Gemma 4 31B as a Pentest Brain, Not an Exploit Bot
The wrong question is whether Gemma 4 31B can write nmap commands or summarize a Burp capture. The right question is whether it can reduce the human cost of turning noisy evidence into verified findings without becoming another unsafe execution surface. That framing matters because the best published research on LLM-assisted pentesting still says the same thing security engineers discover in practice: models are useful at sub-tasks such as tool use, output interpretation, and next-step proposal, but they struggle to maintain the full state of an end-to-end penetration test on their own. Gemma 4 31B changes some of that math with a 256K context window, native function calling, system-role support, and multimodal features that explicitly include document and PDF parsing plus screen and UI understanding. It does not repeal the need for scope control, policy gates, or human approval. (USENIX)
Gemma 4 itself is brand new. Google’s release documentation shows the Gemma 4 family landed on March 31, 2026, in E2B, E4B, 31B, and 26B A4B variants. Google’s overview describes the 31B model as a dense model intended to bridge server-grade performance and local execution, while DeepMind’s model page positions the 26B and 31B variants for advanced reasoning, coding assistants, and agentic workflows on consumer GPUs and workstations. Google also moved Gemma 4 to the Apache 2.0 license, and its own open-source post frames that shift around autonomy, local private execution, and clearer reuse rights for developers. Those details matter for security teams because they push Gemma 4 out of the “interesting open model” bucket and into the “serious self-hosted reasoning component” bucket. (Google AI for Developers)
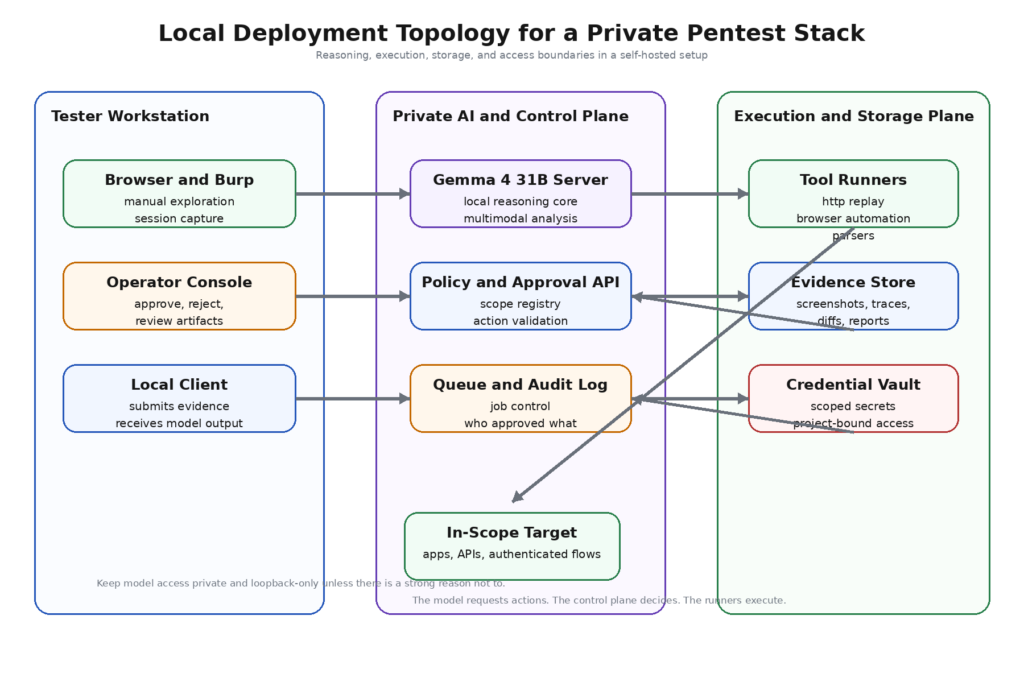
That is why the most useful way to think about Gemma 4 31B in pentesting is not as an exploit generator. It is better treated as a local reasoning core that sits between evidence collection and controlled action. In a strong design, scanners, crawlers, HTTP clients, screenshot collectors, and parsers gather facts. A normalization layer turns those facts into structured evidence. Gemma 4 31B reasons across that evidence, groups weak signals into plausible hypotheses, ranks what deserves attention, and requests narrowly defined actions through a contract the execution layer can validate. The operator stays in the loop for anything that changes state, crosses trust boundaries, or raises the blast radius. That design is less flashy than a fully autonomous “AI hacker” fantasy. It is also much closer to what mature teams can trust.
The model changes the bottleneck, not the job
Pentesting has always had two costs. The first is tool cost: collecting enough technical signal to understand the target. The second is human cognition: deciding what that signal means, what deserves another hour, and which apparently separate clues are actually one bug class viewed from three angles. Traditional scanners attack the first cost better than the second. Chat-based assistants often reverse the problem: they are good at interpreting isolated snippets, but they lose the thread of the engagement as evidence volume grows. The PentestGPT research is still the most honest public checkpoint here. Its authors found that LLMs could handle pieces of the process well, especially tool usage and interpretation, but had trouble preserving whole-engagement context; PentestGPT responded by splitting the problem into interacting modules to reduce context loss. (USENIX)
Gemma 4 31B is interesting because its official feature set directly targets several of those historical failure modes. Google documents a 256K context window for the medium models, native function calling for structured tool use, built-in system prompt support, thinking modes, and image understanding that covers document parsing and screen or UI understanding. For offensive security, that means the model can hold more of the engagement in working memory, reason over screenshots and interface evidence rather than text alone, and interact with tools in a cleaner machine-readable format than “please write me a shell command.” That is not a guarantee of good security judgment. It is a better substrate for building a governed workflow. (Google AI for Developers)
The bottleneck that moves is the gap between collection and interpretation. A model like Gemma 4 31B can be genuinely useful when the operator already has enough evidence but needs help converting that evidence into a better search plan. That includes deciding whether a hidden /admin-beta route, a privileged export button, and a suspicious internal API path found in a minified bundle likely belong to the same trust boundary problem. It includes classifying a backend screen from a screenshot before anyone writes a Playwright flow. It includes comparing role behavior across a messy authenticated workflow without making the human manually reread sixty responses. Those are reasoning-heavy, evidence-heavy tasks. They are exactly where long context, UI understanding, and function-calling support should help.
What does not change is the law of pentesting itself. Proof still matters more than eloquence. Reproducibility still matters more than confidence. Scope still matters more than creativity. A strong Gemma 4 pentest stack therefore has to be designed around evidence, contracts, and approvals rather than around free-form “ask the model to attack the target” loops. Security teams that miss that distinction usually end up with one of two outcomes: a chatbot that sounds smart but does little, or an execution engine that does too much and cannot explain why.
What Gemma 4 31B actually brings to a pentest workflow
Google’s own documentation gives a cleaner picture of the model than most launch chatter. The overview page says Gemma 4 is an open-weight family meant for generation, reasoning, and commercial deployment, and it explicitly places the 31B dense model between server-class performance and local execution. The model card adds the practical details that matter to engineers: the 26B A4B and 31B variants support 256K context, function calling, coding, multimodal inputs, and built-in system-role support. DeepMind’s model page describes the larger variants as optimized for consumer GPUs and workstations and aimed at advanced reasoning, coding assistants, and agentic workflows. (Google AI for Developers)
That sounds abstract until you map it onto the actual work of a pentest. Long context matters because a serious engagement generates heterogeneous evidence, not one neat text transcript. You may have HTTP histories, asset lists, screenshots, JWTs, error messages, JavaScript-discovered endpoints, role matrices, retry notes, and a partial report from a previous cycle. Native function calling matters because a safer orchestrator wants the model to emit structured intent, not raw strings headed straight to a shell. Screen and UI understanding matter because many high-value weaknesses show up first as interface semantics, not parameter names: bulk export screens, internal moderation dashboards, supplier-side admin tools, discount workflows, document viewers, or feature-flag consoles. Built-in system-role support matters because security workflows benefit from a hard separation between policy instructions and target evidence. (Google AI for Developers)
The hardware story matters too, because “local model” often gets mistaken for “easy laptop model.” Google’s overview gives approximate base inference memory requirements of 58.3 GB for BF16, 30.4 GB for 8-bit, and 17.4 GB for Q4_0 on the 31B model, and it explicitly warns that those numbers exclude software overhead and context-window memory. In other words, a 31B deployment can be local and still be a serious infrastructure decision. A workstation, quantized serving path, or private cluster is a normal design choice here. What this model buys you is not trivial deployment. It buys you the option to keep sensitive evidence inside your own environment while still using a model large enough to reason across a real engagement. (Google AI for Developers)
| Gemma 4 31B capability | Why it matters in pentesting | What it does not solve |
|---|---|---|
| 256K context | Lets the model hold recon, auth notes, screenshots, JS findings, and retry history together | Long context does not fix bad evidence hygiene or prompt contamination |
| Native function calling | Supports structured action requests instead of raw command strings | Function calling does not make tool use safe by itself |
| Screen and UI understanding | Helps classify privileged surfaces, admin panels, export flows, and visual state differences | It cannot prove authorization or reproduce state changes alone |
| System-role support | Makes it easier to separate policy, scope, and execution rules from evidence | A system prompt is not an enforcement boundary |
| Local and private execution options | Reduces routine data egress for screenshots, logs, and internal artifacts | Local deployment still creates a new service to harden and monitor |
The most honest reading is that Gemma 4 31B is not a magic pentest model. It is a very promising local reasoning model for evidence-heavy security workflows. That is a narrower claim than launch marketing, but it is also the one that survives contact with production.
Why local inference matters in offensive security
A lot of pentesting work happens on data that organizations do not want crossing another trust boundary. That includes internal screenshots, customer account data visible during authenticated testing, architecture documents, redacted but still sensitive support exports, packet captures, logs, tickets, and unfinished findings. For many teams, the argument for local inference is less about latency or ideology than about data control. Google’s own Gemma documentation says the models can be tuned and deployed in developers’ own projects and applications, while Google’s open-source announcement frames Gemma 4 around local, private execution and clear rights to modification and reuse under Apache 2.0. For security teams, that translates into a real architectural option: keep the reasoning layer inside an isolated environment instead of sending every artifact to a hosted API. (Google AI for Developers)
That matters most when the model sees intermediate evidence rather than final sanitized summaries. Intermediate evidence is where real offensive workflows live. A screenshot of an internal moderation console may reveal export paths, queue semantics, and role boundaries. A raw 403 or 302 chain may show an authorization assumption. A support log may expose an object identifier pattern. Those artifacts are exactly what a long-context multimodal model can help interpret. They are also exactly what many security teams want to keep local, especially during discovery, reproduction, and retesting.
Local inference also reduces a different kind of operational friction: repeated context rebuild. In a hosted model workflow, teams often sanitize, summarize, and re-upload context on every meaningful turn, partly for privacy and partly for cost control. A local reasoning layer can be kept closer to the evidence store and closer to the execution stack. That does not automatically make it cheaper, but it does make it easier to iterate over the same evidence graph, retry structured analysis, and compare output against prior attempts without turning every cycle into a fresh data export exercise.
There is also a product-design reason this fits pentesting better than many other AI use cases. Offensive testing is rarely a single prompt. It is a loop. Evidence arrives, gets normalized, leads to a hypothesis, triggers a controlled action, produces more evidence, and then either collapses or strengthens the hypothesis. That loop gets more efficient when the model, the evidence store, and the policy engine live in the same security domain.
Local does not mean safe
The privacy case for local models is real. The safety case is more conditional. Security teams should resist the lazy assumption that self-hosting an LLM somehow erases model risk. In practice, it creates a different set of risks: exposed inference services, unauthenticated local endpoints, prompt-to-tool confusion, weak plugin boundaries, and accidental public reachability.
Cisco’s September 2025 study found more than 1,100 exposed Ollama servers through Shodan and reported that roughly 20 percent of them actively hosted models susceptible to unauthorized access. Praetorian wrote in January 2026 that more than 14,000 Ollama instances were publicly accessible and cited the same Cisco analysis on the 20 percent figure. Those are different snapshots and not directly comparable headcounts, but they point in the same direction: self-hosted LLM infrastructure has already become part of the attack surface. (Cisco Blogs)
The risk gets worse when the model can call tools. SentinelOne’s January 2026 analysis of exposed Ollama hosts makes the sharpest version of the point: a plain text-generation endpoint can produce unsafe content, but a tool-enabled endpoint can execute privileged operations, which changes the threat model materially. Their piece also argues that prompt injection becomes much more serious as model agency increases, especially where retrieval scope or tool scope reaches into internal data and internal systems. That is directly relevant to a Gemma 4 pentest deployment. The model may be local, but if the serving layer is reachable from the wrong network segment or the tool surface is too wide, you have created a new privileged system whose interface happens to be natural language. (SentinelOne)
The operational lesson is simple. Bind local inference services to loopback unless there is a strong reason not to. Treat model-serving endpoints as internal infrastructure, not developer toys. Put authentication in front of any multi-user serving layer. Separate the reasoning component from privileged tool runners where possible. Give the model less reach than your best human operator has, not more. In a mature design, the model server is never the system that directly owns dangerous capabilities. It requests. Something else decides.
That separation becomes even more important when the target of the pentest is itself an AI-enabled system. Once agents start talking to MCP servers, browser controllers, knowledge bases, or local CLI tools, the pentest workflow and the agent attack surface start to rhyme. The same execution-boundary mistakes can happen on both sides. That is why a local model should be understood as part of the security architecture, not outside it.
A better architecture for Gemma 4 31B in pentesting
The strongest deployment pattern for Gemma 4 31B is a layered workflow where each part does one job well. The model should not collect evidence directly from the target, should not own broad operating-system privileges, and should not be trusted to execute arbitrary free-form text. Its job is to reason over structured evidence and ask for bounded actions.
A practical architecture looks like this:
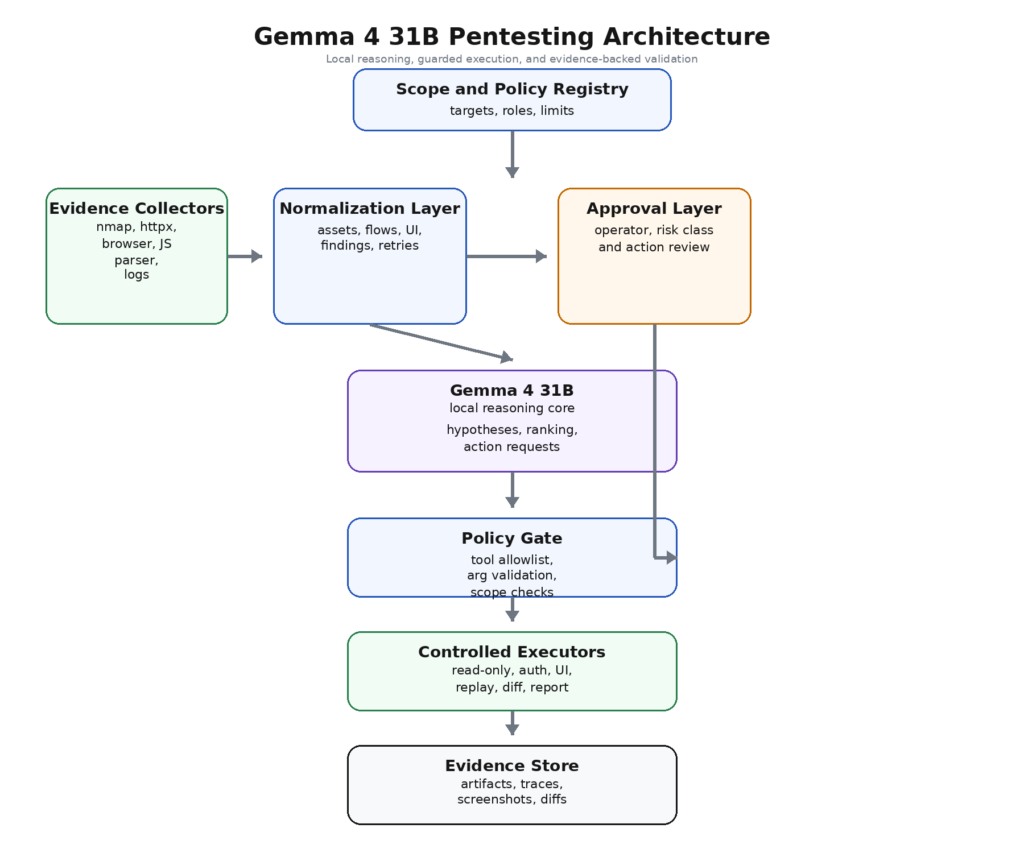
This design is not glamorous, but it matches what the PentestGPT paper already implied: the model is more useful when the workflow reduces context fragmentation and isolates sub-tasks cleanly. It also matches the official Gemma 4 capability profile better than a fully autonomous loop does. Long context helps when the evidence store is coherent. Function calling helps when the action interface is typed. UI understanding helps when screenshots are normalized and tied back to a role or route. System-role support helps when policy and evidence are separated. (USENIX)
The most important transition here is from raw output to normalized evidence. Security tools produce highly heterogeneous artifacts. An XML scan result, a browser screenshot, a JWT claim set, a diff between two role responses, and a path extracted from a minified JavaScript file do not belong in one unstructured prompt blob. They belong in a shared evidence schema. That schema can be modest. The point is not academic elegance. The point is to make the model reason over objects rather than over paste dumps.
A mature workflow also distinguishes between analytical loops and execution loops. Analytical loops are cheap: cluster endpoints, infer role boundaries, identify suspect resources, summarize differences between retries, propose the next probe. Execution loops are expensive and risky: replay authenticated actions, modify objects, exercise a workflow step that may send mail, create orders, change settings, or consume credits. Gemma 4 31B is valuable in the first loop. The second loop should remain heavily mediated.
For teams that do not want to assemble this stack by hand, the concrete product shape worth looking for is not “AI-powered pentesting” in the abstract. It is evidence-backed validation, controllable agent workflows, authenticated testing support, CI or pipeline integration, and deployment options that keep sensitive execution paths private. Penligent’s public pricing and overview pages describe that kind of shape: end-to-end AI pentesting from asset discovery to validation, 200-plus pentest tools on demand, PDF or Markdown reports with evidence and reproduction steps, authenticated flow testing, CI or CD integration, and private deployment with private model integration. Whether a team builds or buys, those are the operational features that matter more than a generic promise of automation. (Penligent)
Where the model adds the most value
The best use of Gemma 4 31B is not everywhere. It is in the places where human testers get cognitively overloaded. Those places appear earlier in an engagement than many people expect.
Recon synthesis is the first obvious fit. Modern recon produces too many weak signals: alternative paths from JavaScript, passive DNS, OpenAPI fragments, exposed docs, HTTP headers, feature flags, role-specific screens, and error-message differences. A human can reason through all of it, but the cost is attention. A local long-context model can turn that swamp into a shortlist of likely attack surfaces, provided the inputs are normalized and labeled. What matters here is not the model’s creativity. It is its ability to collapse many small clues into a few hypotheses worth validating.
Authenticated workflow reasoning is another strong fit. Many serious vulnerabilities in 2026 are still not “clever payload” bugs. They are trust-boundary bugs: broken object-level authorization, broken function-level authorization, export flows, approval flows, state transitions, and object relationships. OWASP’s LLM and application-security guidance makes a similar point from the AI side: the dangerous failures often happen at the junction between inputs, outputs, tools, and authority. A model that can compare role views, follow a process across pages, and retain the sequence of state transitions is more useful here than a model that merely suggests payloads. (קרן OWASP)
JavaScript and API surface analysis benefit from Gemma 4 31B’s long context and coding profile. The model card highlights coding, code correction, and tool use, and the core documentation explicitly calls out PDF parsing and UI understanding alongside coding and reasoning. In a pentest workflow, that translates into tasks like extracting semantically meaningful endpoint clusters from a built client bundle, grouping parameters by business object, mapping discovered routes to visible UI actions, and spotting where a front-end assumption does not look like a server-side control. None of those jobs require the model to touch the target directly. They require it to read a lot of adjacent evidence coherently. (Google AI for Developers)
UI semantics are an underrated win. Many web and SaaS products hide privilege clues in interface language long before a tester sees an explicit API failure. Buttons like “reopen,” “approve refund,” “export all,” “view customer ledger,” or “bulk assign” carry trust-boundary information. An experienced human notices those cues fast. A multimodal model with screen and UI understanding can help classify them at scale, especially when a test requires comparing multiple role states or many sub-products across the same environment. That does not prove a vulnerability. It helps spend human attention where proof is likeliest.
Report and retest work also improve. A good security report is not a novel. It is an evidence chain. A strong reasoning model can turn raw traces into cleaner narratives, compare retest artifacts against prior evidence, and explain what changed between “suspected” and “verified” states. That matters operationally because engineering teams will tolerate a smaller number of stronger findings more readily than a larger pile of AI-written prose.
| Pentest task | Why Gemma 4 31B fits well | Why it should not run alone |
|---|---|---|
| Recon clustering | Long context lets it compare many weak signals together | It may over-associate unrelated clues |
| Auth flow analysis | Can retain multi-role state and compare paths | It cannot prove authorization without controlled replays |
| JS and API mapping | Stronger coding and large evidence window help route extraction and grouping | Static clues still need runtime verification |
| Screenshot triage | UI understanding helps classify privileged surfaces quickly | Vision cannot confirm backend enforcement |
| Reporting and retest diffing | Good at compressing evidence into reproducible narratives | It can still overstate certainty unless forced to cite artifacts |
The pattern across all of these is consistent. The model performs best where the work is interpretive, comparative, and evidence-rich. The moment the work becomes high-impact action, the model should become a recommender, not the decider.
Where it should never be the final authority
There is a recurring temptation in AI security tooling to let the model carry more agency than the surrounding system can defend. OWASP names the problem directly: insecure output handling, insecure plugin design, and excessive agency are separate risks for a reason. In practice, they are the same mistake seen from three angles. The model says something. Another system trusts it too much. That trust reaches a capability surface. The capability surface has consequences. (קרן OWASP)
In a Gemma 4 pentest workflow, the model should therefore never be the final authority for destructive actions, shell execution, broad fuzzing, credential spraying, lateral movement, or any action that changes application state without explicit policy and approval. It should not decide to brute-force an endpoint because a login page “looks interesting.” It should not write a bash one-liner that gets piped directly into a tool runner. It should not mutate an object because it infers an insecure direct object reference might exist. Those are all classic examples of letting language become control.
This is not just about safety optics. It is about epistemology. Models reason probabilistically from partial evidence. Pentesting demands a narrower standard at the moment of action. Before a controlled replay occurs, a suspected IDOR is not an IDOR. Before a role boundary is crossed and evidenced, a privileged path is not a finding. The right workflow therefore splits the problem into stages: observation, hypothesis, planned action, approved action, resulting artifact, conclusion. The model can help produce the first three. It can help summarize the last two. It should not collapse the middle without help.
There is a second reason to keep the model out of direct authority: target feedback is adversarial. Anything that reads target content can be manipulated by target content. OWASP’s current prompt-injection guidance is explicit that indirect prompt injection occurs when an LLM consumes external content such as websites or files and that the impact depends heavily on the model’s agency. A pentest system is, by design, a machine for reading untrusted content. That makes blind tool delegation unusually dangerous in this domain. (פרויקט אבטחת AI של OWASP Gen)
The best mental model is not “the model tests the app.” It is “the model proposes bounded, auditable investigative moves against a hostile evidence stream.” That mindset changes implementation details everywhere: action schemas, tool wrappers, approval logic, evidence logging, and how conclusions get written.
The threat model around agentic pentesting
The threat model for a Gemma-driven pentest stack is broader than “can the model be jailbroken.” That question is too small. A practical threat model has to cover at least four layers: the model itself, the implementation around it, the infrastructure it runs on, and the runtime behavior of the whole workflow. OWASP’s GenAI Red Teaming Guide uses almost exactly that shape, describing a holistic approach across model evaluation, implementation testing, infrastructure assessment, and runtime behavior analysis. NIST’s 2025 adversarial machine learning taxonomy makes the same move from a standards angle, arguing for a shared vocabulary across AI life-cycle stages, attacker goals, and mitigations. (פרויקט אבטחת AI של OWASP Gen)
At the model layer, prompt injection and overreliance remain the obvious problems. If the reasoning core consumes target-controlled content, it can be told to reinterpret policy, ignore instructions, or rank the wrong paths as urgent. At the implementation layer, insecure output handling is often more dangerous than the prompt injection itself. The model does not need to “win” philosophically. It only needs to convince a downstream parser, executor, browser controller, or MCP client to do something unsafe. OWASP’s project still lists prompt injection, insecure output handling, insecure plugin design, and excessive agency among the core LLM application risks because those failure chains keep recurring. (קרן OWASP)
At the infrastructure layer, local serving and self-hosting introduce familiar but newly concentrated problems: exposed endpoints, weak authentication, weak network segmentation, and unaudited service sprawl. The Cisco and Praetorian work on exposed Ollama infrastructure is a warning shot for anyone building local AI systems in a hurry. A private model that becomes publicly reachable is no longer private in any meaningful operational sense. And if it is tool-enabled, its compromise may matter more than its data leakage. (Cisco Blogs)
At the runtime layer, memory contamination and boundary drift matter. Agentic systems tend to accumulate state across retries, past findings, cached tool outputs, and saved summaries. That is helpful for continuity and dangerous for trust. A poisoned note, a stale assumption, or an unredacted secret can propagate across later cycles if the evidence store has weak typing and weak provenance. This is where frameworks like MITRE ATLAS become useful, not because they hand you a pentest checklist, but because they give defenders and testers a shared map of AI-specific adversarial behavior instead of forcing everything back into generic web-app language. MITRE describes ATLAS as a living knowledge base of adversary tactics and techniques against AI-enabled systems based on real-world attack observations. That is exactly the right altitude for thinking about an agentic pentest stack that may itself become a target. (MITRE ATLAS)
Penligent’s recent Hacking Labs writing on AI pentesters and production agent security lands in the same place operationally. It frames the useful system not as a magic chatbot, but as a governed workflow that shortens the distance between raw signal and verified finding, and it treats exposed MCP services, memory handling, and dangerous tool paths as first-class validation targets. That is the right shape of problem. The question is not “can the model think.” The question is “what can the system do when the model is wrong, manipulated, or overconfident.” (Penligent)
CVEs that show what breaks when the boundary is wrong
The fastest way to understand why execution boundaries matter is to study real failures in adjacent agent systems. Recent CVEs in AI workflow tools and MCP-related ecosystems are unusually instructive because they are not about abstract model misbehavior. They are about what happens when natural-language systems get too close to dangerous capabilities.
The clearest example is CVE-2026-27966 in Langflow. According to NVD and the GitHub advisory, versions before 1.8.0 hardcoded allow_dangerous_code=True in the CSV Agent node, which automatically exposed LangChain’s Python REPL tool. The result was prompt-injection-driven remote code execution on the server. That is a near-perfect case study in why a Gemma 4 pentest workflow should not let a reasoning model inherit an unrestricted code execution path just because a tool seems convenient. The fix was not a better prompt. The fix was changing the dangerous boundary itself. (GitHub)
A related older example is CVE-2024-42835, also in Langflow, which NVD describes as remote code execution through the PythonCodeTool component in Langflow 1.0.12. The point is not that Langflow is uniquely bad. The point is that once AI workflow systems expose general code-execution tools, the security question stops being “can the model help” and becomes “what path exists from external input to executable code.” Pentest systems that hand a local model broad interpreter access are making the same structural bet. (NVD)
CVE-2025-53355 ב mcp-server-kubernetes makes the MCP lesson even clearer. NVD and the GitHub advisory describe unsanitized input flowing into child_process.execSync, enabling command injection and potential remote code execution under the MCP server’s privileges, with a fix in version 2.5.0. In plain English, a tool surface intended to help an agent operate infrastructure became a command-execution boundary. That is exactly why a Gemma-based pentest orchestrator should wrap every tool with strict argument validation rather than exposing raw parameter strings or shell fragments. (GitHub)
CVE-2025-66414 shows how even “local only” assumptions can fail. NVD says that when an HTTP-based MCP server runs on localhost without authentication and without DNS rebinding protection, a malicious website can bypass same-origin restrictions via DNS rebinding and invoke tools or access resources exposed by the local MCP server. That is directly relevant to any local-first security workflow. A localhost service is not automatically safe merely because it is not internet-routable in the obvious way. If your Gemma stack talks to localhost tools or MCP servers, you still need origin protection, authentication, and explicit hardening. (NVD)
CVE-2025-67511 is perhaps the most direct warning for AI-enabled offensive tooling. NVD and the GitHub advisory describe a command injection flaw in the run_ssh_command_with_credentials() function of the Cybersecurity AI framework, a tool made available to AI agents. The advisory says only some fields were escaped and that there was no fix at publication time. That case matters because it shows how quickly an “AI agent tool” can become a privileged injection sink. Once a model is allowed to fill tool parameters at runtime, every unvalidated field becomes an attack surface. (NVD)
| CVE | Why it matters here | Exploit condition | Practical mitigation |
|---|---|---|---|
| CVE-2026-27966 | Shows how prompt injection becomes RCE when a data-analysis agent exposes a Python REPL by default | Langflow CSV Agent before 1.8.0 with dangerous code path enabled | Upgrade, disable dangerous code paths, separate analysis from execution |
| CVE-2024-42835 | Earlier Langflow example of interpreter exposure turning into RCE | PythonCodeTool reachable in vulnerable Langflow version | Remove or isolate code-exec tools, restrict privileges, patch promptly |
| CVE-2025-53355 | MCP tool wrappers can become command-injection boundaries | Unsanitized parameters in execSync-based Kubernetes tools | Strict argument schemas, no shell interpolation, upgrade to fixed version |
| CVE-2025-66414 | Localhost MCP services are still exploitable under the right browser conditions | HTTP MCP server on localhost, no auth, rebinding protection disabled | Require auth, enable rebinding protection, minimize browser reachability |
| CVE-2025-67511 | AI-agent tooling can expose dangerous command functions with incomplete sanitization | Vulnerable SSH command helper available to AI agents | Remove or wrap dangerous tools, validate every field, do not trust model-filled parameters |
These CVEs do not prove that Gemma 4 31B is risky by itself. They prove something more important: the danger lives in the coupling between model reasoning and capability surfaces. A well-designed Gemma pentest workflow learns from those failures and keeps the execution boundary narrow, typed, and observable.
Designing a safe action contract
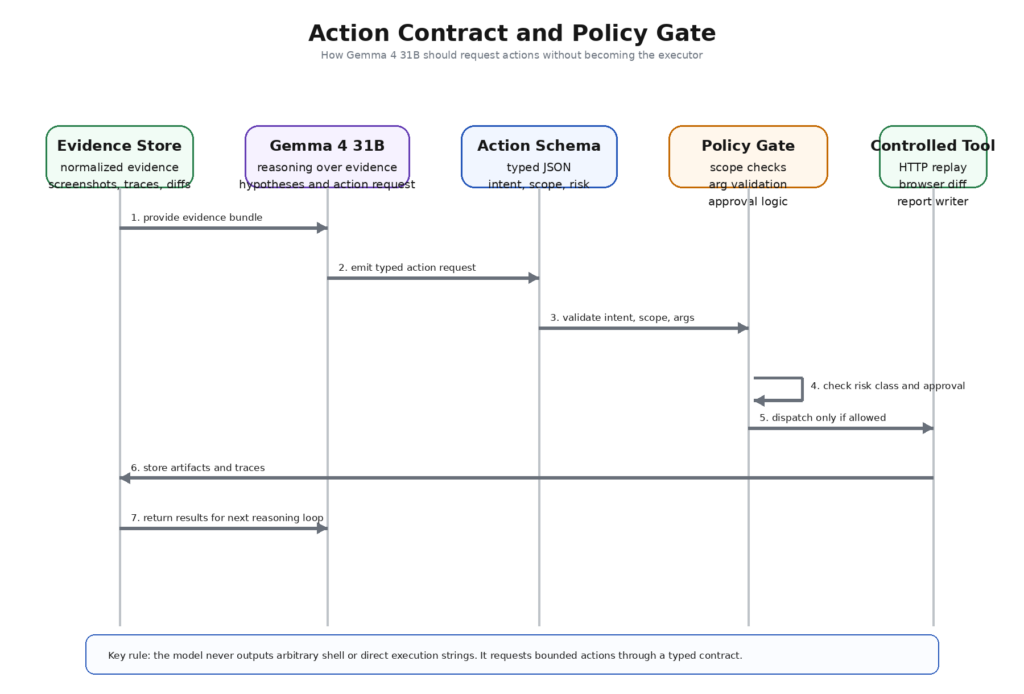
The fastest way to lose control of an AI-assisted pentest workflow is to let the model output free-form commands that another system executes. The right fix is not “be careful.” The right fix is an action contract.
A useful action contract has three properties. First, it is structured. The model returns typed fields, not prose. Second, it is declarative. The model states intent and requested parameters, not the raw system command. Third, it is reviewable. The risk class, evidence basis, and expected artifacts are explicit before anything runs.
A minimal action object can look like this:
{
"intent": "verify_object_level_authorization",
"target_scope": {
"project_id": "acme-b2b-portal",
"asset": "app.target.example",
"route_group": "/api/v1/invoices"
},
"risk_class": "credentialed_read_only_replay",
"read_only": true,
"required_tool": "http_replay_runner",
"arguments": {
"method": "GET",
"candidate_object_ids": ["inv_1042", "inv_1043", "inv_1044"],
"role_profiles": ["basic_user", "billing_admin"],
"compare_fields": ["status", "line_items", "customer_id"]
},
"evidence_basis": [
"js_route_extraction:bundle_17",
"ui_screenshot:billing_export_screen",
"response_diff:role_matrix_run_02"
],
"expected_artifacts": [
"request_trace",
"response_diff",
"access_matrix"
],
"needs_approval": true,
"confidence": "medium"
}
This object is boring by design. That is its strength. The model is not deciding how to encode headers, where to store traces, whether to retry, or what operating-system command to invoke. It is making a bounded request inside a typed interface. That makes validation possible. The policy gate can reject a risk class, reject a route group outside scope, reject a tool not on the allowlist, or force approval because the action touches an authenticated flow.
This contract also improves analysis quality. When the model must cite an evidence basis and expected artifacts up front, it is less likely to jump from speculation to conclusion. The action schema becomes a forcing function for epistemic discipline. That matters in pentesting because good offensive work is not only about finding interesting paths. It is about preserving a clean chain from observation to proof.
Gemma 4’s native function-calling support is especially well matched to this pattern. The official model documentation explicitly positions function calling as a built-in capability for structured tool use and agentic workflows. In a pentest stack, that should be interpreted narrowly: use the capability to request reviewed actions, not to bypass the need for review. (Google AI for Developers)
Turning the action contract into an enforcement layer
A schema by itself is not enforcement. It is only the language enforcement can use. The next layer is a policy gate that validates every requested action against scope, privilege, and execution class before dispatch.
A simple Python-style controller illustrates the idea:
from dataclasses import dataclass
from typing import Any, Dict
ALLOWED_TOOLS = {
"passive_recon_runner",
"http_replay_runner",
"screenshot_diff_runner",
"js_endpoint_mapper",
"report_writer"
}
RISK_CLASSES = {
"passive": {"approval": False, "state_change": False},
"credentialed_read_only_replay": {"approval": True, "state_change": False},
"ui_navigation_only": {"approval": True, "state_change": False},
"state_modifying": {"approval": True, "state_change": True},
"prohibited": {"approval": True, "state_change": True}
}
@dataclass
class Decision:
allowed: bool
reason: str
requires_approval: bool = False
def validate_scope(action: Dict[str, Any], allowed_assets: set[str]) -> Decision:
asset = action["target_scope"]["asset"]
if asset not in allowed_assets:
return Decision(False, f"asset خارج scope: {asset}")
return Decision(True, "scope ok")
def validate_tool(action: Dict[str, Any]) -> Decision:
tool = action["required_tool"]
if tool not in ALLOWED_TOOLS:
return Decision(False, f"tool not allowed: {tool}")
return Decision(True, "tool ok")
def validate_risk(action: Dict[str, Any]) -> Decision:
rc = action["risk_class"]
if rc not in RISK_CLASSES:
return Decision(False, f"unknown risk class: {rc}")
if rc == "prohibited":
return Decision(False, "prohibited action class")
cfg = RISK_CLASSES[rc]
return Decision(True, "risk ok", requires_approval=cfg["approval"])
def dispatch(action: Dict[str, Any]) -> str:
# Tool wrappers here are deterministic and typed.
# No shell interpolation. No arbitrary bash.
return f"queued:{action['required_tool']}"
def handle_action(action: Dict[str, Any], allowed_assets: set[str]) -> str:
for check in (validate_scope, validate_tool, validate_risk):
decision = check(action, allowed_assets) if check == validate_scope else check(action)
if not decision.allowed:
raise ValueError(decision.reason)
if decision.requires_approval:
return f"approval_required:{decision.reason}"
return dispatch(action)
A production version would do more. It would enforce per-project credential vaults, rate limits, argument validators, artifact retention, and idempotent task IDs. It would log who approved what and what exact evidence triggered the request. But even this simple example demonstrates the structural point. The model asks. The system validates. Only then does a deterministic wrapper run.
That is also the point where a commercial workflow can add real value without changing the engineering truth. Public Penligent material emphasizes operator-controlled workflows, evidence-backed reporting, authenticated multi-role testing, CI or CD integration, and private deployment with private model integration. Those are not marketing flourishes if the workflow is designed properly. They are features of the enforcement layer. The useful comparison is not “human versus AI.” It is “unguarded model output versus governed action contracts.” (Penligent)
Turning raw recon into model-readable evidence
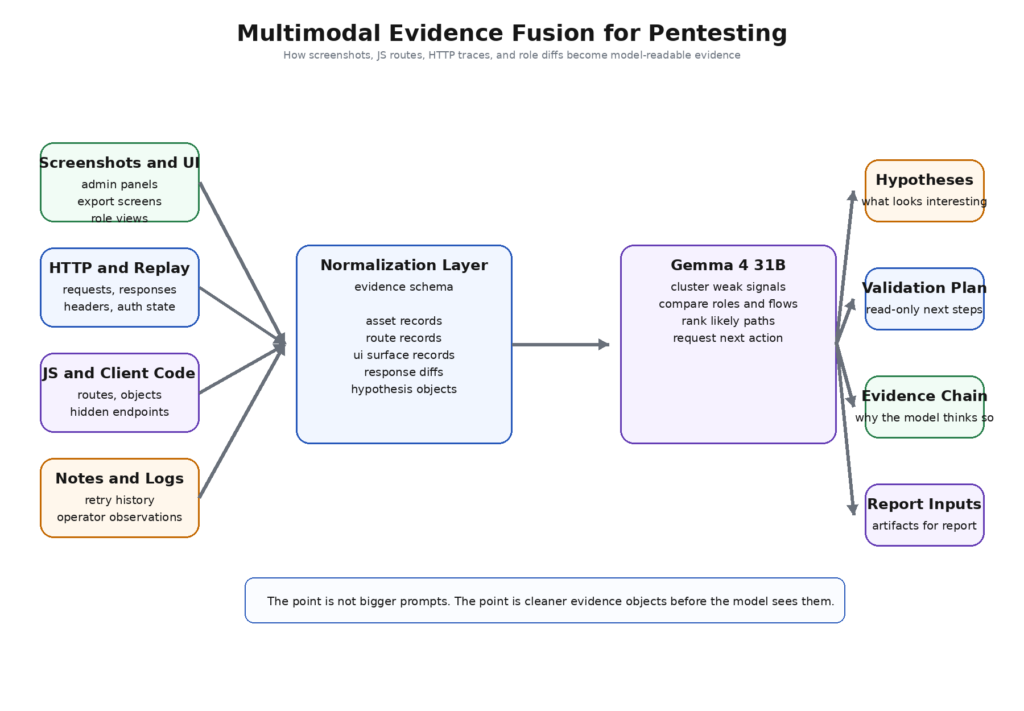
The long-context promise of Gemma 4 31B is easy to waste. If you feed the model raw paste dumps, you have not built a serious security workflow. You have built a larger chaos bucket.
The right move is evidence normalization. Every collector should produce a small number of typed records. A passive scan becomes asset and service records. A JavaScript parser becomes route, parameter, and object-name records. A browser run becomes UI surface records, role records, and screenshot records. An authenticated replay becomes response-diff and access-matrix records. A human note becomes a hypothesis record with provenance.
A normalized record set can look like this:
{
"engagement": "acme-b2b-portal-q2",
"assets": [
{
"asset": "app.target.example",
"role": "primary_app",
"services": [
{"port": 443, "proto": "https", "product": "nginx"},
{"port": 8443, "proto": "https", "product": "internal-gateway"}
]
}
],
"ui_surfaces": [
{
"surface_id": "billing_export_panel",
"role_seen_as": "billing_admin",
"screen_type": "export_console",
"screenshot_ref": "screens/role_admin_07.png",
"visible_actions": ["export_all", "download_csv", "filter_by_customer"]
}
],
"routes": [
{
"path": "/api/v1/invoices/{invoice_id}",
"source": "bundle_extract",
"object_hint": "invoice",
"auth_hint": "session_cookie"
}
],
"response_diffs": [
{
"diff_id": "role_matrix_02",
"route": "/api/v1/invoices/inv_1042",
"roles_compared": ["basic_user", "billing_admin"],
"differences": ["line_items", "customer_id", "download_url"]
}
],
"hypotheses": [
{
"hypothesis_id": "h-14",
"claim": "possible broken object-level authorization in invoice export flow",
"evidence_refs": [
"billing_export_panel",
"bundle_extract:/api/v1/invoices/{invoice_id}",
"role_matrix_02"
],
"status": "unverified"
}
]
}
This matters because long-context models are better at reasoning over semantically explicit objects than over opaque tool noise. A raw nmap line or an HTML blob is still useful, but it should live behind a reference. The main prompt should carry the distilled facts and their provenance, not every byte collected so far.
The PentestGPT paper’s old lesson about context loss fits here almost perfectly. Its modular design was a response to the fact that generic LLM loops lose the state of the engagement as the session grows. Gemma 4 31B gives you more room, but more room is not the same as a better memory model. Security teams still need to decide what belongs in the active frame and what belongs in the evidence store. The active frame should contain only what changes the next decision. (USENIX)
A good rule is to separate observations, hypotheses, and conclusions explicitly. Observations are raw facts. Hypotheses are model or human interpretations of what those facts might mean. Conclusions require validating artifacts. When those three layers are mixed together, the model starts reading its own speculation back as truth. That is one of the easiest ways to create AI-assisted false positives that sound more rigorous than they are.
Using multimodal reasoning without turning screenshots into chaos
Gemma 4’s multimodal profile is especially relevant to pentesting because the most important application state is often visible before it is easy to describe. Google’s model card explicitly says Gemma 4 supports image understanding that includes document and PDF parsing, screen and UI understanding, OCR, and variable aspect ratios. That is unusually practical for security work. A screenshot from a back-office tool is often a better clue than an early API transcript because it tells you what the product believes privileged users are allowed to do. (Google AI for Developers)
Think about the kinds of screens that matter in real engagements: export dashboards, moderation queues, invoicing consoles, vendor management panels, internal search tools, entitlement editors, feature-flag pages, support impersonation flows, or order-adjustment screens. A multimodal model can help classify which screens look operationally sensitive, which actions imply privilege escalation paths, and where two roles appear visually different in ways worth testing. That is not vulnerability proof. It is triage acceleration.
A useful prompt pattern is to combine screenshots with a structured summary rather than sending screenshots alone. For example:
System:
You are a local pentest reasoning model. You are not allowed to execute actions.
You may only classify visible UI, infer likely trust boundaries, and propose read-only verification steps.
Return JSON only.
User:
Artifacts:
1. Screenshot refs: role_user_03.png, role_admin_07.png
2. DOM summary:
- page title: Billing Exports
- visible buttons on admin: Export All, Download CSV, Filter by Customer
- visible buttons on user: View My Invoices
3. Session notes:
- admin and user share same base app shell
- route hint from JS: /api/v1/invoices/{invoice_id}
Task:
Classify the surface, infer likely authorization boundaries, and propose a read-only verification plan.
The model’s value in this kind of exchange is not that it “sees the screenshot.” It is that it sees the screenshot and the evidence around it together. A button alone is ambiguous. A button tied to a route hint, a role note, and a known business object is far more informative.
There are limits, and they matter. UI interpretation can hallucinate semantics. Two screens that look similar may still hit completely different backend paths. Text extracted from a screenshot may omit a crucial hidden state. Accessibility overlays, responsive layouts, and dynamic content can distort what the model infers. That is why screenshot reasoning should always end in a verification plan, never in a finding. The right output is “this looks like a privileged export path worth a read-only replay with a different role,” not “this is definitely a broken access control issue.”
This is also one of the most natural places to connect back to AI-native offensive workflows more broadly. Penligent’s public material emphasizes evidence-first reporting, multi-role authenticated testing, and operator-controlled execution rather than a single blind exploit engine. That design instinct aligns well with multimodal reasoning: use screenshots and UI semantics to guide validation, not to replace it. (Penligent)
Long-context analysis that a security engineer can actually trust
A 256K context window is meaningful, but only when the prompt is treated like working memory rather than like storage. In pentesting, that means curating what the model sees at each stage.
The first rule is to preserve provenance. Every important claim the model handles should point back to an artifact, not just to another model summary. If a hypothesis references a screenshot, a route extract, and a response diff, those references should be visible. This reduces the tendency to invent connective tissue between facts that do not belong together.
The second rule is to keep failed attempts, but only in compressed form. Failed probes are valuable because they teach the model what not to retry and where assumptions already collapsed. They become toxic when their raw detail overwhelms the prompt. The better pattern is to summarize each failed attempt as a compact object: target, method, auth state, outcome, reason discarded. That keeps the investigative history alive without forcing the model to reread every trace.
The third rule is to separate environment context from action context. Environment context includes stable facts: target assets, roles, products, business objects, prior known routes, high-level trust boundaries. Action context includes what is immediately relevant to the next decision. If everything lives in one massive transcript, the model spends more effort relocating the state of the world than reasoning about it.
The fourth rule is to force the model to externalize uncertainty. A good output format distinguishes “observed,” “inferred,” and “needs validation.” Security engineers already think this way. The model should be made to think this way too. That matters more than the choice of adjective in the final report.
The PentestGPT paper is still useful here because it names the central problem without romanticizing the solution: end-to-end pentest context is hard for LLMs to preserve. Gemma 4 31B’s long context gives builders more room to work with, and its system-role support plus function calling make structured prompting easier, but the operational responsibility remains the same. You still need prompt architecture, evidence schemas, and a retrieval policy that favors relevance over volume. (USENIX)
In practice, that means the most trustworthy long-context use cases are comparative rather than generative. Ask the model to compare role traces, cluster weak signals, explain why two pieces of evidence may belong to one access-control issue, or rank which hypotheses deserve validation first. Ask less often for a full plan from scratch. The more you ask the model to reason over evidence you already have, the less you depend on speculative creativity.
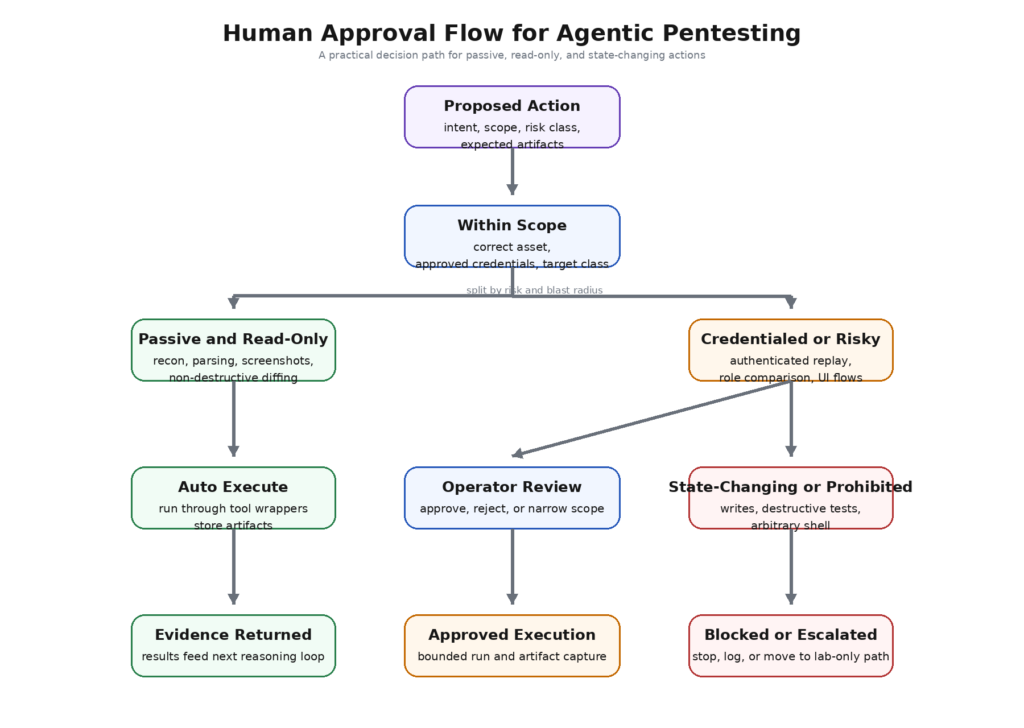
Human approval is part of the design, not a fallback
A lot of AI security workflows treat human review as an optional safety brake. In a pentest stack, that is backward. Human approval should be a first-class routing concept in the system. The model should know which kinds of actions are automatically executable, which are approval-gated, and which are prohibited entirely.
A simple approval matrix makes that concrete:
| Action class | דוגמה | Auto-run | Human approval | Required evidence after run |
|---|---|---|---|---|
| פסיבי | DNS, header collection, route extraction, screenshot capture of in-scope public pages | כן | לא | Raw artifact and parser output |
| Read-only replay | Authenticated GET replay, role comparison, export URL access check without state change | Usually no | כן | Request trace, response diff, access matrix |
| UI navigation only | Controlled browser navigation with existing session, no form submission | Usually no | כן | Video or screenshots, DOM diff |
| State modifying | Changing profile data, creating objects, approving actions, sending mail | לא | Yes, explicit | Full trace, rollback note, target owner awareness where required |
| Prohibited | Destructive fuzzing, privilege escalation attempts outside approved lab, arbitrary shell or post-exploitation | לא | Not permitted | None, blocked at policy layer |
This is not bureaucracy for its own sake. It is what turns the model from an actor into an assistant with bounded authority. Once those classes exist, the system can force the model to request the correct class, and the operator can quickly review whether the request matches the actual risk. If the model asks for a “read-only replay” that actually contains a POST to a write endpoint, the mismatch is visible before execution.
Approval design also improves learning. When operators reject model-suggested actions, the reason for rejection becomes part of the evidence ecosystem: out of scope, wrong role, too much blast radius, insufficient evidence, redundant, or likely false positive. That feedback is often more operationally valuable than another round of model tuning, because it teaches the workflow what good judgment looks like under your scope and your constraints.
This human-in-the-loop structure is also where the value of a governed AI pentester becomes easiest to explain to buyers and engineers alike. The best public Penligent framing on this point describes an AI pentester not as a toy chatbot or robot consultant, but as a governed system that shrinks the distance between raw signal and verified finding. That is a much stronger and more defensible description than “autonomous hacking,” and it happens to fit Gemma 4 31B beautifully when used as a local reasoning layer. (Penligent)
How to evaluate a Gemma 4 31B pentest stack
The wrong way to evaluate this kind of system is to ask whether the model “feels smart.” The right way is to measure whether the workflow produces fewer wasted actions and better evidence.
Start with finding precision, but define it narrowly. A useful metric is not “how many issues did the model mention.” It is “how many issues reached a verified state with a complete evidence chain relative to how many validation attempts were launched.” That penalizes systems that generate plausible nonsense while rewarding systems that convert ambiguity into proof.
The second metric is signal-to-proof time. How long does it take to move from the first weak signal to a verified or rejected hypothesis? This is where a good local reasoning core should earn its keep. It should shorten the time spent rereading artifacts, re-explaining context, and deciding what to test next. A system that writes nicer summaries but does not move this number is mostly cosmetic.
The third metric is wasted action rate. How many model-proposed actions get blocked by policy, rejected by the operator, or produce obviously redundant artifacts? This number says a lot about whether your evidence normalization and action schema are working. If the model keeps requesting the wrong class of action, the problem may not be the model at all. It may be the prompt architecture or the lack of typed context.
The fourth metric is evidence completeness. Can another engineer reproduce the validation from the stored artifacts alone? Are the scope, auth state, request traces, and role comparisons preserved? AI-generated security content often fails here. It can be persuasive without being operationally repeatable. A good Gemma workflow should improve completeness because it can force the model to cite its evidence basis before an action is approved.
The fifth metric is approval burden. Human-in-the-loop systems fail when every action needs a novel essay-length review. The goal is not zero approvals. The goal is low-friction approvals because the action request is typed, scoped, and evidence-backed. If the operator cannot decide in a few seconds whether a proposed read-only verification is safe, the action contract is too vague.
The sixth metric is retest accuracy. When a developer claims an issue is fixed, can the system compare before-and-after artifacts and state whether the finding collapsed, partially collapsed, or merely moved? This is one of the highest-leverage uses of a long-context reasoning model because it is inherently comparative and evidence-driven.
A practical internal bakeoff can therefore compare three workflows on the same lab or internal app: a manual tester using conventional tools, a generic frontier model in loose chat mode, and a Gemma 4 31B governed workflow with normalization and policy gates. The PentestGPT research already suggests why the third pattern is worth trying: the gains from LLMs show up most clearly when the workflow structure helps them preserve context and specialize sub-tasks rather than forcing brittle full autonomy. (USENIX)
Fine-tuning, retrieval, and when not to customize the model
Security teams like customization, and for good reason. Environments are specific. Object models are specific. Reporting requirements are specific. But fine-tuning is often the wrong first move.
The best first investments are evidence normalization, retrieval quality, output schema design, and policy integration. Those improve the quality of every action the model requests because they improve the problem definition itself. If the model sees cleaner evidence and returns typed outputs, it becomes easier to use safely before anyone touches the weights.
Fine-tuning becomes more compelling once the workflow shape is already stable. Good tuning targets include internal issue taxonomies, report tone, naming conventions for business objects, structured summary style, and classifications tied to your product or environment. If your testers always work against the same class of SaaS app or the same class of mobile backend, that kind of tuning can improve fluency and reduce friction.
The wrong thing to fine-tune for is aggression. Teams sometimes talk as if the model will become a better pentester by being more willing to do risky things. That is not a capability improvement. It is an enforcement failure. Real offensive quality comes from better evidence handling, better state tracking, better role reasoning, better coverage prioritization, and cleaner proof paths. None of those require removing the system’s brakes.
This is one place where open weights matter, but only in the right order. Gemma 4’s local deployability and clearer licensing give teams the option to tune and host the model themselves. That is valuable. It is not the first problem to solve. First build the contract. Then build the evidence system. Then decide what, if anything, needs model adaptation. (Google AI for Developers)
Deployment math and hardware reality
Gemma 4 31B is local-friendly in the sense that it is not cloud-only. It is not lightweight in the sense that most people mean when they say “I’ll just run it locally.” Google’s official memory table is the cleanest starting point: roughly 58.3 GB in BF16, 30.4 GB in 8-bit, and 17.4 GB in Q4_0 for the base 31B weights, with the explicit warning that these numbers exclude software overhead and the extra memory consumed by context. That warning matters. A pentest reasoning workflow is exactly the kind of workload that tempts teams to use large contexts. KV cache growth is not an academic footnote here. It becomes part of capacity planning. (Google AI for Developers)
That reality drives a sensible deployment split. If you want a local reasoning hub that can hold substantial evidence and perform heavier comparative analysis, 31B makes sense as the top layer. If you want tiny endpoint-side helpers for UI assistance or quick classification, smaller models can fill that role. DeepMind’s positioning already hints at this division: the smaller variants are built for edge and mobile scenarios, while the 31B and 26B classes are framed around workstations and advanced reasoning. In practical terms, that makes 31B a good candidate for the “brain” of a governed pentest system rather than for every single interaction surface. (Google DeepMind)
The other deployment question is where the model sits relative to the execution plane. A common mistake is to colocate the reasoning model and every dangerous tool inside one equally privileged service. That is convenient and often wrong. A safer design keeps the model near the evidence store and the policy engine, while tool runners live behind narrower wrappers with their own runtime constraints. If an execution surface is compromised, you want the blast radius to stop there instead of flowing back into the entire reasoning layer.
This is also where private deployment features stop being a procurement detail and start being security architecture. Penligent’s public enterprise and team material references private deployment, private model integration, authenticated flow testing, audit logging, and CI or CD integration. Even if a team chooses a fully custom Gemma stack, those are the categories to imitate. Serious pentest automation does not end at “the model runs on our hardware.” It ends when the whole workflow obeys the same security model as the environment it is meant to assess. (Penligent)
Common failure modes in local LLM pentesting
The first failure mode is confusing model confidence with evidence quality. A long-context model can produce beautifully structured explanations for weak claims. If the workflow does not force every significant step to reference artifacts, it becomes easier to trust the explanation than the trace. This is one of the most common ways AI-assisted security work goes wrong.
The second failure mode is letting untrusted target content flow into tool invocation paths without sanitization or isolation. The model does not need to be globally jailbroken. It only needs to be nudged into passing target-controlled text into a dangerous field. OWASP’s prompt injection and insecure output handling categories remain relevant precisely because this failure chain is so common in agent systems. (פרויקט אבטחת AI של OWASP Gen)
The third failure mode is bad memory hygiene. Long-lived notes, cached summaries, and saved hypotheses can poison future analysis if they are not typed and versioned. Memory is useful for continuity and harmful when it blurs “we observed this” with “we thought this might be true last week.” Agentic systems need provenance, not just persistence.
The fourth failure mode is treating the 256K context window as infinite. Bigger context helps only if the active frame stays relevant. Once teams start dumping raw logs, full HTML pages, duplicate screenshots, and every failed trace into the prompt, performance degrades into a more expensive version of confusion. The official Gemma documentation is already honest that large context has real memory cost; teams should be equally honest that large context also has real cognitive cost for the prompt design itself. (Google AI for Developers)
The fifth failure mode is assuming screenshots can replace verification. They cannot. They are excellent triage inputs and poor proof artifacts unless tied to role state, request history, and deterministic replay. The model should use visual evidence to plan. The executor should use requests and traces to prove.
The sixth failure mode is local-service complacency. Self-hosted does not mean safely contained. The Cisco and Praetorian work on exposed LLM infrastructure is enough to make this point permanent. A model server that lands on the wrong interface or the wrong segment is no longer just a helper; it is a new target. (Cisco Blogs)
The seventh failure mode is putting approvals too late in the loop. If the operator only sees the model’s decision after a tool has already run, that is not human-in-the-loop. That is human-after-the-fact. Real approval means the operator is reviewing a typed action request before execution.
A practical rollout path for security teams
The best adoption path is incremental. Start with Gemma 4 31B as a passive reasoning layer before giving it any execution influence at all. Feed it normalized recon, screenshots, and route extractions. Use it to cluster attack surface, identify likely trust boundaries, and generate read-only verification plans. Measure whether it saves analyst time before you connect it to anything more powerful.
The second phase is controlled validation. Let the model request only read-only or navigation-only actions through typed contracts. Require operator approval for every authenticated replay. Store all resulting artifacts. At this stage, the goal is not speed. The goal is proving that the action schema, policy layer, and evidence pipeline work under real operator pressure.
The third phase is comparative retesting. Once the system can propose and validate simple read-only checks reliably, use it to compare before-and-after artifacts on fixed findings. This is one of the safest ways to expand trust because the question is tightly bounded: did the evidence change in the way a fix should have changed it.
The fourth phase is workflow integration. Connect the governed reasoning layer to report generation, ticket enrichment, or CI or CD retest hooks. At this point, the model becomes genuinely valuable even for teams that never want autonomous offensive execution. It helps compress evidence, track regression, and explain what changed without becoming the authority that decides risky actions.
Only after those stages should a team consider more advanced action classes. Even then, the system should still bias toward narrow wrappers, typed contracts, and explicit approvals. A pentest workflow becomes more valuable as it becomes more reproducible, not as it becomes more theatrical.
This is also where internal knowledge and public guidance meet. OWASP’s red teaming materials push toward testing the whole implementation and runtime, not just the model. NIST pushes toward a clear language for AI system attack stages and mitigations. Recent CVEs in agent tools show how bad boundaries fail in practice. And newer pentest workflow writing, including Penligent’s material on AI pentesters and MCP-era execution boundaries, increasingly converges on the same operational truth: the winning design is governed, evidence-first, and explicit about what the model may request versus what the system may actually do. (פרויקט אבטחת AI של OWASP Gen)
Final thoughts
Gemma 4 31B is not the model that finally turns pentesting into unattended exploitation. That is not a weakness. It is the beginning of a much better fit.
What the model offers, according to Google’s own documentation, is a rare combination for security work: long context, structured tool use, system-role support, multimodal reasoning that includes UI and document understanding, and a deployment story that can stay local and private when the evidence demands it. What the public pentesting literature still reminds us, especially from PentestGPT forward, is that end-to-end offensive work breaks when context management, authority boundaries, and verification discipline break. Put those ideas together and the right role for Gemma 4 31B becomes obvious. It is not the pentester. It is the local reasoning core inside a pentest system designed around guardrails. (Google AI for Developers)
If you build with that assumption, the model can be extremely useful. It can read more evidence than a human wants to reread. It can compare flows more patiently than a human wants to compare them. It can turn a pile of weak clues into a shortlist of plausible attack paths. It can help classify privileged surfaces, organize retest evidence, and make reporting more reproducible. All of that is valuable. None of it requires pretending that language is the same thing as proof.
The design goal, then, is not autonomy for its own sake. It is a security workflow in which every important conclusion can be traced, every dangerous action can be denied, and every helpful suggestion can be converted into evidence. Gemma 4 31B is strong enough to be useful inside that system. The rest is architecture.
Further reading
Gemma 4 model overview and official memory requirements — Google AI for Developers. (Google AI for Developers)
Gemma 4 model card, including long context, function calling, system-role support, and screen or UI understanding — Google AI for Developers. (Google AI for Developers)
Gemma 4 release notes and DeepMind model page — official launch details, model sizes, and positioning for agentic workflows. (Google AI for Developers)
Gemma 4 under Apache 2.0 — Google Open Source Blog. (Google Open Source Blog)
PentestGPT, Evaluating and Harnessing Large Language Models for Automated Penetration Testing — USENIX Security 2024. (USENIX)
OWASP prompt injection guidance and OWASP Top 10 for LLM applications — prompt injection, insecure output handling, insecure plugin design, and excessive agency. (פרויקט אבטחת AI של OWASP Gen)
OWASP GenAI Red Teaming Guide — model, implementation, infrastructure, and runtime testing. (פרויקט אבטחת AI של OWASP Gen)
NIST AI 100-2, Adversarial Machine Learning — taxonomy and terminology for AI system attacks and mitigations. (מרכז המשאבים לאבטחת מחשבים של NIST)
CVE and NVD references relevant to agentic execution boundaries — CVE-2026-27966, CVE-2024-42835, CVE-2025-53355, CVE-2025-66414, and CVE-2025-67511. (NVD)
AI Pentester in 2026, How to Test AI Systems Without Confusing the Two — Penligent. (Penligent)
Agentic AI Security in Production, MCP Security, Memory Poisoning, Tool Misuse, and the New Execution Boundary — Penligent. (Penligent)
Pentest AI Tools in 2026, What Actually Works, What Breaks — Penligent. (Penligent)
Overview of Penligent.ai’s Automated Penetration Testing Tool — Penligent. (Penligent)
Plans and Pricing — Penligent, for deployment shape, workflow features, and private model integration details. (Penligent)

