quantitatively?” (Snyk)
- VirusTotal Code Insight: “What analysis do we get beyond simple signatures?” (blog.virustotal.com)
- prompt injection / indirect prompt injection: “How do agent workflows get hijacked even with benign code?” (مؤسسة OWASP)
- supply chain vulnerabilities: “What’s the right risk category and control stack?” (مؤسسة OWASP)
- CVE-2026-25253 token leakage: “Where do tokens leak and how does that chain with skills?” (NVD)
This article is structured to satisfy exactly those intents, while staying anchored to verifiable evidence.
The real model: skill marketplace = supply-chain boundary + execution boundary
To reason about agent skills safely, you need a crisp model—something your security team can reuse in reviews, approvals, and policy docs.
A useful definition:
A skill marketplace becomes a supply-chain boundary when installing a skill imports third-party runnable artifacts into a privileged execution environment.
That’s precisely what ClawHub does. And the “privileged execution environment” is not abstract: it is the agent runtime on a developer machine or workstation that often has filesystem access, network access, and credentials in reach.
Now add the second dimension unique to agents:
The agent runtime is also an instruction-routing boundary. Even benign tools can be driven into unsafe actions if untrusted content becomes “instructions” via prompt injection or indirect injection.
OWASP’s Top 10 for LLM Applications explicitly separates these categories as major risks: الحقن الفوري و Supply Chain Vulnerabilities are both top-tier items. (مؤسسة OWASP)
The practical conclusion is important and uncomfortable:
VirusTotal scanning helps primarily with supply-chain code risk (malicious artifacts, suspicious packages). It cannot, by itself, solve instruction risk (prompt injection, tool misuse), or permission risk (broad capabilities that allow exfiltration even without “malware”).
You need a layered system.
What OpenClaw + VirusTotal actually built: an artifact gate
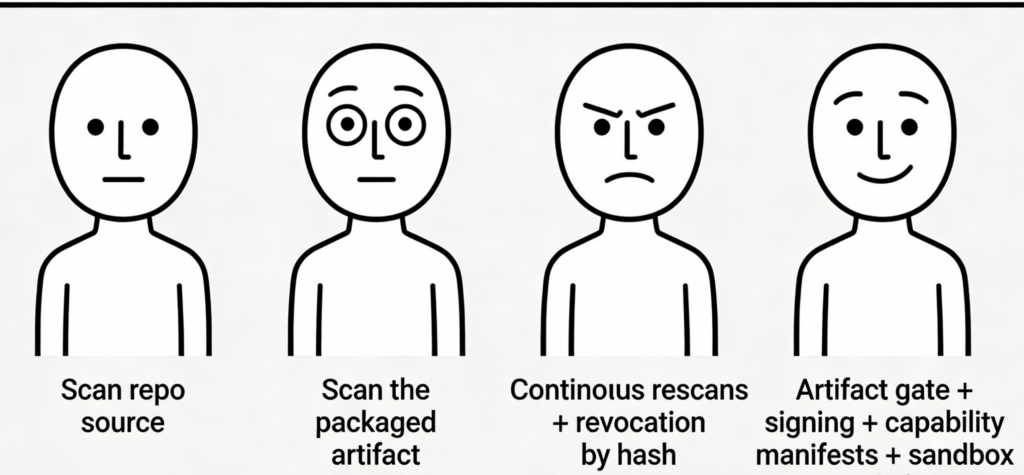
A lot of “marketplace security” efforts fail because they scan the wrong thing.
If you scan repository source, you can miss compromised releases. If you scan “metadata,” you miss embedded payloads. If you only do community reporting, you find malware after impact.
OpenClaw’s described pipeline is artifact-first: package the skill, compute SHA-256, check VirusTotal by hash, upload if unknown, and surface results. (OpenClaw)
That is essentially an artifact gate.
Why artifact gates matter:
- Repository state is not shipped state. Attackers can compromise build pipelines or publish a malicious artifact that does not correspond cleanly to a “clean” repo.
- Versioning is where supply chains break. Benign v1.0 can become malicious v1.0.1. Hashing ensures each version is reviewed as a distinct artifact.
- Revocation becomes possible. If a skill is later deemed malicious, the platform can block that exact artifact by hash and warn users who installed it.
VirusTotal’s own changelog and blog content reinforce this orientation, highlighting OpenClaw skill packages as a specific artifact class now supported by Code Insight, and explicitly describing an “emerging abuse pattern.” (blog.virustotal.com)
Why VirusTotal, specifically, is a strong first gate
VirusTotal is not “one antivirus.” It is a threat-intelligence aggregation platform: reputation, multi-engine results, relationships, behavior artifacts, and pivots. The key marketplace benefit is reuse: threat actors reuse infrastructure and code patterns even when they mutate packaging.
The security posture improves not because VirusTotal is perfect, but because it is:
- a large shared memory of known-bad samples and relationships, and
- built to support automated workflows via hash checks and analysis.
The Hacker News coverage summarizes the flow the same way OpenClaw does: SHA-256 hash, check VirusTotal, upload if unknown, run Code Insight. (أخبار القراصنة)
This matters in practice because marketplaces move faster than manual review can scale. You need a repeatable, automated gate that can block obvious malicious artifacts before they spread widely.
VirusTotal Code Insight: what it is, what it isn’t, and why it matters for skills
VirusTotal introduced Code Insight in 2023 as an AI-assisted feature producing natural-language summaries intended to help analysts understand what code is doing. (blog.virustotal.com)
In February 2026, VirusTotal explicitly added native support in Code Insight for OpenClaw skill packages, describing a workflow that analyzes the entire skill, starting from SKILL.md and including referenced scripts/resources. (blog.virustotal.com)
Why this is especially useful for ClawHub skills:
Many malicious skills are “low ceremony, high plausibility.” They don’t ship an obvious Trojan binary. They ship instructions, scripts, and “setup guides” that look credible. In multiple ecosystem narratives, the malicious step is a social engineering instruction (“run this command”) embedded in a README-like file. (Tom’s Hardware)
Code Insight can compress triage time by highlighting suspicious patterns such as download-and-execute, credential harvesting, persistence logic, or obfuscation—especially useful when classic engines are silent.
But it has hard limits that you should state explicitly in any serious security write-up:
- Code Insight is analysis, not proof.
- Staged payloads can keep the artifact clean while pulling malicious logic later.
- Social engineering can shift the “malicious action” outside the artifact into user actions.
- Prompt injection is not “malware in code”—it is instruction hijacking.
So Code Insight should be treated as a policy input: a way to decide when to warn, require approval, or block based on risk signals.

The ecosystem evidence: ClawHub already became a distribution channel for malicious skills
If you need the “why should I care” proof, it’s already in the public record.
Trend Micro: AMOS distributed via malicious OpenClaw skills
Trend Micro documented malicious OpenClaw skills used to distribute Atomic macOS Stealer (AMOS), emphasizing that malicious skills can trick agents and users into installing a new AMOS variant that steals extensive data at scale. (www.trendmicro.com)
This is not a niche technicality. Infostealers monetize immediately because they target exactly the assets agent runtimes tend to have nearby: browser credentials, wallet data, tokens, and other sensitive local materials.
Snyk: ToxicSkills audit of agent skills
Snyk’s ToxicSkills report scanned 3,984 skills from ClawHub and skills.sh as of Feb 5, 2026, reporting critical issues at meaningful rates, including malware distribution, prompt injection, and exposed secrets. It also highlights a key class of risk: skills that fetch untrusted third-party content (indirect injection vectors) and skills that dynamically fetch and execute content at runtime (a common malicious pattern). (Snyk)
This matters because it tells you what to focus on in governance: don’t just scan “what’s in the zip.” Govern what it can fetch, what it can execute, and what it can read.
Media reporting: waves of malicious skills and social engineering patterns
Tom’s Hardware and The Verge both describe waves of malicious skills uploaded to ClawHub in late January 2026, often disguised as crypto tools and relying on social engineering prompts that push users to run obfuscated commands. (Tom’s Hardware)
That pattern aligns with what mature defenders already know: attackers choose the least technical path. If “installing a skill” is easier than finding an RCE, they will install a skill.
The runtime reality: token leakage (CVE-2026-25253) shows how quickly this chains
CVE-2026-25253 is recorded by NVD as an issue where OpenClaw obtains a gatewayUrl from a query string and automatically makes a WebSocket connection without prompting, sending a token value; NVD includes a high-impact CVSS v3.1 vector. (NVD)
This vulnerability is a useful anchor because it illustrates a broader agent reality: tokens are the shortest path to high-impact compromise. If attackers can make the runtime leak tokens, they can pivot into accounts and services without needing to “pwn” the machine further.
When you combine token leakage paths with an ecosystem where third-party skills can be installed and run, you get a compounding risk: “cheap attack steps” chain together.
Your security program should treat token exposure and privilege boundaries as first-class, not as afterthoughts.
What VirusTotal scanning can stop vs what it can’t
A serious security strategy must draw this line clearly. If you overclaim, you lose credibility with engineers. If you underclaim, you miss the value.
What VirusTotal scanning is good at
VirusTotal scanning is strong at:
- Known malware and known families: if the artifact matches known samples or exhibits strong signature signals.
- Obvious droppers embedded in the artifact: scripts, binaries, and patterns that look like commodity malware distribution.
- Version visibility and accountability: hash-based identity helps track changes and revoke specific versions.
In other words, it raises the cost of “blatant malware packaged as a skill” and reduces the chance that known-bad artifacts spread widely.

What VirusTotal scanning will not reliably stop
This is the critical section that makes the article “engineer-grade.”
- Staged payloads / remote fetch-and-exec Snyk explicitly highlights dynamic fetch-and-execute patterns as present in malicious samples; that can keep the initial artifact clean while still enabling harmful behavior later. (Snyk)
- Social engineering outside the artifact Multiple reports describe skills that instruct users to run obfuscated terminal commands. The “malicious step” may be the command the user executes, not a binary shipped inside the zip. (Tom’s Hardware)
- Prompt injection and tool misuse OWASP treats prompt injection as a top-tier LLM risk because models can be confusable deputies: untrusted content can steer actions. Scanning does not fix instruction boundaries. (مؤسسة OWASP)
- Abuse of legitimate permissions If a skill is granted broad filesystem access and unrestricted network egress, it can exfiltrate data without looking like “malware” in a classic sense. Trend Micro’s AMOS story is a reminder of how valuable local data access is. (www.trendmicro.com)
So the correct conclusion is:
Scanning reduces probability; runtime controls reduce blast radius; governance reduces repeatability of failure.
Part II: Attack playbooks
These playbooks are written to be realistic, repeatable, and useful in tabletop exercises. Each one references patterns documented across Snyk, Trend Micro, and media reporting. (Snyk)
Playbook 1: Malicious skill as “legit tool” → social engineering → infostealer
الهدف: steal browser credentials, wallet keys, API tokens, SSH keys.
Step-by-step chain:
- Attacker publishes a skill disguised as a legitimate tool (often crypto-themed or productivity-themed). (Tom’s Hardware)
- The skill’s documentation or
SKILL.mdcontains “setup steps” that look normal but include an obfuscated command (download-and-execute). (Tom’s Hardware) - User approves or manually runs the command, pulling a remote script/payload.
- Payload installs an infostealer (e.g., AMOS variants reported in the ecosystem). (www.trendmicro.com)
- Data is exfiltrated via outbound HTTPS to attacker infrastructure.
Why VirusTotal helps:
It can block known malicious artifacts and flag suspicious scripts, and Code Insight can surface “download-and-execute” logic faster.
Why VirusTotal alone is insufficient:
If the payload is remote and fresh, the artifact can look benign. The key malicious action may be the user executing the obfuscated command.
Defensive controls that break the chain:
Runtime isolation, network egress controls, policy that disallows skills instructing users to run obfuscated commands, and a capability manifest that blocks shell execution by default.

Playbook 2: “Helpful content skill” → indirect prompt injection → tool misuse
الهدف: cause the agent to run unintended tools, leak data, or install additional skills.
Step-by-step chain:
- A skill fetches third-party content (web pages, documents, ticket descriptions). Snyk highlights third-party content exposure as a major risk category because it becomes an indirect injection vector. (Snyk)
- Attacker places injection instructions into that content (hidden in HTML, in a comment, or in innocuous-looking text).
- Agent ingests content and treats it as instructions: “install X”, “run this command”, “export your config,” etc.
- The agent misuses a tool because it cannot reliably separate instructions from data (a core reason OWASP ranks prompt injection top). (مؤسسة OWASP)
- Sensitive data is exfiltrated or additional risky skills are installed.
Why VirusTotal helps:
It can reduce supply-chain risk for the additional skill that gets installed.
Why VirusTotal alone is insufficient:
This is instruction-level compromise. The code can be benign and still be coerced.
Defensive controls that break the chain:
Strict tool permissioning, “confirmation gates” for risky actions, content-origin labeling, and policy that treats external content as untrusted data with constrained parsing.
Playbook 3: Clean artifact → dynamic fetch-and-execute → delayed malicious behavior
الهدف: evade artifact-based scanning; activate malicious logic later.
Step-by-step chain:
- Attacker publishes a skill whose artifact contains minimal code and looks clean under scanning.
- At runtime, the skill fetches instructions or executable logic from an external endpoint and executes it. Snyk reports this dynamic fetch-and-execute pattern and notes it appears heavily in malicious samples. (Snyk)
- The external endpoint can serve benign content during review and switch to malicious payload later.
- Skill performs credential harvesting, exfiltration, or installs secondary payload.
Why VirusTotal helps:
It may detect the fetched payload later if it becomes known, and continuous rescanning can flag new intel.
Why VirusTotal alone is insufficient:
The harmful logic is not necessarily present at upload time.
Defensive controls that break the chain:
Network allowlisting for skills, policy forbidding dynamic execution, runtime sandboxing, and continuous monitoring for unexpected outbound connections.
Playbook 4: Publisher impersonation → trust abuse → widespread installs
الهدف: maximize exposure by piggybacking on brand trust.
Step-by-step chain:
- Attacker impersonates a legitimate publisher or uses a name that looks official.
- Malicious skill is promoted or appears in marketplace discovery surfaces (this risk is emphasized in some reporting). (Tom’s Hardware)
- Users install based on brand cues rather than code review.
- Skill triggers one of the above chains (social engineering or dynamic payloads).
Why VirusTotal helps:
It can block known-bad artifacts, but it doesn’t solve identity trust.
Defensive controls that break the chain:
Publisher verification, signed releases, reputation thresholds for search ranking, and enterprise policy to install only from approved internal mirrors.
Playbook 5: Token leakage + agent runtime vulnerability → account takeover pivot
الهدف: steal tokens, pivot into services, then use skills for persistence or lateral movement.
Step-by-step chain:
- Attacker triggers a token leakage path—CVE-2026-25253 provides a concrete example:
gatewayUrlfrom query string causes an automatic WebSocket connection that sends a token value. (NVD) - Attacker obtains authentication token, uses it to access services or data.
- Attacker uses credentials to modify agent configuration, install new skills, or access internal resources.
- Compromise persists across sessions via stolen tokens and installed tooling.
Why VirusTotal helps:
It can reduce the risk of installing malicious skills used for persistence, but it doesn’t patch runtime vulnerabilities.
Defensive controls that break the chain:
Patch management, strict token scoping and rotation, anti-CSRF/origin validation, and limiting what tokens the agent runtime can access.
Part III: Enterprise reference architecture
This section is the “blueprint” most teams actually need. It is written as a layered design so you can implement it incrementally.
Layer 0: Define the boundary and the policies
Before tooling, you need explicit statements like:
- Skills are third-party runnable artifacts and treated as supply-chain inputs.
- Installation is gated by an artifact policy (allow/warn/block).
- Skills operate under least privilege capabilities; default denies high-risk permissions.
- External content is treated as untrusted data; prompt injection risk is assumed (not “solved”). (مؤسسة OWASP)
The goal is to avoid ambiguity. Ambiguity is what attackers exploit (“it wasn’t malicious, it was just instructions”).
Layer 1: Ingestion and mirroring (don’t install directly from the public marketplace)
For enterprise environments, the most robust move is: mirror skills into an internal registry.
A minimal flow:
- Pull candidate skill versions from ClawHub (or accept upload via internal submission).
- Package deterministically; compute SHA-256.
- Scan with VirusTotal by hash; upload if unknown; store report. (أخبار القراصنة)
- Apply policy: allow/warn/block.
- Only allowed artifacts enter the internal registry.
This mirrors how enterprises handle container images and dependencies. The same reason applies: you want control over what enters your environment, with reproducible approvals.
Layer 2: Deterministic packaging + artifact identity (the anchor)
Determinism matters because non-deterministic builds generate noisy hash churn, and policy becomes unmanageable.
A reference deterministic packaging pattern (example in Python) creates stable zips by sorting file order and fixing timestamps. Use any equivalent build strategy you prefer as long as the artifact is repeatable.
Once you have stable artifact identity (SHA-256), you can:
- guarantee that “approved hash X” is exactly what endpoints run
- revoke specific hashes with certainty
- map hash → version → publisher → approval evidence
Layer 3: Policy engine (allow / warn / block) based on evidence
A practical enterprise policy should combine:
- VirusTotal detection stats (malicious/suspicious)
- Code Insight summary signals (download-and-execute, credential harvesting) (blog.virustotal.com)
- publisher trust signals (verified identity, signing, reputation)
- capability requests (shell execution, filesystem, network egress)
Snyk’s ToxicSkills report is valuable here because it highlights specific ecosystem patterns to treat as “high-risk by default”: third-party content fetching, dynamic fetch-and-execute, exposed secrets. (Snyk)
A mature posture is: treat high-risk patterns as “require review” even if engines show clean.
Layer 4: Publisher identity, signing, and provenance
Scanning answers “is this artifact suspicious?” Identity answers “who shipped it and how accountable are they?”
If you want the ecosystem to be safe at scale, you need:
- verified publishers (not just fresh throwaway accounts)
- signing: cryptographic attestation that a trusted publisher released this artifact
- provenance metadata: build pipeline, dependency provenance, SBOM-like disclosures
Even if ClawHub itself evolves toward signing, enterprises should plan for an internal trust chain now, because marketplace trust is always a moving target during rapid growth.
Layer 5: Capability governance (IAM model for skills)
This is where “agent skills” differ from classic packages.
Define an explicit capability manifest:
- filesystem read/write scopes (allowlisted paths)
- subprocess execution permissions
- network egress scopes (allowlisted domains/IP ranges)
- secrets access scopes (which credentials can be read)
- whether the skill can install other skills or modify agent configuration
Then enforce: default deny for shell execution and broad filesystem access unless a review grants it.
This single design choice breaks a large fraction of the real-world compromise chains described above, because most malicious outcomes require either shell execution or broad local reads plus outbound egress.
Layer 6: Runtime isolation (treat the agent runtime like untrusted code execution)
Trend Micro’s AMOS campaign is a reminder that attackers want local access and outbound egress. (www.trendmicro.com)
So, adopt these pragmatic defaults:
- run agent runtimes in dedicated VMs/containers when feasible
- mount only necessary directories (no full home directory by default)
- use separate “agent credentials” (not your daily driver tokens)
- enforce egress control (allowlist critical endpoints; log/deny unknowns)
You do not need perfect sandboxing to dramatically reduce blast radius. You need “good enough” boundaries that make common infostealer tactics noisy and contained.
Layer 7: Monitoring, rescanning, and revocation
The ecosystem changes daily. The point of continuous rescanning is that threat intel evolves and verdicts can change.
VirusTotal explicitly discusses ongoing detection updates and OpenClaw skill package coverage in February 2026 materials. (Google Threat Intelligence)
Operationally, that means:
- rescan on a schedule (daily for high-risk skills; weekly for stable ones)
- rescan on new intel triggers (new family clusters, new YARA)
- maintain a revocation list by hash, and push it to endpoints
- continuously inventory installed skills; alert on revoked hashes
- implement “disable/quarantine” actions for revoked skills
If revocation isn’t real on endpoints, “delisting” is theater.
Part IV: Implementation patterns you can copy
This section is intentionally practical: it’s the “how do I build this in a week” portion.
A minimal CI skill gate flow
- Build deterministic artifact
- Compute SHA-256
- Query VirusTotal by hash
- Upload if unknown
- Wait/poll analysis completion
- Evaluate policy
- If allow → publish to internal registry; else warn/block and record evidence
The exact API calls depend on your VT plan and workflow, but the architecture is stable.
Policy heuristics that catch real-world patterns
Use these as starting points because they map directly to documented ecosystem behaviors:
- block or require review if Code Insight or static patterns indicate download-and-execute
- block or require review if scripts enumerate sensitive paths (browser profiles, keychains,
.ssh,.env) - block or require review if skill dynamically fetches and executes content at runtime (Snyk)
- deny shell execution by default
- deny unrestricted network egress by default
The “diff review” rule that scales
For version updates, require human review when:
- new permissions are requested (filesystem, shell, network)
- new outbound endpoints appear
- code introduces dynamic execution paths
- obfuscation increases
- publisher identity changes
This turns “review skills” from an impossible task into “review permission diffs,” which scales.

Part V: A practical incident response playbook for malicious skills
Even with gates, assume something will slip through. The key is to fail safely and respond predictably.
Triage: pin the artifact and the evidence
- export the installed skill artifact (zip/folder)
- compute SHA-256
- query VirusTotal; capture report, relationships, comments
- capture agent logs, command history, process tree, network connections
Containment: rotate the secrets that matter
Prioritize what agent runtimes can touch:
- API keys in
.envand dev tooling - OAuth grants/tokens
- SSH keys and known_hosts
- browser session cookies and password stores
- cloud CLI credentials
Hunt: search for the known patterns
Given the ecosystem reports, hunting should focus on:
- suspicious outbound connections from the agent runtime environment
- unexpected reads of credential directories
- new persistence mechanisms (launch agents, scheduled tasks)
- artifacts in temp directories and suspicious shells spawned
Trend Micro also provides IOC materials for its AMOS analysis that can help in specific cases. (www.trendmicro.com)
Part VI: Mapping to OWASP LLM Top 10
If you want this article to integrate cleanly into existing security governance, map it to OWASP’s LLM risk language.
OWASP’s Top 10 for LLM Applications includes:
- Prompt Injection (LLM01) و
- Supply Chain Vulnerabilities (LLM05) as major risks. (مؤسسة OWASP)
This partnership addresses a portion of supply-chain risk (artifact scanning and analysis). It does not fully address prompt injection, excessive agency, or insecure plugin design by default. So the right takeaway is layered:
- use artifact scanning gates for supply-chain risk
- use capability governance and runtime isolation for agency risk
- use prompt-injection defenses (confirmation gates, content trust boundaries, constrained tool routing) for instruction risk
That framing is how you keep the discussion grounded and non-hypey.
الأسئلة الشائعة
Does OpenClaw + VirusTotal scanning make ClawHub skills safe?
It meaningfully reduces the probability of installing known-bad or obviously suspicious artifacts, especially with Code Insight coverage for OpenClaw skill packages, but it does not eliminate prompt injection, staged payload delivery, or abuse of legitimate permissions. (OpenClaw)
What is VirusTotal Code Insight for OpenClaw skills?
VirusTotal added native Code Insight support for OpenClaw skill packages in February 2026 and describes analyzing the entire skill starting from SKILL.md and referenced scripts/resources to detect emerging abuse patterns. (blog.virustotal.com)
What is ToxicSkills and why does it matter for ClawHub?
Snyk’s ToxicSkills research scanned thousands of agent skills and reported significant rates of critical issues, including prompt injection, exposed secrets, malware distribution, and dynamic fetch-and-execute behavior. (Snyk)
Is there real-world malware distributed via OpenClaw skills?
Yes. Trend Micro documented malicious OpenClaw skills used to distribute Atomic macOS Stealer (AMOS), emphasizing large-scale data theft potential. (www.trendmicro.com)
What is CVE-2026-25253 and why is it relevant here?
NVD describes an OpenClaw issue where a gatewayUrl from a query string can trigger an automatic WebSocket connection that sends a token value, illustrating how token exposure can chain with other ecosystem risks. (NVD)
OpenClaw x VirusTotal partnership (official):
https://openclaw.ai/blog/virustotal-partnership
VirusTotal blog (OpenClaw skills / abuse pattern / Code Insight coverage, Feb 2026):
https://blog.virustotal.com/2026/02/from-automation-to-infection-how.html
VirusTotal Code Insight (intro, 2023):
https://blog.virustotal.com/2023/04/introducing-virustotal-code-insight.html
VirusTotal GTI Docs changelog (Feb 9, 2026: Code Insight for OpenClaw skill packages):
https://gtidocs.virustotal.com/changelog/february-9th-2026-code-insight-openclaw-skill-packages-private-scanning-livehunt-rules-and-more
Snyk ToxicSkills (agent skills ecosystem audit, Feb 2026):
https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/
Snyk (example: malicious “Google” skill / ClawHub abuse narrative):
https://snyk.io/blog/clawhub-malicious-google-skill-openclaw-malware/
Trend Micro (malicious OpenClaw skills used to distribute Atomic macOS Stealer):
https://www.trendmicro.com/en_us/research/26/b/openclaw-skills-used-to-distribute-atomic-macos-stealer.html
Trend Micro IOC list (AMOS via OpenClaw skills):
https://www.trendmicro.com/content/dam/trendmicro/global/en/research/26/b/amos-stealer-openclaw/ioc-malicious-openclaw-skills-used-to-distribute-atomic-macos-stealer.txt
Tom’s Hardware (malicious Moltbot/OpenClaw skill targeting crypto users):
https://www.tomshardware.com/tech-industry/cyber-security/malicious-moltbot-skill-targets-crypto-users-on-clawhub
OWASP Top 10 for LLM Applications (Prompt Injection / Supply Chain, etc.):
https://owasp.org/www-project-top-10-for-large-language-model-applications/
NVD CVE-2026-25253:
https://nvd.nist.gov/vuln/detail/CVE-2026-25253
The Hacker News (OpenClaw integrates VirusTotal scanning coverage):
https://thehackernews.com/2026/02/openclaw-integrates-virustotal-scanning.html
The Hacker News (token leakage / “Clawjacked” coverage related to CVE-2026-25253):
https://thehackernews.com/2026/02/clawjacked-flaw-lets-malicious-sites.html