Un producto de IA puede decir a los usuarios que son privados, anónimos, temporales o de incógnito. Ninguna de esas palabras demuestra a dónde fueron a parar los datos después de que el usuario pulsara enviar. Una propuesta de demanda colectiva presentada el 31 de marzo de 2026 contra Perplexity hizo que esa laguna fuera imposible de ignorar. La demanda alega que Perplexity utilizó tecnologías de rastreo como Meta Pixel, Google Ads, Google DoubleClick y la API de conversiones de Meta para compartir datos conversacionales e identificadores de los usuarios con Meta y Google, incluso cuando un usuario suscrito estaba en modo incógnito. Perplexity, a través de su director de comunicaciones, dijo que no había recibido la demanda correspondiente y que no podía verificar las acusaciones. Las cuestiones legales llevarán su tiempo. Las cuestiones de control ya están aquí.
Esta es la verdadera lección para los creadores de IA, los ingenieros de seguridad y los compradores técnicos. Una etiqueta de privacidad en una interfaz de usuario es una declaración sobre un comportamiento de cara al usuario. No es una prueba sobre la instrumentación del navegador, las canalizaciones de eventos del lado del servidor, los sumideros de análisis, el registro interno, la retención del proveedor, las herramientas de soporte o la forma en que los datos se vinculan a las cuentas. La reclamación es útil porque obliga a plantearse una pregunta aburrida pero importante: si un producto dice que es privado, ¿qué pruebas técnicas y organizativas demostrarían que esa afirmación es realmente cierta en todo el recorrido de los datos?
Para los equipos de cumplimiento, esa pregunta cae directamente en el territorio de SOC 2 e ISO/IEC 27001. El AICPA define un examen SOC 2 como un informe sobre los controles de una organización de servicios relacionados con la seguridad, la disponibilidad, la integridad del procesamiento, la confidencialidad o la privacidad. ISO dice que ISO/IEC 27001 define los requisitos que debe cumplir un sistema de gestión de la seguridad de la información y trata de establecer, implantar, mantener y mejorar continuamente ese sistema. Ninguno de los dos marcos considera la etiqueta de una característica como prueba suficiente por sí misma. Ambos se preocupan por los límites del sistema, los controles, la gestión de riesgos y la prueba de que los controles no sólo se describen, sino que funcionan realmente. (AICPA Y CIMA)
El error que cometen muchas empresas de IA es pequeño pero costoso. Asumen que una reclamación de retención es lo mismo que una reclamación de privacidad. Y no lo es. Borrar un hilo después de 24 horas responde a una pregunta. No responde a si el contenido de la solicitud se copió en la telemetría, si un script de terceros vio el evento de envío, si un proveedor de API retuvo algo, si un administrador pudo inspeccionar el intercambio o si una tubería de experimentación utilizó datos derivados más tarde. En los sistemas de IA, la privacidad nunca es un bit. Es una cadena de decisiones a través de la recogida, transmisión, almacenamiento, acceso y uso secundario. (Perplejidad AI)
La demanda no es el veredicto, pero las cuestiones de control ya están claras
Merece la pena leer detenidamente la denuncia de Perplexity porque es más específica que los titulares. Alega que las tecnologías de rastreo estaban presentes en cuanto un usuario aterrizaba en la página de inicio, antes de que introdujera una solicitud. Además, alega que, una vez que los usuarios empezaban a interactuar con el sistema de IA, esas tecnologías compartían datos conversacionales con Meta y Google, y que los usuarios suscritos en modo incógnito seguían teniendo avisos e identificadores revelados. La denuncia también señala direcciones de correo electrónico, cookies, datos de geolocalización y URL de conversaciones como parte del panorama de datos compartidos. Se trata de alegaciones en una denuncia presentada, no de conclusiones de un tribunal, pero son lo suficientemente detalladas como para enmarcar una revisión seria de ingeniería.
La denuncia es importante porque no describe el fracaso de la privacidad como un misterioso problema de la IA. Describe un problema ordinario de la web y de flujo de datos dentro de un producto de IA. Un usuario abre una página. Se ejecutan scripts. Se crean cookies. Se envían solicitudes. Los eventos se enriquecen. Los identificadores vinculan un sistema a otro. Así es como suelen funcionar las pilas modernas de crecimiento y análisis. El riesgo no es que existan los píxeles. El riesgo es que un producto comercializado para el cuestionamiento íntimo y libre puede, accidental o deliberadamente, dejar que datos puntuales altamente sensibles crucen sistemas construidos para la atribución, la creación de audiencias, la optimización o la elaboración de perfiles.
Esta diferencia es importante por razones jurídicas y técnicas. Una calculadora financiera que filtra etiquetas de eventos es un tipo de problema. Un sistema de inteligencia artificial que hace preguntas sobre el tratamiento del cáncer, el embarazo, los impuestos, la pérdida del empleo o las deudas y luego deja que esas preguntas entren en contacto con la fontanería de la tecnología publicitaria es un tipo de problema distinto, porque la expectativa de confidencialidad del usuario es materialmente diferente. La demanda se apoya en gran medida en esa distinción con ejemplos de salud y financieros. Independientemente de que el tribunal esté finalmente de acuerdo con todas las alegaciones, la lección de diseño ya es obvia: los productos de IA recogen intenciones de usuario inusualmente ricas, y eso eleva el coste de cualquier límite de datos descuidado.
También hay un matiz sutil pero importante en los propios materiales de Perplexity. El centro de ayuda de Perplexity dice que los hilos en modo incógnito caducan en 24 horas y no son recuperables, y otro artículo de ayuda dice que las búsquedas en modo incógnito nunca se almacenan. Al mismo tiempo, la documentación para desarrolladores de Perplexity dice que la API Sonar opera bajo una estricta política de retención de datos cero y sólo recoge metadatos de facturación, mientras que la documentación de Enterprise describe los registros de auditoría que registran las consultas de extremo a extremo, los pasos del agente, las respuestas, las marcas de tiempo, los detalles del usuario como el correo electrónico y la dirección IP, y los cambios de configuración, entregados a un webhook. No se trata de que ninguna de estas afirmaciones sea falsa. La cuestión es que las promesas de privacidad difieren según la superficie, y un comprador que considera "el producto" como una política de datos uniforme ya está pensando con demasiada ligereza. (Perplejidad AI)
Por eso la respuesta adecuada a una historia como ésta no es el tribalismo de marca. Es la descomposición del control. ¿Qué significa exactamente Incógnito. ¿Significa no almacenado en la historia. No retenido en ninguna parte. No utilizado para formación. No se comparte con terceros. No está vinculado a una cuenta. No accesible para los administradores. Diferentes organizaciones entienden diferentes cosas por "privado", y algunos equipos de producto envían la etiqueta antes de terminar de decidir cuál de esos significados están dispuestos a garantizar. Una revisión de seguridad seria rompe esa ambigüedad y pone a prueba cada pieza. (Perplejidad AI)
Qué cubre realmente una declaración de privacidad de la IA y qué no suele cubrir
Cuando un producto dice que un hilo es privado, hay al menos seis cuestiones diferentes ocultas dentro de esa frase. La primera es la visibilidad del historial. ¿Aparecerá la conversación en la barra lateral ordinaria o en el historial del usuario? La segunda es la retención. Si desaparece de la interfaz de usuario, ¿se elimina realmente del almacenamiento activo, las copias de seguridad, las cachés y los sistemas de observabilidad? La tercera es la divulgación. ¿Se envió alguna parte del aviso, URL, título, carga útil o identificador a un tercero durante el procesamiento? La cuarta es la vinculación. Aunque el contenido se haya redactado parcialmente, ¿puede una dirección de correo electrónico, cookie, IP o ID de cuenta volver a conectarlo con una persona conocida? El quinto es el uso secundario. ¿Puede seguir utilizándose el contenido para el entrenamiento de modelos, la evaluación, la mejora de productos, el análisis de abusos o la segmentación publicitaria? La sexta es el alcance del acceso. Qué empleados, sistemas o administradores de la empresa pueden seguir viendo alguna versión de la interacción. (NIST)
Un modo de privacidad suele abordar sólo una o dos de esas dimensiones. Un producto puede implementar honestamente "no guardar esto en el historial visible del usuario" mientras sigue enrutando los metadatos de la solicitud a las herramientas estándar de observabilidad. Un producto puede prometer "hilos anónimos" mientras sigue aceptando cookies del navegador o identificadores de la misma sesión que hacen que la interacción sea enlazable. Un proveedor puede decir "no nos entrenamos con los datos de su API" sin dejar de conservar los metadatos de facturación, los tiempos y la telemetría de selección de modelos. Ninguno de estos estados es automáticamente engañoso. Se vuelven peligrosos cuando la etiqueta pública fomenta una expectativa del usuario más amplia de la que el sistema realmente se gana. (docs.perplexity.ai)
La pila de seguimiento web lo complica aún más. Meta describe Meta Pixel como un fragmento de JavaScript que rastrea la actividad de los visitantes en un sitio web. La API de conversiones de Meta está diseñada para conectar los datos de marketing de los anunciantes, incluidos los eventos del sitio web y de la aplicación, directamente con Meta. La documentación de Google Ads indica que la etiqueta de Google captura información sobre las páginas visitadas por los visitantes, incluida la URL y el título de la página, y que los fragmentos de eventos opcionales pueden transmitir acciones específicas del usuario, como compras, cumplimentación de formularios o registros. La documentación de Google Analytics indica que los eventos recopilados automáticamente se activan mediante interacciones básicas, siempre y cuando la etiqueta de Google o el SDK de Firebase estén instalados. Estas herramientas se crearon para flujos de trabajo de medición y marketing, no para gestionar conversaciones confidenciales de texto libre con un asistente de inteligencia artificial, a menos que se delimiten con sumo cuidado. (Desarrolladores de Facebook)
Ese problema de alcance es la bisagra de la moderna ingeniería de privacidad de la IA. Una superficie de chat no es una página de aterrizaje más. Es un lugar donde los usuarios exteriorizan incertidumbre, miedo, problemas de dinero, exposición legal, preguntas médicas, decisiones de contratación, código fuente, documentos internos, diagramas de arquitectura y detalles de incidentes. En la práctica, un cuadro de consulta de IA suele estar más cerca de un formulario de escalada de soporte, un cuadro de preguntas médicas y un campo de notas confidenciales que de una barra de búsqueda de productos. Si la pila de telemetría circundante no lo reconoce, la empresa puede acabar tratando la parte más sensible del producto como un embudo de conversión normal. (Proyecto OWASP Gen AI Security)
Aquí es donde resulta útil el Marco de Privacidad del NIST. El NIST lo describe como una herramienta voluntaria para ayudar a las organizaciones a identificar y gestionar el riesgo para la privacidad a través de la gestión del riesgo empresarial. Esta formulación es importante. El riesgo para la privacidad no se gestiona con un solo interruptor. Se gestiona decidiendo lo que un sistema puede hacer de forma predecible, lo que los usuarios pueden gestionar y lo bien que se pueden separar o disociar los datos cuando no se requiere una identidad completa. En el momento en que un producto de IA mezcla entradas ricas de texto libre con instrumentación de crecimiento de propósito general, el problema de la privacidad se convierte en un problema de diseño empresarial, no de redacción. (NIST)
OWASP hace la misma observación desde el lado de LLM. Su proyecto de riesgo LLM señala la divulgación de información sensible como una de las principales clases de riesgo y advierte que las aplicaciones LLM pueden exponer información personal, datos comerciales confidenciales, detalles de propiedad y credenciales. También recomienda el saneamiento, una fuerte validación de la entrada y estrictos controles de acceso, al tiempo que señala que el lenguaje de las políticas por sí solo puede fallar ante una inyección rápida u otras desviaciones. En otras palabras, incluso una promesa de privacidad bien formulada es frágil si no está respaldada por un diseño defensivo y una aplicación técnica. (Proyecto OWASP Gen AI Security)
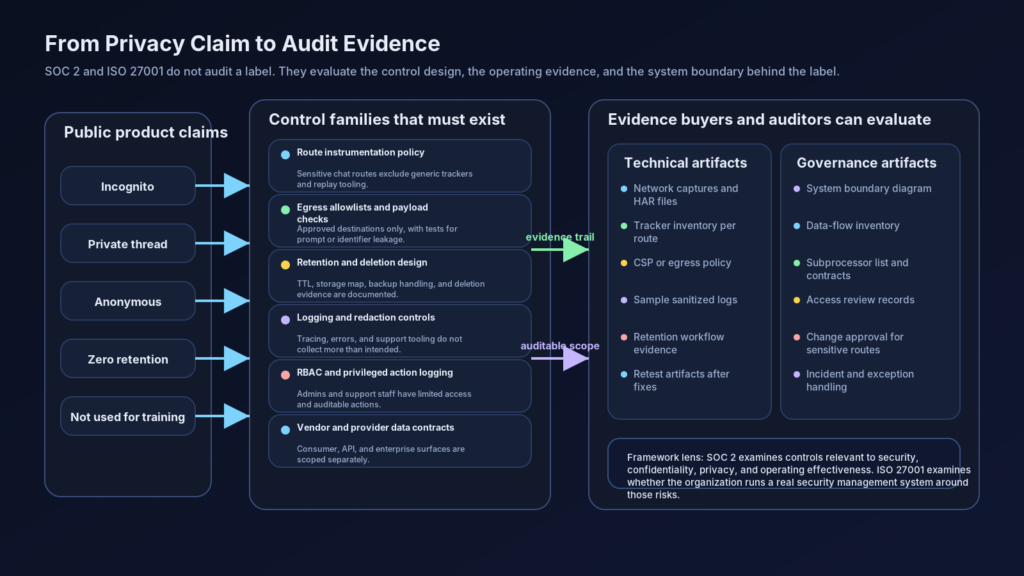
Qué pregunta el SOC 2 sobre un sistema de IA
Un informe SOC 2 no es un sello que dice "confíen en nosotros". El AICPA lo describe como un informe sobre controles relevantes para la seguridad, la disponibilidad, la integridad del procesamiento, la confidencialidad o la privacidad. Su material de Criterios de Servicios de Confianza, de acceso público, enmarca esos criterios como criterios de control utilizados para evaluar e informar sobre los controles de la información y los sistemas utilizados para prestar servicios. Un informe ilustrativo SOC 2 Tipo II del AICPA incluye la afirmación de la dirección, una descripción del sistema, el informe del auditor del servicio y pruebas de los controles con los resultados de dichas pruebas. Es una forma mucho más exigente que un artículo del centro de ayuda o un conmutador de configuración. (AICPA Y CIMA)
Para los productos de IA, esto tiene una consecuencia práctica. Si una empresa dice que una interacción es privada, un revisor orientado al SOC 2 no se detendrá en la redacción. Querrá entender el sistema que hace que la afirmación tenga sentido. Qué componentes procesan la interacción. Qué almacenes de datos contienen copias transitorias o duraderas. Qué subprocesadores reciben algo derivado de la interacción. Cómo se restringe el acceso. Cómo se configura el registro. Cómo funciona el borrado. Cómo se gestionan las excepciones. Cómo sabe la empresa que el control siguió funcionando el mes pasado, no sólo el día en que alguien escribió la política. No son preguntas exóticas de IA. Son preguntas de control clásicas aplicadas a un sistema con forma de IA. (AICPA Y CIMA)
Aquí es también donde la gente abusa de la frase "conforme con SOC 2". En sentido estricto, SOC 2 es un marco de atestación y un régimen de información, no una característica de un producto ni una ley. La cuestión es si una organización de servicios puede describir su sistema y demostrar los controles pertinentes de forma que un auditor independiente pueda examinarlos. Si su producto de chat de IA dice que es privado, pero no puede presentar pruebas de la gobernanza de secuencias de comandos, límites de proveedores, reglas de registro rápido, revisiones de acceso y gestión de excepciones, la etiqueta puede seguir sonando bien en la copia del producto, pero es débil en un entorno de control. (AICPA Y CIMA)
La distinción entre diseño y funcionamiento también es importante. La página de cumplimiento SOC 2 de Google Cloud explica la diferencia convencional entre Tipo I y Tipo II diciendo que un informe de Tipo I cubre el diseño de los controles en un momento dado, mientras que un informe de Tipo II cubre el diseño y la eficacia operativa durante un periodo de tiempo. Esto es importante para la privacidad de la IA porque casi todos los malos resultados en este ámbito se deben a la deriva. Un equipo de crecimiento añade una etiqueta. Un director de producto activa un nuevo evento. Una integración de soporte amplía el alcance. Un proveedor de modelos cambia los valores predeterminados de retención. Una capa de redacción se rompe después de un lanzamiento. El pensamiento de tipo II obliga a los equipos a preocuparse por si los controles siguen funcionando, no por si alguna vez existieron. (Nube de Google)
En los sistemas de IA, la forma más útil de leer la SOC 2 es como una exigencia de claridad del sistema. Si una empresa no puede explicar cómo se desplaza una consulta a través de las superficies del navegador, el backend, el proveedor, el registro y el administrador, entonces toda promesa de privacidad está mal especificada. Si la empresa puede explicar la ruta pero no puede mostrar pruebas y evidencias, la promesa sigue siendo débil. Si la empresa puede mostrar el camino y las pruebas, pero las pruebas sólo existen para un nivel, como la API, mientras que la aplicación de consumo se comporta de forma diferente, la promesa debe tener un alcance limitado. Por eso deben coincidir las etiquetas de los productos, las afirmaciones de los centros de confianza, los documentos de la API y la instrumentación real. (Perplejidad AI)
Lo que la ISO 27001 pide que una etiqueta de características nunca pueda
ISO afirma que ISO/IEC 27001 es la norma más conocida para los sistemas de gestión de la seguridad de la información y define los requisitos que debe cumplir un SGSI. Dice que la norma ayuda a las organizaciones a establecer, implantar, mantener y mejorar continuamente un sistema de gestión de la seguridad de la información y a gestionar los riesgos relacionados con la seguridad de los datos que poseen o manejan. Esa redacción es importante porque enmarca la seguridad y la gobernanza relacionada con la privacidad como un sistema de gestión, no como una colección de características puntuales. (ISO)
Un botón de hilo privado no puede satisfacer esto por sí mismo. Lo que importa es si la organización ha identificado el riesgo de que datos sensibles entren en vías de análisis, de proveedores, de registro o de soporte; si ha asignado propietarios; si ha implantado controles; si ha comprobado si los controles funcionan; y si los ha mejorado cuando ha encontrado lagunas. Esa es la diferencia entre una reclamación de IU y un sistema de control. Una es un mensaje a los usuarios. El otro es una capacidad interna repetible. (ISO)
Para los productos de IA, ISO/IEC 27001 debería empujar a los equipos a plantearse preguntas más amplias que "si almacenamos el hilo". Qué equipos de ingeniería pueden añadir scripts de terceros a las rutas confidenciales. ¿Existe una ruta de aprobación de cambios separada para las superficies de chat que puedan manejar datos confidenciales? ¿Se redactan los registros de avisos antes de entrar en los sistemas de observabilidad? ¿Se revisan los ajustes de retención de proveedores en la adquisición y durante la renovación? ¿Cubren las revisiones de acceso al personal de apoyo y a las herramientas de depuración? ¿Incluye la respuesta a incidentes la divulgación accidental a través de canales de análisis o de salida de modelos? Este es el tipo de preguntas que convierten un lenguaje vago sobre privacidad en un proceso auditable. (ISO)
El marco de gestión de riesgos de la IA del NIST plantea la misma cuestión desde otro ángulo. El NIST afirma que el objetivo del marco es ayudar a gestionar los riesgos para las personas, las organizaciones y la sociedad asociados a la IA, y que el perfil de IA generativa está destinado a un uso voluntario para incorporar consideraciones de fiabilidad en el diseño, el desarrollo, el uso y la evaluación. Este lenguaje es importante porque desalienta una visión superficial del cumplimiento de la IA. Un programa serio de garantía de la IA no se limita a preguntar si el modelo es preciso. Pregunta si el sistema de extremo a extremo gestiona la identidad, la telemetría, el contenido y las operaciones humanas de un modo acorde con los compromisos declarados de la organización. (NIST)
Por lo tanto, un equipo con mentalidad ISO 27001 trata "Incógnito" como una declaración de riesgo que necesita descomposición. Qué activos exactos están en el ámbito de aplicación. Qué escenarios de amenaza se aplican. Qué controles están destinados a reducir el riesgo. Qué pruebas demuestran que esos controles existen y funcionan. Qué riesgo residual queda. Dónde están documentadas las excepciones. Esa es la mentalidad que separa una buena página de confianza de un entorno de control real. (ISO)
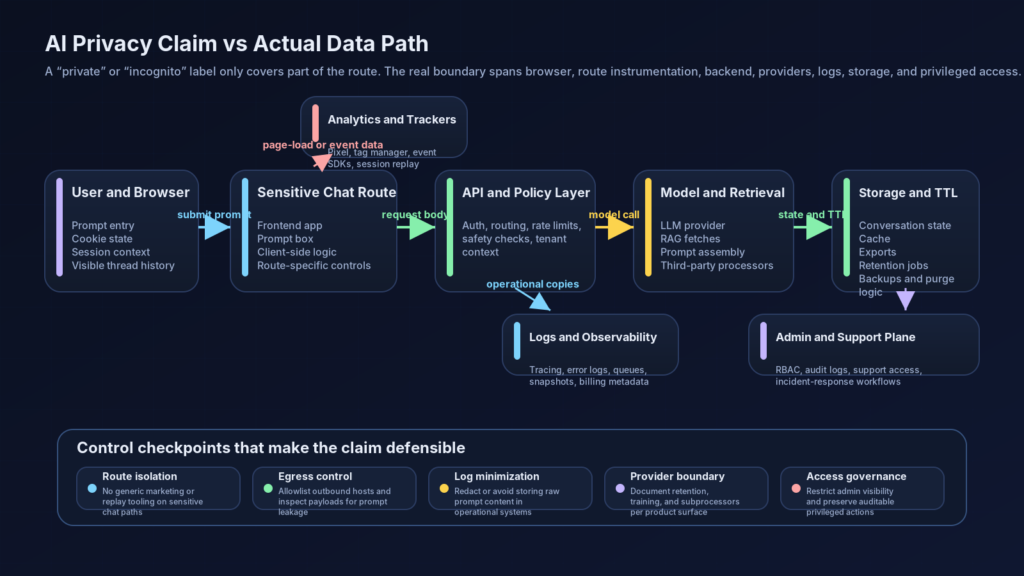
El verdadero flujo de datos de IA que preocupa tanto a los auditores como a los atacantes
La mayoría de los errores de privacidad de la IA se producen porque los equipos razonan sobre la interfaz de usuario visible en lugar de sobre el camino invisible. Un modelo mental mejor es tratar una interacción de IA como un conjunto de elementos de datos distintos que se mueven a través de varios planos: el plano del navegador, el plano de la aplicación, el plano del proveedor, el plano de la observabilidad, el plano del almacenamiento y el plano de las operaciones. Cada plano puede crear copias, derivados o nuevos identificadores. Cada plano puede gobernarse bien o mal. (NIST)
Instrumentación del navegador
El plano del navegador incluye todo lo que se carga en la sesión del usuario: scripts de origen, gestores de etiquetas, bibliotecas de análisis, SDK de pruebas A/B, widgets de chat, herramientas de reproducción de sesiones, gestores de consentimiento y ganchos de telemetría personalizados. La razón por la que este plano es peligroso es sencilla. Ve la interacción antes de que el backend tenga la oportunidad de clasificarla o redactarla. Google Ads dice que la etiqueta de Google captura la URL y el título de la página, y los fragmentos de eventos pueden pasar acciones específicas. Google Analytics afirma que las interacciones básicas pueden generar eventos automáticamente cuando la etiqueta está presente. Meta Pixel realiza un seguimiento de la actividad de los visitantes, y la API de conversiones de Meta admite el envío de eventos de sitios web o aplicaciones. En una ruta de chat de IA, estos mecanismos ordinarios pueden convertirse en un problema de privacidad si el contenido o los identificadores vinculados se filtran en la carga útil. (Ayuda Google)
Lo difícil es que esto puede ocurrir sin un solo actor malicioso. Un ingeniero de frontend añade instrumentación para mejorar el seguimiento de la conversión en un flujo de registro. El mismo componente se reutiliza en una página de chat. Una URL refleja parte de la solicitud para compartir o recuperar. Un título se actualiza con el mensaje para mayor comodidad. Un evento captura campos de texto para mejorar el análisis de formularios. Cada decisión parece razonable a nivel local. Juntas, crean un rastro de salida que nadie pretendía. Por eso, las rutas sensibles de la IA deben tratarse más como páginas de pago o formularios de admisión médica que como páginas genéricas de marketing. (Ayuda Google)
Procesamiento de aplicaciones y API
Una vez que la solicitud abandona el navegador, el plano de aplicación toma el relevo. Las pasarelas API autentican la solicitud. El middleware adjunta identificadores de sesión, información sobre el inquilino o indicadores de experimentación. Las capas de enrutamiento deciden a qué modelo o herramienta llamar. Los componentes de recuperación pueden buscar documentos. Los sistemas de seguridad pueden puntuar los contenidos. Los sistemas de limitación de velocidad y abuso pueden hacer hash o muestrear la entrada. Los ensambladores de respuestas pueden almacenar ventanas de contexto o el estado de los hilos. Para cuando el usuario recibe una respuesta, el sistema puede haber generado varios artefactos internos, aunque la interfaz de usuario diga más tarde que el hilo ha caducado. (docs.perplexity.ai)
Aquí es donde muchos equipos se exceden accidentalmente. Definen la privacidad en términos de la tabla de conversación en la base de datos primaria. Sin embargo, también pueden existir fragmentos en proxies inversos, registros de aplicaciones, intervalos de rastreo, cargas de trabajo fallidas, colas de correo no deseado, instantáneas de depuración, cachés de almacenes de vectores, tickets de revisión de abusos o almacenes de análisis. Una declaración de privacidad defendible debe indicar cuáles de estas vías están excluidas, cuáles se conservan por razones operativas y cuáles son técnicamente imposibles debido a la arquitectura y a las reglas de salida. Si no lo sabe, la promesa aún no está madura. (NIST)
Límites de proveedores y niveles de productos
El plano del proveedor añade otra capa. Los productos de consumo de IA, los espacios de trabajo empresariales y las API suelen tener diferentes comportamientos de retención y supervisión. El propio material público de Perplexity lo ilustra claramente: el centro de ayuda enmarca el modo Incógnito en torno a hilos privados temporales, los documentos de la API dicen que Sonar no retiene datos y sólo conserva los metadatos de facturación, y Enterprise ofrece registros de auditoría que registran intencionadamente las acciones del usuario y del administrador. No son afirmaciones contradictorias. Son contratos de datos diferentes para superficies diferentes. El error de cumplimiento es colapsarlos en una frase de privacidad a nivel de marca. (Perplejidad AI)
Por lo tanto, una revisión seria abarca por superficie. El chat público sin sesión es un sistema. El chat autenticado por el consumidor es otro. El espacio de trabajo de la empresa es otro. Las llamadas API son otro. Los clientes móviles pueden ser otro. Las extensiones del navegador o las funciones de navegación agéntica pueden ser otro. Si su material de confianza no distingue esas superficies, los compradores se ven obligados a inferir, y esas inferencias normalmente serán más amplias de lo que sus abogados o ingenieros pretendían. (Perplejidad AI)
Comportamiento de almacenamiento, eliminación y recuperación
Las afirmaciones sobre borrado sólo son creíbles cuando describen el modelo de almacenamiento. Si los hilos caducan a las 24 horas, ¿significa eso un borrado suave, un borrado duro, un tombstone más una purga asíncrona o una supresión UI? ¿Están las copias de seguridad dentro del alcance? ¿Se invalidan los enlaces compartidos? ¿Se eliminan también las incrustaciones o los resúmenes derivados? ¿Están exentos los registros de auditoría? ¿Puede el personal de soporte restaurar los datos? ¿Qué ocurre en caso de retención legal o investigación de abusos? La mayor parte del lenguaje de privacidad dirigido al usuario no responde a estas preguntas, pero los auditores, los revisores de seguridad y los compradores sofisticados de la empresa sí lo harán. (Perplejidad AI)
Acceso humano y administrativo
A menudo se olvida el plano de operaciones porque se sitúa detrás del producto. Pero es uno de los límites de cumplimiento más importantes. Quién puede inspeccionar un aviso cuando se depura una interrupción. Qué flujos de trabajo de soporte permiten el acceso a capturas de pantalla o transcripciones. Qué acciones administrativas se registran. Cómo se revisan las acciones privilegiadas. La documentación de los registros de auditoría empresarial de Perplexity es instructiva aquí porque enmarca explícitamente la visibilidad de las actividades del usuario y los cambios de configuración como una función de cumplimiento y respuesta a incidentes. Una promesa de privacidad que ignore el plano del administrador es incompleta por definición. (Perplejidad AI)
Cómo comprobar la privacidad de una IA como un ingeniero de seguridad
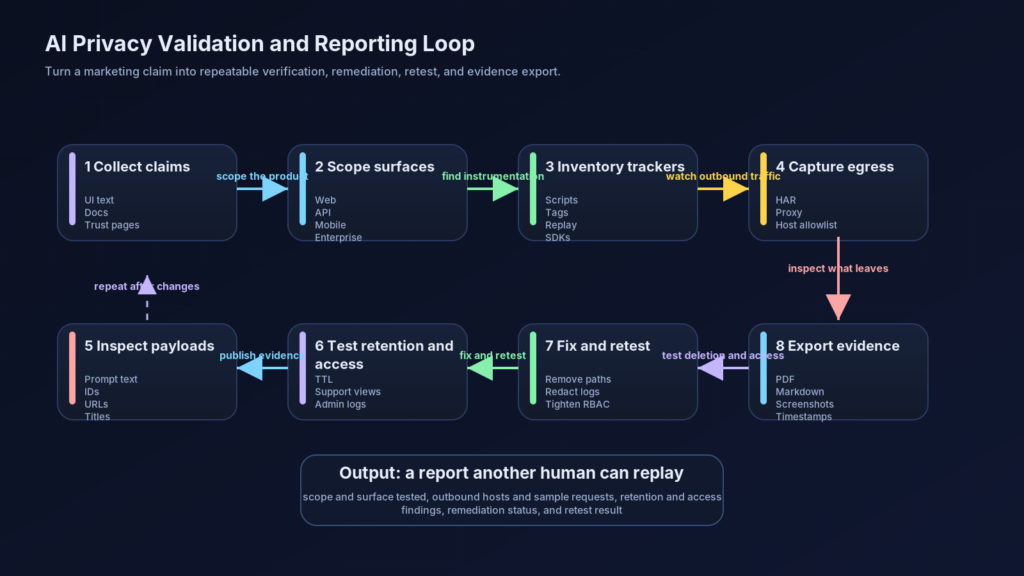
Una reclamación de privacidad debe tratarse del mismo modo que un pentester trata una reclamación de authz. No como un insulto ni como un cumplido. Como una afirmación comprobable. El flujo de trabajo correcto es primero la evidencia: recoger la promesa, enumerar las superficies, observar el tráfico, comparar el comportamiento a través de los estados de cuenta, y preservar artefactos que otra persona pueda reproducir. Esto no sólo es útil para las pruebas ofensivas. Es exactamente el tipo de verificación disciplinada que mejora las pruebas de cumplimiento más adelante. (AICPA Y CIMA)
Comience con la recopilación de promesas. Guarde el texto exacto de la interfaz de usuario, el lenguaje del centro de ayuda, los documentos de la API, las afirmaciones del centro de confianza, las declaraciones de la política de privacidad y la documentación de la empresa que describen el comportamiento. Si el producto dice "no se almacena", "anónimo", "privado", "de incógnito" o "retención cero", copie el contexto exacto en el que aparece la promesa. Muchas disputas surgen porque un equipo cambia discretamente el significado de una frase en distintas superficies sin cambiar la frase en sí. La recopilación de promesas le proporciona una línea de base estable antes de que comience cualquier prueba técnica. (Perplejidad AI)
A continuación, mapee las superficies que va a probar. Como mínimo, separe la web con sesión cerrada, la web gratuita o de pago con sesión abierta, el espacio de trabajo de la empresa, la API pública, la aplicación móvil y cualquier función del navegador o del agente. No asuma que el comportamiento se transfiere entre ellos. Los materiales públicos de Perplexity son un buen recordatorio de que la semántica de retención y registro puede diferir sustancialmente según la interfaz. Sus pruebas deben decir qué superficie examinó realmente. (Perplejidad AI)
A continuación, haga un inventario de la instrumentación antes incluso de enviar una solicitud. Los fallos de privacidad en rutas sensibles suelen empezar con scripts y etiquetas ya presentes en la carga de la página. El primer paso más sencillo es realizar un inventario estático del código fuente o de los activos creados.
rg -n --hidden -S \
'fbq(|gtag(|google_tag_manager|googletagmanager|doubleclick|analytics|segment|mixpanel|amplitud|posthog|sentry|hotjar|fullstory|datadog' \
.
Esto no es una prueba de divulgación. Es sólo un mapa de lo que merece un examen más detenido. Los falsos positivos son de esperar. Lo que importa es si alguna de estas bibliotecas se ejecuta en rutas en las que los usuarios pueden introducir avisos sensibles, y si su configuración puede capturar texto de avisos, títulos de rutas, parámetros de eventos personalizados o identificadores vinculados a cuentas.
El inventario estático debe ir seguido de una captura de red en directo. Utilice DevTools del navegador, Burp, mitmproxy o Playwright para registrar todas las solicitudes salientes en la ruta de destino antes y después del envío de la solicitud. Usted está buscando tres clases de problemas: texto de aviso o paráfrasis que aparecen en URLs, cuerpos JSON, o cargas útiles de formularios; identificadores tales como correo electrónico, IDs de cookies, o IDs de usuarios que van con el evento; y diferencias entre los modos público y "privado" que son más pequeñas de lo que el lenguaje UI implica. La queja contra Perplexity es tan instructiva precisamente porque enmarca el problema de esta manera: no como una fuga mágica de IA, sino como un comportamiento de solicitud saliente.
Una comprobación automatizada ligera suele bastar para detectar malas sorpresas en CI. El siguiente ejemplo registra las solicitudes salientes mientras una prueba de Playwright envía una solicitud, y luego falla si algún nombre de host fuera de una pequeña lista permitida ve tráfico después de la acción de envío.
import { test, expect } from '@playwright/test';
const ALLOWLIST = new Set([
'app.example.ai',
'api.example.ai',
'cdn.example.ai',
logs.ejemplo.ai
]);
test('la ruta de chat sensible no sale a hosts no aprobados', async ({ page }) => {
const visto = [];
page.on('request', req => {
const url = new URL(req.url());
seen.push({
host: url.hostname,
method: req.method(),
resourceType: req.resourceType(),
url: req.url()
});
});
await page.goto('https://app.example.ai/chat');
await page.getByPlaceholder('Pregunta cualquier cosa').fill(
Necesito asesoramiento legal sobre un acuerdo de separación y mi exposición fiscal'
);
await page.keyboard.press('Intro');
await page.waitForTimeout(3000);
const suspicious = seen.filter(r => !ALLOWLIST.has(r.host));
expect(suspicious, JSON.stringify(suspicious, null, 2)).toEqual([]);
});
Este tipo de prueba no sustituye al análisis manual. Le proporciona cobertura de regresión. Si un cambio en el gestor de etiquetas introduce de repente un nuevo dominio saliente en la superficie de chat, querrá saberlo durante el despliegue, no a partir de una queja.
En el lado del navegador, una buena línea de base defensiva es restringir fuertemente donde la ruta sensible puede conectarse en absoluto. Una Content-Security-Policy en modo Report-Only puede ayudar a los equipos a saber con qué está intentando contactar una ruta antes de imponer un bloqueo.
Content-Security-Policy-Report-Only:
default-src 'self';
script-src 'self' https://static.example.ai;
connect-src 'self' https://api.example.ai https://logs.example.ai;
img-src 'self' data:;
style-src 'self' 'unsafe-inline';
report-to default-endpoint;
CSP no es una bala de plata. Las aplicaciones del mismo origen todavía pueden exfiltrar datos a su propio backend, y el reenvío del lado del servidor todavía puede ocurrir más tarde. Pero en rutas de chat sensibles es una función de forzamiento fuerte. Hace visibles las dependencias accidentales de terceros y limita la posibilidad de que una integración genérica de marketing llegue silenciosamente a la parte más sensible del producto.
El siguiente paso es el análisis de la carga útil. Si encuentra eventos salientes, inspecciónelos en busca de contenido directo, títulos reflejados, URL de conversaciones, identificadores vinculados a cuentas o parámetros personalizados de alta cardinalidad. Los productos de IA suelen generar datos secundarios que parecen inofensivos hasta que se vinculan a una persona: identificadores de hilos, identificadores de cohortes de experimentos, huellas dactilares de dispositivos, identificadores de cuentas de facturación, nombres de inquilinos o hashes de correo electrónico. En las revisiones de privacidad, la vinculación suele importar tanto como el contenido en bruto. Un fragmento puntual más un marcador de cuenta estable pueden bastar para crear un problema grave.
Después de comportamiento de la red, prueba de retención honestamente. Cree un hilo en el modo privado reclamado. Compruebe si desaparece de la interfaz de usuario visible. A continuación, compruebe qué más persiste: el historial del navegador, el acceso de enlace directo, los puntos finales de exportación, las vistas del administrador, los registros de auditoría, los flujos de asistencia o las ventanas de eliminación retardada. Si el producto ofrece una superficie API con una pretensión de retención más fuerte que la superficie de consumo, pruebe ambas y mantenga las pruebas separadas. Muchos malentendidos sobre privacidad se deben a que los equipos confunden la visibilidad efímera de la interfaz de usuario con la eliminación real. (Perplejidad AI)
Por último, documente los resultados en un formato que sobreviva a la repetición de las pruebas. Guarde la promesa que probó, el estado de la cuenta, las marcas de tiempo, la ruta, la compilación del navegador, las cabeceras relevantes, las muestras de solicitudes, las capturas de pantalla y la secuencia exacta de reproducción. Aquí es donde las pruebas de privacidad dejan de parecer un truco aislado del equipo rojo y empiezan a convertirse en pruebas útiles para la auditoría. Los programas de cumplimiento no necesitan resultados teatrales. Necesitan artefactos rastreables y un alcance claro. (AICPA Y CIMA)
El mapa práctico que figura a continuación es una interpretación de ingeniería de lo que significan estas promesas cuando se traducen en pruebas de control. No sustituye a la revisión legal ni al alcance de la auditoría, pero es un punto de partida mucho mejor que confiar en el nombre de la función. (AICPA Y CIMA)
| Reclamación de producto | Lo que debe verificarse | Pruebas que importan | Modo de fallo |
|---|---|---|---|
| Hilo privado | Ámbito de acceso, almacenamiento, uso compartido, visibilidad del administrador | Pruebas ACL, modelo de almacenamiento, comportamiento de enlaces compartidos, pruebas admin-view | La interfaz de usuario oculta el historial, pero el backend o la ruta de soporte siguen exponiendo el contenido. |
| Incógnito | Conservación del historial, divulgación a terceros, vinculación de identificadores | Capturas de red, inventario de etiquetas, análisis de cookies, pruebas de borrado | El hilo desaparece de la barra lateral pero las cargas útiles de los eventos siguen saliendo de la ruta |
| Hilo anónimo | Vinculación de identidades, comportamiento de las cookies, continuidad de la sesión | Pruebas de cierre de sesión, correlación de cookies, revisión de asociación de cuentas | No hay inicio de sesión en la cuenta, pero los identificadores estables siguen vinculando el comportamiento |
| Retención cero | Contrato de proveedor, registro de solicitudes, depuración de excepciones | Documentos de proveedores, capturas de paquetes, política de registro de backend, gestión de excepciones | Contenidos no formados, pero conservados en registros o herramientas de apoyo |
| No se utiliza para formación | Controles de linaje de datos y mejora de modelos | Comportamiento de exclusión, formación, exclusiones, configuración de proveedores | La retención operativa o el uso de la evaluación siguen produciéndose incluso sin formación formal |
| Registros de auditoría empresarial | Cobertura de registros, retención, límites de privacidad | Registros de muestra, configuraciones de webhook, RBAC de administrador, reglas de redacción | Los registros destinados a la gobernanza recogen contenidos sensibles en exceso |

Lo que las recientes CVE relacionadas con la IA enseñan sobre el mismo problema
Las reclamaciones de privacidad en los sistemas de IA no sólo se ven cuestionadas por los análisis y el lenguaje político. También las ponen en tela de juicio los fallos de software ordinarios del producto en cuestión. Tres CVE recientes son especialmente útiles porque cada uno de ellos pone de relieve una forma diferente en que las expectativas superficiales pueden divergir del comportamiento real del sistema. (Mozilla)
CVE-2025-3035 muestra que incluso el pegamento de contexto puede filtrarse
El aviso de Mozilla para CVE-2025-3035 dice que en las versiones de Firefox anteriores a la 137, si un usuario utilizaba primero el chatbot de IA en una pestaña y después lo activaba en otra, el título del documento de la pestaña anterior podía filtrarse en el aviso del chat. NVD lo clasifica como CWE-359, exposición de información personal privada. Este es un claro ejemplo de por qué la privacidad de la IA no puede reducirse únicamente a la retención del servidor. Incluso la cola de contexto del lado del navegador alrededor de un asistente puede filtrar información a través de fronteras a las que un usuario no tenía intención de unirse. (Mozilla)
¿Por qué es relevante en este caso? Porque muchos productos de IA integran agresivamente el estado del navegador, las pestañas abiertas, el contexto de los archivos o los metadatos del espacio de trabajo para que el asistente se sienta útil. Cuanto más útil sea el asistente, más cuidadosa debe ser la lógica de vinculación contextual. Un producto puede no enviar nunca nada a Meta o Google y aún así tener un grave problema de privacidad si el contexto de una superficie se filtra a otra. La solución, en este caso, estaba del lado del navegador, pero la lección de diseño se generaliza a los copilotos de IA, los agentes de navegador, los asistentes de empresa y las superposiciones de productividad. (Mozilla)
CVE-2025-43862 muestra que la IU oculta no es lo mismo que la autorización
NVD dice que las versiones de Dify anteriores a la 0.6.12 permitían a un usuario normal acceder y modificar la orquestación APP a pesar de que la interfaz de usuario web no presentaba la orquestación APP a ese usuario. NVD lo describe explícitamente como un fallo de control de acceso y recomienda permisos más estrictos de usuario-rol y RBAC. Esto es muy relevante para el cumplimiento de la IA porque refleja un error mental común: si el usuario no puede ver el control, la capacidad no debe existir. En seguridad, eso nunca es suficiente. La verdadera autorización se encuentra en el backend, no en el diseño del menú. (nvd.nist.gov)
La analogía con las demandas de privacidad debería ser obvia. Un icono de hilo privado o la ausencia de una entrada en el historial indican lo que la interfaz de usuario decidió exponer. No prueba lo que el backend aceptó, almacenó o reenvió. En el caso de Dify, la capacidad oculta seguía existiendo. En los casos de privacidad, la ruta de datos oculta puede seguir existiendo. Por eso las pruebas de control serias deben inspeccionar las comprobaciones de roles, los puntos finales de la API, los modelos de almacenamiento y el comportamiento de salida directamente. La desaparición de la superficie no es un objetivo de control. El cumplimiento del backend sí lo es. (nvd.nist.gov)
CVE-2025-3248 y el posterior aviso de Langflow demuestran que las plataformas de IA siguen necesitando una disciplina de seguridad de aplicaciones estándar.
El aviso revisado de GitHub y el NVD dicen que las versiones de Langflow anteriores a la 1.3.0 eran vulnerables a la inyección de código no autenticado en la aplicación /api/v1/validar/código permitiendo la ejecución remota de código. CISA añadió posteriormente CVE-2025-3248 a su catálogo de vulnerabilidades explotadas conocidas. Posteriormente, un aviso de seguridad de Langflow en GitHub describió una ruta de ejecución remota de código no autenticada en el punto final de creación de flujo público, donde los datos de flujo controlados por el atacante llegaban a exec() sin sandboxing. (GitHub)
No se trata de un artículo sobre privacidad, pero debe incluirse en el mismo porque corrige otro error muy extendido. El cumplimiento de la IA no se sitúa por encima de la seguridad de las aplicaciones. Depende de ella. Si su plataforma de IA expone rutas de ejecución inseguras, autenticación débil o inyección de código backend, su historia de privacidad y auditoría se derrumbará bajo una presión mucho más básica. Los ejemplos de Langflow son útiles porque muestran lo rápido que la infraestructura específica de la IA se convierte en territorio de exploits estándar. Una vez que eso sucede, "tenemos un modo privado" es casi irrelevante a menos que la línea de base de seguridad de la aplicación ordinaria también sea sólida. (GitHub)
En conjunto, estas CVE describen una amplia lección. La privacidad y la conformidad de la IA no son disciplinas separadas que floten sobre la pila. Son el producto de la corrección del navegador, la corrección de la autorización, el alcance del proveedor, la disciplina de registro, la codificación segura y la gobernanza cuidadosa de los datos. Si alguna de estas capas es inmadura, la promesa de confianza será más débil de lo que sugiere la copia del producto. (Mozilla)
Creación de pruebas que puedan respaldar realmente el trabajo de SOC 2 e ISO 27001
A menudo se abusa de la expresión "listo para auditoría". En la práctica, a un auditor o evaluador rara vez le impresiona un PDF lleno de afirmaciones generales. Lo que necesitan es un paquete de pruebas coherente que vincule la descripción del sistema, la intención de la política, la configuración técnica y las pruebas de funcionamiento. Las revisiones de privacidad de la IA son más sólidas cuando preservan tanto el lado de la gobernanza como el de los paquetes. (AICPA Y CIMA)
Como mínimo, ese paquete de pruebas debe incluir un límite actual del sistema para la función de IA. El límite debe mostrar los puntos de entrada del usuario, los navegadores o clientes, la capa de aplicación, el enrutamiento del modelo o las dependencias del proveedor, los sistemas de registro y análisis, las capas de almacenamiento, las superficies de administración o soporte y cualquier subprocesador de terceros que pueda tocar los datos de interacción. Esto no es un teatro de diagramas de arquitectura. Sin claridad en los límites, es casi imposible probar o explicar lo que se supone que cubre una promesa de privacidad. (ISO)
El segundo artefacto esencial es un inventario de flujo de datos específico para la ruta sensible. Una política de privacidad genérica no es suficiente. Necesitas claridad a nivel de ruta o a nivel de característica para lo que entra en la página, qué scripts se ejecutan, a dónde van las peticiones, qué identificadores se adjuntan, qué almacena el backend, qué ve el proveedor, qué retienen los registros y cómo funciona la eliminación. Los materiales públicos de Perplexity son útiles aquí porque muestran cómo diferentes superficies pueden tener honestamente diferentes contratos. Su paquete de pruebas debe ser igualmente específico. (Perplejidad AI)
En tercer lugar, se necesita una prueba de control de cambios en torno a la instrumentación sensible. Si la ruta de un producto puede aceptar datos íntimos, la adición de una nueva etiqueta, SDK, herramienta de reproducción de sesiones o reenviador de eventos del lado del servidor no debe tratarse como un ajuste rutinario de marketing. Debe haber un propietario, una ruta de revisión, una justificación e, idealmente, una comprobación de regresión automatizada para garantizar que ningún punto final recién introducido vea tráfico sensible sin aprobación. Aquí es donde una ingeniería de privacidad madura empieza a parecerse mucho a una seguridad de aplicaciones madura. (NIST)
En cuarto lugar, necesitas pruebas de control de acceso y registro. Quién puede ver los avisos o los artefactos derivados internamente. ¿Están censuradas las herramientas de apoyo? ¿Son los registros de auditoría de la empresa intencionadamente más detallados y, en caso afirmativo, cómo están protegidos? ¿Se registran y revisan las acciones administrativas? ¿Está el propio sumidero de registro delimitado y protegido? La documentación del registro de auditoría empresarial de Perplexity es un buen ejemplo de visibilidad explícita del lado del administrador. Cualquier equipo que venda a clientes sensibles al cumplimiento necesita una claridad equivalente para su propio plano privilegiado. (Perplejidad AI)
En quinto lugar, se necesitan pruebas de eliminación y retención. No basta con decir que un hilo caduca. Muestra el trabajo de borrado, el calendario de retención, cualquier excepción y el comportamiento de las copias de seguridad, los registros y los artefactos vinculados. Si tu API tiene retención de datos cero pero tu superficie de consumo no, dilo. Si se conservan metadatos de facturación o de detección de abusos, dígalo. Un alcance preciso siempre es mejor que un lenguaje amplio que no puede sobrevivir a una pregunta de seguimiento. (docs.perplexity.ai)
En sexto lugar, se necesita una validación independiente. Para las superficies sensibles de IA, esto puede incluir ejercicios de equipo rojo centrados en la privacidad, pentests que prueben explícitamente la telemetría y la salida, auditorías de etiquetas específicas de ruta, revisiones de mesa de escenarios de divulgación accidental y nuevas pruebas después de la corrección. Este es el estrecho margen en el que un flujo de trabajo de seguridad que dé prioridad a las pruebas resulta directamente útil para el trabajo de cumplimiento. El valor no reside en que una herramienta pueda escribir prosa rápidamente. El valor es que puede preservar lo que se probó, lo que se observó, y si el mismo problema se mantuvo fijo después de un cambio. (AICPA Y CIMA)
Los materiales públicos de Penligent son útiles aquí por una sola razón: describen la elaboración de informes en la dirección correcta. La página de inicio de Penligent dice que ofrece informes de un solo clic alineados con SOC 2 e ISO 27001, y su página de precios dice que incluso el nivel gratuito puede exportar informes PDF o Markdown con pruebas y pasos de reproducción. Su artículo sobre los informes hace explícito el punto más importante: el problema no es "cómo hacer que la IA escriba un PDF", sino cómo convertir las pruebas en algo que otro humano pueda verificar. Ese es exactamente el listón que deben utilizar las pruebas de privacidad y la preparación de auditorías. La frase alineado sólo significa algo cuando el artefacto que hay detrás es rastreable y reproducible. (Penligente)
En términos prácticos, eso significa que un informe de seguridad se convierte en útil para el trabajo SOC 2 o ISO 27001 cuando conserva el alcance, las marcas de tiempo, el entorno, los pasos de reproducción, las observaciones de la red, las capturas de pantalla, el estado de la remediación y el estado de la repetición de la prueba. Si estos detalles están presentes, el informe puede servir de apoyo a las pruebas de gestión de vulnerabilidades, el seguimiento de la corrección y las discusiones sobre la mejora del control. Si esos detalles están ausentes, el informe todavía puede parecer pulido, pero es una prueba débil. (Penligente)
La matriz que figura a continuación es una síntesis operativa de los tipos de artefactos que tienden a ser más importantes cuando las reivindicaciones de privacidad de la IA deben sobrevivir a la revisión de seguridad y al escrutinio de auditoría. (AICPA Y CIMA)
| Área de pruebas | Cómo son las buenas pruebas | Por qué es importante |
|---|---|---|
| Límite del sistema | Diagrama de rutas de chat, llamadas a proveedores, registros, análisis, superficies de administración y subprocesadores | Evita reclamaciones de privacidad excesivas o engañosas |
| Inventario de promesas | Capturas de pantalla y texto de la interfaz de usuario, documentos de ayuda, política de privacidad, documentos de la API y páginas de confianza. | Corrige la línea de base de lo que se dijo a los usuarios |
| Inventario de seguimiento | Resultados de la búsqueda de código, exportación del gestor de etiquetas, lista de dependencias ruta por ruta | Muestra si las rutas sensibles llevan telemetría genérica |
| Pruebas de salida | Archivos HAR, rastros de proxy, capturas de Playwright, listas de nombres de host permitidos | Valida si los indicadores o identificadores salen de los límites aprobados |
| Modelo de retención | Mapa de almacén de datos, trabajos TTL, flujo de trabajo de borrado, excepciones de copia de seguridad | Convierte "caduca" en una demanda concreta de almacenamiento |
| Control de acceso | Matriz RBAC, pruebas admin-view, registros de acceso de soporte, registros de revisión | Demuestra que la IU oculta no es la única línea de defensa |
| Controles de registro | Reglas de redacción, ejemplos de registros desinfectados, calendario de conservación de registros | Evita el fracaso de la privacidad mediante sistemas de observabilidad |
| Determinación del proveedor | Documentos de retención de proveedores, configuración de contratos, referencias DPA, configuración de exclusión voluntaria | Distingue los contratos de datos de API, de empresa y de consumidor |
| Validación independiente | Hallazgos de pentest, repetición de pruebas, tickets de corrección, exportación de pruebas | Demuestra la eficacia del control más allá del texto normativo |
| Garantía continua | Comprobaciones de CI para rastreadores, informes CSP, aprobaciones de cambios, cadencia de revisión | Demuestra que los controles se mantienen a lo largo del tiempo |
Los errores que rompen los programas de cumplimiento de la IA
El primer error es considerar el historial del usuario como la historia completa de la privacidad. Un equipo ve que un hilo desaparece de la barra lateral y concluye que el sistema es privado. Este es el mismo error de categoría que Dify ilustró desde el lado de la autorización: lo que la interfaz de usuario ya no muestra no es lo mismo que lo que el backend todavía puede hacer. Las reclamaciones de privacidad que se detienen en el historial visible son superficiales. (nvd.nist.gov)
El segundo error es colapsar todas las superficies del producto en una sola promesa. La web del consumidor, el móvil, la API, el espacio de trabajo de la empresa, el agente del navegador y la consola de administración rara vez se rigen de forma idéntica. Los documentos públicos de Perplexity son útiles precisamente porque revelan diferentes compromisos entre interfaces de consumidor, API y empresa. Cualquier proveedor de IA que venda a compradores técnicos debería ser igual de específico. (Perplejidad AI)
El tercer error es suponer que una opción de exclusión del proveedor o una configuración de "no utilizar para formación" resuelve todo el problema de privacidad. La guía LLM de OWASP es un buen correctivo aquí. La divulgación de información sensible puede ocurrir a través de la salida, enrutamiento o procesamiento, incluso cuando la formación no es el problema. La formación es una vía. El registro, la depuración, la reproducción, el análisis y las integraciones inseguras son otras. (Proyecto OWASP Gen AI Security)
El cuarto error es ignorar la seguridad de las aplicaciones ordinarias porque el equipo cree que el principal riesgo es el comportamiento del modelo. Los avisos de Langflow y el fallo de control de acceso de Dify demuestran por qué esto es una ingenuidad. Los productos de IA siguen fallando por falta de autenticación, ejecución insegura, errores de control de acceso y fugas de contexto. Un programa de privacidad o cumplimiento que pase por alto la seguridad estándar de las aplicaciones heredará esos fallos, esté o no bien redactada la política de privacidad. (nvd.nist.gov)
El quinto error es construir pruebas sólo después de que llegue el cuestionario del cliente. Eso casi garantiza artefactos débiles y afirmaciones imprecisas. El mejor patrón es la captura continua de pruebas: inventarios de etiquetas como código, pruebas de salida a nivel de ruta en CI, comportamiento de borrado documentado por diseño, acceso privilegiado registrado por defecto y afirmaciones de privacidad revisadas cuando se producen cambios en el producto. Esto no es sólo buena ingeniería. También es lo que hace que una conversación sobre SOC 2 o ISO 27001 sea menos dolorosa más adelante. (ISO)
Cómo es realmente una postura sólida sobre la privacidad de la IA
Una postura sólida en materia de privacidad de la IA no es un único distintivo ni una frase de marketing. Es una pila. La promesa pública es estrecha y precisa. La instrumentación de la ruta es intencionadamente limitada. El límite del proveedor está documentado. El plano de registro está redactado o fuertemente delimitado. El plano privilegiado es visible y controlado. El modelo de retención es específico. Las pruebas son repetibles. Las excepciones se anotan. Las pruebas son actuales. Eso es lo que hace que "privado" deje de ser una vibración para convertirse en una declaración de control. (AICPA Y CIMA)
Esa pila también debe ser honesta sobre los límites. Los hilos temporales pueden seguir siendo observables para los administradores de la empresa. Las API pueden tener controles de retención más estrictos que las interfaces de consumo. Los flujos de trabajo de prevención de abusos pueden justificar una recopilación limitada de metadatos operativos. Los incidentes de soporte pueden crear ventanas de excepción limitadas. Los compradores no necesitan un teatro de la perfección. Necesitan precisión. Una demanda limitada que sobreviva al escrutinio vale mucho más que una amplia que se derrumbe al primer seguimiento técnico. (Perplejidad AI)
La demanda contra Perplexity, sea cual sea su resultado, ya ha hecho un favor al mercado. Ha sacado a la luz la ligereza con la que la industria utiliza palabras como privado e incógnito en productos diseñados para absorber la información humana más reveladora. Lo que hay que hacer no es dejarse llevar por el pánico. Hay que elevar los estándares. Si su sistema de inteligencia artificial pide a los usuarios que le confíen mensajes confidenciales, la carga de la prueba recae sobre usted, que debe demostrar qué ocurre con esos mensajes en el navegador, el backend, el proveedor, los registros, el almacenamiento y las personas. Eso es lo que quieren los equipos de seguridad. Es lo que quieren los compradores empresariales. Y es lo que marcos como SOC 2 e ISO/IEC 27001 están empujando a las organizaciones a crear.
Lecturas complementarias y enlaces de referencia
AICPA, SOC 2 Trust Services Criteria overview and related resources. (AICPA Y CIMA)
ISO, ISO/IEC 27001 visión general de los sistemas de gestión de la seguridad de la información. (ISO)
Marco de privacidad del NIST. (NIST)
Marco de gestión de riesgos de IA del NIST y perfil de IA generativa. (NIST)
Top 10 de OWASP para aplicaciones LLM y guía de OWASP sobre divulgación de información sensible. (OWASP)
Aviso de Mozilla y entrada NVD para CVE-2025-3035. (Mozilla)
Entrada NVD para Dify CVE-2025-43862. (nvd.nist.gov)
GitHub advisory, NVD entry, and CISA KEV notice for Langflow CVE-2025-3248, plus the later public-flow advisory. (GitHub)
Perplejidad del centro de ayuda y páginas para desarrolladores sobre el modo Incógnito, la privacidad de la API y los registros de auditoría de la empresa. (Perplejidad AI)
Página de inicio de Penligent. (Penligente)
Fijación de precios por negligencia, incluidas las pruebas y las exportaciones por etapas de reproducción. (Penligente)
Cómo obtener un informe AI Pentest. (Penligente)
AI SOC, ISO 27001, SOC 2 y la pila de seguridad que los equipos de IA reales necesitan en 2026. (Penligente)
Cómo utilizar la IA para el cumplimiento de las normas SOC 2 e ISO 27001 reduciendo costes. (Penligente)

