מדוע "דליפת חשיבה פנימית של OpenClaw" היא סוג של אירוע אמיתי, ולא רק מם
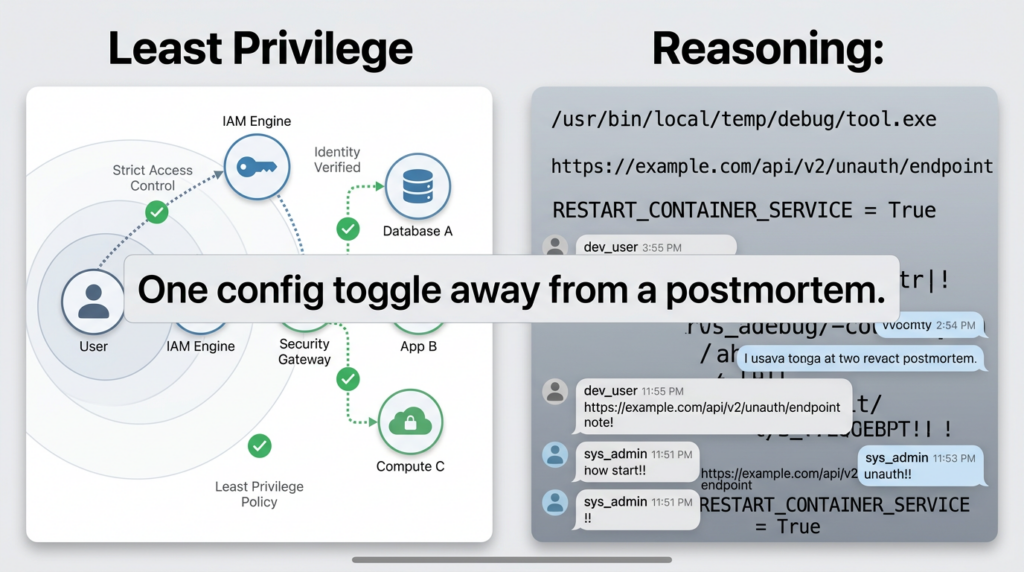
"דליפת ההיגיון הפנימי של OpenClaw" נשמע כמו דיווח על באג בודד. בפועל, מדובר במצב של כשל חוזר ונשנה: OpenClaw בסופו של דבר העברת טקסט של תכנון פנימי או "מחשבות" אל משטחים הנראים למשתמש—לפעמים כהודעות רגילות בתוך Discord או Telegram, לפעמים מוצגות בממשק המשתמש האינטרנטי, ולפעמים נשלחות כהודעה נפרדת המופיעה לפני התשובה הסופית.
זה חשוב משום שתוכן "ההיגיון" אינו תוכן מילוי תמים. בסביבות ריצה של סוכנים, תכנון מפורט כולל לעתים קרובות כוונת הכלי, כתובות URL, נתיבי קבצים, תוצאות ביניים, ולעיתים גם אסימונים או מזהים—אותם פריטים שצוותי האבטחה משקיעים שנים בניסיון למנוע את כניסתם ליומני הצ'אט, למערכות הכרטיסים ולחבילות התמיכה.
החדשות הטובות הן שאפשר להתייחס לזה כמו לכל בעיה אחרת בתחום הנדסת האבטחה: להגדיר מה אסור בשום פנים ואופן לחצות את גבול הפלט, לאכוף זאת בקוד ובהגדרות, ולבצע בדיקות רציפות לאיתור רגרסיות. שאר המאמר בנוי בדיוק סביב נושא זה.
מהו "היגיון פנימי" במונחי OpenClaw, ומה נחשב לדליפה?
OpenClaw פועל בין ערוצי ההודעות לבין ספק LLM אחד או יותר. בצינור זה ניתן לראות כמה סוגים שונים של "נתונים פנימיים":
- חסמים מחשבתיים / חשיבה פנימית: תכנון שנוצר על ידי מודל ואמור להישאר פנימי.
- קריינות כלי עבודה: "תן לי לבדוק את X... עכשיו אני אפעיל את Y..."
- הודעות מערכת / הודעות ברכה: הוראות ומדיניות נסתרות שאסור בשום פנים ואופן להציג כתוכן משתמש.
- פלט מפורט של הכלי: פלט סטנדרטי גולמי, ארגומנטים של כלי, כתובות URL ונתונים שנאספו במהלך פעולות.
דליפה מתרחשת כאשר אחד מהרכיבים הללו מופיע כתוכן גלוי למשתמש בערוץ שאמור לקבל רק התשובה הסופית.
ההנחיות לאבטחה של OpenClaw עצמה מציינות במפורש כי הסברים מפורטים ופלט מפורט עלולים לחשוף פרטים פנימיים, ויש להתייחס אליהם כאל מידע המיועד לאיתור באגים בלבד, במיוחד בקבוצות. (OpenClaw)
ראיות מאומתות לכך שהדליפה מתרחשת בכל הערוצים
זהו אינו חשש תיאורטי. דוחות רבים בנושא מראים כי שיקולים פנימיים ואף תוכן של הנחיות המערכת נחשפים למשתמשים.
Discord, תוכן שנחשב כהודעות רגילות
בפוסט ב-GitHub מתועדת העברת תהליכי חשיבה פנימיים ישירות להודעות ב-Discord במגוון מודלים. כמו כן, מצוין בו כי קיימים שני מרכיבים חשודים: פרמטר "thinking=low" שמוגדר גם במודלים שאינם מבצעים תהליכי חשיבה, וכן כישלון בסינון ה- הנמקה שדה לפני השליחה לערוץ. (GitHub)
צ'אט מקוון, הנחיות מערכת ובלוקי חשיבה המוצגים בממשק המשתמש
בדו"ח נוסף נטען כי עם פתיחת שיחה חדשה, הודעת הברכה של המערכת עשויה להופיע כאילו נשלחה על ידי המשתמש, וכי בלוקי מחשבה נראים גם בממשק הצ'אט. (GitHub)
בטלגרם, מופיעות הודעות נפרדות תחת הכותרת "הנמקה:"
דו"ח ספציפי ל-Telegram מתאר דליפה לסירוגין שבה מופיעה הודעה נוספת המתחילה ב"Reasoning:" ואשר אושר כי היא נראית למשתמשים ב-Telegram ולא רק ביומנים הפנימיים. (GitHub)
WhatsApp, "[openclaw] הנימוק:" מופיע לפני התשובה
תקלה ב-WhatsApp מתארת הודעה הנראית למשתמש, הכוללת טקסט של הנמקה פנימית (שבראשו מופיע הכיתוב "[openclaw] הנמקה:") לפני התשובה הסופית של העוזר. (GitHub)
מדוע זה התפשט כל כך מהר בקהילת האבטחה
ברגע שהדבר מתחיל להופיע בפלטפורמות צ'אט חיצוניות, שני גורמים מגבירים את התופעה:
- זה הופך ל- פגיעה בפרטיות ובאמון שבעלי עניין שאינם בעלי רקע טכני מבחינים בהם מיד.
- זה הופך ל- חתימת אירוע הניתנת לחיפוש—מהנדסים יכולים להדביק את הביטוי המדויק "דליפת היגיון פנימי של OpenClaw" ולהגיע לתיקים הרלוונטיים ולשרשורי הדיון בנושא.
לכן ביטוי זה מתפקד כ"קוד שגיאה של IOC לכישלון תפעולי", ולא כקוריוז נישתי.
מודל סיכונים: מה עלול לדלוף ומדוע על אנשי האבטחה להתייחס לכך
צוותי האבטחה צריכים להתייחס לדליפת מידע כאל חשיפת מידע עם רדיוס פגיעה מצטבר. זה לא רק עניין של הטקסט עצמו; זה עניין של מה שהטקסט מגלה על הסביבה ועל מישור הבקרה שלך.
מה מכילים בדרך כלל הדלפות בסביבות הריצה של הסוכנים
גם כאשר המודלים מנסים לנהוג בזהירות, עקבות ההנמקה והמפורטות כוללות לעתים קרובות:
- הכוונה של הכלי והפעולה, כולל מה שהוא עומד לקרוא או לבצע
- כתובות URL, שמות מארחים, נקודות קצה פנימיות ופרמטרי שאילתה
- נתיבי קבצים, רמזים למבנה התיקיות ושמות סביבות העבודה
- "אני אבדוק את הקובץ config / אבדוק את משתני הסביבה / אפתח את היסטוריית הפעולות"
- תוצאות חלקיות של כלי או נתונים ביניים מובנים
במסמכי האבטחה של OpenClaw מופיעה אזהרה לפיה פלט מפורט עשוי לכלול ארגומנטים של הכלי, כתובות URL ונתונים שהמודל נחשף אליהם, והמלצה להשאיר את האפשרות "reasoning/verbose" מושבתת בחדרים ציבוריים. (OpenClaw)
מדוע זה חמור יותר מדליפת מידע רגילה של צ'אט-בוט
בסביבת ריצה סוכנתית, המודל לא רק עונה על שאלות. הוא משולב במערכת ש:
- מסלולים באפליקציות צ'אט
- שומר על זיכרון הפעלה
- יכול להפעיל כלים ולתקשר עם משאבי המארח
כלומר, דליפה עלולה לחשוף לא רק תוכן, אלא גם כיצד להשפיע על פעולות עתידיות. מודל האבטחה של OpenClaw מדגיש כי הוא תוכנן סביב גבול מפעיל יחיד ואמין, ואינו מיועד לשמש כגבול רב-דיירים עויין עבור משתמשים עוינים החולקים שער גישה אחד. (OpenClaw)
טבלה המציגה את ההשפעות המעשיות
| תופעת דליפה | מדוע זה נושא רגיש | סיכון אופייני במורד הזרם |
|---|---|---|
| קטעי שורת פקודה של המערכת | מציג מדיניות, הרשאות כלים, לוגיקת בקרה | הזרקת פקודות הופכת לקלה יותר, וניסיונות לעקוף את המדיניות נעשים ממוקדים יותר |
| ארגומנטים של כלי וכתובות URL | חושף נקודות קצה פנימיות, אסימונים במחרוזות שאילתה, מבני בקשות | בדיקות בסגנון SSRF, שימוש חוזר בפרטי הזדהות, השערות לגבי תנועה רוחבית |
| נתיבי קבצים ושמות קבצים | מגלה היכן עשויים להסתתר סודות | ניסיונות גניבת מידע ממוקדים, כפייה בסגנון "לך לקרוא את ~/.ssh/…" |
| תפוקות ביניים | מציג נתונים שנאספו מכלי עבודה | דליפה לא מכוונת של מידע אישי מזהה (PII) וכתובות IP ליומני צ'אט של צד שלישי |
| מזהי ערוץ/הפעלה | מגלה כיצד פועל ניתוב | הנדסה חברתית וניסיונות שידור חוזר נגד פעילות תפעולית |

הגורמים העיקריים: לרוב, הדליפה נובעת מאחד מחמשת הפגמים ההנדסיים
תיתקלו בתסמינים שונים בהתאם לספק, למתאם הערוצים ולנתיב הממשק, אך הגורמים הבסיסיים מתרכזים בקבוצה מצומצמת.
1) הספק מחזיר שדה נימוק, והמתאם מעביר אותו
הדיווח ב-Discord מתאר במפורש כי לא הצליחו לסנן את הנמקה שדה לפני שליחת הפלט ל-Discord. (GitHub)
זוהי התקלה הפשוטה ביותר: הצינור מקבל כהלכה שדות מובנים נפרדים, אך אינו מצליח לאכוף את הכלל "final-only" בגבול הערוץ.
2) נתיבי הזרמה מתייחסים ל"חשיבה" כאל אסימונים רגילים
גם אם מסלול התגובה שאינו מבוסס זרם אינו כולל תהליכי חשיבה, לרוב קיים מסלול קוד שונה בזרם. אם המערכת מרכיבה קטעים ומעבירה אותם, היא עלולה בטעות להעביר סוג קטע שגוי לערוץ.
ניתן לראות את המציאות התפעולית בדו"ח Discord: תוכן ההסבר מופיע "לפני התשובה עצמה או במקומה", דבר האופייני לבאגים בשידור חי או בהרכבת הודעות מרובות. (GitHub)
3) באגים בתצוגת ממשק המשתמש, הודעת המערכת הופכת לתוכן של המשתמש
הבעיה בצ'אט המקוון היא דוגמה מובהקת לכשל בתצוגה: טקסט ההודעה המוקדמת של המערכת מוצג בצ'אט כאילו נשלח על ידי המשתמש, וניתן לראות את "בלוקי המחשבה". (GitHub)
זו אינה "התנהגות לדוגמה". מדובר בתקלה בגבול ה-front-end או בעיצוב ההודעה.
4) אפשרויות ניפוי באגים המשמשות בחדרים ציבוריים
בהנחיות האבטחה של OpenClaw מובהר במפורש כי /הנמקה ו /מפורט עלול לחשוף שיקולים פנימיים או תוצאות של כלים שאינם מיועדים לערוצים ציבוריים, ולכן מומלץ להשאיר אותם מושבתים בחדרים ציבוריים. (OpenClaw)
גם אם הדליפה שאתם רואים אינה מכוונת, היא לרוב מחמירה כאשר פונקציות האיתור והתיקון מופעלות באופן נרחב.
5) תצורה שגויה בשילוב עם חשיפה – האינטרנט מגלה את "הנשק העצמי" במהירות
גם אם תתקנו את דליפת ההיגיון, הגישה הכוללת של OpenClaw היא בעלת חשיבות, שכן שערים חשופים מושכים אליהם בדיקות מיידיות. חברת Bitsight מתארת כי הבחינה בעשרות אלפי מופעים חשופים ומציינת כי בדיקות עלולות להגיע במהירות כאשר שער נגיש. (Bitsight)
זה המקום שבו "דליפת ההיגיון" הופכת לחלק משרשרת כשלים רחבה יותר: פלט האיתור והתיקון מדליף פרטים, החשיפה מושכת תוקפים, וכעת יש לתוקף הקשר.
תוכנית בלימה של 15 דקות: עצרו את הדימום לפני שתתחילו לאתר את כל הבאגים
אם אתם נתקלים ב"דליפת היגיון פנימי של openclaw" בערוץ כלשהו, בצעו תחילה את הפעולות הבאות. צעדים אלה נועדו לצמצם את הנזק גם אם טרם זיהיתם את הבאג המדויק.
1) התייחסו לכך כהפרת גבולות, והחליפו את כל מה שעלול היה להיחשף
יש להניח שכל מה שהסוכן יכול היה לראות עשוי להופיע ביומני הצ'אט. יש להחליף או לבטל:
- אסימוני בוט עבור פלטפורמת ההודעות המושפעת
- מפתחות API של הספק שבהם משתמש הסוכן
- אסימוני רענון OAuth ואישורי אפליקציות שהסוכן עשוי היה לקבל גישה אליהם
- כל סוד המאוחסן במארח שהסוכן יכול להתייחס אליו
אם אתם זקוקים לתזכורת לכך שחשיפת אסימונים עלולה להיות הרת אסון מבחינה תפעולית, ההודעות של OpenClaw כוללות מקרים שבהם אסימונים מופיעים ביומנים או בדוחות שגיאות ללא השחרה. (GitHub)
2) השבת את האפשרות "הנמקה" ו-"פירוט" בהקשרים קבוצתיים
ההנחיות של OpenClaw בנושא אבטחה ברורות: שמרו על /הנמקה ו /מפורט מוגבלים בחללים ציבוריים. (OpenClaw)
גם אם הדליפה שלך היא "לא מכוונת", השבתת ממשקים דמויי-איתור באגים מפחיתה את הסיכוי שהפלטפורמה תשדר עקבות פנימיות.
3) צמצמו את חשיפת הרשת, והרחיקו את השער מרשתות שאינן אמינות
התיעוד של OpenClaw מציין את יציאת השער, מצבי הקישור, ואת הסיכון להגדלת שטח התקיפה בעת קישור לממשקים שאינם loopback. (OpenClaw)
אם עליכם לגשת מרחוק, העדיפו פתרון ששומר על קישור לולאה (loopback) ומוסיף שכבת בקרת גישה, במקום לחשוף את השער ישירות.
4) שדרגו לגרסאות מתוקנות עבור בעיות ידועות בעלות חומרה גבוהה
גם אם הבעיה המיידית שלכם היא דליפת היגיון, השימוש בגרסאות שידוע כי הן פגיעות מחליש את כל אמצעי ההגנה האחרים. לבעיות מסוג ClawJacked ולפגיעויות אחרות היו מחזורי תיקון מהירים, ופורסמו דיווחים רבים הממליצים על שדרוג מיידי לגרסאות המתוקנות. (BleepingComputer)
הפתרון הקבוע: לאכוף פלט מסוג "final-only" בגבול הערוץ
הכלת הבעיה קונה לך זמן. הפתרון שניתן ליישם בקנה מידה גדול הוא כלל פשוט:
לא משנה מה המודל מחזיר, ולא משנה מה ממשק המשתמש מציג, רק "תוכן התגובה הסופי" רשאי לעבור מ-OpenClaw לערוצי העברת הודעות חיצוניים.
כלומר, אתה צריך חומר חיטוי שפועל לאחר תוצאת המודל מורכבת ו לפני הוא מועבר למתאם ערוצים.
תכנון של מטהר הפניות
חומר חיטוי יעיל אמור להתמודד עם כל אלה:
- הסר מבנה
הנמקהשדות, אם קיימים - הסר שורות המתחילות ב-"Reasoning:" המופיעות כהודעות נפרדות
- חסימת קטעי שורת פקודה מוכרים של המערכת (תבניות בעלות רמת ודאות גבוהה)
- למנוע את השמעת הקריינות של הכלי בערוצים הדורשים פלט נקי
- ניתן להסתיר סודות לפי תבנית (מפתחות AWS, אסימוני Slack, אסימוני GitHub וכו')
להלן דוגמה בפסאודו-קוד בסגנון TypeScript. התאם אותה לארכיטקטורת מתאם OpenClaw שלך, אך שמור על הרעיון: לבצע חיטוי ברגע האחרון האפשרי, קרוב לגבול הפלט.
// Defensive output sanitizer for messaging channels.
// Goal: ensure only final, user-intended content is emitted.
type ModelResponse = {
content?: string; // final user-facing content
reasoning?: string; // internal-only reasoning field (provider-specific)
tool_calls?: any[];
raw?: any; // provider raw payload (optional)
};
const RE_REASONING_PREFIX = /^\\s*(?:\\[openclaw\\]\\s*)?Reasoning:\\s*/i;
const RE_SYSTEM_PROMPT_HINTS = /(A new session was started|Do not mention internal steps|system prompt)/i;
// Minimal secret patterns (extend carefully; avoid false positives in normal text).
const RE_SECRETS = [
/AKIA[0-9A-Z]{16}/g, // AWS access key id
/xox[baprs]-[0-9A-Za-z-]{10,}/g, // Slack tokens
/ghp_[0-9A-Za-z]{30,}/g, // GitHub PAT (classic)
];
export function sanitizeForExternalChannel(input: ModelResponse | string): string {
let text = typeof input === "string" ? input : (input.content ?? "");
// If the provider returned a separate reasoning field, ignore it completely.
// Never append it to user content.
// (If your pipeline currently merges reasoning->content, stop doing that.)
// Drop stray "Reasoning:" lines if they slipped into content.
text = text
.split("\\n")
.filter(line => !RE_REASONING_PREFIX.test(line))
.join("\\n");
// Block obvious system-prompt leakage patterns.
if (RE_SYSTEM_PROMPT_HINTS.test(text)) {
text = "I can’t display internal instructions. Please rephrase your request.";
}
// Redact common secret formats.
for (const re of RE_SECRETS) text = text.replace(re, "[REDACTED]");
// Trim to avoid empty / whitespace-only posts.
text = text.trim();
// As a last resort, ensure something safe is returned.
if (!text) text = "Done.";
return text;
}
זה אינו תחליף לתיקונים במעלה הזרם, אך הוא מונע סוג שלם של רגרסיות — במיוחד מהסוג המתואר בבעיה ב-Discord, שבה ההנמקה מופיעה לפני הפלט הסופי משום שהמתאם לא מסנן אותה. (GitHub)
הוסף בדיקת רגרסיה המדמה את מצב הכשל המדויק
הדרך המהירה ביותר למנוע את הישנות התופעה היא בדיקה קצרה המזריקה אובייקט תגובה המכיל הנמקה שדה והודעה המתחילה ב"נימוק:".
import { sanitizeForExternalChannel } from "./sanitize"; test("אינו מדליף את שדה ה-reasoning או את השורות Reasoning:", () => { const resp = { content: "Reasoning: אני אחפש ביומנים הפנימיים\\nהנה התשובה הסופית.", reasoning: "שרשרת מחשבות פנימית שאסור בשום אופן לדלוף", };
const out = sanitizeForExternalChannel(resp); expect(out).toBe("הנה התשובה הסופית."); });
אם אתם מפעילים מספר מתאמי ערוצים, בצעו את אותה סדרת בדיקות עבור כל נתיב מתאם. הדוחות של Telegram ו-WhatsApp מראים כי דליפה עשויה להתבטא בהודעות נוספות או בקידומות, בהתאם למתאם. (GitHub)

איתור תפעולי: זיהוי דליפות ביומנים לפני שהמשתמשים מדווחים עליהן
אתה רוצה מערכת התרעה מוקדמת שתתריע בפניך ש"ההיגיון בורח" לפני שזה יופיע בערוץ ציבורי.
גישה קלה ליישום היא לעקוב אחר יומני ההודעות היוצאות (או יומני נתוני ה-webhook) ולהתריע על דפוסים בעלי רמת ודאות גבוהה.
דוגמה ל-#: סריקת יומני הודעות יוצאות לאיתור סימנים לדליפת חשיבה # התאם את נתיב היומן לפריסה שלך.
LOG=/var/log/openclaw/outgoing.log grep -E -n "(\\[openclaw\\]\\s*Reasoning:|^Reasoning:|internal monologue|Do not mention internal steps)" "$LOG" \\ | tail -n 50
זה לעולם לא יהיה מושלם, אך הוא מזהה את הצורות הנפוצות ביותר המופיעות בדוחות על בעיות ציבוריות: קידומות מסוג "הנמקה:" ודליפות מפורשות בסגנון "אין להזכיר שלבים פנימיים". (GitHub)
יש להקשיח את הסביבה, להניח שהסוכן הוא בעל הרשאות מיוחדות ולבודד אותו
גם אם מתבצע ניקוי מושלם של הפלט, עליכם לחזק את סביבת ההפעלה, שכן OpenClaw הוא מישור בקרה בעל הרשאות גבוהות מעצם תכנונו.
תיעוד האבטחה של OpenClaw עצמו מתייחס באופן מפורש למודל האמון שלה: הוא מניח פריסה של עוזר אישי עם גבול מפעיל אחד מהימן, ואינו מתוכנן כגבול אבטחה רב-דייר עויין. (OpenClaw)
הדיווחים בנושא אבטחה חיצונית חוזרים על אותה המלצה מעשית: יש להתייחס ל-OpenClaw כאל ביצוע קוד לא מהימן עם אישורים קבועים, ולהריץ אותו בסביבות מבודדות ולא בתחנות עבודה ארגוניות רגילות. (TechRadar)
צעדי אבטחה מינימליים יעילים
- הקפידו שהשער יישאר מקושר ל-loopback, אלא אם כן יש לכם בקרות גישה קפדניות
- השתמש במארח ייעודי או במכונה וירטואלית עבור סביבת ההפעלה של הסוכן
- יש לצמצם את מספר פרטי הזיהוי ולהחליפם בתדירות גבוהה
- הקפידו להשאיר את הגישה לערוץ ברשימת המאושרים והימנעו מהודעות פרטיות פתוחות לציבור
- להתייחס לתוספות ולמיומנויות כאל גבול בשרשרת האספקה
הניתוח של Bitsight בנוגע למקרים שבהם התגלו נקודות תורפה מדגיש את הסיבה לכך: ברגע שניתן להגיע לשער, ניתן לבצע סריקה במהירות, והתוקפים יכולים לדלג על "שכבת ה-AI" לחלוטין ולכוון את ההתקפה ישירות למישור הבקרה. (Bitsight)
פגיעות CVE והודעות אבטחה שהופכות דליפות היגיון למסוכנות יותר
דליפת היגיון מדווחת לרוב כ"באג" ולא כ-CVE. אך ההשפעה על האבטחה מתעצמת כאשר משלבים אותה עם פגיעויות ידועות המשפיעות על טיפול באסימונים, גישה לקבצים מקומיים וקישוריות לשער.
CVE-2026-25253, גניבת אסימון באמצעות חיבור אוטומטי ל-gatewayUrl
ה-NVD מתאר את CVE-2026-25253 כבעיה שבה OpenClaw משיג כתובת השער ממחרוזת שאילתה ויוצר באופן אוטומטי חיבור WebSocket ללא בקשה, תוך שליחת ערך אסימון. (NVD)
מדוע זה חשוב בהקשר של דליפות מידע:
- הערות נימוק ותיעוד מפורט כוללים לעתים קרובות כתובות URL והקשר של ניתוב
- כל דליפה שחושפת כיצד מטפלים בכתובת ה-URL ובאסימון של השער שלך עלולה לקצר את הדרך של התוקף לגניבת האסימון
- זה מחזק את המדיניות: אסור שאסימונים יופיעו ביומנים, בצ'אט או בממשק המשתמש
CVE-2026-25475, הטיפול בנתיב MEDIA מאפשר קריאה של קבצים מקומיים שרירותיים
ב-NVD מתואר CVE-2026-25475 כפגם שבגרסאות שקדמו ל-2026.1.30, פונקציה מאפשרת נתיבי קבצים שרירותיים, וסוכן יכול לקרוא כל קובץ במערכת על ידי הפקת נתיב MEDIA, מה שמאפשר הוצאת מידע למשתמש/לערוץ. (NVD)
לכך יש השלכות שליליות על דליפת ההיגיון:
- דליפת היגיון עלולה לחשוף נתיבי קבצים שכדאי לכוון אליהם
- דליפת ערוצים עלולה להפוך למנגנון הוצאת מידע אם קיימים פונקציות בסיסיות לקריאת קבצים
- זה מחזק את הטיעון בעד ניקוי פלט והגדרת הרשאות קפדניות לכלים
CISA מציינת את ה-CVE הזה גם בסיכום הפגיעות שלה, מה שמספק אינדיקציה מועילה לאנשי אבטחה העוקבים אחר סדר העדיפויות המוסמך. (CISA)
CVE-2026-26329, מעבר נתיבים בהעלאת קבצים בדפדפן וקריאת קבצים מקומיים, הערה בנוגע לסנכרון NVD
קיים רישום CVE עבור CVE-2026-26329 המתאר פרצת "מעבר נתיב" בפעולת ההעלאה של כלי הדפדפן, המאפשרת לתוקפים בעלי הרשאות לקרוא קבצים שרירותיים ממארח השער בגרסאות שקדמו לגרסה 2026.2.14. (OpenCVE)
בזמן כתיבת שורות אלה, ייתכן שהדף של NVD יציג את ההודעה "CVE ID Not Found" (לא נמצא מזהה CVE), מה שמעיד בדרך כלל על עיתוי סנכרון מסד הנתונים ולא על היעדר הרשומה הבסיסית. (NVD)
שוב, הקשר ברור: אם המערכת שלכם מסוגלת לקרוא קבצים ואתם חושפים מידע תפעולי פנימי בממשק צ'אט, אתם מטשטשים את גבולות הסודיות הן ברמת הכלי והן ברמת התפוקה.
ClawJacked, אתרי אינטרנט החוטפים סוכנים מקומיים, דחיפות התיקון
מספר אתרי אבטחה מדווחים על פרצת אבטחה חמורה המכונה ClawJacked, אשר אפשרה לאתרים זדוניים להשתלט על מופעים מקומיים של OpenClaw; התיקונים שוחררו בסביבות ה-26 בפברואר 2026. (BleepingComputer)
זה לא "דליפת היגיון", אבל זה משנה את האופן שבו צריך להתייחס לכל זמן הריצה:
- אם מתקפה שמקורה בדפדפן מצליחה להשתלט על המערכת, התפוקות והעקבות של הסוכן שלך יהיו בשליטת התוקף
- דליפת היגיון הופכת אז לכלי להנדסה חברתית ולחילוץ נתונים, גם אם היא החלה כבאג
אזהרות בנוגע לחשיפת יומנים ואסימונים
הודעות האבטחה של OpenClaw מתארות גם מקרים שבהם אסימונים עלולים להיחשף בהודעות שגיאה ובדפיקות ערימה, אם יומני הרישום לא עוברים עריכה. (GitHub)
זה מחזק אמת לא נעימה: אתה חייב להגן כל משטח שממנו הטקסט עלול לברוח—צ'אט, ממשק משתמש, יומנים, דוחות קריסה וחבילות תמיכה.
הבטחה מתמשכת: הפכו את "היעדר דליפת היסק" לתכונה שאתם בודקים
אם אתם מפעילים את OpenClaw בסביבה רצינית כלשהי, התייחסו ל"אי-דליפת היגיון פנימי" כאל תכונה שעברה בדיקות רגרסיה.
השתמשו בבדיקת האבטחה המובנית של OpenClaw באופן קבוע
במסמכי האבטחה של OpenClaw מומלץ במפורש להפעיל ביקורת אבטחה של OpenClaw (כולל מצבי Deep ו-Fix) במיוחד לאחר שינוי תצורה או חשיפת נקודות תורפה ברשת. (OpenClaw)
לכל הפחות, צרו שגרה כמו:
בדיקת אבטחה של Openclaw בדיקת אבטחה של Openclaw --deep
לאחר מכן, שלבו את התפוקה בתהליך העבודה השוטף שלכם, בדיוק כפי שהייתם עושים במקרה של סטייה בתשתית.
מטריצת בדיקה פשוטה ברמת הערוץ
הכינו מטריצת בדיקות בסיסית והריצו אותה לאחר כל שדרוג:
| ערוץ | הנחיות למבחן | צפוי | חתימת כשל |
|---|---|---|---|
| דיסקורד | הודעה המפעילה שימוש בכלי רב-שלבי | התשובה הסופית בלבד | "המשתמש הוא...", "ההיגיון:...", קריינות הכלי |
| טלגרם | הודעה המפעילה את תהליך התכנון | התשובה הסופית בלבד | הודעה נפרדת תחת הכותרת "נימוקים:" (GitHub) |
| הודעה המפעילה את תהליך התכנון | התשובה הסופית בלבד | הודעת "[openclaw] נימוק:" (GitHub) | |
| צ'אט מקוון | /new או /reset | לא מוצגת הודעת מערכת | הודעת הפתיחה של המערכת נראית לעין (GitHub) |
הוסף שכבת עריכה של סודות, גם אם אתה "לא מתעד סודות"
העניין הוא לא להסתמך על היגיינה מושלמת במעלה הזרם. העניין הוא שיהיה מנגנון אבטחה סופי שיחסום סודות כאשר הם מופיעים בטעות.
היו זהירים בשימוש בתבניות, מדדו את שיעור התוצאות החיוביות השגויות, והקפידו לטשטש את המידע לפני שתשלחו אותו לפלטפורמות צד שלישי.
השימוש ב-Penligent מתאים רק כאשר זה בא באופן טבעי
אם אתם צוות אבטחה המבצע אימות של פריסת OpenClaw, החלק הקשה ביותר הוא לעתים רחוקות "איתור באג". הקושי האמיתי טמון בהוכחה שהבקרה עדיין תקפה לאחר שדרוגים, החלפת מודלים ושינויים בתצורה. דרך מעשית להפחית את עומס האימות היא להתייחס לסביבת הריצה של הסוכן כמו לכל יעד בעל ערך גבוה אחר, ולבדוק באופן רציף את החשיפה שלו: נגישות לשער, גבולות CVE ידועים, והאם אובייקטים רגישים עלולים לדלוף לממשקי צ'אט.
ניתן להשתמש ב-Penligent במסגרת תהליך אימות זה: לבצע בדיקות אוטומטיות של נקודות החשיפה של OpenClaw הנגישות מבחוץ, לאמת את גבולות התיקונים לבעיות שתועדו בפומבי, וליצור תוצאות ברמת הוכחה המענות על השאלה "האם אנחנו עדיין בטוחים לאחר שינוי זה" במקום להסתמך על תחושת בטן. אם אתם כבר עוקבים אחר השינויים בגבולות האבטחה של OpenClaw, המאמרים הקודמים של Penligent בנושא חיזוק השוק ופרשנות גבולות האבטחה מספקים הקשר שימושי לשילוב בדיקות אלה לתוך נוהל חוזר. (Penligent)
סיכום: מה לעשות עכשיו אם חיפשתם "דליפת חשיבה פנימית ב-OpenClaw"
- אמת אילו נתיבי ערוצים דולפים והאם מדובר בדליפה מובנית
הנמקההעברה, עיבוד ממשק המשתמש או הרכבת הודעות מרובות. (GitHub) - יש לנקוט בצעדים מיידיים: להשבית את האפשרות ל"היסק" ו"פירוט" בחדרים ציבוריים, לצמצם את החשיפה, ולהחליף את מה שעלול להיות בסכנה. (OpenClaw)
- תקן באופן קבוע: אכוף פלט סופי בלבד בגבול האחרון, הוסף בדיקות רגרסיה, ופקח על סימני דליפה. (GitHub)
- יש להגן על המערכת כמו על שירות מיוחס: לבודד את סביבת ההפעלה, להשאיר את השער מחוץ לרשתות לא מהימנות, ולהניח שתחול סטייה. (OpenClaw)
- אל תסתפקו בתיקון "באגים של דליפת נתונים": עקבו אחר תקני CVE המשפיעים על טיפול באסימונים וקריאת קבצים מקומיים, שכן הם מחמירים את ההשלכות של כל דליפה. (NVD)
קישורים מומלצים וקריאה נוספת
- תיעוד אבטחה של OpenClaw, מודל האמון, פקודות ביקורת, הסברים והנחיות מפורטות (OpenClaw)
- דיווח על תקלת דליפת ההיגיון ב-Discord, השערות לגבי הגורם השורשי ל
הנמקההעברת שדה (GitHub) - הנחיות מערכת הצ'אט המקוון ובלוקי חשיבה המוצגים כטקסט הנראה למשתמש (GitHub)
- דו"ח על דליפת מידע ב-Telegram (GitHub)
- דו"ח על דליפת המידע ב-WhatsApp (GitHub)
- ניתוח של Bitsight על מופעים חשופים של OpenClaw ובחינת המציאות (Bitsight)
- סקירה כללית של הארכיטקטורה של Zscaler: שער OpenClaw ומשטחי התעלה (Zscaler)
- דיווח על אזהרה הקשורה למיקרוסופט בנוגע לבידוד ולטיפול בסביבות הרצה של סוכנים כאל ביצוע קוד לא מהימן (TechRadar)
- הערך ב-NVD עבור CVE-2026-25253, אסימון שנשלח במהלך חיבור WebSocket אוטומטי (NVD)
- הערך ב-NVD עבור CVE-2026-25475: טיפול בנתיב MEDIA מאפשר קריאה של קבצים מקומיים שרירותיים (NVD)
- רשומת CVE עבור CVE-2026-26329, מעבר נתיב בהעלאת כלי דפדפן וקריאת קובץ מקומי, וכן הערת סנכרון NVD (OpenCVE)
- דיווחי ClawJacked והקשר של גרסאות התיקון (BleepingComputer)
- Penligent, OpenClaw + VirusTotal ו-ClawHub: הקשר של גבולות שרשרת האספקה (Penligent)
- Penligent, פרשנות לגבולות האבטחה של OpenClaw 2026.2.23 (Penligent)

