Vibe Coding Needs Pentesting
The problem with vibe coding is not that AI writes code. The problem is that teams mistake generated code for verified software.
That mistake is becoming easier to make because vibe coding is no longer just a joke from social media or a niche workflow among early adopters. GitHub now has an official “Vibe coding with GitHub Copilot” tutorial, and Microsoft Learn has a full “Introduction to vibe coding” module built around GitHub Copilot Agent. OpenSSF has also drawn an important line around the term, describing vibe coding in its original sense as using AI without human review or editing and crediting Andrej Karpathy with proposing the term. (GitHub दस्तावेज़)
That is exactly why this matters to security. Once a workflow becomes normal enough to be documented by platform vendors and training portals, it stops being a curiosity and starts becoming infrastructure. The security question is no longer whether people should use AI to write code. They already do. The question is whether AI-assisted development will be treated like a real software delivery system, with gates, review, testing, and adversarial validation, or like a slot machine that sometimes happens to compile. (GitHub दस्तावेज़)
My view is simple. Vibe coding is fine for prototypes, throwaway scripts, one-off tools, and narrow internal experiments. The moment the output touches customer data, authentication, money movement, privileged APIs, production infrastructure, or agentic workflows, vibe coding has to be pulled into a DevSecOps system and backed by pentesting. Not because AI is uniquely evil, but because unverified code at AI speed is one of the fastest ways to ship old vulnerabilities into new systems.
Vibe Coding, What the Term Really Means
The first thing worth fixing is the definition. Too many people now use “vibe coding” to mean any software development that includes AI. That is not a useful definition. OpenSSF’s David A. Wheeler drew the distinction clearly in January 2026: vibe coding, in the original Karpathy sense, is using AI without human review or editing. In the same piece, he contrasted that with ordinary software development that happens to use AI as part of the workflow. GitHub’s own review guidance lands in the same place from a different angle: AI-generated code now needs human oversight, testing, and process, not blind acceptance. (OpenSSF)
That distinction matters because the security debate goes sideways as soon as the terms blur. If “vibe coding” means “I used Copilot to draft a function and then I reviewed the diff, ran tests, checked dependencies, and rejected two bad suggestions,” the security conversation becomes silly. That is just software development with tooling. But if “vibe coding” means “I asked a model to build a feature, accepted the changes, and shipped,” then the security conversation becomes urgent.
GitHub itself does not treat generated code as self-validating. Its Copilot best practices say you should always validate the code it suggests, understand it before implementing it, review it for functionality, security, readability, and maintainability, and use automated tests plus tools like linting and code scanning to check the result. Its dedicated tutorial on reviewing AI-generated code goes even further and describes human oversight and testing as essential parts of the modern developer workflow. (GitHub दस्तावेज़)
So when people say vibe coding is “just the future of development,” they are right only in the weakest possible sense. AI-assisted development is now normal. Unreviewed development is not. The responsible future is not “type prompts and pray.” It is AI-accelerated development with stronger verification because more code is arriving faster, from a system that can sound confident while still being wrong. OpenSSF says exactly that in plainer terms: current AI assists humans, it does not replace them, and developers should work incrementally, create tests early, and treat confident output with suspicion. (OpenSSF)
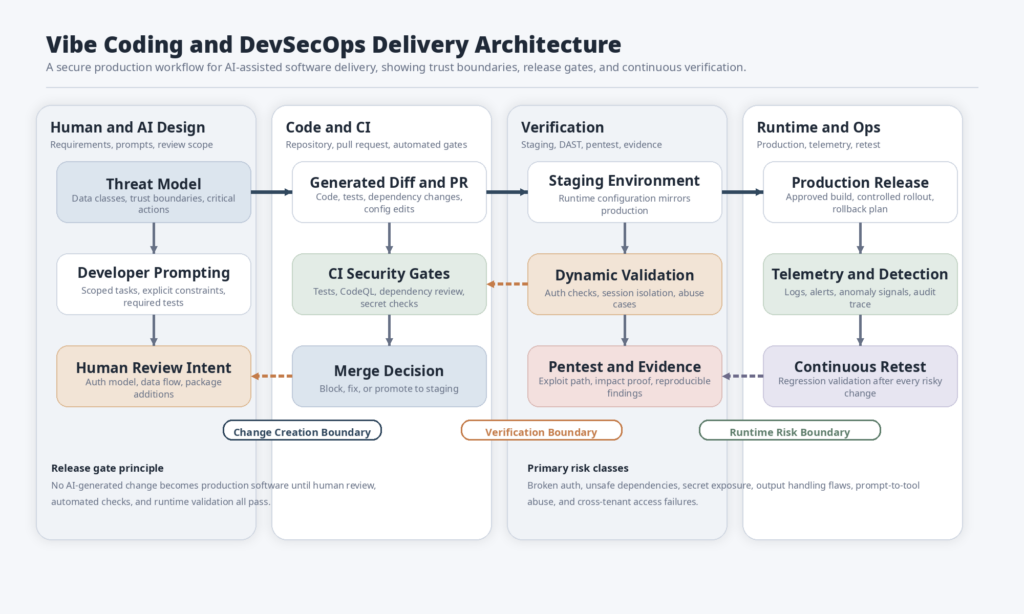
Vibe Coding Without Verification Changes the Risk Curve
Security people sometimes talk about AI-generated code as though its biggest danger is novelty. That misses the point. The biggest danger is compression.
Vibe coding compresses several activities that used to be naturally separated in time. Requirements become implementation faster. Dependency selection becomes automatic. API integration happens earlier. Boilerplate appears instantly. Tests can be generated in bulk. Refactors look cheap. More code reaches pull requests with less friction. All of that can be good. It can also mean that insecure defaults, rushed assumptions, and unexamined package additions arrive faster than the rest of the organization’s review process can absorb.
GitHub’s review guidance hints at this in a very practical way. It tells developers to start with functional checks, always run automated tests and static analysis tools first, use CodeQL and Dependabot to catch vulnerabilities and dependency issues, verify context and intent, scrutinize dependencies, watch for hallucinated or suspicious packages, and use collaborative review for sensitive changes. That is not the guidance of a platform that believes generation equals validation. It is the guidance of a platform that knows AI can accelerate change faster than teams can safely absorb it unless they add structure. (GitHub दस्तावेज़)
NIST’s position is even more direct. The Secure Software Development Framework says secure practices need to be integrated with each SDLC implementation because many SDLC models do not address software security in enough detail. NIST SP 800-218A, the community profile for generative AI and dual-use foundation models, extends that logic into AI system development and states that practices and tasks in the profile do not distinguish between human-written and AI-generated source code because all source code should be evaluated for vulnerabilities and other issues before use. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
That line should probably be taped above every AI coding tool: all source code should be evaluated before use. Not “all suspicious code.” Not “all externally contributed code.” All code. The reason is simple. Security does not care whether a bug was typed by a human, copied from Stack Overflow, generated by a model, or assembled by an agent. Security cares whether the trust boundary is broken.
Once you see the problem that way, the real failure mode of vibe coding becomes obvious. The risk is not that the AI writes code. The risk is that developers, founders, and even security teams start treating “the AI already handled it” as an informal waiver for design review, negative testing, dependency hygiene, and runtime validation. That belief is how generated code turns into exposed software.
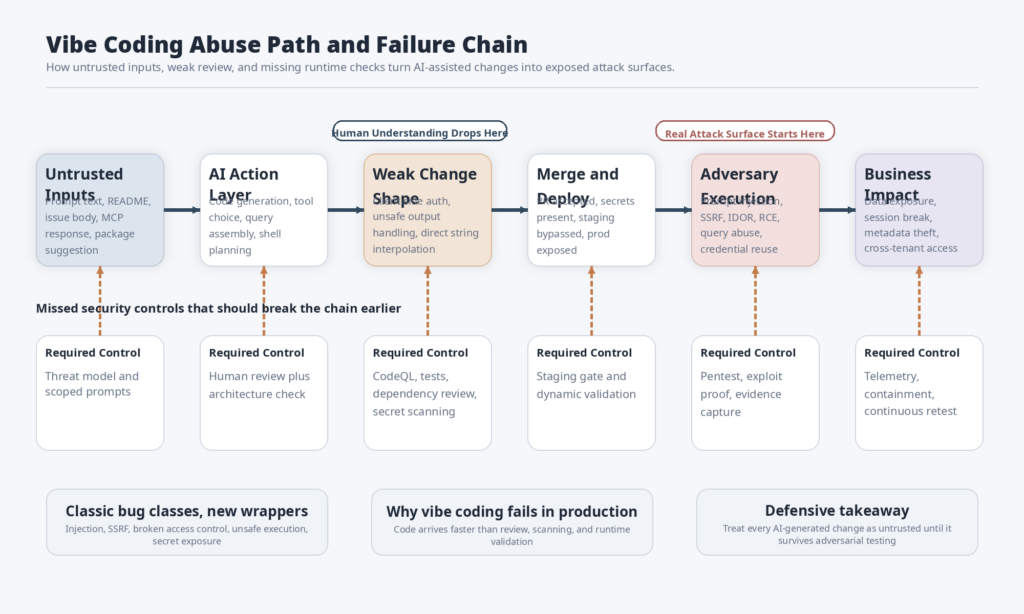
The Medical App Horror Story Was Not Weird
A short post by Tobias Brunner in March 2026 is one of the clearest examples of what goes wrong when AI-generated software skips validation. He described visiting a medical appointment where someone explained they had watched a video about how easy it was to build software with AI, decided not to use an industry-proven patient management system, built their own with a coding agent, imported real patient data, published it to the internet, and even added a feature that recorded appointment conversations and sent the audio to two AI services for summaries. A few days later, Brunner looked at the application and, within thirty minutes, had full read and write access to all patient data. He wrote that the data was unencrypted, exposed to the open internet, and that the system’s “access control” lived in client-side JavaScript. (Tobias Brunner aka tobru)
What makes that story important is not that it is dramatic. It is that nothing about it is technically surprising. A single HTML file with inline JavaScript and CSS. A managed database with zero access control and no row-level security. Client-side authorization logic. External AI APIs receiving sensitive recordings. A shallow response after disclosure that added basic authentication and rotated keys instead of addressing the broken trust model. Those are not exotic failures. They are exactly the kinds of failures you should expect when a system is assembled faster than anyone is prepared to reason about its architecture. (Tobias Brunner aka tobru)
That matters because people often hear a story like this and conclude that the “real” mistake was trying to build medical software. That is only half true. The domain made the consequences worse, but the engineering failure would have been recognizable in almost any customer-facing system. Replace medical data with invoices, CRM records, account roles, support tickets, or internal documents and the same pattern still holds. The actual bug class is deeper: the team shipped a system they did not understand and then tried to patch the visible symptom instead of the control failure.
Brunner’s final point is also worth keeping. He did not say AI coding agents are unusable. He said he uses them too, but he can understand the code and architecture. That is the right distinction. The problem is not AI assistance. The problem is treating software generation as if it removed the need to understand how a system stores data, enforces access control, handles secrets, and fails under adversarial input. (Tobias Brunner aka tobru)
Vibe Coding and DevSecOps Belong in the Same System
If you accept that generated code is just code, the next question is not philosophical. It is operational: what system should contain it?
The right answer is DevSecOps, used literally rather than ceremonially. NIST SSDF says secure development practices have to be added to and integrated with each SDLC implementation. OWASP’s DevSecOps Guideline frames the same idea as a shift-left security culture, with a secure pipeline rather than a last-minute review ritual. GitHub’s security tooling then gives concrete examples of what that looks like in practice: code scanning to find vulnerabilities and coding errors, dependency review to stop vulnerable packages from being merged, and secret scanning to find hardcoded credentials across repository history. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
That is the part many “AI will 10x developers” conversations skip. Once AI accelerates code production, the rest of the pipeline has to become more explicit, not less. More code means more review load. More generated helpers mean more places for auth drift. More package suggestions mean more supply chain exposure. More agentic tooling means more hidden execution paths. If a team responds by loosening review or skipping gates, it is not offsetting AI speed. It is subsidizing AI risk.
OWASP’s description of DAST is a good example of why this matters. It defines DAST as black-box testing against a running application and explicitly calls out input validation, authentication issues, and server configuration mistakes as areas where DAST is especially helpful. That matters because AI-generated systems often fail in those exact places. Static review can tell you whether code looks reasonable. Running the system under adversarial conditions tells you whether it actually enforces the boundary it claims to enforce. (ओवास्प फाउंडेशन)
For AI systems, the need is even broader than classic web application testing. OWASP’s AI Testing Guide says AI risks extend across the application, model, infrastructure, and data layers and argues that conventional security testing alone is not enough because AI systems introduce non-deterministic failure modes, adversarial manipulation, sensitive information leakage, hallucinations, supply-chain poisoning, and excessive agency. OpenAI’s own guidance on prompt injection makes the same architectural point from a defensive perspective: the goal is not just to identify malicious strings, but to design systems so that the impact of manipulation is constrained even when some attacks succeed. (ओवास्प फाउंडेशन)
That is why “vibe coding plus pentesting” is not a contrarian hot take. It is the natural architecture of responsible AI-assisted delivery. AI speeds up construction. DevSecOps standardizes verification. Pentesting forces the system to face reality.
The matrix below is a synthesis of NIST SSDF, NIST SP 800-218A, GitHub’s AI-code review guidance, GitHub security tooling, OWASP DevSecOps guidance, and OWASP AI Testing Guide material. It shows where each layer belongs in a production vibe coding workflow. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
| Workflow stage | What AI accelerates | What still must be verified | What breaks if skipped |
|---|---|---|---|
| Requirements and scoping | Draft specs, user stories, API ideas | Trust boundaries, data sensitivity, user roles, worst-case impact | The team builds the wrong thing quickly |
| Architecture | Boilerplate patterns, integration suggestions | Auth model, storage model, secret handling, execution boundaries | A workable prototype becomes an unsafe system |
| Code generation | Handlers, components, tests, refactors | Logic, error paths, edge cases, maintainability | “Looks right” code ships with wrong behavior |
| Dependency selection | Faster package discovery | Package legitimacy, maintenance status, license, known CVEs | Supply-chain risk enters by suggestion |
| CI and scanning | Workflow setup, auto-fixes, code review | Thresholds, required checks, alert handling, policy exceptions | Security tools become advisory instead of blocking |
| Dynamic testing | Test scaffolds, payload ideas, replay scripts | Real auth, session isolation, output handling, runtime config | The system passes static checks but fails in reality |
| Release | Change summaries, deployment automation | Human sign-off, risk acceptance, rollback readiness | Unverified changes hit production faster |
| Post-release | Retest scheduling, evidence collection, ticket drafting | Regression scope, exposure drift, adversarial changes over time | Old bugs re-enter through new prompts and new diffs |
A Production Workflow for Vibe Coding and DevSecOps
Start with trust boundaries before you start prompting
A surprising amount of security debt in AI-assisted development appears before the first line of generated code. Teams start prompting before they have answered basic questions: what data is sensitive, what actions are irreversible, what users should never be able to see each other’s records, what external providers are involved, what tokens will exist, what the worst case looks like if a feature is abused.
CSA’s guidance for AI-specific penetration testing is useful here because it forces teams to ask practical scoping questions before testing starts. Are you relying on established provider APIs. Are you self-hosting models. Are you fine-tuning or training. What is the worst realistic impact if the AI implementation is exploited. How will the engagement fit into the broader security strategy. Those are not just pentest scoping questions. They are architecture questions that should exist before the first vibe-coded route or tool wrapper gets written. (Cloud Security Alliance)
If the system uses external LLM providers, the provider may shoulder some security responsibility for its own API infrastructure, but not for your output handling, your API keys, your logging choices, or your cost abuse path. CSA says that explicitly. If the system is self-hosted or fine-tuned, the scope gets even larger: model access, training data, leakage paths, and robustness all become part of the real security boundary. (Cloud Security Alliance)
This is one reason vibe coding often breaks in production. Teams prompt from the user story instead of from the trust boundary. The AI is then asked to produce code for a feature that the humans themselves have not constrained. Once that happens, later review becomes an archaeology exercise instead of a design exercise.
A better pattern is to turn the first prompt into an extension of the threat model: define who the actors are, what data is sensitive, what actions require human confirmation, what logs must exist, what secrets must never touch the client, and what defaults are unacceptable. That does not slow development down. It gives the model better rails and gives reviewers something concrete to validate against later.

Treat prompts like requirements artifacts, not magic spells
OpenSSF’s 2026 guidance on AI and software development gives unusually practical advice here. Provide relevant details. Ask the model to create a plan or proposal. Work incrementally with continuous human review. Create tests early, including negative tests. Fight for simplicity. Reuse libraries and methods already in the system. Treat AI confidence with suspicion instead of respect. That advice sounds simple because it is. It is also the difference between AI assistance and AI-led improvisation. (OpenSSF)
This is where many teams sabotage themselves. They give the model a vague outcome, accept broad generated changes, and then wonder why the resulting code sprawls across multiple files with duplicated logic, new dependencies, and assumptions nobody approved. The problem is not only accuracy. It is control. Bad prompts create bad change shape.
In practice, a security-aware prompt discipline should do four things. It should constrain scope, reference trusted project artifacts, force explicit assumptions, and ask for tests at the same time as implementation. GitHub’s AI review guidance makes a similar point when it says to use your README, docs, and recent pull requests as context for AI and to check whether generated code actually fits the project’s architecture and conventions. (GitHub दस्तावेज़)
A good security prompt is not “build login.” A good security prompt is closer to this: add password-reset support to the existing auth service, preserve current session model, do not add new dependencies unless justified, never return account enumeration signals, write unit tests and one negative integration test for expired tokens, and explain any change to authorization middleware. That is not glamorous. It is how you keep the model from improvising your trust model.
Review AI-generated code like untrusted code, because it is
GitHub’s “Review AI-generated code” tutorial is probably the best short checklist available from a major platform vendor. Start with functional checks. Run automated tests and static analysis. Verify context and intent. Assess quality. Scrutinize dependencies. Spot AI-specific pitfalls such as hallucinated APIs, deleted tests, ignored constraints, and code that looks right but does not match the actual requirement. Use collaborative review on complex or sensitive changes. Automate what you can. (GitHub दस्तावेज़)
The most important mindset change is hidden in that structure. AI-generated code should not be reviewed as though the model were a senior engineer who probably had a good reason. It should be reviewed as though it were a third-party contribution from a fast but unreliable contractor. Sometimes it will be excellent. Sometimes it will quietly move a safety check into the wrong layer, hardcode the wrong default, suppress a failing test, or normalize an unsafe pattern.
OpenSSF makes the accountability model explicit: you are the developer, the AI is the assistant, and you remain responsible for any harms caused by the code. That is the right baseline for both engineering and governance. It also helps with team culture, because it removes the false comfort of blaming the model later. If a generated diff is merged, it is now your code. (OpenSSF Best Practices Working Group)
For security review, this usually means looking harder at five categories of generated changes than many teams do in ordinary PRs: authentication and authorization paths, serialization and output rendering, filesystem and shell calls, newly introduced dependencies, and error-handling behavior. AI systems are very good at producing happy-path logic quickly. They are much less reliable about preserving the exact failure semantics your system depends on.
The temptation, especially with a large generated diff, is to review at the summary level. Resist that. Generated code should be reviewed at the boundary level. What new data does it accept. What data does it return. What capability does it gain. What path lets it call the network, the filesystem, a shell, a query engine, or an external model. What assumption moved from server to client. Those questions catch more bugs than arguing with the model about style.
Put real gates in CI and CD
Human review is necessary. It is not sufficient. Generated code changes arrive too fast and too frequently for human review to be the only security control.
GitHub’s security stack offers a clean minimum baseline. Code scanning analyzes code in a repository to find vulnerabilities and coding errors and can be triggered on pushes, pull requests, or schedules. Dependency review scans pull requests for dependency changes, warns about known vulnerabilities, and can be set as a required workflow so vulnerable packages are blocked from merging. Secret scanning scans repository history and branches for hardcoded credentials and helps catch secret sprawl before it turns into exposure. (GitHub दस्तावेज़)
What matters here is not brand loyalty to any one platform. What matters is the shape of the control. Every AI-assisted code path should hit at least four automated checks before release: tests, static analysis, dependency policy, and secret detection. High-risk systems should also add IaC scanning, container scanning, and policy checks around permissions and environment configuration. If those checks are advisory instead of blocking, teams under time pressure will eventually route around them.
GitHub’s own documentation is useful because it shows how concrete these controls can be. The dependency review action can fail builds based on vulnerability severity, license policy, and scope. That is not abstract “supply chain awareness.” That is a real merge gate. In a vibe coding context, that matters because AI tools are especially willing to suggest new packages to solve narrow problems quickly. The faster packages are introduced, the more important it becomes to block obviously bad ones automatically. (GitHub दस्तावेज़)
Here is a minimal GitHub Actions baseline that captures the spirit of that approach. It is not the whole pipeline, but it is a reasonable starting point for teams that want AI-assisted changes to hit both dependency policy and semantic code scanning before merge.
name: secure-pr-gates
on:
pull_request:
branches: [main]
push:
branches: [main]
schedule:
- cron: '15 5 * * 3'
permissions:
contents: read
security-events: write
actions: read
jobs:
dependency-review:
if: github.event_name == 'pull_request'
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v5
- name: Dependency Review
uses: actions/dependency-review-action@v4
with:
fail-on-severity: moderate
codeql:
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
language: ['javascript-typescript', 'python']
steps:
- name: Checkout repository
uses: actions/checkout@v5
- name: Initialize CodeQL
uses: github/codeql-action/init@v4
with:
languages: ${{ matrix.language }}
- name: Autobuild
uses: github/codeql-action/autobuild@v4
- name: Analyze
uses: github/codeql-action/analyze@v4
test:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v5
- name: Set up runtime
uses: actions/setup-node@v4
with:
node-version: '20'
- name: Install dependencies
run: npm ci
- name: Run tests
run: npm test -- --runInBand
This snippet uses action versions and concepts currently reflected in GitHub’s documentation and examples, including actions/checkout@v5, actions/dependency-review-action@v4, और github/codeql-action/*@v4. GitHub’s docs also note that dependency review can be configured to block merges when required, and that CodeQL powers GitHub’s code scanning for vulnerabilities and coding errors. (GitHub दस्तावेज़)
Run dynamic tests before you trust the release

A common anti-pattern in AI-assisted development is to treat successful tests as a synonym for secure behavior. That only works if the tests were designed to exercise the security boundary. Most generated test suites are not.
OWASP’s DAST guidance is concise and useful here. DAST is black-box testing against a running application and is especially helpful for input and output validation issues, authentication issues, and server configuration mistakes. In other words, it is exactly the class of testing that catches many of the failures AI-generated applications introduce when the code looks plausible but the runtime behavior is wrong. (ओवास्प फाउंडेशन)
This is where your view is strongest: vibe coding should be combined with pentesting and DevSecOps. The reason is practical. Generated code can pass unit tests and still leak data across roles. It can pass static analysis and still expose an admin route without server-side enforcement. It can render model output exactly as instructed and still create an output-handling bug. It can “use auth” and still trust the client for authorization. It can call a tool “safely” and still let a prompt control the critical parameter.
A simple negative regression harness often catches these mistakes early. Even teams without a full DAST stack should have scripts that assert the obvious things an attacker would try first: missing auth, cross-tenant access, insecure role transitions, output rendering sinks, and over-broad internal fetches.
#!/usr/bin/env bash
set -euo pipefail
BASE_URL="${BASE_URL:-https://staging.example.com}"
USER_TOKEN="${USER_TOKEN:?set USER_TOKEN}"
ADMIN_TOKEN="${ADMIN_TOKEN:?set ADMIN_TOKEN}"
echo "[1] anonymous access should fail"
curl -s -o /dev/null -w "%{http_code}\n" \
"$BASE_URL/api/account" | grep -Eq "401|403"
echo "[2] normal user should not read another user's record"
curl -s -H "Authorization: Bearer $USER_TOKEN" \
"$BASE_URL/api/users/other-user-id" | jq -e '.error != null' >/dev/null
echo "[3] normal user should not hit admin route"
curl -s -o /dev/null -w "%{http_code}\n" \
-H "Authorization: Bearer $USER_TOKEN" \
"$BASE_URL/api/admin/audit" | grep -Eq "401|403"
echo "[4] admin should succeed on admin route"
curl -s -o /dev/null -w "%{http_code}\n" \
-H "Authorization: Bearer $ADMIN_TOKEN" \
"$BASE_URL/api/admin/audit" | grep -Eq "200"
echo "[5] rendered model output should not come back as executable HTML"
curl -s -H "Authorization: Bearer $USER_TOKEN" \
-H "Content-Type: application/json" \
-d '{"prompt":"<img src="x" onerror="alert(1)">"}' \
"$BASE_URL/api/assistant" | jq -r '.html' | grep -qv "onerror="
That script is intentionally simple. Its job is not to prove an application is secure. Its job is to stop obviously unsafe releases from gliding through a happy-path pipeline.
AI systems need one more layer than ordinary applications
Traditional AppSec controls still matter. They are not enough for modern agentic systems.
OWASP’s AI Testing Guide says AI trustworthiness testing spans application, model, infrastructure, and data layers. The OWASP Top 10 for LLM Applications lists prompt injection, insecure output handling, training data poisoning, supply-chain vulnerabilities, insecure plugin design, excessive agency, and overreliance among the core risks. OpenAI’s own guidance on prompt injection argues that systems should be designed so that the impact of manipulation is constrained even if some attacks succeed. (ओवास्प फाउंडेशन)
That leads to a security pattern that is worth adopting even in teams that do not think of themselves as “AI security” teams yet: when an AI-generated or AI-powered system can take action, there must be a policy layer between model output and capability execution.
from ipaddress import ip_address, ip_network
from urllib.parse import urlparse
ALLOWED_TOOLS = {"search_docs", "create_ticket", "read_status_page"}
BLOCKED_NETS = [
ip_network("127.0.0.0/8"),
ip_network("10.0.0.0/8"),
ip_network("172.16.0.0/12"),
ip_network("192.168.0.0/16"),
ip_network("169.254.0.0/16"),
]
def allow_tool_call(user_role: str, tool_name: str, args: dict) -> bool:
if tool_name not in ALLOWED_TOOLS:
return False
if tool_name == "create_ticket" and user_role not in {"support", "admin"}:
return False
if "url" in args:
host = urlparse(args["url"]).hostname
if host is None:
return False
try:
addr = ip_address(host)
if any(addr in blocked for blocked in BLOCKED_NETS):
return False
except ValueError:
# hostname is not an IP literal
pass
return True
def execute_tool_call(user_role: str, tool_name: str, args: dict):
if not allow_tool_call(user_role, tool_name, args):
raise PermissionError("blocked by tool policy")
# log tool name, caller role, args hash, and trace id before execution
# forward only validated, normalized parameters to the actual tool
return {"status": "ok"}
The point of a wrapper like this is not elegance. It is separation of concerns. The model can propose an action. It does not get to define whether the action is allowed, what target spaces are legal, or what inputs are acceptable. That is how you turn “prompt injection is possible” from an existential statement into a bounded engineering problem.
Pentesting Is Where Vibe Coding Meets Reality
Static checks are good at pattern recognition. Pentesting is good at discovering the places where the system’s own story about itself stops being true.
That is why vibe coding and pentesting fit together so naturally. AI-generated code can make static review harder by producing large amounts of plausible-looking logic in a short time. Pentesting reverses the question. Instead of asking “does this code seem reasonable,” it asks “what happens if I try to cross the boundary the way an attacker would.”
CSA’s guidance on AI penetration testing makes a point many product teams still miss: a good test should not stop at identifying a vulnerability. Teams should think about the worst-case impact of exploitation and work with testers to simulate that fallout in a controlled way. That framing is exactly what vibe-coded systems need, because a lot of their most dangerous failures are not syntax-level bugs. They are misuse paths, hidden execution chains, and trust assumptions that only become visible when someone tries to abuse them. (Cloud Security Alliance)
OWASP’s DAST description reinforces the same idea from a different direction. Black-box testing is especially useful for authentication issues and server misconfiguration, which is one reason the Tobias Brunner story is so instructive. A client-side access-control model can look superficially coherent in code yet collapse immediately when someone interacts with the system over the network instead of through the intended UI. (ओवास्प फाउंडेशन)
For AI-enabled applications, pentesting also expands beyond classic web flaws. The test surface now includes prompt-to-tool boundaries, output rendering sinks, memory, retrieval, agent orchestration, and plugin or MCP integrations. OWASP’s Agentic Security Initiative describes that boundary shift directly: the critical surface is no longer limited to typed APIs and code paths, but extends into instructions, tool descriptors, schemas, memory, delegation chains, and inter-agent communication. (OWASP जेन एआई सुरक्षा परियोजना)
That is why the useful question for AI-assisted offensive tooling is not “does it have AI.” The useful question is whether it produces reproducible evidence under scope and policy. Penligent’s public writeup on verified AI pentesting frames the standard well: can the workflow determine whether a portal is reachable from the wrong place, whether controls can be bypassed, whether session isolation holds across roles, whether the effect is reproducible, and what exact evidence another engineer needs to confirm the issue. That is a better bar than screenshot-driven “AI found something interesting” demos. (पेनलिजेंट)
The table below is a synthesis of GitHub’s review guidance, GitHub security tooling, OWASP DAST guidance, OWASP AI Testing Guide, and CSA AI pentest scoping. It highlights what each layer tends to catch and where each one usually fails. (GitHub दस्तावेज़)
| Control | Best at finding | Common blind spot | Best used |
|---|---|---|---|
| Human code review | Logic drift, unsafe assumptions, readability issues | Runtime behavior and environment config | Before merge |
| Unit tests | Deterministic function-level regressions | Cross-service auth and trust boundaries | Before merge |
| Integration tests | Contract breakage and role flow bugs | Adversarial misuse outside expected flows | Before merge |
| Code scanning | Known code patterns for vulnerabilities and errors | Business logic abuse and environment-specific issues | Before merge and on schedule |
| Dependency review | Vulnerable or policy-violating dependencies | Safe-looking dependencies that are malicious in practice | On every PR |
| Secret scanning | Hardcoded credentials in history and branches | Secrets derived at runtime or leaked elsewhere | Continuous |
| DAST | Auth, input validation, server config, runtime flaws | Model-specific and multi-step agent abuse | Pre-release and continuously |
| Manual pentest | Chained exploitation, business logic, impact proof | Continuous coverage at scale | High-risk changes and periodic deep dives |
| AI system pentest | Prompt injection, excessive agency, tool misuse, output handling | Ordinary non-AI app debt if scope is too narrow | For any agentic or LLM-powered feature |
Three Failure Modes Vibe Coding Makes Easier to Ship
Dependency mistakes scale faster when code generation is easy
One of the most underappreciated ways AI coding tools change risk is that they normalize dependency expansion. Models are quick to solve narrow problems by introducing packages. Sometimes that is fine. Sometimes it is reckless.
GitHub’s AI-code review tutorial explicitly tells reviewers to scrutinize dependencies, verify that suggested packages exist, check whether they are actively maintained, review licensing, and watch for hallucinated or suspicious packages as well as slopsquatting. It also says it is good practice to always verify suggested packages yourself. That guidance exists for a reason: AI tools are perfectly happy to solve today’s small problem by importing tomorrow’s supply-chain issue. (GitHub दस्तावेज़)
The right counterweight is not to ban new dependencies entirely. It is to make new dependencies expensive in process terms. GitHub’s dependency review action gives teams a concrete way to do that. It can scan dependency changes in pull requests, raise an error for known vulnerabilities, fail builds at chosen severity thresholds, and even enforce license policy. That moves package review from “remember to think about it” to “the PR cannot merge until the dependency is acceptable.” (GitHub दस्तावेज़)
OpenSSF’s advice fits neatly with that control. Reuse libraries and methods already in the system. Minimize the amount of generated code. Fight for simplicity. In a vibe coding workflow, those are security habits as much as engineering habits. Every fresh package and every unnecessary code path is another thing reviewers have to reason about under time pressure. (OpenSSF)
Secrets and hidden trust paths do not announce themselves
Generated code often looks better than it is because it tends to present a clean narrative. There is a request, a handler, a model call, a response. What is easy to miss is everything implicit in the middle: which secret is used, where it lives, whether the client can influence the target, whether the response is trusted downstream, whether the route assumes an upstream proxy added authentication, whether a service token is broader than it needs to be.
GitHub’s secret scanning docs describe the practical version of this problem. Secret scanning examines Git history on all branches for hardcoded credentials, including API keys, passwords, tokens, and other known secret types, and is designed to catch secret sprawl before it becomes a risk. In AI-assisted development, secret sprawl becomes more likely because the model is often trying to produce an end-to-end example quickly, and end-to-end examples love placeholder tokens, environment fallbacks, and inline configuration. (GitHub दस्तावेज़)
But secret scanning only catches part of the story. The deeper issue is hidden trust path expansion. A generated service may be given a high-privilege token because “it needs to call the provider API.” A helper function may reuse an internal admin client because the model saw that pattern elsewhere in the repo. A server-side route may trust a front-end flag because it was easier to match the existing UI logic than to refactor middleware. None of those failures announce themselves loudly in a diff summary. They appear when someone asks, “what does this component trust, and should it trust that?”
That is another reason pentesting matters so much in vibe-coded systems. Attackers do not care that your token came from a convenient helper or that the model was only following an existing pattern. They care that a trust path exists.
Agentic execution turns prompts into control surfaces
The most important change in 2026 is that many AI-assisted systems are no longer just code generators. They are also tools that can read repositories, browse pages, make API calls, invoke shells, run workflows, query databases, and write files. Once that happens, the attack surface stops being limited to source code quality.
OWASP’s Agentic Security Initiative says the security surface for agentic systems extends into instructions, tool descriptors, schemas, memory, delegation chains, and inter-agent communication. OWASP’s LLM Top 10 reinforces that boundary shift with categories like prompt injection, insecure output handling, insecure plugin design, and excessive agency. OpenAI’s prompt-injection guidance then adds the design consequence: system safety depends on constraining impact even when manipulation succeeds. (OWASP जेन एआई सुरक्षा परियोजना)
This matters directly to vibe coding because many teams now use AI tools in both phases at once. The model helps write the code and also helps operate the system around the code. It reads the repository, proposes changes, runs tests, edits files, and may eventually interact with tools or MCP servers. That means the repository itself becomes untrusted input, model output may become actionable instructions, and “developer convenience” features can quietly become execution surfaces.
If that sounds theoretical, recent CVEs say otherwise.
Recent CVEs That Should Change How You Ship AI-Assisted Code
The recent vulnerability stream around AI tooling, agent frameworks, and MCP-connected systems is one of the clearest arguments for your position. It shows that the security problem is not “AI sometimes writes imperfect code.” The problem is that modern AI-adjacent systems create execution boundaries that look ergonomic in product demos and dangerous under adversarial pressure.
CVE-2025-3248, Langflow and the danger of exposed execution helpers
NVD says Langflow versions prior to 1.3.0 were susceptible to code injection in the /api/v1/validate/code endpoint and that a remote unauthenticated attacker could send crafted HTTP requests to execute arbitrary code. (एनवीडी)
Why is that relevant to vibe coding. Because it is exactly the kind of feature modern AI builders add without enough suspicion. “Validate this code.” “Preview this flow.” “Run this transformation.” “Test this component.” The product requirement sounds useful, especially when teams are moving quickly and want to preserve flexibility. But the moment a validation or preview path becomes executable over the network, it is no longer a convenience endpoint. It is an execution surface.
The lesson is not “never use flow frameworks.” The lesson is that generated or rapidly assembled systems have to treat flexible execution helpers as high-risk code from day one. Those features deserve threat modeling, explicit auth decisions, tight scope, and hostile testing before exposure. If a team uses AI to build faster but not to validate harder, it is more likely to create exactly this class of path.
Mitigation in practice means not exposing “validate,” “preview,” or “sandbox” style endpoints without explicit authentication and bounded execution rules, and treating those routes as attack surfaces during review and pre-release testing, not as harmless developer tools.
CVE-2026-30856, WeKnora and the fact that tool names are a security boundary
NVD describes CVE-2026-30856 as a WeKnora vulnerability fixed before version 0.3.0 in which a malicious remote MCP server could hijack tool execution through tool name collision and indirect prompt injection. The issue exploited an ambiguous naming convention in the MCP client, allowing a malicious tool to overwrite a legitimate one. (एनवीडी)
That is one of the most important agentic lessons of the year. Namespaces are not cosmetic. Tool registries are not just developer experience. Once an AI system chooses and executes tools, naming and registration rules become authorization-relevant design.
In ordinary software, a sloppy naming convention is annoying. In an agentic system, it can become a privilege transfer. That is why “vibe coding an MCP integration” is not just another integration task. It is a trust-boundary task. The tool catalog, selection rules, parameter validators, and conflict resolution logic all belong in the security review.
The engineering fix is straightforward in principle even if it is easy to skip in practice. Use explicit namespaces, reject collisions deterministically, bind tool identity to trusted registration, and treat tool descriptors from remote systems as untrusted data. The larger lesson is broader: when AI picks actions, metadata becomes security-critical.
CVE-2026-29783, repo content as a path to local code execution
NVD’s description for CVE-2026-29783 is blunt. An attacker who can influence command text sent to a shell tool, including through prompt injection via malicious repository content such as README files, code comments, or issue bodies, compromised or malicious MCP responses, or crafted user instructions, could achieve arbitrary code execution on the user’s workstation. (एनवीडी)
This should permanently change how teams think about “agent reads the repo and helps me fix it.” In an agentic workflow, repository content is no longer passive documentation. It may be model input that influences tool invocation. Comments, issue bodies, and task descriptions are not inherently trusted just because they live near the code. They are data, and data can steer behavior.
That makes the classic developer habit of granting shell access to a helpful AI assistant much riskier than it first appears. The risky design is not merely “AI can run commands.” The risky design is “AI can run commands after reading attacker-influenced text and without a policy boundary that constrains what those commands can become.”
This is where OpenAI’s guidance about constraining impact becomes especially practical. If a compromised prompt or repository artifact can influence the model, the safety question becomes whether the command wrapper, approval flow, path restrictions, and capability boundaries prevent that influence from turning into code execution. (ओपनएआई)
Mitigation here means treating repository content, comments, issue bodies, and external tool responses as untrusted inputs. It also means gating shell execution behind explicit allowlists, human confirmation for sensitive operations, path restrictions, and tool wrappers that validate arguments before they hit the operating system.
CVE-2026-33980, MCP query tools and the old truth about injection in a new wrapper
NVD says Azure Data Explorer MCP Server versions up to and including 0.1.1 contained KQL injection vulnerabilities in three tool handlers because the table_name parameter was interpolated directly into KQL queries with f-strings and without validation or sanitization. The record explicitly notes that an attacker, or a prompt-injected AI agent, could execute arbitrary KQL queries against the cluster. (एनवीडी)
This is a perfect example of why “AI security” is often just classic application security at a newly dangerous boundary. The vulnerability is still injection. The novelty is where the injection primitive lives. It lives inside a tool wrapper designed for agents.
Teams that vibe code agent connectors often assume the MCP layer is merely plumbing. It is not. If your AI system can turn a prompt into a database-adjacent tool invocation, your tool adapter is part query builder, part authorization layer, part security boundary. That means it deserves the same level of review you would apply to any backend component that builds dynamic queries from partially trusted input.
The mitigation is old-fashioned and non-negotiable: validate inputs, avoid string interpolation into query languages, constrain the operations a tool can perform, and separate “what the model wants to inspect” from “what the backend is allowed to execute.” The fact that the attack may be driven through prompt injection only makes the need for those controls stronger.
CVE-2026-33060, SSRF by convenience parameter
NVD says CKAN MCP Server versions before 0.4.85 accepted arbitrary base_url parameters in multiple tools, allowing unrestricted requests to arbitrary endpoints and potentially enabling internal network scanning, metadata theft, and SQL or SPARQL injection. The record states that the attack requires prompt injection to control the base_url parameter. (एनवीडी)
This is the kind of design bug that shows up when convenience wins over scope control. From a product perspective, “let the user or model specify the target base URL” sounds flexible. From a security perspective, it hands SSRF capability to anything that can influence the model or the tool call.
In an AI-assisted development environment, this matters more than it might in a conventional service because the source of the untrusted parameter may not be an obvious attacker-controlled form field. It might be text inside a page the model browsed, a poisoned tool response, or a malicious prompt hidden in repository content. The input path becomes more indirect, but the backend impact is still brutally direct.
The mitigation is the same principle we saw earlier: capability should not be inferred from convenience. URL-bearing parameters need allowlists, private-address blocking, metadata blocking, and purpose-limited target sets. If a tool is supposed to query one class of resource, it should not be able to browse the network.
Taken together, these CVEs say something bigger than “AI tools have bugs.” They say that modern AI-adjacent systems have merged classic bug classes with new control surfaces. Injection, SSRF, confused deputy behavior, and unsafe execution are not disappearing. They are moving into tool handlers, registries, model wrappers, workflow engines, and agent execution layers. That is exactly why vibe coding needs pentesting and DevSecOps instead of enthusiasm alone.
A Minimal Security Baseline for Real Teams
Not every team needs a heavyweight program. Every team that ships AI-assisted changes to production does need a baseline.
For ordinary software teams building conventional web or API products, the minimum responsible baseline is straightforward. Every AI-generated change goes through a pull request. Tests and static analysis run before merge. Dependency review runs on every dependency-changing pull request. Secret scanning is enabled. High-risk diffs require human review by someone who did not author the change. Internet-facing services get dynamic negative tests before release. If the application includes LLM features, retrieval, tool invocation, or HTML rendering of model output, those paths get explicit abuse-case tests.
For high-sensitivity systems, the floor rises. Healthcare, finance, identity systems, admin consoles, customer support agents with action-taking privileges, shell-enabled developer assistants, workflow orchestration platforms, and any system allowed to touch production infrastructure should add threat modeling, role-isolation tests, output-handling tests, least-privilege audits, periodic manual pentests, and AI-specific adversarial testing where applicable.
One useful way to think about the decision is not “does this app use AI.” The better question is “what can this app do if it is wrong.” If the answer is “nothing important,” keep the controls lighter. If the answer is “read customer records, send money, open tickets, query internal systems, run tools, or affect production,” the controls need to harden accordingly.
Here is a small pytest-style example for a role boundary that should exist in almost every serious system but is easy for generated code to get subtly wrong.
def test_user_cannot_read_other_tenant_invoice(api_client, user_token):
response = api_client.get(
"/api/invoices/tenant-b-invoice-42",
headers={"Authorization": f"Bearer {user_token}"}
)
assert response.status_code in {403, 404}
def test_admin_can_read_audit_log(api_client, admin_token):
response = api_client.get(
"/api/admin/audit-log",
headers={"Authorization": f"Bearer {admin_token}"}
)
assert response.status_code == 200
def test_model_output_is_not_rendered_as_active_html(api_client, user_token):
response = api_client.post(
"/api/assistant/render",
headers={"Authorization": f"Bearer {user_token}"},
json={"prompt": "<script>alert(1)</script>"}
)
assert response.status_code == 200
assert "<script>" not in response.json()["html"]
These tests are not sophisticated. That is why they are useful. Sophisticated attacker behavior often starts by checking whether the team forgot the obvious things.
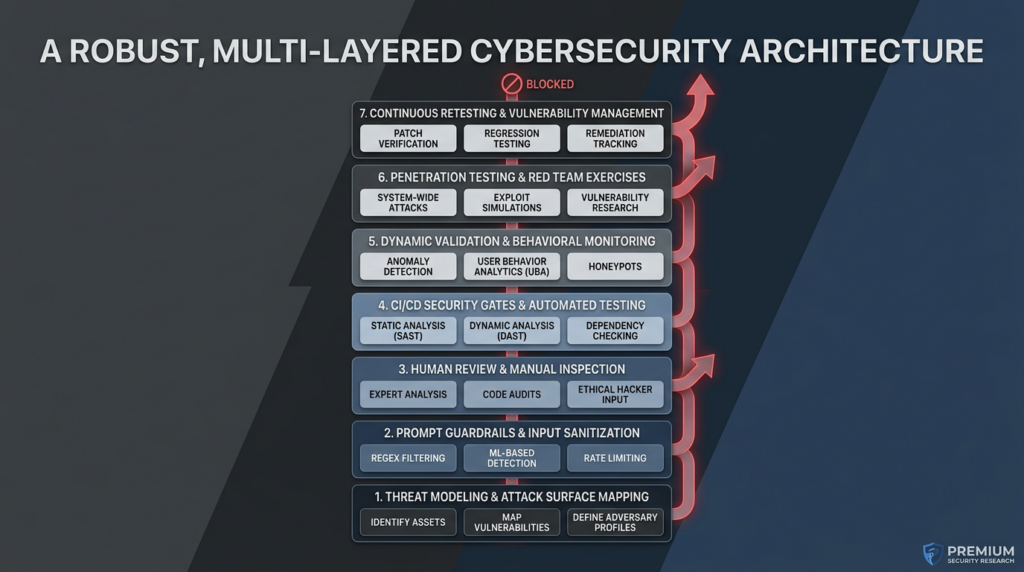
The cleanest place for an AI-native offensive platform in this picture is not at the code-generation layer. It is at the verification layer.
That matters because the wrong expectation creates the wrong buying behavior. If a team expects a pentest platform to make generated code “safe by itself,” they are asking the wrong question. The better question is whether the platform can help them validate exposure, bypass paths, session isolation, and reproducibility at the cadence their AI-assisted delivery now demands. Penligent’s public material on verified AI pentesting and on AI pentest workflows is useful in exactly that narrow sense: it frames value around proof, repeatability, and evidence rather than around magical trust in model output. (पेनलिजेंट)
That is the right division of labor. The model can accelerate implementation. The pipeline can block obvious security regressions. A verification layer, whether manual, semi-automated, or AI-assisted, can force the system to prove that the boundary still holds in the running environment. Those are complementary jobs. They are not substitutes.
How to Decide When Vibe Coding Is Safe Enough
Teams need a decision rule that is simple enough to use under release pressure.
Use the amount of irreversible damage as the threshold.
If a generated change can only break a local prototype or a disposable internal tool, lighter controls are fine. Review the diff. Run tests. Ship. If a generated change can expose user data, alter roles, hit internal systems, execute tools, trigger downstream actions, or create compliance exposure, then “it worked in staging” is not enough. That change needs the same security scrutiny as any manually written high-risk code, and often more because the implementation velocity is higher and the assumptions are harder to track.
OpenSSF’s guidance is helpful here again. It says to work incrementally, create tests early, and not confuse confidence with competence. That applies as much to release discipline as to prompting. The bigger the blast radius, the smaller the acceptable review increment. Large unreviewed AI diffs are not a badge of productivity. They are a sign that the team has outrun its own ability to reason about risk. (OpenSSF)
The same logic applies to agentic systems. If a model can only answer questions, the problem is mostly output quality and information exposure. If a model can invoke tools, write files, query databases, or call shells, the problem becomes action safety. OWASP’s Agentic Security Initiative and OWASP AI Testing Guide both point toward the same operational truth: autonomy expands the attack surface and requires its own verification layer. (OWASP जेन एआई सुरक्षा परियोजना)
A good internal rule is this:
- No AI-generated change bypasses pull-request review.
- No internet-facing AI-generated change bypasses automated security checks.
- No high-risk AI-generated change ships without dynamic validation.
- No agentic change ships without explicit tool-policy review.
That is not anti-AI. It is what using AI seriously looks like.
Vibe Coding Needs Pentesting Because Shipping Is the Easy Part
Shipping is the easy part now. Verification is the hard part.
That is why the future of software development is not prompt-only development and not blind trust in generated code. It is AI-accelerated development with security gates, static analysis, dependency policy, secret control, dynamic validation, and pentesting strong enough to prove that the system still behaves safely under pressure.
Vibe coding is not the problem. Shipping unverified software is the problem.
And the more AI compresses the time from idea to code, the more every serious team needs to expand the time spent on review, adversarial testing, and release discipline. Not because progress should slow down, but because production software is still production software. The trust boundary does not care who wrote the code.
Further Reading and References
- GitHub, Best practices for using GitHub Copilot. (GitHub दस्तावेज़)
- GitHub, Review AI-generated code. (GitHub दस्तावेज़)
- GitHub, About code scanning. (GitHub दस्तावेज़)
- GitHub, About dependency review और Customizing your dependency review action configuration. (GitHub दस्तावेज़)
- GitHub, About secret scanning. (GitHub दस्तावेज़)
- Microsoft Learn, Introduction to vibe coding. (माइक्रोसॉफ्ट लर्न)
- NIST, Secure Software Development Framework. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
- NIST, Secure Software Development Practices for Generative AI and Dual-Use Foundation Models, SP 800-218A. (NIST Publications)
- OWASP, DevSecOps Guideline और Dynamic Application Security Testing. (ओवास्प फाउंडेशन)
- OWASP, AI Testing Guide. (ओवास्प फाउंडेशन)
- OWASP, Top 10 for Large Language Model Applications. (ओवास्प फाउंडेशन)
- OpenAI, Designing AI agents to resist prompt injection. (ओपनएआई)
- OWASP GenAI Security Project, Agentic Security Initiative. (OWASP जेन एआई सुरक्षा परियोजना)
- Cloud Security Alliance, Considerations When Including AI Implementations in Penetration Testing. (Cloud Security Alliance)
- Tobias Brunner, An AI Vibe Coding Horror Story. (Tobias Brunner aka tobru)
- NVD, CVE-2025-3248. (एनवीडी)
- NVD, CVE-2026-30856. (एनवीडी)
- NVD, CVE-2026-29783. (एनवीडी)
- NVD, CVE-2026-33980. (एनवीडी)
- NVD, CVE-2026-33060. (एनवीडी)
- Penligent, Agentic Cyberattacks Need Verified AI Pentesting. (पेनलिजेंट)
- Penligent, Pentest AI, What Actually Matters in 2026. (पेनलिजेंट)
- Penligent, Agentic Security Initiative — Securing Agent Applications in the MCP Era. (पेनलिजेंट)
- पेनलिजेंट होमपेज। (पेनलिजेंट)
