In 2026, that gap is even more important because defenders are overwhelmed by CVE volume, inconsistent exploit maturity labels, patch windows, and an explosion of AI-generated “PoCs” of wildly uneven quality. At the same time, public exploit intelligence is still a core signal in vulnerability prioritization, especially when paired with CISA’s Known Exploited Vulnerabilities catalog and vendor patch guidance. CISA’s KEV data repository exists specifically to make the KEV catalog data easier to consume programmatically and is synchronized shortly after updates to the canonical CISA source. (ギットハブ)
This article is for security engineers, pentesters, vuln management teams, and automation-focused practitioners who want a practical, modern workflow around the keyword exploit db without turning their process into “download random code and pray.”
What Exploit DB Actually Is and What It Is Not
The fastest way to misuse Exploit DB is to assume every entry is equivalent to a production-grade exploit.
It is not.
The official repository description emphasizes breadth and accessibility: exploits, shellcode, and papers from direct submissions, mailing lists, and other public sources, organized into a freely available database. It also explicitly frames the archive as PoCs and exploit material rather than advisories. (ギットハブ)
That means an Exploit-DB entry may be any of the following:
- A rough proof of concept that demonstrates a vulnerability condition
- A working exploit that requires environment-specific adjustments
- A historical artifact useful for understanding bug classes
- A script that is outdated but still valuable for pattern study
- A highly practical exploit that still works in real environments
- A noisy, brittle, or incomplete sample that needs validation
This is exactly why experienced teams do not ask only “Is there an Exploit-DB entry?” They ask:
- Does it match the product/version/build we actually run?
- Is it a pre-auth or post-auth path?
- Is the exploit primitive local, remote, sandboxed, or chained?
- Does it require configuration that is absent in our environment?
- Has it been superseded by a more reliable public PoC elsewhere?
- Can we reproduce the impact safely in a lab or controlled validation flow?
If you use Exploit DB as a signal source そして technical starting point, it is extremely valuable. If you use it as an oracle, it will waste your time.
Why Security Engineers Still Search for “Exploit DB” So Often
The user intent behind the keyword exploit db is usually not “tell me what Exploit-DB is.” In practice, it clusters into a few high-intent workflows:
- Find a public PoC quickly for a known CVE
- Check whether a vulnerability has exploit code in the wild
- Use SearchSploit in Kali to triage version-specific exposures
- Map scanner findings to actionable exploit validation
- Build or improve a red-team / validation playbook
- Estimate real-world exploitability during incident response
A proxy for this intent is how strongly the ecosystem revolves around SearchSploit rather than only the website UI. Kali Linux’s exploitdb package page explicitly documents both the local searchable archive and サーチスプロイト, including CVE searching (--cve), JSON output (-j), path display (-p), mirroring (-m), and even an --nmap automation mode that checks Nmap XML output against service versions. (Kali Linux)
That tells you something important about the actual market demand behind the keyword: many users searching “exploit db” are really searching for operational workflows, not definitions.
I can’t credibly claim an exact “highest CTR keyword” without direct access to live Google Search Console or Google Ads account data for your property. But based on the public tool documentation and the dominance of Kali/SearchSploit usage patterns in practitioner workflows, the most commercially and operationally relevant adjacent intents are typically:
- exploit db
- サーチスプロイト
- exploit db searchsploit
- exploit db CVE search
- exploit db kali
- exploit db download / local archive
That is the intent cluster your article needs to satisfy if you want it to rank and retain technical readers.
Exploit DB and SearchSploit in Kali Linux
Kali’s exploitdb tool page is a strong practical reference because it shows how practitioners actually use the database in daily work. The page lists the exploitdb そして サーチスプロイト binaries, shows installation via sudo apt install exploitdb, and demonstrates that the local archive lives under /usr/share/exploitdb と exploits そして shellcodes directories. It also exposes SearchSploit examples and options directly in the package documentation. (Kali Linux)
That matters for two reasons.
First, it proves that Exploit DB is not just a website lookup experience. It is part of an offline-capable, scriptable workflow.
Second, the documented options hint at mature use cases many teams overlook:
-cvefor CVE-based lookupj/-jsonfor structured automation-nmap file.xmlfor matching scan output to likely exploitsm/-mirrorto copy a selected exploit locally for reviewx/-examinefor quick source inspection in pagert,e,sto reduce false positives when versions matter
This is where a lot of “exploit db” content online is too shallow. It describes the website and stops. Real teams use it as a local exploit intelligence index.
A Practical SearchSploit Mindset
Most failed SearchSploit usage comes from overtrusting fuzzy matches.
For example, if you search a product name and version naively, you may get:
- Similar product families
- Adjacent versions
- Plugin/module names
- Local exploits mixed with remote ones
- DoS PoCs mixed with RCE PoCs
- Old entries that no longer fit your target topology
The Kali docs themselves show options designed to reduce this noise, such as --title, --exact, --strictそして --exclude. (Kali Linux)
Use them.
If your goal is vulnerability validation and not just research browsing, precision beats volume.
The Right Way to Use Exploit DB in a Modern Validation Workflow
A disciplined workflow around Exploit DB usually looks like this:
1) Start from a verified asset and version signal
Do not begin with “find me an exploit.” Begin with:
- A validated product fingerprint
- A build/version number
- An exposed surface (port/protocol/path)
- Authentication context
- Network reachability constraints
- Compensating controls (WAF, reverse proxy, EDR, sandboxing)
Exploit code is only meaningful relative to environment conditions.
2) Query Exploit DB and SearchSploit as one signal source
Use Exploit DB/SearchSploit to answer:
- Is there public exploit material?
- How old is it?
- What vulnerability class is it?
- What preconditions are implied?
- Is it PoC-grade or operationally reliable?
- Does it reference a CVE, vendor version, or EDB-ID you can track?
そこで searchsploit --cve is particularly helpful for fast triage. Kali documents this directly in examples. (Kali Linux)
3) Cross-check with NVD and vendor advisories
Exploit DB helps you understand exploit paths. NVD and vendors help you confirm scope, affected versions, and remediation status.
For example, the NVD entry for CVE-2026-2441 describes a Chrome CSS use-after-free that allowed remote attackers to execute arbitrary code inside a sandbox via a crafted HTML page, and the NVD page also indicates the CVE is in CISA’s KEV catalog. It includes dates and reference links that matter for prioritization and patch governance. (NVD)
4) Check KEV / active exploitation signals
CISA KEV does not tell you everything, but it is a high-value prioritization layer. KEV inclusion means exploitation in the wild is established under CISA’s criteria, and the KEV data repository exists specifically for programmatic consumption and tracking of changes. (ギットハブ)
This helps you avoid a common mistake: spending cycles validating old lab-friendly exploits while active exploitation moves elsewhere.
5) Reproduce safely in a controlled path
Never run PoC code directly against production assets or in environments you do not own or have permission to test.
A safe validation workflow includes:
- Lab or staging clone
- Isolated network segment
- Logging enabled
- Snapshot/rollback capability
- Timeboxed test plan
- Explicit success criteria
- エビデンスの取得
6) Convert “PoC found” into decision-grade evidence
The output security leadership needs is not “Exploit-DB has an entry.”
They need something like:
- Exploitability status: Verified / Not reproduced / Inconclusive
- スコープ Which assets/builds are affected
- Conditions: Auth required, user interaction, config dependencies
- Blast radius: Data access, code execution, privilege boundaries
- Mitigation status: Patch, workaround, compensating controls
- Confidence: What was tested, how, and with what limitations
That is the difference between research activity and security engineering.

Exploit DB Is Not a Replacement for Vulnerability Prioritization
A dangerous anti-pattern is to prioritize only what has a public Exploit-DB entry.
That sounds practical, but it fails in several ways:
- Public exploit code lags some real-world exploitation
- Exploit-db coverage is broad but not exhaustive
- Highly targeted exploitation may not be public
- Newer bug classes may surface first in private reports or repos
- Some public PoCs are low quality while non-public tradecraft is mature
A better prioritization stack combines:
- Asset criticality
- Exposure (internet-facing vs internal)
- Privilege context
- Exploit maturity signals (public PoC, KEV, vendor telemetry)
- Compensating controls
- Detection coverage
- Patch availability and operational risk
Exploit DB is an excellent 入力 to that stack. It should not be the whole stack.
Where Exploit DB Fits in Offensive Security and Purple Teaming
Exploit DB is useful beyond vuln management. In offensive and purple-team operations, it helps in three distinct ways.
Rapid hypothesis generation
When an environment fingerprint suggests a vulnerable service, Exploit DB helps analysts quickly form an exploitation hypothesis:
- Which primitive is likely
- Whether auth bypass exists
- Whether the path is RCE, file read, LPE, or DoS
- Whether chaining is usually required
Reproducibility and training
Even outdated or partially working PoCs are educational if used correctly. They teach:
- Bug class mechanics
- Version-specific fragility
- Environmental assumptions
- Why exploitation sometimes fails outside a lab
That training value is one reason the Exploit Database archive remains relevant.
Validation over assumption
The fastest route to false confidence is to stop at “scanner says vulnerable” or “developer says patched.”
Exploit-aware validation gives defenders evidence.
This is also where automation is becoming more important, because manual reproduction is expensive and inconsistent across teams.
The AI Problem Around Exploit DB in 2026
AI has made exploit research faster and noisier at the same time.
Security teams now routinely encounter:
- AI-written “PoCs” that compile but do not exploit anything
- CVE summaries that merge wrong versions
- Hallucinated flags/options in tooling instructions
- Copy-paste code that ignores auth/session assumptions
- Mislabeling of local vs remote exploitability
- Dangerous weaponization attempts from low-context prompts
Exploit DB becomes more valuable in this environment because it anchors discussion in public artifacts with identifiers, paths, and source material. But it also needs better validation workflows, because AI can dramatically increase the number of bad exploitation attempts your team reviews.
The right question is no longer just “Can AI generate exploit attempts?” It is “Can our process quickly separate useful exploit intelligence from synthetic noise?”
That is why structured pipelines matter:
- normalize signals (CVE, CPE, asset versions)
- enrich with Exploit DB / SearchSploit / KEV / vendor refs
- triage exploitability hypotheses
- verify in controlled environments
- produce evidence-backed remediation guidance
A Practical SearchSploit Workflow You Can Automate
Below is a publishable, non-weaponizing workflow example for defensive validation and lab testing.
# 1) Update the local exploitdb/searchsploit package metadata where supported
searchsploit -u
# 2) Search by CVE (fastest exact-ish starting point)
searchsploit --cve 2021-44228
# 3) Narrow noisy results with title-only and exact matching
searchsploit -t -e "Apache Log4j"
# 4) Inspect results in JSON for automation pipelines
searchsploit --cve 2021-44228 -j > log4shell_searchsploit.json
# 5) Show the local path for a specific EDB-ID (example placeholder)
searchsploit -p 50592
# 6) Examine the source in pager before mirroring
searchsploit -x 50592
# 7) Mirror locally for controlled code review (lab only)
searchsploit -m 50592
The key idea is not the commands themselves. It is the sequence:
- 所在地
- Narrow
- Structure
- Inspect
- Review
- Validate safely
Kali’s documentation supports each of these operational steps through the サーチスプロイト help output and examples. (Kali Linux)
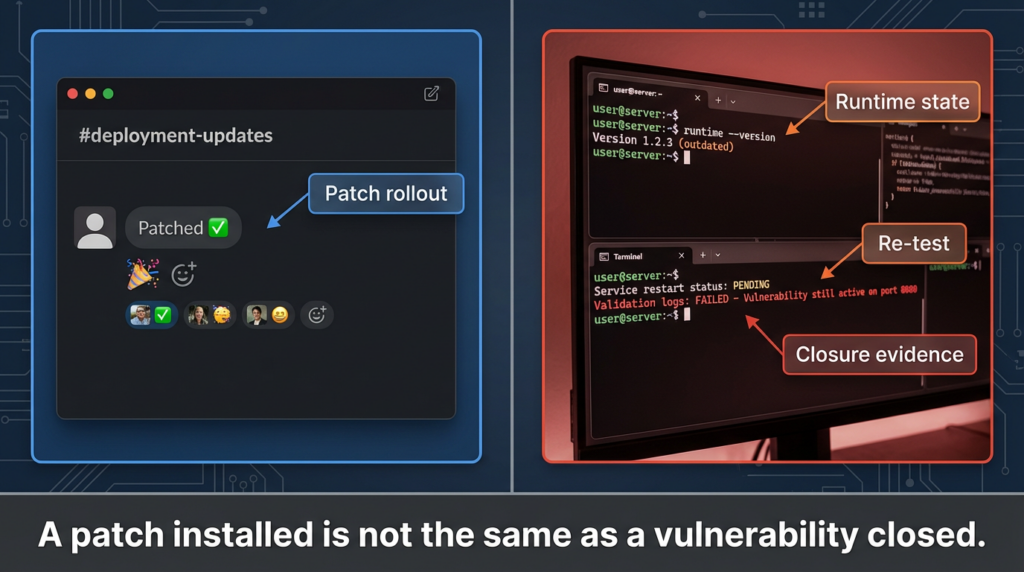
Turning Exploit DB Results into a Triage Table
A lot of teams skip this step and go straight from “PoC found” to “panic” or “ignore.”
A simple triage table dramatically improves consistency.
| フィールド | なぜそれが重要なのか | Example value |
|---|---|---|
| CVE / EDB-ID | Traceability across tools and reports | CVE-2026-2441 / EDB-ID (if present) |
| Asset / Service | Scope and ownership | Chrome on managed endpoints |
| Version match confidence | Reduces false urgency | High / Medium / Low |
| Exploit type | Determines response path | Remote code execution inside sandbox |
| 前提条件 | Affects actual risk | User interaction required |
| Public exploit signal | Triage acceleration | Public PoC / Exploit-DB reference |
| KEV status | Active exploitation prioritization | Yes / No |
| Validation status | Engineering evidence | Verified / Not reproduced / Inconclusive |
| Mitigation path | Actionability | Patch version, policy, compensating controls |
| Evidence link | Auditability | Internal test artifact / ticket / runbook |
This table seems basic, but it solves a recurring problem: vulnerability discussions often mix facts, assumptions, and vendor language without separating them.
Exploit DB helps you populate the exploit-intelligence columns. Your internal validation process fills the rest.
How Exploit DB Relates to KEV and Real-World Risk
Let’s use a current example to illustrate the relationship between public exploit intelligence and prioritization.
The NVD page for CVE-2026-2441 (Chrome CSS use-after-free) documents the vulnerability and notes that it is in CISA’s KEV catalog. It also records key dates including publication and modification timing. (NVD)
Separately, Google’s Chrome release notes for the February 13, 2026 stable desktop update state the fixed versions and explicitly note that Google is aware of an exploit for CVE-2026-2441 in the wild. (Chrome Releases)
That combination of signals is far more actionable than any single source:
- Vendor release note confirms fix versions and in-the-wild exploitation awareness
- NVD normalizes description and references
- KEV elevates operational urgency for defenders
- Exploit DB / public PoCs (if/when present) help validation and education
This is how modern vuln operations should work. Exploit DB is one component in a larger evidence chain.
Common Mistakes When Using Exploit DB
Mistake 1: Treating PoC presence as guaranteed exploitability
Public PoC code can fail for many legitimate reasons:
- Wrong version
- Different build flags
- Patched but still fingerprinted as vulnerable
- Missing configuration assumptions
- Changed offsets/paths/protocol behavior
- Different OS/runtime/library versions
Mistake 2: Ignoring exploit conditions
A “remote code execution” label is not enough. You need to know:
- Does it require authentication?
- Does it require user interaction?
- Is it sandboxed?
- Is additional chaining needed?
- Is the impact limited by deployment architecture?
Mistake 3: Running code before reading it
This is both a security and operational issue. Always inspect source first. SearchSploit’s -x そして -m flow exists for a reason. (Kali Linux)
Mistake 4: Using only website search
Website search is fine for ad hoc browsing. But if you are building repeatable workflows, local and structured searching via SearchSploit is usually better.
Mistake 5: Failing to preserve evidence
Even successful validation can become useless if you cannot answer:
- What exact version was tested?
- Which exploit variant?
- What output/logs prove the result?
- Was the test destructive?
- What changed afterward?
Exploit DB for Defenders, Not Just Pentesters
One reason “exploit db” remains such a durable keyword is that its audience is broader than many people assume.
Vulnerability management teams
Exploit DB helps answer whether a scanner finding is likely to have practical exploit paths worth prioritizing.
Incident responders
When an incident hits a product family with known public exploit material, Exploit DB can accelerate scoping hypotheses and log review priorities.
Detection engineers
Public exploit techniques can inform detection content, especially around protocol misuse, payload patterns, or post-exploitation behavior. The goal is not to copy signatures blindly, but to understand attacker workflow.
Security architecture and engineering
Exploit proofs often reveal architectural trust assumptions that patch notes hide. This can lead to more durable mitigations such as segmentation, hardening, or policy changes.
Penligent publicly positions itself as an AI-powered penetration testing platform focused on automated detection, verification, and exploit execution workflows, including CVE-oriented testing and report generation. Public pages also emphasize support for a large set of tools and “one-click” reporting concepts, which maps naturally to the operational gap between finding a PoC and producing decision-grade validation evidence. (ペンリジェント・アイ)
In practical terms, the bridge is this:
- Exploit DB/SearchSploit helps you find public exploit intelligence
- A validation platform helps you test safely, capture evidence, and standardize reporting
- A good workflow keeps humans in the loop for scope, authorization, and interpretation
That framing avoids hype and matches what real teams actually need.
A second, more specific connection is content strategy and practitioner trust. Penligent’s public “HackingLabs” and technical writeups show a pattern of CVE deep dives aimed at security engineers, which is exactly the audience searching “exploit db” when they want more than a superficial definition. If your article links into those deeper analyses where relevant, it can improve both user experience and on-site topical authority—provided the links are genuinely related to exploit validation, PoCs, and attacker methodology. (ペンリジェント・アイ)
A Defensive Automation Pattern Using Exploit DB Signals
If your readers are AI/security engineers, they usually want something implementable. Here is a safe, non-weaponizing pattern for automating exploit intelligence triage.
# exploit_intel_triage.py
# Defensive triage pattern (no exploit execution)
# Purpose: normalize vulnerability records and enrich with public exploit signals
from dataclasses import dataclass, asdict
from typing import Optional, List
import json
from datetime import datetime
@dataclass
class VulnRecord:
asset: str
product: str
version: str
cve: str
internet_exposed: bool
owner_team: str
@dataclass
class ExploitIntel:
cve: str
searchsploit_hits: int = 0
edb_ids: Optional[List[str]] = None
kev_status: Optional[bool] = None
vendor_fix_available: Optional[bool] = None
notes: str = ""
@dataclass
class TriageDecision:
cve: str
priority: str
validation_required: bool
rationale: str
timestamp: str
def prioritize(v: VulnRecord, intel: ExploitIntel) -> TriageDecision:
score = 0
reasons = []
if v.internet_exposed:
score += 3
reasons.append("internet-exposed asset")
if intel.kev_status:
score += 4
reasons.append("KEV-listed / active exploitation signal")
if intel.searchsploit_hits > 0:
score += 2
reasons.append("public exploit intelligence present")
if intel.vendor_fix_available:
score += 1
reasons.append("patch path exists (fast remediation possible)")
# Simple illustrative policy
if score >= 7:
pr = "P1"
validate = True
elif score >= 4:
pr = "P2"
validate = True
else:
pr = "P3"
validate = False
return TriageDecision(
cve=v.cve,
priority=pr,
validation_required=validate,
rationale="; ".join(reasons) if reasons else "low signal density",
timestamp=datetime.utcnow().isoformat() + "Z"
)
if __name__ == "__main__":
vuln = VulnRecord(
asset="endpoint-fleet",
product="Google Chrome",
version="145.0.7632.60",
cve="CVE-2026-2441",
internet_exposed=False,
owner_team="IT Endpoint Engineering"
)
intel = ExploitIntel(
cve="CVE-2026-2441",
searchsploit_hits=0, # placeholder: populate from internal parser
edb_ids=[],
kev_status=True,
vendor_fix_available=True,
notes="Use vendor release notes + NVD/KEV references for final triage."
)
decision = prioritize(vuln, intel)
print(json.dumps({
"vuln": asdict(vuln),
"intel": asdict(intel),
"decision": asdict(decision)
}, indent=2))
This script intentionally does ない execute exploits. It shows how to turn public exploit intelligence into triage signals that can be routed into patching, validation, or exception review.
That is the level where many teams still have the biggest maturity gap.
Exploit DB and Compliance Conversations
Compliance teams sometimes struggle with exploit intelligence because it feels “offensive.” But exploit-aware validation actually strengthens governance if handled correctly.
A mature compliance/security conversation sounds like this:
- We identified a vulnerability on a scoped asset.
- We checked public exploit availability and active exploitation signals.
- We validated exploitability in a controlled environment.
- We documented conditions and compensating controls.
- We prioritized remediation based on evidence and exposure.
That is much stronger than checkbox patching or generic scanner exports.
If your organization has to defend prioritization decisions to auditors, customers, or regulators, evidence-backed exploitability analysis is often easier to defend than raw CVSS sorting alone.
The Future of Public Exploit Intelligence
Exploit DB remains important, but the ecosystem is broadening.
Security teams increasingly use multiple exploit-intelligence sources, including vendor advisories, CISA KEV, threat intel feeds, curated exploit datasets, and public code repositories. The key challenge is no longer access to exploit-related information. It is signal quality and validation discipline.
Exploit DB’s enduring advantage is its role as a recognizable, practitioner-friendly public archive with a strong CLI workflow through SearchSploit. The official repository and Kali tooling documentation make that operational integration unusually clear. (ギットハブ)
For defenders, the winning strategy in 2026 is not “use Exploit DB more” or “use Exploit DB less.” It is:
- use it intentionally
- pair it with KEV and vendor guidance
- validate in controlled environments
- produce 証拠, not assumptions
- automate the boring parts, not the judgment
That is how you turn an old favorite keyword into a modern security engineering workflow.
最終的な収穫
If someone searches exploit db, they usually do not need another short definition.
They need help answering one of these harder questions:
- Is this vulnerability actually exploitable in my environment?
- How do I safely validate a public PoC claim?
- How do I move from CVE noise to prioritized action?
- How do I automate exploit intelligence without automating recklessness?
Exploit DB is still one of the best starting points for those questions. Just don’t stop there.
Use it as a bridge from vulnerability names to technical reality, then complete the job with version verification, KEV/vendor context, safe reproduction, and evidence-backed remediation.
That is what mature teams do. And it is exactly what technical readers expect from a publishable article in 2026.
External Reading
- Exploit Database official repository (offsoc/exploitdb)
- Kali Linux exploitdb package and SearchSploit documentation
- NVD CVE-2026-2441 entry
- CISA KEV data repository (machine-readable catalog mirror)
- Chrome Releases stable desktop update (Feb 13, 2026) mentioning CVE-2026-2441
- Penligent home page
- Overview of Penligent.ai’s Automated Penetration Testing Tool
- CVE-2026-25253 OpenClaw Bug Enables One-Click Remote Code Execution via Malicious Link
- RAGキラーの解剖:CVE-2025-66516とApache Tika RCEのディープ・ダイブ
- テクニカル・ディープ・ダイブAIセキュリティエンジニアのためのCVE-2026-21440のエクスプロイト分析

