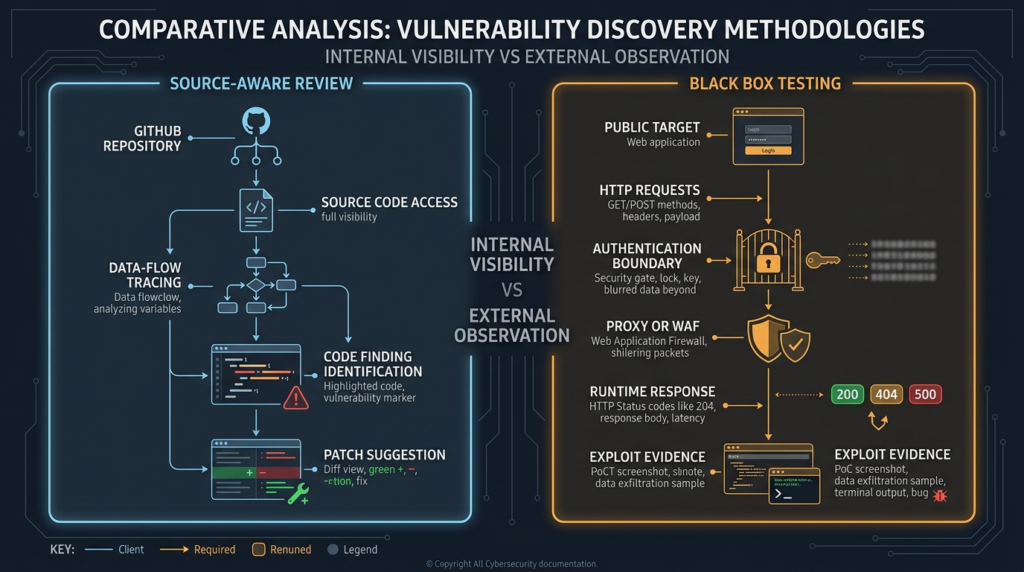
Claude Security is best understood as source-aware security review. It reads codebases, traces data flows across files, validates findings, and suggests patches that humans review before approval. That is valuable. It is also very different from black-box pentesting.
A black-box test starts with a running target, not a repository. The tester sees exposed hosts, web routes, API behavior, authentication boundaries, headers, redirects, session behavior, error patterns, and deployment quirks. The question is not only “Does the code contain a risky path?” The question is “Can an attacker reach that path in the deployed system and prove impact under the rules of engagement?”
That distinction matters because Claude Security is documented around codebase scanning. Anthropic describes it as a Claude.ai capability that scans codebases for security vulnerabilities and suggests targeted patches for human review. The same official help article says it understands context, traces data flows across files, validates findings through multi-stage verification, and lets users move from a finding into a Claude Code session to review the proposed fix. (Claude Help Center)
That is a code-review workflow. It can be very strong at finding issues that depend on source context. It is not the same evidence as an external exploit proof against a deployed application.
The practical lesson for security teams is simple: do not ask one tool to answer every security question. Use source-aware review to find and explain risky code. Use black-box validation to prove whether the deployed system is actually reachable, exploitable, and fixed. The strongest workflow treats an AI code finding as a hypothesis and a black-box test as the proof layer.
Claude Security Is Source-Aware Security Review, Not Black Box Pentesting
The clearest signal is the object being scanned. Claude Security scans codebases. Its findings include code-oriented fields such as location, file path, line number, repository, branch, impact, reproduction steps, recommended fix, severity, status, category, and date created. (Claude Help Center)
That output is built for engineering triage. A developer can open the affected file, inspect the line, understand the surrounding logic, review the recommended patch, and decide whether to merge a change. A security engineer can export findings, send them into a tracking workflow, or push them to notification systems through webhooks. Anthropic’s product page also describes Claude Security as scanning codebases, validating findings, and suggesting patches that teams can review and approve. (クロード)
Black-box pentesting begins from a different premise. NIST defines black-box testing as a methodology that assumes no knowledge of the internal structure and implementation detail of the assessment object. It defines white-box testing as the opposite style: a methodology that assumes explicit and substantial knowledge of the internal structure and implementation detail of the assessment object. (csrc.nist.gov)
By that definition, Claude Security belongs on the white-box side of the evidence model. It may use agentic reasoning instead of only fixed rules. It may catch cross-file logic that traditional scanners miss. It may validate findings before surfacing them. But its core visibility comes from source access, not from interacting with a deployed target as an outside attacker.
That does not make it weak. It makes it specific.
A source-aware tool can see why a parameter reaches a database query. It can see whether a controller calls an authorization helper. It can compare a new pull request against existing secure patterns. It can notice that a dangerous sink is reachable from a public route in the framework. It can often explain a vulnerability more clearly than a scanner that only observes HTTP responses.
A black-box tool can see something else: whether that route exists in the deployed environment, whether the reverse proxy forwards the request, whether authentication middleware is actually active, whether a WAF changes the request, whether a feature flag exposes the endpoint, whether stale instances remain behind a load balancer, and whether the fix is live outside the repository.
Those are not minor details. They are often the difference between a theoretical bug and an incident.
What Claude Security Can See
Claude Security’s documented strengths line up with code-level visibility. The official help article lists vulnerability categories including SQL, command, code, and XSS injection; XXE and ReDoS; path traversal, SSRF, and open redirects; authentication bypass, privilege escalation, IDOR or BOLA, CSRF, and race issues; memory safety; cryptography; deserialization; and protocol or encoding problems. (Claude Help Center)
That is a serious coverage map. Many of those bugs are hard to understand from a single line of code. Consider a typical SSRF finding. A shallow scanner might see fetch(userUrl) and raise an alert. A better review asks more questions. Where does userUrl come from? Is it controlled by an external user? Is it normalized before use? Does the allowlist compare hostnames before or after redirects? Does DNS resolution happen before validation? Does the request run from a network zone that can reach metadata services or internal admin panels? Is the code path behind authentication? Is the endpoint used only by trusted service accounts?
Claude Security is designed to reason over exactly this kind of source context. Anthropic says it traces data flows across files and identifies complex, multi-component vulnerability patterns that traditional scanners might not detect. (Claude Help Center)
Claude Code Review has similar source-aware design. Anthropic’s documentation says Code Review analyzes GitHub pull requests and posts findings as inline comments. It uses specialized agents to examine code changes in the context of the full codebase, looking for logic errors, security vulnerabilities, broken edge cases, and subtle regressions. A verification step checks candidates against actual code behavior before results are posted. (クロード)
This is the right mental model: Claude Security is not merely matching strings. It is trying to understand code behavior.
The GitHub repository for Anthropic’s Claude Code Security Reviewer makes the same point in a narrower pull-request workflow. The README describes it as a GitHub Action that uses Claude Code to analyze code changes for security vulnerabilities with context-aware analysis. Its features include diff-aware scanning, pull request comments, contextual understanding, language-agnostic review, and false-positive filtering. (ギットハブ)
The review command in that repository is especially revealing. It instructs the reviewer to examine modified files, trace data flow from user inputs to sensitive operations, look for privilege boundaries being crossed unsafely, and identify injection points and unsafe deserialization. It also tells the reviewer to avoid noise and focus on high-confidence vulnerabilities with real exploitation potential. (ギットハブ)
That is valuable work. But it is still code work.
What Source Code Still Cannot Prove
A repository is not the running system. That sounds obvious, but many AppSec workflows forget it.
A source-aware finding can say, “This route appears to accept user-controlled input and pass it into a database query without parameterization.” It cannot automatically prove all of the following:
The vulnerable route is deployed in production.
The production service is running the affected branch.
The reverse proxy exposes the path.
The endpoint is reachable from the internet.
The required feature flag is enabled.
The vulnerable code is not dead code.
The WAF does not block the relevant request shape.
The database user has enough privileges for meaningful impact.
The observed environment matches the repository configuration.
The patch has actually reached every instance behind the load balancer.
This is where black-box validation earns its place. OWASP’s Web Security Testing Guide makes the distinction clearly. OWASP notes that source code should be made available for testing when possible because source analysis removes much of the guesswork of black-box testing and can find significant problems that are hard to discover otherwise. But OWASP also lists source-analysis disadvantages, including that source review cannot detect runtime errors easily and that the source being analyzed might not be the same code deployed. (オワスプ)
OWASP describes penetration testing as remotely testing a running application without knowing its inner workings, with the tester acting like an attacker and attempting to find and exploit vulnerabilities. It also warns that penetration testing should not be the primary or only technique because it can identify only a representative sample of risks. (オワスプ)
Both statements can be true. Source review is more complete for many code-level flaws. Black-box testing is more realistic for deployed exposure.
The mature workflow is not source review versus black-box testing. It is source review feeding black-box validation, and black-box results feeding better source review.
The Evidence Gap Between Code Findings and Exploit Proof
A useful security finding needs evidence. But not all evidence has the same meaning.
A code finding proves that a risky pattern exists in source. A runtime proof shows that the pattern can be reached and abused in a specific environment. A production incident shows that someone did reach and abuse it. These are different levels of certainty.
| Security question | Source-aware review is strong | Black-box validation is strong |
|---|---|---|
| Which file and line introduce the risky behavior | はい | いいえ |
| Whether user input reaches a dangerous sink | はい | Sometimes |
| Whether authorization appears missing in code | はい | Sometimes |
| Whether the endpoint is exposed externally | Sometimes | はい |
| Whether a proxy, CDN, or WAF changes behavior | いいえ | はい |
| Whether a feature flag makes the route reachable | Sometimes | はい |
| Whether the deployed version is patched | いいえ | はい |
| Whether the bug is reproducible from an attacker-like position | Sometimes | はい |
| Whether the fix preserves local code style | はい | いいえ |
| Whether the report contains replayable external evidence | いいえ | はい |
A tool like Claude Security can produce a high-quality source-aware finding. That finding may include impact, location, reproduction steps, and a recommended fix. (Claude Help Center)
But the black-box layer still has to ask: what happened when the request crossed the real boundary?
A reverse proxy can normalize paths differently than the application router. An API gateway can strip or add headers. A CDN can cache responses in a way the application never expected. A Kubernetes ingress rule can expose an internal service. A legacy route can remain deployed after code has moved on. A session cookie can behave differently under real SameSite, domain, and TLS conditions. A database permission model can convert a risky query into either minor leakage or catastrophic data access.
None of that is visible from source alone with full certainty.
This is why the phrase “validated finding” needs careful handling. Claude Security validates findings in a source-aware workflow before surfacing them. Anthropic says every finding goes through multi-stage verification and that Claude challenges its own results before presenting them. (Claude Help Center)
That is not the same thing as black-box exploit validation against a deployed target.
A source-aware validation step can reduce false positives. It can confirm that the code path appears coherent. It can check whether the finding contradicts other source context. It can propose a fix that fits the codebase. It cannot replace a live test that confirms the route is reachable and the impact is observable.
Why Claude Security’s Black Box Limit Is a Product Boundary, Not a Failure
It would be inaccurate to say Claude Security “fails” at black-box testing. The better statement is that Claude Security is not documented as a black-box pentesting platform.
Anthropic says Claude Security scans codebases, works with GitHub repositories, produces repository and branch-aware findings, and moves users into Claude Code sessions for patch review. The FAQ says only GitHub-hosted repositories can be scanned today, severity is not configurable, and scans are stochastic by design because an agent adapts its analysis to each run instead of applying fixed pattern matches. (Claude Help Center)
The scope-of-use language also points to code ownership. Anthropic says users may only use Claude Security to scan code that they or their company own and have the necessary rights to scan, and may not scan third-party code or repositories outside their company’s codebases. (Claude Help Center)
That is not the posture of an external attack simulation product. It is the posture of a codebase security review product.
The distinction matters for buyers and practitioners. If a CISO asks, “Can Claude Security tell me whether our public API is externally exploitable?” the precise answer should be: it can help identify code paths that may be exploitable, but external validation still requires testing the deployed API under authorized conditions.
If an AppSec engineer asks, “Can Claude Security replace SAST?” the answer is more nuanced. It may complement or challenge traditional SAST by reasoning across code context, but deterministic static analysis, custom rules, compliance gates, and repeatable query-based workflows still matter. GitHub’s CodeQL, for example, lets teams query code as data and run security checks through code scanning. (GitHub Docs) Semgrep describes its Code product as SAST for first-party code, and its taint analysis tracks untrusted data from sources through propagators to vulnerable sinks. (セムグレップ)
If a pentester asks, “Can Claude Security replace black-box testing?” the answer is no. It was not designed to start from external exposure and work inward.
DAST and Pentesting Still Answer the Outside-In Question
Dynamic testing has a different evidence model. PortSwigger describes DAST as testing security from outside a web application, with no knowledge of the application’s internals, in order to simulate a real attack. (ポートスウィガー)
That does not mean DAST is automatically better. DAST can miss deep logic flaws that require source knowledge. It can struggle with authenticated workflows, complex state machines, anti-automation controls, and business logic that requires domain context. OWASP warns that automated penetration testing tools alone are usually poor for bespoke web applications and that penetration testing should not be the only security technique. (オワスプ)
But DAST and pentesting are still necessary because attackers do not submit pull requests before attacking. They interact with the deployed boundary.
A black-box workflow can answer questions a repository cannot fully settle:
Can an unauthenticated user reach the route?
Can a low-privilege user access another tenant’s object?
Does the application reveal different responses for valid and invalid object IDs?
Does the redirect actually leave the trusted domain?
Does the SSRF path connect to an internal host from the server’s network zone?
Does the CSRF issue work in a real browser session?
Does a race condition produce a measurable state change?
Does the patched build actually reject the previous request?
These questions are not theoretical. They are the heart of exploitability.
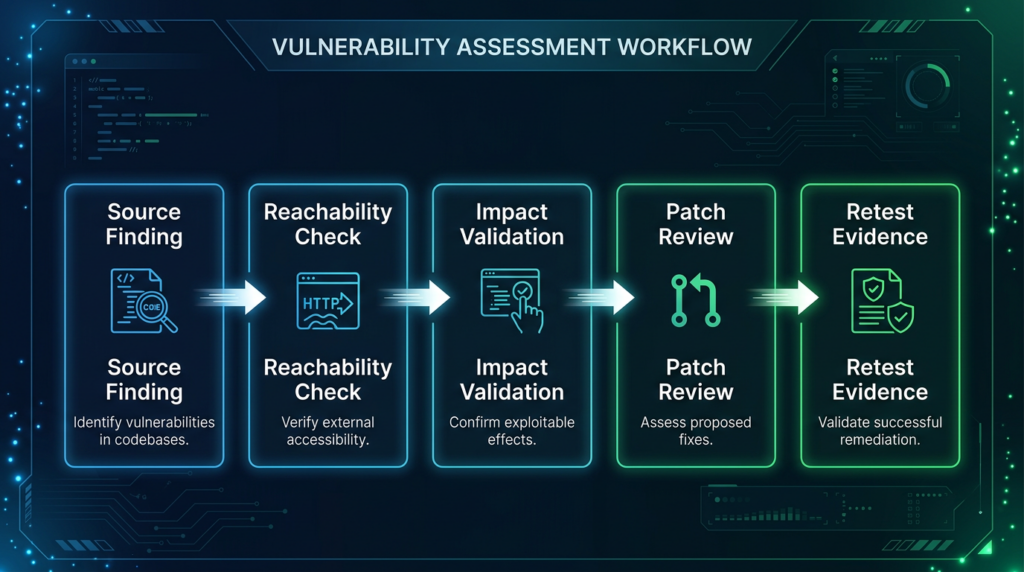
The best security programs build a loop. Source-aware review finds likely flaws earlier. Black-box validation tests the deployed truth. Retesting confirms the fix. Reporting preserves evidence for engineering, leadership, compliance, and future regression checks.
A Practical Model, Hypothesis, Reachability, Impact, Fix, Retest
A clean workflow separates five layers of evidence.
| レイヤー | Main question | Typical evidence |
|---|---|---|
| Hypothesis | What might be vulnerable in the code | Claude Security finding, SAST result, code review note |
| Reachability | Can the suspected path be reached in the target environment | HTTP request, route discovery, auth context, gateway behavior |
| インパクト | What can an attacker actually do | Response differential, unauthorized object access, safe side effect, logs |
| Fix | What change removes the root cause | Patch, code diff, config change, dependency update |
| Retest | Is the deployed issue gone | Replayed request, negative result, version proof, deployment evidence |
Claude Security is strongest in the hypothesis and fix layers. It can also help describe expected reproduction steps from source context. But black-box testing owns reachability, impact, and retest evidence in the deployed environment.
This is also the right place to understand agentic pentesting. Penligent’s public homepage describes controllable agentic workflows where users can edit prompts, lock scope, and customize actions for their environment. Its public materials frame AI-powered pentesting as a workflow that combines natural-language control, scope locking, human-in-the-loop operation, access to security tools, validation, and reporting rather than treating the model as a standalone answer engine. (寡黙)
That is the complementary role. A code-aware system can produce a strong hypothesis. An authorized AI pentesting workflow can help turn that hypothesis into external evidence by mapping the reachable surface, replaying requests, comparing roles, invoking tools under scope, preserving artifacts, and producing retestable reports. Penligent’s own writing on white-box and black-box workflows states the same distinction: white-box testing starts from internal knowledge, while black-box testing starts from a reachable system, a boundary, an attack surface, and limited external visibility. (寡黙)
The point is not that one tool wins. The point is that different evidence layers need different workflows.
Vulnerability Classes That Need Runtime Proof
Many vulnerability categories appear in both code review and black-box testing, but they look different from each side.
| 脆弱性クラス | What source-aware review can show | What black-box validation must prove |
|---|---|---|
| SQLインジェクション | User input reaches query construction without safe binding | A reachable request changes query behavior or exposes a safe observable signal |
| SSRF | User-controlled URL reaches an HTTP client or internal fetcher | The deployed server makes a request from a sensitive network position |
| IDOR or BOLA | Object access lacks ownership or tenant checks | Two real roles produce unauthorized access or response differences |
| CSRF | State-changing route lacks token or relies on weak cookie assumptions | Browser and cookie behavior allow a cross-site state change |
| Open redirect | Redirect destination is user-controlled | The deployed route redirects to an external domain in an abuse-relevant context |
| Command injection | Untrusted input enters shell construction | A reachable input produces a safe, non-destructive command side effect in a lab |
| Deserialization | Untrusted bytes drive object construction | The runtime accepts the content type and library path needed for exploitability |
| Race condition | Non-atomic check and state update exist in code | Concurrent requests create measurable duplicate state or bypass |
| Crypto weakness | Weak primitive, wrong mode, or unsafe comparison exists | The affected data and attacker position make exploitation realistic |
| Path traversal | User input controls file path construction | A deployed route reads or writes outside the intended directory |
Claude Security’s finding categories overlap with many of these classes. Its official list includes injection, SSRF, path traversal, access control flaws, race conditions, memory safety, cryptography, deserialization, and protocol or encoding issues. (Claude Help Center)
But the proof changes outside the repository.
An IDOR is not proven because a controller forgot to call authorize(). It is proven when Account A can access Account B’s object under the tested environment and role model.
An SSRF is not proven because code calls an HTTP client. It is proven when the application can be made to initiate an unintended server-side request under authorized test conditions.
A race condition is not proven because two operations are not obviously atomic. It is proven when concurrent requests produce a state that should not exist.
A command injection is not proven because a shell string is concatenated. It is proven when a safe, controlled test environment shows command execution or an equivalent measurable side effect.
The same distinction is essential for severity. Claude Security assigns severity per finding based on exploitability in the codebase rather than category alone. High severity, for example, maps to issues exploitable by an unauthenticated remote attacker against a default deployment with no meaningful preconditions. (Claude Help Center)
That is a useful source-level severity model. The deployed environment may still raise or lower the real risk.
CVE-2024-3400 Shows Why Deployment Context Decides Risk
CVE-2024-3400 is a useful case study because it was not merely “a command injection bug” in the abstract. It was a command injection vulnerability in the GlobalProtect feature of specific Palo Alto Networks PAN-OS versions and configurations. Palo Alto’s advisory says the issue could enable an unauthenticated attacker to execute arbitrary code with root privileges on the firewall, and it lists affected and unaffected PAN-OS versions and product scopes. (セキュリティ.paloaltonetworks.com)
NVD describes the same issue as command injection resulting from arbitrary file creation in the GlobalProtect feature of PAN-OS, affecting specific versions and distinct feature configurations. NVD also records that CISA added it to the Known Exploited Vulnerabilities catalog on April 12, 2024. (NVD)
CISA published an alert the same day noting that Palo Alto Networks had released workaround guidance for the command injection vulnerability affecting PAN-OS 10.2, 11.0, and 11.1. (CISA)
For this article, the important lesson is not the exploit mechanics. The lesson is that real risk depended on deployed facts:
Which PAN-OS version was running.
Whether the affected GlobalProtect configuration was enabled.
Whether the device was exposed to untrusted networks.
Whether threat-prevention or vendor workarounds were in place before the patch.
Whether logs showed exploitation attempts.
Whether the fixed release had reached the actual firewall.
A source-aware analysis can help explain why a command injection exists. It can identify unsafe file creation or command construction patterns. But the enterprise remediation question is broader: are our exposed devices in the vulnerable configuration right now?
That requires asset discovery, version checking, configuration review, external exposure validation, patch confirmation, and post-exploitation hunting. A repository-level finding is not enough because the vulnerable object is not just code. It is code plus feature configuration plus network exposure plus operational state.
This is why black-box and gray-box validation remain critical during major CVE response. The team needs to know whether the affected service is reachable, whether a detection rule fires, whether the mitigation actually changes externally visible behavior, and whether the patched version is live.
CVE-2023-34362 Shows Why HTTP Reachability Changes Everything
CVE-2023-34362 in Progress MOVEit Transfer is another clean example. NVD describes it as a SQL injection vulnerability in the MOVEit Transfer web application that could allow an unauthenticated attacker to gain access to the MOVEit Transfer database. It also notes that exploitation of unpatched systems could occur via HTTP or HTTPS and that the issue was exploited in the wild in May and June 2023. (NVD)
CISA and the FBI reported that the CL0P ransomware group exploited CVE-2023-34362 affecting MOVEit Transfer software and that the intrusion began with SQL injection into the MOVEit Transfer web application. (CISA)
A source-aware review can identify SQL injection patterns. It can trace user input into a query. It can look for missing parameterization, unsafe dynamic SQL, framework-specific escape bypasses, and authentication assumptions.
But incident response for MOVEit-style exposure requires more than code review. Teams need to know whether they operate affected versions, whether those instances are internet-facing, whether patches were applied, whether exploitation indicators exist, whether unauthorized files were written, whether database access occurred, and whether data exfiltration is plausible.
Black-box proof does not mean firing dangerous exploit payloads at production. In a responsible program, it may mean confirming version exposure, checking route behavior, validating that the vulnerable interface is not reachable, testing a safe vendor-provided detection method, reviewing logs, or replaying a harmless request in staging.
The key is that the risk lives at the web boundary. A SQL injection in a web application becomes operationally urgent when an unauthenticated HTTP path reaches it.
That is why a code finding needs environmental enrichment. Is the application behind a VPN? Is it public? Is it patched? Is the vulnerable module enabled? Are there compensating controls? Did the fix reach the deployed instance? Does the report contain reproducible evidence, or only a scanner line item?
A codebase scanner cannot settle all of those questions alone.
CVE-2023-4966 Shows Why Runtime State Can Beat Source Assumptions
CitrixBleed, tracked as CVE-2023-4966, shows another side of the same problem. CISA and partners responded to active, targeted exploitation of CVE-2023-4966 affecting Citrix NetScaler ADC and NetScaler Gateway. (CISA)
Mandiant reported zero-day exploitation beginning in late August 2023 and n-day exploitation after Citrix’s publication. Mandiant also investigated multiple successful exploitations that resulted in takeover of legitimate user sessions on NetScaler ADC and Gateway appliances, bypassing password and multi-factor authentication. (グーグル・クラウド)
Citrix’s own bulletin said exploits of CVE-2023-4966 on unmitigated appliances had been observed and strongly urged customers to install updated versions. (support.citrix.com)
This is not a simple “line of bad code” story from a defender’s perspective. The operational risk involves appliance configuration, exposed gateways, active sessions, memory disclosure, session token handling, patch status, and session invalidation. NVD also records CVE-2023-4966 in CISA’s Known Exploited Vulnerabilities catalog and includes the required action to apply mitigations and kill active and persistent sessions per vendor instructions, or discontinue use if mitigations are unavailable. (NVD)
That last part is crucial. Patching alone may not remove risk if stolen sessions remain valid. The deployed system has state. Attackers exploit state. Defenders must validate state.
Source-aware review can help discover memory safety issues. It can reason about unsafe buffer handling. It can explain how a leak might occur. But the defensive workflow still has to answer deployed-system questions:
Which appliances are exposed?
Which versions are running?
Are they configured as affected Gateway or AAA virtual servers?
Were active and persistent sessions cleared?
Do logs show suspicious session reuse?
Can monitoring detect the post-exploitation behavior?
Does the external boundary still expose the vulnerable service?
That is black-box and operational validation territory.
How to Turn a Claude Security Finding Into Black Box Validation
The safest way to combine source-aware AI review with black-box proof is to treat every code finding as a structured hypothesis.
A good hypothesis contains five facts:
The suspected vulnerability class.
The source entry point.
The sensitive sink or unsafe operation.
The preconditions required for exploitation.
The expected external behavior if the issue is real.
For example, a Claude Security finding might say that a route accepts a user-controlled object ID and returns data without checking ownership. The source-aware evidence may be strong. The black-box task is to prove whether a user in Role A can retrieve an object owned by User B in a deployed test environment.
That validation should not begin with random scanning. It should begin with a scoped test plan.
Finding ID:
Source finding:
Repository and branch:
Suspected vulnerability class:
Affected route or function:
Target environment:
Authorization owner:
Allowed test accounts:
Out-of-scope actions:
Preconditions:
Expected safe proof:
Required logs:
Retest owner:
The plan should explicitly define what will not be tested. That is not bureaucracy. It protects the target, the tester, and the evidence.
For an IDOR or BOLA hypothesis, the proof might use two authorized test accounts and two test-owned objects. For an SSRF hypothesis, the proof should use a controlled collaborator endpoint or internal test endpoint, not sensitive cloud metadata services. For a command injection hypothesis, the proof belongs in a lab or staging environment, and the observable side effect should be harmless. For a race condition, the proof should use disposable test resources and strict rate limits.
The output should be evidence, not vibes.
A strong black-box validation record includes the request, response, timestamp, account role, target environment, affected object, expected behavior, observed behavior, logs if available, and a retest command. The report should also state what was not tested. That prevents the common mistake of turning a narrow proof into an overbroad claim.
Penligent’s public writing on AI pentest reports makes the same evidence-first point: a credible AI pentest report still needs scope, test boundaries, reproducible evidence, exploit conditions, impact, remediation, and a handoff to the people who will fix the issue. (寡黙)
That is the standard an AI-assisted workflow should meet.
Safe Command Line Checks for Authorized Validation
The following examples are intentionally generic. They use placeholder domains and safe validation patterns. They are not a license to test systems you do not own or have explicit permission to assess.
A basic external exposure check can start with service and header visibility:
nmap -sV --top-ports 100 -Pn app.example.com
That command does not prove a vulnerability. It helps answer a narrower question: what services appear reachable from the tester’s network position?
HTTP route and header checks can establish baseline behavior:
curl -i https://app.example.com/health
curl -i https://app.example.com/api/version
curl -I https://app.example.com/
For an authorization hypothesis, two low-privilege test accounts are more useful than a scanner. The point is to compare behavior across roles.
curl -s \
-H "Authorization: Bearer $USER_A_TOKEN" \
https://app.example.com/api/orders/1001 | jq .
curl -s \
-H "Authorization: Bearer $USER_B_TOKEN" \
https://app.example.com/api/orders/1001 | jq .
If User B should not see Order 1001, the second response matters. A 403 または 404 may indicate the control is working. A full object response may support the finding. But the report should include the object ownership setup, the account roles, and the environment. Without that context, the evidence is weak.
For a safe retest after an authorization fix:
printf "User A expected access:\n"
curl -s -o /tmp/user_a.out -w "%{http_code}\n" \
-H "Authorization: Bearer $USER_A_TOKEN" \
https://staging.example.com/api/orders/1001
printf "User B expected denial:\n"
curl -s -o /tmp/user_b.out -w "%{http_code}\n" \
-H "Authorization: Bearer $USER_B_TOKEN" \
https://staging.example.com/api/orders/1001
diff -u /tmp/user_a.out /tmp/user_b.out || true
For a race-condition hypothesis in a staging environment with disposable test data, controlled concurrency can test whether state changes more than once. The command below is only a skeleton. It should be used only when the endpoint, account, object, and rate are approved.
seq 1 20 | xargs -I{} -P 5 curl -s -o /dev/null -w "%{http_code}\n" \
-H "Authorization: Bearer $TEST_TOKEN" \
-X POST \
https://staging.example.com/api/test-coupon/redeem
The evidence is not the command. The evidence is the final state: was the coupon redeemed once or multiple times? Were duplicate credits issued? Did logs show conflicting writes? Was the test object isolated from real users?
For header and proxy behavior, the safe goal is to understand how the deployed stack responds, not to bypass controls.
curl -i \
-H "X-Forwarded-Host: test.example.invalid" \
-H "X-Forwarded-Proto: https" \
https://staging.example.com/
If a source-aware finding warns about Host header trust or cache poisoning risk, black-box validation should be designed carefully. Many cache and proxy tests can affect other users if run in production. Use staging, cache-busting test paths, explicit approval, and clean-up steps.
A Minimal Evidence Template
A black-box proof should be easy to replay. A future engineer should be able to understand exactly what happened without reading a chat transcript or trusting an AI summary.
# Finding Evidence
Finding ID:
Title:
Source:
Repository:
Branch:
Code location:
Target environment:
Test date:
Tester:
Authorization reference:
## Scope
In scope:
Out of scope:
Rate limits:
Data safety constraints:
## Hypothesis
Vulnerability class:
Suspected entry point:
Suspected sink:
Required role:
Required feature flag:
Expected impact:
## Test Setup
Test account A:
Test account B:
Test object:
Target URL:
Build or release version:
Relevant configuration:
## Reproduction Steps
1.
2.
3.
## Request Evidence
```http
REQUEST GOES HERE
Response Evidence
RESPONSE GOES HERE
Observed Impact
What was accessed, changed, leaked, or bypassed:
制限事項
What was not tested:
What remains uncertain:
Fix
Owner:
パッチ
Configuration change:
Deployment target:
Retest
Retest date:
Retest command:
Expected result:
Actual result:
Status:
References and Further Reading
For the official product context, read Anthropic’s documentation on Use Claude Security,
the Claude Security product page, Claude for Securityその Claude Code Review documentation, and Anthropic’s open-source Claude Code Security Reviewer, including its security review command. For security testing foundations, see the OWASP ウェブ・セキュリティ・テスト・ガイド, its introduction to source analysis and penetration testingその OWASPトップ10, NIST’s definitions of black-box testing そして white-box testing, GitHub’s documentation on CodeQL code scanning, Semgrep’s SAST documentation, Semgrep’s taint analysis guide, and PortSwigger’s explanation of DAST security testing. For real-world vulnerability context, review Palo Alto Networks’ advisory for CVE-2024-3400, CISA’s alert on パン・オス CVE-2024-3400, the NVD entry for CVE-2024-3400, the CISA and FBI advisory on CL0P exploitation of MOVEit Transfer, the NVD entry for CVE-2023-34362, CISA’s guidance on CitrixBleed CVE-2023-4966, Mandiant’s analysis of session hijacking via Citrix NetScaler CVE-2023-4966, and the NVD entry for CVE-2023-4966. For related Penligent resources, see the Penligent homepage, Codex for White-Box Audits, Black-Box Pentesting for Proof, Claude Code Security and Penligent, From White-Box Findings to Black-Box Proof, Pentest AI Agents, Real Tool Execution Is the Line Between AI Pentesting and a Toyそして AIペンテストレポートの入手方法.