CVE-2026-43121 is not a generic “Linux root bug.” It is a race in a narrow, high-performance receive path: io_uring zero-copy receive, usually shortened to ZCRX. The confirmed issue sits in the lifetime handling around ZCRX network I/O vectors. A non-atomic reference update can let two paths return the same niov to a freelist, corrupting freelist state and leading to a four-byte out-of-bounds write past a kernel heap allocation. NVD’s current record describes the race between io_zcrx_put_niov_uref() और io_zcrx_scrub(), the resulting double push to the freelist, and the later u32 write beyond the kvmalloc-allocated freelist array. As of the current NVD entry, the record is still undergoing enrichment and does not yet carry an NVD CVSS score. (एनवीडी.एनआईएसटी.जीओवी)
That distinction matters. The bug is real. The fix is real. The memory corruption primitive is real enough to be assigned a CVE and documented in kernel-linked records. What needs more care is the way some public write-ups frame the full exploit chain. The widely shared ZCRX write-up presents a narrative from a small freelist overflow to heap shaping, KASLR recovery, and root. That is useful as a research path, but parts of the full local privilege escalation story have been disputed in the public oss-security thread, including a modprobe_path step that appears to assume privileges whose absence is normally the point of a local privilege escalation exploit. Jens Axboe also pointed to an earlier fix for the underlying user reference race that had already been backported to stable trees. (seclists.org)
The practical reading is sharper than either “nothing to see” or “instant root everywhere.” CVE-2026-43121 is a kernel memory-corruption bug in a fast path that connects userspace, NIC receive queues, page-pool-backed memory, reference counters, and teardown logic. It deserves patching and exposure review. It does not justify treating every Linux host as affected. The affected surface depends on kernel version, backport state, ZCRX build configuration, hardware support, and privileges such as CAP_NET_ADMIN.
Why io_uring ZCRX exists
io_uring was designed to reduce I/O overhead by letting applications submit work and receive completions through shared rings rather than paying a syscall cost for every operation. The model is powerful because it compresses the hot path between user programs and the kernel. That same compression is why io_uring bugs tend to be security-sensitive: user-controlled state, kernel lifetime rules, pinned buffers, asynchronous completion, and cross-CPU execution often meet in the same code.
ZCRX extends that idea into network receive. The official Linux kernel documentation describes io_uring zero-copy receive as a feature that removes the kernel-to-user copy on the network receive path, allowing packet data to be received directly into userspace memory. It differs from TCP_ZEROCOPY_RECEIVE because it does not impose the same strict alignment requirements and does not require the application to mmap() और munmap() each receive window. It also differs from kernel-bypass frameworks such as DPDK because packet headers still pass through the kernel TCP stack normally. (docs.kernel.org)
That design is attractive for high-throughput workloads. The kernel documentation also makes clear that ZCRX depends on specific NIC capabilities. It needs header and data split so packet headers can land in kernel memory while payloads land directly in userspace memory. It needs flow steering so selected flows are directed to receive queues configured for ZCRX. It also needs RSS configuration so non-ZCRX traffic is steered away from queues dedicated to the feature. (docs.kernel.org)
This is not a typical socket receive path. It is a negotiated path among application buffers, NIC queues, page pools, kernel metadata, and io_uring completion semantics. The security invariant is simple to say and hard to maintain: a network I/O vector must be returned to the freelist exactly once, only after the last user reference is gone, even when refill, scrub, completion, and teardown paths race on different CPUs.
The ZCRX security boundary
The vulnerable area is easier to understand if ZCRX is treated as a resource lifecycle system rather than just a performance feature.
A ZCRX area has a set of network I/O vectors, often called niovs. Those vectors represent receive slots that can be handed to the NIC-backed receive path and later returned for reuse. A freelist tracks which slots are available. A reference counter tracks whether userspace still has a reference to a slot. A scrub path cleans up stale or dying state. A refill path returns slots when userspace is done with them. Teardown paths must unwind whatever is still in flight.
The invariant is:
For every niov:
The final reference transition from 1 to 0 must happen once.
The niov must be pushed back to the freelist once.
free_count must never exceed the number of niovs in the area.
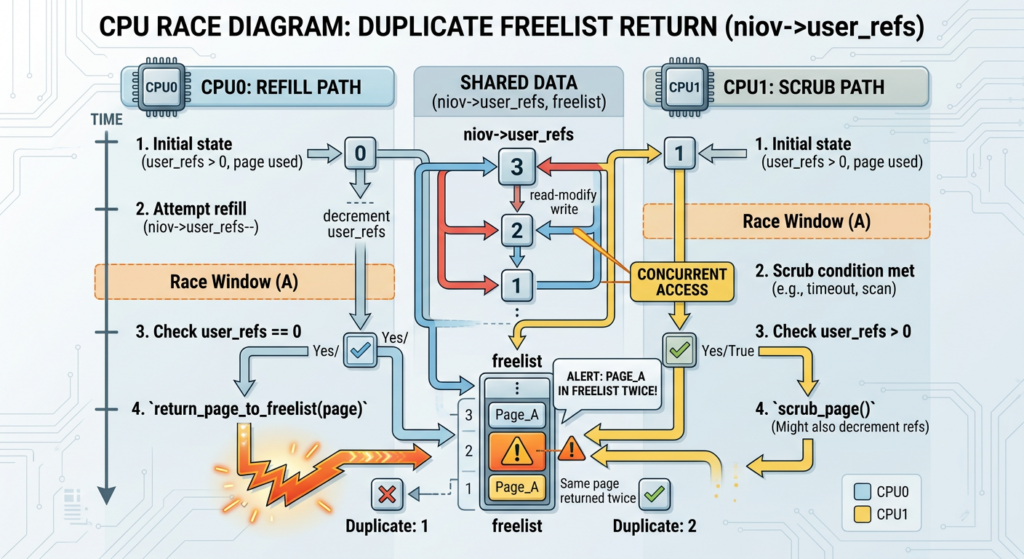
CVE-2026-43121 breaks that invariant through concurrency. The official NVD description says io_zcrx_put_niov_uref() used a non-atomic check-then-decrement pattern, while io_zcrx_scrub() modified the same counter with atomic_xchg() without holding the same lock. On SMP systems, one CPU can be in the refill path while another CPU is in the scrub path. Both can believe they are responsible for returning the final reference. (एनवीडी.एनआईएसटी.जीओवी)
A simplified model looks like this:
/*
* Simplified vulnerable pattern.
* This is not the exact kernel source.
*/
if (atomic_read(&niov->user_refs)) {
atomic_dec(&niov->user_refs);
if (atomic_read(&niov->user_refs) == 0)
io_zcrx_return_niov(niov);
}
The problem is not that atomics are absent everywhere. The problem is that a read followed by a separate decrement is not a single atomic decision. Another CPU can change the value between the check and the decrement. Once that window exists, a cleanup path and a refill path can both act on the same logical “last reference.”
The fixed pattern is conceptually different:
/*
* Simplified fixed pattern.
* The key idea is atomic compare-and-exchange:
* only one CPU can win the transition from refs to refs - 1.
*/
u32 refs = atomic_read(&niov->user_refs);
do {
if (!refs)
return;
} while (!atomic_try_cmpxchg(&niov->user_refs, &refs, refs - 1));
if (refs == 1)
io_zcrx_return_niov(niov);
The important change is not cosmetic. atomic_try_cmpxchg() turns “I saw a value, then I changed it later” into “I changed the value only if it is still exactly the value I observed.” If another CPU wins first, the losing CPU sees the new state and does not perform a second return.
CVE-2026-43121 in one table
| क्षेत्र | Current public detail |
|---|---|
| सीवीई | CVE-2026-43121 |
| अवयव | Linux kernel io_uring/zcrx |
| कीट वर्ग | Race condition leading to double-free style freelist corruption and u32 out-of-bounds write |
| मूल कारण | Non-atomic check-then-decrement of user_refs racing with scrub logic that uses atomic_xchg() without the same lock |
| Confirmed memory effect | Same niov can be pushed twice to the freelist, causing free_count to exceed nr_iovs; later pushes can write a u32 past the freelist allocation |
| Official fix direction | Replace the non-atomic read-then-decrement with an atomic compare-and-exchange loop |
| NVD status | Undergoing enrichment, no NVD CVSS score listed in the current record |
| Practical exposure | Depends on kernel version, stable backport state, build configuration, ZCRX use, NIC support, and privileges |
| Research risk | Kernel heap corruption from a small write can still be exploitable under the right heap and privilege conditions |
NVD’s description is especially useful because it compresses the race into a two-CPU scenario: CPU0 in refill opens a window after reading the reference count, CPU1 in scrub zeroes the same reference and returns the niov, then CPU0 completes its decrement and returns it again. That duplicate return pushes the same item into the freelist twice. Subsequent freelist pushes can write past the end of the allocated array. (एनवीडी.एनआईएसटी.जीओवी)
The stable changelog for Linux 6.18.16 includes the upstream commit for “io_uring/zcrx: fix user_ref race between scrub and refill paths” and notes the vulnerable pattern as atomic_read followed by a separate atomic_dec. The changelog also ties the fix to 34a3e60821ab, the commit implementing the ZCRX page-pool memory provider. (cdn.kernel.org)
The four-byte write is small, not harmless
A four-byte write can sound underwhelming. In userland application bugs, a four-byte out-of-bounds write may be difficult to weaponize if it lands in padding or crashes the process. Kernel heap bugs deserve a different threat model.
Kernel objects are dense. Fields are often small. A u32 can be a reference count, flag set, length, index, credential-related field, list metadata fragment, or low half of a pointer on systems where heap placement makes partial pointer corruption useful. Even when a four-byte write is not immediately arbitrary write, it can be a bridge into a larger primitive: corrupt one field, cause an over-read, leak a kernel pointer, break KASLR, or redirect a later operation.
That is why the right question is not “can four bytes root a host?” The right question is “under this allocator, this object layout, this kernel build, this hardening profile, this privilege model, and this hardware setup, can the four-byte write be steered into something security-relevant?”
The original ZCRX public write-up takes that path. It frames the primitive as a controlled u32 written one element past the freelist and then discusses heap shaping with System V message queues, msg_msg objects, KASLR recovery, and a path toward root. The article is useful because it thinks like an exploit developer: it does not stop at the bug; it asks what object can be placed next to the vulnerable allocation and how a weak primitive can be amplified. (ze3tar.github.io)
But exploit narratives need evidentiary discipline. The oss-security discussion includes skepticism about parts of the full chain. In particular, Jens Axboe questioned a modprobe_path write step that appeared to rely on /proc/sys/kernel/modprobe being writable with CAP_SYS_ADMIN, noting that if the attacker already has such privilege, it undermines the value of that step as proof of local privilege escalation. (seclists.org)
A defensible security write-up should therefore separate these claims:
| Claim | Confidence from public sources | Practical interpretation |
|---|---|---|
ZCRX had a user_refs race between scrub and refill paths | उच्च | Confirmed by CVE and stable changelog |
The race can double-return a niov to the freelist | उच्च | Confirmed by CVE description |
| The corrupted freelist state can lead to a u32 OOB write | उच्च | Confirmed by CVE description |
| A defensive freelist bounds check was added later | उच्च | Public patch adds WARN_ON_ONCE(free_count >= num_niovs) before writing |
| A full generic root exploit works across affected kernels | Not established from the cited official sources | Treat as research-dependent unless reproduced under defined conditions |
| Any Linux host is affected | False | Exposure depends on version, config, hardware, privileges, and backports |
The defensive freelist check
A second patch, “io_uring/zcrx: warn on freelist violations,” adds an explicit invariant check before writing to the freelist:
if (WARN_ON_ONCE(area->free_count >= area->nia.num_niovs))
return;
area->freelist[area->free_count++] = net_iov_idx(niov);
The patch note says the freelist should already be sized to accept a free niov, but the added warning checks the invariant defensively and helps catch double-free issues. The patch was applied as commit 04756ab59ac4eaf2a4f807cca8f4dde859bc02d9 in the io_uring tree. (lore.gnuweeb.org)
This kind of defensive check is valuable, but it should not be confused with the root race fix. The stronger fix is to prevent two paths from returning the same niov in the first place. The bounds check prevents a corrupted free_count from becoming an out-of-bounds write at that site. The compare-and-exchange change prevents the double-return condition that makes freelist state inconsistent.
In mature kernel engineering, both layers are desirable. One protects the invariant at the state transition. The other protects the memory write site if the invariant is violated anyway. Security failures often become exploitable when code assumes an internal invariant is impossible to break. ZCRX shows why defensive programming still matters in performance-sensitive paths.
Why this bug is tied to performance engineering
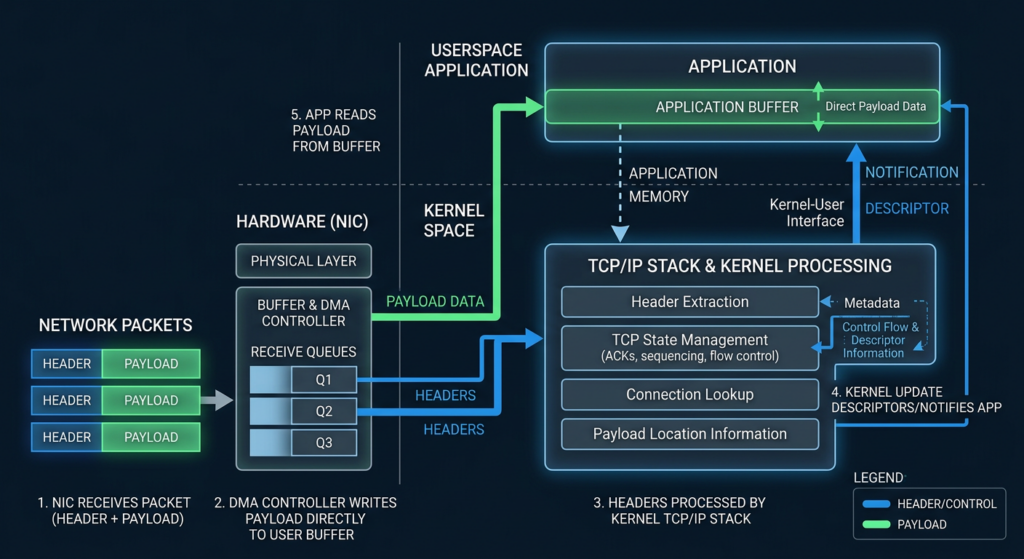
High-performance networking pushes Linux toward designs where ownership is shared across layers that used to be more isolated. A traditional receive path can copy packet payloads from kernel memory to userspace memory. That copy is expensive, but it also forms a simple boundary. Once zero-copy receive is introduced, the same payload lifecycle may involve a userspace-visible region, NIC DMA behavior, TCP stack processing, page-pool memory providers, and io_uring completions.
That is not bad engineering. It is the cost of speed. The official ZCRX documentation describes the feature as removing the kernel-to-user copy while still letting packet headers be processed by the kernel stack. It also shows that NIC setup is out of band and requires queue, split, RSS, and flow steering configuration. (docs.kernel.org)
The security consequence is that cleanup paths become as important as the steady-state fast path. Many memory-safety bugs do not occur while the normal path is cleanly receiving packets. They occur when the interface goes down, a queue is reconfigured, an io_uring is closed, a device is removed, userspace returns buffers at the same time as a scrub path runs, or a refcount reaches zero under contention.
That is why teardown code must be treated as attack surface. It often sees the strangest interleavings and the least common test coverage. A path that “should only run during cleanup” can still be attacker-influenced if a local user can create the resource, generate receive pressure, alter interface state, or race close and refill actions.
Exposure is narrower than normal Linux LPE
CVE-2026-43121 should not be triaged like a kernel bug reachable by every unprivileged user on a default desktop. The ZCRX path is specialized.
The Linux kernel documentation states that ZCRX needs NIC hardware features such as header/data split, flow steering, and RSS configuration. It also shows setup commands using ethtool to configure queues, TCP data split, RSS, and flow steering. (docs.kernel.org)
The oss-security report that requested CVE assignment described exploitation requirements including CAP_NET_ADMIN, a NIC supporting page-pool-backed memory providers such as mlx5 or nfp, and a kernel built with CONFIG_IO_URING_ZCRX=y. That report also claimed tests on a Kali 6.19.11 kernel with an mlx5 ConnectX-6 NIC. The requirements came from the reporter, not from a final vendor advisory, so they should be treated as useful but not sufficient by themselves. (seclists.org)
A practical exposure review should ask five questions:
| Question | यह क्यों मायने रखती है | Example signal |
|---|---|---|
| Does the kernel contain the vulnerable ZCRX code path | No code, no exposure | Kernel version and vendor backport status |
| Is ZCRX built in or available | Disabled build options reduce attack surface | CONFIG_IO_URING_ZCRX=y or module availability |
| Is compatible NIC hardware present and configured | ZCRX depends on hardware receive features | mlx5, nfp, header/data split, flow steering |
| Can an untrusted local workload reach the setup path | Kernel memory corruption needs a reachable trigger | CAP_NET_ADMIN, privileged containers, network plugins |
| Has the stable backport landed | Distribution kernels may differ from upstream version numbers | Vendor changelog, package advisory, kernel build changelog |
Version numbers alone are not enough. Distribution kernels carry backports. A 6.18 kernel may contain the fix, while another kernel with a newer-looking version string may not. The stable changelog for Linux 6.18.16 includes the io_uring/zcrx user_ref race fix, which is exactly why defenders should check vendor package history rather than only upstream version labels. (cdn.kernel.org)
How to check a Linux host without exploiting anything
The following checks are deliberately read-only. They are meant for exposure triage, not exploitation.
Start with the running kernel:
uname -a
uname -r
Check whether the kernel configuration exposes ZCRX. On many distributions, one of these paths will work:
zgrep CONFIG_IO_URING_ZCRX /proc/config.gz 2>/dev/null || true
grep CONFIG_IO_URING_ZCRX /boot/config-$(uname -r) 2>/dev/null || true
A result such as this means the option is enabled:
CONFIG_IO_URING_ZCRX=y
A result such as this means it is not built into that kernel:
# CONFIG_IO_URING_ZCRX is not set
If neither file exists, the host may not expose its kernel config. On Debian and Ubuntu systems, the /boot/config-* path is common. On containerized systems, remember that the container sees the host kernel, not a separate container kernel.
Next, check whether the kernel package includes a vendor fix. Examples:
# Debian or Ubuntu style
dpkg -l 'linux-image*' | awk '/^ii/ {print $2, $3}'
# RHEL, Fedora, Amazon Linux, SUSE style
rpm -qa 'kernel*' | sort
Then consult the vendor’s CVE page or changelog for CVE-2026-43121. Debian’s tracker mirrors the same core description of the race in io_uring/zcrx, while Red Hat’s public security data lists CVE-2026-43121 with the Bugzilla description “kernel: io_uring/zcrx: fix user_ref race between scrub and refill paths” and maps it to CWE-366, a race condition category. (Debian Security Tracker)
Check whether high-risk containers have network administration capabilities. On a host, this quick scan can reveal processes with effective capabilities, though decoding them requires a tool such as capsh:
for p in /proc/[0-9]*; do
if [ -r "$p/status" ]; then
awk -v pid="${p##*/}" '
/^Name:/ {name=$2}
/^CapEff:/ {print pid, name, $2}
' "$p/status"
fi
done | sort -n
Decode a capability mask:
capsh --decode=0000000000000000
Inside a container, check the current process:
grep -E 'CapEff|CapPrm|CapBnd' /proc/self/status
capsh --print 2>/dev/null | sed -n '/Current:/p;/Bounding set/p'
If a container has CAP_NET_ADMIN, treat it as more sensitive. CAP_NET_ADMIN is often granted to networking components, service meshes, packet capture tools, VPN agents, CNI plugins, and troubleshooting containers. That does not automatically make CVE-2026-43121 exploitable, but it changes the risk conversation because the bug is tied to network queue setup and teardown paths.
Check NIC driver and queue features:
ip -o link show
ethtool -i eth0 2>/dev/null || true
ethtool -l eth0 2>/dev/null || true
ethtool -k eth0 2>/dev/null | sed -n '1,80p'
The kernel documentation’s ZCRX setup examples use ethtool -L for queues, ethtool -G for TCP data split, ethtool -X for RSS, and ethtool -N for flow steering. Their presence in your environment does not prove ZCRX is active, but they are relevant when auditing systems that deliberately use zero-copy receive. (docs.kernel.org)
Container risk is about capability boundaries
Many organizations underestimate local kernel bugs because “the attacker needs local access.” In modern infrastructure, local access often means code execution in a container, CI job, plugin runner, notebook, build worker, ML workload, or developer sandbox. If that workload runs on a shared kernel, a local privilege escalation bug may cross a boundary the organization cares about.
For CVE-2026-43121, the capability boundary is central. A normal application container without network administration privileges, without direct access to relevant NIC configuration, and without the ability to exercise the ZCRX path is much less interesting than a privileged networking container. A CNI plugin, packet processor, observability agent, or troubleshooting pod with expanded privileges deserves more attention.
A Kubernetes review can start with workload specs:
kubectl get pods -A -o json \
| jq -r '
.items[] as $pod
| $pod.spec.containers[]
| select(.securityContext.capabilities.add[]? == "NET_ADMIN"
or .securityContext.privileged == true)
| [
$pod.metadata.namespace,
$pod.metadata.name,
.name,
(.securityContext.privileged // false),
(.securityContext.capabilities.add // [])
] | @tsv
'
The same idea applies outside Kubernetes. Look for Docker containers launched with --privileged, --cap-add=NET_ADMIN, host networking, or direct device exposure:
docker ps --format '{{.ID}} {{.Names}}' | while read id name; do
docker inspect "$id" \
--format "$name privileged={{.HostConfig.Privileged}} capadd={{.HostConfig.CapAdd}} network={{.HostConfig.NetworkMode}}"
done
These commands do not detect CVE-2026-43121. They identify the workloads most likely to matter if a ZCRX kernel bug is reachable.
Detection is difficult because the bug is a race
There is no reliable network IOC for this class of issue. The vulnerable state transition happens inside the kernel. If exploitation fails, the system may crash, warn, or produce allocator corruption. If exploitation succeeds, the attacker may leave few direct traces tied to ZCRX.
The best defensive telemetry is layered:
| Signal | मूल्य | Limit |
|---|---|---|
Kernel warnings involving io_uring/zcrx, freelist, page pool, or refcounting | Can reveal invariant violations or failed attempts | Absence does not prove safety |
| KASAN, KFENCE, or debug kernel reports in test fleets | Strong for pre-production detection | Rarely enabled in production |
Audit of privileged containers and CAP_NET_ADMIN grants | Helps reduce reachability | Does not detect exploitation |
| Kernel package and config inventory | Best for patch validation | Requires accurate vendor mapping |
| Network interface configuration changes | Useful if the trigger involves interface teardown or queue changes | High noise in networking hosts |
A simple kernel log sweep:
journalctl -k --since "7 days ago" \
| grep -Ei 'io_uring|zcrx|freelist|user_ref|page_pool|WARN|KASAN|slab|corruption'
Or with डीएमएसजी:
dmesg -T \
| grep -Ei 'io_uring|zcrx|freelist|user_ref|page_pool|WARN|KASAN|slab|corruption'
For hosts where interface state changes are sensitive, auditd can observe privileged network-control activity. The exact rule set depends on architecture and distribution, but an example starting point is:
sudo auditctl -a always,exit -F arch=b64 -S ioctl -k net-ioctl-watch
sudo auditctl -a always,exit -F arch=b64 -S setsockopt -k net-sockopt-watch
Then search:
sudo ausearch -k net-ioctl-watch
sudo ausearch -k net-sockopt-watch
These rules can be noisy. They are not ZCRX-specific. They are useful only during focused investigation or on tightly scoped systems.
For short-lived debugging on a lab host, bpftrace can observe ioctl-heavy behavior:
sudo bpftrace -e '
tracepoint:syscalls:sys_enter_ioctl
{
printf("%s pid=%d fd=%d request=0x%x\n", comm, pid, args->fd, args->cmd);
}'
Use this kind of tracing carefully. It is operational telemetry, not exploit detection. The strongest remediation remains patching the kernel and reducing unnecessary capabilities.
Patch and mitigation priorities
The most important fix is the kernel update that removes the race. The stable changelog shows the upstream race fix backported into Linux 6.18.16, and NVD references kernel.org stable commits for the CVE. (cdn.kernel.org)
A patch plan should look like this:
| Priority | Action | क्यों |
|---|---|---|
| 1 | Confirm whether your vendor kernel contains the CVE-2026-43121 fix | Distribution backports matter more than raw upstream version strings |
| 2 | Update kernels on hosts with ZCRX-capable networking and privileged local workloads | These systems have the most relevant exposure |
| 3 | Reboot into the fixed kernel | Kernel package installation alone is not enough |
| 4 | Remove CAP_NET_ADMIN from containers that do not need it | Reduces reachability for this and future network-kernel bugs |
| 5 | टालना --privileged containers for routine troubleshooting | Privileged containers turn many kernel bugs into boundary-crossing risks |
| 6 | Review NIC queue and zero-copy receive experiments | Experimental fast paths should not be exposed to untrusted tenants |
| 7 | Keep kernel warnings from production hosts centrally searchable | Useful for catching invariant failures and unstable exploit attempts |
A conservative hardening pass for container platforms should include:
# Kubernetes, find privileged workloads
kubectl get pods -A -o json \
| jq -r '
.items[] as $pod
| $pod.spec.containers[]
| select(.securityContext.privileged == true)
| "\($pod.metadata.namespace)\t\($pod.metadata.name)\t\(.name)"
'
# Kubernetes, find NET_ADMIN grants
kubectl get pods -A -o json \
| jq -r '
.items[] as $pod
| $pod.spec.containers[]
| select(.securityContext.capabilities.add[]? == "NET_ADMIN")
| "\($pod.metadata.namespace)\t\($pod.metadata.name)\t\(.name)"
'
Remove capabilities by default:
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
Add back only what a workload truly needs:
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
Do not replace patching with capability cleanup. Capability cleanup reduces reachability. It does not fix the kernel.
Why vendor status can differ from upstream status
Kernel vulnerability triage is messy because there are three timelines:
| Timeline | उदाहरण |
|---|---|
| Upstream development | A bug is introduced or fixed in mainline or an io_uring branch |
| Stable backport | The fix is backported to maintained stable releases |
| Distribution release | Debian, Ubuntu, Red Hat, SUSE, Amazon Linux, Kali, and others ship a kernel package containing selected backports |
The oss-security thread shows this clearly. The initial CVE request described a freelist OOB write and referenced a later defensive bounds-check commit. In the same thread, Jens Axboe said he believed the issue was fixed by commit 003049b1c4fb8aabb93febb7d1e49004f6ad653b, “io_uring/zcrx: fix user_ref race between scrub and refill paths,” and that it was already in stable. (seclists.org)
NVD later assigned CVE-2026-43121 to that race fix. The stable changelog shows a backport commit for Linux 6.18.16. Red Hat’s public security data and Debian’s tracker both list the CVE with the same core description. (एनवीडी.एनआईएसटी.जीओवी)
For defenders, the lesson is simple: do not stop at the blog post date. Check your vendor’s shipped kernel. Check the changelog. Check whether the running kernel after reboot is actually the fixed one.
The role of the later WARN_ON check
The later patch that warns on freelist violations is still important. It adds a direct guard at the freelist write site:
if (WARN_ON_ONCE(area->free_count >= area->nia.num_niovs))
return;
The patch author described it as a defensive invariant check to catch double-free issues, and Jens Axboe’s apply message records the commit ID in the io_uring tree. (lore.gnuweeb.org)
This patch is a good example of defense in depth. The reference-count race fix prevents the state corruption. The bounds check prevents a corrupted state from becoming an immediate out-of-bounds write at that location. A hardened subsystem often needs both because complex asynchronous code can acquire new paths over time.
A defender should not treat the WARN_ON patch as proof that older kernels are safe. It is a guardrail. The root cause is the lifetime race.
Related Linux kernel CVEs that sharpen the risk model
CVE-2026-43121 is easiest to understand alongside other Linux kernel local privilege escalation bugs, not because they share the same root cause, but because they show how small lifetime or memory-state mistakes can become root under the right conditions.
CVE-2023-2598 and io_uring buffer registration
CVE-2023-2598 was an io_uring flaw in fixed buffer registration. NVD describes it as an out-of-bounds access to physical memory beyond the end of the buffer, enabling full local privilege escalation. (एनवीडी.एनआईएसटी.जीओवी)
The relevance is not that CVE-2023-2598 and CVE-2026-43121 are the same bug. They are not. The relevance is that io_uring repeatedly sits near high-value kernel attack surfaces: registered buffers, shared rings, asynchronous completions, pinned memory, and fast paths designed to avoid overhead. Those are exactly the places where a single lifetime invariant can have privilege impact.
CVE-2024-1086 and kernel double-free exploitation
CVE-2024-1086 is a Linux netfilter nf_tables use-after-free that can be exploited for local privilege escalation. NVD describes the bug as a condition where nft_verdict_init() allows positive values as drop errors, leading nf_hook_slow() to cause a double-free when NF_DROP is issued with a drop error resembling NF_ACCEPT. (एनवीडी.एनआईएसटी.जीओवी)
The relevance to ZCRX is the exploitation class. Double-free and use-after-free bugs are dangerous because they break object ownership. Once the same logical object can be freed or returned twice, the allocator may hand out overlapping state or let one subsystem corrupt another subsystem’s object. CVE-2026-43121’s confirmed race is not the same netfilter bug, but it belongs to the same broad family of “ownership invariant breaks under concurrency.”
CVE-2026-31431 and the danger of confusing four-byte stories
Copy Fail, CVE-2026-31431, is another Linux local privilege escalation that gained attention because a small write primitive could become root. Penligent’s own technical write-up summarizes it as a Linux kernel local privilege escalation in authencesn, where AF_ALG, splice(), and AEAD decryption behavior can place four controlled bytes into the page cache of a readable file. (पेनलिजेंट)
It is relevant because it prevents sloppy reasoning. “Four bytes to root” is not one vulnerability class. In Copy Fail, the primitive concerns page cache behavior and setuid binary manipulation. In ZCRX, the primitive concerns a freelist overflow after a race in a zero-copy receive path. Both involve small writes. The exploitability model is completely different.
The practical attacker model
A realistic attacker model for CVE-2026-43121 is not “remote packet hits server and gets root.” Based on public information, a more defensible model is:
Attacker has local code execution on a Linux host or container.
The host kernel includes the affected ZCRX code path.
ZCRX is built and reachable.
The attacker has enough network administration privilege or equivalent local control to exercise relevant setup or teardown behavior.
Compatible NIC and queue configuration exist.
The attacker can shape timing and heap state enough to trigger the race and make the resulting corruption useful.
Every line narrows exposure. That does not make the bug unimportant. It makes triage more accurate.
For a single-tenant bare-metal database host with no ZCRX use, no untrusted local users, no privileged containers, and a vendor kernel already carrying the stable fix, the risk is low after verification. For a multi-tenant high-performance networking host running experimental io_uring ZCRX workloads with containers that have CAP_NET_ADMIN, the risk is much higher until patched and hardened.
The common mistakes defenders make
The first mistake is version-string triage. A raw uname -r result is a starting point, not an answer. Stable and distribution backports can make two kernels with similar version strings very different. Always map the running package to vendor advisories or changelogs.
The second mistake is treating local privilege escalation as low priority. Local access is common after phishing, web RCE, CI compromise, exposed notebooks, dependency confusion, stolen SSH keys, or container escape attempts. Kernel LPE often turns a limited foothold into durable control.
The third mistake is ignoring capabilities. CAP_NET_ADMIN is powerful. It allows a process to administer networking features that are often adjacent to kernel attack surface. Many containers receive it for convenience during debugging and never lose it.
The fourth mistake is assuming a crash is harmless. A failed race exploit may leave a kernel warning, allocator crash, or page-pool corruption. That is still a security signal. A kernel crash on a host running untrusted workloads should trigger root-cause investigation, not just a reboot.
The fifth mistake is copying exploit claims into risk registers without validating the preconditions. If a public write-up says “root,” ask: root from what starting privilege, on which kernel build, with what capabilities, on what hardware, with what hardening disabled, and with what proof?
A clean validation workflow
An exposure validation workflow for CVE-2026-43121 should produce evidence, not just a severity label.
Start with asset inventory:
hostnamectl
uname -a
cat /etc/os-release
Capture kernel config:
{
echo "kernel=$(uname -r)"
zgrep CONFIG_IO_URING_ZCRX /proc/config.gz 2>/dev/null || true
grep CONFIG_IO_URING_ZCRX /boot/config-$(uname -r) 2>/dev/null || true
} | tee zcrx-kernel-config.txt
Capture package state:
# Debian or Ubuntu
apt-cache policy linux-image-$(uname -r) 2>/dev/null | tee kernel-package.txt
# RPM-based systems
rpm -q --changelog kernel 2>/dev/null \
| grep -Ei 'CVE-2026-43121|io_uring|zcrx|user_ref|freelist' \
| head -50
Capture relevant capabilities:
grep -E 'CapEff|CapPrm|CapBnd' /proc/self/status | tee self-caps.txt
capsh --print 2>/dev/null | tee capsh-print.txt
Capture container privilege posture:
docker ps --format '{{.ID}} {{.Names}}' 2>/dev/null \
| while read id name; do
docker inspect "$id" \
--format "$name privileged={{.HostConfig.Privileged}} capadd={{.HostConfig.CapAdd}} network={{.HostConfig.NetworkMode}}"
done | tee docker-privileges.txt
Capture network driver information:
for dev in $(ls /sys/class/net | grep -v '^lo$'); do
echo "### $dev"
ethtool -i "$dev" 2>/dev/null || true
ethtool -l "$dev" 2>/dev/null || true
done | tee nic-info.txt
Then make a decision:
| प्रमाण | Decision |
|---|---|
| Fixed vendor kernel running after reboot | Record as remediated |
| ZCRX not built and no vendor exposure | Record as not exposed by configuration |
| ZCRX enabled, relevant NIC, privileged workloads | Patch urgently and remove unnecessary capabilities |
| Unknown config but privileged multi-tenant host | Treat as potentially exposed until vendor status is confirmed |
| Kernel warnings involving ZCRX or freelist | Escalate to incident review and patch verification |
In an authorized testing workflow, an AI-assisted platform can be useful only if it keeps this evidence chain intact. Penligent is positioned around AI-powered penetration testing workflows that combine traditional tools and guided validation, and its 2026 writing emphasizes evidence-driven validation rather than treating scanner output as proof. In a kernel CVE workflow like this, the useful role is not “auto-exploit the host”; it is to keep target inventory, version checks, capability review, command output, and remediation retest evidence tied to a repeatable task record. (पेनलिजेंट)
That distinction is important. Kernel LPE validation should be governed. Production systems do not need a risky exploit attempt to prove exposure. They need accurate kernel state, configuration state, privilege state, vendor fix status, and a clean retest after reboot.
Mitigation details for platform teams
For platform teams, the most valuable mitigation is reducing the number of workloads that can reach sensitive kernel attack surface. CVE-2026-43121 is a good reason to review long-standing exceptions.
Remove broad privileges from general workloads:
securityContext:
privileged: false
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
Avoid host networking unless required:
spec:
hostNetwork: false
hostPID: false
hostIPC: false
Use namespace and admission controls to block privilege drift. A Kyverno-style policy can reject containers that request NET_ADMIN unless they run in an approved namespace:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: restrict-net-admin
spec:
validationFailureAction: Enforce
rules:
- name: block-net-admin-outside-networking
match:
any:
- resources:
kinds:
- Pod
exclude:
any:
- resources:
namespaces:
- kube-system
- networking
validate:
message: "NET_ADMIN is restricted to approved networking namespaces."
pattern:
spec:
containers:
- =(securityContext):
=(capabilities):
X(add): ["NET_ADMIN"]
The exact policy language should be tested before enforcement, but the principle is stable: capabilities are part of vulnerability exposure. If a kernel bug requires a capability, reducing that capability changes risk.
For bare-metal high-performance networking hosts, document whether ZCRX is intentionally used. If it is not used, disable experimental paths where possible through kernel config and deployment standards. If it is used, isolate workloads, pin kernel versions, and test updates in staging with realistic NIC configuration.
Why io_uring remains worth defending rather than disabling everywhere
It is tempting to look at io_uring CVEs and conclude that the interface is too risky. That is too simple. io_uring exists because modern systems need efficient asynchronous I/O. High-performance databases, proxies, storage systems, and network services benefit from reducing syscall and copy overhead. ZCRX pushes that logic further into receive-side networking.
The better security stance is selective exposure. Production systems should not expose every fast path to every workload. Container platforms should not hand out broad capabilities by default. Development clusters should not silently become kernel exploit labs. High-performance systems should receive kernel updates faster than low-risk endpoints because their feature set often sits closer to complex kernel paths.
The kernel’s ZCRX documentation itself shows the operational complexity: queue setup, header/data split, RSS, and flow steering must be configured correctly before the feature works. (docs.kernel.org) That complexity is a reminder that ZCRX is not a generic default path for every Linux process. It should be treated as a specialized performance feature with a matching security review.
What security researchers can learn from the ZCRX bug
For researchers, CVE-2026-43121 is a useful case study in weak primitive amplification.
The path begins with a concurrency bug, not a clean linear overflow. That means reproducing it requires timing and state. The memory corruption is a u32 write, not arbitrary write. That means exploitability depends on allocator placement and target object selection. The attack surface is gated by hardware and privileges. That means a lab exploit may not generalize across real environments. The public exploit narrative became controversial because some privilege assumptions were not cleanly separated from the escalation goal.
That combination is common in modern kernel work. Easy bugs are rare. Valuable bugs often start as narrow races, partial writes, refcount mistakes, or teardown-only crashes. The hard part is not only finding them. The hard part is proving impact without blurring assumptions.
A high-quality exploitability report should state:
Kernel build:
Distribution:
Config flags:
Hardware:
Required capabilities:
Namespaces:
Hardening settings:
Trigger path:
Primitive:
Corrupted object:
Leak method:
Write method:
Privilege transition:
Reliability:
Crashes observed:
Fix tested:
Without those details, “root” is a conclusion without enough evidence.
What defenders can learn from the public debate
The oss-security thread around this issue is also a process lesson. Vulnerability reports increasingly mix confirmed findings, generated analysis, incomplete exploit ideas, and real patches. Solar Designer noted in the thread that AI-generated reports can complicate handling, while also saying that such reports are not necessarily useless. (seclists.org)
That is the new reality. Security teams will see more reports that are partly right, partly confused, and partly ahead of vendor wording. The correct response is not to reject them wholesale or accept every claim. The correct response is to pin each claim to evidence.
For CVE-2026-43121, the evidence supports the race, double-return, and u32 OOB write. The evidence supports the existence of a stable fix for the user_ref race and a later defensive freelist check. The evidence does not support treating every public full-chain claim as a vendor-confirmed root exploit across all affected systems.
That kind of precision keeps vulnerability management useful.
Remediation checklist
Use this checklist for real environments:
| कदम | Done |
|---|---|
| Identify all Linux hosts running kernels that may contain io_uring ZCRX | |
जाँचें CONFIG_IO_URING_ZCRX or vendor equivalent | |
| Identify hosts with ZCRX-capable NICs and high-performance receive configuration | |
Identify containers and services with CAP_NET_ADMIN or privileged mode | |
| Check vendor advisory or changelog for CVE-2026-43121 | |
| Patch and reboot affected hosts | |
| Confirm the running kernel after reboot | |
Remove unnecessary CAP_NET_ADMIN grants | |
| Search kernel logs for ZCRX, freelist, page-pool, slab, or KASAN warnings | |
| Record evidence for auditors and retest after maintenance |
A minimal post-patch verification script:
#!/usr/bin/env bash
set -euo pipefail
echo "== Host =="
hostnamectl 2>/dev/null || hostname
cat /etc/os-release 2>/dev/null || true
echo
echo "== Running kernel =="
uname -a
echo
echo "== ZCRX config =="
zgrep CONFIG_IO_URING_ZCRX /proc/config.gz 2>/dev/null \
|| grep CONFIG_IO_URING_ZCRX /boot/config-$(uname -r) 2>/dev/null \
|| echo "kernel config not readable"
echo
echo "== Recent kernel warnings of interest =="
journalctl -k --since "14 days ago" 2>/dev/null \
| grep -Ei 'io_uring|zcrx|freelist|user_ref|page_pool|KASAN|slab|corruption' \
|| echo "no matching kernel log lines found"
echo
echo "== Current process capabilities =="
grep -E 'CapEff|CapPrm|CapBnd' /proc/self/status || true
capsh --print 2>/dev/null | sed -n '/Current:/p;/Bounding set/p' || true
This script does not prove exploitability. It gives responders a clean evidence bundle for triage.
अंतिम मूल्यांकन
CVE-2026-43121 is a precise reminder that performance features are security features once they cross trust boundaries. io_uring ZCRX exists to make receive-side networking faster by removing a copy and letting payloads land directly in userspace memory while the kernel still handles headers. That design is valuable. It also makes lifetime accounting unforgiving.
The confirmed bug is a race in user_refs handling. One path reads and decrements in separate steps. Another path can zero the same counter during scrub. Under the wrong interleaving, the same niov is returned twice. The freelist count can exceed the number of entries. A later push can write four bytes past the end of the freelist allocation. The fix uses atomic compare-and-exchange to make the reference transition safe, and a later defensive patch warns and returns if the freelist invariant is already broken. (एनवीडी.एनआईएसटी.जीओवी)
The risk is real but bounded. It is not a remote worm bug. It is not automatically reachable on every Linux host. It is a local kernel memory-corruption issue in a specialized fast path, with exposure shaped by kernel build, backports, NIC support, ZCRX configuration, and local privileges. Hosts running privileged networking workloads deserve urgent review. Hosts without the feature or with the stable fix already running should document that evidence and move on.
The strongest defense is boring and reliable: run a fixed kernel, reboot into it, remove unnecessary network administration capabilities, restrict privileged containers, and keep kernel warning telemetry searchable. The more ambitious lesson is cultural: treat small kernel primitives with respect, but do not promote exploit claims beyond the evidence. Four bytes can matter. Facts matter more.
अधिक पठन और संदर्भ
Linux kernel documentation for io_uring zero-copy receive explains the ZCRX design, hardware requirements, and NIC setup expectations. (docs.kernel.org)
NVD’s CVE-2026-43121 record documents the io_uring/zcrx user_refs race, double freelist push, and u32 out-of-bounds write, with enrichment still pending. (एनवीडी.एनआईएसटी.जीओवी)
The Linux 6.18.16 stable changelog includes the backport for “io_uring/zcrx: fix user_ref race between scrub and refill paths.” (cdn.kernel.org)
The io_uring patch “warn on freelist violations” adds the defensive free_count >= num_niovs check before writing to the freelist. (lore.gnuweeb.org)
The oss-security CVE request thread records the public discussion, including the original OOB write report, later reproduction claims, and maintainer skepticism about parts of the full exploit narrative. (seclists.org)
The ze3tar ZCRX write-up is useful as a research-oriented exploit narrative, but its full local privilege escalation chain should be read alongside the oss-security discussion. (ze3tar.github.io)
The snailsploit analysis summarizes the race condition, double-free, out-of-bounds write, and upstream fix from the researcher perspective. (snailsploit)
NVD’s CVE-2023-2598 record provides useful historical context for io_uring fixed-buffer memory exposure and local privilege escalation risk. (एनवीडी.एनआईएसटी.जीओवी)
NVD’s CVE-2024-1086 record is relevant background for Linux kernel double-free and local privilege escalation risk in another subsystem. (एनवीडी.एनआईएसटी.जीओवी)
Penligent’s Copy Fail analysis covers CVE-2026-31431, a different Linux local privilege escalation where a small write primitive has a very different root cause and exploit model. (पेनलिजेंट)
Penligent’s AI pentesting and automated penetration testing resources are useful for teams building evidence-driven validation workflows around CVE triage, patch verification, and remediation retesting. (पेनलिजेंट)

