Gemma 4 31B : un cerveau de test, pas un robot d'exploitation
La mauvaise question est de savoir si Gemma 4 31B peut écrire nmap ou résumer une capture Burp. La bonne question est de savoir s'il peut réduire le coût humain de la transformation de preuves bruyantes en résultats vérifiés sans devenir une autre surface d'exécution dangereuse. Ce cadrage est important car les meilleures recherches publiées sur le pentesting assisté par LLM disent toujours la même chose que les ingénieurs en sécurité découvrent dans la pratique : les modèles sont utiles pour les tâches secondaires telles que l'utilisation des outils, l'interprétation des résultats et la proposition de l'étape suivante, mais ils ont du mal à maintenir l'état complet d'un test de pénétration de bout en bout par leurs propres moyens. Gemma 4 31B change un peu la donne avec une fenêtre contextuelle de 256K, l'appel de fonctions natives, la prise en charge des rôles système et des fonctionnalités multimodales qui incluent explicitement l'analyse de documents et de PDF, ainsi que la compréhension de l'écran et de l'interface utilisateur. Il ne supprime pas la nécessité d'un contrôle de l'étendue, de barrières politiques ou d'une approbation humaine. (USENIX)
Gemma 4 lui-même est tout nouveau. La documentation de Google montre que la famille Gemma 4 a été lancée le 31 mars 2026, dans les variantes E2B, E4B, 31B et 26B A4B. L'aperçu de Google décrit le modèle 31B comme un modèle dense destiné à faire le lien entre les performances de niveau serveur et l'exécution locale, tandis que la page du modèle de DeepMind positionne les variantes 26B et 31B pour le raisonnement avancé, les assistants de codage et les flux de travail agentiques sur les GPU grand public et les stations de travail. Google a également fait passer Gemma 4 sous la licence Apache 2.0, et son propre post open-source encadre ce changement autour de l'autonomie, de l'exécution privée locale et de droits de réutilisation plus clairs pour les développeurs. Ces détails sont importants pour les équipes de sécurité, car ils font passer Gemma 4 du statut de "modèle ouvert intéressant" à celui de "composant de raisonnement auto-hébergé sérieux". (Google AI pour les développeurs)
C'est pourquoi la façon la plus utile d'envisager Gemma 4 31B dans le pentesting n'est pas de le considérer comme un générateur d'exploits. Il est préférable de le considérer comme un noyau de raisonnement local qui se situe entre la collecte de preuves et l'action contrôlée. Dans une conception solide, les scanners, les crawlers, les clients HTTP, les collecteurs de captures d'écran et les analyseurs syntaxiques recueillent des faits. Une couche de normalisation transforme ces faits en preuves structurées. Gemma 4 31B raisonne sur ces preuves, regroupe les signaux faibles en hypothèses plausibles, classe ce qui mérite l'attention et demande des actions étroitement définies par le biais d'un contrat que la couche d'exécution peut valider. L'opérateur reste dans la boucle pour tout ce qui change d'état, franchit les limites de la confiance ou augmente le rayon d'action. Cette conception est moins tape-à-l'œil qu'un fantasme de "pirate de l'IA" entièrement autonome. Elle est également beaucoup plus proche de ce à quoi les équipes matures peuvent faire confiance.
Le modèle modifie le goulot d'étranglement, pas le travail
Le pentesting a toujours eu deux coûts. Le premier est le coût de l'outil : collecter suffisamment de signaux techniques pour comprendre la cible. Le second est la cognition humaine : décider de la signification de ce signal, de ce qui mérite une heure de plus, et des indices apparemment distincts qui sont en fait une seule classe de bogues vue sous trois angles. Les scanners traditionnels s'attaquent mieux au premier coût qu'au second. Les assistants basés sur le chat inversent souvent le problème : ils sont bons pour interpréter des bribes isolées, mais ils perdent le fil de l'engagement au fur et à mesure que le volume de preuves augmente. La recherche PentestGPT reste le point de contrôle public le plus honnête en la matière. Ses auteurs ont constaté que les LLM pouvaient bien gérer certaines parties du processus, en particulier l'utilisation et l'interprétation des outils, mais qu'ils avaient du mal à préserver le contexte de l'engagement dans son ensemble ; PentestGPT a réagi en divisant le problème en modules interactifs afin de réduire la perte de contexte. (USENIX)
Gemma 4 31B est intéressant parce que son ensemble de fonctionnalités officielles cible directement plusieurs de ces modes d'échec historiques. Google documente une fenêtre contextuelle de 256K pour les modèles moyens, l'appel de fonctions natives pour l'utilisation d'outils structurés, la prise en charge de l'invite système intégrée, les modes de réflexion et la compréhension de l'image qui couvre l'analyse de documents et la compréhension de l'écran ou de l'interface utilisateur. Pour la sécurité offensive, cela signifie que le modèle peut conserver une plus grande partie de l'engagement dans la mémoire de travail, raisonner sur des captures d'écran et des preuves d'interface plutôt que sur du texte seul, et interagir avec des outils dans un format lisible par la machine plus propre que "écrivez-moi une commande shell s'il vous plaît". Cela ne garantit pas un bon jugement en matière de sécurité. C'est un meilleur substrat pour la construction d'un flux de travail gouverné. (Google AI pour les développeurs)
Le goulot d'étranglement qui se déplace est l'écart entre la collecte et l'interprétation. Un modèle comme Gemma 4 31B peut s'avérer véritablement utile lorsque l'opérateur dispose déjà de suffisamment de preuves, mais qu'il a besoin d'aide pour les convertir en un meilleur plan de recherche. Il s'agit notamment de décider si un /admin-beta un bouton d'exportation privilégié et un chemin d'accès à l'API interne suspect trouvé dans un paquet minifié appartiennent probablement au même problème de limite de confiance. Cela inclut la classification d'un écran de backend à partir d'une capture d'écran avant que quiconque n'écrive un flux Playwright. Il s'agit de comparer le comportement des rôles dans un flux de travail authentifié désordonné sans obliger l'humain à relire manuellement soixante réponses. Il s'agit là de tâches à forte intensité de raisonnement et de preuves. C'est exactement là que le contexte long, la compréhension de l'interface utilisateur et le soutien à l'appel de fonction devraient aider.
Ce qui ne change pas, c'est la loi du pentest elle-même. La preuve compte toujours plus que l'éloquence. La reproductibilité compte toujours plus que la confiance. Le champ d'application est toujours plus important que la créativité. Une pile de pentest Gemma 4 solide doit donc être conçue autour de preuves, de contrats et d'approbations plutôt qu'autour de boucles libres de type "demander au modèle d'attaquer la cible". Les équipes de sécurité qui ne font pas cette distinction se retrouvent généralement avec l'un des deux résultats suivants : un chatbot qui semble intelligent mais qui ne fait pas grand-chose, ou un moteur d'exécution qui en fait trop et qui ne peut pas expliquer pourquoi.
Ce que Gemma 4 31B apporte réellement au flux de travail d'un pentest
La documentation de Google donne une image plus claire du modèle que la plupart des discussions de lancement. La page de présentation indique que Gemma 4 est une famille de poids ouverte destinée à la génération, au raisonnement et au déploiement commercial, et elle place explicitement le modèle dense 31B entre les performances de classe serveur et l'exécution locale. La fiche du modèle ajoute les détails pratiques qui importent aux ingénieurs : les variantes 26B A4B et 31B prennent en charge le contexte 256K, l'appel de fonction, le codage, les entrées multimodales et la prise en charge intégrée du rôle du système. La page du modèle de DeepMind décrit les variantes les plus grandes comme étant optimisées pour les GPU et les stations de travail grand public et destinées au raisonnement avancé, aux assistants de codage et aux flux de travail agentiques. (Google AI pour les développeurs)
Cela semble abstrait jusqu'à ce que vous l'appliquiez au travail réel d'un pentest. Le contexte long est important car un engagement sérieux génère des preuves hétérogènes, et non une transcription textuelle soignée. Vous pouvez avoir des historiques HTTP, des listes d'actifs, des captures d'écran, des JWT, des messages d'erreur, des points de terminaison découverts en JavaScript, des matrices de rôles, des notes de réessai et un rapport partiel d'un cycle précédent. L'appel de fonctions natives est important car un orchestrateur plus sûr veut que le modèle émette une intention structurée, et non des chaînes brutes dirigées directement vers un shell. La compréhension de l'écran et de l'interface utilisateur est importante car de nombreuses faiblesses de grande valeur apparaissent d'abord dans la sémantique de l'interface, et non dans les noms de paramètres : écrans d'exportation en vrac, tableaux de bord de modération interne, outils d'administration côté fournisseur, flux de travail de remise, visionneuses de documents ou consoles de drapeaux de fonctionnalités. La prise en charge intégrée du rôle du système est importante, car les flux de sécurité bénéficient d'une séparation nette entre les instructions politiques et les preuves cibles. (Google AI pour les développeurs)
L'histoire du matériel est également importante, car le "modèle local" est souvent confondu avec le "modèle d'ordinateur portable facile". L'aperçu de Google donne des exigences approximatives de mémoire d'inférence de base de 58,3 Go pour BF16, 30,4 Go pour 8 bits et 17,4 Go pour Q4_0 sur le modèle 31B, et il avertit explicitement que ces chiffres excluent les frais généraux du logiciel et la mémoire de la fenêtre contextuelle. En d'autres termes, un déploiement 31B peut être local et constituer une décision d'infrastructure sérieuse. Une station de travail, un chemin de desserte quantifié ou un cluster privé constituent un choix de conception normal dans ce cas. Ce modèle ne permet pas un déploiement trivial. Il vous permet de conserver des preuves sensibles dans votre propre environnement tout en utilisant un modèle suffisamment grand pour raisonner sur un engagement réel. (Google AI pour les développeurs)
| Gemma 4 Capacité 31B | L'importance du pentesting | Ce qu'il ne résout pas |
|---|---|---|
| Contexte 256K | Permet au modèle de conserver ensemble la reconnaissance, les notes d'authentification, les captures d'écran, les résultats JS et l'historique des tentatives. | Un contexte long ne permet pas de remédier à une mauvaise hygiène des preuves ou à une contamination rapide. |
| Appel de fonctions natives | Prise en charge des demandes d'action structurées au lieu des chaînes de commande brutes | L'appel d'une fonction ne rend pas l'utilisation d'un outil sûre en soi |
| Compréhension de l'écran et de l'interface utilisateur | Permet de classer les surfaces privilégiées, les panneaux d'administration, les flux d'exportation et les différences d'état visuel. | Il ne peut pas prouver l'autorisation ou reproduire seul les changements d'état |
| Soutien au rôle du système | Facilite la séparation de la politique, du champ d'application et des règles d'exécution des preuves | Une invite du système n'est pas une limite d'application |
| Options d'exécution locale et privée | Réduit la sortie de données de routine pour les captures d'écran, les journaux et les artefacts internes | Le déploiement local crée toujours un nouveau service à renforcer et à surveiller. |
La lecture la plus honnête est que Gemma 4 31B n'est pas un modèle de pentest magique. Il s'agit d'un modèle de raisonnement local très prometteur pour les flux de travail de sécurité à forte intensité de preuves. Cette affirmation est plus restrictive que le marketing de lancement, mais c'est aussi celle qui survit au contact avec la production.
L'importance de l'inférence locale dans la sécurité offensive
Une grande partie du travail de pentesting se fait sur des données que les organisations ne veulent pas voir franchir une autre frontière de confiance. Cela inclut les captures d'écran internes, les données des comptes clients visibles pendant les tests authentifiés, les documents d'architecture, les exportations de support expurgées mais toujours sensibles, les captures de paquets, les journaux, les tickets et les résultats inachevés. Pour de nombreuses équipes, l'argument en faveur de l'inférence locale est moins une question de latence ou d'idéologie que de contrôle des données. La documentation Gemma de Google indique que les modèles peuvent être adaptés et déployés dans les projets et applications des développeurs, tandis que l'annonce open-source de Google encadre Gemma 4 autour de l'exécution locale et privée et des droits clairs de modification et de réutilisation dans le cadre d'Apache 2.0. Pour les équipes de sécurité, cela se traduit par une véritable option architecturale : conserver la couche de raisonnement dans un environnement isolé au lieu d'envoyer chaque artefact à une API hébergée. (Google AI pour les développeurs)
Cela est d'autant plus important lorsque le modèle voit des preuves intermédiaires plutôt que des résumés finaux aseptisés. C'est dans les preuves intermédiaires que se trouvent les véritables flux de travail offensifs. Une capture d'écran d'une console de modération interne peut révéler les chemins d'exportation, la sémantique des files d'attente et les limites des rôles. Une chaîne 403 ou 302 brute peut montrer une hypothèse d'autorisation. Un journal d'assistance peut révéler un modèle d'identification d'objet. Ces artefacts sont exactement ce qu'un modèle multimodal à contexte long peut aider à interpréter. C'est aussi exactement ce que de nombreuses équipes de sécurité veulent garder au niveau local, en particulier lors de la découverte, de la reproduction et des nouveaux tests.
L'inférence locale réduit également un autre type de friction opérationnelle : la reconstruction répétée du contexte. Dans un flux de travail de modèle hébergé, les équipes nettoient, résument et rechargent souvent le contexte à chaque tour significatif, en partie pour des raisons de confidentialité et en partie pour contrôler les coûts. Une couche de raisonnement locale peut être maintenue plus proche du magasin de preuves et plus proche de la pile d'exécution. Cela ne la rend pas automatiquement moins chère, mais il est plus facile d'itérer sur le même graphe de preuves, de réessayer une analyse structurée et de comparer les résultats avec les tentatives précédentes sans transformer chaque cycle en un nouvel exercice d'exportation de données.
Il y a également une raison de conception de produit qui fait que cela correspond mieux au pentesting qu'à beaucoup d'autres cas d'utilisation de l'IA. Les tests offensifs sont rarement une simple invite. Il s'agit d'une boucle. Les preuves arrivent, sont normalisées, conduisent à une hypothèse, déclenchent une action contrôlée, produisent d'autres preuves, et enfin effondrent ou renforcent l'hypothèse. Cette boucle est d'autant plus efficace que le modèle, l'entrepôt de preuves et le moteur de politique se trouvent dans le même domaine de sécurité.
Local ne veut pas dire sûr
L'intérêt des modèles locaux pour la protection de la vie privée est réel. Le cas de la sécurité est plus conditionnel. Les équipes de sécurité doivent résister à l'hypothèse paresseuse selon laquelle l'auto-hébergement d'un LLM efface en quelque sorte le risque lié au modèle. En pratique, cela crée un ensemble différent de risques : services d'inférence exposés, points d'extrémité locaux non authentifiés, confusion entre l'invite et l'outil, limites de plugin faibles et accessibilité publique accidentelle.
L'étude de Cisco de septembre 2025 a trouvé plus de 1 100 serveurs Ollama exposés via Shodan et a indiqué qu'environ 20 % d'entre eux hébergeaient activement des modèles susceptibles de faire l'objet d'un accès non autorisé. Praetorian a écrit en janvier 2026 que plus de 14 000 instances d'Ollama étaient accessibles au public et a cité la même analyse de Cisco sur le chiffre de 20 %. Ces chiffres sont différents et ne sont pas directement comparables, mais ils vont dans le même sens : l'infrastructure LLM auto-hébergée fait déjà partie de la surface d'attaque. (Blogs Cisco)
Le risque s'aggrave lorsque le modèle peut appeler des outils. L'analyse de janvier 2026 de SentinelOne sur les hôtes Ollama exposés présente la version la plus précise de ce point : un point d'extrémité générant du texte simple peut produire un contenu dangereux, mais un point d'extrémité doté d'un outil peut exécuter des opérations privilégiées, ce qui modifie considérablement le modèle de menace. L'article fait également valoir que l'injection rapide devient beaucoup plus sérieuse à mesure que l'agence du modèle augmente, en particulier lorsque la portée de l'extraction ou de l'outil atteint les données et les systèmes internes. Cela concerne directement le déploiement d'un pentest Gemma 4. Le modèle peut être local, mais si la couche de service est accessible à partir du mauvais segment de réseau ou si la surface de l'outil est trop large, vous avez créé un nouveau système privilégié dont l'interface se trouve être le langage naturel. (SentinelOne)
La leçon opérationnelle est simple. Lier les services d'inférence locaux à la boucle, à moins qu'il n'y ait une bonne raison de ne pas le faire. Traiter les points d'extrémité servant de modèle comme une infrastructure interne, et non comme des jouets de développeur. Placer l'authentification en amont de toute couche de service multi-utilisateurs. Séparer, dans la mesure du possible, le composant de raisonnement des outils d'exécution privilégiés. Donner au modèle moins de portée que n'en a votre meilleur opérateur humain, pas plus. Dans une conception mature, le serveur de modèle n'est jamais le système qui possède directement les capacités dangereuses. Il demande. Quelque chose d'autre décide.
Cette séparation devient encore plus importante lorsque la cible du pentest est elle-même un système doté d'IA. Lorsque les agents commencent à communiquer avec des serveurs MCP, des contrôleurs de navigateur, des bases de connaissances ou des outils CLI locaux, le flux de travail du pentest et la surface d'attaque de l'agent commencent à rimer. Les mêmes erreurs de limite d'exécution peuvent se produire des deux côtés. C'est pourquoi un modèle local doit être considéré comme faisant partie de l'architecture de sécurité, et non comme extérieur à celle-ci.
Une meilleure architecture pour Gemma 4 31B dans le pentesting
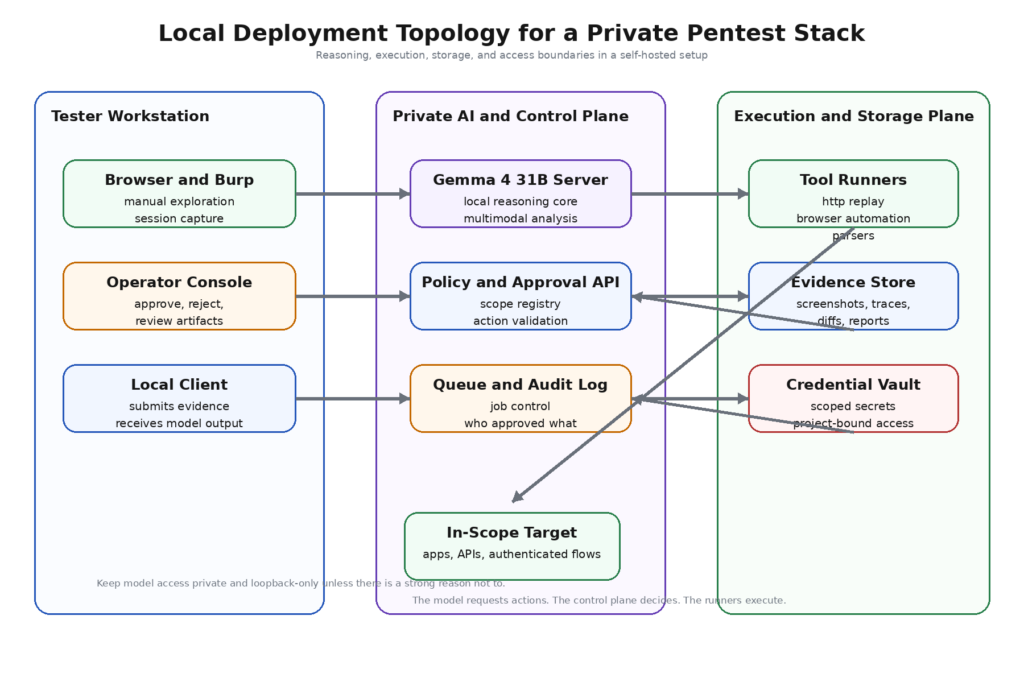
Le modèle de déploiement le plus solide pour Gemma 4 31B est un flux de travail en couches où chaque partie fait bien son travail. Le modèle ne doit pas collecter de preuves directement auprès de la cible, ne doit pas disposer de privilèges étendus sur le système d'exploitation et ne doit pas être autorisé à exécuter un texte arbitraire de forme libre. Son travail consiste à raisonner sur des preuves structurées et à demander des actions limitées.
Une architecture pratique se présente comme suit :
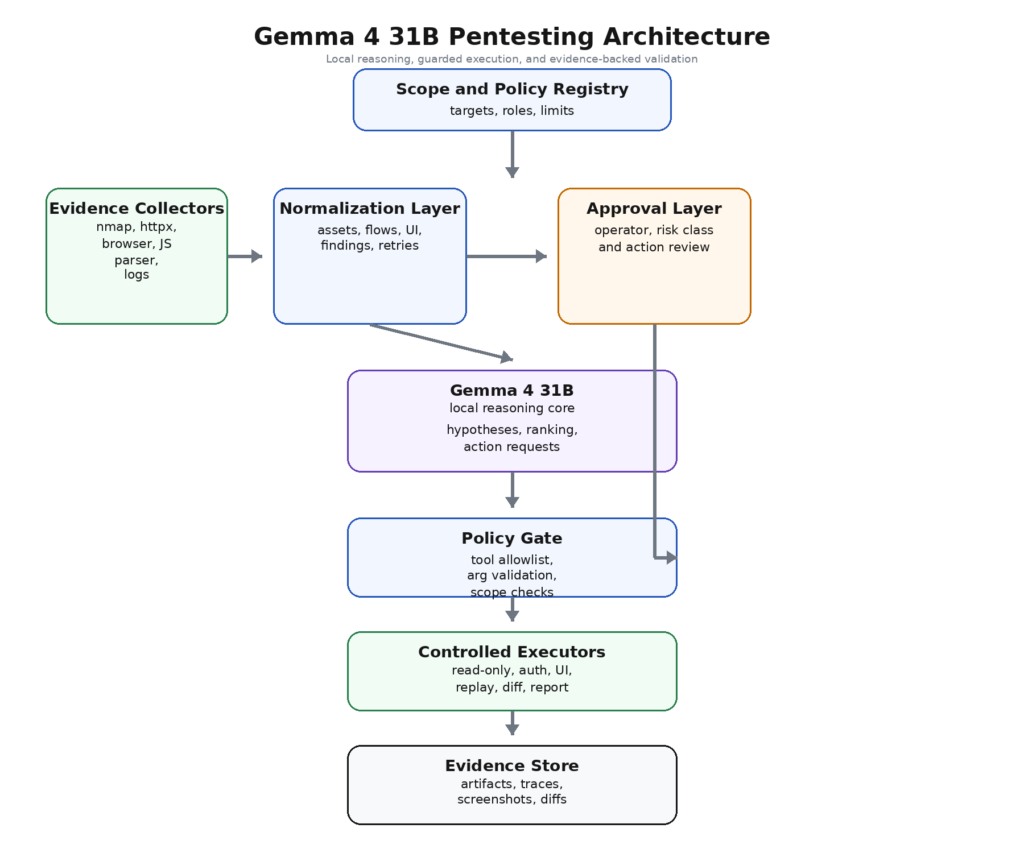
Cette conception n'est pas glamour, mais elle correspond à ce que le document PentestGPT laissait déjà entendre : le modèle est plus utile lorsque le flux de travail réduit la fragmentation du contexte et isole proprement les sous-tâches. Il correspond également mieux au profil de capacité officiel de Gemma 4 qu'une boucle entièrement autonome. Le contexte long est utile lorsque la réserve de preuves est cohérente. L'appel de fonction est utile lorsque l'interface d'action est typée. La compréhension de l'interface utilisateur est facilitée lorsque les captures d'écran sont normalisées et liées à un rôle ou à un itinéraire. La prise en charge du rôle du système est facilitée lorsque la politique et les preuves sont séparées. (USENIX)
La transition la plus importante ici est le passage d'un résultat brut à des preuves normalisées. Les outils de sécurité produisent des artefacts très hétérogènes. Un résultat d'analyse XML, une capture d'écran de navigateur, un ensemble de revendications JWT, une différence entre deux réponses de rôle et un chemin d'accès extrait d'un fichier JavaScript minifié n'appartiennent pas à un blob d'invite non structuré. Ils appartiennent à un schéma de preuves partagé. Ce schéma peut être modeste. Il ne s'agit pas d'élégance académique. Il s'agit de faire en sorte que le modèle raisonne sur des objets plutôt que sur des vidages de pâte.
Un flux de travail mature fait également la distinction entre les boucles d'analyse et les boucles d'exécution. Les boucles analytiques sont peu coûteuses : regrouper les points d'extrémité, déduire les limites des rôles, identifier les ressources suspectes, résumer les différences entre les tentatives, proposer la sonde suivante. Les boucles d'exécution sont coûteuses et risquées : rejouer des actions authentifiées, modifier des objets, exécuter une étape du flux de travail qui peut envoyer du courrier, créer des commandes, modifier des paramètres ou consommer des crédits. Gemma 4 31B est utile dans la première boucle. La deuxième boucle doit rester fortement médiatisée.
Pour les équipes qui ne souhaitent pas assembler cette pile à la main, la forme concrète du produit à rechercher n'est pas le "pentesting alimenté par l'IA" dans l'abstrait. Il s'agit d'une validation étayée par des preuves, de flux de travail d'agents contrôlables, d'un support de test authentifié, d'une intégration de CI ou de pipeline, et d'options de déploiement qui gardent les chemins d'exécution sensibles privés. Les pages de prix et de présentation de Penligent décrivent ce type de forme : pentesting AI de bout en bout, de la découverte des actifs à la validation, plus de 200 outils de pentest à la demande, des rapports PDF ou Markdown avec des preuves et des étapes de reproduction, des tests de flux authentifiés, l'intégration CI ou CD, et le déploiement privé avec l'intégration de modèles privés. Qu'une équipe construise ou achète, ces caractéristiques opérationnelles sont plus importantes qu'une promesse générique d'automatisation. (Penligent)
Là où le modèle apporte le plus de valeur ajoutée
La meilleure utilisation de Gemma 4 31B n'est pas partout. Elle se situe là où les testeurs humains sont surchargés sur le plan cognitif. Ces endroits apparaissent plus tôt dans un engagement que ce à quoi beaucoup s'attendent.
La synthèse de reconnaissance est la première solution évidente. La reconnaissance moderne produit trop de signaux faibles : chemins alternatifs à partir de JavaScript, DNS passif, fragments OpenAPI, documents exposés, en-têtes HTTP, indicateurs de fonctionnalités, écrans spécifiques à un rôle et différences dans les messages d'erreur. Un humain peut raisonner à travers tout cela, mais le coût est l'attention. Un modèle local de contexte long peut transformer ce marécage en une liste restreinte de surfaces d'attaque probables, à condition que les entrées soient normalisées et étiquetées. Ce n'est pas la créativité du modèle qui importe ici. Ce qui compte ici, ce n'est pas la créativité du modèle, mais sa capacité à rassembler de nombreux petits indices en quelques hypothèses dignes d'être validées.
Le raisonnement sur le flux de travail authentifié est un autre point fort. De nombreuses vulnérabilités graves en 2026 ne sont toujours pas des bogues de "charge utile intelligente". Il s'agit de bogues liés à la confiance : autorisation au niveau de l'objet non respectée, autorisation au niveau de la fonction non respectée, flux d'exportation, flux d'approbation, transitions d'état et relations entre les objets. Les orientations de l'OWASP en matière de LLM et de sécurité des applications soulèvent un point similaire du point de vue de l'IA : les défaillances dangereuses se produisent souvent à la jonction entre les entrées, les sorties, les outils et l'autorité. Un modèle capable de comparer les vues des rôles, de suivre un processus à travers les pages et de conserver la séquence des transitions d'état est plus utile ici qu'un modèle qui se contente de suggérer des charges utiles. (Fondation OWASP)
L'analyse de JavaScript et de la surface de l'API bénéficie du long contexte et du profil de codage de Gemma 4 31B. La carte de modèle met en évidence le codage, la correction du code et l'utilisation d'outils, et la documentation de base mentionne explicitement l'analyse PDF et la compréhension de l'interface utilisateur en plus du codage et du raisonnement. Dans un flux de travail de pentest, cela se traduit par des tâches telles que l'extraction de groupes de points d'extrémité sémantiquement significatifs à partir d'un bundle client construit, le regroupement de paramètres par objet métier, le mappage des itinéraires découverts aux actions visibles de l'interface utilisateur, et le repérage des cas où une supposition frontale ne ressemble pas à un contrôle côté serveur. Aucune de ces tâches n'exige que le modèle touche directement la cible. Ils exigent qu'il lise de manière cohérente un grand nombre d'éléments de preuve adjacents. (Google AI pour les développeurs)
La sémantique de l'interface utilisateur est un avantage sous-estimé. De nombreux produits web et SaaS cachent des indices de privilèges dans le langage de l'interface bien avant qu'un testeur ne voie une défaillance explicite de l'API. Des boutons tels que "rouvrir", "approuver le remboursement", "exporter tout", "voir le registre des clients" ou "attribuer en bloc" contiennent des informations sur les limites de la confiance. Un humain expérimenté remarque rapidement ces indices. Un modèle multimodal avec une compréhension de l'écran et de l'interface utilisateur peut aider à les classer à l'échelle, en particulier lorsqu'un test nécessite de comparer plusieurs états de rôle ou de nombreux sous-produits dans le même environnement. Cela ne prouve pas une vulnérabilité. Cela permet de concentrer l'attention humaine là où la preuve est la plus probable.
Le travail de rapport et de retest s'améliore également. Un bon rapport de sécurité n'est pas un roman. C'est une chaîne de preuves. Un modèle de raisonnement solide peut transformer des traces brutes en récits plus clairs, comparer les artefacts de retest à des preuves antérieures et expliquer ce qui a changé entre les états "suspectés" et "vérifiés". Cela est important d'un point de vue opérationnel, car les équipes d'ingénieurs toléreront plus facilement un petit nombre de résultats solides qu'un grand nombre de textes rédigés par l'IA.
| Tâche de pentest | Pourquoi Gemma 4 31B s'adapte bien | Pourquoi il ne doit pas fonctionner seul |
|---|---|---|
| Recon clustering | Le contexte long lui permet de comparer plusieurs signaux faibles ensemble | Il peut associer de manière excessive des indices sans rapport les uns avec les autres |
| Analyse du flux d'authentification | Possibilité de conserver l'état multirôle et de comparer les trajectoires | Il n'est pas possible de prouver l'existence d'une autorisation sans procéder à des essais contrôlés |
| Cartographie JS et API | Un codage plus fort et une fenêtre de preuves plus large facilitent l'extraction et le regroupement des itinéraires. | Les indices statiques doivent toujours être vérifiés au moment de l'exécution |
| Triage des captures d'écran | La compréhension de l'interface utilisateur permet de classer rapidement les surfaces privilégiées | Vision ne peut pas confirmer l'application du backend |
| Diffusion de rapports et de nouveaux tests | Bonne capacité à comprimer les preuves dans des récits reproductibles | Elle peut encore surestimer la certitude si elle n'est pas obligée de citer des artefacts. |
Le schéma qui se dégage de tous ces éléments est cohérent. Le modèle est plus performant lorsque le travail est interprétatif, comparatif et riche en preuves. Dès que le travail devient une action à fort impact, le modèle doit devenir un outil de recommandation et non de décision.
Alors qu'il ne devrait jamais être l'autorité finale
Il y a une tentation récurrente dans les outils de sécurité de l'IA de laisser le modèle porter plus d'agence que le système environnant ne peut défendre. L'OWASP nomme le problème directement : la gestion non sécurisée des sorties, la conception non sécurisée des plugins et l'agence excessive sont des risques distincts pour une raison. En pratique, il s'agit de la même erreur vue sous trois angles. Le modèle dit quelque chose. Un autre système lui fait trop confiance. Cette confiance atteint une surface de capacité. La surface de capacité a des conséquences. (Fondation OWASP)
Dans un flux de travail de pentest Gemma 4, le modèle ne devrait donc jamais être l'autorité finale pour les actions destructrices, l'exécution d'un shell, le fuzzing large, la pulvérisation d'informations d'identification, le mouvement latéral ou toute action qui modifie l'état de l'application sans politique explicite et sans approbation. Il ne doit pas décider de forcer brutalement un point de terminaison parce qu'une page de connexion "semble intéressante". Il ne doit pas écrire un one-liner en bash qui sera envoyé directement dans un tool runner. Il ne doit pas muter un objet parce qu'il en déduit qu'une référence d'objet directe non sécurisée pourrait exister. Il s'agit là d'exemples classiques où l'on laisse le langage prendre le contrôle.
Il ne s'agit pas seulement d'une question d'optique de sécurité. Il s'agit d'épistémologie. Les modèles raisonnent de manière probabiliste à partir de preuves partielles. Le pentesting exige une norme plus stricte au moment de l'action. Avant qu'une relecture contrôlée ne se produise, un IDOR suspecté n'est pas un IDOR. Avant qu'une limite de rôle ne soit franchie et prouvée, un chemin privilégié n'est pas une découverte. Le bon flux de travail divise donc le problème en plusieurs étapes : observation, hypothèse, action planifiée, action approuvée, artefact résultant, conclusion. Le modèle peut aider à produire les trois premières étapes. Il peut aider à résumer les deux dernières. Il ne doit pas s'effondrer au milieu sans aide.
Il existe une deuxième raison de ne pas soumettre le modèle à l'autorité directe : le retour d'information sur les cibles est contradictoire. Tout ce qui lit le contenu cible peut être manipulé par le contenu cible. Les conseils actuels de l'OWASP sur l'injection d'invite sont explicites sur le fait que l'injection d'invite indirecte se produit lorsqu'un LLM consomme du contenu externe tel que des sites web ou des fichiers et que l'impact dépend fortement de l'agence du modèle. Un système de pentest est, de par sa conception, une machine qui lit des contenus non fiables. Cela rend la délégation d'outils aveugles exceptionnellement dangereuse dans ce domaine. (Projet de sécurité Gen AI de l'OWASP)
Le meilleur modèle mental n'est pas "le modèle teste l'application". C'est "le modèle propose des actions d'investigation limitées et vérifiables contre un flux de preuves hostiles". Cet état d'esprit modifie les détails de la mise en œuvre dans tous les domaines : schémas d'action, enveloppes d'outils, logique d'approbation, enregistrement des preuves et rédaction des conclusions.
Le modèle de menace autour du pentesting agentique
Le modèle de menace pour une pile de pentest pilotée par Gemma est plus large que "le modèle peut-il être jailbreaké". Cette question est trop restreinte. Un modèle de menace pratique doit couvrir au moins quatre couches : le modèle lui-même, l'implémentation qui l'entoure, l'infrastructure sur laquelle il s'exécute et le comportement de l'ensemble du flux de travail pendant l'exécution. Le GenAI Red Teaming Guide de l'OWASP utilise presque exactement cette forme, décrivant une approche holistique de l'évaluation du modèle, des tests d'implémentation, de l'évaluation de l'infrastructure et de l'analyse du comportement d'exécution. La taxonomie 2025 du NIST sur l'apprentissage automatique des adversaires va dans le même sens du point de vue des normes, en préconisant un vocabulaire commun pour les étapes du cycle de vie de l'IA, les objectifs des attaquants et les mesures d'atténuation. (Projet de sécurité Gen AI de l'OWASP)
Au niveau du modèle, l'injection rapide et la confiance excessive restent les problèmes les plus évidents. Si le noyau de raisonnement consomme du contenu contrôlé par la cible, il peut être amené à réinterpréter la politique, à ignorer les instructions ou à classer les mauvais chemins comme urgents. Au niveau de la mise en œuvre, la gestion non sécurisée des sorties est souvent plus dangereuse que l'injection d'invite elle-même. Le modèle n'a pas besoin de "gagner" d'un point de vue philosophique. Il lui suffit de convaincre un analyseur syntaxique, un exécuteur, un contrôleur de navigateur ou un client MCP en aval de faire quelque chose de dangereux. Le projet de l'OWASP répertorie toujours l'injection d'invite, la gestion non sécurisée des sorties, la conception non sécurisée des plugins et l'agence excessive parmi les risques principaux des applications LLM parce que ces chaînes d'échec se répètent. (Fondation OWASP)
Au niveau de l'infrastructure, le service local et l'auto-hébergement introduisent des problèmes familiers mais nouvellement concentrés : points d'extrémité exposés, authentification faible, segmentation faible du réseau et expansion des services non vérifiés. Les travaux de Cisco et de Praetorian sur l'infrastructure Ollama exposée sont un coup de semonce pour tous ceux qui construisent des systèmes d'IA locaux à la hâte. Un modèle privé qui devient accessible au public n'est plus privé dans un sens opérationnel significatif. Et s'il est équipé d'outils, sa compromission peut être plus importante que la fuite de données. (Blogs Cisco)
Au niveau de l'exécution, la contamination de la mémoire et la dérive des limites sont importantes. Les systèmes agentiques ont tendance à accumuler les états à travers les tentatives, les résultats antérieurs, les résultats des outils mis en cache et les résumés sauvegardés. Cela est utile pour la continuité et dangereux pour la confiance. Une note empoisonnée, une hypothèse périmée ou un secret non expurgé peuvent se propager dans les cycles ultérieurs si la mémoire des preuves a un typage et une provenance faibles. C'est là que des cadres comme ATLAS de MITRE deviennent utiles, non pas parce qu'ils vous donnent une liste de contrôle de pentest, mais parce qu'ils donnent aux défenseurs et aux testeurs une carte partagée des comportements adverses spécifiques à l'IA au lieu de tout forcer à revenir à un langage générique d'application web. MITRE décrit ATLAS comme une base de connaissances vivante des tactiques et techniques des adversaires contre les systèmes basés sur l'IA, basée sur des observations d'attaques dans le monde réel. C'est exactement l'altitude qu'il faut pour penser à une pile de pentest agentique qui pourrait elle-même devenir une cible. (MITRE ATLAS)
Le récent article du Hacking Labs de Penligent sur les pentesters IA et la sécurité des agents de production se situe au même endroit d'un point de vue opérationnel. Il présente le système utile non pas comme un chatbot magique, mais comme un flux de travail régi qui réduit la distance entre le signal brut et le résultat vérifié, et il traite les services MCP exposés, la gestion de la mémoire et les chemins d'outils dangereux comme des cibles de validation de première classe. C'est la bonne forme de problème. La question n'est pas de savoir si le modèle peut penser. La question est "que peut faire le système lorsque le modèle est erroné, manipulé ou trop confiant". (Penligent)
Les CVE qui montrent ce qui se passe lorsque la frontière n'est pas respectée
Le moyen le plus rapide de comprendre pourquoi les limites d'exécution sont importantes est d'étudier les défaillances réelles des systèmes d'agents adjacents. Les récents CVE dans les outils de flux de travail d'IA et les écosystèmes liés aux MCP sont particulièrement instructifs parce qu'ils ne concernent pas un comportement erroné d'un modèle abstrait. Il s'agit de ce qui se passe lorsque des systèmes en langage naturel s'approchent trop près de capacités dangereuses.
L'exemple le plus clair est CVE-2026-27966 dans Langflow. Selon NVD et l'avis de GitHub, les versions antérieures à 1.8.0 codaient en dur allow_dangerous_code=True dans le nœud CSV Agent, qui exposait automatiquement l'outil Python REPL de LangChain. Il en a résulté une exécution de code à distance par injection sur le serveur. C'est une étude de cas presque parfaite qui montre pourquoi un flux de travail de pentest Gemma 4 ne devrait pas laisser un modèle de raisonnement hériter d'un chemin d'exécution de code sans restriction juste parce qu'un outil semble pratique. La solution n'était pas une meilleure invite. La solution consistait à modifier la frontière dangereuse elle-même. (GitHub)
Un exemple plus ancien est CVE-2024-42835également dans Langflow, que NVD décrit comme une exécution de code à distance par le biais du composant PythonCodeTool dans Langflow 1.0.12. Il ne s'agit pas de dire que Langflow est uniquement mauvais. Le fait est qu'une fois que les systèmes de flux de travail d'IA exposent des outils généraux d'exécution de code, la question de sécurité cesse d'être "le modèle peut-il aider" et devient "quel chemin existe-t-il entre l'entrée externe et le code exécutable". Les systèmes de pentest qui donnent à un modèle local un large accès à l'interpréteur font le même pari structurel. (NVD)
CVE-2025-53355 en mcp-server-kubernetes rend la leçon du MCP encore plus claire. La NVD et l'avis de GitHub décrivent des données non hygiénisées qui s'écoulent dans le système processus_enfant.execSyncpermettant l'injection de commandes et l'exécution potentielle de code à distance sous les privilèges du serveur MCP, avec un correctif dans la version 2.5.0. En clair, une surface d'outils destinée à aider un agent à faire fonctionner l'infrastructure est devenue une limite d'exécution de commande. C'est exactement la raison pour laquelle un orchestrateur de pentest basé sur Gemma devrait envelopper chaque outil avec une validation stricte des arguments plutôt que d'exposer des chaînes de paramètres brutes ou des fragments de shell. (GitHub)
CVE-2025-66414 montre que même les hypothèses "local only" peuvent échouer. NVD indique que lorsqu'un serveur MCP basé sur HTTP fonctionne sur localhost sans authentification et sans protection DNS, un site web malveillant peut contourner les restrictions de même origine via DNS rebinding et invoquer des outils ou accéder à des ressources exposées par le serveur MCP local. Cela est directement lié à tout flux de travail de sécurité "local first". Un service local n'est pas automatiquement sûr simplement parce qu'il n'est pas routable vers l'internet de manière évidente. Si votre pile Gemma communique avec des outils ou des serveurs MCP locaux, vous avez toujours besoin d'une protection de l'origine, d'une authentification et d'un renforcement explicite. (NVD)
CVE-2025-67511 est peut-être l'avertissement le plus direct concernant les outils offensifs basés sur l'IA. NVD et l'avis de GitHub décrivent une faille d'injection de commande dans le logiciel run_ssh_command_with_credentials() du cadre de cybersécurité de l'IA, un outil mis à la disposition des agents de l'IA. L'avis indique que seuls certains champs ont été échappés et qu'il n'y avait pas de correctif au moment de la publication. Ce cas est important car il montre à quelle vitesse un "outil d'agent d'IA" peut devenir un puits d'injection privilégié. Une fois qu'un modèle est autorisé à remplir les paramètres de l'outil au moment de l'exécution, chaque champ non validé devient une surface d'attaque. (NVD)
| CVE | Pourquoi c'est important ici | Condition d'exploitation | Atténuation pratique |
|---|---|---|---|
| CVE-2026-27966 | Montre comment l'injection de prompt devient RCE lorsqu'un agent d'analyse de données expose par défaut une REPL Python | Langflow CSV Agent avant 1.8.0 avec un chemin de code dangereux activé | Mise à niveau, désactivation des chemins de code dangereux, séparation de l'analyse et de l'exécution |
| CVE-2024-42835 | Exemple antérieur de Langflow d'exposition d'un interprète se transformant en RCE | PythonCodeTool accessible dans la version vulnérable de Langflow | Supprimer ou isoler les outils d'exécution de code, restreindre les privilèges, appliquer rapidement les correctifs. |
| CVE-2025-53355 | Les enveloppes d'outils MCP peuvent devenir des limites d'injection de commandes | Paramètres non assainis en execSync-Outils Kubernetes basés sur la technologie | Schémas d'arguments stricts, pas d'interpolation de shell, mise à jour vers la version corrigée |
| CVE-2025-66414 | Les services MCP de l'hôte local sont toujours exploitables dans les bonnes conditions de navigation. | Serveur HTTP MCP sur localhost, pas d'authentification, protection contre le rebinding désactivée | Exiger l'authentification, activer la protection contre le rebindage, minimiser l'accessibilité du navigateur |
| CVE-2025-67511 | Un outil d'agent d'intelligence artificielle peut exposer des fonctions de commande dangereuses avec une désinfection incomplète. | Les agents d'intelligence artificielle disposent d'une aide à la commande SSH vulnérable | Retirer ou envelopper les outils dangereux, valider chaque champ, ne pas faire confiance aux paramètres remplis par le modèle. |
Ces CVE ne prouvent pas que Gemma 4 31B est risqué en soi. Ils prouvent quelque chose de plus important : le danger réside dans le couplage entre le raisonnement de modèle et les surfaces de capacité. Un flux de travail de pentest Gemma bien conçu apprend de ces échecs et maintient la limite d'exécution étroite, typée et observable.
Concevoir un contrat d'action sûr
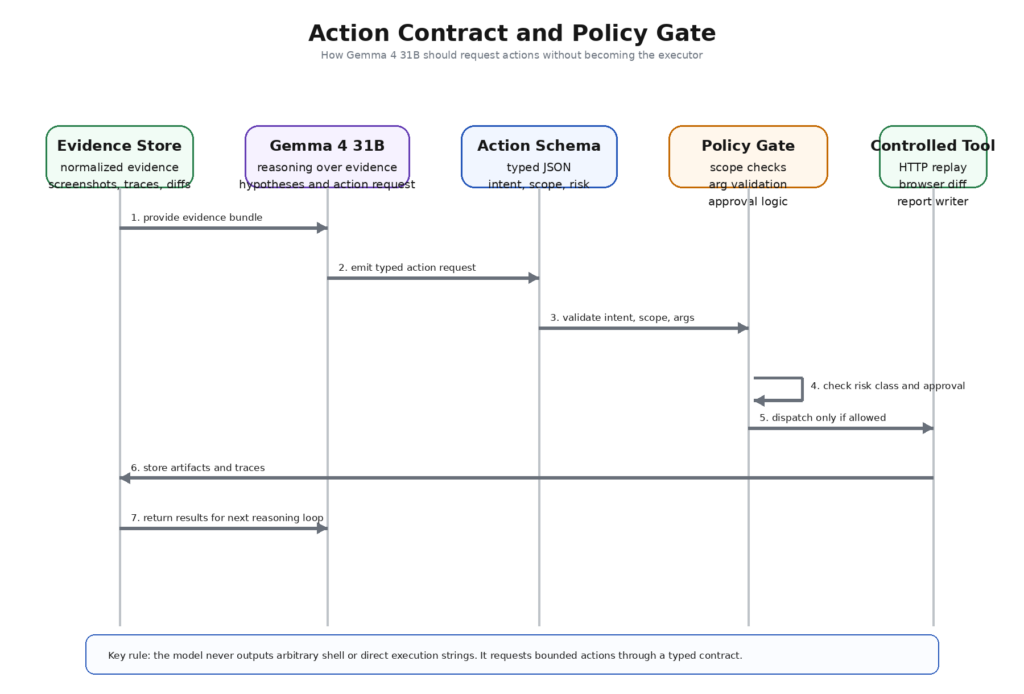
Le moyen le plus rapide de perdre le contrôle d'un flux de travail de pentest assisté par l'IA est de laisser le modèle émettre des commandes de forme libre qu'un autre système exécute. La bonne solution n'est pas de "faire attention". La bonne solution est un contrat d'action.
Un contrat d'action utile possède trois propriétés. Premièrement, il est structuré. Le modèle renvoie des champs typés, et non de la prose. Deuxièmement, il est déclaratif. Le modèle énonce l'intention et les paramètres requis, et non la commande brute du système. Troisièmement, il est révisable. La classe de risque, la base de preuves et les artefacts attendus sont explicites avant toute exécution.
Un objet d'action minimal peut ressembler à ceci :
{
"intent" : "verify_object_level_authorization",
"target_scope" : {
"project_id" : "acme-b2b-portal",
"asset" : "app.target.example",
"route_group" : "/api/v1/invoices"
},
"risk_class" : "credentialed_read_only_replay",
"read_only" : true,
"required_tool" : "http_replay_runner",
"arguments" : {
"method" : "GET",
"candidate_object_ids" : ["inv_1042", "inv_1043", "inv_1044"],
"profils_de_rôle" : ["basic_user", "billing_admin"],
"compare_fields" : ["status", "line_items", "customer_id"].
},
"evidence_basis" : [
"js_route_extraction:bundle_17",
"ui_screenshot:billing_export_screen",
"response_diff:role_matrix_run_02"
],
"expected_artifacts" : [
"request_trace",
"response_diff",
"matrice_d'accès"
],
"needs_approval" : true,
"confidence" : "moyen"
}
Cet objet est ennuyeux de par sa conception. C'est ce qui fait sa force. Le modèle ne décide pas comment coder les en-têtes, où stocker les traces, s'il faut réessayer ou quelle commande du système d'exploitation invoquer. Il s'agit d'une requête limitée à l'intérieur d'une interface typée. Cela rend la validation possible. La porte d'entrée de la politique peut rejeter une classe de risque, rejeter un groupe d'itinéraires en dehors du champ d'application, rejeter un outil qui ne figure pas sur la liste d'autorisation ou forcer l'approbation parce que l'action touche un flux authentifié.
Ce contrat améliore également la qualité de l'analyse. Lorsque le modèle doit citer d'emblée une base de preuves et les artefacts attendus, il est moins susceptible de passer de la spéculation à la conclusion. Le schéma d'action devient une fonction de forçage pour la discipline épistémique. C'est important pour le pentesting, car un bon travail offensif ne consiste pas seulement à trouver des chemins intéressants. Il s'agit de préserver une chaîne propre de l'observation à la preuve.
Le support natif de Gemma 4 pour l'appel de fonctions est particulièrement bien adapté à ce modèle. La documentation officielle du modèle positionne explicitement l'appel de fonction comme une capacité intégrée pour l'utilisation d'outils structurés et de flux de travail agentiques. Dans une pile de pentest, cela doit être interprété de manière restrictive : utiliser la capacité à demander des actions révisées, et non pas à contourner le besoin de révision. (Google AI pour les développeurs)
Transformer le contrat d'action en une couche d'exécution
Un schéma en lui-même n'est pas une application. Il n'est que le langage que l'application peut utiliser. La couche suivante est une porte de politique qui valide chaque action demandée par rapport au champ d'application, au privilège et à la classe d'exécution avant de la distribuer.
Un simple contrôleur de type Python illustre l'idée :
from dataclasses import dataclass
from typing import Any, Dict
ALLOWED_TOOLS = {
"passive_recon_runner",
"http_replay_runner",
"screenshot_diff_runner",
"js_endpoint_mapper",
"report_writer"
}
RISK_CLASSES = {
"passive" : {"approval" : False, "state_change" : False},
"credentialed_read_only_replay" : {"approval" : True, "state_change" : False True, "state_change" : False},
"ui_navigation_only" : {"approval" : True, "state_change" : False} : True, "state_change" : False},
"state_modifying" : {"approval" : True, "state_change" : False} : True, "state_change" : True},
"interdit" : {"approval" : True, "state_change" : True}, "interdit" : {"approval" : True, "state_change" : True}, "prohibited" : {"approval" : True True, "state_change" : True}
}
@dataclass
classe Decision :
allowed : bool
reason : str
requires_approval : bool = False
def validate_scope(action : Dict[str, Any], allowed_assets : set[str]) -> Decision :
asset = action["target_scope"]["asset"]
if asset not in allowed_assets :
return Decision(False, f "asset خارج scope : {asset}")
return Decision(True, "scope ok")
def validate_tool(action : Dict[str, Any]) -> Decision :
tool = action["required_tool"]
if tool not in ALLOWED_TOOLS :
return Decision(False, f "outil non autorisé : {outil}")
return Decision(True, "outil ok")
def validate_risk(action : Dict[str, Any]) -> Decision :
rc = action["risk_class"]
si rc n'est pas dans RISK_CLASSES :
return Decision(False, f "classe de risque inconnue : {rc}")
si rc == "interdit" :
return Decision(False, "Classe d'action interdite")
cfg = RISK_CLASSES[rc]
return Decision(True, "risque ok", requires_approval=cfg["approval"])
def dispatch(action : Dict[str, Any]) -> str :
# Les wrappers d'outils sont déterministes et typés.
# Pas d'interpolation de shell. Pas de bash arbitraire.
return f "queued:{action['required_tool']}"
def handle_action(action : Dict[str, Any], allowed_assets : set[str]) -> str :
for check in (validate_scope, validate_tool, validate_risk) :
decision = check(action, allowed_assets) if check == validate_scope else check(action)
if not decision.allowed :
raise ValueError(decision.reason)
if decision.requires_approval :
return f "approbation_required:{decision.reason}"
return dispatch(action)
Une version de production irait plus loin. Elle mettrait en place des coffres-forts d'accréditation par projet, des limites de taux, des validateurs d'arguments, la rétention d'artefacts et des identifiants de tâches idempotentes. Elle enregistrerait qui a approuvé quoi et quelle preuve exacte a déclenché la demande. Mais même cet exemple simple démontre le point structurel. Le modèle demande. Le système valide. Ce n'est qu'ensuite qu'une enveloppe déterministe s'exécute.
C'est également à ce stade qu'un flux de travail commercial peut apporter une réelle valeur ajoutée sans modifier la vérité technique. Le matériel de Public Penligent met l'accent sur les flux de travail contrôlés par l'opérateur, les rapports étayés par des preuves, les tests multirôles authentifiés, l'intégration CI ou CD et le déploiement privé avec l'intégration de modèles privés. Il ne s'agit pas là d'artifices de marketing si le flux de travail est conçu correctement. Ce sont des caractéristiques de la couche d'application. La comparaison utile n'est pas "humain contre IA". La comparaison utile n'est pas "l'homme contre l'IA", mais "les résultats d'un modèle non protégé contre les contrats d'action régis". (Penligent)
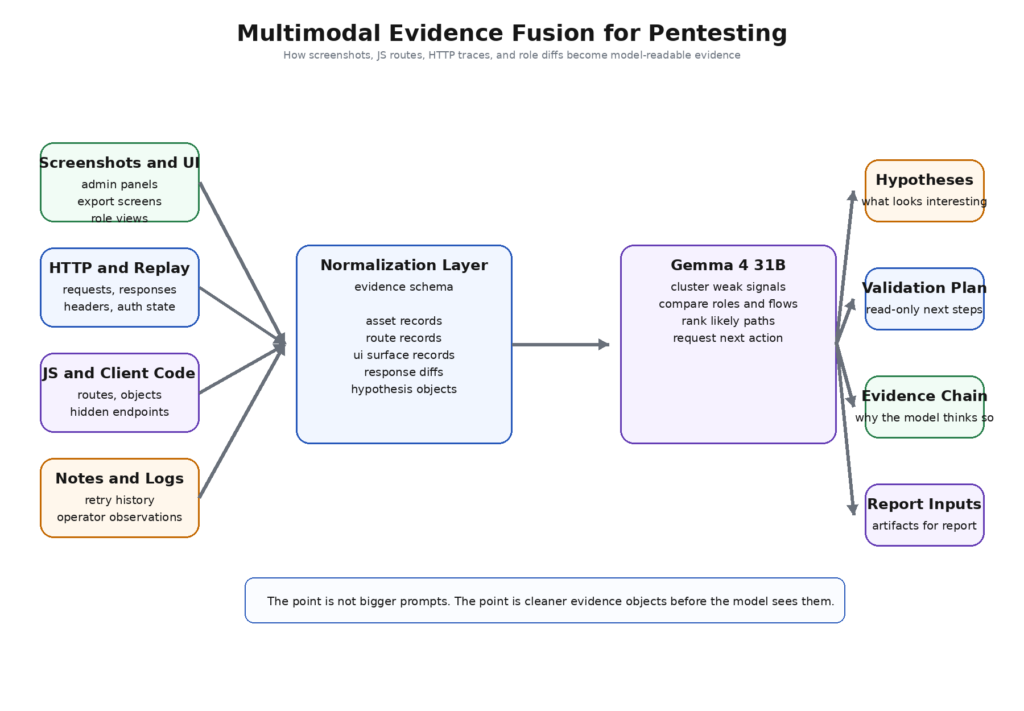
Transformer la reconnaissance brute en preuves lisibles par le modèle
La promesse d'un contexte long de Gemma 4 31B est facile à gâcher. Si vous alimentez le modèle avec des dumps de pâte brute, vous n'avez pas construit un flux de travail de sécurité sérieux. Vous avez construit un plus grand seau de chaos.
La bonne solution consiste à normaliser les preuves. Chaque collectionneur devrait produire un petit nombre de documents dactylographiés. Un balayage passif produit des enregistrements de biens et de services. Un analyseur JavaScript produit des enregistrements d'itinéraires, de paramètres et de noms d'objets. L'exécution d'un navigateur produit des enregistrements de surface d'interface utilisateur, des enregistrements de rôle et des enregistrements de capture d'écran. Une relecture authentifiée se traduit par des enregistrements de différences de réponses et de matrices d'accès. Une note humaine devient un enregistrement d'hypothèse avec provenance.
Un jeu d'enregistrements normalisés peut se présenter comme suit :
{
"engagement" : "acme-b2b-portal-q2",
"assets" : [
{
"asset" : "app.target.example",
"role" : "primary_app",
"services" : [
{"port" : 443, "proto" : "https", "product" : "nginx"},
{"port" : 8443 8443, "proto" : "https", "produit" : "internal-gateway"}
]
}
],
"ui_surfaces" : [
{
"surface_id" : "billing_export_panel",
"role_seen_as" : "billing_admin",
"screen_type" : "export_console",
"screenshot_ref" : "screens/role_admin_07.png",
"visible_actions" : ["export_all", "download_csv", "filter_by_customer"].
}
],
"routes" : [
{
"path" : "/api/v1/invoices/{invoice_id}",
"source" : "bundle_extract",
"object_hint" : "invoice",
"auth_hint" : "session_cookie"
}
],
"response_diffs" : [
{
"diff_id" : "role_matrix_02",
"route" : "/api/v1/invoices/inv_1042",
"roles_compared" : ["basic_user", "billing_admin"],
"differences" : ["line_items", "customer_id", "download_url"].
}
],
"hypotheses" : [
{
"hypothesis_id" : "h-14",
"claim" : "possible rupture de l'autorisation au niveau de l'objet dans le flux d'exportation de la facture",
"evidence_refs" : [
"billing_export_panel",
"bundle_extract:/api/v1/invoices/{invoice_id}",
"role_matrix_02"
],
"status" : "unverified"
}
]
}
Cela est important car les modèles à contexte long sont plus aptes à raisonner sur des objets sémantiquement explicites que sur un bruit d'outil opaque. Un modèle nmap ou un blob HTML est toujours utile, mais il doit être placé derrière une référence. L'invite principale doit contenir les faits distillés et leur provenance, et non chaque octet collecté jusqu'à présent.
La vieille leçon du document PentestGPT sur la perte de contexte s'applique ici presque parfaitement. Sa conception modulaire était une réponse au fait que les boucles LLM génériques perdent l'état de l'engagement au fur et à mesure que la session se développe. Gemma 4 31B vous donne plus d'espace, mais plus d'espace n'est pas la même chose qu'un meilleur modèle de mémoire. Les équipes de sécurité doivent encore décider ce qui appartient au cadre actif et ce qui appartient à l'entrepôt de preuves. Le cadre actif ne doit contenir que ce qui modifie la décision suivante. (USENIX)
Une bonne règle consiste à séparer explicitement les observations, les hypothèses et les conclusions. Les observations sont des faits bruts. Les hypothèses sont des modèles ou des interprétations humaines de ce que ces faits pourraient signifier. Les conclusions nécessitent des artefacts de validation. Lorsque ces trois couches sont mélangées, le modèle commence à lire ses propres spéculations comme des vérités. C'est l'un des moyens les plus faciles de créer des faux positifs assistés par l'IA qui semblent plus rigoureux qu'ils ne le sont.
Utiliser le raisonnement multimodal sans transformer les captures d'écran en chaos
Le profil multimodal de Gemma 4 est particulièrement pertinent pour le pentesting, car l'état le plus important de l'application est souvent visible avant d'être facile à décrire. La carte modèle de Google indique explicitement que Gemma 4 prend en charge la compréhension des images, y compris l'analyse des documents et des PDF, la compréhension de l'écran et de l'interface utilisateur, la reconnaissance optique des caractères (OCR) et les rapports d'aspect variables. C'est exceptionnellement pratique pour le travail de sécurité. Une capture d'écran d'un outil d'arrière-guichet est souvent un meilleur indice qu'une transcription d'API précoce, car elle vous indique ce que le produit pense que les utilisateurs privilégiés sont autorisés à faire. (Google AI pour les développeurs)
Pensez aux types d'écrans qui comptent dans les engagements réels : tableaux de bord d'exportation, files d'attente de modération, consoles de facturation, panneaux de gestion des fournisseurs, outils de recherche interne, éditeurs de droits, pages de drapeaux de fonctionnalités, flux d'usurpation d'identité de l'assistance ou écrans d'ajustement des commandes. Un modèle multimodal peut aider à classer les écrans qui semblent sensibles d'un point de vue opérationnel, les actions qui impliquent des voies d'escalade des privilèges et les cas où deux rôles semblent visuellement différents d'une manière qui mérite d'être testée. Il ne s'agit pas d'une preuve de vulnérabilité. Il s'agit d'une accélération du triage.
Il est utile de combiner des captures d'écran avec un résumé structuré plutôt que d'envoyer uniquement des captures d'écran. Par exemple :
Système :
Vous êtes un modèle de raisonnement pentest local. Vous n'êtes pas autorisé à exécuter des actions.
Vous ne pouvez que classer les interfaces utilisateur visibles, déduire les limites de confiance probables et proposer des étapes de vérification en lecture seule.
Retournez uniquement du JSON.
Utilisateur :
Artéfacts :
1. Captures d'écran : role_user_03.png, role_admin_07.png
2. Résumé DOM :
- titre de la page : Exportations de facturation
- boutons visibles sur l'admin : Exporter tout, Télécharger CSV, Filtrer par client
- boutons visibles pour l'utilisateur : Voir mes factures
3. Notes de session :
- l'administrateur et l'utilisateur partagent le même shell de l'application de base
- Indication de route à partir de JS : /api/v1/invoices/{invoice_id}
Tâche :
Classer la surface, déduire les limites d'autorisation probables et proposer un plan de vérification en lecture seule.
La valeur du modèle dans ce type d'échange n'est pas qu'il "voit la capture d'écran". C'est qu'il voit la capture d'écran et les preuves qui l'entourent ensemble. Un bouton seul est ambigu. Un bouton lié à une indication d'itinéraire, à une note de rôle et à un objet commercial connu est beaucoup plus instructif.
Il y a des limites, et elles sont importantes. L'interprétation de l'interface utilisateur peut halluciner la sémantique. Deux écrans qui se ressemblent peuvent néanmoins emprunter des chemins complètement différents. Un texte extrait d'une capture d'écran peut omettre un état caché crucial. Les superpositions d'accessibilité, les mises en page réactives et le contenu dynamique peuvent fausser ce que le modèle déduit. C'est pourquoi le raisonnement à partir d'une capture d'écran doit toujours aboutir à un plan de vérification, jamais à une conclusion. Le bon résultat est "ceci ressemble à un chemin d'exportation privilégié qui mérite une relecture en lecture seule avec un rôle différent", et non pas "ceci est certainement un problème de contrôle d'accès non respecté".
C'est également l'un des endroits les plus naturels pour faire le lien avec les flux de travail offensifs natifs de l'IA de manière plus générale. Les documents publics de Penligent mettent l'accent sur les rapports "evidence-first", les tests multirôles authentifiés et l'exécution contrôlée par l'opérateur plutôt que sur un moteur d'exploitation unique et aveugle. Cet instinct de conception s'aligne bien sur le raisonnement multimodal : utiliser les captures d'écran et la sémantique de l'interface utilisateur pour guider la validation, et non pour la remplacer. (Penligent)
Analyse du contexte long à laquelle un ingénieur en sécurité peut réellement se fier
Une fenêtre contextuelle de 256 Ko est utile, mais uniquement lorsque l'invite est traitée comme une mémoire de travail plutôt que comme un espace de stockage. Dans le pentesting, cela signifie qu'il faut gérer ce que le modèle voit à chaque étape.
La première règle consiste à préserver la provenance. Chaque affirmation importante traitée par le modèle doit renvoyer à un artefact, et pas seulement à un autre résumé de modèle. Si une hypothèse fait référence à une capture d'écran, à un extrait de route et à une réponse diff, ces références doivent être visibles. Cela réduit la tendance à inventer un tissu conjonctif entre des faits qui n'ont rien à voir ensemble.
La deuxième règle consiste à conserver les tentatives infructueuses, mais uniquement sous forme comprimée. Les tentatives infructueuses sont précieuses car elles apprennent au modèle ce qu'il ne faut pas réessayer et où les hypothèses se sont déjà effondrées. Ils deviennent toxiques lorsque leurs détails bruts submergent l'invite. Le meilleur schéma consiste à résumer chaque tentative échouée sous la forme d'un objet compact : cible, méthode, état de l'authentification, résultat, raison de l'abandon. Cela permet de conserver l'historique de l'enquête sans obliger le modèle à relire chaque trace.
La troisième règle consiste à séparer le contexte de l'environnement de celui de l'action. Le contexte de l'environnement comprend des faits stables : actifs cibles, rôles, produits, objets commerciaux, itinéraires antérieurs connus, limites de confiance de haut niveau. Le contexte d'action comprend ce qui est immédiatement pertinent pour la prochaine décision. Si tout se trouve dans une transcription massive, le modèle consacre plus d'efforts à relocaliser l'état du monde qu'à raisonner à son sujet.
La quatrième règle consiste à forcer le modèle à externaliser l'incertitude. Un bon format de sortie fait la distinction entre "observé", "déduit" et "à valider". Les ingénieurs en sécurité pensent déjà de cette manière. Le modèle doit être amené à penser de la même manière. Cela importe plus que le choix de l'adjectif dans le rapport final.
Le document PentestGPT est toujours utile ici parce qu'il nomme le problème central sans romancer la solution : le contexte de pentest de bout en bout est difficile à préserver pour les LLM. Le long contexte de Gemma 4 31B donne aux constructeurs plus d'espace pour travailler, et son support de rôle de système ainsi que l'appel de fonction rendent l'invite structurée plus facile, mais la responsabilité opérationnelle reste la même. Vous avez toujours besoin d'une architecture d'invite, de schémas de preuves et d'une politique d'extraction qui favorise la pertinence plutôt que le volume. (USENIX)
Dans la pratique, cela signifie que les cas d'utilisation du contexte long les plus fiables sont comparatifs plutôt que génératifs. Demandez au modèle de comparer les traces de rôle, de regrouper les signaux faibles, d'expliquer pourquoi deux éléments de preuve peuvent appartenir à un même problème de contrôle d'accès ou de classer les hypothèses qui méritent d'être validées en premier. Demandez moins souvent un plan complet à partir de zéro. Plus vous demandez au modèle de raisonner à partir des éléments dont vous disposez déjà, moins vous dépendez de la créativité spéculative.
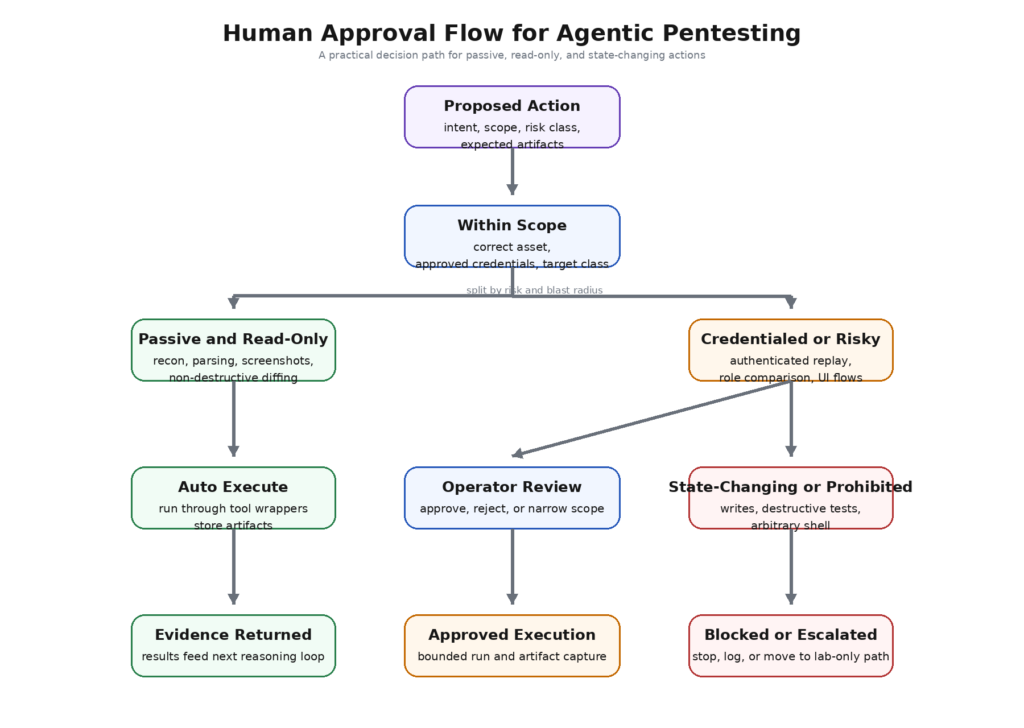
L'approbation humaine fait partie de la conception, ce n'est pas une solution de repli
Beaucoup de flux de sécurité de l'IA traitent l'examen humain comme un frein de sécurité optionnel. Dans une pile de pentest, c'est à l'envers. L'approbation humaine devrait être un concept de routage de première classe dans le système. Le modèle doit savoir quels types d'actions sont automatiquement exécutables, lesquelles sont soumises à approbation et lesquelles sont totalement interdites.
Une simple matrice d'approbation permet de concrétiser cela :
| Classe d'action | Exemple | Exécution automatique | Approbation humaine | Preuves requises après l'exécution |
|---|---|---|---|---|
| Passif | DNS, collecte d'en-têtes, extraction d'itinéraires, capture d'écran des pages publiques concernées | Oui | Non | Artéfact brut et sortie de l'analyseur |
| Relecture en lecture seule | Relecture d'un GET authentifié, comparaison des rôles, vérification de l'accès à l'URL d'exportation sans changement d'état | Généralement non | Oui | Trace de la demande, différence de réponse, matrice d'accès |
| Navigation dans l'interface utilisateur uniquement | Navigation contrôlée avec une session existante, sans soumission de formulaire | Généralement non | Oui | Vidéo ou captures d'écran, DOM diff |
| Modification de l'état | Modification des données du profil, création d'objets, approbation d'actions, envoi de courrier | Non | Oui, explicite | Trace complète, note de retour en arrière, connaissance du propriétaire de la cible si nécessaire |
| Interdit | Fuzzing destructeur, tentatives d'escalade des privilèges en dehors des laboratoires agréés, shell arbitraire ou post-exploitation. | Non | Non autorisé | Aucun, bloqué au niveau de la politique |
Il ne s'agit pas de bureaucratie pour le plaisir. C'est ce qui transforme le modèle d'acteur en assistant doté d'une autorité limitée. Une fois que ces classes existent, le système peut forcer le modèle à demander la bonne classe, et l'opérateur peut rapidement vérifier si la demande correspond au risque réel. Si le modèle demande une "relecture en lecture seule" qui contient en réalité un POST vers un point de terminaison d'écriture, l'incohérence est visible avant l'exécution.
La conception de l'approbation améliore également l'apprentissage. Lorsque les opérateurs rejettent des actions suggérées par le modèle, la raison du rejet devient partie intégrante de l'écosystème de preuves : hors du champ d'application, mauvais rôle, rayon d'explosion trop important, preuves insuffisantes, redondantes ou vraisemblablement faux positifs. Ce retour d'information est souvent plus utile sur le plan opérationnel qu'une autre série d'ajustements du modèle, car il apprend au flux de travail à quoi ressemble un bon jugement dans le cadre de votre champ d'application et de vos contraintes.
Cette structure humaine dans la boucle est également l'endroit où la valeur d'un pentester d'IA gouverné devient plus facile à expliquer aux acheteurs et aux ingénieurs. Le meilleur cadrage public de Penligent sur ce point décrit un pentester d'IA non pas comme un chatbot jouet ou un robot consultant, mais comme un système gouverné qui réduit la distance entre le signal brut et le résultat vérifié. Il s'agit d'une description beaucoup plus forte et défendable que le "piratage autonome", et elle correspond parfaitement à Gemma 4 31B lorsqu'elle est utilisée comme couche de raisonnement local. (Penligent)
Comment évaluer une pile de pentest Gemma 4 31B ?
La mauvaise façon d'évaluer ce type de système est de se demander si le modèle "semble intelligent". La bonne façon est de mesurer si le flux de travail produit moins d'actions inutiles et de meilleures preuves.
Commencez par trouver la précision, mais définissez-la de manière étroite. Une mesure utile n'est pas "combien de problèmes le modèle a-t-il mentionnés", mais "combien de problèmes ont atteint un état vérifié avec une chaîne de preuves complète par rapport au nombre de tentatives de validation". Il s'agit de savoir "combien de questions ont atteint un état vérifié avec une chaîne de preuves complète par rapport au nombre de tentatives de validation qui ont été lancées". Cela pénalise les systèmes qui génèrent des absurdités plausibles tout en récompensant les systèmes qui transforment l'ambiguïté en preuve.
La deuxième mesure est le délai entre le signal et la preuve. Combien de temps faut-il pour passer du premier signal faible à une hypothèse vérifiée ou rejetée ? C'est là qu'un bon noyau de raisonnement local devrait gagner sa place. Il devrait réduire le temps passé à relire les artefacts, à réexpliquer le contexte et à décider des prochains tests. Un système qui rédige des résumés plus agréables mais qui ne fait pas évoluer ce chiffre est essentiellement cosmétique.
La troisième mesure est le taux d'actions inutiles. Combien d'actions proposées par le modèle sont bloquées par la politique, rejetées par l'opérateur ou produisent des artefacts manifestement redondants ? Ce chiffre en dit long sur l'efficacité de la normalisation des preuves et du schéma d'action. Si le modèle continue à demander la mauvaise classe d'action, le problème n'est peut-être pas du tout le modèle. Il peut s'agir de l'architecture de l'invite ou de l'absence de contexte typé.
La quatrième mesure est l'exhaustivité des preuves. Un autre ingénieur peut-il reproduire la validation à partir des seuls artefacts stockés ? Le champ d'application, l'état d'authentification, les traces de requête et les comparaisons de rôles sont-ils préservés ? Le contenu de sécurité généré par l'IA échoue souvent à ce niveau. Il peut être convaincant sans être reproductible sur le plan opérationnel. Un bon flux de travail Gemma devrait améliorer l'exhaustivité parce qu'il peut forcer le modèle à citer sa base de preuves avant qu'une action ne soit approuvée.
La cinquième mesure est la charge d'approbation. Les systèmes à boucle humaine échouent lorsque chaque action doit faire l'objet d'un nouvel examen sous forme de dissertation. L'objectif n'est pas d'obtenir zéro approbation. L'objectif est d'obtenir des approbations peu contraignantes parce que la demande d'action est saisie, délimitée et étayée par des preuves. Si l'opérateur ne peut pas décider en quelques secondes si une vérification en lecture seule proposée est sûre, le contrat d'action est trop vague.
La sixième mesure est la précision des retests. Lorsqu'un développeur affirme qu'un problème est résolu, le système peut-il comparer les artefacts avant et après et indiquer si la découverte s'est effondrée, partiellement effondrée ou simplement déplacée ? Il s'agit de l'une des utilisations les plus utiles d'un modèle de raisonnement en contexte long, car il est intrinsèquement comparatif et axé sur les preuves.
Un bakeoff interne pratique peut donc comparer trois flux de travail sur le même laboratoire ou application interne : un testeur manuel utilisant des outils conventionnels, un modèle générique de frontière en mode de discussion libre, et un flux de travail gouverné par Gemma 4 31B avec des portes de normalisation et de politique. La recherche PentestGPT suggère déjà pourquoi le troisième modèle vaut la peine d'être essayé : les gains des LLM apparaissent plus clairement lorsque la structure du flux de travail les aide à préserver le contexte et à spécialiser les sous-tâches plutôt que d'imposer une autonomie totale fragile. (USENIX)
Ajustement, récupération, et quand ne pas personnaliser le modèle
Les équipes de sécurité aiment la personnalisation, et ce pour de bonnes raisons. Les environnements sont spécifiques. Les modèles d'objets sont spécifiques. Les exigences en matière de rapports sont spécifiques. Mais la mise au point est souvent la première étape à ne pas franchir.
Les meilleurs premiers investissements sont la normalisation des preuves, la qualité de la recherche, la conception des schémas de sortie et l'intégration des politiques. Ces éléments améliorent la qualité de chaque action demandée par le modèle parce qu'ils améliorent la définition même du problème. Si le modèle voit des preuves plus nettes et renvoie des sorties typées, il devient plus facile de l'utiliser en toute sécurité avant que quiconque ne touche aux poids.
Le réglage fin devient plus contraignant lorsque la forme du flux de travail est déjà stable. Parmi les bonnes cibles de réglage figurent les taxonomies internes des problèmes, le ton des rapports, les conventions de dénomination des objets commerciaux, le style des résumés structurés et les classifications liées à votre produit ou à votre environnement. Si vos testeurs travaillent toujours avec la même classe d'application SaaS ou la même classe de backend mobile, ce type de réglage peut améliorer la fluidité et réduire les frictions.
La mauvaise chose à régler est l'agressivité. Les équipes parlent parfois comme si le modèle allait devenir un meilleur pentester en étant plus disposé à prendre des risques. Il ne s'agit pas d'une amélioration des capacités. Il s'agit d'un échec dans l'application de la loi. La véritable qualité offensive provient d'une meilleure gestion des preuves, d'un meilleur suivi des états, d'un meilleur raisonnement sur les rôles, d'une meilleure priorisation de la couverture et de chemins de preuve plus propres. Aucun de ces éléments ne nécessite de supprimer les freins du système.
C'est un domaine où les poids ouverts sont importants, mais seulement dans le bon ordre. La possibilité de déploiement local de Gemma 4 et les licences plus claires donnent aux équipes la possibilité de régler et d'héberger le modèle elles-mêmes. C'est un atout précieux. Ce n'est pas le premier problème à résoudre. Il faut d'abord élaborer le contrat. Puis construire le système de preuves. Ensuite, il faut décider ce qui, le cas échéant, nécessite une adaptation du modèle. (Google AI pour les développeurs)
Mathématiques de déploiement et réalité matérielle
Gemma 4 31B est adapté à l'environnement local dans le sens où il n'est pas exclusivement dans le nuage. Il n'est pas léger au sens où l'entendent la plupart des gens lorsqu'ils disent "je vais juste l'exécuter localement". La table de mémoire officielle de Google est le point de départ le plus propre : environ 58,3 Go en BF16, 30,4 Go en 8 bits et 17,4 Go en Q4_0 pour les poids de base 31B, avec l'avertissement explicite que ces chiffres excluent la surcharge logicielle et la mémoire supplémentaire consommée par le contexte. Cet avertissement est important. Un flux de travail de raisonnement de pentest est exactement le type de charge de travail qui incite les équipes à utiliser de grands contextes. La croissance du cache KV n'est pas une note de bas de page académique. Elle fait partie intégrante de la planification des capacités. (Google AI pour les développeurs)
Cette réalité conduit à une répartition judicieuse des déploiements. Si vous souhaitez un centre de raisonnement local capable de contenir des preuves substantielles et d'effectuer des analyses comparatives plus lourdes, le modèle 31B a du sens en tant que couche supérieure. Si vous voulez de minuscules aides côté terminal pour l'assistance de l'interface utilisateur ou une classification rapide, des modèles plus petits peuvent remplir ce rôle. Le positionnement de DeepMind laisse déjà entrevoir cette division : les variantes les plus petites sont conçues pour les scénarios en périphérie et mobiles, tandis que les classes 31B et 26B sont conçues pour les postes de travail et le raisonnement avancé. En termes pratiques, cela fait du 31B un bon candidat pour le "cerveau" d'un système pentest gouverné plutôt que pour chaque surface d'interaction. (Google DeepMind)
L'autre question relative au déploiement est de savoir où se situe le modèle par rapport au plan d'exécution. Une erreur courante consiste à placer le modèle de raisonnement et tous les outils dangereux à l'intérieur d'un service tout aussi privilégié. C'est pratique, mais c'est souvent une erreur. Une conception plus sûre maintient le modèle près du magasin de preuves et du moteur de politique, tandis que les outils d'exécution vivent derrière des enveloppes plus étroites avec leurs propres contraintes d'exécution. Si une surface d'exécution est compromise, vous voulez que le rayon d'action s'arrête là au lieu de s'étendre à l'ensemble de la couche de raisonnement.
C'est également à ce stade que les caractéristiques du déploiement privé cessent d'être un détail d'approvisionnement pour devenir une architecture de sécurité. Les documents de Penligent destinés aux entreprises publiques et aux équipes font référence au déploiement privé, à l'intégration de modèles privés, aux tests de flux authentifiés, à la journalisation des audits et à l'intégration de CI ou de CD. Même si une équipe choisit une pile Gemma entièrement personnalisée, ce sont les catégories à imiter. L'automatisation sérieuse des pentests ne s'arrête pas à "le modèle fonctionne sur notre matériel". Elle se termine lorsque l'ensemble du flux de travail obéit au même modèle de sécurité que l'environnement qu'il est censé évaluer. (Penligent)
Modes d'échec courants dans le pentesting LLM local
Le premier mode d'échec consiste à confondre la confiance dans le modèle avec la qualité des preuves. Un modèle à contexte long peut produire des explications magnifiquement structurées pour des affirmations faibles. Si le flux de travail n'oblige pas chaque étape importante à faire référence à des artefacts, il devient plus facile de faire confiance à l'explication qu'à la trace. C'est l'une des façons les plus courantes dont les travaux de sécurité assistés par l'IA tournent mal.
Le deuxième mode d'échec consiste à laisser un contenu cible non fiable s'infiltrer dans les chemins d'invocation de l'outil sans assainissement ni isolation. Le modèle n'a pas besoin d'être globalement "jailbreaké". Il suffit de le pousser à transmettre du texte contrôlé par la cible dans un champ dangereux. Les catégories "prompt injection" et "insecure output handling" de l'OWASP restent pertinentes précisément parce que cette chaîne de défaillance est si courante dans les systèmes d'agents. (Projet de sécurité Gen AI de l'OWASP)
Le troisième mode d'échec est une mauvaise hygiène de la mémoire. Les notes de longue date, les résumés mis en cache et les hypothèses sauvegardées peuvent empoisonner l'analyse future s'ils ne sont pas dactylographiés et versionnés. La mémoire est utile pour la continuité et nuisible lorsqu'elle confond "nous avons observé ceci" avec "nous avons pensé que cela pourrait être vrai la semaine dernière". Les systèmes agentiques ont besoin d'une provenance, et pas seulement d'une persistance.
Le quatrième mode d'échec consiste à considérer la fenêtre contextuelle de 256 Ko comme infinie. Un contexte plus large n'est utile que si la trame active reste pertinente. Une fois que les équipes commencent à déverser des logs bruts, des pages HTML complètes, des captures d'écran dupliquées et toutes les traces d'échec dans le prompt, la performance se dégrade en une version plus coûteuse de la confusion. La documentation officielle de Gemma est déjà honnête sur le fait qu'un contexte large a un coût de mémoire réel ; les équipes devraient être tout aussi honnêtes sur le fait qu'un contexte large a également un coût cognitif réel pour la conception de l'invite elle-même. (Google AI pour les développeurs)
Le cinquième mode d'échec consiste à supposer que les captures d'écran peuvent remplacer la vérification. Ce n'est pas le cas. Elles constituent d'excellents intrants de triage et de mauvais artefacts de preuve, à moins qu'elles ne soient liées à l'état du rôle, à l'historique des demandes et à la relecture déterministe. Le modèle doit utiliser des preuves visuelles pour planifier. L'exécutant doit utiliser les requêtes et les traces pour prouver.
Le sixième mode d'échec est la complaisance à l'égard des services locaux. Auto-hébergé ne signifie pas contenu en toute sécurité. Les travaux de Cisco et de Praetorian sur l'infrastructure LLM exposée suffisent à rendre ce point permanent. Un serveur modèle qui atterrit sur la mauvaise interface ou le mauvais segment n'est plus seulement une aide, c'est une nouvelle cible. (Blogs Cisco)
Le septième mode d'échec consiste à placer les approbations trop tard dans la boucle. Si l'opérateur ne voit la décision du modèle qu'après l'exécution de l'outil, il ne s'agit pas d'un être humain dans la boucle, mais d'un être humain après coup. C'est de l'humain après coup. Une véritable approbation signifie que l'opérateur examine une demande d'action saisie avant l'exécution.
Un parcours de déploiement pratique pour les équipes de sécurité
La meilleure voie d'adoption est incrémentale. Commencez par utiliser Gemma 4 31B en tant que couche de raisonnement passive avant de lui donner une quelconque influence sur l'exécution. Alimentez-le avec des reconnaissances normalisées, des captures d'écran et des extractions d'itinéraires. Utilisez-le pour regrouper la surface d'attaque, identifier les limites de confiance probables et générer des plans de vérification en lecture seule. Mesurez s'il fait gagner du temps à l'analyste avant de le connecter à quelque chose de plus puissant.
La deuxième phase est celle de la validation contrôlée. Laissez le modèle demander uniquement des actions de lecture ou de navigation par le biais de contrats typés. Exiger l'approbation de l'opérateur pour chaque relecture authentifiée. Stocker tous les artefacts qui en résultent. À ce stade, l'objectif n'est pas la rapidité. L'objectif est de prouver que le schéma d'action, la couche de politique et le pipeline de preuves fonctionnent sous la pression réelle de l'opérateur.
La troisième phase est celle des nouveaux tests comparatifs. Une fois que le système peut proposer et valider des contrôles simples en lecture seule de manière fiable, utilisez-le pour comparer les artefacts avant et après les résultats corrigés. C'est l'un des moyens les plus sûrs d'accroître la confiance, car la question est étroitement délimitée : la preuve a-t-elle changé de la manière dont la correction aurait dû le faire ?
La quatrième phase est l'intégration des flux de travail. Connectez la couche de raisonnement gouverné à la génération de rapports, à l'enrichissement des tickets ou aux crochets de retests CI ou CD. À ce stade, le modèle devient réellement utile, même pour les équipes qui ne souhaitent jamais une exécution offensive autonome. Il permet de comprimer les preuves, de suivre la régression et d'expliquer ce qui a changé sans devenir l'autorité qui décide des actions risquées.
Ce n'est qu'après ces étapes qu'une équipe devrait envisager des classes d'action plus avancées. Même dans ce cas, le système doit toujours privilégier les enveloppes étroites, les contrats dactylographiés et les approbations explicites. Un flux de travail de pentest prend de la valeur à mesure qu'il devient plus reproductible, et non pas à mesure qu'il devient plus théâtral.
C'est également à ce niveau que les connaissances internes et les orientations publiques se rejoignent. Les documents de l'équipe rouge de l'OWASP incitent à tester l'ensemble de l'implémentation et de l'exécution, et pas seulement le modèle. Le NIST s'efforce d'élaborer un langage clair pour les étapes d'attaque des systèmes d'IA et les mesures d'atténuation. Les récents CVE dans les outils d'agent montrent comment les mauvaises limites échouent dans la pratique. Et les nouveaux écrits sur le flux de travail des pentest, y compris le matériel de Penligent sur les pentesters de l'IA et les limites d'exécution de l'ère MCP, convergent de plus en plus vers la même vérité opérationnelle : la conception gagnante est gouvernée, la preuve d'abord, et explicite sur ce que le modèle peut demander par rapport à ce que le système peut réellement faire. (Projet de sécurité Gen AI de l'OWASP)
Dernières réflexions
Gemma 4 31B n'est pas le modèle qui transforme enfin le pentesting en exploitation sans surveillance. Ce n'est pas une faiblesse. C'est le début d'une bien meilleure adaptation.
Ce que le modèle offre, selon la documentation de Google, est une combinaison rare pour le travail de sécurité : un contexte long, une utilisation structurée des outils, un soutien du rôle du système, un raisonnement multimodal qui inclut la compréhension de l'interface utilisateur et des documents, et une histoire de déploiement qui peut rester locale et privée lorsque les preuves l'exigent. Ce que la littérature publique sur le pentesting nous rappelle toujours, en particulier depuis PentestGPT, c'est que le travail offensif de bout en bout se brise lorsque la gestion du contexte, les limites de l'autorité et la discipline de vérification se brisent. Si l'on réunit ces idées, le rôle de Gemma 4 31B devient évident. Ce n'est pas le pentester. C'est le noyau de raisonnement local à l'intérieur d'un système de pentest conçu autour de garde-fous. (Google AI pour les développeurs)
Si l'on part de cette hypothèse, le modèle peut être extrêmement utile. Il peut lire plus de preuves qu'un humain ne veut en relire. Il peut comparer les flux avec plus de patience qu'un être humain ne veut le faire. Il peut transformer une pile d'indices faibles en une liste restreinte de chemins d'attaque plausibles. Il peut aider à classer les surfaces privilégiées, à organiser les preuves de retests et à rendre les rapports plus reproductibles. Tout cela est précieux. Rien de tout cela ne nécessite de prétendre que le langage est la même chose que la preuve.
L'objectif de la conception n'est donc pas l'autonomie pour elle-même. Il s'agit d'un flux de travail de sécurité dans lequel chaque conclusion importante peut être retracée, chaque action dangereuse peut être refusée et chaque suggestion utile peut être convertie en preuve. Gemma 4 31B est suffisamment puissant pour être utile au sein de ce système. Le reste est de l'ordre de l'architecture.
Pour en savoir plus
Vue d'ensemble du modèle Gemma 4 et exigences officielles en matière de mémoire - Google AI for Developers. (Google AI pour les développeurs)
Carte modèle Gemma 4, comprenant le contexte long, l'appel de fonctions, la prise en charge du rôle du système et la compréhension de l'écran ou de l'interface utilisateur - Google AI for Developers. (Google AI pour les développeurs)
Gemma 4 release notes and DeepMind model page - détails officiels du lancement, tailles des modèles et positionnement pour les flux de travail agentiques. (Google AI pour les développeurs)
Gemma 4 sous Apache 2.0 - Google Open Source Blog. (Blog Google Open Source)
PentestGPT, évaluation et exploitation de grands modèles linguistiques pour les tests de pénétration automatisés - USENIX Security 2024. (USENIX)
Conseils de l'OWASP en matière d'injection rapide et Top 10 de l'OWASP pour les applications LLM - injection rapide, traitement non sécurisé des sorties, conception non sécurisée des plugins et agence excessive. (Projet de sécurité Gen AI de l'OWASP)
OWASP GenAI Red Teaming Guide - modèle, mise en œuvre, infrastructure et tests d'exécution. (Projet de sécurité Gen AI de l'OWASP)
NIST AI 100-2, Adversarial Machine Learning - taxonomie et terminologie des attaques et des mesures d'atténuation des systèmes d'IA. (Centre de ressources en sécurité informatique du NIST)
Références CVE et NVD relatives aux limites d'exécution agentiques - CVE-2026-27966, CVE-2024-42835, CVE-2025-53355, CVE-2025-66414 et CVE-2025-67511. (NVD)
AI Pentester en 2026, comment tester les systèmes d'IA sans les confondre - Penligent. (Penligent)
Sécurité de l'IA agentique en production, sécurité des MCP, empoisonnement de la mémoire, mauvaise utilisation des outils et nouvelle limite d'exécution - Penligent. (Penligent)
Pentest AI Tools in 2026, What Actually Works, What Breaks - Penligent. (Penligent)
Présentation de l'outil de test de pénétration automatisé de Penligent.ai - Penligent. (Penligent)
Plans et tarifs - Penligent, pour la forme de déploiement, les fonctionnalités de flux de travail et les détails d'intégration du modèle privé. (Penligent)

