AI vulnerability discovery has crossed an uncomfortable threshold. The question is no longer whether ordinary models can reason about code, security controls, exploitability, and tool output. Many of them already can. The harder question is whether a security team can turn that fragmented intelligence into a controlled workflow that keeps state, tests hypotheses, executes tools safely, verifies evidence, and produces findings another engineer can reproduce.
That distinction matters because the public conversation still tends to over-credit the model and under-credit the system around it. Anthropic’s Mythos Preview work showed that a frontier model could identify serious vulnerabilities, including a subtle OpenBSD TCP SACK bug introduced in 1998. Anthropic described a chain involving SACK state tracking, incomplete range validation, signed integer overflow, and a null pointer write that could remotely crash an OpenBSD host responding over TCP. (Red Anthropic) That is an important signal. It shows that modern models can reason across old code, weird edge cases, and exploitability constraints.
But the more useful lesson is broader. Niels Provos later argued that vulnerability discovery is “an orchestration problem, not a frontier-model problem,” and reported that his IronCurtain workflows replicated frontier-style findings and discovered new zero-days using commercial models such as Opus 4.6 and Sonnet 4.6 as well as Z.AI’s GLM 5.1. (Niels Provos) The exact results still require the usual caution around disclosure timing, unpatched issues, and independent validation. The engineering direction is clear: the model matters, but the model is not the whole machine.
A single model prompt can suggest a bug. A real AI vulnerability discovery workflow has to do more. It has to understand scope, inspect a codebase or target, preserve investigative state, rank hypotheses, build or invoke harnesses, run tools, parse results, recover from failure, stop unsafe actions, and produce evidence that survives review. The difference between those two modes is the difference between a clever assistant and a security system.
The bottleneck moved from intelligence to use
The first wave of AI security discussion asked a simple question: can a model help with hacking? That was the wrong long-term framing. A better question is: how much useful security work can be extracted from the intelligence that already exists?
Ordinary models are no longer blank autocomplete engines. They can summarize unfamiliar code, map call paths, explain parser behavior, reason about dangerous input boundaries, translate tool output into next steps, and help write tests. They can also make mistakes, overstate confidence, lose context, hallucinate APIs, and confuse a plausible weakness with a reachable vulnerability. Both statements are true.
That is why the bottleneck has shifted. The central constraint is not raw intelligence alone. It is task structure.
Security research is not one thought. It is a long series of narrowing moves. A researcher starts with a broad surface, then asks which components parse untrusted input, which code paths cross privilege boundaries, which dependencies have relevant history, which inputs reach dangerous sinks, which assumptions are not enforced, which crashes are exploitable, which behaviors are reproducible, and which findings matter enough to report. A model can help with many of those moves, but only if the surrounding system keeps the investigation coherent.
This is the same pattern that showed up in earlier LLM penetration testing research. PentestGPT reported that LLMs were capable in subtasks such as using testing tools, interpreting outputs, and proposing next actions, while still struggling to maintain an integrated understanding of the overall testing scenario. Its response was not simply “use a bigger model.” It introduced three self-interacting modules to preserve context and manage subtasks. (arXiv)
That design lesson has aged well. The industry keeps rediscovering the same thing under different labels: agents, copilots, scaffolds, harnesses, workflows, task graphs, finite-state machines, memory systems, evaluation loops. The names vary. The underlying requirement is stable: security work needs state.
A bug hunter who forgets what they already tested wastes time. A model that forgets what it already tested wastes tokens. A human who cannot prove impact submits noise. A model that cannot prove impact generates plausible reports. A team that cannot replay a finding cannot trust it. An AI system that cannot replay a finding should not be treated as a discovery system.
AI vulnerability discovery means more than bug prediction
The phrase AI vulnerability discovery is often used too loosely. It can mean anything from a chatbot explaining CVEs to a tool-connected system that finds and verifies new vulnerabilities in a real codebase. Those are not the same thing.
A useful definition is narrower: AI vulnerability discovery is the use of models inside a structured security workflow to identify, test, validate, and explain previously unknown or environment-specific weaknesses. That workflow may involve source code, binaries, web applications, APIs, cloud configurations, dependencies, containers, or production-like test environments. The key is not that the model says “this looks risky.” The key is that the system turns a hypothesis into evidence.
| Mode | Para qué sirve | Useful for | Where it breaks |
|---|---|---|---|
| Chatbot security assistant | Explains vulnerability classes, suggests commands, summarizes advisories | Learning, triage, syntax help, initial brainstorming | Loses state, cannot prove reachability, may invent details |
| Security copilot | Helps a human write tests, parse tool output, draft reports | Speeding up expert workflows | Human still owns the chain of reasoning and validation |
| Orchestrated AI security workflow | Maintains state, calls tools, builds harnesses, verifies behavior, records evidence | Repeated testing, large codebases, attack path validation, safer automation | Requires scope control, execution boundaries, cost budgets, auditability |
| Autonomous vulnerability research system | Runs multi-stage discovery and validation with minimal human intervention | Scaled code review, CVE reproduction, regression testing, controlled research | High risk if permissions, disclosure, or evidence standards are weak |
The last two categories are where the field is moving. They are also where safety engineering becomes unavoidable. Once a model can call tools, read files, modify code, browse internal systems, or run commands, the AI system becomes part of the security boundary. Prompt quality alone cannot make that safe.
NIST SP 800-115 frames technical security testing as a process that includes planning and conducting tests, analyzing findings, and developing mitigation strategies. (csrc.nist.gov) OWASP’s Web Security Testing Guide similarly describes web security testing as a structured discipline for web applications and services, not a loose collection of payloads. (owasp.org) AI does not remove that structure. It makes structure more important because the system can now move faster than a human reviewer can casually track.
The right mental model is not “AI replaces the pentester.” It is “AI expands the number of hypotheses a security workflow can generate and test.” The discovery system still needs rules, scope, validation, and accountable handoff.
Why single-prompt vulnerability research fails
A single prompt can be impressive. It can read a function and notice an unchecked length. It can identify a missing authorization check in a controller. It can recognize an unsafe deserialization pattern. It can propose a fuzzing strategy. That is useful, but it is not enough.
Single-prompt research fails for predictable reasons.
First, it loses investigative memory. Real vulnerability discovery often depends on small observations that only become meaningful later. A model may notice that one parser assumes a normalized path, another function performs normalization after authorization, and a third route exposes a user-controlled path segment. None of those facts alone proves a vulnerability. The relationship between them might.
Second, it cannot reliably separate suspicion from reachability. Security engineers know the difference between “dangerous-looking code” and “attacker-controlled input reaches this sink under realistic conditions.” Models often blur that boundary unless forced into a verification loop.
Third, it struggles with negative results. Good research is full of dead ends. The function was unreachable. The input was sanitized earlier. The crash only occurs in a test-only build. The dependency version is not used in production. The API returns the same object because the two test accounts belong to the same tenant. A workflow must remember those failures so the system does not rediscover them.
Fourth, it has no natural execution boundary. Asking a model to “test this” is not the same as giving it a safe container, scoped credentials, a network allowlist, a cost limit, and a record of every tool call. Without those controls, agentic security work becomes a risk transfer exercise.
Fifth, it may optimize for narrative instead of proof. Models are strong at writing coherent explanations. That strength becomes dangerous when the evidence is weak. A report that sounds like a real bug but cannot be replayed is worse than no report because it consumes reviewer time and erodes trust.
A better pattern is to force every hypothesis through a loop:
observe -> hypothesize -> plan -> execute -> record -> verify -> rank -> report or discard
That loop looks simple. In practice, each step needs machinery. Observations need storage. Hypotheses need identifiers. Plans need scope checks. Execution needs sandboxing. Records need immutable artifacts. Verification needs reproducible commands. Ranking needs severity and confidence. Reports need enough context for another engineer to replay the finding.
The model is only one component in that loop.
What the orchestration layer actually does
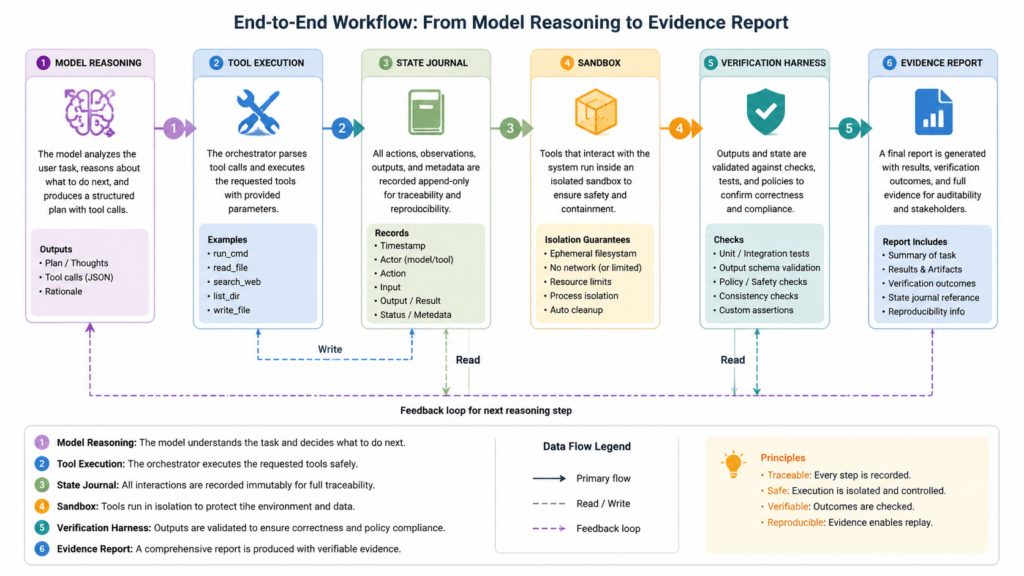
The orchestration layer is the part of an AI vulnerability discovery system that turns model intelligence into security work. It decides what the model sees, what it can do, what state is preserved, when tools run, when humans approve actions, how evidence is stored, and when the system stops.
A strong orchestration layer usually has eight responsibilities.
| Componente | Role in AI vulnerability discovery | Common failure when missing |
|---|---|---|
| Scope definition | Defines allowed targets, repositories, accounts, domains, tools, and test intensity | The agent drifts into unauthorized or irrelevant work |
| Target model | Maps assets, routes, files, dependencies, trust boundaries, roles, and data flows | The model tests random surfaces without strategy |
| State journal | Records observations, hypotheses, actions, failures, and evidence | The model repeats itself or loses the thread |
| Tool router | Chooses static analysis, fuzzing, HTTP replay, dependency scanning, unit tests, or manual review | The workflow stays at the level of advice |
| Execution sandbox | Runs tools in a controlled environment with network and filesystem limits | Prompt injection or tool misuse can cause damage |
| Verification harness | Converts a suspected issue into reproducible proof | Findings remain speculative |
| Human approval gates | Escalates risky actions, destructive tests, external network access, and disclosure steps | Autonomy outruns accountability |
| Report builder | Produces replayable evidence, impact explanation, limitations, and remediation guidance | The result cannot be trusted or handed off |
Provos’s IronCurtain work is useful because it makes these ideas concrete. His vuln-discovery workflow uses a finite-state machine with a central Orchestrator agent and an append-only execution journal. The journal allows the workflow to maintain state, test hypotheses, and let specialized agents begin with fresh context windows while rehydrating from on-disk artifacts. (Niels Provos)
That is the right shape. Long vulnerability research cannot depend on a single swollen context window. The system needs durable external memory: files, logs, databases, traces, harness outputs, coverage reports, crash artifacts, diffs, and prior decisions. The model should read the relevant slice of that state, act, and write back to it.
IronCurtain also illustrates the security side of orchestration. Its GitHub documentation explicitly treats the agent as untrusted and assumes the LLM may be compromised by prompt injection or drift. It routes interactions through semantically meaningful tool calls, checks each call against policy, runs agents inside isolation boundaries, and records audit logs. (GitHub) That mindset is essential for offensive automation. A model that helps find vulnerabilities is also a model that can be tricked, confused, or misused.
A practical orchestration layer does not trust the model to be safe. It makes unsafe behavior harder to express, easier to detect, and less damaging when it occurs.
State is the difference between a demo and a researcher
A demo can show a model finding one bug. A researcher can explain what was tested, what was ruled out, why the finding matters, and how to reproduce it. State is what separates the two.
A good state system for AI vulnerability discovery should capture at least five categories of information.
The first is target state. This includes repository commit, build flags, dependency versions, reachable services, route maps, API schemas, authentication roles, test accounts, operating system, container images, and environment variables. Without target state, a finding cannot be reproduced.
The second is investigation state. This includes hypotheses, confidence scores, related files, source-sink paths, candidate payloads, coverage notes, tool results, and failed branches. Without investigation state, the model cannot reason over time.
The third is execution state. This includes commands run, tool versions, exit codes, stdout, stderr, generated files, crash IDs, sanitizer traces, HTTP transcripts, and timing. Without execution state, evidence becomes storytelling.
The fourth is decision state. This includes why one path was chosen over another, why a finding was discarded, why a tool was allowed, why a risky action required approval, and who approved it. Without decision state, auditability disappears.
The fifth is reporting state. This includes the final proof, minimal reproduction steps, impact boundaries, affected versions, mitigation, retest steps, and unresolved uncertainty. Without reporting state, the work cannot move into engineering action.
A simple local workflow can start with a file-based journal. It does not need to be elegant at first. It needs to be consistent.
from __future__ import annotations
import json
import subprocess
import time
from dataclasses import dataclass, asdict
from pathlib import Path
from typing import Literal
ROOT = Path("ai-vuln-workflow")
JOURNAL = ROOT / "journal.jsonl"
EVIDENCE = ROOT / "evidence"
EVIDENCE.mkdir(parents=True, exist_ok=True)
Decision = Literal["allow", "deny", "needs_human_approval"]
@dataclass
class Event:
ts: float
kind: str
summary: str
data: dict
def write_event(kind: str, summary: str, data: dict | None = None) -> None:
event = Event(
ts=time.time(),
kind=kind,
summary=summary,
data=data or {},
)
with JOURNAL.open("a", encoding="utf-8") as f:
f.write(json.dumps(asdict(event), sort_keys=True) + "\n")
def policy_check(command: list[str]) -> Decision:
joined = " ".join(command)
blocked = ["rm -rf", "curl http://169.254.169.254", "nc -e"]
if any(pattern in joined for pattern in blocked):
return "deny"
external_network_tools = {"curl", "wget", "nmap", "ffuf"}
if command and command[0] in external_network_tools:
return "needs_human_approval"
return "allow"
def run_command(command: list[str], evidence_name: str) -> None:
decision = policy_check(command)
write_event(
kind="policy_decision",
summary=f"Policy decision for command: {decision}",
data={"command": command, "decision": decision},
)
if decision != "allow":
return
result = subprocess.run(
command,
capture_output=True,
text=True,
timeout=60,
check=False,
)
out_file = EVIDENCE / f"{evidence_name}.json"
out_file.write_text(
json.dumps(
{
"command": command,
"returncode": result.returncode,
"stdout": result.stdout,
"stderr": result.stderr,
},
indent=2,
),
encoding="utf-8",
)
write_event(
kind="tool_result",
summary=f"Command completed with exit code {result.returncode}",
data={"evidence": str(out_file)},
)
write_event(
kind="hypothesis",
summary="Candidate parser issue needs local unit-level validation",
data={
"confidence": "medium",
"required_evidence": [
"minimal crashing input",
"sanitizer output",
"affected commit",
],
},
)
run_command(["python", "-m", "pytest", "tests/test_parser_boundaries.py"], "parser_boundary_pytest")
This skeleton is intentionally modest. It does not exploit anything. It shows the shape of a safe workflow: every hypothesis and tool result becomes an artifact, policy is checked before execution, and evidence is written to a stable location. A production system would need stronger sandboxing, deterministic builds, secrets handling, identity controls, network policy, and structured approval.
The important point is that the model should not be the database. The model should be a reasoning component that reads and writes state through controlled interfaces.
Evidence beats plausible findings
Security teams do not need more plausible bug reports. They need evidence.
A model can produce a convincing explanation of why a function might overflow. It can be wrong. A scanner can flag a dependency. It may not be reachable. A code search can find a dangerous sink. It may only be reachable from a trusted admin path. A web test can show different responses between users. The difference may be personalization rather than broken authorization.
Evidence is what removes ambiguity.
For memory safety work, evidence might be a crashing input, sanitizer trace, minimized reproducer, debugger backtrace, register state, coverage trace, and affected commit. For a web authorization issue, evidence might be two test accounts, object creation steps, replayed requests, response diffs, expected policy, observed violation, and proof that the lower-privileged account accessed data it should not. For a dependency CVE, evidence might be the exact vulnerable package version, reachable code path, runtime class loading proof, container image digest, and safe validation that the vulnerable behavior exists in that environment.
Provos summarized the verification discipline in his OpenBSD replication work as “hypothesize statically, validate by execution.” In his workflow, a proof of concept meant an executable harness that triggers the vulnerability to prove reachability and surface memory corruption, not merely a static suspicion. (Niels Provos)
That discipline should be non-negotiable. AI-generated findings must be treated as candidates until they pass evidence gates.
A practical evidence standard can look like this:
| Finding type | Weak evidence | Strong evidence |
|---|---|---|
| Memory corruption | Model says an index can go out of bounds | Sanitizer trace, minimized input, crashing commit, root cause path |
| BOLA or IDOR | One account can request a URL with another ID | Two-account replay, object ownership proof, response diff, policy violation |
| SSRF | Endpoint accepts a URL parameter | Controlled callback proof, network egress logs, allowlist bypass analysis |
| Known CVE | Package scanner reports a vulnerable version | Version plus reachability plus safe behavior validation |
| Supply chain risk | Package has suspicious metadata | Reproducible build mismatch, malicious build step, maintainer or provenance anomaly |
| Logic flaw | Model says behavior is inconsistent | Specification, expected state transition, actual state transition, replayable proof |
The strongest AI vulnerability discovery systems will not be the ones that generate the most findings. They will be the ones that discard the most weak findings before they waste human time.
What the OpenBSD SACK example really proves
The OpenBSD SACK example is worth studying because it is not a shallow pattern match.
SACK, defined by RFC 2018, lets a TCP receiver acknowledge selected byte ranges rather than only acknowledging a continuous prefix of received data. Anthropic’s writeup explains that OpenBSD added SACK in 1998, and that Mythos Preview identified a vulnerability in the OpenBSD implementation that could crash any OpenBSD host responding over TCP. The issue involved how the kernel tracked SACK “holes,” an unchecked start range, a case where a single SACK block could delete the only hole and trigger an append path, and signed integer overflow that made an impossible condition appear true. (Red Anthropic)
This is exactly the kind of bug that makes AI vulnerability discovery interesting. It is not just “grep for strcpy.” The model had to reason about a protocol feature, a linked-list state machine, integer wraparound, assumptions about valid sequence numbers, and the effect of a maliciously crafted input. It also had to connect those facts to an operational impact: remote denial of service.
The case also shows why exploitation and validation matter. Anthropic reported that the OpenBSD SACK finding was the most critical OpenBSD vulnerability discovered by Mythos Preview after a thousand scaffold runs, with the successful run costing under 50 dollars but the total thousand-run scaffold costing under 20,000 dollars. (Red Anthropic) The hindsight cost of one successful run is not the same as the expected cost of search. That distinction is important for teams trying to budget AI discovery work. Discovery is probabilistic. A system may need many runs, many seeds, and many dead ends.
Provos’s replication adds another lesson. In his first test, the workflow identified the bug but stopped short of executing it because the prompting and journal-keeping were not yet sufficient and the secure container could not boot an OpenBSD VM. He then concluded that early hypothesis exploration could use lightweight harnesses such as single-function fuzzing, while final proof required the VM path. (Niels Provos)
That is a practical architecture pattern. Do not start with the heaviest environment. Start with cheap validation that kills bad hypotheses early. Escalate to expensive, realistic validation only when the candidate survives.
A mature workflow might validate a low-level bug in layers:
| Capa | Propósito | Example artifact |
|---|---|---|
| Static path review | Determine whether untrusted input can reach risky code | Source-sink trace |
| Unit harness | Exercise a function or parser in isolation | Local test binary and input corpus |
| Instrumented run | Observe memory safety behavior | ASan, UBSan, crash logs |
| System harness | Confirm behavior in a realistic environment | VM crash, service log, packet trace |
| Impact report | Explain operational consequence | Reproduction steps and remediation guidance |
That tiered structure keeps costs under control and prevents the system from treating every suspicion as a full exploit development project.
AI does not erase fuzzing, static analysis, or human judgment
AI vulnerability discovery works best when it connects older security techniques instead of pretending to replace them.
Fuzzing is still valuable because it gives empirical feedback. Static analysis is still valuable because it covers large code surfaces cheaply. SBOM and dependency analysis are still valuable because known vulnerable components remain a major source of exposure. Manual review is still valuable because business logic, impact, and disclosure judgment are not purely mechanical. The model’s role is to help move between these techniques.
A strong AI workflow can ask:
A static analyzer flagged 200 integer conversion warnings. Which ones are near untrusted input?
A fuzzer found 40 crashes. Which crashes are unique? Which are likely security-relevant? Which have stable reproducers?
A dependency scanner found 18 CVEs. Which packages are reachable? Which are in production images? Which are blocked by configuration?
An API map shows 300 routes. Which routes handle object IDs? Which require multiple roles to test? Which mutate state?
A patch changed a boundary check. Can a test be generated to confirm the previous behavior and prevent regression?
The model can help prioritize. The tools provide grounding. The orchestrator keeps state. The human sets risk tolerance and approves sensitive steps. That combination is more powerful than any component alone.
The same logic applies to exploit generation. Anthropic argued that exploit generation has defensive value because it helps triage whether a vulnerability is actually important. In the FreeBSD section of the Mythos report, Anthropic wrote that attempting exploitation revealed that defenses initially thought to make a stack buffer overflow unexploitable did not prevent the attack in that case. (Red Anthropic) That is a serious point. Exploitability analysis can prevent defenders from dismissing a real issue as theoretical.
But exploit generation also creates obvious dual-use risk. Responsible systems need safe targets, disclosure controls, and strict authorization. For most enterprise defenders, the goal should be safe proof of impact, not weaponized exploit development. A crash proof, access-control replay, controlled callback, or sanitizer trace is often enough to prioritize remediation without building a deployable exploit chain.
CVE reproduction shows where the economics are heading
The economics of vulnerability validation are changing faster than many teams are prepared for.
CVE-GENIE, a 2025 research system, describes an LLM-based multi-agent framework that takes CVE entries as input, gathers relevant resources, reconstructs vulnerable environments, and reproduces verifiable exploits. Its authors report reproducing about 51 percent of 841 CVEs from 2024 and 2025, or 428 CVEs, with verifiable exploits at an average cost of 2.77 dollars per CVE. (arXiv)
That result should not be exaggerated. A research benchmark is not the same as full enterprise exploitability. CVE reproduction in a controlled environment does not prove that a specific company is exposed. Some CVEs are easier to reproduce than others. Some require unusual configurations, credentials, race timing, or environmental conditions. Some exploit paths are too dangerous to validate directly in production.
Still, the direction is important. The cost of moving from advisory text to working validation is falling. That changes the defender’s timeline.
When a CVE drops, attackers do not need to understand the whole product. They need one working path. Patches, advisories, test cases, commit diffs, Docker images, and public discussions all become raw material. AI agents can help collect that material, infer vulnerable conditions, attempt reproduction, and package the result. That does not mean every attacker becomes elite. It means the middle of the skill distribution moves upward.
For defenders, the answer is not panic. It is evidence automation. The right internal question after a critical CVE is not “is this scary?” It is:
Are we running the affected product or library?
Which versions and builds are present?
Is the vulnerable code path reachable in our environment?
What privileges or preconditions are required?
Can we safely validate exposure?
What temporary mitigations reduce risk before patching?
How do we prove the fix worked?
That is an orchestration problem.
Three CVEs that explain the workflow problem

Real vulnerabilities show why AI security systems need more than model reasoning. Different classes of vulnerability require different kinds of orchestration.
| CVE | Why it matters for AI vulnerability discovery | What the workflow must do |
|---|---|---|
| CVE-2021-44228, Log4Shell | A widely embedded library flaw where exposure depends on dependency presence, configuration, reachability, and attacker-controlled logging paths | Find vulnerable versions, map runtime usage, test safe callbacks, prioritize exposed systems, verify patching |
| CVE-2023-34362, MOVEit Transfer | A zero-day SQL injection in a managed file transfer application exploited in real-world ransomware activity | Identify exposed products, validate affected versions, review access logs, confirm patch status, model data exposure risk |
| CVE-2024-3094, XZ Utils | A supply chain compromise where malicious code was introduced through upstream tarballs and build process manipulation | Compare source provenance, inspect build artifacts, verify versions, audit package sources, monitor authentication-sensitive paths |
Log4Shell remains the cleanest example of why CVE matching is not enough. NVD describes CVE-2021-44228 as an Apache Log4j2 issue where JNDI features in configuration, log messages, or parameters did not protect against attacker-controlled LDAP and related endpoints, allowing arbitrary code execution when message lookup substitution was enabled. (nvd.nist.gov) CISA added the vulnerability to its Known Exploited Vulnerabilities catalog and required federal remediation for affected assets where updates existed. (nvd.nist.gov)
A naive AI tool can summarize that advisory. A useful AI vulnerability discovery workflow has to answer whether a given environment actually logs attacker-controlled input through a vulnerable Log4j path. That requires dependency inspection, build artifact analysis, runtime configuration review, safe callback infrastructure, container or host inventory, and retesting.
MOVEit Transfer shows a different shape. NVD describes CVE-2023-34362 as a SQL injection vulnerability in the MOVEit Transfer web application that could allow an unauthenticated attacker to access the database. (nvd.nist.gov) CISA and FBI reported that the CL0P ransomware group exploited the zero-day vulnerability affecting MOVEit Transfer. (CISA) Here the workflow problem is not just code analysis. It is exposure management, patch verification, log review, data impact, and incident response. A model can help explain SQL injection. The orchestrator must connect product inventory, internet exposure, version state, and evidence.
XZ Utils is more subtle. NVD describes CVE-2024-3094 as malicious code discovered in upstream xz tarballs starting with version 5.6.0, involving extra build files and complex obfuscation that extracted a prebuilt object file and modified functions during the liblzma build process. (nvd.nist.gov) CISA described the issue as a reported supply chain compromise affecting the XZ Utils data compression library, which may be present in Linux distributions. (CISA) This is the kind of high-value problem that does not look like a normal vulnerable endpoint. It requires provenance checks, build reproducibility, package analysis, maintainer behavior, and OS distribution context.
These CVEs point to the same conclusion. The model’s text reasoning is useful, but the value comes from connecting reasoning to environment-specific evidence.
Web and API bugs reward orchestration more than payload lists
Many high-value application vulnerabilities are not found by spraying payloads. They are found by understanding state.
Broken Object Level Authorization is the obvious example. OWASP API Security Top 10 2023 ranks Broken Object Level Authorization as API1 and explains that attackers exploit vulnerable endpoints by manipulating object IDs in paths, query strings, headers, or payloads. OWASP also notes that every API endpoint receiving an object ID and acting on that object should check whether the logged-in user has permission to perform the requested action. (owasp.org)
A scanner can detect some ID patterns. It cannot automatically know all business rules. It may not know which account owns which object, whether two users are in the same tenant, whether a manager role should see subordinate records, whether a support role has delegated access, or whether a response difference is sensitive.
An orchestrated AI workflow can be useful because it can maintain a role model. It can create or use multiple test accounts, record object ownership, replay requests across identities, compare responses, and ask whether the observed behavior violates the intended policy.
A safe BOLA validation pattern can look like this:
#!/usr/bin/env bash
set -euo pipefail
BASE_URL="https://staging.example.com"
OBJECT_ID="project_12345"
USER_A_TOKEN="$(cat tokens/user_a.txt)"
USER_B_TOKEN="$(cat tokens/user_b.txt)"
mkdir -p evidence/bola
curl -sS \
-H "Authorization: Bearer ${USER_A_TOKEN}" \
"${BASE_URL}/api/projects/${OBJECT_ID}" \
| jq -S . > evidence/bola/user_a_owner_response.json
curl -sS \
-H "Authorization: Bearer ${USER_B_TOKEN}" \
"${BASE_URL}/api/projects/${OBJECT_ID}" \
| jq -S . > evidence/bola/user_b_cross_access_response.json
diff -u \
evidence/bola/user_a_owner_response.json \
evidence/bola/user_b_cross_access_response.json \
> evidence/bola/response_diff.patch || true
cat > evidence/bola/expected_policy.txt <<EOF
Expected policy:
- User A owns ${OBJECT_ID}
- User B belongs to a different tenant
- User B should receive 403 or a response with no sensitive object data
EOF
This script is not an exploit. It is a controlled validation pattern for an authorized staging environment. The value is not the curl syntax. The value is the evidence structure: two identities, one object, expected policy, observed behavior, response diff, and replayable artifacts.
SSRF has a similar problem. OWASP’s SSRF Prevention Cheat Sheet explains that SSRF abuses an application to interact with internal or external networks or the machine itself, often through mishandled URLs, webhooks, callbacks, or internal service requests. It also distinguishes cases where allowlisting trusted destinations is possible from cases where an application must send requests to arbitrary external destinations. (cheatsheetseries.owasp.org)
An AI system testing SSRF needs more than payload memory. It needs to understand where remote fetch functionality exists, what destinations should be allowed, whether DNS rebinding matters, whether cloud metadata addresses are blocked, whether redirects are followed, whether internal egress logs show a request, and whether a test can be performed safely.
Again, this is orchestration.
Logic bugs are where ordinary models can become surprisingly useful
Memory corruption gets attention because it has a long tradition of technical prestige. But many real-world application failures are logic failures. Authentication bypass. Broken tenant isolation. Misordered state transitions. Missing approval checks. Business workflows that assume a previous step happened but never enforce it.
Logic bugs are a good fit for model reasoning because they require comparing intended behavior with implemented behavior. Anthropic’s Mythos report makes a similar point: it says logic bugs are historically harder to search for automatically because tools like fuzzers cannot easily identify an action that “should be prohibited,” and that Mythos Preview was able to distinguish intended behavior from actual behavior, such as understanding that a login function should only permit authorized users. (Red Anthropic)
This is where ordinary models can matter. A model does not need to be the strongest in the world to notice that a workflow says “only project admins can approve invoices,” while the API endpoint only checks that the user is authenticated. It needs enough context: route, role, object, policy, and state transition. The orchestrator must supply that context and then test the hypothesis.
The hard part is not naming the bug. It is creating the right situation.
For a workflow bug, the system may need to:
Create a project as User A.
Invite User B with a viewer role.
Generate an invoice as User A.
Attempt approval as User B.
Record whether the API accepts the transition.
Check downstream side effects.
Repeat after patch.
Preserve every request and response.
The model can plan and interpret. The workflow must execute and remember.
This is also why bug bounty economics are likely to polarize. Low-complexity bugs that follow common patterns will become easier to find and cheaper to validate. High-complexity bugs that require domain modeling, multi-account state, chained primitives, and clean impact proof will become more valuable because they are harder to automate and more directly tied to business risk.
The bug bounty market will not get uniformly cheaper
AI will not make all vulnerability research cheap. It will make common vulnerability discovery cheaper and exceptional vulnerability research more expensive.
That is a market pressure, not a guaranteed law. Bug bounty pricing depends on program maturity, asset value, duplicate rates, disclosure rules, exploitability, business impact, and researcher reputation. But the direction is reasonable.
When many researchers can use AI-assisted workflows to find low-hanging issues, the supply of those reports increases. Duplicates rise. Programs become stricter. Triage teams demand better proof. Simple reflected XSS, basic exposed panels, known vulnerable components, shallow misconfigurations, and repeated low-impact IDORs become less scarce.
At the same time, truly valuable findings become more valuable. A clean cross-tenant authorization break in a major SaaS product is still hard. A browser exploit chain remains hard. A supply chain compromise remains hard. A vulnerability that crosses identity, billing, workflow, and data boundaries remains hard. A finding that includes minimal reproduction, safe proof, clear impact, patch guidance, and regression tests saves the defender real engineering time.
| Capa | Likely AI effect | Market consequence |
|---|---|---|
| Known CVE matching | Easier to automate | Lower value unless environment-specific reachability is proven |
| Basic recon and enumeration | Much faster | Less differentiation among researchers |
| Common web bugs | More reports and more duplicates | Higher proof standards |
| Stateful authorization bugs | Better AI assistance, still needs careful setup | Strong value when evidence is clean |
| Supply chain and build-system issues | Better anomaly detection, still expert-heavy | High value when provenance and impact are proven |
| Exploit chain construction | More AI help, still constrained by defenses and context | Premium value for safe, responsible proof |
| Remediation-ready reporting | Easier drafting, but hard evidence still matters | More valuable as triage burden grows |
The middle gets compressed. The top gets sharper.
The same pattern applies inside companies. AI will reduce the cost of first-pass review, dependency triage, and repetitive validation. It will not eliminate the need for senior engineers who understand exploitability, architecture, identity systems, disclosure risk, and production constraints. In fact, those people may become more important because they will supervise larger volumes of machine-generated security evidence.
A reference workflow for AI vulnerability discovery
A practical AI vulnerability discovery workflow should be boring in the best way. It should look like security engineering, not magic.
The input should include authorization scope. For source-code work, that means repository, commit, allowed branches, build instructions, test commands, and forbidden actions. For black-box work, that means domains, IP ranges, rate limits, accounts, test windows, destructive-action rules, and data-handling requirements. For dependency work, that means SBOMs, lockfiles, container images, runtime inventory, and deployment context.
The workflow should then build a target model. For code, it can index files, map entry points, parse dependency manifests, extract routes, identify parsers, and find dangerous sinks. For web and API testing, it can crawl authorized surfaces, import OpenAPI specs, map roles, record session behavior, and identify object IDs. For infrastructure, it can map exposed services, versions, cloud resources, and identity edges.
The model should generate hypotheses only after target modeling. That prevents the common failure where an AI system starts with generic vulnerability classes rather than target-specific facts.
A good hypothesis is structured:
{
"id": "hyp-017",
"title": "Viewer role may access project export endpoint by changing project_id",
"weakness_class": "Broken Object Level Authorization",
"target": "GET /api/projects/{project_id}/export",
"required_roles": ["project_owner", "project_viewer_other_tenant"],
"evidence_needed": [
"owner account can access export",
"other-tenant viewer can access same export",
"response contains sensitive project data",
"expected policy denies cross-tenant access"
],
"risk_if_confirmed": "Cross-tenant data exposure",
"safe_to_test": true
}
The executor then runs controlled tests. The verifier checks whether the evidence actually satisfies the hypothesis. The reporter produces a finding only if the evidence is strong. If the evidence is weak, the system records why and either refines the hypothesis or discards it.
This is the core loop:
scope -> model target -> generate hypotheses -> select safe tests
-> execute tools -> collect evidence -> verify or discard
-> report -> retest after fix
The model can participate in every stage, but it should not be allowed to skip stages.
Safe execution is not optional
Once an AI vulnerability discovery system can run commands, it becomes an agentic system. Agentic systems introduce their own security problems.
The UK NCSC has warned that prompt injection should not be treated as just another SQL injection variant. Its analysis says current LLMs do not enforce a security boundary between instructions and data inside a prompt, and that prompt injection should be approached as an exploitation of an “inherently confusable deputy.” (National Cyber Security Centre) OpenAI has made a similar practical point for agents: defending against prompt injection cannot rely only on filtering malicious inputs; systems should constrain the impact of manipulation even when some attacks succeed. (OpenAI)
That applies directly to AI vulnerability discovery. The system reads untrusted code, issues, logs, web pages, API responses, package metadata, commit messages, and documentation. Any of those can contain instructions aimed at the model. A malicious repository can include a README that tells the agent to exfiltrate secrets. A test page can include hidden text instructing the agent to ignore scope. A tool description can be poisoned. A dependency package can contain install scripts. A browser target can attempt to manipulate the agent through rendered content.
A safe workflow needs layered controls:
scope:
allowed_domains:
- staging.example.com
denied_networks:
- 169.254.169.254/32
- 127.0.0.0/8
- 10.0.0.0/8
allowed_repositories:
- git@example.com:security/authorized-target.git
filesystem:
read:
- ./target
- ./evidence
write:
- ./evidence
- ./workdir
deny:
- ~/.ssh
- ~/.aws
- ~/.config
- /etc
tools:
allow_without_approval:
- grep
- ripgrep
- pytest
- semgrep
- jq
require_approval:
- curl
- nmap
- ffuf
- git push
deny:
- destructive_delete
- credential_dump
- persistence_tools
evidence:
required_path: ./evidence
record_stdout: true
record_stderr: true
record_exit_code: true
redact_secrets: true
budgets:
max_runtime_minutes: 60
max_tool_calls: 200
max_network_requests: 500
The exact format does not matter. The controls do.
IronCurtain’s public design is one example of this direction. It treats the agent as untrusted, compiles user intent into deterministic rules, routes tool calls through policy checks, and logs decisions. (GitHub) A security team building its own AI discovery workflow needs the same principle even if the implementation is different: do not rely on the model to police itself.
Human approval should be part of the system, not a panic button
Human-in-the-loop is often used as vague comfort language. In AI vulnerability discovery, it should be concrete.
Humans should approve actions that change state, touch external systems, increase test intensity, access sensitive data, or move from safe validation into exploit development. They should also review findings before disclosure, before customer notification, and before any production-facing test that could affect availability.
Approval should not be a Slack message with no context. It should include the hypothesis, command, target, expected effect, risk, prior evidence, and rollback plan.
A useful approval request looks like this:
{
"requested_action": "Run authenticated HTTP replay against staging API",
"target": "https://staging.example.com/api/projects/project_12345/export",
"reason": "Validate BOLA hypothesis hyp-017 with two approved test accounts",
"expected_effect": "Read-only GET requests, no mutation expected",
"risk": "Low",
"rate_limit": "2 requests total",
"evidence_output": "evidence/hyp-017/",
"requires_sensitive_data_access": false
}
A weak approval request says:
Can I test the endpoint?
The first request lets a human make a decision. The second only creates the appearance of control.
Human approval also improves learning. When a reviewer denies a tool call, the reason should go into the journal. The model should see that future similar actions need a safer plan. This is how a workflow becomes less reckless over time without giving the model unlimited autonomy.
AI changes patch windows and validation expectations
Public vulnerability timelines are already compressed. The more AI improves at CVE reproduction and exploit adaptation, the less time defenders have between disclosure and reliable attacker tooling.
Anthropic’s Mythos report explicitly discusses N-day vulnerabilities as a dangerous case because the vulnerability is publicly disclosed and patched, the patch can act as a roadmap, and the main barrier is the time required to turn the patch into a working exploit. (Red Anthropic) That is exactly where automation matters. AI does not need to discover a new zero-day to change risk. It can accelerate the conversion of known bugs into working tests.
This means vulnerability management has to move from list-based prioritization to evidence-based prioritization.
A CVSS score is useful. KEV status is useful. EPSS-style likelihood is useful. Asset criticality is useful. But none of those alone answers the operational question: can this be exploited here, through our exposed surface, with our configuration, and with meaningful impact?
AI orchestration can help answer that question faster. It can ingest advisories, map assets, inspect versions, generate safe validation plans, run checks in staging, and produce remediation evidence. It can also help retest after patching, which is often where vulnerability management quietly fails.
The output should not be “CVE found.” It should be:
Affected system.
Affected version or configuration.
Reachability.
Required privileges.
Safe validation result.
Potential impact.
Mitigation or patch.
Retest evidence.
Residual uncertainty.
That is the difference between vulnerability intelligence and vulnerability operations.
Where authorized AI pentesting products fit into the workflow
Some teams will build internal AI vulnerability discovery systems. Others will use commercial platforms. The evaluation criteria should be the same either way: scope control, state management, tool orchestration, safe execution, evidence capture, reproducibility, and operator review.
Penligent is relevant in this context because its public product language focuses on agentic workflows, controllable actions, scoped prompts, and evidence-first results rather than simply presenting AI as a chat layer. Its homepage describes agentic workflows that users can control, including prompt editing and scope locking, and emphasizes reproducible evidence for findings. (Penligente) Its own writing on AI pentest tools also draws a useful line between scanner-plus-chatbot behavior and systems that can maintain context, handle stateful applications, prove impact, and leave behind reproducible evidence. (Penligente)
That is the right comparison frame for any product in this category. The question is not whether it uses AI. The question is whether it turns AI into controlled security work. A tool that summarizes scanner output may save time. A tool that can test an authorized target, preserve evidence, and support replayable validation changes the workflow.
For buyers and security leads, the practical test is simple: seed a staging environment with one known dependency CVE, one object-level authorization issue, one SSRF-like remote fetch sink, and one false positive. Then ask the system to work under a written scope. The evaluation should measure whether it finds the right surface, avoids forbidden actions, proves real issues, discards weak ones, and produces evidence another engineer can replay.
Ordinary models can find bugs, but not all bugs become equal
The claim that ordinary models can contribute to vulnerability discovery should not be confused with the claim that all models are equal or that expert skill no longer matters.
Model quality still matters. Stronger models generally reason better across long code paths, subtle constraints, unfamiliar APIs, and exploitability barriers. They may recover from tool failures more gracefully. They may write better harnesses. They may avoid more false positives. Provos’s GLM 5.1 example is interesting precisely because it suggests that open-weight or non-frontier models can become useful when embedded in a strong workflow, not because the choice of model becomes irrelevant. (Niels Provos)
The better statement is this: once models cross a threshold of useful reasoning, orchestration becomes the multiplier. A mid-tier model in a strong workflow may outperform a stronger model used as a one-shot assistant. A frontier model in a weak workflow may produce impressive but hard-to-trust output. The best results come from capable models inside disciplined systems.
This has a direct implication for teams choosing tools or designing internal platforms. Do not evaluate only benchmark headlines. Evaluate the operating model.
Can the system build and run a local harness?
Can it preserve state across days?
Can it identify when it lacks evidence?
Can it stop before destructive testing?
Can it handle multiple identities?
Can it reason over source code and runtime behavior?
Can it produce a minimal reproduction?
Can it retest after a patch?
Can it show every tool call?
Can a human override it?
A “yes” to those questions matters more than a leaderboard screenshot.
The high end of vulnerability research becomes more valuable
As AI makes basic discovery cheaper, high-end vulnerability research becomes more differentiated.
The high end has several traits.
It crosses boundaries. The bug may involve a browser renderer, sandbox escape, kernel privilege escalation, and persistence boundary. Anthropic reported that Mythos Preview could chain vulnerabilities in contexts such as Linux local privilege escalation and browser JIT heap sprays, while withholding details for unpatched issues. (Red Anthropic) Whether every claim survives later public analysis is less important than the direction: chaining is the premium skill.
It understands business logic. A serious SaaS authorization flaw is rarely obvious from one endpoint. It may require account hierarchy, tenant rules, billing state, object lifecycle, role inheritance, and workflow timing.
It handles ambiguity. High-end researchers know when a crash is not exploitable, when a theoretical issue is not reachable, when a patch is incomplete, and when a bug is actually a duplicate of a known issue.
It produces clean proof. The best findings are not the loudest. They are the easiest to verify.
It respects disclosure. High-impact vulnerability research requires coordination, restraint, and clear communication. AI does not remove that obligation.
AI will help with all of this, but it will not flatten it. Instead, it will raise the baseline. Researchers who only relied on rote payloads will face more competition. Researchers who understand systems, evidence, and impact will have better tools.
The low end becomes a volume problem
Low-complexity vulnerability discovery will increasingly look like volume management.
Known vulnerable components, exposed admin panels, default credentials in lab-like environments, shallow reflected XSS, basic open redirects, simple misconfigurations, and obvious missing authorization checks are all easier to search for with AI-assisted tooling. That does not make them irrelevant. Some low-complexity issues still cause real incidents. It does mean the bottleneck shifts from finding them to filtering, validating, deduplicating, and fixing them.
Security teams will need better intake standards. A report should include enough evidence to reproduce the issue. Automated reports should label confidence and limitations. Findings without reachability should be treated differently from findings with safe proof. Duplicate detection should improve. Patch verification should be automated where possible.
Bug bounty programs may become stricter about evidence. Internal teams may require proof templates. Automated scanners may be expected to attach replay artifacts. AI-generated reports that lack proof will be ignored faster.
This is healthy. It pushes the market toward verified risk instead of vulnerability-shaped text.
Building an internal AI vulnerability discovery program
A company starting today should not begin by asking an agent to “find zero-days in our code.” That is too broad. Start with bounded workflows.
Good first workflows include:
Dependency reachability validation for a narrow technology stack.
Authorization regression tests for high-risk API objects.
SSRF sink inventory and safe egress validation.
Parser fuzzing for one internal file format.
Patch diff review for critical third-party CVEs.
Reproduction of past internal vulnerabilities as regression tests.
Each workflow should have a small scope, clear evidence requirements, and a human owner. The goal is not maximum autonomy on day one. The goal is reliable loops.
A useful maturity path looks like this:
| Escenario | Objetivo | Ejemplo |
|---|---|---|
| Assisted review | Use models to speed up expert analysis | Summarize code paths, draft tests, explain tool output |
| Structured validation | Use workflows to verify known classes | BOLA replay, dependency reachability, SSRF egress check |
| Multi-agent orchestration | Split tasks across specialist agents | Mapper, hypothesis generator, harness builder, verifier |
| Continuous retesting | Turn findings into regression checks | Run replay tests after every release |
| Research automation | Search for new weaknesses in bounded targets | Parser fuzzing plus model-guided triage |
| Evidence operations | Integrate findings into engineering systems | Tickets, PRs, retest logs, audit trail |
The most important artifact is not the model prompt. It is the evidence format.
Every confirmed finding should answer:
What is affected?
What was expected?
What happened instead?
What exact steps reproduce it?
What data proves it?
What is the impact?
What are the limits of the proof?
What should be changed?
How was the fix retested?
If an AI system cannot produce that, it is not ready to own discovery.
Avoiding the most common design mistakes
Teams building AI vulnerability discovery systems tend to repeat the same mistakes.
The first mistake is giving the agent too much authority too early. Broad filesystem access, unrestricted network access, real credentials, and write permissions turn a research assistant into an internal threat. Start with read-only access and escalate deliberately.
The second mistake is treating model output as evidence. A model’s explanation is not proof. It can describe proof, help collect proof, and package proof, but the proof must come from observed behavior, code, artifacts, or reproducible tests.
The third mistake is ignoring false positives. If a system produces too many weak findings, engineers will stop reading. The workflow should have an aggressive discard path.
The fourth mistake is skipping negative memory. A good journal records what failed. Otherwise the model keeps retrying dead ends with different wording.
The fifth mistake is mixing trusted and untrusted context. Source code, README files, issue comments, API responses, websites, and tool descriptions may contain adversarial instructions. Treat them as data. Do not let them silently change tool policy.
The sixth mistake is overfitting to demos. A system that works on a vulnerable lab may fail on SSO, rate limits, tenant models, flaky services, long build times, or incomplete documentation. Evaluate on messy targets.
The seventh mistake is ignoring cost. Provos reported that a single run against a moderately sized codebase consumed roughly 10 million tokens on Opus or Sonnet, with estimated costs of 150 dollars or 30 dollars per investigation respectively, while GLM 5.1 runs averaged more tokens but comparable cost to Sonnet under the cited pricing. (Niels Provos) Even if prices change, the lesson remains: autonomous research burns tokens quickly. Budgets and stop conditions matter.
Verification patterns that work
Different vulnerability classes need different verification patterns. A workflow should know which pattern fits the hypothesis.
For memory safety, use compiler sanitizers where possible. Build with ASan, UBSan, or relevant platform tooling. Minimize crashing inputs. Preserve exact build flags. Record commit hashes. Avoid claiming exploitability from a crash alone.
For authorization, use multiple identities. Record ownership. Compare expected and observed access. Avoid testing with accounts that share admin groups, tenants, or inherited permissions unless the test is explicitly about those relationships.
For SSRF, use controlled callback endpoints and egress logs. Do not target cloud metadata endpoints or internal systems unless explicitly authorized and safely simulated. Prefer staging environments with known mock services.
For dependency CVEs, combine version detection with reachability. A vulnerable package in a dead code path may still need patching, but it is not the same as an exposed vulnerable service.
For supply chain anomalies, compare source repository, release tarball, build scripts, dependency changes, maintainer changes, signatures, and reproducible build outputs. XZ Utils showed why repository content alone may not tell the whole story. (nvd.nist.gov)
For logic bugs, define the expected policy first. A model should not decide after the fact that a behavior is bad. It should compare observed behavior against a stated rule, specification, role matrix, or product requirement.
Reporting needs to become more machine-readable
AI vulnerability discovery will generate more candidate findings. Human triage will not scale unless reports become more structured.
A good report can still be readable, but its core should be machine-readable:
{
"finding_id": "FIND-2026-041",
"title": "Cross-tenant project export via object ID substitution",
"status": "confirmed",
"confidence": "high",
"affected_asset": "staging.example.com",
"weakness": "Broken Object Level Authorization",
"expected_policy": "Users cannot export projects outside their tenant",
"observed_behavior": "User B exported User A's project by changing project_id",
"evidence": [
"evidence/bola/user_a_owner_response.json",
"evidence/bola/user_b_cross_access_response.json",
"evidence/bola/response_diff.patch"
],
"impact": "Unauthorized access to project export data across tenant boundary",
"preconditions": [
"Valid low-privilege account",
"Knowledge of project_id"
],
"fix_recommendation": [
"Enforce object-level authorization on export endpoint",
"Add regression test for cross-tenant access",
"Log denied access attempts"
],
"retest": {
"command": "./tests/replay_hyp_017.sh",
"expected_result": "403 for cross-tenant user"
}
}
This format helps humans and machines. It supports deduplication, ticket creation, regression testing, and audit. It also forces the AI system to separate evidence from explanation.
The prose report can then explain the story clearly. The structured report preserves the facts.
Defenders need their own orchestration advantage
Offensive automation will not wait for defenders to feel ready. Attackers can use open models, local tooling, patched-diff analysis, leaked exploit fragments, and agentic workflows without the same compliance constraints that vendors place on public systems. That does not mean every attacker becomes sophisticated. It means defenders should assume that repetitive vulnerability research tasks will continue to get cheaper.
The defensive answer is not to ban AI security tooling. It is to build safer, more accountable AI security tooling.
That means using models inside controlled environments. It means requiring evidence. It means treating agents as untrusted. It means using human approval for risky steps. It means logging actions. It means retesting fixes. It means connecting vulnerability intelligence to environment-specific validation. It means training security teams to supervise workflows rather than manually repeating every low-level step.
The organizations that benefit most will not be the ones that ask models the most questions. They will be the ones that turn answers into tested security artifacts.
The next edge is knowing how to use intelligence
The next stage of AI security is not about finding the single smartest model. It is about building the best system for using available intelligence.
Ordinary models already have enough capability to assist with real vulnerability discovery when the task is structured well. They can read code, form hypotheses, call tools through safe interfaces, interpret results, and help create evidence. Frontier models will push the ceiling higher, especially for complex exploit chains and unfamiliar systems. But the durable advantage belongs to orchestration: state, tools, evidence, policy, approval, and replay.
That shift will polarize security work. Common findings will become cheaper because AI will increase supply and reduce the labor needed to validate routine issues. Exceptional findings will become more valuable because they require deeper system understanding, cleaner proof, and responsible judgment. The middle will be squeezed. The top will be sharper.
AI vulnerability discovery is not magic. It is a workflow. The teams that understand that will move faster without losing control.
Lecturas complementarias y referencias
Niels Provos, Finding Zero-Days with Any Model. (Niels Provos)
Antrópico, Claude Mythos Preview. (Red Anthropic)
IronCurtain, official site and GitHub documentation. (ironcurtain.dev)
PentestGPT research paper. (arXiv)
CVE-GENIE, automated multi-agent CVE reproduction research. (arXiv)
NIST SP 800-115, Guía técnica de pruebas y evaluación de la seguridad de la información. (csrc.nist.gov)
Guía de pruebas de seguridad web de OWASP. (owasp.org)
OWASP API Security Top 10 2023, Broken Object Level Authorization. (owasp.org)
OWASP Server-Side Request Forgery Prevention Cheat Sheet. (cheatsheetseries.owasp.org)
NVD, CVE-2021-44228 Log4Shell. (nvd.nist.gov)
NVD, CVE-2023-34362 MOVEit Transfer. (nvd.nist.gov)
NVD and CISA, CVE-2024-3094 XZ Utils. (nvd.nist.gov)
UK NCSC, Prompt injection is not SQL injection. (National Cyber Security Centre)
OpenAI, Designing AI agents to resist prompt injection. (OpenAI)
Penligent, official homepage. (Penligente)
Penligente, AI Pentest Tool, cómo será el ataque automatizado real en 2026. (Penligente)
Penligente, NIST CVE Prioritization as AI Speeds Up Vulnerability Discovery. (Penligente)
Penligente, AI Vulnerability Research Is Collapsing the Patch Window. (Penligente)

