On February 20, 2026, Anthropic announced Claude Code Security, a new capability built into Claude Code on the web and released as a limited research preview. It scans codebases for vulnerabilities and proposes targeted patches for human review, with a multi-stage verification step meant to filter false positives before an analyst even sees them. (Anthropic)
If that sounds like yet another security feature bolted onto an AI coding assistant, it’s worth remembering what happened next. The same day, Bloomberg reported a sharp, correlated selloff across multiple public cybersecurity names and a steep drop in a major cybersecurity ETF, framed as investor fear that “security scanning” is collapsing from a category into a feature. (Bloomberg.com)
The market reaction is not proof that traditional vendors are obsolete. It is, however, a clean signal that investors and security leaders have started to price in a new assumption: frontier models can now perform a kind of semantic vulnerability discovery that didn’t scale before, and that changes where the bottlenecks are. Anthropic’s own red-team writeup about “0-days at scale” makes the same point from the defensive side: AI models can find high-severity vulnerabilities in widely used open source, and defenders should move quickly while the window exists. (Red Anthropic)
This article breaks down what Claude Code Security appears to be doing under the hood, where it truly differs from SAST, fuzzing, and DAST, how to integrate it without creating a new kind of alert fatigue, and how to connect “code findings” to evidence-based exploitation testing when you actually need proof.
What Anthropic Actually Shipped
Anthropic’s product announcement is specific about three design choices that matter more than the marketing labels.
Claude Code Security is presented as:
- A codebase scanning and patch suggestion workflow embedded into Claude Code on the web. (Anthropic)
- A multi-stage verification pipeline where Claude re-examines findings to prove or disprove them and filter false positives. (Anthropic)
- A human-in-the-loop system where nothing is applied without human approval. (해커 뉴스)
That last point is not a footnote. It is an explicit admission that even a high-performing model can generate plausible but wrong fixes, or correct fixes that violate product constraints, compatibility promises, performance budgets, or security invariants you didn’t encode in text.
So the right mental model is not “AI replaces secure code review.” It’s “AI becomes a new discovery layer, but governance and verification still define whether you can trust it.”

Why Rule-Based Scanners Hit a Ceiling
Static analysis is not one thing. It’s a spectrum: pattern rules, taint tracking, symbolic execution, reachability modeling, and a lot of engineering tradeoffs around speed, coverage, and noise. Still, most teams experience SAST as a mismatch between volume and value: too many findings that don’t become exploitable reality, and too many misses in cross-module logic.
A credible way to ground that pain is to look at the triage economics. StackHawk has been publicly arguing that many AppSec teams spend at least 40% of their time triaging SAST alerts, and that when you validate at runtime, a large portion of those findings can be unexploitable in practice. (StackHawk, Inc.) The exact percentage will vary by org, but the structural point is stable: if your pipeline produces low-signal alerts faster than your team can prove them, the system collapses into “security theater plus fatigue.”
Meanwhile, the supply side is exploding. Veracode’s 2025 GenAI Code Security Report found 45% of AI-generated code samples failed security tests and introduced OWASP Top 10 vulnerabilities in their evaluation. (Veracode) More code, more dependencies, more surface area, and more “verification debt.”
Those two forces together are why “a better scanner” is not enough. The new requirement is not just finding issues. It’s finding issues in a way that is closer to how a human reviewer reasons about exploitability and intent, while still being automatable.
The Claude Code Security Thesis in One Sentence
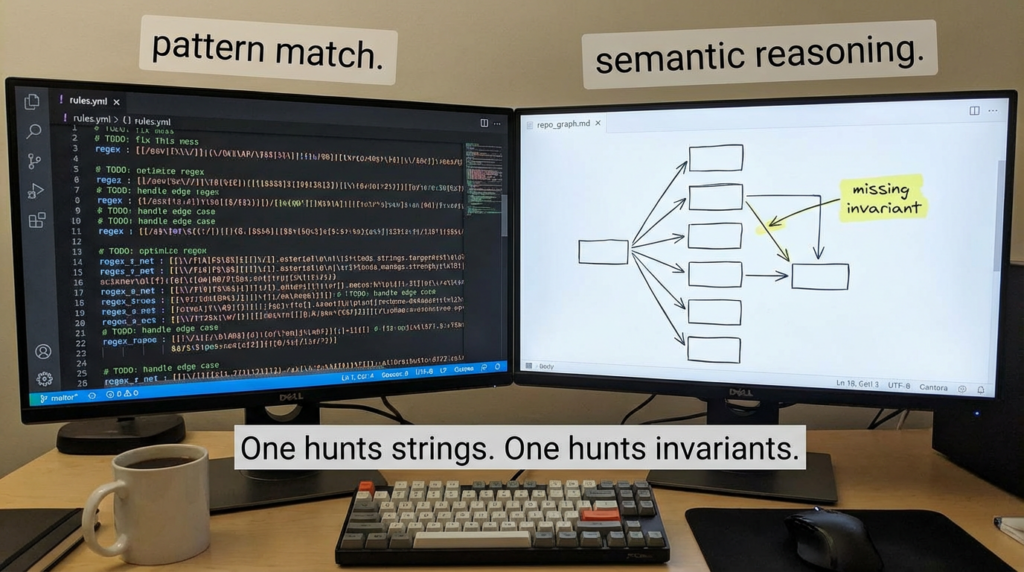
Traditional SAST mostly asks: “Does this code match a known bad pattern?”
Claude Code Security is aiming to ask: “Given what this system is trying to do, where are the security invariants weak, and can I argue that a bug is real, reachable, and worth fixing?”
Anthropic and several secondary reports describe it as reasoning about the codebase like a human security researcher, tracing data flows through the application, and understanding how components interact. (해커 뉴스)
The difference is not philosophical. It changes what “coverage” means.
Step One: Whole-Repository Context and Why Long Context Matters
One practical constraint has always limited deep automated reasoning: context fragmentation.
A classic SAST rule runs over a file or a function and looks for an AST shape. A more advanced analyzer may build call graphs and track taint across boundaries, but it still has to encode the world in formal structures. That’s why complex business logic bugs and multi-component authorization flaws remain hard: they don’t look like one forbidden pattern. They look like a chain of “reasonable” decisions that becomes unsafe only in combination.
Anthropic has been pushing long-context capabilities as a first-class feature, and the Opus 4.6 release notes explicitly mention a 1M token context window in beta (with 200K context as the general baseline in multiple places). (Anthropic)
Long context doesn’t automatically create understanding. But it does remove a hard ceiling: the model can ingest more of your codebase at once, which makes cross-file reasoning and architectural summarization less brittle.
In security terms, this matters because exploitability is rarely local. It is path-dependent.
Step Two: Cross-File Data Flow as a Reasoning Problem
Most real incidents are not “a single dangerous function call.” They are “untrusted input moved across boundaries until it hits a sink.”
To make that concrete, here’s a simplified cross-file flow that frequently defeats shallow scanning:
Request input (controller)
-> parsing and normalization (middleware)
-> domain logic (service)
-> permission check (maybe conditional)
-> persistence layer query building (repo/DAO)
-> sink (SQL/command/template/render)
A rule-based scanner can often flag the sink. It struggles to prove the path and the missing guard, especially if validation happens in a framework hook, a decorator, a feature flag branch, or a helper function defined elsewhere.
Anthropic’s description of Claude Code Security emphasizes tracing data flows and understanding component interaction patterns. (해커 뉴스) That phrasing implies the model is not only reading code but attempting to reconstruct these chains in natural language reasoning, then using its own verification loop to decide whether the chain is convincing.
This is where “LLM as a semantic engine” differs from “LLM as a UI for traditional SAST.”
A large segment of the market’s “AI SAST” claims are really AI-assisted triage: run classic SAST, then use an LLM to summarize, cluster, and propose fixes. That can be valuable, but it doesn’t fundamentally expand the class of vulnerabilities you can find. Several vendor comparisons explicitly describe that split: detection still comes from traditional rules and dataflow engines, and AI improves usability after the fact. (corgea.com)
Claude Code Security is being positioned closer to the other camp: “agentic” or “reasoning-first” analysis, where the model is doing more of the discovery work itself. (해커 뉴스)

Step Three: Multi-Stage Verification as an Anti-Hallucination Control
Security teams do not adopt scanners because the scanner is confident. They adopt scanners because they can predict the scanner’s failure modes.
Anthropic’s announcement describes a multi-stage verification process in which Claude re-examines each result and tries to prove or disprove its own finding to filter out false positives. (Anthropic)
That matters because the fastest way to kill trust is a flood of plausible but wrong findings. The broader industry has been wrestling with that for years under the label “false positive tax,” and it shows up everywhere from SOC alert fatigue to AppSec backlogs. (netcraft.com)
The best interpretation of “multi-stage verification” is that it turns vulnerability reporting into an internal debate:
- Stage A generates hypotheses (“this looks like a bug”).
- Stage B attacks the hypothesis (“show me the path, show me reachability, show me conditions”).
- Stage C forces specificity (“what input, what call chain, what impact”).
- Stage D assigns severity and confidence for human review.
Anthropic also says findings are assigned severity ratings. (Anthropic) External writeups echo that the results land in a dashboard for analysts to review, with suggested patches and human approval required. (해커 뉴스)
If you’ve lived through SAST fatigue, you can see why this design is existential. The tool’s success will be defined less by “how many findings it can produce,” and more by “how often engineers agree the findings are real and worth fixing.”
The 500+ Vulnerabilities Claim and What It Does and Does Not Prove
Anthropic’s red-team research page “0-Days” states that AI models can now find high-severity vulnerabilities at scale and frames Opus 4.6 as a continuation of that trajectory. (Red Anthropic) Major security outlets reported that Claude Opus 4.6 found 500+ previously unknown high-severity flaws in open-source projects including Ghostscript, OpenSC, and CGIF. (해커 뉴스)
Those reports are the backbone of the narrative: if these codebases endured extensive fuzzing and long-term scrutiny, why did a model find so much so quickly?
The strongest, defensible conclusion is narrower than the hype:
- LLM-style reasoning can surface classes of vulnerabilities that are not easily expressed as static patterns, and can do so without years of tool tuning. (해커 뉴스)
- That capability can be productized into a workflow (Claude Code Security) within weeks of research disclosure. (Venturebeat)
What it does not prove:
- That “traditional scanners are dead.” Traditional SAST still provides deterministic guarantees, scalable baselines, and policy enforcement in CI.
- That every codebase will see similar yields. Vulnerability density varies wildly by language, age, code style, and test maturity.
- That AI findings are automatically exploitable or production-relevant. That depends on reachability, environment, mitigations, and attacker constraints.
The real shift is that the discovery frontier moved. That’s why markets reacted even at preview stage, as Bloomberg framed it: the fear is not one product, it’s category compression. (Bloomberg.com)
A Practical Taxonomy of What AI Reasoning Finds Better
To operationalize this, it helps to classify “hard bugs” by why classic automation misses them.
Patch bypass and incomplete fixes
These are bugs where the “shape” looks safe in one place but unsafe elsewhere, often because a patch landed in one path and missed a sibling path. Your own Penligent coverage of CVE-2023-43208 is a clean example of the pattern: it’s described as an incomplete patch bypass for a prior issue (CVE-2023-37679), and the security lesson is that “patching the headline” is not the same as closing the class. (펜리전트)
This is exactly where repository-wide reasoning shines: read the fix, infer the invariant, then search for “other places that should have been fixed the same way.”
Algorithm-state vulnerabilities
These are bugs where the trigger is a specific sequence of internal states rather than “one bad call.” Fuzzing can struggle here because coverage is not the same as reaching the right state machine configuration. Anthropic’s CGIF mention in its broader 500+ narrative is often cited as an example of bugs that survive huge fuzzing investments because the input needs to satisfy algorithmic constraints. (해커 뉴스)
Authorization and multi-component logic
These are “works as designed” locally but unsafe globally: mismatched assumptions, confused deputy flows, and permission checks that are present but misplaced. These are classic business-logic failures that pattern rules often can’t express.
How to Use Claude Code Security Without Creating a New Kind of Noise
A mature rollout plan treats AI reasoning as a tier, not a replacement.
Here is a deployment pattern that is realistic in US engineering orgs with CI/CD and existing AppSec investments.
Tiered pipeline model
| 레이어 | Tooling style | What it’s best at | What it cannot guarantee |
|---|---|---|---|
| Baseline | SAST rules and reachability | Known patterns, policy enforcement, fast feedback | Semantic intent, deep cross-module logic |
| Deep discovery | AI reasoning audit | Cross-file reasoning, patch-bypass hunting, novel logic flaws | Determinism, repeatability without drift |
| Proof | Runtime validation, sandbox repro | Exploitability evidence, environment-specific truth | Full source coverage, early SDLC integration |
| Governance | Human review + tests | Prevents unsafe fixes, enforces domain constraints | Scale if your org doesn’t resource it |
This is not theoretical. It aligns with what vendors and researchers keep repeating: AI improves discovery, but verification is still the bottleneck that decides whether findings are actionable. (Anthropic)
Metrics that actually matter
Stop measuring “number of findings.” Measure:
- Engineer agreement rate: how often developers accept the finding as real.
- Time-to-proof: how fast you can reproduce or dismiss.
- Fix throughput with regression safety: fixes merged plus tests added.
- Backlog decay: does the queue shrink or grow?
Semgrep’s own public material on AI-assisted triage is useful here: their framing is explicitly about taking triage load off humans while maintaining trust and agreement. (Semgrep)
A Concrete Workflow You Can Copy
1) Start with a “thin slice” target selection
Pick one of these:
- A C/C++ parsing library, image/PDF processing path, crypto wrapper, or deserializer
- A high-value authorization boundary: “who can do what” endpoints
- A new AI-generated subsystem that shipped without deep review
The selection logic is grounded in risk: memory-unsafe languages and high-complexity boundary code generate the most asymmetric failures.
2) Run deterministic baselines first
Keep Semgrep/CodeQL or equivalent as your guardrails. You want deterministic checks that catch the obvious and enforce policy.
Example CodeQL command you might already have in CI:
codeql database create db --language=javascript --source-root .
codeql database analyze db codeql/javascript-queries:codeql-suites/javascript-security-and-quality.qls \\
--format=sarif-latest --output=codeql-results.sarif
3) Use AI reasoning for deep audit and hypothesis generation
Treat Claude Code Security as a hypothesis engine that returns:
- The vulnerability claim
- The reasoning chain and file/line references
- The proposed patch
- Severity and confidence signals (Anthropic)
4) Require proof artifacts for “critical” merges
For high severity, require at least one of:
- A minimal repro input that triggers the bug
- A unit/integration test that fails pre-fix and passes post-fix
- A runtime validation step in a sandbox
That requirement is the difference between “AI-assisted code review” and “evidence-based AppSec.”
CVE Anchors That Map Cleanly to This Shift
You asked for high-impact and newer CVEs where relevant. The goal here is not to pad the article with CVE name-dropping, but to show how AI reasoning and verification connect to real vulnerability archetypes.
CVE-2023-43208 as a patch bypass archetype
CVE-2023-43208 is described as a critical unauthenticated RCE in Mirth Connect and is widely discussed as an incomplete patch situation tied to CVE-2023-37679. (펜리전트)
Why it matters in this article: patch bypass bugs are exactly where “read the patch, infer the invariant, search for missed siblings” beats “match a pattern.”
A scanner that only matches “dangerous sink” patterns often can’t see that a fix landed incompletely. A reasoning model can.
CVE-2026-20841 as an execution boundary archetype
Your Penligent coverage frames CVE-2026-20841 as part of a broader “execution boundary” story in Windows Notepad and highlights why classification and descriptions can shift as understanding evolves. (펜리전트)
Why it matters here: when “text becomes execution,” security is not just about sinks. It’s about implicit trust boundaries across components. Reasoning-based analysis is often better at surfacing boundary assumptions, but you still need concrete verification to avoid overclaiming impact.
CVE-2023-48022 as AI infrastructure reality check
Penligent’s broader agentic tooling writeup references CVE-2023-48022 in the Ray ecosystem as an example of unauthenticated RCE risk in modern AI infrastructure. (펜리전트)
Why it matters: as code scanning becomes more powerful, the attacker’s ability to find “the next Ray” accelerates. Defense has to connect code-level discovery to environment-level exploitability faster than before.
The Hidden Driver: Verification Debt in Vibe Coding
Even if you ignore the market selloff, the engineering trend is enough to justify AI code audits.
Veracode’s 2025 report found 45% of AI-generated code samples failed security tests and introduced OWASP Top 10 vulnerabilities. (Veracode)
That does not mean “AI coding is unsafe.” It means a large portion of AI output is “functionally plausible but security-incomplete,” and the bottleneck is no longer typing code; it is verifying code.
This is why the most strategic framing of Claude Code Security is not “a scanner.” It’s an attempt to shrink verification debt by automating a portion of expert reasoning while adding a verification loop and human approval.
Where Claude Code Security Will Still Need Traditional Tools
A reasoning model can be strong and still benefit from deterministic engines.
Deterministic reachability and policy enforcement
SAST tools can encode organizational policy: disallow certain APIs, require safe wrappers, enforce crypto constraints, block secrets, enforce sanitization usage. That’s not glamorous, but it prevents entire classes of regressions.
Runtime truth
Many vulnerabilities are environment-dependent:
- A path is unreachable in production due to routing config.
- A sink is protected by a framework sanitizer.
- A mitigation exists in a reverse proxy or WAF.
Runtime validation is how you turn “maybe” into “yes or no.” StackHawk’s argument that runtime testing can reveal large fractions of unexploitable SAST findings is one example of why that layer matters. (StackHawk, Inc.)
A Mini Playbook for Security Leaders
If you’re making a 2026 budget decision, here is a grounded, actionable way to evaluate Claude Code Security-like tools.
Run a bake-off on one repository
- Choose a repo with known history: legacy components plus active development.
- Run baseline SAST and record:
- findings count
- time to triage
- developer agreement rate
- Run AI reasoning audit and record:
- net new true positives
- time to prove/disprove
- patch acceptance rate
- Require proof artifacts for “critical” issues.
What “success” should look like
- The AI tool finds a small number of issues that matter and that your baseline did not.
- The AI tool provides enough chain-of-reasoning and references that engineers can verify quickly.
- The patch suggestions are close enough to reduce cognitive load, but not auto-merged. (Anthropic)
If you instead get “lots of interesting theories,” you’ve just reinvented alert fatigue.
Resource Links
- Anthropic announcement: Claude Code Security limited research preview (Anthropic)
- Anthropic red team research: 0-Days (Red Anthropic)
- The Hacker News coverage of Claude Code Security (해커 뉴스)
- The Hacker News coverage of 500+ high-severity flaws in Ghostscript/OpenSC/CGIF (해커 뉴스)
- Bloomberg market report on cybersecurity stock slide (Bloomberg.com)
- Opus 4.6 release notes and long-context mention (Anthropic)
- Veracode 2025 GenAI Code Security Report summary (Veracode)
- StackHawk survey claim on SAST triage time (StackHawk, Inc.)
- ACM paper on alert fatigue in SOCs (ACM 디지털 라이브러리)
- CVE-2023-43208 patch bypass analysis (펜리전트)
- AI Agents Hacking execution boundary article (펜리전트)
- OpenClaw indirect instruction and agent risk (펜리전트)
- PentestGPT alternatives and CVE-2023-48022 reference (펜리전트)
- Windows Notepad execution boundary and CVE-2026-20841 (펜리전트)

