The Apple M5 Mythos story is easy to overread. A small team says it built a working macOS kernel exploit with help from a frontier AI model in five days. That sounds like a clean headline: AI broke Apple. It is not that simple.
The safer and more useful reading is sharper. AI-assisted exploit development is compressing the time between a credible vulnerability signal and a working proof. That does not mean every system can now be automatically exploited. It does not mean a Web testing platform can reproduce a hardware-dependent macOS kernel exploit. It does mean defenders need to rethink how quickly they can answer one operational question: are we actually affected, and can we prove it?
Calif’s disclosure described a data-only macOS kernel local privilege escalation chain targeting macOS 26.4.1 build 25E253 on bare-metal Apple M5 hardware with kernel Memory Integrity Enforcement enabled. The chain reportedly starts from an unprivileged local user, uses normal system calls, and ends with a root shell. Calif also stated that full technical details will be released only after Apple fixes the vulnerabilities and attack path. (Calif)
That last sentence matters. The public material is not enough to reproduce the exploit, and a responsible technical article should not invent the missing pieces. The lesson is not “copy this exploit.” The lesson is that exploitability is moving faster, and the old gap between discovery, proof, and remediation is becoming harder to rely on.
The Apple M5 case without the mythology
The M5 case became news because it sits at the intersection of three hard problems: memory corruption, hardware-backed mitigation, and AI-assisted vulnerability research.
Apple’s Memory Integrity Enforcement is not a marketing toggle. Apple describes MIE as a multi-year engineering effort combining Apple silicon hardware and operating system support to provide always-on memory safety protection. Apple’s public technical description links MIE to Arm Memory Tagging Extension and Enhanced Memory Tagging Extension, while also explaining why synchronous, always-on enforcement across important attack surfaces is technically demanding. (Apple Security Research)
Calif’s claim is significant because the reported exploit survived that protection on real M5 hardware. Cyber Security News summarized the public details similarly: a working kernel local privilege escalation exploit against macOS 26.4.1 on bare-metal M5 hardware, with MIE active, moving from a normal local user account to a root shell. (साइबर सुरक्षा समाचार)
But the public record still leaves important limits. There is no full technical report yet. There is no public patch analysis. There is no public exploit source. There is no validated independent reproduction from the wider research community. Calif’s own post says the 55-page report will be published after Apple ships a fix. (Calif)
That does not make the claim meaningless. It makes the claim bounded. Good security writing lives inside those boundaries.
The most credible reading is this:
| Publicly described fact | What it supports | What it does not support |
|---|---|---|
| The chain targets macOS 26.4.1 on M5 hardware | The environment is specific, not generic | It does not prove other Mac generations or OS builds are affected |
| The exploit is described as kernel local privilege escalation | The starting point is local low privilege, not remote unauthenticated access | It does not imply drive-by remote compromise |
| Kernel MIE was reportedly enabled | The case is relevant to hardware-backed memory safety | It does not mean MIE is broadly useless |
| Mythos Preview helped identify bugs and assisted development | AI contributed to discovery and engineering | It does not prove full autonomy |
| Full details are withheld until a fix | Responsible disclosure is still in progress | It does not provide enough public information for reproduction |
The right story is not that mitigations have failed. The right story is that mitigations raise cost, and AI may be changing the cost curve.
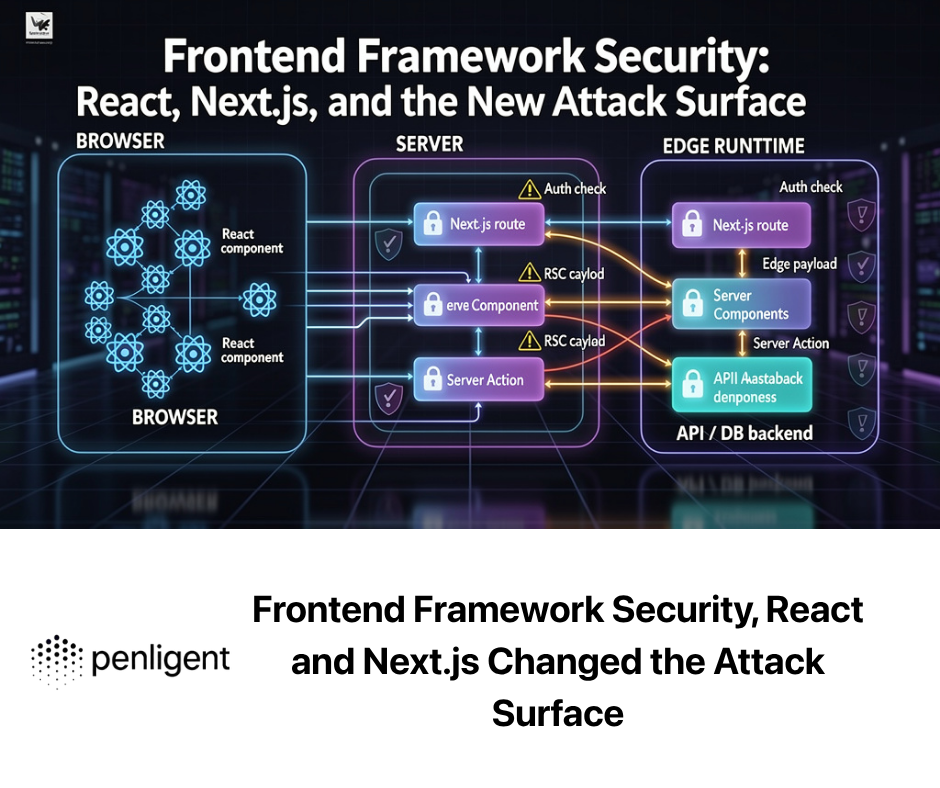
What AI-assisted exploit development actually changes
Exploit development is not one task. It is a pipeline.
A model may help read a patch. It may cluster suspicious code paths. It may identify a known bug class. It may generate a harness. It may suggest a crash minimization strategy. It may compare logs across attempts. It may propose candidate primitives. It may help write a report. Those are different jobs with different failure modes.
Calif’s post is careful on this point. The team says Mythos Preview helped identify the bugs and assisted throughout exploit development, but also says the bugs belonged to known bug classes and that bypassing MIE still required human expertise. (Calif)
That is the pattern defenders should expect more often: not a fully autonomous “hack everything” agent, but an expert system that reduces the cost of the boring, iterative, high-context work around vulnerability research.
Anthropic’s Project Glasswing materials point in the same direction from the defensive side. Anthropic says Claude Mythos Preview is being used by partners to find and fix vulnerabilities in critical systems, and describes planned work around local vulnerability detection, black-box binary testing, endpoint security, and penetration testing. Anthropic also says it does not plan to make Mythos Preview generally available, reflecting the dual-use risk of this class of model. (मानवजनित)
OpenAI’s Daybreak page uses similar language for defenders: AI can help reason across codebases, identify subtle vulnerabilities, validate fixes, and move from discovery to remediation faster, while requiring trust, verification, safeguards, and accountability. (ओपनएआई)
The common word is not “magic.” It is validation.
AI-assisted exploit development changes the economics of several stages:
| मंच | Traditional bottleneck | AI-assisted acceleration | Remaining human responsibility |
|---|---|---|---|
| Discovery | Reading large codebases, patches, diffs, crash reports | Fast code comprehension, suspicious pattern clustering, variant search | Decide whether the signal is security-relevant |
| Triage | Separating crash noise from exploitable behavior | Summarizing crash conditions, mapping data flow, comparing similar bugs | Avoid overclaiming exploitability |
| Environment reasoning | Matching versions, configs, mitigations, privileges | Extracting affected version ranges and deployment conditions | Verify the target actually matches |
| Harnessing | Building repeatable test programs or requests | Drafting scaffolds, fixtures, replay scripts | Keep tests safe and scoped |
| Exploit path planning | Turning a bug into a security primitive | Suggesting routes from primitive to impact | Validate every step experimentally |
| Evidence capture | Preserving logs, requests, outputs, screenshots | Structuring artifacts and report notes | Ensure evidence proves the claim |
| Remediation validation | Rechecking after patch | Generating retest steps and regression checks | Confirm the fix closes the actual path |
The mistake is to compress all of that into one phrase: “AI found an exploit.” In real programs, each stage needs a different control.
A PoC is not the same thing as a verified finding
A proof of concept is often described casually as “the code that proves the bug.” That description is incomplete.
A PoC may be a script, a compiled binary, a crafted file, a request sequence, a browser workflow, or a minimal test case. Its purpose is to demonstrate that a condition exists. It is not always an exploit. It is not always safe. It is not always reliable. It may only work under one build, one configuration, one timing condition, or one lab environment.
A working exploit is stronger. It turns the vulnerability into a security impact: code execution, privilege escalation, data access, authentication bypass, lateral movement, sandbox escape, or another effect that matters.
A reproduction is different again. It means another operator can trigger the same result in a defined environment with documented prerequisites.
A verified finding is what security teams actually need. It includes affected environment facts, safe reproduction steps, evidence, impact, business context, remediation, and retest logic.
| Term | Minimum meaning | Evidence needed | सामान्य गलती |
|---|---|---|---|
| Vulnerability signal | Something may be wrong | Advisory, crash, diff, suspicious behavior, tool output | Treating every signal as an incident |
| प्रमाण-संकल्पना | A condition can be demonstrated | Input, request, script, crash, unauthorized result, observable change | Treating a lab PoC as production exploitability |
| Working exploit | The condition can produce security impact | Controlled impact proof such as privilege change, command execution in lab, data access proof | Running unsafe payloads before scope and approval |
| Reproduction | The effect can be repeated in a defined environment | Version, config, commands, logs, screenshots, timestamps | Omitting environment details |
| Verified finding | A security team can act on it | Evidence chain, affected scope, impact, remediation, retest steps | Generating a polished report without proof |
For the Apple M5 case, a successful reproduction would not mean “the blog post was convincing.” It would mean a matching M5/macOS/MIE environment, a low-privilege starting user, a controlled run, and evidence that the process reaches root without administrator authorization. Because the public technical path is withheld, outside teams cannot responsibly reproduce that chain today from public information alone.
For Web and API vulnerabilities, the evidence looks different. It may be a request that returns another user’s object, a role matrix showing authorization failure, a server log proving unexpected code path execution, a patch retest showing the behavior no longer occurs, or a browser trace showing a business process can be skipped.
The principle is the same: proof is not a story. Proof is replayable evidence.
The proof window is becoming the real race
Security teams often think in patch windows. A vendor discloses a vulnerability. A CVE is assigned. A scanner detects affected assets. Engineers test patches. Operations deploy them. Security retests.
That model assumes defenders have time to move from awareness to action before exploitation becomes common. That assumption is getting weaker.
Google Cloud’s M-Trends 2026 reporting says mean time to exploit has dropped to an estimated negative seven days, meaning exploitation is often observed before a patch is available. The same Google Cloud material frames edge and core network devices as important blind spots because many cannot run traditional EDR telemetry. (गूगल क्लाउड)
Google Threat Intelligence Group also reported a maturing shift toward industrial-scale use of generative models in adversarial workflows, including AI-enabled malware and AI-assisted operational scaling. (गूगल क्लाउड)
The exact numbers will vary by dataset, vulnerability class, and sector. The durable lesson is not that every CVE becomes exploited immediately. The lesson is that timing assumptions are no longer safe.
The more useful metric is the proof window: the time between a credible vulnerability signal and a defender’s ability to prove whether a specific environment is affected.
That window includes several questions:
| Question | यह क्यों मायने रखती है |
|---|---|
| Do we run the affected product or component? | Asset inventory is the first filter |
| Is the affected version exposed? | A vulnerable package may not be reachable |
| Is the vulnerable feature enabled? | Many CVEs are configuration-bound |
| Is authentication required? | Risk changes with role and exposure |
| Is there a safe validation path? | Proof must not damage systems |
| What evidence proves impact? | Security teams need more than severity text |
| Has the fix closed the path? | Patch completion requires retest |
AI-assisted exploit development matters because it can shorten the attacker’s side of the same window. AI-assisted defense matters only if it shortens the defender’s side faster.
Why the Apple M5 exploit is not a Web testing workflow
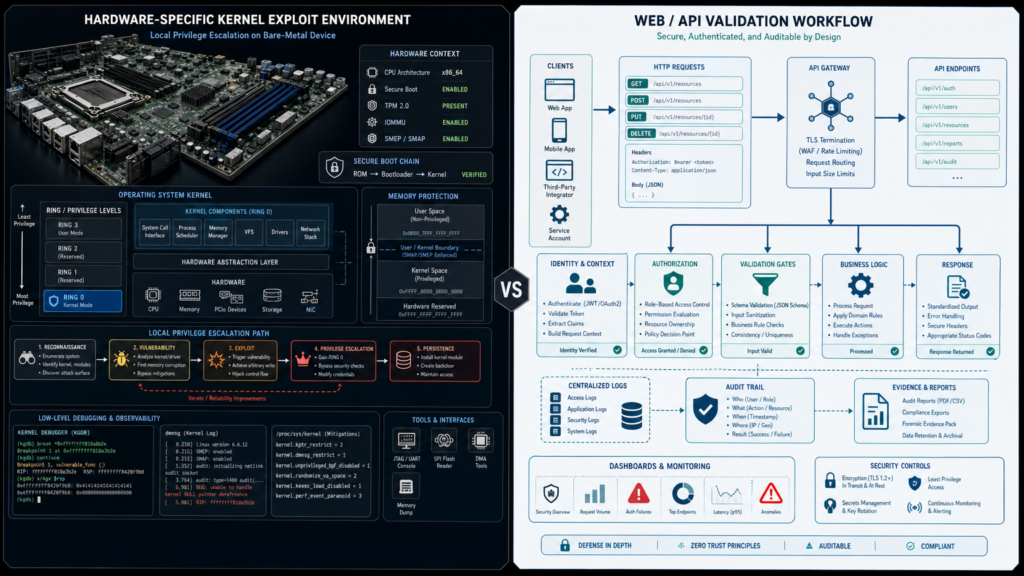
This distinction is important enough to state plainly: a macOS kernel local privilege escalation exploit is not a Web application vulnerability.
A kernel exploit depends on the local operating system, kernel build, memory layout, CPU behavior, mitigation state, syscall paths, exploit primitives, and often timing or heap shaping. The Apple M5 case is even more specific because it involves bare-metal hardware and kernel MIE.
A Web or API vulnerability depends on reachable application behavior: HTTP requests, authentication state, object references, input parsing, server-side calls, browser state, API authorization, file handling, queue behavior, or tool invocation.
Those worlds overlap conceptually, but they do not share the same reproduction environment.
| आयाम | Kernel LPE on Apple M5 | Web/API/Agent validation |
|---|---|---|
| Starting position | Local user on target machine | Remote or authenticated application user |
| Main interface | System calls, kernel objects, memory behavior | HTTP, WebSocket, browser, API, tool calls |
| पर्यावरण | Specific hardware, OS build, mitigation state | Service version, deployment config, auth roles |
| Proof | Privilege change, kernel crash, root shell, controlled primitive | Unauthorized access, controlled action, data exposure, server behavior |
| Lab model | Dedicated hardware, restore image, debug logs | Staging environment, container, test tenant, replay proxy |
| Automation fit | Limited and highly specialized | Stronger fit when scope and safety controls exist |
| Public write-up risk | High if exploit details are unpatched | Safer when validation is scoped and non-destructive |
This is why a credible product narrative should not claim to automatically reproduce arbitrary kernel exploits in a sandbox. That is not how hardware-bound kernel research works.
The transferable lesson is narrower and stronger: if AI can accelerate high-end exploit research, then exposed Web, API, business logic, and AI-agent attack surfaces need faster, evidence-driven validation. Those are the environments where request replay, role switching, browser automation, API testing, tool execution, and report generation can operate safely under authorization.
Web and API security are where proof automation becomes operational
Web and API vulnerabilities have one advantage for defenders: they often leave observable behavior at the application boundary.
A broken object-level authorization issue can be tested by comparing what User A and User B can access. OWASP’s API Security Top 10 describes BOLA as a class where attackers manipulate object identifiers in paths, query strings, headers, or payloads to access objects they should not be allowed to reach. (ओवास्प फाउंडेशन)
A business logic flaw can be tested by changing sequence, state, role, timing, or quantity. OWASP’s Web Security Testing Guide explains that business logic testing requires unconventional thinking about whether an application enforces the intended process order or fails open when steps are skipped. (ओवास्प फाउंडेशन)
That is exactly where AI can help, if it is properly bounded. The model can read API responses, infer object relationships, compare two users’ permissions, suggest safe probes, explain why a 403 changed to a 200, and draft a finding. But it still needs a workflow that preserves scope, identity, request history, rate limits, and evidence.
NIST SP 800-115 remains useful because it frames technical security testing as a lifecycle that includes planning, conducting tests, analyzing findings, and developing mitigation strategies, not just running tools. (एनआईएसटी कंप्यूटर सुरक्षा संसाधन केंद्र)
AI does not remove that lifecycle. It makes the lifecycle faster and less forgiving.
Four CVEs that show why Web and AI-tooling validation matters
The best way to understand modern proof work is to look at vulnerabilities where exploitability depends on specific application behavior. The following cases are not related to Apple M5, but they are relevant to AI-assisted Web, API, and agent-tooling validation because they show where runtime proof matters.
| सीवीई | Product or area | यह क्यों मायने रखती है | Safer validation focus | Fix or mitigation |
|---|---|---|---|---|
| CVE-2026-31816 | Budibase | Universal auth bypass through webhook query pattern behavior | Confirm affected version and auth boundary behavior in authorized lab | Upgrade beyond affected releases and verify middleware checks |
| CVE-2026-26216 | Crawl4AI Docker API | Unauthenticated RCE path through unsafe hook execution | Check exposure of Docker API deployment and patched version, avoid arbitrary command execution on production | Upgrade to 0.8.0 or later and restrict API exposure |
| CVE-2026-31975 | Claude Code UI / Cloud CLI | WebSocket shell command injection in AI coding UI tooling | Confirm version and WebSocket access control, inspect logs for unexpected shell spawn | Upgrade to 1.25.0 or later |
| CVE-2026-29039 | changedetection.io | XPath arbitrary file read through dangerous XPath functions | Confirm affected version and whether untrusted users can control filters | Upgrade to 0.54.4 or later |
CVE-2026-31816 is useful because it is not a memory corruption bug. It is an authorization failure. NVD describes a Budibase server middleware issue where a webhook pattern matched against a full URL with query parameters could cause authentication, authorization, role checks, and CSRF protection to be skipped for server-side API endpoints. (एनवीडी)
That kind of bug is perfect for evidence-first validation. A scanner can say “affected version.” A verified finding needs more: the endpoint, the expected access control, the unauthorized role, the observed response, and a patch retest.
CVE-2026-26216 is different. NVD describes Crawl4AI versions before 0.8.0 as containing a Docker API deployment RCE issue where the /crawl endpoint accepted a hooks parameter containing Python code executed with निष्पादित करें, के साथ __import__ available in allowed builtins. (एनवीडी)
For defenders, the safe validation question is not “can we run a command on the server?” The first questions are whether the Docker API deployment is exposed, whether the version is affected, whether authentication and network controls restrict access, and whether patched behavior rejects unsafe hook execution. Production proof should avoid destructive payloads and should use a controlled staging replica whenever command execution is involved.
CVE-2026-31975 is especially relevant to AI tooling. NVD describes Cloud CLI, also known as Claude Code UI, as affected before 1.25.0 by OS command injection via WebSocket shell behavior, where fields taken from WebSocket messages were interpolated into a bash command string without sanitization. (एनवीडी)
This is the kind of issue teams will see more often as coding agents, local UIs, shell wrappers, MCP servers, browser automation tools, and AI assistants become part of engineering environments. The attack surface is not just the model. It is the glue around the model.
CVE-2026-29039 shows a quieter but common pattern: data-processing features that become file access primitives. NVD describes changedetection.io before 0.54.4 as failing to validate or sanitize XPath expressions to block dangerous functions, allowing attackers to read files accessible to the application process. (एनवीडी)
The lesson across all four cases is the same. A real finding requires applicability, not just a CVE match.
A safer workflow for AI-assisted Web and API validation
The most dangerous version of AI-assisted exploit development is unbounded: give a model a target, let it choose tools, let it generate payloads, and let it write a report.
That is not security engineering. That is gambling with better prose.
A safer workflow starts with scope, identity, evidence, and promotion gates.
assessment:
name: "authorized-web-api-validation"
target_owner: "example-internal-security-team"
environment: "staging"
allowed_hosts:
- "https://staging-api.example.com"
- "https://staging-app.example.com"
forbidden_actions:
- "destructive data modification"
- "credential dumping"
- "persistence"
- "testing outside listed hosts"
- "production exploit payloads"
rate_limits:
max_requests_per_second: 3
burst: 10
identities:
- role: "standard_user"
purpose: "baseline access"
- role: "manager_user"
purpose: "role comparison"
- role: "admin_user"
purpose: "expected privileged behavior"
approval_required_for:
- "payloads that may execute commands"
- "large-scale fuzzing"
- "file read validation"
- "state-changing business logic tests"
evidence_required:
- "raw request"
- "raw response"
- "timestamp"
- "identity used"
- "expected behavior"
- "observed behavior"
- "retest after fix"
This kind of manifest does not make testing exciting. It makes it governable.
An AI system can use the manifest to reject out-of-scope actions, choose safer probes, preserve artifacts, and explain why a candidate issue should not be promoted yet. Without it, the same model becomes a fluent generator of risk.
A safe first pass should prefer non-destructive checks:
# Confirm the service identity and response behavior without sending exploit payloads.
TARGET="https://staging-api.example.com"
curl -sS -i "$TARGET/health" \
-H "Accept: application/json" \
| tee evidence/healthcheck.raw.txt
curl -sS -i "$TARGET/version" \
-H "Accept: application/json" \
| tee evidence/version.raw.txt
For authorization testing, the proof is usually comparative:
# Capture the same object request with two authorized test identities.
OBJECT_ID="demo-object-1001"
curl -sS -i "$TARGET/api/objects/$OBJECT_ID" \
-H "Authorization: Bearer $TOKEN_USER_A" \
| tee evidence/object_user_a.raw.txt
curl -sS -i "$TARGET/api/objects/$OBJECT_ID" \
-H "Authorization: Bearer $TOKEN_USER_B" \
| tee evidence/object_user_b.raw.txt
The important part is not the command. The important part is the comparison:
python3 - <<'PY'
from pathlib import Path
a = Path("evidence/object_user_a.raw.txt").read_text(errors="ignore")
b = Path("evidence/object_user_b.raw.txt").read_text(errors="ignore")
def status(raw):
first = raw.splitlines()[0] if raw.splitlines() else ""
return first
print("User A:", status(a))
print("User B:", status(b))
if "HTTP/2 200" in b or "HTTP/1.1 200" in b:
print("Review required: second identity appears to access the object.")
else:
print("No unauthorized success status observed in this simple check.")
PY
This is not an exploit. It is a controlled validation pattern for an authorized environment. That difference matters.
For AI-assisted workflows, the system should store evidence in a structured way:
{
"finding_id": "candidate-017",
"target": "staging-api.example.com",
"category": "authorization",
"hypothesis": "A lower-privileged user may access an object owned by another user.",
"environment": "staging",
"identities": ["standard_user", "manager_user"],
"requests": [
"evidence/object_user_a.raw.txt",
"evidence/object_user_b.raw.txt"
],
"expected_behavior": "User B should receive 403 or 404 for User A's object.",
"observed_behavior": "Pending human review.",
"risk_state": "candidate",
"promotion_requirements": [
"confirm object ownership",
"confirm response body contains sensitive object data",
"confirm behavior is not intended sharing",
"retest after authorization fix"
]
}
The model can summarize this evidence. It can suggest the next safe check. It can draft a finding. But the workflow should not let it promote the issue to “verified” until the evidence supports that state.
Penligent’s public product materials describe controlled agentic workflows, editable prompts, scope locking, tool execution, verification, and reporting for authorized testing. That kind of capability belongs in Web, API, business logic, and agent-security workflows where behavior can be exercised through bounded requests and tools, not in unsupported claims about automatically reproducing hardware-specific kernel exploit chains. (पेनलिजेंट)
Evidence beats severity language
AI is good at writing. That is useful and dangerous.
A model can make a weak finding sound decisive. It can turn a version match into an exploit claim. It can assign confident language to a test that only proved reachability. It can summarize a CVE advisory correctly but miss the configuration condition that makes the issue irrelevant.
The antidote is evidence discipline.
A verified Web/API finding should include:
| Evidence item | यह क्यों मायने रखती है |
|---|---|
| Target and environment | Prevents confusion between staging, production, and lab |
| Affected component and version | Links the finding to a real exposure |
| Authentication role used | Shows whether the issue is unauthenticated, low-privileged, or privileged |
| Raw request and response | Allows another engineer to replay or inspect |
| Expected behavior | Makes the security control explicit |
| Observed behavior | Shows the deviation |
| Impact proof | Connects behavior to security consequence |
| Safety notes | Shows what was not tested and why |
| उपचार | Gives engineering a path forward |
| Retest result | Confirms closure |
For a BOLA issue, the impact proof may be another user’s object returned to the wrong identity. For an arbitrary file read issue, it should be a harmless file in a test environment, not /etc/shadow on production. For an RCE-class issue, the safest proof is often in a staging replica or a vendor-provided lab, with a benign command and explicit approval.
A finding without replayable evidence is a hypothesis. It may be a good hypothesis, but it should not be reported as proof.
Detection logic for Web, API, and AI-agent attack surfaces
AI-assisted exploit development also changes detection. It can generate more variants, more plausible traffic, and more adaptive behavior. Defenders should not assume every attempt looks like a known public PoC.
Detection needs to focus on behavior and control boundaries.
| Attack surface | Signals worth watching | Useful logs | Common false positives | Hardening direction |
|---|---|---|---|---|
| API authorization | Cross-user object access, repeated ID walking, 200 responses where 403 is expected | API gateway, app logs, authz decision logs | QA scripts, migrations, support tooling | Object-level authorization on every access path |
| Web business logic | Step skipping, replayed state transitions, abnormal quantities, repeated checkout mutations | App events, session logs, fraud logs | Power users, test automation | Server-side state machines and invariant checks |
| WebSocket tools | Shell-like commands, unexpected project paths, abnormal session IDs | WebSocket server logs, process creation logs | Developer tools and CI agents | Strict authentication, command allowlists, escaping, no shell interpolation |
| AI agent tools | Unusual tool calls, prompt-to-tool mismatch, sensitive file access attempts | Agent audit logs, tool broker logs, file access logs | Legitimate developer automation | Tool permission model, approval gates, workspace trust |
| File parsing and XPath-like features | Attempts to read local paths, environment files, metadata endpoints | App logs, WAF logs, file access telemetry | Monitoring tools, admin imports | Function allowlists, sandboxing, path restrictions |
| SSRF-like behavior | Requests to metadata IPs, internal hostnames, unusual schemes | Egress proxy, DNS logs, app logs | Health checks, internal integrations | Egress filtering, URL parsing hardening, metadata protection |
| RCE-class probes | Child process creation, outbound callbacks, command separators | EDR, container logs, process audit | Build tools, legitimate scripts | Remove shell execution paths, least privilege containers |
The point is not to create a giant signature list. The point is to monitor boundary violations.
AI-assisted systems are good at mutating surface syntax. They are less able to hide the business fact that a low-privilege user accessed another tenant’s object, a WebSocket endpoint spawned a shell, or an application tried to read a local file it should never touch.
Why model-only security fails in the middle
The beginning of security testing is exciting. The system finds a candidate issue.
The end is visible. The report says high severity.
The middle is where most failures happen.
The middle asks boring questions:
- Is the feature enabled?
- Is the endpoint reachable from the attacker’s position?
- Which role is required?
- Is the observed behavior intended delegation?
- Does the affected code path run in this deployment?
- Is the issue patched but the scanner stale?
- Can the proof be repeated?
- Did the test change state?
- Is there evidence that another engineer can inspect?
AI can help answer these questions, but only if the workflow collects the underlying facts.
The ExploitGym paper makes a related point from the evaluation side. It defines exploitation as turning a vulnerability into concrete impact such as unauthorized file access or code execution, and describes exploitation as difficult because it requires low-level reasoning, runtime adaptation, and long-horizon progress. The benchmark packages tasks in reproducible environments and shows that frontier models can exploit a non-trivial fraction of instances, but the framing remains explicit: exploitation is a hard, dual-use capability that needs rigorous evaluation. (arXiv)
That is a useful reality check. A model can be impressive and still require scaffolding. A workflow can be automated and still require human gates. A finding can be plausible and still not be verified.
A practical promotion gate for verified findings
A promotion gate is a simple policy: a candidate does not become a verified finding until it meets evidence criteria.
from dataclasses import dataclass
@dataclass
class FindingEvidence:
raw_request: bool
raw_response: bool
affected_version_confirmed: bool
authorized_scope: bool
expected_behavior_written: bool
observed_behavior_written: bool
impact_demonstrated_safely: bool
remediation_available: bool
retest_plan_written: bool
def can_promote_to_verified(e: FindingEvidence) -> bool:
required = [
e.raw_request,
e.raw_response,
e.affected_version_confirmed,
e.authorized_scope,
e.expected_behavior_written,
e.observed_behavior_written,
e.impact_demonstrated_safely,
e.remediation_available,
e.retest_plan_written,
]
return all(required)
candidate = FindingEvidence(
raw_request=True,
raw_response=True,
affected_version_confirmed=True,
authorized_scope=True,
expected_behavior_written=True,
observed_behavior_written=True,
impact_demonstrated_safely=False,
remediation_available=True,
retest_plan_written=True,
)
print("verified" if can_promote_to_verified(candidate) else "candidate only")
This example is intentionally simple. In a real workflow, the gate would also account for severity, data sensitivity, tenant impact, exploit safety, approvals, and whether the test was performed in staging or production.
The important habit is state separation. Candidate, validated, verified, accepted risk, fixed, and retested are different states. AI should not blur them.
The right way to treat CVE reproduction
CVE reproduction is not a ritual where someone copies a payload and celebrates a shell. It is an applicability process.
A mature workflow looks like this:
| कदम | Question | Output |
|---|---|---|
| 1. Read primary sources | What does the vendor or CVE record actually say? | Affected versions and conditions |
| 2. Map assets | Do we run it? Where? | Asset list |
| 3. Confirm exposure | Is the vulnerable interface reachable? | Network and auth context |
| 4. Check configuration | Is the vulnerable feature enabled? | Applicability decision |
| 5. Choose safe proof | Can impact be shown without damage? | Validation plan |
| 6. Run controlled test | What happened? | Raw evidence |
| 7. Human review | Does evidence prove the claim? | Verified or rejected finding |
| 8. Remediate | What change closes the path? | Patch, config, or compensating control |
| 9. Retest | Is the path closed? | Closure evidence |
ProjectDiscovery made a similar operational point in a 2026 post: LLMs can produce impressive vulnerability findings, but without a verification loop, more scanning creates more triage rather than more security. (ProjectDiscovery)
That sentence should be pinned inside every AI security workflow. Discovery is cheapening. Proof is the bottleneck.
How defenders should adapt when proof gets faster
The defensive response should not be panic. Panic creates bad automation. Bad automation creates noise, unsafe tests, and reports nobody trusts.
The better response is to rebuild the validation loop.
Prioritize internet-facing and agent-facing surfaces first
AI-assisted attackers benefit most when the target interface is easy to reach, easy to test, and easy to retry. That makes public Web apps, APIs, VPNs, edge devices, developer tools, exposed dashboards, WebSocket services, and AI-agent tool brokers high-priority validation targets.
Separate version risk from exploitability
A vulnerable version is a starting point, not a conclusion. Ask whether the vulnerable code path is exposed, enabled, authenticated, reachable, and relevant to your deployment.
Build staging replicas for dangerous classes
For RCE, file read, deserialization, template injection, SSRF, and command injection, production proof can be risky. A staging replica with realistic configuration, test secrets, egress controls, and full logging is often the safer place to validate impact.
Use role matrices for authorization bugs
Authorization bugs are often invisible without multiple identities. Every serious API validation workflow should maintain test users across roles, tenants, object ownership states, and feature flags.
Preserve raw artifacts
A report summary is not evidence. Store raw requests, responses, logs, screenshots, terminal output, hashes, timestamps, and retest results.
Require human approval for impact escalation
AI can propose a next step. It should not automatically escalate from a benign probe to command execution or file read proof without policy and approval.
Retest after remediation
The proof window does not close when a ticket is marked done. It closes when the original path no longer works and the evidence shows why.
Penligent has written about the post-Mythos AI pentesting problem as a workflow issue rather than a model leaderboard issue, emphasizing scope control, evidence preservation, retest discipline, and the path from signal to proof. That framing is the right one for authorized Web, API, business logic, and agent-security testing because those surfaces can be exercised through bounded runtime behavior rather than speculative claims. (पेनलिजेंट)
Common mistakes in AI-assisted exploit validation
The first mistake is treating a PoC as proof of production risk. A PoC proves that something can happen somewhere. It does not prove that it can happen in your environment.
The second mistake is treating CVSS as operational priority. CVSS is useful, but it does not know your exposure, compensating controls, tenant model, feature flags, or asset value.
The third mistake is treating AI-generated reports as evidence. A report is packaging. Evidence comes first.
The fourth mistake is ignoring negative results. A failed reproduction is useful if it explains why the target is not affected: patched version, feature disabled, endpoint not exposed, authentication required, compensating control effective, or test inconclusive.
The fifth mistake is using production as a lab. Some validation can be safely performed in production with non-destructive probes. Some cannot. The line should be written down before testing begins.
The sixth mistake is overstating product capability. No serious tool should claim to reproduce every CVE across every environment. Kernel exploits, firmware bugs, hardware side channels, local privilege escalation chains, and unpatched memory corruption paths require specialized labs and human expertise. Web/API automation is powerful, but it is not universal exploit magic.
The seventh mistake is forgetting that AI systems are themselves attack surfaces. Local coding agents, Web UIs, browser automation wrappers, tool brokers, and MCP-style connectors need authentication, authorization, sandboxing, prompt injection defenses, audit logs, and safe defaults.
अक्सर पूछे जाने वाले प्रश्न
What is AI-assisted exploit development?
- AI-assisted exploit development means using AI systems to support parts of the vulnerability-to-impact workflow, such as code review, bug classification, harness generation, log analysis, variant search, payload reasoning, or report drafting.
- It does not necessarily mean the AI system autonomously found and exploited a target from start to finish.
- The most realistic high-end pattern is expert-led work where AI reduces iteration time and helps navigate large technical search spaces.
- It is dual-use: the same capability can help defenders validate and fix issues, or help attackers move faster.
Is a PoC the same as a working exploit?
- No. A PoC proves a condition or vulnerability behavior exists under certain assumptions.
- A working exploit turns that condition into a concrete security impact, such as unauthorized access, code execution, sandbox escape, or privilege escalation.
- A PoC may be unstable, lab-only, version-specific, or non-destructive.
- A verified finding needs more than a PoC: it needs affected environment facts, replayable evidence, impact explanation, remediation, and retest steps.
Can AI automatically reproduce any CVE?
- No. CVEs vary widely across Web apps, APIs, libraries, operating systems, hardware, firmware, cloud services, and local tools.
- Some Web/API issues can be validated through safe request and response evidence in authorized environments.
- Kernel, hardware, firmware, and local privilege escalation vulnerabilities may require dedicated devices, exact builds, special debugging, and exploit engineering.
- A responsible AI security workflow should state supported attack surfaces clearly and avoid “any CVE” claims.
Why is the Apple M5 Mythos case not the same as Web or API testing?
- The Apple M5 case is a hardware and operating-system-specific kernel local privilege escalation claim.
- It depends on macOS version, M5 hardware, kernel MIE state, local execution, and undisclosed exploit details.
- Web and API testing usually works through HTTP, WebSocket, browser behavior, authentication roles, and application responses.
- The transferable lesson is speed: AI may shorten exploit development timelines, so defenders need faster validation for the attack surfaces they can safely test.
What evidence proves a Web or API vulnerability is real?
- Raw requests and responses showing the unexpected behavior.
- The identity, role, tenant, and object ownership context used during the test.
- A clear statement of expected behavior versus observed behavior.
- Proof of security impact, such as unauthorized data access or unauthorized state change, collected safely.
- Version, configuration, and exposure details.
- A retest showing the issue is fixed after remediation.
How should teams validate RCE-class issues safely?
- Prefer staging or a dedicated lab that mirrors production configuration.
- Confirm version, exposure, authentication, and feature enablement before any impact test.
- Use benign, approved proof actions, not destructive commands or sensitive file access.
- Capture process logs, application logs, and request traces.
- Require human approval before moving from reachability checks to impact validation.
How does AI change vulnerability management for defenders?
- It increases the speed at which vulnerability signals can be analyzed, tested, and turned into proof.
- It also increases the amount of noise if findings are not validated.
- Defenders should invest in evidence pipelines, asset context, role-aware testing, safe lab environments, and retest automation.
- The key metric should be time from credible signal to verified decision, not just number of findings discovered.
What should buyers ask vendors claiming AI exploit validation?
- Which attack surfaces are actually supported?
- How is scope enforced?
- What actions require human approval?
- What evidence is captured for each finding?
- Can findings be replayed and retested?
- How does the system avoid promoting speculative issues?
- Does the vendor distinguish Web/API validation from kernel, hardware, or local exploit research?
The durable lesson
AI-assisted exploit development does not eliminate security engineering. It raises the standard for it.
The Apple M5 Mythos case is important because it shows how fast expert-led exploit work may become when frontier models enter the loop. It should not be used as proof that every vulnerability can be automatically reproduced, or that Web security tools can safely emulate hardware-bound kernel research. That would be the wrong lesson.
The right lesson is operational. Defenders need to shrink their own proof window. They need to know what they run, what is exposed, what is affected, what can be safely validated, what evidence proves impact, and whether the fix actually worked.
The future advantage will not belong to the team with the most dramatic exploit story. It will belong to the team that turns weak signals into verified action faster, without losing scope control, safety, or trust.