Gemma 4 31Bはペンテスト・ブレイン、エクスプロイト・ボットではない
ジェマ4世31Bが書けるかどうかというのが間違った質問だ。 ナマップ コマンドを実行したり、Burpキャプチャを要約したりすることができる。正しい質問は、LLMが、もう1つの安全でない実行サーフェスになることなく、ノイズの多い証拠を検証された発見に変えるための人的コストを削減できるかどうかということです。というのも、LLM支援ペンテストに関する最もよく公表されている研究は、セキュリティ・エンジニアが実際に発見したことと同じことを言っているからです:モデルは、ツールの使用、出力の解釈、次のステップの提案のようなサブタスクでは役に立ちますが、それだけではエンドツーエンドの侵入テストの完全な状態を維持するのに苦労するからです。Gemma 4 31Bは、256Kのコンテキストウィンドウ、ネイティブ関数呼び出し、システムロールサポート、文書とPDFの解析に加え画面とUIの理解を明確に含むマルチモーダル機能により、その計算の一部を変更する。しかし、スコープ・コントロールやポリシー・ゲート、人間の承認が必要でなくなったわけではない。(USENIX)
ジェンマ4自体は新しい。グーグルのリリース文書によると、Gemma 4ファミリーは2026年3月31日に上陸し、E2B、E4B、31B、26B A4Bのバリエーションがある。Googleの概要では、31Bモデルはサーバーグレードのパフォーマンスとローカル実行の橋渡しを目的とした高密度モデルであると説明されており、DeepMindのモデルページでは、26Bと31BのバリエーションはコンシューマーGPUやワークステーション上での高度な推論、コーディングアシスタント、エージェント型ワークフロー向けと位置づけられている。Googleはまた、Gemma 4をApache 2.0ライセンスに移行し、自律性、ローカルのプライベート実行、開発者のための明確な再利用権を中心にシフトする独自のオープンソースポストフレームを作成した。これらの詳細は、Gemma 4を "興味深いオープンモデル "から "本格的な自己ホスト型推論コンポーネント "に押し上げるため、セキュリティ・チームにとって重要である。(開発者向けグーグルAI)
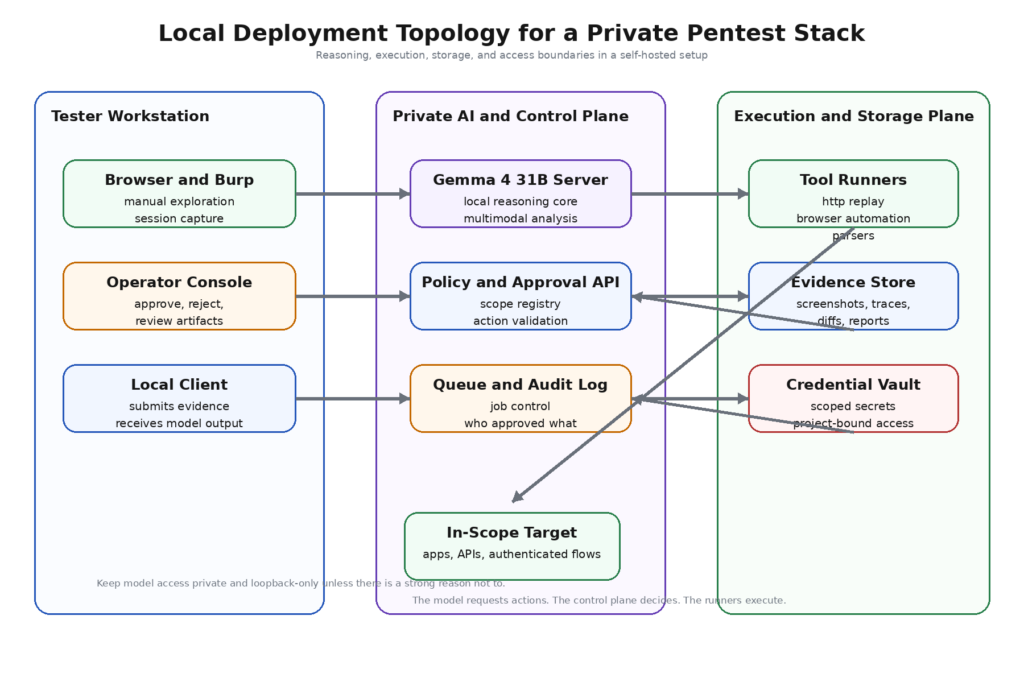
そのため、ペンテストにおいてGemma 4 31Bをエクスプロイト・ジェネレーターとして考えるのではなく、エクスプロイト・ジェネレーターとして考えるのが最も有用な方法である。それは、証拠収集と制御されたアクションの間に位置するローカルな推論コアとして扱った方が良い。強力な設計では、スキャナ、クローラ、HTTPクライアント、スクリーンショットコレクター、パーサーが事実を収集する。正規化レイヤーはこれらの事実を構造化された証拠に変える。Gemma 4 31Bは、そのエビデンスを横断的に推論し、弱いシグナルをもっともらしい仮説にグループ分けし、注意を払うべきものをランク付けし、実行レイヤーが検証可能なコントラクトを通じて、限定的に定義されたアクションを要求する。オペレーターは、状態が変化したり、信頼の境界を越えたり、爆発半径が広がったりした場合に、ループにとどまる。このデザインは、完全に自律的な「AIハッカー」の空想よりも派手ではない。また、成熟したチームが信頼できるものにはるかに近い。
モデルはボトルネックを変えるのであって、仕事を変えるのではない
ペンテストには常に2つのコストがかかる。1つ目はツールコスト:ターゲットを理解するのに十分な技術的シグナルを集めること。もう一つは、人間の認識力である。そのシグナルが何を意味するのか、何が別の時間に値するのか、そしてどの一見別々の手がかりが実際には3つの角度から見た1つのバグクラスなのかを判断することである。従来のスキャナーは、2つ目のコストよりも1つ目のコストの方が高い。チャットベースのアシスタントは、しばしばこの問題を逆転させる。孤立したスニペットを解釈するのは得意だが、証拠量が増えるにつれてエンゲージメントの糸が切れてしまう。PentestGPTの研究は、ここでの最も正直な公的チェックポイントである。PentestGPTの研究者たちは、LLMがプロセスの一部、特にツールの使い方や解釈はうまく処理できるが、エンゲージメント全体のコンテキストを保持するのは難しいことを発見した。(USENIX)
Gemma 4 31Bが興味深いのは、公式の機能セットがこれらの歴史的な失敗モードのいくつかを直接ターゲットにしているからだ。Googleは、ミディアムモデルのための256Kのコンテキストウィンドウ、構造化されたツール使用のためのネイティブ関数呼び出し、ビルトインシステムプロンプトサポート、思考モード、ドキュメント解析とスクリーンまたはUI理解をカバーする画像理解を文書化している。攻撃的なセキュリティの場合、このモデルはワーキングメモリにより多くのエンゲージメントを保持し、テキストだけでなくスクリーンショットやインターフェイスの証拠から推論し、"シェルコマンドを書いてください "よりもきれいな機械可読形式でツールと対話できることを意味する。それは、優れたセキュリティ判断を保証するものではない。それは、管理されたワークフローを構築するためのより良い基盤なのだ。(開発者向けグーグルAI)
動くボトルネックは、収集と解釈の間のギャップである。Gemma 4 31Bのようなモデルは、オペレーターがすでに十分な証拠を持っているが、その証拠をより良い検索プランに変換する手助けが必要な場合に、純粋に役に立つ。これには、隠れた /管理者ベータ ルート、特権的なエクスポートボタン、そして最小化されたバンドルで見つかった疑わしい内部APIパスは、同じ信頼境界問題に属している可能性が高い。誰かがPlaywrightフローを書く前に、スクリーンショットからバックエンド画面を分類することも含まれる。認証が乱雑なワークフロー全体でロールの振る舞いを比較することも含まれる。これらは、推論が多く、証拠が多い作業だ。これらはまさに、長い文脈、UIの理解、機能呼び出しのサポートが役立つべきところである。
変わらないのは、ペンテストの法則そのものである。証明は依然として雄弁さよりも重要である。再現性は依然として自信よりも重要である。スコープは依然として創造性よりも重要である。したがって、強力なジェンマ4のペンテストスタックは、自由形式の「モデルにターゲットを攻撃するように依頼する」ループではなく、証拠、契約、承認を中心に設計されなければならない。この違いを見逃しているセキュリティチームは、通常、2つの結果のうちの1つに行き着く。それは、賢く聞こえるがほとんど何もしないチャットボットか、あるいは、やりすぎるがその理由を説明できない実行エンジンだ。
Gemma 4 31Bがペンテストのワークフローにもたらすもの
Google自身のドキュメントは、ローンチ時の雑談よりも、このモデルについてより明確なイメージを与えている。概要ページでは、Gemma 4は生成、推論、商用展開を目的としたオープンウェイトファミリーであり、31Bの高密度モデルをサーバークラスのパフォーマンスとローカル実行の間に明確に位置づけている。26BのA4Bと31Bのバリエーションは、256Kコンテキスト、関数呼び出し、コーディング、マルチモーダル入力、組み込みシステムロールサポートをサポートしている。DeepMindのモデル・ページでは、コンシューマー向けGPUとワークステーション向けに最適化され、高度な推論、コーディング・アシスタント、エージェント型ワークフローを目的とした、より大きなバリエーションについて説明している。(開発者向けグーグルAI)
ペンテストの実際の仕事に当てはめてみるまでは、抽象的に聞こえるかもしれない。深刻なエンゲージメントでは、1つの整然としたテキストの記録ではなく、異種混合の証拠が生成されるため、長いコンテキストが重要になります。HTTP履歴、アセットリスト、スクリーンショット、JWT、エラーメッセージ、JavaScriptで発見されたエンドポイント、ロールマトリックス、リトライノート、以前のサイクルからの部分的なレポートなどがあるかもしれない。より安全なオーケストレーターは、シェルに直接向かう生の文字列ではなく、構造化されたインテントをモデルが発することを望んでいるため、ネイティブ関数の呼び出しが重要になる。一括エクスポート画面、内部モデレーションダッシュボード、サプライヤー側管理ツール、割引ワークフロー、ドキュメントビューア、または機能フラグコンソールなど、多くの価値の高い弱点が、パラメータ名ではなく、インターフェースのセマンティクスとして最初に現れるため、画面とUIの理解が重要になる。セキュリティワークフローは、ポリシーの指示とターゲットとなるエビデンスの間のハードな分離から利益を得るため、組み込みのシステムロールサポートが重要である。(開発者向けグーグルAI)
ハードウェアの話も重要だ。"ローカルモデル "はしばしば "簡単なラップトップモデル "と誤解されるからだ。グーグルの概要によれば、31Bモデルの推論に必要なベースメモリーの概算は、BF16で58.3GB、8ビットで30.4GB、Q4_0で17.4GBとなっており、この数字にはソフトウェアのオーバーヘッドとコンテキストウィンドウのメモリーは含まれていないと明確に警告している。言い換えれば、31Bのデプロイはローカルであっても、重大なインフラストラクチャの決定となりうる。ワークステーション、量子化されたサービング・パス、またはプライベート・クラスタは、ここでは通常の設計選択である。このモデルで得られるのは、些細なデプロイメントではない。それは、実際のエンゲージメントを推論するのに十分な大きさのモデルを使用しながらも、機密性の高い証拠を自分の環境内に保持するオプションを提供することである。(開発者向けグーグルAI)
| ジェマ 4 31Bケイパビリティ | ペンテストで重要な理由 | 解決できないこと |
|---|---|---|
| 256Kコンテキスト | リコン、認証メモ、スクリーンショット、JS所見、リトライ履歴をモデルに保持させる。 | 長いコンテクストは、悪い証拠衛生や迅速な汚染を修正するものではない。 |
| ネイティブ関数呼び出し | 生のコマンド文字列の代わりに、構造化されたアクション・リクエストに対応 | 関数の呼び出しだけでは、ツールの使用は安全ではない |
| 画面とUIの理解 | 特権サーフェス、管理パネル、エクスポートフロー、視覚的な状態の違いを分類するのに役立ちます。 | 認可を証明することも、状態の変化を再現することもできない。 |
| システム・ロール・サポート | ポリシー、スコープ、実行ルールとエビデンスの分離を容易にする。 | システムプロンプトは強制境界ではない |
| ローカルおよびプライベート実行オプション | スクリーンショット、ログ、内部アーティファクトのためのルーチンデータの排出を削減します。 | ローカル展開でも、ハード化と監視のために新しいサービスが作成されます。 |
最も正直な読み方は、Gemma 4 31Bは魔法のペンテストモデルではないということだ。Gemma 4 31Bは、エビデンスを多用するセキュリティ・ワークフローにとって、非常に有望なローカル推論モデルである。これは、発売時のマーケティングよりも狭い範囲での主張だが、本番での接触に耐えうるものでもある。
攻撃的安全保障において局所推論が重要な理由
多くのペンテスト作業は、組織が別の信頼境界を越えてほしくないデータに対して行われる。これには、内部スクリーンショット、認証されたテスト中に見える顧客アカウントデータ、アーキテクチャ文書、冗長化されているが機密性の高いサポートエクスポート、パケットキャプチャ、ログ、チケット、未完成の調査結果などが含まれる。多くのチームにとって、ローカル推論の議論は、レイテンシーやイデオロギーよりも、データコントロールの問題である。一方、グーグルのオープンソースの発表では、Gemma 4は、Apache 2.0のもとで、ローカルでプライベートな実行と明確な修正と再利用の権利を中心に組み立てられている。セキュリティ・チームにとって、これは本当のアーキテクチャの選択肢になる。すべてのアーティファクトをホストされたAPIに送るのではなく、隔離された環境内に推論レイヤーを保持するのだ。(開発者向けグーグルAI)
それが最も重要なのは、モデルが最終的なサニタイズされたサマリーではなく、中間的な証拠を見るときである。中間証拠は、実際の攻撃的なワークフローが存在する場所である。内部モデレーションコンソールのスクリーンショットは、エクスポートパス、キューのセマンティクス、役割の境界を明らかにするかもしれない。生の403または302チェーンは、認可の仮定を示すかもしれない。サポートログは、オブジェクト識別子のパターンを明らかにするかもしれない。これらの成果物は、まさにロングコンテキストのマルチモーダルモデルが解釈するのに役立つものである。また、多くのセキュリティチームが、特に、発見、再現、および、再試験の間、ローカルに保存しておきたいと考えているものです。
ローカル推論はまた、異なる種類の運用上の摩擦を軽減する。ホストされたモデルのワークフローでは、チームはしばしば、意味のあるターンごとにコンテキストをサニタイズし、要約し、再アップロードする。ローカルの推論レイヤーは、エビデンスストアに近く、実行スタックに近い。しかし、同じエビデンスグラフを反復し、構造化分析を再試行し、すべてのサイクルを新しいデータエクスポートの練習にすることなく、以前の試行と出力を比較することが容易になります。
また、他の多くのAIの使用例よりも、ペンテストに適しているという製品設計上の理由もある。攻撃的なテストが1回のプロンプトで終わることはほとんどない。それはループである。証拠が到着し、正規化され、仮説につながり、制御されたアクションがトリガーされ、さらに証拠が生成され、そして仮説が崩れるか強化される。このループは、モデル、エビデンスストア、ポリシーエンジンが同じセキュリ ティドメインに存在する場合に、より効率的になる。
地元=安全ではない
ローカルモデルのプライバシーケースは現実的だ。安全性のケースはもっと条件付きだ。セキュリティチームは、LLMをセルフホストすることで、モデルのリスクをどうにか消し去ることができるという、いい加減な思い込みに抵抗しなければならない。実際には、LLMは、公開された推論サービス、認証されていないローカル・エンドポイント、プロンプトとツールの混乱、弱いプラグイン境界、偶発的な公開可能性など、別のリスクを生み出す。
シスコの2025年9月の調査では、Shodanを通じて1,100台以上のOllamaサーバーが公開されていることが判明し、そのうちの約20パーセントが不正アクセスの影響を受けやすいモデルをアクティブにホストしていると報告している。Praetorianは2026年1月に、14,000以上のOllamaインスタンスが一般にアクセス可能であり、20%という数字について同じCiscoの分析を引用していると書いている。これらは異なるスナップショットであり、人数を直接比較することはできないが、同じ方向性を示している。(シスコブログ)
モデルがツールを呼び出すことができる場合、リスクはさらに悪化する。SentinelOneが2026年1月に行ったOllamaホストの暴露に関する分析は、この点を最も鋭く言い当てている。プレーンテキストを生成するエンドポイントは安全でないコンテンツを生成できるが、ツールを使用できるエンドポイントは特権的な操作を実行できるため、脅威モデルが大きく変わる。このことは、脅威のモデルを大きく変える。また、プロンプト・インジェクションは、特に検索範囲やツールの範囲が内部データや内部システムにまで及ぶような、モデル・エージェンシーが増加するにつれて、より深刻になるとも論じている。これは、Gemma 4のペンテスト・デプロイメントに直接関係する。モデルはローカルかもしれないが、もしサービング・レイヤーが間違ったネットワーク・セグメントから到達可能であったり、ツール・サーフェスが広すぎたりすると、たまたまインターフェイスが自然言語である新しい特権システムを作ってしまうことになる。(センチネルワン)
運用上の教訓は単純だ。よほどの理由がない限り、ローカルの推論サービスをループバックにバインドすること。モデルを提供するエンドポイントは、開発者のおもちゃではなく、内部のインフラとして扱う。マルチユーザーサービングレイヤーの前に認証を置く。可能な限り、推論コンポーネントを特権ツールランナーから分離する。モデルに与えるリーチは、人間の最高のオペレーターが持つリーチよりも少なくする。成熟した設計では、モデルサーバーは決して危険な能力を直接所有するシステムではありません。それは要求する。他の何かが決定する。
この分離は、ペンテストのターゲット自体がAI対応システムである場合、さらに重要になります。エージェントがMCPサーバ、ブラウザコントローラ、ナレッジベース、あるいはローカルCLIツールと対話し始めると、ペンテストのワークフローとエージェントの攻撃対象が韻を踏み始めます。同じ実行境界のミスが双方で起こりうる。これが、ローカルモデルがセキュリティアーキテクチャの外部ではなく、その一部として理解されるべき理由です。
ペンテストにおけるGemma 4 31Bのより良いアーキテクチャ
Gemma 4 31Bの最強のデプロイメントパターンは、各パートが1つの仕事をうまくこなすレイヤードワークフローである。モデルはターゲットから直接エビデンスを収集すべきではなく、広範なオペレーティングシステム特権を所有すべきではなく、任意のフリーフォームテキストの実行を信頼すべきではない。その仕事は、構造化された証拠を推論し、制限されたアクションを求めることである。
実用的なアーキテクチャはこうだ:
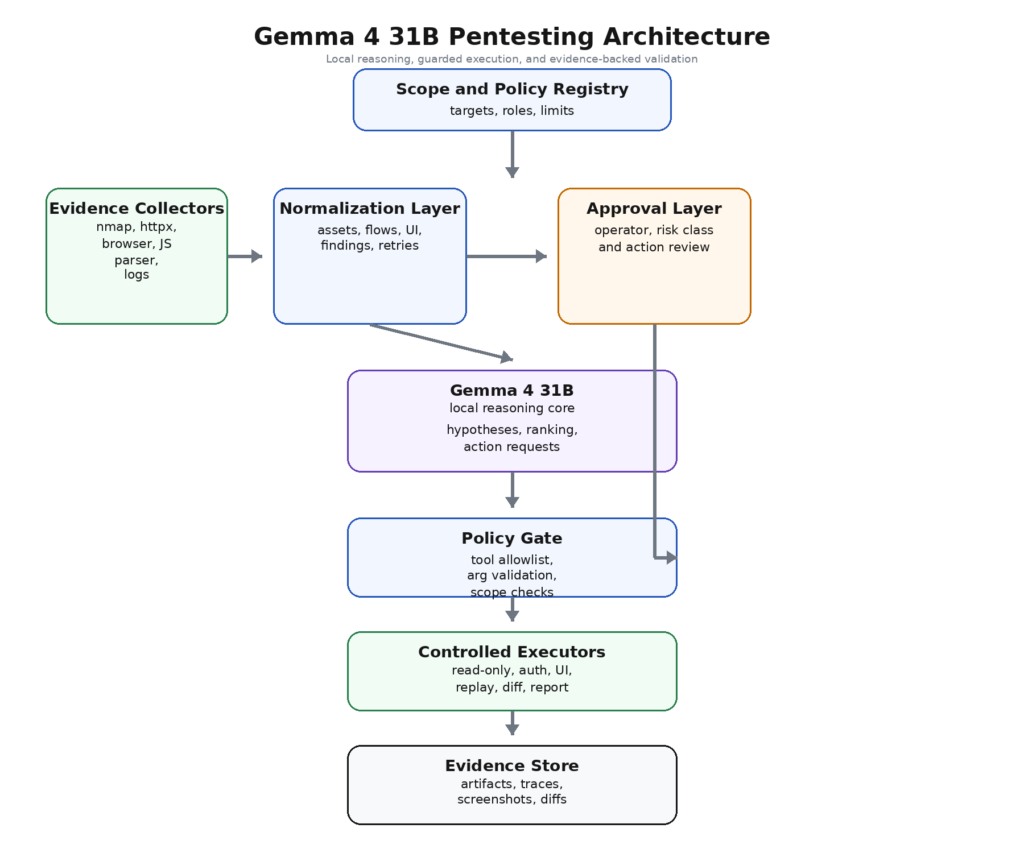
このデザインは華やかさには欠けるが、PentestGPTの論文ですでに示唆されていたことと一致している。ワークフローがコンテキストの断片化を減らし、サブタスクをきれいに分離するとき、このモデルはより有用になる。また、完全に自律的なループよりも、公式のGemma 4の能力プロファイルにマッチしている。長いコンテキストは、エビデンスストアが首尾一貫しているときに役立つ。関数呼び出しは、アクションインターフェイスがタイプされているときに役立つ。UIの理解は、スクリーンショットが正規化され、ロールやルートに結びつけられるときに役立つ。システムロールサポートは、ポリシーとエビデンスが分離されている場合に役立ちます。(USENIX)
ここで最も重要なのは、生の出力から正規化された証拠への移行である。セキュリティツールは、非常に異質な成果物を生成する。XMLスキャン結果、ブラウザのスクリーンショット、JWTクレームセット、2つのロールレスポンス間の差分、そして、最小化されたJavaScriptファイルから抽出されたパスは、1つの構造化されていないプロンプトの塊には属しません。それらは共有されたエビデンススキーマに属する。そのスキーマはささやかなものでよい。重要なのは学術的なエレガンスではない。重要なのは、ペーストのダンプではなく、オブジェクトに対してモデルを推論させることである。
成熟したワークフローでは、分析ループと実行ループを区別する。分析ループは安価である:エンドポイントのクラスタリング、役割の境界の推測、疑わしいリソースの特定、再試行間の差分の要約、次のプローブの提案。実行ループは高価でリスクが高い:認証されたアクションの再生、オブジェクトの修正、メール送信、オーダーの作成、設定の変更、クレジットの消費などのワークフローのステップを実行する。Gemma 4 31Bは最初のループで価値がある。2つ目のループは、メディエーションが多いままであるべきである。
このスタックを手作業で組み立てたくないチームにとって、探す価値のある具体的な製品の形は、抽象的な「AIを活用したペンテスト」ではない。エビデンスに裏打ちされた検証、制御可能なエージェントワークフロー、認証されたテストサポート、CIやパイプラインの統合、機密性の高い実行パスを非公開にするデプロイオプションなどである。Penligentの公開価格と概要ページには、そのような形が記載されています:資産の発見から検証までのエンドツーエンドのAIペンテスト、オンデマンドの200以上のペンテストツール、エビデンスと再現ステップを含むPDFまたはMarkdownレポート、認証されたフローテスト、CIまたはCDの統合、プライベートモデルの統合によるプライベートデプロイメント。チームが構築するか購入するかにかかわらず、これらは自動化の一般的な約束よりも重要な運用機能です。(寡黙)
モデルが最も付加価値を生む場所
ジェンマ4 31Bのベストな使い方は、どこにでもあるわけではない。それは、人間のテスターが認知的に過負荷になる場所にある。そのような場所は、多くの人が予想するよりも早い段階で現れる。
偵察合成は、最初に明らかに適合する。JavaScriptからの代替パス、パッシブDNS、OpenAPIフラグメント、公開されたドキュメント、HTTPヘッダー、機能フラグ、ロール固有の画面、エラーメッセージの違いなどだ。人間はそれらすべてを推論することができるが、その代償は注意力である。ローカルのロングコンテキストモデルは、入力が正規化され、ラベル付けされていれば、その沼地を可能性の高い攻撃対象のショートリストに変えることができる。ここで重要なのは、モデルの創造性ではない。多くの小さな手がかりを、検証する価値のあるいくつかの仮説にまとめる能力である。
認証されたワークフロー推論もまた、強力に適合する。2026年の深刻な脆弱性の多くは、まだ「巧妙なペイロード」のバグではない。それらは信頼境界のバグである。壊れたオブジェクトレベルの認可、壊れた機能レベルの認可、エクスポートフロー、承認フロー、状態遷移、オブジェクトの関係。OWASPのLLMとアプリケーションセキュリティガイダンスは、AIの側面から同じようなポイントを指摘している。役割のビューを比較し、ページ間のプロセスを追跡し、状態遷移のシーケンスを保持することができるモデルは、単にペイロードを提案するモデルよりもここで有用です。(OWASP財団)
JavaScriptとAPIサーフェス解析は、Gemma 4 31Bの長いコンテキストとコーディングプロファイルの恩恵を受けている。モデルカードはコーディング、コード修正、ツール使用を強調し、コアドキュメントはコーディングと推論と並んでPDF解析とUI理解を明示的に呼びかけている。ペンテストワークフローでは、ビルドされたクライアントバンドルから意味的に意味のあるエンドポイントクラスタを抽出する、ビジネスオブジェクトごとにパラメータをグループ化する、発見されたルートを目に見えるUIアクションにマッピングする、フロントエンドの想定がサーバーサイドコントロールに見えない場所を発見する、といったタスクに変換されます。これらの仕事はどれも、モデルがターゲットに直接触れることを必要としません。それらは、隣接する多くの証拠を首尾一貫して読み取ることを必要とする。(開発者向けグーグルAI)
UIセマンティクスは過小評価されている。多くのWebやSaaS製品は、テスターが明示的なAPIの失敗を目にするずっと前に、特権の手がかりをインターフェース言語に隠している。再開」、「払い戻しの承認」、「すべてエクスポート」、「顧客台帳の表示」、「一括割り当て」のようなボタンは、信頼境界情報を伝えます。経験豊富な人間は、これらの合図に素早く気づく。画面とUIを理解したマルチモーダルモデルは、特にテストが複数の役割の状態や多くのサブプロダクトを同じ環境で比較する必要がある場合、それらを大規模に分類するのに役立ちます。これは脆弱性を証明するものではない。証明の可能性が最も高いところに人間の注意を向けるのに役立つ。
報告書と再試験の仕事も向上する。優れたセキュリティ報告書は小説ではない。それは証拠の連鎖である。強力な推論モデルは、未加工のトレースをよりすっきりした物語に変え、再試験の成果物を以前の証拠と比較し、「疑われる」状態と「検証された」状態の間で何が変化したかを説明することができる。エンジニアリング・チームは、AIが書いた散文の山よりも、少数の強力な発見をより容易に許容するので、これは運用上重要である。
| ペンテスト・タスク | ジェマ4 31Bがフィットする理由 | 単独で走るべきでない理由 |
|---|---|---|
| 再クラスタリング | 長いコンテクストにより、多くの弱い信号をまとめて比較できる | 無関係な手がかりを過剰に関連付ける可能性がある |
| 認証フロー分析 | マルチロールの状態を保持し、パスを比較できる | コントロールされたリプレーがなければ、オーソライズを証明することはできない |
| JSとAPIのマッピング | より強力なコーディングと大きなエビデンスウィンドウが、ルート抽出とグループ化に役立つ | 静的な手がかりでも実行時の検証が必要 |
| スクリーンショットのトリアージ | UIを理解することで、特権サーフェスの迅速な分類が可能に | ビジョンはバックエンドの施行を確認できない |
| レポートと再試験 | 証拠を再現可能な語りに圧縮するのが得意 | 人工物を引き合いに出さなければ、まだ確実性を誇張することができる。 |
これらすべてのパターンは一貫している。解釈的で、比較的で、証拠が豊富な仕事において、モデルは最高のパフォーマンスを発揮する。作品がインパクトのある行動になった瞬間、モデルは決定者ではなく推奨者になるはずだ。
最終的な権威であってはならないところ
AIセキュリティ・ツールには、周囲のシステムが防御できる以上のエージェンシーをモデルに持たせる誘惑が繰り返し存在します。OWASPはこの問題を直接的に指摘しています:安全でない出力処理、安全でないプラグイン設計、そして過剰なエージェンシーは、理由があって別々のリスクなのです。実際には、これらは3つの角度から見た同じ間違いなのだ。モデルが何かを言う。別のシステムはそれを信用しすぎる。その信頼は能力表面に達する。ケイパビリティ・サーフェスには結果が伴う。(OWASP財団)
従って、Gemma 4 のペンテストワークフローでは、モデルは、破壊的なアクション、シェルの実行、広範なファジング、クレデンシャル の散布、横方向への移動、あるいは、明示的なポリシーと承認なしにアプリケーションの状態を変更するアクションの最終的な権限者にな るべきではありません。ログインページが "面白そうだから "という理由で、エンドポイントをブルートフォースすることを決定すべきではありません。ツール・ランナーに直接パイプで送られるようなbashのワンライナーを書くべきではありません。安全でない直接オブジェクト参照が存在するかもしれないと推測して、オブジェクトを変異させてはならない。これらはすべて、言語が制御不能になる典型的な例だ。
これは単なる安全光学の話ではない。認識論の問題なのだ。モデルは部分的な証拠から確率的に推論する。ペンテストは、行動の瞬間により狭い基準を要求する。コントロールされたリプレイが起こる前は、IDORの疑いのある選手はIDORではない。役割の境界が横断され、証明される前に、特権パスは発見ではない。したがって、正しいワークフローは、問題を次の段階に分割する:観察、仮説、計画されたアクション、承認されたアクション、結果として生じる成果物、結論。このモデルは、最初の3つを生み出すのに役立つ。最後の2つを要約するのを助けることができる。助けなしに中間を崩してはならない。
ターゲット・フィードバックは敵対的である。ターゲットのコンテンツを読むものはすべて、ターゲットのコンテンツによって操作される可能性がある。OWASPの現在のプロンプト・インジェクション・ガイダンスは、間接的なプロンプト・インジェクションはLLMがウェブサイトやファイルなどの外部コンテンツを消費するときに発生し、その影響はモデルのエージェンシーに大きく依存することを明示しています。ペンテストシステムは、設計上、信頼されていないコンテンツを読むための機械である。そのため、この領域では、盲目的なツールの委譲は異常に危険なのです。(OWASP Gen AIセキュリティプロジェクト)
最良のメンタルモデルとは、"モデルがアプリをテストする "ことではない。モデルは、敵対的な証拠の流れに対して、制限された、監査可能な調査の動きを提案する」である。その考え方は、アクションスキーマ、ツールラッパー、承認ロジック、証拠ロギング、結論の書き方など、あらゆるところで実装の詳細を変える。
エージェント型ペンテストをめぐる脅威モデル
ジェンマ主導のペンテストスタックの脅威モデルは、"ジェイルブレイクされる可能性 "よりも幅広い。この質問は小さすぎる。実用的な脅威モデルは、少なくとも4つのレイヤーをカバーしなければならない:モデルそれ自体、それを取り巻く実装、それが実行されるインフラ、そしてワークフロー全体の実行時の振る舞いである。OWASPのGenAI Red Teaming Guideは、モデル評価、実装テスト、インフラ評価、ランタイム動作分析にまたがる全体的なアプローチを記述しており、ほぼその形状を使用している。NISTの2025年版敵対的機械学習分類法も標準の観点から同じ動きをし、AIのライフサイクルの段階、攻撃者の目標、緩和策にまたがる共通の語彙を主張している。(OWASP Gen AIセキュリティプロジェクト)
モデルレイヤーでは、プロンプトインジェクションとオーバーリライアンスが依然として明らかな問題である。推論コアがターゲットに制御されたコンテンツを消費する場合、ポリシーを再解釈したり、指示を無視したり、間違ったパスを緊急とランク付けしたりするように指示される可能性がある。実装層では、安全でない出力処理は、プロンプト注入そのものよりも危険で あることが多い。モデルは哲学的に「勝つ」必要はない。下流のパーサ、実行者、ブラウザコントローラ、MCPクライアントに安全でないことをさせる必要があるだけである。OWASPのプロジェクトは、プロンプトインジェクション、安全でない出力処理、安全でないプラグインの設計、そして過剰なエージェンシーを、LLMアプリケーションのリスクの中核に挙げている。(OWASP財団)
インフラ層では、ローカル・サービングとセルフ・ホスティングは、エンドポイントの露出、脆弱な認証、脆弱なネットワーク・セグメンテーション、未監査のサービス・スプロールといった、おなじみだが新たに集中した問題を引き起こす。CiscoとPraetorianによるOllamaインフラの公開は、ローカルAIシステムの構築を急ぐ人々への警告だ。一般にアクセス可能になったプライベート・モデルは、もはや運用上の意味においてプライベートではない。そして、もしそれがツール化されているのであれば、その妥協はデータ漏洩よりも重要かもしれない。(シスコブログ)
ランタイム層では、メモリ汚染と境界ドリフトが問題となる。エージェントシステムは、再試行、過去の発見、キャッシュされたツール出力、保存されたサマリーなどの状態を蓄積する傾向がある。これは継続性にとっては有益であるが、信頼性にとっては危険である。毒の入ったメモ、古くなった仮定、または修正されていない秘密は、証拠ストアが弱い型付けと弱い証明性を持っている場合、後のサイクルにわたって伝播する可能性がある。MITRE ATLASのようなフレームワークが有用になるのは、ペンテストチェックリストを渡すからではなく、すべてを一般的なウェブアプリ言語に強制的に戻す代わりに、AI特有の敵対行動の共有マップを防御者とテスト担当者に与えるからである。MITREはATLASを、実際の攻撃観察に基づいたAI対応システムに対する敵の戦術とテクニックの生きた知識ベースと説明している。それはまさに、それ自身がターゲットになるかもしれないエージェント型ペンテストスタックについて考えるのに適した高度である。(MITRE ATLAS)
Penligent社が最近Hacking Labsで発表したAIペンテスターとプロダクション・エージェントのセキュリティに関する記事は、運用面では同じ場所に位置している。それは、有用なシステムを魔法のチャットボットとしてではなく、生の信号と検証された発見との間の距離を縮める管理されたワークフローとして枠組みを作り、公開されたMCPサービス、メモリ処理、危険なツールパスを第一級の検証対象として扱っている。これが正しい問題の形だ。問題は "モデルが考えることができるか "ではない。問題は、"モデルが間違っていたり、操作されていたり、過信していたりするときに、システムは何ができるか "である。(寡黙)
境界線を間違えると何が壊れるかを示すCVE
なぜ実行境界が重要なのかを理解する最も手っ取り早い方法は、隣接するエージェントシステムにおける実際の障害を研究することである。AIワークフローツールやMCP関連のエコシステムにおける最近のCVEは、抽象的なモデルの誤動作に関するものではないため、非常に有益である。自然言語システムが危険な機能に近づきすぎたときに何が起こるかについてである。
最も明確な例は CVE-2026-27966 を修正した。NVDとGitHubのアドバイザリによると、1.8.0より前のバージョンではハードコードされていた。 allow_dangerous_code=True をCSVエージェントノードに追加し、LangChainのPython REPLツールを自動的に公開しました。その結果、サーバ上でプロンプトインジェクションによるリモートコード実行が発生しました。これは、なぜGemma 4のペンテストワークフローが、ツールが便利そうだからという理由で、推論モデルに制限のないコード実行パスを継承させてはいけないかを示す、ほぼ完璧なケーススタディです。修正は、より良いプロンプトではなかった。危険な境界そのものを変更したのだ。(ギットハブ)
関連する古い例は以下の通り。 CVE-2024-42835NVDはLangflow 1.0.12のPythonCodeToolコンポーネントを使ったリモートコード実行と説明している。ポイントは、Langflowが唯一悪いということではない。ポイントは、AIワークフローシステムが一般的なコード実行ツールを公開すると、セキュリティの問題は、"モデルが手助けできるかどうか "ではなく、"外部入力から実行可能コードまでどのような経路が存在するか "になるということです。ローカル・モデルに広範なインタプリタ・アクセスを渡すペンテスト・システムは、同じ構造的な賭けをすることになる。(NVD)
CVE-2025-53355 で mcp-server-kubernetes はMCPの教訓をさらに明確にしている。NVDとGitHubのアドバイザリーには、サニタイズされていない入力が次のように流れ込むと書かれている。 child_process.execSyncバージョン2.5.0で修正されました。わかりやすく言うと、エージェントのインフラ運用を支援するためのツール表面が、コマンド実行の境界になってしまったのです。これこそが、GemmaベースのPentestオーケストレータが、生のパラメータ文字列やシェルフラグメントを公開するのではなく、すべてのツールを厳格な引数検証でラップすべき理由です。(ギットハブ)
CVE-2025-66414 は、「ローカルのみ」の仮定でさえも失敗する可能性があることを示している。NVDによると、HTTPベースのMCPサーバーが認証もDNSリバインディング保護もなくlocalhost上で動作している場合、悪意のあるウェブサイトはDNSリバインディングによって同一生成元制限を回避し、ローカルMCPサーバーが公開するツールを呼び出したり、リソースにアクセスしたりすることができるという。これは、ローカル優先のセキュリティ・ワークフローに直接関係する。ローカルホストのサービスは、単に明白な方法でインターネットにルーティング可能でないというだけで、自動的に安全というわけではない。GemmaスタックがローカルホストのツールやMCPサーバーと会話する場合、オリジン保護、認証、明示的なハードニングが必要です。(NVD)
CVE-2025-67511 はおそらく、AIを利用した攻撃ツールに対する最も直接的な警告だろう。NVDとGitHubの勧告には、コマンドインジェクションの欠陥が記述されている。 ラン_ssh_command_with_credentials() これは、AIエージェントが利用できるツールであるCybersecurity AIフレームワークの機能である。この勧告によると、エスケープされたのは一部のフィールドのみで、公表時点では修正されていないという。このケースが重要なのは、「AIエージェント・ツール」がいかに早く特権的なインジェクション・シンクになり得るかを示しているからだ。ひとたびモデルが実行時にツールのパラメータを入力することを許可されると、検証されていないすべてのフィールドが攻撃対象となる。(NVD)
| CVE | なぜここが重要なのか | 悪用条件 | 実用的な緩和策 |
|---|---|---|---|
| CVE-2026-27966 | データ分析エージェントがデフォルトでPython REPLを公開する場合、プロンプト・インジェクションがどのようにRCEになるかを示す。 | 危険なコードパスを有効にした1.8.0より前のラングフローCSVエージェント | アップグレード、危険なコードパスの無効化、解析と実行の分離 |
| CVE-2024-42835 | インタプリタの露出がRCEに転化した、先のLangflowの例 | PythonCodeToolが脆弱なLangflowのバージョンで到達可能 | コードエグゼックツールの削除または隔離、権限の制限、迅速なパッチ適用 |
| CVE-2025-53355 | MCPツール・ラッパーはコマンド・インジェクションの境界となりうる | のサニタイズされていないパラメータ execSync-ベースのKubernetesツール | 厳格な引数スキーマ、シェル補間なし、修正版へのアップグレード |
| CVE-2025-66414 | ローカルホストのMCPサービスは、適切なブラウザの条件下ではまだ悪用可能である。 | localhost上のHTTP MCPサーバー、認証なし、リバインド保護無効 | 認証の必要性、再バインディングの保護、ブラウザの到達可能性の最小化 |
| CVE-2025-67511 | AIエージェントのツールは不完全なサニタイズで危険なコマンド関数を公開する可能性がある | AIエージェントが利用可能な脆弱なSSHコマンドヘルパー | 危険なツールは削除するかラップする、すべてのフィールドを検証する、モデルで埋められたパラメータを信用しない。 |
これらのCVEは、Gemma 4 31Bがそれ自体で危険であることを証明するものではない。危険は、モデル推論とケイパビリティ・サーフェスの結合に潜んでいるのだ。よく設計されたGemmaのペンテストワークフローは、これらの失敗から学び、実行境界を狭く、型付けし、観測可能な状態に保つ。
安全な行動契約を設計する
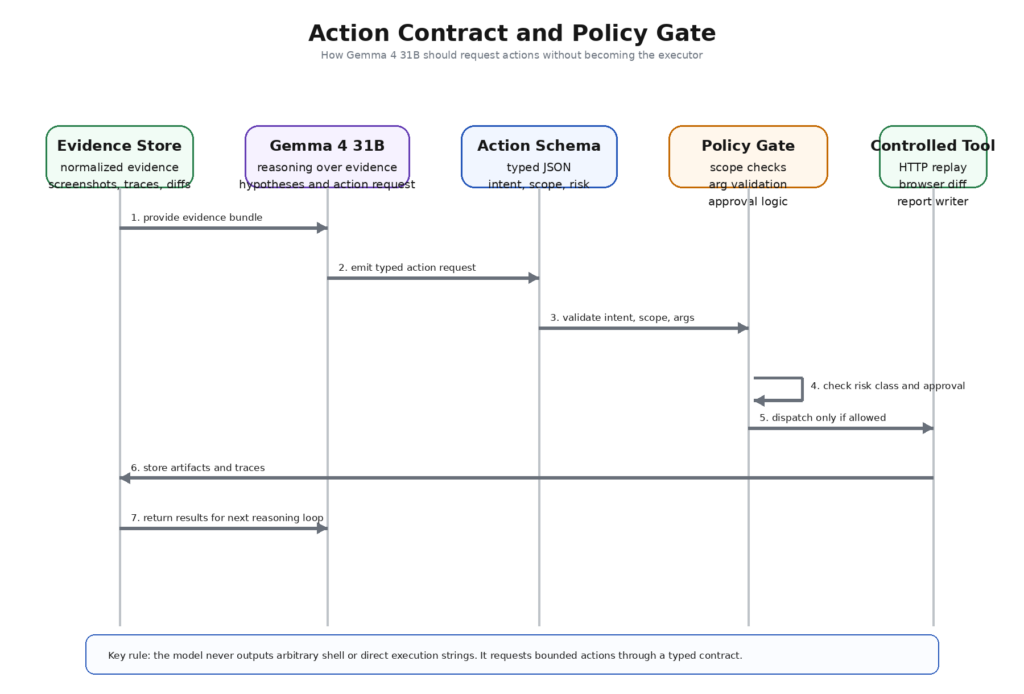
AIが支援するペンテストワークフローのコントロールを失う最も手っ取り早い方法は、別のシステムが実行する自由形式のコマンドをモデルに出力させることだ。正しい修正は、"注意すること "ではない。正しい修正とは、行動契約である。
有用な行動契約には3つの特性がある。第一に、構造化されている。モデルは型付けされたフィールドを返す。第二に、宣言的である。モデルには、生のシステムコマンドではなく、意図と要求されたパラメータが記述される。第三に、レビュー可能である。リスククラス、エビデンスの根拠、期待される成果物は、何かを実行する前に明示される。
最小限のアクション・オブジェクトは次のようになる:
{
"intent":"verify_object_level_authorization"、
"target_scope":{
"project_id":"acme-b2b-portal"、
"asset":"app.target.example"、
"route_group":"/api/v1/invoices"
},
"risk_class":"credentialed_read_only_replay"、
"read_only": true、
"required_tool":「http_replay_runner"、
"引数":{
"method":"GET"、
"candidate_object_ids":候補オブジェクトID": ["inv_1042", "inv_1043", "inv_1044"]、
"role_profiles":"role_profiles": ["basic_user", "billing_admin"]、
"compare_fields":"status", "line_items", "customer_id"], "compare_fields": ["status", "line_items", "customer_id"].
},
"evidence_basis":[
"js_route_extraction:bundle_17"、
"ui_screenshot:billing_export_screen"、
"response_diff:role_matrix_run_02"
],
"expected_artifacts":[
"request_trace"、
"response_diff"、
"access_matrix"
],
"needs_approval": true、
"confidence":信頼度": "中程度"
}
このオブジェはデザイン的につまらない。それが強みなのだ。このモデルは、ヘッダーをどのようにエンコードするか、トレースをどこに保存するか、リトライするかどうか、どのオペレーティング・システム・コマンドを呼び出すか、などを決定するものではない。型付けされたインターフェイスの中で、制限されたリクエストを行っているのだ。それが検証を可能にする。ポリシーゲートはリスククラスを拒否したり、スコープ外のルートグループを拒否したり、許可リストにないツールを拒否したり、アクションが認証されたフローに触れるので承認を強制したりすることができる。
この契約は分析の質も向上させる。モデルが証拠となる根拠と期待される成果物を前もって挙げなければならない場合、推測から結論に飛びつく可能性が低くなる。行動スキーマは、認識論的規律を強制する機能となる。これはペンテストにおいて重要なことである。というのも、優れた攻撃的な仕事とは、興味深いパスを見つけることだけではないからである。それは、観察から証明までのきれいな連鎖を維持することだからである。
Gemma 4のネイティブな関数呼び出しサポートは、このパターンに特によくマッチしている。公式のモデル・ドキュメントでは、関数呼び出しは、構造化されたツールの使用やエージェント的なワークフローのための組み込み機能であると明確に位置づけられている。ペンテストスタックでは、それは狭く解釈されるべきです。レビューの必要性を回避するためではなく、レビューされたアクションを要求するために能力を使うのです。(開発者向けグーグルAI)
行動契約を執行層に変える
スキーマそれ自体はエンフォースメントではない。スキーマはエンフォースメントが使用できる言語でしかない。次のレイヤーは、ディスパッチする前に、要求されたすべてのアクションをスコープ、権限、実行クラスに対して検証するポリシー・ゲートである。
シンプルなPythonスタイルのコントローラーがそのアイデアを示している:
from dataclasses import dataclass
from typing import Any, Dict
allowed_tools = {(許可されたツール
"passive_recon_runner"、
"http_replay_runner"、
"screenshot_diff_runner"、
"js_endpoint_mapper"、
"report_writer"
}
risk_classes = {
"passive":承認」:{:False, "state_change":False}、
"credentialed_read_only_replay":{承認":True、"状態変更":False}:True, "state_change": False:False}、
"ui_navigation_only":ui_navigation_only": {"approval": True:True、"state_change": False:False}、
"state_modifying":{"承認": True、"状態変更": FalseTrue、"state_change": False:True}、
「禁止」:{承認": true:true, "state_change": true:真}である。
}
データ・クラス
クラス Decision:
allowed: bool
理由: str
requires_approval: bool = False
def validate_scope(action: Dict[str, Any], allowed_assets: set[str]) -> Decision:
asset = action["target_scope"]["asset"] とする。
assetがallowed_assetsにない場合
return Decision(False, "asset خارج scope: {asset}")
return Decision(True, "スコープOK")
def validate_tool(action: Dict[str, Any]) -> Decision:
tool = action["required_tool"]を実行する。
tool が ALLOWED_TOOLS にない場合:
return Decision(False, "ツールは許可されていません: {tool}")
return Decision(True, "ツールOK")
def validate_risk(action: Dict[str, Any]) -> Decision:
rc = action["risk_class"]
もしrcがRISK_CLASSESになければ
return Decision(False, f "不明なリスククラス:{rc}")
if rc == "prohibited":
return Decision(False, "禁止アクションクラス")
cfg = RISK_CLASSES[rc].
return Decision(True, "リスクOK", requires_approval=cfg["approval"])
def dispatch(action: Dict[str, Any]) -> str:
# ここでのツールラッパーは決定論的で型付けされている。
# シェルの補間はありません。任意のbashは使えない。
return f "queued:{action['required_tool']}"
def handle_action(action: Dict[str, Any], allowed_assets: set[str]) -> str:
for check in (validate_scope, validate_tool, validate_risk):
decision = check(action, allowed_assets) if check == validate_scope else check(action)
if not decision.allowed:
raise ValueError(decision.reason)
if decision.requires_approval:
return f "承認が必要な場合:{decision.reason}"
return dispatch(action)
製品版ではさらに多くのことができる。プロジェクトごとの認証情報保管庫、レート制限、引数バリデーター、成果物保持、べき等タスクIDを強制する。誰が何を承認し、どのような正確な証拠がリクエストのトリガーとなったかを記録するだろう。しかし、この単純な例でさえ、構造的なポイントを示している。モデルは要求する。システムは検証する。そして決定論的なラッパーが実行される。
それはまた、商用ワークフローがエンジニアリングの真理を変えることなく真の価値を付加できるポイントでもある。公開されているPenligentの資料では、オペレータが制御するワークフロー、証拠に裏付けられたレポート、認証されたマルチロールテスト、CIまたはCDの統合、プライベートモデルの統合によるプライベートデプロイメントが強調されている。ワークフローが適切に設計されていれば、これらはマーケティング上の宣伝ではない。これらはエンフォースメントレイヤーの機能である。有用な比較は「人間対AI」ではない。それは "無防備なモデル出力対管理されたアクション契約 "である。(寡黙)
生のリコンをモデルで読める証拠に変える
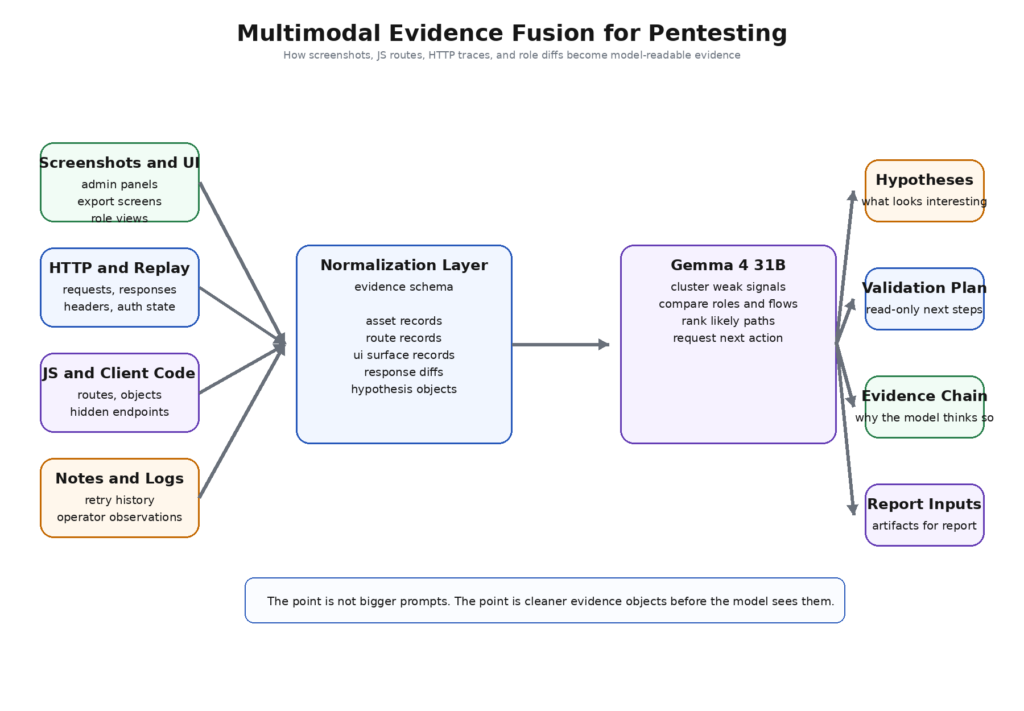
Gemma 4 31Bのロング・コンテキストの約束は簡単に無駄になる。もしモデルに生のペーストのダンプを与えるのであれば、まじめなセキュリティ・ワークフローを構築したことにはならない。より大きなカオスのバケツを作ってしまったのだ。
正しい動きはエビデンスの正規化である。すべてのコレクターは、少数のタイプされた記録を作成すべきである。パッシブスキャンはアセットとサービスのレコードになる。JavaScriptパーサーはルート、パラメータ、オブジェクト名のレコードになる。ブラウザの実行は、UIサーフェスレコード、ロールレコード、およびスクリーンショットレコードになる。認証されたリプレイは、response-diffとaccess-matrixのレコードになる。人間のメモは、実績のある仮説レコードになる。
正規化されたレコードセットは次のようになる:
{
"エンゲージメント":"acme-b2b-portal-q2",
"assets":[
{
"asset":"app.target.example"、
"role":"primary_app"、
"services":[
{"port":443, "proto":「https", "product":「nginx"}、
{"port":8443, "proto":「https"、"product":「内部ゲートウェイ"}。
]
}
],
"ui_surfaces":[
{
"surface_id":"billing_export_panel"、
"role_seen_as":"billing_admin"、
"screen_type":"export_console"、
"screenshot_ref":"screens/role_admin_07.png"、
"visible_actions":["export_all"、"download_csv"、"filter_by_customer"].
}
],
"routes":[
{
"path":"/api/v1/invoices/{invoice_id}"、
"source":"bundle_extract"、
"object_hint":"invoice"、
"authint":"session_cookie"
}
],
"response_diffs":[
{
"diff_id":"role_matrix_02"、
"route":"/api/v1/invoices/inv_1042"、
"roles_compared":["roles_compared": "basic_user", "billing_admin"]、
"differences":["line_items", "customer_id", "download_url"]。
}
],
「仮説":[
{
"hypothesis_id":"h-14",
"claim":"請求書エクスポートフローでオブジェクトレベルの認可が壊れている可能性"、
"evidence_refs":[
"billing_export_panel"、
"bundle_extract:/api/v1/invoices/{invoice_id}"、
"role_matrix_02"
],
"status":"unverified"
}
]
}
これは、ロングコンテクスト・モデルが、不透明なツールノイズよりも、意味的に明示的なオブジェクトに対する推論に優れているためである。生の ナマップ 行やHTMLの塊はまだ役に立つが、リファレンスの後ろに置くべきだ。メインプロンプトは、これまでに収集されたすべてのバイトではなく、抽出された事実とその出所を伝えるべきである。
PentestGPTの論文にある、コンテキストの喪失に関する古い教訓は、ここにほぼ完璧に当てはまる。そのモジュール設計は、一般的なLLMループがセッションが大きくなるにつれてエンゲージメントの状態を失うという事実への対応だった。Gemma 4 31Bは、より多くのスペースを与えてくれるが、より多くのスペースは、より優れたメモリ・モデルとは同じではない。セキュリティ・チームは、何がアクティブ・フレームに属し、何がエビデンス・ストアに属するかを決める必要がある。アクティブ・フレームには、次の決定を変えるものだけを入れるべきだ。(USENIX)
良いルールは、観察、仮説、結論を明確に分けることである。観察とは生の事実である。仮説は、それらの事実が意味することのモデルまたは人間による解釈である。結論は、人工物の検証を必要とする。これら3つの層が混ざり合うと、モデルは自分自身の推測を真実として読み返し始める。これは、実際よりも厳格に聞こえるAI支援による偽陽性を作り出す最も簡単な方法の一つである。
スクリーンショットをカオスにすることなく、マルチモーダル推論を使う
Gemma 4のマルチモーダルなプロファイルは、特にペンテストに関連している。なぜなら、最も重要なアプリケーションの状態は、それが簡単に記述される前に、しばしば目に見えるからだ。グーグルのモデルカードによると、Gemma 4は、ドキュメントやPDFの解析、画面やUIの理解、OCR、可変アスペクト比を含む画像理解に対応している。これはセキュリティの仕事には珍しく実用的だ。バックオフィスツールのスクリーンショットは、初期のAPIトランスクリプトよりも良い手がかりになることが多い。(開発者向けグーグルAI)
輸出ダッシュボード、モデレーションキュー、請求書発行コンソール、ベンダー管理パネル、内部検索ツール、エンタイトルメントエディタ、機能フラグページ、サポートなりすましフロー、注文調整画面など、実際の業務で重要な画面について考えてみよう。マルチモーダルモデルは、どの画面が操作上センシティブに見えるか、どのアクションが権限昇格パスを意味するか、2つのロールがテストする価値のある方法で視覚的に異なって見えるかを分類するのに役立つ。これは脆弱性の証明ではない。それはトリアージの高速化である。
便利なプロンプトパターンは、スクリーンショットだけを送るのではなく、スクリーンショットと構造化された要約を組み合わせることです。例えば
システム
あなたはローカルのペンテスト推論モデルです。アクションを実行することはできません。
目に見える UI を分類し、信頼できそうな境界を推測し、読み取り専用の検証ステップを提案することしかできません。
JSONのみを返す。
ユーザー
アーティファクト:
1.スクリーンショット参照:role_user_03.png、role_admin_07.png
2.DOMの要約:
- ページのタイトル:請求書エクスポート
- 管理画面に表示されるボタン全てエクスポート, CSVダウンロード, 顧客別フィルター
- ユーザに見えるボタン請求書を見る
3.セッションメモ:
- adminとuserは同じベースアプリシェルを共有する
- JSからのルートヒント: /api/v1/invoices/{invoice_id}
タスク:
サーフェスを分類し、認可の可能性が高い境界を推測し、読み取り専用の検証計画を提案する。
このようなやり取りにおけるモデルの価値は、"スクリーンショットを見る "ことではない。スクリーンショットとその周りの証拠を一緒に見ることである。ボタンだけでは曖昧である。ルートヒント、ロールノート、既知のビジネスオブジェクトと結びついたボタンは、はるかに有益です。
限界はある。UIの解釈はセマンティクスを幻覚する可能性がある。似ているように見える2つの画面でも、バックエンドの経路は全く異なるかもしれない。スクリーンショットから抽出されたテキストは、重要な隠された状態を省略するかもしれない。アクセシビリティオーバーレイ、レスポンシブレイアウト、ダイナミックコンテンツは、モデルが推測するものを歪める可能性がある。これが、スクリーンショットの推論が常に検証計画で終わるべきであり、決して発見で終わるべきでない理由である。正しいアウトプットは、"これは、別のロールで読み取り専用のリプレイを行う価値のある特権的なエクスポートパスのようだ。"であって、"これは間違いなく、アクセス制御が壊れている問題だ。"ではない。
これはまた、より広範なAIネイティブ攻撃ワークフローに戻る最も自然な場所の1つです。Penligentの公開資料では、単一のブラインドエクスプロイトエンジンではなく、エビデンスファーストのレポート、マルチロール認証テスト、オペレーター制御の実行が強調されている。スクリーンショットやUIセマンティクスは、検証を置き換えるのではなく、検証を導くために使用するのだ。(寡黙)
セキュリティ・エンジニアが実際に信頼できるロング・コンテキスト分析
256Kのコンテキストウィンドウは意味があるが、それはプロンプトがストレージのようにではなく、ワーキングメモリのように扱われる場合に限られる。ペンテストでは、各段階でモデルが何を見るかを管理することを意味する。
第一のルールは、出所を保持することである。モデルが扱うすべての重要な主張は、他のモデルの要約ではなく、成果物を指し示すべきである。仮説がスクリーンショット、ルート抽出、レスポンスの差分を参照する場合、それらの参照は可視化されるべきである。こうすることで、一緒になるべきでないファクト間の結合組織を捏造する傾向を減らすことができる。
第二のルールは、失敗したプローブは圧縮された形でのみ保存することである。失敗したプローブは、再挑戦してはいけないものや、すでに崩壊した仮定をモデルに教えてくれるからだ。生の詳細がプロンプトを圧倒するとき、それらは有害になる。より良いパターンは、失敗した各試行をコンパクトなオブジェクトとしてまとめることである:ターゲット、メソッド、認証状態、結果、破棄された理由。そうすることで、モデルにすべてのトレースを読み直すことを強いることなく、調査履歴を生かすことができる。
3つ目のルールは、環境コンテキストと行動コンテキストを分離することである。環境コンテキストには安定した事実が含まれる:対象資産、役割、製品、ビジネスオブジェクト、事前に知られているルート、高レベルの信頼境界線。行動コンテキストには、次の意思決定にすぐに関連するものが含まれる。すべてが1つの巨大なトランスクリプトに存在する場合、モデルはそれについて推論するよりも、世界の状態を再配置することに多くの労力を費やす。
第4のルールは、モデルに不確実性を外部化させることである。良い出力形式は、"観察された"、"推測された"、"検証が必要 "を区別する。セキュリティエンジニアはすでにこのように考えています。モデルもこのように考えるようにすべきです。これは、最終報告書の形容詞の選択よりも重要なことです。
PentestGPTの論文は、解決策をロマンチックに語ることなく、中心的な問題を挙げているので、ここでも有用である。Gemma 4 31Bの長いコンテキストのおかげで、構築者はより多くの作業スペースを得ることができ、システムロールサポートと関数呼び出しによって、構造化されたプロンプトの作成が容易になった。プロンプト・アーキテクチャ、エビデンス・スキーマ、そして量よりも関連性を優先する検索ポリシーが依然として必要である。(USENIX)
実際には、最も信頼できるロングコンテキストのユースケースは、生成的というよりむしろ比較的であることを意味する。ロールのトレースを比較したり、弱いシグナルをクラスタリングしたり、2つの証拠がなぜ1つのアクセス制御の問題に属するのかを説明したり、どの仮説が最初に検証に値するかをランク付けしたりするように、モデルに求めてください。ゼロからの完全な計画を求める頻度は少なくしてください。すでに持っている証拠を推論するようモデルに求めれば求めるほど、推測的な創造性に頼ることが少なくなります。
人間の承認はデザインの一部であり、予備ではない
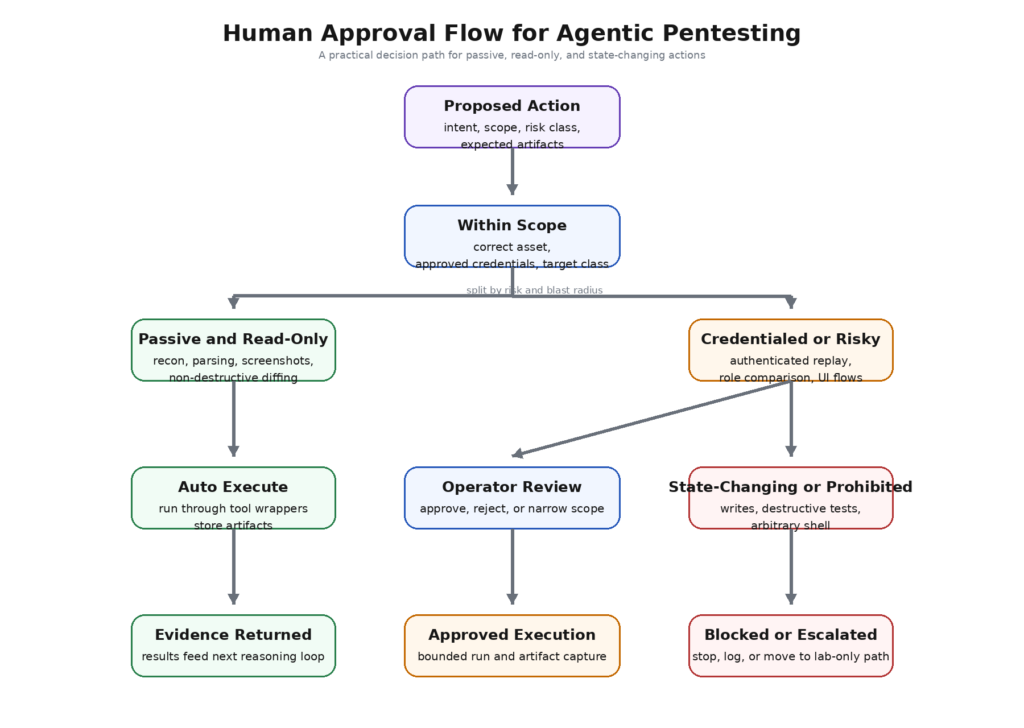
多くのAIセキュリティ・ワークフローは、人間のレビューをオプションの安全ブレーキとして扱っている。ペンテストスタックでは、それは逆効果である。人間の承認は、システムの第一級のルーティング概念であるべきだ。このモデルは、どの種類のアクションが自動的に実行可能で、どれが承認制で、どれが完全に禁止されているかを知っていなければならない。
シンプルな承認マトリックスがそれを具体化する:
| アクションクラス | 例 | オートラン | 人間の承認 | 走行後に必要な証拠 |
|---|---|---|---|---|
| パッシブ | DNS、ヘッダー収集、ルート抽出、対象公開ページのスクリーンショットキャプチャ | はい | いいえ | 生のアーティファクトとパーサー出力 |
| 読み取り専用再生 | 認証されたGETの再生、役割の比較、状態を変更しないエクスポートURLのアクセスチェック | 通常は | はい | リクエストトレース、レスポンス差分、アクセスマトリックス |
| UIナビゲーションのみ | 既存のセッションでブラウザのナビゲーションを制御。 | 通常は | はい | ビデオまたはスクリーンショット、DOM diff |
| 州の修正 | プロフィールデータの変更、オブジェクトの作成、アクションの承認、メールの送信 | いいえ | はい。 | 完全なトレース、ロールバックノート、必要に応じてターゲット所有者の認識 |
| 禁止 | 破壊的なファジング、承認された研究室以外での特権昇格の試み、任意のシェルやポストエクスプロイト | いいえ | 不可 | なし、ポリシー層でブロック |
これは官僚主義そのものではない。モデルをアクターから、限定された権限を持つアシスタントに変えるものなのだ。いったんこれらのクラスが存在すれば、システムはモデルに正しいクラスを要求するよう強制することができ、オペレータは要求が実際のリスクと一致しているかどうかをすばやく確認することができる。モデルが "読み取り専用リプレイ "を要求し、実際には書き込みエンドポイントへのPOSTが含まれていた場合、その不一致は実行前に可視化される。
承認デザインは学習も向上させる。オペレータがモデルから提案されたアクションを却下する場合、却下の理由はエビデンスエコシステムの一部となります:範囲外、役割違い、爆発半径が大きすぎる、エビデンス不足、冗長、偽陽性の可能性が高いなど。このフィードバックは、モデルのチューニングよりも運用上価値がある場合が多い。
このヒューマン・イン・ザ・ループの構造は、バイヤーやエンジニアにAIペンテスターの価値を説明するのが最も簡単なところでもあります。この点に関して、Penligentの最も一般的なフレーミングは、AIペンテスターをおもちゃのチャットボットやロボット・コンサルタントとしてではなく、生の信号と検証された発見との間の距離を縮めるガバメント・システムとして説明している。これは「自律的なハッキング」よりもはるかに強力で擁護可能な説明であり、ローカルな推論レイヤーとして使用される場合、Gemma 4 31Bに見事に適合する。(寡黙)
Gemma 4 31B ペンテストスタックの評価方法
この種のシステムを評価する間違った方法は、モデルが "賢く感じるかどうか "を問うことである。正しい方法は、ワークフローが無駄なアクションを減らし、より良いエビデンスを生み出すかどうかを測定することである。
精度を見つけることから始めるが、それを狭く定義する。有用な指標は、"モデルがいくつの問題に言及したか "ではない。それは、"何回の検証を試みたかに対して、いくつの問題が完全な証拠の連鎖によって検証された状態に達したか "である。これは、もっともらしいナンセンスを生み出すシステムにはペナルティを与える一方で、あいまいさを証明に変えるシステムには報酬を与えることになる。
つ目の指標は、信号から証明までの時間である。最初の弱いシグナルから検証された仮説、あるいは否定された仮説に至るまで、どれくらいの時間がかかるか?ここが優れた局所推論コアがその役割を果たすべき場所である。アーティファクトを読み直し、コンテキストを再説明し、次に何をテストするかを決定する時間を短縮する必要がある。よりきれいな要約を書くが、この数字を動かさないシステムは、ほとんど化粧品である。
3つ目の指標は、無駄なアクション率である。いくつのモデル提案アクションがポリシーによってブロックされるか、オペレータによって拒否されるか、明らかに冗長な成果物を生成するか。この数値は、エビデンスの正規化とアクションスキーマが機能しているかどうかについて多くを語っています。モデルが間違ったクラスのアクションを要求し続ける場合、問題はモデルではないかもしれません。プロンプトアーキテクチャか、型付けされたコンテキストの欠如かもしれません。
4つ目の指標は、エビデンスの完全性である。別のエンジニアが、保存された成果物だけから検証を再現できるか?スコープ、認証状態、リクエストトレース、ロールの比較は保存されていますか?AIが生成したセキュリティコンテンツは、しばしばここで失敗します。AIが生成したセキュリティコンテンツは、運用上再現可能でなくても説得力がある。優れた Gemma ワークフローは、アクションが承認される前に、モデルにその根拠を引用させることができるため、完全性を向上させるはずです。
第五の指標は承認負担である。すべてのアクションに小論文のような斬新なレビューが必要な場合、ヒューマン・イン・ザ・ループ・システムは失敗する。ゴールは承認ゼロではない。ゴールは、アクション要求がタイプされ、スコープが設定され、エビデンスが裏付けされているので、摩擦の少ない承認である。もしオペレータが、提案された読み取り専用検証が安全かどうかを数秒で判断できなければ、アクション契約は曖昧すぎる。
第6の指標は、再テストの正確さである。開発者が問題が修正されたと主張するとき、システムはその前後の成果物を比較し、発見が崩壊したのか、部分的に崩壊したのか、単に移動しただけなのかを述べることができるだろうか?これは、本質的に比較と証拠駆動型であるため、ロングコンテキストの推論モデルの最も活用度の高い使い方の1つです。
すなわち、従来のツールを使用した手動テスター、ルーズチャットモードのジェネリックフロンティアモデル、そして正規化とポリシーゲートを備えたGemma 4 31Bガバナーワークフローである。PentestGPTの研究は、3つ目のパターンを試す価値がある理由をすでに示唆している。LLMの利益は、ワークフロー構造が、もろい完全な自律性を強制するのではなく、コンテキストを保持し、サブタスクを特化することを支援する場合に、最も明確に現れる。(USENIX)
モデルの微調整、検索、カスタマイズしない場合
セキュリティ・チームはカスタマイズを好むが、それには理由がある。環境は特殊である。オブジェクトモデルは特殊である。レポート要件も特殊だ。しかし、微調整は往々にして最初の一手を誤る。
最初の投資として最適なのは、エビデンスの正規化、検索品質、出力スキーマの設計、ポリシーの統合である。これらは問題定義そのものを改善するため、モデルが要求するすべてのアクションの質を向上させる。もしモデルがよりクリーンな証拠を見て、型付けされた出力を返すなら、誰もウェイトに触れないうちに安全に使うことが容易になる。
ワークフローの形状がすでに安定している場合、微調整はより説得力のあるものになります。チューニングの対象として適しているのは、社内の課題分類法、レポートのトーン、ビジネスオブジェクトの命名規則、構造化されたサマリーのスタイル、製品や環境に結びついた分類などである。テスターが常に同じクラスのSaaSアプリや同じクラスのモバイルバックエンドに対して作業するのであれば、そのようなチューニングを行うことで、流動性を向上させ、摩擦を減らすことができる。
ファインチューニングで間違っているのは攻撃性だ。チームはときどき、危険なことをより進んでやるようになることで、そのモデルがより優れたペンテスターになるかのように話すことがある。それは能力の向上ではない。それはエンフォースメントの失敗である。真の攻撃的品質は、より良い証拠処理、より良い状態追跡、より良い役割推論、より良いカバレッジの優先順位付け、よりクリーンな証明パスから生まれる。どれもシステムのブレーキを外す必要はない。
これは、オープンウエイトが重要な場所のひとつであるが、適切な順序があるだけである。Gemma 4のローカルなデプロイ可能性と明確なライセンスは、チーム自身がモデルをチューニングし、ホスティングする選択肢を与えてくれる。これは価値あることだ。解決すべき最初の問題ではない。まず契約を構築する。次にエビデンスシステムを構築する。その上で、モデルの適合が必要なものがあるとすれば、それは何かを決定する。(開発者向けグーグルAI)
展開の数学とハードウェアの現実
Gemma 4 31Bは、クラウド・オンリーではないという意味でローカル・フレンドリーだ。多くの人が "ローカルで動かすから "と言うときの意味での軽量ではない。グーグルの公式メモリ表が最もクリーンな出発点である。31Bの基本ウェイトの場合、BF16でおよそ58.3GB、8ビットで30.4GB、Q4_0で17.4GBであり、これらの数字にはソフトウェアのオーバーヘッドとコンテキストによって消費される余分なメモリは含まれていないという明確な警告がある。この警告は重要である。ペンテストの推論ワークフローは、まさにチームが大きなコンテキストを使用するよう誘惑するようなワークロードである。KVキャッシュの増加は、ここでは学術的な脚注ではない。容量計画の一部となる。(開発者向けグーグルAI)
この現実が、理にかなった配備の分担を促している。実質的な証拠を保持し、より重い比較分析を実行できるローカルな推論ハブが必要なら、31Bは最上位レイヤーとして理にかなっている。UI支援や迅速な分類のためにエンドポイント側の小さなヘルパーが必要な場合は、より小さなモデルがその役割を果たすことができる。DeepMindの位置づけは、すでにこの区分けを示唆している。小さなバリエーションはエッジとモバイルのシナリオ用に構築され、31Bと26Bのクラスはワークステーションと高度な推論を中心に組み立てられている。実用面では、31Bはすべてのインタラクションサーフェス用ではなく、ガバメントされたペンテストシステムの "頭脳 "に適している。(グーグル ディープマインド)
もう1つのデプロイの問題は、実行プレーンに対してモデルがどこに位置するかということである。よくある間違いは、推論モデルとあらゆる危険なツールを、等しく特権的なサービス内に配置することです。これは便利だが、しばしば間違っている。より安全な設計は、モデルをエビデンスストアとポリシーエンジンの近くに置き、ツールランナーは独自の実行時制約を持つより狭いラッパーの後ろに置きます。実行サーフェスが侵害された場合、推論レイヤー全体に戻るのではなく、そこで爆発半径を止めたい。
これは、プライベートデプロイメント機能が調達の細部にとどまらず、セキュリティアーキテクチャとして機能し始めるところでもある。Penligentの公開されているエンタープライズとチームの資料では、プライベートデプロイメント、プライベートモデルの統合、認証されたフローテスト、監査ロギング、CIまたはCDの統合について言及している。チームが、完全にカスタム化された Gemma スタックを選択するとしても、これらのカテゴリーは模倣すべきものである。本格的なペンテストの自動化は、"我々のハードウェア上でモデルが動作する "ことでは終わらない。ワークフロー全体が、評価対象の環境と同じセキュリティモデルに従ったときに終わるのです。(寡黙)
ローカルLLMペンテストにおける一般的な失敗モード
最初の失敗モードは、モデルの信頼性とエビデンスの質を混同していることである。ロングコンテキストモデルは、弱い主張に対して美しく構造化された説明を生成することができる。ワークフローがすべての重要なステップで成果物を参照することを強制しなければ、トレースよりも説明を信頼することが容易になります。これは、AIが支援するセキュリティ作業がうまくいかない最も一般的な方法の1つです。
2つ目の失敗モードは、信頼されていないターゲット・コンテンツを、サニタイズもアイソレーションもせずにツールの呼び出しパスに流してしまうことだ。モデルがグローバルにジェイルブレイクされる必要はない。ターゲットが制御するテキストを危険なフィールドに渡すように誘導するだけでよい。OWASP のプロンプト・インジェクションと安全でない出力処理のカテゴリーは、まさにこの失敗の連鎖がエージェント・ システムで非常に一般的であるため、関連し続けます。(OWASP Gen AIセキュリティプロジェクト)
3つ目の失敗モードは、メモリの衛生状態が悪いことだ。長く保存されたメモ、キャッシュされた要約、保存された仮説は、タイプ分けやバージョン管理がされていないと、将来の分析に悪影響を及ぼす可能性がある。メモリは継続性のために有用であるが、"我々はこれを観察した "と "我々は先週これが真実かもしれないと考えた "が曖昧になると有害である。エージェント・システムには、永続性だけでなく、実証性が必要である。
4つ目の失敗モードは、256Kのコンテキスト・ウィンドウを無限として扱うことだ。大きなコンテキストが役立つのは、アクティブなフレームが関連性を保っている場合だけである。チームが生ログ、完全なHTMLページ、重複したスクリーンショット、そしてあらゆる失敗したトレースをプロンプトにダンプし始めると、パフォーマンスはより高価な混乱のバージョンへと劣化する。Gemmaの公式ドキュメントは、大きなコンテキストが実際のメモリコストを持っていることをすでに正直に伝えている。(開発者向けグーグルAI)
5つ目の失敗モードは、スクリーンショットが検証の代わりになると思い込んでいることだ。それはできない。役割の状態、リクエストの履歴、決定論的な再生に結びつかない限り、スクリーンショットは優れたトリアージ入力であり、証明の成果物としては不十分である。モデルは計画を立てるために視覚的な証拠を使うべきである。実行者は証明するためにリクエストとトレースを使うべきである。
第6の失敗モードは、ローカルサービスの自己満足である。自前でホストしているということは、安全に封じ込められているということではない。シスコとプレトリアンがLLMのインフラを公開したことは、この点を永続させるのに十分だ。誤ったインターフェースや誤ったセグメントに置かれたモデルサーバーは、もはや単なるヘルパーではなく、新たなターゲットとなる。(シスコブログ)
第七の失敗モードは、承認をループ内で遅らせることである。もしオペレーターが、ツールがすでに実行された後にしかモデルの決定を見ないのであれば、それはヒューマン・イン・ザ・ループではない。それは事後的な承認である。真の承認とは、オペレータが実行前にタイプされたアクション要求をレビューすることを意味する。
セキュリティ・チームのための実践的なロールアウト・パス
最適な採用方法は漸進的である。Gemma 4 31Bに実行の影響力を与える前に、受動的な推論レイヤーとしてスタートする。正規化されたリコン、スクリーンショット、ルート抽出を与える。攻撃サーフェイスのクラスタリング、信頼境界の特定、読み取り専用の検証プランの生成に使用する。より強力なものに接続する前に、アナリストの時間を節約できるかどうかを測定する。
第二段階は、コントロールされたバリデーションである。型付けされたコントラクトを通じて、モデルに読み取り専用またはナビゲーション専用のアクションのみを要求させる。認証されたすべての再生に対して、オペレーターの承認を要求する。すべての結果の成果物を保存する。この段階では、ゴールはスピードではない。ゴールは、アクションスキーマ、ポリシーレイヤー、エビデンスパイプラインが実際のオペレータのプレッシャーの下で機能することを証明することである。
第3段階は、比較再テストである。システムが単純な読み取り専用チェックを確実に提案し、検証できるようになったら、それを使って、修正された発見について、修正前と修正後の成果物を比較する。これは、信頼を拡大する最も安全な方法の一つである。なぜなら、質問には厳密な制約があるからである。
第四段階はワークフロー統合である。統治された推論レイヤーをレポート生成、チケットエンリッチメント、CIやCDの再テストフックに接続する。この時点で、自律的な攻撃的実行を決して望まないチームにとってさえ、このモデルは純粋に価値あるものになる。リスクを伴う行動を決定する権威になることなく、証拠を圧縮し、リグレッションを追跡し、何が変わったかを説明するのに役立つ。
このような段階を経て初めて、チームはより高度なアクションクラスを検討すべきである。その場合でも、システムは狭いラッパー、タイプ化されたコントラクト、明示的な承認にバイアスをかけるべきである。ペンテスト・ワークフローは、再現性が高くなるにつれて価値が高まるのであって、芝居がかりになるにつれて価値が高まるのではない。
これはまた、社内の知識と公的なガイダンスが出会う場所でもある。OWASPのレッドチーム資料は、モデルだけでなく、実装とランタイム全体をテストすることを推進している。NISTは、AIシステムの攻撃段階と緩和策について明確な言語化を推進している。エージェント・ツールにおける最近のCVEは、悪い境界が実際にどのように失敗するかを示している。そして、AIペンテスターとMCP時代の実行境界に関するPenligentの資料を含む、新しいペンテスト・ワークフローの記述は、同じ運用上の真実に収束しつつあります。(OWASP Gen AIセキュリティプロジェクト)
最終的な感想
ジェマ4 31Bは、最終的にペンテストを無人搾取に変えるモデルではない。それは弱点ではない。それは、より良い適合の始まりなのだ。
グーグル社自身の文書によると、このモデルが提供するものは、セキュリティ作業にとって稀な組み合わせである。長いコンテクスト、構造化されたツールの使用、システムロールサポート、UIと文書の理解を含むマルチモーダルな推論、そして、証拠が要求するときにローカルで非公開でいられるデプロイメントストーリーである。特にPentestGPT以降の一般的なペンテストに関する文献が私たちに思い起こさせるのは、エンドツーエンドの攻撃的な作業は、コンテキスト管理、権限の境界、検証の規律が崩れたときに中断されるということです。これらの考えをまとめると、Gemma 4 31Bの正しい役割は明白になる。それはペンテスターではない。それは、ガードレールを中心に設計されたペンテスト・システム内のローカルな推論コアなのだ。(開発者向けグーグルAI)
その前提で作れば、モデルは非常に役に立つ。人間が読み直したいと思う以上の証拠を読み取ることができる。人間が比較したがるよりも根気よくフローを比較することができる。弱い手がかりの山を、もっともらしい攻撃経路のショートリストに変えることができる。特権サーフェスを分類し、再テストの証拠を整理し、レポートの再現性を高めることができる。これらはすべて価値がある。いずれも、言語が証明と同じものであるかのように装う必要はない。
つまり、設計目標はそれ自体のための自律性ではない。あらゆる重要な結論がトレースされ、あらゆる危険な行動が否定され、あらゆる有益な提案が証拠に変換されるようなセキュリティのワークフローである。Gemma 4 31Bは、そのようなシステムの内部で役立つのに十分な強さを持っている。あとはアーキテクチャだ。
さらに読む
Gemma 4モデルの概要と必要メモリ - Google AI for Developers.(開発者向けグーグルAI)
長いコンテキスト、関数呼び出し、システムロールサポート、画面やUIの理解を含むGemma 4モデルカード - Google AI for Developers.(開発者向けグーグルAI)
Gemma 4 のリリースノートと DeepMind のモデルページ - 公式発表の詳細、モデルのサイズ、エージェント型ワークフローの位置付け。(開発者向けグーグルAI)
Gemma 4 under Apache 2.0 - Google Open Source Blog.(グーグル・オープンソース・ブログ)
PentestGPT、自動ペネトレーションテストのための大規模言語モデルの評価と活用 - USENIX Security 2024.(USENIX)
OWASP プロンプト・インジェクション・ガイダンスと LLM アプリケーションのための OWASP トップ 10 - プロンプト・インジェクション、安全でない出力処理、安全でないプラグイン設計、および過剰なエージェンシー。(OWASP Gen AIセキュリティプロジェクト)
OWASP GenAI Red Teaming Guide - モデル、実装、インフラ、ランタイムテスト。(OWASP Gen AIセキュリティプロジェクト)
NIST AI 100-2、敵対的機械学習 - AI システムの攻撃と緩和のための分類と用語。(NISTコンピュータセキュリティリソースセンター)
エージェント実行境界に関連する CVE および NVD 参照 - CVE-2026-27966、CVE-2024-42835、CVE-2025-53355、CVE-2025-66414、および CVE-2025-67511。(NVD)
2026年のAIペンテスター、AIシステムを混同せずにテストする方法 - Penligent.(寡黙)
生産現場におけるエージェント型AIのセキュリティ、MCPセキュリティ、メモリポイズニング、ツールの悪用、そして新たな実行境界 - Penligent.(寡黙)
2026年のペンテストAIツール、実際に機能するもの、壊れるもの - Penligent.(寡黙)
Penligent.aiの自動ペネトレーションテストツールの概要 - Penligent.(寡黙)
プランと価格 - Penligent、展開形状、ワークフロー機能、プライベートモデル統合の詳細について。(寡黙)

