문구 AI red team assistant sounds precise until you try to buy one, build one, or trust one inside an actual engagement.
In practice, the label gets applied to at least four different things. Sometimes it means a security chatbot that can explain a CVE or suggest a Burp workflow. Sometimes it means a copilot that reads logs and proposes next steps while a human does the real testing. Sometimes it means an agent that can operate a browser, replay HTTP requests, inspect code, and call tools. Sometimes it means a broader validation platform that can string together reconnaissance, hypothesis generation, verification, and reporting. Collapsing those into one category hides the part that matters most in offensive work: whether the system can help produce reproducible evidence under explicit constraints, rather than just plausible text. NIST still frames penetration testing as constrained security testing that attempts to circumvent security features, and SP 800-115 still anchors technical testing in planning, execution, analysis, and mitigation rather than free-form experimentation. OpenAI’s external red teaming paper similarly defines AI red teaming as a structured effort to find flaws and vulnerabilities in an AI system, not a prompt contest divorced from system behavior. (csrc.nist.gov)
That distinction matters more now because the risk surface is no longer “the model said something weird.” Google’s AI Red Team puts the point bluntly: many of the security issues that matter only materialize once a model is integrated into products and given the ability to act or access sensitive information. Anthropic makes a similar point for browser-capable agents, where every page, embedded document, and action surface becomes a potential injection path. The official Model Context Protocol documentation makes the same shift visible from another angle: once an assistant can interact with tools, OAuth flows, third-party APIs, local services, and external resources, the problem stops being just model behavior and becomes a full security architecture problem. (Google 클라우드)
A useful AI red team assistant, then, is not “an LLM for hacking.” It is a human-supervised offensive testing assistant that helps organize, execute, verify, and document parts of an authorized engagement inside a bounded control plane. The control plane matters as much as the model. It defines scope, identities, approval rules, tool permissions, evidence requirements, and cleanup expectations. Without that, the assistant is usually either too weak to matter or too dangerous to trust. (csrc.nist.gov)
AI red team assistant, assistant, copilot, agent, or platform
Before arguing about product claims or engineering choices, it helps to separate the major categories.
| 카테고리 | Typical capabilities | What it usually cannot do reliably | Main failure mode |
|---|---|---|---|
| Security chatbot | Explain concepts, summarize logs, draft commands, discuss CVEs | Maintain engagement state, verify exploitability, preserve evidence, operate safely on live targets | Produces confident text that feels like proof |
| Pentest copilot | Suggest commands, analyze findings, help triage scanner output, keep notes | Enforce scope, independently validate impact, control tools end to end | Gets treated as an operator instead of an advisor |
| AI red team assistant | Track hypotheses, call bounded tools, replay requests, assist browser validation, gather evidence, support retesting | Safely operate without hard boundaries, improvise around missing controls, replace human judgment on impact | Scope drift, injection-led tool misuse, false positives presented as findings |
| Autonomous validation platform | Coordinate multi-step workflows, maintain memory, retest at scale, generate evidence bundles and reports | Magically solve authorization, governance, or human review | Overbroad autonomy and hidden assumptions become systemic risk |
This is not a semantic exercise. It changes how you evaluate the system, what permissions you give it, and what success looks like. Microsoft’s public Security Copilot materials define an agent as a semi-autonomous or autonomous computational entity that can perceive conditions, make decisions, and use connected tools. They also distinguish static tool selection from dynamic tool selection, and that distinction is directly relevant in offensive workflows: a system that can only call a declared set of tools inside a defined run is much easier to reason about than one that can dynamically expand its tool universe midstream. Microsoft’s agent FAQ also emphasizes that administrators set the agent’s identity and role-based access control, which is a good baseline reminder that any assistant doing meaningful work needs an explicit security principal, not an implicit trust bubble. (Microsoft Learn)
The difference between “assistant” and “agent” is even more important in red teaming than in blue-team automation. On the defensive side, an agent can often be constrained to workflows like triage, enrichment, or recommendation. In offensive work, the same pattern may imply network access, authenticated sessions, browser actions, local file reads, or command execution. That means an AI red team assistant needs the workflow awareness of an agent but the operating discipline of a regulated test harness. Treat it like a better chat window and you will either underuse it or lose control of it. (Microsoft Learn)
What changes when the model can act
The key mistake in many AI security conversations is evaluating the model in isolation while ignoring the harness around it. OpenAI’s red teaming paper explicitly defines AI systems as one or more models integrated with additional components such as data inputs, hardware, software, and interfaces. That is the right unit of analysis for a red team assistant. A model with no tools can still leak instructions or hallucinate. A model with a browser, local filesystem access, shell execution, and a few MCP servers can delete branches, upload secrets, replay authenticated actions, or poison its own downstream reasoning. (cdn.openai.com)
Google’s AI Red Team says prompt injection risk has grown as agents moved from simple question answering into complex multi-step workflows that simultaneously ingest sensitive data and perform critical actions. Anthropic says browser-use agents face a large attack surface because every webpage, embedded document, and dynamic script is a potential injection vector, and because browser agents can take many different actions such as navigation, form filling, and downloads. OWASP’s prompt injection guidance adds an important corrective for people hoping retrieval or fine-tuning will solve the problem: neither RAG nor fine-tuning fully mitigates prompt injection vulnerabilities. (Google 클라우드)
The change is not only technical. It is operational. A static scanner fails in familiar ways: incomplete coverage, noisy signatures, shallow context. An acting assistant fails in compound ways. It may misread a scope note, absorb untrusted instructions from a page, choose an unsafe tool, perform a state-changing action, and then describe the outcome in a way that sounds internally coherent. That is why “how smart is the model” is a secondary question. The primary question is whether the system can be forced to behave like a bounded testing instrument instead of a general-purpose operator. (Google 클라우드)
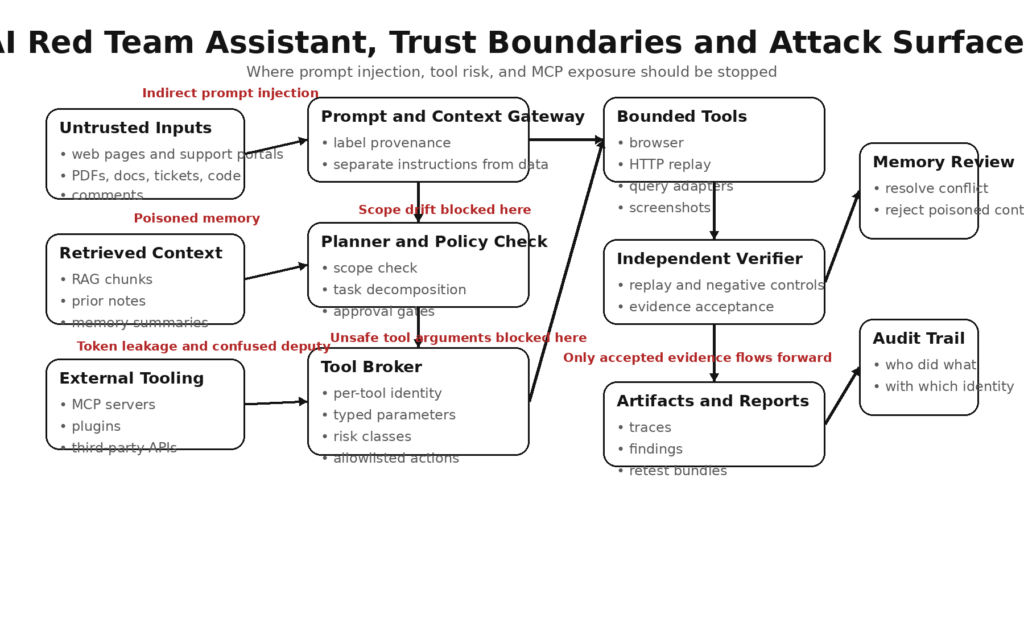
A threat model for an AI red team assistant
If you want to understand where these systems break, model the assistant as a chain with six attack surfaces: inputs, memory, tools, protocols, environment, and outputs.
Inputs
Inputs include direct user prompts, issue tickets, internal notes, API documentation, PDFs, HTML, RAG context, emails, commit diffs, and scanner output. Every one of those may contain instructions, misleading artifacts, hidden text, or adversarial framing. Unit 42’s reporting on web-based indirect prompt injection is important here because it shows this is no longer just a laboratory curiosity. Their write-up describes hidden or manipulated instructions embedded in benign web content, comments, metadata, or user-generated text that later get consumed by LLM-based tools during normal tasks such as summarization or content analysis. They also report observing multiple distinct techniques in the wild rather than a single toy example. (Unit 42)
Memory
Memory sounds helpful until it becomes a contamination channel. A memory store can accumulate wrong assumptions, over-trusted user feedback, malicious summaries, or attacker-controlled context that later gets treated as trusted operating state. Microsoft’s public FAQ for Security Copilot agents notes that users can submit feedback to be stored in memory and that they should review feedback for ambiguity and conflict. That is a mild product-language version of a harder security fact: persistent memory is another place where injection and poisoning can survive beyond a single turn. (Microsoft Learn)
Tools
Tools include shells, browsers, HTTP clients, SQL or KQL query adapters, screenshotters, local filesystems, package managers, git operations, and external APIs. The risk is not just dangerous tools. Safe tools become dangerous when they are attached to unsafe instructions or high-value credentials. A browser in read-only mode is one thing. A browser that can authenticate into a production admin console and click through workflow decisions is another. A query tool can be useful for evidence collection, but unsafe parameter handling turns it into an injection surface. (인류학)
Protocols and integrations
Model Context Protocol, plugin frameworks, proxy servers, OAuth bridges, and agent SDKs add another layer of attack surface. MCP’s own security documentation warns about confused deputy problems, poor consent isolation, and token-handling mistakes. These are exactly the kinds of problems that turn an assistant from “a model with a tool” into “a poorly isolated identity broker with system access.” (모델 컨텍스트 프로토콜)
Environment and identity
The environment includes container boundaries, CI runners, localhost services, SSH keys, cookies, API keys, and cloud roles. Teams often assume local equals safe, but current MCP ecosystem CVEs show otherwise. If an HTTP-based local server lacks DNS rebinding protection or proper authentication, a malicious page can reach services that developers thought were invisible to the web. (GitHub)
Outputs and downstream actions
Outputs are not harmless. A generated report can embed wrong conclusions. A remediation suggestion can become a misconfiguration. A pull request can ship a backdoor. A “safe summary” can contain a poisoned instruction that gets re-consumed later. In other words, the assistant’s output surface can become the next system’s input surface. That is why evidence and replay matter more than eloquence. (csrc.nist.gov)
A compact way to think about the threat model is this:
| Surface | Common failure | Real consequence | Control priority |
|---|---|---|---|
| User and content inputs | Prompt injection, hidden instructions, false context | Unsafe tool choice, leakage, mis-prioritized testing | 높음 |
| Memory and summaries | Persistent poisoning, stale assumptions | Repeated bad actions and wrong findings | 높음 |
| Tools | Overbroad permissions, bad parameter handling | Command execution, data misuse, state changes | 중요 |
| MCP and plugins | Token misuse, consent confusion, localhost exposure | Unauthorized API access, exfiltration, proxy abuse | 중요 |
| Environment | Excessive local or cloud privileges | Host compromise, credential theft, destructive actions | 중요 |
| Outputs | Unsupported conclusions, poisoned artifacts | Bad reports, false confidence, unsafe follow-on actions | 높음 |
This is also where many evaluations go wrong. Teams ask whether the model can generate payloads or summarize a chain. They do not ask whether the assistant can preserve its constraints after reading a hostile issue comment, whether it can distinguish evidence from speculation, or whether it will refuse a dangerous path when an attached tool makes that path available. Those are the questions that decide whether the system belongs in an engagement at all. (Google 클라우드)
What a usable assistant needs, scope, identity, evidence, and verification
A serious AI red team assistant is not built by bolting a shell onto a model. It is built by giving the model a disciplined operating environment.
Scope comes first
Red team automation becomes reckless the moment scope is an afterthought. NIST’s penetration testing definitions emphasize specific constraints, and SP 800-115 frames technical testing around planning before execution. A working assistant therefore starts with machine-readable scope: authorized hosts, test identities, forbidden actions, rate limits, approved hours, destructive-action policy, data handling requirements, and output retention rules. If scope only exists in human prose, the assistant will eventually violate it. (csrc.nist.gov)
Here is one illustrative pattern:
engagement:
name: "staging-multitenant-api-q2"
scope:
domains:
- "staging.api.example.test"
ip_ranges:
- "203.0.113.0/28"
forbidden:
- "production"
- "customer_data_export"
- "credential_rotation"
identities:
- name: "tenant_a_reader"
permissions: ["read_only"]
- name: "tenant_b_reader"
permissions: ["read_only"]
tools:
allow:
- "http_replay"
- "browser_readonly"
- "screenshot"
- "diff_responses"
- "grep_logs"
deny:
- "shell_exec"
- "git_push"
- "package_install"
- "external_webhook"
approvals:
require_human_for:
- "state_changing_http"
- "credential_export"
- "external_network"
- "any_new_tool"
evidence:
require:
- "request_trace"
- "response_trace"
- "timestamp"
- "identity_context"
- "replay_result"
The point of a policy like this is not bureaucracy. It is to turn the engagement into a constrained runtime so the assistant cannot quietly widen its own operating envelope. That design choice lines up with Microsoft’s distinction between static and dynamic tool selection and with MCP’s emphasis on explicit user consent and tool safety. (Microsoft Learn)
Least privilege has to be real, not rhetorical
Least privilege sounds obvious until you look at how many assistant prototypes run with broad local filesystem access, environment variables loaded into the process, browser sessions tied to powerful user accounts, and tool adapters that inherit whatever the host can reach. Microsoft’s public documentation for Security Copilot agents emphasizes that administrators assign the agent identity and RBAC. MCP’s security material warns against sloppy authorization patterns and token misuse. Those are not defender-only lessons. In an offensive assistant, every identity must have a purpose, and every purpose must be narrower than the human operator’s full account. (Microsoft Learn)
That means separate identities for reading a wiki, replaying HTTP requests, capturing screenshots, or querying staging logs. It means short-lived credentials over static tokens. It means local tools should not inherit cloud secrets just because the workstation happens to have them. It means there should be no ambiguous “operator mode” where the model can do anything the host can do. (모델 컨텍스트 프로토콜)
Planner, executor, verifier must be separate roles
One of the most common mistakes in agent design is letting the same model hypothesize, execute, interpret, and approve its own work. That is efficient in demos and dangerous in real testing. OpenAI’s external red teaming paper argues that red teaming is one component of a broader evaluation portfolio and can help seed more systematic evaluations. AISI’s methodology goes further in a practical direction by breaking work into planning and preparation, conducting attacks, and reporting with improvement plans. That structure is useful because it implies separation of function rather than a single all-knowing loop. (cdn.openai.com)
In an AI red team assistant, the planner proposes a bounded test contract. The executor performs a permitted action. The verifier asks whether the evidence actually supports the claim. The reporter packages artifacts, context, and caveats. Those roles can still be model-assisted, but they should not be merged into one unchecked narrative engine.
A minimal verifier pattern can be expressed like this:
def accept_finding(f):
return all([
f.scope_check_passed,
f.primary_trace is not None,
f.replay_trace is not None,
f.identity_context is not None,
f.negative_control_passed,
f.side_effects_documented,
f.impact_statement_is_supported
])
This looks simple because it should be simple. A finding is not accepted because the model sounds convincing. It is accepted because the evidence bundle clears the bar. That mindset also helps limit hallucinated severity inflation, which is one of the fastest ways to destroy trust in AI-assisted testing. (csrc.nist.gov)
Logs need to be artifacts, not afterthoughts
Google’s discussion of its AI red team emphasizes strict rules of engagement, no real customer data in exercises, and detailed activity logging. That is the right default. An offensive assistant should record prompts, tool inputs, tool outputs, approvals, identity used, scope object in effect, and evidence hashes. Without those, you do not have an assistant you can review; you have a stochastic story generator attached to side effects. (Google 클라우드)
Verification must account for non-determinism
Traditional exploit verification assumes a certain amount of stability. AI-linked behaviors are often less stable. AISI’s practical methodology notes that attack signatures should be repeated because system behavior can be probabilistic and non-deterministic. Anthropic’s published work on browser prompt-injection defenses uses attack success rate under repeated attempts rather than a one-shot pass/fail mindset. That tells you something important: the assistant should not elevate a one-off response anomaly into a confirmed finding without replay, control comparisons, and evidence consistency. (Japan AISI)
Prompt injection is not a chatbot bug, it is an assistant operating risk
Prompt injection gets discussed so often that it can start to sound abstract. In an AI red team assistant, it is not abstract at all. It is often the shortest path from “helpful automation” to “unsafe delegated behavior.”
OWASP defines prompt injection as a vulnerability where user prompts alter model behavior or outputs in unintended ways, and it explicitly notes that such instructions do not need to be human-visible if they are parsed by the model. OWASP also states that RAG and fine-tuning do not fully mitigate the problem. That matters because many assistants are marketed as “enterprise safe” simply because they read from approved documents or rely on retrieval rather than open chat. If those documents, comments, or pages can be influenced by an attacker, the retrieval boundary does not remove the injection boundary. (OWASP Gen AI 보안 프로젝트)
Indirect prompt injection is especially relevant to assistants because assistants consume content as part of workflow, not just conversation. Unit 42 describes web-based indirect prompt injection as manipulated instructions embedded in benign content that an LLM later processes during routine tasks. They also describe observed attack intents including review evasion, phishing promotion, data leakage, prompt leakage, and unauthorized actions. Even where a specific campaign does not result in confirmed compromise, the threat model is already realistic enough to matter to anyone building or using an acting assistant. (Unit 42)
Anthropic’s browser-defense work makes the same risk concrete. A browser-capable agent sees a huge volume of untrusted material and has many ways to act on it. The problem is not limited to exotic HTML tricks. A normal web page, support ticket, or issue description can become a command source if the assistant cannot separate task-relevant data from attacker-planted instructions. That is why browser use is not just “more convenient input.” It is an expansion of the adversarial surface. (인류학)
This has a direct implication for offensive testing workflows. Red teams constantly read untrusted content: bug bounty program docs, exposed repos, changelogs, help centers, leaked configuration fragments, public issue trackers, test accounts, internal wikis during authorized assessments, and target-controlled application responses. An assistant that cannot treat these as adversarial inputs is not safe enough to sit inside the workflow. (Google 클라우드)
The right goal is not to pretend prompt injection can be eliminated. It is to design the assistant so injection has nowhere dangerous to land. That means read-only defaults, high-friction boundaries around state-changing tools, prompt provenance tracking, content labeling, context compartmentalization, and output verification that does not trust the model’s own summary of what just happened. (인류학)
MCP, local tools, and the false comfort of localhost
If prompt injection is the most discussed problem in assistant security, MCP-style integration security is the most underappreciated one.
MCP is an open protocol for connecting LLM applications to external data and tools. The protocol’s official documentation discusses both convenience features and the security implications that come with them, including data privacy, user consent, tool safety, and more specialized problems such as confused deputy behavior. The security best practices document warns that poorly designed MCP proxy servers can let malicious clients obtain authorization without proper user consent, especially when shared static client IDs, dynamic registration, and consent cookies mix badly. (모델 컨텍스트 프로토콜)
That matters to an AI red team assistant because MCP changes the trust boundary in two ways.
First, it tends to normalize the idea that a model can speak to many tools through a common protocol. That is operationally useful and security-sensitive at the same time. It increases the number of possible action paths and the chance that a safe-looking tool call can reach a powerful backend through a proxy the operator does not fully understand. (모델 컨텍스트 프로토콜)
Second, it encourages developers to run services locally and assume locality is equivalent to safety. Recent CVEs show the opposite. CVE-2026-34742 affected the MCP Go SDK before 1.4.0 because DNS rebinding protection was disabled by default for certain HTTP handlers, making it possible for a malicious website to reach a localhost MCP server if other protections were absent. Similar DNS rebinding issues were disclosed for the Python MCP SDK before 1.23.0 and the TypeScript SDK before 1.24.0. The lesson is broader than any one language: if your assistant exposes HTTP-based local services, the browser becomes part of your attack surface whether you wanted it to or not. (GitHub)
The same pattern appears in token-handling mistakes. MCP security guidance explicitly calls token passthrough an anti-pattern because it can undermine authorization boundaries and client isolation. A red team assistant that inherits user tokens, forwards them across servers, or shares them across contexts may be operationally convenient and architecturally unsound. The result may be unauthorized API use that looks like legitimate assistant traffic. (모델 컨텍스트 프로토콜)
For practitioners, the minimum questions are straightforward. Does each client get isolated consent? Are tokens audience-restricted and short-lived? Does localhost exposure include DNS rebinding defenses? Are tools categorized by risk rather than lumped together as generic “skills”? Can the operator see which identity each tool call used? If the answer is vague, the integration layer is not mature enough for serious offensive work. (모델 컨텍스트 프로토콜)
Real CVEs that map directly to assistant design failures
The easiest way to cut through hand-wavy AI security claims is to look at actual vulnerability classes around agents, MCP integrations, and tool-connected coding environments. The interesting pattern is that the most relevant flaws are rarely “the model got jailbroken” in isolation. They are usually failures of configuration trust, identity separation, local exposure, or unsafe tool mediation.
| CVE | 구성 요소 | 취약점 유형 | Why it matters for AI red team assistants |
|---|---|---|---|
| CVE-2025-53098 | Roo Code | Prompt-to-config-to-command execution path | Shows how a model can be induced to write unsafe config that later executes with user approval |
| CVE-2025-34072 | Deprecated Anthropic Slack MCP Server | Sensitive data exfiltration via automatic link unfurling | Shows how message previews and external links can leak assistant-accessible data |
| CVE-2026-34742 | MCP Go SDK | DNS rebinding protection disabled by default on certain HTTP paths | Shows localhost is part of the web attack surface if exposed through HTTP |
| CVE-2025-66416 | MCP Python SDK | Missing default DNS rebinding protection | Same lesson in another runtime |
| CVE-2025-66414 | MCP TypeScript SDK | Missing default DNS rebinding protection | Same lesson in another runtime |
| CVE-2026-33980 | Azure Data Explorer MCP Server | KQL injection in tool handlers | Shows query tools can become backend injection surfaces when parameters are not safely mediated |
CVE-2025-53098, Roo Code and the danger of letting prompts rewrite trust
The GitHub advisory for CVE-2025-53098 describes an issue in Roo Code where project-level .roo/mcp.json configuration could be used to achieve arbitrary command execution. The advisory explains a plausible chain: a malicious prompt can cause the agent to write a crafted command into the configuration, and if the user has auto-approved file modifications, arbitrary command execution can follow. That is not an exotic LLM weakness. It is a classic boundary failure where prompt-controlled content is allowed to modify executable trust material. (GitHub)
For an AI red team assistant, this is an important caution. Many offensive workflows legitimately involve config files, runbooks, task manifests, or local harness definitions. If the model can rewrite those files as part of a “helpful” flow, then configuration becomes part of the code-execution chain. The fix is not just patching one product version. The general mitigation is to treat policy and configuration as protected assets: separate edit permissions from runtime permissions, require human review for executable config changes, and never let assistant-generated config become trusted runtime state without validation. (GitHub)
CVE-2025-34072, Slack MCP link unfurling and hidden exfil paths
CVE-2025-34072 affected a deprecated Anthropic Slack MCP Server and involved sensitive data exfiltration through automatically unfurled attacker-crafted links. That matters because many assistant deployments touch chat systems, ticketing systems, or collaboration platforms where “preview this link” feels harmless. In reality, preview and enrichment paths often run with access to contextual data or secrets that the original attacker should never receive. (GitHub)
The lesson for a red team assistant is that the distinction between “tool action” and “background convenience feature” is often false. Link unfurling, content summarization, metadata extraction, and auto-enrichment can all become exfiltration surfaces if they happen on attacker-controlled content. The mitigation direction is to disable automatic enrichment on untrusted inputs, isolate tokens used for messaging integrations, and require an explicit mediation layer between external content and assistant-visible context. (GitHub)
CVE-2026-34742, localhost is not a free trust boundary
The disclosure around CVE-2026-34742 in the MCP Go SDK is useful because it breaks a persistent bad assumption: “It only listens on localhost, so it’s fine.” Before fixed versions, DNS rebinding protection was disabled by default in certain HTTP-based handlers, creating a path for malicious websites to reach local MCP services under the right conditions. Similar default-protection gaps were later documented for the Python and TypeScript SDKs. (GitHub)
For an AI red team assistant, that means local-only tool exposure is not enough. If the assistant also operates a browser, reads web content, or shares the host with a normal browser session, the line between local and remote gets thinner than teams expect. Strong mitigations include DNS rebinding defenses, mandatory authentication even on local services, strict origin checks where applicable, host-level firewalling, and refusal to expose high-impact tools over generic HTTP when narrower IPC options are available. (모델 컨텍스트 프로토콜)
CVE-2026-33980, query mediation is part of tool safety
CVE-2026-33980 affected an Azure Data Explorer MCP server through KQL injection in tool handlers where user-controlled input was unsafely interpolated. This is a useful example because it shows how a seemingly passive “data retrieval” capability becomes an execution surface when the mediation layer is weak. An assistant does not need shell access to do damage. If it can influence backend queries against sensitive data stores, that is enough. (GitHub)
The general lesson is that tool safety is not just about which tool is callable. It is also about how arguments are translated into the backend system. A secure assistant should prefer typed parameters, allowlisted operations, prepared queries where the backend supports them, and verifier-side checks that distinguish “retrieved expected dataset” from “assistant synthesized a broad exploratory query because it sounded helpful.” (모델 컨텍스트 프로토콜)
These CVEs also expose a broader truth. In assistant security, the sharp edges cluster around the harness and the adapters. That is why it is misleading to market a system as safe simply because the base model has good refusal behavior. The relevant question is whether the whole path from prompt to tool to environment to artifact has been engineered as a secure pipeline. (cdn.openai.com)
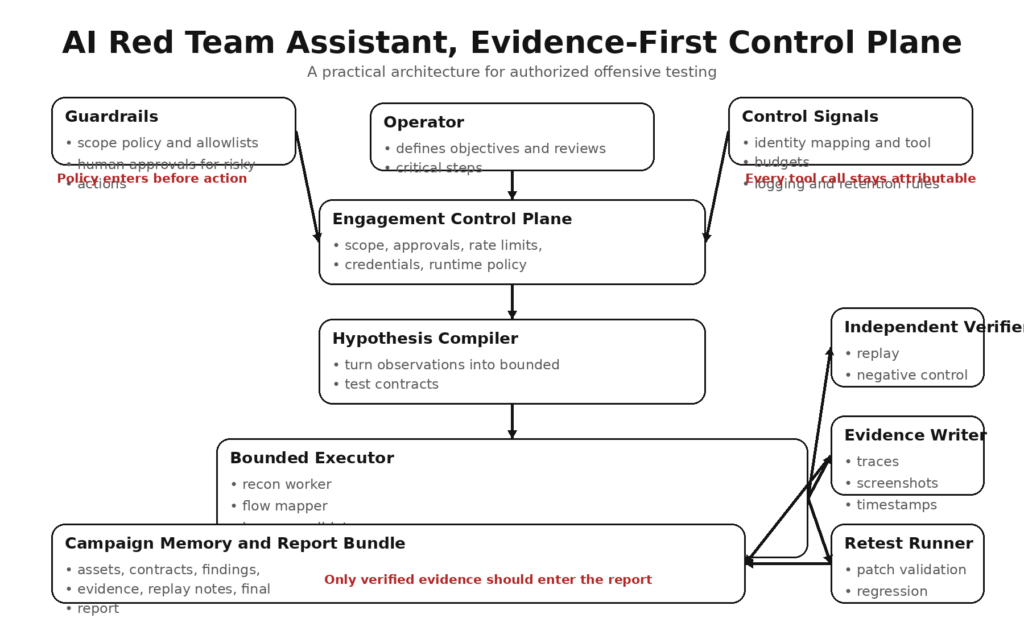
A practical architecture for authorized offensive testing

A workable architecture for an AI red team assistant looks less like a chatbot and more like a constrained test rig.
1. Engagement control plane
This layer owns authorization, scope, timing, tool inventory, identities, rate controls, logging rules, and destructive-action policy. It should be the only place where the assistant learns what it is allowed to do. That design aligns with the process orientation in NIST SP 800-115 and with the broader governance and risk management framing in NIST’s Generative AI Profile. (csrc.nist.gov)
2. Hypothesis compiler
The assistant should not jump straight from observations to action. It should first convert observations into bounded test contracts. A contract might say: “Compare object read access for two read-only identities against a staging API endpoint using replay-only tooling, preserve request/response traces, no state changes.” This is where the system translates noisy reconnaissance into something testable and reviewable. AISI’s methodology is useful here because it treats attack planning as a disciplined stage rather than an improvised continuation of reconnaissance. (Japan AISI)
3. Bounded executor
The executor runs the contract using only declared tools and identities. It does not decide it suddenly needs package installation, new network access, or an extra integration because the model feels curious. Static tool sets are easier to audit than dynamic expansion. If dynamic expansion is necessary, it should happen under explicit approval. Microsoft’s agent component guidance is relevant here because it highlights the safety and predictability benefits of fixed tool sets. (Microsoft Learn)
4. Independent verifier
The verifier does not ask, “Did the model think that worked?” It asks, “Can this be replayed, under the same constraints, with the same claim?” OpenAI’s red teaming work emphasizes that red teaming should inform broader, repeatable evaluations rather than act as the sole measure of system risk. A verifier in offensive workflows serves the same role by forcing evidence through a narrower acceptance gate. (cdn.openai.com)
5. Evidence writer
Every meaningful action should leave a bundle: timestamps, prompts or task IDs, tool calls, identity in use, request and response traces, screenshots if relevant, negative controls, replay outcomes, and cleanup notes. Google’s AI Red Team talks about detailed activity logs and attack narratives; offensive assistants should produce something similar but with enough technical precision that another engineer can reproduce the path. (Google 클라우드)
6. Retest runner
Findings degrade quickly if they cannot be revalidated after a patch or environment change. An assistant that helps build replayable tests is much more valuable than one that produces dramatic one-off transcripts. Promptfoo’s public guidance is useful here because it treats red teaming as systematic probing that can be repeated and measured across many probes and iterations, including CI-style workflows. (프롬프트푸)
In practice, teams evaluating this category usually care less about whether the model sounds impressive and more about whether the workflow is controllable. Public Penligent materials are notable here because they emphasize operator-controlled agentic workflows, editable prompts, and scope-aware action boundaries rather than pure autonomy theater. That is the right direction for this class of system: offensive assistance should feel more like a tightly managed harness than an unbounded operator. (penligent.ai)
What the assistant should actually do during an engagement
A good AI red team assistant helps most in the parts of an assessment that are structured, repetitive, and evidence-heavy.
Reconnaissance organization
The assistant can cluster observations from docs, routes, APIs, and response patterns into testable attack hypotheses. The important word is testable. It should not turn “interesting” into “vulnerable.” It should turn “these two roles appear to receive different filters for the same object family” into “compare object-level authorization under these identities using replay-only requests.” (csrc.nist.gov)
Authenticated flow mapping
Assistants are useful at tracking stateful application flows: session acquisition, CSRF token handling, multi-step forms, role changes, feature flags, and object references. This is where plain chat systems usually fail, because they lose state and over-generalize. A bounded assistant can instead keep a task tree, store sanitized flow checkpoints, and help the operator decide which transitions are worth testing. (penligent.ai)
Controlled replay and comparison
The assistant is particularly valuable when it can replay low-risk requests across multiple identities, diff results, and preserve artifacts. That supports classic authorization testing, business-logic testing, and regression testing without granting the system open-ended freedom. The key is to keep the tool layer narrow and the evidence requirements strict. (csrc.nist.gov)
Evidence packaging
Most of the pain in real engagements is not discovering an idea. It is proving the idea, documenting it clearly, and preserving enough context for retesting. An assistant that can assemble traces, screenshots, object identifiers, role context, timestamps, impact notes, and remediation hints into a stable finding format is genuinely useful. One that can only draft flashy summaries is not. (csrc.nist.gov)
Retesting after remediation
This is one of the best uses for AI assistance because the target behavior is narrow and the acceptance criteria are concrete. The assistant can re-run prior comparisons, confirm that negative controls still behave properly, and update the evidence bundle. This aligns with the broader idea from OpenAI’s and AISI’s materials that red teaming insights should feed repeatable evaluation rather than remain trapped in a one-time session. (cdn.openai.com)
The distinction between “suggestion” and “verified finding” matters here. Penligent’s public writing on AI pentest copilots and evidence-first harnesses makes that distinction explicitly, and it is a helpful way to evaluate any tool in this category. If a vendor cannot show you how suggestions become confirmed findings under bounded execution and replay, you are probably looking at a smart interface, not an assistant that can hold up under real testing. (penligent.ai)
Example, an authorized multi-tenant access-control test
The safest way to explain the workflow is with a synthetic but realistic example.
Assume an authorized engagement against a staging environment for a multi-tenant SaaS application. The objective is narrow: verify whether read-only users from Tenant A can access object metadata belonging to Tenant B through an API endpoint. The environment is staging, the identities are approved, and the policy forbids state-changing actions or mass enumeration. That setup mirrors NIST’s emphasis on testing under explicit constraints. (csrc.nist.gov)
The assistant’s job is not to “hack the app.” Its job is to help transform observations into a safe test sequence. It receives the OpenAPI description, a few captured baseline requests from each role, and the engagement policy. It notices that object references are UUID-like, the response schema includes tenant-scoped metadata, and the same resource family is reachable from both identities under different list views. It proposes a read-only comparison contract rather than an open-ended enumeration plan. (Japan AISI)
A human reviewer approves the contract because it stays inside scope and uses only replay tooling. The executor then performs a minimal set of requests: one known-good read by Tenant A for an A-owned object, one known-good read by Tenant B for a B-owned object, and a cross-tenant replay using the same path structure but no write operations, no parameter fuzzing, and no volume. The verifier then checks whether the cross-tenant replay returned an authorization failure, a partial disclosure, or a full object response. It also performs a negative control using a clearly nonexistent object reference to distinguish authorization bypass from inconsistent error handling. (csrc.nist.gov)
An illustrative replay block might look like this:
GET /api/v1/documents/9b3d3c8f-tenant-b-object HTTP/1.1
Host: staging.api.example.test
Authorization: Bearer TENANT_A_READER_TOKEN
Accept: application/json
X-Trace-Mode: replay
The assistant should not decide on its own that one surprising response proves a vulnerability. Instead, the verifier checks for consistency. Did the same result occur twice? Did it happen only under one identity? Was the object definitely owned by the other tenant? Did the response include sensitive fields or only public metadata? Was there any caching artifact or stale proxy behavior that could explain the result? Those are the questions that distinguish evidence from excitement. (Japan AISI)
If the finding holds, the report bundle should contain the baseline traces, the cross-tenant replay, the negative control, the identities used, timestamps, the exact acceptance criteria, and a narrow impact statement. Something like “read-only cross-tenant metadata disclosure confirmed for document objects under endpoint X” is much better than “critical tenant isolation failure” unless the evidence supports a stronger claim. The assistant can help draft the report, but the severity statement still belongs under human review. (csrc.nist.gov)
This example is deliberately modest, and that is the point. An AI red team assistant earns trust by helping with bounded, reviewable verification work. If it cannot do this well, it has no business being trusted with broader autonomy. (Microsoft Learn)
Why automation lies at the moments that matter most
Automation is great at producing motion. It is less reliable at producing proof.
OpenAI’s paper is explicit that red teaming is one input into a broader evaluation and governance stack, not a standalone guarantee. AISI’s practical guide treats repeated attacks and structured reporting as necessary because single observations are not enough. Promptfoo’s guidance emphasizes systematic probing and measurable outcomes across many runs. Together, these sources point to the same lesson: offensive AI automation is most likely to mislead you when the system is allowed to convert uncertain signals into strong conclusions. (cdn.openai.com)
Here are the common failure modes:
A scanner hit becomes an “exploit path” because the assistant can explain why it might matter. A browser artifact becomes “confirmed data access” because the model narrates the page state confidently. A one-shot anomalous response becomes a stable vulnerability because the assistant is rewarded for decisive language. A generated severity rating outruns the evidence. A remediation suggestion becomes trusted even though the assistant never verified the root cause. (csrc.nist.gov)
This is also where highly capable language models can make things worse. Stronger reasoning can make unsupported narratives sound more coherent. That does not mean models are useless. It means the acceptance boundary has to remain non-linguistic: traces, controls, replays, and clear scope checks. Humans do not need the assistant to sound smart. They need it to keep the work organized without manufacturing certainty. (cdn.openai.com)
Open-source tools such as Garak, Promptfoo, and Microsoft’s Counterfit are useful precisely because they reinforce this measurement mindset in different ways. Promptfoo emphasizes automated adversarial probing and evaluation of AI application behavior. Garak presents itself as an LLM vulnerability scanner. Counterfit automates security testing for AI systems and maps to adversarial ML techniques. None of these tools magically replace system-level validation, but together they illustrate the right habit: use automation to expand coverage and regression, not to waive proof requirements. (프롬프트푸)
A defender’s view, what blue teams and platform owners should log and control
Blue teams do not have to guess how to evaluate these systems. The same properties that make an assistant useful to red teams make it observable to defenders.
NIST’s Generative AI Profile is helpful because it treats security, privacy, and other risks as lifecycle concerns that need to be managed through governance, mapping, measurement, and management functions. Google’s SAIF similarly frames AI security as an extension of existing security foundations, detection, response, and automated defenses. Those documents are not specific to offensive assistants, but the controls translate well. (nvlpubs.nist.gov)
A platform team overseeing an AI red team assistant should capture at least the following classes of telemetry:
| Telemetry class | 중요한 이유 |
|---|---|
| Prompt and task metadata | Reconstruct operator intent and identify injection sources |
| Tool call audit trail | See what actually happened, not what the assistant later claimed |
| Identity and credential mapping | Tie each action to the precise account or token used |
| Content provenance | Distinguish trusted documentation from untrusted web or user content |
| Approval events | Review whether high-risk boundaries were bypassed or overused |
| Evidence artifact hashes | Preserve integrity of screenshots, traces, and report bundles |
| Memory changes | Detect poisoning, conflict, and stale assumptions entering persistent state |
Microsoft’s public Security Copilot agent material also contains a valuable operational clue: even in a defensive product, users are told to review agent decision-making before acting, and stored feedback needs attention because of ambiguity and conflict. That should lower the tolerance for offensive products claiming “set and forget” autonomy. If a platform that Microsoft itself describes as preview-worthy still expects human review and memory hygiene, an AI red team assistant should not promise less scrutiny while taking on more dangerous tasks. (Microsoft Learn)
Defenders should also decide in advance which actions trigger a hard stop. Examples include any attempt to export credentials, any unapproved external network call, any change to executable configuration, any access to production-labeled systems, and any broadening of the tool set beyond the current engagement policy. These are not model-level safeguards. They are control-plane safeguards, and they are easier to reason about. (모델 컨텍스트 프로토콜)
Buying or building, the questions that matter
If you are evaluating a vendor or an internal prototype, there is a short list of technical questions that separates serious systems from demo-grade ones.
- Can the assistant enforce machine-readable scope, or does it only read scope in natural language.
- Are tools statically declared, dynamically added, or both.
- Can high-risk actions require explicit human approval.
- Is there a separate verifier path, or does the same model approve its own findings.
- What evidence artifacts are mandatory before a finding is accepted.
- How does the system handle untrusted web content, issue text, PDFs, or RAG results.
- Does memory exist, and if so, how is poisoning or ambiguity reviewed.
- What identities do tools run as, and how narrow are those identities.
- If MCP is involved, how are consent, token isolation, and localhost exposure controlled.
- Can findings be replayed after remediation.
- Can the operator distinguish suggestions from verified findings.
- Are logs complete enough that another engineer can reconstruct the run. (Microsoft Learn)
A weak answer to any one of these questions does not necessarily disqualify a system. But a weak answer to several usually means the product is optimizing for demo fluidity rather than engagement integrity. That tradeoff may be acceptable for research or note-taking. It is not acceptable for a tool that claims to assist real offensive testing. (csrc.nist.gov)
What the term should mean going forward
문구 AI red team assistant is worth keeping, but only if it means something stricter than “security chatbot with tool access.”
A real assistant in this category should operate under explicit authorization, run with narrow identities, consume untrusted content without blindly obeying it, separate planning from execution and verification, preserve artifacts by default, and treat replayable evidence as more important than eloquent narration. The model matters, but the harness matters more. OpenAI’s and AISI’s public materials both point toward structure, repeatability, and multi-stage evaluation rather than improvisation. Google’s and Anthropic’s public work makes clear that integration surfaces and acting capability are where the real risks show up. MCP’s own security guidance makes it plain that the protocol and adapter layer cannot be treated as an implementation detail. (cdn.openai.com)
That is the standard worth using whether you are buying a product, building an internal system, or trying to understand the latest wave of “agentic security” claims. If the assistant cannot produce bounded action, clean evidence, and reviewable behavior, it is not ready for a real engagement. It is still just a convincing interface. (csrc.nist.gov)
추가 읽기 및 참고 자료
- Microsoft AI Red Team, overview and planning principles for red teaming AI systems. (Microsoft Learn)
- OpenAI, OpenAI’s Approach to External Red Teaming. (cdn.openai.com)
- NIST SP 800-115, 정보 보안 테스트 및 평가에 대한 기술 가이드. (csrc.nist.gov)
- NIST, Artificial Intelligence Risk Management Framework, Generative Artificial Intelligence Profile. (nvlpubs.nist.gov)
- Google, Google’s Secure AI Framework, SAIF. (Safety Center)
- Google Cloud, How Google Does It, Building an Effective AI Red Team. (Google 클라우드)
- OWASP, LLM01 Prompt Injection. (OWASP Gen AI 보안 프로젝트)
- OWASP, Top 10 for Agentic Applications for 2026. (OWASP Gen AI 보안 프로젝트)
- Model Context Protocol, 사양 그리고 Security Best Practices. (모델 컨텍스트 프로토콜)
- 인류학, Mitigating the Risk of Prompt Injections in Browser Use. (인류학)
- 인류학, Claude Code Auto Mode, A Safer Way to Skip Permissions. (인류학)
- Unit 42, Fooling AI Agents, Web-Based Indirect Prompt Injection Observed in the Wild. (Unit 42)
- Promptfoo, LLM Red Teaming Guide. (프롬프트푸)
- Garak, open-source LLM vulnerability scanner. (Garak)
- Counterfit, open-source automation for security testing AI systems. (Microsoft)
- AI 펜테스트 툴, 2026년 실제 자동화된 공격의 모습. (penligent.ai)
- AI Pentest Copilot, From Smart Suggestions to Verified Findings. (penligent.ai)
- Claude Code Harness for AI Pentesting. (penligent.ai)

