What Kali Actually Shipped, and Why Everyone’s Talking About It
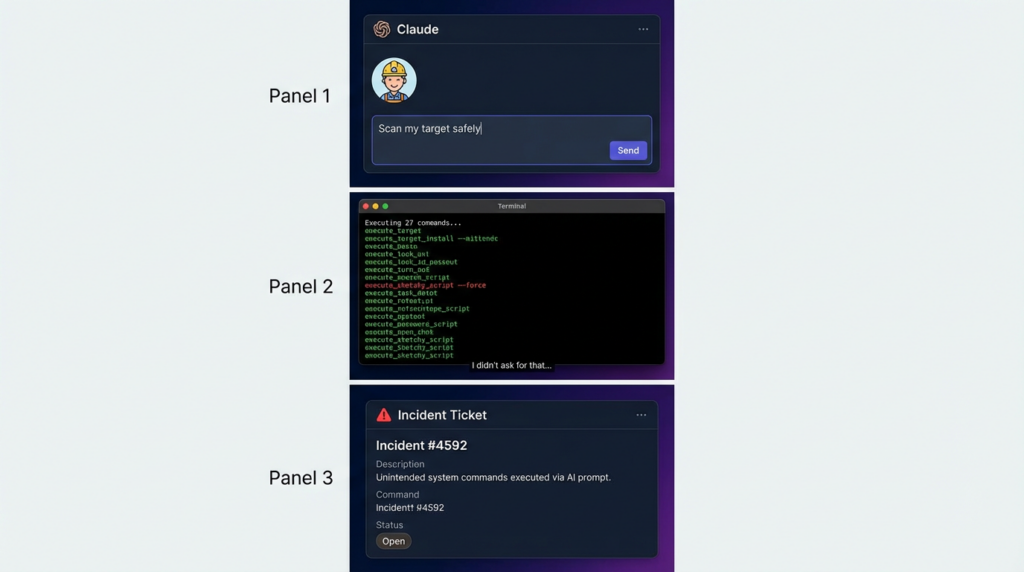
The headline is simple: Kali Linux can now be driven by Anthropic’s Claude in natural language, and those prompts can be translated into live terminal commands executed on a Kali host. The “glue” is the Model Context Protocol (MCP), and the Kali-side bridge is packaged as mcp-kali-server. In the workflow described publicly, Claude Desktop runs on a user’s workstation (macOS is explicitly documented), connects over SSH to a Kali box, and then uses MCP tool calls to run commands like nmap, gobustero rizo—looping until the original prompt is satisfied.(Noticias sobre ciberseguridad)
This is a genuine usability leap. The friction of “remembering exact flags,” maintaining long multi-step command sequences, and stitching outputs into a coherent narrative is real. A natural-language interface can compress that work—especially for repetitive reconnaissance and quick validation.
But the more important technical truth is what this integration really does:
It turns a general-purpose LLM into an execution orchestrator on a machine that holds offensive security tooling.
That’s not just convenience. That’s a new execution boundary. And if you don’t treat it like one, it will eventually bite you.
MCP in One Page: The Convenience Layer That Also Expands Your Attack Surface
Kali’s own documentation lays out the “three system” model: a UI client (Claude Desktop), an attacking box (Kali), and the cloud LLM (Claude Sonnet 4.5 in their write-up). The loop is straightforward: prompt → model interprets → requests an action through MCP → server executes → output returns → model decides what to do next.(Kali Linux)
Red Hat’s explanation of MCP is useful because it frames the risk in plain language: MCP servers can execute commands or perform API calls, and prompt injection becomes materially more dangerous once the model can take actions rather than only generate text.(Red Hat)
So the honest framing is:
- MCP solves the N×M integration problem: many models, many tools, one protocol.
- MCP also centralizes a trust problem: the model must decide which tool to use and cómo, often based on inputs you didn’t author (web pages, README files, scan output, issue descriptions, copied pastebins, etc.).
That’s exactly why MCP is exciting—and exactly why it needs to be treated like production infrastructure, not a fun weekend plugin.
The Three Failure Modes Security Teams Keep Relearning
1) Indirect Prompt Injection: Your Tools Become a Mouthpiece
The fastest way to misunderstand LLM + tooling is to assume the model is only following your intent. In reality, the model is absorbing and acting on everything in context: tool descriptions, command output, HTML it fetched, README files it read, banner strings, error messages, JSON returned by APIs.
Researchers have repeatedly warned that tool ecosystems can be “poisoned” through the metadata and outputs that models consume. CyberArk describes “Tool Poisoning Attack” dynamics—where the model can be manipulated via tool descriptions or tool-provided content, even without the user explicitly requesting the malicious action.(CyberArk)
Invariant Labs similarly warned about tool poisoning in MCP contexts and why it’s dangerous: users don’t see all tool instructions, models are trained to follow them, and malicious behavior can be disguised behind legitimate functions.(Invariant Labs)
The takeaway: in an MCP-based pentesting workflow, you must treat every external string as potentially adversarial, including the output of your own tools.
2) MCP Servers Reintroduce Classic Bugs—Now They’re “LLM-Triggerable”
This is the part that should permanently end the “it’s just a local tool” complacency.
In January 2026, The Hacker News detailed three vulnerabilities in Anthropic’s official Git MCP server (mcp-server-git) that could be exploited via prompt injection to read/delete arbitrary files and, under certain conditions, help achieve code execution when chained with other MCP servers. The CVEs are:
- CVE-2025-68143: path traversal / arbitrary path acceptance in
git_init - CVE-2025-68144: argument injection via unsanitized git CLI args in
git_diff/git_checkout - CVE-2025-68145: path validation weakness around repository scoping
THN also describes a chain where Git MCP vulnerabilities plus a Filesystem MCP server can be used to write .git/config and trigger a “clean filter” execution path—classic software exploitation mechanics, except the initial ignition can be prompt injection.(Noticias Hacker)
This is not theoretical. It’s the modern form of “data becomes instructions,” except now instructions can become actions on your machine.
3) Composition Risk: The More MCP Servers You Add, the More the Boundary Leaks
Single servers are risky. Multiple servers are worse because you can chain capabilities:
- one tool reads content
- another writes files
- another executes commands
- another calls cloud APIs
- another touches credentials
Security research and vendor guidance increasingly emphasize this “confused deputy” style of risk in MCP ecosystems, where the model becomes the deputy that can be tricked into using its permissions incorrectly. Red Hat explicitly discusses prompt injection risk in MCP contexts because of the model’s ability to select and invoke tools.(Red Hat)
Snyk also frames MCP as a new prompt-injection exploitation vector and recommends treating MCP servers like untrusted third-party code and testing them for classic vulnerability classes (command injection, path traversal, SSRF).(Snyk Labs)
Why This Matters Specifically for Kali + Claude
Kali’s integration is powerful because it’s direct. The same directness is what makes it a poor default for real pentesting teams operating on real assets.
CybersecurityNews’ summary describes a setup where Claude Desktop is the natural language interface, and Kali runs mcp-kali-server which can execute terminal commands—making “port scan + check security.txt” a single prompt that Claude interprets and iterates on.(Noticias sobre ciberseguridad)
Kali’s own blog post includes the same example prompt, and explicitly notes this is “a way,” not necessarily “the best way,” with privacy and acceptability concerns depending on your threat model.(Kali Linux)
That cautious framing is correct—and it should be taken further:
The hidden cost is operational responsibility
When you wire a general LLM into a privileged tool host, the security burden shifts to the operator:
- you must sandbox execution
- you must constrain tool access
- you must review logs
- you must sanitize outputs
- you must assume prompt injection will happen
- you must handle incidents when the model “helpfully” goes off-script
Most teams don’t fail because they lack Nmap flags. They fail because they don’t have guardrails.
A Practical Comparison: Claude-in-Kali vs a Purpose-Built Pentesting Platform
Below is the most honest way to compare the two approaches—not “which model is smarter,” but “which system produces reliable outcomes under real constraints.”
| Dimensión | Kali + Claude via MCP | Purpose-built platform such as Penligent |
|---|---|---|
| Primary strength | Flexible natural-language orchestration over arbitrary tools | End-to-end pentesting workflow designed around evidence, repeatability, and control |
| Default execution boundary | Often wide unless you deliberately constrain it | Typically narrower by product design (task scoping, workflow structure, and operational controls) |
| Prompt injection resilience | Depends heavily on operator hardening and safe tool design | Better positioned to implement consistent guardrails because the workflow is centralized |
| Reproducibility | You must capture prompts, tool output, versions, environment details | Workflow artifacts can be first-class: tasks, results, verification steps, and reports |
| Team operations | DIY: policies, logging, gating, access control | Centralized: easier to standardize across users and targets |
| Failure mode | “The model did something unexpected” becomes an incident | “The platform blocked an unsafe action” is the desired default |
| Best fit | Solo expert, lab work, CTF-like tasks, controlled environments | Teams, production targets, compliance needs, evidence-driven verification, repeatable reporting |
This is why “Claude is not enough” is not an insult to Claude. It’s a statement about product shape.
A general LLM plus a command bridge is an adapter. Penetration testing in the real world is a flujo de trabajo.
If You Still Want Kali + Claude, Here’s the Minimum Safe Setup
Kali’s tool page tells you how to install mcp-kali-server and shows it’s a Flask-based API bridge with a default port and client tooling (kali-server-mcp, mcp-server).(Kali Linux)
CybersecurityNews also describes SSH key-based access as part of the setup.(Noticias sobre ciberseguridad)
That’s enough to make it work. It’s not enough to make it safe.
Step 1: Put the Kali execution host behind a hard boundary
Objetivo: assume the execution host is disposable.
- Run Kali in an isolated VM or container host.
- No shared credentials folders.
- No SSH agent forwarding.
- Minimal outbound network by default; open only what you need.
Step 2: Make command execution allowlisted, not free-form
Even if you trust your own prompts, you should not trust copied inputs, target content, or tool output that the model will “read.”
A simple pattern is to wrap tool execution with an allowlist policy:
#!/usr/bin/env bash
# /usr/local/bin/mcp-allowlist-run
set -euo pipefail
cmd="$1"
shift || true
# Strict allowlist of tools and subcommands
case "$cmd" in
nmap|curl|wget|gobuster|nikto|sqlmap|ffuf)
;;
*)
echo "BLOCKED: tool not allowlisted: $cmd" >&2
exit 13
;;
esac
# Block dangerous shell metacharacters in args (baseline)
for arg in "$@"; do
if [[ "$arg" =~ [\\;\\&\\|\\`\\<\\>\\$\\(] ]]; then
echo "BLOCKED: suspicious arg: $arg" >&2
exit 14
fi
done
exec "/usr/bin/$cmd" "$@"
This is not perfect security. It is a baseline that stops the most obvious “model decided to run something creative” failures.
Step 3: Drop privileges—never run MCP execution as root
Kali’s examples often show commands being run as root in demos because it’s convenient. Convenience is not a security property.
- Create a dedicated low-privilege user, e.g.
mcpbot - Utilice
sudoersto allow only specific commands with fixed flags if necessary - Deny interactive shells
Step 4: Treat SSH as a first-class risk surface
Because this setup relies on SSH connectivity, it inherits the reality that SSH vulnerabilities and misconfigurations matter—especially when people run Kali in the cloud.
A good reminder is CVE-2024-6387 (regreSSHion): a signal handler race condition regression in OpenSSH’s server (sshd) that can be triggered remotely without authentication under certain conditions, and has been widely documented along with mitigations like patching/upgrading or adjusting LoginGraceTime as a workaround.(NVD)
If your Kali host is reachable from the internet, your “AI pentesting helper” can accidentally become “a new high-value SSH target.”
Step 5: Log everything and make sessions replayable
If you can’t answer these questions, you’re not ready to run this against meaningful targets:
- What exact commands were executed?
- With what versions of tools?
- From which host?
- With which environment variables?
- What outputs did the model see before it chose the next action?
The Real Point: Why Penligent Is Often the Better Default
If you’re a solo researcher doing controlled work, Kali + Claude via MCP can be a productivity boost—particularly when you know exactly what tools you want and you can recognize when the model is drifting.
But for teams, the default should be a system that is designed around:
- repeatable workflows
- evidence-based verification
- auditable artifacts
- consistent guardrails
That’s where a purpose-built AI pentesting platform like Penligente naturally fits. Not because “Claude is weak,” but because Claude-in-Kali is an integration pattern that pushes too much operational risk onto the user.
In practical terms, teams usually want outcomes like:
- “Run recon with a consistent depth across 10–100 targets”
- “Verify exploitability with evidence, not just ‘looks vulnerable’ heuristics”
- “Generate a report that a security lead can sign off on”
- “Re-run the same verification after patching and compare deltas”
Those are workflow requirements. You can build them around MCP, but you will be reinventing a platform—piecemeal—while accepting the security debt that comes with it.
Penligent’s positioning—an AI-driven pentesting platform rather than a generic LLM command runner—maps more directly to that reality, especially when you need standardized execution, repeatability, and reporting across many engagements. (If you’re already operating Penligent in your process, Claude+MCP can still be useful as a lab-side assistant, not your primary production workflow.)

CVEs You Should Associate with “LLM + Tool Execution,” Not Just “MCP News”
CVE-2025-68143, CVE-2025-68144, CVE-2025-68145 — The case study everyone should read
These Anthropic MCP Git server issues matter because they demonstrate the new normal:
- classic vulnerability classes (path traversal, argument injection)
- activated by prompt injection
- amplified when chained with other tool servers (filesystem write + git config trickery)
If your mental model is still “prompt injection is just embarrassing text output,” this incident should update it.(Noticias Hacker)
CVE-2024-6387 — When your orchestration depends on SSH, SSH becomes part of the threat model
Kali’s described integration uses SSH key auth to connect client and server. That’s fine, but it means patch hygiene and SSH hardening are part of the AI workflow’s safety posture. The NVD and multiple security advisories document CVE-2024-6387 and mitigations/workarounds when patching is not immediately possible.(Noticias sobre ciberseguridad)
Decision Framework: When to Use Which
Utilice Kali + Claude via MCP when:
- you’re in a controlled lab
- you can sandbox the execution host
- you understand prompt injection and tool poisoning
- you primarily want speed for recon / one-off tasks
Prefer a purpose-built platform like Penligent when:
- you have multiple targets per month
- you need consistent depth and repeatability
- you need auditability and reporting
- you want guardrails to be the default, not an afterthought
That’s the real conclusion behind “using Claude is worse than using Penligent”: the wrong default is not the model—it’s the execution shape.
Referencias
https://cybersecuritynews.com/kali-linux-integrates-claude-ai/ (Kali + Claude via MCP summary) https://www.kali.org/blog/kali-llm-claude-desktop/ (Kali official walkthrough)
https://www.kali.org/tools/mcp-kali-server/ (mcp-kali-server package details)
https://modelcontextprotocol.io/docs/tutorials/security/security_best_practices (MCP security best practices) https://www.redhat.com/en/blog/model-context-protocol-mcp-understanding-security-risks-and-controls (prompt injection + MCP risk framing) https://www.cyberark.com/resources/threat-research-blog/poison-everywhere-no-output-from-your-mcp-server-is-safe (tool poisoning dynamics)
https://invariantlabs.ai/blog/mcp-security-notification-tool-poisoning-attacks (tool poisoning in MCP context)
https://labs.snyk.io/resources/prompt-injection-mcp/ (prompt injection exploitation + hardening guidance) https://thehackernews.com/2026/01/three-flaws-in-anthropic-mcp-git-server.html (CVE-2025-68143/68144/68145 + chaining scenario) https://penligent.ai/ https://www.penligent.ai/hackinglabs/cve-2026-2441-the-chrome-css-zero-day-that-demands-proof-not-promises-2/ [Cited: turn0search15] https://www.penligent.ai/hackinglabs/the-ghost-in-the-shell-a-deep-technical-anatomy-of-cve-2026-24061/ [Cited: turn0search7] https://www.penligent.ai/hackinglabs/es/cve-2026-25142-the-ghost-accessor-rce-deconstructing-the-sandboxjs-escape/ [Cited: turn0search2] https://www.penligent.ai/hackinglabs/fr/cve-2026-the-vulnerability-landscape-when-identity-breaks-and-legacy-code-bites-back/ [Cited: turn0search4]

