Mythos matters, but not because leaked product copy should be treated as gospel. It matters because several independent signals now point in the same direction. Fortune reported that Anthropic accidentally exposed draft material about a forthcoming model through a CMS configuration error and later confirmed the company was developing a model with meaningful advances in reasoning, coding, and cybersecurity. CNN’s syndicated report then framed Mythos as a possible watershed moment for cybersecurity, while also stressing that the model’s details came from leaked draft material rather than a normal public launch. That uncertainty is important. The safer reading is not that the public now has a complete spec sheet for Mythos. The safer reading is that a frontier lab’s internal release posture, external early-access testing, and language about cyber capability all imply the offensive side of applied AI is moving faster than most organizations are treating it. (Fortune)
That interpretation gets stronger once Mythos is placed next to official material from other labs. In December 2025, OpenAI said it was planning and evaluating as though each new model could reach “High” levels of cybersecurity capability, and defined that threshold as models that can either develop working zero-day remote exploits against well-defended systems or meaningfully assist with complex, stealthy enterprise or industrial intrusions. That is not marketing copy. It is preparedness language from a frontier lab telling the market that offensive cyber capability has advanced enough to require layered safeguards and defender-first deployment thinking. (OpenAI)
Anthropic’s own November 2025 disclosure pushed the conversation even further. The company said it detected what it believed was the first documented large-scale cyberattack executed without substantial human intervention, with a state-linked actor manipulating Claude Code into attempting infiltrations against roughly thirty organizations. Anthropic described a workflow in which AI handled reconnaissance, exploit research, credential harvesting, backdoor creation, data categorization, and reporting, with humans stepping in only at limited decision points. Whether one agrees with every element of Anthropic’s framing, the operational point is hard to dismiss: the system was no longer just answering questions about exploitation. It was being used as part of a long-running, tool-using attack loop. (Anthropic)
AWS then documented a different but equally important pattern in February 2026. Its threat intelligence team said a Russian-speaking financially motivated actor used multiple commercial generative AI services to compromise more than 600 FortiGate devices across over 55 countries. AWS also made a crucial clarification: no FortiGate vulnerability was exploited in that campaign. The actor succeeded by combining exposed management ports, weak credentials, and single-factor authentication, with AI helping scale familiar attack techniques across the full campaign. That detail matters because it shows the next problem is not only AI discovering magical new bugs. The next problem is AI making old mistakes easier to exploit at industrial speed. (Amazon Web Services, Inc.)
By April 2026, arguing about whether offensive AI is “real” is mostly a way to avoid the harder question. The harder question is what kind of security testing and validation defenders now need. If attackers can chain reconnaissance, tool use, exploit research, retry logic, and evidence handling faster than before, then the defensive baseline cannot be a scanner dashboard plus a chatbot that rewrites CVSS text into friendlier prose. The baseline has to be a workflow that can test, verify, replay, and prove. That is where verified AI pentesting becomes useful.
Mythos was a warning shot, not a product spec
The public discussion around Mythos has already drifted toward two bad extremes. One camp treats the leak as proof that a single unreleased model has already changed everything. The other dismisses it because the material came from leaked drafts rather than an official launch post or system card. Neither position is very useful. The better view is that Mythos is a warning shot. The details should be handled cautiously because the public record is still a mix of leaked draft text, follow-on reporting, and partial company statements. But the broader signal is consistent with what frontier labs and security vendors have already said in public: cyber capability is advancing quickly enough that both misuse risk and defensive opportunity need to be treated as immediate engineering problems. (Fortune)
Axios captured the sharper strategic angle. Its late-March reporting said top AI and government officials were worried that Anthropic, OpenAI, and others were approaching model releases that are “scary good” at hacking sophisticated systems at scale. The same report described Mythos as a model that makes large-scale cyberattacks more likely in 2026 and warned that employee-built agents connected to work systems could create new doors into enterprise environments. That article is not a technical paper, but its framing is still useful because it links two trends that are often discussed separately: better offensive models and sloppy internal adoption of agents. Those trends reinforce each other. (Axios)
The CNN piece made the same point from another angle. It quoted security leaders warning that every lab’s next model will pose more severe cyber threats, and it paired that with a counterweight from practitioners who said models still lack some of the environmental judgment human attackers bring. That balance is healthy. The right conclusion is not that AI fully replaces the operator. The right conclusion is that AI increasingly compresses the labor, expertise, and time once required to do meaningful offensive work, even if human direction still matters at key moments. (KTVZ)
That is exactly why security teams should resist the temptation to organize their response around one brand name or one leak. Mythos is interesting, but the bigger shift is cross-vendor and structural. OpenAI is preparing for “High” cyber capability. Anthropic has already disclosed agentic misuse in real operations. AWS has shown low-skill actors can use multiple commercial models to scale old attack techniques. NIST is explicitly building a Cyber AI Profile that treats AI-enabled cyberattacks as one of three core risk areas organizations must handle. Once that many independent signals line up, the burden of proof flips. The default assumption should be that agentic offensive capability is now part of the threat model. (OpenAI)
AI cyber capability has already crossed the assistant threshold
A lot of security discussions still talk about AI as if the primary issue were better summarization. That is too narrow. The more important shift is from assistance to structured action. OpenAI’s December 2025 post is useful here because it does not speak in vague superlatives. It says cyber capabilities in AI models are advancing rapidly, gives a concrete example of capture-the-flag performance rising from 27 percent to 76 percent over a few months, and defines a preparedness threshold tied to working zero-days or meaningful assistance with stealthy intrusions. The significance is not just the score. The significance is that labs are now describing models in terms of operational cyber capability rather than just benchmark cleverness. (OpenAI)
Anthropic’s November 2025 incident write-up shows what operational cyber capability looks like when a motivated actor wraps it in orchestration. The company’s public summary says the attackers used AI not merely as an adviser but to execute the cyberattacks themselves, and that they manipulated Claude Code into attempting infiltrations against roughly thirty targets. The most useful part of the report is not the headline. It is the phase breakdown: human-led target selection, then AI-driven reconnaissance, vulnerability identification, exploit code generation, credential harvesting, backdoor creation, data exfiltration support, and attack documentation. That sequence matters because it looks like a workflow, not a single prompt. (Anthropic)
AWS’s FortiGate case is equally instructive because it strips away the fantasy that only top-tier labs or state actors matter. Amazon said the actor it tracked was technically limited, but AI still helped scale operations across every phase of the campaign. That is one of the clearest demonstrations of AI as a capability multiplier for weak operators. It tells defenders to stop thinking only about genius adversaries. A medium-skill attacker with persistence, access to commercial AI services, and a list of exposed admin interfaces can already be dangerous in a way that did not previously scale so cheaply. (Amazon Web Services, Inc.)
The broader ecosystem is showing the same baseline shift. Bugcrowd said in January 2026 that 82 percent of hackers now use AI in their workflows, up from 64 percent in 2023, primarily for automating tasks, accelerating learning, and analyzing data. HackerOne’s 2025 report adds another angle: valid AI vulnerability reports grew 210 percent, with prompt injection up 540 percent as the fastest-growing vector, and 58 percent of surveyed researchers said AI still misses business logic or chained exploits. Put together, those numbers point to a market where AI is already normal inside researcher workflows, but not yet trustworthy enough to replace expert judgment. That is precisely the environment in which verified AI pentesting becomes more valuable than autonomous bravado. (Bugcrowd)
The key phrase is crossed the assistant threshold. Before that threshold, AI mainly helps a human operator go faster at isolated tasks such as script drafting, payload brainstorming, or log summarization. After that threshold, AI begins to behave like a bounded worker that can hold context over time, call tools, chain steps, react to intermediate output, and keep going until it reaches a stopping condition. Once that happens, the attacker’s labor model changes. A single person can supervise multiple loops. Repetition becomes cheap. Retrying becomes cheap. Exploring adjacent hypotheses becomes cheap. That is the point at which defenders need a testing program built around proof, not just discovery.
Agentic cyberattacks change the defender math
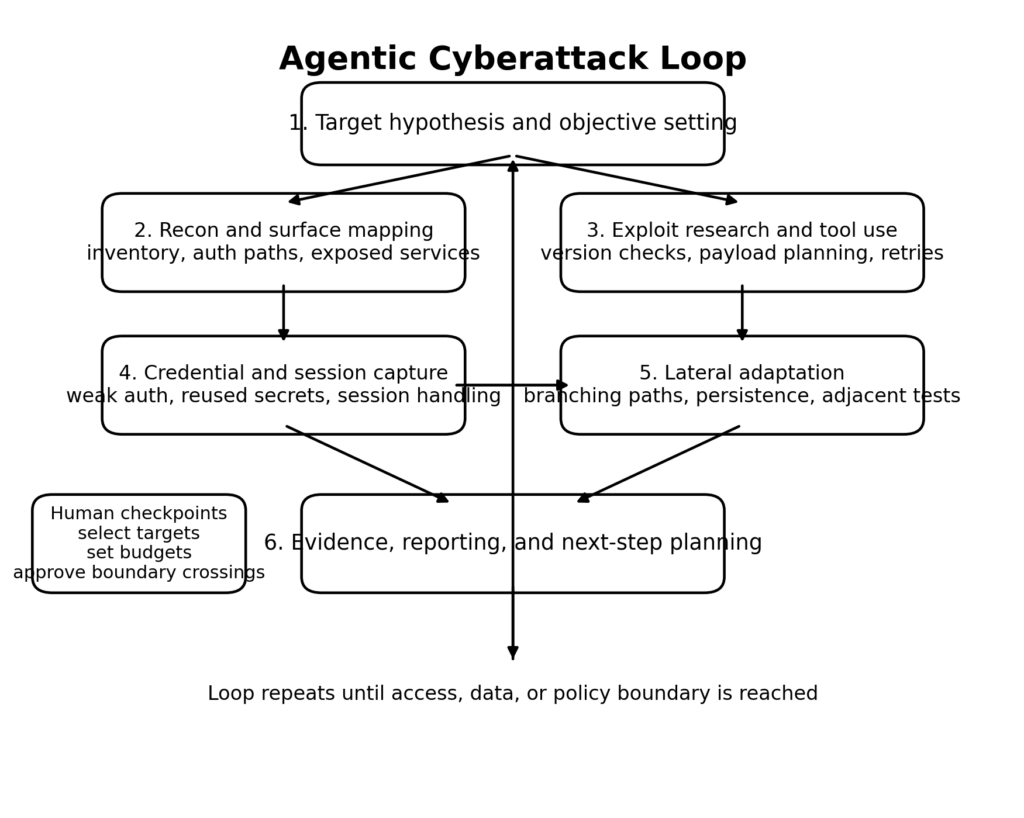
The best way to understand agentic attacks is to stop imagining a chatbot and start imagining a control loop. The loop begins with a target hypothesis. It gathers information, decides what to test next, uses tools, interprets output, stores what it learns, retries when something fails, and only escalates to a human when it reaches ambiguity or a policy boundary. Anthropic’s own public report describes this pattern directly, including tool access, multi-phase execution, and long-running behavior with only limited human intervention. That is why “agentic” matters. The problem is not simply that a model can write exploit code. The problem is that it can keep working. (Anthropic)
This changes the defender’s math in at least four ways. First, speed improves. A model can move from reconnaissance to exploit hypothesis generation in seconds, especially on well-documented software or widely understood misconfigurations. Second, persistence improves. The loop does not get bored, does not need sleep, and does not forget to try adjacent variants unless the orchestrator is badly designed. Third, skill transfer improves. Tasks that once demanded deep operator familiarity can be decomposed into smaller jobs that a weaker actor can supervise. Fourth, reporting improves. Anthropic’s report explicitly noted that Claude was used to produce comprehensive documentation of the attack, including helpful files of stolen credentials and systems analyzed. Better attacker documentation means better reuse and better handoff between campaigns. (Anthropic)
The FortiGate case adds a fifth factor: old weaknesses become more dangerous when the cost of exploiting them at scale falls. AWS said the campaign did not require novel FortiGate exploitation. It required exposed management ports, weak credentials, and single-factor authentication. In other words, the barrier was not deep exploit development. The barrier was disciplined, repeated, high-volume execution. AI lowered that barrier. This is a crucial point for defenders because it means basic exposure management and identity hardening become even more valuable, not less, in the age of agentic attacks. (Amazon Web Services, Inc.)
At the same time, the math does not collapse entirely in favor of the attacker. Anthropic publicly acknowledged that Claude sometimes hallucinated credentials or claimed to have extracted secret data that was actually public. CNN also quoted practitioners who said advanced models still lack some of the context a human attacker has about what information is truly valuable inside an organization. HackerOne’s report adds a similar caution from researchers who say AI still misses business logic and chained exploit reasoning. Those limits matter. They mean defenders should not respond with panic. They should respond with engineering discipline. The right response to an unreliable but rapidly improving attacker primitive is a tighter verification loop on the defensive side. (Anthropic)
One of the biggest mistakes security teams make here is confusing coverage avec truth. Agentic systems can touch many more paths than a human can in the same period. That does not make every conclusion correct. A model may misread state, confuse a CDN response for origin behavior, reuse a polluted authenticated session, or claim exploitability based on a response pattern that is not actually privilege-bearing. If a defender treats broader coverage as equivalent to stronger evidence, the result is a flood of AI-shaped noise. The real problem to solve is not how to generate more candidate findings. The real problem is how to confirm which of those findings survive replay and independent verification.
Why AI copilots and scanners are not AI pentesting
The term “AI pentesting” is now stretched so loosely that it often hides the very distinctions security buyers most need to make. NIST’s definition is still the anchor point. Penetration testing, in NIST’s glossary, is testing that verifies the extent to which a system, device, or process resists active attempts to compromise its security. NIST SP 800-115 adds that technical security testing includes planning and conducting tests, analyzing findings, and developing mitigation strategies. That definition is useful because it immediately excludes a large class of products that can talk fluently about vulnerabilities but cannot verify exploitability in context. (csrc.nist.gov)
OWASP’s Web Security Testing Guide makes the same point from the application side. Real web testing spans identity management, authentication, authorization, session management, input validation, business logic, configuration, and more. OWASP’s business-logic material is especially important because it reminds readers that many meaningful failures are not simple payload bugs. They are workflow mistakes, step ordering issues, state mismatches, and assumptions that only become visible when a tester reasons across multiple requests and roles. A tool that cannot hold state, reason about flow, and verify server-side behavior is not doing general web pentesting just because it can explain SQL injection. (Fondation OWASP)
That is why scanners, copilots, and verified AI pentesting should be treated as different classes of capability.
| Capability class | What it does well | What it usually misses | Best use case | Biggest misuse risk |
|---|---|---|---|---|
| Vulnerability scanner | Broad enumeration, version matching, obvious misconfigurations, internet-scale inventory | Authenticated state, business logic, exploitability in a specific environment, chainable impact | Continuous exposure monitoring and hygiene | Treating a matched signature as proof of risk |
| AI copilot | Summarization, code review assistance, payload brainstorming, hypothesis generation, report drafting | Independent verification, reliable state handling, bounded execution, reproducible evidence | Helping a human tester think faster | Mistaking a persuasive explanation for a confirmed finding |
| Verified AI pentesting workflow | Recon-first planning, bounded active checks, stateful replay, independent confirmation, evidence packaging | Full replacement of expert judgment on ambiguous business logic or scope decisions | Authorized offensive validation and retesting | Over-granting permissions and turning the workflow into an unsupervised executor |
The difference is not academic. It changes procurement, scope design, workflow design, and what a report actually means. A scanner can say a login portal exists. A copilot can suggest what to test around that portal. A verified AI pentesting workflow should be able to determine, within authorization and policy, whether the portal is reachable from the wrong place, whether its controls can be bypassed, whether a session stays isolated across roles, whether the effect is reproducible, and what exact evidence another engineer needs to confirm the issue.
That distinction is already visible in some of the better public writing from offensive-security vendors. Penligent’s recent technical posts are useful here because they do not define AI pentesting as scanner output with nicer prose. They define it around whether a system can maintain context, handle stateful applications, prove impact, and produce evidence another engineer can reproduce, and they describe a harness that separates planning, execution, verification, and reporting rather than collapsing everything into one chat loop. Even if a team never adopts Penligent, that framing is closer to what mature buyers should demand from any tool in this category. (Penligent)
Verified AI pentesting, a better baseline for security teams
By verified AI pentesting, I mean an agentic workflow that can generate offensive hypotheses, execute bounded checks within explicit authorization, preserve the application state necessary to test real behavior, and then prove or disprove its own claims with independent evidence. The last part is what matters most. The workflow is not finished when the model says “I exploited it.” It is finished when the claim survives replay under controlled conditions and produces artifacts that someone else can inspect. That is a very different standard from “the model sounded convincing.” (csrc.nist.gov)
A useful way to think about this baseline is to ask six questions of any “AI pentest” system. Can it stay inside scope without relying on operator luck. Can it separate read-only planning from state-changing action. Can it maintain authenticated state across a multi-step flow. Can it distinguish candidate findings from validated findings. Can it show exactly what it did. Can another human replay the evidence. If the answer to several of those questions is no, the system may still be valuable, but it is not yet a reliable pentesting workflow.
This is also where some of the hype around fully autonomous red teaming starts to fall apart. Full autonomy sounds impressive until the first false positive turns into wasted engineering work, or the first over-broad permission set causes the system to test the wrong environment, or the first “successful” exploit turns out to be a session artifact that cannot be replayed. In real organizations, the winning workflows are rarely the most autonomous ones. They are the ones that preserve control and shorten the path from signal to proof.
Penligent’s public product language is notable on that point because it explicitly frames the system around “agentic workflows you control,” and its newer technical posts lean toward human-in-the-loop, evidence-first offensive validation rather than unconstrained autonomy. That is the right direction for the category. The useful question is not whether an agent can issue commands. The useful question is whether scope can be locked, actions bounded, and evidence preserved well enough for another engineer to retest and ship a fix. (Penligent)
A reference architecture for verified AI pentesting
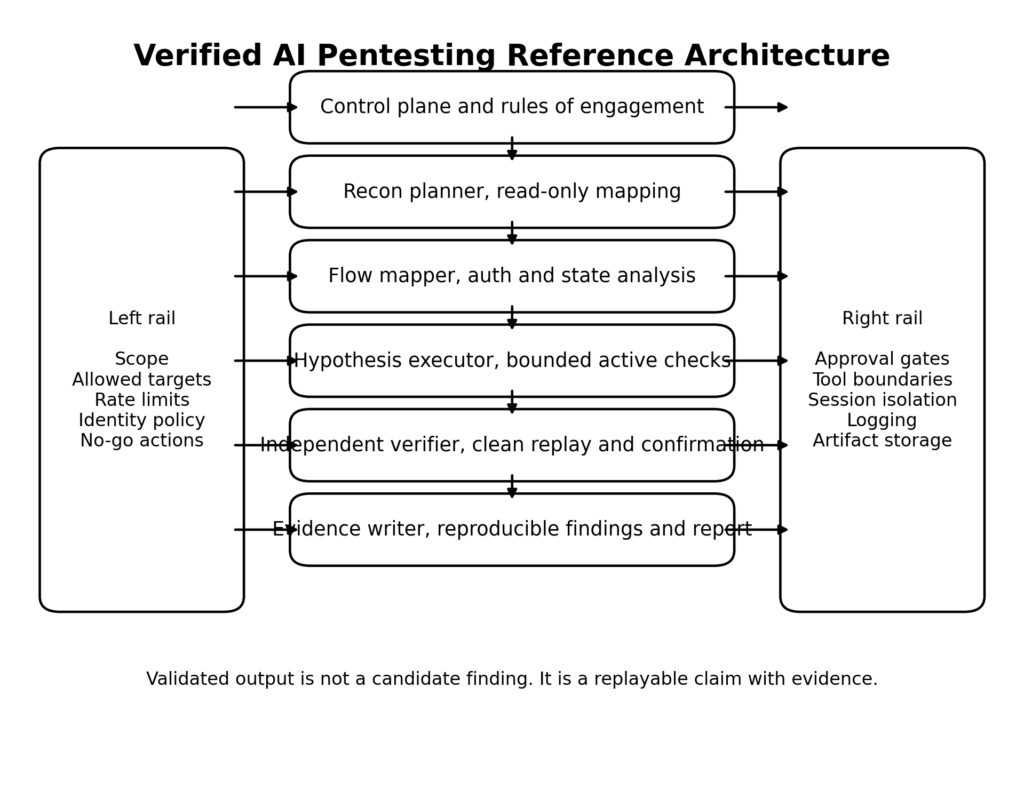
A verified AI pentesting system should be designed like a controlled testing platform, not like a single brilliant prompt. The more agentic the workflow becomes, the more architecture matters. Anthropic’s public Claude Code material is helpful here, not because coding agents and pentesting are the same thing, but because the docs reveal concrete design patterns that map well to authorized offensive validation: read-only planning modes, specialized subagents, tool access boundaries, permissions models, sandboxing, hooks, and context management. The lesson is that useful agent behavior comes from the surrounding system, not just the model. (Claude)
Control plane and rules of engagement for AI pentesting
The first layer has to be a control plane. Before the workflow sees a target, it needs machine-readable scope, approved credentials, rate limits, disallowed actions, data handling rules, and logging requirements. This is not bureaucracy for its own sake. It is what stops a fast system from becoming a sloppy one. NIST’s emerging Cyber AI Profile is useful because it explicitly organizes the problem across three focus areas: securing AI systems, conducting AI-enabled cyber defense, and thwarting AI-enabled cyberattacks. A mature pentesting workflow sits in the overlap. It uses AI for defense, but it must itself be secured, and it exists precisely because AI-enabled attacks are real. (NIST)
At a minimum, the control plane should answer these questions before a single active request is sent. Which domains and IPs are in scope. Which accounts may be used, at what privilege levels. Which actions are read-only, which are allowed with approval, and which are categorically forbidden. What constitutes proof. Where artifacts are stored. When human approval is required. Which tools have network egress. How retries are bounded. Most failed AI security workflows do not fail because the model is too weak. They fail because the surrounding policy is too vague.
A simple machine-readable starting point can look like this:
engagement:
name: customer-portal-retest
scope:
domains:
- app.example.com
- api.example.com
cidrs:
- 203.0.113.0/28
identities:
- name: basic-user
type: test_account
- name: readonly-admin
type: test_account
forbidden_actions:
- destructive writes
- data exfiltration beyond seeded test records
- password spraying
- mass file download
approval_required_for:
- authenticated state changes
- privilege escalation attempts
- any action above 30 requests per minute
evidence_requirements:
- browser replay
- raw HTTP request and response pair
- server-side log confirmation when available
logging:
store_commands: true
store_http_transcripts: true
store_screenshots: true
That file is not glamorous, but it forces the system to act like a test harness instead of a free-roaming assistant. It also creates a contract that humans can audit later.
Recon first, action later in AI pentesting
Anthropic’s public material on Plan Mode is one of the most transferable ideas from the coding world. The docs describe Plan Mode as read-only exploration used for research and requirement gathering before changes are made. In offensive validation, the equivalent move is recon-first planning. Start by crawling, mapping assets, identifying auth boundaries, clustering endpoints, and enumerating likely trust edges before doing anything state-changing. This reduces noise, preserves evidence quality, and dramatically lowers the chance that an agent wastes time on irrelevant tests. (Claude API Docs)
Recon-first planning is also the best antidote to the false confidence of large models. A model that starts active testing too early tends to anchor on the first plausible weakness it notices. A model that is forced to stay in a planning phase for a while will often build a better map of where the risky paths actually are. In practice, that means spending the early part of a run on questions like these: Which endpoints require authentication. Which roles exist. Which flows are multi-step. Which state tokens are reused. Which admin interfaces are externally reachable. Which third-party integrations expand the boundary. The answers are rarely flashy, but they determine whether later validation is meaningful.
Specialized subagents beat one giant prompt
Anthropic’s Claude Code docs explicitly support custom subagents with their own prompts, tools, permission modes, and optional scoped MCP servers. That design pattern maps surprisingly well to pentesting because the jobs inside a real engagement are different enough that they should not share the same context and permissions. Reconnaissance is not browser flow mapping. Browser flow mapping is not exploit validation. Exploit validation is not reporting. When one agent does all of it, tool access sprawls, context gets polluted, and error attribution becomes difficult. (Claude API Docs)
A better pattern is to split the workflow into explicit workers:
| Couche | Primary job | Typical tools | Permission boundary | Failure it avoids |
|---|---|---|---|---|
| Recon worker | Inventory, endpoint discovery, role surface mapping | DNS, HTTP, crawl, browser read-only | No writes, no privileged auth | Early destructive or noisy action |
| Flow mapper | Understand multi-step app behavior and auth transitions | Browser, proxy, request capture | Test accounts only | Missing business logic and state edges |
| Hypothesis executor | Run bounded checks against high-signal candidates | HTTP client, browser, approved CLI | Approval required for risky actions | Unfocused exploit spam |
| Independent verifier | Replay evidence and confirm effect | Separate browser session, fresh tokens, log checks | No hypothesis generation | Self-confirming false positives |
| Evidence writer | Package proof, steps, artifacts, and limitations | Structured storage, screenshot, diff | No target interaction | Loss of auditability |
This layout is slower than a single omnipotent loop in one narrow sense: there is more structure. But it is faster in the only sense that matters to a real security team. The output is easier to trust.
Permissioning, sandboxing, and the approval trap
Anthropic’s March 2026 write-up on Claude Code auto mode should be required reading for anyone building or buying agentic security workflows. The company says users approve 93 percent of permission prompts and warns that repeated clicking leads to approval fatigue. That is a crucial lesson for security tooling. If the human approves almost everything, “human in the loop” can degenerate into theater. A constant stream of prompts is not the same thing as meaningful control. (Anthropic)
The same post also lays out the tradeoff space cleanly. Sandboxing is safer but adds maintenance overhead and can break capabilities that need network or host access. Disabling permissions entirely is low-friction but unsafe in most situations. Manual prompts sit somewhere in the middle, but the real-world tendency to rubber-stamp them undermines their value. For AI pentesting, the implication is simple: do not rely on prompt spam as your main safety model. Use explicit scope, allowlists, rate limits, classifiers, and isolated execution environments where possible. Reserve human approvals for genuine boundary crossings, not every trivial action. (Anthropic)
Anthropic’s subagent documentation reinforces the same lesson from another angle. Subagents can inherit or restrict tools, use different permission modes, and even get access to MCP servers that the parent conversation does not see. That is exactly the kind of granularity AI pentesting needs. The recon worker should not have the same privileges as the executor. The evidence writer should not have target interaction tools at all. The verifier should operate with fresh state and narrower assumptions than the hypothesis generator. Permission design is not an implementation detail. It is a core part of correctness. (Claude API Docs)
MCP and the real execution boundary
The Model Context Protocol matters here because it turns an AI system from a text reasoner into a connected actor. Anthropic introduced MCP as an open standard for secure, two-way connections between data sources and AI-powered tools, and its own cyber-espionage report explicitly notes that the tools used in these attacks are often accessed through MCP. That means the execution boundary of an agent is no longer just its prompt. It includes repositories, browsers, databases, admin consoles, internal search, and whatever custom servers the organization exposes. (Anthropic)
This has two consequences. First, every connector is part of the security boundary. A read-only browser connector is not the same risk as a shell with unrestricted network egress. A search connector is not the same risk as a database connector. Second, prompt security is not enough. Even a perfectly aligned model becomes dangerous if the tool layer is over-permissioned and poorly scoped. The right security question is not “Do we trust the model.” The right question is “What can this composed system actually touch, and under what rules.”
Independent verification in AI pentesting
The single highest-leverage feature in a real AI pentesting workflow is an independent verifier. Not a second opinion from the same agent after it rereads its own output. A genuinely distinct verification path. Anthropic’s public reporting on offensive misuse is useful here because it quietly exposes the core weakness of autonomy: models can hallucinate. They can claim credentials exist when they do not. They can claim success when the evidence is ambiguous. If the same agent that generated the claim is allowed to validate it, the system is vulnerable to self-confirming error. (Anthropic)
A practical verifier should do at least one of four things. It should replay the browser path from a clean session. It should replay the API path with fresh tokens and exact request capture. It should cross-check the claim against server-side telemetry, such as a log entry or object state transition. Or it should confirm the effect through an orthogonal tool, such as a second client implementation or a role-specific visibility check. The critical design choice is that the verifier consumes evidence rather than reusing the hypothesis generator’s assumptions.
A minimal evidence object can look like this:
{
"finding_id": "AUTHZ-004",
"title": "Cross-tenant invoice access through direct object reference",
"hypothesis": "A basic user can retrieve another tenant's invoice by changing invoice_id",
"preconditions": [
"basic-user test account",
"two seeded tenant accounts",
"fresh browser session"
],
"reproduction": [
"Log in as tenant A basic user",
"Open invoice list and capture invoice request",
"Replace invoice_id with known tenant B invoice",
"Replay request with original session token"
],
"expected_effect": "Tenant B invoice metadata becomes visible to tenant A",
"verification": {
"method": [
"browser replay from clean session",
"raw HTTP transcript",
"object access log confirmation"
],
"status": "confirmed"
},
"artifacts": [
"screenshot.png",
"request.txt",
"response.txt",
"log-snippet.txt"
],
"limitations": [
"validated only on staging",
"effect limited to metadata, not file download"
]
}
That schema is intentionally boring. Boring is good. Boring is what lets another engineer tell the difference between “interesting hypothesis” and “verified risk.”

Fortinet CVE-2024-55591 and CVE-2025-24472, why edge admin paths are perfect agentic targets
If you want a category of vulnerability that becomes more dangerous in the age of agentic attacks, start with internet-facing management planes. Fortinet’s PSIRT lists CVE-2024-55591 and CVE-2025-24472 together in a critical advisory, marks them as unauthenticated, and notes they are known exploited. NVD’s description of CVE-2024-55591 says a remote attacker can gain super-admin privileges via crafted requests to the Node.js websocket module. NVD’s description of CVE-2025-24472 narrows the second issue more precisely, saying an unauthenticated attacker with prior knowledge of upstream and downstream device serial numbers may gain super-admin privileges on the downstream device if Security Fabric is enabled, using crafted CSF proxy requests. CISA added CVE-2024-55591 to the KEV catalog in January 2025 and also lists CVE-2025-24472 in the KEV catalog. (FortiGuard Labs)
These CVEs are highly relevant to agentic threat models for a simple reason. They are edge-resident, admin-oriented, and high-value. A system that can continuously enumerate exposed interfaces, distinguish management paths from user paths, correlate banners and product fingerprints, and decide which checks are worth running can dramatically reduce the labor required to find and exploit such exposures. Even when a specific CVE is patched, the pattern remains: exposed admin planes plus weak or bypassable authentication are ideal targets for machine-scale iteration.
The FortiGate campaign AWS documented in 2026 reinforces that point from the opposite direction. The actor did not need a new Fortinet zero-day. Exposed management ports, weak credentials, and single-factor authentication were enough when combined with AI-assisted scaling. The lesson for defenders is not “watch only for the latest CVE.” The lesson is “treat admin surface exposure as a force multiplier problem.” When a critical auth bypass exists, the risk is obvious. When no such bug exists, exposed admin paths are still dangerous because AI lowers the cost of trying adjacent paths, credential reuse, and configuration abuse. (Amazon Web Services, Inc.)
A safe, authorized validation pattern for your own environment is to begin with exposure confirmation, not exploitation. For example:
#!/usr/bin/env bash
# Run only against systems you own or are explicitly authorized to test.
while read -r host; do
echo "=== $host ==="
nmap -Pn -p 443,8443,10443 --open "$host"
curl -k -I --max-time 5 "https://$host/" | head -n 5
for path in /login /remote/login /remote/fgt_lang /admin /ssl-vpn/login; do
code=$(curl -k -s -o /dev/null -w "%{http_code}" --max-time 5 "https://$host$path")
if [ "$code" != "000" ] && [ "$code" != "404" ]; then
echo "$path -> HTTP $code"
fi
done
done < approved_targets.txt
That script does not prove exploitability, and it should not. What it does is identify the places where exploitability would matter most. In a verified AI pentesting workflow, the next step is not “fire every payload.” The next step is to decide which exposed surfaces deserve a bounded, logged, approval-backed validation path.
Mitigation has to be layered. Patch affected Fortinet versions according to the vendor advisory. Remove public access to management interfaces wherever possible. Require phishing-resistant MFA and private administrative access paths. Disable or tightly restrict features that expand trust paths if they are not needed. And most importantly, do not let asset exposure management and identity hardening sit in separate workstreams. The AWS case is a reminder that AI can turn bad coordination between those teams into attacker leverage. (FortiGuard Labs)
PAN-OS CVE-2024-3400, why internet edge RCE collapses response time
Palo Alto Networks’ CVE-2024-3400 is another useful example because it shows how internet edge RCEs fit into the same general pattern. The vendor advisory says the vulnerability is a command injection resulting from arbitrary file creation in the GlobalProtect feature of PAN-OS and may allow an unauthenticated attacker to execute arbitrary code with root privileges on affected firewalls. Palo Alto also clarified that Cloud NGFW, Panorama appliances, and Prisma Access are not impacted. CISA published guidance on the issue in April 2024. (Palo Alto Networks Security)
This CVE matters here for two reasons. First, it is the kind of vulnerability that instantly rewards good target selection. If a workflow can accurately identify exposed GlobalProtect surfaces and match them to affected configurations, the time from internet inventory to meaningful attack attempts can shrink fast. Second, even before a reliable exploit path is automated, AI can accelerate everything around the exploit: environment triage, version parsing, campaign clustering, attack path prioritization, and post-compromise note-taking. That is why teams should stop thinking only in terms of “Can the model produce exploit code.” A better question is “How much of the surrounding operator labor can the model now replace or compress.”
The defensive takeaway is similar to the Fortinet case but slightly broader. For edge RCEs, validated exposure inventory is everything. Which internet-facing assets terminate remote access. Which features are enabled. Which devices are reachable from the wrong networks. Which logs would tell you the issue was abused. Which controls would limit blast radius if the edge is lost. A verified AI pentesting workflow is particularly valuable here because it can turn vendor bulletins and asset data into environment-specific proof tasks rather than generic patch panic.
A good validation sequence for your own estate would start with configuration truth. Confirm whether the relevant feature is enabled. Confirm whether the management or remote-access surface is reachable from untrusted networks. Confirm what compensating controls exist, such as IP restrictions, inline access brokers, or segmentation. Only then decide whether a more active check is warranted within authorization. The point is to translate a headline CVE into an environment-specific risk statement instead of letting the organization oscillate between complacency and generic urgency.
Detection and validation, a practical workflow for security teams
The fastest way to lose value from AI in security is to use it only at the PDF stage. By the time a finding is being turned into prose, most of the important work is already over. The right place to apply AI is earlier: asset correlation, candidate path generation, replay planning, evidence packaging, and retest support. But those uses only help when paired with clear validation checkpoints.
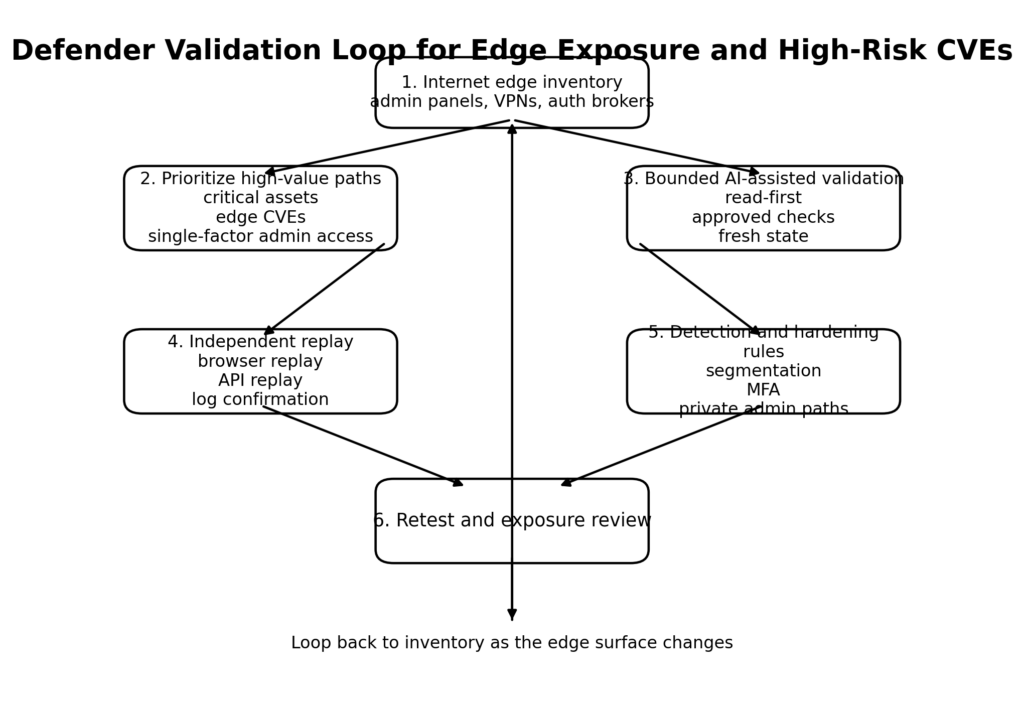
A practical workflow for security teams can be organized into six stages.
First, build an internet-edge truth set. This means finding every management interface, auth broker, VPN gateway, staging environment, and forgotten admin panel that is reachable from untrusted networks. The AWS FortiGate case is a reminder that attackers do not need novelty when the exposure map is sloppy. They need reachable surfaces. (Amazon Web Services, Inc.)
Second, classify the exposure by value and by operator cost. A public marketing site is not the same thing as a public admin plane. An authenticated portal with strong session boundaries is not the same thing as a shared control panel behind single-factor login. AI is most dangerous when it can spend cheap cycles against high-value, low-entropy surfaces. That is why admin endpoints, edge devices, and repetitive business workflows should be near the top of the validation queue.
Third, force the AI system into a recon-first, policy-aware mode before allowing active tests. Anthropic’s public Plan Mode and subagent model are useful patterns to borrow here. Let a planning worker map the attack surface. Let a flow worker understand authentication and business steps. Only then let an executor touch anything that could change state. (Claude API Docs)
Fourth, separate hypothesis generation from confirmation. This is the stage where many AI security programs quietly fail. A candidate finding is not a finding. A screenshot is not proof. A surprising response code is not proof. A working exploit in a polluted browser session is not proof. The verifier has to replay the effect from clean state with preserved preconditions and, when possible, cross-check the claim against server logs or object state.
Fifth, serialize the evidence. A finding should have a stable identifier, scoped target, preconditions, exact steps, artifacts, and a confidence statement that reflects what was truly confirmed. This is the difference between AI as writing aid and AI as operational accelerator. The former creates cleaner paragraphs. The latter creates a handoff the next engineer can use.
Sixth, feed the result back into detection and hardening. A verified offensive finding is not only a ticket for the application team. It is input for the blue team, IAM team, asset management team, and platform team. NIST’s Cyber AI Profile is helpful because it treats thwarting AI-enabled attacks and using AI for defense as connected activities, not separate universes. A mature organization closes that loop. (NIST)
A basic detection query for management-interface pressure might look like this:
let AdminPaths = dynamic([
"/login",
"/admin",
"/remote/login",
"/ssl-vpn/login",
"/api/v1/auth",
"/php/login.php"
]);
AppRequests
| where UrlPath has_any (AdminPaths)
| summarize
requests=count(),
failed_auth=countif(StatusCode in (401,403)),
distinct_sources=dcount(SourceIp),
user_agents=dcount(UserAgent)
by bin(Timestamp, 5m), Host
| where requests > 100 or failed_auth > 20 or distinct_sources > 15
| order by Timestamp desc
And a corresponding Sigma-style sketch for identity noise around admin surfaces could look like this:
title: Suspicious burst against management interfaces
id: 8f2f0c78-3c57-4c65-9f89-verified-ai-pentest-example
status: experimental
logsource:
category: webserver
detection:
selection:
cs-uri-stem|contains:
- "/admin"
- "/remote/login"
- "/ssl-vpn/login"
condition: selection
fields:
- c-ip
- cs-user-agent
- cs-host
- sc-status
level: medium
Those examples are intentionally generic. The point is not that one canned rule solves the problem. The point is that validated offensive work should become concrete telemetry logic, not just a paragraph in a report.
Why business logic still forces humans into the loop
One of the most persistent misconceptions about agentic offense is that once the model can chain tools, the hard part is over. OWASP’s business-logic guidance is a useful reminder that this is not true. Business logic flaws often depend on sequence, role, timing, data relationships, and assumptions buried in workflow design. A model may be good at spotting patterns in documentation or code, but it can still miss what makes a flow economically or operationally interesting inside a real system. (Fondation OWASP)
HackerOne’s 2025 report makes the same point from the researcher side. It says 58 percent of surveyed researchers believe AI misses business logic or chained exploits, and only 12 percent believe it could replace them. That finding should shape how teams deploy AI in pentesting. Use AI to expand coverage, accelerate triage, formalize replay steps, and prepare evidence. Keep humans responsible for value judgment, scope judgment, and interpreting ambiguous multi-step flows. The mistake is not using AI. The mistake is asking it to collapse the gap between “maybe” and “proved” without the right control structure. (HackerOne)
This is also why state handling matters so much. A business-logic issue often appears only when the same user moves through a flow in a nonstandard order, when one role inherits cached state from another, when a token is valid longer than the UI suggests, or when direct object access bypasses the intended path. These are not things a stateless summarizer catches. They require replay, clean sessions, controlled accounts, and evidence discipline. In practice, the best AI systems here are not the ones that “think hardest.” They are the ones that help the human tester preserve and reason about state without losing track of what was actually confirmed.
Common failure modes in agentic AI security testing
The first common failure mode is over-permissioning. Teams get excited about autonomy, connect the agent to too many systems, and then mistake reach for capability. A model that can touch the shell, browser, source repo, issue tracker, secrets store, and internal wiki is not automatically more useful. It is often just harder to reason about. MCP and similar connector patterns make this even more important because the practical execution boundary of the system keeps expanding. (Anthropic)
The second failure mode is approval theater. Anthropic’s own data point that users approve 93 percent of permission prompts should permanently weaken the argument that frequent pop-ups equal safety. A human who clicks through every prompt is not exercising meaningful control. Real control comes from predeclared boundaries, tool-specific allowlists, scoped identities, isolated execution, and high-friction gates only where they matter. (Anthropic)
The third failure mode is self-verification. This is where a model proposes a vulnerability, runs a half-convincing check, interprets its own noisy output as success, and then drafts a polished report that makes the whole chain sound more trustworthy than it was. The more fluent the system is, the more dangerous this becomes. Independent replay is not optional. It is the price of trust.
The fourth failure mode is treating environment context as an afterthought. A CVE may be critical and still irrelevant to your specific topology. A suspicious behavior may be reproducible and still low impact in your access model. Conversely, a medium-severity issue in a shared admin workflow may be far more important than a headline-grabbing version match. Environment-aware validation is what separates meaningful offensive testing from generic security theater.
The fifth failure mode is letting employee-built agents create new attack paths into internal systems without governance. Axios called this “shadow AI,” and while the term is broader than pentesting, the operational warning is real. If teams casually connect agents to work systems, internal tools, or sensitive data sources, they can widen the attack surface before they have even established how those agents are supposed to be governed. That risk belongs in the same conversation as offensive AI, not in a separate policy memo. (Axios)
What security buyers should ask before they trust an AI pentest tool
A technical buyer evaluating this category should ask boring questions first. How is scope expressed. How are identities handled. What happens when the system is uncertain. Can it keep a clean authenticated state. Does it distinguish candidate findings from verified ones. What artifacts does it store. Can a human reviewer replay the steps. How is tool access limited. What does the approval model actually do in practice. Those questions reveal far more than a feature matrix full of “autonomous” adjectives.
The right evaluation criterion is not whether the system can produce offensive-looking activity. Many tools can do that. The right criterion is whether the system can move from observation to defensible proof without losing control. That is why NIST’s language still matters, why OWASP’s breadth still matters, and why the recent public reporting from OpenAI, Anthropic, AWS, Bugcrowd, and HackerOne should be read together. The market is telling us that attacker scale is rising, that researchers already use AI heavily, and that business logic and evidence quality still keep humans central. The winning products will be the ones built for that reality rather than against it. (csrc.nist.gov)
The real shift is from AI that explains risk to AI that proves risk
The offensive AI conversation is easy to derail because it is full of dramatic nouns: zero-day, autonomous, spyware, superhuman, cyber weapon. Some of that language describes real movement in the field. But the more useful distinction is less cinematic. The real shift is from AI that explains risk to AI that proves risk. Explaining risk is helpful, but it is still mostly a language task. Proving risk requires control planes, state handling, scoped execution, independent verification, evidence objects, and replayable findings. That is the engineering problem security teams should be solving right now.
Mythos, if and when it arrives publicly, will not be the only model that matters. OpenAI has already said it is preparing for frontier models that may reach High cyber capability. Anthropic has already documented agentic misuse. AWS has already shown AI can amplify low-skill operations at scale. NIST is already telling organizations to think in terms of securing AI systems, using AI for defense, and thwarting AI-enabled attacks together. The sensible move now is not to wait for one more dramatic launch headline. The sensible move is to harden the places where agentic attackers get the most leverage and to build a verification workflow strong enough to tell you what is real before an adversary does. (OpenAI)
Further reading and references
- OpenAI, Strengthening cyber resilience as AI capabilities advance. (OpenAI)
- Anthropic, Disrupting the first reported AI-orchestrated cyber espionage campaign. (Anthropic)
- AWS Security Blog, AI-augmented threat actor accesses FortiGate devices at scale. (Amazon Web Services, Inc.)
- NIST, Draft NIST Guidelines Rethink Cybersecurity for the AI Era. (NIST)
- NIST NCCoE, Cyber AI Profile. (nccoe.nist.gov)
- NIST CSRC, tests de pénétration glossary entry. (csrc.nist.gov)
- NIST SP 800-115, Guide technique pour les tests et l'évaluation de la sécurité de l'information. (csrc.nist.gov)
- OWASP, Web Security Testing Guide. (Fondation OWASP)
- OWASP, Introduction to Business Logic. (Fondation OWASP)
- Fortinet PSIRT, FG-IR-24-535. (FortiGuard Labs)
- NVD, CVE-2024-55591 et CVE-2025-24472. (NVD)
- Palo Alto Networks, CVE-2024-3400. (Palo Alto Networks Security)
- CISA, Palo Alto Networks Releases Guidance for Vulnerability in PAN-OS CVE-2024-3400. (cisa.gov)
- Bugcrowd, Inside the Mind of a Hacker 2026 announcement. (Bugcrowd)
- HackerOne, Hacker-Powered Security Report 2025. (HackerOne)
- CNN syndicated reporting on Mythos via KTVZ. (KTVZ)
- Fortune reporting on the Mythos leak and Anthropic’s CMS error. (Fortune)
- Penligent, Claude Mythos and Cyber Security, What the Leak Actually Tells Defenders. (Penligent)
- Penligent, AI Pentest Tool, What Real Automated Offense Looks Like in 2026. (Penligent)
- Penligent, Claude Code Harness for AI Pentesting. (Penligent)
- Penligent, AI Red Team Assistant, What Holds Up in a Real Engagement. (Penligent)
- Penligent homepage. (Penligent)