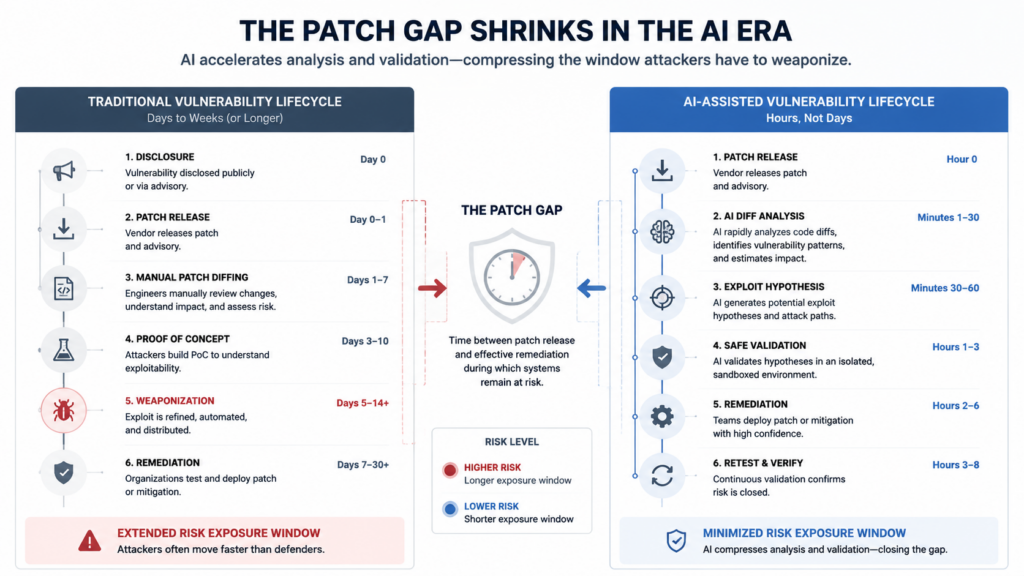
The patch gap is no longer a quiet administrative delay. It is an exploitation window.
For years, defenders could often assume that a public patch bought them some time. Attackers still had to compare the vulnerable and fixed versions, reverse engineer the bug, build a proof of concept, adapt it to real environments, find exposed targets, and turn the whole thing into a campaign. That work took skill. It also took time.
That assumption is weakening.
CISA’s June 2026 Binding Operational Directive 26-04 gives U.S. federal civilian agencies only three calendar days to address the highest-risk categories of vulnerabilities by fixing, disabling, or removing exposed vulnerable assets from the internet, while lower-risk categories receive longer deadlines. Reuters reported that the shorter timeline was driven in part by concern that AI is compressing the defender response window. (Reuters)
Anthropic’s June 2026 N-day research makes the same pressure concrete from the offensive side. In controlled experiments, Claude Mythos Preview generated working code-execution exploits for 8 of 18 recent Firefox SpiderMonkey security patches and full Windows kernel privilege-escalation chains for 8 of 21 Windows kernel patches, with some proof-of-concept work arriving in minutes and some working exploits in hours. Anthropic’s own conclusion was blunt: “N-hour” is now closer to the reality defenders face than the older phrase “N-day.” (red.anthropic.com)
That does not mean every disclosed vulnerability becomes instantly exploitable. It does not mean every criminal operator suddenly becomes a kernel exploit developer. It does not mean a model can magically bypass asset visibility, authentication, exploit delivery, EDR, network controls, or operational mistakes. Real attacks still require target discovery, infrastructure, delivery, persistence, evasion, and post-compromise decisions.
But it does mean the old operating model is too slow.
A security team that learns about a critical vulnerability on Monday, waits for the weekly scanner on Friday, opens tickets the following week, patches the following month, and retests during the next quarterly pentest is no longer operating in the same time scale as AI-assisted exploitation. The question is not whether organizations should patch faster. They should. The deeper question is whether they can verify risk fast enough to know what to patch first, what to isolate, what to monitor, what to retest, and what evidence proves the dangerous path is closed.
That is where continuous AI pentesting becomes security infrastructure.
Not as a slogan. Not as an excuse to let autonomous agents roam across production. Not as a replacement for skilled security engineers. Continuous AI pentesting is the discipline of using authorized AI-assisted offensive workflows to repeatedly validate high-risk attack paths after meaningful changes in software, infrastructure, threat intelligence, exposure, identity, or remediation status. It connects vulnerability intelligence to real deployable proof.
A scanner says, “This version may be vulnerable.”
Continuous AI pentesting asks, “Can the exposed system in this environment be used to create real security impact, and can we prove that the fix works?”
N-day used to mean known but not yet closed
A zero-day is a vulnerability unknown to the software maintainer or without an available fix. An N-day is different. It is already disclosed. It may already have a patch. The danger comes from the gap between disclosure and full remediation across real systems.
That gap can exist for many reasons. Some assets are forgotten. Some are internet-facing but not owned by the team receiving the advisory. Some vendors ship patches before customers can test them. Some enterprise systems require maintenance windows. Some products are embedded in appliances. Some dependencies are transitive and invisible to the application owner. Some systems are technically patched but still expose old vulnerable behavior through a backported package, a stale container, a shadow service, or a missed node behind a load balancer.
Attackers do not need every organization to be slow. They need enough organizations to be slow.
Patch diffing is one reason N-days are dangerous. Once a vendor publishes a fix, the patch itself can reveal where the bug lives. In open-source projects, attackers can compare source changes directly. In closed-source software, they can compare patched and unpatched binaries, inspect symbols, use decompilers, and infer the vulnerability from changed control flow. Anthropic’s N-day study describes this dynamic clearly: a patch can become a roadmap to the bug, and a working exploit may become a matter of time. (red.anthropic.com)
The historic defender advantage was that this work required scarce expertise. Browser exploitation, kernel exploitation, heap shaping, use-after-free analysis, and reliable privilege escalation are not commodity skills. That scarcity bought defenders time. It did not make N-days safe, but it kept many vulnerabilities from becoming mass-exploited immediately after disclosure.
AI changes that economics in two ways.
First, it can speed up expert work. A skilled exploit developer with a good harness can ask an AI agent to inspect diffs, summarize reachable code paths, generate candidate triggers, compile and test PoCs, interpret crashes, and iterate faster.
Second, it can make some parts of exploit development accessible to operators who would not have completed the workflow manually. The model does not need to be perfect to matter. It only needs to remove enough bottlenecks that more actors can attempt more vulnerabilities in less time.
The difference between the old and new response model looks like this:
| 스테이지 | Older defender assumption | AI-compressed reality | Defensive implication |
|---|---|---|---|
| Patch release | A fix starts the remediation clock | A fix may also start the exploit-development clock | Treat high-risk patches as intelligence events, not routine maintenance |
| Reverse engineering | Requires scarce specialist effort | AI can accelerate diff analysis, decompilation review, and hypothesis generation | Prioritize vulnerabilities whose patches reveal reachable exposed code paths |
| Proof of concept | Often takes days or weeks for difficult targets | Some PoCs can be produced in minutes or hours under controlled conditions | Do not wait for public PoC availability before triage |
| 무기화 | Still requires real-world adaptation | AI can assist with debugging, environment adaptation, and chaining | Validate exposure and compensating controls before exploit code circulates |
| 해결 방법 | Patch when the normal change window allows | Highest-risk exposed assets may need isolation or emergency mitigation | Build decision paths for patch, disable, remove, segment, or monitor |
| Retesting | Often delayed until the next assessment | Fix verification must happen inside the response window | Treat retesting as part of remediation, not a later audit task |
The key point is not that AI removes all attacker friction. The key point is that it removes enough friction to make “we will handle it next cycle” a dangerous default.
AI exploit research should be read carefully, not sensationally
The Anthropic N-day results are important, but they should not be exaggerated.
The Firefox tests used a controlled harness around SpiderMonkey, Firefox’s JavaScript engine. The model received the public diff, component name, Mozilla severity rating, and instrumented vulnerable and patched command-line builds. It did not receive restricted Bugzilla details, the reporter’s reproducer, or advisory text. That setup is meaningful because it resembles what an attacker may infer from public patch data, but it is still a harnessed experiment rather than a complete browser campaign. (red.anthropic.com)
The Windows tests were harder because the model worked without source code. It received vulnerable and patched binaries, public debug symbols, decompilation, function-level diffs, and Microsoft advisory text. The grader verified crashes and privilege escalation in a controlled Windows Server 2025 virtual machine. That is a serious benchmark, especially because the successful Windows outcomes were low-privilege to SYSTEM privilege escalations, but it still isolates one part of an attack chain rather than a full intrusion operation. (red.anthropic.com)
The same caution applies to academic benchmarking. ExploitGym, submitted to arXiv in May 2026, evaluates AI agents on 898 instances sourced from real-world vulnerabilities across userspace programs, Google’s V8 JavaScript engine, and the Linux kernel. The paper reports that exploitation remains challenging, but frontier models can exploit a non-trivial fraction of vulnerabilities in reproducible environments. That result supports the trend without pretending every exploit task is solved. (arXiv)
This distinction matters for security leaders. Panic produces bad security. Dismissal produces worse security.
A grounded reading is stronger: AI is not making exploitation universally trivial, but it is compressing the attack lifecycle for a growing class of vulnerabilities. The closer a vulnerability is to a well-defined patch, a reachable component, a reproducible crash, a known bug class, and an available test harness, the more likely AI can accelerate the path from disclosure to proof.
For defenders, the practical lesson is clear. Do not build your vulnerability program around public exploit maturity alone. By the time exploit code is widely shared, the fastest attackers may already have working variants.
Continuous AI pentesting starts where monitoring ends
Continuous monitoring is already a recognized security concept. NIST defines information security continuous monitoring as maintaining ongoing awareness of information security, vulnerabilities, and threats to support organizational risk management decisions. NIST also clarifies that “continuous” does not mean literally uninterrupted measurement; it means controls and risks are assessed at a frequency sufficient to support risk-based decisions. (NIST 컴퓨터 보안 리소스 센터)
That definition is useful because it keeps the word “continuous” honest. Continuous does not mean reckless. Continuous means risk-timed.
Vulnerability scanning and exposure monitoring are necessary. They tell you that a service exists, a package changed, a CVE may apply, a port is open, a certificate changed, a container is running an old base image, or a gateway is exposed. They are the sensory layer of a modern security program.
But monitoring does not always prove exploitability. It does not prove that a vulnerable code path is reachable. It does not prove that a WAF blocks the dangerous request. It does not prove that the service is protected by a compensating control. It does not prove that a patch fixed the behavior rather than only the banner. It does not prove that a business-logic authorization flaw still leaks another tenant’s data after the developer says it is fixed.
That is the gap continuous AI pentesting fills.
NIST SP 800-115 describes penetration testing as security testing in which assessors mimic real-world attacks to identify ways to circumvent the security features of a system, application, or network. The publication also frames security testing around planning, execution, analysis, reporting, and mitigation, not simply “finding bugs.” (NIST 간행물)
Continuous AI pentesting combines those two ideas. It brings the evidence discipline of penetration testing closer to the operating cadence of continuous monitoring.
A mature program separates the layers:
| 레이어 | Primary question | Best output | What it cannot prove alone |
|---|---|---|---|
| 자산 인벤토리 | What do we own and expose | Systems, owners, services, environments, business criticality | Whether an attacker can create impact |
| Vulnerability intelligence | What threats and CVEs matter now | KEV status, vendor advisories, exploit chatter, affected versions | Whether the vulnerable path exists in your deployment |
| Vulnerability scanning | What looks vulnerable | Version signals, fingerprints, misconfigurations, missing patches | Whether the finding is exploitable or mitigated |
| 지속적인 모니터링 | What changed | New exposure, drift, new packages, new routes, new identities | Whether the change creates an attack path |
| Continuous AI pentesting | Can the current state be abused | Reproduced behavior, impact proof, evidence, retest status | Whether upstream engineering will prevent future bug classes |
| Remediation engineering | What changed to reduce risk | Patch, config change, code fix, isolation, rollback | Whether the original attack path is actually closed without retest |
The most important row is the last mile between “risk signal” and “verified risk.” That is where many organizations lose time. They have alerts, dashboards, CVEs, spreadsheets, and tickets, but they do not have enough proof to prioritize decisively.
Continuous AI pentesting should shorten that distance.
A useful definition of continuous AI pentesting
Continuous AI pentesting is an authorized, evidence-driven process that uses AI-assisted agents, security tools, scripts, traffic capture, browser automation, and human approval gates to repeatedly validate high-risk attack hypotheses after meaningful changes in assets, software, configuration, vulnerability intelligence, identity flows, or remediation status.
That definition has several important constraints.
It is authorized. The scope must be explicit. The agent should know what domains, IP ranges, APIs, environments, test accounts, techniques, and time windows are allowed. It should also know what is excluded.
It is evidence-driven. A model-generated suspicion is not a finding. A finding needs preconditions, reproduction steps, observed behavior, affected assets, impact, remediation, and retest instructions.
It is risk-triggered. Continuous does not mean testing everything all the time. It means testing when the risk picture changes enough to justify adversarial verification.
It is tool-grounded. The AI layer should not replace mature security tools. It should call them, interpret their output, preserve artifacts, and decide what to do next under policy.
It is human-governed. High-risk actions, production-sensitive steps, destructive payloads, data access, persistence tests, and lateral movement simulations need approval rules.
It is closed-loop. A continuous AI pentesting program is incomplete until fixes are retested and evidence is updated.
A bad version of this idea is easy to imagine: a chatbot wired to a shell, pointed at production, with vague instructions to “find vulnerabilities.” That is not continuous AI pentesting. That is a control failure.
A good version is closer to a flight control system for offensive verification: scope files, target inventory, trigger rules, tool policies, rate limits, approval gates, evidence stores, issue tracking, retest workflows, and audit logs.
A minimal scope file might look like this:
engagement:
name: "external-api-kev-validation"
owner: "appsec"
authorization_ticket: "SEC-2026-1187"
environment: "staging-first, production-read-only"
targets:
include:
- "https://api.example.com"
- "https://auth.example.com"
exclude:
- "https://payments.example.com/refunds"
- "third-party managed tenant environments"
- "customer data export endpoints"
test_accounts:
- role: "standard_user"
username_ref: "vault://pentest/api-standard-user"
- role: "tenant_admin"
username_ref: "vault://pentest/api-tenant-admin"
allowed_actions:
passive_discovery: true
active_probing: true
authenticated_replay: true
safe_cve_validation: true
destructive_testing: false
persistence_simulation: false
lateral_movement: false
limits:
max_requests_per_minute: 60
require_human_approval_for:
- "state-changing requests"
- "payloads that may trigger denial of service"
- "access to sensitive data classes"
- "tests outside staging"
evidence:
store_http_traces: true
store_tool_output: true
redact_tokens: true
retention_days: 30
The file is not paperwork. It is a technical control. It turns “authorized testing” into machine-readable boundaries. It gives the AI system less room to improvise in dangerous ways and gives human reviewers something concrete to audit.
Trigger logic matters more than fixed cadence
Annual penetration tests still have value. Quarterly assessments still have value. Manual deep dives still have value. But a fixed calendar cannot be the only trigger when attackers respond to changes faster than the calendar.
Continuous AI pentesting should begin with trigger logic.
A trigger is an event that changes the probability or impact of exploitation enough to justify targeted validation. It may come from vulnerability intelligence, asset changes, code changes, identity changes, dependency changes, network exposure, or completed remediation.
| 트리거 | What to validate | Evidence that matters | Typical owner | 일반적인 실수 |
|---|---|---|---|---|
| CISA KEV addition | Whether any owned asset is exposed and whether the vulnerable path is reachable | Asset match, version evidence, safe behavioral proof, mitigation status | Security operations and AppSec | Treating KEV as a generic severity label instead of an action trigger |
| Vendor advisory for edge device | Whether internet-facing gateways, VPNs, WAFs, load balancers, or management planes match affected conditions | Config evidence, exposed service proof, logs since earliest exploitation date | Infrastructure security | Looking only at software version and ignoring vulnerable configuration |
| Monthly patch release with critical RCE or EoP | Whether high-value endpoints, servers, or services have exploitable exposure before fleet patch completion | Patch state, exploitability rating, compensating controls, target criticality | Vulnerability management | Sorting only by CVSS and ignoring reachability |
| New public API route | Whether authentication, authorization, rate limits, object access, and tenant boundaries hold | Role-differential responses, request traces, token transitions | AppSec and API owners | Testing only the UI and missing direct API access |
| Auth or session logic change | Whether session fixation, privilege carryover, token reuse, MFA bypass, or role confusion appears | Cookie changes, JWT claims, replay results, audit logs | Identity and application teams | Assuming a passing unit test proves deployed behavior |
| New third-party integration | Whether callbacks, tokens, secrets, webhooks, and scopes are constrained | OAuth scopes, webhook signatures, token storage, callback replay traces | Integration owner | Treating vendor trust as a substitute for boundary testing |
| Dependency upgrade or downgrade | Whether the changed parser, auth library, serializer, image processor, or network stack is reachable | SBOM diff, runtime path evidence, safe probe result | Engineering and AppSec | Assuming SCA status equals runtime exploitability |
| Completed fix for prior finding | Whether the exact original path fails safely after remediation | Before-and-after reproduction, expected denial behavior, regression test | Engineering owner | Closing the ticket after deploy without retesting |
| WAF, proxy, CDN, or routing change | Whether normalization, header trust, path handling, host validation, and auth forwarding changed | Header traces, route mapping, cache behavior, proxy logs | Platform security | Treating infrastructure changes as non-security changes |
This trigger matrix keeps continuous AI pentesting from becoming noisy. The goal is not to generate more security work. The goal is to put adversarial verification where uncertainty and impact are highest.
CVE-2026-50751 shows why edge validation has to be fast
Check Point’s CVE-2026-50751 is a useful example because it combines several patterns that punish slow response: remote access infrastructure, deprecated protocol support, certificate-validation logic, authentication bypass, active exploitation, and ransomware-linked post-compromise activity.
Check Point disclosed active exploitation of CVE-2026-50751 in June 2026. The vulnerability affects Check Point Remote Access VPN and Mobile Access deployments configured to use the deprecated IKEv1 key exchange protocol. Check Point states that a logic flaw in certificate validation can let an attacker establish a VPN session without a valid user password, effectively bypassing authentication. Additional post-authentication activity is still required to access internal resources or escalate privileges. (Check Point Blog)
That nuance matters. CVE-2026-50751 is not described as a direct remote code execution flaw. The immediate impact is unauthorized VPN session establishment under affected conditions. But that is still severe because VPN access can put an attacker inside a trust boundary where internal services, identity systems, file shares, management interfaces, and lateral movement opportunities may become reachable.
Public guidance also shows why version-based scanning alone is not enough. Rapid7 summarized the vulnerable condition as deployments using deprecated IKEv1 where gateways accept legacy Remote Access clients and do not require a machine certificate. The Center for Internet Security similarly describes limiting factors: Remote Access VPN or Mobile Access enabled, IKEv1 enabled for remote access, legacy clients accepted, and no machine certificate requirement. (Rapid7)
A continuous AI pentesting workflow for a vulnerability like this should not start by attempting to exploit production. It should start by answering bounded questions:
| 질문 | Safe validation approach | 증거 |
|---|---|---|
| Do we run affected products | Asset inventory, vendor portal, config management, gateway list | Product and version records |
| Is Remote Access VPN or Mobile Access enabled | Configuration review and external service fingerprinting | Gateway config, exposed service evidence |
| Is deprecated IKEv1 enabled for remote access | Config audit and approved non-destructive protocol checks | IKE policy evidence |
| Are legacy clients accepted | Gateway policy review | Remote access client policy |
| Is a machine certificate required | Authentication policy review | Certificate requirement config |
| Were there suspicious sessions before patching | Log review from the earliest observed exploitation window | VPN logs, source IPs, session anomalies |
| Is the mitigation effective | Repeat non-destructive config checks after update | Before-and-after evidence |
Check Point’s advisory says incident response teams should prioritize forensic log audits and configuration reviews from the earliest observed exploitation date of May 7, 2026, because exploitation attempts increased in early June and at least one observed case involved post-compromise activity associated with a Qilin ransomware affiliate. (Check Point Blog)
That is exactly the type of event that should trigger continuous AI pentesting. The AI system can help collect the asset list, map gateways to owners, parse config exports, prepare safe verification steps, summarize logs, and assemble evidence. Human operators should approve any action that touches production remote-access behavior.
The defensive actions are also concrete: apply the vendor updates, disable deprecated IKEv1 where possible, remove legacy client support, require machine certificates, and review logs for unauthorized VPN sessions and follow-on behavior. (Check Point Blog)
The broader lesson is bigger than Check Point. Edge devices are often the shortest path from public internet to internal access. Continuous AI pentesting is valuable here because the risky condition is usually not just “a CVE exists.” It is the intersection of product, version, exposed role, protocol mode, legacy compatibility, certificate requirements, and attacker-visible access.
Patch Tuesday is no longer just a patching event
Microsoft’s June 2026 Patch Tuesday illustrates a different kind of scale problem. BleepingComputer reported that Microsoft fixed 200 flaws, including six zero-days, five publicly disclosed vulnerabilities, and one actively exploited vulnerability. Trend Micro’s Zero Day Initiative counted more than 200 CVEs across Windows, Office, Edge, Azure, .NET, Visual Studio, GitHub Copilot, Defender, Exchange Server, Hyper-V, Secure Boot, and BitLocker. (컴퓨터)
No security team can manually deep-test every patched issue in a large enterprise. The point of continuous AI pentesting is not to try. The point is to combine vulnerability intelligence with asset context and exploitability hypotheses.
A useful workflow looks like this:
- Ingest the vendor advisory and vulnerability metadata.
- Identify assets that run affected products or expose affected components.
- Prioritize internet-facing systems, identity infrastructure, remote access, high-value servers, privileged user endpoints, and systems with sensitive data paths.
- Separate vulnerabilities that require local access from those reachable remotely.
- Identify whether public disclosure, active exploitation, KEV status, or exploit-development research increases urgency.
- Run safe validation for the highest-risk subset.
- Patch or mitigate.
- Retest and preserve evidence.
The CISA KEV catalog remains a key input because it tracks vulnerabilities known to be exploited in the wild. CISA also maintains a public GitHub mirror of KEV data in CSV and JSON formats, synchronized with the canonical source, to make the data easier to consume programmatically. (cisa.gov)
A small triage script can help combine KEV data with an internal asset inventory. It does not prove exploitability. It only identifies where validation should start.
#!/usr/bin/env python3
"""
Defensive triage helper:
- Reads an internal asset inventory with columns: asset, owner, product, version, exposure
- Reads a local copy of CISA KEV JSON
- Prints assets whose product text loosely matches KEV vendor or product fields
This is not exploit validation. It is a prioritization aid.
"""
import csv
import json
from pathlib import Path
ASSETS = Path("assets.csv")
KEV = Path("known_exploited_vulnerabilities.json")
def normalize(value: str) -> str:
return (value or "").strip().lower()
with KEV.open("r", encoding="utf-8") as f:
kev_data = json.load(f)
vulns = kev_data.get("vulnerabilities", [])
with ASSETS.open("r", encoding="utf-8") as f:
assets = list(csv.DictReader(f))
for asset in assets:
product_text = normalize(asset.get("product", ""))
if not product_text:
continue
for vuln in vulns:
vendor = normalize(vuln.get("vendorProject", ""))
product = normalize(vuln.get("product", ""))
cve = vuln.get("cveID", "")
due = vuln.get("dueDate", "")
known = " ".join([vendor, product])
if product_text in known or product in product_text:
print(
f"{asset['asset']} | owner={asset['owner']} | "
f"product={asset['product']} | exposure={asset['exposure']} | "
f"possible_kev={cve} | due={due}"
)
The output of a script like this should feed a human-reviewed queue. A continuous AI pentesting agent can then enrich the queue: look for external exposure, compare versions, check whether the vulnerable feature is enabled, propose safe probes, and draft retest steps. It should not jump from a fuzzy match to exploitation.
That distinction is central. AI can make triage faster, but trustworthy security still depends on proof.
Why CVSS cannot carry the whole prioritization burden
CVSS is useful for severity normalization. It is not enough for operational prioritization.
Two vulnerabilities with similar CVSS scores can require very different action. One may require local access on a low-value workstation. Another may affect an internet-facing VPN gateway that can bypass authentication. One may be theoretically severe but hard to reach. Another may have a lower score but is actively exploited at scale. One may be patched everywhere. Another may still exist in a forgotten appliance.
CISA’s SSVC model is valuable because it moves prioritization toward decisions. CISA describes SSVC decision outcomes such as Track, Track*, Attend, and Act, based on values including exploitation status, technical impact, automatable, mission prevalence, and public well-being impact. (cisa.gov)
Continuous AI pentesting should fit into that decision model as the evidence-producing layer. It helps answer questions like:
| Decision factor | What scanners can tell you | What continuous AI pentesting can add |
|---|---|---|
| Exploitation status | KEV status, exploit feeds, public PoC references | Whether your exposed asset exhibits the vulnerable behavior |
| Technical impact | CVSS impact fields, advisory text | Whether impact is reachable under your auth, network, and data conditions |
| Automatable | Known exploit simplicity, network reachability | Whether the attack path is repeatable and safe to simulate |
| Mission prevalence | Asset tags, business criticality | Which real workflows, tenants, roles, or data paths are affected |
| Remediation confidence | Patch deployment status | Before-and-after retest proof |
This is why continuous AI pentesting should not be owned only by the red team. It belongs at the intersection of AppSec, vulnerability management, platform engineering, incident response, and product security.
The best programs turn vulnerability response into a loop:
Signal → Hypothesis → Safe validation → Impact judgment → Remediation → Retest → Evidence archive.
AI is useful because it can keep that loop moving. It can summarize advisories, map affected conditions, build task trees, call tools, parse logs, compare HTTP responses, write small safe scripts, preserve artifacts, and draft reports. But the loop still needs owners, rules, and review.
Historical cases show that patch gaps do not close themselves
The N-hour framing is new, but the patch-gap problem is not. Several major incidents show why “known vulnerability” does not mean “solved vulnerability.”
Log4Shell, CVE-2021-44228
Log4Shell is the classic example of a vulnerability that remained dangerous because of dependency sprawl. NVD describes CVE-2021-44228 as a flaw in Apache Log4j2 where an attacker controlling log messages or log parameters could execute arbitrary code loaded from LDAP servers when message lookup substitution was enabled. (NVD)
The exploitation condition was deceptively simple: if untrusted data reached a vulnerable Log4j logging path in a way that triggered JNDI lookup behavior, the application could be compromised. The difficulty for defenders was not only patching known direct dependencies. It was finding every indirect, embedded, shaded, containerized, packaged, and vendor-supplied copy of Log4j across an enterprise.
Academic measurement of the Log4Shell incident found a rush of scanning shortly after disclosure and continued malicious scanning after the initial wave. That long tail is the part many organizations underestimate. (arXiv)
A continuous AI pentesting program would not “solve Log4Shell” by running a single scanner once. It would repeatedly ask:
- Which internet-facing services run Java or vendor products that may embed Log4j?
- Which applications actually log attacker-controlled headers, parameters, paths, usernames, or user agents?
- Which mitigations are in place at runtime?
- Which patched services still run old containers?
- Which vendors have not confirmed remediation?
- Which detections show continued probes?
- Which safe test signals can prove the vulnerable lookup behavior is absent?
That is the difference between inventory compliance and adversarial verification.
MOVEit Transfer, CVE-2023-34362
MOVEit Transfer shows how an internet-facing business application can become a data-theft pathway. NVD describes CVE-2023-34362 as a SQL injection vulnerability in the MOVEit Transfer web application that could allow an unauthenticated attacker to gain access to the MOVEit Transfer database in affected versions. (NVD)
The risk was not only SQL injection as a bug class. The risk was where the product sat in business workflows: managed file transfer, sensitive data exchange, and external access. When a file transfer system is compromised, the impact often jumps directly to data exposure.
A continuous AI pentesting response to a MOVEit-like advisory should prioritize:
- External exposure of the transfer application.
- Affected version and patch status.
- Whether emergency mitigations are applied.
- Web shell indicators and unusual file access.
- Database access patterns.
- Evidence of unauthorized downloads.
- Post-patch retesting of affected endpoints.
The lesson is that not all internet-facing apps are equal. A low-traffic admin system that stores regulated files deserves a different validation priority than a public marketing page with no sensitive data path.
Citrix Bleed, CVE-2023-4966
Citrix Bleed is important because it shows why non-RCE vulnerabilities can still be urgent. NVD identifies CVE-2023-4966 as a Citrix NetScaler ADC and NetScaler Gateway buffer overflow vulnerability in CISA’s KEV catalog. CISA’s required action included applying mitigations and killing all active and persistent sessions per vendor instructions. (NVD)
NetScaler’s own update stated that CVE-2023-4966 could result in unauthorized data disclosure and later noted credible reports of targeted attacks consistent with session hijacking. (NetScaler)
The operational lesson is subtle: patching alone may not remove stolen session material. If a vulnerability leaks tokens, a fixed appliance may still have active compromised sessions. That is why CISA’s required action included killing sessions, not only applying an update.
A continuous AI pentesting workflow should therefore validate the full remediation condition:
- Is the appliance patched?
- Were active and persistent sessions cleared?
- Are new tokens generated after patching?
- Do logs show suspicious session reuse?
- Are downstream systems monitoring anomalous access?
- Are privileged sessions constrained?
This is where evidence matters. “Patched” is not always the same as “safe.”
The architecture of continuous AI pentesting
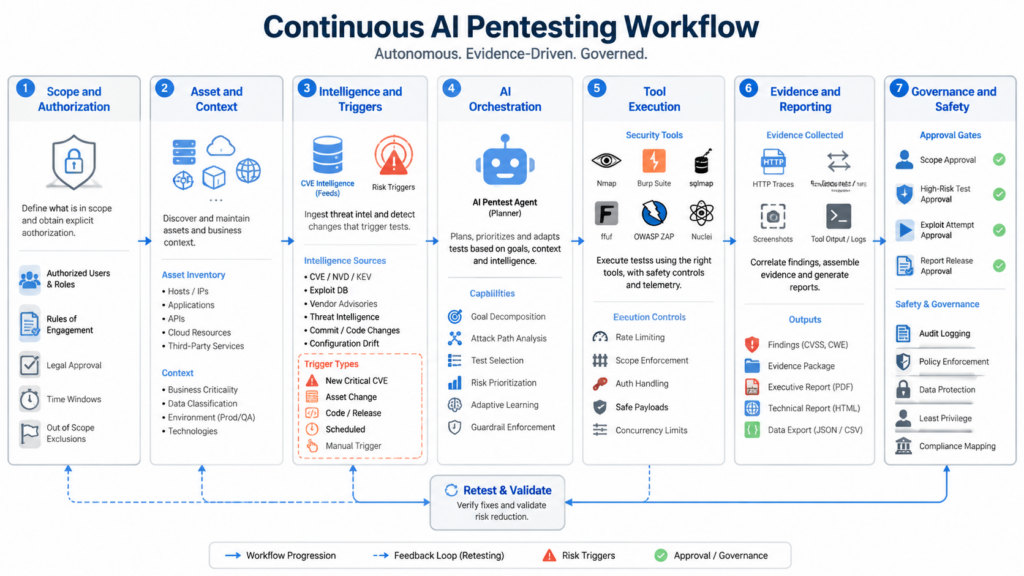
Continuous AI pentesting needs an architecture, not only a model.
A practical architecture has seven layers.
| 레이어 | 목적 | 예제 |
|---|---|---|
| Scope and authorization | Prevent uncontrolled testing | Rules of engagement, asset allowlist, exclusions, test windows, rate limits |
| Asset and context | Tell the system what exists and what matters | CMDB, cloud inventory, SBOM, API catalog, ownership, business criticality |
| Intelligence and triggers | Decide when validation is needed | CISA KEV, vendor advisories, Patch Tuesday, exploit research, code deploys, config drift |
| Orchestration | Break work into bounded tasks | Recon, fingerprinting, safe validation, role comparison, retest, report update |
| Tool execution | Ground AI decisions in real outputs | nmap, nuclei, HTTP proxy, browser automation, SCA, logs, SIEM queries, custom scripts |
| Evidence and reporting | Preserve proof and decisions | HTTP traces, screenshots, command outputs, config snapshots, reproduction steps |
| Governance and safety | Keep speed under control | Approval gates, audit logs, destructive-test blocks, token redaction, escalation paths |
The AI agent sits mostly in the orchestration layer. It should not be treated as the policy authority. Its job is to propose and execute bounded tasks under rules.
A safe agent loop looks like this:
1. Read authorized scope and trigger context.
2. Identify affected assets and unknowns.
3. Build test hypotheses.
4. Choose the least intrusive validation method.
5. Request approval if policy requires it.
6. Run approved tools or scripts.
7. Store raw evidence.
8. Distinguish observations from confirmed findings.
9. Recommend remediation or compensating controls.
10. Retest after changes.
This is also the place where platforms matter. Penligent, for example, describes an agentic AI pentesting workflow oriented around vulnerability discovery, finding verification, exploit execution under authorized testing, evidence-first reproducibility, controlled workflows, 200 plus supported industry tools, and one-click reports aligned with SOC 2 and ISO 27001 expectations. Its homepage also states that the tool is for authorized security testing only and requires explicit permission from the target owner. (펜리전트)
That kind of product shape is relevant because continuous AI pentesting is not just “model quality.” It is the system around the model: scope control, tool access, artifact capture, finding lifecycle, retest support, and report handoff. A related Penligent article on continuous penetration testing makes the same operational distinction: continuous testing should mean risk-timed, evidence-driven adversarial verification tied to meaningful change events, not endless exploitation attempts against production. (펜리전트)
The product is not the principle. The principle is that AI-assisted offensive testing must be embedded in a controlled workflow to become useful infrastructure.
Scanner, BAS, manual pentest, and continuous AI pentesting are different jobs
Security buyers often collapse categories because vendors use overlapping language. That creates confusion.
A vulnerability scanner, breach and attack simulation platform, manual pentest, and continuous AI pentesting workflow may all touch similar assets, but they answer different questions.
| Capability | Primary question | 힘 | 약점 |
|---|---|---|---|
| Vulnerability scanner | What known issues or misconfigurations may exist | Breadth, repeatability, asset coverage | False positives, limited business logic, weak exploit proof |
| SCA and SBOM tooling | Which dependencies are present and vulnerable | Dependency visibility, CI integration | Runtime reachability may be unclear |
| BAS | Do known attacker behaviors trigger controls | Detection and control validation | Often pattern-driven and less suited to novel app logic |
| Manual pentest | Can skilled humans find and exploit meaningful flaws | Creativity, judgment, deep chaining | Limited cadence, cost, point-in-time coverage |
| Continuous AI pentesting | Can high-risk changed conditions be validated quickly and repeatedly | Speed, evidence continuity, retesting, tool orchestration | Requires strong scope, governance, and human review |
The strongest programs use all of them. The mistake is expecting one category to do every job.
Continuous AI pentesting is especially useful when the work is repetitive but not trivial. Examples include:
- Revalidating a known broken access control path after each fix.
- Testing whether a newly exposed service matches a high-risk advisory.
- Comparing role-based API behavior across tenants.
- Checking whether a WAF or proxy change affects auth forwarding.
- Turning a CVE advisory into safe environment-specific validation steps.
- Preserving before-and-after evidence for engineering and audit teams.
- Retesting mitigations after patch deployment.
That work is often too specific for broad scanners and too frequent for manual consulting cycles. It is exactly where AI-assisted orchestration can reduce toil while preserving human accountability.
Evidence is the unit of trust
The most dangerous phrase in AI pentesting is “the AI found a vulnerability.”
A model cannot simply assert a vulnerability into existence. A scanner finding is not always a confirmed finding. A version string is not proof. A crash is not always exploitability. A successful request is not always a security boundary violation. A sensitive-looking response may be test data. A token may be expired. A “patched” version may be backported. An error message may be harmless.
A good continuous AI pentesting workflow uses a finding lifecycle.
| 스테이지 | 의미 | Report status |
|---|---|---|
| Observation | A tool or model saw something suspicious | Not a vulnerability |
| Hypothesis | There is a plausible abuse path | Needs validation |
| Reproduced behavior | A controlled test repeated the behavior | Candidate finding |
| Impact confirmed | The behavior violates a security boundary or creates realistic risk | Reportable finding |
| Fix proposed | Engineering has a concrete remediation path | Still open |
| Fix deployed | A patch or config change is live | Not closed yet |
| Fix verified | The original path no longer reproduces and expected denial behavior is observed | Closed |
| Regression monitored | The same class is covered by tests or triggers | Operationally mature |
For web and API testing, raw HTTP evidence is often the most useful artifact. A report should show the role used, request path, relevant headers, sanitized body, response status, security boundary, and difference between expected and observed behavior.
A role comparison harness can be simple:
#!/usr/bin/env python3
"""
Defensive API role comparison template.
Use only against authorized test environments and test accounts.
"""
import os
import requests
BASE_URL = os.environ["BASE_URL"]
USER_TOKEN = os.environ["STANDARD_USER_TOKEN"]
ADMIN_TOKEN = os.environ["TENANT_ADMIN_TOKEN"]
def get_invoice(token: str, invoice_id: str):
headers = {"Authorization": f"Bearer {token}"}
return requests.get(
f"{BASE_URL}/api/v1/invoices/{invoice_id}",
headers=headers,
timeout=10,
)
own_invoice = "inv_test_owned_by_standard_user"
other_tenant_invoice = "inv_test_owned_by_other_tenant"
tests = [
("standard user own invoice", USER_TOKEN, own_invoice),
("standard user other tenant invoice", USER_TOKEN, other_tenant_invoice),
("tenant admin own tenant invoice", ADMIN_TOKEN, own_invoice),
]
for name, token, invoice_id in tests:
response = get_invoice(token, invoice_id)
print(f"{name}: HTTP {response.status_code}, length={len(response.text)}")
if response.status_code == 200:
print(response.text[:300])
This is not a universal BOLA detector. It is a pattern: use dedicated test accounts, controlled identifiers, explicit expectations, and reproducible output. A continuous AI pentesting agent can generate and adapt harnesses like this, but the authorization model and data handling rules must come from the team.
Safe CVE validation is harder than banner checking
CVE validation is one of the best uses of continuous AI pentesting, and one of the easiest places to produce bad findings.
A banner may be hidden, proxied, wrong, backported, or unrelated to the reachable code path. A package may be present but unused. A vulnerable class may exist in a dependency but never load. A patch may be applied without changing the exposed version string. A cloud vendor may mitigate an issue at the edge while the internal component still reports an affected version.
A responsible CVE validation flow should separate six questions:
| 질문 | 중요한 이유 | Example evidence |
|---|---|---|
| Is the product present | Avoid testing irrelevant systems | Service fingerprint, package inventory, owner confirmation |
| Is the affected version present | Establish possible exposure | Version output, SBOM, vendor console |
| Is the vulnerable feature enabled | Many CVEs require specific configuration | Config export, API behavior, admin setting |
| Is the vulnerable path reachable | Code presence is not enough | Safe probe, route evidence, role access |
| Are mitigations active | Patching is not the only control | WAF rule, disabled protocol, certificate requirement |
| Is the fix verified | Closure requires behavior change | Before-and-after retest |
For CVE-2026-50751, the feature conditions matter: Remote Access or Mobile Access, deprecated IKEv1, legacy client acceptance, and no machine certificate requirement. (Rapid7)
For Log4Shell, runtime reachability matters: attacker-controlled data must reach a vulnerable logging path with dangerous lookup behavior. (NVD)
For Citrix Bleed, session invalidation matters: patching without killing active and persistent sessions may leave stolen sessions usable. (NVD)
For MOVEit, exposure and data access matter: an unauthenticated SQL injection in an internet-facing transfer system has a different risk profile from an internal-only component with no sensitive database. (NVD)
AI can assist with the reasoning, but the validation standard stays the same: prove the condition safely or say it remains unconfirmed.
Detection engineering should receive pentest evidence, not just findings
Continuous AI pentesting should feed detection engineering. If an offensive validation produces no usable defensive signal, the organization loses part of the value.
Every validated finding should ask:
- What logs should have shown this?
- Did the SIEM alert?
- Did the WAF record the request?
- Did EDR see the process or script?
- Did identity logs show abnormal token use?
- Did the cloud audit trail record the action?
- Would the SOC understand the alert without the pentest context?
A finding record should include a detection section:
Detection notes:
- Expected log source: API gateway access logs
- Expected fields: user_id, tenant_id, route, status_code, request_id
- Observed anomaly: standard_user accessed invoice_id owned by another tenant
- Existing alert: none
- Suggested detection:
- Alert when authenticated user retrieves object where object.tenant_id != user.tenant_id
- Add request_id correlation between API gateway and application authorization logs
- Track repeated 403 to 200 transitions on object identifiers
The purpose is not to turn every pentest into a SOC project. The purpose is to connect proof of exploitability with proof of visibility. A vulnerability that cannot be fixed immediately may still be monitored. A vulnerability that has been fixed may still deserve a regression detection. A vulnerability class that repeats across services may deserve a secure coding rule, an API gateway control, or a CI test.
Continuous AI pentesting becomes more valuable when it generates reusable defensive knowledge.
Retesting is not optional
Many vulnerability programs stop too early.
Discovery is not closure. Ticket creation is not closure. Patch deployment is not closure. A developer comment saying “fixed” is not closure. Even a passing unit test may not be closure if the original issue involved deployed routing, proxy behavior, tenant data, legacy clients, or a specific production configuration.
Retesting is where trust is earned.
A strong retest record includes:
Finding:
Broken object-level authorization in invoice API
Original behavior:
A standard user could retrieve invoice metadata belonging to another tenant by changing invoice_id in the path.
Fix:
API now checks tenant ownership before returning invoice metadata.
Retest date:
2026-06-11
Retest account:
standard_user_test_01
Retest request:
GET /api/v1/invoices/inv_test_owned_by_other_tenant
Expected result:
HTTP 403 or non-enumerable HTTP 404 with no invoice metadata.
Observed result:
HTTP 403. Response body contains no invoice_id, amount, tenant_id, or billing period.
Status:
Fix verified.
An AI agent can make this repeatable. It can preserve the original request, rerun it after remediation, compare response status and body, redact tokens, update the report, and mark the issue as fix verified. Human reviewers should still inspect high-impact findings, but they should not have to reconstruct the test from memory.
This retest loop is one of the main reasons continuous AI pentesting belongs in security infrastructure. It turns offensive testing from a one-time event into a repeatable control.
Production safety depends on policy, not hope
Continuous AI pentesting can be safe for production only when the workflow enforces constraints. Hope is not a control.
A safe production policy should address:
| 제어 | 목적 |
|---|---|
| Explicit authorization | Prevent out-of-scope testing |
| Asset allowlist | Keep discovery bounded |
| Exclusion list | Protect fragile systems and third parties |
| Test accounts | Avoid real customer or employee data |
| Rate limits | Reduce operational impact |
| Payload policy | Block destructive or denial-of-service tests |
| Human approval gates | Review high-risk actions |
| Token redaction | Prevent evidence stores from becoming secrets stores |
| Emergency stop | Give operations a way to halt testing |
| Audit log | Preserve who approved and ran each action |
A simple action policy can look like this:
action_policy:
passive:
approval: "not_required"
examples:
- "read public headers"
- "collect DNS records"
- "inspect TLS certificate"
low_risk_active:
approval: "not_required_if_rate_limited"
examples:
- "safe HTTP route discovery"
- "non-destructive authenticated GET requests"
medium_risk:
approval: "security_engineer_required"
examples:
- "authenticated POST to staging"
- "role-based replay with test accounts"
- "CVE validation requiring crafted but non-destructive input"
high_risk:
approval: "security_manager_required"
examples:
- "state-changing production request"
- "payload that may affect availability"
- "test involving sensitive data class"
prohibited:
examples:
- "data exfiltration from real users"
- "persistence installation"
- "credential dumping"
- "unapproved lateral movement"
- "denial-of-service testing"
The policy should be enforced by the workflow, not merely placed in a document. The agent should be unable to perform prohibited actions. Human approval should be logged. Evidence should be redacted. Scope should be locked.
This is the difference between controlled continuous AI pentesting and unsafe automation.
The first 90 days of implementation
A team does not need to implement a perfect system before getting value. A staged rollout is safer.
Days 1 to 30, build the risk queue
Start with visibility and trigger rules.
- Create an inventory of internet-facing assets, remote access systems, identity services, public APIs, admin panels, file transfer systems, and high-value internal applications.
- Map each asset to an owner.
- Ingest CISA KEV, major vendor advisories, and internal deploy events.
- Define which triggers require immediate validation.
- Create scope templates for web, API, VPN, cloud, and dependency validation.
- Define prohibited actions and approval gates.
- Pick one or two high-risk workflows for pilot testing.
Useful early metrics:
| Metric | 중요한 이유 |
|---|---|
| Time to exposure awareness | How quickly the team knows it may be affected |
| Owner coverage | Whether every high-risk asset has someone accountable |
| Trigger precision | Whether alerts create useful validation tasks |
| Unknown asset rate | Whether shadow systems dominate the queue |
Days 31 to 60, automate safe validation
Add repeatability.
- Connect asset inventory to vulnerability intelligence.
- Build safe validation playbooks for common conditions: exposed service, affected version, feature enabled, auth boundary changed, fix retest.
- Add HTTP proxy capture and browser automation for web workflows.
- Add role-based API comparison for authorization testing.
- Store evidence in a consistent structure.
- Integrate with issue tracking.
- Require retest steps before closure.
Useful metrics:
| Metric | 중요한 이유 |
|---|---|
| Time to validation | How quickly the team moves from signal to proof |
| False positive rate | Whether the workflow reduces or increases noise |
| 증거의 완전성 | Whether engineering can reproduce findings |
| Retest completion rate | Whether fixes are actually verified |
Days 61 to 90, make it operational infrastructure
Move from pilot to program.
- Add CI/CD triggers for high-risk code paths.
- Add cloud and routing change triggers.
- Add SIEM enrichment from pentest evidence.
- Create exception handling for systems that cannot patch quickly.
- Build executive reporting around risk closure, not vulnerability counts.
- Review safety logs and approval patterns.
- Train AppSec and engineering teams on reading evidence.
Useful metrics:
| Metric | 중요한 이유 |
|---|---|
| Time to remediation | Whether validation leads to fixes |
| Time to retest | Whether closure is fast enough |
| Regression rate | Whether the same bug class returns |
| Compensating control usage | Whether unpatchable systems have real mitigations |
| High-risk open exposure | The number that should keep shrinking |
The 90-day goal is not full autonomy. The goal is a reliable loop for the assets and vulnerability classes that matter most.
Common failure modes
Continuous AI pentesting fails when teams confuse speed with maturity.
Treating AI output as proof
AI can summarize, hypothesize, and assist. It cannot replace evidence. Every report should separate observations, hypotheses, reproduced behavior, and confirmed impact.
Testing outside scope
Autonomy increases the cost of vague authorization. Scope must be machine-readable and enforced. Root domains, subdomains, third-party systems, production paths, and test windows need explicit rules.
Ignoring rate limits
Automated recon and browser testing can generate operational noise. Rate limits and test windows are safety controls, not courtesy settings.
Confusing version detection with exploitability
Version checks are useful, but they can mislead. Backports, proxies, disabled features, and unreachable code paths are common. CVE validation needs behavior and configuration evidence.
Retesting too late
If retesting waits for the next quarterly assessment, continuous AI pentesting loses much of its value. Retest should be part of remediation.
Letting reports become unreadable
A report with every scanner signal is not useful. A good report contains confirmed findings, dismissed candidates, evidence, impact, remediation, and retest status.
Forgetting detection
Offensive proof should improve defensive visibility. If a validated attack path leaves no alert, that is a detection gap worth tracking.
Running destructive tests by default
Continuous validation should use the least intrusive method that answers the question. Destructive testing belongs only in explicitly approved environments.
What buyers and security leaders should ask
The buying question is not “Does the tool use AI?” That is too shallow.
Better questions include:
| 질문 | Strong answer |
|---|---|
| How does the system enforce scope | Machine-readable allowlists, exclusions, action policies, and audit logs |
| How does it distinguish hypotheses from findings | Clear lifecycle from signal to verified impact |
| What tools can it call | Mature scanners, CLI tools, browser automation, proxy capture, APIs, and custom scripts |
| How are high-risk actions approved | Human approval gates with logged decisions |
| How is evidence stored | Raw commands, HTTP traces, screenshots, config evidence, redaction, retention policy |
| How does retesting work | Original reproduction steps can be rerun after remediation |
| How does it handle CVEs | Affected conditions, reachability, mitigations, and safe validation, not banner checks only |
| Can it support detection engineering | Findings include expected logs, observed telemetry, and detection gaps |
| Can teams edit reports | Reports should be usable by engineering, security, and compliance stakeholders |
| What happens when the AI is wrong | Human review, raw evidence, reproducibility, and false-positive tracking |
The market will keep producing AI security claims. Security teams should reward the systems that produce proof.
자주 묻는 질문
What is continuous AI pentesting
- Continuous AI pentesting is an authorized security testing process that uses AI-assisted agents and traditional security tools to repeatedly validate high-risk attack paths.
- It is triggered by meaningful changes such as new CVEs, KEV additions, exposed assets, code deployments, dependency updates, authentication changes, or completed fixes.
- The goal is not constant exploitation. The goal is faster evidence: whether a real deployed system is exposed, whether the vulnerable path is reachable, whether impact is realistic, and whether remediation worked.
- A mature workflow includes scope, approval gates, rate limits, evidence capture, remediation guidance, and retesting.
How is continuous AI pentesting different from vulnerability scanning
- Vulnerability scanning is broad and signal-oriented. It identifies possible vulnerable versions, misconfigurations, missing patches, or known patterns.
- Continuous AI pentesting is validation-oriented. It asks whether the suspected issue can create real impact in the current environment.
- Scanners are still necessary. Continuous AI pentesting should use scanner output as one input, not replace it.
- The strongest workflow connects scanning, asset context, vulnerability intelligence, safe exploitability checks, evidence, remediation, and retest status.
Does AI make every N-day exploitable in hours
- No. Exploitability still depends on bug class, target complexity, available patch data, harness quality, mitigations, reachability, and attacker skill.
- AI is strongest when the vulnerability has clear patch diffs, reproducible behavior, available binaries or source changes, and a testable environment.
- Research from Anthropic and ExploitGym shows that frontier models can accelerate exploit development for some real-world vulnerability classes, but exploitation remains uneven and context-dependent. (red.anthropic.com)
- Defenders should not assume every vulnerability is instantly weaponized, but they should stop relying on long exploit-development delays as a safety margin.
What should trigger a continuous AI pentest
- A new CISA KEV entry affecting owned technology.
- A vendor advisory for an internet-facing or identity-adjacent product.
- A critical Patch Tuesday item that affects exposed or high-value assets.
- A new public API, authentication flow, admin surface, or third-party integration.
- A dependency change involving parsers, serializers, auth libraries, image processors, crypto, or network stacks.
- A WAF, CDN, proxy, routing, or certificate change.
- A completed fix for a previously confirmed vulnerability.
Is continuous AI pentesting safe for production systems
- It can be safe only when scope, rate limits, allowed actions, test accounts, and approval gates are enforced.
- Production testing should default to the least intrusive method that answers the validation question.
- Destructive payloads, denial-of-service tests, real data exfiltration, persistence, credential dumping, and lateral movement should be prohibited unless a separate written authorization explicitly permits them in a controlled environment.
- Evidence should be redacted, tokens should be protected, and emergency stop procedures should be available.
How should teams validate CVEs without creating risk
- Start with asset and configuration evidence before any active testing.
- Confirm whether the affected product, version, feature, and exposure condition apply.
- Prefer vendor-supported checks, configuration review, safe probes, and non-destructive behavioral validation.
- Use dedicated test accounts and staging environments where possible.
- Treat exploitation attempts, state-changing actions, and sensitive data access as high-risk steps requiring explicit approval.
- After remediation, rerun the original safe validation path and document the before-and-after behavior.
Does continuous AI pentesting replace human pentesters
- No. It reduces repetitive work and shortens the path from signal to evidence, but human judgment remains essential.
- Humans are needed for scope decisions, exploit safety, business impact, legal boundaries, ambiguous findings, and final reporting.
- AI is best used for task decomposition, tool orchestration, output parsing, evidence organization, and retest automation.
- Manual pentesters remain critical for novel attack chains, subtle business logic, complex exploitation, and adversarial creativity.
Closing judgment
N-hour exploitation does not mean defenders should panic. It means they should stop treating validation as a slow, occasional ceremony.
The mature question is no longer only “Did we apply the patch?” It is “Did we identify the exposed assets, confirm whether the vulnerable condition applies, validate the real attack path safely, deploy the fix or mitigation, retest the original path, preserve the evidence, and improve detection?”
That is why continuous AI pentesting is becoming security infrastructure. It gives security teams a way to operate closer to the speed of modern vulnerability disclosure without abandoning control, scope, or proof. The organizations that adapt fastest will not be the ones that run the most tools. They will be the ones that turn high-risk uncertainty into verified evidence before attackers turn it into access.