Anthropic did not frame Claude Mythos Preview as another incremental model release. It framed the model as a cybersecurity event serious enough to withhold from general availability, limit to an invitation-only defensive program, and pair with a new disclosure policy built around machine-scale vulnerability discovery. Anthropic’s own documentation says Mythos Preview is an unreleased, general-purpose frontier model, available only as a gated research preview for defensive cybersecurity work under Project Glasswing, with no self-serve sign-up. (Anthropic)
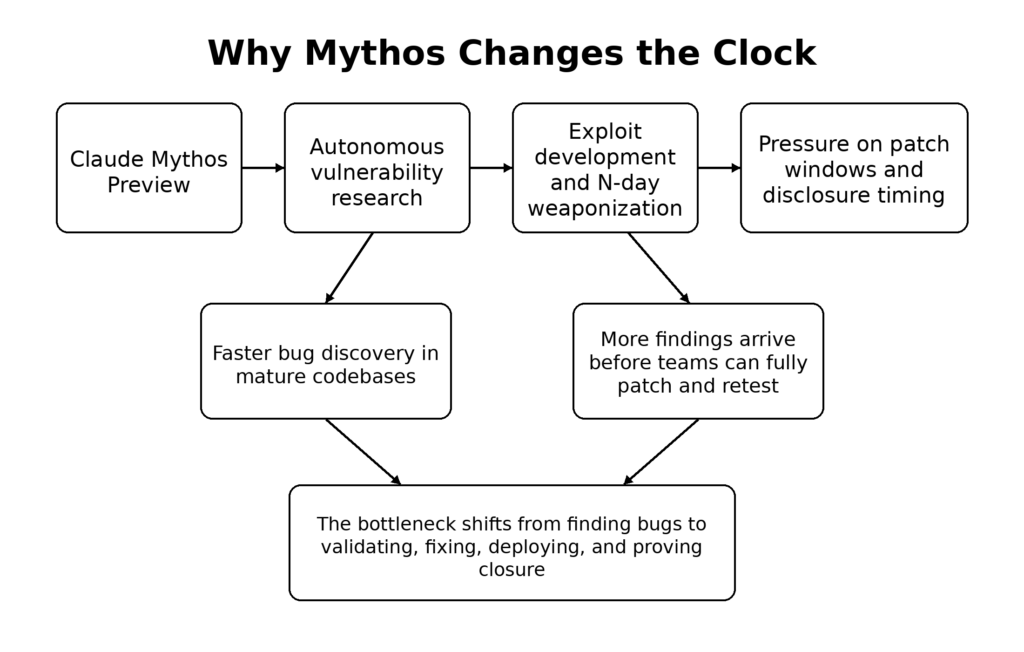
That framing matters because it changes the default question. The question is no longer whether frontier models can help with security work. Anthropic’s public record already answers that. The real question is what kind of security work has crossed the line from “interesting lab demo” into “operationally disruptive capability,” and which parts of the public conversation have run ahead of what outsiders can independently verify. Anthropic says Mythos Preview found and exploited zero-days in every major operating system and every major web browser, while also reporting that more than 99 percent of its findings remain undisclosed because they are not yet patched. That combination is exactly why this moment feels different: the capability claims are large, but the public proof set is intentionally small. (red.anthropic.com)
The right reading is neither complacent nor breathless. Claude Mythos Preview does not publicly prove that AI has solved every form of black-box internet-facing penetration testing. It does, however, provide the strongest public evidence so far that AI vulnerability research, exploit development, and N-day weaponization are moving quickly enough to force changes in patch windows, disclosure processes, and validation workflows. The “new zero-day era” is not a slogan. It is a change in tempo. (red.anthropic.com)
Claude Mythos Preview changes the burden of proof in AI vulnerability research
Anthropic’s main technical write-up makes four claims that security engineers should treat as the center of gravity. First, Mythos Preview is a general-purpose model whose cybersecurity capabilities emerged from broader gains in code, reasoning, and agentic autonomy rather than from narrow exploit-specific training. Second, Anthropic says those capabilities now include source-visible zero-day discovery, exploit construction, reverse engineering of stripped binaries, and conversion of known vulnerabilities into working exploits. Third, Anthropic is explicit that these abilities create a transitional period in which attackers may gain more than defenders if release practices do not change. Fourth, the company is acting on that conclusion by restricting access and building Project Glasswing around major operators of critical software. (red.anthropic.com)
That combination is new in public AI security writing. Earlier Anthropic material on Mozilla and Firefox had already shown that Claude Opus 4.6 could identify novel bugs in a major browser codebase, submit 112 unique reports, and help drive fixes in Firefox 148. Anthropic also published a carefully limited exploitation result for Opus 4.6: out of several hundred attempts and about $4,000 in API credits, the model managed to turn Firefox bugs into functioning exploits only twice, and even those worked only in an intentionally weakened test environment. That public record told defenders something important but still fairly bounded: AI bug finding was becoming world-class faster than AI exploit development. (Anthropic)
Mythos Preview changes that balance. Anthropic says that when it re-ran the Firefox exploit benchmark with Mythos Preview, the model produced working exploits 181 times and reached register control in 29 more cases. On its internal OSS-Fuzz-style benchmark, Anthropic says Sonnet 4.6 and Opus 4.6 mostly topped out at low-severity crash tiers, while Mythos Preview reached full control-flow hijack on ten fully patched targets. Those are not just bigger numbers. They imply that exploit development is no longer the clearly lagging half of the pipeline. (red.anthropic.com)
Anthropic’s risk report adds another layer that is easy to miss in the headlines. The public redacted report says Mythos Preview appears to be the best-aligned model Anthropic has released, but also says it is significantly more capable, more autonomous, and particularly strong at software engineering and cybersecurity tasks. The same report says Anthropic identified errors in its training, monitoring, evaluation, and security processes during Mythos development and concludes that overall risk is “very low, but higher than for previous models.” That is a governance signal as much as a safety one. More capable systems can be better behaved on average and still create more operational risk because they are entrusted with more difficult tasks, given broader affordances, and better able to work around obstacles. (Anthropic)
Project Glasswing and why Anthropic did not make Mythos Preview general access
Project Glasswing is not a side note. It is the policy response to Anthropic’s capability assessment. Anthropic’s official announcement says the project brings together Amazon Web Services, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks to secure critical software. Anthropic says it formed the project because Mythos Preview revealed a stark fact: AI models have reached a level of coding capability where they can surpass all but the most skilled humans at finding and exploiting software vulnerabilities. (Anthropic)
That statement is stronger than the usual “AI can help with AppSec” claim. It says the model is not merely an assistant for code review, triage, or patch drafting. It says the model belongs in the same conversation as top-end vulnerability researchers. The official platform documentation reinforces that Anthropic is treating this as a tightly controlled research preview for defensive cybersecurity workflows only, with no self-serve access. That is unusual enough on its own, but what really matters is the operational logic behind it: if a model can compress exploit research, then release management and disclosure management become security functions, not just product functions. (Anthropic)
Anthropic’s coordinated vulnerability disclosure policy makes that logic explicit. The company says it aims to follow a 90-day disclosure deadline, escalate to an external coordinator when maintainers do not respond within 30 days, target a seven-day patch or mitigation window for actively exploited critical vulnerabilities, and generally wait 45 days after a patch is available before publishing full technical details. Those timelines are recognizable to anyone who has lived through normal coordinated disclosure, but the difference here is the assumed volume and cadence. Anthropic says reports are human-reviewed, AI-originated findings are labeled as such, and submission volume to a project should be paced to what maintainers can absorb. That is not just process hygiene. It is an admission that AI can produce more vulnerability output than traditional maintainer workflows were designed to absorb. (Anthropic)
This is where “zero-day era” becomes practical rather than rhetorical. If machine-assisted discovery scales faster than vendor triage and downstream patch deployment, then the constraining factor in security stops being raw discovery talent and becomes organizational throughput. The teams that adapt fastest will not be the ones with the flashiest demo. They will be the ones that can decide, validate, patch, retest, and redeploy faster than new findings accumulate. (red.anthropic.com)
What the public record proves today, and what it does not

The cleanest way to think about Mythos Preview is to separate the public record into three buckets: independently checkable cases, technically detailed but vendor-authored cases, and broad claims whose detailed evidence remains private because patches are not ready. Anthropic’s own post says over 99 percent of the vulnerabilities it found have not yet been patched and therefore cannot be responsibly disclosed. That single fact explains most of the confusion around the launch. The public conversation is treating all claims as equally visible, but they are not. (red.anthropic.com)
| Capability area | Public evidence | What outsiders can verify today | What remains mostly private |
|---|---|---|---|
| Open-source zero-day discovery | Anthropic published detailed patched examples in OpenBSD, FFmpeg, and FreeBSD, plus additional unnamed findings. (red.anthropic.com) | OpenBSD errata 025 and FreeBSD SA-26:08 are public; FFmpeg 8.1 is public; specific patch and advisory artifacts exist. (openbsd.org) | Most remaining findings are undisclosed because they are unpatched. (red.anthropic.com) |
| Autonomous exploit development | Anthropic published FreeBSD exploitation details, N-day Linux exploit write-ups, and benchmark gains over Opus 4.6. (red.anthropic.com) | The benchmark numbers and exploit narratives are public, but replication requires the same bugs, harnesses, and environments. (red.anthropic.com) | Many browser and OS exploit chains remain embargoed. (red.anthropic.com) |
| Reverse engineering of stripped binaries | Anthropic says Mythos reconstructs plausible source from stripped binaries, then analyzes reconstructed source plus the original binary. (red.anthropic.com) | The methodology is public. The underlying closed-source targets and results are mostly not. (red.anthropic.com) | Most case material remains non-public. (red.anthropic.com) |
| Web application logic vulnerabilities | Anthropic publicly lists categories such as auth bypass, login bypass, and destructive DoS. (red.anthropic.com) | Category-level evidence is public. Detailed case studies are not. (red.anthropic.com) | Public proof of black-box internet-facing web pentesting remains limited. (penligent.ai) |
| Release controls and governance | Project Glasswing, invitation-only access, and a dedicated CVD policy are public. (Anthropic) | The release posture is fully visible. | The exact internal thresholds that drove that posture are only partly visible through the redacted risk report. (Anthropic) |
The most common overstatement in discussions around Mythos is to collapse those buckets into one. Anthropic has published unusually strong evidence for source-visible vulnerability discovery and increasingly strong evidence for exploit construction. It has not published a reproducible public case showing Mythos autonomously performing the full black-box web application testing loop against a live internet target with the kinds of messy state, identity, rate-limits, compensating controls, and environmental quirks that define real application pentesting. Anthropic’s own scaffold description says the project-under-test and its source code are placed in an isolated container. Its reverse-engineering section says reconstructed source and the original binary are provided offline. That is real and important capability, but it is not the same thing as public proof of universal black-box pentest automation. (red.anthropic.com)
That distinction matters because buyers, red teams, and security leaders need a stable vocabulary. White-box AI exploit research is already strategically important. Black-box internet-scale validation is a different question. Confusing the two creates bad procurement, bad expectations, and bad engineering priorities. The right conclusion is not that Mythos is overhyped. The right conclusion is that exploit research acceleration is very real, while some of the broadest application-security interpretations remain ahead of the public evidence. (red.anthropic.com)
Anthropic’s methodology matters as much as the outcomes
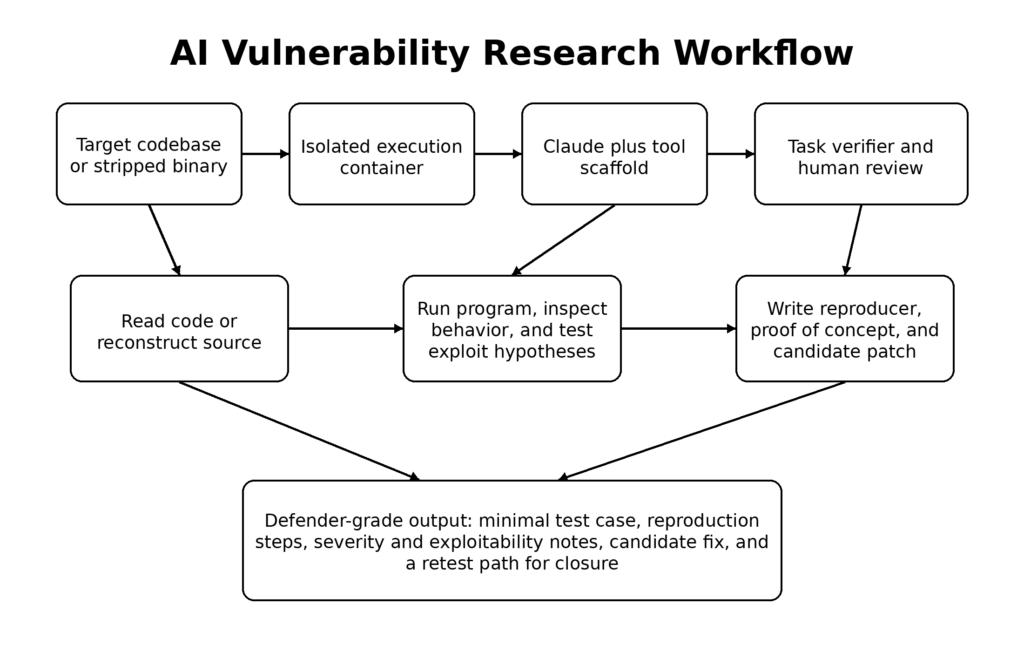
One reason Mythos deserves serious attention is that Anthropic did not present its results as mystery magic. The company spent a meaningful share of the paper on methodology, and those methodological details are exactly where defenders should be paying attention. Anthropic says it chose to focus on memory safety vulnerabilities first for pragmatic reasons: they are common, severe, and relatively easy to verify with tools like AddressSanitizer. The paper also says the research team had sufficient exploitation experience to validate findings efficiently. That is a quieter but crucial point. AI vulnerability research does not remove the need for expert validation. It changes where expertise sits in the loop. (red.anthropic.com)
The scaffold Anthropic describes is also revealing. The company says it launches an isolated container that includes the project-under-test and its source code, invokes Claude Code with Mythos Preview, and prompts it at a high level to find a security vulnerability. Claude then reads code, forms hypotheses, runs the program, confirms or rejects suspicions, adds debug logic or uses debuggers, and eventually emits either “no bug” or a bug report with proof-of-concept and reproduction steps. That workflow looks less like a chatbot and more like a junior-to-mid vulnerability researcher with infinite patience, fast context switching, and a willingness to keep trying. (red.anthropic.com)
The Mozilla collaboration provides a useful earlier template for how that sort of system becomes useful rather than noisy. Anthropic says Claude Opus 4.6 found a Use After Free in Firefox’s JavaScript engine after about twenty minutes of exploration, after which researchers independently validated the bug and submitted it with a proposed patch. Mozilla then helped shape the reporting process and encouraged bulk submission of crashing test cases. Anthropic’s write-up of that work emphasizes three trust-building artifacts in submissions: minimal test cases, detailed proofs of concept, and candidate patches. Those are not cosmetic. They are the exact ingredients that let maintainers convert model output into engineering action. (Anthropic)
Anthropic also puts heavy weight on what it calls task verifiers. In the Mozilla piece, it argues that models perform best when they can check their own work against trusted signals, both for confirming the original bug and for validating proposed fixes against regressions. That lesson generalizes far beyond Firefox. A security team that plugs a model into a repository without a strong verifier layer is building an expensive hallucination pipeline. A team that gives a model a trusted crash oracle, test harness, regression suite, and controlled execution environment is building something much closer to an engineering instrument. (Anthropic)
OpenBSD and the value of finding an old bug in a hard target
Anthropic’s OpenBSD case is the sort of example that security professionals latch onto because it is both concrete and symbolically loaded. Anthropic says Mythos Preview found what became a now-patched 27-year-old bug in OpenBSD’s TCP Selective Acknowledgment handling. OpenBSD’s official 7.8 errata confirms that patch 025, dated March 25, 2026, addressed a condition where TCP packets with invalid SACK options could crash the kernel. The corresponding patch artifact shows that the fix added a lower-bound check on sack.start relative to snd_una and also guarded an append path with p != NULL. (openbsd.org)
Anthropic’s technical explanation fills in why the bug is interesting. The write-up says OpenBSD tracked SACK state as a linked list of holes. The end of an acknowledged range was checked against the send window, but the start was not. That set up a logic path where a single SACK block could delete the only hole in the list and also attempt to append a new hole, eventually writing through a null pointer. Anthropic further explains that TCP sequence number wraparound and signed comparisons made an apparently impossible condition reachable. Whether or not a reader agrees with every interpretive detail in Anthropic’s explanation, the public patch and the official errata make it clear that the bug class was real and the fix was not cosmetic. (red.anthropic.com)
The OpenBSD example matters for three reasons. First, it shows that public proof does not have to arrive as a glamorous RCE or a headline CVE. OpenBSD labeled this a reliability fix, but a remotely triggerable kernel crash is still a security problem with real operational impact. Second, it demonstrates the kind of boundary-condition reasoning that models are starting to do well: state machines, arithmetic edge cases, sentinel assumptions, and “this should be unreachable” branches. Third, it highlights the way AI changes search economics. Anthropic says it found the OpenBSD bug after roughly a thousand scaffold runs, at a total cost under $20,000, while also finding dozens of additional issues, and says the specific successful run cost under $50 only in hindsight. That is not proof that zero-day hunting is suddenly cheap in a general sense, but it is strong evidence that parts of the search process are becoming far more parallelizable. (red.anthropic.com)
Here is a stripped-down defensive pseudocode sketch of the kind of boundary logic that matters in SACK processing:
if (sack.end > snd_max)
ignore();
if (sack.start < snd_una)
ignore(); // OpenBSD patch added a check like this
walk_hole_list();
delete_or_shrink_holes();
if (last_hole != NULL && rcv_lastsack < sack.start)
append_new_hole();
The point is not that defenders should memorize one OpenBSD bug. The point is that AI systems are now good enough to keep worrying at stateful boundary logic that fuzzers may not easily reach and humans may not revisit for years. That changes how much faith teams can place in the idea that a mature codebase has already been “looked at enough.” (ftp.openbsd.org)
FFmpeg and why semantic edge cases matter more than crash counts
The FFmpeg case is a different kind of warning. Anthropic says Mythos Preview found a 16-year-old vulnerability in FFmpeg’s H.264 codec. The company’s explanation focuses on how FFmpeg tracks which slice owns each macroblock in a frame. Anthropic says the table entries are 16-bit integers, the slice counter is a 32-bit integer with no upper bound, and the table is initialized with memset(..., -1, ...), leaving 65535 as a sentinel for “unowned.” If an attacker produces a frame with 65,536 slices, slice number 65535 collides with the sentinel and the decoder can conclude a nonexistent neighbor belongs to the same slice, leading to an out-of-bounds write and a crash. Anthropic says the underlying sentinel assumption dates back to the 2003 H.264 introduction and became exploitable after a 2010 refactor, which the project history still reflects. (red.anthropic.com)
This example is useful precisely because Anthropic does not oversell it. The company explicitly says the bug is not critical severity and would likely be hard to turn into a functioning exploit. That restraint is important. Too many AI security discussions treat every discovered memory bug as if it were one gadget away from total compromise. The better lesson is subtler: models are starting to reason effectively about semantic invariants, sentinel values, type widths, and rare but valid input structures that traditional fuzzing may under-sample. That kind of reasoning widens the search space for vulnerability discovery even when the resulting bug is not trivially weaponizable. (red.anthropic.com)
FFmpeg also gives defenders an operational anchor. Anthropic says three Mythos-identified FFmpeg vulnerabilities were fixed in FFmpeg 8.1, and FFmpeg’s official site confirms that version 8.1 “Hoare” shipped on March 16, 2026. That is the kind of connective tissue security teams need to care about now: not just that a model found a bug, but whether the finding can be tracked into a release train, whether downstream consumers know they need to update, and whether package maintainers and product teams are set up to absorb AI-assisted disclosure volume. (red.anthropic.com)
| Public Mythos case | Why it matters technically | What defenders should learn |
|---|---|---|
| OpenBSD SACK | Stateful protocol logic, edge arithmetic, linked-list maintenance under wraparound conditions. (red.anthropic.com) | Mature network stacks still hide brittle assumptions. “No recent crashes” is not proof of safety. |
| FFmpeg H.264 | Sentinel collisions, integer width mismatch, rare but spec-legal structures, and semantic misuse of initialization patterns. (red.anthropic.com) | Fuzzing remains necessary but not sufficient; symbolic and semantic reasoning are getting better. |
| FreeBSD RPCSEC_GSS | Classic stack overflow plus exploit construction in a real kernel-facing service path. (The FreeBSD Project) | AI is no longer confined to crash discovery; it is increasingly relevant to exploit engineering. |
| Linux ipset N-day | One-bit write primitives can still be promoted into root with patient exploit chaining. (red.anthropic.com) | Patch latency is more dangerous when models can accelerate exploit development. |
FreeBSD CVE-2026-4747 and what public source disagreement looks like
The FreeBSD case is probably the most important public Mythos example because it is where AI vulnerability discovery, exploit construction, and source disagreement all meet. Anthropic says Mythos Preview fully autonomously identified and then exploited a 17-year-old remote code execution vulnerability in FreeBSD’s NFS server, triaged as CVE-2026-4747, and describes it as allowing complete control of the server starting from an unauthenticated user anywhere on the internet. Anthropic’s technical write-up attributes the bug to an RPCSEC_GSS path that copies attacker-controlled data into a 128-byte stack buffer with insufficient length checking, enabling a conventional ROP attack under unusually favorable conditions. (red.anthropic.com)
FreeBSD’s official advisory confirms the core of that description but is more conservative in how it talks about impact. The advisory says each RPCSEC_GSS data packet is validated by a routine that copies a portion of the packet into a stack buffer without ensuring the buffer is large enough, and that a malicious client can trigger a stack overflow without authenticating first. But when it describes impact, the same advisory says kernel-space remote code execution is possible by an authenticated user able to send packets to the kernel’s NFS server while kgssapi.ko is loaded, and says user-space RPC servers linked against the vulnerable library are remotely exploitable from any client able to send them packets. NVD mirrors that more cautious impact language and, at the time reflected in the public page, shows an ADP score of 8.8 High while NVD’s own score was not yet populated. (The FreeBSD Project)
That discrepancy is exactly the kind of thing defenders need to get used to in the AI era. There are at least three plausible readings of the difference. One is that triggering the stack overflow is unauthenticated, while the vendor remained conservative about the conditions for reliable kernel RCE. Another is that Anthropic’s successful exploit chain demonstrated a stronger end state than the advisory was prepared to generalize at disclosure time. A third is that the difference simply reflects the usual gap between a research write-up focused on technical ceiling and a vendor advisory focused on bounded, supportable statements. What matters is not choosing sides theatrically. What matters is reading both sources carefully and resisting the urge to flatten them into a single oversimplified sentence. (red.anthropic.com)
The remediation story is also worth noting. FreeBSD’s advisory says all supported versions were affected and lists corrected branches including 15.0-RELEASE-p5, 14.4-RELEASE-p1, 14.3-RELEASE-p10, and 13.5-RELEASE-p11, alongside stable branch corrections. It also says no workaround is available, except that systems without kgssapi.ko loaded are not vulnerable in the kernel path. That is a classic example of why patch operations, not just advisory subscriptions, will decide who stays safe in a world where AI can help build exploits faster. (The FreeBSD Project)
A practical first-response workflow for FreeBSD estates looks like this:
# Identify running kernel and userland versions
freebsd-version -ku
# Check whether the kernel RPCSEC_GSS module is present
kldstat | grep kgssapi
# If you use base packages
sudo pkg upgrade -r FreeBSD-base
# If you use binary distribution sets
sudo freebsd-update fetch
sudo freebsd-update install
sudo shutdown -r now
Those commands are not a substitute for maintenance discipline, but they illustrate the real security question. In the Mythos era, “is there a patch” becomes the easy part. “Did I inventory, prioritize, deploy, and verify it fast enough” is the hard part. (The FreeBSD Project)
Linux kernel CVE-2024-53141 and why N-day is now a first-class threat model
If the FreeBSD case shows zero-day-to-exploit potential, the Linux ipset example shows why N-day exploitation needs to move up the priority stack for defenders. NVD describes CVE-2024-53141 as a Linux kernel issue in bitmap_ip_uadt where a missing range check can lead to a high-severity local vulnerability. The NVD page shows a CVSS 3.1 score of 7.8 High and affected version ranges across multiple kernel lines. Ubuntu’s advisory description mirrors the same root cause, explaining that when IPSET_ATTR_IP_TO is absent but IPSET_ATTR_CIDR exists, values are processed in a way that leaves a missing range check and allows the vulnerability to occur. (nvd.nist.gov)
Anthropic’s contribution in the Mythos post is not to claim discovery of that bug. It explicitly says this section concerns an N-day that Mythos Preview was given. The point was exploitation. Anthropic’s write-up walks through how an out-of-bounds index in ipset can be transformed into a bounded one-bit write primitive, then patiently amplified through physical-page adjacency, PTE manipulation, and eventual tampering with the page cache entry for /usr/bin/passwd to achieve root. Whether or not every reader wants to follow that chain in full, the security meaning is obvious: patched local vulnerabilities that once sat in the “we’ll get to it soon” bucket are becoming more dangerous if models can compress the exploit-engineering labor needed to weaponize them. (red.anthropic.com)
This is where the CISA Known Exploited Vulnerabilities catalog becomes more relevant, not less. CISA describes the KEV catalog as a resource to help the cybersecurity community and network defenders manage remediation based on evidence of exploitation in the wild. The KEV idea has always been that not all CVEs deserve equal urgency. Mythos-like capabilities do not invalidate that logic. They intensify it. If machine assistance reduces the time from patch diff to exploit, then defenders need to treat “publicly patched and reachable in my environment” as a far more aggressive escalation condition than they did a few years ago. (सीआईएसए)
The operational mistake many organizations still make is to sort patch queues by public severity labels alone. That was never ideal, and it becomes worse as exploit development accelerates. In the near term, teams should bias triage toward a combination of factors: exposed attack surface, privilege boundary crossings, memory corruption primitives, recent patch recency, exploit-relevant commit clarity, and the availability of verifiers that make AI-assisted reproduction cheap. A crisp patch note plus a reachable deployment path is now more dangerous than a scarier-sounding CVSS in a component nobody can hit. (red.anthropic.com)
Reverse engineering, browser chains, and the public limits of the Mythos story
Anthropic’s boldest claims extend beyond the cases outsiders can fully inspect today. The paper says Mythos Preview can take a closed-source, stripped binary, reconstruct plausible source code for it, then analyze the reconstructed source together with the original binary to find vulnerabilities. It also says the model autonomously found read and write primitives in multiple browsers, chained them into JIT heap sprays, and in one case combined a browser exploit with sandbox escape and local privilege escalation so that a malicious webpage could ultimately write directly to the operating system kernel. Those are extraordinary statements. Anthropic is careful to hedge some of them with future commitments to reveal details after patching. (red.anthropic.com)
Security readers should take two lessons from that section. The first is that offline reverse engineering and exploit research are themselves major capabilities. Reconstructing plausible source from stripped binaries is valuable even if it is not yet public proof of universally reliable binary-only vulnerability research at scale. The second is that the public proof boundary still matters. Anthropic is telling readers that these things happened, but the detailed artifacts needed for independent external replication are largely not public yet. That does not make the claims false. It means the confidence level should be phrased correctly. “Strong vendor-authored evidence with limited public reproducibility” is different from “publicly settled fact.” (red.anthropic.com)
That distinction becomes even more important when the conversation shifts from source-visible exploit research to internet-facing web application testing. Anthropic publicly lists important classes of logic bugs, including complete authentication bypasses, account login bypasses, and destructive denial-of-service conditions. Those bug classes matter a great deal in real SaaS environments. But Anthropic’s public write-up does not give detailed public case studies for those findings, and its strongest methodological evidence remains concentrated in source-visible or offline contexts. A useful way to state the situation is this: Mythos Preview has clearly advanced the state of AI exploit research, but the public record has not yet fully closed the gap between high-information exploit research and end-to-end black-box web pentesting against live systems. (red.anthropic.com)
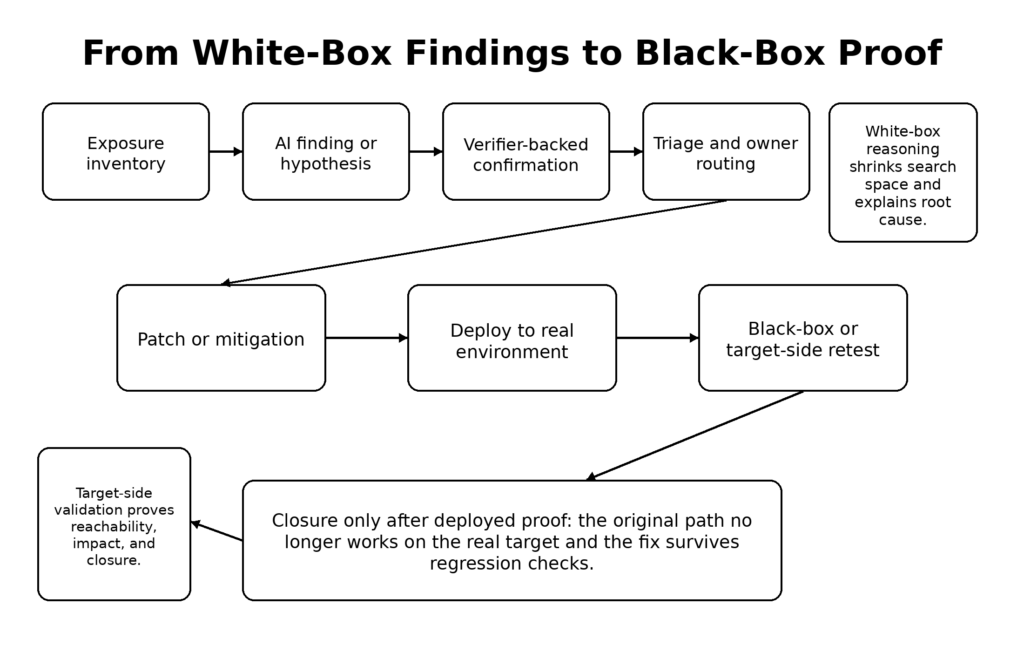
That is also why mature teams should stop treating white-box reasoning and black-box validation as competing product categories. They are different stages in a more reliable security loop. Penligent’s public technical writing on this split is directionally useful here: it argues that source-aware AI can narrow the search and map likely root causes, while target-facing validation is still required to prove reachability and impact in the deployed environment. That is a sensible reading of the Mythos moment. The labor that is clearly compressing first is the expensive front half of exploit research. The labor that still requires careful system interaction is proof against the real target surface. (penligent.ai)
Memory safety remains central, but logic bugs do not disappear
It is tempting to read the Mythos launch as a giant advertisement for memory-safe languages, and there is some truth in that. The strongest public case material Anthropic has published so far is heavily concentrated in memory-unsafe territory: OpenBSD TCP handling, FreeBSD kernel RPCSEC_GSS, FFmpeg’s H.264 decoder, and Linux kernel exploitation chains. U.S. government guidance has been moving in the same direction for years. In December 2023, NSA, CISA, and partners published “The Case for Memory Safe Roadmaps,” arguing that moving toward memory-safe languages can eliminate broad classes of memory-safety vulnerabilities. In June 2025, NSA and CISA again emphasized that reducing memory-related vulnerabilities is critical and that the consequences of failing to address them can include breaches, crashes, and operational disruption. (U.S. Department of War)
But the Mythos paper also makes clear why memory safety cannot be the whole answer. Anthropic says Mythos Preview found multiple complete authentication bypasses, account login bypasses, and denial-of-service conditions that could remotely delete data or crash a service. It also describes a Linux kernel KASLR bypass that comes not from a classic out-of-bounds read but from a deliberately exposed kernel pointer. Those are logic and design failures, not just memory-management mistakes. A migration to Rust or another memory-safe language would shrink one very important risk surface, but it would not neutralize authorization gaps, security-model mismatches, or information leaks that are “working as coded” and still unsafe. (red.anthropic.com)
| Vulnerability family in the Mythos discussion | What language safety can help with | What it does not solve |
|---|---|---|
| Memory corruption in parsers, kernels, and network stacks | Eliminates or reduces many out-of-bounds reads, writes, UAFs, and double frees when the safe subset is actually used. (U.S. Department of War) | Unsafe escape hatches, FFI boundaries, and design mistakes still matter. Anthropic’s memory-safe VMM example depended on an unsafe operation. (red.anthropic.com) |
| Auth bypass and login logic errors | Little direct help beyond safer implementation hygiene. | Broken authorization logic, trust-boundary mistakes, and workflow flaws still survive. (red.anthropic.com) |
| Information leaks and KASLR bypasses | May reduce some memory-derived leaks. | Deliberate exposure of pointers or metadata can remain exploitable even in memory-safe code. (red.anthropic.com) |
The practical takeaway is that security leaders should resist false binaries. They do not need to choose between memory safety and exploit-response speed. They need both. Memory-safe roadmaps are long-horizon structural risk reduction. Faster verification, patching, and retesting are near-term operational necessities in a world where exploit development is accelerating before the installed base can be rewritten. (U.S. Department of War)
The defender playbook for the Mythos era
Anthropic’s public advice to defenders is direct, and it is one of the most useful parts of the release. The company says organizations should think beyond vulnerability finding into triage, deduplication, reproduction steps, candidate patching, cloud misconfiguration review, PR review, and migration work. It explicitly argues that teams should shorten patch cycles, revisit patch enforcement, enable auto-update where possible, treat dependency bumps carrying CVE fixes as urgent, revisit disclosure handling, and automate incident response because faster discovery will bring more attempts against the disclosure-to-patch window. (penligent.ai)
That guidance is correct, but it helps to translate it into a concrete operating model. The immediate changes security teams need are not mystical. They are procedural and measurable.
First, separate model hypotheses from verified findings. A model may be very good at generating vulnerability candidates, but the organization should only let a finding move into high-priority remediation when it has passed a verifier layer. Depending on the target, that verifier might be ASan, a regression harness, a reproducer, a failing integration test, a crash-minimized proof of concept, or a target-facing validation run in an authorized environment. This is the lesson Anthropic drew from Firefox, and it is the minimum requirement for keeping signal quality high as model output volume rises. (Anthropic)
Second, move from calendar-based security work to queue-based security work. A quarterly review cycle made some sense when the bottleneck was human discovery. It makes less sense if model-assisted discovery is producing validated findings every day. The right unit of management is now a continuously refreshed queue with clear aging rules, exploitability clues, asset criticality, and retest status. Organizations that still treat security testing as a report-delivery event are going to feel slow even if they buy the newest tools. (red.anthropic.com)
Third, treat candidate patches as first-class artifacts. Anthropic’s Mozilla experience is a reminder that bug reports are dramatically more useful when they include minimal test cases, PoCs, and candidate fixes. The candidate patch does not need to be merged blindly. It does need to exist early enough that engineers can reason about blast radius and closure in the same conversation. In a machine-speed vulnerability flow, the handoff from “found a bug” to “have a plausible fix” needs to happen in hours or days, not in separate organizational silos over multiple weeks. (Anthropic)
Fourth, enforce closure with retesting, not optimism. One of the easiest ways to lose ground in the Mythos era is to ship a patch, mark a ticket as done, and never rerun the original finding path from the outside. Real systems have proxies, gateways, feature flags, stale instances, canary pools, background workers, and configuration drift. A code diff is not the same thing as deployed closure. This is the point where black-box or gray-box validation still matters, and it is also the point where teams that already use target-facing validation platforms have an advantage. Penligent’s public materials, for example, describe an agentic workflow centered on controlled task execution, scope control, and evidence collection against real targets. Whether a team uses that exact platform or not, the architectural instinct is right: model reasoning should end in auditable evidence, not in persuasive prose. (penligent.ai)
A compact example of a model-ready vulnerability record looks like this:
{
"report_id": "AI-2026-0410-0017",
"component": "rpcsec_gss",
"asset_class": "kernel_nfs",
"claim_type": "stack_overflow",
"evidence_source": "reproducer_plus_human_validation",
"internet_exposed": true,
"exploitability_state": "publicly_described_vendor_claim",
"patch_status": "vendor_patch_available",
"owner_team": "platform_kernel",
"retest_required": true,
"notes": "Do not escalate to critical until verifier artifacts are attached and deployed closure is confirmed."
}
That sort of structure is more important than whichever model generated the initial text. Once the model is producing meaningful output, the quality of your schema, routing, and validation process starts to matter more than the elegance of the prompt. (Anthropic)
Here is a simple Python example for prioritizing inbound AI-generated findings into a patch queue. It is intentionally boring, which is the point. The hard part is not fancy ranking math. It is building a repeatable process that reflects real exploit pressure.
from dataclasses import dataclass
@dataclass
class Finding:
component: str
internet_exposed: bool
verifier_passed: bool
patch_available: bool
privilege_boundary: bool
memory_corruption: bool
days_open: int
def priority_score(f: Finding) -> int:
score = 0
if f.internet_exposed:
score += 30
if f.verifier_passed:
score += 25
if f.patch_available:
score += 15
if f.privilege_boundary:
score += 15
if f.memory_corruption:
score += 10
if f.days_open > 7:
score += 10
if f.days_open > 30:
score += 10
return score
queue = [
Finding("rpcsec_gss", True, True, True, True, True, 2),
Finding("ffmpeg_h264", False, True, True, False, True, 10),
Finding("internal_auth_flow", True, False, False, True, False, 5),
]
for item in sorted(queue, key=priority_score, reverse=True):
print(item.component, priority_score(item))
Teams can extend that with environment ownership, business criticality, change-freeze windows, or dependency lineage. The important idea is that verifier-backed, internet-exposed, privilege-crossing findings should rise quickly, especially when a patch already exists and an AI system can help others turn it into a weapon faster than before. (सीआईएसए)

Thirty-day, ninety-day, and one-hundred-eighty-day actions for security teams
| Time horizon | What to change now | Why it matters in the zero-day era |
|---|---|---|
| First 30 days | Inventory externally reachable services, kernel-facing services, and critical parsers; identify where AI-generated findings would land operationally; define verifier requirements for high-priority reports. (The FreeBSD Project) | Most teams already have tools. They do not yet have a fast enough routing and validation loop. |
| First 90 days | Add structured triage fields, candidate patch expectations, and mandatory retests; tighten patch SLAs for reachable memory-corruption and auth-path issues; predefine disclosure escalation paths. (Anthropic) | AI-assisted discovery increases report volume and compresses the safe delay between patch availability and exploitability. |
| First 180 days | Build continuous target-facing revalidation for high-risk surfaces; align AppSec, SRE, and platform teams around a common closure definition; expand memory-safe roadmaps where feasible. (U.S. Department of War) | The durable response is a faster operating loop plus structural reduction of bug-prone code. |
The biggest mistake teams will make is trying to answer the Mythos moment with procurement theater. Buying a model access plan or a “security AI” add-on will not save an organization whose patch governance is slow, whose owners are ambiguous, whose validators are weak, and whose deployment evidence is missing. The second biggest mistake will be to dismiss all of this because the broadest claims are not yet independently reproducible. That is too strict a standard for operational planning. When a vendor has already published patched cases in OpenBSD, FreeBSD, and FFmpeg; documented major benchmark jumps; and altered release and disclosure policy around the model, defenders do not need perfect public replication to justify changing their workflows. (openbsd.org)
What security buyers should ask after Mythos Preview
Technical buyers evaluating AI security products in 2026 should be much more demanding than the current market norm. The first question is whether the product’s strongest evidence comes from source-visible analysis or from target-facing validation. That is not a trick question. Both are valuable, but they answer different problems. If a vendor’s best examples all rely on local code access, stripped-binary reconstruction, or offline harnesses, then buyers should not infer that the product has already proven live black-box testing against production-like environments. Anthropic’s public record is a useful case study in how easy it is for those categories to blur in marketing conversation. (red.anthropic.com)
The second question is what verifier layer exists. Anthropic’s own work repeatedly points back to verifiers: ASan, regression tests, minimal reproducer artifacts, and proof of closure. A system that can produce beautiful explanations without a reliable verifier is a triage assistant at best, not a trustworthy security workflow. Buyers should ask to see the artifact trail, not just the summary screen. (red.anthropic.com)
The third question is how the platform handles retesting and closure. Vulnerability finding without target-side revalidation creates ticket debt. In the current market, some public materials from Penligent are useful precisely because they insist on separating white-box findings from black-box proof and making evidence a first-class output. Buyers should reward that distinction wherever they find it. The question is not whether a tool “uses AI.” The question is whether it can help move a finding from hypothesis to verified exposure to verified closure. (penligent.ai)
The fourth question is what disclosure and operator-load assumptions the vendor is making. Anthropic had to publish a dedicated coordinated disclosure operating policy because AI-generated discovery can overwhelm maintainers if handled irresponsibly. Any serious platform that claims to produce security findings at scale should be able to explain how it prevents report floods, how it labels AI-originated material, how humans validate it, and how it avoids turning maintainers into unpaid triage infrastructure. (Anthropic)
Claude Mythos Preview is a milestone, not the end of the story
The cleanest conclusion is also the least fashionable one. Claude Mythos Preview is the strongest public signal so far that AI exploit research has crossed into a new phase. Anthropic has published concrete patched cases, meaningful benchmark deltas, a restricted-access release posture, and a disclosure framework designed around machine-assisted discovery. That is enough to justify major defensive changes now. (red.anthropic.com)
At the same time, the public record still has edges that should be named honestly. Most findings remain private because they are not patched. The broadest claims about browsers, web logic bugs, and closed-source targets are not yet independently reproducible from public artifacts. The FreeBSD case shows that even among high-quality sources, impact language can diverge between the discovering lab and the vendor advisory. Those are not reasons to dismiss the moment. They are reasons to read it carefully. (red.anthropic.com)
What Mythos changes first is not the philosophical question of whether AI can hack. That question is already obsolete. What it changes is the clock. It shortens the interval between discovery and usable insight. It threatens to shorten the interval between patch availability and exploitability. It raises the value of verifiers, candidate patches, and retests. It makes disclosure throughput and patch governance part of the security perimeter. Teams that understand that will adapt in time. Teams that wait for perfect public proof of every claim will probably still get there, but they will get there later than they should. (red.anthropic.com)
Further reading and reference links
- Anthropic, Assessing Claude Mythos Preview’s cybersecurity capabilities. (red.anthropic.com)
- Anthropic, Project Glasswing. (Anthropic)
- Anthropic, Coordinated vulnerability disclosure for Claude-discovered vulnerabilities. (Anthropic)
- Anthropic, Claude Mythos Preview risk report, public redacted version. (Anthropic)
- Anthropic, Partnering with Mozilla to improve Firefox’s security. (Anthropic)
- OpenBSD 7.8 errata and patch 025 for invalid SACK options. (openbsd.org)
- FreeBSD security advisory SA-26:08.rpcsec_gss and NVD entry for CVE-2026-4747. (The FreeBSD Project)
- NVD and vendor records for Linux kernel CVE-2024-53141. (nvd.nist.gov)
- FFmpeg 8.1 release page and the historical 2010 H.264 refactor commit Anthropic cites. (ffmpeg.org)
- NSA and CISA guidance on memory-safe roadmaps and memory-safe languages. (U.S. Department of War)
- Penligent, Claude Mythos Preview Is Not Black Box Pentesting. (penligent.ai)
- Penligent, Claude Code Security and Penligent: From White-Box Findings to Black-Box Proof. (penligent.ai)
- Penligent homepage. (penligent.ai)

