DeepClaude is interesting because it exposes a split that enterprise buyers have been moving toward for a while: the agent experience and the model backend no longer have to be the same product.
The public DeepClaude repository describes a simple but important idea. It keeps Claude Code’s terminal-based agent loop, file reading, file editing, bash execution, git operations, subagent behavior, and multi-step workflow, while routing model calls to DeepSeek V4 Pro, OpenRouter, or another Anthropic-compatible backend. The repository calls this “swapping the brain while keeping the body.” That phrasing is informal, but the architecture signal is real. The tool loop is becoming a durable interface. The model is becoming a replaceable backend. (ギットハブ)
DeepSeek’s own documentation points in the same direction. Its coding-agent integration guide shows how developers can configure Claude Code to use DeepSeek’s Anthropic-format API by setting environment variables such as anthropic_base_url, ANTHROPIC_AUTH_TOKEN, ANTHROPIC_MODEL, and separate defaults for Opus, Sonnet, Haiku, and subagent calls. The same page also documents integrations with OpenCode and OpenClaw. (DeepSeek API Docs)
That is the bigger story. Enterprises are not just looking for cheaper tokens. They are looking for control over the agent control plane.
A mature AI agent is not only a chat box with a better model behind it. It is a system that holds state, calls tools, reads files, writes files, invokes APIs, runs commands, summarizes outputs, retries failed steps, saves evidence, escalates risky actions, and records what happened. In that system, the model is only one component. The harness, the policy layer, the sandbox, the model router, the credential boundary, and the audit trail are just as important.
For consumer tools, convenience usually wins. For enterprise AI agents, control wins.
DeepClaude exposed the split
The old mental model for AI tools was simple: one product, one model provider, one account, one billing relationship, one data path. That model works well enough when the tool is mostly answering questions. It starts to break down when the tool becomes an operator.
A coding agent can open files, inspect source code, run tests, write patches, call package managers, use git, and execute scripts. A security agent can scan targets, read HTTP traffic, analyze authentication flows, triage vulnerabilities, validate CVEs, and produce reports. A cloud operations agent can query logs, restart services, inspect IAM policies, open tickets, and change infrastructure. Once the agent can act, the buyer is no longer evaluating only language-model quality. The buyer is evaluating a controlled execution system.
DeepClaude matters because it separates the experience of a strong agent harness from the economics and governance of a specific model backend. The user still interacts with a familiar coding-agent loop. The model endpoint changes.
That separation is more than a hack. It reflects a general enterprise pattern:
| レイヤー | What it owns | なぜそれが重要なのか |
|---|---|---|
| Agent harness | The loop, context, tools, state, memory, and session flow | This is the durable user and workflow experience |
| Model backend | Reasoning and generation | This can change by task, cost, jurisdiction, or sensitivity |
| Policy layer | Scope, approvals, tool rules, network rules, file rules | This keeps agent action inside enterprise boundaries |
| Sandbox | Where generated code and commands run | This limits blast radius when outputs are wrong or malicious |
| Credential boundary | Secrets, tokens, vault access, short-lived credentials | This prevents prompt injection from becoming credential theft |
| Audit layer | Event logs, tool calls, prompts, outputs, evidence, reports | This makes the system reviewable and defensible |
In a closed agent product, these layers are often fused together. That can make the first demo feel smooth. It can also make enterprise approval harder because the buyer cannot easily answer basic questions: which model saw this data, where did the prompt go, which tool ran, which credentials were exposed, which network destinations were reachable, and whether the same workflow can run in a private environment.
Swappable backends make those questions explicit. They do not solve every problem by themselves, but they make the architecture discussable.
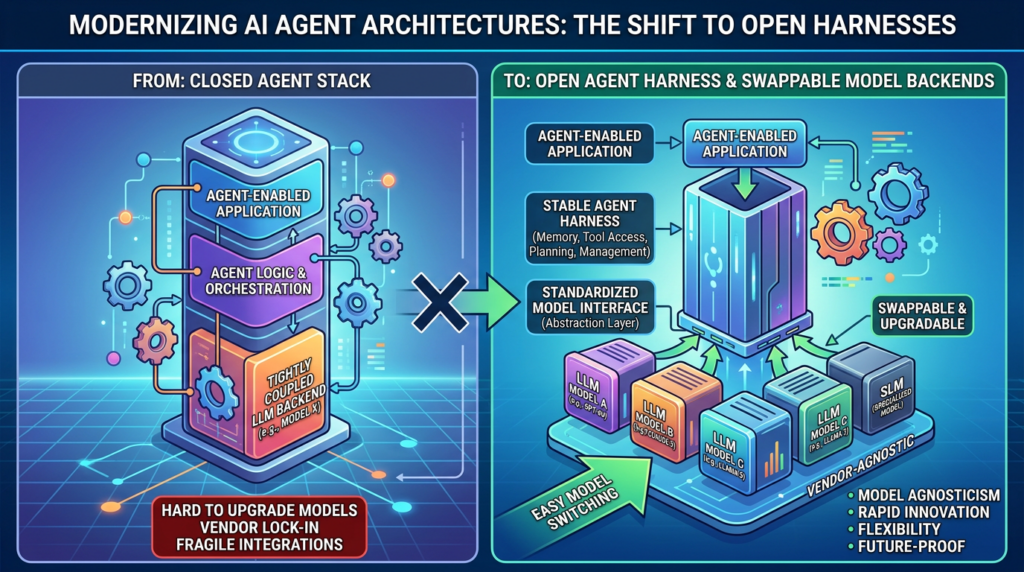
The agent harness is becoming the durable layer
Anthropic’s own engineering writing on managed agents describes a similar decomposition. The company says it virtualized three components of an agent: the session, described as an append-only log of what happened; the harness, described as the loop that calls Claude and routes tool calls; and the sandbox, described as an execution environment where code can run and files can be edited. Anthropic’s stated design goal was to let each component be swapped without disturbing the others. (anthropic.com)
That is a useful way to think about enterprise AI systems. The session is not just a transcript. It is the operational record. The harness is not just a wrapper around an API call. It is the scheduler, router, policy enforcement point, and recovery loop. The sandbox is not just a convenience. It is where untrusted or semi-trusted action happens.
Anthropic also describes why placing the session, harness, and sandbox in one container created reliability and security problems. A coupled container made failures harder to debug, made sessions fragile, and created awkward assumptions about where customer infrastructure lived. The fix was to decouple the “brain” and harness from the “hands” that execute actions. (anthropic.com)
That lesson applies beyond Claude. The enterprise architecture question is not “Can the model call tools?” The better question is “Can the system control tool use across time, teams, failures, credentials, environments, and audit requirements?”
An enterprise harness usually needs at least eight capabilities.
First, it needs durable session state. Agent loops can run for minutes or hours. They can hit rate limits, failed commands, tool timeouts, and user interruptions. If the harness crashes, the session should be recoverable from an event log, not lost inside process memory.
Second, it needs context governance. A long-running agent cannot keep every event in the model context forever. The harness must decide what to summarize, what to retrieve, what to hide, what to preserve as evidence, and what never enters a model prompt at all.
Third, it needs tool mediation. A model should not get direct, unstructured access to the entire machine. Tool calls need schemas, permissions, validation, input rewriting, and post-execution checks.
Fourth, it needs policy enforcement outside the model. A model can be instructed to stay in scope, but the enforcement point should not be a sentence in a system prompt. Scope should be machine-readable and enforced before network calls, file reads, shell commands, scans, or API calls happen.
Fifth, it needs sandbox orchestration. Generated code, shell commands, browser automation, and scanner execution should happen inside controlled environments with limited files, limited network, and disposable state.
Sixth, it needs credential separation. The model should not read raw secrets. Generated code should not inherit broad environment variables. Tokens should be scoped, short-lived, and mediated through proxies or vaults.
Seventh, it needs model routing. Different tasks deserve different models. A low-risk summarization step should not necessarily burn the same expensive model used for a high-stakes vulnerability determination.
Eighth, it needs complete auditability. Enterprise users need to reconstruct who asked what, which model was called, which tool ran, what output was returned, which evidence was saved, and which human approved the next step.
When these capabilities live in the harness and surrounding control plane, the model backend can be swapped more safely. When they live implicitly inside a closed vendor workflow, the enterprise buyer inherits the vendor’s assumptions.
Closed agent products break down at the security boundary
A closed AI agent can be excellent for individuals. It can also be hard to approve inside security-sensitive organizations.
The problem is not that closed systems are always unsafe. Many closed systems are well engineered. The problem is that enterprise security teams need answers that are often difficult to get from black-box products. They need to know where sensitive data goes, whether logs are retained, which subprocesses run, how tools are restricted, whether the model provider can be changed, whether prompts are stored, whether outputs are used for training, whether the system can run in a private network, and whether every action can be audited.
The more powerful the agent, the sharper those questions become.
A passive chatbot may see a sanitized error message. A coding agent may see proprietary source code, 環境 references, internal package names, API schemas, commit history, and incident notes. A security agent may see target domains, private subdomains, HTTP requests, response bodies, cookies, test accounts, scanning output, exploit hypotheses, screenshots, and evidence for unresolved vulnerabilities. An operations agent may see logs, cloud resource names, IAM policies, deployment scripts, and production runbooks.
That is why “we use a strong model” is not enough for enterprise trust. The stronger the model becomes, the more valuable it is to attach it to real tools. The moment real tools appear, the security boundary expands.
OWASP’s LLM Top 10 captures several of the risks that become worse in tool-using systems: prompt injection, insecure output handling, supply chain vulnerabilities, sensitive information disclosure, insecure plugin design, and excessive agency. OWASP describes excessive agency as unchecked autonomy that can jeopardize reliability, privacy, and trust. It also warns that insecure plugin design can create severe outcomes such as remote code execution when tools process untrusted inputs with insufficient access control. (owasp.org)
Those are not abstract concerns. They are the everyday design problems of AI agents.
A closed product can hide these problems behind a clean UI. An enterprise system has to expose them as controllable architecture.
BYOK is useful but incomplete
Bring Your Own Key is a good step. It lets the customer choose a model provider, manage its own billing relationship, apply enterprise terms with the model vendor, and sometimes route usage through an existing cloud account. It can also make experimentation faster because teams can test different providers without waiting for the agent vendor to renegotiate everything.
But BYOK does not automatically mean local control.
If an agent sends proprietary source code, vulnerability evidence, target data, HTTP traces, prompt history, or internal documentation to a third-party model API, the data still leaves the enterprise boundary. The fact that the API key belongs to the customer changes billing and contractual control. It does not by itself solve data residency, internal network isolation, offline use, or sensitive workload restrictions.
That distinction matters most in security work. A normal coding assistant may touch confidential code. An AI pentesting agent may touch information that is more sensitive than the code itself: live target behavior, exploitable configurations, authentication artifacts, proof of impact, request histories, and remediation timelines. Even if the model provider has strong privacy terms, the enterprise may still have policies that restrict this data from leaving a VPC, a region, a classified network, or a regulated environment.
A useful maturity path looks like this:
| Deployment mode | What it solves | What remains unresolved |
|---|---|---|
| Vendor SaaS | Fast onboarding, managed infrastructure, simple updates | Data egress, fixed trust assumptions, limited private-network access |
| BYOK SaaS | Customer-owned model billing and provider choice | Sensitive prompts and outputs may still leave the environment |
| Private cloud or VPC | Better network control and regional isolation | Still depends on external model endpoints unless paired with private inference |
| On-prem deployment | Stronger data locality and integration with internal systems | Requires enterprise operations, patching, monitoring, and capacity planning |
| Air-gapped local agent | Maximum isolation for sensitive labs | Hardest to update, benchmark, patch, and scale |
BYOK gives enterprises model choice. Local deployment gives them operational control.
Neither one is a silver bullet. The mature design often combines them. A team may run local models for sensitive data handling, route low-risk public tasks to cheaper external models, use a high-end frontier model for narrow reasoning steps, and keep the harness, policy layer, evidence store, and audit trail inside its own environment.
That is the architecture enterprises are moving toward: not one model, but a governed model portfolio.
Local deployment changes the enterprise risk model
Local deployment is often discussed as a privacy feature. That is true, but incomplete. Its deeper value is that it changes who controls the operational boundary.
In a local or private deployment, the enterprise can decide which files the agent can read, which hosts it can reach, which credentials it can use, which logs are retained, which users can approve risky actions, which models can receive sensitive content, and which evidence becomes part of a report. The enterprise can integrate the agent with existing identity, network, monitoring, and audit systems. The system becomes part of internal infrastructure instead of a remote assistant with partial context.
That matters for regulated industries and security-sensitive work.
A bank may not want unreleased application code, transaction logic, fraud rules, or internal hostnames leaving its network. A healthcare organization may need to prevent patient data from entering external prompts. A government contractor may need to run testing in isolated environments. A critical-infrastructure operator may need strict network segmentation. A security team may want to test pre-production systems that are not reachable from the public internet.
Local deployment also reduces one of the most uncomfortable tradeoffs in enterprise AI adoption: the tradeoff between agent usefulness and data minimization. Agents become more useful when they can see more context. They become riskier when that context leaves the organization. Local deployment lets the enterprise provide richer context while keeping the data path under internal control.
That does not make the system automatically safe. A local agent can still delete files, leak secrets to allowed destinations, run unsafe commands, or be manipulated by indirect prompt injection. The difference is that the enterprise can put the agent inside the same defense-in-depth model it uses for other high-risk internal systems.
Local deployment enables controls such as:
| コントロール | Enterprise value |
|---|---|
| Internal-only model endpoint | Sensitive prompts and outputs stay within controlled infrastructure |
| Network egress allowlist | Agent tools can reach only approved domains, APIs, or target ranges |
| Local evidence store | Vulnerability artifacts remain available for audit and retesting |
| Short-lived credentials | Stolen tokens expire quickly and are scoped to a task |
| Tool-level approvals | Risky actions require human confirmation or change-ticket linkage |
| SIEM integration | Agent actions become security telemetry |
| VPC or subnet placement | Agents can test private assets without public exposure |
| Region-specific deployment | Data residency requirements are easier to satisfy |
| Offline lab mode | Sensitive research can run without external connectivity |
The point is not that every enterprise must run every model on-prem. The point is that enterprise AI agents need deployment choice. Some tasks can run in SaaS. Some can run with BYOK. Some need VPC. Some need local inference. Some need air-gapped labs. A serious agent architecture should support that range instead of forcing all work through one vendor path.
The real threat model is tool access, not chat output
Many AI security discussions still focus on whether a model says something unsafe. That matters, but tool-using agents raise a more practical risk: what can the agent do after it says something?
A model output that suggests a bad command is one class of problem. A model output that becomes a tool call is a different class. The second one touches the operating system, repository, browser, network, API, database, scanner, ticketing system, or cloud account.
Tool access is where agent risk becomes operational.
A coding agent with broad shell access can run package installers, execute test scripts, invoke build tools, modify configuration, and push code. A security agent can run scanners, fuzz endpoints, replay HTTP requests, attempt authentication checks, and generate reports. A cloud agent can query resources, change policies, restart services, or rotate keys. Even if every action is intended to be helpful, the system needs a strict blast-radius model.
OWASP’s prompt injection guidance explains why this is hard. A prompt injection vulnerability occurs when user prompts or external content alter model behavior in unintended ways. OWASP distinguishes direct prompt injection from indirect prompt injection, where an LLM consumes external content such as websites or files that contain hidden or adversarial instructions. OWASP also notes that prompt injection can lead to sensitive information disclosure, unauthorized access to functions available to the LLM, and arbitrary command execution in connected systems. (OWASP Gen AIセキュリティプロジェクト)
Indirect prompt injection is especially relevant to enterprise agents because they constantly read untrusted or semi-trusted content. A coding agent reads README files, issues, dependency scripts, and test output. A security agent reads HTTP responses, JavaScript bundles, web pages, scan results, and exploit documentation. A support agent reads customer tickets and attachments. An operations agent reads logs and runbooks. Any of those inputs can contain instructions aimed at the model.
A safe design does not assume the model will ignore hostile instructions. It assumes the model may be influenced and constrains what the resulting tool calls can do.
A minimal control set looks like this:
| リスク | Weak control | Stronger control |
|---|---|---|
| Agent reads a malicious web page | Tell the model to ignore untrusted instructions | Treat web content as data, enforce tool policy outside the model |
| Agent sees a fake instruction to exfiltrate secrets | Rely on system prompt hierarchy | Deny secret file reads and block unknown network egress |
| Agent proposes a destructive command | Ask user to approve everything | Use deny rules, scoped approvals, and sandbox rollback |
| Agent uses a broad API tool | Trust model reasoning | Replace broad tools with narrow task-specific tools |
| Agent writes insecure code | Review final diff only | Run tests, static analysis, policy checks, and human review |
| Agent validates a vulnerability claim | Trust scanner output | Require reproducible evidence and impact explanation |
The most important design principle is simple: the model can propose, but policy must decide.
Prompt injection becomes a control-plane problem
A system prompt is not a security boundary. It is an instruction to a probabilistic component.
That does not mean system prompts are useless. They are useful for behavior shaping, role definition, tool etiquette, and explanation quality. But when an agent can call real tools, the enforcement layer must sit outside the prompt.
A practical policy layer should inspect tool calls before execution. It should understand the active user, engagement scope, target allowlist, current task, data classification, model backend, approval state, and command risk. It should then allow, deny, ask, rewrite, or route the action.
For example, a security team may want the following rules:
scope:
engagement_id: "web-prod-q2"
allowed_targets:
- "https://app.example.com"
- "https://api.example.com"
denied_targets:
- "https://payments-admin.example.com"
allowed_time_window:
start: "2026-05-05T01:00:00Z"
end: "2026-05-05T05:00:00Z"
files:
deny_read:
- ".env"
- "secrets/**"
- "**/id_rsa"
- "**/credentials.json"
allow_write:
- "artifacts/**"
- "reports/**"
network:
default: "deny"
allow_domains:
- "app.example.com"
- "api.example.com"
- "cve.circl.lu"
- "nvd.nist.gov"
commands:
allow:
- "nmap -sV *"
- "httpx *"
- "nuclei -u *"
ask:
- "sqlmap *"
- "ffuf *"
- "python *"
deny:
- "rm -rf *"
- "curl * | sh"
- "cat **/.env"
- "scp *"
This kind of policy is not enough by itself, but it is better than asking a model to remember the rules. The rules become machine-readable. They can be reviewed. They can be versioned. They can be tied to an engagement. They can be tested. They can be enforced before the action.
For more advanced teams, policy can be expressed in a dedicated engine. A simplified Rego-style policy might look like this:
package agent.policy
default allow := false
default require_approval := false
allowed_target(host) {
host == "app.example.com"
}
allowed_target(host) {
host == "api.example.com"
}
deny_reason[msg] {
input.tool == "Read"
endswith(input.path, ".env")
msg := "Reading .env files is blocked for this engagement"
}
deny_reason[msg] {
input.tool == "Bash"
contains(input.command, "curl")
contains(input.command, "| sh")
msg := "Piping remote scripts into a shell is blocked"
}
require_approval {
input.tool == "Bash"
startswith(input.command, "sqlmap")
}
allow {
input.tool == "HttpRequest"
allowed_target(input.host)
}
allow {
input.tool == "Bash"
startswith(input.command, "nmap -sV")
input.approval_state == "approved"
}
The important feature is not the specific syntax. The important feature is that the model is no longer the only thing deciding what happens. The model can generate intent. The policy layer controls execution.
That is the enterprise difference between a clever agent demo and an approved system.
Secrets belong behind proxies, not prompts
Secrets are where weak agent architecture becomes dangerous.
A naive design puts secrets in environment variables, gives the agent shell access, and hopes the model will not read or leak them. That design is fragile. If the model can run arbitrary commands in the same environment where secrets live, then a prompt injection only needs to steer it toward reading the environment, opening a credential file, or making an outbound request.
Vercel’s writing on agentic security boundaries frames the issue clearly. It separates four actors: the agent, the agent’s secrets, generated code execution, and the filesystem or broader environment. Vercel argues that the question is whether these actors live in one trust domain or whether security boundaries are drawn between them. It warns that when there are no boundaries, an agent on a developer laptop can read 環境 files and SSH keys, while generated code can steal secrets, delete data, and reach whatever services the environment can reach. (Vercel)
Anthropic makes a similar point in its managed-agents architecture. In the coupled design, untrusted code generated by Claude ran in the same container as credentials. Anthropic describes the structural fix as ensuring that tokens are never reachable from the sandbox where generated code runs. It describes patterns such as using repository access tokens during sandbox initialization, storing OAuth tokens in a secure vault, and routing MCP calls through a proxy so the harness is not made aware of credentials. (anthropic.com)
Vercel’s recommended stronger pattern combines sandboxing with secret injection. In that model, the harness runs as trusted software on standard compute, generated code runs in an isolated sandbox, and secrets are injected at the network level instead of being exposed where generated code can read or exfiltrate them. (Vercel)
The enterprise pattern is clear:
| Secret handling pattern | リスク | Better use |
|---|---|---|
| Put secrets in the prompt | High risk of disclosure through model output or logs | 避ける |
| Put broad secrets in environment variables | Generated code or shell tools may read them | Avoid for agent sandboxes |
| Let agent fetch secrets directly from vault | Better audit, but still risky if the agent can request too much | Use only with narrow policies |
| Use short-lived task credentials | Limits lifetime and scope of compromise | Good default |
| Use network-level credential proxy | Lets tools act without reading raw secrets | Stronger for production |
| Use per-tool scoped credentials | Prevents broad lateral use | Strongest when feasible |
A security agent may need authenticated access to a test application. A coding agent may need to pull from a private repository. A cloud agent may need read-only access to resource inventory. Those needs are legitimate. The question is not whether the agent needs capability. The question is whether capability is represented as raw secrets the model can read or as controlled actions mediated by infrastructure.
Local deployment helps because the enterprise can run the vault, proxy, network controls, and audit logs inside its own environment. But the design still matters. A local deployment with broad environment variables and unrestricted shell access is not safer than a cloud deployment with proper isolation. “Local” is a placement decision. “Safe” is an architecture decision.
Model routing is the enterprise pattern
A swappable backend is the starting point. A model router is the enterprise version.
Not every task deserves the same model. Agent systems generate many different kinds of work: planning, classification, summarization, code modification, vulnerability reasoning, report writing, tool-output compression, log analysis, data extraction, test generation, and human-facing explanation. Some of these tasks require high reasoning quality. Some require low latency. Some require strict privacy. Some require low cost. Some require long context. Some require tool-call reliability. Some require a model that can run fully offline.
Routing all tasks to one model is simple. It is rarely optimal.
DeepSeek’s current pricing page is useful because it shows why agent economics are changing. As of the cited documentation, DeepSeek V4 Flash and V4 Pro support a 1M context length, JSON output, tool calls, and Anthropic-format access. The page lists per-1M-token pricing and notes discounted pricing for V4 Pro through May 31, 2026, as well as a reduction in cache-hit input prices. It also warns that product prices may vary and recommends checking the page for current pricing. (DeepSeek API Docs)
The exact numbers will change over time. The architectural lesson will not. Agent systems are token multipliers. A single user request can trigger multiple model calls, tool calls, summarization steps, retries, subagents, report generation, and verification loops. If every step uses the highest-cost model, the system becomes expensive and unpredictable. If every step uses the cheapest model, the system may become unreliable at the moments that matter.
A sane enterprise router can classify work by sensitivity and difficulty:
model_routing:
defaults:
low_risk:
backend: "local-qwen-or-deepseek-distill"
reason: "No sensitive external data and low reasoning risk"
medium_risk:
backend: "byok-cloud-model"
reason: "Moderate reasoning need with customer-owned API key"
high_risk:
backend: "frontier-model-with-human-review"
reason: "Security-critical or business-impacting judgment"
rules:
- task_type: "scan_output_summarization"
sensitivity: "internal"
backend: "local-model"
max_tokens: 4000
- task_type: "http_trace_classification"
sensitivity: "confidential"
backend: "local-model"
redact_before_model: true
- task_type: "business_logic_vulnerability_analysis"
sensitivity: "restricted"
backend: "frontier-model"
require_human_review: true
- task_type: "report_draft"
sensitivity: "confidential"
backend: "byok-cloud-model"
redact:
- "cookies"
- "authorization_headers"
- "customer_pii"
- task_type: "exploit_validation_decision"
sensitivity: "restricted"
backend: "frontier-model"
require_evidence: true
require_human_approval: true
A router should consider at least six variables.
First, data sensitivity. Public documentation can go to more providers than private source code, authentication traces, or unresolved vulnerability evidence.
Second, task difficulty. Formatting, clustering, and summarization can often use cheaper models. Multi-step reasoning, ambiguous exploitability analysis, and business logic review may require stronger models.
Third, tool-call reliability. Some models handle tool schemas, JSON, and structured outputs better than others. A cheap model that frequently produces malformed calls can cost more through retries.
Fourth, latency. Local inference may be faster for small models and predictable workloads. Cloud frontier models may be slower or rate-limited during peak usage.
Fifth, cost and budget. Agent loops need per-task budgets, not just per-user quotas. A runaway tool loop can become a billing incident.
Sixth, jurisdiction and contractual constraints. Some workloads may be restricted to specific regions, cloud providers, or internal infrastructure.
This is why the future is not one model. It is a controlled portfolio.
Cost control is not just cheaper tokens
DeepClaude became popular partly because it made the cost difference visible. The project’s README presents DeepSeek and other backends as lower-cost alternatives while preserving the Claude Code workflow. The exact savings depend on pricing, workload, model choice, caching, and usage pattern, so enterprise teams should not treat any repository estimate as a procurement calculation. But the direction is clear: agent cost is no longer a fixed property of the UI. It can be routed, measured, and optimized. (ギットハブ)
The mistake is to reduce the issue to “use a cheaper model.” Agent cost has several drivers:
| Cost driver | なぜそれが重要なのか | コントロール |
|---|---|---|
| System prompt size | Agent prompts, tool definitions, policies, and memory can be large | Compress tools, lazy-load skills, cache stable context |
| Tool output size | Scanners, logs, tests, and traces can produce huge output | Summarize locally, store raw output outside model context |
| Retry loops | Failed tool calls and malformed outputs multiply cost | Validate schemas before execution, cap retries |
| サブエージェント | Parallel agents can multiply calls quickly | Assign budgets per subagent |
| Long context | Large codebases and HTTP traces can create expensive prompts | Retrieve narrow slices, use evidence pointers |
| レポート作成 | Final reports can be long and repetitive | Use templates and structured evidence |
| Human approval delays | Long sessions may require state persistence | Store durable session logs outside context windows |
A practical agent budget should live next to the policy layer. It should limit calls by engagement, user, task, model, and risk class. It should fail closed when the cost ceiling is reached, not quietly continue.
An example budget policy might look like this:
{
"engagement_id": "web-prod-q2",
"budget": {
"total_usd": 150.00,
"per_task_usd": 12.00,
"per_model_call_usd": 1.50,
"max_retries_per_tool": 2,
"max_subagents": 3
},
"routing_overrides": {
"summarization": "local-model",
"asset_clustering": "local-model",
"final_security_judgment": "frontier-model"
},
"on_budget_exceeded": {
"action": "pause",
"notify": ["security-lead@example.com"],
"preserve_session": true
}
}
Cost controls also improve safety. A model denial-of-service condition is not always an external attack. Sometimes it is a poorly bounded agent loop that keeps reading large files, summarizing the same scan output, or spawning subagents without a stopping condition. OWASP includes model denial of service in its LLM risk taxonomy, warning that resource-heavy operations can cause service disruptions and increased costs. (owasp.org)
The enterprise answer is not only procurement negotiation. It is engineering.
A practical deployment pattern for local enterprise AI agents
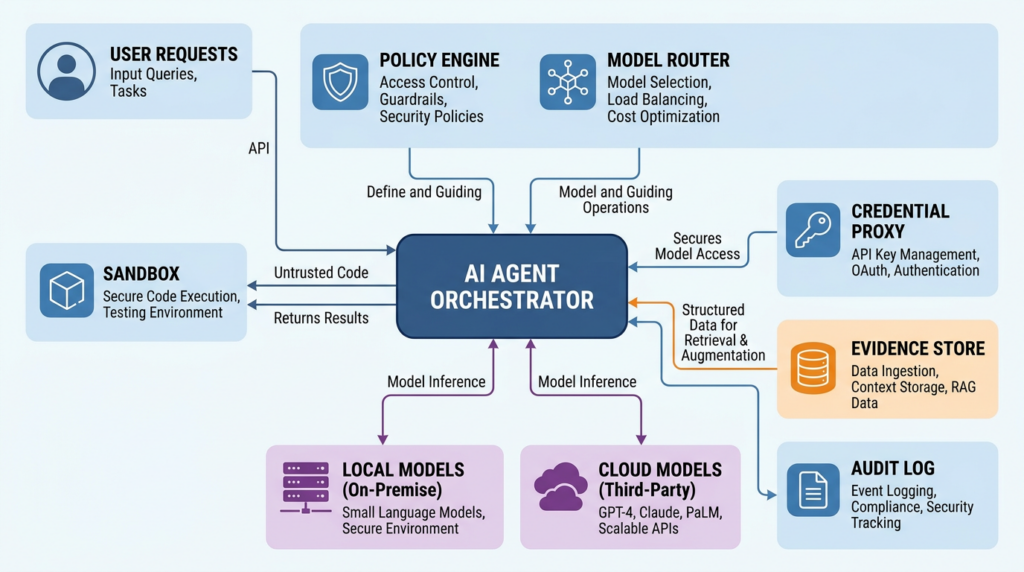
A serious local or private AI agent deployment should look less like a chatbot installation and more like a controlled workload platform.
One reasonable architecture has ten components:
| コンポーネント | 責任 | Security requirement |
|---|---|---|
| User interface | CLI, web UI, IDE, or ticket workflow | Strong identity and role-aware permissions |
| Agent orchestrator | Runs the agent loop and coordinates state | Durable sessions and failure recovery |
| Policy engine | Enforces scope, tool, file, network, and approval rules | Runs outside the model |
| Model router | Chooses local, BYOK, or cloud model per task | Sensitivity-aware routing |
| Local model endpoint | Handles private or low-cost inference | Isolated runtime and monitored capacity |
| Cloud model gateway | Calls external providers when allowed | Redaction, logging, and contract controls |
| Tool sandbox | Runs commands, scans, generated code, and tests | Ephemeral, least privilege, constrained egress |
| Credential proxy | Mediates access to secrets and APIs | No raw secrets in model context |
| Evidence store | Saves raw outputs, traces, screenshots, and artifacts | Tamper-resistant and access-controlled |
| Report layer | Produces findings and retest material | Separates hypothesis from verified evidence |
A simplified deployment flow looks like this:
User or workflow
-> Agent orchestrator
-> Policy engine
-> Model router
-> Local model endpoint
-> BYOK cloud model gateway
-> Approved frontier model
-> Tool sandbox
-> Scoped network
-> Credential proxy
-> Evidence store
-> Audit log
-> Report output
The sandbox deserves special attention. For security teams, it is tempting to give the agent a full Kali environment with broad network access, mounted home directories, browser cookies, SSH keys, and cloud credentials. That is convenient. It is also dangerous.
A safer first pattern is to make the sandbox disposable, narrow, and boring.
docker run --rm -it \
--name agent-tool-sandbox \
--network bridge \
--read-only \
--tmpfs /tmp \
--tmpfs /var/tmp \
-v "$PWD/artifacts:/artifacts:rw" \
-v "$PWD/wordlists:/wordlists:ro" \
--cap-drop ALL \
--security-opt no-new-privileges \
kalilinux/kali-rolling /bin/bash
This is not a complete production sandbox. Docker alone is not a perfect security boundary, and many real deployments should use stronger isolation such as VMs, microVMs, hardened Kubernetes nodes, or managed sandbox products. But the pattern is useful: do not mount the user’s home directory, do not mount SSH keys, do not mount cloud credentials, do not give unnecessary Linux capabilities, do not give broad persistent write access, and save evidence to a controlled artifact directory.
For Kubernetes-style environments, network policy should be explicit:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: agent-sandbox-egress
namespace: ai-agent-lab
spec:
podSelector:
matchLabels:
app: agent-sandbox
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchLabels:
name: credential-proxy
ports:
- protocol: TCP
port: 8443
- to:
- namespaceSelector:
matchLabels:
name: evidence-store
ports:
- protocol: TCP
port: 443
Most production policies will need DNS, package mirrors, approved target ranges, and internal APIs. The point is that default-open egress is the wrong default for tool-using agents. If a prompt injection convinces an agent to exfiltrate a secret, network policy should still block the destination.
The audit log should also be structured. A plain chat transcript is not enough.
{
"event_type": "tool_call",
"event_id": "evt_01HX",
"timestamp": "2026-05-05T03:14:12Z",
"user": "analyst@example.com",
"engagement_id": "web-prod-q2",
"model_backend": "local-model",
"tool": "HttpRequest",
"tool_input_hash": "sha256:...",
"target": "https://api.example.com/v1/profile",
"policy_decision": "allow",
"approval_id": null,
"sandbox_id": "sandbox-8842",
"evidence_refs": [
"s3://internal-evidence/web-prod-q2/evt_01HX-response.txt"
],
"redactions_applied": [
"authorization_header",
"session_cookie"
]
}
This type of record allows a team to answer the questions that matter after the fact. Which model saw the data? Which tool ran? Was the action in scope? Which policy allowed it? Was a human approval required? Where is the evidence? Were secrets redacted?
That is what enterprise adoption requires.
Security testing and CVE validation need evidence
AI agents are especially attractive in security testing because security work contains a lot of repetitive analysis. A model can summarize scan output, cluster endpoints, explain stack traces, generate test hypotheses, produce report drafts, and help compare observed behavior against known vulnerability patterns.
But security testing is also where agent output can become misleading fastest. A scanner finding is not proof. A version match is not proof. A model explanation is not proof. A screenshot without reproduction steps is not proof. A CVE reference without environmental validation is not proof.
NIST SP 800-115 is old, but its core framing is still useful. The publication exists to help organizations plan and conduct technical information security tests, analyze findings, and develop mitigation strategies. It emphasizes practical recommendations for testing and assessment processes, including benefits and limitations of specific techniques. (NISTコンピュータセキュリティリソースセンター)
That discipline matters more, not less, when AI is in the loop.
A good AI-assisted CVE validation workflow should ask:
| Question | なぜそれが重要なのか |
|---|---|
| Is the affected component actually present | Version banners and dependency names can be misleading |
| Is the vulnerable code path reachable | Many CVEs require a specific feature, parser, endpoint, or configuration |
| Is the vulnerable version deployed in the tested environment | Repositories and production deployments often differ |
| Is authentication required | Exploitability changes when access is restricted |
| Is a mitigation already applied | WAF rules, feature flags, backports, and config changes matter |
| Is there safe proof | Security teams need evidence without damaging systems |
| Is the result reproducible | Reports must support retesting and remediation |
| Is the business impact clear | Technical possibility is not the same as operational risk |
CVE-2024-3094, the xz Utils backdoor, is a useful case for this article because it shows why software supply-chain trust matters for agent tooling. NVD describes malicious code discovered in upstream xz tarballs starting with versions 5.6.0 and 5.6.1. The build process extracted a prebuilt object file from a disguised test file and modified liblzma, allowing software linked against the library to have interactions intercepted or modified. NVD lists the CVSS v3.1 base score from Red Hat as 10.0 critical. (NVD)
The relevance is not that every AI agent is vulnerable to xz. The relevance is that tool-using agents depend on local toolchains, package managers, plugins, MCP servers, wrappers, scanners, and install scripts. A local deployment reduces data egress, but it does not remove supply-chain risk. If an enterprise gives an agent a compromised tool, the fact that the model is local will not save the environment.
A safer agent testing workflow should therefore include dependency review and environment pinning.
# Example baseline checks for an agent tool image
cat /etc/os-release
dpkg -l | grep -E 'xz-utils|liblzma|openssh'
python -m pip freeze --all > artifacts/pip-freeze.txt
npm ls --all --json > artifacts/npm-tree.json 2>/dev/null || true
sha256sum /usr/local/bin/* > artifacts/local-bin-sha256.txt 2>/dev/null || true
For containers, teams should pin images by digest rather than mutable tags when possible:
tool_sandbox:
image: "registry.example.com/security/agent-tools@sha256:4e3b..."
update_policy: "manual-review"
sbom_required: true
vulnerability_scan_required: true
allowed_package_sources:
- "https://mirror.example.com/debian"
- "https://pypi.internal.example.com"
This may sound heavy, but it is normal security engineering. The agent is not exempt from the same supply-chain scrutiny as CI/CD, endpoint tooling, EDR, or scanners. In some ways, it deserves more scrutiny because it can combine reasoning, tool execution, and access to sensitive context.
AI pentesting is the sharpest test of agent architecture
AI pentesting is one of the hardest places to fake maturity because the workflow forces the system to handle scope, tools, evidence, risk, and reporting together.
A general chatbot can explain SQL injection. A command generator can suggest an ナマップ command. A scanner can produce a list of possible issues. A real pentest workflow needs more. It needs authorized scope, discovery, enumeration, hypothesis generation, safe validation, evidence capture, false-positive reduction, reporting, remediation guidance, and retesting.
Penligent’s public homepage emphasizes controllable agentic workflows, including editing prompts, locking scope, and customizing actions for an environment. It also presents Penligent as an AI-powered penetration testing tool and describes one-click access to more than 200 Kali tools in its public materials. (寡黙) Penligent’s writing on pentest AI agents makes the same architectural point more directly: AI pentesting becomes useful when the model is placed inside a controlled execution field where it can observe, call tools, receive feedback, preserve evidence, and operate under explicit scope. (寡黙)
That is the right frame for the category. The product question is not whether a model can talk like a hacker. The question is whether the system can safely close the loop from target context to verified finding.
For teams evaluating AI security tools, the key test is evidence. Can the system show what it tested, what it observed, which command or request produced the result, which scope rule allowed it, which model interpreted it, and what a human needs to retest? Can it distinguish a hypothesis from a verified finding? Can it preserve raw artifacts without leaking secrets into model context? Can it stop when a target moves out of scope? Can it run in the environment where the sensitive data lives?
Those questions are more important than a polished demo.
Local models help privacy, but they do not remove risk
Local model infrastructure is powerful, but it should not become a new myth.
A local model can reduce exposure of sensitive prompts to third-party APIs. It can support offline labs. It can make costs more predictable for high-volume tasks. It can allow the enterprise to customize deployment, monitoring, and access. It can make data residency easier. It can support internal workflows that a public SaaS model cannot reach.
But local models also introduce tradeoffs.
They require hardware capacity or a private inference service. They may lag frontier models on complex reasoning. They require patching, monitoring, prompt logging, model-version tracking, and performance evaluation. They may produce weaker tool calls or less reliable structured output. They may need quantization, batching, or context-management tradeoffs. They may be paired with unsafe local tools. They may be over-trusted because they are inside the network.
Most importantly, local inference does not solve prompt injection. A malicious webpage, README, issue comment, PDF, or scan output can still influence a local model. If the model has broad tool access, the risk remains.
Local deployment changes the control surface. It does not eliminate the need for controls.
A local agent deployment still needs:
| 必要条件 | Reason |
|---|---|
| Tool allowlists and denylists | The model should not decide its own authority |
| Network egress policy | Data cannot leak to arbitrary destinations |
| Credential proxying | Raw secrets should not enter the model context |
| Sandboxed execution | Generated code and tools need a blast-radius boundary |
| Session audit logs | Teams need to reconstruct actions |
| Model routing records | Reviewers need to know which backend saw which data |
| Redaction and data classification | Sensitive content needs handling rules |
| Dependency scanning | Local tools and plugins can be compromised |
| Human approval gates | Some actions should never be fully autonomous |
| Retestable evidence | Security findings must be reproducible |
The best architecture treats local models as one backend in a governed portfolio, not as a magical safety layer.
The procurement checklist for enterprise AI agents
Technical buyers should ask different questions now. “Which model do you use?” is no longer enough.
A better checklist looks like this:
| Area | Questions to ask |
|---|---|
| Data path | Where do prompts, tool outputs, files, screenshots, traces, and reports go? Can sensitive data be kept local? |
| Backend choice | Can the enterprise choose the model provider? Is BYOK supported? Can local models be used? |
| 配備 | Is SaaS the only option? Is VPC, private cloud, on-prem, or air-gapped deployment possible? |
| Model routing | Can different tasks use different models based on sensitivity, cost, and risk? |
| Tool control | Are tools allowlisted? Can commands, files, APIs, and network destinations be denied by policy? |
| 施行範囲 | Is target scope machine-enforced or only written in a prompt? |
| 秘密 | Can secrets be kept out of prompts and sandboxes? Are short-lived credentials supported? |
| Sandboxing | Where do shell commands, generated code, scanners, and browser sessions run? Are environments disposable? |
| Network egress | Can outbound traffic be restricted by domain, IP range, protocol, and task? |
| Audit | Can the team export prompts, responses, tool calls, approvals, evidence links, model versions, and policy decisions? |
| エビデンス | Does the system preserve raw artifacts and distinguish hypotheses from verified findings? |
| Identity | Does the system integrate with SSO, RBAC, service accounts, and existing IAM? |
| Incident response | Can a session be paused, killed, replayed, or investigated after suspicious behavior? |
| Supply chain | How are plugins, MCP servers, tools, containers, and dependencies reviewed and updated? |
| Cost governance | Are budgets enforced per user, task, engagement, model, and subagent? |
This checklist separates real systems from impressive demos. A demo can show an agent fixing a bug or finding a vulnerability. An enterprise system has to survive production constraints: multiple users, multiple projects, sensitive data, compliance review, procurement questions, failure recovery, audit, and incident response.
Model backends will keep changing
DeepSeek V4 is important now because it puts pressure on agent economics and provider assumptions. Its official documentation shows Anthropic-format access, 1M context, tool calls, JSON output, and low listed pricing relative to many frontier-model workflows as of the current page. (DeepSeek API Docs) But the specific model is not the permanent center of gravity.
Models will keep changing. Prices will change. Context windows will grow. Local inference will improve. Open weights will get stronger. Cloud providers will add enterprise controls. Some models will be better at code. Some will be better at long context. Some will be better at tool calls. Some will be better at security reasoning. Some will be cheaper. Some will be allowed in one jurisdiction and restricted in another.
The stable layer should be the agent control plane.
That control plane should let the enterprise change model backends without rebuilding the workflow. It should let a team route sensitive tasks to local inference, public documentation tasks to cheaper APIs, high-stakes analysis to stronger models, and final security conclusions through human review. It should preserve a consistent policy model across all of those choices.
That is why DeepClaude is more than a clever wrapper. It is a visible example of a larger separation. Developers like the agent loop. Enterprises need the loop to be governable. The model backend is becoming one dependency behind that loop.
The direction of travel
Enterprise AI agents are moving toward infrastructure.
That does not mean every company will run its own model cluster. It means the agent must fit into enterprise infrastructure patterns: identity, network segmentation, secrets management, logging, audit, policy-as-code, sandboxing, vulnerability management, cost controls, and incident response.
The best agent systems will be boring in the right places. They will make powerful actions explicit. They will write durable logs. They will keep secrets out of prompts. They will run untrusted code in isolated environments. They will distinguish data from instructions. They will route models based on sensitivity and task type. They will preserve evidence. They will support local deployment when the workload requires it. They will let enterprises change model providers without losing the workflow.
The future of enterprise AI agents will not be decided by one model provider. It will be decided by who controls the harness, the tools, the data boundary, and the deployment environment.
BYOK gives enterprises choice. Local deployment gives them control. Swappable backends make the model layer negotiable. A governed harness makes the agent usable.
For security teams, that is the practical lesson. Do not ask only whether an agent is smart. Ask whether it can be trusted inside your boundary.
Further reading and references
DeepClaude GitHub repository, for the public example of keeping a Claude Code-style agent loop while routing model calls to DeepSeek V4 Pro, OpenRouter, or another Anthropic-compatible backend. (ギットハブ)
DeepSeek API documentation on integrating DeepSeek models with Claude Code, OpenCode, and OpenClaw. (DeepSeek API Docs)
DeepSeek Models and Pricing documentation, for current model capabilities, context length, tool-call support, Anthropic-format endpoint information, and listed pricing. (DeepSeek API Docs)
Anthropic Engineering, Scaling Managed Agents, for the session, harness, and sandbox decomposition and the security rationale for separating credentials from generated-code execution. (anthropic.com)
Vercel, Security boundaries in agentic architectures, for a clear treatment of agent secrets, generated code, sandboxing, and network-level secret injection. (Vercel)
OWASP Top 10 for Large Language Model Applications, for prompt injection, insecure output handling, excessive agency, supply chain vulnerabilities, and other LLM application risks. (owasp.org)
OWASP LLM01 Prompt Injection, for direct and indirect prompt injection definitions and agent impact examples. (OWASP Gen AIセキュリティプロジェクト)
NIST SP 800-115, Technical Guide to Information Security Testing and Assessment, for disciplined security testing, finding analysis, and mitigation framing. (NISTコンピュータセキュリティリソースセンター)
NVD record for CVE-2024-3094, the xz Utils backdoor, for a concrete supply-chain case relevant to local agent toolchains and dependency trust. (NVD)
Penligent homepage, for public product positioning around AI-powered penetration testing, controllable agentic workflows, scope locking, customizable actions, and tool-connected security work. (寡黙)
Penligent documentation, for installation and usage material related to the agentic AI hacking workflow. (寡黙)
Penligent, Pentest ai agents, Real Tool Execution Is the Line Between AI Pentesting and a Toy, for a related discussion of scoped execution fields, tool use, evidence capture, and AI pentesting workflow design. (寡黙)
Penligent, Inside Claude Code, The Architecture Behind Tools, Memory, Hooks, and MCP, for a related technical breakdown of Claude Code-style agent architecture and governance surfaces. (寡黙)
Penligent, AI Pentester in 2026, How to Test AI Systems Without Confusing the Two, for related analysis on evidence-first AI pentesting, deployment mistakes, and governed security workflows. (寡黙)