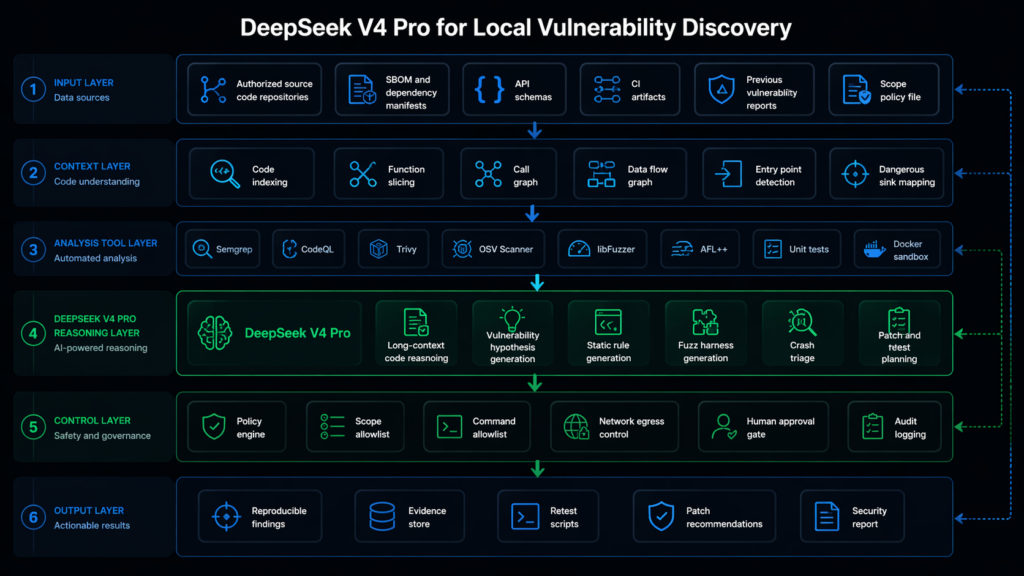
DeepSeek V4 Pro can be useful for local automated vulnerability discovery. It is not a magic bug hunter. The practical answer is more interesting than either hype or dismissal: DeepSeek V4 Pro can become the reasoning layer inside a controlled vulnerability research system, but the system still needs static analysis, fuzzing, sandbox execution, policy controls, evidence capture, and human review.
As of April 24, 2026, DeepSeek’s official V4 Preview materials describe DeepSeek V4 Pro as a Mixture of Experts model with 1.6 trillion total parameters, 49 billion activated parameters, and one million token context support. DeepSeek’s API documentation also lists V4 Pro and V4 Flash as current model options, with support for thinking and non-thinking modes, JSON output, tool calls, OpenAI format access, and Anthropic format access. The Hugging Face model card for DeepSeek V4 Pro lists open weights, MIT licensing, local inference instructions, model conversion steps, and a model table that identifies V4 Pro as a 1.6T total parameter model with 49B activated parameters and mixed FP4 plus FP8 precision for the instruct model. (api-docs.deepseek.com)
That fact changes the local deployment conversation. A 49B activated parameter count does not mean a 49B model footprint. In an MoE model, only a subset of experts is activated per token, which can reduce per-token compute. The weights, routing, expert storage, KV cache, context length, framework support, and interconnect cost still matter. DeepSeek’s own local inference notes point to model weight conversion, multi-process torchrun execution, model parallel settings, and multi-node inference rather than a one-command laptop install. (Hugging Face)
The right question is therefore not “Can I run DeepSeek V4 Pro locally and let it hack?” The right question is “Can I build a local, authorized, evidence-driven vulnerability discovery pipeline where DeepSeek V4 Pro improves reasoning, harness generation, triage, and reporting?” The answer is yes, if the engineering constraints are respected.
The honest feasibility answer
For a small team, a single workstation, or a MacBook, full local DeepSeek V4 Pro deployment is not the first move. DeepSeek V4 Pro is a frontier-scale MoE model. Its official model card lists 1.6T total parameters, 49B activated parameters, one million context length, and mixed precision model downloads. That points toward serious inference infrastructure, not casual local use. DeepSeek’s local inference README shows conversion and torchrun-based execution with model parallelism, and the V4 model card recommends large context settings for maximum reasoning mode. (Hugging Face)
For a well-funded security lab, cloud security vendor, enterprise AppSec team, or research group with multi-node accelerators, local deployment can be justified. The reason is not raw novelty. The reason is control. Security teams may need private code, unreleased patches, customer artifacts, crash traces, authentication flows, proprietary API schemas, and internal threat models to stay inside their own trust boundary. A local model can reduce data exposure and give the team more freedom to build custom tool orchestration around sensitive repositories.
For most teams, the better first architecture is hybrid. Use smaller local models, DeepSeek V4 Flash, or existing static analysis tools for high-frequency tasks. Use DeepSeek V4 Pro through a controlled endpoint for difficult reasoning, long-context review, cross-file hypothesis generation, and triage. Keep the execution layer local and auditable. Do not send secrets, private keys, full production logs, or unrestricted customer data into any model endpoint unless the organization has reviewed data handling, retention, contractual, and regulatory requirements.
The most important design principle is simple: the model should not be the source of truth. The model proposes. Tools test. Sandboxes reproduce. Humans approve disclosure and remediation. Evidence wins.
Automated vulnerability discovery is not automated exploitation
The phrase “automated vulnerability discovery” is often abused. In a serious engineering context, it does not mean pointing an autonomous agent at random internet targets. It does not mean asking an LLM to generate exploit payloads until something breaks. It does not mean bypassing bug bounty scope, rate limits, authentication boundaries, or production safety controls.
A defensible vulnerability discovery system works inside authorized boundaries. It can operate on owned source code, internal services, staging environments, customer-approved pentest targets, open-source projects under responsible disclosure norms, or intentionally vulnerable labs. NIST SP 800-115 frames technical security testing as a planned process for conducting tests, analyzing findings, and developing mitigation strategies, not as uncontrolled tool execution. (csrc.nist.gov)
In practice, automated vulnerability discovery means a closed loop:
| Stage | What happens | What the model can do | What must verify it |
|---|---|---|---|
| Scope control | Define allowed repos, hosts, branches, accounts, and test depth | Parse policy and refuse out-of-scope work | Signed scope file, operator approval |
| Code intake | Read code, manifests, schemas, tests, and historical findings | Summarize architecture and identify risky components | Repository metadata, build system, dependency scanner |
| Static analysis | Run CodeQL, Semgrep, SCA, secret scanning, and custom queries | Generate candidate rules and explain findings | Tool output, query results, reviewer judgment |
| Fuzzing | Generate or improve harnesses, build, run, and triage crashes | Draft harnesses, repair compile errors, propose seed corpora | Compiler, sanitizer, coverage, crash reproducer |
| Dynamic validation | Test known-safe proof paths in sandbox or staging | Plan minimal verification steps | Sandboxed execution, logs, replayable artifacts |
| Triage | Decide exploitability, reachability, prerequisites, and impact | Link code paths, configs, and runtime behavior | Human review, debugger output, traces |
| Remediation | Suggest patch direction and retest | Draft patch ideas and regression tests | Maintainer review, CI, unit tests, security tests |
| Reporting | Produce clear findings with evidence | Convert artifacts into readable reports | Replay steps, screenshots, logs, hashes |
This distinction matters because LLMs are strongest in the messy middle of the workflow. They are good at understanding code structure, summarizing large files, connecting logs to code, drafting queries, proposing fuzzing targets, identifying recurring anti-patterns, and turning raw artifacts into coherent findings. They are not reliable enough to be trusted as the sole judge of vulnerability reality.
A model can say a function “looks exploitable.” That is not a finding. A finding needs reproducible conditions, affected version or commit, reachable code path, impact explanation, mitigation, and artifacts another engineer can replay.

Why DeepSeek V4 Pro is interesting for this workflow
DeepSeek V4 Pro is relevant because vulnerability research is heavily context-bound. A serious bug often sits across multiple files, build flags, parser states, authorization checks, API schemas, dependency versions, or business rules. Long context and strong code reasoning can help, especially when the pipeline feeds the model curated evidence rather than dumping an entire repository into one prompt.
DeepSeek’s V4 model card describes a hybrid attention architecture using Compressed Sparse Attention and Heavily Compressed Attention, with a claim that DeepSeek V4 Pro requires 27 percent of the single-token inference FLOPs and 10 percent of the KV cache compared with DeepSeek V3.2 in a one million token context setting. The same model card describes mHC, the Muon optimizer, and a post-training pipeline involving domain-specific expert cultivation and consolidation. Those details matter because long-context vulnerability research is often limited by context cost and memory pressure, not only benchmark scores. (Hugging Face)
The model card also reports agentic and coding benchmark results, including SWE-bench Verified, SWE Pro, Terminal Bench 2.0, MCPAtlas, and Toolathlon. Benchmarks do not prove real-world vulnerability discovery performance. They do, however, support a narrower claim: DeepSeek V4 Pro was explicitly positioned and evaluated for coding, long-context, and agentic work, which overlaps with the kind of reasoning needed in vulnerability research systems. (Hugging Face)
DeepSeek’s API docs add another practical point: V4 Pro supports tool calls and JSON output. In a vulnerability pipeline, those features are more important than chat quality. The agent needs structured outputs that can be validated, stored, replayed, rejected, or passed into deterministic tools. (api-docs.deepseek.com)
A useful local security agent should return something like this, not a vague paragraph:
{
"finding_hypothesis": {
"class": "unsafe_deserialization",
"confidence": "medium",
"files": ["src/importer/config_loader.py"],
"entry_points": ["POST /api/import"],
"suspected_sink": "yaml.load",
"preconditions": [
"attacker can upload a configuration file",
"server uses FullLoader or unsafe default loader",
"import endpoint is reachable by a low-privilege authenticated user"
],
"verification_plan": [
"confirm loader type",
"run Semgrep rule for yaml.load",
"write unit test using benign proof payload",
"do not execute destructive payloads"
],
"evidence_required": [
"static match",
"call path",
"test result",
"patch diff"
]
}
}
That kind of structured reasoning can be checked. A plain “this is critical” cannot.
The deployment choices that actually make sense
There are four realistic ways to use DeepSeek V4 Pro or the V4 family in local vulnerability discovery.
| Deployment pattern | Best fit | Strength | Main limitation |
|---|---|---|---|
| Full local DeepSeek V4 Pro | Large security labs, AI security vendors, enterprises with accelerator clusters | Maximum control over code and artifacts | High hardware, operations, and serving complexity |
| Local V4 Flash with Pro for hard cases | Mid-size AppSec and red team groups | Better cost and latency balance | Complex cross-repo reasoning may still need Pro |
| API-first with local execution | Teams validating the workflow before infrastructure investment | Fastest path to useful results | Data governance and context minimization are mandatory |
| Smaller local model first, V4 Pro later | Startups, individual researchers, internal prototypes | Cheap architecture testing | Model behavior may not transfer perfectly |
The worst approach is to start by buying hardware before proving the workflow. Many teams do not fail because the model is weak. They fail because the system around the model has no evidence discipline. They feed in too much context, do not define scope, do not build in deterministic tools, do not store artifacts, and cannot tell a hallucinated finding from a reproducible bug.
A practical team should prototype the pipeline on a smaller model or API endpoint first. Once the team can repeatedly turn a repository into static findings, candidate harnesses, crash evidence, patch suggestions, and retest artifacts, it can decide whether full local DeepSeek V4 Pro deployment is worth the cost.

Local deployment does not mean laptop deployment
A local model can mean many things. It can mean a developer laptop, a workstation, an on-prem GPU server, a private cloud cluster, or a sovereign AI infrastructure environment. DeepSeek V4 Pro sits at the high end of that spectrum.
| Environment | Suitable role in this workflow | Realistic expectation |
|---|---|---|
| MacBook class laptop | Prompt design, report review, small local model experiments, static tool orchestration | Not a practical target for full V4 Pro |
| Single 24 GB GPU workstation | Small local models, log summarization, limited code review, tool wrappers | Not enough for full V4 Pro weights |
| Multi-GPU workstation | Prototyping with smaller MoE or quantized models, local agent testing | Useful for workflow development, still not ideal for full Pro |
| 8 GPU enterprise node | Serious model serving experiments, V4 Flash or large-model inference depending on framework support | Requires careful memory and parallelism planning |
| Multi-node accelerator cluster | Full local V4 Pro research deployment | Practical only with strong MLOps and distributed inference expertise |
| Private API endpoint | Controlled model service with local execution and policy controls | Often the most pragmatic first production design |
DeepSeek’s own inference README demonstrates model weight conversion and torchrun execution with a model parallel variable, plus multi-node inference. That is a very different operating model from a desktop app or an Ollama pull. (Hugging Face)
For security teams, this has a strategic consequence. The first budget line should not be “biggest model.” It should be “reproducible pipeline.” A weaker model inside a disciplined pipeline often beats a frontier model inside a chaotic one.
A reference architecture for local AI vulnerability discovery
A good architecture separates reasoning, execution, and evidence.
flowchart TD
A[Authorized source code and scope file] --> B[Code indexing and slicing]
A --> C[Dependency and SBOM analysis]
A --> D[Build and test metadata]
B --> E[Static analysis tools]
C --> E
D --> E
E --> F[Candidate findings and risky code regions]
F --> G[DeepSeek V4 Pro reasoning service]
G --> H[Rule generation]
G --> I[Fuzz harness generation]
G --> J[Triage and root cause analysis]
G --> K[Patch and retest planning]
H --> L[CodeQL and Semgrep execution]
I --> M[Sandboxed fuzzing and tests]
K --> N[CI retest job]
L --> O[Evidence store]
M --> O
N --> O
J --> O
O --> P[Human review]
P --> Q[Finding report]
P --> R[Patch ticket or disclosure package]
S[Policy engine] --> G
S --> L
S --> M
S --> N
The policy engine is not decoration. It is what keeps an AI-assisted vulnerability research system from becoming an unsafe automation layer. It should know which repositories are in scope, which commands are allowed, whether outbound network access is blocked, whether exploit validation requires approval, whether production targets are forbidden, and whether destructive tests are disabled.
A minimal policy file can look like this:
project: "authorized-internal-repo"
scope:
repositories:
- "git@example.com:security-lab/parser-service.git"
branches:
- "main"
- "security-review/*"
environments:
- "local-docker"
- "ci-sandbox"
execution:
network_egress: "blocked_by_default"
allow_external_hosts:
- "pypi.org"
- "github.com"
destructive_actions: "forbidden"
exploit_validation:
requires_human_approval: true
allowed_only_in:
- "local-docker"
- "ci-sandbox"
model:
allow_secret_input: false
max_file_chunk_tokens: 12000
require_citations_to_artifacts: true
output_format: "json"
logging:
store_prompts: true
store_tool_outputs: true
store_build_logs: true
store_reproducer_hashes: true
That policy should be enforced in code. A model instruction is not enough. Models can misunderstand, overgeneralize, or comply with a badly framed request. The orchestrator must decide what can run.
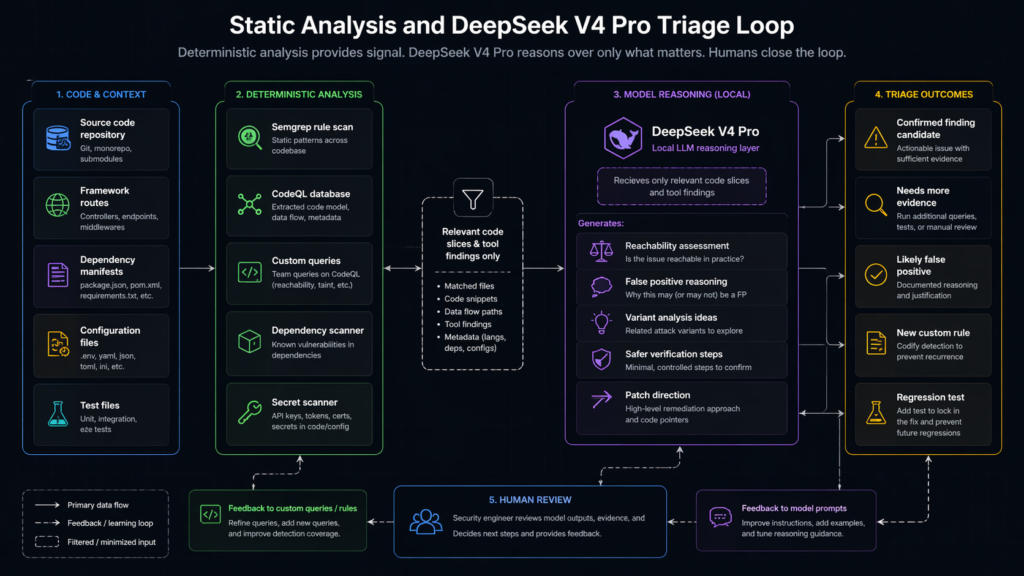
Static analysis is the backbone, not a legacy component
Static analysis remains central because it gives the model something concrete to reason about. CodeQL describes itself as a way to query code as though it were data and to find variants of vulnerabilities across codebases. That is exactly the kind of deterministic substrate an LLM needs. (CodeQL)
Without static analysis, the model is forced to infer too much from raw files. With static analysis, the model can focus on interpretation, expansion, and triage. It can ask better questions:
Is this sink reachable from a user-controlled entry point?
Does the framework sanitize this value before the sink?
Does the project use a custom wrapper that changes the semantics?
Can we generalize this finding into a query that finds variants?
Is the same anti-pattern present in older branches?
Can we write a regression test that proves the patch worked?
Here is a safe Semgrep rule example for a common Python issue. It is not a full vulnerability proof. It is a starting point for review.
rules:
- id: python-unsafe-yaml-load
languages:
- python
severity: WARNING
message: "yaml.load can deserialize unsafe objects. Use yaml.safe_load unless this input is fully trusted."
patterns:
- pattern: yaml.load($DATA, ...)
- pattern-not: yaml.load($DATA, Loader=yaml.SafeLoader, ...)
- pattern-not: yaml.load($DATA, Loader=yaml.CSafeLoader, ...)
metadata:
category: security
cwe:
- "CWE-502"
confidence: medium
A DeepSeek V4 Pro driven workflow should not stop after this match. It should ask whether $DATA is user-controlled, whether the endpoint is authenticated, whether the loader argument is truly unsafe, whether tests cover this path, and whether a patch changes behavior.
A simple static analysis orchestration step can look like this:
mkdir -p artifacts/semgrep artifacts/codeql artifacts/model
semgrep scan \
--config ./rules \
--json \
--output artifacts/semgrep/results.json \
./repo
codeql database create artifacts/codeql/db \
--language=python \
--source-root ./repo
codeql database analyze artifacts/codeql/db \
--format=sarif-latest \
--output=artifacts/codeql/results.sarif \
./queries/security
The model then receives the relevant slices, not the entire repository:
{
"task": "triage_static_finding",
"scope_id": "authorized-internal-repo",
"finding_source": "semgrep",
"rule_id": "python-unsafe-yaml-load",
"matched_file": "repo/app/imports/config_loader.py",
"matched_function": "load_user_config",
"callers": [
"repo/app/routes/imports.py:import_config"
],
"tool_evidence": {
"semgrep_result": "artifacts/semgrep/results.json",
"code_slice": "artifacts/slices/config_loader.load_user_config.txt"
},
"required_output": [
"preconditions",
"reachability_assessment",
"safe_verification_plan",
"patch_options",
"false_positive_reasons"
]
}
The output should be judged by whether it leads to verifiable next steps, not whether it sounds impressive.
LLM generated fuzzing is one of the strongest use cases
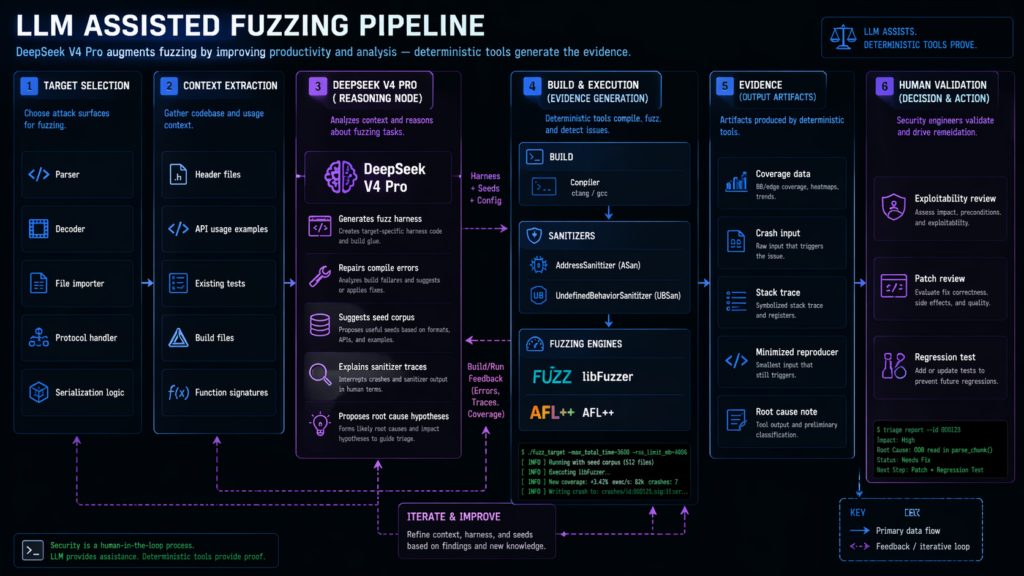
The best evidence for LLM-assisted vulnerability discovery is not generic pentest chat. It is AI-generated fuzzing work.
Google’s OSS-Fuzz team reported in November 2024 that AI-generated and enhanced fuzz targets found 26 new vulnerabilities in open-source projects, including CVE-2024-9143 in OpenSSL. Google described this as a milestone for automated vulnerability finding, noting that the new AI-generated targets added hundreds of thousands of lines of coverage across OSS-Fuzz projects and found bugs in code that already had extensive fuzzing history. (Google Online Security Blog)
The open-source oss-fuzz-gen repository describes a framework that generates fuzz targets for real-world C, C++, Java, and Python projects with LLMs and evaluates them through OSS-Fuzz. It tracks metrics such as compilability, runtime crashes, runtime coverage, and line coverage differences against existing human-written fuzz targets. (GitHub)
That is the pattern local DeepSeek V4 Pro deployments should copy. The model should not simply “find bugs.” It should generate harnesses, repair compile failures, propose seeds, read sanitizer output, explain crashes, and produce minimal reproducers.
A safe harness-generation task might look like this:
{
"task": "generate_fuzz_harness",
"language": "c",
"project": "local-parser-library",
"target_function": "parse_config_buffer",
"source_file": "src/parser.c",
"header_file": "include/parser.h",
"constraints": [
"local repository only",
"no network access",
"no file system writes except temporary corpus directory",
"use libFuzzer style LLVMFuzzerTestOneInput",
"do not include exploit payloads",
"focus on parser stability and memory safety"
],
"required_output": [
"harness_code",
"build_command",
"seed_corpus_suggestions",
"expected_sanitizers",
"triage_notes"
]
}
A minimal harness may look like this:
#include <stddef.h>
#include <stdint.h>
#include "parser.h"
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (data == NULL || size == 0) {
return 0;
}
parser_result_t result = parse_config_buffer((const char *)data, size);
if (result.error_message != NULL) {
parser_free_error(result.error_message);
}
if (result.document != NULL) {
parser_free_document(result.document);
}
return 0;
}
The harness itself is not the discovery. Discovery happens only when it builds, runs under sanitizers, reaches interesting code, produces a crash or suspicious behavior, and the team can reproduce and understand the root cause.
A local fuzzing stage could be:
clang -fsanitize=address,undefined,fuzzer \
-Iinclude \
fuzz/fuzz_parse_config.c \
src/parser.c \
-o artifacts/fuzz/fuzz_parse_config
mkdir -p artifacts/fuzz/corpus artifacts/fuzz/findings
./artifacts/fuzz/fuzz_parse_config \
artifacts/fuzz/corpus \
-max_total_time=600 \
-artifact_prefix=artifacts/fuzz/findings/
DeepSeek V4 Pro can then read sanitizer traces and source slices. But the final finding must still be grounded in the crash artifact, minimized input, stack trace, commit hash, and patch test.
CVE-2024-9143 shows why exploitability language matters
CVE-2024-9143 is a useful case because it was discovered through AI-assisted OSS-Fuzz work and because its impact requires careful explanation. NVD describes it as an issue where use of low-level GF 2^m elliptic curve APIs with untrusted explicit values for the field polynomial can lead to out-of-bounds reads or writes. NVD also notes that practical vulnerable use cases are likely limited because common ECC protocol encodings generally do not allow the problematic input values, and problematic cases would involve unusual explicit binary curve parameters. (nvd.nist.gov)
That is exactly the kind of nuance automated systems often miss. A low-quality AI report might say “OpenSSL remote code execution, critical risk.” A credible report would say:
The affected API family can produce out-of-bounds memory access when given certain untrusted explicit binary field polynomial values. In common X.509 certificate processing, the problematic input may not be representable through the relevant encoding. The finding is still important because it affects a critical cryptographic library and demonstrates that AI-generated fuzz targets can reach under-tested API surfaces. Exploitability depends on whether an application exposes the affected low-level APIs to attacker-controlled explicit curve parameters.
That style of explanation is not pedantry. It is the difference between useful security work and alert pollution.
DeepSeek V4 Pro can help write that explanation, but only if the pipeline feeds it the NVD entry, upstream advisory, code context, tool output, and application-specific usage evidence. Without those anchors, it may overstate the risk.
Big Sleep shows the promise and the boundary
Google Project Zero and DeepMind’s Big Sleep work is another important reference point. Project Zero reported in 2024 that Big Sleep found an exploitable stack buffer underflow in SQLite, reported it to developers in early October, and the issue was fixed the same day before it appeared in an official release. Project Zero described it as the first public example of an AI agent finding a previously unknown exploitable memory-safety issue in widely used real-world software. (projectzero.google)
That does not mean every security team can now press a button and get zero-days. It means AI agents can help with real vulnerability research when wrapped in a serious research process. Big Sleep did not replace vulnerability researchers. It encoded parts of their workflow, focused on real code, and still operated within a disclosure and validation process.
The lesson for DeepSeek V4 Pro is direct. The model is valuable when it is part of a system that can ask precise questions, inspect code, run tests, evaluate variants, and preserve evidence. It is far less valuable when used as a free-form chat oracle.
A strong local pipeline should borrow the Big Sleep pattern:
- Start from a focused target or variant class.
- Use tools to collect code and runtime evidence.
- Let the model reason over constrained context.
- Confirm with deterministic execution.
- Report responsibly before public disclosure.
- Keep humans in the loop for severity, ethics, and remediation.
CVE-2024-3094 reminds us that source code is not the whole supply chain
The XZ Utils backdoor, CVE-2024-3094, is relevant for a different reason. NVD describes malicious code in upstream XZ tarballs beginning with versions 5.6.0, where the liblzma build process extracted a prebuilt object file from a disguised test file and modified functions in the library. CISA also issued an alert about the reported supply chain compromise affecting XZ Utils versions 5.6.0 and 5.6.1. (nvd.nist.gov)
This case is a warning against narrow “code scanner” thinking. A vulnerability discovery system that only reads repository source files may miss differences between a Git tag and a release tarball. It may miss generated files, build scripts, suspicious binary blobs, maintainer-account anomalies, or CI provenance gaps.
A local DeepSeek V4 Pro pipeline can help inspect build scripts, compare artifacts, summarize suspicious diffs, and generate questions for maintainers. But it should be paired with supply chain tooling:
git clone https://example.com/project.git repo
cd repo
git verify-tag v1.2.3 || true
mkdir -p ../artifacts/supply-chain
git archive --format=tar v1.2.3 > ../artifacts/supply-chain/git-tag.tar
sha256sum ../artifacts/supply-chain/git-tag.tar \
> ../artifacts/supply-chain/hashes.txt
# Compare release tarball to repository archive only for projects where you have
# permission or where the artifact is publicly distributed for verification.
diffoscope \
../artifacts/supply-chain/git-tag.tar \
../artifacts/supply-chain/release.tar \
> ../artifacts/supply-chain/diffoscope.txt
The model can then read diffoscope.txt and classify differences:
{
"task": "supply_chain_diff_review",
"artifact": "artifacts/supply-chain/diffoscope.txt",
"questions": [
"Are there files present in the release artifact but absent from the repository tag?",
"Are generated build scripts materially different?",
"Are binary objects or compressed test fixtures introduced?",
"Do any differences affect compilation, linking, or runtime behavior?",
"Which findings need maintainer confirmation?"
],
"required_tone": "cautious and evidence-bound"
}
This is a good example of where LLMs help without pretending to be omniscient. The model can reduce review time and make suspicious differences easier to understand. It cannot prove malicious intent by itself.
The model should reason over evidence, not raw chaos
One of the largest mistakes in local LLM security systems is dumping a whole repository into a long-context model and asking for vulnerabilities. Long context is powerful, but unstructured context still creates noise.
A better pipeline builds a code evidence graph:
{
"entry_points": [
{
"type": "http_route",
"method": "POST",
"path": "/api/import",
"handler": "app.routes.import_config"
}
],
"sources": [
{
"name": "request.files['config']",
"trust": "user_controlled"
}
],
"transforms": [
{
"function": "normalize_upload",
"file": "app/imports/normalizer.py"
}
],
"sinks": [
{
"function": "yaml.load",
"file": "app/imports/config_loader.py",
"risk": "unsafe_deserialization"
}
],
"guards": [
{
"function": "require_login",
"status": "present"
},
{
"function": "require_admin",
"status": "not_found"
}
],
"tests": [
{
"file": "tests/test_import_config.py",
"coverage": "happy_path_only"
}
]
}
Now the model can answer a real question: “Does the evidence suggest a reachable unsafe deserialization risk, and what safe test would prove or disprove it?” That is much better than “Find bugs in this repo.”
The same structure works for access control, SSRF, command injection, template injection, path traversal, XML parsing, JWT handling, webhook verification, and tenant isolation. OWASP’s Top 10 remains useful here because it identifies classes that still matter in modern web applications, including broken access control, injection, vulnerable and outdated components, software and data integrity failures, and SSRF. (owasp.org)
Broken access control is especially important because OWASP reports that it moved to the top category in the 2021 Top 10 and includes issues such as parameter tampering, insecure direct object references, missing API access controls, privilege elevation, JWT manipulation, and CORS misconfiguration. (owasp.org)
SSRF is another good example. OWASP defines SSRF flaws as cases where an application fetches a remote resource without validating the user-supplied URL, allowing attackers to cause requests to unintended destinations even across network controls. That is a logic and architecture issue, not just a string-matching issue. (owasp.org)
DeepSeek V4 Pro may help reason about these classes because they often require cross-file and cross-request context. But the model still needs role definitions, API schemas, sample requests, expected authorization boundaries, and safe replay tests.
A minimum viable local pipeline
A team can build a useful first version in one week without full DeepSeek V4 Pro local deployment. The goal is not to solve all vulnerability discovery. The goal is to create a repeatable evidence loop.
Day one: define scope, sandbox, and artifact storage.
mkdir -p avd-pipeline/{repo,artifacts,rules,queries,prompts,reports,sandbox}
touch avd-pipeline/scope.yaml
touch avd-pipeline/run.log
Day two: run baseline tools.
semgrep scan --config auto --json --output artifacts/semgrep.json repo
trivy fs \
--format json \
--output artifacts/trivy.json \
repo
codeql database create artifacts/codeql-db \
--language=javascript-typescript \
--source-root repo
Day three: build code slices around entry points and risky sinks.
from pathlib import Path
import json
REPO = Path("repo")
OUT = Path("artifacts/slices")
OUT.mkdir(parents=True, exist_ok=True)
RISKY_KEYWORDS = [
"eval(",
"exec(",
"yaml.load",
"child_process.exec",
"subprocess.Popen",
"requests.get",
"open(",
"jwt.decode"
]
for path in REPO.rglob("*"):
if path.suffix not in {".py", ".js", ".ts", ".java", ".go", ".c", ".cpp"}:
continue
text = path.read_text(errors="ignore")
matches = [kw for kw in RISKY_KEYWORDS if kw in text]
if not matches:
continue
rel = path.relative_to(REPO)
record = {
"file": str(rel),
"matched_keywords": matches,
"content": text[:20000]
}
out_file = OUT / (str(rel).replace("/", "__") + ".json")
out_file.write_text(json.dumps(record, indent=2), encoding="utf-8")
Day four: ask the model to generate specific hypotheses from slices and tool output. The prompt should demand uncertainty, evidence, and verification steps.
You are reviewing authorized source code inside a local security sandbox.
Use only the provided tool output and code slices.
Do not claim a vulnerability is confirmed unless there is evidence.
For each hypothesis, return JSON with:
- weakness_class
- files
- entry_points
- source_to_sink_path
- preconditions
- safe_verification_steps
- likely_false_positive_reasons
- patch_direction
- evidence_needed
Do not generate destructive payloads.
Do not suggest testing outside the authorized local sandbox.
Day five: run generated tests, fuzz harnesses, or static queries in the sandbox.
Day six: triage results with model assistance, but require tool evidence.
Day seven: produce a report with replayable steps and retest instructions.
This is not glamorous. It is useful. It gives the team a place to measure whether DeepSeek V4 Pro improves throughput, reduces false positives, finds new paths, or simply writes nicer summaries.
A safe orchestration skeleton
A local agent should not be a shell with a model attached. It should be a constrained orchestrator.
import json
import subprocess
from pathlib import Path
from typing import Any
ROOT = Path(".").resolve()
ARTIFACTS = ROOT / "artifacts"
ARTIFACTS.mkdir(exist_ok=True)
ALLOWED_COMMANDS = {
"semgrep": ["semgrep", "scan", "--config", "auto", "--json", "--output", "artifacts/semgrep.json", "repo"],
"trivy": ["trivy", "fs", "--format", "json", "--output", "artifacts/trivy.json", "repo"],
}
def run_allowed(name: str) -> dict[str, Any]:
if name not in ALLOWED_COMMANDS:
raise ValueError(f"Command is not allowed: {name}")
result = subprocess.run(
ALLOWED_COMMANDS[name],
cwd=ROOT,
text=True,
capture_output=True,
timeout=900,
check=False,
)
record = {
"command_name": name,
"returncode": result.returncode,
"stdout_tail": result.stdout[-4000:],
"stderr_tail": result.stderr[-4000:],
}
(ARTIFACTS / f"{name}.run.json").write_text(
json.dumps(record, indent=2),
encoding="utf-8"
)
return record
def load_artifact(path: str) -> Any:
artifact_path = (ROOT / path).resolve()
if not str(artifact_path).startswith(str(ARTIFACTS)):
raise ValueError("Artifact path outside allowed directory")
return json.loads(artifact_path.read_text(encoding="utf-8"))
def build_model_task() -> dict[str, Any]:
semgrep_summary = load_artifact("artifacts/semgrep.json")
return {
"task": "triage_authorized_static_results",
"rules": [
"Do not claim confirmation without evidence",
"Do not propose destructive testing",
"Only use local sandbox verification",
"Return JSON only"
],
"tool_output": {
"semgrep": semgrep_summary
}
}
if __name__ == "__main__":
run_allowed("semgrep")
task = build_model_task()
(ARTIFACTS / "model_task.json").write_text(
json.dumps(task, indent=2),
encoding="utf-8"
)
This skeleton intentionally does not let the model run arbitrary commands. It does not scan external targets. It does not execute payloads. It collects local evidence and prepares a structured task for the reasoning layer.
That is the right direction for a DeepSeek V4 Pro security pipeline: deterministic tools, bounded actions, structured model tasks, and persistent artifacts.
What DeepSeek V4 Pro should do inside the pipeline
DeepSeek V4 Pro should be used where reasoning density is high and deterministic tools need interpretation.
| Task | Good use of DeepSeek V4 Pro | Required non-model evidence |
|---|---|---|
| Cross-file code review | Identify likely source-to-sink paths across large code slices | Call graph, static matches, tests |
| Variant analysis | Suggest additional patterns after one confirmed bug | CodeQL or Semgrep query results |
| Harness generation | Draft fuzz targets and repair build errors | Compiler output, sanitizer output, coverage |
| Crash triage | Connect stack trace to root cause and patch direction | Reproducer, stack trace, minimized input |
| Access control review | Compare expected roles against actual checks | API schema, role matrix, request replay |
| SSRF review | Identify URL fetch paths and missing network controls | Code path, configuration, safe unit test |
| Dependency reachability | Explain whether vulnerable package usage is reachable | Lockfile, SCA output, call sites |
| Report writing | Convert evidence into a clear finding | Logs, screenshots, hashes, commit IDs |
| Retest planning | Generate safe regression checks | Patch diff, CI result |
It should not be trusted for these tasks without guardrails:
| Risky task | Why the model should not own it alone |
|---|---|
| Deciding authorization scope | Scope is a legal and contractual boundary |
| Running exploit modules | Unsafe without human approval and sandboxing |
| Claiming real-world exploitability | Requires environment evidence and reviewer judgment |
| Prioritizing business impact | Requires asset criticality and organizational context |
| Public disclosure timing | Requires maintainer coordination and policy review |
| Secret handling | Requires deterministic filtering and access control |
| Production testing | Requires explicit approval, rate limits, and rollback plans |
This is the central engineering point: the model should accelerate expert work, not erase accountability.
Long context is useful only after context selection
DeepSeek V4 Pro’s one million token context is attractive for code review. But large context can create bad habits. Sending too much irrelevant code makes the model slower, more expensive, and easier to distract. The better pattern is staged context selection.
First, index the repository. Identify languages, frameworks, route definitions, public handlers, parsers, deserializers, database calls, authentication middleware, authorization checks, template rendering, file operations, outbound HTTP clients, cryptographic usage, and dangerous sinks.
Second, build slices around candidate paths. A slice should include the entry point, data transformations, guards, sink, tests, configuration, and relevant types. It should not include the whole repo unless the model truly needs it.
Third, ask specific questions. “Find all bugs” is weak. “Does this user-controlled YAML import path reach unsafe deserialization without an admin-only guard?” is strong.
Fourth, force the model to state uncertainty. The output should distinguish confirmed facts, inferred hypotheses, missing evidence, and safe next steps.
A good DeepSeek V4 Pro prompt for code review is closer to an engineering ticket than a chat message:
Review the attached authorized code slice for a possible SSRF weakness.
Known expected policy:
- Only admins should be able to configure webhooks.
- Webhook URLs must not target private IP ranges.
- Redirects to private ranges must be blocked.
- DNS rebinding should be considered.
Evidence included:
- Route handler
- Webhook service
- URL validation helper
- Unit tests
- Deployment egress policy
Return:
1. Confirmed facts from code
2. Possible weakness hypotheses
3. Missing evidence
4. Safe local tests
5. Patch options
6. False positive reasons
Do not claim exploitability unless the code and tests prove it.
This kind of prompt uses long context responsibly. It gives the model a bounded problem and a standard of proof.
Agentic coding benchmarks are not vulnerability benchmarks
DeepSeek V4 Pro’s reported coding and agentic results are relevant, but they should not be overread. SWE-bench and terminal benchmarks measure abilities that overlap with security research: editing code, following tasks, using tools, understanding software projects, and resolving issues. They do not prove that a model can safely and reliably discover exploitable vulnerabilities in arbitrary real systems. (Hugging Face)
Security research has extra burdens. A normal code task can be correct if tests pass. A vulnerability finding needs adversarial reasoning, reachability, exploit preconditions, impact, affected versions, environmental conditions, patch safety, and disclosure discipline. A model can be strong at coding and still weak at exploitability judgment.
That is why benchmark-driven claims should be kept narrow. DeepSeek V4 Pro is promising for local vulnerability discovery because it is a strong long-context coding and agentic model with open weights. It still needs a security-specific system around it.
Evidence-driven reporting is part of discovery

A vulnerability that cannot be explained and reproduced is not operationally useful. The report is not a writing exercise. It is the final rendering of the evidence chain.
A credible AI-assisted finding should contain:
| Field | Why it matters |
|---|---|
| Finding ID | Stable tracking through fix and retest |
| Affected commit or version | Prevents vague claims |
| Scope | Shows authorization and test boundary |
| Weakness class | Maps to remediation and education |
| Entry point | Shows how input reaches the code |
| Preconditions | Prevents overstatement |
| Evidence | Logs, traces, screenshots, crash files, request samples |
| Reproduction steps | Lets another engineer verify |
| Impact | Explains what changes for confidentiality, integrity, or availability |
| False positive considerations | Shows honest analysis |
| Patch recommendation | Gives engineering a path forward |
| Retest procedure | Turns the finding into a closed loop |
Penligent’s public writing on AI pentest reporting makes a similar point from an offensive testing perspective: an AI pentest report is only useful if it can survive retest, and credible reporting needs scope, boundaries, reproducible evidence, exploit conditions, impact, remediation, and clean handoff. That aligns with how a local DeepSeek V4 Pro vulnerability research pipeline should behave: the output is not just prose, it is an evidence package. (Penligent)
For teams already doing authorized AI-assisted validation against web applications or external attack surfaces, Penligent can sit downstream of a local code-research pipeline. The local model can work on private source, suspicious code paths, and candidate fixes; a controlled testing platform can help validate authorized assets, preserve evidence, and turn results into reports. Penligent’s own documentation also states that its platform is for authorized security testing only and requires explicit permission from the target owner, which is the right operating boundary for any AI-driven offensive workflow. (Penligent)
A practical report template
A local pipeline can generate a finding in this shape:
# Finding AVD-2026-004
## Summary
The configuration import endpoint may deserialize attacker-controlled YAML with an unsafe loader. The issue is not confirmed as exploitable until the team verifies the loader behavior in the current runtime configuration.
## Scope
Repository: parser-service
Commit: 9f3a12c
Environment: local Docker sandbox
Authorization: internal security review
## Evidence
Static match:
- Rule: python-unsafe-yaml-load
- File: app/imports/config_loader.py
- Function: load_user_config
Reachability:
- Entry point: POST /api/import
- Caller: app.routes.import_config
- Authentication: require_login present
- Admin authorization: not found in provided slice
## Preconditions
- Attacker has a valid low-privilege account
- Import endpoint accepts uploaded YAML
- Runtime loader is unsafe
- Imported document is processed server-side
## Safe verification plan
1. Add a unit test using a benign custom tag that demonstrates unsafe constructor behavior without executing system commands.
2. Confirm whether yaml.safe_load breaks expected legitimate imports.
3. Add regression test for the fixed loader.
4. Run Semgrep rule again after patch.
## Patch direction
Replace yaml.load with yaml.safe_load unless the application requires custom tags. If custom tags are required, register a narrow allowlist of constructors and reject all unknown tags.
## Retest
Run:
- pytest tests/test_import_config.py
- semgrep scan with rule python-unsafe-yaml-load
This is the tone a model should be pushed toward. It does not inflate severity. It does not invent exploitability. It gives the engineer a path to confirmation.
Building a DeepSeek V4 Pro research loop with CodeQL
CodeQL is especially useful for variant analysis. After one vulnerability is confirmed, the model can help generalize the pattern into a query. The human reviewer should still inspect the query and results.
A simplified workflow:
codeql database create artifacts/codeql-db \
--language=javascript-typescript \
--source-root repo
codeql query run queries/custom/unsafe_redirect.ql \
--database artifacts/codeql-db \
--output artifacts/codeql/unsafe_redirect.bqrs
codeql bqrs decode artifacts/codeql/unsafe_redirect.bqrs \
--format=json \
--output artifacts/codeql/unsafe_redirect.json
The model task:
{
"task": "review_codeql_results",
"query": "queries/custom/unsafe_redirect.ql",
"results": "artifacts/codeql/unsafe_redirect.json",
"source_slices": [
"artifacts/slices/routes__auth.ts.json",
"artifacts/slices/lib__redirect.ts.json"
],
"instructions": [
"Classify each result as likely true positive, likely false positive, or needs evidence",
"Identify missing sanitizers or framework protections",
"Suggest one safe unit test per likely true positive",
"Do not claim production impact without runtime evidence"
]
}
This is where a frontier-scale long-context model can shine. It can compare multiple results, detect framework-specific protections, and write a cleaner query iteration. But the CodeQL database and query output remain the evidence.
Dependency findings need reachability, not panic
Software composition analysis often produces too many findings. A model can help prioritize, but only when paired with reachability evidence.
Semgrep’s supply chain documentation describes reachable findings as cases where a codebase uses both a vulnerable dependency version and a vulnerable usage pattern. That distinction is critical. A vulnerable package in a lockfile does not always mean the vulnerable function is reachable in the application. (semgrep.dev)
A local DeepSeek V4 Pro pipeline should therefore ask:
Is the vulnerable package present?
Is the affected version present?
Is the vulnerable function imported?
Is it reachable from a real entry point?
Does the application configuration enable the vulnerable behavior?
Is the affected component internet-facing, authenticated, internal, or test-only?
Is there a safe way to confirm without destructive testing?
This reduces alert fatigue and helps engineers fix the right things first.
Web and API testing still need state
AI-assisted local code review is strongest when combined with application behavior. OWASP’s broken access control examples are a reminder that many real bugs are about state, roles, object ownership, and workflow boundaries. (owasp.org)
A local pipeline can ingest a role matrix:
roles:
viewer:
can:
- "GET /api/projects/:id"
cannot:
- "POST /api/projects"
- "DELETE /api/projects/:id"
- "GET /api/admin/users"
editor:
can:
- "GET /api/projects/:id"
- "POST /api/projects"
cannot:
- "DELETE /api/projects/:id"
- "GET /api/admin/users"
admin:
can:
- "*"
It can compare that against route definitions:
{
"route": "DELETE /api/projects/:id",
"handler": "deleteProject",
"middleware": ["requireLogin"],
"missing_expected_middleware": ["requireRole('admin')"],
"model_question": "Does the code enforce the role matrix, or does it only check authentication?"
}
A model can reason about the mismatch. A test must prove it.
def test_viewer_cannot_delete_project(client, viewer_token, project):
response = client.delete(
f"/api/projects/{project.id}",
headers={"Authorization": f"Bearer {viewer_token}"}
)
assert response.status_code in {401, 403}
This is a safe, useful pattern. It turns LLM reasoning into regression tests rather than uncontrolled exploitation.
The safest way to handle dynamic validation
Dynamic validation should start in local tests and sandbox environments. Production testing should require explicit approval, narrow scope, rate limits, logging, and rollback planning.
A good validation ladder is:
| Level | Environment | Allowed activity |
|---|---|---|
| 1 | Static analysis only | No execution |
| 2 | Unit test | Benign proof of behavior |
| 3 | Local Docker sandbox | Fuzzing, sanitizer runs, replay tests |
| 4 | Staging | Non-destructive auth and workflow checks |
| 5 | Production | Only approved, low-risk, tightly scoped validation |
The model should not be able to jump levels. The orchestrator should enforce the ladder.
validation_levels:
static_only:
network: false
filesystem_write: "artifacts_only"
human_approval: false
local_sandbox:
network: false
filesystem_write: "sandbox_only"
human_approval: false
staging:
network: "staging_only"
rate_limit: "strict"
destructive_payloads: false
human_approval: true
production:
network: "approved_targets_only"
rate_limit: "very_strict"
destructive_payloads: false
human_approval: true
change_window_required: true
This is especially important for agentic models. Tool calls are useful, but tool calls create execution risk. DeepSeek’s documentation lists tool call support for V4 models, which makes structured orchestration possible. That same capability should be wrapped with policy enforcement. (api-docs.deepseek.com)
Cost and performance should be measured by findings, not tokens
A local DeepSeek V4 Pro deployment will consume real infrastructure. But the most meaningful performance metric is not tokens per second. It is security throughput with evidence.
Track metrics such as:
| Metric | Why it matters |
|---|---|
| Static findings triaged per hour | Measures analyst acceleration |
| True positive rate after human review | Measures signal quality |
| New code coverage from generated harnesses | Measures fuzzing value |
| Build success rate for generated harnesses | Measures practical automation |
| Crash reproducer rate | Measures evidence quality |
| Patch suggestion acceptance rate | Measures developer usefulness |
| Retest pass rate | Measures closure |
| Findings with complete artifacts | Measures report reliability |
| Out-of-scope action attempts blocked | Measures safety |
A model that produces fewer but better hypotheses may be more valuable than one that floods the queue. Vulnerability discovery is not a content generation task. Volume can hurt.
Common failure modes
The failure modes are predictable.
The first is context flooding. Teams put too much code into the model and receive broad, shallow findings. Fix it with slicing, call graphs, tool output, and targeted questions.
The second is scanner summarization masquerading as pentesting. A chat layer over Semgrep, CodeQL, or Nuclei output may improve readability, but it is not autonomous vulnerability discovery. Real discovery creates new hypotheses and tests them.
The third is severity inflation. The model sees a dangerous function and labels it critical without reachability or preconditions. Fix it by requiring evidence fields.
The fourth is unsafe automation. The model suggests dynamic tests against systems outside scope. Fix it with a policy engine and command allowlist.
The fifth is poor artifact handling. If the system does not store commit hashes, tool versions, logs, model prompts, crash files, and patch diffs, the report cannot survive retest.
The sixth is no feedback loop. If reviewer decisions do not flow back into rules, prompts, and harness templates, the system will keep making the same mistakes.
The seventh is relying on one model. DeepSeek V4 Pro may be strong, but no single model should own the whole pipeline. Use deterministic tools, smaller models, specialized scanners, and human review.
A useful team workflow
A realistic weekly workflow for an AppSec or security research team looks like this:
Monday: Select two or three high-risk repositories. Pull recent changes, dependency updates, and previous findings. Run static analysis and dependency scanning.
Tuesday: Generate focused code slices around changed entry points, parsers, auth-sensitive routes, and dangerous sinks. Ask DeepSeek V4 Pro for hypotheses and candidate variant queries.
Wednesday: Run generated Semgrep or CodeQL queries. Review results. Accept only findings with plausible source-to-sink paths.
Thursday: Generate fuzz harnesses for parsers, decoders, file importers, and protocol handlers. Run them in a local sanitizer-enabled sandbox.
Friday: Triage crashes, reduce test cases, write patches or tickets, and generate evidence-backed reports. Human reviewers decide severity and disclosure path.
This is boring in the best way. It is repeatable. It can be measured. It does not depend on the model being perfect.
What to use V4 Flash for
DeepSeek V4 Flash is not just a cheaper fallback. The official V4 materials position it as a smaller model with 284B total parameters and 13B activated parameters, supporting the same one million context length in the V4 series. DeepSeek’s API pricing page lists V4 Flash and V4 Pro as the current V4 API models with the same major API features. (api-docs.deepseek.com)
In a security workflow, Flash-class models are often enough for:
Log summarization
Finding deduplication
Report formatting
Simple static finding explanation
Test name generation
Patch note drafting
Dependency advisory summarization
Artifact indexing
Prompt routing
Low-risk triage preclassification
Save V4 Pro for:
Hard cross-file reasoning
Complex exploitability assessment
Variant analysis
Long-context architecture review
Fuzz harness repair across unfamiliar build systems
Multi-step access control analysis
Root cause explanation for crashes
Patch trade-off analysis
This tiered design is more cost-effective and safer than pushing every task into the largest model.
Human reviewers still own the hard calls
AI systems can accelerate vulnerability discovery, but they do not remove human responsibility. A reviewer must still answer:
Is this in scope?
Is the affected code reachable?
What are the real prerequisites?
Could the proposed validation harm data or availability?
Is there a safer proof?
Is the severity accurate for this environment?
Who owns the fix?
What is the disclosure path?
Does the report include enough evidence?
Did the retest actually prove closure?
The stronger the model, the more important these controls become. A weak model fails visibly. A strong model can produce convincing but wrong analysis.
What would make a local DeepSeek V4 Pro deployment worth it
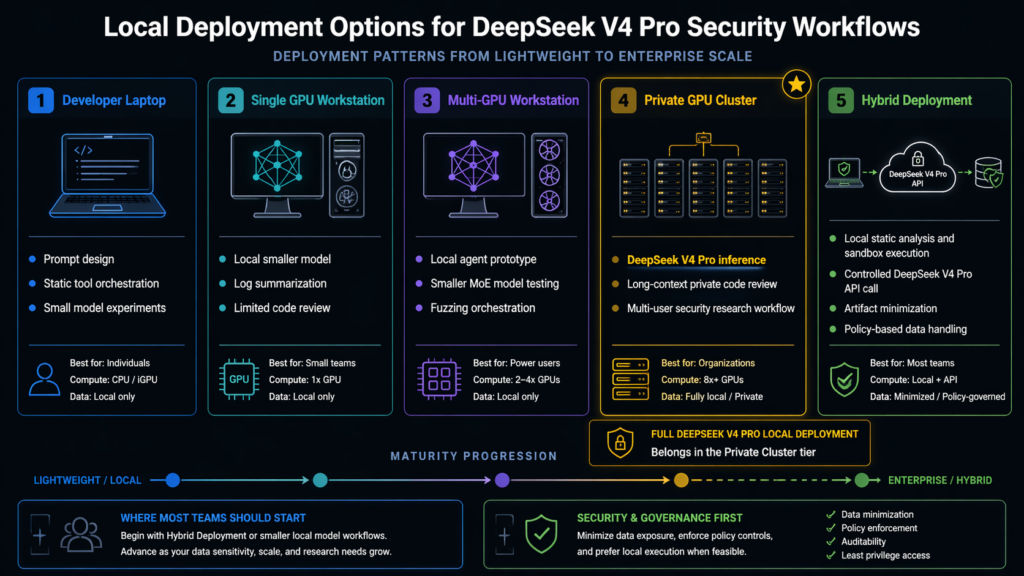
Full local V4 Pro deployment becomes worth serious consideration when several conditions are true.
The team has highly sensitive code or customer artifacts that cannot leave a controlled environment. The team already has a working pipeline with static analysis, fuzzing, sandbox execution, and evidence storage. The team has enough review volume that model latency and API cost materially affect operations. The team has MLOps skills for distributed inference. The team can measure security outcomes, not just model usage. The team has governance for prompt logs, artifact retention, access control, and abuse prevention.
Without those conditions, local deployment may become an expensive distraction. The team may get more value by improving code slicing, query generation, harness generation, and report evidence.
The role of AI pentest platforms around local code research
Local vulnerability discovery and AI pentesting are related but not identical. Local code research starts from source, build artifacts, tests, and dependencies. AI pentesting starts from running systems, application behavior, exposed assets, authentication flows, and evidence of impact. Mature programs need both.
Penligent’s public material describes AI pentesting in terms of target modeling, tool orchestration, validation, evidence, operator control, and reporting, while distinguishing real penetration testing workflows from scanner-plus-chatbot experiences. That distinction maps well to the local DeepSeek V4 Pro discussion: the model can improve reasoning, but the workflow still needs verification and evidence. (Penligent)
For a team building an internal research system, a practical division of labor is clear. Use the local model pipeline for private code review, harness generation, variant analysis, and patch reasoning. Use authorized testing workflows for exposed assets, API behavior, retesting, and report evidence. Keep both under scope control.
The bottom line
DeepSeek V4 Pro makes local AI-assisted vulnerability discovery more plausible, especially for teams that need long-context reasoning over private code. It does not make vulnerability research automatic in the simplistic sense.
The winning architecture is not “LLM plus shell.” It is a controlled system:
Static analysis finds candidate patterns.
Fuzzing generates runtime evidence.
Sandboxes contain execution.
The model connects context and proposes next steps.
Humans approve high-risk actions.
Reports preserve replayable proof.
Retests close the loop.
That is the version of local automated vulnerability discovery worth building.
If you have a serious cluster and a strong security engineering team, DeepSeek V4 Pro can be the reasoning core. If you are still proving the workflow, start smaller: run static analysis, generate slices, use V4 Pro through a controlled endpoint for hard reasoning, collect artifacts, and measure whether the model helps find and close real issues. The model is powerful, but the system design decides whether it becomes a research advantage or an expensive source of elegant false positives.
Further reading and references
DeepSeek V4 Preview Release, official DeepSeek API documentation. (api-docs.deepseek.com)
DeepSeek V4 Pro model card and local inference notes on Hugging Face. (Hugging Face)
DeepSeek API model details, pricing, tool calls, JSON output, and model names. (api-docs.deepseek.com)
DeepSeek API quick start and OpenAI-compatible API examples. (api-docs.deepseek.com)
Google Project Zero, From Naptime to Big Sleep. (projectzero.google)
Google Online Security Blog, Leveling Up Fuzzing, Finding more vulnerabilities with AI. (Google Online Security Blog)
Google oss-fuzz-gen repository. (GitHub)
CodeQL documentation. (CodeQL)
DARPA AI Cyber Challenge. (AICyberChallenge)
NIST SP 800-115, Technical Guide to Information Security Testing and Assessment. (csrc.nist.gov)
OWASP Top 10 2021. (owasp.org)
OWASP Broken Access Control. (owasp.org)
OWASP Server Side Request Forgery. (owasp.org)
NVD CVE-2024-9143. (nvd.nist.gov)
NVD CVE-2024-3094. (nvd.nist.gov)
Penligent, AI Pentest Tool, What Real Automated Offense Looks Like in 2026. (Penligent)
Penligent, How to Get an AI Pentest Report. (Penligent)
Penligent documentation and authorized-use notice. (Penligent)
Penligent, Rethinking Automated Vulnerability Discovery with LLM-Powered Static Analysis. (Penligent)