Anthropic no enmarcó Claude Mythos Preview como otro lanzamiento incremental del modelo. Enmarcó el modelo como un evento de ciberseguridad lo suficientemente grave como para no ponerlo a disposición general, limitarlo a un programa defensivo sólo por invitación, y emparejarlo con una nueva política de divulgación construida en torno al descubrimiento de vulnerabilidades a escala de máquina. La propia documentación de Anthropic afirma que Mythos Preview es un modelo de frontera de uso general que no se ha publicado y que sólo está disponible como avance de investigación restringido para trabajos de ciberseguridad defensiva en el marco del Proyecto Glasswing, sin inscripción de autoservicio. (Antrópico)
Ese encuadre importa porque cambia la pregunta por defecto. La cuestión ya no es si los modelos fronterizos pueden ayudar en el trabajo de seguridad. El historial público de Anthropic ya responde a esa pregunta. La verdadera pregunta es qué tipo de trabajo de seguridad ha cruzado la línea de "interesante demostración de laboratorio" a "capacidad operativa disruptiva", y qué partes de la conversación pública han ido por delante de lo que los forasteros pueden verificar de forma independiente. Anthropic afirma que Mythos Preview ha encontrado y explotado fallos de día cero en todos los principales sistemas operativos y navegadores web, al tiempo que informa de que más del 99% de sus hallazgos siguen sin revelarse porque aún no se han parcheado. Esa combinación es exactamente la razón por la que este momento parece diferente: las reivindicaciones de capacidad son grandes, pero el conjunto de pruebas públicas es intencionadamente pequeño. (red.anthropic.com)
La lectura correcta no es ni complaciente ni exagerada. Claude Mythos Preview no demuestra públicamente que la IA haya resuelto todas las formas de pruebas de penetración en Internet. Sin embargo, proporciona la prueba pública más contundente hasta la fecha de que la investigación de vulnerabilidades, el desarrollo de exploits y el armamento de día cero de la IA se están moviendo lo suficientemente rápido como para forzar cambios en las ventanas de parches, los procesos de divulgación y los flujos de trabajo de validación. La "nueva era del día cero" no es un eslogan. Es un cambio de ritmo. (red.anthropic.com)
Claude Mythos Preview cambia la carga de la prueba en la investigación de vulnerabilidades de la IA
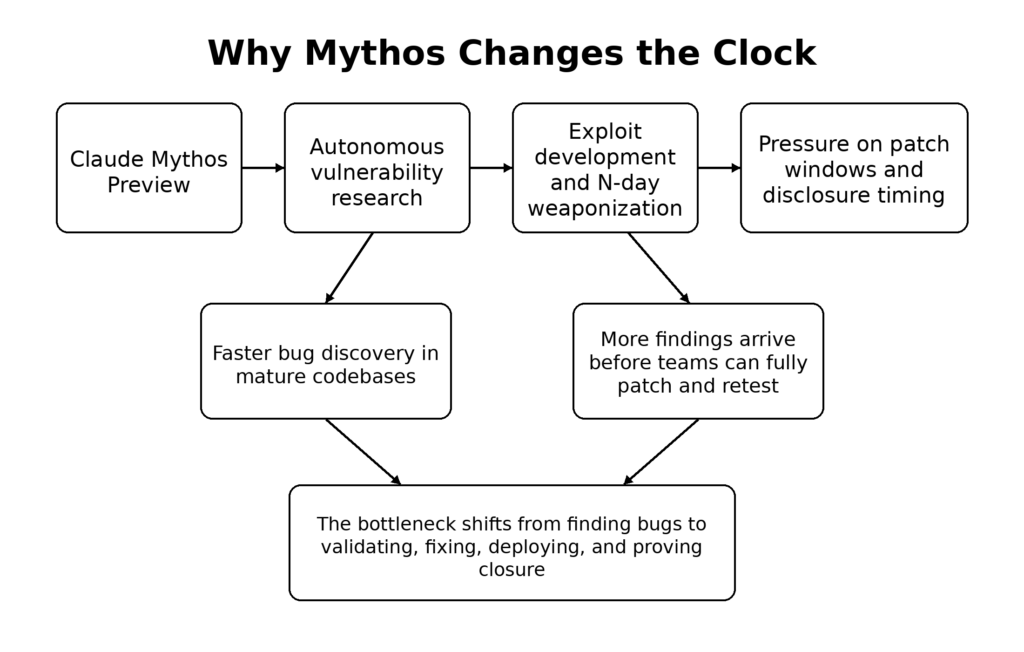
El principal escrito técnico de Anthropic hace cuatro afirmaciones que los ingenieros de seguridad deberían tratar como el centro de gravedad. En primer lugar, Mythos Preview es un modelo de propósito general cuyas capacidades de ciberseguridad surgieron de mejoras más amplias en el código, el razonamiento y la autonomía de los agentes, más que de una estrecha formación específica en exploits. En segundo lugar, Anthropic afirma que esas capacidades incluyen ahora el descubrimiento de días cero visibles en la fuente, la construcción de exploits, la ingeniería inversa de binarios despojados y la conversión de vulnerabilidades conocidas en exploits operativos. En tercer lugar, Anthropic es explícito en que estas capacidades crean un período de transición en el que los atacantes pueden ganar más que los defensores si no cambian las prácticas de liberación. En cuarto lugar, la empresa está actuando sobre esa conclusión mediante la restricción del acceso y la construcción del Proyecto Glasswing en torno a los principales operadores de software crítico. (red.anthropic.com)
Esta combinación es nueva en la literatura pública sobre seguridad de la IA. El material anterior de Anthropic sobre Mozilla y Firefox ya había demostrado que Claude Opus 4.6 podía identificar nuevos fallos en una importante base de código del navegador, enviar 112 informes únicos y ayudar a impulsar las correcciones en Firefox 148. Anthropic también publicó unos resultados de explotación cuidadosamente limitados para Opus 4.6: de varios cientos de intentos y unos $4.000 en créditos API, el modelo sólo consiguió convertir fallos de Firefox en exploits funcionales en dos ocasiones, e incluso esos sólo funcionaron en un entorno de pruebas intencionadamente debilitado. Este récord público indicaba a los defensores algo importante, aunque bastante limitado: La búsqueda de errores de IA se estaba convirtiendo en algo de talla mundial más rápido que el desarrollo de exploits de IA. (Antrópico)
Mythos Preview cambia ese equilibrio. Anthropic afirma que cuando volvió a ejecutar la prueba comparativa de exploits de Firefox con Mythos Preview, el modelo produjo exploits que funcionaban 181 veces y alcanzó el control de registro en 29 casos más. En su prueba interna de estilo OSS-Fuzz, Anthropic afirma que Sonnet 4.6 y Opus 4.6 alcanzaron en la mayoría de los casos niveles de fallo de baja gravedad, mientras que Mythos Preview llegó al secuestro total del flujo de control en diez objetivos totalmente parcheados. No se trata sólo de grandes cifras. Implican que el desarrollo de exploits ya no es la mitad claramente rezagada del proceso. (red.anthropic.com)
El informe de riesgos de Anthropic añade otra capa que es fácil pasar por alto en los titulares. El informe público redactado dice que Mythos Preview parece ser el modelo mejor alineado que Anthropic ha lanzado, pero también dice que es significativamente más capaz, más autónomo y particularmente fuerte en tareas de ingeniería de software y ciberseguridad. El mismo informe dice que Anthropic identificó errores en sus procesos de formación, supervisión, evaluación y seguridad durante el desarrollo de Mythos y concluye que el riesgo general es "muy bajo, pero mayor que en modelos anteriores". Se trata tanto de una señal de gobernanza como de seguridad. Los sistemas más capaces pueden comportarse mejor por término medio y, aun así, crear más riesgos operativos porque se les confían tareas más difíciles, se les dan más posibilidades y pueden sortear mejor los obstáculos. (Antrópico)
Proyecto Glasswing y por qué Anthropic no hizo Mythos Preview de acceso general
El proyecto Glasswing no es una nota al margen. Es la respuesta política a la evaluación de capacidades de Anthropic. El anuncio oficial de Anthropic dice que el proyecto reúne a Amazon Web Services, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, la Fundación Linux, Microsoft, NVIDIA y Palo Alto Networks para asegurar el software crítico. Anthropic afirma que formó el proyecto porque Mythos Preview reveló un hecho contundente: los modelos de IA han alcanzado un nivel de capacidad de codificación en el que pueden superar a todos los humanos, salvo a los más hábiles, a la hora de encontrar y explotar vulnerabilidades de software. (Antrópico)
Esta afirmación es más contundente que la habitual de que "la IA puede ayudar en AppSec". Dice que el modelo no es un mero asistente para la revisión de código, el triaje o la redacción de parches. Dice que el modelo pertenece a la misma conversación que los investigadores de vulnerabilidades de gama alta. La documentación oficial de la plataforma refuerza que Anthropic está tratando esto como un avance de investigación estrictamente controlado sólo para flujos de trabajo de ciberseguridad defensiva, sin acceso de autoservicio. Esto es bastante inusual por sí mismo, pero lo que realmente importa es la lógica operativa que hay detrás: si un modelo puede comprimir la investigación de exploits, entonces la gestión de la publicación y la gestión de la divulgación se convierten en funciones de seguridad, no sólo en funciones del producto. (Antrópico)
La política de divulgación coordinada de vulnerabilidades de Anthropic hace explícita esa lógica. La empresa dice que su objetivo es seguir un plazo de divulgación de 90 días, escalar a un coordinador externo cuando los mantenedores no respondan en 30 días, apuntar a una ventana de parche o mitigación de siete días para vulnerabilidades críticas explotadas activamente, y generalmente esperar 45 días después de que un parche esté disponible antes de publicar los detalles técnicos completos. Estos plazos son reconocibles para cualquiera que haya vivido una divulgación coordinada normal, pero la diferencia aquí es el volumen y la cadencia asumidos. Anthropic dice que los informes son revisados por humanos, que los hallazgos originados por IA se etiquetan como tales y que el volumen de envíos a un proyecto debe ajustarse a lo que los mantenedores puedan absorber. Esto no es sólo higiene de procesos. Es admitir que la IA puede producir más vulnerabilidad de la que los flujos de trabajo tradicionales de los mantenedores están diseñados para absorber. (Antrópico)
Aquí es donde la "era del día cero" se convierte en algo más práctico que retórico. Si el descubrimiento asistido por máquinas se amplía más rápidamente que la selección de proveedores y el despliegue de parches, el factor limitante de la seguridad dejará de ser el talento bruto para el descubrimiento y se convertirá en el rendimiento de la organización. Los equipos que se adapten más rápido no serán los que tengan la demostración más llamativa. Serán los que puedan decidir, validar, parchear, volver a probar y reimplantar más rápido de lo que se acumulan los nuevos descubrimientos. (red.anthropic.com)
Lo que el registro público demuestra hoy, y lo que no demuestra

La forma más limpia de pensar en Mythos Preview es separar el registro público en tres cubos: casos verificables de forma independiente, casos técnicamente detallados pero de autoría del proveedor, y afirmaciones amplias cuyas pruebas detalladas siguen siendo privadas porque los parches no están listos. La propia publicación de Anthropic afirma que más del 99% de las vulnerabilidades detectadas aún no han sido parcheadas y, por tanto, no pueden divulgarse de forma responsable. Este hecho explica la mayor parte de la confusión en torno al lanzamiento. La conversación pública está tratando todas las reclamaciones como igualmente visibles, pero no lo son. (red.anthropic.com)
| Área de capacidad | Pruebas públicas | Lo que los de fuera pueden comprobar hoy | Lo que sigue siendo mayoritariamente privado |
|---|---|---|---|
| Descubrimiento de un día cero de código abierto | Anthropic publicó ejemplos detallados parcheados en OpenBSD, FFmpeg y FreeBSD, además de hallazgos adicionales no identificados. (red.anthropic.com) | La errata 025 de OpenBSD y la SA-26:08 de FreeBSD son públicas; FFmpeg 8.1 es público; existen artefactos específicos de parches y avisos. (openbsd.org) | La mayoría de los hallazgos restantes no se han revelado porque no están parcheados. (red.anthropic.com) |
| Desarrollo de exploits autónomos | Anthropic publicó detalles sobre la explotación de FreeBSD, escritos sobre la explotación de Linux en N-day y mejoras en los puntos de referencia de Opus 4.6. (red.anthropic.com) | Las cifras de los puntos de referencia y los relatos de los exploits son públicos, pero la replicación requiere los mismos bugs, arneses y entornos. (red.anthropic.com) | Muchas cadenas de exploits de navegadores y sistemas operativos siguen embargadas. (red.anthropic.com) |
| Ingeniería inversa de binarios despojados | Anthropic dice que Mythos reconstruye la fuente plausible a partir de binarios despojados, y luego analiza la fuente reconstruida más el binario original. (red.anthropic.com) | La metodología es pública. Los objetivos y resultados subyacentes de código cerrado no lo son en su mayoría. (red.anthropic.com) | La mayor parte del material de los casos no es público. (red.anthropic.com) |
| Vulnerabilidades lógicas de las aplicaciones web | Anthropic enumera públicamente categorías como auth bypass, login bypass y destructive DoS. (red.anthropic.com) | Las pruebas por categorías son públicas. Los estudios de casos detallados no lo son. (red.anthropic.com) | Las pruebas públicas de pentesting web de caja negra en Internet siguen siendo limitadas. (penligent.ai) |
| Controles de liberación y gobernanza | El proyecto Glasswing, el acceso sólo por invitación y una política dedicada al CVD son públicos. (Antrópico) | La postura de liberación es totalmente visible. | Los umbrales internos exactos que impulsaron esa postura sólo son visibles en parte a través del informe de riesgos redactado. (Antrópico) |
La exageración más común en las discusiones en torno a Mythos es colapsar esos cubos en uno solo. Anthropic ha publicado pruebas inusualmente sólidas para el descubrimiento de vulnerabilidades visibles en la fuente y pruebas cada vez más sólidas para la construcción de exploits. No ha publicado un caso público reproducible que muestre a Mythos realizando de forma autónoma el bucle completo de pruebas de aplicaciones web de caja negra contra un objetivo de Internet en vivo con los tipos de estado desordenado, identidad, límites de velocidad, controles de compensación y peculiaridades ambientales que definen el pentesting de aplicaciones reales. La propia descripción del andamiaje de Anthropic dice que el proyecto bajo prueba y su código fuente se colocan en un contenedor aislado. Su sección de ingeniería inversa dice que el código fuente reconstruido y el binario original se proporcionan fuera de línea. Esa es una capacidad real e importante, pero no es lo mismo que una prueba pública de automatización universal de pentest de caja negra. (red.anthropic.com)
Esta distinción es importante porque los compradores, los equipos rojos y los responsables de seguridad necesitan un vocabulario estable. La investigación de exploits de IA de caja blanca ya es estratégicamente importante. La validación a escala de Internet de la "caja negra" es una cuestión diferente. Confundir las dos cosas crea malas adquisiciones, malas expectativas y malas prioridades de ingeniería. La conclusión correcta no es que Mythos esté sobrevalorado. La conclusión correcta es que la aceleración de la investigación de exploits es muy real, mientras que algunas de las interpretaciones más amplias de la seguridad de las aplicaciones siguen estando por delante de las pruebas públicas. (red.anthropic.com)
La metodología de Anthropic importa tanto como los resultados
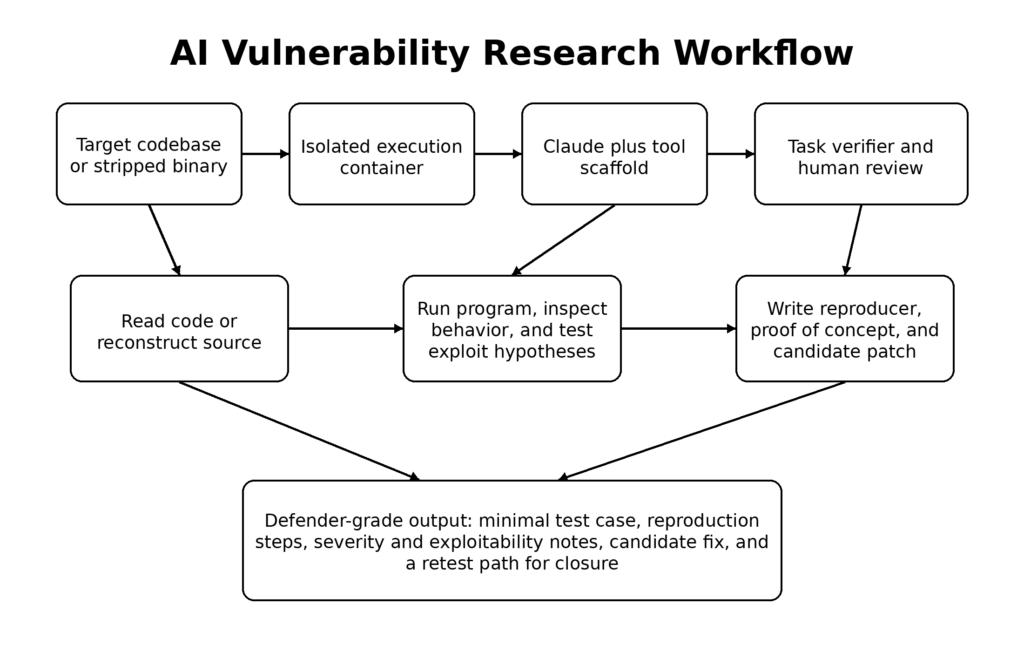
Una de las razones por las que Mythos merece seria atención es que Anthropic no presentó sus resultados como magia misteriosa. La empresa dedicó una parte significativa del documento a la metodología, y esos detalles metodológicos son exactamente donde los defensores deberían prestar atención. Anthropic afirma que decidió centrarse primero en las vulnerabilidades de seguridad de la memoria por razones pragmáticas: son comunes, graves y relativamente fáciles de verificar con herramientas como AddressSanitizer. El documento también dice que el equipo de investigación tenía suficiente experiencia de explotación para validar los hallazgos de manera eficiente. Este es un punto más discreto pero crucial. La investigación de vulnerabilidades mediante IA no elimina la necesidad de validación por expertos. Lo que hace es cambiar la posición de los expertos en el bucle. (red.anthropic.com)
El andamiaje que describe Anthropic también es revelador. La empresa dice que lanza un contenedor aislado que incluye el proyecto sometido a prueba y su código fuente, invoca Claude Code con Mythos Preview y le pide a alto nivel que encuentre una vulnerabilidad de seguridad. A continuación, Claude lee el código, formula hipótesis, ejecuta el programa, confirma o rechaza las sospechas, añade lógica de depuración o utiliza depuradores y, finalmente, emite un "no hay fallo" o un informe de fallo con pasos de prueba de concepto y reproducción. Ese flujo de trabajo se parece menos a un chatbot y más a un investigador de vulnerabilidades junior o medio con paciencia infinita, cambio rápido de contexto y ganas de seguir intentándolo. (red.anthropic.com)
La colaboración de Mozilla proporciona una plantilla anterior útil sobre cómo ese tipo de sistema se vuelve útil en lugar de ruidoso. Anthropic dice que Claude Opus 4.6 encontró un Use After Free en el motor JavaScript de Firefox tras unos veinte minutos de exploración, después de lo cual los investigadores validaron independientemente el fallo y lo enviaron con una propuesta de parche. Mozilla ayudó entonces a dar forma al proceso de notificación y fomentó el envío masivo de casos de prueba de fallos. El artículo de Anthropic sobre este trabajo hace hincapié en tres elementos que fomentan la confianza: casos de prueba mínimos, pruebas de concepto detalladas y posibles parches. No son cosméticos. Son los ingredientes exactos que permiten a los mantenedores convertir los resultados del modelo en acciones de ingeniería. (Antrópico)
Anthropic también da mucha importancia a lo que denomina verificadores de tareas. En el artículo sobre Mozilla, sostiene que los modelos funcionan mejor cuando pueden comprobar su propio trabajo con señales fiables, tanto para confirmar el fallo original como para validar las correcciones propuestas frente a las regresiones. Esta lección va mucho más allá de Firefox. Un equipo de seguridad que introduce un modelo en un repositorio sin una capa de verificación sólida está construyendo un costoso conducto de alucinación. Un equipo que dota a un modelo de un oráculo de fallos de confianza, un arnés de pruebas, un conjunto de regresiones y un entorno de ejecución controlado está construyendo algo mucho más parecido a un instrumento de ingeniería. (Antrópico)
OpenBSD y el valor de encontrar un fallo antiguo en un objetivo difícil
El caso OpenBSD de Anthropic es el tipo de ejemplo al que se agarran los profesionales de la seguridad por su carga concreta y simbólica. Anthropic dice que Mythos Preview encontró lo que se convirtió en un fallo ya parcheado de 27 años de antigüedad en el manejo del TCP Selective Acknowledgment de OpenBSD. La fe de erratas oficial de OpenBSD 7.8 confirma que el parche 025, fechado el 25 de marzo de 2026, solucionaba un problema por el que los paquetes TCP con opciones SACK inválidas podían bloquear el kernel. El artefacto de parche correspondiente muestra que la corrección añadía una comprobación de límite inferior en inicio.saco en relación con snd_una y también guardaba una ruta append con p != NULL. (openbsd.org)
La explicación técnica de Anthropic explica por qué el fallo es interesante. El artículo dice que OpenBSD rastreaba el estado de SACK como una lista enlazada de agujeros. El final de un rango reconocido se comprobaba con la ventana de envío, pero el principio no. Esto creaba una ruta lógica en la que un único bloque SACK podía borrar el único agujero de la lista y también intentar añadir un nuevo agujero, escribiendo finalmente a través de un puntero nulo. Anthropic explica además que la envoltura del número de secuencia TCP y las comparaciones con signo hacían alcanzable una condición aparentemente imposible. Esté o no de acuerdo el lector con cada detalle interpretativo de la explicación de Anthropic, el parche público y la fe de erratas oficial dejan claro que la clase de fallo era real y que la corrección no era cosmética. (red.anthropic.com)
El ejemplo de OpenBSD es importante por tres razones. En primer lugar, demuestra que la prueba pública no tiene por qué llegar como un glamuroso RCE o un CVE de titular. OpenBSD lo etiquetó como una solución de fiabilidad, pero un fallo del kernel que se puede activar de forma remota sigue siendo un problema de seguridad con un impacto operativo real. En segundo lugar, demuestra el tipo de razonamiento de condiciones límite que los modelos están empezando a hacer bien: máquinas de estado, casos aritméticos límite, suposiciones centinela y ramas "esto debería ser inalcanzable". En tercer lugar, pone de relieve la forma en que la IA cambia la economía de la búsqueda. Anthropic afirma que encontró el fallo de OpenBSD tras unas mil ejecuciones del andamiaje, con un coste total inferior a $20.000, al tiempo que hallaba docenas de problemas adicionales, y afirma que la ejecución exitosa específica costó menos de $50 sólo a posteriori. Esto no prueba que la caza de días cero sea de repente barata en un sentido general, pero es una prueba contundente de que partes del proceso de búsqueda se están volviendo mucho más paralelizables. (red.anthropic.com)
He aquí un esbozo de pseudocódigo defensivo simplificado del tipo de lógica límite que importa en el procesamiento SACK:
if (sack.end > snd_max)
ignorar();
if (sack.start < snd_una)
ignore(); // El parche de OpenBSD añade una comprobación como ésta
lista_agujeros();
delete_or_shrink_holes();
if (last_hole != NULL && rcv_lastsack < sack.start)
append_new_hole();
La cuestión no es que los defensores deban memorizar un fallo de OpenBSD. La cuestión es que los sistemas de IA son ahora lo suficientemente buenos como para seguir preocupándose por la lógica de estado límite que los fuzzers no pueden alcanzar fácilmente y los humanos pueden no volver a revisar durante años. Eso cambia cuánta fe pueden depositar los equipos en la idea de que una base de código madura ya ha sido "suficientemente revisada". (ftp.openbsd.org)
FFmpeg y por qué los casos semánticos son más importantes que el número de fallos
El caso de FFmpeg es otro tipo de advertencia. Anthropic dice que Mythos Preview encontró una vulnerabilidad de 16 años en el códec H.264 de FFmpeg. La explicación de la empresa se centra en la forma en que FFmpeg rastrea a qué slice pertenece cada macrobloque de un fotograma. Anthropic dice que las entradas de la tabla son enteros de 16 bits, el contador de rebanadas es un entero de 32 bits sin límite superior, y la tabla se inicializa con memset(..., -1, ...)dejando 65535 como centinela de "sin dueño". Si un atacante produce una trama con 65.536 rebanadas, el número de rebanada 65535 colisiona con el centinela y el descodificador puede concluir que un vecino inexistente pertenece a la misma porción, lo que lleva a una escritura fuera de los límites y a un bloqueo. Anthropic afirma que la suposición subyacente del centinela se remonta a la introducción de H.264 en 2003 y se hizo explotable tras una refactorización de 2010, que el historial del proyecto sigue reflejando. (red.anthropic.com)
Este ejemplo es útil precisamente porque Anthropic no lo exagera. La empresa dice explícitamente que el fallo no es de gravedad crítica y que probablemente sería difícil convertirlo en un exploit funcional. Esta moderación es importante. Demasiados debates sobre la seguridad de la IA tratan cada fallo de memoria descubierto como si estuviera a un gadget de comprometerla por completo. La mejor lección es más sutil: los modelos están empezando a razonar eficazmente sobre invariantes semánticas, valores centinela, anchos de tipo y estructuras de entrada raras pero válidas que el fuzzing tradicional puede infravalorar. Este tipo de razonamiento amplía el espacio de búsqueda para el descubrimiento de vulnerabilidades, incluso cuando el fallo resultante no es trivialmente armable. (red.anthropic.com)
FFmpeg también proporciona a los defensores un ancla operativa. Anthropic afirma que tres vulnerabilidades de FFmpeg identificadas por Mythos se solucionaron en FFmpeg 8.1, y el sitio oficial de FFmpeg confirma que la versión 8.1 "Hoare" se envió el 16 de marzo de 2026. Este es el tipo de tejido conectivo que los equipos de seguridad deben tener en cuenta ahora: no sólo que un modelo haya encontrado un fallo, sino si el hallazgo puede ser rastreado en un tren de versiones, si los consumidores saben que necesitan actualizar, y si los mantenedores de paquetes y los equipos de producto están preparados para absorber el volumen de divulgación asistida por IA. (red.anthropic.com)
| Caso Mythos público | Por qué importa técnicamente | Lo que deben aprender los defensores |
|---|---|---|
| SACK de OpenBSD | Lógica de protocolo con estados, aritmética de bordes, mantenimiento de listas enlazadas en condiciones envolventes. (red.anthropic.com) | Las pilas de red maduras aún esconden suposiciones frágiles. "La ausencia de accidentes recientes no es prueba de seguridad. |
| FFmpeg H.264 | Colisiones de centinelas, desajuste de anchura de enteros, estructuras raras pero legales según las especificaciones y uso semántico incorrecto de los patrones de inicialización. (red.anthropic.com) | El fuzzing sigue siendo necesario pero no suficiente; el razonamiento simbólico y semántico está mejorando. |
| FreeBSD RPCSEC_GSS | Desbordamiento de pila clásico más construcción de exploit en una ruta de servicio real orientada al kernel. (El proyecto FreeBSD) | La IA ya no se limita al descubrimiento de accidentes; cada vez es más relevante para la ingeniería de explotaciones. |
| Linux ipset N-day | Las primitivas de escritura de un bit aún pueden promocionarse a raíz con encadenamiento de exploits pacientes. (red.anthropic.com) | La latencia de los parches es más peligrosa cuando los modelos pueden acelerar el desarrollo de exploits. |
FreeBSD CVE-2026-4747 y cómo es el desacuerdo sobre el código fuente público
El caso de FreeBSD es probablemente el ejemplo público más importante de Mythos, porque en él confluyen el descubrimiento de vulnerabilidades por IA, la construcción de exploits y el desacuerdo sobre las fuentes. Anthropic afirma que Mythos Preview identificó y explotó de forma totalmente autónoma una vulnerabilidad de ejecución remota de código de hace 17 años en el servidor NFS de FreeBSD, clasificada como CVE-2026-4747, y la describe como una vulnerabilidad que permite el control total del servidor desde un usuario no autenticado en cualquier lugar de Internet. El informe técnico de Anthropic atribuye el fallo a una ruta RPCSEC_GSS que copia datos controlados por el atacante en un búfer de pila de 128 bytes con una comprobación de longitud insuficiente, lo que permite un ataque ROP convencional en condiciones inusualmente favorables. (red.anthropic.com)
El aviso oficial de FreeBSD confirma el núcleo de esa descripción, pero es más conservador en cuanto al impacto. El aviso dice que cada paquete de datos RPCSEC_GSS es validado por una rutina que copia una parte del paquete en un búfer de pila sin asegurarse de que el búfer es lo suficientemente grande, y que un cliente malicioso puede provocar un desbordamiento de pila sin autenticarse primero. Pero cuando describe el impacto, el mismo aviso dice que la ejecución remota de código en el espacio del kernel es posible por un usuario autenticado capaz de enviar paquetes al servidor NFS del kernel mientras kgssapi.ko se carga, y dice que los servidores RPC del espacio de usuario enlazados contra la biblioteca vulnerable son explotables remotamente desde cualquier cliente capaz de enviarles paquetes. NVD refleja ese lenguaje de impacto más cauteloso y, en el momento reflejado en la página pública, muestra una puntuación ADP de 8,8 Alto mientras que la propia puntuación de NVD aún no estaba poblada. (El proyecto FreeBSD)
Esa discrepancia es exactamente el tipo de cosas a las que los defensores deben acostumbrarse en la era de la IA. Hay al menos tres lecturas plausibles de la diferencia. Una es que la activación del desbordamiento de pila no está autenticada, mientras que el proveedor se mantuvo conservador sobre las condiciones para un RCE fiable del kernel. Otra es que la exitosa cadena de exploits de Anthropic demostró un estado final más fuerte de lo que el aviso estaba preparado para generalizar en el momento de la divulgación. Una tercera es que la diferencia simplemente refleja la brecha habitual entre un escrito de investigación centrado en el techo técnico y un aviso de proveedor centrado en declaraciones limitadas y apoyables. Lo importante no es elegir un bando teatralmente. Lo que importa es leer ambas fuentes con atención y resistirse a la tentación de simplificarlas en una sola frase. (red.anthropic.com)
La historia de la corrección también es digna de mención. El aviso de FreeBSD dice que todas las versiones soportadas estaban afectadas y enumera las ramas corregidas, incluyendo 15.0-RELEASE-p5, 14.4-RELEASE-p1, 14.3-RELEASE-p10 y 13.5-RELEASE-p11, junto con las correcciones de la rama estable. También dice que no hay ninguna solución disponible, excepto que los sistemas sin kgssapi.ko cargados no son vulnerables en la ruta del kernel. Este es un ejemplo clásico de por qué las operaciones de parcheo, y no sólo las suscripciones a avisos, decidirán quién permanece a salvo en un mundo en el que la IA puede ayudar a construir exploits más rápidamente. (El proyecto FreeBSD)
Un flujo de trabajo práctico de primera respuesta para los estamentos de FreeBSD tiene este aspecto:
# Identificar las versiones en ejecución del kernel y userland
freebsd-version -ku
# Comprobar si el módulo RPCSEC_GSS del kernel está presente
kldstat | grep kgssapi
# Si utiliza paquetes base
sudo pkg upgrade -r FreeBSD-base
# Si utiliza conjuntos de distribución binarios
sudo freebsd-update fetch
sudo freebsd-update install
sudo shutdown -r ahora
Estos comandos no sustituyen a la disciplina de mantenimiento, pero ilustran la verdadera cuestión de seguridad. En la era Mythos, "¿hay un parche?" se convierte en la parte fácil. "¿Lo he inventariado, priorizado, desplegado y verificado lo suficientemente rápido?" es la parte difícil. (El proyecto FreeBSD)
Linux kernel CVE-2024-53141 y por qué N-day es ahora un modelo de amenaza de primera clase
Si el caso de FreeBSD muestra un potencial de explotación de día cero, el de Linux ipset muestra por qué la explotación de N-day debe ascender en la escala de prioridades de los defensores. NVD describe CVE-2024-53141 como un problema del kernel de Linux en bitmap_ip_uadt donde una comprobación de rango omitida puede conducir a una vulnerabilidad local de alta gravedad. La página NVD muestra una puntuación CVSS 3.1 de 7.8 Alta y rangos de versiones afectadas a través de múltiples líneas del kernel. La descripción del aviso de Ubuntu refleja la misma causa raíz, explicando que cuando IPSET_ATTR_IP_TO está ausente pero IPSET_ATTR_CIDR existe, los valores se procesan de forma que falta una comprobación de rango y permite que se produzca la vulnerabilidad. (nvd.nist.gov)
La aportación de Anthropic en el post de Mythos no es reivindicar el descubrimiento de ese fallo. Dice explícitamente que esta sección se refiere a un día N que se dio a Mythos Preview. La cuestión era la explotación. El escrito de Anthropic explica cómo un índice fuera de límites en ipset puede transformarse en una primitiva de escritura limitada de un bit, y luego amplificarse pacientemente mediante la adyacencia de páginas físicas, la manipulación de PTE y la eventual manipulación de la entrada de caché de página para /usr/bin/passwd para alcanzar la raíz. Tanto si el lector quiere seguir la cadena completa como si no, el significado para la seguridad es obvio: las vulnerabilidades locales parcheadas que antes se quedaban en el cubo de "nos ocuparemos de ellas pronto" se están volviendo más peligrosas si los modelos pueden comprimir el trabajo de ingeniería de exploits necesario para convertirlas en armas. (red.anthropic.com)
Aquí es donde el catálogo CISA Known Exploited Vulnerabilities se vuelve más relevante, no menos. CISA describe el catálogo KEV como un recurso para ayudar a la comunidad de ciberseguridad y a los defensores de la red a gestionar la remediación basada en la evidencia de explotación en la naturaleza. La idea de KEV siempre ha sido que no todas las CVE merecen la misma urgencia. Las capacidades tipo Mythos no invalidan esa lógica. La intensifican. Si la asistencia de las máquinas reduce el tiempo desde la difusión del parche hasta la explotación, entonces los defensores necesitan tratar "parcheado públicamente y accesible en mi entorno" como una condición de escalada mucho más agresiva que hace unos años. (CISA)
El error operativo que muchas organizaciones siguen cometiendo es clasificar las colas de parches únicamente por etiquetas públicas de gravedad. Eso nunca fue lo ideal, y empeora a medida que se acelera el desarrollo de exploits. A corto plazo, los equipos deben sesgar el triaje hacia una combinación de factores: superficie de ataque expuesta, cruce de límites de privilegios, primitivas de corrupción de memoria, reciente actualización de parches, claridad de commit relevante para el exploit y disponibilidad de verificadores que abaraten la reproducción asistida por IA. Una nota de parche nítida más una ruta de despliegue alcanzable es ahora más peligrosa que un CVSS de sonido aterrador en un componente que nadie puede atacar. (red.anthropic.com)
Ingeniería inversa, cadenas de navegación y los límites públicos de la historia de Mythos
Las afirmaciones más atrevidas de Anthropic van más allá de los casos que los intrusos pueden inspeccionar a fondo hoy en día. El documento afirma que Mythos Preview puede tomar un binario despojado de código cerrado, reconstruir un código fuente plausible para él y, a continuación, analizar el código fuente reconstruido junto con el binario original para encontrar vulnerabilidades. También dice que el modelo encontró de forma autónoma primitivas de lectura y escritura en múltiples navegadores, las encadenó en JIT heap sprays y, en un caso, combinó un exploit de navegador con escape de sandbox y escalada de privilegios local para que una página web maliciosa pudiera, en última instancia, escribir directamente en el núcleo del sistema operativo. Son afirmaciones extraordinarias. Anthropic se cuida de cubrir algunas de ellas con futuros compromisos de revelar detalles tras la aplicación de parches. (red.anthropic.com)
Los lectores de seguridad deberían aprender dos lecciones de esta sección. La primera es que la ingeniería inversa offline y la investigación de exploits son en sí mismas capacidades importantes. Reconstruir una fuente plausible a partir de binarios despojados es valioso, incluso si todavía no es una prueba pública de investigación de vulnerabilidades a escala universalmente fiable sólo a partir de binarios. La segunda es que el límite de la prueba pública sigue siendo importante. Anthropic está diciendo a los lectores que estas cosas sucedieron, pero los artefactos detallados necesarios para la replicación externa independiente en gran medida no son públicos todavía. Esto no significa que las afirmaciones sean falsas. Significa que el nivel de confianza debe expresarse correctamente. "Pruebas sólidas de autoría del vendedor con reproducibilidad pública limitada" es diferente de "hecho públicamente establecido". (red.anthropic.com)
Esta distinción adquiere aún más importancia cuando la conversación pasa de la investigación de exploits visibles en la fuente a las pruebas de aplicaciones web en Internet. Anthropic enumera públicamente importantes clases de bugs lógicos, entre los que se incluyen la evasión completa de la autenticación, la evasión del inicio de sesión en la cuenta y las condiciones destructivas de denegación de servicio. Estas clases de errores son muy importantes en entornos SaaS reales. Pero el informe público de Anthropic no ofrece estudios de casos públicos detallados de esos hallazgos, y sus pruebas metodológicas más sólidas siguen concentrándose en contextos visibles en origen o fuera de línea. Una forma útil de plantear la situación es la siguiente: Mythos Preview ha hecho avanzar claramente el estado de la investigación de exploits de IA, pero el registro público aún no ha cerrado completamente la brecha entre la investigación de exploits de alta información y el pentesting web de caja negra de extremo a extremo contra sistemas vivos. (red.anthropic.com)
También por eso los equipos maduros deben dejar de tratar el razonamiento de caja blanca y la validación de caja negra como categorías de productos que compiten entre sí. Son etapas diferentes en un bucle de seguridad más fiable. El escrito técnico público de Penligent sobre esta división es útil en este sentido: argumenta que la IA consciente de la fuente puede reducir la búsqueda y mapear las causas raíz probables, mientras que la validación orientada al objetivo sigue siendo necesaria para demostrar la alcanzabilidad y el impacto en el entorno desplegado. Es una lectura sensata del momento Mythos. El trabajo que claramente se está comprimiendo primero es la costosa primera mitad de la investigación de exploits. El trabajo que todavía requiere una cuidadosa interacción con el sistema es la prueba contra la superficie del objetivo real. (penligent.ai)
La seguridad de la memoria sigue siendo fundamental, pero los fallos lógicos no desaparecen
Resulta tentador interpretar el lanzamiento de Mythos como un gigantesco anuncio de lenguajes seguros para la memoria, y hay algo de verdad en ello. El material público más sólido que Anthropic ha publicado hasta ahora se concentra en territorio no seguro para la memoria: Manejo de TCP en OpenBSD, RPCSEC_GSS del kernel de FreeBSD, decodificador H.264 de FFmpeg y cadenas de explotación del kernel de Linux. Las directrices del gobierno estadounidense llevan años avanzando en la misma dirección. En diciembre de 2023, la NSA, CISA y sus socios publicaron "The Case for Memory Safe Roadmaps" (El caso de las hojas de ruta seguras en memoria), argumentando que avanzar hacia lenguajes seguros en memoria puede eliminar amplias clases de vulnerabilidades de seguridad en memoria. En junio de 2025, la NSA y la CISA volvieron a insistir en que reducir las vulnerabilidades relacionadas con la memoria es fundamental y que las consecuencias de no abordarlas pueden incluir brechas, bloqueos e interrupciones operativas. (Departamento de Guerra de EE.UU.)
Pero el documento de Mythos también deja claro por qué la seguridad de la memoria no puede ser toda la respuesta. Según Anthropic, Mythos Preview ha descubierto múltiples sorteos de autenticación completa, sorteos de inicio de sesión de cuentas y condiciones de denegación de servicio que podrían borrar datos de forma remota o bloquear un servicio. También describe una derivación de KASLR del kernel de Linux que no proviene de una clásica lectura fuera de los límites, sino de un puntero del kernel deliberadamente expuesto. Se trata de fallos lógicos y de diseño, no sólo de errores en la gestión de la memoria. Una migración a Rust u otro lenguaje seguro para la memoria reduciría una superficie de riesgo muy importante, pero no neutralizaría las brechas de autorización, los desajustes en el modelo de seguridad o las fugas de información que "funcionan como están codificadas" y siguen siendo inseguras. (red.anthropic.com)
| La familia de la vulnerabilidad en el debate sobre Mythos | En qué puede ayudar la seguridad lingüística | Lo que no resuelve |
|---|---|---|
| Corrupción de memoria en analizadores sintácticos, núcleos y pilas de red | Elimina o reduce muchas lecturas, escrituras, UAF y liberaciones dobles fuera de los límites cuando se utiliza realmente el subconjunto seguro. (Departamento de Guerra de EE.UU.) | Las escotillas de escape inseguras, los límites de FFI y los errores de diseño siguen importando. El ejemplo del VMM seguro en memoria de Anthropic dependía de una operación insegura. (red.anthropic.com) |
| Errores lógicos de autenticación y de inicio de sesión | Poca ayuda directa más allá de una higiene de aplicación más segura. | La lógica de autorización rota, los errores en los límites de confianza y los fallos en el flujo de trabajo aún sobreviven. (red.anthropic.com) |
| Fugas de información y desvíos de KASLR | Puede reducir algunas fugas derivadas de la memoria. | La exposición deliberada de punteros o metadatos puede seguir siendo explotable incluso en código seguro para la memoria. (red.anthropic.com) |
La conclusión práctica es que los responsables de la seguridad deben resistirse a los falsos binarios. No necesitan elegir entre la seguridad de la memoria y la velocidad de respuesta a los exploits. Necesitan ambas. Las hojas de ruta seguras para la memoria son una reducción del riesgo estructural a largo plazo. Una verificación, aplicación de parches y repetición de pruebas más rápidas son necesidades operativas a corto plazo en un mundo en el que el desarrollo de exploits se acelera antes de que se pueda reescribir la base instalada. (Departamento de Guerra de EE.UU.)
El libro de jugadas del defensor para la era Mythos
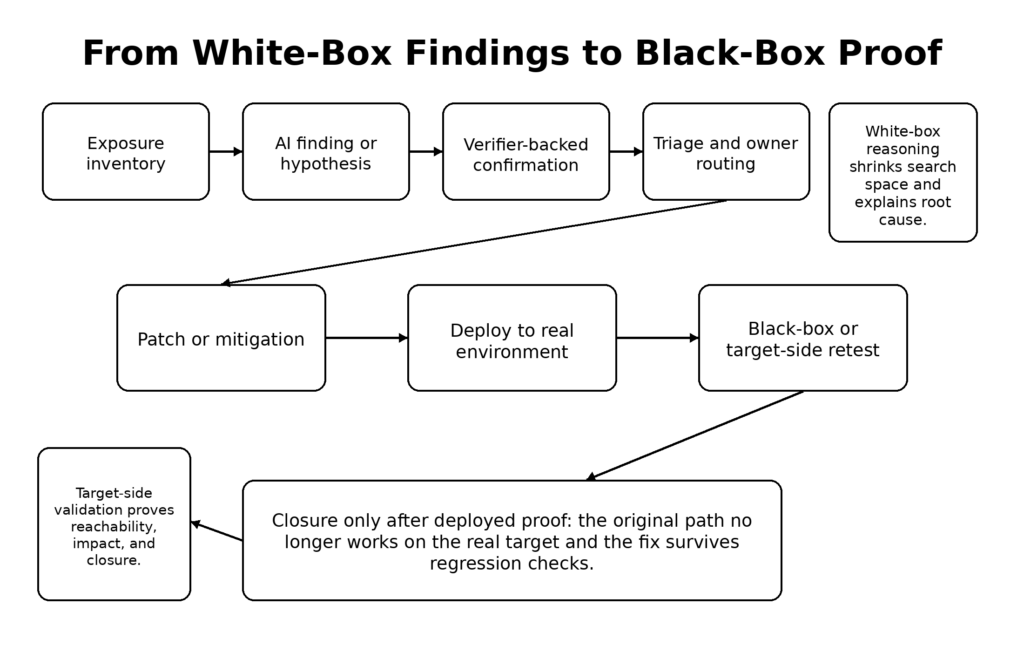
El consejo público de Anthropic a los defensores es directo, y es una de las partes más útiles del comunicado. La empresa dice que las organizaciones deben pensar más allá de la búsqueda de vulnerabilidades en el triaje, la deduplicación, los pasos de reproducción, la aplicación de parches candidatos, la revisión de la desconfiguración de la nube, la revisión de relaciones públicas y el trabajo de migración. Argumenta explícitamente que los equipos deben acortar los ciclos de parches, revisar la aplicación de parches, activar la actualización automática cuando sea posible, tratar como urgentes los saltos de dependencia que lleven correcciones de CVE, revisar la gestión de la divulgación y automatizar la respuesta a incidentes, porque un descubrimiento más rápido conllevará más intentos contra la ventana de divulgación a parche. (penligent.ai)
Esa orientación es correcta, pero ayuda traducirla en un modelo operativo concreto. Los cambios inmediatos que necesitan los equipos de seguridad no son místicos. Son procedimentales y mensurables.
En primer lugar, hay que separar las hipótesis del modelo de los hallazgos verificados. Un modelo puede ser muy bueno para generar candidatos a vulnerabilidades, pero la organización sólo debe permitir que un hallazgo pase a la reparación de alta prioridad cuando haya superado una capa verificadora. Dependiendo del objetivo, ese verificador podría ser ASan, un arnés de regresión, un reproductor, una prueba de integración fallida, una prueba de concepto minimizada de fallos o una validación de cara al objetivo ejecutada en un entorno autorizado. Esta es la lección que Anthropic extrajo de Firefox, y es el requisito mínimo para mantener alta la calidad de la señal a medida que aumenta el volumen de salida del modelo. (Antrópico)
En segundo lugar, pasar del trabajo de seguridad basado en calendarios al trabajo de seguridad basado en colas. Un ciclo de revisión trimestral tenía cierto sentido cuando el cuello de botella era el descubrimiento humano. Tiene menos sentido si el descubrimiento asistido por modelos está produciendo hallazgos validados todos los días. La unidad de gestión adecuada es ahora una cola continuamente actualizada con reglas de antigüedad claras, pistas de explotabilidad, criticidad de los activos y estado de repetición de las pruebas. Las organizaciones que todavía tratan las pruebas de seguridad como un evento de entrega de informes se van a sentir lentas incluso si compran las herramientas más nuevas. (red.anthropic.com)
En tercer lugar, tratar los parches candidatos como artefactos de primera clase. La experiencia de Anthropic con Mozilla nos recuerda que los informes de errores son mucho más útiles cuando incluyen casos de prueba mínimos, pruebas de concepto y posibles correcciones. El parche candidato no tiene por qué fusionarse a ciegas. Sí es necesario que exista con la suficiente antelación para que los ingenieros puedan razonar sobre el radio de explosión y el cierre en la misma conversación. En un flujo de vulnerabilidades a velocidad de máquina, el paso de "he encontrado un fallo" a "tengo una solución plausible" tiene que producirse en horas o días, no en silos organizativos separados durante varias semanas. (Antrópico)
En cuarto lugar, imponga el cierre con nuevas pruebas, no con optimismo. Una de las maneras más fáciles de perder terreno en la era Mythos es enviar un parche, marcar un ticket como hecho, y nunca volver a ejecutar la ruta de búsqueda original desde el exterior. Los sistemas reales tienen proxies, puertas de enlace, banderas de características, instancias obsoletas, grupos de canarios, trabajadores en segundo plano y deriva de configuración. Una diferencia de código no es lo mismo que un cierre desplegado. Este es el punto en el que la validación de caja negra o de caja gris sigue siendo importante, y también es el punto en el que los equipos que ya utilizan plataformas de validación orientadas al objetivo tienen ventaja. Los materiales públicos de Penligent, por ejemplo, describen un flujo de trabajo centrado en la ejecución controlada de tareas, el control del alcance y la recopilación de pruebas contra objetivos reales. Tanto si un equipo utiliza esa plataforma exacta como si no, el instinto arquitectónico es correcto: el razonamiento de modelos debe terminar en pruebas auditables, no en prosa persuasiva. (penligent.ai)
Un ejemplo compacto de un registro de vulnerabilidad preparado para el modelo tiene este aspecto:
{
"report_id": "AI-2026-0410-0017",
"component": "rpcsec_gss",
"asset_class": "kernel_nfs",
"claim_type": "stack_overflow",
"evidence_source": "reproductor_más_validación_humana",
"internet_exposed": true,
"exploitability_state": "publicly_described_vendor_claim",
"patch_status": "vendor_patch_available",
"owner_team": "platform_kernel",
"retest_required": true,
"notes": "No escalar a crítico hasta que se adjunten artefactos verificadores y se confirme el cierre del despliegue."
}
Ese tipo de estructura es más importante que el modelo que haya generado el texto inicial. Una vez que el modelo produce resultados significativos, la calidad del esquema, el enrutamiento y el proceso de validación empiezan a importar más que la elegancia del mensaje. (Antrópico)
He aquí un sencillo ejemplo en Python para priorizar los hallazgos generados por la IA en una cola de parches. Es intencionadamente aburrido, que es el punto. La parte difícil no es la matemática de clasificación de lujo. Es construir un proceso repetible que refleje la presión real de los exploits.
from dataclasses import dataclass
@clasedatos
clase Hallazgo:
componente: str
internet_expuesto: bool
verificador_pasado: bool
patch_available: bool
privilege_boundary: bool
corrupción_memoria: bool
days_open: int
def puntuación_prioridad(f: Hallazgo) -> int:
puntuación = 0
si f.internet_expuesto:
puntuación += 30
si f.verifier_passed:
puntuación += 25
si f.patch_available:
puntuación += 15
si f.privilege_boundary:
puntuación += 15
si f.memory_corruption:
puntuación += 10
si f.days_open > 7:
puntuación += 10
si f.days_open > 30
puntuación += 10
devolver puntuación
cola = [
Finding("rpcsec_gss", Verdadero, Verdadero, Verdadero, Verdadero, 2),
Finding("ffmpeg_h264", False, True, True, False, True, 10),
Finding("internal_auth_flow", True, False, False, True, False, 5),
]
for item in ordenados(cola, clave=puntuación_prioridad, inverso=Verdadero):
print(elemento.componente, puntuación_prioridad(elemento))
Los equipos pueden ampliar esto con la propiedad del entorno, la criticidad del negocio, las ventanas de congelación de cambios o el linaje de dependencias. La idea importante es que los descubrimientos respaldados por verificadores, expuestos a Internet y con privilegios cruzados deberían aumentar rápidamente, especialmente cuando ya existe un parche y un sistema de IA puede ayudar a otros a convertirlo en un arma más rápido que antes. (CISA)

Acciones a treinta, noventa y ciento ochenta días para los equipos de seguridad
| Horizonte temporal | Qué cambiar ahora | Por qué es importante en la era del día cero |
|---|---|---|
| Primeros 30 días | Inventariar los servicios accesibles desde el exterior, los servicios orientados al núcleo y los analizadores críticos; identificar dónde aterrizarían operativamente los hallazgos generados por IA; definir los requisitos del verificador para los informes de alta prioridad. (El proyecto FreeBSD) | La mayoría de los equipos ya disponen de herramientas. Aún no disponen de un bucle de enrutamiento y validación lo suficientemente rápido. |
| Primeros 90 días | Añadir campos de triaje estructurados, expectativas de parches candidatos y repeticiones de pruebas obligatorias; reforzar los acuerdos de nivel de servicio de los parches para problemas de corrupción de memoria alcanzable y ruta de autenticación; predefinir rutas de escalado de divulgación. (Antrópico) | El descubrimiento asistido por IA aumenta el volumen de informes y comprime la demora segura entre la disponibilidad del parche y la explotabilidad. |
| Primeros 180 días | Construir una revalidación continua de cara al objetivo para las superficies de alto riesgo; alinear los equipos de AppSec, SRE y plataforma en torno a una definición común de cierre; ampliar las hojas de ruta seguras para la memoria cuando sea factible. (Departamento de Guerra de EE.UU.) | La respuesta duradera es un bucle operativo más rápido y una reducción estructural del código propenso a los errores. |
El mayor error que cometerán los equipos es intentar responder al momento Mythos con teatro de adquisiciones. Comprar un modelo de plan de acceso o un complemento de "IA de seguridad" no salvará a una organización cuya gobernanza de parches es lenta, cuyos propietarios son ambiguos, cuyos validadores son débiles y cuyas pruebas de despliegue faltan. El segundo gran error será descartar todo esto porque las afirmaciones más amplias aún no son reproducibles de forma independiente. Es una norma demasiado estricta para la planificación operativa. Cuando un proveedor ya ha publicado casos parcheados en OpenBSD, FreeBSD y FFmpeg; ha documentado importantes saltos en los puntos de referencia; y ha alterado la política de publicación y divulgación en torno al modelo, los defensores no necesitan una reproducción pública perfecta para justificar el cambio de sus flujos de trabajo. (openbsd.org)
Lo que deben preguntarse los compradores de seguridad tras el avance de Mythos
Los compradores técnicos que evalúen productos de seguridad de IA en 2026 deberán ser mucho más exigentes que la norma actual del mercado. La primera pregunta es si las pruebas más sólidas del producto proceden del análisis visible en origen o de la validación orientada al objetivo. No es una pregunta capciosa. Ambas son valiosas, pero responden a problemas diferentes. Si los mejores ejemplos de un proveedor se basan en el acceso al código local, la reconstrucción de binarios despojados, o arneses fuera de línea, entonces los compradores no deben inferir que el producto ya ha demostrado las pruebas de caja negra en vivo en entornos similares a la producción. El historial público de Anthropic es un estudio de caso útil sobre lo fácil que es que esas categorías se difuminen en una conversación de marketing. (red.anthropic.com)
La segunda cuestión es qué capa verificadora existe. El propio trabajo de Anthropic apunta repetidamente a los verificadores: ASan, pruebas de regresión, artefactos reproductores mínimos y pruebas de cierre. Un sistema que puede producir hermosas explicaciones sin un verificador fiable es un asistente de triaje en el mejor de los casos, no un flujo de trabajo de seguridad digno de confianza. Los compradores deben pedir ver el rastro de los artefactos, no sólo la pantalla de resumen. (red.anthropic.com)
La tercera cuestión es cómo gestiona la plataforma la repetición de pruebas y el cierre. El hallazgo de vulnerabilidades sin revalidación del lado del objetivo crea deuda de entradas. En el mercado actual, algunos materiales públicos de Penligent son útiles precisamente porque insisten en separar los hallazgos de caja blanca de las pruebas de caja negra y hacer de las pruebas un resultado de primera clase. Los compradores deberían recompensar esa distinción dondequiera que la encuentren. La cuestión no es si una herramienta "utiliza IA". La cuestión es si puede ayudar a que un hallazgo pase de la hipótesis a la exposición verificada y al cierre verificado. (penligent.ai)
La cuarta pregunta es qué supuestos de divulgación y de carga de operadores está haciendo el proveedor. Anthropic tuvo que publicar una política operativa de divulgación coordinada dedicada porque los descubrimientos generados por la IA pueden abrumar a los mantenedores si se manejan de forma irresponsable. Cualquier plataforma seria que pretenda producir descubrimientos de seguridad a escala debería ser capaz de explicar cómo evita las inundaciones de informes, cómo etiqueta el material originado por la IA, cómo lo validan los humanos y cómo evita convertir a los mantenedores en infraestructura de triaje no remunerada. (Antrópico)
Claude Mythos Preview es un hito, no el final de la historia
La conclusión más limpia es también la menos de moda. Claude Mythos Preview es la señal pública más fuerte hasta el momento de que la investigación de exploits de IA ha entrado en una nueva fase. Anthropic ha publicado casos concretos parcheados, deltas de referencia significativos, una postura de liberación de acceso restringido y un marco de divulgación diseñado en torno al descubrimiento asistido por máquinas. Esto es suficiente para justificar cambios defensivos importantes. (red.anthropic.com)
Al mismo tiempo, el registro público sigue teniendo aristas que deben nombrarse con honestidad. La mayoría de los hallazgos siguen siendo privados porque no están parcheados. Las afirmaciones más generales sobre navegadores, fallos lógicos de la web y objetivos de código cerrado aún no son reproducibles de forma independiente a partir de artefactos públicos. El caso de FreeBSD demuestra que incluso entre fuentes de alta calidad, el lenguaje de impacto puede divergir entre el laboratorio descubridor y el aviso del proveedor. Estas no son razones para descartar el momento. Son razones para leerlo con atención. (red.anthropic.com)
Lo que Mythos cambia primero no es la cuestión filosófica de si la IA puede piratear. Esa cuestión ya está obsoleta. Lo que cambia es el reloj. Acorta el intervalo entre el descubrimiento y el conocimiento útil. Amenaza con acortar el intervalo entre la disponibilidad de parches y la explotabilidad. Aumenta el valor de los verificadores, los parches candidatos y las repeticiones de pruebas. Hace que el rendimiento de la divulgación y la gestión de los parches formen parte del perímetro de seguridad. Los equipos que lo entiendan se adaptarán a tiempo. Los equipos que esperan una prueba pública perfecta de cada afirmación probablemente lo conseguirán, pero lo harán más tarde de lo que deberían. (red.anthropic.com)
Lecturas complementarias y enlaces de referencia
- Antrópico, Evaluación de las capacidades de ciberseguridad de Claude Mythos Preview. (red.anthropic.com)
- Antrópico, Proyecto Glasswing. (Antrópico)
- Antrópico, Divulgación coordinada de vulnerabilidades descubiertas por Claude. (Antrópico)
- Antrópico, Claude Mythos Informe de riesgo previoversión pública redactada. (Antrópico)
- Antrópico, Colaboración con Mozilla para mejorar la seguridad de Firefox. (Antrópico)
- OpenBSD 7.8 errata y parche 025 para opciones SACK inválidas. (openbsd.org)
- Aviso de seguridad de FreeBSD SA-26:08.rpcsec_gss y entrada NVD para CVE-2026-4747. (El proyecto FreeBSD)
- NVD y registros de proveedores para el kernel de Linux CVE-2024-53141. (nvd.nist.gov)
- La página de la versión 8.1 de FFmpeg y el commit histórico de refactorización de H.264 de 2010 que cita Anthropic. (ffmpeg.org)
- Orientaciones de la NSA y el CISA sobre hojas de ruta seguras para la memoria y lenguajes seguros para la memoria. (Departamento de Guerra de EE.UU.)
- Penligente, Claude Mythos Preview no es pentesting de caja negra. (penligent.ai)
- Penligente, Claude Code Security y Penligent: De los hallazgos de caja blanca a las pruebas de caja negra. (penligent.ai)
- Página de inicio de Penligent. (penligent.ai)

