La comparaison de StackHawk du 26 mars 2026 a mis le doigt sur un point important. Le pentesting par l'IA n'est pas la même chose que le DAST par la gauche. L'article compare Horizon3.ai, PentestGPT, Penligent, HackerAI et XBOW, puis positionne explicitement StackHawk comme la couche d'exécution continue qui complète les évaluations plus approfondies au lieu de les remplacer. Ce cadrage est utile, car une trop grande partie de ce marché est encore aplatie dans un seau paresseux d'"outil de sécurité IA" qui cache ce que ces produits font réellement. (StackHawk, Inc.)
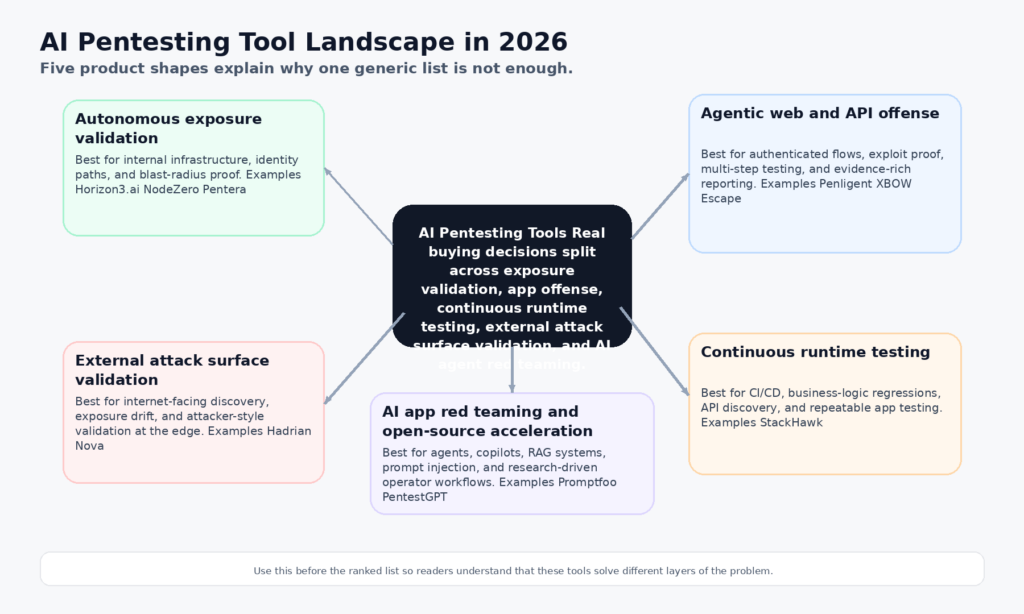
Elle est également incomplète. D'ici avril 2026, toute personne qui évalue sérieusement les outils de pentesting de l'IA ne choisit plus dans une seule catégorie. Ils comparent plusieurs formes de produits à la fois : validation autonome de l'infrastructure, attaque agentique du web et des API, tests d'exécution CI/CD avec couverture de la logique métier, validation continue de l'exposition externe, équipe rouge d'application d'IA et accélération de l'opérateur open-source. Horizon3.ai, Penligent, XBOW, Escape, Pentera, Aikido, StackHawk, Hadrian, Promptfoo et PentestGPT font tous partie de la même conversation d'achat, mais ils ne résolvent pas le même problème. (Horizon3.ai)
Cette différence est plus importante en 2026 qu'elle ne l'était il y a un an. La ligne utile n'est plus "utilise-t-elle l'IA", mais "peut-elle raisonner sur l'état de l'application ? Il s'agit de savoir s'il peut raisonner sur l'état de l'application, prouver l'exploitabilité en toute sécurité, préserver une chaîne de preuves et s'adapter à la manière dont vos équipes d'ingénierie et de sécurité travaillent réellement. Certains outils sont plus performants lorsqu'ils émulent un attaquant dans une infrastructure active. D'autres sont plus performants lorsqu'ils attaquent des flux web authentifiés. Certains sont plus performants lorsqu'ils fonctionnent en continu en CI/CD. Certains sont destinés aux agents d'intelligence artificielle et aux systèmes RAG plutôt qu'aux piles web classiques. Les acheteurs qui ignorent ces limites finissent par choisir le mauvais outil, même si la démo semble impressionnante.
Les points forts et les points faibles de la comparaison StackHawk
La partie la plus intéressante de l'article de StackHawk est la séparation entre les tests offensifs périodiques et plus profonds et les tests d'exécution continus à proximité des développeurs. Les pages produits de StackHawk renforcent ce point : sa plateforme met l'accent sur la découverte d'API à partir de référentiels sources, les tests de logique métier pour BOLA et BFLA, et les tests de sécurité LLM à l'intérieur des analyses DAST existantes en CI/CD. Il s'agit là d'un modèle opérationnel très différent de celui d'une plateforme conçue pour passer de manière autonome de la découverte à la validation des exploits sur une cible vivante. (StackHawk, Inc.)
L'écart se situe au niveau de l'étendue. L'article de StackHawk est intentionnellement étroit. Il met en avant cinq outils nommés, puis ajoute StackHawk comme couche continue. Cela laisse de côté plusieurs plates-formes qui comptent désormais dans les évaluations réelles : Escape pour les tests Web et API axés sur l'exploitabilité, Pentera pour la validation déterministe de l'exposition avec une nouvelle interface en langage naturel, Aikido pour les chemins d'attaque à travers le code, le nuage et le temps d'exécution, Hadrian pour la validation de l'exposition externe 24/7 et sa nouvelle couche de pentesting agentique Nova, et Promptfoo pour les applications et les agents d'intelligence artificielle en équipe rouge. Ces omissions ne rendent pas l'article de StackHawk erroné. Elles le rendent insuffisant en tant que plan d'achat pour 2026. (StackHawk, Inc.)
Les catégories qui définissent les outils de pentesting de l'IA en 2026
La première catégorie est celle de la validation autonome de l'exposition. NodeZero et Pentera en sont les exemples les plus clairs. Leurs documents publics s'articulent autour de chemins d'attaque éprouvés, de preuves d'exploitation, d'impact et de vérification après remédiation. Cela les rend particulièrement efficaces dans les environnements où il ne s'agit pas simplement de "trouver un bogue", mais de montrer comment un attaquant passe d'un point d'ancrage à un impact commercial significatif. (Horizon3.ai)
La deuxième catégorie est celle des offensives agentiques sur le web et les API. Penligent, XBOW et Escape se situent dans cette catégorie, bien que chacun s'oriente différemment. Le produit public de Penligent met l'accent sur le pentesting AI de bout en bout, de la découverte des actifs à la validation, sur plus de 200 outils à la demande et sur des exportations PDF ou Markdown riches en éléments de preuve. XBOW met l'accent sur les agents autonomes et les validateurs déterministes, de sorte que les résultats n'apparaissent qu'après une validation contrôlée. Escape met l'accent sur la preuve d'exploitabilité, les chaînes d'attaque en plusieurs étapes et les rapports faciles à élaborer pour les applications et les API modernes. (penligent.ai)
La troisième catégorie est celle des tests d'exécution continus intégrés au développement. StackHawk appartient à cette catégorie. Ses documents publics indiquent explicitement qu'il cartographie les applications et les API à partir du code source, qu'il automatise les tests d'autorisation multi-utilisateurs pour BOLA et BFLA, et qu'il teste cinq problèmes du Top 10 de l'OWASP LLM dans le cadre des analyses DAST existantes. Cela le rapproche davantage d'une couche de sécurité continue que d'un opérateur offensif autonome. (StackHawk, Inc.)
La quatrième catégorie est la validation de la surface d'attaque externe. Le positionnement public d'Hadrian s'articule autour du pentesting agentique sur la surface d'attaque externe, avec une découverte continue, une validation de type attaquant et une couche Nova nouvellement lancée pour des tests autonomes en profondeur. Il ne s'agit pas du même problème que le pentesting de la logique commerciale authentifiée dans l'application, mais il s'agit d'une catégorie réelle et de plus en plus précieuse pour les organisations tournées vers l'Internet. (hadrian.io)
La cinquième catégorie est celle du red teaming des applications d'IA et de l'accélération des opérateurs open-source. Promptfoo appartient à la première moitié de cette phrase, avec une couverture publique de l'injection rapide, de l'exfiltration de données et de plus de 50 types de vulnérabilités pour les systèmes d'IA. PentestGPT appartient à la seconde moitié, avec un cadre agentique open-source qui reste très pertinent pour les chercheurs individuels, les laboratoires et les équipes qui veulent composer leurs propres flux de travail plutôt que d'acheter une plateforme d'entreprise. (promptfoo.dev)
Classement des 10 meilleurs outils de pentesting IA
Le classement ci-dessous n'est pas un concours de beauté ni une liste de ceux qui parlent le plus fort d'"agentivité". Il donne plus de poids à six éléments qui changent réellement les résultats.
La première est la preuve. Une plateforme utile devrait réduire la distance entre un problème plausible et les preuves auxquelles un ingénieur en sécurité peut se fier. Le second est la connaissance de l'état. L'autorisation, le traitement des sessions, les relations entre les objets, l'enchaînement des tâches et les possibilités de suivi sont plus importants que la génération de charges utiles génériques dans les applications modernes. Le troisième est le contrôle de l'opérateur. Les systèmes autonomes ont besoin de garde-fous, d'étapes de validation et d'un moyen d'arrêter ou de façonner l'exécution. Le quatrième est la fidélité des rapports. Les preuves, les étapes de reproduction et le transfert des mesures correctives sont importants, car les résultats ne deviennent réels que lorsque l'ingénierie les accepte. Le cinquième est l'adéquation au déploiement. Un outil peut être excellent pour les tests d'exécution CI/CD et ne pas être le bon choix pour la validation de l'exposition externe. Le sixième est la clarté du produit public. En 2026, c'est important car de nombreux fournisseurs cachent encore la tarification, la portée ou la forme réelle du flux de travail derrière un langage vague.
Ces critères expliquent pourquoi Horizon3.ai reste en tête, et pourquoi Penligent se classe en deuxième position tout en ayant certains des avantages les plus importants en matière de flux de travail quotidien dans ce domaine.
Les 10 meilleurs outils de pentesting IA en 2026
| Rang | Outil | Catégorie primaire | Meilleure adéquation | Pourquoi il se classe ici | Preuves |
|---|---|---|---|---|---|
| 1 | Horizon3.ai NodeZero | Validation autonome de l'exposition | Validation par les entreprises de l'infrastructure, de l'identité et des voies d'attaque | L'accent public le plus fort est mis sur la vérification du cheminement, de la preuve, de l'impact et de la remédiation, ainsi que sur la maturité du pentesting autonome. | (Horizon3.ai) |
| 2 | Penligent | Flux de travail offensif agentique | Les équipes veulent un seul système, de la découverte à la validation et à l'exportation des rapports. | Large flux de travail public, de la découverte des actifs à la validation, plus de 200 outils, exportation de preuves et rapports en un seul clic. | (penligent.ai) |
| 3 | XBOW | Sécurité offensive autonome | Tests offensifs d'applications web profondes avec proof gates | La validation non destructive contrôlée et les validateurs déterministes lui confèrent une grande crédibilité. | (xbow.com) |
| 4 | S'évader | Pentesting de l'IA sur le web et les API | Applications modernes à base d'API et à forte composante d'authentification | La preuve de l'exploitabilité, les chaînes à plusieurs étapes et les rapports axés sur l'ingénierie sont des points forts. | (escape.tech) |
| 5 | Pentera | Validation de la sécurité par l'IA | Validation de l'exposition des grandes entreprises et tests de contrôle | Une histoire de validation déterministe forte, des chemins d'attaque validés et des conseils en langage naturel dans Pentera 8 | (Pentera) |
| 6 | L'attaque de l'Aïkido | Pentesting de l'IA à travers le code et le nuage | Les équipes qui veulent des graphes d'attaque à travers le code, les conteneurs, le cloud et l'exécution. | Un bon positionnement public autour des voies d'attaque réelles et de la validation des correctifs, en mettant l'accent sur les tests en lecture seule. | (Sécurité de l'aïkido) |
| 7 | StackHawk | Tests d'exécution en continu | Les équipes qui ont besoin de tests de sécurité et de logique d'entreprise en mode d'exécution natif CI/CD | Excellente couche continue pour les tests BOLA, BFLA, API discovery et LLM, mais pas une plateforme offensive autonome complète. | (StackHawk, Inc.) |
| 8 | Hadrian Nova | Validation de l'exposition externe | Organisations axées sur la dérive de l'exposition à l'internet | Fort d'une découverte et d'une validation externes continues, avec la nouvelle couche de pentesting de Nova | (hadrian.io) |
| 9 | Promptfoo | L'équipe d'application de l'IA | Équipes sécurisant les agents, les copilotes, les applications RAG et LLM | L'une des meilleures plateformes spécialisées dans les tests d'abus d'IA agentique, et non dans le pentesting classique de réseaux ou de sites web. | (promptfoo.dev) |
| 10 | PentestGPT | Accélération de l'opérateur en source ouverte | Chercheurs, laboratoires et équipes de sécurité soucieuses de leur budget | Forte dynamique des logiciels libres et valeur du flux de travail agentique, mais encore moins régi que les plates-formes d'entreprise | (GitHub) |
Pourquoi Horizon3.ai se place en tête
NodeZero semble toujours être le choix global le plus sûr pour les organisations qui veulent un pentesting autonome avec le moins de sauts conceptuels possible. Le langage de sa plateforme publique s'articule autour de trois mots importants : chemin, preuve et impact. Horizon3.ai affirme que les clients bénéficient d'une visibilité sur les chemins d'attaque prouvés, de résumés étape par étape, de preuves d'exploitation, de recommandations d'atténuation et de vérification des correctifs. Les documents publics montrent également que l'entreprise étend cette même philosophie au pentesting autonome des applications web, bien que le mouvement des applications web soit encore présenté comme étant en accès anticipé. Cette combinaison de maturité dans la validation de l'exposition et de clarté dans le cadrage des preuves est la raison pour laquelle elle reste en tête. (Horizon3.ai)
La raison pour laquelle NodeZero ne remporte pas tout simplement la catégorie est la forme du champ d'application. L'histoire publique est la plus forte autour du pentesting et de la validation autonomes, et non autour d'un banc d'essai offensif plus large contrôlé par l'opérateur. Cette distinction est importante car de nombreuses équipes en 2026 veulent plus que "me dire quel chemin a fonctionné". Elles veulent aussi une orchestration multi-outils, un workflow flexible, et un transfert serré de la découverte à l'artefact de preuve et au rapport. C'est dans cet espace que Penligent devient particulièrement intéressant.
Pourquoi Penligent se classe en deuxième position et se distingue encore
Penligent se classe en deuxième position, mais ses avantages en termes de flux de travail sont parmi les plus clairs du marché. Les pages publiques du produit indiquent qu'il est conçu pour le pentesting AI de bout en bout, de la découverte des actifs à la validation, avec une cartographie automatisée de la surface d'attaque, un sondage de base, plus de 200 outils de pentest à la demande et des rapports PDF ou Markdown exportables avec des preuves et des étapes de reproduction. La page d'accueil met également en avant un flux de travail offensif en trois étapes que de nombreuses équipes souhaitent réellement : trouver des vulnérabilités, vérifier les résultats, exécuter des exploits, suivis de rapports en un clic alignés sur SOC 2 et ISO 27001. La forme de ce produit public est exceptionnellement cohérente. (penligent.ai)
Cette cohérence est la raison pour laquelle Penligent se situe au-dessus de XBOW, Escape, Pentera et de la plupart des autres concurrents dans ce classement. XBOW a une histoire de preuve et de validation très forte. Escape est fort dans les tests d'applications modernes. Pentera est fort en validation d'entreprise. Mais les documents publics de Penligent combinent plus d'éléments du flux de travail offensif pratique en un seul endroit : découverte, accès aux outils, validation, exécution d'exploits, exportation de preuves et rapports formatés. En d'autres termes, il s'agit moins d'un moteur à usage unique que d'une table de travail. (penligent.ai)
Un autre avantage réel est la friction de l'évaluation. Penligent expose une page de tarification publique et un niveau d'entrée à coût zéro avec le flux de travail de base, ce qui est encore peu commun parmi les plates-formes de pentesting agentique d'entreprise. Cela ne prouve pas qu'elle soit meilleure. Il est plus facile pour les praticiens de tester le flux de travail réel au lieu d'acheter une démo narrative. Pour les ingénieurs qui se préoccupent de savoir si le système peut produire des preuves utilisables et des rapports reproductibles, ce type de validation à faible friction est important.
La raison pour laquelle elle n'occupe pas la première place est le signal de maturité. Horizon3.ai dispose de l'historique public le plus clair concernant les chemins d'attaque éprouvés et la vérification de la remédiation à l'échelle de l'entreprise. Le flux de travail public de Penligent est plus large et, d'une certaine manière, plus attrayant pour les équipes de terrain, mais le marché a encore moins de références publiques indépendantes et tierces autour de lui qu'autour des titulaires plus anciens de la validation de l'exposition. Cette différence n'est pas anodine. C'est la différence entre "ceci semble être l'expérience la plus complète pour l'opérateur" et "ceci est le défaut le moins risqué à l'échelle de l'entreprise".
Les arguments en faveur de XBOW en troisième position
XBOW est l'un des outils les plus pointus du marché lorsqu'il s'agit d'attaquer les applications de manière autonome et en profondeur. La page officielle de sa plateforme est d'une précision rafraîchissante : les résultats ne sont révélés qu'après confirmation de l'exploitabilité par des défis contrôlés et non destructifs, et le système combine des agents autonomes, des validateurs déterministes et un véritable outil offensif pour les grands environnements de production. C'est exactement le genre de langage que les acheteurs de sécurité devraient récompenser, parce qu'il éloigne la discussion du risque théorique et l'oriente vers des preuves contrôlées. (xbow.com)
XBOW se classe ici en dessous de Penligent parce que la forme du produit public semble plus étroite. Ce n'est pas une critique. La spécialisation est souvent une force. Mais si le facteur décisif est l'exhaustivité du flux de travail public de bout en bout à travers la découverte, l'orchestration d'outils larges, la validation et le transfert de preuves, Penligent a le profil public le plus large aujourd'hui. Si le facteur décisif est de savoir si vous voulez un spécialiste de l'offense autonome très concentré avec des portes de preuve strictes, XBOW mérite une attention très sérieuse.
Escape fait partie des meilleurs pour les tests modernes de sites web et d'API
Escape est l'un des produits les plus robustes de ce comparatif pour les équipes qui vivent au sein d'applications web modernes, d'API, de SPA et de flux authentifiés complexes. Sa page officielle de pentesting AI met l'accent sur les évaluations continues alimentées par l'IA, les preuves d'exploitabilité, les chaînes d'attaques agentiques en plusieurs étapes et les rapports que les auditeurs et les ingénieurs utiliseront. Ce langage correspond à l'endroit où se situe la vraie douleur en 2026 : l'écart entre les résultats d'un scanner et les résultats auxquels l'ingénierie fait suffisamment confiance pour les classer par ordre de priorité. (escape.tech)
Escape se situe légèrement en dessous de XBOW et Penligent parce que son positionnement public est plus centré sur les applications que sur l'orchestration de flux de travail offensif à large spectre ou la validation à l'échelle de l'entreprise. Pour une entreprise ayant une forte empreinte API, cette limitation peut être exactement ce qui la rend attrayante. Une plateforme ciblée est souvent plus facile à mettre en œuvre qu'une plateforme qui s'adresse à tous les acheteurs.
Pentera reste une plateforme d'entreprise sérieuse
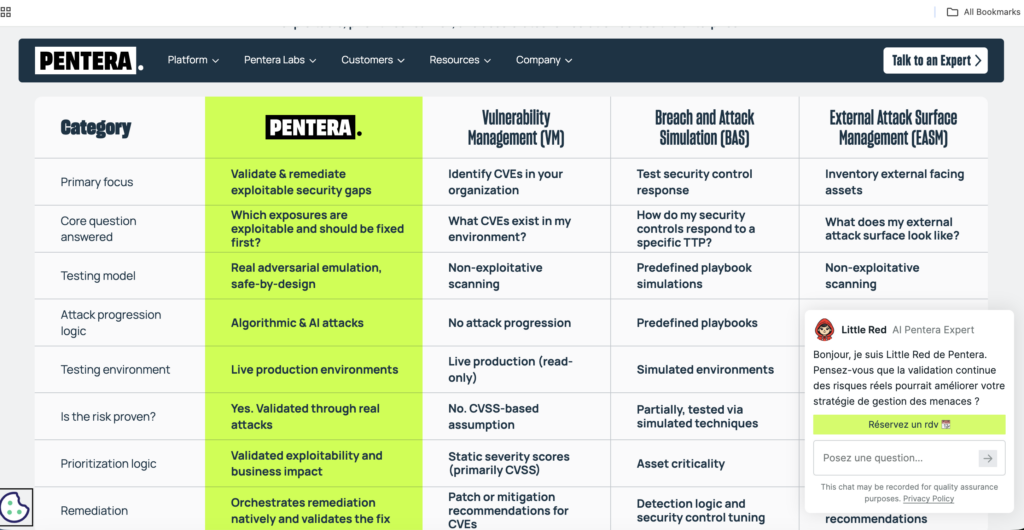
La plateforme de Pentera reste l'un des exemples publics les plus solides de validation de l'exposition fondée sur des voies d'attaque validées et des boucles de remédiation. Les documents officiels de la plateforme mettent l'accent sur la priorisation et la correction des voies d'attaque validées, puis sur un nouveau test pour confirmer la réduction mesurable de l'exposition. La page publique de la plateforme montre également des charges utiles générées par l'IA qui s'adaptent au contexte de l'application, de l'identité et des données découvertes. En mars 2026, Pentera a annoncé Pentera Peer dans Pentera 8, une interface en langage naturel qui permet aux utilisateurs de guider les tests contradictoires et d'interroger les chemins d'attaque validés de manière interactive tout en restant ancrés dans un moteur d'attaque déterministe. (Pentera)
Pentera se classe en dessous de Penligent parce qu'il ressemble davantage à une plateforme de validation qu'à un vaste outil de travail pour les opérateurs. C'est peut-être exactement ce qu'il faut pour de nombreuses entreprises. Une plateforme de validation est souvent ce que vous voulez lorsque le mandat est la réduction de l'exposition et les tests de contrôle plutôt que l'expérimentation offensive flexible. Mais si votre équipe souhaite une surface de travail offensive plus pratique, Penligent semble plus large d'après les preuves publiques.
Il est devenu difficile d'ignorer l'Aikido Attack
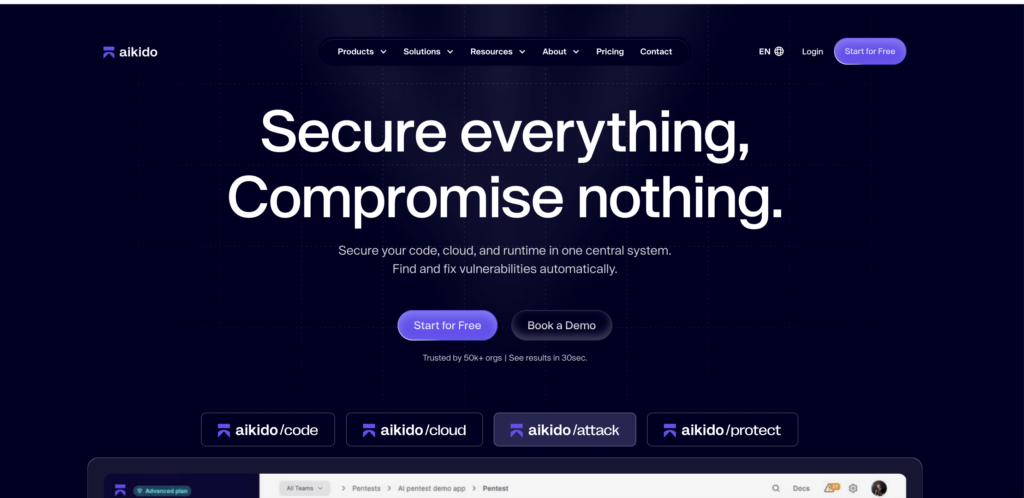
Le matériel public d'Aikido est remarquable car il tente de relier le code, le cloud, les conteneurs et le runtime en un seul graphe d'attaque. La page officielle du produit promet des pentests AI autonomes qui découvrent de véritables chemins d'attaque, valident les correctifs et fournissent des résultats rapidement, tout en mettant l'accent sur l'accès en lecture seule. Il montre alors les chemins d'attaque à travers le code et le nuage plutôt que des découvertes isolées au niveau de l'exécution. Cela rend Aikido pertinent pour les équipes qui veulent que la conversation sur les pentests soit connectée au reste de leur domaine d'ingénierie au lieu d'être piégée dans un produit ponctuel. (Sécurité de l'aïkido)
Aikido se classe derrière Pentera parce que le récit de la preuve publique n'est pas encore aussi éprouvé ou spécifique que les anciens titulaires de la validation. Il se classe au-dessus de StackHawk parce qu'il essaie de faire plus que des tests d'exécution continus. Pour les acheteurs qui souhaitent avoir une vision large et interconnectée des chemins d'attaque et qui sont à l'aise avec un mouvement plus récent, Aikido est l'un des ajouts les plus intéressants au champ de 2026.
StackHawk n'est pas un pentester autonome et c'est très bien ainsi.

StackHawk ne doit pas être considéré comme une tentative ratée de pentesting autonome. Ses documents publics parlent de quelque chose de différent et de plus pratique. Il cartographie les applications et les API à partir du code source, automatise les tests d'autorisation multi-utilisateurs pour trouver BOLA et BFLA, et exécute les tests de sécurité LLM dans le cadre des analyses DAST existantes en CI/CD. Il ne s'agit pas de fonctionnalités secondaires. Ce sont des réponses à un vrai problème : les pentests périodiques profonds sont précieux, mais ils ne protègent pas toutes les demandes d'extraction. (StackHawk, Inc.)
C'est la raison pour laquelle StackHawk se classe parmi les dix premiers, même s'il ne s'agit pas d'un pur "agent de pentest d'IA". Dans de nombreux programmes réels, c'est la couche continue qui empêche les développeurs de réintroduire exactement le type de failles que les outils offensifs plus lourds trouvent lors d'évaluations plus ciblées. Si votre objectif est de remplacer un flux de travail offensif de type humain, StackHawk n'est pas le premier choix. Si votre objectif est de combler le fossé entre les changements apportés aux applications et le retour d'information sur la sécurité d'exécution, il s'agit de l'un des produits les plus utiles sur le marché.
Hadrien est le plus fort au bord extérieur
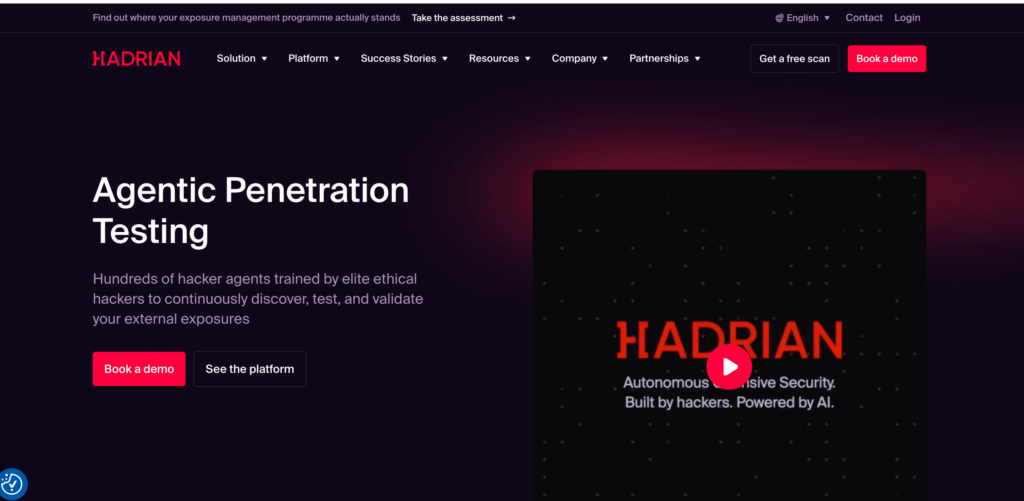
Le positionnement public d'Hadrien est clair. Il s'agit de la surface d'attaque externe. L'entreprise décrit maintenant sa plateforme comme un pentesting agentique à travers la périphérie externe, découvrant, testant et validant continuellement les expositions externes, et en mars 2026, elle a officiellement lancé Nova comme une solution de pentesting agentique pour des tests autonomes profonds dans la gestion de l'exposition externe. Cela rend Hadrian très pertinent pour les organisations où la plus grande question opérationnelle n'est pas "comment tester chaque flux de travail interne", mais "qu'est-ce qui vient d'être exposé, exploitable ou dérivé sur la surface orientée vers l'internet". (hadrian.io)
Hadrian se classe en dessous de StackHawk parce que son champ d'action est plus étroit et externe de par sa conception. Il se classe au-dessus de Promptfoo et de PentestGPT parce que la validation de l'exposition externe est une exigence de base du programme de sécurité pour de nombreuses organisations, et pas seulement une niche spécialisée. Si votre surface d'attaque change fréquemment et que la dérive de l'exposition publique est le risque principal, Hadrian mérite d'être beaucoup plus haut dans votre liste de sélection interne qu'il ne le serait dans un article générique sur les "meilleurs outils de pentesting AI".
Promptfoo est l'un des meilleurs outils pour les systèmes d'IA, pas pour les systèmes classiques.
Promptfoo a sa place dans cette conversation car le pentesting de l'IA ne signifie plus seulement "utiliser l'IA pour pentester des logiciels traditionnels". Cela signifie également "tester des systèmes d'IA qui peuvent agir". La page officielle de Promptfoo consacrée aux équipes rouges met l'accent sur les tests de sécurité dynamiques pour les applications d'IA, les équipes rouges agentiques adaptées au cas d'utilisation de l'application et la couverture de plus de 50 types de vulnérabilités, y compris l'injection rapide et l'exfiltration de données RAG. Cela en fait l'un des meilleurs outils spécialisés du marché pour sécuriser les agents utilisant des outils, les copilotes et les systèmes fondés sur la connaissance. (promptfoo.dev)
Promptfoo arrive en neuvième position parce qu'il ne s'agit pas d'un remplacement général pour le pentesting du web, de l'API, du cloud ou de l'infrastructure. Il est mieux compris comme le spécialiste le plus important de la liste. Les équipes qui développent des produits d'IA devraient probablement l'évaluer plus tôt que certains des outils généraux les mieux classés. Les équipes qui sécurisent une pile SaaS traditionnelle sans une surface d'IA significative peuvent ne pas en avoir besoin du tout.
PentestGPT reste le point de départ des logiciels libres
PentestGPT reste important parce qu'il représente la voie la plus accessible vers les tests offensifs agentiques pour de nombreux praticiens. Le référentiel officiel du projet met l'accent sur les tests de pénétration assistés par l'IA dans de multiples catégories, les visites en direct, l'architecture extensible et le retour d'information en temps réel sur l'activité. Sa version de décembre 2025 mettait également l'accent sur un pipeline de tests de pénétration agentique, un déploiement Docker et des rapports de référence. Cela ne le rend pas prêt pour l'entreprise dans le même sens que Horizon3.ai ou Pentera, mais cela le rend tout à fait pertinent. (GitHub)
Sa place en dixième position n'est pas un désaveu. Elle reflète la gouvernance, la maturité des rapports et l'adéquation opérationnelle. Dans de nombreux laboratoires, groupes de recherche et équipes de sécurité aux ressources limitées, PentestGPT peut être l'outil le plus utilisé de toute cette liste parce qu'il est ouvert, adaptable et proche de l'opérateur. Pour les acheteurs qui ont besoin de contrôles solides, d'un traitement prévisible des preuves et d'un transfert formel, les plates-formes commerciales ont toujours l'avantage.
Deux outils adjacents que vous devriez encore connaître
Burp AI mérite l'attention, même s'il ne fait pas partie de ce top 10. PortSwigger le positionne comme un outil de compréhension et d'automatisation alimenté par l'IA pour Burp Suite Professional, en commençant par l'analyse du contrôle d'accès brisé améliorée par l'IA et la prise en charge de l'extension via l'API Montoya. Cela rend Burp AI utile pour les testeurs pratiques qui vivent déjà dans Burp et veulent une accélération sans quitter leur flux de travail existant. Il ne s'agit toutefois pas d'une plateforme de test de pénétration entièrement autonome. (portswigger.net)
Le Codex Security mérite également l'attention en tant que catégorie voisine. L'aperçu de recherche d'OpenAI de mars 2026 indique qu'elle construit un contexte de projet approfondi, crée un modèle de menace modifiable, valide les résultats dans des environnements en bac à sable si possible et propose des correctifs avec un contexte spécifique au système. Cela est plus proche d'un agent de sécurité d'application de contexte de code que d'un pentester d'exécution offensive en direct, mais la direction de la validation en premier est importante parce qu'elle montre la direction que prend l'outil de sécurité de l'IA de manière plus générale. (OpenAI)
Qu'est-ce qui différencie un véritable flux de travail de pentest d'IA d'un scanner avec un chatbot ?
La première ligne de démarcation est l'état. Le Top 10 de la sécurité des API de l'OWASP place toujours les échecs d'autorisation au centre des risques liés aux API, et API3, dans l'édition 2023, encadre explicitement le problème autour de l'autorisation non respectée au niveau de la propriété de l'objet. Un outil qui ne peut pas raisonner sur les rôles, la propriété, les relations entre objets ou l'ordre des étapes passera à côté des vulnérabilités qui causent réellement des brèches dans les applications modernes. C'est pourquoi les tests de logique commerciale multi-utilisateurs de StackHawk sont importants, pourquoi l'accent mis par Escape sur l'exploitabilité est important, et pourquoi les plateformes qui parlent de preuve et de chemin sont plus intéressantes que les plateformes qui promettent simplement plus de résultats. (owasp.org)
La deuxième ligne de démarcation est la validation. Le modèle public de XBOW indique que l'IA découvre et que la logique valide. La plateforme publique de Pentera et l'annonce de Pentera Peer mettent l'accent sur un moteur d'attaque déterministe fondé sur des résultats validés. La plateforme publique de NodeZero met l'accent sur des voies d'attaque éprouvées et sur la vérification des correctifs. Le Codex Security d'OpenAI met l'accent sur les tests de pression en bac à sable pour distinguer le signal du bruit. Il s'agit là de différentes mises en œuvre de la même leçon : les résultats non validés de l'IA constituent une dette opérationnelle. (xbow.com)
La troisième ligne de démarcation est la qualité des preuves. Le travail d'Anthropic sur Firefox avec Mozilla est utile ici, non pas parce qu'il prouve qu'un modèle est magique, mais parce qu'il montre le centre de gravité du marché. Anthropic affirme que Claude Opus 4.6 a trouvé 22 vulnérabilités dans Firefox en février 2026, et Mozilla affirme que la collaboration a mis en évidence 90 bogues supplémentaires, avec des erreurs de logique que le fuzzing traditionnel n'avait pas découvertes auparavant. La conclusion est simple : "L'IA peut trouver des bogues" n'est plus la norme. Le critère est de savoir si le système peut mettre en évidence des résultats significatifs, réduire le bruit et soutenir une boucle de correction et de vérification. (anthropic.com)
La quatrième ligne de démarcation est de savoir si l'outil comprend que les systèmes d'IA eux-mêmes font désormais partie de la surface d'attaque. Le Top 10 de l'OWASP pour les applications agentiques en 2026 officialise ce changement, en traitant les systèmes d'IA autonomes et utilisant des outils comme un problème de sécurité distinct. Promptfoo existe parce que tester un agent RAG pour l'injection de prompt ou l'utilisation abusive d'outils n'est pas le même problème d'ingénierie que tester une API React ou Java classique pour IDOR ou SSRF. Les acheteurs qui les regroupent dans un même panier finissent généralement par acheter trop dans un endroit et par ne pas assez tester dans un autre. (Projet de sécurité Gen AI de l'OWASP)
Trois modèles de vulnérabilité récents qui mettent en évidence les faiblesses des tests d'intelligence artificielle
Le contournement de l'autorisation de Next.js montre l'importance des tests d'authentification
CVE-2025-29927 est un exemple clair de l'importance de l'état et du contexte d'autorisation. NVD indique qu'avant les versions corrigées, les contrôles d'autorisation dans l'intergiciel Next.js pouvaient être contournés, et recommande spécifiquement de bloquer les requêtes externes portant la balise x-middleware-subrequest si l'application d'un correctif est impossible. Ce n'est pas le genre de problème qu'un "scanner d'IA" superficiel peut détecter de manière fiable en lançant des charges utiles génériques sur les points de terminaison. Un outil utile doit comprendre comment l'autorisation est appliquée, où se trouve cette application, et comment le comportement de la demande change le long du chemin de contrôle. (nvd.nist.gov)
Cette vulnérabilité nous rappelle également que les tests de logique d'entreprise ne sont pas simplement une étiquette plus agréable pour les DAST. Il s'agit d'un problème de test différent. Si votre plateforme ne peut pas modéliser le contexte de l'utilisateur, le comportement du bord et les flux spécifiques au rôle, elle sera plus forte sur les résultats faciles et plus faible sur les questions sur lesquelles les équipes d'ingénieurs discutent réellement.
React Server Components RCE montre l'importance d'une validation sûre et d'un re-test rapide
L'avis de décembre 2025 de Next.js pour CVE-2025-66478 décrivait une vulnérabilité critique dans le protocole React Server Components qui pourrait conduire à l'exécution de code à distance lors du traitement de requêtes contrôlées par un attaquant dans des environnements App Router non corrigés. L'avis listait les versions corrigées et indiquait qu'il n'y avait pas d'autre solution que la mise à jour. C'est exactement le type de problème pour lequel un flux de travail moderne de pentesting de l'IA devrait exceller après la divulgation : inventorier rapidement les systèmes affectés, valider en toute sécurité, documenter l'impact et soutenir les nouveaux tests immédiatement après le déploiement du correctif. (nextjs.org)
La leçon pratique est que l'outil que vous choisissez doit avoir un bon mode de fonctionnement après la divulgation, et pas seulement un mode de découverte tape-à-l'œil. C'est là que les plateformes axées sur la validation sont généralement plus performantes que les outils axés sur le dialogue en ligne. Une fois qu'un avis de haute sévérité tombe, la question est rarement "pouvez-vous m'expliquer le bogue". La question est "pouvez-vous me dire si cette instance est accessible, exploitable et corrigée maintenant".
Le cluster Veeam de mars 2026 montre pourquoi les chaînes d'attaques sont plus efficaces que les résultats isolés.
L'avis de Veeam du 12 mars 2026 est un bon exemple d'entreprise car il ne décrit pas un problème isolé. Il décrit de multiples failles sérieuses dans Backup and Replication 12.3.2.4165 et les versions antérieures de la version 12, y compris deux RCE d'utilisateurs de domaine authentifiés, la manipulation arbitraire de fichiers sur un référentiel de sauvegarde, l'élévation locale de privilèges sur des serveurs Windows, et un chemin d'accès de la visionneuse de sauvegarde à un RCE en tant qu'utilisateur de la version 12 de Backup and Replication. postgres l'utilisateur. Il s'agit là d'un problème de chaîne d'attaque, et non d'un problème de case à cocher de scanner. (Veeam Software)
C'est précisément la raison pour laquelle des plateformes telles que NodeZero et Pentera continuent d'obtenir de si bons résultats dans les environnements d'entreprise. Lorsque le risque est une séquence d'actions valides se déplaçant à travers des privilèges réels et des limites de confiance, la valeur réside dans la démonstration du chemin et de l'impact, puis dans la vérification de la correction. Le volume de recherche pur est une distraction à ce niveau.
Construire un pipeline de pentesting d'IA basé sur les preuves
Un pipeline de pentest IA utile commence toujours par une discipline en matière de champ d'application et d'environnement. La différence en 2026, c'est que les meilleurs systèmes se chargent d'une plus grande partie du travail mécanique entre ces deux étapes.
# 1. Reconnaissance en fonction de la portée
nmap -sV -Pn target.example.com -oA recon/target
httpx -json -l assets.txt -o recon/http.json
# 2. Normaliser les actifs et le contexte d'authentification
python build_target_context.py \N- --hosts recon/target_context.py
--hosts recon/target.xml \N- --http recon/http.json
--http recon/http.json \N-roles auth/roles.json \N-roles auth/roles.json
--roles auth/roles.json \N--Context/target_context.xml
> context/target-context.json
# 3. Génération de problèmes pour les candidats
python run_agentic_tests.py \N- --context context/target-context.json \N--context.json
--context context/target-context.json \N --mode safe-validation \N
--mode safe-validation \N--mode safe-validation \N--mode safe-validation \N--mode safe-validation
--out findings/raw.json
# 4. approbation humaine avant validation approfondie
python review_gate.py findings/raw.json findings/approved.json
# 5. Collecte contrôlée de preuves
python collect_artifacts.py \N-approved findings/approved.json
--approved findings/approved.json \N--mise à jour des preuves
--out evidence/
# 6. Génération de rapports
python render_report.py \N--Modification du rapport
--evidence evidence/ \N- --format markdown
--format markdown \N
--out reports/final.md
Ce qui importe dans ce flux de travail, ce ne sont pas les noms de fichiers exacts. Ce qui compte, c'est la structure. La reconnaissance est distincte du raisonnement. Le raisonnement est distinct de la validation approfondie. La validation est distincte de la collecte d'artefacts. La collecte d'artefacts est séparée du rapport. Cette séparation rend le système plus sûr, rend les résultats plus reproductibles et donne aux évaluateurs humains la possibilité d'intervenir avant que la plateforme ne passe du statut de "signal intéressant" à celui d'"allégation significative sur le plan opérationnel".
C'est également la raison pour laquelle les produits les plus performants sur ce marché convergent toujours vers les mêmes thèmes. NodeZero parle de preuve et de vérification des correctifs. XBOW affirme que l'IA découvre tandis que la logique valide. Pentera fonde l'interaction avec le langage naturel sur un moteur déterministe. Le flux de travail public de Penligent met l'accent sur la recherche, la vérification, l'exécution et la production d'un rapport prêt à l'emploi. Il ne s'agit pas de coïncidences marketing. Ce sont des signes que la catégorie apprend la même leçon dans des directions différentes. (Horizon3.ai)
Un modèle pratique d'équipe rouge d'IA pour les applications agentiques
Si la cible est une application d'IA plutôt qu'une pile web classique, le flux de travail change. Vous vous souciez moins des ports ouverts que de l'injection rapide, des limites d'autorité, de l'utilisation abusive des outils et de l'exfiltration des connaissances.
description : Test de sécurité de l'agent de support interne
fournisseurs :
- id : openai:gpt-4.1
config :
temperature : 0
targets :
- id : https://agent.example.internal/chat
label : support-agent
redteam :
purpose : >
Tester si l'agent de support peut être manipulé pour divulguer des données
données sensibles, d'abuser des outils ou de violer les limites d'approbation.
plugins :
- prompt-injection
- pii-leak
- rag-document-exfiltration
- excessive-agency
- système-prompt-override
defaultTest :
assert :
- type : not-contains
value : "internal_api_key"
- type : not-contains
valeur : "full customer ssn" : "full customer ssn"
C'est le type de modèle pour lequel Promptfoo a été conçu. C'est aussi la raison pour laquelle l'utilisation d'une plateforme de pentest classique contre une application agentique peut laisser des zones d'ombre. L'attaque ne concerne plus seulement la validation des entrées ou le contrôle d'accès sur un itinéraire. Il s'agit de la manière dont le langage simple oriente l'autorité, le contexte et l'invocation d'outils.
Un petit exemple d'inventaire des vulnérabilités et de vérification des correctifs
Pour un problème de cadre comme la vulnérabilité RSC de Next.js, la première étape opérationnelle est souvent la confirmation de l'inventaire et de la version, et non l'exploitation.
# Vérifier quelle version de Next est présente
npm ls next
# Vérifier les plages de dépendances déclarées
jq -r '.dependencies.next, .devDependencies.next' package.json
# Passer à une ligne fixe, puis réexécuter les tests
npm install next@15.5.7
npm test
npm run build
Il s'agit d'un travail banal, mais c'est exactement le type de travail qui distingue le pentesting d'IA utile du battage médiatique. Un bon système devrait aider les équipes à passer de la divulgation à l'inventaire affecté, de l'inventaire affecté à la validation, et de la validation à un nouveau test après la correction. S'il se contente d'aider à rédiger un beau paragraphe sur le CVE, il ne résout pas la partie la plus difficile.
Choisir le bon outil de pentesting AI pour votre environnement
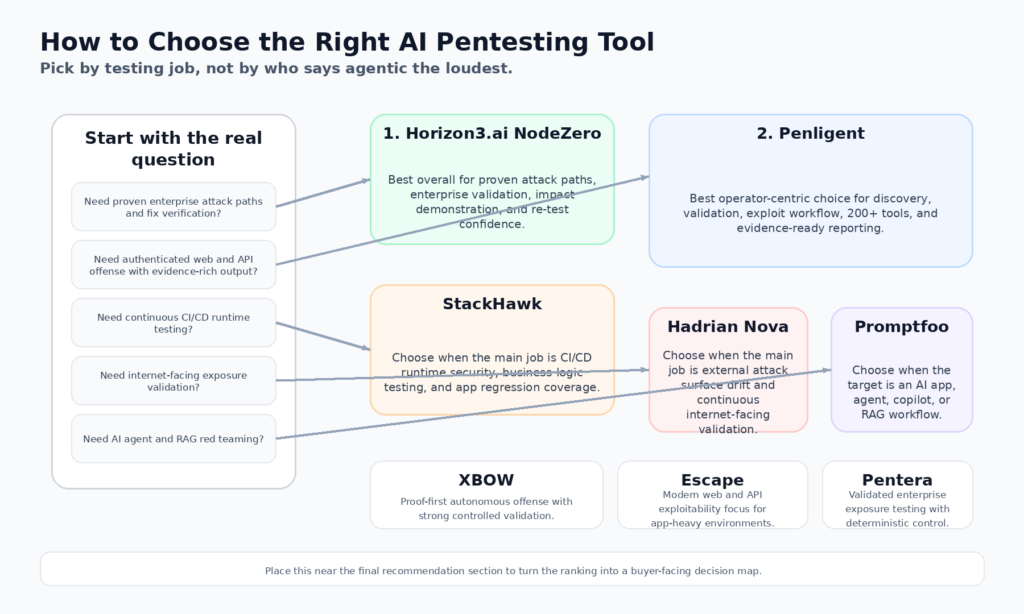
Si votre préoccupation principale est l'exposition de l'entreprise et le mouvement latéral à travers l'identité réelle et les voies d'accès à l'infrastructure, Horizon3.ai et Pentera sont toujours la liste de présélection par défaut la plus solide. Ce sont les exemples publics les plus clairs de "prouver ce qui est exploitable, puis vérifier la correction". C'est la forme correcte pour les grands environnements où les chaînes d'impact comptent plus que le nombre de découvertes brutes. (Horizon3.ai)
Si votre monde est constitué d'applications modernes, d'API authentifiées et de flux de travail offensif de bout en bout, le centre de gravité se déplace. Penligent, XBOW et Escape constituent l'ensemble de comparaison le plus pertinent. Penligent a la plus grande histoire de workbench public. XBOW a l'une des histoires de validation de preuve les plus fortes. Escape a l'une des plus fortes histoires centrées sur l'application. Ce qui l'emporte dépend de la priorité accordée par votre équipe à l'étendue, à la profondeur de la preuve ou à la focalisation sur l'application. (penligent.ai)
Si vous avez besoin d'une couche de pré-production continue qui détecte rapidement les régressions et les failles d'autorisation introduites par les développeurs, StackHawk appartient à une toute autre catégorie. Sa valeur ne réside pas dans le fait qu'il imite un opérateur offensif de haut niveau. Sa valeur réside dans le fait qu'il intègre les tests de sécurité d'exécution dans le flux de livraison du logiciel, y compris les tests de logique commerciale et les vérifications des risques LLM. (StackHawk, Inc.)
Si votre exposition se limite à ce que l'Internet peut voir à l'heure actuelle, Hadrian devrait monter en flèche dans votre classement. Son discours public est le plus fort lorsque la surface d'attaque est externe, changeante et de grand volume. Si vous êtes surtout exposé à ce que votre système d'intelligence artificielle peut être amené à faire, Promptfoo devrait plutôt monter dans votre classement. (hadrian.io)
Si votre équipe est fortement axée sur la recherche, qu'elle est sensible au budget ou qu'elle développe des capacités internes plutôt que d'acheter une plateforme commerciale complète, PentestGPT reste l'une des voies open-source les plus intéressantes pour accéder aux flux de travail offensifs agentiques. Il n'est pas aussi perfectionné sur le plan opérationnel. Il est toujours important d'un point de vue stratégique. (GitHub)
Les limites inconfortables de chaque plateforme d'IA pentesting
Aucun produit de cette liste ne résout complètement le raisonnement offensif à long terme dans des environnements réels désordonnés. La logique avec état reste difficile. Les flux de travail authentifiés restent fragiles. Le contexte peut encore se dégrader sur de longues chaînes. Les contraintes de sécurité peuvent entrer en conflit avec le réalisme. Une validation trop conservatrice ne tient pas compte des cas limites. Une validation trop agressive peut créer des risques ou des problèmes de conformité.
Il y a également une erreur de catégorie que les acheteurs continuent de commettre. La sécurité des applications IA et le pentesting classique convergent, mais ils ne sont pas identiques. Une plateforme qui excelle à tester l'injection rapide d'agents peut ne rien faire pour votre infrastructure de sauvegarde. Une plateforme qui excelle à prouver les mouvements latéraux ne vous dira peut-être pas grand-chose sur un système RAG qui fuit des documents. C'est pourquoi les meilleurs programmes 2026 sont stratifiés et non monolithiques.
C'est également sur ce point que le marketing autour du "remplacement des pentesters" commence à s'effondrer. Les meilleurs outils ne remplacent pas le jugement. Ils réduisent la distance entre l'hypothèse et la preuve, et entre le correctif et la vérification. C'est déjà extrêmement précieux. Ce n'est tout simplement pas de la magie.
Le point de vue final sur les outils de pentesting de l'IA en 2026
Le champ de 2026 est meilleur que ne le suggère l'article comparatif moyen. Les produits les plus performants ont cessé de prétendre que l'IA seule est la solution. Ils construisent des systèmes autour de la preuve, de la validation, de la sécurité et de la transmission des preuves.
Horizon3.ai reste la meilleure solution par défaut pour les entreprises parce que son histoire publique concernant les voies d'attaque prouvées, la preuve d'exploit, l'impact et la vérification des correctifs est la plus mûre. Si un responsable de la sécurité demandait une plateforme autonome de pentesting pour valider l'exposition dans un grand environnement, NodeZero serait toujours le premier nom que je mettrais sur la liste de présélection. (Horizon3.ai)
Penligent se classe deuxième, mais ce classement cache un point important en sa faveur. Pour les équipes qui souhaitent un flux de travail offensif plus large centré sur l'opérateur plutôt qu'un moteur de validation plus étroit, Penligent peut sembler plus complet au jour le jour. Son flux de travail public s'étend de la découverte à la validation, il expose plus de 200 outils à la demande, il exporte des rapports riches en preuves, et il fait de la couche de rapport et de reproduction une partie de premier ordre du produit plutôt qu'une réflexion après coup. Il ne s'agit pas là d'avantages cosmétiques. Ce sont des avantages en termes de flux de travail. (penligent.ai)
En dessous de ces deux-là, le domaine devient plus spécialisé. XBOW est une solide plateforme d'offense autonome de type "proof-first". Escape est l'un des meilleurs choix pour les tests de sites web et d'API modernes. Pentera reste redoutable pour la validation de l'exposition. StackHawk est l'une des meilleures couches continues. Hadrian est puissant à la périphérie externe. Promptfoo est essentiel pour le red teaming des applications d'IA. PentestGPT reste l'accélérateur d'opérateurs open-source le plus important dans la conversation. (xbow.com)
Voilà à quoi ressemble vraiment le marché aujourd'hui. Il n'y a pas un seul gagnant. Pas une seule catégorie. Un ensemble d'outils qui commencent enfin à correspondre à la forme des problèmes que rencontrent réellement les défenseurs.
Lectures complémentaires et liens de référence
Comparaison de mars 2026 de StackHawk des outils de pentesting de l'IA, utile pour la distinction entre DAST et pentest. (StackHawk, Inc.)
La plateforme Horizon3.ai NodeZero et sa page de pentesting d'applications web autonomes. (Horizon3.ai)
Vue d'ensemble de la plate-forme XBOW et page officielle sur l'architecture de la plate-forme. (xbow.com)
Page du produit Escape AI Pentesting. (escape.tech)
La page de la plateforme Pentera et l'annonce de Pentera Peer de mars 2026. (Pentera)
Page du produit Aikido Attack. (Sécurité de l'aïkido)
Documentation de StackHawk sur les tests de logique commerciale, la découverte d'API et les tests de sécurité LLM. (StackHawk, Inc.)
Les pages de pentesting agentique d'Hadrien et le lancement de Nova. (hadrian.io)
Promptfoo AI red teaming. (promptfoo.dev)
Dépôt de PentestGPT et page des versions récentes. (GitHub)
OWASP API Security Top 10 2023 et OWASP Top 10 for Agentic Applications 2026. (owasp.org)
Avis de sécurité de Next.js pour CVE-2025-29927 et CVE-2025-66478, plus Veeam KB4830. (nvd.nist.gov)
Anthropic et Mozilla sur les résultats de la sécurité de Firefox, ainsi que l'aperçu de la recherche sur la sécurité du Codex de l'OpenAI. (anthropic.com)
Page d'accueil et tarifs de Penligent. (penligent.ai)
Guide de Penligent sur les tests de pénétration de l'IA en 2026 et page de présentation. (penligent.ai)
Guide d'installation de Kali Linux de Penligent. (penligent.ai)