L'annonce du Mythos d'Anthropic a poussé beaucoup de gens à se poser la mauvaise question. La version la plus bruyante était : "Quel modèle est maintenant le meilleur hacker ?". La version la plus utile est plus difficile et plus opérationnelle : de quelle quantité de modèle avez-vous besoin à chaque étape d'un test de pénétration, quel échafaudage doit-il exister autour de lui, comment vérifiez-vous ce qu'il dit, et qu'achetez-vous réellement par dollar lorsque vous passez d'un signal candidat à une découverte défendable ? Les documents publics d'Anthropic décrivent un système, pas une invite magique. Le projet Glasswing affirme que Mythos Preview a trouvé des milliers de vulnérabilités "zero-day" dans tous les principaux systèmes d'exploitation et navigateurs, et l'article de l'équipe rouge d'Anthropic décrit un échafaudage simple mais réel : lancer un conteneur isolé, laisser le modèle inspecter le code et exécuter la cible, itérer avec le débogage, et produire un rapport de bogue avec des étapes de preuve de concept. La réponse d'AISLE ne nie pas cette capacité. Elle a fait valoir qu'une grande partie de ce qui est important dans ce pipeline est déjà disponible pour des modèles plus petits, moins chers et, dans certains cas, à poids ouvert, une fois que le flux de travail est structuré correctement. (anthropic.com)
Cette distinction est importante car l'expression "AI pentesting" commence à être utilisée pour presque tout ce qui est équipé d'un LLM et d'un scanner. La norme NIST SP 800-115 définit toujours les tests de sécurité technique en fonction de la planification, de l'exécution, de l'analyse des résultats et de la stratégie d'atténuation. Le guide des tests de sécurité Web de l'OWASP traite toujours les tests de sécurité comme un cadre discipliné pour l'évaluation des applications et des services Web, et non comme une série de commentaires générés par un modèle. Le Top 10 de l'OWASP sur la sécurité des API place toujours l'autorisation de niveau objet brisée en tête de liste, car les défaillances graves dans les systèmes réels se situent généralement dans les relations entre objets, les limites des rôles, les transitions d'état et la logique commerciale, et pas seulement dans les chaînes de caractères correspondant à des modèles. Une fois cette base rétablie, le débat sur les Mythos devient beaucoup plus facile à raisonner. Un test de pénétration n'est pas une réponse modèle. Il s'agit d'un processus délimité et probant qui transforme l'incertitude en preuve. (csrc.nist.gov)
La meilleure contribution d'AISLE à la discussion n'est pas d'avoir "démystifié" Mythos. C'est qu'elle a décomposé le pipeline. L'histoire publique d'Anthropic comprime naturellement l'analyse, la reconnaissance des vulnérabilités, le triage, l'évaluation de l'exploitabilité, la construction de l'exploit et la remédiation en une seule capacité continue. AISLE soutient que cette compression est pratique d'un point de vue rhétorique mais trompeuse d'un point de vue opérationnel. Dans son cadre, la cybersécurité par l'IA est une pile de tâches différentes avec des propriétés d'échelle différentes : balayage à large spectre, détection des vulnérabilités, triage et discrimination des faux positifs, génération de correctifs et, parfois, construction d'exploits. Son autre point est celui que les équipes de sécurité devraient internaliser : la fonction de production pour la sécurité de l'IA ne se limite pas à l'intelligence par jeton. Elle inclut également les jetons par dollar, les jetons par seconde et l'expertise en matière de sécurité intégrée dans l'échafaudage qui achemine, valide et contraint le modèle. Il ne s'agit pas d'une petite correction. C'est la différence entre l'achat d'une démo et la construction d'un cabinet. (AISLE)
L'IA pentesting est encore un flux de travail, pas un modèle géant
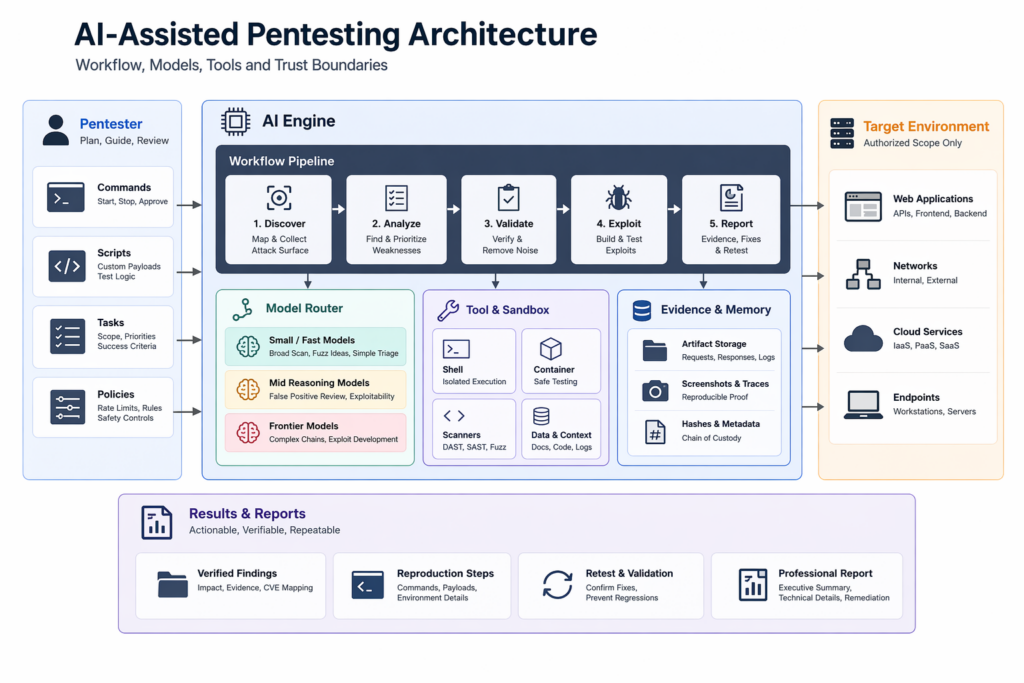
La meilleure façon de comprendre le pentesting de l'IA en 2026 est de cesser de le considérer comme un concours de raisonnement abstrait et de commencer à le traiter comme un problème de conception de flux de travail. Un véritable flux de travail en matière de sécurité doit faire plusieurs choses bien à la fois. Il doit réduire le champ d'application sans perdre le contexte important. Il doit conserver l'état à travers les requêtes, les rôles ou les sessions. Il doit distinguer un problème plausible d'un problème reproductible. Elle doit préserver suffisamment de preuves pour qu'un autre ingénieur puisse rejouer ce qui s'est passé. Il doit éviter d'exagérer l'impact lorsqu'une condition n'est pas réellement réalisable. Et si le système fait de l'exploitation active ou de la validation, il doit faire tout cela sans enfreindre la discipline du champ d'application ou produire des preuves qui ne peuvent pas survivre à l'examen. Il s'agit là d'exigences techniques avant d'être des exigences de modèle. (csrc.nist.gov)
C'est la raison pour laquelle la récente conversation sur les critères de référence s'éloigne discrètement des "futilités de sécurité" statiques et s'oriente vers des tâches de bout en bout. Le test CTI-REALM de Microsoft s'articule explicitement autour de l'ingénierie de la détection dans le monde réel plutôt que sur des questions et réponses isolées. Il teste la lecture des renseignements sur les menaces, l'exploration de la télémétrie, l'itération sur la logique KQL et Sigma, et la validation des résultats par rapport à la vérité de terrain. Le domaine exact est l'ingénierie de détection plutôt que le pentesting, mais la leçon structurelle est la même : un benchmark de sécurité devient plus utile à mesure qu'il se rapproche du flux de travail que les humains doivent réellement mener à bien. L'avenir de l'évaluation offensive évoluera probablement dans la même direction. La meilleure évaluation ne se contentera pas de demander si un modèle peut décrire un bogue. Elle demandera si un système limité peut trouver le bon endroit pour regarder, séparer le bruit du signal, prouver la condition, préserver la trace de l'artefact et communiquer le résultat d'une manière à laquelle un autre ingénieur peut faire confiance. (Microsoft)
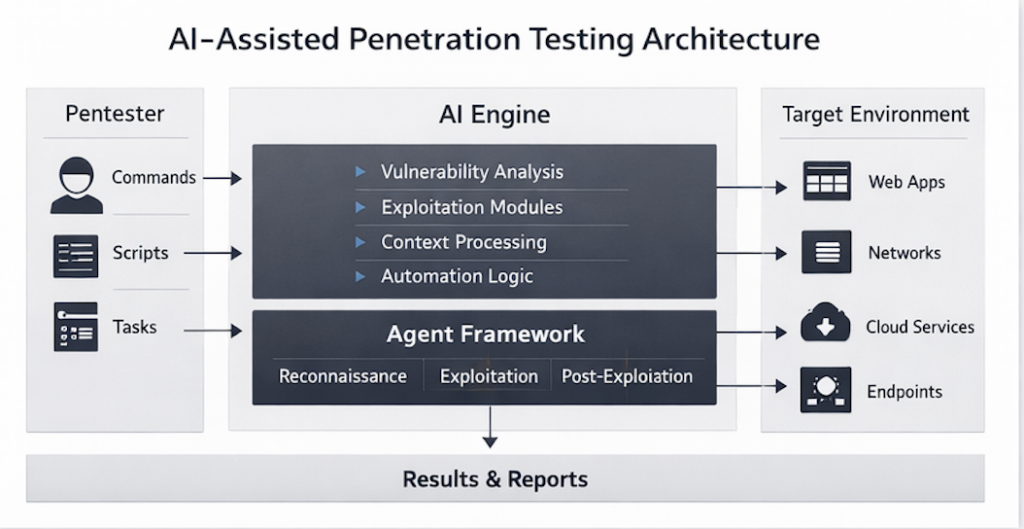
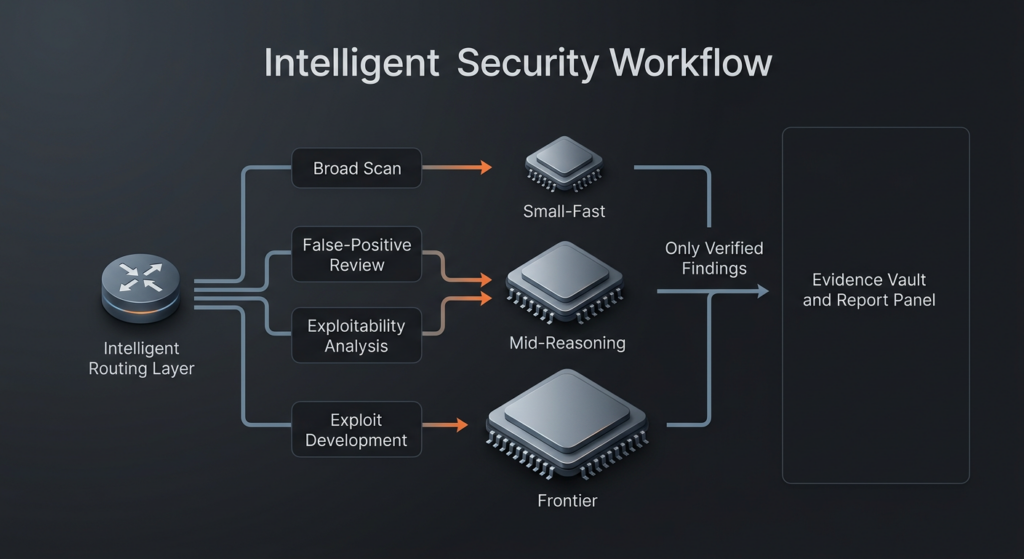
Une architecture de pentesting IA utile ressemble donc moins à un monolithe qu'à une équipe de relais. Un modèle rapide et bon marché peut souvent effectuer le travail de premier passage consistant à inventorier les points d'extrémité, à regrouper les itinéraires, à repérer les modèles de cadre ou à identifier les zones de code qui valent la peine d'être escaladées. Un modèle de raisonnement un peu plus solide peut se charger du filtrage des faux positifs, du classement de l'exploitabilité et du nettoyage des hypothèses. Le modèle le plus coûteux ne doit pas être le modèle par défaut pour tout. Il doit être votre niveau d'escalade pour les endroits où l'espace de recherche est suffisamment étroit et la valeur attendue suffisamment élevée pour que le raisonnement au niveau de la frontière vaille la peine d'être payé. C'est la version pratique de votre argument principal : l'objectif n'est pas de louer le modèle le plus intelligent du monde à chaque étape. L'objectif est d'exprimer la bonne quantité d'intelligence à la bonne étape dans le cadre d'un flux de travail qui ne gaspille pas la couverture, l'argent ou l'attention de l'examinateur. (AISLE)
Le tableau ci-dessous synthétise cette vision du pipeline en utilisant la décomposition d'AISLE, l'échafaudage divulgué d'Anthropic et le cadre classique du pentest du NIST et de l'OWASP. (Rouge Anthropique)
| Stade du pipeline | Ce que fait réellement le système | Goulot d'étranglement dominant | Les modèles petits ou moyens suffisent souvent | Quand un modèle de frontière gagne sa vie | Garde-corps technique non négociable |
|---|---|---|---|---|---|
| Réduction des actifs et du contexte | Cartographier la cible et réduire l'espace de recherche | Couverture et rapidité | Oui | Rarement | Limites strictes du champ d'application et manifestes cibles |
| Découverte des candidats | Mise en évidence de chemins, d'itinéraires ou de comportements suspects dans le code | Largeur par dollar | Oui | Occasionnellement | Journaux reproductibles de ce qui a été examiné |
| Triage et contrôle des faux positifs | Distinguer les questions plausibles des questions réelles | Précision et contexte | Souvent | Parfois | Grilles d'évaluation avant promotion |
| Évaluation de l'exploitabilité | Estimer si l'impact est réel dans cet environnement | Raisonnement tenant compte de l'environnement | Parfois | Souvent | Des hypothèses environnementales claires |
| Exploiter la construction | Transformer une condition en impact sur le travail | Recherche contrainte à long terme | Moins souvent | Fréquemment | Contrôles d'exécution et d'approbation isolés |
| Rapport et nouveau test | Traduire les résultats en quelque chose de fiable pour un autre ingénieur | Qualité des artefacts et reproductibilité | Oui | Rarement | Étapes de reproduction, deltas et preuve de ré-épreuve |
Les petits modèles ont déjà plus d'importance que beaucoup ne veulent l'admettre
Les expériences d'AISLE sont précieuses parce qu'elles s'attaquent au problème au bon niveau. L'entreprise n'a pas prétendu que de petits modèles pouvaient reproduire de manière autonome l'intégralité du pipeline anthropique sur de grands dépôts. Elle a posé une question plus restreinte : une fois le code pertinent isolé, quelle part du raisonnement public de la vitrine Mythos les modèles bon marché ou ouverts peuvent-ils récupérer ? Cela se rapproche beaucoup plus de la manière dont un système de découverte bien construit fonctionne réellement. Un bon échafaudage passe du temps à réduire l'ensemble des candidats. Au moment où vous demandez à un modèle de raisonner sérieusement, vous ne devriez pas encore lui jeter toute une base de code en espérant qu'il vous inspire. (AISLE)
Lors du test de réplication NFS de FreeBSD effectué par AISLE, chaque modèle évalué a détecté le débordement. Cela inclut GPT-OSS-20b, décrit comme un modèle 20B MoE avec 3,6B paramètres actifs, qui, selon AISLE, a coûté environ $0.11 par million de tokens et a tout de même correctement raisonné vers une conclusion critique d'exécution de code à distance dans la fonction isolée. Dans le cas d'OpenBSD SACK, la différence est flagrante. Le modèle le plus petit n'a pas récupéré la chaîne complète, mais un modèle ouvert de 5,1 milliards de jetons actifs l'a fait. De manière plus générale, l'entreprise a constaté que les classements se modifiaient considérablement d'une tâche à l'autre, y compris dans le cadre d'un exercice de discrimination des faux positifs de l'OWASP, où les modèles ouverts plus petits ont surpassé plusieurs modèles frontières. Que l'on soit ou non d'accord avec chaque détail de la méthodologie d'AISLE, le signal macro est difficile à ignorer : il n'existe pas de meilleur modèle unique et stable pour toutes les tâches de sécurité, et la pente de la capacité n'est pas lisse. (AISLE)
Ce résultat ne devrait pas choquer les pentesters expérimentés. Le travail de sécurité est plein de difficultés inégales. Un défaut de contrôle d'accès caché dans un flux de travail à trois rôles peut être plus difficile à valider qu'un problème de corruption de la mémoire dont l'oracle de crash est propre. Un ennuyeux sosie d'injection SQL peut être plus difficile à trier correctement qu'un débordement de pile bruyant mais réel, si ce dernier présente des signaux évidents de corruption de mémoire et que le premier nécessite un raisonnement subtil sur la manière dont les données circulent réellement. Les tâches diffèrent tellement qu'un seul label "meilleur modèle" est souvent moins informatif qu'une politique de routage. La question utile n'est pas de savoir quel modèle gagne la catégorie. Il s'agit de savoir quel modèle l'emporte à cette étape, dans ce budget contextuel, avec ce validateur, à ce prix, avec cette exigence de temps de latence. (AISLE)
Il s'agit également d'une question fondamentale d'économie de la recherche. Si la recherche de candidats et l'examen de première instance peuvent être effectués à un coût très faible, un défenseur peut se permettre une couverture beaucoup plus large. AISLE présente directement cet argument : des milliers de détectives adéquats effectuant une recherche étendue peuvent être plus performants qu'un seul détective brillant qui doit deviner où chercher. En pratique, cela signifie qu'une équipe de sécurité peut obtenir un signal plus utile en saturant le pipeline initial avec des modèles peu coûteux et en réservant le raisonnement coûteux aux résultats qui survivent aux barrières de preuves. L'idée semble anti-climatique parce qu'elle est plus managériale que mythique. C'est également ainsi que les programmes de sécurité matures gagnent généralement. Ils ne maximisent pas la brillance à chaque étape. Ils maximisent le rendement sans perdre la confiance. (AISLE)
Le mythe a toujours son importance lorsque le travail devient difficile
Cela ne signifie pas que les modèles de frontière ne sont plus pertinents. Les données d'Anthropic suggèrent que l'écart est toujours significatif dans la partie la plus difficile de la pile. Dans son rapport Red Team, Anthropic indique que Mythos Preview est dans une ligue différente d'Opus 4.6 en ce qui concerne le développement d'exploits autonomes. Sur un benchmark dérivé de vulnérabilités précédemment trouvées dans le moteur JavaScript de Firefox, Anthropic indique qu'Opus 4.6 a produit des exploits fonctionnels seulement deux fois sur plusieurs centaines de tentatives, tandis que Mythos Preview a produit 181 exploits fonctionnels et a atteint le contrôle de registre 29 fois supplémentaires. La société indique également que Mythos Preview a identifié et exploité de manière autonome une vulnérabilité de FreeBSD vieille de 17 ans, CVE-2026-4747, après avoir analysé des centaines de fichiers dans le noyau. Il ne s'agit pas de gains insignifiants à la limite de la distribution. Il s'agit de deltas importants dans la région où l'exploitation passe de "il y a probablement quelque chose qui ne va pas ici" à "je peux faire ce mouvement". (Rouge Anthropique)
C'est important car la construction d'un exploit est une compétence différente de la reconnaissance d'une vulnérabilité. Elle exige souvent une planification à plus long terme, une adaptation aux contraintes, une réutilisation créative des éléments constitutifs et suffisamment de persévérance pour itérer à travers les stratégies qui ont échoué. De nombreux flux de travail de sécurité n'ont jamais besoin d'un tel niveau d'autonomie. De nombreux cas d'utilisation défensifs ou axés sur la validation s'arrêtent bien avant que l'exploitation ne soit totalement militarisée. Mais si votre flux de travail a besoin de générer des exploits en profondeur sous contrainte, la capacité du modèle de frontière n'est pas un détail de marketing. C'est la différence entre une condition candidate et une chaîne de travail. La bonne conclusion n'est pas que le modèle le plus puissant n'est pas nécessaire. La bonne conclusion n'est pas que le modèle le plus puissant n'est pas nécessaire, mais que le modèle le plus puissant doit être placé là où son avantage est réellement composé, plutôt que d'être brûlé à chaque passage de faible valeur. (Rouge Anthropique)
L'architecture même d'Anthropic laisse entrevoir la même leçon. Le rapport public de l'équipe rouge de l'entreprise ne décrit pas un scénario dans lequel Mythos invente spontanément des bogues venus de nulle part. Il décrit un environnement conteneurisé, l'accès au code, l'expérimentation itérative, la validation et la génération de rapports de bogues. En d'autres termes, même à la frontière, les meilleurs résultats du modèle apparaissent lorsqu'il est intégré dans une structure qui lui donne un lieu, une mémoire, des outils, un retour d'information et une condition de réussite. Il ne s'agit pas d'une faiblesse dans l'affirmation. C'est l'essentiel. Plus le modèle est performant, plus le flux de travail qui l'entoure prend de la valeur, car le coût d'un échec sans contrainte augmente avec la capacité. (Rouge Anthropique)
L'économie du pentesting de l'IA porte sur des résultats vérifiés, et non sur le théâtre d'essai.
Les équipes de sécurité doivent se méfier de toute discussion sur les prix qui commence et se termine par le coût des jetons. La véritable unité de compte dans le pentesting n'est pas le "coût par million de jetons". Elle est plus proche du coût par résultat vérifié, du coût par vrai positif retenu après examen humain, du temps écoulé entre le signal initial et la preuve reproductible, et du coût de l'attention de l'examinateur brûlée sur le bruit. La définition du NIST va déjà dans ce sens en incluant l'analyse et l'atténuation, et pas seulement la détection. Dans les opérations de sécurité, une découverte qui ne peut pas survivre à la relecture a une valeur négative. Elle consomme de l'attention, crée une dette de rapport et peut dégrader la confiance dans l'ensemble de la chaîne de production. (csrc.nist.gov)
La page du projet Glasswing d'Anthropic indique que l'aperçu de Mythos sera disponible pour les participants à $25 par million de jetons d'entrée et $125 par million de jetons de sortie après la période de crédit d'utilisation, avec jusqu'à $100 millions de crédits engagés au cours de l'aperçu de recherche. L'article d'AISLE, en revanche, fait état d'un coût de $0,11 par million de jetons pour un modèle actif de 3,6 milliards sur l'une de ses tâches de réplication. Ces chiffres ne sont pas parfaitement des pommes pour des pommes, mais l'orientation est suffisamment évidente pour ne pas forcer une fausse précision : les différences de prix entre les modèles sont importantes, et cela compte à partir du moment où vous arrêtez de penser à des démonstrations et commencez à penser à des flux de travail de production soutenus et répétés. Un système qui choisit par défaut le modèle le plus cher à chaque étape n'est pas "sérieux" par définition. Il peut simplement être non rentable et mal acheminé. (anthropic.com)
La meilleure façon d'envisager la question des coûts est de se demander dans quelle mesure l'utilisation d'un modèle frontière modifie le résultat final. Si un modèle bon marché peut correctement regrouper les itinéraires, identifier la surface d'attaque probable ou rejeter les faux positifs évidents, chaque dollar que vous dépensez en utilisant un modèle frontière pour répéter ce travail est un dollar que vous ne pouvez pas dépenser pour une validation plus profonde, des tentatives d'exploitation à plus long terme, des tests de flux authentifiés ou de nouveaux tests après les corrections. Une bonne économie du pentesting est donc une question d'allocation d'étapes. Une couverture bon marché permet d'acheter de la surface. Un raisonnement plus solide permet d'obtenir de la clarté. Le raisonnement aux frontières permet de réaliser des tentatives de percée là où l'espace de recherche a déjà été suffisamment comprimé pour que l'intelligence, et non l'étendue, soit le facteur limitant. (AISLE)
Le tableau ci-dessous est un tableau de bord plus utile pour l'économie du pentesting de l'IA que n'importe quelle diapositive de référence d'un fournisseur. Il s'agit d'une synthèse du flux de travail et de la logique de tarification reflétés dans les sources ci-dessus. (csrc.nist.gov)
| Métrique | Pourquoi cela importe plus que les scores de référence bruts | Distorsion commune | Ce qu'une équipe disciplinée doit demander |
|---|---|---|---|
| Coût par résultat vérifié | C'est là que le signal devient une valeur défendable | Compter chaque candidat comme une victoire | Combien de résultats survivent à la relecture et à l'examen ? |
| Coût par vrai positif conservé après triage | Le bruit détruit la confiance des évaluateurs | Des décomptes de "problèmes constatés" gonflés | Quelle est la charge de rejet des faux positifs ? |
| Délai entre le signal et la preuve | La vitesse n'a d'importance que si elle aboutit à des preuves | Mesurer uniquement le temps de la première hypothèse | Combien de temps faudra-t-il attendre avant qu'il y ait un reproducteur et une trace d'artefact ? |
| Couverture par dollar | Des modèles bon marché peuvent élargir l'espace de recherche | Utilisation excessive de modèles coûteux sur des scènes faciles | Quelles sont les étapes saturées de couverture à bas prix ? |
| Temps de re-test après remédiation | La valeur de sécurité ne persiste que si les correctifs sont vérifiés | Rapport sans nouveau test | Quelle est la rapidité avec laquelle le flux de travail peut confirmer un correctif ? |
| Minutes humaines par découverte promue | Le véritable goulot d'étranglement est généralement l'attention portée à l'examinateur. | Cacher le travail de nettoyage des analystes | Combien d'efforts manuels sont encore nécessaires pour chaque constatation vérifiée ? |
Des cas concrets montrent que le flux de travail dépasse la mythologie des modèles
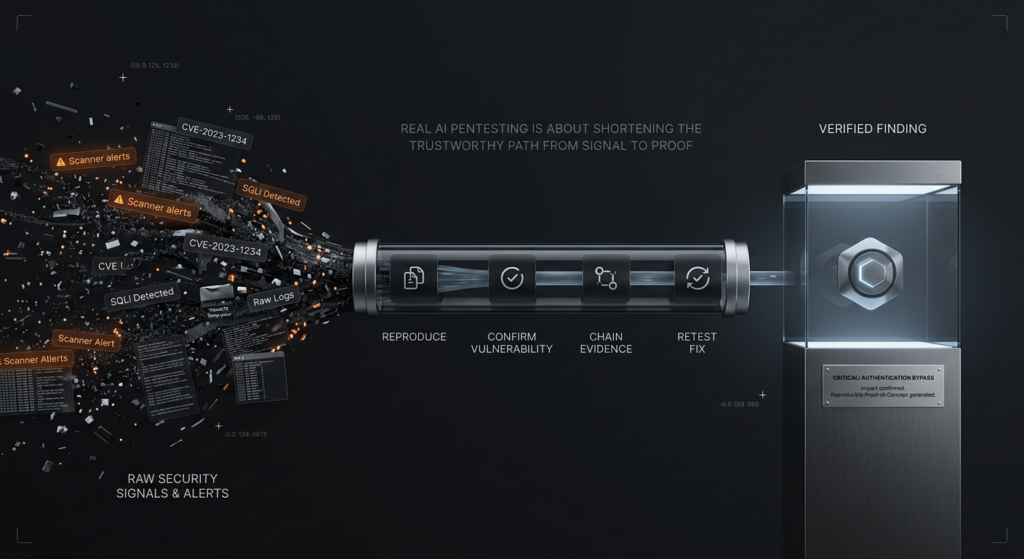
L'écart entre le "comportement intéressant du modèle" et la "valeur réelle du pentesting" devient évident lorsque l'on examine les classes de vulnérabilités réelles. L'important n'est pas qu'un LLM puisse les décrire. L'important est de savoir si un système peut correctement restreindre le contexte, comprendre l'applicabilité, valider l'impact et préserver la preuve sans fabriquer de la confiance. Les cas ci-dessous sont utiles parce qu'ils mettent l'accent sur différentes parties du pipeline. Certains récompensent le raisonnement sémantique. Certains récompensent la sensibilisation à l'environnement. Certains punissent les équipes qui confondent la connaissance des CVE avec la connaissance de l'exploitabilité. D'autres encore ne conviennent pas à l'esprit d'un scanner pur. Toutes tendent vers la même conclusion : la qualité du modèle est importante, mais c'est la conception du flux de travail qui détermine si cette qualité se traduit par un travail de sécurité fiable. (Le projet FreeBSD)
CVE-2026-4747, FreeBSD RPCSEC_GSS et la différence entre détection et preuve
CVE-2026-4747 est l'exemple le plus clair car il apparaît à la fois dans la vitrine d'Anthropic et dans l'avis officiel de FreeBSD. FreeBSD indique qu'il s'agit d'une faille d'exécution de code à distance dans la validation des paquets RPCSEC_GSS affectant toutes les versions supportées au moment de la divulgation, et attribue le mérite à "Nicholas Carlini utilisant Claude, Anthropic". L'article de l'équipe rouge d'Anthropic décrit Mythos Preview comme ayant identifié et exploité le bogue de manière totalement autonome après avoir analysé des centaines de fichiers dans le noyau, tandis que la réplication d'AISLE affirme qu'une fois que la fonction vulnérable est isolée et que le contexte architectural pertinent est fourni, même des modèles plus petits peuvent reconnaître le débordement et raisonner jusqu'à l'impact critique. C'est exactement le type de cas qui sépare la recherche à l'échelle de la repo du raisonnement sur les vulnérabilités localisées. Cela ne prouve pas que les petits modèles peuvent faire tout le travail. Il prouve qu'une grande partie de la "partie intelligente" devient accessible bien plus tôt dans la courbe de capacité du modèle que beaucoup ne le supposaient. (Le projet FreeBSD)
La leçon opérationnelle est encore plus utile que la leçon symbolique. La CVE-2026-4747 ne fait pas seulement les gros titres parce qu'elle est associée à l'IA. Elle est importante parce qu'elle se situe à l'intersection de l'analyse du protocole, du contexte du noyau, de la gravité de l'exploit et de la validation. Un flux de travail de pentesting qui se contente de dire "débordement possible dans le chemin d'authentification" n'est pas suffisant. Un flux de travail sérieux doit préserver les hypothèses sur les paquets, la région du code, l'argument d'exploitabilité, l'environnement exact et les étapes de reproduction. C'est pourquoi la bonne mesure du succès n'est pas "le modèle a trouvé un bogue". C'est "le système a produit un résultat qu'un autre ingénieur peut corriger et auquel il peut faire confiance". (csrc.nist.gov)
OpenBSD SACK, un raisonnement subtil où le routage commence à avoir de l'importance
Le bogue SACK d'OpenBSD mentionné dans le billet d'Anthropic est un meilleur test de raisonnement subtil que le cas de FreeBSD. Anthropic le décrit comme un bogue vieux de 27 ans, maintenant corrigé, dans un système d'exploitation réputé pour sa sécurité. La réplication d'AISLE est utile parce qu'elle rend explicite la difficulté sous-jacente : le problème n'est pas un modèle de corruption de mémoire caricaturalement évident. Il s'agit d'une validation de limite inférieure, d'un dépassement de capacité signé dans les macros de comparaison de séquences et d'une chaîne qui conduit à une condition de pointeur nul uniquement dans le cas de valeurs de paquets soigneusement choisies. AISLE rapporte qu'un modèle ouvert de 5,1 milliards d'actifs a récupéré l'intégralité de la chaîne publique alors que plusieurs autres modèles ont échoué à une partie du raisonnement. Il ne s'agit pas d'un tour de victoire pour les petits modèles. Il s'agit d'une leçon de routage. Certaines étapes sont déjà banalisées. D'autres exigent encore une escalade sélective. (Rouge Anthropique)
La conclusion pratique pour les pentesters est que les bogues subtils sont précisément là où un système devrait être conservateur avec des promotions. Un modèle qui dit en toute confiance "robuste à de tels scénarios" lors d'un passage et qui récupère ensuite une chaîne d'exploitation complexe dans une autre famille de modèles nous rappelle que le consensus entre les modèles n'est pas la même chose que la vérité. Pour cette catégorie de problèmes, le flux de travail doit préserver les hypothèses du paquet, les conditions limites et les artefacts de preuve exécutables avant qu'une conclusion ne fasse autorité. Plus la chaîne de raisonnement est difficile, plus la porte de la preuve doit être solide. (AISLE)
FFmpeg H.264, la sémantique peut vaincre l'intuition de la force brute
L'exemple de FFmpeg d'Anthropic est important pour une autre raison. La société affirme que Mythos Preview a trouvé une vulnérabilité vieille de 16 ans dans le chemin du décodeur H.264, impliquant une inadéquation entre un compteur de tranches de 32 bits et une table de propriété de 16 bits initialisée avec une valeur sentinelle. Anthropic explique que le bogue a survécu à un examen approfondi dans l'un des projets médiatiques les plus testés au monde, y compris des années de fuzzing. Que l'on veuille mettre l'accent sur l'âge, la réputation de la base de code ou l'historique des tests, la leçon d'ingénierie est la même : tous les bogues de grande valeur ne ressemblent pas aux types de fautes que les stratégies de recherche traditionnelles font remonter facilement à la surface. Certaines défaillances résident dans des inadéquations sémantiques, des hypothèses sentinelles et des constructions d'états rares qu'il est tout à fait raisonnable de ne pas voir si votre système est principalement optimisé pour des signatures connues ou une reconnaissance superficielle des formes. (Rouge Anthropique)
Cela fait de FFmpeg un argument de poids pour les flux de travail mixtes. Les scanners purs sont faibles en ce qui concerne les pièges sémantiques. Les agents de raisonnement purs sans validateurs sont enclins à l'excès de confiance. Le bon système associe l'exploration sémantique à un validateur suffisamment puissant pour rejeter les mauvaises histoires. Dans les contextes de sécurité de la mémoire, il peut s'agir d'un assainisseur ou d'un oracle de crash. Dans le contexte des applications web, il peut s'agir d'un harnais de relecture et d'un modèle d'état tenant compte des privilèges. Dans les contextes d'API, il peut s'agir d'une relecture des transactions différenciée par rôle entre les objets. Le modèle gagnant n'est pas de "remplacer les outils par le langage", mais d'"utiliser le langage pour guider les outils". Il s'agit d'"utiliser le langage pour guider les outils vers les bonnes expériences". (Rouge Anthropique)
CVE-2024-3094, XZ et les limites du pentesting de l'IA à la une des journaux
La porte dérobée XZ est un correctif utile parce qu'elle punit les raisonnements simplistes sur les vulnérabilités. NVD décrit un code malveillant dans les archives xz en amont à partir de la version 5.6.0, avec des instructions de construction supplémentaires extrayant un fichier objet caché qui modifie le comportement de liblzma pendant la construction. Il s'agit là d'un problème de chaîne d'approvisionnement et d'artefact de version, et non d'un simple problème de lecture de code dans la version. Un système qui se contente d'analyser les arbres des sources ou les bannières de version peut facilement passer à côté de ce qui importe le plus. Le véritable enseignement est que l'applicabilité peut dépendre du chemin de publication, de l'environnement de construction, de l'intégration des paquets et du comportement de distribution en aval. C'est exactement le genre de cas où l'assistance de l'IA ne vaut que par les preuves et la provenance qu'elle peut retrouver. (nvd.nist.gov)
Pour l'IA pentesting, CVE-2024-3094 est une mise en garde contre la confusion entre la compréhension des informations sur les vulnérabilités et la validation opérationnelle. Un modèle qui peut expliquer XZ de manière éloquente ne vous a pas aidé à moins que le système ne puisse répondre à des questions plus difficiles : la version affectée a-t-elle réellement été introduite, votre chemin de construction a-t-il consommé les artefacts altérés, quelles versions de paquets ont traversé ce chemin, quels binaires ont lié la bibliothèque modifiée, et quelle frontière de confiance a échoué. C'est dans les cas de chaînes d'approvisionnement que l'histoire du "plus grand modèle gagne" s'effondre le plus rapidement, car le goulot d'étranglement est souvent la provenance, et non la prose. (nvd.nist.gov)
CVE-2024-6387, regreSSHion et la différence entre gravité et praticité
NVD décrit CVE-2024-6387 comme une régression de sécurité dans le serveur OpenSSH où une condition de course dans le traitement des signaux peut permettre à un attaquant distant non authentifié de déclencher un comportement dangereux en échouant à l'authentification dans une limite de temps. Le point important de cet article n'est pas le débat sur l'exploitabilité dans des environnements spécifiques. Il s'agit du fait que le flux de travail doit tenir compte de l'environnement, du calendrier, de l'exposition et de la priorité opérationnelle réelle plutôt que de s'arrêter à un "bogue critique à distance". De nombreux systèmes de sécurité IA semblent convaincants précisément là où ils sont le moins utiles : ils peuvent réaffirmer la gravité sans faire le travail plus difficile du raisonnement sur l'applicabilité. (nvd.nist.gov)
C'est pourquoi le classement de l'exploitabilité ne devrait pas être délégué à un seul passage du texte du modèle. Un système utile devrait demander si le service est orienté vers l'internet, si la version affectée est exposée en premier lieu, si des contrôles compensatoires modifient la fenêtre d'attaque, et à quoi ressemblerait la condition de preuve attendue dans le cadre d'une validation sûre. Un modèle peut aider. Un flux de travail doit décider. Plus l'équipe est mature, moins elle doit être impressionnée par la reformulation fluide de la description du CVE et plus elle doit s'intéresser à ce que le système peut prouver à propos de cet environnement. (csrc.nist.gov)
CVE-2024-3400 et CVE-2024-4577, l'applicabilité n'est pas facultative
La description de la CVE-2024-3400 par NVD est directe : une injection de commande résultant de la création d'un fichier arbitraire dans GlobalProtect sur des versions PAN-OS spécifiques et des configurations de fonctionnalités peut permettre l'exécution d'un code racine non authentifié, alors que Cloud NGFW, les appliances Panorama et Prisma Access ne sont pas impactés. La CVE-2024-4577 est également liée à la configuration, mais d'une manière différente : NVD indique que les versions de PHP affectées sur Windows en mode CGI peuvent mal interpréter les caractères sous des pages de code spécifiques et permettre des options PHP contrôlées par l'attaquant, avec des conséquences pouvant aller jusqu'à l'exécution de code arbitraire. Ces exemples illustrent parfaitement la raison pour laquelle un véritable pentesting par l'IA ne peut s'arrêter à la recherche de CVE. Il doit répondre à des questions de configuration. La fonction est-elle activée ? Le type d'appareil est-il concerné ? Le mode CGI est-il utilisé ? Quelle est la page de code en jeu ? La condition peut-elle être atteinte à partir du chemin exposé ? (nvd.nist.gov)
Il ne s'agit pas de cas particuliers. Ce sont des exemples ordinaires qui montrent pourquoi le milieu du pentesting est plus difficile que l'avant. L'étape initiale consiste à remarquer la possibilité. Le milieu consiste à trier la vérité de l'environnement du langage générique du risque. C'est au milieu que le flux de travail, la récupération, la conservation des données et la collecte des preuves gagnent leur vie. C'est aussi là que les modèles de petite ou moyenne taille peuvent souvent faire de l'excellent travail si le système a déjà recueilli les faits environnementaux appropriés. Le goulot d'étranglement n'est pas toujours la profondeur du raisonnement abstrait. Parfois, il s'agit de savoir si le flux de travail s'est même donné la peine de recueillir les faits qui rendent une vulnérabilité réelle. (csrc.nist.gov)
Le tableau ci-dessous condense le modèle. Il s'agit d'une aide à la décision plutôt que d'un catalogue. (Le projet FreeBSD)
| Cas | Pourquoi c'est important ici | Ce qu'il ne faut pas faire si l'on ne s'intéresse qu'aux modèles | Ce qu'un système axé sur le flux de travail peut apporter de plus |
|---|---|---|---|
| CVE-2026-4747 FreeBSD RPCSEC_GSS | Exemple clair de découverte, de gravité et de preuve | Confusion entre raisonnement isolé et autonomie de bout en bout | Isolement des fonctions, contexte des paquets, reproducteur, trace d'artefact |
| Bogue SACK d'OpenBSD | Tests de raisonnement subtil et de logique d'exploitabilité | Traite une explication fiable comme une vérité de base | Validation en plusieurs étapes et promotion conservatrice |
| Défaut de FFmpeg H.264 | Les bogues sémantiques peuvent survivre à des tests intensifs | Surindex sur les failles compatibles avec les signatures | Raisonnement sémantique lié aux validateurs |
| CVE-2024-3094 XZ | Le contexte de la chaîne d'approvisionnement l'emporte sur l'analyse à la source uniquement | Suppose que l'inspection de la base de données est suffisante | Analyse de la provenance, du chemin de construction et de l'artefact de mise à jour |
| CVE-2024-6387 regreSSHion | La gravité n'est pas la même chose que la priorité opérationnelle | Répétition du langage CVE sans jugement d'applicabilité | Validation tenant compte de l'exposition et de l'environnement |
| CVE-2024-3400 PAN-OS | L'importance des caractéristiques et de l'étendue du produit | Ignore les conditions préalables de configuration | Contrôles d'applicabilité tenant compte des produits |
| CVE-2024-4577 PHP-CGI | L'importance de la langue et du mode d'exécution | Traite la correspondance des versions comme une preuve d'exploitabilité | Validation de l'exécution et des pages de code |
Construire le flux de travail qui rend les petits modèles utiles
Un système réaliste de pentesting par l'IA commence par des limites, et non par des invites. Avant qu'un modèle ne voie une cible, le système doit déjà connaître les hôtes autorisés, les classes d'hôtes interdites, le taux de requête maximal, les identités et les rôles disponibles pour les tests authentifiés, les catégories d'actions qui nécessitent une approbation explicite et les artefacts qui doivent être conservés pour un examen ultérieur. Les modèles deviennent dangereux surtout lorsqu'ils ne sont pas intégrés dans des politiques qui survivent à leur fluidité momentanée. Un agent fort n'est pas plus sûr parce qu'il est plus fort. Il est plus sûr parce qu'il est plus précisément limité. C'est aussi vrai pour un modèle de frontière que pour un modèle bon marché. (csrc.nist.gov)
Un simple manifeste de portée n'est pas très prestigieux, mais c'est ce qui fait la différence entre un flux de travail régi et une cascade. La structure ci-dessous n'est pas censée constituer un fichier de production complet. Elle montre le minimum d'informations que le flux de travail doit formaliser avant qu'un agent ne commence à effectuer des tests actifs.
engagement :
target_id : prod-api-2026-04
propriétaire : security-team@example.com
authorization_ticket : CHG-48219
allowed_hosts :
- api.example.com
- auth.example.com
forbidden_hosts :
- payments.internal.example.com
- admin-vpn.example.com
allowed_identities :
- client_basic
- client_premium
- support_agent
actions_interdites :
- suppression destructive de données
- réinitialisation des mots de passe pour les utilisateurs réels
- escalade des privilèges de production en dehors de la porte d'approbation
limites de taux :
max_rps : 3
rafale : 10
evidence :
output_dir : findings/prod-api-2026-04
save_http : true
save_screenshots : true
save_terminal_logs : true
save_reproducers : true
escalade :
frontier_model_required_for :
- business_logic_chain
- tentative d'évasion en bac à sable
- synthèse de l'exploit en plusieurs étapes
Une fois que les limites existent, la première étape doit généralement être peu coûteuse et large. Inventorier les points d'arrivée. Regrouper les itinéraires similaires. Tirer de la documentation et des conseils sur le cadre de travail. Comparer les réponses entre les différents rôles. Enregistrez les délais, les redirections, les transitions de cookies et les identifiants d'objets. Dans les missions à forte intensité de code, indexez le projet et classez les régions susceptibles d'être critiques en termes de sécurité. Dans les tests web dynamiques, cartographiez les états et les transitions. Il s'agit là d'une réduction de l'espace de recherche. C'est là que les modèles peu coûteux et les outils déterministes fonctionnent bien ensemble. Vous ne demandez pas encore une percée. Vous achetez de l'ampleur organisée. (AISLE)
C'est au cours de la deuxième étape que de nombreux systèmes commencent à gaspiller de l'argent. Au lieu d'acheminer chaque point suspect vers le plus grand modèle disponible, un flux de travail discipliné pose une question plus restreinte : un modèle modeste et un validateur peuvent-ils régler ce problème ? Pour les travaux de sécurité de la mémoire, cela peut signifier un assainisseur, un oracle de crash ou un reproducteur minimisé. Pour les travaux sur le web et les API, cela peut signifier une relecture différentielle entre les rôles, les identificateurs d'objets ou les états du flux de travail. Pour les CVEs sensibles à la configuration, cela peut signifier la capture de l'environnement avant l'escalade de l'hypothèse. Un modèle ne doit pas être promu parce que le bogue semble grave. Il doit être promu parce que le validateur dit que l'incertitude est maintenant limitée par l'intelligence plutôt que par les preuves. (Rouge Anthropique)
La politique de routage peut être esquissée sous forme de code. Là encore, l'important n'est pas la mise en œuvre exacte. Il s'agit de faire en sorte que le choix du modèle devienne une décision politique liée à la qualité des preuves, et non un défaut permanent lié au prestige du fournisseur.
def choose_model(stage, signal_strength, validator_confidence, complexity) :
if stage in {"asset_mapping", "endpoint_clustering", "first_pass_review"} :
return "petit_modèle_rapide"
if stage in {"triage", "false_positive_review"} :
si validator_confidence >= 0.8 :
return "petit_ou_moyen_modèle"
return "modèle_de_raisonnement_moyen"
si étape dans {"exploitability_assessment", "business_logic_analysis"} :
si complexité == "élevée" :
return "modèle_frontière"
return "modèle_de_raisonnement_moyen"
si étape dans {"exploit_construction", "sandbox_escape", "multi_bug_chain"} :
retour "frontier_model"
return "modèle_de_raisonnement_moyen"
C'est également à ce stade que les récits des produits les plus sains de la catégorie commencent à se ressembler. La page d'accueil publique de Penligent ne présente pas le travail comme "demander le meilleur modèle et espérer". Elle met en avant un flux opérationnel en trois étapes : "Trouver les vulnérabilités. Vérifier les résultats. Exécuter des exploits", et l'associe à des "résultats probants que vous pouvez reproduire" et "Modifier les invites, verrouiller le champ d'application et personnaliser les actions en fonction de votre environnement". Même si un acheteur ne touche jamais ce produit, ce sont les bonnes questions à poser à toute plateforme dans cet espace car elles correspondent à de véritables exigences d'ingénierie : la preuve avant la promotion, les artefacts avant les revendications, et le contrôle de l'opérateur avant le théâtre de l'autonomie. (penligent.ai)
Le pipeline d'artefacts est tout aussi important que le routeur de modèles. Si un flux de travail ne préserve pas suffisamment de matière première pour rejouer une découverte plus tard, il s'entraîne discrètement à présenter des suppositions comme des faits. C'est le moyen le plus rapide de détruire la confiance dans les tests assistés par l'IA. Le fragment de coquille ci-dessous est intentionnellement ennuyeux. C'est pourquoi il est utile.
TARGET_ID="prod-api-2026-04"
OUT="findings/$TARGET_ID/candidate-017"
mkdir -p "$OUT"
cp scope.yaml "$OUT/"
cp target-map.json "$OUT/"
cp request.txt "$OUT/"
cp response.txt "$OUT/"
cp role-a-session.txt "$OUT/"
cp role-b-session.txt "$OUT/"
cp payload.txt "$OUT/"
cp terminal.log "$OUT/"
cp screenshot.png "$OUT/"
cp reproducer.sh "$OUT/"
cp notes.md "$OUT/"
sha256sum "$OUT"/* > "$OUT/artifact_hashes.txt"
Les bonnes preuves de sécurité sont souvent ennuyeuses avant d'être précieuses. Le modèle peut aider à rédiger des notes, à comparer des traces, à expliquer un crash ou à suggérer la prochaine branche à tester. Mais le flux de travail a toujours besoin de faits environnementaux, de requêtes brutes, de résultats d'exécution et d'un chemin de relecture. Ce n'est pas de l'anti-AI. C'est la façon d'empêcher l'IA de devenir un amplificateur de confiance pour des affirmations non vérifiées. (penligent.ai)
L'établissement de rapports est la dernière étape, et non le premier résultat visible.
L'une des habitudes les plus néfastes des outils de sécurité de l'IA est de générer des rapports de qualité avant que le système ne les ait mérités. Le cadre du NIST est utile ici parce qu'il place l'analyse et l'atténuation dans le processus de test plutôt qu'après. Un rapport n'est pas le produit d'un modèle de langage intelligent. C'est l'emballage d'un résultat vérifié. Cela semble évident, mais un nombre surprenant d'acteurs du marché se trompent encore de séquence. Un système trouve un indice, rédige une histoire et laisse le rapport lui-même transformer l'incertitude en autorité. Les pentesters devraient refuser ce modèle. Les acheteurs doivent le punir. (csrc.nist.gov)
Un modèle beaucoup plus sain consiste à définir une porte de promotion. Un candidat ne devient pas une découverte vérifiée parce que l'explication semble bonne ou que l'estimation CVSS semble plausible. Il devient vérifié lorsque le flux de travail dispose de suffisamment d'artefacts pour rejouer le problème, de suffisamment de contexte environnemental pour soutenir l'applicabilité et de suffisamment de preuves pour rendre la remédiation utile plutôt que spéculative. Une porte minimale peut être exprimée dans une logique de politique.
def promote_to_verified(candidate):
required = [
candidate.reproducer,
candidate.artifacts.http_or_binary_trace,
candidate.environment_notes,
candidate.impact_statement,
candidate.remediation_basis,
]
if not all(required):
return False, "missing required artifacts"
if candidate.finding_type == "access_control" and not candidate.role_differential_proof:
return False, "missing authorization differential evidence"
if candidate.finding_type == "memory_corruption" and not candidate.validator_signal:
return False, "missing crash or sanitizer validation"
if candidate.severity in {"critical", "high"} and not candidate.retest_plan:
return False, "missing retest criteria"
return True, "verified"
C'est l'endroit où la livraison de produits et la discipline d'ingénierie se rencontrent enfin. Les pages de prix et de produits de Penligent mettent l'accent sur l'exportation de rapports avec des étapes de preuve et de reproduction, sur la reproduction d'exploits en un clic avec des rapports sur la chaîne de preuves, et sur la livraison prête pour l'audit par l'équipe. Les documents publics de Hacking Labs concernant les rapports de pentest d'IA définissent également le problème comme étant de prouver ce qui s'est passé plus tard, et non pas simplement de générer un PDF plus joli maintenant. Cette orientation est techniquement saine car elle traite les rapports comme une expression en aval des artefacts plutôt que comme un substitut aux artefacts. Une fois de plus, la leçon se généralise au-delà d'un seul fournisseur : les systèmes dignes de confiance sont ceux qui peuvent vous dire comment une affirmation devient une preuve. (penligent.ai)
Les modes d'échec qui piègent encore les équipes
L'erreur la plus facile à commettre est d'acheter le plus grand modèle disponible et de tout faire passer par lui. C'est une erreur grave. Elle produit souvent la pire combinaison de coûts, de latence et de lassitude des examinateurs. Les étapes faciles sont surprovisionnées. Les étapes difficiles échouent toujours parce que le goulot d'étranglement n'était pas l'intelligence, mais la discipline contextuelle ou les validateurs manquants. L'équipe conclut alors que l'AI pentesting "ne fonctionne pas", alors que le vrai problème est qu'elle a traité la qualité du modèle comme un substitut à la qualité du flux de travail. Le cadrage d'AISLE autour des jetons par dollar, des jetons par seconde et de l'expertise de sécurité intégrée est un antidote utile. Dans les pipelines sérieux, la vitesse et la couverture ne sont pas des notes secondaires. Elles font partie de l'équation des capacités. (AISLE)
Une deuxième erreur consiste à confondre l'augmentation du nombre de scanners avec les tests de pénétration. Les conseils de l'OWASP en matière de tests restent larges pour une bonne raison. Les tests réels incluent le mappage, le comportement authentifié, la gestion des états, les contrôles d'autorisation et la logique d'entreprise. Un système qui ne peut pas préserver un contexte multirôle ou raisonner sur la propriété d'un objet peut toujours être utile, mais il ne fait pas de pentesting général au sens fort où l'entendent la plupart des praticiens. Ceci est particulièrement important pour les API, où l'autorisation au niveau de l'objet brisée reste un risque majeur parce que les identifiants voyagent à travers les itinéraires, les en-têtes, les charges utiles et l'état implicite du flux de travail. Un assistant IA qui ne comprend pas ce terrain aura tendance à produire un volume élevé de texte sur la sécurité et un faible volume de preuves sur le risque. (owasp.org)
Une troisième erreur consiste à considérer les démonstrations d'exploitation comme l'ensemble de la valeur. Mythos est devenu célèbre parce que la construction d'exploits est vivante et effrayante, et les données d'Anthropic suggèrent que la capacité de frontière dans cette région est réelle. Mais de nombreuses organisations n'échouent pas parce qu'elles n'ont pas d'auteur d'exploits parfaitement autonome. Elles échouent parce qu'elles ne peuvent pas assurer le triage en fonction de l'environnement, les tests de flux de travail authentifiés, la capture de preuves reproductibles ou les nouveaux tests après l'application de correctifs. Les programmes de sécurité sont généralement bloqués par la conversion d'un signal brut en une action fiable. C'est pourquoi les systèmes les plus puissants du marché mettent de plus en plus l'accent sur les résultats vérifiés, la reproductibilité et la qualité de la livraison. L'exploit effrayant n'est pas sans importance. Ce n'est tout simplement pas le seul goulot d'étranglement, et souvent pas le premier. (Rouge Anthropique)
Une quatrième erreur est d'ignorer la neutralisation humaine. Les systèmes agentiques plus forts ont besoin de contrôles plus stricts, pas plus lâches. Le cadrage public de Penligent autour d'un champ d'action verrouillé et d'actions personnalisables est sain pour la même raison que l'échafaudage conteneurisé d'Anthropic est sain : le système n'est utile dans un environnement réel que si les opérateurs peuvent contraindre où il agit et comment les actions risquées sont encouragées. L'autonomie sans gouvernance n'est pas la maturité. C'est de la confiance empruntée. (Rouge Anthropique)
Ce que les équipes devraient réellement mesurer
À ce stade, les bonnes mesures devraient sembler évidentes, mais la plupart des équipes ne les instrumentent toujours pas correctement. Elles mesurent les problèmes trouvés, les deltas de référence ou le temps d'analyse moyen et ne tiennent pas compte des variables qui déterminent si un programme de pentesting d'IA est digne de confiance. Les indicateurs de base devraient mesurer la conversion du signal en preuve, la durabilité des résultats examinés et le coût de cette conversion. Ce sont les variables qui révèlent si le flux de travail est réellement en train d'apprendre. (csrc.nist.gov)
| Métrique | Ce qui est bon | Ce qui ne va pas | Pourquoi c'est important |
|---|---|---|---|
| Taux de conversion des candidats en candidats vérifiés | Plus faible mais stable et explicable | Un taux élevé sur le papier parce que les candidats bénéficient d'une promotion excessive | Indique si les barrières de sécurité sont réelles |
| Délai moyen de reproduction | Manque prévisible de classes répétables | Longues et chaotiques malgré des démonstrations impressionnantes | Mesure l'utilité opérationnelle |
| Minutes de l'examinateur par résultat promu | Déclin au fil du temps | Charge de nettoyage cachée pour les analystes | Permet de savoir si l'IA compresse ou exporte le travail. |
| Taux de réussite aux tests de rattrapage après remédiation | Un niveau élevé et bien documenté | Les conclusions disparaissent dans l'arriéré des rapports | Indique si la livraison ferme la boucle |
| Dépenses du modèle par étape | La plupart des dépenses sont concentrées sur les étapes difficiles | La plupart des dépenses sont gaspillées sur des étapes faciles | Révèle si la politique de routage est saine d'esprit |
| Part de découverte de la logique d'entreprise | Augmentation au fur et à mesure que les tests d'état s'améliorent | Proche de zéro car le flux de travail ne quitte jamais le mode scanner | Indique si le système peut gérer le risque d'une application réelle |
La question d'achat la plus importante en 2026 n'est donc pas "Quel modèle utilisez-vous ?". C'est "Comment votre système transforme-t-il un signal brut en un résultat vérifié, et quels sont les artefacts qui existent à chaque étape ?" Une deuxième question importante est "Où dépensez-vous votre budget de raisonnement coûteux ?" Si un fournisseur ne peut répondre à l'une ou l'autre de ces questions avec précision, il s'agit probablement d'une histoire de modèle et non d'un flux de travail de pentesting. Cela ne rend pas le produit inutile. Cela signifie simplement que vous ne devriez pas l'acheter comme s'il résolvait le problème le plus difficile. (csrc.nist.gov)
Le pentesting de l'IA après Mythos signifie routage et non adoration
Le mythe est important. Les documents publics d'Anthropic font qu'il est impossible de rejeter honnêtement cette idée. Le modèle semble avoir repoussé la frontière de manière significative en matière d'exploitation autonome, et le projet Glasswing n'est pas une annonce mineure. Anthropic indique que l'initiative comprend des partenaires de lancement majeurs, plus de 40 organisations supplémentaires, des engagements importants en matière de crédits d'utilisation et un plan explicite pour étudier comment les pratiques de sécurité devraient évoluer en réponse. Il ne s'agit pas d'un petit signal. C'est le signe que les principaux laboratoires estiment que la cybersécurité est devenue l'un des domaines les plus importants du monde réel pour les modèles agentiques avancés. (anthropic.com)
AISLE est important pour la raison opposée mais tout aussi importante. Il oblige le secteur à cesser de raconter la sécurité de l'IA comme si toutes les capacités arrivaient en un seul bloc indivisible. Ses résultats suggèrent que des parties importantes du pipeline sont déjà accessibles à des modèles plus petits et moins coûteux, en particulier une fois que le chemin de code ou le contexte cible a été réduit. Il recadre également le succès autour de l'acceptation par le mainteneur, de la remédiation fiable et de la conception au niveau du système. Ces éléments sont plus proches des besoins réels des équipes de sécurité que n'importe quel classement abstrait du "meilleur cyber-modèle". (AISLE)
La bonne synthèse n'est pas un compromis pour le plaisir. Elle est plus pointue que cela. Les modèles frontières deviennent très importants au sommet de la pile, en particulier pour la génération d'exploits contraints et le raisonnement à long terme. Mais le véritable fossé dans le pentesting de l'IA n'est pas le plus grand modèle en lui-même. Il s'agit du chemin de confiance le plus court entre le signal et la preuve. Ce chemin est construit à partir du contrôle de l'étendue, de la réduction du contexte, de l'acheminement du modèle, des validateurs, de la préservation des artefacts, de la discipline de retest et de la livraison qu'un autre ingénieur peut vérifier. Si vous construisez bien ce chemin, les petits modèles deviennent étonnamment puissants. Si vous le construisez mal, même le meilleur modèle au monde vous donnera surtout une prose coûteuse. (Rouge Anthropique)
Pour les équipes qui construisent ou achètent dans cette catégorie, c'est la véritable leçon de l'après-Mythos. Ne demandez pas seulement qui a le plus d'intelligence. Demandez plutôt qui sait où les dépenser, où les contraindre et comment le prouver. En 2026, c'est ce qui différencie une démonstration de sécurité impressionnante d'un flux de travail de sécurité qui peut réellement vivre au sein d'une organisation d'ingénierie. (csrc.nist.gov)
Pour en savoir plus
- Anthropic, Projet Glasswing. (anthropic.com)
- Anthropic Frontier Red Team, Claude Mythos Preview. (Rouge Anthropique)
- AISLE, AI Cybersecurity After Mythos, The Jagged Frontier. (AISLE)
- Microsoft, benchmark CTI-REALM et travaux du CSEM sur la sécurité de l'IA. (Microsoft)
- NIST SP 800-115, Guide technique pour les tests et l'évaluation de la sécurité de l'information. (csrc.nist.gov)
- Guide OWASP des tests de sécurité sur le Web. (owasp.org)
- OWASP API Security Top 10 2023. (owasp.org)
- Avis de FreeBSD pour CVE-2026-4747. (Le projet FreeBSD)
- Page d'accueil négligente. (penligent.ai)
- Penligent, AI Pentest Tool, What Real Automated Offense Looks Like in 2026. (penligent.ai)
- Penligent, le pentester de l'IA en 2026. (penligent.ai)
- Penligent, The 2026 Ultimate Guide to AI Penetration Testing. (penligent.ai)