Fable 5 and Mythos 5 were not just two new Claude model names. They were an early public example of a harder problem now facing every frontier AI company: what should happen when the same underlying model is useful enough for normal software engineering, research, and agentic work, but also strong enough in cybersecurity that unrestricted access could change the economics of vulnerability discovery and exploit development?
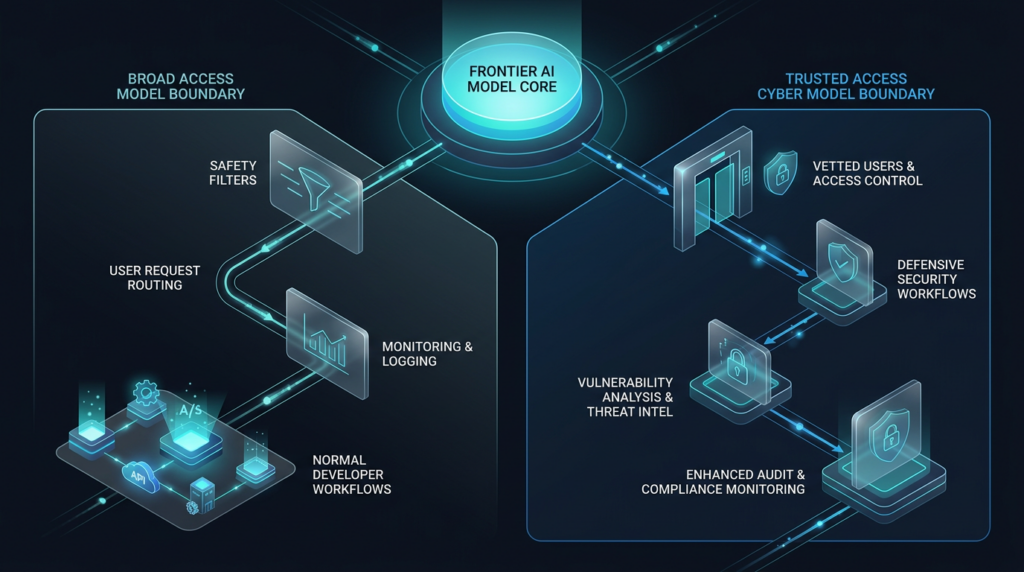
Anthropic’s answer was to split the capability into two product boundaries. Fable 5 was released as a Mythos-class model for broad use, with conservative safeguards around high-risk domains such as cybersecurity and biology. Mythos 5 was described as the same underlying model, but with some safeguards lifted for a small group of vetted cyber defenders and infrastructure providers through Project Glasswing. Anthropic said the safeguards, not a separate base model, were the reason the two models had different names. (인류학)
That distinction matters more than the launch branding. Fable and Mythos show that the model itself is no longer the whole product. The product is the model plus its safety policy, access rules, monitoring layer, permitted use cases, data-retention terms, deployment context, and tool boundary. In ordinary SaaS terms, that may sound like packaging. In AI security terms, it is a new release pattern for cyber-capable intelligence.
The controversy that followed only made the split more visible. On June 12, 2026, Anthropic said the U.S. government had issued an export-control directive requiring the company to suspend all access to Fable 5 and Mythos 5 by foreign nationals, including foreign-national Anthropic employees inside the United States. Anthropic said it had to disable the two models for all customers to ensure compliance, while access to other Anthropic models was not affected. (인류학)
The shutdown is the headline. The split is the more durable signal. Fable and Mythos asked a question the security industry can no longer avoid: when a frontier model becomes strong enough to help find, validate, and chain software vulnerabilities, should it be released as a single general-purpose assistant, or as a family of controlled capabilities?
The Short Version, Fable Was the Public Boundary and Mythos Was the Trusted Cyber Boundary
Anthropic described Fable 5 as a Mythos-class model built for broad availability. In its launch post, the company said Fable 5 and Mythos 5 could work autonomously for longer than previous Claude models and highlighted improvements in software engineering, knowledge work, vision, memory, and life sciences research. It also said that Fable 5 was available to developers as claude-fable-5 through the Claude API, with both Fable 5 and Mythos 5 priced at $10 per million input tokens and $50 per million output tokens at launch. (인류학)
Fable 5 was not positioned as a weak model. It was positioned as a powerful one with stronger controls. Anthropic wrote that releasing a model this capable came with risks and that, without safeguards, Fable 5’s cybersecurity capabilities could be misused. For that reason, some high-risk queries would receive a response from Claude Opus 4.8 instead. Anthropic also said the conservative safeguards might catch harmless requests and that they triggered, on average, in less than 5% of sessions. (인류학)
Mythos 5 occupied a different boundary. Anthropic’s model page described Claude Mythos 5 as its most capable model for cybersecurity and biology research, available only to a small but growing set of customers through trusted access programs. The same page stated that Fable 5 was the same underlying model as Mythos 5 with robust safeguards for cybersecurity and biology, and that using Mythos 5 required accepting a 30-day data-retention policy for safety monitoring. (인류학)
That makes the Fable and Mythos distinction unusually important. Many model launches are about raw capability: context length, coding score, cost, latency, benchmark rank, multimodal ability. This launch was also about boundaries. Fable was the broad-access boundary. Mythos was the trusted cyber boundary. Both pointed to the same underlying reality: frontier models are becoming difficult to govern through one-size-fits-all release models.
| 차원 | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Underlying model | Same underlying model as Mythos 5, according to Anthropic | Same underlying model as Fable 5, according to Anthropic |
| Product role | Broad-access Mythos-class model | Restricted cyber and biology research model |
| Cyber safeguards | Stronger safeguards, with some high-risk queries routed away from Fable | Some cyber safeguards lifted for vetted use cases |
| Initial audience | General users, developers, and enterprise customers before suspension | Project Glasswing partners and vetted trusted-access users |
| Risk logic | Make Mythos-level general capability broadly usable while reducing risky cyber and bio outputs | Give trusted defenders access to higher-risk capabilities for defensive work |
| Monitoring and data | Governed by Anthropic’s normal product and safety policies | Anthropic states Mythos 5 use requires 30-day data retention for safety monitoring |
| Practical meaning | A powerful model behind a stricter public boundary | A powerful model behind a trusted-user boundary |
This table is not just a product comparison. It is a useful mental model for the next phase of AI security. The key variable is not only “how smart is the model?” The key variable is “what boundary is wrapped around the model?”
Why Fable 5 Was Not Just a Sanitized Model
The easy but wrong interpretation is that Fable was the safe model and Mythos was the dangerous one. That framing is too simple.
Fable 5 still inherited the broad reasoning, coding, vision, and long-running task capabilities that made the underlying model valuable. Anthropic said Fable 5 could perform codebase-wide engineering work, handle complex knowledge tasks, interpret images and figures, and operate more effectively in long-horizon agent settings than earlier Claude models. The company also called Fable 5 a Mythos-class model, a tier it described as sitting above Opus in capability. (인류학)
The important design move was not that Fable removed cyber-relevant intelligence. That would not be realistic for a frontier coding model. A model that can understand a large codebase, reason about patches, identify logic errors, and debug failing tests will inevitably possess some security-relevant skill. Software engineering and vulnerability research share too much of the same substrate: control flow, data flow, invariants, assumptions, edge cases, unsafe parsing, authentication checks, serialization boundaries, memory behavior, and specification gaps.
Fable’s design was instead an attempt to mediate the highest-risk uses of that capability. Anthropic described safeguards that rerouted certain risky requests, and later said those safeguards were intentionally strong enough that many users found them overly broad. In the June 12 statement, Anthropic said Fable had been red-teamed for thousands of hours by the U.S. government, the UK AI Security Institute, private third parties, and internal teams before launch. The company also stated that no testers had found a universal jailbreak that broadly bypassed the model’s safeguards across a wide range of cyber capabilities. (인류학)
That language is careful. Anthropic did not claim perfect jailbreak resistance. In fact, it said perfect jailbreak resistance does not appear possible today and that every safeguard in the industry is vulnerable to some non-universal jailbreaks. The goal was defense in depth: make jailbreaks narrow or expensive, monitor for successful attacks, and respond quickly. (인류학)
For security readers, that is the real lesson. Fable was not a claim that cyber risk can be eliminated by a refusal layer. It was a claim that public access to a highly capable model can be made more acceptable if certain categories of output are blocked, rerouted, monitored, or degraded. Whether that is sufficient is exactly what the Fable dispute exposed.
Why Mythos 5 Was Not Just a More Powerful Claude
Mythos 5 was not only a benchmark story. It was a distribution story.
Anthropic introduced Mythos 5 as an upgrade to Claude Mythos Preview, initially deployed through Project Glasswing in collaboration with the U.S. government. The launch post said Mythos 5 was the same underlying model as Fable 5, but with safeguards lifted in some areas for a small group of cyber defenders and infrastructure providers. Anthropic also said it intended to expand access through a broader trusted access program. (인류학)
Project Glasswing itself started earlier, in April 2026, as an initiative involving major infrastructure and security organizations. Anthropic listed launch partners including Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Its stated purpose was to apply Claude Mythos Preview to defensive security work on critical software. (인류학)
This is the more interesting pattern. Mythos was not released as a normal public API endpoint for anyone who could pay. It was attached to a claim about trusted cyber defense. Anthropic said Project Glasswing partners would use Mythos Preview to find and fix vulnerabilities or weaknesses in foundational systems, with anticipated work including local vulnerability detection, black-box testing of binaries, securing endpoints, and penetration testing of systems. (인류학)
That makes Mythos a prototype for a category we should expect to see more often: restricted cyber-capable AI. The question is not merely whether the model can find bugs. The question is whether the provider can define who gets access, which tasks are allowed, how activity is monitored, how disclosures are handled, and how the resulting vulnerability pipeline is managed.
A raw model that can reason about exploitability is one thing. A trusted-access cyber model that sits inside a program for critical infrastructure security is another. Mythos matters because it forces the AI industry to separate capability from access.
Cybersecurity Became the Breaking Point Because Usefulness and Misuse Are the Same Skill
Cybersecurity is where the helpful-harmful boundary becomes hardest to draw. A model that can understand why a patch fixes a memory-safety bug can often infer how the bug might be triggered. A model that can audit authentication logic can sometimes explain a bypass. A model that can help a maintainer identify missing certificate-validation checks can also help an attacker understand the security impact of those checks if the code remains unpatched.
This is not a moral paradox. It is a technical one.
Anthropic’s own research on Mythos Preview made the dual-use nature explicit. The company said Mythos Preview was capable of identifying and exploiting zero-day vulnerabilities in every major operating system and every major web browser when directed by a user. Anthropic also stated that more than 99% of the vulnerabilities it found had not yet been patched, limiting what it could publicly disclose. (Frontier Red Team)
The same post described capabilities that matter directly to exploit development: chaining multiple vulnerabilities, producing local privilege escalation exploits, building exploit primitives, and working with logic bugs that are difficult for conventional fuzzers to validate. Anthropic said the capabilities were not explicitly trained as exploit skills, but emerged from general improvements in code, reasoning, and autonomy. (Frontier Red Team)
That last point should make defenders pay attention. If exploit development improves as a downstream effect of better coding and reasoning, then cyber capability may not remain confined to models explicitly trained for security. A general-purpose model that becomes much better at code migration, patch reasoning, test generation, symbolic reasoning, and long-context analysis may also become better at finding the edge cases that security teams care about.
This is why Fable and Mythos are best understood together. Fable represents the attempt to make high general capability broadly available without giving every user the highest-risk outputs. Mythos represents the attempt to give defenders more of the risky capability under controlled conditions. Both are responses to the same underlying fact: cyber ability is no longer a niche add-on. It is emerging from general model progress.
The N-Day Problem, When Patch Windows Collapse
The strongest technical argument for caring about Mythos-class models is not that they magically create vulnerabilities. It is that they can compress the time between vulnerability disclosure, patch release, and working exploit.
Anthropic’s N-day research measured how well models could turn patches into proof-of-concept crashes and then into working exploits. In one Firefox-focused experiment, Anthropic said Mythos Preview produced working PoCs for 14 of 18 vulnerabilities, with 13 arriving within 40 minutes and the final PoC bringing the total to roughly three hours. In the exploit phase, Mythos Preview reportedly produced eight different working exploits in roughly 12 hours, outperforming other tested Claude models. (Frontier Red Team)
In another experiment involving Windows vulnerabilities, Anthropic reported that Mythos Preview reached 18 of 21 vulnerabilities with PoCs and produced eight full privilege-escalation exploits, at a cost of about $15,700 in API credits. Anthropic’s conclusion was blunt: the time-intensive step of turning some N-days into working exploits had collapsed into hours in its test setting. (Frontier Red Team)
These results need to be read carefully. A benchmark harness is not the open internet. A model running in a prepared environment with staged inputs, budget, and graders is not the same as a real intrusion campaign. Exploitation in the wild still depends on target exposure, mitigations, system configuration, telemetry, EDR behavior, patch state, access path, and operational tradecraft.
Still, the defender’s problem is real. If a model can accelerate the patch-to-PoC process under controlled conditions, then staged patch rollouts, monthly maintenance cycles, and slow triage pipelines become more fragile. The old assumption was that weaponizing a complex patch often required scarce expert time. Mythos-class systems suggest that assumption may not hold for some classes of bugs.
For defenders, the right response is not panic. It is to shorten the validation loop. When a critical patch lands, teams need to know faster whether they are exposed, whether the affected code path is reachable, whether compensating controls actually reduce risk, and whether remediation has taken effect. The value of AI-assisted security should be measured against that operational clock.
Project Glasswing Was a Defensive Distribution Model, Not a Normal Beta
Project Glasswing deserves more attention than the shutdown narrative gives it. It was not a normal preview program where early adopters get a faster model. It was a defensive distribution strategy for a model Anthropic believed could reshape cybersecurity.
Anthropic’s initial Project Glasswing page said Mythos Preview had found thousands of high-severity vulnerabilities, including in major operating systems and browsers, and that the effort was intended to put those capabilities to work for defensive purposes. It also said Anthropic was committing up to $100 million in usage credits for Mythos Preview and $4 million in direct donations to open-source security organizations. (인류학)
By May 2026, Anthropic reported that most initial partners had each found hundreds of critical or high-severity vulnerabilities in their software, and that partners collectively had found more than ten thousand. It also said Mozilla found and fixed 271 vulnerabilities in Firefox 150 while testing Mythos Preview, and that the UK AI Security Institute reported Mythos Preview as the first model to solve both of its cyber ranges end to end. (인류학)
Those claims are significant, but the most important detail is the bottleneck. Anthropic’s update said Mythos Preview had scanned more than 1,000 open-source projects and estimated 23,019 vulnerabilities in total, including 6,202 high or critical severity. Of the high or critical-rated findings that had been carefully assessed, Anthropic reported a 90.6% true-positive rate and said 62.4% were confirmed as high or critical severity. The same update emphasized that human capacity to triage, report, design, and deploy patches had become the bottleneck. (인류학)
That is the practical future of AI vulnerability discovery. The model may increase finding volume. It may reduce the cost of initial analysis. But the hard work does not disappear. Someone still has to confirm the bug, determine affected versions, reproduce the issue safely, avoid duplicate reports, coordinate disclosure, write the patch, ship the fix, update downstream packages, monitor exploitation, and retest.
| Pipeline stage | What AI can accelerate | What still needs strong human or process control | Main failure risk |
|---|---|---|---|
| Code and binary review | Finding suspicious patterns, unusual invariants, reachable crashes, patch deltas | Scoping, repository context, build assumptions, environment realism | Plausible but wrong findings |
| Exploitability triage | Turning a crash or patch into a clearer impact hypothesis | Deciding whether a real attacker can reach the condition | Overstating severity |
| Reproduction | Generating harnesses, test cases, and validation scripts | Running safely in authorized environments | Accidentally crossing scope |
| Disclosure | Drafting reports and technical explanations | Coordinating with maintainers and affected vendors | Premature exposure of unpatched details |
| 해결 방법 | Suggesting fixes and regression tests | Reviewing patch safety and compatibility | Breaking production behavior |
| Retesting | Re-running proof checks after patching | Confirming full remediation across versions and deployments | False confidence from narrow tests |
| Reporting | Converting evidence into readable security reports | Legal, compliance, and customer-specific framing | Missing audit evidence |
This is why Mythos should not be understood only as “an AI that finds vulnerabilities.” The deeper shift is pipeline pressure. If AI increases the front-end volume of valid findings, the downstream security process must become faster, more disciplined, and more evidence-driven.
CVE-2026-5194 Shows What AI-Assisted Vulnerability Discovery Looks Like in Practice
CVE-2026-5194 is one of the clearest public examples connected to the Glasswing and Anthropic security context. NVD describes it as a wolfSSL certificate-verification flaw involving missing hash or digest-size and Object Identifier checks. According to NVD, the issue could allow digests smaller than allowed to be accepted when verifying ECDSA certificates, reducing the security of ECDSA certificate-based authentication if the public CA key is known. NVD states the issue affects ECDSA/ECC verification when EdDSA or ML-DSA is also enabled. (NVD)
The severity is not cosmetic. NVD lists a CVSS v3.1 base score of 9.1 critical, while the CNA score shown on the NVD page is CVSS v4.0 9.3 critical. The affected version range listed in the NVD enrichment is wolfSSL from 3.12.0 up to, but excluding, 5.9.1. The NVD page also references wolfSSL’s patch pull request. (NVD)
wolfSSL’s own security page says CVE-2026-5194 was fixed in version 5.9.1 and recommends that builds with both ECC and EdDSA or ML-DSA enabled and performing certificate verification update to the latest wolfSSL release. The same page credits Nicholas Carlini from Anthropic for the report. (wolfSSL)
This CVE is valuable because it is not a simple “AI found RCE” story. It is a trust-validation failure in a cryptographic library. The technical issue sits in certificate verification, not in a flashy memory-corruption primitive. That makes it a good example of why AI-assisted vulnerability discovery can matter even when the bug is subtle, configuration-dependent, and hard to explain.
It also shows why vulnerability reporting still needs discipline. A responsible security team cannot stop at “critical wolfSSL bug.” It needs to answer precise questions:
| 질문 | Why it matters for CVE-2026-5194 |
|---|---|
| Which versions are affected? | NVD lists wolfSSL 3.12.0 through versions before 5.9.1 as affected. |
| Which configurations matter? | The public descriptions emphasize ECDSA/ECC verification when EdDSA or ML-DSA is also enabled. |
| What is the impact class? | The issue affects certificate-based authentication, so the impact is trust failure rather than ordinary application logic failure. |
| What is the fix? | wolfSSL lists version 5.9.1 as the fixed version. |
| Who should prioritize it? | Systems that depend on wolfSSL certificate verification in affected configurations should treat it seriously. |
| What should not be assumed? | Not every wolfSSL deployment has the same exposure; configuration and usage matter. |
That is the kind of work Mythos-class systems may accelerate but not replace. The model can help detect a subtle invariant failure. It can help draft a reproduction. It can help explain impact. But the final output still needs affected-version mapping, vendor coordination, patch validation, and deployment guidance.
For security teams evaluating Fable, Mythos, or any AI-assisted vulnerability discovery tool, CVE-2026-5194 is a useful test case. A weak workflow will produce a dramatic headline. A mature workflow will produce a precise risk statement, a safe reproduction path, a patch recommendation, and a retest plan.
The Shutdown Exposed a Missing Rulebook
The June 12 shutdown turned the Fable and Mythos split into a policy controversy. Anthropic said the U.S. government directive arrived at 5:21pm Eastern Time and did not provide specific details of the national security concern. The company said it understood the government believed it had become aware of a method of bypassing or jailbreaking Fable 5. Anthropic said it reviewed a demonstration of the technique being used to identify a small number of previously known, minor vulnerabilities, and that other publicly available models could discover them without requiring a bypass. (인류학)
Anthropic’s position was that a narrow potential jailbreak should not be grounds for recalling a commercial model deployed to hundreds of millions of people. The company also argued that if such a standard were applied across the industry, it would essentially halt all new model deployments for frontier providers. (인류학)
Reuters later reported that more than 50 cybersecurity leaders urged the U.S. government to lift restrictions on Anthropic’s Fable 5 and Mythos 5 models, arguing that the curbs could hamper efforts to find and fix software flaws. Reuters also reported that the letter said Anthropic’s models were not uniquely capable of finding security flaws and weaponizing exploits, and that rival models offered similar abilities. (Reuters)
The dispute reveals a missing rulebook. If a guarded model has a narrow jailbreak, does that justify suspending access? If a restricted model is useful to defenders, who qualifies as a trusted defender? If similar cyber capabilities exist in competing models, should enforcement target one model, one provider, one release pattern, or the entire class of systems? If a model is safe enough for broad coding tasks but unsafe for unrestricted exploit development, what technical controls are sufficient?
None of those questions has an easy answer. But Fable and Mythos made them concrete.
The White House had already recognized the connection between frontier AI and cybersecurity in a June 2, 2026 executive order. That order directed agencies to facilitate access to AI-enabled cybersecurity tools, including covered frontier models where appropriate, for agencies and critical infrastructure operators. It also called for an AI cybersecurity clearinghouse to coordinate scanning for software vulnerabilities, validate those vulnerabilities, and prioritize remediation and patch distribution. (The White House)
The same order called for a classified benchmarking process to assess advanced cyber capabilities of AI models and determine the threshold at which a model should be designated a “covered frontier model.” It also described a voluntary framework where developers could provide the government with access to covered frontier models before release to trusted partners, under confidentiality, cybersecurity, insider-risk, and intellectual-property protections. (The White House)
That policy context matters because it shows the contradiction at the center of the Fable and Mythos story. Governments want advanced AI for defense. They also fear misuse. They want trusted access for critical infrastructure. They also worry about who counts as trusted. They want innovation. They also want a way to prevent dangerous capability diffusion.
Fable and Mythos did not create that contradiction. They made it visible.
Guardrails Are Not Enough When the Model Can Use Tools
A cyber-capable model becomes more dangerous when it is connected to tools. That does not mean every tool-connected model is unsafe. It means the security boundary moves from text generation to execution governance.
OWASP’s LLM guidance is useful here. The OWASP Top 10 for Large Language Model Applications lists prompt injection, insecure output handling, insecure plugin design, excessive agency, sensitive information disclosure, and supply-chain vulnerabilities among major risks. OWASP defines prompt injection as crafted inputs that alter an LLM’s behavior in unintended ways, and notes that jailbreaking is a form of prompt injection where the attacker causes the model to disregard safety protocols. (owasp.org)
The practical implication is simple: a refusal layer may reduce harmful text output, but a tool-connected cyber agent needs more than refusal. It needs scoped tools, sandboxed execution, network limits, logging, approval gates, target authorization, rate limits, and post-action evidence. If a model can run a scanner, read a repository, launch a browser, modify a request, execute a script, or create a patch, the system must govern what happens after the model decides.
This is especially important for AI pentesting and AI-assisted red teaming. A general chat model answering a question about SQL injection is one risk profile. An agent that can map an attack surface, generate payloads, run a headless browser, replay authenticated requests, and write a report is a different profile. The second system needs workflow controls, not just model-level safety text.
A safe architecture for cyber-capable AI should look more like this:
cyber_ai_policy:
purpose: "authorized_defensive_security_testing"
user_requirements:
identity_verification: required
organization_verification: required_for_external_targets
role_based_access:
- security_engineer
- application_owner
- compliance_reviewer
target_authorization:
required: true
accepted_evidence:
- domain_ownership
- written_scope_statement
- bug_bounty_program_scope
- internal_asset_inventory
default_scope: "deny"
capability_routing:
public_model:
allowed:
- secure_code_review
- vulnerability_explanation
- remediation_guidance
- defensive_detection_logic
restricted:
- exploit_chain_generation
- stealth_or_evasion_guidance
- unauthorized_target_testing
trusted_cyber_model:
allowed_with_approval:
- exploitability_validation_in_lab
- patch_diff_risk_analysis
- binary_behavior_testing
- authenticated_flow_testing
tool_controls:
network_access: "scoped_to_authorized_targets"
shell_access: "sandboxed"
scanner_rate_limit: "strict"
credential_handling: "no_persistent_storage"
destructive_actions: "human_approval_required"
evidence:
log_tool_calls: true
capture_http_requests: true
capture_screenshots: true
preserve_reproduction_steps: true
redact_secrets: true
disclosure:
unpatched_third_party_vulnerability:
public_output: "blocked"
coordinated_disclosure: required
This configuration is not a product spec. It is a control pattern. The point is to separate capability from permission. A model may be capable of suggesting an exploit path. That does not mean the deployed system should allow it in every context.
The Real Product Is the Boundary Around the Model
Fable and Mythos show that AI security products will be judged by their boundaries as much as their models.
That is already true in ordinary security tooling. A vulnerability scanner is not valuable merely because it can send requests quickly. It is valuable if it can stay in scope, authenticate safely, avoid destructive behavior, reduce false positives, preserve evidence, and produce remediation guidance that engineers can act on. An AI pentesting system raises the same requirements, but the stakes are higher because the model can adapt, infer, and chain actions.
For a cyber-capable AI system, the boundary should answer at least eight questions:
| Control question | 중요한 이유 |
|---|---|
| Who is the user? | Identity and eligibility decide whether high-risk capability should be exposed. |
| What target is authorized? | Cyber testing without target authorization becomes abuse. |
| What is the task boundary? | “Find security issues” is too broad without scope, timing, and allowed techniques. |
| Which tools can the model call? | Tool access can turn text reasoning into real-world action. |
| What requires human approval? | Exploit validation, destructive actions, and sensitive data access need checkpoints. |
| What is logged? | Security teams need evidence, auditability, and abuse investigation. |
| What is retained? | Model providers and enterprises must manage sensitive code, vulnerabilities, and logs. |
| How is remediation verified? | A finding is not closed until the fix is retested against the original condition. |
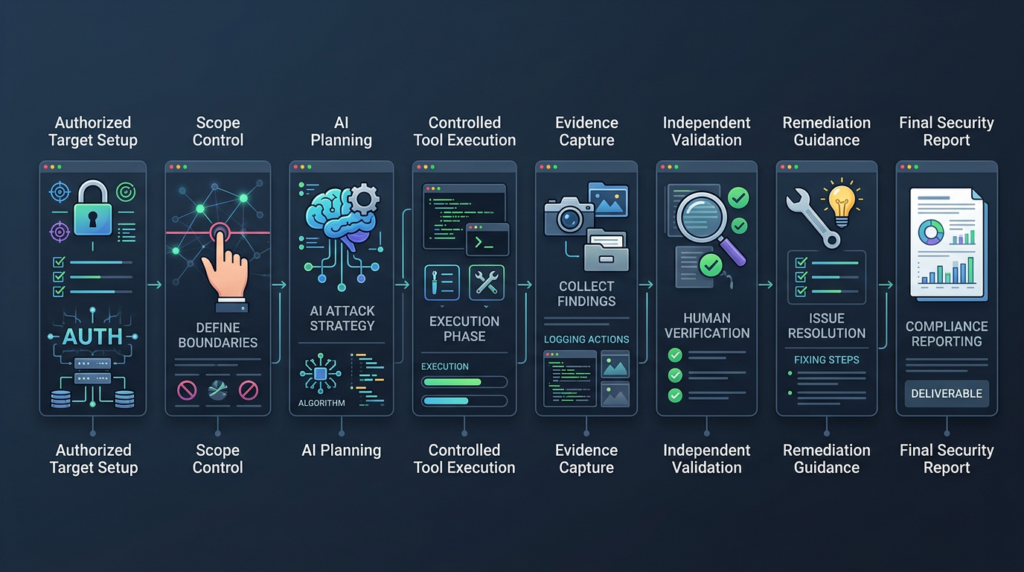
This is where AI pentesting platforms have a clearer role than raw model APIs. A raw model may reason about a vulnerability, but an enterprise security team needs an authorized workflow: define the target, map the attack surface, test safely, validate independently, preserve evidence, avoid hallucinated findings, and generate a report that engineers and auditors can use.
Penligent’s AI pentesting page describes this kind of workflow in concrete terms: black-box attack-surface mapping, multi-agent testing, verified findings only, independent sub-agent validation, headless-browser verification, human-in-the-loop control, and SOC 2 and ISO 27001 aligned editable reports. It also states that Penligent is for authorized security testing only and requires explicit permission from the target owner. (펜리전트)
That product pattern aligns with the broader lesson from Fable and Mythos. The future of AI security will not be a choice between “raw unrestricted model” and “no model.” The useful middle ground is controlled execution: strong models inside scoped, auditable, evidence-driven security workflows.
How Security Teams Should Evaluate Fable, Mythos, and Similar AI Cyber Models
Security teams should not evaluate AI cyber models the way they evaluate ordinary chatbots. A model that can summarize a CVE is not the same as a model that can validate exploitability. A model that can write a unit test is not the same as one that can create a reliable crash harness. A model that can explain a patch is not the same as one that can chain primitives into privilege escalation.
A useful evaluation should separate five layers.
First, evaluate code and vulnerability reasoning. Give the model known vulnerable code, patched code, and intentionally flawed internal examples. Ask it to identify root cause, affected paths, exploitability conditions, and remediation strategy. Do not reward confident guesses. Reward source-grounded reasoning and correct uncertainty.
Second, evaluate reproduction discipline. A useful cyber model should be able to propose a safe reproduction plan in a lab environment, not merely produce an alarming description. The plan should specify environment, build flags, vulnerable version, patched version, expected signal, and safety limits.
Third, evaluate tool behavior. If the model can call tools, test whether it stays within target scope, respects rate limits, avoids destructive actions, and asks for approval before sensitive steps. The test should include indirect prompt injection attempts in repository files, issue comments, web pages, and API responses.
Fourth, evaluate reporting quality. A finding should include impact, affected component, evidence, reproduction steps, remediation, confidence, false-positive risk, and retest steps. Security teams should penalize vague “possible vulnerability” reports with no proof path.
Fifth, evaluate operational fit. The model is only useful if the organization can triage what it finds. A team that receives 2,000 plausible findings and can validate 20 per week does not have an AI advantage. It has a bottleneck.
A practical test plan might look like this:
# Build an authorized local evaluation set.
mkdir -p ai-cyber-eval/{targets,patches,reports,evidence}
# Add intentionally vulnerable toy services, historical patched CVEs,
# and internal code samples approved for testing.
# Do not run these tests against public systems without permission.
cat > ai-cyber-eval/scope.txt <<'EOF'
Allowed:
- Local lab services on 127.0.0.1
- Internal demo repositories approved for security testing
- Historical CVE reproductions in isolated containers
- Patch-diff analysis using public advisories
Disallowed:
- Public internet scanning
- Credential attacks
- Persistence
- Evasion
- Data exfiltration
- Any target not explicitly listed
EOF
The command is intentionally simple. The control is the point. Before testing the model, define the scope. If the model cannot operate inside a written scope, it is not ready for serious security work.
What Fable and Mythos Mean for Bug Bounty Hunters and Red Teams
Bug bounty hunters, red teamers, and pentesters should read the Fable and Mythos split with both interest and caution.
The interesting part is obvious. Models are getting better at the work that consumes security researchers’ time: reading unfamiliar code, finding suspicious patterns, explaining weird behavior, drafting test cases, mapping endpoints, reviewing patches, and turning messy observations into structured reports. For authorized testing, that can mean faster coverage and better evidence.
The caution is just as important. AI-generated security hypotheses are not findings. A bug bounty report still needs proof, scope, impact, and clean reproduction. A red-team result still needs rules of engagement and deconfliction. A pentest report still needs defensible evidence and remediation. A model can accelerate the path, but it can also hallucinate impact, miss environmental constraints, or suggest out-of-scope actions.
Fable’s safeguards and Mythos’s trusted access model point to the same operational rule: the more powerful the model, the more explicit the boundary must be.
For bug bounty hunters, that boundary is the program scope. For red teams, it is the rules of engagement. For internal security teams, it is the asset inventory and authorization chain. For AI vendors, it is the user eligibility, tool policy, logging, and abuse monitoring layer.
A strong AI security workflow should therefore preserve a simple invariant: no model action should be more privileged than the authorization behind it.
What Enterprises Should Do Now
Enterprises do not need to wait for a perfect regulatory framework before building better AI security practices. The Fable and Mythos story points to several immediate actions.
Start by separating AI usage categories. General coding assistance, secure code review, vulnerability explanation, patch-diff analysis, lab exploitability validation, internet-facing scanning, and autonomous tool execution should not live under the same policy. They carry different risks.
Next, require explicit target authorization for AI-assisted testing. A prompt saying “test this domain” is not authorization. The workflow should bind the test to asset ownership, bug bounty scope, internal approval, or a written engagement.
Then, control tool access. The highest-risk jump happens when a model moves from explaining to executing. If the system can run scanners, browsers, shells, fuzzers, or exploit frameworks, tool calls should be sandboxed, logged, rate-limited, and scoped.
After that, build a triage pipeline. AI-discovered findings should enter a queue with severity, confidence, affected asset, evidence, reproducibility, and owner. Without triage, the organization will drown in unreviewed output.
Finally, shorten patch verification. If models make N-day exploit development faster, then teams need faster exposure analysis, compensating controls, and retesting. The goal is not only to patch faster. It is to know faster whether the patch matters for your environment.
| Enterprise task | Better practice after Fable and Mythos |
|---|---|
| AI coding assistance | Allow broadly with repository controls and secret scanning |
| Secure code review | Allow with internal code policies and evidence capture |
| Patch-diff analysis | Allow for defensive triage, restrict exploit-generation output |
| Lab exploitability validation | Require isolated environment and approval |
| Internet-facing scanning | Require asset ownership and rate limits |
| Autonomous tool execution | Require sandboxing, logs, and human approval gates |
| External model use with sensitive code | Review data retention, jurisdiction, vendor security, and disclosure obligations |
| AI-generated vulnerability reports | Require human validation before filing, patching, or escalation |
The teams that benefit most from AI cyber models will not be the ones that hand the model the most power. They will be the ones that give the model enough power to help, enough structure to stay useful, and enough oversight to remain trustworthy.
Common Misreadings of Fable and Mythos
The first misreading is that Fable was safe and Mythos was unsafe. The better distinction is that Fable and Mythos were two safety boundaries around the same underlying model. Fable attempted broad access with stronger safeguards. Mythos attempted restricted access with more cyber capability exposed to vetted users.
The second misreading is that safeguards solve the problem. Safeguards help, but Anthropic itself acknowledged that perfect jailbreak resistance does not appear possible today. OWASP’s prompt-injection guidance also makes clear that prompt injection and jailbreaking remain structural risks for LLM applications, especially when models process external content or influence tool execution. (인류학)
The third misreading is that restricting one model eliminates the threat. Reuters reported that cybersecurity leaders argued Anthropic’s models were not uniquely capable and that other models offered similar abilities. Whether or not one agrees with that claim in full, the general direction is clear: cyber-relevant AI capability is spreading, and policy focused only on one model release will struggle to address the broader system-level trend. (Reuters)
The fourth misreading is that AI-discovered vulnerabilities are automatically valid. Anthropic’s own Glasswing update shows the opposite: even when true-positive rates are strong after assessment, triage and validation remain central. The model can accelerate discovery, but human review and coordinated remediation still determine whether a finding becomes a fixed vulnerability. (인류학)
The fifth misreading is that enterprises should avoid AI security testing entirely. That is not realistic. Attackers will use AI. Developers will use AI. Security vendors will use AI. The better enterprise posture is not blanket avoidance, but controlled adoption: authorized targets, bounded tools, evidence, retesting, and governance.
자주 묻는 질문
What is the difference between Claude Fable 5 and Claude Mythos 5?
- Anthropic described Fable 5 and Mythos 5 as the same underlying model with different safeguards and access boundaries.
- Fable 5 was the broader-access Mythos-class model, with conservative safeguards around high-risk domains such as cybersecurity and biology.
- Mythos 5 was the restricted version for vetted cybersecurity and biology research use cases, with some safeguards lifted.
- Anthropic stated that Fable’s safeguards were the reason the models had different names. (인류학)
Why did Anthropic create two versions instead of one model?
- A single release boundary is hard to defend when a model is useful for both general work and high-risk cyber tasks.
- Fable 5 allowed Anthropic to release Mythos-level general capability more broadly while restricting some cyber and bio outputs.
- Mythos 5 allowed selected defenders to use more cyber-capable functionality under trusted access conditions.
- The split reflects a broader industry problem: frontier AI models may need capability-specific access controls rather than one public setting.
Was Fable 5 taken offline because it was proven unsafe?
- Anthropic said the U.S. government issued an export-control directive requiring suspension of access by foreign nationals.
- Anthropic said the government did not provide specific details of the national security concern.
- Anthropic’s understanding was that the concern involved a method for bypassing or jailbreaking Fable 5.
- Anthropic disputed that a narrow potential jailbreak involving known minor vulnerabilities justified recalling a commercial model. (인류학)
What makes Mythos 5 important for cybersecurity?
- Mythos 5 followed Mythos Preview, which Anthropic said showed major improvements in vulnerability discovery and exploit development.
- Project Glasswing gave selected defenders access to Mythos Preview for work on critical software and infrastructure.
- Anthropic reported that Project Glasswing partners found large numbers of high or critical vulnerabilities, though those findings still required human triage and remediation.
- Mythos matters because it represents restricted distribution of cyber-capable AI, not just a stronger chatbot. (인류학)
Can AI models really find zero-day vulnerabilities?
- Anthropic reported that Mythos Preview found and exploited zero-day vulnerabilities in major operating systems and browsers during testing.
- Public details are limited because Anthropic said most of the vulnerabilities had not yet been patched.
- A model finding a vulnerability is not the same as a complete real-world attack campaign.
- The defensible claim is that frontier AI appears to be reducing the time and expertise needed for some vulnerability discovery and exploit-development tasks, especially in controlled environments. (Frontier Red Team)
What does CVE-2026-5194 show about AI-assisted vulnerability discovery?
- CVE-2026-5194 is a wolfSSL certificate-verification flaw involving missing digest-size and OID checks.
- NVD lists it as critical, with wolfSSL versions from 3.12.0 up to but excluding 5.9.1 affected.
- wolfSSL credits Nicholas Carlini from Anthropic for the report and lists 5.9.1 as the fixed version.
- The case shows that AI-assisted security work can surface subtle trust-validation bugs, but real value depends on precise affected-version analysis, configuration context, patching, and retesting. (NVD)
How should security teams safely test AI cyber models?
- Use only authorized targets, lab environments, internal repositories, or bug bounty scopes where testing is explicitly allowed.
- Separate explanation tasks from execution tasks; tool use should require stricter controls.
- Log tool calls, prompts, outputs, environment state, and evidence.
- Require human approval for exploit validation, destructive actions, credential handling, or external scanning.
- Measure false positives, reproducibility, patch validation, and reporting quality, not just how impressive the model sounds.
How should companies think about tools like Fable, Mythos, and AI pentesting platforms?
- Treat them as cyber workflows, not just chat interfaces.
- Ask what the system can do, what it is allowed to do, who approved the target, and how actions are logged.
- Prefer systems that preserve evidence, support retesting, and keep humans in control of high-risk steps.
- The right question is not only “which model is strongest?” It is “which workflow makes strong capability safe, scoped, auditable, and useful for defense?”
The Lasting Lesson
Fable and Mythos may be remembered less as two Claude model names than as an early map of frontier AI’s next product boundary. One underlying model became two release surfaces. One capability stack became a public assistant and a trusted cyber model. One launch forced the industry to ask whether safeguards, access programs, and government rules can keep pace with AI systems that are becoming useful in the most sensitive parts of cybersecurity.
The answer is not to pretend cyber-capable AI can be made harmless. It cannot. The same skills that help defenders find bugs faster can help attackers reason faster. The answer is also not to block defenders from the tools they need while assuming adversaries will wait. They will not.
The workable path is controlled capability: strong models, explicit scope, trusted access where needed, bounded tools, human approval for high-risk actions, careful monitoring, coordinated disclosure, and evidence that security teams can verify. Fable showed what broad access with safeguards might look like. Mythos showed what restricted cyber access might look like. The security industry now has to build the operational layer that makes both ideas usable.

