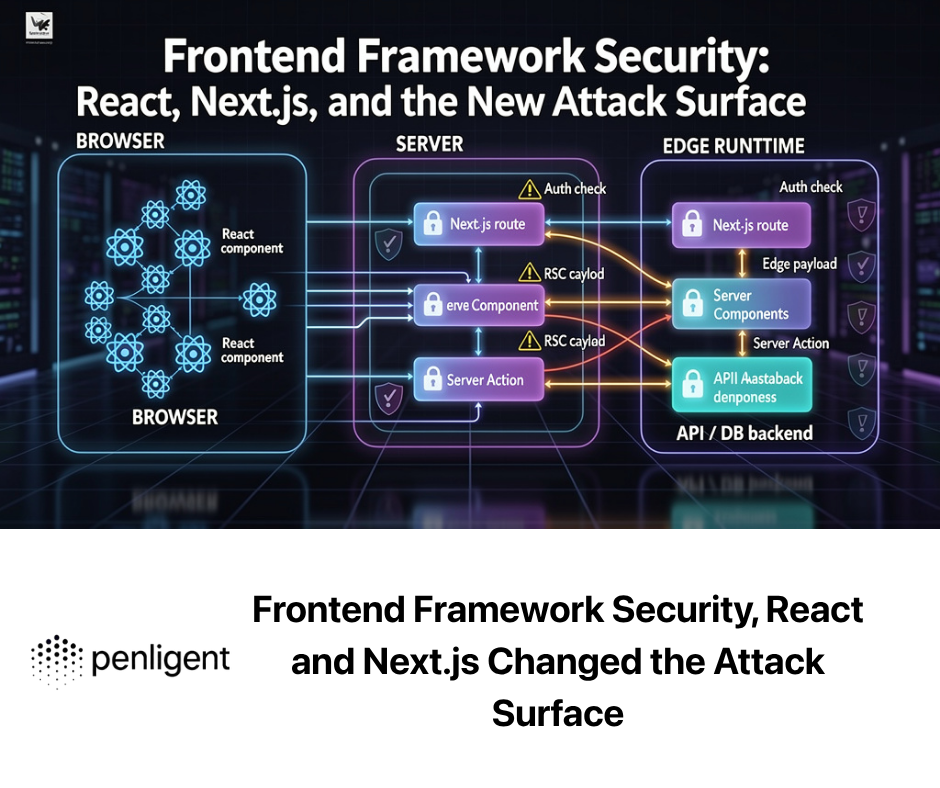
AI offensive security has crossed an important line. The serious question is no longer whether frontier models can help security researchers. They can. The better question is what they can do reliably, what still breaks when the target is live, and where human judgment remains the difference between a plausible bug claim and a validated exploit.
Recent public evidence gives a sharper answer than the usual hype cycle. Anthropic’s Claude Mythos Preview was presented as a major jump in cyber capability, with Anthropic warning that models able to automatically identify and exploit vulnerabilities at scale could change the security equilibrium. Anthropic also said Mythos Preview would not be made generally available, while expressing a longer-term goal of safely deploying Mythos-class models for cybersecurity use cases. (Red Anthropic)
Axios reported the same transition from the practitioner side: early users of Anthropic and OpenAI cyber-capable models found that these systems still require significant human expertise to operate well. Its key framing was not that AI-powered cybersecurity has failed, but that the next phase may depend less on fully autonomous hacking and more on how humans direct, validate, and operationalize increasingly powerful systems. (योग्य)
XBOW’s evaluation of Mythos made the technical boundary even clearer. XBOW called Mythos a major advance and especially strong at source-code auditing, but also said it was “good, but less powerful” at validating exploits, with mixed judgment that could be literal, conservative, and prone to overstating practical relevance. (Xbow)
That is the real line in AI offensive security right now.
Models are getting good at finding vulnerability candidates. They are much less reliable at proving exploitability in messy, stateful, live systems. The hard part is no longer only “Can the model see the bug?” The hard part is “Can the system prove the bug matters, safely, reproducibly, and in the target’s actual environment?”
The debate is less divided than it looks
The public conversation around AI offensive security often sounds contradictory because different people are describing different layers of the workflow.
Anthropic’s public Mythos post emphasizes the scale and speed of model-driven vulnerability research. AISI’s evaluation found that Claude Mythos Preview represented a step up over earlier frontier models, with strong performance on CTF tasks and multi-step cyber-attack simulations. In AISI’s “The Last Ones” corporate network simulation, described as a 32-step attack range estimated to take human professionals around 20 hours, Mythos completed the full range in 3 out of 10 attempts and averaged 22 out of 32 steps. (AI Security Institute)
OpenAI’s own cyber direction points in the same general direction. OpenAI announced an expansion of Trusted Access for Cyber and described GPT-5.4-Cyber as a more cyber-permissive model for vetted defenders, with access controlled through verification and additional deployment restrictions. (ओपनएआई) AISI later evaluated GPT-5.5 and said it was one of the strongest models tested on its cyber tasks, with expert-level performance close to Mythos and strong results on vulnerability research and exploitation-style tasks. (AI Security Institute)
Those are real advances. They should not be dismissed.
But the same source base also warns against a simplistic “AI replaces offensive security teams” conclusion. AISI explicitly notes limitations in its ranges, including the absence of active defenders, defensive tooling, and alert penalties that real-world environments usually have. It also notes that some cyber tasks test skills in isolation. (AI Security Institute)
That caveat matters. A model can perform extremely well in a controlled cyber range and still struggle with a production application whose behavior depends on identity providers, brittle session state, undocumented business rules, rate limits, customer data boundaries, WAF behavior, reverse proxy routing, and legacy code nobody wants to touch.
XBOW’s evaluation sits exactly at that boundary. XBOW tested Mythos inside Claude Code and as a raw model through its API as an engine for XBOW agents, and it explicitly separated those cases because orchestration, tools, prompting, and live-site access materially affect outcomes. (Xbow) That is one of the most important sentences in the whole debate. A raw model is not an offensive system. It is a reasoning engine that may or may not have the operational body needed to test reality.
The most accurate current view is therefore not “AI offensive security is fake” or “AI offensive security is solved.” It is this:
AI is becoming very strong at producing vulnerability leads. Real offensive value still depends on validation infrastructure, tool control, environment awareness, and human judgment.
Why AI is getting good at vulnerability discovery
The progress is not mysterious. Many parts of vulnerability discovery map well to what frontier models do best.
They read code. They summarize intent. They compare implementation against common failure patterns. They can reason across files. They can combine comments, configuration, dependencies, and API behavior into a plausible security hypothesis.
A simple example makes the point:
def find_user(username):
query = "SELECT * FROM users WHERE username = '" + username + "'"
return db.execute(query)
A traditional static analyzer may catch this if a rule matches the language, framework, and sink. A capable model does not need the exact same brittle signature. It can recognize the unsafe construction, infer attacker-controlled input, identify the database sink, and explain why parameterized queries would be safer.
That kind of semantic flexibility matters.
The same applies to command execution:
import os
def run_backup(path):
os.system("tar -czf backup.tar.gz " + path)
A model can reason that path may be attacker-controlled, that shell concatenation changes the threat model, and that the safer pattern is an argument-vector API such as subprocess.run साथ shell=False.
The more interesting cases span multiple files.
# controller.py
def export_report(request):
name = request.args.get("name")
return report_service.export(name)
# report_service.py
def export(name):
return storage.read_file("/reports/" + name)
# storage.py
def read_file(path):
with open(path, "r") as f:
return f.read()
A model can connect route input to filesystem access, recognize path traversal risk, and suggest validation around canonical paths, allowlisted filenames, or object IDs. That is not magic. It is a useful generalization over a known vulnerability class.
This is why AI-assisted source-code auditing is improving quickly. Models can hold more surrounding context than many older tools, and they can reason in the same mixed language that software teams actually use: code, comments, tests, configs, docs, and deployment notes.
Daniel Stenberg’s account of Mythos scanning curl is a good reality check because it includes both skepticism and practical respect. Mythos produced five “confirmed security vulnerabilities” in curl, but after human review the curl team reduced that to one confirmed low-severity vulnerability, three false positives, and one ordinary bug. Yet Stenberg also stressed that AI-powered code analyzers are significantly better at finding security flaws and mistakes in source code than traditional analyzers, and that projects not using AI code analyzers may leave attackers more time to find flaws first. (daniel.haxx.se)
That is the right middle ground.
AI code analysis is valuable. It is not self-validating.
Vulnerability discovery and exploit validation are different jobs
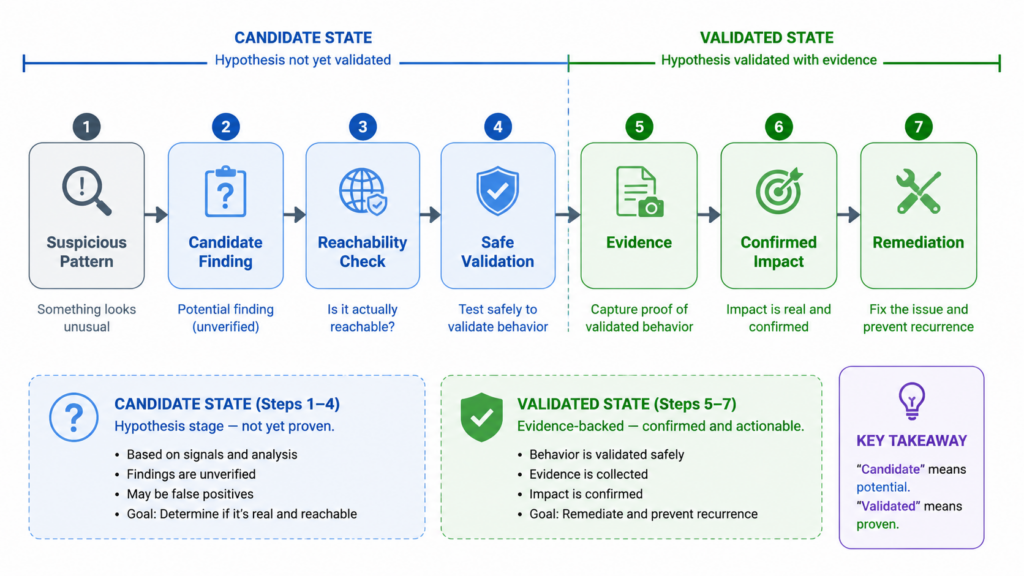
A vulnerability candidate is a claim about possibility.
A validated exploit is a claim about reality.
Those are different standards of proof.
A candidate finding may say:
- user input appears to reach a sensitive sink;
- a dependency version appears affected by a CVE;
- an endpoint appears to miss an authorization check;
- a parser appears to accept unsafe input;
- a template engine appears reachable from user-controlled content.
A validated finding must answer harder questions:
- Is the code path reachable by an attacker?
- Does the attacker control enough input to matter?
- Does authentication or role state block the path?
- Does deployment change the behavior?
- Can the issue be reproduced safely?
- What evidence proves impact?
- Is the impact meaningful enough to fix before other work?
That is where many AI offensive security workflows break.
A model can say “this looks like SSRF.” A pentester has to determine whether the application can reach internal networks, whether redirects are followed, whether DNS rebinding works, whether metadata endpoints are blocked, whether response content is returned, whether the request is server-side at all, and whether testing is safe in the authorized environment.
A model can say “this looks like command injection.” A validation system has to determine whether input reaches a shell, whether metacharacters survive normalization, whether the process has useful permissions, whether output is observable, whether the target is a test environment, and whether the proof avoids destructive behavior.
A model can say “this looks like broken access control.” A live tester has to replay roles, cookies, CSRF tokens, state transitions, object IDs, tenant boundaries, and API/frontend mismatches.
The difference is not academic. It determines whether an AI-generated report helps an engineering team or wastes its time.
Runtime reality breaks clean code reasoning
Code analysis is abstract. Exploitation is environmental.
A model reading source code may infer that a request parameter can reach a dangerous function. But the live deployment may include controls the source snapshot does not capture:
- reverse proxy rewrites;
- request body limits;
- path normalization;
- WAF rules;
- feature flags;
- disabled routes;
- service mesh policy;
- outbound firewall rules;
- container filesystem restrictions;
- patched transitive dependencies;
- browser security headers;
- identity-provider claims mapping;
- CDN caching behavior.
The reverse also happens. Source code may look safe in isolation, while the deployed system is vulnerable because of configuration, dependency composition, or an unexpected trust boundary.
XBOW’s evaluation says this directly. It notes that many exploitable issues do not appear as obvious defects in application source code; they emerge from configuration, dependencies, deployment choices, or the way otherwise safe components are combined. It also says live-site access mattered more than source-code access in some benchmark conditions, even where the vulnerability was present in code. (Xbow)
That point should reshape how teams evaluate AI offensive security tools. A model that reads code beautifully is not automatically a live pentesting system. A system that interacts with live behavior safely, preserves state, replays evidence, and validates impact is solving a different problem.
White-box AI auditing is not black-box offensive security

White-box security review and black-box offensive testing overlap, but they are not interchangeable.
White-box AI auditing sees the application as a developer sees it:
- source code;
- dependency manifests;
- configuration files;
- tests;
- comments;
- architecture;
- build logic.
Black-box AI offensive security sees the application as an attacker sees it:
- exposed routes;
- HTTP behavior;
- redirects;
- cookies;
- sessions;
- CSRF handling;
- tenant IDs;
- API errors;
- browser state;
- rate limits;
- timing behavior;
- deployment quirks.
The following distinction is often where buying decisions and technical arguments go wrong.
| आयाम | White-box AI audit | Black-box AI offensive testing |
|---|---|---|
| Main input | Source code, configs, dependency files | Live endpoints, traffic, browser state |
| Strongest use | Finding candidate weaknesses | Proving reachable impact |
| Typical blind spot | Deployment behavior | Hidden code paths |
| Best evidence | Trace from source to sink | Reproducible request, response, artifact, or state change |
| Risk | Overstating practical impact | Unsafe testing if scope and controls are weak |
| Human role | Review reasoning and patch scope | Approve risky steps, judge impact, preserve safety |
A broken access control example shows why this matters.
The source code may show a decorator:
@requires_auth
def download_invoice(invoice_id):
return invoice_service.render(invoice_id)
A source-code model may mark the endpoint as protected. A black-box test may reveal the real problem:
- the API checks login but not tenant ownership;
- the frontend hides other tenants’ invoices, but the backend accepts direct IDs;
- session refresh changes claims inconsistently;
- mobile API and web API enforce different authorization logic;
- admin-only UI actions are exposed through an old route.
No amount of generic “auth decorator exists” reasoning proves access control. Authorization is behavior over state. It has to be exercised.
The reverse is also true. A model may flag a dangerous-looking function, but live behavior may prove it unreachable. The endpoint may require an internal service token, be disabled in production, sanitize input upstream, or run inside a sandbox with no meaningful privileges.
AI offensive security has to deal with both errors: missing real attack paths and inventing practical impact where none exists.
Real CVEs show why exploitability is contextual
CVE records are useful because they force a discipline that AI bug reports often lack: affected versions, conditions, severity, references, and remediation.
They also show why exploitability is more than pattern matching.
Log4Shell, CVE-2021-44228
CVE-2021-44228 is a useful case because the vulnerable pattern was infamous, easy to discuss, and still easy to misunderstand. NVD describes Apache Log4j2 versions 2.0-beta9 through 2.15.0, with certain exceptions, as vulnerable because JNDI features used in configuration, log messages, and parameters did not protect against attacker-controlled LDAP and related endpoints. NVD also records a CVSS 3.1 base score of 10.0 critical. (एनवीडी.एनआईएसटी.जीओवी)
An AI system can help find Log4j exposure by reading dependency manifests, container layers, SBOMs, Java build files, or code paths that log attacker-controlled input.
That is useful, but it does not prove a working exploit.
Validation still has to answer:
- Is
लॉग4जे-कोरpresent, not onlylog4j-api? - Is the affected version actually loaded at runtime?
- Has the relevant behavior been removed or disabled?
- Does attacker-controlled input reach a logging path?
- Does the application normalize, reject, or sanitize the input?
- Is outbound network access blocked?
- Is the target already patched through vendor packaging?
- Does the validation method avoid unsafe callback or payload behavior?
A safe authorized inventory check might begin with dependency inspection, not live exploitation:
mvn dependency:tree | grep -E "log4j-core|log4j-api"
For SBOM-driven environments:
jq '.components[]
| select(.name | test("log4j"; "i"))
| {name, version, purl}' sbom.json
These commands do not prove exploitability, but they establish exposure candidates without touching production behavior. That is often the correct first step.
Spring4Shell, CVE-2022-22965
Spring4Shell is an even cleaner example of deployment-specific exploitability. The Spring advisory states that a Spring MVC or Spring WebFlux application running on JDK 9+ may be vulnerable to RCE via data binding, but the specific exploit requires Tomcat as a WAR deployment. It also says the default Spring Boot executable jar deployment is not vulnerable to that specific exploit, while affected Spring Framework users should upgrade to fixed versions. (घर)
That advisory is a direct warning against version-only reasoning.
A scanner or AI agent that sees spring-webmvc and an affected Spring Framework version may generate a candidate finding. A strong validation workflow has to add deployment context:
- JDK version;
- Spring Framework version;
spring-webmvcयाspring-webfluxusage;- Tomcat as the servlet container;
- WAR packaging;
- exposed data binding routes;
- fixed framework version or vendor mitigation.
A safe internal check might combine dependency and packaging evidence:
mvn dependency:tree | grep -E "spring-webmvc|spring-webflux|spring-beans"
find target/ -maxdepth 2 -type f | grep -E "\.war$|\.jar$"
java -version
Even then, a finding should not jump straight to “critical exploitable RCE” unless the exploit conditions are actually present and authorized validation has produced reproducible evidence.
Spring4Shell is exactly the kind of issue that exposes weak AI offensive security workflows. The candidate is easy. The proof is conditional.
MOVEit Transfer, CVE-2023-34362
CVE-2023-34362 shows the opposite side of the problem: internet-facing enterprise software where validation and remediation urgency are high, but unsafe testing can make things worse.
NVD describes CVE-2023-34362 as a SQL injection vulnerability in Progress MOVEit Transfer that could allow an unauthenticated attacker to access the MOVEit Transfer database. NVD also notes that exploitation occurred in the wild in May and June 2023, that exploitation of unpatched systems could occur over HTTP or HTTPS, and that the CVSS 3.1 base score is 9.8 critical. The record also shows that the vulnerability is in CISA’s Known Exploited Vulnerabilities Catalog, with required action to apply updates per vendor instructions. (एनवीडी.एनआईएसटी.जीओवी) (एनवीडी.एनआईएसटी.जीओवी)
For AI offensive security, the lesson is not “generate SQL injection payloads faster.” The useful lesson is operational:
- identify exposed MOVEit instances;
- confirm product and version safely;
- verify patch status;
- check logs and indicators of compromise;
- avoid destructive validation against production;
- escalate confirmed exposure quickly.
A model can help triage advisories, parse asset inventories, summarize exposure, and draft remediation tickets. But a responsible validation workflow should avoid turning a known exploited enterprise vulnerability into an uncontrolled test.
The practical standard is evidence without reckless impact.
| सीवीई | Why it matters for AI offensive security | Exploitability depends on | Safer validation focus |
|---|---|---|---|
| CVE-2021-44228 | Shows the gap between dependency detection and working exploitability | Loaded dependency, logging path, JNDI behavior, egress, mitigations | SBOM, dependency tree, runtime config, safe exposure confirmation |
| CVE-2022-22965 | Shows why deployment conditions matter | JDK 9+, Tomcat, WAR packaging, Spring MVC/WebFlux, affected versions | Version plus packaging plus route reachability |
| CVE-2023-34362 | Shows the urgency of validated internet-facing risk | Exposed MOVEit instance, affected version, patch state, compromise evidence | Patch verification, asset exposure, logs, incident response |
The common lesson is simple: a CVE match is not the same as exploit proof. AI can shorten the path from advisory to investigation. It should not erase the validation boundary.
False positives are not the deepest problem
Security teams often describe the AI problem as false positives. That is real, but it is not precise enough.
The deeper problem is false exploitability.
A false positive says:
“There is no issue.”
A false exploitability claim says:
“There may be some weakness, but the reported attack path is not reachable, reproducible, safe to test, or practically important.”
False exploitability is expensive because it looks more convincing than ordinary noise. It often arrives with fluent reasoning, code snippets, severity language, and confident remediation advice. It can push engineering teams into unnecessary emergency work while real issues wait.
Cisco’s Foundry Security Spec captures this problem sharply. Its constitution says frontier models can produce fluent, confident, plausible vulnerability claims that are wrong at a rate that makes unreviewed output worthless. Cisco says the fix was not asking the model to be more careful, but requiring claims to be checkable and then checking them. (गिटहब)
That sentence should be printed above every AI security triage queue.
The correct output for a candidate should not be:
“Critical RCE confirmed.”
It should be something closer to:
{
"status": "candidate",
"claim": "User-controlled input may reach a shell-like sink",
"reachability": "unknown",
"exploitability": "unproven",
"evidence": [
"controller.py:42 reads request parameter",
"runner.py:88 constructs command string"
],
"safe_to_test": false,
"next_step": "confirm route exposure and input controllability in staging"
}
That is less dramatic, but far more useful.
A mature AI offensive security workflow should promote findings through states, not jump from suspicion to severity.
def promote_finding(finding):
if not finding.evidence:
return "discard"
if not finding.reachability_confirmed:
return "candidate"
if not finding.input_controllability_confirmed:
return "needs_validation"
if finding.safe_test_completed and finding.impact_confirmed:
return "validated"
return "review_required"
The point is not the code. The point is the discipline.
A finding should not enter a developer’s emergency queue just because the model sounds confident. It should survive an evidence gate.
Cisco’s checkable-claims idea is the right direction
Cisco’s Foundry Security Spec is important because it frames AI security evaluation as a system, not a prompt.
The spec’s constitution says detection is high-volume and low-precision by design, and that only findings promoted through triage should reach issue trackers, operator inboxes, or reviewer reports. It warns that surfacing every candidate buries signal and trains operators to ignore the system. (गिटहब)
That matches what AppSec teams already know from years of SAST, DAST, dependency scanning, and bug bounty triage. More findings do not automatically mean more security. Sometimes they mean more queue debt.
The difference with frontier models is that the noise is often better written. It reads like expert output even when it is not supported by evidence.
That creates a new operational requirement: every AI-generated vulnerability claim should be structured so another system or human can check it.
A useful AI offensive security finding should include:
- affected asset;
- observed input point;
- suspected sink;
- reachability evidence;
- reproduction constraints;
- safe test status;
- expected impact;
- actual observed impact;
- uncertainty;
- remediation suggestion;
- links to raw artifacts.
A poor finding says:
“Authentication bypass exists.”
A better finding says:
“User with role viewer can request GET /api/admin/export?id=123 and receive a 200 response containing fields normally visible only to admin. Evidence includes two replayed requests using separate role-bound sessions in staging. No destructive action was performed.”
That is the difference between text and proof.
A model is not an offensive security system
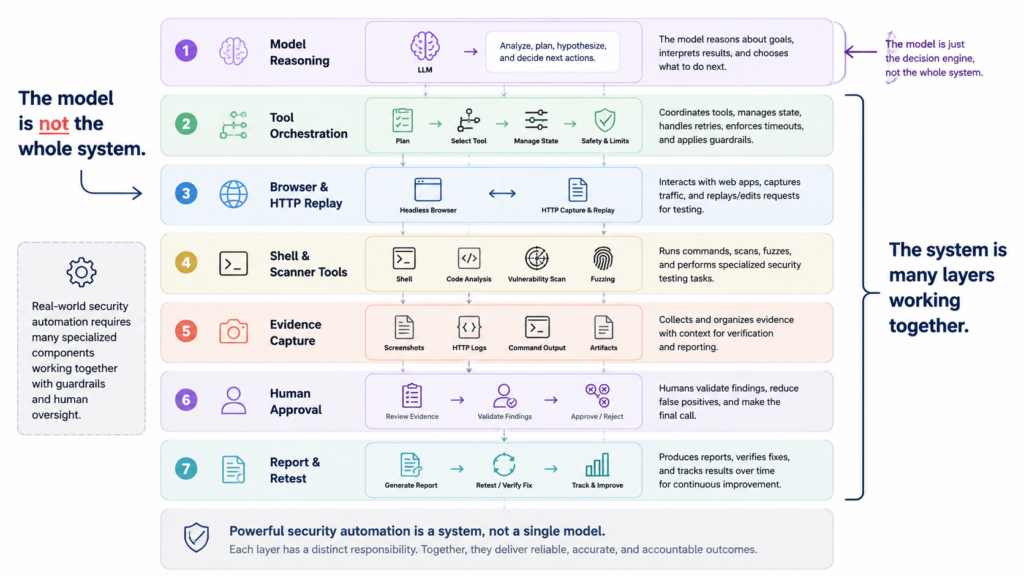
XBOW’s phrase “a model is a brain without a body” is useful because it cuts through most of the confusion. (Xbow)
A brain can reason. Offensive security also needs hands, eyes, memory, and brakes.
A practical AI offensive security system needs:
- scoped target control;
- authenticated browser sessions;
- HTTP interception and replay;
- shell or tool execution in controlled environments;
- request mutation;
- rate limiting;
- state memory;
- artifact capture;
- policy gates;
- non-destructive validation modes;
- human approval boundaries;
- reporting that preserves raw evidence.
Without those pieces, a model may produce impressive analysis and still fail to prove the bug.
This is why the industry is moving toward agentic systems rather than one-shot model answers. Microsoft’s MDASH announcement is one example from the defensive side. Microsoft said its multi-model agentic scanning harness helped researchers find 16 new vulnerabilities across the Windows networking and authentication stack, including four critical remote code execution flaws. (microsoft.com)
The important part is not only the number of vulnerabilities. It is the architecture implied by the result: multi-model, agentic, task-oriented scanning rather than a single chat answer.
XBOW’s own evaluation makes the same architectural point from an offensive testing perspective. It says the ideal pattern is to analyze source code to find a lead, probe the live site to understand how the weakness appears in deployment, and then craft an exploit from that combined evidence. (Xbow)
That sequence is the real shape of AI offensive security:
- Read.
- Hypothesize.
- Test.
- Observe.
- Adapt.
- Prove.
- Report.
Most weak AI security demos stop at step two.
Live-site validation is where the toolchain matters
Live-site testing is not simply “let the model send requests.”
It requires controlled interaction.
For a web application, the system may need to:
- log in as multiple roles;
- maintain cookies;
- preserve CSRF tokens;
- follow redirects;
- replay requests;
- compare role-bound responses;
- detect state changes;
- avoid destructive operations;
- throttle traffic;
- store raw evidence.
For APIs, it may need to:
- understand OpenAPI specs;
- generate valid objects;
- avoid bulk destructive actions;
- compare tenant boundaries;
- distinguish validation errors from authorization errors;
- preserve request IDs and response bodies.
For cloud and infrastructure testing, it may need to:
- map identities and permissions;
- avoid creating persistence;
- avoid data exfiltration;
- use read-only checks when possible;
- record exact commands;
- link behavior to ATT&CK-style follow-on risk without overclaiming.
That is why “AI offensive security” is a systems engineering category, not a model leaderboard category.
A safe authorized validation command might look ordinary:
nuclei -u https://staging.example.com \
-severity critical,high \
-jsonl \
-rate-limit 3 \
-o nuclei-authorized-results.jsonl
The value is not the command itself. The value comes from scope control, staging environment selection, rate limiting, output preservation, and follow-up human review.
An agent that can run tools but cannot explain what evidence supports its claim is dangerous. An agent that can explain but cannot test reality is incomplete. A useful system has to do both.
Penligent’s public site describes an AI-powered penetration testing workflow around finding vulnerabilities, verifying findings, executing exploits, evidence-first results, support for 200-plus industry tools, and operator-controlled agentic workflows. It also explicitly frames the product for authorized security testing. (पेनलिजेंट.एआई) That positioning is naturally related to the exploit-validation problem because the hard part is not generating a bug claim; it is moving from signal to scoped proof with artifacts a human can review. Penligent’s related article on pentest AI tools in 2026 makes a similar distinction across AI-driven web and API pentesting, autonomous enterprise pentesting, security validation, and AI-native application security agents. (पेनलिजेंट.एआई)
The broader pattern is the same across vendors and research systems: raw model capability matters, but the workflow around the model determines whether the output becomes useful security evidence.
The curl result is a warning against both hype and cynicism
The curl Mythos result is easy to misread.
One side can say: Mythos found only one low-severity vulnerability, so the hype is overblown.
Another side can say: curl is unusually mature, heavily fuzzed, deeply audited, and not representative of ordinary codebases.
Both points can be true.
Stenberg’s write-up says Mythos produced five “confirmed” security issues, of which the curl team accepted one as a confirmed low-severity vulnerability after review, with the rest reduced to false positives or a normal bug. He also wrote that AI-powered code analyzers are significantly better than traditional analyzers at finding flaws and that teams not using them may be leaving opportunity for attackers. (daniel.haxx.se)
That is exactly the balanced lesson AI offensive security needs.
AI is useful enough that serious projects should use it.
AI is not reliable enough that serious projects should trust it without review.
This is not a contradiction. It is normal security engineering.
Fuzzers did not remove human security engineers. Static analyzers did not remove AppSec teams. SCA did not remove dependency owners. EDR did not remove incident responders. Each tool changed the workflow and raised the baseline. AI offensive security is doing the same, but with a louder interface and more convincing prose.
The danger is not only that AI misses bugs. It is that AI makes unproven claims sound finished.
The attacker asymmetry is real
A defender needs accuracy, auditability, safety, and prioritization.
An attacker needs advantage.
That asymmetry matters.
A defender cannot flood engineering teams with thousands of speculative issues. An attacker can run many hypotheses and keep the few that work.
A defender must avoid destructive production tests. An attacker does not have that constraint.
A defender must preserve compliance boundaries. An attacker does not care.
This is why AI offensive security can be strategically important even before it becomes fully autonomous. Attackers do not need a perfect end-to-end AI hacker. They benefit from:
- faster recon;
- faster code reading;
- easier exploit adaptation;
- better scripting;
- cheaper vulnerability triage;
- improved phishing and social engineering;
- quicker chaining of known techniques.
Axios captured this tension through practitioner comments: defenders still need human expertise to get the best value, while adversarial hackers may not face the same learning curve because exploitation is already their domain. (योग्य)
That should push defenders toward faster validation, not panic.
The right response is not to pretend AI offense is fake. It is to build systems that make defensive verification faster than attacker exploitation.
What AI offensive security can do well today
A realistic capability map is more useful than a binary yes/no judgment.
| Task | Current capability | Practical caution |
|---|---|---|
| Source-code audit | Strong and improving | Review severity, reachability, and patch quality |
| Dependency analysis | Strong for candidate exposure | Confirm runtime loading and deployment conditions |
| Reverse engineering | Improving rapidly | Validate exploit reliability and assumptions |
| CTF-style exploitation | Strong in controlled settings | CTFs are not production networks |
| Cyber range execution | Emerging but significant | Ranges may lack active defenders and messy business logic |
| Web recon | Useful | Scope and rate limits matter |
| Exploit hypothesis generation | Strong | Hypotheses are not proof |
| Live exploit validation | Mixed | Needs tools, state, evidence, and approval |
| Multi-step chaining | Emerging | Reliability drops as state and environment complexity rise |
| Fully autonomous black-box pentesting | Not reliable enough for unsupervised use | Human control remains necessary |
That table is less exciting than “AI replaces hackers,” but it is closer to what practitioners can use.
For most teams, the immediate value is not replacing expert pentesters. It is compressing the loop between observation and validation:
- summarize code faster;
- find suspicious paths earlier;
- generate test hypotheses;
- run non-destructive checks;
- cluster duplicate findings;
- preserve evidence;
- draft clearer reports;
- suggest fixes;
- help retest.
That is already valuable.
What should count as a validated AI security finding
A validated finding should survive a simple evidence standard.
It should contain enough information for another qualified person to reproduce the result under the same scope.
At minimum:
| क्षेत्र | Required question |
|---|---|
| Asset | What system, endpoint, repository, package, or component is affected? |
| Entry point | What attacker-controlled input starts the path? |
| पूर्व शर्तें | What role, configuration, version, feature flag, or environment is required? |
| प्रमाण | What request, response, log, trace, or artifact proves behavior? |
| प्रभाव | What security property is violated? |
| Safety | Was the validation non-destructive and within scope? |
| Reproducibility | Can another reviewer repeat it? |
| उपचार | What fix addresses the root cause, not only the symptom? |
| Confidence | What remains uncertain? |
A candidate can be useful without meeting all of those criteria. It just should not be labeled as validated.
That status distinction prevents AI output from poisoning the triage queue.
A practical state model might look like this:
| Status | Meaning | Allowed destination |
|---|---|---|
| Candidate | Suspicious pattern or hypothesis | Internal review queue |
| Needs validation | Some evidence, but reachability or impact unproven | Security analyst queue |
| Validated | Reproducible, scoped, evidence-backed | Engineering ticket |
| Exploited in test | Safe proof of impact in authorized environment | Priority remediation |
| Not exploitable | Weakness not reachable or impact not meaningful | Archive with rationale |
| Duplicate | Already known or covered by existing ticket | Link and close |
AI tools should make these distinctions explicit. If every output is “critical,” nothing is critical.
Safe adoption for AppSec teams
AppSec teams should use AI offensive security as an acceleration layer, not as an authority layer.
The safest pattern is:
- Let AI expand discovery.
- Require evidence for promotion.
- Keep risky validation under human approval.
- Send only validated findings to developers.
- Preserve raw artifacts.
- Retest after remediation.
The biggest operational mistake is to pipe AI findings directly into Jira with scary severity labels. That creates the same failure mode Cisco warns about: lots of plausible claims, weak coverage signal, and operator fatigue. Cisco’s public Foundry announcement described organizations investing in AI-assisted security and getting hallucinated findings, false positives at scale, and no coverage signal, then positioned its spec as scaffolding for turning frontier models into security evaluation systems. (सिस्को ब्लॉग्स)
A better AppSec workflow is strict about promotion.
उदाहरण:
{
"finding_id": "APP-2026-017",
"title": "Possible tenant boundary bypass in invoice export",
"status": "needs_validation",
"asset": "staging-api.example.com",
"entry_point": "GET /api/invoices/export?id=",
"preconditions": [
"authenticated user",
"viewer role",
"known invoice id from another tenant"
],
"evidence": [
"request replay pending",
"source trace suggests missing tenant filter"
],
"risk": "potential horizontal access control issue",
"next_step": "run two-role replay in staging with test tenants",
"destructive": false
}
That is not as flashy as “AI found a breach.” It is how real security work survives contact with engineering teams.
Safe adoption for red teams
Red teams can benefit from AI, but they should keep control over risk.
AI is useful for:
- recon planning;
- attack path brainstorming;
- payload mutation in lab settings;
- tooling glue code;
- report drafting;
- log interpretation;
- deconfliction notes;
- mapping findings to likely defensive telemetry.
AI should not automatically perform:
- destructive state changes;
- credential dumping;
- persistence;
- lateral movement;
- bulk data access;
- real customer data interaction;
- unsafe exploit attempts against production.
A mature red-team AI workflow should define explicit human approval points. For example:
| कदम | AI autonomy level | Human approval |
|---|---|---|
| Passive recon | उच्च | Scope review |
| Authenticated crawling in staging | Medium to high | Pre-approved test users |
| Candidate vulnerability analysis | उच्च | Analyst review before escalation |
| Non-destructive validation | मध्यम | Rules-based approval |
| Auth bypass testing | Low to medium | Required |
| Privilege escalation testing | कम | Required |
| Data access proof | कम | Required and minimized |
| Post-exploitation simulation | Very low | Explicit approval |
This is not bureaucracy. It is how teams get machine speed without machine recklessness.
Safe adoption for bug bounty hunters
Bug bounty programs are already feeling the AI effect. Maintainers and triage teams have complained for years about low-quality automated reports. Frontier models make the reports more articulate, which can make the problem worse if the evidence is weak.
A good AI-assisted bug bounty report should still include:
- exact affected asset;
- account roles used;
- reproduction steps;
- request and response evidence;
- impact explanation;
- scope confirmation;
- non-destructive proof;
- clear distinction between observed and inferred behavior.
A bad report says:
“Possible RCE because input reaches parser.”
A good report says:
“Using two test accounts under the authorized program scope, I confirmed that account A can retrieve account B’s invoice PDF by changing the invoice_id parameter. The response includes account B’s email and billing address. No modification or bulk access was performed.”
AI can help write the second report. It cannot invent the evidence.
What buyers should ask vendors
Security buyers should stop asking only whether a product “uses AI.”
That question is no longer useful.
Better questions:
- Does the system distinguish candidate findings from validated findings?
- What evidence is required before a finding becomes a ticket?
- Can the system replay requests?
- Can it preserve browser state?
- Can it test authenticated flows?
- How does it prevent destructive actions?
- How are scope limits enforced?
- Can humans approve high-risk steps?
- Does it support staging-first validation?
- How does it handle false exploitability?
- Can findings be traced back to raw artifacts?
- Can it retest after remediation?
- Does it support code-plus-live behavior, or only one side?
The answers will separate serious AI offensive security systems from chat interfaces wrapped around scanner output.
Why bigger models will not solve everything
Model capability matters. It would be foolish to pretend otherwise.
AISI’s evaluations show rapid progress. Anthropic’s Mythos work, OpenAI’s cyber access program, Microsoft’s MDASH architecture, XBOW’s evaluation, and Cisco’s Foundry work all point to the same future: models will become more capable, and security teams will use them. (AI Security Institute)
But larger models do not remove the need for:
- target state;
- live interaction;
- scoped execution;
- evidence capture;
- safe validation;
- environment-specific reasoning;
- human judgment.
A bigger brain without a body is still missing the body.
A more capable model may produce better hypotheses, better code reading, and better exploit plans. It still needs tool access to test reality. It still needs guardrails to avoid unsafe behavior. It still needs a review process to distinguish “sounds likely” from “proved.”
The future of AI offensive security will not be decided only by who has the strongest model. It will be decided by who builds the best validation loop around it.
The exploit reality wall
The exploit reality wall is the point where fluent reasoning meets live systems.
It appears when:
- the payload fails because encoding changes;
- the route is not reachable in production;
- the role boundary behaves differently than expected;
- the vulnerable function is behind an internal-only path;
- the dependency is present but not loaded;
- the exploit requires egress that is blocked;
- the proof would be destructive;
- the model cannot preserve session state;
- the issue exists but impact is low;
- the report sounds critical but evidence is thin.
Every serious AI offensive security system hits this wall.
The question is what happens next.
Weak systems hallucinate around it. They produce confident prose.
Better systems ask for evidence. They downgrade uncertainty. They try safe tests. They preserve artifacts. They involve humans at the right points.
The best systems will become less theatrical and more useful.
अक्सर पूछे जाने वाले प्रश्न
Can AI offensive security tools replace pentesters?
- Not reliably for full live engagements.
- They can accelerate source review, recon, triage, hypothesis generation, non-destructive validation, and reporting.
- Human testers remain important for scope interpretation, exploit safety, ambiguous impact calls, business logic reasoning, and final validation.
- The better framing is not replacement. It is compression of repetitive work and expansion of coverage.
Why is exploit validation harder than vulnerability discovery?
- Discovery can rely on pattern recognition and code reasoning.
- Validation requires runtime reachability, attacker controllability, environment context, safe proof, and business impact analysis.
- Live systems introduce authentication, session state, middleware, deployment differences, and safety constraints.
- A plausible bug becomes valuable only when it is reproducible and tied to impact.
Why do AI security models overstate exploitability?
- Models are good at recognizing dangerous-looking patterns.
- They may treat possibility as probability.
- They may not see deployment controls, feature flags, reverse proxies, runtime mitigations, or access boundaries.
- They often generate fluent explanations even when evidence is incomplete.
- Strong workflows force claims to be checkable before they reach engineers.
Is source-code auditing enough for offensive security?
- नहीं।
- Source review is excellent for finding candidate weaknesses early.
- Black-box testing is still needed to observe live behavior, authentication state, routing, browser behavior, and deployment-specific issues.
- The best results usually come from combining source-code leads with live validation.
What should count as a validated AI security finding?
- The affected asset is identified.
- The attacker-controlled entry point is clear.
- Preconditions such as role, version, configuration, and environment are stated.
- Evidence includes reproducible request, response, log, trace, or artifact data.
- The validation was performed within authorized scope and avoided unnecessary destructive behavior.
- The impact is explained without exaggeration.
- Remaining uncertainty is stated.
Are traditional scanners obsolete?
- नहीं।
- Scanners remain useful for repeatable checks, known CVEs, configuration issues, and broad coverage.
- AI adds value by reasoning over ambiguous context, connecting evidence, generating hypotheses, and explaining impact.
- The strongest workflows combine deterministic scanning, AI reasoning, live validation, and human review.
Can AI chain multiple vulnerabilities?
- Sometimes, especially in controlled ranges or well-instrumented environments.
- Reliability drops as chains require more state, timing, credentials, environmental knowledge, and safe decision-making.
- AI can help propose chains, but human operators should review high-risk transitions such as privilege escalation, data access, and lateral movement.
How should security teams safely adopt AI offensive security?
- Start with non-destructive use cases such as code review, advisory triage, dependency investigation, and staging validation.
- Require evidence gates before findings become engineering tickets.
- Keep human approval for auth bypass, privilege escalation, state-changing tests, and production activity.
- Preserve raw artifacts for every validated finding.
- Track false exploitability, not only false positives.
- Treat AI output as acceleration, not authority.
समापन
AI offensive security is real. The capability jump is not just marketing, and teams that ignore it will work slower than teams that learn how to use it carefully.
But the winning systems will not be the ones that produce the most confident vulnerability claims. Confidence is cheap. Proof is expensive.
The useful boundary is clear: finding suspicious code is a reasoning task; proving exploitability is an execution task. Real security value appears when a system can move from candidate to evidence, from evidence to impact, and from impact to a fix that developers can trust.
The future of AI offensive security will belong to tools and teams that can prove what they claim.