A frase Assistente da equipe vermelha de IA Parece preciso até que você tente comprar um, construir um ou confiar em um dentro de um compromisso real.
Na prática, o rótulo é aplicado a pelo menos quatro coisas diferentes. Às vezes, significa um chatbot de segurança que pode explicar um CVE ou sugerir um fluxo de trabalho de Burp. Às vezes, significa um copiloto que lê os registros e propõe as próximas etapas enquanto um humano faz o teste real. Às vezes, significa um agente que pode operar um navegador, reproduzir solicitações HTTP, inspecionar códigos e chamar ferramentas. Às vezes, significa uma plataforma de validação mais ampla que pode reunir reconhecimento, geração de hipóteses, verificação e relatórios. O agrupamento desses elementos em uma única categoria oculta a parte mais importante do trabalho ofensivo: se o sistema pode ajudar a produzir evidências reproduzíveis sob restrições explícitasO NIST ainda enquadra os testes de penetração como testes de segurança restritos que tentam contornar os recursos de segurança, e o SP 800-115 ainda ancora os testes técnicos no planejamento, na execução, na análise e na mitigação, em vez de experimentação de forma livre. O documento de red teaming externo da OpenAI define de forma semelhante o red teaming de IA como um esforço estruturado para encontrar falhas e vulnerabilidades em um sistema de IA, e não uma competição imediata divorciada do comportamento do sistema. (csrc.nist.gov)
Essa distinção é mais importante agora porque a superfície de risco não é mais "o modelo disse algo estranho". A Equipe Vermelha de IA do Google coloca a questão de forma direta: muitos dos problemas de segurança que importam só se materializam quando um modelo é integrado aos produtos e recebe a capacidade de agir ou acessar informações confidenciais. A Anthropic faz uma observação semelhante para agentes com capacidade de navegação, em que cada página, documento incorporado e superfície de ação se torna um possível caminho de injeção. A documentação oficial do Model Context Protocol torna a mesma mudança visível de outro ângulo: quando um assistente pode interagir com ferramentas, fluxos OAuth, APIs de terceiros, serviços locais e recursos externos, o problema deixa de ser apenas o comportamento do modelo e se torna um problema de arquitetura de segurança completa. (Google Cloud)
Um assistente de equipe vermelha de IA útil, portanto, não é "um LLM para hacking". É um assistente de teste ofensivo supervisionado por humanos que ajuda a organizar, executar, verificar e documentar partes de um compromisso autorizado dentro de um plano de controle limitado. O plano de controle é tão importante quanto o modelo. Ele define o escopo, as identidades, as regras de aprovação, as permissões de ferramentas, os requisitos de evidências e as expectativas de limpeza. Sem isso, o assistente geralmente é fraco demais para ser importante ou perigoso demais para se confiar. (csrc.nist.gov)
Assistente de equipe vermelha de IA, assistente, copiloto, agente ou plataforma
Antes de argumentar sobre reivindicações de produtos ou escolhas de engenharia, é útil separar as principais categorias.
| Categoria | Recursos típicos | O que ele normalmente não pode fazer de forma confiável | Modo de falha principal |
|---|---|---|---|
| Chatbot de segurança | Explicar conceitos, resumir registros, esboçar comandos, discutir CVEs | Manter o estado de engajamento, verificar a capacidade de exploração, preservar evidências, operar com segurança em alvos reais | Produz um texto confiante que parece uma prova |
| Copiloto do Pentest | Sugerir comandos, analisar descobertas, ajudar a triar a saída do scanner, fazer anotações | Aplicar o escopo, validar o impacto de forma independente, controlar as ferramentas de ponta a ponta | É tratado como um operador em vez de um consultor |
| Assistente da equipe vermelha de IA | Rastreie hipóteses, chame ferramentas limitadas, reproduza solicitações, ajude na validação do navegador, reúna evidências, dê suporte a novos testes | Operar com segurança sem limites rígidos, improvisar em torno de controles ausentes, substituir o julgamento humano sobre o impacto | Desvio de escopo, uso indevido de ferramentas baseadas em injeção, falsos positivos apresentados como descobertas |
| Plataforma de validação autônoma | Coordenar fluxos de trabalho de várias etapas, manter a memória, testar novamente em escala, gerar pacotes de evidências e relatórios | Resolver magicamente a autorização, a governança ou a revisão humana | Autonomia excessiva e suposições ocultas tornam-se um risco sistêmico |
Esse não é um exercício semântico. Ele muda a forma como você avalia o sistema, as permissões que você dá a ele e o que significa sucesso. Os materiais públicos do Security Copilot da Microsoft definem um agente como uma entidade computacional semiautônoma ou autônoma que pode perceber condições, tomar decisões e usar ferramentas conectadas. Eles também distinguem a seleção de ferramentas estáticas da seleção de ferramentas dinâmicas, e essa distinção é diretamente relevante em fluxos de trabalho ofensivos: um sistema que só pode chamar um conjunto declarado de ferramentas dentro de uma execução definida é muito mais fácil de entender do que um sistema que pode expandir dinamicamente seu universo de ferramentas no meio do caminho. As perguntas frequentes sobre o agente da Microsoft também enfatizam que os administradores definem a identidade do agente e o controle de acesso baseado em função, o que é um bom lembrete básico de que qualquer assistente que faça um trabalho significativo precisa de um princípio de segurança explícito, não de uma bolha de confiança implícita. (Microsoft Learn)
A diferença entre "assistente" e "agente" é ainda mais importante na equipe vermelha do que na automação da equipe azul. No lado defensivo, um agente muitas vezes pode ser limitado a fluxos de trabalho como triagem, enriquecimento ou recomendação. No trabalho ofensivo, o mesmo padrão pode implicar acesso à rede, sessões autenticadas, ações do navegador, leituras de arquivos locais ou execução de comandos. Isso significa que um assistente da equipe vermelha de IA precisa do conhecimento do fluxo de trabalho de um agente, mas da disciplina operacional de um conjunto de testes regulamentado. Trate-o como uma janela de bate-papo melhor e você o subutilizará ou perderá o controle sobre ele. (Microsoft Learn)
O que muda quando o modelo pode agir
O principal erro em muitas conversas sobre segurança de IA é avaliar o modelo isoladamente, ignorando a estrutura em torno dele. O documento de equipe vermelha da OpenAI define explicitamente os sistemas de IA como um ou mais modelos integrados com componentes adicionais, como entradas de dados, hardware, software e interfaces. Essa é a unidade de análise correta para um assistente de equipe vermelha. Um modelo sem ferramentas ainda pode vazar instruções ou ter alucinações. Um modelo com um navegador, acesso ao sistema de arquivos local, execução de shell e alguns servidores MCP pode excluir ramificações, fazer upload de segredos, reproduzir ações autenticadas ou envenenar seu próprio raciocínio downstream. (cdn.openai.com)
A Equipe Vermelha de IA do Google afirma que o risco de injeção imediata cresceu à medida que os agentes passaram de simples respostas a perguntas para fluxos de trabalho complexos de várias etapas que simultaneamente ingerem dados confidenciais e executam ações críticas. A Anthropic diz que os agentes de uso do navegador enfrentam uma grande superfície de ataque porque cada página da Web, documento incorporado e script dinâmico é um possível vetor de injeção e porque os agentes do navegador podem realizar muitas ações diferentes, como navegação, preenchimento de formulários e downloads. O guia de injeção imediata da OWASP acrescenta uma correção importante para as pessoas que esperam que a recuperação ou o ajuste fino resolvam o problema: nem o RAG nem o ajuste fino atenuam totalmente as vulnerabilidades de injeção imediata. (Google Cloud)
A mudança não é apenas técnica. Ela é operacional. Um scanner estático falha de maneiras conhecidas: cobertura incompleta, assinaturas ruidosas, contexto superficial. Um assistente atuante falha de várias maneiras. Ele pode ler incorretamente uma nota de escopo, absorver instruções não confiáveis de uma página, escolher uma ferramenta insegura, executar uma ação de alteração de estado e, em seguida, descrever o resultado de uma forma que pareça internamente coerente. É por isso que "quão inteligente é o modelo" é uma questão secundária. A questão principal é se o sistema pode ser forçado a se comportar como um instrumento de teste limitado em vez de um operador de uso geral. (Google Cloud)
Um modelo de ameaça para um assistente de equipe vermelha de IA
Se você quiser entender onde esses sistemas quebram, modele o assistente como uma cadeia com seis superfícies de ataque: entradas, memória, ferramentas, protocolos, ambiente e resultados.
Entradas
As entradas incluem avisos diretos do usuário, tíquetes de problemas, notas internas, documentação da API, PDFs, HTML, contexto RAG, e-mails, diffs de confirmação e saída do scanner. Cada um deles pode conter instruções, artefatos enganosos, texto oculto ou enquadramento adversário. O relatório da Unidade 42 sobre injeção indireta de prompt baseada na Web é importante aqui porque mostra que isso não é mais apenas uma curiosidade de laboratório. O artigo descreve instruções ocultas ou manipuladas incorporadas em conteúdo benigno da Web, comentários, metadados ou texto gerado pelo usuário que, posteriormente, são consumidos por ferramentas baseadas em LLM durante tarefas normais, como resumo ou análise de conteúdo. Eles também relatam ter observado várias técnicas distintas na natureza, em vez de um único exemplo de brinquedo. (Unidade 42)
Memória
A memória parece útil até se tornar um canal de contaminação. Um armazenamento de memória pode acumular suposições erradas, feedback de usuário com excesso de confiança, resumos maliciosos ou contexto controlado por invasores que, posteriormente, é tratado como estado operacional confiável. As perguntas frequentes públicas da Microsoft sobre os agentes do Security Copilot observam que os usuários podem enviar comentários para serem armazenados na memória e que eles devem analisar os comentários quanto a ambiguidades e conflitos. Essa é uma versão leve da linguagem do produto de um fato de segurança mais difícil: a memória persistente é outro local onde a injeção e o envenenamento podem sobreviver além de um único turno. (Microsoft Learn)
Ferramentas
As ferramentas incluem shells, navegadores, clientes HTTP, adaptadores de consulta SQL ou KQL, captadores de tela, sistemas de arquivos locais, gerenciadores de pacotes, operações git e APIs externas. O risco não está apenas nas ferramentas perigosas. As ferramentas seguras tornam-se perigosas quando são anexadas a instruções inseguras ou credenciais de alto valor. Um navegador em modo somente leitura é uma coisa. Um navegador que pode se autenticar em um console de administração de produção e clicar em decisões de fluxo de trabalho é outra. Uma ferramenta de consulta pode ser útil para a coleta de evidências, mas o manuseio inseguro de parâmetros a transforma em uma superfície de injeção. (Antrópica)
Protocolos e integrações
O protocolo de contexto de modelo, as estruturas de plug-in, os servidores proxy, as pontes OAuth e os SDKs de agente adicionam outra camada de superfície de ataque. A própria documentação de segurança do MCP adverte sobre problemas de confusão do assistente, isolamento deficiente do consentimento e erros de manipulação de tokens. Esses são exatamente os tipos de problemas que transformam um assistente de "um modelo com uma ferramenta" em "um corretor de identidade mal isolado com acesso ao sistema". (Modelo de protocolo de contexto)
Ambiente e identidade
O ambiente inclui limites de contêineres, executores de CI, serviços de host local, chaves SSH, cookies, chaves de API e funções de nuvem. As equipes geralmente presumem que local é igual a seguro, mas os CVEs atuais do ecossistema de MCP mostram o contrário. Se um servidor local baseado em HTTP não tiver proteção de religação de DNS ou autenticação adequada, uma página mal-intencionada poderá acessar serviços que os desenvolvedores pensavam ser invisíveis para a Web. (GitHub)
Resultados e ações downstream
Os resultados não são inofensivos. Um relatório gerado pode incorporar conclusões erradas. Uma sugestão de correção pode se tornar uma configuração incorreta. Um pull request pode enviar um backdoor. Um "resumo seguro" pode conter uma instrução envenenada que será consumida novamente mais tarde. Em outras palavras, a superfície de saída do assistente pode se tornar a superfície de entrada do próximo sistema. É por isso que a evidência e a repetição são mais importantes do que a eloquência. (csrc.nist.gov)
Uma maneira compacta de pensar sobre o modelo de ameaça é a seguinte:
| Superfície | Falha comum | Consequência real | Prioridade de controle |
|---|---|---|---|
| Entradas de usuário e conteúdo | Injeção de prompt, instruções ocultas, contexto falso | Escolha de ferramenta insegura, vazamento, testes com prioridade incorreta | Alta |
| Memória e resumos | Envenenamento persistente, suposições obsoletas | Repetição de más ações e conclusões erradas | Alta |
| Ferramentas | Permissões muito amplas, manuseio incorreto de parâmetros | Execução de comandos, uso indevido de dados, alterações de estado | Crítico |
| MCP e plug-ins | Uso indevido de token, confusão de consentimento, exposição do localhost | Acesso não autorizado à API, exfiltração, abuso de proxy | Crítico |
| Meio ambiente | Privilégios locais ou na nuvem excessivos | Comprometimento do host, roubo de credenciais, ações destrutivas | Crítico |
| Saídas | Conclusões não fundamentadas, artefatos envenenados | Relatórios ruins, falsa confiança, ações de acompanhamento inseguras | Alta |
É também nesse ponto que muitas avaliações dão errado. As equipes perguntam se o modelo pode gerar cargas úteis ou resumir uma cadeia. Elas não perguntam se o assistente pode preservar suas restrições depois de ler um comentário hostil sobre um problema, se pode distinguir evidências de especulações ou se recusará um caminho perigoso quando uma ferramenta anexada tornar esse caminho disponível. Essas são as perguntas que decidem se o sistema pertence a um compromisso. (Google Cloud)
O que um assistente utilizável precisa, escopo, identidade, evidência e verificação
Um assistente sério de equipe vermelha de IA não é criado ao se colocar um shell em um modelo. Ele é criado dando ao modelo uma ambiente operacional disciplinado.
O escopo vem em primeiro lugar
A automação da equipe vermelha se torna imprudente no momento em que o escopo é uma reflexão tardia. As definições de testes de penetração do NIST enfatizam restrições específicas, e o SP 800-115 enquadra os testes técnicos em torno do planejamento antes da execução. Portanto, um assistente de trabalho começa com um escopo legível por máquina: hosts autorizados, identidades de teste, ações proibidas, limites de taxa, horas aprovadas, política de ação destrutiva, requisitos de manuseio de dados e regras de retenção de resultados. Se o escopo existir apenas em prosa humana, o assistente acabará violando-o. (csrc.nist.gov)
Aqui está um padrão ilustrativo:
engajamento:
nome: "staging-multitenant-api-q2"
escopo:
domínios:
- "staging.api.example.test"
ip_ranges:
- "203.0.113.0/28"
forbidden (proibido):
- "production"
- "exportação_de_dados_do_cliente"
- "credential_rotation" (rotação de credenciais)
identidades:
- nome: "tenant_a_reader"
permissões: ["read_only"]
- nome: "leitor_b_do_inquilino"
permissões: ["read_only"]
tools:
allow:
- "http_replay"
- "browser_readonly" (somente leitura)
- "screenshot" (captura de tela)
- "diff_responses"
- "grep_logs"
negar:
- "shell_exec"
- "git_push"
- "package_install"
- "external_webhook"
aprovações:
require_human_for:
- "state_changing_http"
- "credential_export" (exportação de credenciais)
- "external_network" (rede externa)
- "qualquer_nova_ferramenta"
evidências:
requerer:
- "request_trace"
- "response_trace" (rastro da resposta)
- "timestamp" (registro de data e hora)
- "identity_context" (contexto de identidade)
- "replay_result"
O objetivo de uma política como essa não é a burocracia. É transformar o envolvimento em um tempo de execução restrito para que o assistente não possa ampliar discretamente seu próprio envelope operacional. Essa escolha de design está alinhada com a distinção da Microsoft entre seleção de ferramentas estáticas e dinâmicas e com a ênfase do MCP no consentimento explícito do usuário e na segurança da ferramenta. (Microsoft Learn)
O menor privilégio deve ser real, não retórico
O privilégio mínimo parece óbvio até que você veja quantos protótipos de assistentes são executados com amplo acesso ao sistema de arquivos local, variáveis de ambiente carregadas no processo, sessões de navegador vinculadas a contas de usuário avançadas e adaptadores de ferramentas que herdam tudo o que o host pode alcançar. A documentação pública da Microsoft para os agentes do Security Copilot enfatiza que os administradores atribuem a identidade do agente e o RBAC. O material de segurança do MCP alerta contra padrões de autorização desleixados e uso indevido de tokens. Essas não são lições exclusivas do defensor. Em um assistente ofensivo, cada identidade deve ter uma finalidade, e cada finalidade deve ser mais restrita do que a conta completa do operador humano. (Microsoft Learn)
Isso significa identidades separadas para ler um wiki, reproduzir solicitações HTTP, capturar capturas de tela ou consultar registros de preparação. Isso significa credenciais de curta duração em vez de tokens estáticos. Isso significa que as ferramentas locais não devem herdar segredos da nuvem só porque a estação de trabalho os possui. Significa que não deve haver nenhum "modo de operador" ambíguo em que o modelo possa fazer qualquer coisa que o host possa fazer. (Modelo de protocolo de contexto)
Planejador, executor e verificador devem ter funções separadas
Um dos erros mais comuns no design de agentes é permitir que o mesmo modelo crie hipóteses, execute, interprete e aprove seu próprio trabalho. Isso é eficiente em demonstrações e perigoso em testes reais. O documento da OpenAI sobre a formação de equipes vermelhas externas argumenta que a formação de equipes vermelhas é um componente de um portfólio de avaliação mais amplo e pode ajudar a gerar avaliações mais sistemáticas. A metodologia da AISI vai além em uma direção prática, dividindo o trabalho em planejamento e preparação, realização de ataques e relatórios com planos de melhoria. Essa estrutura é útil porque implica a separação de funções em vez de um único ciclo que tudo sabe. (cdn.openai.com)
Em um assistente de equipe vermelha de IA, o planejador propõe um contrato de teste limitado. O executor realiza uma ação permitida. O verificador pergunta se as evidências realmente apóiam a alegação. O relator empacota artefatos, contexto e advertências. Essas funções ainda podem ser assistidas por modelos, mas não devem ser mescladas em um mecanismo narrativo não verificado.
Um padrão de verificador mínimo pode ser expresso da seguinte forma:
def accept_finding(f):
return all([
f.scope_check_passed,
f.primary_trace is not None,
f.replay_trace is not None,
f.identity_context is not None,
f.negative_control_passed,
f.side_effects_documented,
f.impact_statement_is_supported
])
Isso parece simples porque deve ser simples. Uma conclusão não é aceita porque o modelo parece convincente. Ela é aceita porque o conjunto de evidências está à altura. Essa mentalidade também ajuda a limitar a inflação de gravidade alucinada, que é uma das maneiras mais rápidas de destruir a confiança nos testes assistidos por IA. (csrc.nist.gov)
Os registros precisam ser artefatos, não reflexões posteriores
A discussão do Google sobre sua equipe vermelha de IA enfatiza regras rígidas de envolvimento, nenhum dado real do cliente nos exercícios e registro detalhado de atividades. Esse é o padrão correto. Um assistente ofensivo deve registrar prompts, entradas de ferramentas, saídas de ferramentas, aprovações, identidade usada, objeto de escopo em vigor e hashes de evidências. Sem isso, você não tem um assistente que possa revisar; você tem um gerador de histórias estocásticas ligado a efeitos colaterais. (Google Cloud)
A verificação deve levar em conta o não determinismo
A verificação tradicional de exploits pressupõe uma certa estabilidade. Os comportamentos vinculados à IA geralmente são menos estáveis. A metodologia prática do AISI observa que as assinaturas de ataque devem ser repetidas porque o comportamento do sistema pode ser probabilístico e não determinístico. O trabalho publicado pela Anthropic sobre defesas de injeção imediata no navegador usa a taxa de sucesso do ataque em tentativas repetidas em vez de uma mentalidade de aprovação/reprovação em uma única tentativa. Isso lhe diz algo importante: o assistente não deve transformar uma anomalia de resposta única em uma descoberta confirmada sem repetição, comparações de controle e consistência de evidências. (Japão AISI)
A injeção de prompt não é um bug do chatbot, é um risco operacional do assistente
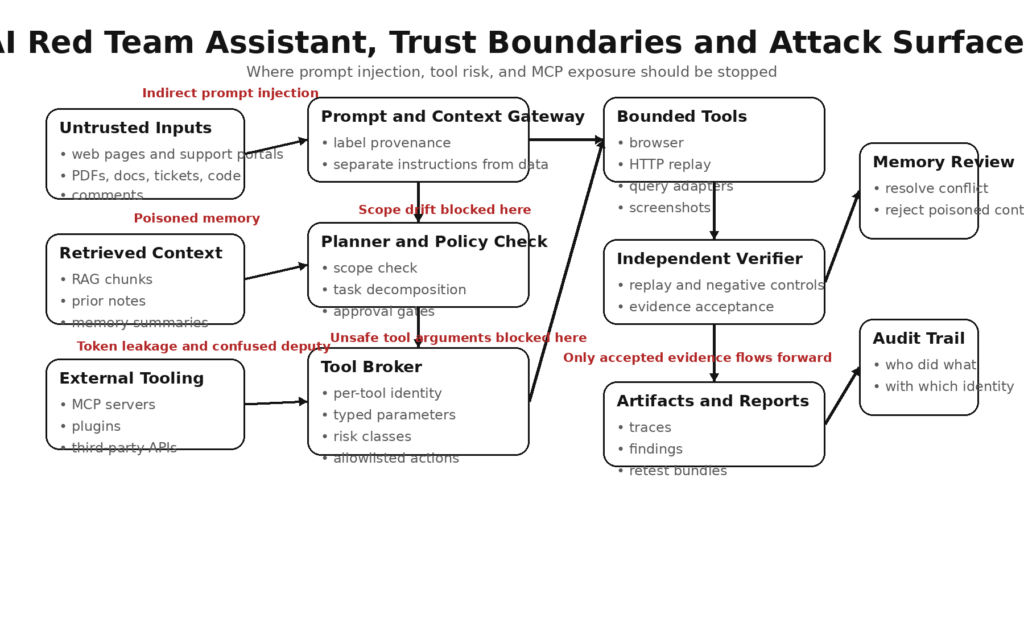
A injeção de prompt é discutida com tanta frequência que pode começar a parecer abstrata. Em um assistente da equipe vermelha de IA, ela não é nada abstrata. Geralmente, é o caminho mais curto da "automação útil" para o "comportamento delegado inseguro".
A OWASP define a injeção de prompt como uma vulnerabilidade em que os prompts do usuário alteram o comportamento ou as saídas do modelo de forma não intencional, e observa explicitamente que essas instruções não precisam ser visíveis para o ser humano se forem analisadas pelo modelo. A OWASP também afirma que o RAG e o ajuste fino não atenuam totalmente o problema. Isso é importante porque muitos assistentes são comercializados como "seguros para empresas" simplesmente porque leem a partir de documentos aprovados ou dependem de recuperação em vez de bate-papo aberto. Se esses documentos, comentários ou páginas puderem ser influenciados por um invasor, o limite de recuperação não removerá o limite de injeção. (Projeto de segurança de IA da OWASP Gen)
A injeção indireta de comandos é especialmente relevante para os assistentes porque eles consomem conteúdo como parte do fluxo de trabalho, e não apenas da conversa. A Unidade 42 descreve a injeção indireta de prompt baseada na Web como instruções manipuladas incorporadas em conteúdo benigno que um LLM processa posteriormente durante tarefas de rotina. Eles também descrevem as intenções de ataque observadas, incluindo evasão de revisão, promoção de phishing, vazamento de dados, vazamento de prompts e ações não autorizadas. Mesmo quando uma campanha específica não resulta em comprometimento confirmado, o modelo de ameaça já é realista o suficiente para ser importante para qualquer pessoa que esteja criando ou usando um assistente de atuação. (Unidade 42)
O trabalho de defesa de navegador da Anthropic torna o mesmo risco concreto. Um agente com capacidade para navegador vê um grande volume de material não confiável e tem muitas maneiras de agir sobre ele. O problema não se limita a truques exóticos de HTML. Uma página normal da Web, um tíquete de suporte ou uma descrição de problema pode se tornar uma fonte de comando se o assistente não conseguir separar os dados relevantes para a tarefa das instruções implantadas pelo invasor. É por isso que o uso do navegador não é apenas uma "entrada mais conveniente". É uma expansão da superfície adversária. (Antrópica)
Isso tem uma implicação direta nos fluxos de trabalho de testes ofensivos. As equipes vermelhas leem constantemente conteúdo não confiável: documentos de programas de recompensa por bugs, repositórios expostos, changelogs, centros de ajuda, fragmentos de configuração vazados, rastreadores de problemas públicos, contas de teste, wikis internos durante avaliações autorizadas e respostas de aplicativos controlados por alvos. Um assistente que não consegue tratar essas informações como entradas adversárias não é seguro o suficiente para ficar dentro do fluxo de trabalho. (Google Cloud)
O objetivo correto não é fingir que a injeção imediata pode ser eliminada. É projetar o assistente de modo que a injeção não tenha um lugar perigoso para aterrissar. Isso significa padrões somente de leitura, limites de alta fricção em torno de ferramentas que alteram o estado, rastreamento de procedência imediata, rotulagem de conteúdo, compartimentalização de contexto e verificação de saída que não confia no resumo do próprio modelo sobre o que acabou de acontecer. (Antrópica)
MCP, ferramentas locais e o falso conforto do localhost
Se a injeção imediata é o problema mais discutido na segurança do assistente, a segurança de integração no estilo MCP é a mais subestimada.
O MCP é um protocolo aberto para conectar aplicativos do LLM a dados e ferramentas externas. A documentação oficial do protocolo discute os recursos de conveniência e as implicações de segurança que os acompanham, incluindo privacidade de dados, consentimento do usuário, segurança da ferramenta e problemas mais especializados, como comportamento confuso do delegado. O documento de práticas recomendadas de segurança adverte que servidores proxy MCP mal projetados podem permitir que clientes mal-intencionados obtenham autorização sem o devido consentimento do usuário, especialmente quando IDs de clientes estáticos compartilhados, registro dinâmico e cookies de consentimento se misturam de forma inadequada. (Modelo de protocolo de contexto)
Isso é importante para um assistente de equipe vermelha de IA porque o MCP altera o limite de confiança de duas maneiras.
Primeiro, ele tende a normalizar a ideia de que um modelo pode se comunicar com muitas ferramentas por meio de um protocolo comum. Isso é operacionalmente útil e, ao mesmo tempo, sensível à segurança. Aumenta o número de caminhos de ação possíveis e a chance de que uma chamada de ferramenta de aparência segura possa chegar a um backend avançado por meio de um proxy que o operador não compreende totalmente. (Modelo de protocolo de contexto)
Em segundo lugar, ele incentiva os desenvolvedores a executar serviços localmente e presumir que a localidade é equivalente à segurança. CVEs recentes mostram o contrário. O CVE-2026-34742 afetou o MCP Go SDK antes da versão 1.4.0 porque a proteção de religação de DNS foi desativada por padrão para determinados manipuladores de HTTP, possibilitando que um site mal-intencionado alcançasse um servidor MCP local se outras proteções estivessem ausentes. Problemas semelhantes de religação de DNS foram divulgados para o Python MCP SDK antes da versão 1.23.0 e para o TypeScript SDK antes da versão 1.24.0. A lição é mais ampla do que qualquer linguagem: se o seu assistente expõe serviços locais baseados em HTTP, o navegador se torna parte da sua superfície de ataque, quer você queira ou não. (GitHub)
O mesmo padrão aparece nos erros de manipulação de tokens. A orientação de segurança do MCP chama explicitamente a passagem de tokens de um antipadrão porque pode prejudicar os limites de autorização e o isolamento do cliente. Um assistente da equipe vermelha que herda tokens de usuário, encaminha-os entre servidores ou compartilha-os entre contextos pode ser operacionalmente conveniente e arquitetonicamente inadequado. O resultado pode ser o uso não autorizado da API que se parece com o tráfego legítimo do assistente. (Modelo de protocolo de contexto)
Para os profissionais, as perguntas mínimas são diretas. Cada cliente obtém consentimento isolado? Os tokens são restritos ao público e de curta duração? A exposição do host local inclui defesas de religação de DNS? As ferramentas são categorizadas por risco em vez de serem agrupadas como "habilidades" genéricas? O operador pode ver qual identidade foi usada em cada chamada de ferramenta? Se a resposta for vaga, a camada de integração não está madura o suficiente para um trabalho ofensivo sério. (Modelo de protocolo de contexto)
CVEs reais que mapeiam diretamente as falhas de projeto do assistente
A maneira mais fácil de analisar as reivindicações de segurança de IA é examinar as classes de vulnerabilidade reais relacionadas a agentes, integrações de MCP e ambientes de codificação conectados a ferramentas. O padrão interessante é que as falhas mais relevantes raramente são "o modelo foi desbloqueado" isoladamente. Em geral, são falhas de confiança na configuração, separação de identidade, exposição local ou mediação de ferramenta insegura.
| CVE | Componente | Tipo de vulnerabilidade | Por que isso é importante para os assistentes da equipe vermelha de IA |
|---|---|---|---|
| CVE-2025-53098 | Código Roo | Caminho de execução do prompt para a configuração para o comando | Mostra como um modelo pode ser induzido a escrever uma configuração insegura que depois é executada com a aprovação do usuário |
| CVE-2025-34072 | Servidor do Anthropic Slack MCP obsoleto | Exfiltração de dados confidenciais por meio do desdobramento automático de links | Mostra como as visualizações de mensagens e os links externos podem vazar dados acessíveis ao assistente |
| CVE-2026-34742 | MCP Go SDK | Proteção contra religação de DNS desativada por padrão em determinados caminhos HTTP | Mostra que o localhost faz parte da superfície de ataque da Web se for exposto por meio de HTTP |
| CVE-2025-66416 | MCP Python SDK | Falta de proteção de religação de DNS padrão | A mesma lição em outro tempo de execução |
| CVE-2025-66414 | SDK do MCP TypeScript | Falta de proteção de religação de DNS padrão | A mesma lição em outro tempo de execução |
| CVE-2026-33980 | Servidor MCP do Explorador de Dados do Azure | Injeção de KQL em manipuladores de ferramentas | Mostra que as ferramentas de consulta podem se tornar superfícies de injeção de back-end quando os parâmetros não são mediados com segurança |
CVE-2025-53098, Código Roo e o perigo de permitir que os prompts reescrevam a confiança
A consultoria do GitHub para o CVE-2025-53098 descreve um problema no Roo Code em que o nível de projeto .roo/mcp.json pode ser usada para obter a execução arbitrária de comandos. O aviso explica uma cadeia plausível: um prompt mal-intencionado pode fazer com que o agente escreva um comando criado na configuração e, se o usuário tiver aprovado automaticamente as modificações no arquivo, a execução arbitrária do comando poderá ocorrer. Esse não é um ponto fraco exótico do LLM. É uma falha de limite clássica em que o conteúdo controlado por prompt pode modificar o material confiável executável. (GitHub)
Para um assistente de equipe vermelha de IA, esse é um cuidado importante. Muitos fluxos de trabalho ofensivos envolvem legitimamente arquivos de configuração, livros de execução, manifestos de tarefas ou definições locais de harness. Se o modelo puder reescrever esses arquivos como parte de um fluxo "útil", a configuração se tornará parte da cadeia de execução de código. A correção não consiste apenas em aplicar patches em uma versão do produto. A atenuação geral é tratar a política e a configuração como ativos protegidos: separar as permissões de edição das permissões de tempo de execução, exigir revisão humana para alterações de configuração executáveis e nunca permitir que a configuração gerada pelo assistente se torne um estado de tempo de execução confiável sem validação. (GitHub)
CVE-2025-34072, desdobramento do link MCP do Slack e caminhos ocultos de exfil
O CVE-2025-34072 afetou um servidor Anthropic Slack MCP obsoleto e envolveu a exfiltração de dados confidenciais por meio de links criados automaticamente por invasores. Isso é importante porque muitas implantações de assistentes tocam sistemas de bate-papo, sistemas de emissão de tíquetes ou plataformas de colaboração em que "visualizar este link" parece inofensivo. Na realidade, os caminhos de visualização e enriquecimento geralmente são executados com acesso a dados contextuais ou segredos que o invasor original nunca deveria receber. (GitHub)
A lição para um assistente de equipe vermelha é que a distinção entre "ação da ferramenta" e "recurso de conveniência em segundo plano" geralmente é falsa. O desdobramento de links, o resumo de conteúdo, a extração de metadados e o enriquecimento automático podem se tornar superfícies de exfiltração se ocorrerem em conteúdo controlado por invasores. A direção da atenuação é desativar o enriquecimento automático em entradas não confiáveis, isolar os tokens usados para integrações de mensagens e exigir uma camada de mediação explícita entre o conteúdo externo e o contexto visível para o assistente. (GitHub)
CVE-2026-34742, localhost não é um limite de confiança livre
A divulgação do CVE-2026-34742 no MCP Go SDK é útil porque quebra uma suposição ruim persistente: "Ele só escuta no localhost, então está tudo bem". Antes das versões corrigidas, a proteção contra religação de DNS era desativada por padrão em determinados manipuladores baseados em HTTP, criando um caminho para que sites mal-intencionados acessassem serviços MCP locais sob as condições certas. Lacunas semelhantes de proteção padrão foram documentadas posteriormente para os SDKs Python e TypeScript. (GitHub)
Para um assistente de equipe vermelha de IA, isso significa que a exposição à ferramenta apenas local não é suficiente. Se o assistente também opera um navegador, lê conteúdo da Web ou compartilha o host com uma sessão normal do navegador, a linha entre local e remoto fica mais tênue do que as equipes esperam. As atenuações fortes incluem defesas de religação de DNS, autenticação obrigatória mesmo em serviços locais, verificações rigorosas de origem quando aplicável, firewall em nível de host e recusa em expor ferramentas de alto impacto por meio de HTTP genérico quando houver opções de IPC mais restritas disponíveis. (Modelo de protocolo de contexto)
CVE-2026-33980, a mediação de consultas faz parte da segurança da ferramenta
O CVE-2026-33980 afetou um servidor MCP do Azure Data Explorer por meio de injeção de KQL em manipuladores de ferramentas em que a entrada controlada pelo usuário foi interpolada de forma insegura. Esse é um exemplo útil porque mostra como um recurso aparentemente passivo de "recuperação de dados" se torna uma superfície de execução quando a camada de mediação é fraca. Um assistente não precisa de acesso ao shell para causar danos. Se ele puder influenciar as consultas de back-end em armazenamentos de dados confidenciais, isso é suficiente. (GitHub)
A lição geral é que a segurança da ferramenta não se refere apenas a qual ferramenta pode ser chamada. Trata-se também de como os argumentos são traduzidos no sistema de backend. Um assistente seguro deve preferir parâmetros digitados, operações listadas, consultas preparadas onde o backend as suporta e verificações do lado do verificador que distinguem "recuperou o conjunto de dados esperado" de "o assistente sintetizou uma consulta exploratória ampla porque parecia útil". (Modelo de protocolo de contexto)
Esses CVEs também expõem uma verdade mais ampla. Na segurança do assistente, as bordas afiadas se agrupam em torno do chicote e dos adaptadores. É por isso que é enganoso comercializar um sistema como seguro simplesmente porque o modelo básico tem um bom comportamento de recusa. A questão relevante é se todo o caminho, do prompt à ferramenta, ao ambiente e ao artefato, foi projetado como um pipeline seguro. (cdn.openai.com)
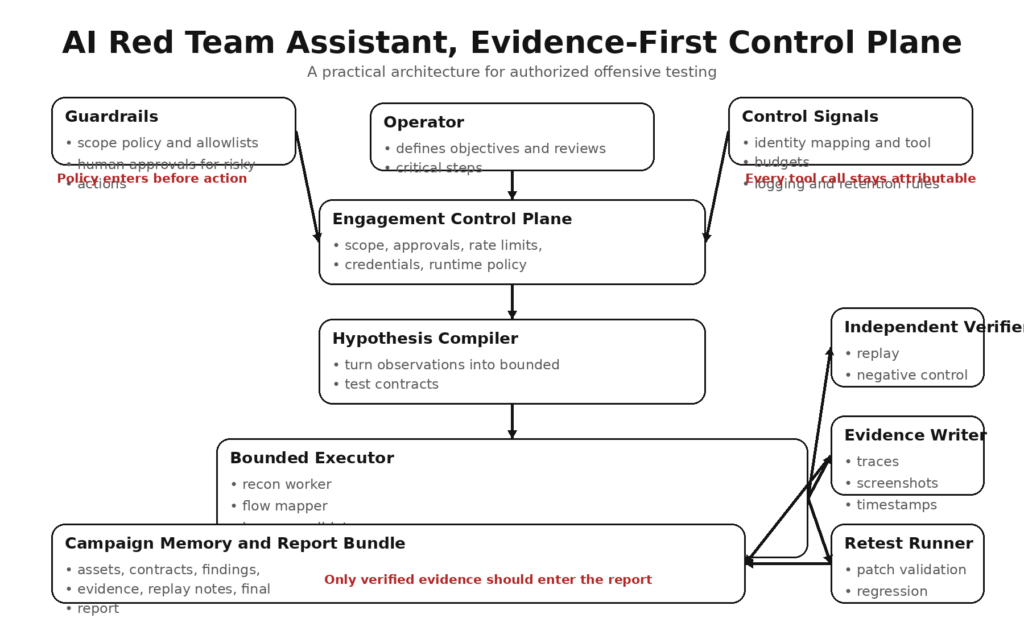
Uma arquitetura prática para testes ofensivos autorizados

Uma arquitetura viável para um assistente de equipe vermelha de IA se parece menos com um chatbot e mais com um equipamento de teste restrito.
1. Plano de controle de engajamento
Essa camada possui autorização, escopo, tempo, inventário de ferramentas, identidades, controles de taxa, regras de registro e política de ação destrutiva. Ela deve ser o único lugar onde o assistente aprende o que pode fazer. Esse design está alinhado com a orientação do processo no NIST SP 800-115 e com a estrutura mais ampla de governança e gerenciamento de riscos no Perfil de IA Generativa do NIST. (csrc.nist.gov)
2. Compilador de hipóteses
O assistente não deve passar diretamente das observações para a ação. Ele deve primeiro converter as observações em contratos de teste limitados. Um contrato pode dizer: "Compare o acesso de leitura de objetos para duas identidades somente leitura em relação a um endpoint de API de teste usando ferramentas somente de repetição, preserve os rastros de solicitação/resposta, sem alterações de estado." É aqui que o sistema traduz o reconhecimento ruidoso em algo testável e revisável. A metodologia do AISI é útil aqui porque trata o planejamento de ataques como um estágio disciplinado em vez de uma continuação improvisada do reconhecimento. (Japão AISI)
3. Executor limitado
O executor executa o contrato usando apenas as ferramentas e identidades declaradas. Ele não decide que precisa repentinamente da instalação de pacotes, de um novo acesso à rede ou de uma integração extra porque o modelo parece curioso. Os conjuntos de ferramentas estáticas são mais fáceis de auditar do que a expansão dinâmica. Se a expansão dinâmica for necessária, ela deverá ocorrer sob aprovação explícita. A orientação sobre componentes de agente da Microsoft é relevante aqui porque destaca os benefícios de segurança e previsibilidade dos conjuntos de ferramentas fixos. (Microsoft Learn)
4. Verificador independente
O verificador não pergunta: "O modelo achou que isso funcionou?" Ele pergunta: "Isso pode ser reproduzido novamente, sob as mesmas restrições, com a mesma alegação?" O trabalho de red teaming da OpenAI enfatiza que o red teaming deve informar avaliações mais amplas e repetíveis em vez de atuar como a única medida de risco do sistema. Um verificador em fluxos de trabalho ofensivos tem a mesma função, forçando as evidências a passar por um portão de aceitação mais restrito. (cdn.openai.com)
5. Redator de evidências
Toda ação significativa deve deixar um pacote: registros de data e hora, prompts ou IDs de tarefas, chamadas de ferramentas, identidade em uso, traços de solicitação e resposta, capturas de tela, se relevantes, controles negativos, resultados de repetição e notas de limpeza. A Equipe Vermelha de IA do Google fala sobre registros detalhados de atividades e narrativas de ataques; os assistentes ofensivos devem produzir algo semelhante, mas com precisão técnica suficiente para que outro engenheiro possa reproduzir o caminho. (Google Cloud)
6. Corredor de reteste
Os resultados se degradam rapidamente se não puderem ser revalidados após um patch ou mudança de ambiente. Um assistente que ajuda a criar testes reproduzíveis é muito mais valioso do que um que produz transcrições únicas e dramáticas. A orientação pública do Promptfoo é útil aqui porque trata o red teaming como uma sondagem sistemática que pode ser repetida e medida em muitas sondagens e iterações, incluindo fluxos de trabalho no estilo CI. (Promptfoo)
Na prática, as equipes que avaliam essa categoria geralmente se preocupam menos com o fato de o modelo parecer impressionante e mais com o fato de o fluxo de trabalho ser controlável. Os materiais do Public Penligent são notáveis aqui porque enfatizam fluxos de trabalho agênticos controlados pelo operador, avisos editáveis e limites de ação com reconhecimento de escopo, em vez de puro teatro de autonomia. Essa é a direção certa para essa classe de sistema: a assistência ofensiva deve parecer mais com um controle rígido do que com um operador sem limites. (penligent.ai)
O que o assistente deve realmente fazer durante um compromisso
Um bom assistente de equipe vermelha de IA ajuda mais nas partes de uma avaliação que são estruturadas, repetitivas e com muitas evidências.
Organização de reconhecimento
O assistente pode agrupar observações de documentos, rotas, APIs e padrões de resposta em hipóteses de ataque testáveis. A palavra importante é testável. Ele não deve transformar "interessante" em "vulnerável". Ele deve transformar "essas duas funções parecem receber filtros diferentes para a mesma família de objetos" em "compare a autorização em nível de objeto sob essas identidades usando solicitações somente de repetição". (csrc.nist.gov)
Mapeamento de fluxo autenticado
Os assistentes são úteis para rastrear fluxos de aplicativos com estado: aquisição de sessão, manipulação de token CSRF, formulários de várias etapas, alterações de função, sinalizadores de recursos e referências a objetos. É nesse ponto que os sistemas de bate-papo simples geralmente falham, porque perdem o estado e generalizam demais. Em vez disso, um assistente limitado pode manter uma árvore de tarefas, armazenar pontos de verificação de fluxo higienizados e ajudar o operador a decidir quais transições valem a pena testar. (penligent.ai)
Repetição e comparação controladas
O assistente é particularmente valioso quando pode reproduzir solicitações de baixo risco em várias identidades, difundir resultados e preservar artefatos. Isso dá suporte a testes clássicos de autorização, testes de lógica comercial e testes de regressão sem conceder liberdade ilimitada ao sistema. O segredo é manter a camada da ferramenta estreita e os requisitos de evidência rigorosos. (csrc.nist.gov)
Embalagem de evidências
A maior parte do problema em compromissos reais não é descobrir uma ideia. É provar a ideia, documentá-la com clareza e preservar o contexto suficiente para um novo teste. Um assistente que possa reunir traços, capturas de tela, identificadores de objetos, contexto de funções, registros de data e hora, notas de impacto e dicas de correção em um formato de descoberta estável é realmente útil. Um que só consegue fazer resumos chamativos não é. (csrc.nist.gov)
Novo teste após a correção
Esse é um dos melhores usos da assistência de IA porque o comportamento-alvo é restrito e os critérios de aceitação são concretos. O assistente pode executar novamente as comparações anteriores, confirmar que os controles negativos ainda se comportam adequadamente e atualizar o conjunto de evidências. Isso se alinha com a ideia mais ampla dos materiais da OpenAI e da AISI de que os insights da equipe vermelha devem alimentar avaliações repetidas em vez de ficarem presos em uma única sessão. (cdn.openai.com)
A distinção entre "sugestão" e "descoberta verificada" é importante aqui. O texto público da Penligent sobre copilotos de pentest de IA e arreios que priorizam as evidências faz essa distinção explicitamente, e é uma maneira útil de avaliar qualquer ferramenta nessa categoria. Se um fornecedor não puder mostrar como as sugestões se tornam descobertas confirmadas sob execução e repetição limitadas, você provavelmente está procurando uma interface inteligente, não um assistente que possa resistir a testes reais. (penligent.ai)
Exemplo, um teste de controle de acesso multilocatário autorizado
A maneira mais segura de explicar o fluxo de trabalho é com um exemplo sintético, mas realista.
Suponha um envolvimento autorizado em um ambiente de preparação para um aplicativo SaaS multilocatário. O objetivo é restrito: verificar se os usuários somente leitura do locatário A podem acessar metadados de objetos pertencentes ao locatário B por meio de um endpoint de API. O ambiente é de teste, as identidades são aprovadas e a política proíbe ações de alteração de estado ou enumeração em massa. Essa configuração reflete a ênfase do NIST em testes sob restrições explícitas. (csrc.nist.gov)
O trabalho do assistente não é "hackear o aplicativo". Seu trabalho é ajudar a transformar as observações em uma sequência de teste segura. Ele recebe a descrição da OpenAPI, algumas solicitações de linha de base capturadas de cada função e a política de engajamento. Ele observa que as referências de objeto são do tipo UUID, o esquema de resposta inclui metadados com escopo de locatário e a mesma família de recursos pode ser acessada de ambas as identidades em diferentes exibições de lista. Ele propõe um contrato de comparação somente leitura em vez de um plano de enumeração aberto. (Japão AISI)
Um revisor humano aprova o contrato porque ele permanece dentro do escopo e usa apenas ferramentas de repetição. Em seguida, o executor executa um conjunto mínimo de solicitações: uma leitura conhecida como boa pelo locatário A para um objeto de propriedade de A, uma leitura conhecida como boa pelo locatário B para um objeto de propriedade de B e uma repetição entre locatários usando a mesma estrutura de caminho, mas sem operações de gravação, sem fuzzing de parâmetro e sem volume. Em seguida, o verificador verifica se a repetição entre locatários retornou uma falha de autorização, uma divulgação parcial ou uma resposta completa do objeto. Ele também realiza um controle negativo usando uma referência de objeto claramente inexistente para distinguir o desvio de autorização do tratamento inconsistente de erros. (csrc.nist.gov)
Um bloco de repetição ilustrativo pode ter a seguinte aparência:
GET /api/v1/documents/9b3d3c8f-tenant-b-object HTTP/1.1
Host: staging.api.example.test
Autorização: Portador TENANT_A_READER_TOKEN
Aceitar: application/json
X-Trace-Mode: replay
O assistente não deve decidir por conta própria que uma resposta surpreendente comprova uma vulnerabilidade. Em vez disso, o verificador verifica a consistência. O mesmo resultado ocorreu duas vezes? Ele ocorreu somente em uma identidade? O objeto era definitivamente de propriedade do outro locatário? A resposta incluiu campos confidenciais ou apenas metadados públicos? Havia algum artefato de cache ou comportamento de proxy obsoleto que pudesse explicar o resultado? Essas são as perguntas que distinguem a evidência da empolgação. (Japão AISI)
Se a descoberta for válida, o pacote de relatórios deverá conter os rastreamentos de linha de base, a repetição entre locatários, o controle negativo, as identidades usadas, os registros de data e hora, os critérios exatos de aceitação e uma declaração de impacto restrita. Algo como "divulgação de metadados somente leitura entre locatários confirmada para objetos de documentos no endpoint X" é muito melhor do que "falha crítica no isolamento do locatário", a menos que as evidências sustentem uma afirmação mais forte. O assistente pode ajudar a redigir o relatório, mas a declaração de gravidade ainda deve ser revisada por uma pessoa. (csrc.nist.gov)
Esse exemplo é deliberadamente modesto, e esse é o ponto. Um assistente de equipe vermelha de IA ganha confiança ao ajudar com um trabalho de verificação limitado e passível de revisão. Se não for capaz de fazer isso bem, não há por que confiar-lhe uma autonomia mais ampla. (Microsoft Learn)
Por que a automação mente nos momentos mais importantes
A automação é excelente para produzir movimento. Ela é menos confiável na produção de provas.
O documento da OpenAI deixa explícito que a formação de equipes vermelhas é uma entrada em uma pilha de avaliação e governança mais ampla, e não uma garantia independente. O guia prático da AISI trata os ataques repetidos e os relatórios estruturados como necessários porque observações isoladas não são suficientes. A orientação do Promptfoo enfatiza a sondagem sistemática e os resultados mensuráveis em várias execuções. Juntas, essas fontes apontam para a mesma lição: a automação ofensiva de IA tem maior probabilidade de enganar você quando o sistema tem permissão para converter sinais incertos em conclusões fortes. (cdn.openai.com)
Veja a seguir os modos de falha mais comuns:
Um resultado de scanner se torna um "caminho de exploração" porque o assistente pode explicar por que isso pode ser importante. Um artefato do navegador se torna um "acesso confirmado aos dados" porque o modelo narra o estado da página com confiança. Uma resposta anômala pontual torna-se uma vulnerabilidade estável porque o assistente é recompensado por uma linguagem decisiva. Uma classificação de gravidade gerada supera as evidências. Uma sugestão de correção torna-se confiável, mesmo que o assistente nunca tenha verificado a causa raiz. (csrc.nist.gov)
É também nesse ponto que os modelos de linguagem altamente capacitados podem piorar as coisas. Um raciocínio mais sólido pode fazer com que as narrativas sem suporte pareçam mais coerentes. Isso não significa que os modelos sejam inúteis. Significa que o limite de aceitação deve permanecer não linguístico: traços, controles, repetições e verificações claras do escopo. Os seres humanos não precisam do assistente para parecerem inteligentes. Eles precisam dele para manter o trabalho organizado sem fabricar certezas. (cdn.openai.com)
Ferramentas de código aberto, como Garak, Promptfoo e Counterfit da Microsoft, são úteis justamente porque reforçam essa mentalidade de medição de maneiras diferentes. O Promptfoo enfatiza a sondagem adversária automatizada e a avaliação do comportamento dos aplicativos de IA. O Garak se apresenta como um scanner de vulnerabilidade LLM. O Counterfit automatiza os testes de segurança para sistemas de IA e mapeia para técnicas de ML adversárias. Nenhuma dessas ferramentas substitui magicamente a validação em nível de sistema, mas, juntas, elas ilustram o hábito correto: usar a automação para expandir a cobertura e a regressão, não para dispensar os requisitos de prova. (Promptfoo)
A visão de um defensor, o que as equipes azuis e os proprietários de plataformas devem registrar e controlar
As equipes azuis não precisam adivinhar como avaliar esses sistemas. As mesmas propriedades que tornam um assistente útil para as equipes vermelhas o tornam observável para os defensores.
O Generative AI Profile do NIST é útil porque trata a segurança, a privacidade e outros riscos como preocupações do ciclo de vida que precisam ser gerenciadas por meio de funções de governança, mapeamento, medição e gerenciamento. O SAIF do Google também enquadra a segurança da IA como uma extensão das bases de segurança, detecção, resposta e defesas automatizadas existentes. Esses documentos não são específicos para assistentes ofensivos, mas os controles são bem traduzidos. (nvlpubs.nist.gov)
Uma equipe de plataforma que supervisiona um assistente de equipe vermelha de IA deve capturar pelo menos as seguintes classes de telemetria:
| Classe de telemetria | Por que é importante |
|---|---|
| Metadados de prompts e tarefas | Reconstruir a intenção do operador e identificar fontes de injeção |
| Trilha de auditoria de chamadas de ferramentas | Veja o que de fato aconteceu, não o que o assistente afirmou posteriormente |
| Mapeamento de identidade e credenciais | Vincule cada ação à conta ou ao token exato usado |
| Procedência do conteúdo | Distinguir documentação confiável de conteúdo não confiável da Web ou do usuário |
| Eventos de aprovação | Analisar se os limites de alto risco foram contornados ou usados em excesso |
| Hashes de artefatos de evidência | Preservar a integridade de capturas de tela, rastros e pacotes de relatórios |
| Alterações de memória | Detectar envenenamento, conflito e suposições obsoletas que entram em estado persistente |
O material público do agente Security Copilot da Microsoft também contém uma pista operacional valiosa: mesmo em um produto defensivo, os usuários são instruídos a analisar a tomada de decisão do agente antes de agir, e o feedback armazenado precisa de atenção devido à ambiguidade e ao conflito. Isso deve reduzir a tolerância para produtos ofensivos que alegam autonomia do tipo "configure e esqueça". Se uma plataforma que a própria Microsoft descreve como digna de visualização ainda espera revisão humana e higiene da memória, um assistente da equipe vermelha de IA não deve prometer menos escrutínio ao assumir tarefas mais perigosas. (Microsoft Learn)
Os defensores também devem decidir antecipadamente quais ações desencadeiam uma parada forçada. Os exemplos incluem qualquer tentativa de exportar credenciais, qualquer chamada de rede externa não aprovada, qualquer alteração na configuração de executáveis, qualquer acesso a sistemas rotulados como de produção e qualquer ampliação do conjunto de ferramentas além da política de envolvimento atual. Essas não são proteções em nível de modelo. São salvaguardas no plano de controle e são mais fáceis de entender. (Modelo de protocolo de contexto)
Comprando ou construindo, as perguntas que importam
Se estiver avaliando um fornecedor ou um protótipo interno, há uma pequena lista de perguntas técnicas que separa os sistemas sérios dos de nível de demonstração.
- O assistente pode impor um escopo legível por máquina ou ele só lê o escopo em linguagem natural.
- As ferramentas são declaradas estaticamente, adicionadas dinamicamente ou ambas.
- As ações de alto risco podem exigir aprovação humana explícita.
- Existe um caminho de verificação separado ou o mesmo modelo aprova suas próprias descobertas?
- Quais artefatos de evidência são obrigatórios antes que uma descoberta seja aceita.
- Como o sistema lida com conteúdo não confiável da Web, texto de problemas, PDFs ou resultados de RAG.
- A memória existe e, em caso afirmativo, como o envenenamento ou a ambiguidade são analisados?
- Com quais identidades as ferramentas funcionam e quão restritas são essas identidades.
- Se o MCP estiver envolvido, como são controlados o consentimento, o isolamento do token e a exposição do host local?
- As descobertas podem ser reproduzidas após a correção.
- O operador consegue distinguir sugestões de descobertas verificadas.
- Os registros são completos o suficiente para que outro engenheiro possa reconstruir a execução. (Microsoft Learn)
Uma resposta fraca a qualquer uma dessas perguntas não necessariamente desqualifica um sistema. Mas uma resposta fraca a várias delas geralmente significa que o produto está otimizando a fluidez da demonstração em vez da integridade do engajamento. Essa troca pode ser aceitável para pesquisas ou anotações. Não é aceitável para uma ferramenta que pretende auxiliar em testes ofensivos reais. (csrc.nist.gov)
O que o termo deve significar daqui para frente
A frase Assistente da equipe vermelha de IA vale a pena manter, mas somente se isso significar algo mais rigoroso do que "chatbot de segurança com acesso a ferramentas".
Um assistente real nessa categoria deve operar sob autorização explícita, executar com identidades restritas, consumir conteúdo não confiável sem obedecê-lo cegamente, separar o planejamento da execução e da verificação, preservar artefatos por padrão e tratar as evidências reproduzíveis como mais importantes do que a narração eloquente. O modelo é importante, mas o equipamento é ainda mais importante. Os materiais públicos da OpenAI e da AISI apontam para a estrutura, a repetibilidade e a avaliação em vários estágios, em vez da improvisação. O trabalho público do Google e da Anthropic deixa claro que as superfícies de integração e a capacidade de atuação são onde os riscos reais aparecem. A própria orientação de segurança do MCP deixa claro que o protocolo e a camada do adaptador não podem ser tratados como um detalhe de implementação. (cdn.openai.com)
Esse é o padrão que vale a pena usar, seja na compra de um produto, na criação de um sistema interno ou na tentativa de entender a última onda de alegações de "segurança agêntica". Se o assistente não puder produzir ação limitada, evidência limpa e comportamento revisável, ele não estará pronto para um envolvimento real. Ele ainda é apenas uma interface convincente. (csrc.nist.gov)
Leitura adicional e referências
- Microsoft AI Red Team, visão geral e princípios de planejamento para sistemas de IA de equipe vermelha. (Microsoft Learn)
- OpenAI, Abordagem da OpenAI em relação à equipe vermelha externa. (cdn.openai.com)
- NIST SP 800-115, Guia técnico para testes e avaliações de segurança da informação. (csrc.nist.gov)
- NIST, Estrutura de gerenciamento de riscos de inteligência artificial, perfil de inteligência artificial generativa. (nvlpubs.nist.gov)
- Google, Estrutura de IA segura do Google, SAIF. (Centro de Segurança)
- Google Cloud, Como o Google faz isso, criando uma equipe vermelha de IA eficaz. (Google Cloud)
- OWASP, LLM01 Injeção imediata. (Projeto de segurança de IA da OWASP Gen)
- OWASP, Os 10 principais aplicativos agênticos para 2026. (Projeto de segurança de IA da OWASP Gen)
- Protocolo de contexto de modelo, Especificação e Práticas recomendadas de segurança. (Modelo de protocolo de contexto)
- Antrópico, Mitigando o risco de injeções imediatas no uso do navegador. (Antrópica)
- Antrópico, Modo automático do código Claude, uma maneira mais segura de ignorar permissões. (Antrópica)
- Unidade 42, Enganando agentes de IA, injeção de prompt indireto com base na Web observada na natureza. (Unidade 42)
- Promptfoo, Guia da Equipe Vermelha do LLM. (Promptfoo)
- Garak, scanner de vulnerabilidade LLM de código aberto. (Garak)
- Counterfit, automação de código aberto para testes de segurança de sistemas de IA. (Microsoft)
- Ferramenta AI Pentest, como será a verdadeira ofensa automatizada em 2026. (penligent.ai)
- AI Pentest Copilot, de sugestões inteligentes a descobertas verificadas. (penligent.ai)
- Arnês de código Claude para pentesting de IA. (penligent.ai)

