La question la plus utile en matière d'IA offensive à l'heure actuelle n'est pas de savoir si les modèles peuvent contribuer aux tests de pénétration. Ils le peuvent. La question la plus difficile est de savoir si l'économie fonctionne. Si la réponse était déjà positive à l'échelle de l'internet, l'internet public se présenterait différemment : plus de sondages autonomes constants, plus d'enchaînements d'exploits bon marché spécifiques à une cible, et plus de tentatives persistantes de compromission à faible coût contre des organisations ordinaires plutôt que contre des cibles de grande valeur. Ce n'est pas ce que suggèrent les faits. La réalité actuelle est plus restreinte et plus intéressante. Le pentesting par IA est déjà rentable pour des travaux limités, de grande valeur et reproductibles. Elle n'a pas encore de sens économique en tant que substitut universel d'une exploitation de masse bon marché. (openai.com)
Cette distinction commence par la définition même des tests de pénétration. Le NIST ne décrit pas le pentesting comme le fait de demander à un LLM ce qui pourrait ne pas fonctionner. Il décrit les tests de pénétration comme des tests de sécurité dans lesquels les évaluateurs imitent des attaques réelles afin d'identifier les moyens de contourner les dispositifs de sécurité d'une application, d'un système ou d'un réseau. Dans la pratique, les tests réels combinent souvent plusieurs faiblesses afin d'obtenir un accès plus important que ne le permettrait un seul problème. C'est pourquoi la question du coût est si importante. Un résumé de scanner ne coûte pas cher. Une tentative crédible de modéliser un attaquant, d'exercer une pression sur un système réel, de vérifier l'impact et de préserver les preuves ne l'est pas. (owasp.org)
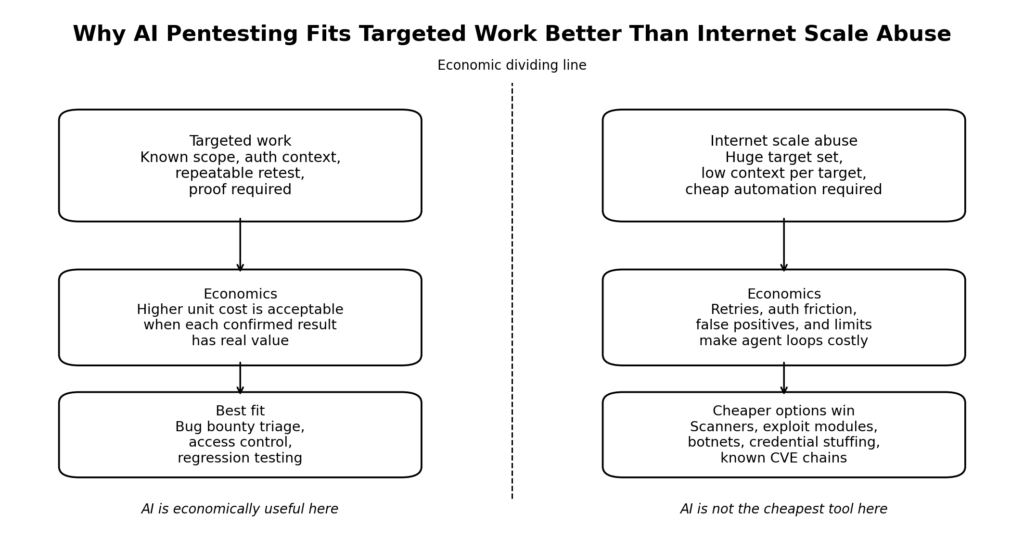
Le bon titre n'est donc pas que l'IA pentesting est trop chère pour avoir de l'importance. Le bon titre est que le pentesting par IA est déjà économiquement viable lorsque la cible est suffisamment précieuse, que le flux de travail est suffisamment structuré et que le résultat doit être suffisamment vérifié. La situation économique est bien pire lorsque la tâche est vaste, non authentifiée, bruyante et très variable. C'est la ligne de démarcation entre un flux de travail d'entreprise défendable et le fantasme d'un agent qui pirate à peu de frais l'ensemble de l'internet pendant que vous dormez. (USENIX)
L'économie du pentesting par l'IA commence par les tarifs pratiqués par les fournisseurs
La façon la plus simple de constater que le travail agentique n'est pas bon marché est de regarder ce que font les fournisseurs de modèles eux-mêmes. Les documents de tarification actuels d'OpenAI indiquent des niveaux de prix plus élevés pour une utilisation plus intensive et plus persistante, et la tarification de son API sépare clairement l'inférence de modèle d'outils tels que la recherche sur le web et les conteneurs. La tarification actuelle d'Anthropic présente les niveaux Max à des prix mensuels plus élevés et positionne séparément les agents gérés par Claude pour les travaux asynchrones de longue durée. Il ne s'agit pas des prix ou des limites d'un produit de chat de base. Ce sont des signaux de prix pour les utilisateurs qui sont censés exécuter des charges de travail plus longues, plus denses et plus lourdes en termes d'outils. (openai.com)
Anthropic est encore plus explicite en ce qui concerne les développeurs. Son guide des coûts Claude Code indique que l'utilisation moyenne est d'environ six dollars par développeur et par jour, que quatre-vingt-dix pour cent des coûts quotidiens restent inférieurs à douze dollars et que l'utilisation par équipe se situe souvent autour de cent à deux cents dollars par développeur et par mois avec des schémas d'utilisation de type Sonnet. En d'autres termes, l'un des signaux publics les plus forts sur le marché n'est pas que les agents sont fondamentalement libres aujourd'hui. C'est que les agents créent déjà une facture d'exploitation reconnaissable, même dans un cas d'utilisation de codage courant. (IntuitionLabs)
Du côté de l'API, l'histoire est la même, mais sous une forme plus granulaire. La page de tarification publique d'OpenAI mentionne actuellement GPT-5.4 mini à soixante-quinze cents par million de jetons d'entrée et quatre dollars cinquante par million de jetons de sortie, tandis que la recherche sur le web et l'utilisation des conteneurs sont facturées séparément. La page de tarification d'Anthropic mentionne Claude Sonnet 4.6 à trois dollars par million de jetons d'entrée et quinze dollars par million de jetons de sortie en tarification standard, et note que les sessions d'agents gérés sont facturées aux tarifs modèles, tandis que la recherche web à l'intérieur des sessions est également facturée séparément. Anthropic propose également la prise en charge d'un contexte d'un million de jetons sur certains modèles au prix standard, ce qui est pratique mais rappelle également que le contexte long est une surface de coût réelle, et non une mémoire gratuite. (openai.com)
Cette structure de prix est importante pour le travail de sécurité parce que ce travail est exceptionnellement bon pour transformer une réponse utile en de nombreuses réponses enchaînées avec des outils. Un véritable pentest ne s'arrête pas à une bonne idée. Il s'étend à l'énumération, aux invites de suivi, à l'interprétation des résultats des outils, à l'ajustement des charges utiles, à la gestion de l'authentification, à la validation des exploits, à l'acquisition de preuves et à l'établissement de rapports. Les flux de travail de sécurité agentique sont donc beaucoup plus proches des agents de codage et des agents de recherche que du chat ordinaire. L'économie de l'unité doit être jugée en conséquence. (plateforme.claude.com)
Le coût du pentesting en IA n'est pas un chiffre unique, c'est une pile.
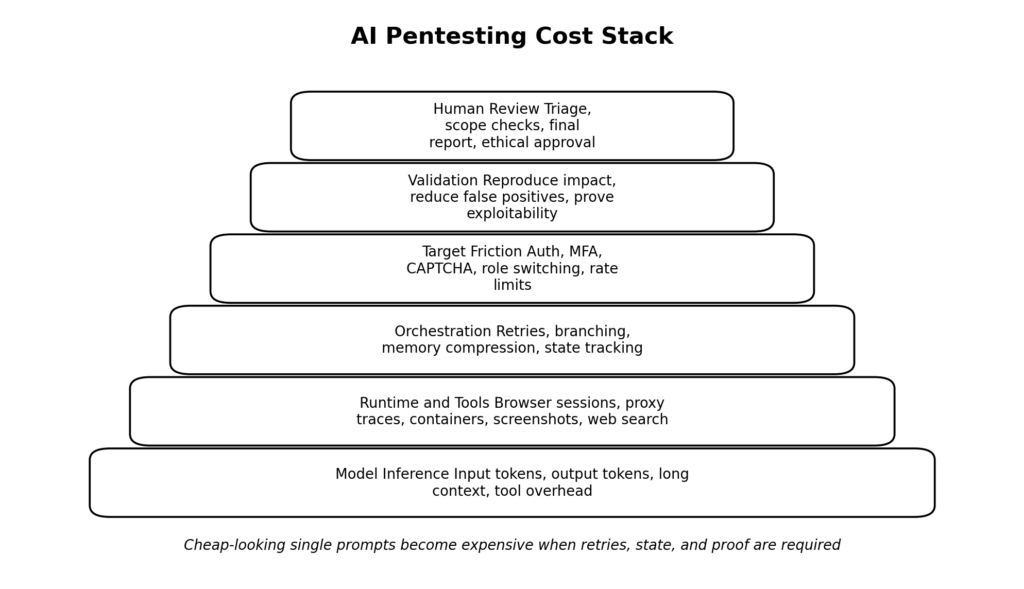
La plupart des gens demandent ce que coûte le pentesting en IA comme s'il y avait un chiffre unique. Ce n'est pas le cas. Il s'agit plutôt d'un empilement de coûts, et la différence entre un flux de travail rentable et un flux de travail non rentable est généralement déterminée par les couches qui dominent.
| Couche de coût | Ce que vous payez réellement | Pourquoi la croissance est-elle plus rapide que prévu ? |
|---|---|---|
| Inférence de modèle | Jetons d'entrée, jetons de sortie, contexte long, entrée visuelle | Recon est bruyant, la sortie de l'outil est verbeuse, l'historique composé est réessayé. |
| Outil et durée d'exécution | Recherche sur le web, sessions shell, conteneurs, automatisation des navigateurs | Chaque action utile crée davantage d'états, de journaux, de captures d'écran et d'artefacts. |
| Orchestration | Boucles de réflexion, ramification, résumé, compression de la mémoire | Récupération des défaillances et multiplication des appels d'exploration |
| Accès aux cibles | Comptes, données semées, gestion de l'AMF, configuration de tests sûrs | Les tests authentifiés sont souvent plus coûteux que la logique d'exploitation. |
| Validation | Reproduire l'impact, réduire les faux positifs, prouver l'exploitabilité | La plupart des conclusions des candidats meurent ici |
| Examen humain | Triage, application du champ d'application, rédaction finale, garde-fous éthiques | Les clients et les programmes de primes veulent toujours des preuves, pas des vibrations |
L'erreur cruciale consiste à n'évaluer que la première ligne. Si l'on ne tient compte que de l'inférence du modèle, certaines charges de travail de pentesting par l'IA semblent étonnamment bon marché. Si l'on tient compte de l'ensemble de la pile, en particulier des tentatives et de l'examen humain, l'économie change rapidement. Cela correspond à la manière dont OpenAI et Anthropic exposent les prix : ils ne regroupent pas tout dans un tarif forfaitaire magique pour un travail agentique sérieux. Ils mesurent les parties coûteuses parce que ces parties sont réelles. (openai.com)
Le sol est bon marché, le flux de travail complet ne l'est pas
D'un point de vue purement mécanique, les prix des modèles modernes peuvent faire paraître trivial un seul tour à forte teneur en texte. Avec les tarifs mini GPT-5.4 actuels d'OpenAI, même des invites assez volumineuses peuvent encore sembler peu coûteuses en termes de jetons bruts. Les tarifs bruts de l'API d'Anthropic racontent une histoire similaire à petite échelle : un passage minutieux sur la documentation d'une cible, les échantillons de réponse et les fichiers JavaScript peut coûter très peu par rapport à la valeur potentielle d'une bonne piste. (openai.com)
Mais le pentesting se comporte rarement comme une simple invite bien formée. Il se comporte comme un arbre. Le modèle demande plus de points d'extrémité. La sortie du proxy est plus importante que prévu. Un flux de connexion est interrompu et nécessite une séquence différente. Un BOLA candidat s'avère être un problème de cache. L'exploit ne fonctionne qu'avec un seul rôle. Le rapport a besoin d'un chemin de preuve propre. L'agent relit l'état antérieur parce que la branche de la tâche a dérivé. Chacun de ces événements entraîne des coûts supplémentaires. La facture des jetons directs peut encore être gérable, mais la facture du flux de travail augmente parce que chaque branche consomme également de l'attention humaine, du temps d'horloge et de la confiance. C'est à ce moment-là que l'inférence bon marché cesse d'être la mesure pertinente. (USENIX)
Un modèle de coût qui ne tient pas compte de l'échec d'une branche est particulièrement trompeur dans le domaine de la sécurité. Les grands modèles de langage sont bons pour comprimer des données désordonnées en étapes suivantes plausibles. Ils sont beaucoup moins fiables lorsqu'il s'agit de savoir rapidement et avec certitude si une branche vaut la peine d'être poursuivie. Les tests de sécurité souffrent donc d'une forme brutale de dépenses cachées : de nombreuses branches produisent un travail articulé mais économiquement inutile. (USENIX)
Une petite calculatrice est plus honnête qu'un slogan
Un simple estimateur permet de mieux cerner le problème. Il ne s'agit pas d'une référence ni d'un devis de fournisseur. Il s'agit d'un modèle pratique de budgétisation pour un pentest agentique unique.
def estimate_ai_pentest_run(
input_mtok,
output_mtok,
modèle_in_usd_per_mtok,
modèle_out_usd_per_mtok,
web_search_calls=0,
web_search_usd_per_call=0.01,
sessions_conteneurs=0,
container_usd_per_session=0.03,
retry_multiplier=1.0,
human_review_hours=0.0,
reviewer_hourly_usd=0.0,
) :
model_cost = (input_mtok * model_in_usd_per_mtok) + (output_mtok * model_out_usd_per_mtok)
tool_cost = (web_search_calls * web_search_usd_per_call) + (container_sessions * container_usd_per_session)
automation_cost = (model_cost + tool_cost) * retry_multiplier
human_cost = human_review_hours * reviewer_hourly_usd
total_cost = automation_cost + human_cost
return {
"model_cost_usd" : round(model_cost, 2),
"tool_cost_usd" : round(tool_cost, 2),
"automation_cost_after_retries_usd" : round(automation_cost, 2),
"human_review_cost_usd" : round(human_cost, 2),
"total_cost_usd" : round(total_cost, 2),
}
example = estimate_ai_pentest_run(
input_mtok=1.8,
output_mtok=0.25,
model_in_usd_per_mtok=0.75,
modèle_out_usd_per_mtok=4.50,
appels_recherche_web=12,
sessions_conteneurs=10,
multiplicateur de tentatives = 2,3,
human_review_hours=1.5,
reviewer_hourly_usd=125,
)
print(exemple)
L'intérêt d'une telle calculatrice n'est pas le résultat exact. C'est la discipline qu'elle impose. Une fois que vous avez ajouté les tentatives, les appels à l'outil et l'examen humain, le coût dominant peut ne plus être le modèle du tout. Cette idée correspond à l'orientation de la tarification actuelle des fournisseurs : OpenAI facture séparément les outils tels que la recherche sur le web et les conteneurs, et Anthropic expose séparément l'utilisation du modèle, les frais généraux des outils, la facturation des agents gérés et les coûts d'exploitation moyens de Claude Code. (openai.com)
Comparons maintenant deux cas pratiques. Dans une tâche légère de reconnaissance du web public, le modèle peut lire un peu de HTML, une poignée de fichiers JavaScript et peut-être une description OpenAPI publique. Cela peut être très peu coûteux. Dans un test SaaS authentifié avec changement de rôle, jetons CSRF, permutations d'ID d'objet, captures d'écran, traces de proxy répétées et tentatives de validation, le même flux de travail peut coûter un ordre de grandeur plus élevé avant même que le rapport ne soit prêt à être soumis. La différence n'est pas que la deuxième cible est plus difficile dans l'abstrait. La différence est que le second objectif impose plus d'état, plus de friction et plus d'endroits où échouer. (USENIX)
Pourquoi les mathématiques de la prime aux bugs de l'IA sont plus sévères que les mathématiques de l'entreprise
Les acheteurs d'entreprise et les chercheurs de bogues résolvent des équations différentes. Une équipe d'entreprise se préoccupe de savoir si l'IA réduit le temps nécessaire à la vérification du risque, augmente la couverture, réduit les faux positifs ou diminue la quantité d'attention requise de la part des responsables par engagement. Un chasseur de bogues solitaire se préoccupe du gain attendu moins les coûts de temps, d'outillage et d'échec. Le même agent peut sembler attrayant dans la première équation et médiocre dans la seconde.
Les plateformes de piratage indiquent déjà que l'on s'oriente vers un modèle augmenté par l'homme plutôt que vers un modèle entièrement autonome. Le rapport 2026 de Bugcrowd indique que l'adoption de l'IA par les pirates informatiques a atteint 82 % et décrit le changement comme une intelligence augmentée par l'homme plutôt qu'un remplacement de l'homme. Le rapport 2025 HackerOne's Hacker-Powered Security Report indique qu'il s'appuie sur plus de 580 000 vulnérabilités validées, quatre-vingt-un millions de dollars de paiements cette année-là et des informations provenant de 1 950 programmes d'entreprise, tout en signalant une croissance de deux cent dix pour cent des rapports de vulnérabilité IA valides et une augmentation de cinq cent quarante pour cent de l'injection rapide en tant que vecteur d'attaque. L'IA n'est plus hypothétique dans les flux de travail des pirates. Elle est opérationnelle. Mais les données publiques font état d'une augmentation et d'une extension de la surface plutôt que d'un remplacement total du jugement humain. (Bugcrowd)
Le rapport 2026 de Bugcrowd aborde le même sujet de manière plus directe. L'IA est de plus en plus utile pour les problèmes courants, le triage répétitif et une couverture plus large, mais les voies d'attaque les plus valables dépendent toujours fortement de la compréhension du fonctionnement réel de la cible. Il s'agit là d'une description presque directe de la répartition de l'économie des primes aux bugs. Les tâches à faible contexte et à volume élevé sont celles pour lesquelles l'automatisation est la plus utile. Les chaînes spécifiques à une cible, à contexte élevé et à forte rémunération sont exactement là où l'avantage humain résiduel est le plus difficile à supprimer. (Bugcrowd)
C'est pourquoi l'IA peut améliorer le flux de travail d'un bounty tout en laissant le retour sur investissement final ambigu. Si l'IA vous aide à auditer plus de JavaScript, à organiser les points de terminaison, à rédiger une meilleure preuve et à résumer l'impact plus clairement, il s'agit d'une valeur réelle. Si elle vous conduit également à travers dix impasses sûres sur une cible stateful avant que vous n'abandonniez le chemin, la valeur peut s'évaporer. Dans le cadre du bug bounty, le coût caché de l'échec n'est pas théorique. C'est la différence entre une soumission correcte et une journée perdue.
L'IA est déjà rentable pour les chasseurs de bogues
Les cas d'utilisation de l'IA les plus rentables dans le cadre du bug bounty ne sont pas ceux qui semblent les plus autonomes dans une démo. Ce sont ceux qui éliminent les changements de contexte coûteux d'un travail que le chercheur comprend encore.
Le rapport 2026 de Bugcrowd et les documents connexes décrivent l'IA comme une aide à la qualité des rapports, à l'élargissement de la couverture et à l'augmentation des résultats pour le même budget. Cela correspond à l'utilisation qu'en font de nombreux chercheurs. L'IA aide à analyser les gros paquets de JavaScript, à regrouper les modèles de points d'extrémité répétés, à résumer la logique commerciale, à expliquer les en-têtes inhabituels, à générer des variantes de charge utile ou à peaufiner un récit de vulnérabilité afin que l'équipe du programme puisse le reproduire plus rapidement. Ces tâches ne sont pas très glorieuses, mais c'est précisément là que les chasseurs solitaires perdent du temps. Lorsque l'IA compresse cette boucle, elle peut augmenter le débit sans prétendre garantir des découvertes. (Bugcrowd)
Les signaux émis par PortSwigger vont dans le même sens. La documentation de Burp AI insiste sur le fait que l'utilisateur garde le contrôle, que les fonctionnalités ne sont pas exécutées à moins d'être explicitement activées et que l'IA est utilisée pour améliorer des tâches telles que la validation du contrôle d'accès, la génération de séquences de connexion et l'exploration des problèmes. Ce qui est remarquable, c'est ce que Burp AI ne promet pas. Il ne promet pas un agent non supervisé qui remplace le testeur. Il promet une validation plus rapide, moins d'impasses et moins de frictions manuelles au sein d'un outil auquel le testeur fait déjà confiance. C'est exactement ce à quoi ressemble aujourd'hui une IA économiquement rationnelle dans le domaine du bug bounty. (owasp.org)
Cette position sur les produits n'est pas de la prudence pour elle-même. Il s'agit d'un aveu économique. Si un fournisseur d'AppSec mature pensait que l'exploitation bon marché, générale et autonome était déjà la voie de valeur dominante, son message public serait différent. Au lieu de cela, la proposition de valeur est centrée sur la réduction des faux positifs, la continuité du flux de travail et l'automatisation contrôlée par l'opérateur. C'est dans ces domaines que le rapport coût-signal est déjà bon. (owasp.org)
Pourquoi les faux positifs coûtent plus cher que les factures symboliques
Le problème économique central du pentesting de l'IA n'est pas le prix par jeton. Il s'agit du prix par résultat validé.
Un flux de travail de sécurité peut tolérer un grand nombre d'inférences bon marché. Il ne peut tolérer une inférence bon marché sans fin qui ne converge pas. Chaque question candidate qui meurt tardivement est coûteuse. Il a consommé le contexte de la cible, le temps de l'agent et l'attention de l'évaluateur. Dans le cas d'un bug bounty, il peut également consommer de l'énergie émotionnelle rare. Un flux de travail qui vous maintient dans une curiosité productive vaut plus qu'un flux de travail qui produit des absurdités articulées avec une grande confiance.
C'est l'une des raisons pour lesquelles le contrôle d'accès reste une catégorie si révélatrice. Le Top 10 actuel de l'OWASP maintient le contrôle d'accès brisé en tête, et le Top 10 de l'OWASP API Security continue de mener avec l'autorisation brisée au niveau de l'objet. Ce sont exactement les types de failles qui sont faciles à décrire et souvent difficiles à prouver à grande échelle parce qu'elles nécessitent un état authentifié, une comparaison entre l'utilisateur et le rôle, et une compréhension minutieuse de la portée de l'objet. Les documents de PortSwigger relatifs à l'IA soulignent également la difficulté de réduire les faux positifs dans les tests de contrôle d'accès. Il s'agit là d'une description exceptionnellement honnête de la rupture économique : les bogues liés au contrôle d'accès sont précieux, courants et douloureux, de sorte que la réduction des faux positifs a une réelle valeur monétaire. (owasp.org)
L'implication est plus grande que le contrôle d'accès. Toute classe de vulnérabilité facile à dénombrer mais coûteuse à valider deviendra un champ de bataille pour l'économie de l'IA. Celui qui réduit le coût de la preuve ou de la réfutation de l'impact d'un candidat l'emporte, même si le modèle sous-jacent n'est pas beaucoup plus performant.
L'exploitation de masse traditionnelle reste moins coûteuse que le piratage agentique à l'échelle de l'internet.
C'est la partie que de nombreuses discussions négligent. L'internet ne fait pas l'objet d'attaques constantes de la part d'agents, en partie parce qu'une grande partie de l'exploitation de masse rentable n'a jamais eu besoin d'un raisonnement coûteux de la part d'agents.
Lorsqu'une vulnérabilité est accessible à distance, normalisée, facile à identifier et à déclencher dans un contexte limité, la voie offensive la moins coûteuse n'est généralement pas un agent d'intelligence artificielle réfléchi. Il s'agit d'un scanner fin, d'un contrôle déterministe, d'un module d'exploitation, d'un dispositif de bourrage d'informations d'identification ou d'un réseau de zombies. L'économie de l'exploitation de masse récompense la répétabilité et non l'élégance. C'est pourquoi l'automatisation à l'ancienne est toujours aussi importante.
Quelques CVE récents à fort impact mettent en évidence la différence.
Log4Shell montre à quoi ressemble une exploitation bon marché à l'échelle de l'internet
NVD décrit CVE-2021-44228, Log4Shell, comme une faille dans Log4j 2 où les messages de journal contrôlés par un attaquant ou les paramètres de journal peuvent conduire à l'exécution de code arbitraire par le biais de consultations JNDI. L'enregistrement NVD note que ce comportement a été désactivé par défaut dans la version 2.15.0 et entièrement supprimé dans la version 2.16.0. Les versions antérieures pouvaient être atténuées en désactivant les consultations ou en supprimant la classe JndiLookup. D'un point de vue économique, Log4Shell était presque parfait pour une exploitation de masse : à l'échelle de l'internet, standardisé, facile à tester et dévastateur lorsqu'il est présent. Un attaquant n'avait pas besoin d'un agent à long terme pour savoir si une cible valait la peine d'être examinée de nouveau. Une charge utile bon marché, un balayage à grande échelle et une infrastructure d'exploitation existante correspondaient déjà au modèle commercial. (nvd.nist.gov)
Cette distinction est importante. Lorsque les gens imaginent l'IA pirater l'ensemble de l'internet, ils imaginent souvent l'IA remplacer toute l'automatisation. Dans la pratique, le flux de travail offensif le moins cher et le plus rapide pour un bogue de type Log4Shell était déjà disponible sans boucles d'agents coûteuses. L'IA pouvait aider à hiérarchiser, résumer ou adapter les charges utiles, mais elle n'était pas nécessaire pour rendre l'attaque économiquement viable. (nvd.nist.gov)
MOVEit montre comment les bogues externes non authentifiés s'industrialisent rapidement
NVD décrit CVE-2023-34362 dans Progress MOVEit Transfer comme une faille d'injection SQL dans l'application web qui pourrait permettre à un attaquant non authentifié d'accéder à la base de données, d'en déduire la structure et le contenu, et d'exécuter des instructions SQL qui modifient ou suppriment des éléments de la base de données. Les dossiers publics et les avis ont lié la faille à une exploitation dans le monde réel. Une fois encore, c'est l'aspect économique qui compte. MOVEit n'est pas devenu une classe d'incidents majeurs parce que les attaquants disposaient d'un moteur de raisonnement autonome magique. Il l'est devenu parce que la vulnérabilité était de grande valeur, non authentifiée, orientée vers l'internet et suffisamment standard pour être utilisée comme arme. Une fois que cela est vrai, l'attaque la moins chère n'est pas un agent général coûteux. Il s'agit d'une industrialisation ciblée autour d'une voie d'exploitation. (nvd.nist.gov)
ScreenConnect rappelle une fois de plus que les plans de gestion externes sont spéciaux
NVD décrit CVE-2024-1709 comme un contournement d'authentification dans ConnectWise ScreenConnect 23.9.7 et les versions antérieures, qui peut permettre un accès direct à des informations confidentielles ou à des systèmes critiques. D'un point de vue économique, les interfaces de gestion compriment la prise de décision des attaquants. Si la surface est exposée et que la faille est grave, la valeur attendue par tentative réussie est élevée. Ce type de cible n'a pas besoin d'un agent général sophistiqué pour être attrayant. Il faut un moyen rapide de trouver des instances exposées et de tester un chemin connu. (nvd.nist.gov)
C'est là que de nombreuses conversations sur l'IA s'éloignent de la réalité. L'existence d'agents plus puissants n'efface pas la domination économique de l'automatisation conventionnelle contre les vulnérabilités standardisées, très payantes et orientées vers l'internet.
La chaîne Ivanti montre pourquoi les chaînes d'exploitation normalisées sont plus efficaces que le raisonnement libre des agents.
NVD décrit CVE-2023-46805 comme un contournement d'authentification dans Ivanti Connect Secure et Ivanti Policy Secure qui permet à un attaquant distant d'accéder à des ressources restreintes en contournant les vérifications de contrôle. Dans le même groupe de vulnérabilités, des failles d'exécution de commande telles que CVE-2024-21887 ont rendu le chaînage encore plus dangereux. D'un point de vue économique, il s'agit d'un exemple presque parfait de la raison pour laquelle les chaînes d'exploitation standardisées restent moins chères que les attaques agentives libres. Une fois la chaîne connue, le travail ne consiste pas à comprendre la logique commerciale de cette entreprise à partir de zéro. Le travail consiste à trouver les dispositifs exposés, à valider les versions, à exécuter la chaîne et à passer à autre chose. Même si l'IA aide à emballer la chaîne ou à l'expliquer, la marge provient de la standardisation et de la répétition. (nvd.nist.gov)
C'est pourquoi l'internet n'attend pas un agent de test universel pour devenir dangereux. Les domaines les plus rentables de l'automatisation offensive ont déjà trouvé leur voie. L'IA devient économiquement plus intéressante lorsque le problème n'est pas déjà réductible à un modèle d'exploitation connu.
Le pentesting par IA est le plus judicieux lorsque le contexte est coûteux et que la réutilisation est possible.
Le cas d'utilisation actuel le plus important pour le pentesting par l'IA n'est pas l'exploitation de masse. Il s'agit de la gestion coûteuse du contexte.
Cela comprend le mappage d'applications authentifiées, l'organisation de traces de proxy volumineuses, l'interprétation de résultats bruyants, la création de contrôles de suivi ciblés, la validation de problèmes probables de contrôle d'accès, la réalisation de nouveaux tests après correction et la conversion d'observations brutes en éléments de preuve reproductibles. Il s'agit de tâches pour lesquelles l'expertise humaine reste importante, mais le temps de l'homme est la partie la plus coûteuse. Si l'IA réduit ce temps sans compromettre la fiabilité, l'économie peut fonctionner même si la facture des jetons n'est pas triviale.
C'est également à ce niveau que la recherche originale de PentestGPT est toujours d'actualité. Le document USENIX Security 2024 a introduit un cadre construit autour de multiples modules auto-interactifs pour atténuer la perte de contexte et améliorer les sous-tâches de pentesting automatisées. Des recherches plus récentes, telles que Shell or Nothing, ont affiné le contrôle de la réalité en signalant que les systèmes existants ont encore du mal à obtenir des shells de système dans des conditions réalistes, tout en montrant que de meilleurs systèmes de gestion de la mémoire et des exploits peuvent réduire le temps d'exécution et le coût financier. La tendance est claire. L'IA est une réalité. La valeur est réelle. Le plus difficile n'est pas de faire en sorte que le modèle ressemble à celui d'un pentester. La difficulté consiste à faire converger l'ensemble du système vers un impact vérifié sans dépenser trop d'argent ni trop d'attention de la part des réviseurs en cours de route. (USENIX)
L'économie du pentesting par l'IA est plus performante dans les flux de travail délimités
Les flux de travail de pentesting IA les plus rentables aujourd'hui ont tendance à partager trois caractéristiques. Ils sont limités, réutilisables et orientés vers la preuve.
| Type de flux de travail | Pourquoi l'économie fonctionne-t-elle ? | Pourquoi la rupture économique ? |
|---|---|---|
| Cartographie authentifiée et comparaison des rôles | Un temps humain précieux est économisé et le contexte peut être réutilisé pour de nombreux contrôles. | Se casse la figure si l'ouverture de session et la configuration du compte dominent le travail |
| Contrôle d'accès et vérification BOLA | L'IA peut regrouper des modèles d'objets et contribuer à réduire les faux positifs | S'interrompt si l'agent ne peut pas maintenir un état de rôle cohérent. |
| Nouveaux tests après les corrections | La cible et le chemin d'exploitation sont déjà connus | Rupture si la remédiation a modifié l'application plus que prévu |
| Emballage des éléments de preuve et rédaction d'un rapport | L'IA compresse les écrits, les captures d'écran, les notes et les étapes de reproduction. | Elle est rompue si la constatation sous-jacente n'a jamais été véritablement validée. |
| Balayage large non authentifié | Peu coûteux s'il est traité comme une simple reconnaissance | Les ruptures se produisent lorsque les gens confondent recon et pentesting |
| Compromis autonome à l'échelle de l'internet | Rarement utile par rapport à une automatisation plus simple | Ruptures sur le coût, les limites de taux, les faux positifs et la variabilité de la cible |
La définition du pentesting par le NIST et l'accent mis par l'OWASP sur le contrôle d'accès rendent ces flux de travail délimités particulièrement importants. Les tests de pénétration consistent en des tentatives actives de déjouer les contrôles de sécurité et s'appuient souvent sur des combinaisons de problèmes. Le contrôle d'accès défaillant et l'autorisation au niveau de l'objet restent essentiels parce qu'ils se situent juste à la limite où l'automatisation est utile, mais où la preuve reste importante. C'est à cette limite que l'IA peut produire un véritable effet de levier économique. (owasp.org)
Un flux de travail de pentesting d'IA gouverné est également le moment où la conception du produit commence à être plus importante que le marketing du modèle. Les documents publics en anglais de Penligent présentent à plusieurs reprises un pentester IA comme un système gouverné qui réduit la distance entre le signal brut et la découverte vérifiée. Ce cadre est économiquement important car la partie coûteuse du travail de sécurité est rarement la première hypothèse. C'est le chemin qui mène de l'indice bruyant à la preuve défendable. (Penligent)
La même idée apparaît sur les pages publiques de Penligent sous une forme différente : flux de travail contrôlés par l'opérateur, contrôle de la portée, et exécution humaine dans la boucle plutôt qu'autonomie aveugle. Qu'une équipe utilise Penligent ou non, cette orientation de la conception est révélatrice. Le produit à valeur financière n'est pas celui qui promet de pirater quoi que ce soit. C'est celui qui aide un testeur humain à prouver ce qui est important plus rapidement, avec un contrôle plus étroit de la portée et des actions. (Penligent)
La taxe cachée sur le piratage autonome
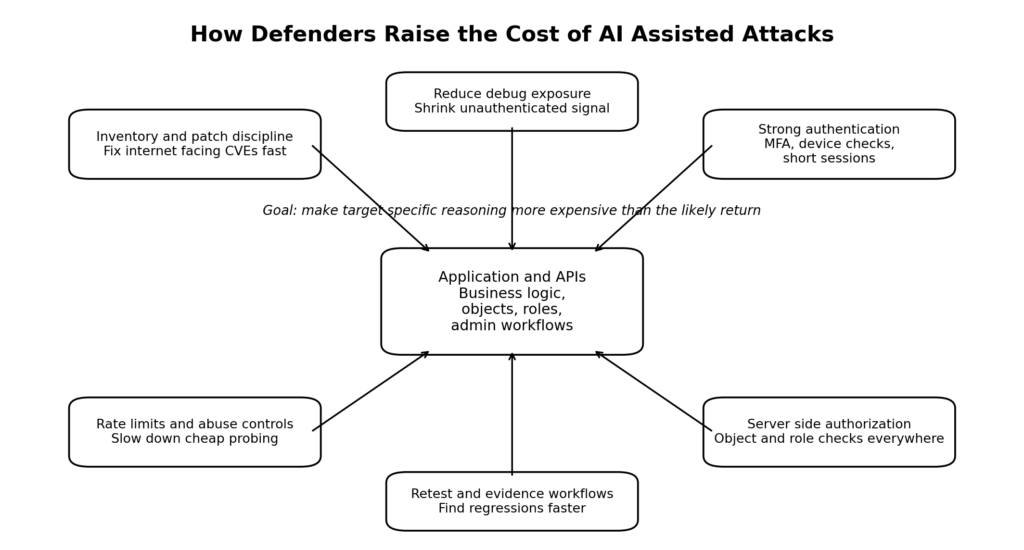
Même si le prix des modèles baissait demain, le piratage autonome entraînerait toujours des taxes cachées qui n'apparaissent pas dans une comparaison forfaitaire par jeton.
La première taxe est la ramification. Le travail de sécurité évolue rarement en ligne droite. Chaque paramètre inconnu, chaque rôle alternatif, chaque API cachée ou chaque transition d'état étrange crée une nouvelle branche. Un embranchement n'est pas simplement un autre achèvement. C'est une nouvelle occasion de recharger le contexte, de rééditer les appels d'outils, de rassembler des artefacts et, plus tard, d'expliquer pourquoi la branche a eu de l'importance ou n'en a pas eu. Les dommages économiques causés par les branches sont amplifiés par le fait que nombre d'entre elles échouent tardivement.
La deuxième taxe est la friction entre les cibles. MFA, CAPTCHA, device binding, short session lifetimes, signed requests, rate limits, and anti-bot controls all push the attacker away from a cheap generic loop and towards more expensive per-target adaptation. C'est l'une des raisons pour lesquelles le Top 10 de l'OWASP sur la sécurité des API est utile d'un point de vue économique. Le BOLA est souvent facile à repérer, mais il a toujours besoin d'un état correct et d'un traitement des objets pour être validé. La consommation illimitée de ressources et les flux commerciaux sensibles rappellent que la structure de la cible influe sur l'économie de l'abus. (owasp.org)
La troisième taxe est la friction entre les fournisseurs dans les environnements hébergés. La documentation actuelle d'Anthropic sur les limites de taux indique que l'utilisation de l'API de Claude est régie par des limites de dépenses et des limites de taux, et sa documentation sur les agents gérés expose des plafonds de demande distincts pour les opérations de création et de lecture. Cela ne rend pas les abus impossibles, et les attaquants sérieux peuvent s'auto-héberger ou répandre l'utilisation. Mais cela signifie que l'infrastructure des agents hébergés n'est pas sans friction. La plateforme elle-même impose des garde-fous économiques et opérationnels. (plateforme.claude.com)
Une déduction technique raisonnable en découle. Les agents hébergés du modèle de la frontière sont actuellement mal adaptés aux abus aveugles à l'échelle de l'internet parce qu'ils combinent un coût de fonctionnement non nul avec des contrôles externes des tarifs et des dépenses. Les modèles ouverts et auto-hébergés suppriment certains de ces contrôles, mais l'opérateur doit alors payer ailleurs : le temps du GPU, l'infrastructure, l'effort d'intégration, la qualité du modèle et la fiabilité de l'outil. La facture se déplace. Elle ne disparaît pas.
Un garde-fou budgétaire est un contrôle de sécurité, pas seulement un contrôle financier
Les équipes d'IA pentesting les plus fortes traitent de plus en plus la politique budgétaire comme une partie de la politique d'exécution. Il ne s'agit pas seulement d'une préoccupation financière. Il s'agit également d'une question de qualité, car un flux de travail qui est autorisé à brûler des branches sans fin est souvent un flux de travail qui n'a pas appris à s'arrêter.
politique d'exécution :
scope_lock : true
max_input_tokens_per_run : 2500000
max_output_tokens_per_run : 400000
max_web_search_calls : 20
max_container_sessions : 12
max_retry_depth : 3
max_parallel_branches : 4
require_human_review_for :
- escalade_du_privilège
- actions_de_changement_d'état
- rétroactions_externes
- tests_destructifs
conditions d'arrêt :
- résultats_non_déterministes_répétés
- dérive_de_l'authentification_non_résolue
- confiance_inférieure_au_seuil
- coût_par_recherche_validée_dépasse_le_budget
La logique d'une telle politique s'aligne sur les données plus générales du marché. OpenAI et Anthropic fixent toutes deux séparément le prix de l'utilisation des modèles et des outils. Anthropic documente séparément les limites de dépenses et les limites de taux des agents gérés. L'outil de sécurité IA de PortSwigger permet à l'opérateur de garder le contrôle et rend l'activation explicite. Les produits matures dans ce domaine continuent de converger vers la même leçon : un contrôle plus strict de l'utilisation des outils n'est pas une restriction de la valeur. C'est souvent ce qui protège la valeur. (openai.com)
Ce que les défenseurs doivent faire face à cette réalité économique
La leçon à tirer pour la défense n'est pas que l'offensive de l'IA est surestimée. Il s'agit plutôt d'optimiser les attaques qui deviennent moins chères et d'augmenter les coûts partout ailleurs.
Commencez par les surfaces qui sont déjà peu coûteuses à exploiter à grande échelle. Les plans de gestion orientés vers l'Internet, les appliances de transfert de fichiers, les passerelles VPN, les bibliothèques largement déployées et les flux d'administration accessibles de l'extérieur sont les domaines où l'automatisation standardisée l'emporte. Les exemples de CVE ci-dessus ne sont pas des curiosités historiques. Ils illustrent ce que les défenseurs continuent de sous-estimer. Si une faille est accessible à distance, de grande valeur et reproductible, on peut supposer que les attaquants n'ont pas besoin d'un agent général coûteux pour la monétiser. (nvd.nist.gov)
Ensuite, regardez les cibles pour lesquelles l'IA est utile. Le contrôle d'accès défaillant, BOLA, l'utilisation abusive d'API authentifiées, les flux commerciaux sensibles et la dérive des permissions sont tous suffisamment difficiles pour résister à l'automatisation naïve et suffisamment courants pour justifier des tests structurés assistés par l'IA. Les documents actuels de l'OWASP le montrent clairement. Le contrôle d'accès défaillant reste la première catégorie du Top 10 de l'OWASP, et le Top 10 de la sécurité des API est toujours en tête avec BOLA parce que les identificateurs d'objets sont faciles à manipuler pour les attaquants et faciles à sous-protéger pour les développeurs. Si l'IA aide les attaquants et les défenseurs à raisonner plus rapidement sur ces conditions, la vitesse de vérification fait partie de l'avantage en matière de sécurité. (owasp.org)
C'est pourquoi les nouveaux tests vérifiés sont si importants. Les équipes de sécurité n'ont pas seulement besoin de plus de résultats. Elles ont besoin de moins de résultats ambigus, d'une confirmation plus rapide de l'impact réel et de tests de régression moins coûteux après les changements. Un flux de travail capable de rejouer une attaque, de prouver que le bogue existe toujours et de conserver les preuves l'emporte généralement sur un flux de travail qui se contente de générer plus de prose sur les problèmes possibles.
Du point de vue de la conception, les meilleures mesures défensives augmentent souvent les exigences de contexte spécifiques à l'attaquant. Une séparation plus stricte des rôles, des sessions de plus courte durée, de meilleurs contrôles d'autorisation des objets, des inventaires d'actifs plus propres, une exposition réduite au débogage, des fonctions d'administration délimitées et des limites de débit significatives augmentent la quantité de raisonnement spécifique à la cible qu'un attaquant doit effectuer. Cela ne rend pas les attaques impossibles. Cela les rend moins économiques.
Le signal du marché provenant des données de sécurité de l'IA n'est pas du confort, c'est de la compression
Le rapport de HackerOne faisant état d'une croissance rapide des rapports de vulnérabilité valides en matière d'IA ne doit pas être considéré comme la preuve que tout le travail offensif devient autonome. Il faut plutôt y voir la preuve que la surface d'attaque s'étend et que la distance entre la recherche et la soumission se réduit. Le rapport 2026 de Bugcrowd indique que l'IA aide déjà les chercheurs à couvrir plus de terrain et à produire de meilleurs rapports pour le même budget. Il s'agit là de signaux de compression. Il y a plus de travail par unité d'effort humain. Cela revêt une importance stratégique, même si personne n'a construit une machine à pirater universelle et bon marché. (HackerOne)
C'est également la raison pour laquelle le débat public est souvent confus. D'un côté, on dit que l'offensive de l'IA est surestimée parce qu'elle ne pirate pas tout de manière autonome. L'autre affirme que l'IA offensive est sous-estimée parce qu'elle rend déjà les chercheurs plus rapides. Les deux ont en partie raison. L'erreur est de les considérer comme une seule et même revendication. L'IA ne se généralise pas encore à peu de frais à l'ensemble de l'internet, et l'IA modifie déjà l'économie de la validation de grande valeur. Les deux peuvent être vraies en même temps.
Les prochaines années ne ressembleront pas à un chaos autonome et libre
L'avenir le plus plausible à court terme n'est pas le chaos autonome et libre. Il est plus ciblé, plus économique et plus structuré que cela.
Il est clair que la recherche progresse. Shell or Nothing indique que les systèmes actuels ont encore du mal à obtenir des shells dans des conditions réalistes, mais aussi qu'une meilleure architecture d'agents peut réduire le temps et le coût financier et fonctionner sur des déploiements à l'échelle d'un ordinateur portable. Les produits des fournisseurs évoluent vers une infrastructure d'agents de premier ordre, une utilisation plus riche des outils, des contextes plus longs et une capacité de paiement plus élevée. Les outils de sécurité évoluent vers une validation assistée par l'IA plutôt que vers un théâtre de l'IA. Ces tendances n'indiquent pas un monde où l'IA n'est pas pertinente. Elles indiquent un monde où la marge se situe au niveau de la conception du système, de la discipline de vérification et du contrôle des coûts. (arXiv)
C'est pourquoi la question la plus importante en matière de sécurité offensive est d'ordre économique et non mystique. Le système peut-il convertir un contexte coûteux en signal vérifié de manière suffisamment économique pour justifier son utilisation continue ? Pour les flux de travail limités de grande valeur, la réponse est déjà oui assez souvent pour que cela compte. Pour les compromis autonomes sans discernement à l'échelle de l'internet, la réponse est encore non, assez souvent pour que cela ait autant d'importance.
La conséquence pratique est simple. Les défenseurs devraient moins s'inquiéter d'une vision de science-fiction où l'IA libre piraterait tout et partout que d'un changement très réel déjà en cours : L'IA rend moins coûteuse la transformation d'une reconnaissance désordonnée en pistes d'attaque plausibles, moins coûteuse la validation des résultats probables en matière de sécurité, moins coûteuse la réalisation de nouveaux tests après les changements et moins coûteuse la transformation des preuves en résultats exploitables. C'est plus qu'il n'en faut pour modifier l'équilibre du travail de sécurité.