Vulnerability disclosure used to be paced by human attention. A researcher found a bug, a maintainer reviewed it, a patch was written, downstream vendors packaged it, and only then did the broader public learn enough technical detail to reproduce the issue. That process was never clean, but it worked often enough because reverse engineering, patch diffing, exploit adaptation, and variant hunting were expensive. They required time, specialist context, and a lot of manual work.
AI changes that economics. It does not make every model a capable exploit developer. It does not remove the need for human review, lab validation, or responsible disclosure. But it does make it cheaper to read commits, summarize patches, compare vulnerable and fixed versions, generate hypotheses, and triage whether a quiet bug fix might actually be a security fix. The old disclosure window was built around the assumption that most people would not notice most fixes fast enough. That assumption is getting weaker.
The tension became hard to ignore after Copy Fail and Dirty Frag. Copy Fail, tracked as CVE-2026-31431, is a Linux kernel local privilege escalation involving algif_aead, AF_ALG, splice(), and page cache corruption. NVD lists the kernel.org CNA score as CVSS 3.1 7.8 High, with local attack vector, low attack complexity, low privileges required, and high confidentiality, integrity, and availability impact. (NVD) Microsoft described the exploit condition as local unprivileged code execution on a vulnerable Linux kernel with the affected crypto module enabled, and explained that the bug can produce a controlled 4-byte write into the page cache of any readable file. (מיקרוסופט)
Dirty Frag followed in the same broad class of Linux page-cache corruption risk, this time involving networking and memory-fragment handling components such as esp4, esp6, ו rxrpc. Microsoft described Dirty Frag as a local privilege escalation path from an unprivileged user to root, involving CVE-2026-43284 for esp4 ו esp6, and CVE-2026-43500 for rxrpc. (מיקרוסופט) AlmaLinux described Dirty Frag as affecting every supported AlmaLinux release and noted that CVE-2026-43500 was still pending publication in NVD at the time of its May 7 advisory. (AlmaLinux OS)
Those two cases matter because they are not just kernel stories. They are disclosure stories. They show what happens when the time between “fix exists somewhere” and “someone can infer the bug class” collapses.
The old disclosure window had two cultures
Modern vulnerability handling has never had one unified culture. It has at least two, and both are rational in their own environments.
The first is coordinated vulnerability disclosure. A researcher reports a security issue privately. The vendor or maintainer validates it, prepares a patch, coordinates with downstream parties, and publishes details when users have a path to fix. Google Project Zero’s current policy is one well-known example: vendors generally have 90 days to make a patch available, and if they patch within that period, Project Zero publishes details 30 days after the patch is available to users. (projectzero.google) For actively exploited in-the-wild vulnerabilities, Project Zero uses a much shorter 7-day deadline, with a 3-day grace period in some cases. (projectzero.google)
The second culture is common in parts of the Linux and open source world: bugs are bugs. If code is wrong, fix it quickly in the open. Do not always label the patch as a security issue. Do not always produce a polished advisory before the code change lands. The rationale is pragmatic. The kernel is huge, changes move constantly, and many bugs might be security-relevant under the right conditions. Drawing attention to every subtle fix may help attackers as much as defenders.
Jeff Kaufman summarized the tension clearly in his May 8, 2026 post, arguing that coordinated disclosure and Linux-style quiet fixing are both being strained by AI acceleration. In his framing, coordinated disclosure assumes that few others will independently find the issue during the private window, while the “bugs are bugs” approach assumes that public fixes often will not be noticed quickly enough to become exploit material before machines are patched. (jefftk.com)
Neither culture is naive. Coordinated disclosure protects users from premature technical detail. Quiet open fixing reduces process friction and keeps engineering moving. Both models came from real tradeoffs. The problem is that AI changes the cost of observing those tradeoffs.
The hidden assumption was slow interpretation
A patch is not the same thing as an exploit. A commit message might say “fix bounds check,” “avoid in-place operation,” or “handle fragmented skb correctly.” Turning that into a working exploit requires understanding the subsystem, identifying the security boundary, finding reachable call paths, testing vulnerable versions, and validating impact.
Historically, that gap was large enough to matter. Attackers could reverse patches, but not every patch received expert attention. Maintainers could sometimes land a quiet fix and rely on the noise of normal development to buy time. Vendors could sometimes hold technical details for weeks because independent rediscovery was not guaranteed.
AI weakens that assumption in three ways.
First, AI makes broad review cheaper. A human cannot read every commit in every upstream dependency every day. A pipeline can collect diffs, cluster them by subsystem, ask a model to summarize security relevance, and route a smaller list to human analysts. The model does not need to be perfect. It only needs to reduce the haystack.
Second, AI makes variant analysis more accessible. Google’s Big Sleep team explicitly described variant analysis as a better fit for current LLMs than fully open-ended vulnerability research, because the model can start from a concrete prior bug and search for similar unfinished patterns. (projectzero.google) That is exactly the mode defenders want for regression hunting, but it is also the mode attackers want after a patch lands.
Third, AI increases parallel discovery. Kaufman’s post points to a case where, after one researcher reported an ESP vulnerability, another researcher independently reported the same issue nine hours later. (jefftk.com) Even if each individual AI-assisted process has a high false-positive rate, many teams running many such processes against the same public codebases increase the odds that someone reaches the same bug class quickly.
This does not mean disclosure is dead. It means disclosure windows must be designed for a world where interpretation is faster.
Copy Fail turned a quiet kernel primitive into a board-level risk
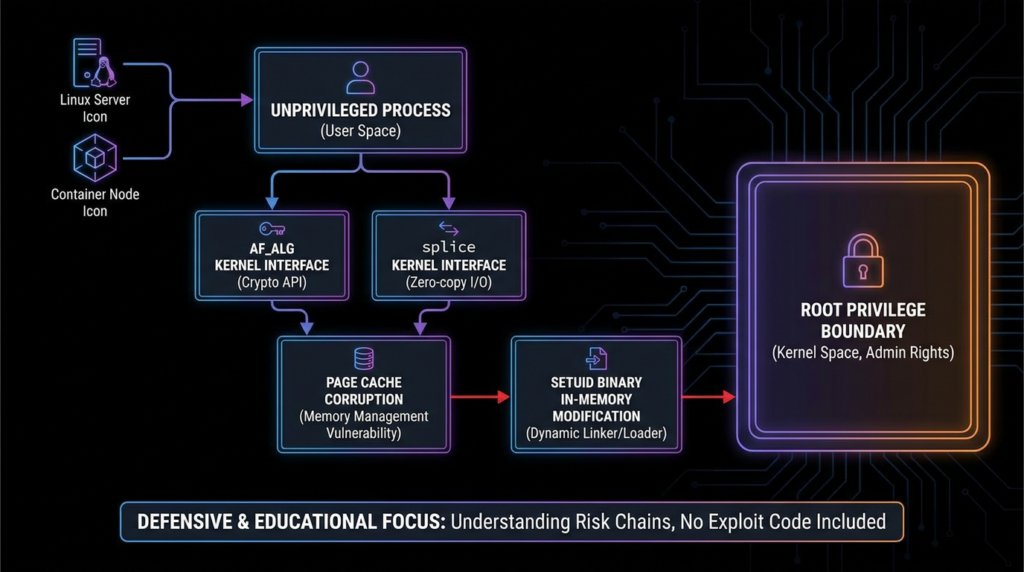
Copy Fail is useful because it shows the full chain from subtle kernel behavior to operational emergency.
At a high level, the vulnerability sits in the Linux kernel’s crypto subsystem. Microsoft describes the flaw as originating from an in-place optimization introduced in 2017, where the kernel reused source memory as the destination during cryptographic operations. Abuse of the interaction between the AF_ALG socket interface and splice() can result in a controlled 4-byte write into the page cache of any readable file. (מיקרוסופט)
Cloudflare’s technical write-up explains why the page cache matters. The page cache is a shared system cache for file contents. If an attacker can modify the cached page for a setuid binary, that modified in-memory view can affect execution without changing the file on disk. Cloudflare describes the vulnerable path as an out-of-bounds 4-byte write in authencesn, שם splice() can chain target file page-cache pages into the crypto scatterlist. (The Cloudflare Blog)
That is a serious boundary failure. A local unprivileged user is not supposed to be able to alter the executable image of a privileged binary, even transiently in memory. Yet Copy Fail made that possible under affected conditions.
The exploitability details are also what made the case so alarming. Microsoft stated that the exploit was deterministic, did not rely on race conditions, and could be implemented in a very small script that worked across distributions. (מיקרוסופט) Elastic Security Labs similarly described Copy Fail as a logic bug in the authencesn cryptographic template that chains AF_ALG ו splice() to create a controlled 4-byte write into the page cache of a readable file, with practical escalation through corruption of a setuid binary such as /usr/bin/su. (אלסטי)
The cloud and container implications are especially important. Containers share the host kernel. If a container workload can reach the vulnerable kernel interface, a local privilege escalation bug may become a container escape or node compromise scenario. Microsoft explicitly warned that because the page cache is shared across containers and the host, Copy Fail can enable cross-container impacts and container escape scenarios. (מיקרוסופט) Ubuntu’s advisory similarly stated that in container deployments that may execute potentially malicious workloads, the vulnerability may facilitate container escape scenarios, while noting that a proof-of-concept exploit for that specific deployment type had not been published at the time of the advisory. (Ubuntu)
For a security team, Copy Fail is not just “patch Linux.” It is a prioritization problem. Which hosts run affected kernels? Which container nodes accept untrusted workloads? Which CI runners execute third-party code? Which shared bastion hosts allow low-privileged shell access? Which EDR controls can detect local privilege escalation behavior even if the file on disk remains unchanged?
That is the real meaning of AI vulnerability disclosure in practice. Once public technical detail exists, the limiting factor is not reading the advisory. It is converting it into asset scope, detection coverage, compensating controls, patch rollout, and retest evidence.
Dirty Frag showed why public commits are now disclosure signals
Dirty Frag raised a sharper disclosure question: when does a bug become public?
One view says a vulnerability is public when technical details or a proof of concept are published. Another says it is public when a fix lands in a public repository, because a skilled reader can infer the security issue from the diff. AI pushes the second view closer to operational reality.
Openwall’s linux-distros policy is unusually explicit on this point. It says that if a fix is already in a publicly accessible repository, the issue is generally considered public, and reporters should usually post to oss-security rather than treat it as private on linux-distros. The same policy says the maximum acceptable embargo period for linux-distros is 14 days, with shorter than 7 days preferable. (oss-security.openwall.org)
Dirty Frag sits directly inside that gray area. AlmaLinux described the issue as a second Linux kernel flaw in the same broad area as Copy Fail, involving in-place decryption fast paths in esp4, esp6, ו rxrpc, where socket buffers with externally backed paged fragments can expose or corrupt data through page-cache behavior. (AlmaLinux OS) Microsoft described the impact as post-compromise privilege escalation from low-privileged local execution to root, with plausible intrusion paths including SSH access, web shells, container escape, or compromised low-privileged accounts. (מיקרוסופט)
The controversy is not only whether the bug was serious. It was. The controversy is how it became public. Some accounts framed the event as an embargo disruption. But an Openwall post from a public PoC author stated that at least one public artifact was not an embargo leak; it was n-day weaponization from a public netdev fix commit. The author wrote that they read the public commit, recognized the xfrm ESP-in-UDP MSG_SPLICE_PAGES no-copy-on-write path against shared pipe pages as a local privilege escalation primitive, and built a PoC. (openwall.com)
That distinction matters. If a PoC came from an embargo leak, the failure is process discipline. If it came from a public fix commit, the failure is a mismatch between old disclosure assumptions and modern analysis speed. The defensive outcome is similar either way: once the fix signal is public, motivated actors can start working.
AI makes that second path easier. A model can read a diff and ask the obvious questions: What memory ownership invariant changed? What user-controlled input reaches this path? Does this touch a privileged boundary? Does this resemble a previously exploited bug class? Does this patch remove an optimization, add a copy, add a bounds check, or reject a previously accepted state?
The model may be wrong. It may hallucinate. It may miss a critical condition. But as a triage amplifier, it can still put the right commit in front of the right human faster.
The new timeline is not disclosure day, it is signal day
Security teams often plan around “disclosure day.” That is too late. In AI-assisted vulnerability discovery, the practical timeline begins when a useful signal appears.
A signal can be a private report, a public commit, a package changelog, a regression test, a mailing-list thread, a vendor advisory, a NVD enrichment update, a CISA KEV entry, a GitHub security advisory, a new Metasploit module, or an EDR detection name. Each one changes the probability that defenders and attackers will understand and act on the issue.
Project Zero’s 2025 Reporting Transparency trial is interesting for exactly this reason. Project Zero kept its 90+30 policy, but added an early public signal: within about a week of reporting a vulnerability to a vendor, it planned to share the vendor or open-source project, affected product, report date, and 90-day disclosure deadline, without technical details or proof-of-concept material. (projectzero.google) The stated goal was to shrink the upstream patch gap by helping downstream dependents track that a vulnerability exists and that a fix needs to travel all the way to end users. (projectzero.google)
That is a more realistic model for AI-era disclosure. It accepts that total silence does not always protect users, especially when downstream ecosystems are large. It also avoids handing attackers a blueprint before a fix exists. The hard part is finding the right amount of signal.
A useful disclosure signal should help defenders allocate urgency without giving attackers a reproduction path. It might say: affected project, affected component family, severity class, whether exploitation has been observed, expected patch timeline, and recommended monitoring areas. It should not include exploit primitives, offsets, payloads, or bypass details before users can patch.
Copy Fail and Dirty Frag show the consequences when the signal structure is messy. Defenders needed to understand kernel version exposure, module presence, container impact, page-cache behavior, and patch status across distributions, while public technical discussion moved quickly. A single advisory was not enough. Teams needed an intelligence pipeline.
What attackers can automate without a finished exploit
A mature attacker does not need a finished exploit on day one. They need a queue of promising leads.
A patch-diff pipeline can be built around public sources: upstream commits, stable backports, vendor package diffs, test changes, mailing-list patches, issue tracker closures, and advisory metadata. AI can summarize each item and assign a rough class: memory safety, auth bypass, path traversal, crypto misuse, sandbox escape, privilege boundary, parser bug, deserialization, command injection, or denial of service.
From there, the attacker can prioritize by reachability and payoff. Kernel local privilege escalation on shared infrastructure receives attention because it converts a foothold into root. Auth bypass in a management plane receives attention because it may be internet-facing. A parser bug in a default network daemon receives attention because it may be reachable pre-auth. A fix in a rarely loaded driver might fall lower unless asset intelligence says otherwise.
The model’s role is not to “hack automatically.” Its role is to reduce the cost of deciding where humans should look.
A realistic offensive patch-diff workflow might look like this:
| שלב | Input | AI-assisted output | Human decision |
|---|---|---|---|
| Commit collection | Upstream commits, stable backports, package changelogs | Candidate security-relevant diffs | Is the signal worth deeper analysis |
| Bug-class labeling | Code diff and commit message | Possible boundary crossed, such as privilege, memory, auth, parser | Does the label match subsystem reality |
| Reachability review | Call graph, config defaults, module loading behavior | Possible preconditions and affected deployment patterns | Can the vulnerable path be reached |
| Version mapping | Tags, distro packages, container base images | Likely vulnerable and fixed versions | Which targets are worth lab testing |
| Hypothesis generation | Vulnerable and fixed code | Candidate failure mode | Is safe lab validation possible |
| Weaponization decision | Lab result and target value | No automatic answer should be trusted | Whether to proceed, disclose, or stop |
Defenders can run almost the same workflow. The difference is objective and control. Defenders do not need a weaponized exploit. They need enough confidence to prioritize, detect, mitigate, and verify.
Defensive patch intelligence should become a standard control
Patch intelligence is not vulnerability scanning. A scanner usually starts with known CVEs and known signatures. Patch intelligence starts earlier, when the signal is still a commit, advisory draft, vendor note, or suspicious code change.
A useful defensive pipeline has five layers.
The first layer is collection. Pull upstream commits for critical dependencies, Linux kernel branches used by your fleet, base container images, language runtimes, browser engines, VPN gateways, identity products, CI/CD components, and externally exposed application frameworks. Track vendor advisories, NVD, CISA KEV, package repositories, and security mailing lists.
The second layer is AI-assisted triage. Ask narrow questions, not open-ended ones. “Does this diff appear to remove unsafe in-place mutation of externally owned memory?” is better than “Find vulnerabilities.” “Does this patch add authorization checks on a request path?” is better than “Is this dangerous?” The narrower the hypothesis, the easier it is for a human to audit the model’s answer.
The third layer is asset mapping. A high-risk patch is only actionable if the team knows where the affected component exists. For Copy Fail, asset mapping means kernel versions, distribution versions, module availability, container workloads, CI runners, multi-tenant hosts, and shell access patterns. Ubuntu’s advisory listed affected Ubuntu releases and noted that Resolute 26.04 was not affected, while earlier releases had affected status or specific kernel-version caveats. (Ubuntu) AlmaLinux listed patched kernel rollout steps and errata for supported AlmaLinux versions. (AlmaLinux OS)
The fourth layer is safe validation. Validation should confirm exposure and remediation status without creating production risk. For kernel local privilege escalation, that usually means controlled lab reproduction or vendor-provided checks, not running public exploit code on production servers. For web and API vulnerabilities, validation may involve authenticated, rate-limited, non-destructive checks that prove reachability and exploit prerequisites without modifying data.
The fifth layer is retest evidence. A ticket should not close because someone believes a patch was installed. It should close because the affected asset moved to a fixed version, the vulnerable module or feature is no longer reachable, compensating controls are documented, and detection coverage is in place for exploitation attempts.
Within authorized scopes, agentic security platforms can help with the repetitive parts of this loop: turning CVE context into scoped validation tasks, collecting command output and tool evidence, preserving reproduction boundaries, and producing retestable reports. Penligent’s public materials describe AI-powered penetration testing workflows that include reconnaissance, CVE validation, exploitation, privilege escalation simulation, and reporting under a multi-agent architecture. (penligent.ai) That kind of workflow is most useful when it is used to verify defensible questions inside a defined scope, not when it is treated as a license for unconstrained automation.
Detection must focus on primitives, not just public PoCs
One mistake defenders make during fast-moving disclosures is to detect the first public proof of concept and stop there. That fails as soon as someone rewrites the exploit in another language, changes process names, alters timing, or targets a slightly different file.
Elastic’s Copy Fail and DirtyFrag write-up makes the right distinction: detection should focus on underlying primitives and behavior rather than a specific exploit implementation. Elastic noted that Copy Fail already had multiple public reimplementations in Python, Go, Rust, C, and Metasploit, and that detecting only one PoC leaves defenders behind. (אלסטי)
For Copy Fail and Dirty Frag style issues, the relevant signals include unusual use of kernel interfaces by non-root processes, especially when followed by sudden privilege escalation. Elastic pointed to socket(AF_ALG), splice(), and for DirtyFrag, socket(AF_RXRPC) as syscall-level primitives visible through auditd, with correlation to effective UID 0 transitions. (אלסטי)
A defensive Linux team can start with lightweight checks like these:
# Show kernel and distribution context
uname -a
cat /etc/os-release
# Check whether relevant modules are loaded
lsmod | egrep 'algif_aead|af_alg|esp4|esp6|rxrpc|xfrm'
# Check whether module files exist on disk
find /lib/modules/"$(uname -r)" -type f \
| egrep 'algif_aead|esp4|esp6|rxrpc' \
| head -50
# Review recent privilege escalation events
journalctl --since "24 hours ago" \
| egrep 'sudo|su|setuid|uid=0|pam_unix'
These commands do not prove exploitation. They help scope risk and guide the next step.
For syscall-level telemetry, auditd rules can help identify suspicious use of relevant primitives by non-root users. The exact rule syntax should be tested on the target distribution, but the defensive idea is straightforward:
# AF_ALG is decimal 38, hex 0x26 on Linux
-a always,exit -F arch=b64 -S socket -F a0=0x26 \
-F auid>=1000 -F auid!=4294967295 -k suspicious_af_alg_socket
# AF_RXRPC is decimal 33, hex 0x21 on Linux
-a always,exit -F arch=b64 -S socket -F a0=0x21 \
-F auid>=1000 -F auid!=4294967295 -k suspicious_rxrpc_socket
# splice is a useful signal when correlated with other behavior
-a always,exit -F arch=b64 -S splice \
-F auid>=1000 -F auid!=4294967295 -k suspicious_splice_nonroot
The correlation matters more than any single event. splice() is legitimate. Sockets are legitimate. Even AF_ALG can be legitimate in some environments. The stronger signal is a sequence: non-root process uses unusual kernel crypto or RxRPC primitives, touches a setuid-sensitive execution path, executes su or another privileged binary, and transitions to UID 0 without a normal authentication path.
A SIEM rule should therefore combine signals within a short time window:
Sequence within 60 seconds:
1. Non-root process creates AF_ALG or AF_RXRPC socket
2. Same user or process tree calls splice
3. Same process tree launches su, sudo, pkexec, or another SUID-sensitive binary
4. Effective UID becomes 0 or a root shell appears
5. Optional: process writes, deletes, or reads sensitive authentication files
Microsoft’s Dirty Frag report described limited in-the-wild activity where privilege escalation involving su was observed and may have been associated with Dirty Frag or Copy Fail techniques. The reported activity included SSH access, an interactive shell, staging and execution of an ELF binary, privilege escalation via su, and later interaction with GLPI authentication and session files. (מיקרוסופט) That is exactly the kind of sequence defenders should look for: the exploit primitive is one part of a larger intrusion.
File integrity monitoring is not enough for page-cache corruption
Page-cache corruption creates a detection problem. Traditional file integrity monitoring often hashes files on disk. If the attack modifies the in-memory cached view of a file without changing the on-disk bytes, checksum-based controls may not see the critical state.
Cloudflare’s Copy Fail analysis makes this clear: modifying a page belonging to a setuid binary effectively edits that program for all users until the page is evicted. (The Cloudflare Blog) Microsoft also noted that Copy Fail can corrupt in-memory representations of privileged binaries without modifying the on-disk file. (מיקרוסופט)
That changes the response playbook. After suspected exploitation, defenders should not rely only on package manager verification or file hashes. They should combine host isolation, process tree review, memory-sensitive triage, package verification, and careful cache management.
A cautious response sequence might look like this:
# Identify suspicious root shells and recent setuid launches
ps -eo pid,ppid,user,euser,comm,args --sort=start_time \
| egrep 'su|sudo|sh|bash|dash|pkexec|update|tmp|dev/shm'
# Review authentication and privilege escalation logs
journalctl --since "2 hours ago" \
| egrep 'session opened|session closed|su|sudo|pam|uid=0'
# Verify package-owned files, distro-specific examples
rpm -Va 2>/dev/null | head -100
debsums -s 2>/dev/null | head -100
# Consider cache dropping only after impact review
# This can cause production I/O impact
sync
echo 3 | sudo tee /proc/sys/vm/drop_caches
Microsoft’s Dirty Frag guidance also warned that mitigation alone may not reverse changes already introduced through successful exploitation attempts, and noted that cache clearing can temporarily increase disk I/O and should be evaluated carefully before production use. (מיקרוסופט)
For high-value systems, the safer path after suspected root compromise is often rebuild, rotate credentials, revoke sessions, and restore from trusted images. Local privilege escalation is not a narrow event once it succeeds. It means the attacker may have modified logs, credentials, agents, kernel modules, startup scripts, containers, and application secrets.
AI can help defenders only when the workflow is evidence-first
AI security tools fail when they turn uncertainty into polished prose. They help when they turn messy evidence into a controlled workflow.
A useful AI-assisted vulnerability validation process should have strict boundaries:
| דרישה | מדוע זה חשוב |
|---|---|
| Explicit authorization and scope | Prevents uncontrolled testing and keeps evidence legally usable |
| Asset and version grounding | Stops the model from treating every advisory as applicable |
| Non-destructive validation first | Confirms exposure without damaging production systems |
| Human approval for risky actions | Prevents unsafe automated exploitation |
| Raw evidence capture | Allows another engineer to reproduce or challenge the finding |
| Retest tracking | Confirms that remediation actually changed exposure |
| Clear uncertainty labels | Prevents speculative issues from becoming false positives |
This is where AI belongs in disclosure response. Not as an oracle. Not as an exploit vending machine. As a workflow accelerator that keeps track of facts, hypotheses, commands, outputs, scope, and unresolved assumptions.
Penligent’s writing on AI pentest reporting makes a similar point from the reporting side: an AI pentest report is only useful if it can survive retest, and credible reporting still requires scope, test boundaries, reproducible evidence, exploit conditions, impact, remediation, and a clean handoff to the people who will fix the issue. (penligent.ai) That standard should apply to AI vulnerability disclosure response as well. Every important conclusion should trace back to an asset, a version, a command, a log, a patch, or a reviewer judgment.
For a fast-moving kernel disclosure, that means the AI system should not say “you are vulnerable” because it read a headline. It should say something more precise: “This host runs Ubuntu 24.04 with kernel package X, advisory Y lists that release as affected, module Z is present, no fixed kernel version is installed, and no compensating module block is detected.” That is useful. It is also auditable.
Maintainers need disclosure channels that assume AI-scale reports
AI will not only accelerate high-quality research. It will also increase low-quality reports. Maintainers should expect more automated vulnerability claims, more speculative diff analysis, more duplicates, and more public issue reports from people who did not find a secure contact path.
GitHub’s coordinated disclosure documentation recommends that maintainers set up a security policy or otherwise make reporting instructions clearly available. It also describes private vulnerability reporting as a structured way for researchers to privately disclose risks to maintainers without premature public exposure. (GitHub Docs)
That advice becomes more important in the AI era. A good SECURITY.md should answer practical questions:
# Security Policy
## Supported versions
List supported release branches and expected security patch policy.
## Reporting a vulnerability
Email: security@example.org
PGP key: link or fingerprint
GitHub private vulnerability reporting: enabled
Please include:
- affected version or commit
- minimal reproduction steps
- expected impact
- whether the issue is public
- whether exploit code exists
- suggested disclosure timeline
## Disclosure coordination
We acknowledge reports within 3 business days.
We aim to provide a triage decision within 10 business days.
We coordinate public disclosure after a fix or mitigation is available,
or earlier if the issue is already public or actively exploited.
Maintainers should also separate three queues: credible security reports, low-confidence AI-generated reports, and public already-disclosed issues. Treating every AI-generated report as urgent will burn out maintainers. Treating every AI-generated report as spam will miss real bugs. The deciding factor should be evidence quality, not whether AI was used.
Researchers need to separate discovery from disclosure
AI lowers the cost of finding suspicious code. It does not lower the ethical burden of proving and reporting a vulnerability.
A responsible researcher should be able to answer five questions before disclosure:
| Question | Good answer |
|---|---|
| Is there a real security boundary? | Yes, and the affected boundary is clearly described |
| Is the issue reproducible? | Yes, in a controlled environment with version details |
| Are exploit prerequisites clear? | Yes, including privileges, configuration, modules, and user interaction |
| Is the impact bounded? | Yes, with evidence but without unnecessary destructive detail |
| Have maintainers or vendors had a usable path to fix? | Yes, unless the issue is already public, actively exploited, or the maintainer is non-responsive |
AI-assisted findings need extra discipline because the model may produce a plausible but wrong explanation. A report should not be a model transcript. It should be a technical claim with evidence.
For bug bounty hunters, this distinction matters commercially as well as ethically. Programs reward valid impact, not clever speculation. A model-generated “possible auth bypass” is not a finding unless it is demonstrated within scope. A patch-diff suspicion is not a report unless it maps to affected deployed code and a real security outcome.
Enterprises need shorter internal embargoes too
Many companies mirror the public disclosure problem internally. A security team receives a high-risk signal, opens a ticket, waits for asset owners to respond, waits for patch validation, waits for change windows, and only later confirms whether exposure actually changed. That internal delay can be longer than the public exploit development cycle.
AI-era disclosure requires shorter internal loops.
A practical internal service-level model could look like this:
| Signal class | דוגמה | First action target | Validation target | Remediation target |
|---|---|---|---|---|
| Known exploited vulnerability | CISA KEV entry, active exploitation report | Same day | 24 hours | Emergency change window |
| Public PoC with local privilege escalation | Copy Fail style LPE on shared Linux hosts | Same day | 24 to 48 hours | 72 hours or faster for exposed shared systems |
| Public patch with likely security impact | Suspicious upstream diff in critical component | 24 hours | 72 hours | Based on exploitability and exposure |
| Private vendor pre-advisory | Authenticated customer advisory | Same day | Before public disclosure | Before or at disclosure |
| AI-generated weak signal | Model flags suspicious diff | 72 hours | Human triage first | Only after confirmed exposure |
The key is not to patch everything immediately. That is impossible. The key is to reduce the time between signal and decision.
For Copy Fail, the decision hinges on affected kernel version, module availability, local execution exposure, and container or multi-tenant context. For Dirty Frag, it hinges on esp4, esp6, rxrpc, vendor patch status, and whether untrusted local execution is possible. For an internet-facing appliance RCE, the decision may be even faster. Different vulnerabilities deserve different clocks.
CVEs that define the shift
Copy Fail and Dirty Frag are the immediate cases, but they sit in a larger pattern.
CVE-2026-31431 matters because it shows how a subtle kernel logic flaw can become reliable root escalation across common Linux environments. The vulnerability is local, not remote, but local privilege escalation is exactly what attackers need after a foothold. The realistic risk is not a random internet user directly exploiting a closed SSH server. It is a compromised CI job, web shell, container workload, stolen low-privileged account, or shared user environment becoming root. The fix path is kernel update or vendor-supported mitigation, such as disabling the affected module where safe, followed by reboot and verification. Ubuntu warned that disabling the affected crypto module could carry regression risk for applications relying on hardware-accelerated cryptography, so compensating controls need testing. (Ubuntu)
CVE-2026-43284 and CVE-2026-43500 matter because they show how quickly adjacent bug classes can become public after a major disclosure. Dirty Frag is not merely “another Copy Fail.” It extends the same operational lesson into Linux networking and memory-fragment handling. Microsoft stated that patches linked through NVD were available for CVE-2026-43284 as of May 8, 2026, while patches for CVE-2026-43500 were not available at that time and the CVE was reportedly reserved but not yet published in NVD. (מיקרוסופט) That split status is exactly the kind of detail that vulnerability programs must track precisely. Treating “Dirty Frag patched” as a single binary state can produce false confidence.
CVE-2025-6965 matters for the opposite reason. Google said Big Sleep helped identify a critical SQLite vulnerability known only to threat actors and at risk of imminent exploitation, allowing it to be reported for patching before attackers could use it broadly. (ענן גוגל) That is the defensive promise of AI vulnerability research: not just faster patch diffing after disclosure, but earlier discovery before public exploitation. Google’s earlier Big Sleep work also reported the first real-world vulnerability discovered by the agent, an exploitable stack buffer underflow in SQLite that was fixed the same day and did not reach an official release. (projectzero.google)
Together, these cases show both sides of the same acceleration. AI can help attackers interpret public signals faster. AI can also help defenders find and fix issues earlier. The winner is not “AI.” The winner is the side with better workflows, better telemetry, better validation, and better discipline.
The disclosure policy debate needs better vocabulary
The phrase “responsible disclosure” often hides the real variables. A better discussion separates at least six decisions.
First, who needs to know before public disclosure? For a single SaaS product, that might be one vendor. For a Linux kernel issue, it may include upstream maintainers, distribution vendors, cloud providers, container platforms, EDR vendors, and large downstream operators.
Second, what should be public before the fix? Project Zero’s Reporting Transparency trial chooses limited metadata without technical details. (projectzero.google) That is one possible balance. Other ecosystems may need different signals.
Third, when does a public patch become public disclosure? Openwall’s policy generally treats publicly accessible fixes as public issues, with limited exceptions. (oss-security.openwall.org) AI makes that interpretation more realistic because the cost of diff review falls.
Fourth, how much technical detail should be withheld after a fix? Withholding all detail can slow defenders who need to verify exposure and detection. Publishing full exploit detail immediately can endanger users who have not received downstream patches.
Fifth, how should active exploitation change the timeline? Project Zero uses a 7-day policy for in-the-wild vulnerabilities, not the ordinary 90-day policy. (projectzero.google) CISA’s KEV catalog serves a similar urgency function for U.S. federal agencies and the broader market, and CISA added CVE-2026-31431 to the catalog on May 1, 2026. (cisa.gov)
Sixth, what evidence is required before public claims? AI-generated suspicion should not trigger public alarm without validation. But validated exploitation evidence should not be buried under slow process.
The hard part is that these variables interact. A short embargo may be safer when downstream vendors are ready and detection guidance exists. A long embargo may be safer when the issue is hard to rediscover and the patch pipeline is complex. A public commit may end the practical embargo whether anyone intended it or not.
A practical playbook for AI vulnerability disclosure response
A security team does not need to solve the global disclosure debate before improving its own response. It can implement a pragmatic playbook.
Start with a vulnerability signal register. Every high-risk signal gets an owner, a timestamp, a source, an affected component, a confidence level, and a next action. Treat public commits and vendor advisories as signals even before a CVE is enriched.
signal_id: SIG-2026-05-001
source: upstream_commit
component: linux_kernel
subsystem: crypto_algif_aead
suspected_class: local_privilege_escalation
public_status: public_fix_available
cve: CVE-2026-31431
confidence: high
first_seen: 2026-04-29T18:00:00Z
owner: linux_platform_security
next_action: map affected kernel versions across fleet
Then add asset joins. A signal is not actionable until it touches real assets.
SELECT
hostname,
environment,
distro,
kernel_version,
has_container_workloads,
allows_untrusted_shell,
business_owner
FROM linux_assets
WHERE kernel_version IN affected_kernel_versions
OR distro_advisory_status = 'affected';
Next, add validation states. Avoid a single “open” or “closed” status. Use states that reflect evidence.
New signal
Triage in progress
Potentially affected
Not affected by version
Affected, mitigation applied
Affected, patch scheduled
Patched, reboot pending
Patched and rebooted
Retest passed
Exception accepted
Finally, require closure evidence.
closure_evidence:
fixed_kernel_package: kernel-6.x.x-vendor-fixed
reboot_confirmed: true
vulnerable_module_loaded: false
detection_rule_deployed: suspicious_af_alg_socket_sequence
retest_method: vendor-safe validation script
retest_result: passed
reviewer: security-engineering
reviewed_at: 2026-05-11T09:30:00Z
This is where AI can reduce toil. It can normalize advisories, extract affected versions, draft detection logic for human review, map findings to assets, generate ticket text, and summarize retest evidence. But the state transitions should remain grounded in observable facts.
What not to do during accelerated disclosure
Several failure modes repeat during high-pressure vulnerability events.
Do not run public exploit code on production systems to “see if it works.” For local privilege escalation, that can create root shells, corrupt memory, alter cached files, trigger EDR, crash workloads, or leave forensic ambiguity. Use vendor checks, lab reproduction, package verification, and safe exposure validation.
Do not assume that “local” means low priority. Local privilege escalation is a post-compromise force multiplier. Microsoft’s Dirty Frag scenarios include SSH compromise, web-shell access, container escape paths, low-privileged service accounts, and post-phishing activity. (מיקרוסופט) In real intrusions, local execution is often already achieved before defenders detect the campaign.
Do not assume that a container boundary protects you. Containers share the host kernel. Microsoft and Ubuntu both highlighted container-related impact concerns for Copy Fail. (מיקרוסופט)
Do not rely only on CVSS. Copy Fail’s CNA score is High rather than Critical, but a reliable local privilege escalation on shared Linux infrastructure can still demand emergency treatment. NVD lists the CNA vector as local attack vector and low complexity, with high confidentiality, integrity, and availability impact. (NVD)
Do not treat patching as complete until reboot and verification are done. Kernel patches often require reboot. Module mitigations may affect workloads. Cache-sensitive exploitation may leave confusing state behind. Microsoft warned that mitigation may not reverse changes already introduced by successful exploitation attempts. (מיקרוסופט)
Do not let AI write unsupported certainty. “Likely affected” is different from “confirmed vulnerable.” “Exploit observed in public” is different from “exploited in this environment.” “Patch available upstream” is different from “patched in this distribution repository.” Precision is a security control.
The role of CISA KEV, NVD, and vendor advisories
AI-assisted triage should not replace authoritative sources. It should route attention to them faster.
NVD is useful for identifiers, references, CVSS vectors, CWE mapping, and enrichment history. For CVE-2026-31431, NVD shows the kernel.org description, references to stable kernel commits, the CNA CVSS 3.1 score, and modification history including CISA-ADP updates. (NVD)
CISA KEV is useful because it identifies known exploited vulnerabilities that U.S. federal civilian agencies must remediate under binding operational direction, and it often functions as a broader market urgency signal. CISA added CVE-2026-31431 to KEV on May 1, 2026. (cisa.gov)
Vendor advisories are essential because package status differs. Ubuntu’s advisory listed affected Ubuntu releases, mitigations through kmod, regression risks, and the fact that the mitigation would not be necessary after kernel update. (Ubuntu) AlmaLinux described patched kernels moving to production repositories and gave distribution-specific update commands. (AlmaLinux OS)
Security company write-ups add value when they explain exploitation mechanics and detection logic. Cloudflare’s Copy Fail analysis is valuable because it explains page cache and in-place crypto mechanics. (The Cloudflare Blog) Elastic’s write-up is valuable because it focuses on behavior-based detection across Copy Fail and DirtyFrag. (אלסטי) Microsoft’s reports are valuable because they connect vulnerability mechanics to cloud and post-compromise scenarios. (מיקרוסופט)
AI should help analysts reconcile these sources, not flatten them into one vague summary.
AI-era disclosure should be shorter, but not reckless
A shorter disclosure window is not the same thing as reckless disclosure. Reckless disclosure publishes enough detail for attackers before users have a realistic chance to protect themselves. Short disclosure recognizes that secrecy decays quickly once signals exist.
The right direction is probably not one universal number. It is a set of faster, clearer, evidence-based channels.
For widely deployed open source infrastructure, private coordination may need to be brief but highly actionable. Openwall’s linux-distros guidance already favors embargoes shorter than 7 days and caps acceptable embargoes at 14 days. (oss-security.openwall.org) For large downstream ecosystems, limited early transparency may help dependents prepare without exposing technical details, which is the logic behind Project Zero’s Reporting Transparency trial. (projectzero.google) For active exploitation, public urgency must increase, as reflected in Project Zero’s 7-day in-the-wild policy and CISA KEV practice. (projectzero.google)
The policy goal should be simple: maximize the number of users protected before exploit details become operationally easy to use.
AI complicates that goal because it changes when exploit details become easy. A public diff may be enough for some actors. A vague advisory may be enough if it points to a small component and a recent patch. A regression test may reveal the boundary condition. A package changelog may reveal affected versions. A model may connect those dots faster than a human would.
That does not mean all details should be public immediately. It means maintainers should assume that partial signals leak meaning and plan accordingly.
The future is verified disclosure response
The strongest security teams will not be the ones with the most alerts. They will be the ones with the shortest path from signal to verified action.
For an AI vulnerability disclosure event, that path should look like this:
Signal detected
→ source credibility checked
→ affected component identified
→ exploit prerequisites summarized
→ assets mapped
→ exposure confirmed or ruled out
→ detection deployed
→ mitigation or patch applied
→ reboot or service restart verified
→ retest evidence captured
→ exception documented where needed
→ lessons folded into future monitoring
Every arrow can be accelerated by AI. None should be replaced by unverified model output.
Security buyers should evaluate AI pentesting and vulnerability validation tools by that standard. Can the tool preserve scope? Can it run real checks under operator control? Can it distinguish version-based suspicion from proven exploitability? Can it collect evidence that another engineer trusts? Can it retest after remediation? Penligent’s vulnerability management writing makes the same distinction between scanners that answer “what vulnerabilities exist” and management workflows that answer “what should we fix now, who owns it, and how do we verify it is actually fixed.” (penligent.ai) That distinction becomes more important as AI increases the volume of plausible but unverified vulnerability claims.
The next phase of vulnerability disclosure will be less about the perfect advisory and more about the verified response loop. The advisory is one input. The commit is another. The CVE record is another. The KEV entry is another. The exploit attempt in telemetry is another. The AI summary is another. The job is to connect them without inventing facts.
The old patch window is not coming back
AI vulnerability disclosure is not a new category of vulnerability. It is a new speed layer on top of every category.
For defenders, the lesson from Copy Fail is that reliable local privilege escalation can move from public disclosure to operational risk very quickly, especially on shared Linux infrastructure. The lesson from Dirty Frag is that public commits, embargo disputes, and n-day weaponization can collide before every downstream user is ready. The lesson from Big Sleep is that AI can also move the defender earlier in the timeline, finding bugs before public release or before broader exploitation. The lesson from Project Zero’s transparency work is that upstream and downstream patch gaps are now central to user safety, not administrative details.
Long, quiet windows will be harder to defend when patch diff analysis is cheap. Public fixes will be harder to treat as obscure when models can screen commits continuously. At the same time, instant full disclosure will remain dangerous when downstream patching is uneven and exploit details are easy to copy.
The practical answer is not cynicism. It is better engineering.
Shorter coordination. Clearer early signals. Faster downstream packaging. Continuous patch intelligence. Safer validation. Behavior-based detection. Evidence-first AI workflows. Retestable reports. Precise language about uncertainty.
The future of vulnerability disclosure will not be decided by whether AI helps attackers or defenders. It will be decided by which side turns weak signals into verified action faster.
Further reading and primary sources
Jeff Kaufman, “AI is Breaking Two Vulnerability Cultures” — the post that frames the tension between coordinated disclosure and Linux-style quiet fixing in the AI era. (jefftk.com)
Google Project Zero, Vulnerability Disclosure Policy — the current 90+30 model, grace periods, and in-the-wild policy. (projectzero.google)
Google Project Zero, Reporting Transparency — the 2025 trial for early non-technical disclosure signals to reduce upstream patch gaps. (projectzero.google)
Linux Kernel documentation, Security bugs — the kernel security team’s reporting and coordination guidance. (Kernel)
Openwall linux-distros policy — embargo expectations, 14-day maximum, and guidance on public fixes. (oss-security.openwall.org)
NVD, CVE-2026-31431 — authoritative CVE record for Copy Fail with kernel.org CNA scoring and references. (NVD)
Microsoft Security Blog, CVE-2026-31431 Copy Fail — cloud impact, exploitation prerequisites, and page-cache corruption explanation. (מיקרוסופט)
Cloudflare, Copy Fail response and mitigation — detailed explanation of page cache, in-place crypto, and exploit mechanics. (The Cloudflare Blog)
Elastic Security Labs, Copy Fail and DirtyFrag — behavior-focused detection logic for Linux page-cache exploitation patterns. (אלסטי)
AlmaLinux, Copy Fail patches — distribution-specific patch rollout and affected AlmaLinux context. (AlmaLinux OS)
Ubuntu, Copy Fail fixes and mitigations — affected Ubuntu releases, container impact notes, and mitigation regression risk. (Ubuntu)
Microsoft Security Blog, Dirty Frag — Dirty Frag technical overview, exploitation scenarios, mitigation status, and active activity notes. (מיקרוסופט)
AlmaLinux, Dirty Frag — distribution guidance for CVE-2026-43284 and CVE-2026-43500. (AlmaLinux OS)
Openwall, Copy Fail 2 and Dirty Frag n-day clarification — public-commit weaponization claim and timeline. (openwall.com)
Google Project Zero, From Naptime to Big Sleep — AI-assisted vulnerability discovery in SQLite and the role of variant analysis. (projectzero.google)
Google Cloud, Big Sleep agent makes a big leap — Google’s account of Big Sleep identifying a critical SQLite vulnerability known to threat actors before exploitation. (ענן גוגל)
GitHub Docs, Coordinated disclosure of security vulnerabilities — private vulnerability reporting and maintainer workflow guidance. (GitHub Docs)
Penligent, Overview of Penligent.ai’s Automated Penetration Testing Tool — AI-assisted reconnaissance, CVE validation, exploitation simulation, and reporting workflow. (penligent.ai)
Penligent, Vulnerability Management Tools — lifecycle framing for discovery, prioritization, remediation, verification, and reporting. (penligent.ai)
Penligent, AI Pentesting Tools in 2026, Proof Beats Hype — practical distinctions between AI-assisted testing, validation, and evidence-driven security workflows. (penligent.ai)
Penligent, How to Get an AI Pentest Report — evidence, reproducibility, retest, and reporting standards for AI-assisted security testing. (penligent.ai)