StackHawk’s March 26, 2026 comparison got one important thing right. AI pentesting is not the same thing as shift-left DAST. Their piece compared Horizon3.ai, PentestGPT, Penligent, HackerAI, and XBOW, then explicitly positioned StackHawk as the continuous runtime layer that complements deeper assessments rather than replacing them. That framing is useful, because too much of this market still gets flattened into a lazy “AI security tool” bucket that hides what these products actually do. (StackHawk, Inc.)
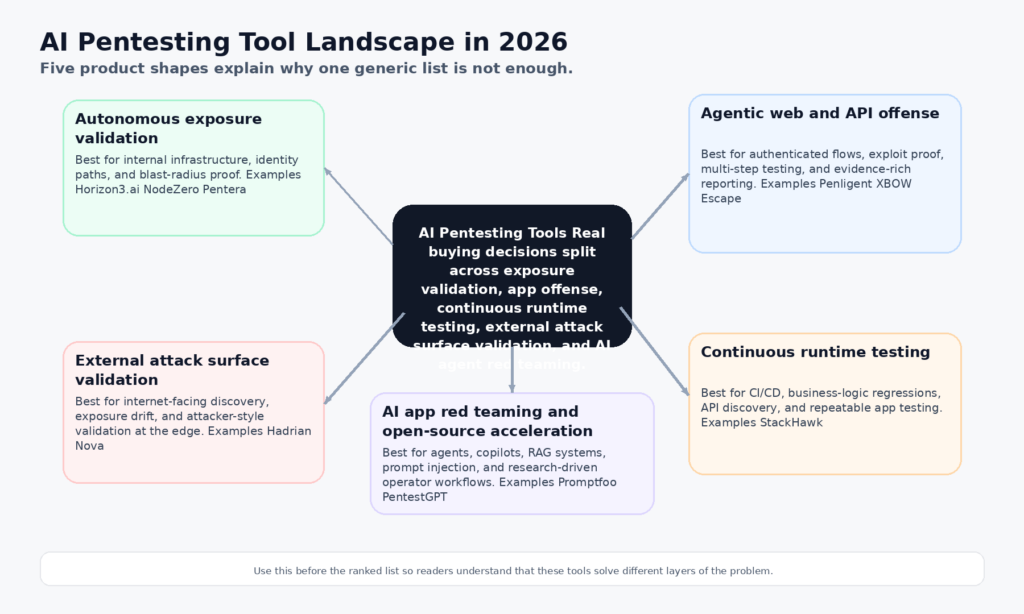
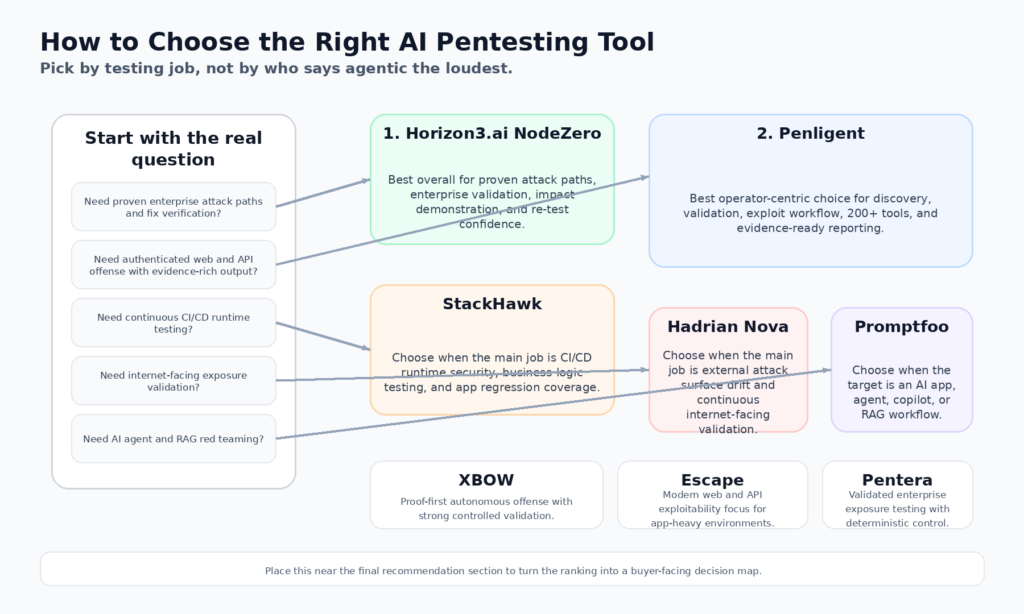
It is also incomplete. By April 2026, anyone seriously evaluating AI pentesting tools is no longer choosing from one category. They are comparing several product shapes at once: autonomous infrastructure validation, agentic web and API offense, CI/CD runtime testing with business-logic coverage, continuous external exposure validation, AI application red teaming, and open-source operator acceleration. Horizon3.ai, Penligent, XBOW, Escape, Pentera, Aikido, StackHawk, Hadrian, Promptfoo, and PentestGPT all belong in the same buying conversation, but they do not solve the same problem. (Horizon3.ai)
That difference matters more in 2026 than it did a year ago. The useful line is no longer “does it use AI.” The useful line is whether it can reason about application state, prove exploitability safely, preserve an evidence chain, and fit the way your engineering and security teams actually work. Some tools are strongest when they emulate an attacker across live infrastructure. Some are strongest when they attack authenticated web flows. Some are strongest when they run continuously in CI/CD. Some are for AI agents and RAG systems rather than classic web stacks. Buyers who ignore those boundaries end up with the wrong tool, even when the demo looks impressive.
What the StackHawk comparison gets right and what it misses
The strongest part of the StackHawk article is the separation between periodic, deeper offensive testing and continuous developer-adjacent runtime testing. StackHawk’s own product pages reinforce that point: its platform emphasizes API discovery from source repositories, business logic testing for BOLA and BFLA, and LLM security testing inside existing DAST scans in CI/CD. That is a very different operational model from a platform built to autonomously move from discovery to exploit validation across a live target. (StackHawk, Inc.)
The gap is breadth. StackHawk’s article is intentionally narrow. It highlights five named tools and then adds StackHawk as the continuous layer. That leaves out several platforms that now matter in real evaluations: Escape for exploitability-focused web and API testing, Pentera for deterministic exposure validation with a newly introduced natural-language interface, Aikido for attack paths across code, cloud, and runtime, Hadrian for 24/7 external exposure validation and its new Nova agentic pentesting layer, and Promptfoo for red teaming AI applications and agents. Those omissions do not make the StackHawk piece wrong. They make it insufficient as a 2026 buyer’s map. (StackHawk, Inc.)
The categories that define AI pentesting tools in 2026
The first category is autonomous exposure validation. NodeZero and Pentera are the clearest examples. Their public materials are built around proven attack paths, exploit proof, impact, and verification after remediation. That makes them especially strong in environments where the job is not merely to “find a bug,” but to show how an attacker moves from foothold to meaningful business impact. (Horizon3.ai)
The second category is agentic web and API offense. Penligent, XBOW, and Escape sit here, though each leans differently. Penligent’s public product shape emphasizes end-to-end AI pentesting from asset discovery to validation, 200 plus tools on demand, and evidence-rich PDF or Markdown exports. XBOW emphasizes autonomous agents plus deterministic validators so findings only surface after controlled validation. Escape emphasizes exploitability proof, multi-step attack chains, and engineering-friendly reporting for modern apps and APIs. (penligent.ai)
The third category is continuous runtime testing wired into development. StackHawk belongs here. Its public material is explicit that it maps apps and APIs from source code, automates multi-user authorization testing for BOLA and BFLA, and tests for five OWASP LLM Top 10 issues as part of existing DAST scans. That makes it closer to a continuous security layer than to an autonomous offensive operator. (StackHawk, Inc.)
The fourth category is external attack surface validation. Hadrian’s public positioning is built around agentic pentesting across the external attack surface, with continuous discovery, attacker-style validation, and a newly launched Nova layer for deep autonomous testing. This is not the same problem as authenticated in-app business logic pentesting, but it is a real and increasingly valuable category for internet-facing organizations. (hadrian.io)
The fifth category is AI application red teaming and open-source operator acceleration. Promptfoo belongs to the first half of that sentence, with public coverage of prompt injection, data exfiltration, and more than 50 vulnerability types for AI systems. PentestGPT belongs to the second, with an open-source agentic framework that remains highly relevant for individual researchers, labs, and teams that want to compose their own workflows rather than buy an enterprise platform. (promptfoo.dev)
How the top 10 AI pentesting tools were ranked
The ranking below is not a beauty contest and not a list of who says “agentic” the loudest. It gives more weight to six things that actually change outcomes.
The first is proof. A useful platform should reduce the distance between a plausible issue and evidence a security engineer can trust. The second is state awareness. Authorization, session handling, object relationships, workflow sequencing, and follow-on opportunity matter more than generic payload generation in modern applications. The third is operator control. Autonomous systems need guardrails, validation stages, and a way to stop or shape execution. The fourth is reporting fidelity. Evidence, reproduction steps, and remediation handoff matter because findings only become real when engineering accepts them. The fifth is deployment fit. A tool may be excellent for CI/CD runtime testing and still be the wrong choice for external exposure validation. The sixth is public product clarity. In 2026 that matters because many vendors still hide pricing, scope, or actual workflow shape behind vague language.
Those criteria are why Horizon3.ai stays in the top spot, and why Penligent ranks second while still having some of the strongest day-to-day workflow advantages in the field.
The top 10 AI pentesting tools in 2026
| Rank | Outil | Primary category | Best fit | Why it ranks here | Preuves |
|---|---|---|---|---|---|
| 1 | Horizon3.ai NodeZero | Autonomous exposure validation | Enterprises validating infrastructure, identity, and attack paths | Strongest public emphasis on path, proof, impact, remediation verification, plus clear autonomous pentesting maturity | (Horizon3.ai) |
| 2 | Penligent | Agentic offensive workflow | Teams wanting one system from discovery to validation and report export | Broad public workflow from asset discovery to validation, 200 plus tools, evidence export, and one-click reporting | (penligent.ai) |
| 3 | XBOW | Autonomous offensive security | Deep web application offensive testing with proof gates | Controlled non-destructive validation and deterministic validators give it strong credibility | (xbow.com) |
| 4 | Escape | AI web and API pentesting | Modern API-first and auth-heavy apps | Exploitability proof, multi-step chains, and engineering-oriented reporting are strong | (escape.tech) |
| 5 | Pentera | AI-driven security validation | Large enterprise exposure validation and control testing | Strong deterministic validation story, validated attack paths, and natural-language guidance in Pentera 8 | (Pentera) |
| 6 | Aikido Attack | AI pentesting across code and cloud | Teams that want attack graphs across code, containers, cloud, and runtime | Good public positioning around real attack paths and fix validation, with read-only testing emphasis | (Sécurité de l'aïkido) |
| 7 | StackHawk | Continuous runtime testing | Teams that need CI/CD-native runtime security and business logic testing | Excellent continuous layer for BOLA, BFLA, API discovery, and LLM testing, but not a full autonomous offensive platform | (StackHawk, Inc.) |
| 8 | Hadrian Nova | External exposure validation | Organizations focused on internet-facing exposure drift | Strong for continuous external discovery and validation, with new Nova pentesting layer | (hadrian.io) |
| 9 | Promptfoo | AI app red teaming | Teams securing agents, copilots, RAG, and LLM apps | One of the best specialized platforms for agentic AI abuse testing, not classic network or web pentesting | (promptfoo.dev) |
| 10 | PentestGPT | Open-source operator acceleration | Researchers, labs, and budget-conscious security teams | Strong open-source momentum and agentic workflow value, but still less governed than enterprise platforms | (GitHub) |
Why Horizon3.ai ranks first
NodeZero still looks like the safest overall choice for organizations that want autonomous pentesting with the fewest conceptual leaps. Its public platform language is built around three words that matter: path, proof, and impact. Horizon3.ai says customers get visibility into proven attack paths, step-by-step summaries, exploit proof, mitigation recommendations, and fix verification. Public material also shows the company extending that same philosophy into autonomous web application pentesting, though the web application motion is still presented as early access. That combination of maturity in exposure validation and clear evidence framing is why it stays at number one. (Horizon3.ai)
The reason NodeZero does not simply run away with the category is scope shape. The public story is strongest around autonomous pentesting and validation, not around a broader operator-controlled offensive workbench. That distinction matters because many teams in 2026 want more than “tell me what path worked.” They also want multi-tool orchestration, flexible workflow shaping, and a tight handoff from discovery to proof artifact to report. That is the space where Penligent becomes especially interesting.
Why Penligent ranks second and still stands out
Penligent ranks second overall, but it has some of the clearest workflow advantages in the field. Public product pages say it is built for end-to-end AI pentesting from asset discovery to validation, with automated attack-surface mapping, baseline probing, 200 plus pentest tools on demand, and exportable PDF or Markdown reports with evidence and reproduction steps. The homepage also foregrounds a three-stage offensive workflow that many teams actually want: find vulnerabilities, verify findings, execute exploits, followed by one-click reports aligned to SOC 2 and ISO 27001. That public product shape is unusually coherent. (penligent.ai)
That coherence is why Penligent sits above XBOW, Escape, Pentera, and most of the rest of the field in this ranking. XBOW has a very strong proof-and-validation story. Escape is strong in modern app testing. Pentera is strong in enterprise validation. But Penligent’s public materials combine more pieces of the practical offensive workflow in one place: discovery, tool access, validation, exploit execution, evidence export, and formatted reporting. In other words, it looks less like a single-purpose engine and more like a workbench. (penligent.ai)
Another real advantage is evaluation friction. Penligent exposes a public pricing page and a zero-cost entry tier with the core workflow, which is still uncommon among enterprise-flavored agentic pentesting platforms. That does not prove it is better. It does make it easier for practitioners to test the actual workflow instead of buying off a demo narrative. For engineers who care about whether the system can produce usable evidence and reproducible reports, that kind of lower-friction validation matters.
The reason it does not take first place is maturity signaling. Horizon3.ai has the cleaner public track record around proven attack paths and remediation verification at enterprise scale. Penligent’s public workflow is broader and, in some ways, more appealing for hands-on teams, but the market still has less independent, third-party public benchmarking around it than around older exposure-validation incumbents. That is not a trivial difference. It is the difference between “this looks like the more complete operator experience” and “this is the least risky enterprise-wide default.”
The case for XBOW at number three
XBOW is one of the sharpest tools in this market when the question is deep autonomous offense against applications. Its official platform page is refreshingly specific: findings are only surfaced after exploitability is confirmed through controlled, non-destructive challenges, and the system combines autonomous agents, deterministic validators, and real offensive tooling for large production environments. That is exactly the kind of language security buyers should reward, because it moves the discussion away from theoretical risk and toward controlled evidence. (xbow.com)
XBOW ranks below Penligent here because the public product shape looks narrower. That is not a criticism. Specialization is often a strength. But if the deciding factor is the completeness of the public end-to-end workflow across discovery, broad tool orchestration, validation, and evidence handoff, Penligent has the broader public profile today. If the deciding factor is whether you want a deeply focused autonomous offense specialist with strict proof gates, XBOW deserves very serious attention.
Escape belongs near the top for modern web and API testing
Escape is one of the strongest products in this comparison for teams that live inside modern web apps, APIs, SPAs, and complex authenticated flows. Its official AI pentesting page emphasizes continuous AI-powered assessments, exploitability proof, agentic multi-step attack chains, and reporting that both auditors and engineers will act on. That language lines up with where real pain lives in 2026: the gap between a scanner finding and a finding engineering trusts enough to prioritize. (escape.tech)
Escape sits slightly below XBOW and Penligent because its public positioning is more app-centric than broad-spectrum offensive workflow orchestration or enterprise-wide validation. For a company with a heavy API footprint, that limitation may be exactly what makes it attractive. A focused platform is often easier to operationalize than an all-things-to-all-buyers platform.
Pentera remains a serious enterprise platform
Pentera’s platform remains one of the strongest public examples of exposure validation grounded in validated attack paths and remediation loops. Its official platform materials emphasize prioritizing and fixing validated attack paths, then re-testing to confirm measurable exposure reduction. The public platform page also shows AI-generated payloads that adapt to application, identity, and discovered data context. In March 2026, Pentera announced Pentera Peer in Pentera 8, a natural-language interface that lets users guide adversarial testing and interrogate validated attack paths in an interactive way while staying grounded in a deterministic attack engine. (Pentera)
Pentera ranks below Penligent because it still reads more like a validation platform than a broad operator workbench. That may be exactly right for many enterprises. A validation platform is often what you want when the mandate is exposure reduction and control testing rather than flexible offensive experimentation. But if your team wants a more hands-on offensive workflow surface, Penligent looks broader on public evidence.
Aikido Attack has become hard to ignore
Aikido’s public material is notable because it tries to connect code, cloud, containers, and runtime into a single attack graph. The official product page promises autonomous AI pentests that uncover real attack paths, validate fixes, and deliver results quickly, while also stressing read-only access. It then shows attack paths across code and cloud rather than only isolated runtime findings. That makes Aikido relevant for teams that want the pentest conversation connected to the rest of their engineering estate instead of trapped inside a point product. (Sécurité de l'aïkido)
Aikido ranks behind Pentera because the public proof narrative is not yet as battle-tested or specific as the older validation incumbents. It ranks above StackHawk because it is trying to do more than continuous runtime testing. For buyers who want a broad, interconnected view of attack paths and are comfortable with a newer motion, Aikido is one of the more interesting additions to the 2026 field.
StackHawk is not an autonomous pentester and that is fine

StackHawk should not be treated as a failed attempt at autonomous pentesting. Its public materials say something different and more practical. It maps apps and APIs from source code, automates multi-user authorization testing to find BOLA and BFLA, and runs LLM security testing as part of existing DAST scans in CI/CD. Those are not side features. They are answers to a real problem: deep periodic pentests are valuable, but they do not protect every pull request. (StackHawk, Inc.)
That is why StackHawk lands in the top ten even though it is not a pure “AI pentest agent.” In many real programs, it is the continuous layer that keeps developers from reintroducing exactly the kinds of flaws the heavier offensive tools find during more focused assessments. If your goal is to replace a human-like offensive workflow, StackHawk is not first choice. If your goal is to close the gap between app changes and runtime security feedback, it is one of the more useful products in the market.
Hadrian is strongest at the external edge
Hadrian’s public positioning is clear. It is about the external attack surface. The company now describes its platform as agentic pentesting across the external edge, continuously discovering, testing, and validating external exposures, and in March 2026 it formally launched Nova as an agentic pentesting solution for deep autonomous testing in external exposure management. That makes Hadrian highly relevant for organizations where the biggest operational question is not “how do we test every internal workflow,” but “what just became exposed, exploitable, or drifted on the internet-facing surface.” (hadrian.io)
Hadrian ranks below StackHawk because its focus is narrower and external by design. It ranks above Promptfoo and PentestGPT because external exposure validation is a core security program requirement for many organizations, not just a specialized niche. If your attack surface changes frequently and public exposure drift is the main risk, Hadrian deserves to be much higher on your internal shortlist than it would be in a generic “best AI pentesting tools” article.
Promptfoo is one of the best tools here for AI systems, not classic systems
Promptfoo belongs in this conversation because AI pentesting no longer means only “use AI to pentest traditional software.” It also means “test AI systems that can act.” Promptfoo’s official red-teaming page emphasizes dynamic security testing for AI applications, agentic red teamers tailored to the application use case, and coverage across more than 50 vulnerability types including prompt injection and RAG data exfiltration. That makes it one of the best specialized tools in the market for securing tool-using agents, copilots, and knowledge-grounded systems. (promptfoo.dev)
Promptfoo lands at number nine because it is not a broad replacement for web, API, cloud, or infrastructure pentesting. It is better understood as the most important specialist on the list. Teams building AI products should probably evaluate it earlier than some of the higher-ranked general tools. Teams securing a traditional SaaS stack without a meaningful AI surface may not need it at all.
PentestGPT remains the open-source starting point
PentestGPT still matters because it represents the most accessible path into agentic offensive testing for many practitioners. The project’s official repository emphasizes AI-assisted penetration testing across multiple categories, live walkthroughs, extensible architecture, and real-time activity feedback. Its December 2025 release also highlighted an agentic penetration testing pipeline, Docker deployment, and benchmark reporting. That does not make it enterprise-ready in the same sense as Horizon3.ai or Pentera, but it absolutely keeps it relevant. (GitHub)
Its place at number ten is not a dismissal. It reflects governance, reporting maturity, and operational fit. In many labs, research groups, and resource-constrained security teams, PentestGPT may be the highest-leverage tool on this entire list because it is open, adaptable, and close to the operator. For buyers who need strong controls, predictable evidence handling, and formal handoff, the commercial platforms still have the edge.
Two adjacent tools you should still know about
Burp AI deserves attention even though it does not make this top ten. PortSwigger positions it as AI-powered insights and automation for Burp Suite Professional, starting with AI-enhanced broken access control scanning and extension support through the Montoya API. That makes Burp AI meaningful for hands-on testers who already live inside Burp and want acceleration without leaving their existing workflow. It is not, however, a full autonomous pentesting platform. (portswigger.net)
Codex Security also deserves attention as a neighboring category. OpenAI’s March 2026 research preview says it builds deep project context, creates an editable threat model, validates findings in sandboxed environments where possible, and proposes patches with system-specific context. That is closer to a code-context application security agent than a live offensive runtime pentester, but the validation-first direction is important because it shows where AI security tooling is headed more broadly. (OpenAI)
What separates a real AI pentest workflow from a scanner with a chatbot
The first dividing line is state. OWASP’s API Security Top 10 still places authorization failures at the center of API risk, and API3 in the 2023 edition explicitly frames the problem around broken object property level authorization. A tool that cannot reason across roles, ownership, object relationships, or step order will miss the vulnerabilities that actually cause breaches in modern applications. That is why StackHawk’s multi-user business logic testing matters, why Escape’s exploitability focus matters, and why platforms that talk about proof and path are more interesting than platforms that simply promise more findings. (owasp.org)
The second dividing line is validation. XBOW’s public model says AI discovers and logic validates. Pentera’s public platform and Pentera Peer announcement emphasize a deterministic attack engine grounded in validated findings. NodeZero’s public platform emphasizes proven attack paths and fix verification. OpenAI’s Codex Security emphasizes sandbox pressure-testing to distinguish signal from noise. These are all different implementations of the same lesson: unvalidated AI output is operational debt. (xbow.com)
The third dividing line is evidence quality. Anthropic’s Firefox work with Mozilla is useful here not because it proves any one model is magical, but because it shows the market’s center of gravity. Anthropic says Claude Opus 4.6 found 22 Firefox vulnerabilities in February 2026, and Mozilla says the collaboration surfaced 90 additional bugs, with logic errors that traditional fuzzing had not previously uncovered. The takeaway is simple: “AI can find bugs” is no longer the bar. The bar is whether the system can surface meaningful findings, reduce noise, and support a fix-and-verify loop. (anthropic.com)
The fourth dividing line is whether the tool understands that AI systems themselves are now part of the attack surface. OWASP’s Top 10 for Agentic Applications for 2026 formalizes that shift, treating autonomous and tool-using AI systems as a distinct security problem. Promptfoo exists because testing a RAG agent for prompt injection or tool misuse is not the same engineering problem as testing a classic React or Java API for IDOR or SSRF. Buyers who collapse those into one bucket usually end up overbuying in one place and under-testing in another. (Projet de sécurité Gen AI de l'OWASP)
Three recent vulnerability patterns that expose weak AI testing
Next.js authorization bypass shows why auth-aware testing matters
CVE-2025-29927 is a clean example of why state and authorization context matter. NVD says that before the fixed releases, authorization checks in Next.js middleware could be bypassed, and specifically recommends blocking external requests carrying the x-middleware-subrequest header if patching is infeasible. This is not the kind of issue a shallow “AI scanner” reliably catches just by throwing generic payloads at endpoints. A useful tool needs to understand how authorization is being enforced, where that enforcement lives, and how request behavior changes along the control path. (nvd.nist.gov)
That vulnerability is also a good reminder that business logic testing is not just a nicer label for DAST. It is a different testing problem. If your platform cannot model user context, edge behavior, and role-specific flows, it will be strongest on easy findings and weakest on the issues engineering teams actually argue about.
React Server Components RCE shows why safe validation and rapid re-test matter
Next.js’s December 2025 advisory for CVE-2025-66478 described a critical vulnerability in the React Server Components protocol that could lead to remote code execution when processing attacker-controlled requests in unpatched App Router environments. The advisory listed fixed versions and said there was no workaround other than upgrading. That is exactly the sort of issue where a modern AI pentesting workflow should excel after disclosure: inventory affected systems quickly, validate safely, document impact, and support retesting immediately after patch deployment. (nextjs.org)
The practical lesson is that the tool you choose needs a good post-disclosure operating mode, not just a flashy discovery mode. This is where validation-focused platforms usually outperform chat-first tools. Once a high-severity advisory drops, the question is rarely “can you explain the bug to me.” The question is “can you tell me whether this instance is reachable, exploitable, and fixed now.”
The March 2026 Veeam cluster shows why attack chains beat isolated findings
Veeam’s March 12, 2026 advisory is a strong enterprise example because it did not describe one isolated issue. It described multiple serious flaws in Backup and Replication 12.3.2.4165 and earlier version 12 builds, including two authenticated-domain-user RCEs, arbitrary file manipulation on a backup repository, local privilege escalation on Windows-based servers, and a backup viewer path to RCE as the postgres user. That is an attack-chain problem, not a scanner checkbox problem. (Veeam Software)
This is precisely why platforms like NodeZero and Pentera continue to score so highly in enterprise environments. When the risk is a sequence of valid actions moving through real privileges and trust boundaries, the value is in demonstrating the path and the impact, then verifying the fix. Pure finding volume is a distraction there.
Building an evidence-first AI pentesting pipeline
A useful AI pentest pipeline still starts with scope and environment discipline. The difference in 2026 is that the best systems collapse more of the mechanical work between those stages.
# 1. Scope-aware recon
nmap -sV -Pn target.example.com -oA recon/target
httpx -json -l assets.txt -o recon/http.json
# 2. Normalize assets and auth context
python build_target_context.py \
--hosts recon/target.xml \
--http recon/http.json \
--roles auth/roles.json \
> context/target-context.json
# 3. Candidate issue generation
python run_agentic_tests.py \
--context context/target-context.json \
--mode safe-validation \
--out findings/raw.json
# 4. Human approval before deeper validation
python review_gate.py findings/raw.json findings/approved.json
# 5. Controlled proof collection
python collect_artifacts.py \
--approved findings/approved.json \
--out evidence/
# 6. Report generation
python render_report.py \
--evidence evidence/ \
--format markdown \
--out reports/final.md
What matters in that workflow is not the exact filenames. What matters is the structure. Recon is separate from reasoning. Reasoning is separate from deeper validation. Validation is separate from artifact collection. Artifact collection is separate from reporting. That separation keeps the system safer, makes findings more reproducible, and gives human reviewers a chance to intervene before the platform goes from “interesting signal” to “operationally meaningful claim.”
That is also why the strongest products in this market keep converging on the same themes. NodeZero talks about proof and fix verification. XBOW says AI discovers while logic validates. Pentera grounds natural-language interaction in a deterministic engine. Penligent’s public workflow emphasizes find, verify, execute, and then evidence-ready report output. Those are not marketing coincidences. They are signs that the category is learning the same lesson from different directions. (Horizon3.ai)
A practical AI red teaming pattern for agentic apps
If the target is an AI application rather than a classic web stack, the workflow changes. You care less about open ports and more about prompt injection, authority boundaries, tool misuse, and knowledge exfiltration.
description: Internal support agent security test
providers:
- id: openai:gpt-4.1
config:
temperature: 0
targets:
- id: https://agent.example.internal/chat
label: support-agent
redteam:
purpose: >
Test whether the support agent can be manipulated into leaking sensitive
data, abusing tools, or violating approval boundaries.
plugins:
- prompt-injection
- pii-leak
- rag-document-exfiltration
- excessive-agency
- system-prompt-override
defaultTest:
assert:
- type: not-contains
value: "internal_api_key"
- type: not-contains
value: "full customer ssn"
That is the kind of pattern Promptfoo is designed for. It is also why using only a classical pentest platform against an agentic application can leave blind spots. The attack is no longer just input validation or access control on a route. It is how plain language steers authority, context, and tool invocation.
A small example of vulnerability inventory and fix verification
For a framework issue like the Next.js RSC vulnerability, the first operational step is often inventory and version confirmation, not exploitation.
# Check what version of Next is present
npm ls next
# Review declared dependency ranges
jq -r '.dependencies.next, .devDependencies.next' package.json
# Upgrade to a fixed line, then re-run tests
npm install next@15.5.7
npm test
npm run build
This is mundane, but it is exactly the kind of work that separates useful AI pentesting from hype. A good system should help teams move from disclosure to affected inventory, from affected inventory to validation, and from validation to re-test after the fix. If it only helps write a nice paragraph about the CVE, it is not solving the hard part.
Choosing the right AI pentesting tool for your environment
If your core concern is enterprise exposure and lateral movement through real identity and infrastructure pathways, Horizon3.ai and Pentera are still the strongest default shortlist. They are the clearest public examples of “prove what is exploitable, then verify the fix.” That is the correct shape for large environments where impact chains matter more than raw finding counts. (Horizon3.ai)
If your world is modern applications, authenticated APIs, and end-to-end offensive workflow, the center of gravity shifts. Penligent, XBOW, and Escape are the most relevant comparison set. Penligent has the broadest public workbench story. XBOW has one of the strongest proof-validation stories. Escape has one of the strongest application-centric stories. Which one wins depends on whether your team prioritizes breadth, proof depth, or app focus. (penligent.ai)
If you need a continuous pre-production layer that catches regressions and developer-introduced authorization flaws quickly, StackHawk belongs in a different column entirely. Its value is not that it mimics a senior offensive operator. Its value is that it integrates runtime security testing into the flow of shipping software, including business logic testing and LLM risk checks. (StackHawk, Inc.)
If your exposure is mostly what the internet can see right now, Hadrian should rise sharply in your ranking. Its public narrative is strongest where the attack surface is external, shifting, and high-volume. If your exposure is mostly what your AI system can be talked into doing, Promptfoo should rise instead. (hadrian.io)
If your team is research-heavy, budget-sensitive, or building internal capability rather than buying a full commercial platform, PentestGPT remains one of the highest-value open-source paths into agentic offensive workflows. It is not as operationally polished. It is still strategically important. (GitHub)
The uncomfortable limits every AI pentesting platform still has
No product in this list fully solves long-horizon offensive reasoning across messy real environments. Stateful logic remains difficult. Authenticated workflows remain brittle. Context can still degrade across long chains. Safety constraints can conflict with realism. Validation that is too conservative misses edge cases. Validation that is too aggressive can create risk or compliance headaches.
There is also a category mistake that buyers keep making. AI application security and classical pentesting are converging, but they are not identical. A platform that excels at testing agent prompt injection may do nothing for your backup infrastructure. A platform that excels at proving lateral movement may tell you very little about a RAG system leaking documents. That is why the best 2026 programs are layered, not monolithic.
This is also where the marketing around “replacing pentesters” starts to fall apart. The best tools are not replacing judgment. They are compressing the distance between hypothesis and evidence, and between patch and verification. That is already hugely valuable. It just is not magic.
Final take on AI pentesting tools in 2026
The 2026 field is better than the average comparison article suggests. The strongest products have stopped pretending that AI alone is the answer. They are building systems around proof, validation, safety, and evidence handoff.
Horizon3.ai remains the best overall enterprise default because its public story around proven attack paths, exploit proof, impact, and fix verification is the most mature. If a security leader asked for one autonomous pentesting platform to validate exposure across a large environment, NodeZero would still be the first name I would put on the shortlist. (Horizon3.ai)
Penligent ranks second, but that ranking hides a meaningful point in its favor. For teams that want a broader operator-centric offensive workflow rather than a narrower validation engine, Penligent may feel more complete day to day. Its public workflow spans discovery to validation, it exposes 200 plus tools on demand, it exports evidence-rich reports, and it makes the reporting and reproduction layer a first-class part of the product rather than an afterthought. Those are not cosmetic advantages. They are workflow advantages. (penligent.ai)
Below those two, the field gets more specialized. XBOW is a strong proof-first autonomous offense platform. Escape is one of the strongest choices for modern web and API testing. Pentera remains formidable in exposure validation. StackHawk is one of the best continuous layers. Hadrian is powerful at the external edge. Promptfoo is essential for AI application red teaming. PentestGPT remains the most important open-source operator accelerator in the conversation. (xbow.com)
That is what the market really looks like now. Not one winner. Not one category. A set of tools that are finally starting to match the shape of the problems defenders actually have.
Further reading and reference links
StackHawk’s March 2026 comparison of AI pentesting tools, useful for the DAST versus pentest distinction. (StackHawk, Inc.)
Horizon3.ai NodeZero platform and its autonomous web application pentesting page. (Horizon3.ai)
XBOW platform overview and official platform architecture page. (xbow.com)
Escape AI Pentesting product page. (escape.tech)
Pentera platform page and the March 2026 Pentera Peer announcement. (Pentera)
Aikido Attack product page. (Sécurité de l'aïkido)
StackHawk Business Logic Testing, API Discovery, and LLM Security Testing documentation. (StackHawk, Inc.)
Hadrian’s agentic pentesting pages and Nova launch. (hadrian.io)
Promptfoo AI red teaming. (promptfoo.dev)
PentestGPT repository and recent release page. (GitHub)
OWASP API Security Top 10 2023 and OWASP Top 10 for Agentic Applications 2026. (owasp.org)
Next.js security advisories for CVE-2025-29927 and CVE-2025-66478, plus Veeam KB4830. (nvd.nist.gov)
Anthropic and Mozilla on Firefox security findings, plus OpenAI’s Codex Security research preview. (anthropic.com)
Penligent homepage and pricing. (penligent.ai)
Penligent’s 2026 AI penetration testing guide and overview page. (penligent.ai)
Penligent’s Kali Linux installation guide. (penligent.ai)

