A model that writes convincing exploit code is not automatically useful for pentesting. A model that explains a vulnerability clearly is not automatically able to verify it. A model that scores well on coding or agent benchmarks is not automatically safe to connect to scanners, browsers, shells, credentials, or production-like targets.
That distinction matters when comparing GPT-5.5 and Claude Opus 4.7 for pentesting.
OpenAI describes GPT-5.5 as a model built for complex real-world work such as coding, research, analysis, documents, spreadsheets, and tool-based tasks. OpenAI’s system card also emphasizes better task understanding, tool use, and persistence across complex work compared with earlier models. Anthropic describes Claude Opus 4.7 as its most capable generally available model for complex reasoning and agentic coding, with documentation pointing to improved agentic coding and availability through the Claude API and major cloud platforms. (OpenAI)
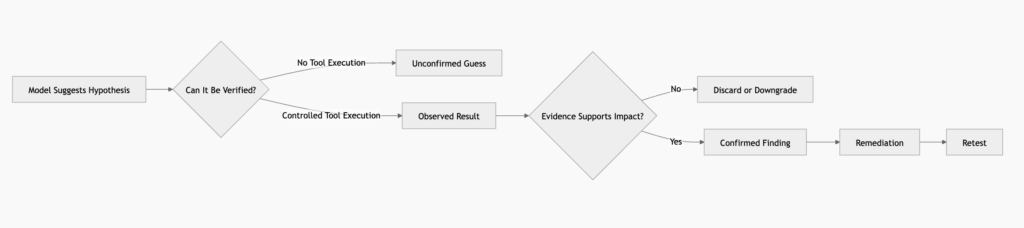
Those are useful signals, but they are not the same as a public, standardized, end-to-end pentesting benchmark. A real pentest is not a single prompt. It is a controlled loop of scope validation, reconnaissance, attack surface modeling, vulnerability hypothesis generation, tool execution, evidence collection, impact analysis, remediation guidance, and retesting. A model can assist several of those steps, but the value comes from the workflow, not from the model name alone.
The right question is not simply whether GPT-5.5 or Claude Opus 4.7 is “better for pentesting.” The better question is where each model type fits inside an authorized security testing workflow, what it can safely automate, where it needs tools, and where a human tester still has to make the call.
Model comparisons break down when pentesting is treated as one task
Pentesting is often discussed as if it were one activity: find bugs. In practice, it is a chain of different tasks with different failure modes.
A recon task rewards breadth, normalization, and disciplined note-taking. An attack surface mapping task rewards pattern recognition and consistency. A business logic review rewards deep reasoning over roles, state, and trust boundaries. A PoC drafting task rewards code fluency and careful handling of preconditions. A verification task rewards repeatability, evidence, and restraint. A reporting task rewards clarity and precision.
One model may be strong at turning messy notes into a clean test plan. Another may be strong at reading long system descriptions and spotting a broken authorization assumption. Neither is a replacement for a scanner, a proxy, a browser, a shell, a staging environment, a proof trail, or permission to test.
That is why broad model benchmarks can mislead security teams. A model can perform well on general coding, agentic task, or reasoning benchmarks and still fail in a pentesting context if it invents endpoints, misses scope boundaries, produces unsafe commands, overlooks rate limits, or treats an unverified response as a confirmed vulnerability.
The same problem appears in the other direction. A model can be weak at polished writing but still useful in one part of a pentest if it reliably extracts endpoints from JavaScript, normalizes HTTP traffic, or generates clear retest checklists. The scoring unit for pentesting should not be the model. It should be the task inside the workflow.
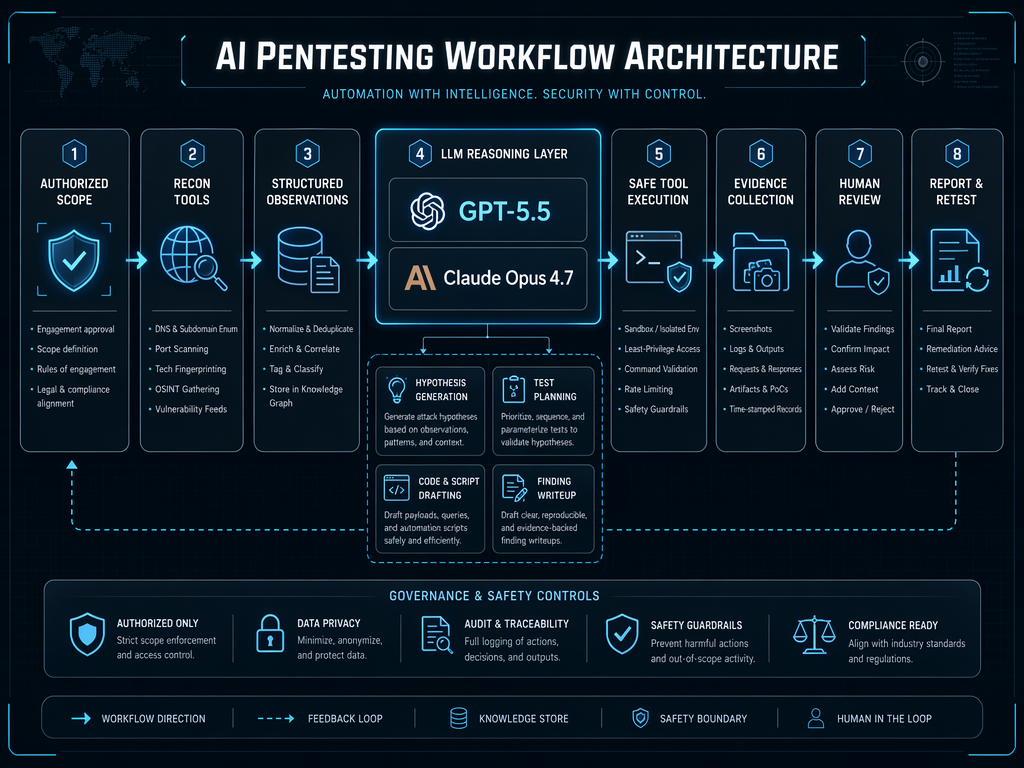
What matters in AI-assisted pentesting
A useful AI pentesting workflow depends on five capabilities.
| Capability | What it means in a pentest | Why it matters |
|---|---|---|
| Context handling | Reading and organizing code, logs, HTTP traffic, JavaScript bundles, API schemas, screenshots, prior reports, and target notes | Most real findings depend on context, not one isolated request |
| Security reasoning | Forming plausible vulnerability hypotheses from roles, state transitions, trust boundaries, and data flows | Many serious bugs are logic failures rather than obvious signatures |
| Code and payload drafting | Creating safe scripts, request replays, test harnesses, templates, and controlled PoC material | Testers need reproducible steps, not just descriptions |
| Tool orchestration | Calling or coordinating tools such as nmap, httpx, ffuf, nuclei, Burp Suite, Playwright, custom scripts, and log parsers | LLMs reason, but tools measure reality |
| Verification and evidence | Confirming behavior, excluding false positives, preserving requests and responses, documenting impact, and supporting retest | A report without evidence is not a pentest finding |
GPT-5.5 and Claude Opus 4.7 should be compared across those dimensions, not as abstract personalities.
OpenAI’s public positioning makes GPT-5.5 especially relevant to structured coding, research, analysis, documents, and tool-heavy work. Anthropic’s public positioning makes Claude Opus 4.7 especially relevant to complex reasoning and agentic coding. Those descriptions suggest likely areas of fit, but they do not prove pentest superiority by themselves. (OpenAI)
A serious security team should treat both models as components in a controlled system. The model proposes. The tool executes. The evidence decides. The human tester owns the scope, risk, and final judgment.
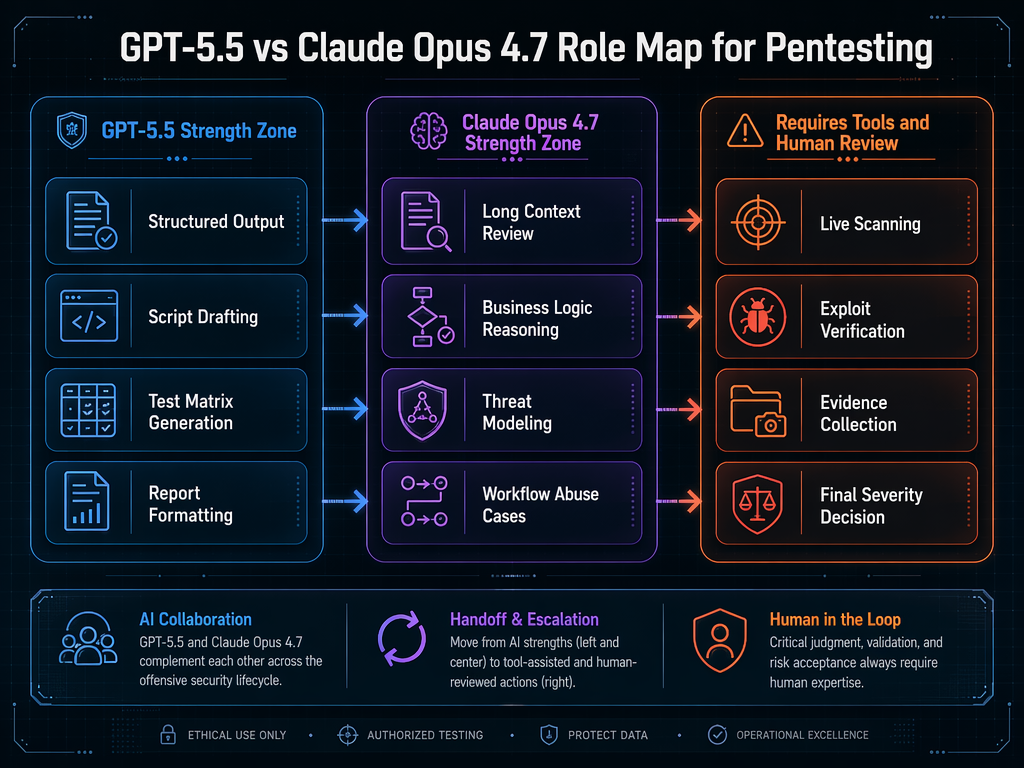
GPT-5.5 in a pentesting workflow
GPT-5.5 is most interesting for pentesting when the task is structured, tool-aware, and output-sensitive.
That includes turning rough recon into a test plan, converting HTTP traffic into a table of endpoints, drafting scripts that replay authorized requests, summarizing noisy scanner output, generating report sections from verified evidence, and helping a tester keep the workflow consistent across many assets.
A common pentesting failure is not lack of ideas. It is loss of structure. After several hours of recon, a tester may have subdomains, ports, screenshots, JavaScript files, API routes, tokens, redirects, error pages, WAF behavior, authentication notes, and half-formed hypotheses scattered across terminal output and proxy history. A model that can normalize that data into a structured attack surface map can save time, but only if the data remains traceable to raw evidence.
A useful GPT-5.5-style task might look like this:
You are helping with an authorized security test.
Input:
- A list of discovered hosts
- HTTP status codes
- Page titles
- Detected technologies
- Notes from proxy traffic
- Scope restrictions
Task:
Create a test matrix with:
- Asset
- Observed function
- Authentication requirement
- Interesting endpoints
- Likely risk category
- Suggested safe test
- Required evidence
- Do not mark anything as confirmed without proof
The important part is the last line. In pentesting, the model should not be rewarded for sounding confident. It should be rewarded for separating observed facts from hypotheses.
GPT-5.5 may also be useful for code-adjacent work. For example, a tester can ask it to draft a Python script that replays a known authorized request and records status code, selected headers, response length, and a hash of the response body. That does not prove a vulnerability by itself, but it helps make verification repeatable.
import hashlib
import json
import sys
from datetime import datetime, timezone
import requests
def sha256_text(value: str) -> str:
return hashlib.sha256(value.encode("utf-8", errors="replace")).hexdigest()
def replay_request(url: str, headers: dict, timeout: int = 10) -> dict:
response = requests.get(url, headers=headers, timeout=timeout, allow_redirects=False)
return {
"timestamp_utc": datetime.now(timezone.utc).isoformat(),
"url": url,
"status_code": response.status_code,
"content_length": len(response.text),
"body_sha256": sha256_text(response.text),
"selected_headers": {
key: response.headers.get(key)
for key in ["content-type", "location", "server", "cache-control"]
if key in response.headers
},
}
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python replay_check.py https://target.example/path")
sys.exit(1)
target_url = sys.argv[1]
# Use only authorized test credentials and approved targets.
request_headers = {
"User-Agent": "authorized-security-test",
"Accept": "text/html,application/json",
}
result = replay_request(target_url, request_headers)
print(json.dumps(result, indent=2))
That script is intentionally modest. It does not exploit anything. It helps preserve repeatable observations. In real work, the tester would extend it with approved authentication headers, request bodies, role comparisons, or response assertions. The value is not that the model “hacked” the target. The value is that it helped make testing more consistent.
GPT-5.5 is also likely to be useful in report generation, but only if the report is evidence-driven. A good prompt should include raw request and response excerpts, reproduction steps, affected roles, timestamps, screenshots, and a clear statement of what was verified. A bad prompt asks the model to “write a critical vulnerability report” from a vague note. That is how hallucinated impact enters the final deliverable.
Claude Opus 4.7 in a pentesting workflow
Claude Opus 4.7 is most interesting where the task requires sustained reasoning over context.
That often means business logic testing, authorization modeling, multi-step flows, tenant isolation, payment logic, audit log behavior, workflow state transitions, and reviewing long documents or code fragments. These are areas where simple signature scanning is weak.
Anthropic’s documentation describes Claude Opus 4.7 as a strong model for complex tasks and agentic coding, and its model documentation positions Opus 4.7 as the starting point for the most complex tasks. That makes it a plausible fit for deep review work, especially when the tester gives it enough structured context and asks it to reason in terms of roles, preconditions, state, and evidence. (Anthropic)
A useful Claude-style task might be:
You are reviewing an authorized SaaS workflow for access control issues.
Actors:
- Organization owner
- Organization admin
- Project manager
- Read-only member
- External guest
Workflow:
- Invite user
- Assign project role
- Upload file
- Generate share link
- Revoke access
- Export audit log
Task:
Identify test hypotheses only.
For each hypothesis, include:
- Required role A
- Required role B
- State transition
- API or UI surface to inspect
- What evidence would confirm the issue
- What evidence would disprove it
Do not claim a vulnerability is confirmed.
That prompt does not ask the model to produce a weaponized payload. It asks the model to reason about the system. This is the kind of work where a strong long-context reasoning model can help a human tester see what to test next.
For example, Claude might identify that a revoked guest link should be tested after role downgrade, after organization transfer, after file replacement, and after audit log export. The model may not know whether the bug exists. It can, however, help build a better test plan.
That distinction is central. In logic-heavy pentesting, the AI should be used to expand and discipline the tester’s hypothesis space. It should not be treated as an oracle.
Reconnaissance
Recon is the first place where AI can save time, and also the first place where it can create false confidence.
A typical authorized recon workflow may include subdomain discovery, DNS inspection, HTTP probing, port scanning, screenshotting, JavaScript collection, certificate review, and technology fingerprinting. The model should not be the tool that discovers the facts. It should help organize the facts produced by tools.
A safe recon workflow may look like this:
# Only run against assets that are explicitly in scope.
subfinder -d example.com -silent > subdomains.txt
httpx -l subdomains.txt \
-title \
-status-code \
-tech-detect \
-follow-redirects \
-json \
-o httpx-results.json
nmap -iL subdomains.txt \
-sV \
--top-ports 100 \
-oA nmap-top-ports
The model can then classify the results:
Input:
- httpx-results.json
- nmap service summary
- scope notes
Task:
Group assets into:
- Marketing and static sites
- Login surfaces
- Admin surfaces
- API hosts
- File or media surfaces
- Developer or staging-looking surfaces
- Unknown
For each group, suggest safe next tests and required evidence.
Do not suggest testing assets outside scope.
GPT-5.5 may be a strong fit for turning recon output into structured tables, JSON, and checklists. Claude Opus 4.7 may be a strong fit when recon results need to be interpreted alongside long documentation, architecture notes, or previous pentest findings.
Neither should decide scope. Scope is a legal and operational boundary, not a model inference task.
Attack surface mapping
Attack surface mapping is where many AI pentesting workflows become useful. Raw recon tells you what exists. Attack surface mapping tells you what might matter.
A model-assisted attack map should preserve observed evidence and separate it from hypotheses. A practical schema can look like this:
{
"asset": "https://app.example.com",
"surface_type": "authenticated_web_app",
"observed_endpoints": [
{
"method": "GET",
"path": "/api/projects/{project_id}",
"source": "proxy_history",
"auth_required": true,
"observed_roles": ["admin", "member"],
"sensitive_data_seen": ["project_name", "owner_id"],
"hypotheses": [
{
"risk": "broken_access_control",
"test": "compare response for admin-owned project and member-owned project",
"confirmation_evidence": "member receives data for project outside assigned scope",
"disproof_evidence": "server returns 403 or scoped response for unauthorized project"
}
]
}
]
}
This is the right level of abstraction for AI assistance. The model helps organize the test surface, but the finding still depends on controlled requests and evidence.
GPT-5.5 may be useful for transforming proxy exports, scanner output, and notes into a schema like this. Claude Opus 4.7 may be useful for reading the schema alongside product documentation and identifying missing role transitions or state-dependent tests.
The model comparison becomes practical only when tied to the artifact being produced. If the artifact is a structured endpoint inventory, GPT-5.5-style structured output may be valuable. If the artifact is a business logic test plan, Claude-style long-context reasoning may be valuable. If the artifact is proof, neither model is enough.
Vulnerability hypothesis generation
A vulnerability hypothesis is not a vulnerability. It is a testable idea.
That distinction keeps AI-assisted pentesting honest. The model can propose that an endpoint might be vulnerable to IDOR, SSRF, insecure direct file access, weak object-level authorization, prompt injection, or excessive agent permissions. But the final report should only include what was verified.
Traditional application risks remain relevant. OWASP Top 10 2021 includes categories such as broken access control, injection, insecure design, security misconfiguration, vulnerable and outdated components, and identification and authentication failures. These categories map directly to many pentesting workflows. (OWASP Foundation)
AI-native application risks also matter. OWASP’s Top 10 for LLM Applications includes risks such as prompt injection, sensitive information disclosure, supply chain vulnerabilities, excessive agency, system prompt leakage, vector and embedding weaknesses, misinformation, and unbounded consumption. Prompt injection is especially relevant when an application allows untrusted content to influence model behavior or tool calls. (OWASP Foundation)
A model-assisted hypothesis table might look like this:
| Surface | Hypothesis | Required test | Evidence that confirms | Evidence that disproves |
|---|---|---|---|---|
| Project API | Broken object-level authorization | Request project A as user assigned only to project B | User B receives project A data | 403, 404, or scoped response |
| File preview | Insecure file access | Try approved role comparison after link revocation | Revoked user can still access file | Link invalidated server-side |
| Webhook configuration | SSRF-like behavior | Use approved internal-safe callback host | Server-side request reaches callback unexpectedly | No request or strict allowlist behavior |
| AI support bot | Prompt injection | Put adversarial instructions in user-controlled content | Bot reveals restricted context or calls unauthorized tool | Bot treats content as data and refuses unsafe tool use |
| Admin action | Missing audit control | Perform role-sensitive action in test tenant | No audit event for sensitive action | Audit event includes actor, time, object, and action |
GPT-5.5 may help generate a broad matrix quickly. Claude Opus 4.7 may help reason through multi-step variations. A tester should use both outputs as candidate hypotheses, not findings.
Exploit and PoC drafting
Exploit drafting is where AI comparisons become risky.
A model can generate code that looks plausible but fails against the real system. It can omit preconditions, misunderstand authentication, invent parameters, mishandle CSRF, miss tenant boundaries, or accidentally suggest destructive behavior. In authorized work, the safest use is not “write me an exploit.” It is “help me build a controlled verification harness for a specific hypothesis using approved evidence.”
For example, when testing access control in a permitted environment, the goal may be to compare responses between two authorized test users:
import hashlib
import json
from dataclasses import dataclass
import requests
@dataclass
class TestUser:
name: str
bearer_token: str
def fingerprint_response(response: requests.Response) -> dict:
body = response.text or ""
return {
"status_code": response.status_code,
"length": len(body),
"sha256": hashlib.sha256(body.encode("utf-8", errors="replace")).hexdigest(),
"content_type": response.headers.get("content-type"),
}
def fetch_as_user(url: str, user: TestUser) -> dict:
response = requests.get(
url,
headers={
"Authorization": f"Bearer {user.bearer_token}",
"Accept": "application/json",
"User-Agent": "authorized-access-control-test",
},
timeout=10,
allow_redirects=False,
)
return {
"user": user.name,
"url": url,
"fingerprint": fingerprint_response(response),
}
def compare_access(url: str, users: list[TestUser]) -> list[dict]:
return [fetch_as_user(url, user) for user in users]
if __name__ == "__main__":
# Use only approved test users and in-scope URLs.
admin = TestUser(name="admin_test_user", bearer_token="REPLACE_WITH_TEST_TOKEN")
member = TestUser(name="member_test_user", bearer_token="REPLACE_WITH_TEST_TOKEN")
target = "https://app.example.com/api/projects/123"
print(json.dumps(compare_access(target, [admin, member]), indent=2))
This does not bypass anything. It helps compare expected and unexpected access behavior in an authorized test. A model can help draft this kind of harness, but a human still needs to define the roles, target, preconditions, expected access matrix, and acceptable test limits.
A Nuclei template skeleton can also be useful when used carefully for internal validation, but it must not turn a guess into a confirmed issue:
id: internal-access-control-check-template
info:
name: Internal Access Control Check Template
author: security-team
severity: info
description: >
Skeleton for authorized internal validation.
Customize only for approved targets and non-destructive checks.
requests:
- method: GET
path:
- "{{BaseURL}}/api/replace-with-approved-path"
headers:
Authorization: "Bearer {{token}}"
User-Agent: "authorized-security-test"
matchers-condition: and
matchers:
- type: status
status:
- 200
- type: word
part: body
words:
- "replace-with-controlled-test-marker"
The template is only a starting point. In real testing, the matcher must correspond to approved evidence. A generic 200 OK is not a vulnerability. A sensitive object returned to an unauthorized role under controlled conditions may be.
GPT-5.5 may be a strong assistant for producing clean scripts, templates, and report-ready artifacts. Claude Opus 4.7 may be a strong assistant for checking whether the test logic actually matches the business rule. The best workflow may use one model to draft and another to critique, followed by tool execution and human review.
Verification is the real bottleneck
Verification is where most AI-only pentesting claims collapse.
A finding is not confirmed because a model says it is plausible. A finding is confirmed when the tester can show reproducible behavior, controlled conditions, impact, and evidence. The evidence must be specific enough for engineering to reproduce and fix the issue.
A good verification record includes:
| Evidence item | Why it matters |
|---|---|
| Scope confirmation | Shows the tested asset was authorized |
| Test account roles | Proves the role boundary being tested |
| Preconditions | Makes the issue reproducible |
| Raw request | Shows exactly what was sent |
| Raw response | Shows exactly what the server returned |
| Timestamp | Supports investigation and log correlation |
| Screenshot or recording | Helps non-security stakeholders understand the issue |
| Negative control | Shows expected behavior for a user who should not have access |
| Positive control | Shows expected behavior for a user who should have access |
| Retest result | Confirms whether remediation worked |
Models can help format this evidence. They cannot replace it.
This is also where AI agent safety becomes important. If a model is allowed to run tools, browse internal systems, modify state, or access credentials, the workflow must include guardrails. OWASP’s LLM risk categories such as prompt injection, sensitive information disclosure, excessive agency, and unbounded consumption are not abstract concerns. They become practical risks when an agent reads untrusted content and then decides what commands to run. (OWASP Foundation)
A safer AI pentesting loop should enforce:
| Control | Practical implementation |
|---|---|
| Scope boundary | Allowlist domains, IP ranges, and test tenants |
| Command restrictions | Approved tool profiles and blocked destructive flags |
| Credential isolation | Short-lived test tokens, least privilege, no production secrets in prompts |
| Human approval gates | Manual approval before state-changing or high-volume actions |
| Evidence logging | Store commands, requests, responses, timestamps, and model outputs |
| Rate limits | Prevent accidental denial of service |
| Prompt injection handling | Treat target-controlled text as untrusted data |
| Retest workflow | Separate initial finding from remediation verification |
A model that is excellent at reasoning can still be unsafe if it is given excessive authority. A model that is excellent at coding can still produce a harmful command if the workflow lacks constraints.
MITRE ATLAS is useful here because it frames adversarial behavior against AI-enabled systems as a living knowledge base based on real-world observations. It reinforces the point that AI systems themselves need threat modeling, not just performance testing. (atlas.mitre.org)
CVEs show why workflow matters more than model confidence
Real vulnerabilities show why AI assistance must be grounded in verification.
CVE-2021-44228, known as Log4Shell, is a useful example. The vulnerability affected Apache Log4j 2 and was widely exploited after disclosure. NVD identifies it as an Apache Log4j2 remote code execution vulnerability, and CISA added it to the Known Exploited Vulnerabilities Catalog with urgent remediation requirements. CISA also warned that malicious actors continued exploiting Log4Shell against unpatched public-facing systems. (nvd.nist.gov)
An AI model can help with Log4Shell-related work in several ways. It can parse dependency inventories, summarize vendor advisories, generate a checklist for exposed Java services, classify scanner output, and draft remediation guidance. It can help a tester distinguish between “uses Log4j somewhere” and “has a reachable vulnerable code path.” But it cannot simply declare a system exploitable because a package name appears in a file.
The real question is reachability and configuration. Is the vulnerable version present? Is the vulnerable functionality reachable? Is JNDI lookup behavior enabled or mitigated? Is the affected service internet-facing? Was the patch applied? Are there compensating controls? Is there evidence of exploitation in logs? Those questions require artifacts, not model confidence.
This pattern applies to newer supply chain and development workflow issues as well. CISA’s KEV Catalog is an authoritative source for vulnerabilities known to have been exploited in the wild, and it is useful as an input to prioritization. But KEV presence does not replace environment-specific validation. A model can help map KEV entries to asset inventories and remediation plans, but the organization still needs version data, exposure data, and ownership. (cisa.gov)
AI-native risks do not always arrive as traditional CVEs. Prompt injection, tool misuse, excessive agency, insecure output handling, and retrieval system manipulation often arise from system design rather than one patchable library defect. OWASP’s LLM Top 10 is better suited than a CVE list for those cases because it describes classes of application risk. (OWASP Foundation)
That is why a practical comparison of GPT-5.5 and Claude Opus 4.7 should include both traditional AppSec and AI system risks. A modern pentest may include a normal web application, a RAG feature, a support chatbot, an internal automation agent, a CI/CD pipeline, and a permissioned tool layer. The model is only one part of that system.
A practical model selection matrix
The table below is a more useful way to compare GPT-5.5 and Claude Opus 4.7 than declaring a winner.
| Pentest task | GPT-5.5 may be a better fit when | Claude Opus 4.7 may be a better fit when | Do not rely on a model alone |
|---|---|---|---|
| Recon organization | You need structured tables, JSON, checklists, and clean summaries from tool output | You need to interpret recon alongside long architecture notes or prior reports | Scope validation, asset ownership, and rate limits |
| Attack surface mapping | You need consistent endpoint classification and test matrix generation | You need deeper reasoning over roles, workflows, and business processes | Whether an endpoint is actually vulnerable |
| JavaScript and API review | You need route extraction, parameter grouping, and scriptable next steps | You need long-context interpretation of complex front-end behavior | Confirming hidden endpoints are in scope |
| Business logic testing | You need a repeatable matrix of role comparisons | You need to reason through multi-step state transitions | Final impact assessment |
| PoC drafting | You need clean Python, shell, or template skeletons for approved tests | You need critique of assumptions and missing preconditions | Running payloads, especially destructive or state-changing ones |
| Scanner output triage | You need normalization, deduplication, and report-ready summaries | You need deeper review of ambiguous findings | Confirming true positives |
| AI feature testing | You need structured prompt injection test cases and logging formats | You need reasoning about tool permissions, memory, retrieval, and data boundaries | Allowing an agent to act without guardrails |
| Reporting | You need polished, consistent, evidence-driven finding writeups | You need careful explanation of nuanced logic flaws | Severity assignment without evidence |
| Retesting | You need reproducible retest checklists | You need analysis of whether the fix changes the threat model | Declaring closure without fresh evidence |
This matrix also explains why teams often get better results from a hybrid workflow than from one model. Claude Opus 4.7 can be used as a reasoning partner for complex flows. GPT-5.5 can be used as a structured automation and reporting partner. Tools execute. Evidence decides.
AI pentesting for traditional web apps
For a traditional web application, the model’s usefulness depends heavily on the quality of input.
Weak input:
Find vulnerabilities in this app.
Better input:
Authorized test context:
- Target: staging.example.com
- Scope: staging.example.com only
- Out of scope: production, third-party services, denial-of-service testing
- Roles: owner, admin, member, guest
- Known features: project creation, file upload, comments, export, invite flow
- Evidence available: proxy history, OpenAPI schema, screenshots
Task:
Build a safe test matrix for broken access control and insecure file access.
Separate observed facts from hypotheses.
Include required evidence for each hypothesis.
The second prompt gives the model boundaries and asks for testable hypotheses. This is where both GPT-5.5 and Claude Opus 4.7 can be useful.
For broken access control, the model can produce a role matrix:
| Action | Owner | Admin | Member | Guest | Test focus |
|---|---|---|---|---|---|
| View project | Yes | Yes | If assigned | No | Object ownership and tenant boundary |
| Edit project | Yes | Yes | Maybe | No | Role downgrade and stale permission |
| Upload file | Yes | Yes | Maybe | No | File ownership and path access |
| Share file | Yes | Maybe | Maybe | No | Revocation and public link control |
| Export data | Yes | Maybe | No | No | Sensitive data exposure |
The tester then converts this into requests, role comparisons, and evidence. The model helps with coverage. It does not confirm the bug.
AI pentesting for APIs
APIs are a strong use case for model-assisted pentesting because they produce structured artifacts. OpenAPI specs, Postman collections, proxy exports, JSON responses, and logs can all be parsed and compared.
A model can help identify:
- Endpoints with object identifiers
- Role-sensitive actions
- Bulk operations
- Export endpoints
- Admin-looking paths
- File operations
- Webhook or callback parameters
- Search and filter parameters
- State-changing methods
- Inconsistent authentication patterns
A safe API analysis prompt might be:
Analyze this OpenAPI excerpt for authorized security testing.
Return:
- Endpoints with object identifiers
- Endpoints that appear role-sensitive
- Endpoints that change state
- Endpoints that may expose sensitive data
- Suggested access-control tests
- Required positive and negative controls
Rules:
- Do not claim a vulnerability exists.
- Do not suggest destructive tests.
- Assume only approved test accounts are available.
GPT-5.5 may be useful when the output needs to be strict JSON or a test plan that can be fed into automation. Claude Opus 4.7 may be useful when the API is tied to a complicated business workflow and the key risk is not visible from the schema alone.
AI pentesting for LLM and agent features
The comparison becomes more interesting when the target itself uses LLMs or agents.
An AI-powered support assistant may retrieve internal documents. A coding assistant may inspect repositories. A customer service bot may call tools. A workflow agent may create tickets, send messages, or query internal APIs. These systems introduce risks that traditional web scanners often miss.
OWASP’s LLM Top 10 is relevant here because it includes prompt injection, sensitive information disclosure, insecure output handling, excessive agency, system prompt leakage, vector and embedding weaknesses, and unbounded consumption. (OWASP Foundation)
A model-assisted test plan for an LLM feature should include:
| Risk | Test idea | Safe evidence |
|---|---|---|
| Prompt injection | Place untrusted instructions in user-controlled content and check whether the model treats them as instructions | Model refuses to follow untrusted content or treats it as data |
| Sensitive information disclosure | Ask whether retrieved context contains secrets, credentials, or private records | No restricted data appears in output |
| Excessive agency | Attempt to trigger a tool call beyond the user’s permission | Tool call is blocked or requires approval |
| Insecure output handling | Check whether model output is rendered unsafely in the UI | Output is escaped or sanitized |
| Retrieval boundary failure | Ask about another tenant’s private content | Retrieval returns only authorized content |
Claude Opus 4.7 may be helpful for reasoning about tool permissions, memory, retrieval boundaries, and multi-step prompt injection chains. GPT-5.5 may be helpful for generating structured test cases, logging schemas, and repeatable evaluation harnesses.
A simple logging schema for LLM feature testing might look like this:
{
"test_id": "llm-prompt-injection-001",
"feature": "support_assistant",
"tenant": "approved_test_tenant",
"user_role": "member",
"input_source": "uploaded_document",
"untrusted_content_marker": "TEST_MARKER_DO_NOT_EXECUTE",
"expected_behavior": "model treats document content as untrusted data",
"observed_behavior": "",
"tool_calls_attempted": [],
"restricted_data_exposed": false,
"evidence": {
"prompt": "",
"model_output": "",
"application_logs": "",
"timestamp_utc": ""
}
}
The point is not to “jailbreak harder.” The point is to test whether the application architecture correctly separates instructions, data, tools, identity, and permissions.
The execution gap
The biggest limitation of AI in pentesting is not only reasoning. It is execution.
A model can say, “This endpoint may have IDOR.” The tool must send the request. The server must respond. The tester must compare roles. The evidence must show unauthorized access. The report must explain impact. Engineering must patch. The tester must retest.
That loop is where many AI workflows fail. They stop at plausible analysis.
A good AI-assisted pentesting system should have a feedback loop:
Scope
↓
Recon tools
↓
Structured observations
↓
Model-generated hypotheses
↓
Approved tool execution
↓
Evidence collection
↓
Model-assisted triage
↓
Human review
↓
Report
↓
Retest
The model sits in the reasoning and formatting layers. It can also plan tool calls if the system allows it. But the tool layer and evidence layer must remain explicit.
Agentic systems increase both value and risk. The more freedom the model has, the more important it becomes to restrict scope, commands, credentials, data access, and output handling. Prompt injection becomes more dangerous when the model can act. Excessive agency becomes more dangerous when the model can modify state. Secret leakage becomes more dangerous when prompts include tokens, logs, or internal documents.
This is why AI pentesting needs architecture, not just prompts.
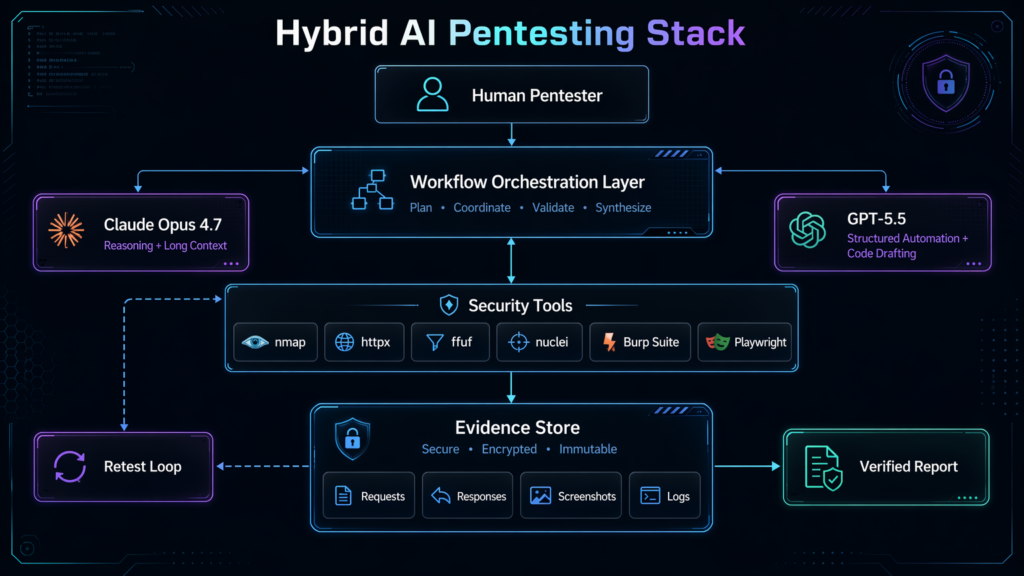
In authorized workflows where teams need to connect model reasoning with scanners, controlled execution, verification artifacts, and report generation, platforms such as Penligent can reduce the manual glue work between analysis and evidence. The important requirement is not that an AI assistant suggests a possible issue. It is that the workflow can run approved tests, preserve proof, support human review, and make retesting repeatable.
Reporting is a security control
Reporting is often treated as the boring final step. In AI-assisted pentesting, it is a control against hallucination.
A good report forces the model to ground every claim in evidence. If the model cannot point to a request, response, screenshot, log entry, role comparison, version number, or configuration state, the claim should be marked as a hypothesis or removed.
A practical finding structure looks like this:
Title:
Broken access control allows a project member to view another project
Status:
Confirmed in staging
Affected asset:
https://staging.example.com/api/projects/{project_id}
Preconditions:
- Authorized test tenant
- Test user A assigned to Project A
- Test user B assigned to Project B
- User B has no assigned access to Project A
Steps to reproduce:
1. Authenticate as User A and request Project A.
2. Confirm expected 200 response.
3. Authenticate as User B and request the same Project A endpoint.
4. Observe whether the server returns Project A data.
Evidence:
- Request 1 timestamp
- Response 1 status and body excerpt
- Request 2 timestamp
- Response 2 status and body excerpt
- Screenshot or proxy capture
Impact:
A user without project access can read project metadata and related records.
Root cause:
Server-side authorization appears to trust object identifiers without enforcing project membership.
Remediation:
Enforce object-level authorization on every project read path.
Add tests for cross-project access by role.
Retest:
Repeat the same role comparison after patch deployment.
A model can help write this cleanly. But the evidence must come first.
Common mistakes when using GPT-5.5 or Claude Opus 4.7 for pentesting
The first mistake is treating a model comparison as a pentest result. “GPT-5.5 found more issues” or “Claude reasoned better” means little unless the test set, scope, targets, tools, evidence rules, and grading criteria are defined.
The second mistake is letting the model decide severity without enough context. Severity depends on asset sensitivity, exploitability, affected users, data exposure, authentication requirements, compensating controls, and business impact. A model can draft a severity rationale, but the tester must validate it.
The third mistake is using AI to generate payloads before defining safe test boundaries. Payload generation should follow scope, preconditions, and non-destructive constraints. It should not be the first step.
The fourth mistake is ignoring negative controls. A role-based access bug is much more convincing when the report shows both expected access and blocked access. Without controls, the tester may mistake normal behavior for a vulnerability.
The fifth mistake is feeding secrets into prompts. API keys, session cookies, private customer data, internal credentials, and sensitive logs should be handled with strict redaction and access controls.
The sixth mistake is letting an AI agent read untrusted content and then run tools without guardrails. That is the classic setup for prompt injection against agentic systems.
The seventh mistake is using AI-generated reports that sound polished but do not preserve raw proof. A clean report without evidence is not a reliable deliverable.
The eighth mistake is skipping retest. A finding is not closed because a developer says it is fixed. It is closed when the original verification path no longer reproduces under controlled conditions.
A defensible way to evaluate both models in your own team
A team that wants to compare GPT-5.5 and Claude Opus 4.7 for pentesting should create a controlled evaluation rather than rely on impressions.
The evaluation should include real but safe internal targets, intentionally vulnerable labs, prior anonymized findings, or staging workflows. The tasks should be separated by phase.
A practical evaluation design:
| Evaluation task | Input | Expected output | Scoring |
|---|---|---|---|
| Recon normalization | httpx, nmap, screenshots | Asset groups and next-step matrix | Completeness, scope safety, clarity |
| API attack mapping | OpenAPI spec and proxy logs | Role-sensitive endpoint map | Correctness, useful hypotheses |
| Logic review | Workflow description and roles | Test hypotheses with controls | Depth, missing cases, false assumptions |
| Script drafting | Approved request pattern | Safe replay script | Correctness, safety, maintainability |
| Scanner triage | Nuclei or SAST output | Deduplicated finding list | False positive handling |
| Evidence reporting | Raw request and response proof | Technical finding | Accuracy, reproducibility, impact clarity |
| Retest planning | Patch notes and original finding | Retest checklist | Coverage and precision |
Do not grade the model on whether it sounds smart. Grade it on whether it improves the workflow.
Good scoring questions include:
- Did it preserve scope?
- Did it separate facts from hypotheses?
- Did it invent endpoints or evidence?
- Did it ask for missing preconditions?
- Did it produce safe, non-destructive next steps?
- Did it generate useful artifacts?
- Did it reduce manual work without reducing confidence?
- Did it make retesting easier?
- Did it handle untrusted content safely?
- Did it make the human reviewer faster?
This kind of evaluation will produce a better answer than a generic “GPT-5.5 vs Claude Opus 4.7” debate.
When GPT-5.5 is the safer default
GPT-5.5 may be the safer default when the task requires structured output, code scaffolding, tool planning, repeatable documentation, or converting messy security notes into operational artifacts.
Examples include:
- Turning recon into a test matrix
- Generating JSON schemas for attack surface data
- Drafting controlled Python replay scripts
- Creating report templates
- Summarizing scanner output
- Producing remediation checklists
- Building retest plans
- Formatting evidence into consistent findings
The key is to use it as a structured workflow assistant, not as an autonomous attacker.
When Claude Opus 4.7 is the safer default
Claude Opus 4.7 may be the safer default when the task requires deeper reasoning over long or ambiguous context.
Examples include:
- Reviewing complex authorization models
- Understanding multi-step business workflows
- Analyzing product documentation for abuse cases
- Reasoning about tenant isolation
- Reviewing agent tool permissions
- Identifying missing preconditions in a test plan
- Critiquing a proposed finding for weak evidence
- Threat modeling AI features and retrieval systems
The key is to use it as a reasoning partner, not as a source of final truth.
The best answer is often both, plus tools
For real pentesting, the strongest architecture is usually not one model. It is a controlled workflow that uses different strengths at different points.
A practical hybrid workflow might use Claude Opus 4.7 to reason through the target’s roles, workflows, and abuse cases. It might use GPT-5.5 to turn those hypotheses into structured test matrices, replay scripts, report sections, and retest checklists. Scanners, proxies, browsers, and custom scripts perform the actual measurements. Evidence is stored. A human tester reviews and signs off.
That architecture also makes model upgrades less risky. If the workflow is well designed, the team can swap or compare models without rebuilding the entire pentest process. The artifacts stay the same: scope, observations, hypotheses, tool results, evidence, findings, remediation, retest.
This is where AI-native pentesting tooling becomes more useful than one-off prompting. Penligent’s public materials describe an AI-powered penetration testing workflow that connects traditional tools such as nmap, Metasploit, Burp Suite, and SQLmap into an AI-driven process, with emphasis on automated testing, verification, and reporting. That kind of orchestration layer is closer to the operational need than a raw chat session, provided the testing remains authorized, scoped, and evidence-driven. (Penligent)
Final verdict
GPT-5.5 vs Claude Opus 4.7 is the wrong question if it means choosing one universal winner for pentesting.
A better conclusion is narrower and more useful:
GPT-5.5 is likely to be more attractive for structured automation, code-adjacent tasks, tool-aware workflows, and report production when the tester needs clean, repeatable artifacts.
Claude Opus 4.7 is likely to be more attractive for complex reasoning, long-context review, business logic analysis, and threat modeling when the tester needs to understand why a system might fail.
Neither model is a pentest by itself.
The winning workflow is a loop: authorized scope, real recon, structured context, model-assisted reasoning, controlled tool execution, evidence collection, human review, reporting, and retesting. The model can make that loop faster and more consistent. It cannot remove the need for proof.
Further reading and references
OpenAI, Introducing GPT-5.5. (OpenAI)
OpenAI, GPT-5.5 System Card. (OpenAI)
Anthropic, Claude Opus 4.7. (Anthropic)
Anthropic, Introducing Claude Opus 4.7. (Anthropic)
Anthropic, Claude model documentation. (Claude API Docs)
Anthropic, Claude release notes. (Claude API Docs)
OWASP Top 10 2021. (OWASP Foundation)
OWASP Top 10 for LLM Applications. (OWASP Foundation)
OWASP LLM01, Prompt Injection. (OWASP Gen AI Security Project)
MITRE ATLAS. (atlas.mitre.org)
CISA Known Exploited Vulnerabilities Catalog. (cisa.gov)
NVD, CVE-2021-44228. (nvd.nist.gov)
CISA advisory on continued Log4Shell exploitation. (cisa.gov)
Penligent homepage. (Penligent)
Overview of Penligent.ai’s Automated Penetration Testing Tool. (Penligent)
PentestAI and the Next Phase of AI Automated Penetration Testing. (Penligent)