OpenAI Daybreak and Anthropic Mythos are easy to frame as a vendor race. That framing is too small.
The real story is that AI is changing the economics of vulnerability research. Low-signal findings are becoming easier to produce, cheaper to generate, and harder for maintainers to triage. High-value vulnerabilities are moving in the opposite direction. A bug that is reachable, exploitable, reproducible, tied to business impact, and backed by clean evidence is becoming more valuable, not less.
That is the useful way to read the current OpenAI Daybreak vs Anthropic Mythos debate. Daybreak is not simply “OpenAI’s Mythos.” Mythos is not simply “Anthropic’s cyber model.” Both efforts point toward the same structural shift: AI can compress the time required to discover candidate issues, but the scarce work is increasingly validation, prioritization, safe patching, and retesting.
OpenAI describes Daybreak as a cyber defense initiative that combines GPT-5.5 and Codex Security to identify threats, generate patches, and verify remediation across code and systems. OpenAI’s related Trusted Access for Cyber model splits access into tiers, with GPT-5.5 for broad use, GPT-5.5 with Trusted Access for Cyber for verified defensive work, and GPT-5.5-Cyber for more specialized authorized workflows such as red teaming, penetration testing, and controlled validation. (OpenAI)
Anthropic’s Project Glasswing centers on Claude Mythos Preview, which Anthropic describes as a gated research preview and a general-purpose frontier model especially strong at coding, agentic tasks, and cybersecurity. Anthropic says Mythos Preview has identified many zero-day vulnerabilities across critical infrastructure, but that claim should be read precisely as Anthropic’s claim unless a specific finding is independently confirmed by the affected project, vendor, or third-party evaluator. (Anthropisch)
The better question is not which lab has the more impressive launch page. The better question is what happens to security work when AI can produce more plausible vulnerability candidates than humans can review, patch, and verify.
Daybreak and Mythos are solving different parts of the same problem
Daybreak and Mythos overlap, but they are not the same kind of thing.
Daybreak is best understood as a defensive workflow layer around OpenAI models, trusted access controls, and Codex Security. OpenAI’s own Codex Security description emphasizes project context, editable threat models, validation, patch generation, and post-remediation revalidation. It is not only about finding a suspicious code path. It is about reducing noise, validating findings in context where possible, producing fixes, and closing the loop after a merge. (OpenAI)
Mythos is presented differently. Anthropic describes Claude Mythos Preview as a highly capable frontier model with enough offensive and defensive cyber capability that access is gated. Project Glasswing is framed around using that capability to harden critical software before similar capabilities diffuse more broadly. (Anthropisch)
That distinction matters. One is more visibly packaged as a software defense pipeline. The other is more visibly packaged as a restricted frontier capability for finding and fixing deep defects in important codebases. Both still face the same hard boundary: a vulnerability report is not a security result until it survives validation.
| Dimension | OpenAI Daybreak | Anthropic Mythos and Project Glasswing | Practical reading |
|---|---|---|---|
| Public positioning | Cyber defense initiative built around GPT-5.5, Trusted Access for Cyber, GPT-5.5-Cyber, and Codex Security | Gated research preview and critical software hardening effort centered on Claude Mythos Preview | Daybreak is framed as an operating model; Mythos is framed as controlled access to a powerful capability |
| Main workflow | Threat modeling, vulnerability discovery, patch suggestions, validation, remediation verification | Deep code review, vulnerability discovery, exploit reasoning, critical software defense | Both still need human review, safe test harnesses, and maintainer confirmation |
| Access model | Tiered access based on trust and intended defensive use | Restricted research preview with selected partners | Access control is part of the product, not an afterthought |
| Best-fit evidence | Project context, validated findings, patches, revalidation | Source-level findings, model-assisted audits, partner hardening results | Evidence quality matters more than model branding |
| Main risk | Generating confident but still incomplete results if project context or runtime context is wrong | Overstating “confirmed” findings before maintainers validate them | AI security output must be treated as candidate evidence until proven |
| Most important question | Did the system reduce noise and close the remediation loop? | Did the finding survive expert review and produce a real fix? | The winner is the workflow that produces trusted fixes, not the loudest finding count |
The public evaluations make the comparison more interesting. The UK AI Security Institute reported that Claude Mythos Preview showed a step up over previous frontier models on capture-the-flag tasks and multi-step cyber-attack simulations. It later reported that GPT-5.5 was one of the strongest models it had tested on cyber tasks and was the second model to solve one of its multi-step cyber-attack simulations end to end. (AI Security Institute)
AISI also published a broader analysis on the rate of autonomous AI cyber capability progress. It estimated that, in its narrow cyber task suite, the length of tasks frontier models can complete autonomously has been doubling on the order of months, not years. It also cautioned that these benchmarks do not directly tell us how performance will translate against defended real-world systems. (AI Security Institute)
That caution is important. Cyber benchmarks can show capability progress, but real security work is messier. Real systems have stale dependencies, partial rollouts, broken staging parity, undocumented business logic, weird reverse proxies, unusual authentication flows, and release schedules that cannot be solved by a model alone.
Hacker News focused on proof, not press releases
The Hacker News discussion around Mythos is useful because it does not reward vendor claims by default. It asks the questions security engineers ask after every impressive demo: Was the bug real? Could it be reproduced? How many false positives were there? Did maintainers confirm it? Was the result due to the model, the harness, the human operator, or the target codebase?
The Mozilla case is the strongest public example on the positive side. Mozilla wrote that Firefox 150 included 271 security bug fixes identified by Claude Mythos Preview, and that Mozilla fixed 423 security bugs in April overall. Mozilla’s post also makes clear that the result came from a broader engineering process involving test harnesses, AI-assisted analysis, existing fuzzing work, and human security review. (Mozilla Hacks – the Web developer blog)
Hacker News treated that Mozilla post as a major discussion point, with the thread reaching hundreds of points and comments. The community’s focus was not just the number 271. It was whether those fixes represented independently exploitable vulnerabilities, internal security-hardening bugs, fuzzing-assisted discoveries, or a mixed class of issues that still required careful interpretation. (news.ycombinator.com)
The curl case became the reality check. Daniel Stenberg, curl’s maintainer, published a detailed account of a Mythos-assisted review of curl. The report presented five “confirmed” vulnerabilities, but curl ultimately confirmed only one low-severity CVE planned for a future release; Stenberg wrote that the scan found zero memory-safety vulnerabilities and that the review was a hand-driven analysis using LLM subagents, not automated SAST tooling. (daniel.haxx.se)
That does not prove Mythos is weak. curl is a heavily reviewed, security-conscious project with a long history of being hammered by fuzzers, static analyzers, humans, and previous AI-assisted reports. It does prove something more important: “confirmed by the model” is not the same as “confirmed by the maintainer.”
Hacker News commenters split along predictable but useful lines. Some saw the curl result as evidence that Mythos was “another tool,” not a revolution. Others argued that finding even one low-severity issue in curl is not embarrassing, because curl is unusually hardened compared with ordinary enterprise code. Both readings can be true at the same time. (news.ycombinator.com)
The synthesis is simple: AI-assisted vulnerability discovery is real, but the value is target-dependent and workflow-dependent. The same model may produce impressive results against a large browser codebase with rich harnesses and more modest results against a smaller, mature, aggressively audited C project. The difference is not only the model. It is the target, the harness, the available context, the validation standard, and the maintainer’s tolerance for ambiguity.
AI polarizes the bug market
AI does not make every bug worthless. It makes weak findings easier to produce.
That is a very different claim.
A low-value report usually has one or more of these properties: it is based only on a version string; it cannot prove the vulnerable code path is reachable; it lacks a safe reproduction path; it confuses theoretical weakness with exploitability; it reports a known issue without showing that the target is actually affected; or it uses AI-generated language to look polished while adding no evidence.
Those reports will become more common. A model can read an advisory, identify affected versions, scan public metadata, write a plausible report, and produce a remediation paragraph in seconds. That does not mean the report is wrong. It means the marginal cost of producing plausible but incomplete security claims is collapsing.
High-value vulnerability work sits at the other end. It proves that a real attacker can reach the vulnerable path under realistic conditions, that the impact matters, that the finding is not a duplicate, that the recommended fix addresses the root cause, and that the fix survives retesting.
The bug bounty market already hints at this split. Google said its Vulnerability Reward Program paid more than $17 million in 2025, an all-time high, to more than 700 researchers, and that its total VRP payouts since 2010 reached $81.6 million. Google also expanded AI-related reward work, including an AI Vulnerability Reward Program and AI-related categories in Chrome. (blog.google)
HackerOne’s 2025 reporting also points toward more AI in offensive workflows. HackerOne said autonomous agents submitted more than 560 valid reports, while its broader report described rising AI vulnerability reports and an emerging “hackbot” arms race. (HackerOne)
Those facts do not support the lazy claim that AI kills bug bounty. They support a sharper claim: AI raises the floor for what counts as a serious report. If a model can produce a generic version-matching report, that report becomes less valuable. If a researcher uses AI to build a clean exploitability argument, test it safely, eliminate false positives, and document business impact, that researcher becomes more valuable.
The market split looks like this:
| Finding type | What AI changes | Likely market effect | What still creates value |
|---|---|---|---|
| Version-only known CVE report | Easy to generate at scale | Lower value, more duplicates | Proof that the affected code path is actually reachable and unpatched |
| Static code smell | Easier to identify across large repos | More noise unless ranked by context | Data-flow proof, reachability, exploit preconditions, patch guidance |
| Low-impact misconfiguration | Easier to discover and describe | More common, lower bounty pressure | Evidence of real exposure, privilege impact, or sensitive data access |
| Variant of a known bug | Faster variant hunting | Higher volume of plausible candidates | Maintainer-confirmed variant with minimal false positives |
| Auth bypass or business logic flaw | AI can assist but not fully replace stateful testing | Still valuable | Reproducible path through real workflow state |
| Exploit chain | AI can help connect steps | More valuable if proven safely | Cross-boundary impact, persistence of evidence, controlled validation |
| Patch bypass | AI can diff, reason, and test variants | Increasingly valuable | Demonstrated failure of the fix and safe regression test |
The important word is “proven.” AI can generate a lot of vulnerability-shaped text. Security teams do not need more vulnerability-shaped text. They need evidence that a human owner can act on.
The discovery pipeline scales faster than the remediation pipeline
AI can parallelize discovery. Remediation is harder to parallelize.
A model can inspect many files at once, search for variants of old CVEs, compare a patch against historical vulnerabilities, summarize a dependency tree, and produce a plausible proof-of-concept outline. A security team can run several agents across several repositories or products. That compresses discovery time.
Patching does not compress as cleanly. A fix still needs an owner. The owner needs to understand the intended behavior. The patch needs to avoid breaking customers. Tests need to be added. Old branches may need backports. A release train may need to wait. Customers may need advisories. A WAF rule may reduce immediate exposure but not remove the bug. A patch may appear correct and still fail against a slightly different input path.
OpenAI’s own Daybreak and Codex Security positioning implicitly acknowledges this bottleneck. The public material emphasizes not only finding issues but also generating patches and verifying remediation, and Codex Security explicitly describes revalidation after remediation as part of the loop. (OpenAI Help Center)
That loop is where the AI security race becomes operationally serious. If an organization only accelerates discovery, it may become less secure in practice because it creates a larger backlog of untriaged, unowned, unresolved issues. If it accelerates validation and repair, it can reduce actual risk.
| Bühne | AI can accelerate | Why humans and systems still matter |
|---|---|---|
| Candidate discovery | Code search, variant hunting, advisory matching, fuzzing hints, dependency analysis | Models may overstate confidence or miss deployment-specific constraints |
| Reachability analysis | Call graph review, route mapping, config review, SBOM correlation | Runtime behavior, feature flags, auth state, and traffic paths may differ from code assumptions |
| Exploitability assessment | Safe PoC planning, sandbox reproduction, payload minimization | Authorization, legal scope, safety controls, and environment isolation are non-negotiable |
| Prioritätensetzung | Severity reasoning, business context summarization, duplicate clustering | Asset criticality, data sensitivity, customer exposure, and regulatory context require ownership |
| Patch design | Root-cause analysis, suggested code changes, regression test drafts | Maintainers must preserve intended behavior and avoid breaking compatibility |
| Release | Backport planning, advisory drafting, upgrade instructions | Deployment windows, customer dependencies, and release governance dominate speed |
| Retest | Automated checks, original-path replay, variant tests | A “fixed” version must be verified in the actual environment, not only in a branch |
The asymmetry creates the uncomfortable situation many teams are about to face. They will be able to find more than they can fix.
That is not a reason to avoid AI. It is a reason to build disciplined queues. Every AI-assisted security workflow should separate candidate findings from verified findings. It should make uncertainty visible. It should record the evidence that changed the status of a finding. It should make retesting part of the same workflow, not a separate afterthought.
CVE-2025-55182 shows why exposure is harder than version matching
CVE-2025-55182, the React Server Components vulnerability disclosed in December 2025, is a clean example of the new validation problem.
The React team described it as a critical security vulnerability in React Server Components affecting versions 19.0, 19.1.0, 19.1.1, and 19.2.0 of react-server-dom-webpack, react-server-dom-parcel, and react-server-dom-turbopack, with a CVSS score of 10.0. NVD describes it as a pre-authentication remote code execution vulnerability caused by unsafe deserialization of payloads from HTTP requests to Server Function endpoints. (Reagieren Sie)
At first glance, this looks like an easy AI win. Ask a model to scan package manifests. Ask it to identify affected package versions. Ask it to draft upgrade instructions. Ask it to generate a non-destructive validation checklist. That is useful.
But real exposure is not the same as an affected package in package-lock.json.
A team still needs to answer practical questions:
| Validation question | Warum das wichtig ist |
|---|---|
| Is the affected package installed directly or only through a framework? | Direct dependency ownership affects upgrade path and urgency |
| Is React Server Components actually enabled? | Installed code may not be reachable |
| Are Server Function endpoints exposed to untrusted users? | Pre-auth exposure changes severity and remediation priority |
| Is the vulnerable package bundled into a deployed artifact? | Repo state may not match production state |
| Are patched versions deployed everywhere? | Canary, staging, edge, and old serverless functions may diverge |
| Are logs showing suspicious RSC or Flight requests? | Exploitation attempts may begin before all assets are found |
| Did the patch remove the vulnerable behavior or only block one payload shape? | Variant risk matters after a public critical RCE |
A safe validation workflow for this class of issue starts with inventory and evidence, not live exploitation against production. For example, a defensive team can begin with package discovery:
# Run inside authorized repositories or build artifacts only.
# The goal is dependency inventory, not exploitation.
npm ls react-server-dom-webpack react-server-dom-parcel react-server-dom-turbopack --all
grep -R "\"react-server-dom-webpack\"\\|\"react-server-dom-parcel\"\\|\"react-server-dom-turbopack\"" \
package.json package-lock.json pnpm-lock.yaml yarn.lock 2>/dev/null
A team can then add a CI guardrail to block known affected versions. The exact version policy should follow the vendor advisory and the organization’s package manager, but the principle is simple: do not let known vulnerable RSC package lines re-enter the build after the emergency patch.
name: dependency-security-check
on:
pull_request:
push:
branches:
- main
jobs:
block-affected-rsc-packages:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Check installed React Server Components packages
run: |
node <<'NODE'
const fs = require("fs");
const lockFiles = ["package-lock.json", "pnpm-lock.yaml", "yarn.lock"];
const affected = [
"react-server-dom-webpack",
"react-server-dom-parcel",
"react-server-dom-turbopack"
];
let found = false;
for (const file of lockFiles) {
if (!fs.existsSync(file)) continue;
const body = fs.readFileSync(file, "utf8");
for (const pkg of affected) {
if (body.includes(pkg)) {
console.log(`[review-required] ${pkg} appears in ${file}`);
found = true;
}
}
}
if (found) {
console.log("Review package versions against the vendor advisory before merging.");
process.exit(1);
}
console.log("No targeted RSC package names found in lockfiles.");
NODE
That check is intentionally conservative. It does not prove exploitability. It prevents silent reintroduction and forces a human to review affected packages. For a critical RCE class, that is often the right first gate.
Logs can also provide useful non-destructive evidence. A team can search for unusual requests to known RSC-related routes or suspicious request bodies without publishing exploit payloads:
# Example only. Adjust fields and paths to your log format.
# Use on authorized logs from your own environment.
jq -r '
select(
(.request_uri // "" | test("_rsc|server-action|flight"; "i"))
or
(.headers["content-type"] // "" | test("text/x-component|multipart"; "i"))
)
| {
ts: .timestamp,
ip: .remote_addr,
method: .method,
uri: .request_uri,
status: .status,
user_agent: .headers["user-agent"]
}
' access.log.jsonl
The point is not that these commands solve CVE-2025-55182. They show the right posture: inventory, reachability, exposure, evidence, patch, retest. AI can help at every stage, but it should not be allowed to turn an affected dependency into a confident exploit claim without proof.
Log4Shell taught the same lesson at internet scale
Log4Shell, tracked as CVE-2021-44228, is the canonical example of why discovery and remediation are different problems. NVD describes the vulnerability as a flaw in Apache Log4j2 where attacker-controlled data in log messages or parameters could trigger remote code execution through JNDI lookups in affected versions. (NVD)
Finding vulnerable versions was only the beginning. Organizations had to locate direct and transitive dependencies, identify embedded Log4j copies in commercial software, deal with shadow applications, apply emergency mitigations, upgrade, and then verify that vulnerable behavior was gone across production environments.
AI would have helped in many parts of that crisis. It could have searched repositories, explained dependency trees, drafted SBOM queries, clustered duplicate alerts, generated test plans, and summarized vendor advisories. It would not have eliminated the hard parts: asset ownership, patch rollout, third-party software uncertainty, and long-tail retesting.
A defensive query for Log4Shell-style exposure might start with dependency and artifact discovery:
# Defensive inventory only. Run in owned environments.
find /opt /srv /app -type f \( -name "*.jar" -o -name "*.war" -o -name "*.ear" \) \
-print 2>/dev/null | while read -r artifact; do
if unzip -l "$artifact" 2>/dev/null | grep -qi "log4j-core"; then
echo "[review] $artifact contains log4j-core"
fi
done
That command does not prove exploitability. It creates an evidence queue. The next step is to identify version, reachability, JVM flags, mitigation state, exposure to attacker-controlled input, and whether the vulnerable lookup path can run.
This is where AI-assisted triage can be genuinely useful. It can turn raw artifact lists into owner-specific tasks. It can compare mitigation guidance against runtime configuration. It can draft service-specific retest steps. It can help write regression tests. But the workflow must preserve uncertainty.
A good internal status label is not “AI found Log4Shell.” A good status label is one of these:
| Status | Bedeutung |
|---|---|
| Candidate | A signal suggests possible exposure, but no reachability or version proof exists |
| Affected dependency | A vulnerable component is present in a build, image, or host |
| Reachable path confirmed | Attacker-controlled input can reach logging code or a relevant sink |
| Mitigated | A temporary control reduces exploitability, but root cause may remain |
| Gepatcht | Vulnerable component or behavior has been removed |
| Retested | Original and variant checks confirm the fix in the deployed environment |
That language matters because it prevents AI from flattening the difference between suspicion and proof.
XZ Utils shows why source visibility is not enough
CVE-2024-3094, the XZ Utils backdoor, is a different kind of warning. NVD describes malicious code in upstream xz tarballs starting with version 5.6.0, where complex obfuscation in the build process extracted a prebuilt object from disguised test files and modified liblzma functions during build. CISA warned about malicious code embedded in XZ Utils 5.6.0 and 5.6.1. (NVD)
This was not a normal bug pattern. It was a supply-chain compromise involving release artifacts, build logic, trust in maintainers, and differences between repository state and packaged tarballs. The original oss-security disclosure described the upstream repository and tarballs as backdoored after suspicious behavior was observed around liblzma. (openwall.de)
AI-assisted code review may help detect suspicious build scripts, obfuscated test files, or unusual diffs. But XZ illustrates why the problem cannot be reduced to “scan source code.” A backdoor can live in release artifacts, generated files, CI behavior, maintainer workflows, or build-time transformations that are not obvious in the repository tree a model sees.
A defensive check for XZ-style risk needs provenance and artifact verification, not only code review:
# Defensive package inventory for Linux hosts.
# Use vendor guidance to decide whether a version is affected in your distribution.
xz --version 2>/dev/null || true
dpkg -l | grep -E '^ii\s+(xz-utils|liblzma)' || true
rpm -qa | grep -E '^(xz|xz-libs|liblzma)' || true
# Review package origin and build metadata where available.
apt-cache policy xz-utils 2>/dev/null || true
rpm -qi xz xz-libs 2>/dev/null || true
Again, the command is not the answer. The answer is a workflow that asks the right questions:
| Frage | Why it matters for supply-chain compromise |
|---|---|
| Which version is installed? | Affected version ranges define initial exposure |
| Which distribution built the package? | Vendor patches and build flags may change impact |
| Was the package installed during the risk window? | Timing can separate theoretical exposure from actual exposure |
| Does the affected library load into sensitive processes? | Impact depends on runtime integration |
| Can the build artifact be traced to a trusted source? | Source repository review may miss altered release tarballs |
| Is there evidence of suspicious behavior? | Process, auth, and performance anomalies may be early indicators |
AI can help ask and answer these questions faster. It cannot replace the need for artifact provenance, vendor trust, and runtime evidence.
Heartbleed reminds us that small bugs can carry huge value
CVE-2014-0160, better known as Heartbleed, is useful because it separates bug complexity from impact. NVD describes Heartbleed as an OpenSSL issue where successful exploitation could leak memory locations that may contain sensitive information such as cryptographic keys and passwords. (NVD)
Heartbleed was not valuable because it required a long exploit chain. It was valuable because it affected a critical cryptographic library, was remotely triggerable, and could expose secrets. In an AI-saturated vulnerability market, this distinction becomes even more important.
A high-value bug does not have to be aesthetically complex. It has to be impactful.
AI will likely find many small mistakes. Most will not be Heartbleed. The rare ones that combine reachability, sensitive impact, and widespread deployment will become more valuable precisely because AI will flood the market with low-impact lookalikes.
White-box AI is a major advantage, but it answers a different question
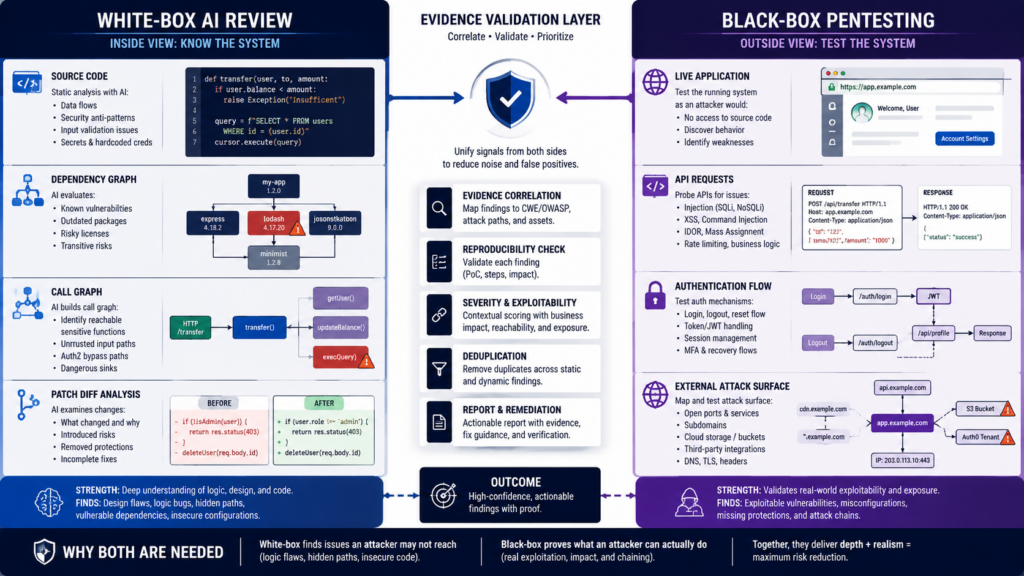
White-box security review starts with internal visibility. NIST defines white-box testing as a methodology that assumes explicit and substantial knowledge of the internal structure and implementation details of the assessment object. NIST defines black-box testing as testing that assumes no knowledge of the internal structure and implementation details. OWASP’s Web Security Testing Guide also distinguishes white-box testing such as source code analysis from black-box testing such as penetration testing. (csrc.nist.gov)
That difference is not academic. It changes the evidence.
A white-box AI reviewer can inspect code paths that a black-box tester may never reach. It can compare a patch to the vulnerable code it replaced. It can reason about data flow from an untrusted parser to a dangerous sink. It can read route definitions, authorization middleware, serialization logic, build scripts, and dependency manifests. It can search for variants of old bugs across a codebase.
A black-box tester starts from the outside. The tester sees exposed endpoints, authentication flows, response behavior, state transitions, cookies, headers, rate limits, proxy behavior, and deployment mistakes. That is closer to adversary reality, but it may miss hidden internal paths that are not obvious from the boundary.
Neither view is complete.
| Frage | White-box AI review | Black-box pentesting |
|---|---|---|
| What evidence does it start with? | Source code, diffs, dependencies, architecture notes, configs, tests | Reachable assets, HTTP behavior, auth flows, responses, traffic, deployed state |
| What does it find well? | Logic flaws, insecure defaults, unsafe deserialization, missing authorization checks, patch regressions, dangerous sinks | Exposure drift, broken access control, deploy mistakes, auth bypass, business logic abuse, real exploitability |
| What can it overstate? | Reachability and real-world exploitability | Absence of hidden internal defects |
| What can it understate? | Deployment-specific controls or compensating mitigations | Deep code paths that require source visibility |
| Best stage | Design review, pre-merge review, diff review, dependency audit, patch review | Pre-release validation, production-safe testing, external exposure assessment, post-fix retest |
| Strongest output | Code-grounded finding with root-cause explanation and patch guidance | Reproducible attack path with request/response evidence and observed impact |
White-box access is a real advantage. Anyone who has done serious application security knows this. Seeing the source removes guesswork. It lets the reviewer trace trust boundaries, model state, and understand whether a bug is a real design failure or an unreachable branch.
But white-box findings still need external validation when the question is attacker impact. The source can say a dangerous endpoint exists. The deployment may put it behind an internal network boundary. The code can say a check is missing. A gateway may enforce it. The reverse can also happen: the source may look safe, while production routing, headers, feature flags, or identity provider behavior breaks the intended security model.
This is why the useful future is not white-box AI versus black-box pentesting. It is white-box AI before black-box validation.
A source-aware model can identify the strongest candidates. A controlled black-box workflow can test whether those candidates matter in the deployed system.
The new security bottleneck is evidence discipline
Security teams should stop asking only, “Can AI find vulnerabilities?”
The better question is, “Can the workflow turn a vulnerability candidate into evidence another engineer can trust?”
A good AI-assisted vulnerability workflow should preserve every important transition:
finding_lifecycle:
- state: candidate
required_evidence:
- source_signal
- affected_component
- initial_reasoning
cannot_claim:
- exploitability
- production_impact
- state: affected
required_evidence:
- affected_version_or_code_path
- deployment_presence
- owner
cannot_claim:
- external_reachability_without_route_evidence
- state: reachable
required_evidence:
- route_or_call_path
- auth_context
- runtime_configuration
cannot_claim:
- impact_without_safe_validation
- state: validated
required_evidence:
- safe_reproduction_steps
- observed_result
- logs_or_artifacts
- scope_confirmation
- state: fixed
required_evidence:
- patch_reference
- root_cause_mapping
- regression_test
- state: retested
required_evidence:
- original_path_recheck
- variant_recheck
- environment
- timestamp
This is boring, and that is why it works. It prevents the most common failure mode in AI security: a polished report that hides uncertainty.
AI systems should be forced to say what they know and what they do not know. They should distinguish source evidence from runtime evidence. They should separate a vulnerable dependency from an exploitable service. They should record the command, environment, scope, output, and assumptions behind every claim.
For authorized testing teams, this is where AI-assisted pentesting platforms become useful only if they preserve evidence rather than produce more text. Penligent’s public materials describe an agentic AI pentesting workflow with scope control, user-controlled agentic actions, verification, and reporting; its related writing on white-box audits and black-box proof makes the same practical distinction between internal code visibility and external validation. Those claims should be evaluated the same way as any other tool claim: by the quality of the evidence chain, the safety boundaries around execution, and the ability to retest after remediation. (penligent.ai)
The best security reports are not the longest. They are the ones a maintainer can replay.
A safe validation workflow for AI-reported issues
An AI-reported vulnerability should enter a disciplined queue, not a panic channel.
The workflow below works for known CVEs, AI-discovered source issues, and suspected patch bypasses. It assumes authorized systems only.
Start with scope
The first step is not a prompt. It is authorization.
Define the target assets, repositories, environments, allowed test types, disallowed actions, rate limits, time window, contacts, logging expectations, and rollback conditions. A model should not decide whether an active test is permitted. That belongs in the engagement rules.
A minimal scope file can be simple:
test_scope:
organization: example-corp
authorized_by: security-owner@example.com
environments:
- name: staging
base_url: https://staging.example.com
active_testing_allowed: true
- name: production
base_url: https://www.example.com
active_testing_allowed: false
passive_checks_allowed: true
allowed_actions:
- dependency_inventory
- log_review
- configuration_review
- non_destructive_http_checks
- sandbox_reproduction
- patch_retest
prohibited_actions:
- credential_theft
- persistence
- data exfiltration
- destructive payloads
- denial_of_service
- testing_third_party_assets_without_permission
evidence_required:
- timestamp
- environment
- command_or_request_summary
- observed_result
- remediation_recommendation
- retest_result
That file is not bureaucracy. It is what keeps AI-assisted testing from drifting into unsafe behavior.
Collect context before asking for conclusions
A model with no context will overgeneralize. Before asking it whether a system is vulnerable, collect the context that determines the answer.
For a web application, that often includes:
# Dependency inventory
npm ls --all > evidence/npm-tree.txt
pip freeze > evidence/python-freeze.txt
go list -m all > evidence/go-modules.txt
# Runtime and deployment hints
env | sort > evidence/env-redacted.txt
kubectl get deploy,svc,ingress -n app-namespace > evidence/k8s-summary.txt
# Routes and build artifacts, adjusted to framework
find . -maxdepth 4 -type f \
\( -name "routes.*" -o -name "middleware.*" -o -name "next.config.*" -o -name "vite.config.*" \) \
-print > evidence/framework-files.txt
Sensitive data should be redacted before being sent to any model or external service. Security context is useful; secrets are not necessary for most triage.
Separate reachable code from installed code
Many AI-generated reports fail here. They identify an affected package or dangerous function and jump straight to exploitation. That is not enough.
Reachability needs evidence. In source review, that may be a call path. In black-box testing, that may be a route and request sequence. In runtime review, that may be logs showing attacker-controlled input hitting the affected component.
A simple reachability note should look like this:
Finding: Possible unsafe deserialization in server action handler
Evidence:
- Affected package appears in pnpm-lock.yaml.
- Route /api/action maps to server action handler in app/actions.ts.
- Middleware requires no authenticated session for POST requests to this route.
- Staging logs show external POST traffic to the route.
- No destructive payload was sent. Validation used a benign canary request.
Unproven:
- Arbitrary code execution has not been demonstrated.
- Production exposure has not been actively tested.
- WAF behavior in production may differ from staging.
That note is more valuable than a confident but unsupported “critical RCE” label.
Use sandbox reproduction before live validation
When a vulnerability class involves RCE, deserialization, authentication bypass, or data access, the safest path is usually local or sandbox reproduction first. Live production testing should be non-destructive unless there is explicit authorization and a strong operational reason.
A sandbox validation plan might be:
sandbox_validation:
objective: reproduce vulnerable behavior without touching production
inputs:
- vulnerable package version
- minimal app route
- patched package version
checks:
- vulnerable build shows expected unsafe behavior with benign marker
- patched build rejects or safely handles same marker
- regression test fails before patch and passes after patch
outputs:
- minimal reproduction repository
- test command
- patch reference
- risk explanation
This kind of plan is especially useful for critical CVEs. It gives developers something they can run without asking them to trust a model’s claim.
Preserve request and response evidence, but do not leak secrets
For black-box validation, the evidence should be enough to replay the issue but not enough to expose customers or secrets.
A good evidence bundle includes:
- Target environment: staging
- Timestamp: 2026-05-14T03:20:11Z
- Tester identity: security-team@example.com
- Authorization reference: SEC-2026-0514
- Request summary: POST to /api/example with benign marker
- Response summary: 500 error with stack trace confirming vulnerable path
- Logs: application log excerpt with request ID
- Impact: attacker-controlled input reaches unsafe parser before auth check
- Data accessed: none
- Destructive action: none
- Fix recommendation: move auth check before parser and update affected dependency
- Retest result: patched build returns 401 before parser execution
The point is not to make AI write prettier reports. The point is to make evidence survivable.
How to rank AI-generated vulnerability candidates
Severity labels are not enough. CVSS can help, but it cannot replace local context.
A candidate critical vulnerability in a dead code path is not equal to a high vulnerability on an internet-exposed identity service. A medium issue in a payment workflow may matter more than a nominally severe bug blocked by multiple controls. AI can help draft severity reasoning, but the ranking should be explicit.
A practical scoring model can combine six questions:
| Factor | Frage | Warum das wichtig ist |
|---|---|---|
| Exposure | Can an untrusted actor reach the vulnerable path? | Reachability is the first filter for real-world risk |
| Privilege | Does exploitation require authentication or special role state? | Pre-auth and low-privilege paths deserve faster response |
| Auswirkungen | What can the attacker actually do? | RCE, auth bypass, and sensitive data access outrank cosmetic impact |
| Reliability | Can the issue be reproduced safely and consistently? | Reliable exploitation changes both urgency and confidence |
| Blast radius | How many assets, tenants, users, or environments are affected? | Broad exposure can outrank a single high-value host |
| Fix confidence | Is there a clear patch and regression test? | Unclear fixes create retest and variant risk |
A YAML policy can make that concrete:
priority_policy:
p0:
conditions:
- pre_auth: true
- impact_any:
- remote_code_execution
- tenant_escape
- credential_exposure
- reachable_from_internet: true
required_action: immediate_owner_assignment_and_safe_mitigation
p1:
conditions:
- authenticated_low_privilege: true
- impact_any:
- privilege_escalation
- sensitive_data_access
- business_logic_abuse
- reproducible: true
required_action: fix_in_current_release_cycle
p2:
conditions:
- affected_component_present: true
- reachability_uncertain: true
required_action: complete_reachability_analysis_before_severity_escalation
p3:
conditions:
- theoretical_or_static_only: true
- no_runtime_path: true
required_action: track_or_close_with_evidence
The policy forces AI output into operational reality. A model can propose a label, but it must satisfy evidence requirements.
What Daybreak and Mythos imply for bug bounty hunters
For bug bounty hunters, the AI shift is double-edged.
The good news is that AI can make a strong researcher faster. It can summarize large JavaScript bundles, trace source maps, cluster endpoints, write helper scripts, compare documentation against actual API behavior, draft clean reproduction steps, and help reason about variants.
The bad news is that every other researcher gets similar assistance. If the target is a known CVE, a public endpoint, a shallow misconfiguration, or a common scanner finding, AI will compress the time advantage quickly. The bounty value of shallow discovery goes down when many people can do it at the same time.
The defensible strategy is to move up the value chain:
| Old advantage | AI-era replacement |
|---|---|
| Running more tools than other hunters | Understanding target-specific business logic better |
| Submitting faster version-match reports | Proving actual reachability and impact |
| Finding common payload-class bugs | Chaining issues across auth, state, and trust boundaries |
| Writing long reports | Writing concise reports with clean replay evidence |
| Hunting only public CVEs | Finding variants, patch bypasses, and workflow-specific abuse |
| Depending on luck | Building repeatable methodology and evidence capture |
A bug bounty report that says “the dependency is vulnerable” will age badly. A report that says “this endpoint is reachable without authentication, this request path reaches the vulnerable component, this benign marker proves code path control, this patch version eliminates the behavior, and here are the logs” will still be valuable.
AI makes weak reports cheaper. It makes strong reports more obviously strong.
What Daybreak and Mythos imply for security teams
For security teams, the challenge is not choosing a side in the OpenAI Daybreak vs Anthropic Mythos debate. The challenge is designing an internal process that can absorb AI-speed discovery without drowning.
The first rule is to protect triage quality. Every AI-generated finding should enter a queue with required fields: affected asset, evidence type, confidence, reachability, impact, owner, remediation path, and retest plan. Findings without enough evidence should be treated as candidates, not vulnerabilities.
The second rule is to measure false positives honestly. If a model produces 100 issues and 70 require human review but only 5 become real fixes, the model may still be useful, but the review cost must be counted. Maintainers care about cost. The curl example matters because a “confirmed” label carried more confidence than the maintainer review supported. (daniel.haxx.se)
The third rule is to connect security testing to engineering systems. A finding that cannot become a ticket, pull request, test, patch, advisory, or suppression rule is not finished. It is only information.
The fourth rule is to plan for retesting. AI can help generate regression tests and rerun safe checks after a fix. That matters because patch bypasses and incomplete mitigations are common in real incidents.
The fifth rule is to support maintainers. Open source projects are already strained by low-quality vulnerability reports. AI can make that worse. A responsible disclosure workflow should reduce maintainer burden by including minimal reproduction, affected versions, clear impact, non-destructive evidence, and willingness to help verify fixes.
The most common mistakes in AI-assisted vulnerability work
The first mistake is treating an AI finding as a confirmed vulnerability. A model can be right and still lack evidence. The finding should be labeled as a candidate until source, runtime, or reproduction evidence supports it.
The second mistake is treating a vulnerable dependency as exploitability. Dependencies can be present but unused, bundled but unreachable, deployed in a protected context, or patched by distribution-specific backports. The reverse can also be true: a patched dependency may not have reached every production asset.
The third mistake is confusing white-box precision with external impact. Source visibility can identify a dangerous path, but black-box validation determines whether an attacker can reach and abuse that path in the deployed system.
The fourth mistake is confusing black-box silence with safety. A black-box test can miss hidden code paths, rare state transitions, role-specific behavior, and deep dependency bugs. White-box review may find problems that external testing did not trigger.
The fifth mistake is skipping the evidence chain. Screenshots and prose are not enough for serious security work. Teams need request IDs, logs, version evidence, commands, outputs, timestamps, environment names, patches, and retest results.
The sixth mistake is overusing exploit generation. For known critical vulnerabilities, many teams can validate exposure safely through inventory, reachability, logs, and sandbox reproduction before any live exploit attempt. Active exploitation belongs only inside authorized, controlled conditions.
The seventh mistake is failing to separate mitigation from remediation. A WAF rule, feature flag, or network block may reduce immediate exposure. It may not remove the vulnerable code or dependency. AI reports should track both.
The eighth mistake is measuring success by finding count. A model that produces fewer findings but higher-confidence fixes may be more valuable than a model that produces hundreds of plausible reports.
A practical operating model for the next year
The next year of AI security work should be built around a layered model.
Use white-box AI review to scan code, diffs, dependencies, patches, and variants. Use black-box validation to test real deployed behavior. Use fuzzing and harnesses where the target supports them. Use SBOM and asset inventory to find exposure. Use CI checks to prevent reintroduction. Use structured evidence to move findings through the queue. Use retesting as a first-class stage.
A practical stack does not need to be glamorous:
1. Asset inventory
- domains, repos, services, APIs, owners, environments
2. Dependency and SBOM visibility
- package managers, containers, lockfiles, runtime artifacts
3. White-box AI review
- source paths, diff review, variant hunting, patch reasoning
4. Static and dynamic testing
- SAST, fuzzing, unit tests, integration tests, safe canaries
5. Black-box validation
- auth-aware testing, business logic, external exposure, request evidence
6. Triage and ownership
- priority, owner, due date, compensating controls, customer impact
7. Patch and regression testing
- root-cause fix, test coverage, variant checks
8. Retest and evidence archive
- verified fix, remaining risk, report export, audit trail
The key is sequencing. Do not send every candidate into active testing. Do not ask developers to patch unvalidated noise. Do not wait for perfect proof before applying an emergency mitigation to a critical exposed asset. Use the right level of evidence for the decision being made.
Is restricted access the right model for cyber AI?
Both OpenAI and Anthropic are wrestling with the same dual-use problem. A model that helps a defender validate a patch can help an attacker refine an exploit. A model that helps a maintainer find a memory corruption bug can help an adversary search for variants. A model that can reason over enterprise code can also reason over stolen code.
OpenAI’s Trusted Access for Cyber approach uses identity and trust-based access to reduce unnecessary refusals for verified defensive work while maintaining safeguards against malicious activity such as credential theft, stealth, persistence, malware deployment, or exploitation of third-party systems. (OpenAI)
Anthropic’s Project Glasswing uses a more restricted preview model around Mythos and selected partners, with the public rationale that advanced cyber capabilities should first be used to reinforce critical software before wider diffusion. (Anthropisch)
There is no perfect access model. Broad access helps more defenders. Restricted access reduces immediate misuse but concentrates capability among selected organizations. The operational question is not only who gets access. It is what logging, accountability, scope control, rate limiting, disclosure process, and safety review surround the capability.
For security teams, the access debate should produce one concrete policy: advanced AI cyber work must be bound to authorization, evidence, and auditability.
FAQ
Is OpenAI Daybreak a direct competitor to Anthropic Mythos?
- Not exactly. OpenAI Daybreak is publicly framed as a cyber defense initiative that combines models, Trusted Access for Cyber, GPT-5.5-Cyber, and Codex Security workflows.
- Anthropic Mythos Preview is framed as a gated frontier model capability used through Project Glasswing to help secure critical software.
- The overlap is real: both target AI-assisted vulnerability discovery and defense.
- The difference is important: Daybreak is more visibly workflow-oriented, while Mythos is more visibly capability-and-access-oriented.
Does AI make bug bounties less valuable?
- AI makes low-signal reports less valuable because version matching, generic advisory summaries, and shallow scanner findings become easier to produce.
- AI can make high-quality reports more valuable because strong researchers can use it to validate reachability, build safer reproductions, analyze variants, and write clearer evidence.
- The bounty market is likely to reward verified impact more strongly while filtering out generic AI-generated noise.
- The key distinction is not “AI-generated” versus “human-generated.” It is “proven” versus “unproven.”
Why is white-box AI security review different from black-box pentesting?
- White-box review starts with internal knowledge such as source code, diffs, dependencies, configuration, and architecture.
- Black-box pentesting starts with externally observable behavior such as endpoints, requests, authentication flows, and deployed responses.
- White-box AI can find deep logic issues and unsafe code paths earlier.
- Black-box testing proves whether those issues are reachable and exploitable in the deployed environment.
- Mature teams should connect both approaches instead of treating one as a replacement for the other.
What should a security team do when AI reports a vulnerability?
- Label the finding as a candidate until evidence supports it.
- Confirm affected versions, code paths, deployment presence, and ownership.
- Determine whether the vulnerable path is reachable by an untrusted actor.
- Prefer non-destructive validation, sandbox reproduction, and log-based evidence before active testing.
- Record the evidence chain: commands, outputs, requests, logs, environment, patch, and retest result.
- Escalate only when impact and reachability are clear.
How should teams validate CVE exposure safely?
- Start with inventory: package versions, SBOMs, containers, deployed artifacts, and runtime configuration.
- Check reachability: routes, endpoints, auth requirements, feature flags, network exposure, and logs.
- Use vendor advisories and official CVE or NVD records to confirm affected versions and patches.
- Reproduce in a sandbox when the vulnerability class is dangerous.
- Avoid destructive live exploitation unless explicitly authorized and operationally necessary.
- After patching, retest the original path and likely variants.
Will AI overwhelm open-source maintainers with low-quality reports?
- It can, and in some places it already has.
- AI lowers the cost of generating polished but weak reports.
- Maintainers need fewer speculative reports and more minimal, reproducible, well-scoped findings.
- Responsible reporters should include affected versions, reproduction steps, impact, non-destructive evidence, and proposed fixes where possible.
- Projects and platforms may need stronger intake rules to distinguish evidence-backed reports from AI-generated noise.
What does a good AI-assisted pentest report need to include?
- Clear scope and authorization boundaries.
- Affected asset, endpoint, component, or code path.
- Reproduction steps that another engineer can follow.
- Evidence such as request summaries, response behavior, logs, version proof, and screenshots only where useful.
- Impact explained in business and technical terms.
- Remediation guidance tied to the root cause.
- Retest results after the fix.
- Explicit uncertainty where exploitability or production exposure has not been proven.
Should companies give advanced cyber models broad access?
- Broad access can help defenders move faster, especially smaller teams that lack specialist capacity.
- Uncontrolled access can also help attackers refine exploit development and scale reconnaissance.
- A practical access model should include identity verification, scoped authorization, logging, misuse monitoring, and clear rules around active testing.
- The safest enterprise use is not “let the model hack freely.” It is controlled defensive work with evidence, approvals, and audit trails.
The scarce thing is no longer the first signal
OpenAI Daybreak vs Anthropic Mythos is not just a model comparison. It is a preview of a security market where the first signal becomes cheap and the verified result becomes expensive.
AI will find more candidate vulnerabilities. Some will be real. Some will be duplicates. Some will be unreachable. Some will be low impact. Some will be serious enough to matter immediately. The teams that win will not be the teams that generate the longest finding list. They will be the teams that build the strongest path from candidate to proof, from proof to patch, and from patch to retest.
White-box AI review will be a major advantage because code visibility matters. Black-box validation will remain essential because deployed reality matters. Bug bounty hunters who can prove impact will still get paid. Maintainers who demand evidence will be right to do so. Security teams that measure AI by verified fixes instead of raw findings will get the most value.
The vulnerability market is not flattening. It is splitting. Low-value bugs are becoming abundant. Verified, exploitable, high-impact vulnerabilities are becoming more valuable.

