The wrong way to ask about Claude 4.7 is whether it is “good at hacking.” The right question is narrower and much more useful: where does Claude Opus 4.7 add real value inside an authorized pentest or red-team engagement, and where do Anthropic’s safeguards, product boundaries, and the physics of real targets still stop it from being a trustworthy final operator. Anthropic itself answered part of that question when it released Opus 4.7 on April 16, 2026. The company described it as its most capable generally available model, stronger than Opus 4.6 on advanced software engineering, long-running work, and vision-heavy tasks, while also making it the first generally available Claude release to ship with new real-time cyber safeguards meant to detect and block prohibited or high-risk cyber requests. (인류학)
That combination matters more than the benchmark table. Pentesting is not a pure reasoning contest, and red teaming is not just exploit generation with a nicer interface. NIST defines penetration testing as security testing that mimics real-world attacks in an attempt to identify ways to circumvent security features, while SP 800-115 frames testing as part of a larger process that includes planning, analyzing findings, and developing mitigation strategies. OWASP’s Web Security Testing Guide does the same thing in web applications: it treats testing as a structured discipline, not a one-shot stunt. A model can be very smart and still be assigned the wrong job description. (csrc.nist.rip)
Claude 4.7 deserves serious attention from security teams because it pushes on the parts of the workflow that are usually the hardest to scale with humans alone: absorbing large codebases, correlating artifacts across tools, reading screenshots and UI states, holding long investigative threads together, and turning vague security hunches into bounded next steps. But it also arrives in a policy and product environment that explicitly refuses to treat “strong cyber model” as synonymous with “open offensive operator.” Anthropic says requests that indicate prohibited or high-risk cybersecurity use may now be blocked, and it offers a Cyber Verification Program for legitimate defensive users whose work overlaps with dual-use categories such as penetration testing, vulnerability research, and red-teaming. (Claude Platform)
That means the useful answer is not yes or no. Claude 4.7 is good for some parts of pentest and red-team work, mediocre for others, and a bad fit for a few things that people still keep trying to force onto frontier models. Treat it as a scoped security reasoning layer attached to tools, permissions, browser state, and independent verifiers, and it can save real time. Treat it as a free-roaming exploit bot that should decide scope, proof, risk, and stopping conditions on its own, and it becomes a fast way to produce smart-looking mistakes. (Claude API 문서)
Claude 4.7 changed the security question
Anthropic did not ship Opus 4.7 as a generic incremental model refresh. It shipped a model that it says is stronger on advanced software engineering, instruction-following, long-horizon agentic work, knowledge work, vision, and memory; supports a 1 million token context window and 128,000 maximum output tokens; and adds higher-resolution image understanding that matters specifically for screenshot, document, and computer-use workflows. At the same time, Anthropic explicitly says Opus 4.7 is less broadly capable than Claude Mythos Preview and that it is being used as the first generally available model on which to deploy the company’s new cyber safeguards. (인류학)
That dual move matters because it breaks the lazy “better model equals better offensive agent” story. Anthropic is publicly saying two things at once. First, modern Claude models are getting good enough that the company is openly discussing vulnerability research, penetration testing, and red-teaming as legitimate use cases for approved professionals. Second, those same capabilities are now strong enough that the company believes a stronger real-time cyber defense layer is warranted on its most capable models. If you are a security engineer, the implication is straightforward: raw capability is no longer the only constraint you need to think about. Deployment policy, access surface, permission model, and verification architecture are now first-order design variables. (인류학)
That is a healthier frame than the old “can it hack” discourse anyway. Red-team and pentest work are full of jobs that are difficult not because they require wizard-level exploitation, but because they require compressing too much context into the next correct move. A tester may need to reconcile a frontend flow, a permission model, a few traces, a proxy history, an IaC repo, a hotfix diff, and a confusing admin path before deciding whether a finding is worth touching in production-like conditions. That is exactly the kind of cognitive load that long context and strong visual understanding are meant to reduce. (Claude Platform)
At the same time, many of the hardest parts of offensive work are hard for reasons that do not disappear when the model gets more capable. Live exploit proof depends on target state. Scope discipline depends on authorization, business constraints, and operator judgment. Risk classification depends on environmental nuance. Patch validation depends on evidence, not elegance. The people who get the most from Claude 4.7 will be the ones who assign it to the parts of the problem where intelligence is bottlenecked by context, not the parts where proof is bottlenecked by reality. (csrc.nist.gov)
What Anthropic actually shipped in Claude Opus 4.7
A lot of discussion about frontier models collapses into vague praise, but for security teams the details matter. Claude Opus 4.7 is Anthropic’s most capable generally available model for complex reasoning and agentic coding. The official release and model documentation say it supports a 1M token context window, 128k maximum output tokens, adaptive thinking, and the same broad set of tools and platform features as Opus 4.6. Anthropic also says it is the first Claude model with high-resolution image support, raising maximum image resolution to 2576px and 3.75MP, with 1:1 pixel coordinate mapping that specifically benefits computer-use and screenshot understanding workflows. (Claude Platform)
Those are not cosmetic changes in security work. Long context changes what you can keep in one investigative thread. High-resolution vision changes whether screenshots of a browser, a proxy history, a stack trace, a firewall UI, or a permissioned admin console are still usable after they pass through the model. Pixel-accurate coordinate handling changes how well a browser-automation or desktop-automation harness can line up the model’s reasoning with what is actually visible. Anthropic’s own computer-use documentation frames the tool as a screenshot-plus-mouse-plus-keyboard interface for autonomous desktop interaction, and says Claude achieves state-of-the-art single-agent performance on WebArena, a benchmark for multi-step web navigation. That does not mean “Claude can do a pentest,” but it does mean the visual layer is no longer a toy. (Claude API 문서)
Anthropic also introduced task budgets in Opus 4.7. A task budget is not a hard cap. It is an advisory token budget that the model can see across the full agentic loop, including thinking, tool calls, tool results, and final output. For security workflows, that matters because the worst agent behavior often appears in open-ended loops where the model loses discipline, over-explores low-value branches, or burns context on verbose self-explanation. A model that can be nudged to prioritize work as budget is consumed is easier to wrap in a repeatable offensive-security harness. (Claude Platform)
The migration details matter just as much. Anthropic removed extended thinking budgets in Opus 4.7. If you send the old thinking: {"type": "enabled", "budget_tokens": N} pattern, you get a 400 error; adaptive thinking is now the only supported “thinking on” mode. The migration guide also says non-default temperature, top_p및 top_k values will error, assistant-message prefills must be removed, and teams should re-benchmark cost and latency because Opus 4.7 uses a new tokenizer that may use up to 35 percent more tokens for the same fixed text. Security teams that run long logs, large repos, bulky HTTP traces, and high-res screenshots should not treat “same nominal pricing as 4.6” as “same real bill.” (Claude Platform)
That cost nuance is worth spelling out because it is easy to miss. Anthropic kept Opus 4.7 at the same published base API rates as Opus 4.6, with $5 per million input tokens and $25 per million output tokens. It also says Opus 4.7 includes the full 1M context window at standard pricing rather than charging a long-context premium. But the same pricing table says the new tokenizer can increase token usage by up to 35 percent for the same fixed text. For a team that wants to push screenshots, long markdown notes, code, YAML, SARIF, and browser artifacts through one model turn, the price story is a throughput story, not just a sticker-price story. (인류학)
The table below translates those release facts into what actually matters during a real security engagement. It combines Anthropic’s release documentation with the practical concerns of pentesters who care more about usable evidence and bounded automation than about benchmark chest-thumping. (인류학)
| Claude 4.7 capability | Documented fact | Why a pentester should care | What can still go wrong |
|---|---|---|---|
| Long context | 1M token context window, 128k max output | Lets one investigation carry repo context, logs, screenshots, and notes together | More context can still amplify noise, false assumptions, and cost |
| High-res vision | 2576px and 3.75MP image support, 1:1 coordinate mapping | Better reading of UI state, stack traces, screenshots, and browser flows | Seeing more state does not prove exploitability |
| Task budgets | Advisory budget across the full agentic loop | Reduces runaway loops in open-ended workflows | Too small a budget can cause shallow work or refusals |
| Adaptive thinking | Only supported thinking mode in Opus 4.7 | Better fit for mixed difficulty tasks and agent loops | Old harnesses break if they rely on deprecated patterns |
| Same base API pricing as 4.6 | $5 input and $25 output per million tokens | Easier migration planning on paper | New tokenizer can still increase effective cost |
| Standard long-context pricing | Full 1M context at standard pricing | Makes repo-scale or artifact-heavy sessions more feasible | Long, image-heavy sessions can still get expensive fast |
Cyber safeguards changed the operating reality
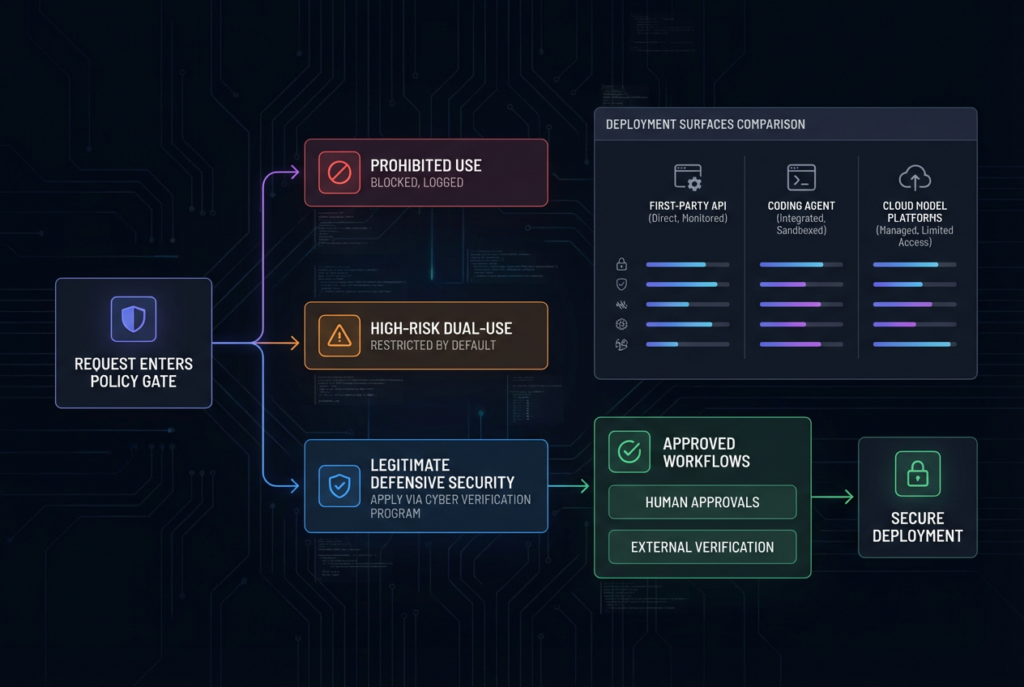
The strongest reason not to write a hype piece about Claude 4.7 is that Anthropic itself does not market Opus 4.7 as an unconstrained cyber model. Its support documentation says the company is rolling out real-time cyber safeguards on its most capable Claude models and that these safeguards are designed to automatically detect and block requests that may indicate prohibited or high-risk cyber usage. Anthropic splits the blocked space into two categories. The first is prohibited use, such as ransomware code development or mass data exfiltration, which remains blocked and is not adjustable through the self-serve Cyber Verification Program. The second is high-risk dual use, including vulnerability exploitation and offensive security tooling development, which is blocked by default but can be adjusted for legitimate defensive users through the CVP. (support.claude.com)
That distinction is the article. The most relevant work for professional pentesters often lives exactly in that dual-use zone. That includes reasoning about exploit chains, validating whether a flaw is reachable in practice, generating controlled proof steps, or building bounded offensive utilities for authorized assessments. Anthropic is not saying that such work is inherently malicious. It is saying that the model’s default deployment now assumes those tasks are sensitive enough to require a tighter approval path. If you ignore that and write as though Opus 4.7 is just a smarter version of unconstrained Claude, you are no longer describing the actual product surface. (support.claude.com)
The Cyber Verification Program is the mechanism Anthropic created for that tension. Its support page says the CVP is a free application-based program designed to help legitimate security professionals continue working on dual-use tasks with less interruption. Anthropic explicitly calls out vulnerability research, penetration testing, and red-teaming as legitimate uses that may need reduced restrictions. It also says it aims to respond to applications within two business days. That is a meaningful signal for defensive security teams because it acknowledges that real authorized security work often overlaps with content filters that would be appropriate for the general public. (support.claude.com)
But the CVP also exposes an operational wrinkle that many buyers will miss. Opus 4.7 is available across Claude products and Anthropic’s API, and Anthropic also says it is available on Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. Yet the cyber-safeguards support page says the Cyber Verification Program is not available on Bedrock at this time and not available on Vertex at this time. It also says organizations on Zero Data Retention are not currently eligible for the CVP. In other words, access to the model and access to a lower-friction legitimate cyber workflow are not identical questions. The deployment surface you choose can directly determine whether your security team is blocked on exactly the work it wants to do. (인류학)
That is why security teams should think of “Claude 4.7 for pentesting” as a system design problem, not a raw model-choice problem. On one end, a team using Claude.ai casually for brainstorming is working inside a different permission and policy envelope than a team building on the Anthropic API with hooks, tool confirmation, and controlled sessions. On another axis, a team on Bedrock or Vertex may have model access but no CVP path, which can materially affect workflow reliability if dual-use prompts are part of routine work. The technical question and the governance question now touch the same wire. (support.claude.com)
The matrix below is the practical version of that reality. It is not a feature comparison for procurement slides. It is the question a security lead has to answer before rolling Claude 4.7 into a real engagement flow. (인류학)
| Access surface | Opus 4.7 available | CVP path | What it means for pentest teams |
|---|---|---|---|
| Claude.ai and first-party Anthropic surfaces | 예 | 예 | Best fit if you need the most direct path to legitimate cyber-use adjustment |
| Anthropic API | 예 | 예 | Strongest option for building your own guarded workflow with tools, hooks, and verifiers |
| Claude Code | 예 | Yes through first-party path | Best practical surface for repo review, bounded commands, and approval-driven work |
| BYOK on first-party path | 예 | 예 | Useful when teams want their own billing and the same policy path as Anthropic first-party |
| Microsoft Foundry | 예 | 예 | Potential enterprise route, but approvals are tied to Azure identifiers |
| Amazon Bedrock | 예 | No at this time | Model access does not equal CVP access, which can matter in dual-use workflows |
| Google Vertex AI | 예 | No at this time | Same mismatch as Bedrock |
| Zero Data Retention organizations | Depends on surface | Not currently eligible | Strong privacy posture can still create friction for CVP-dependent cyber work |
Pentesting is a workflow, not a single model task

The most common mistake in evaluating AI for offensive security is collapsing unlike jobs into one word. “Pentesting” becomes shorthand for source review, route mapping, browser-state analysis, exploit authoring, patch triage, remediations, report writing, and sometimes even scope management. That is not how real engagements work. NIST SP 800-115 explicitly frames technical testing as a process that includes planning, conducting tests, analyzing findings, and developing mitigation strategies. OWASP WSTG is similarly structured around categories of tests rather than one universal motion. When people ask whether a model is good for pentesting, what they really need is a phase-by-phase answer. (csrc.nist.gov)
That phase model is also how you keep model claims honest. A model may be excellent at condensing a sprawling repository into a plausible threat model and terrible at deciding whether a live browser-only business-logic issue is truly exploitable against the deployed target. It may be excellent at interpreting UI state or explaining a diff and terrible at choosing the right moment to stop, escalate, or discard an attack path. It may be great at generating retest sequences and still fail to provide enough proof for a finding to be actionable. The phrase “AI is good at pentesting” usually hides all of those distinctions. (인류학)
A useful decomposition for Claude 4.7 looks like this: scoping and target understanding, recon and codebase orientation, browser-state and screenshot interpretation, hypothesis generation, controlled validation, patch review and remediation retesting, and final reporting. Those are not arbitrary buckets. They line up with what OWASP and NIST treat as structured security work, and they happen to match the places where Anthropic’s published tools and research provide the clearest evidence. That is also why the answer to the title is not symmetrical. Claude 4.7 is far stronger in some of these buckets than in others. (csrc.nist.gov)
Where Claude 4.7 is strongest in a pentest workflow
The best place to start is not with exploitation. It is with cognitive compression. Claude 4.7 is strongest when the real bottleneck is turning too much context into the next bounded, useful security action. That shows up again and again in real offensive work: large codebases, auth flows spread across services, undocumented flag behavior, browser state that only appears after a specific sequence, remediation diffs that fix the obvious path but leave a side door open, or confusing artifacts that have to become a credible finding package by the end of the engagement. Anthropic’s own product surfaces are optimized for exactly that kind of long-running context-to-action loop. (Claude Platform)
Claude 4.7 in recon and codebase orientation
Recon in serious security work is less about one more banner grab and more about getting oriented fast enough that the first active tests are not wasted. In source-assisted work, that often means understanding how authentication is actually handled, where authorization decisions are cached or bypassed, which endpoints cross trust boundaries, where feature flags mask old behavior, how background jobs interact with user-visible state, and which environment assumptions shape the security model. Claude Code’s documented common workflows already look a lot like the questions a reviewer asks during security triage: what are the key architecture patterns, how does authentication work, which files handle a given flow, and how does the execution path move front end to backend to storage. (Claude API 문서)
This is where a million tokens is not just a specification sheet. A security tester often wants to hold route definitions, middleware chains, client code, deployment manifests, error logs, and notes from a proxy session together long enough to see whether the story is coherent. Without that, findings get fragmented. A tester may notice an endpoint that looks dangerous in isolation but miss the environment guardrail that kills it, or ignore a harmless-looking UI path that becomes meaningful once it is combined with a stale role cache and a feature-flag mismatch. Claude 4.7 is well suited to the “compress the whole shape before you touch production-like state” phase because its strongest documented upgrades live exactly there: long-horizon work, knowledge work, and larger context. (Claude Platform)
There is also a risk management reason to start here. Anthropic’s Claude Code security model uses strict read-only permissions by default and requires explicit permission for actions such as editing files and executing commands. That maps well to how a safe pentest copilot should be introduced into a workflow: read and reason first, then earn more capability only when you know which bounded action is justified. The public security docs also describe sandboxed bash with filesystem and network isolation, but security teams should treat that as a later stage control, not the opening move. The more the model learns before it can act, the more precise and less noisy the active phase becomes. (Claude API 문서)
A minimal read-mostly pattern is enough to show the point. Anthropic’s Agent SDK supports agents that can read files, glob, grep, and search without immediately granting write or network-heavy capabilities. Used properly, that lets a security team ask Claude 4.7 to map auth and permission boundaries before it ever touches a live command path. The pattern below is not a finished pentest harness, but it is a much better starting point than giving an agent unrestricted Bash and hoping policy will catch the damage later. (Claude API 문서)
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions
PROMPT = """
Review this application in read-only mode.
1. Identify the files that control authentication and authorization.
2. Trace the login flow from client to server.
3. List suspected trust boundaries, role checks, and risky assumptions.
4. Do not propose exploitation steps yet. Focus on structure and preconditions.
"""
async def main():
async for message in query(
prompt=PROMPT,
options=ClaudeAgentOptions(
allowed_tools=["Read", "Glob", "Grep"]
),
):
if hasattr(message, "result"):
print(message.result)
asyncio.run(main())
That kind of read-first pattern is not glamorous, but it solves a real problem. Most wasted motion in a modern application test does not come from failing to invent a brilliant exploit. It comes from failing to understand the target’s actual shape before testing begins. Claude 4.7 is more useful at reducing that waste than it is at replacing the later proof stage. (Claude API 문서)
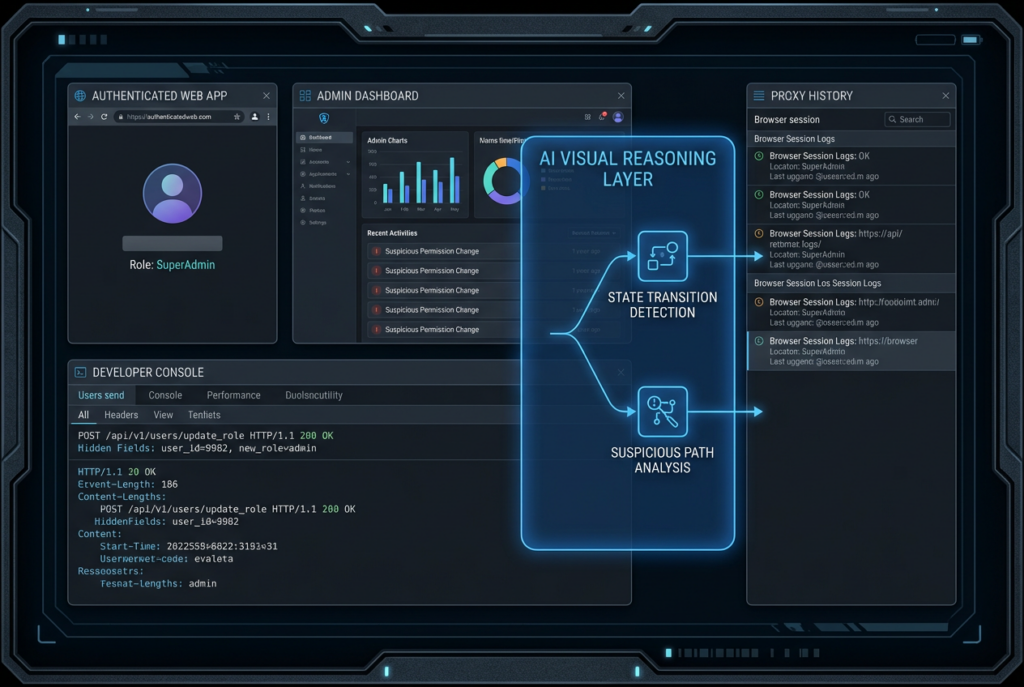
Claude 4.7 in screenshot analysis and browser-state understanding
A lot of offensive findings live in state, not code. They depend on what the browser actually shows after a specific series of actions, which hidden field appears after a role change, what partial admin surface is exposed after a token refresh, or which error message leaks backend behavior only when the UI reaches an unusual branch. That is why the vision upgrades in Opus 4.7 matter to security teams more than generic “multimodal” marketing usually does. Anthropic says the model’s maximum image resolution increased from 1568px and 1.15MP to 2576px and 3.75MP, and that this specifically improves screenshot, artifact, and document understanding. For browser or desktop automation, it also says coordinate mapping is now 1:1 with actual pixels. (Claude Platform)
That connects directly to the company’s computer-use tooling. Anthropic’s documentation describes the computer use tool as a screenshot-driven interface with mouse and keyboard control for autonomous desktop interaction. It further says Claude performs at state-of-the-art among single-agent systems on WebArena. This does not mean a Claude-driven browser harness is ready to replace a human tester on every app. It does mean visual ambiguity is becoming less of a bottleneck for agentic security workflows that need to understand authenticated UI state, multistep navigation, or operational consoles that are hard to express as raw HTTP alone. (Claude API 문서)
The early-access feedback Anthropic included in the Opus 4.7 launch makes the same point from a security angle. XBOW’s CEO said that for the computer-use work at the heart of XBOW’s autonomous penetration testing, Opus 4.7 scored 98.5 percent on its visual-acuity benchmark versus 54.5 percent for Opus 4.6, removing a major bottleneck for classes of work that were previously not usable. That is not an independent industry standard, and it should not be treated as one. But it is still useful signal. When a company that builds autonomous penetration-testing workflows says the biggest upgrade it saw was visual acuity, that lines up with the practical experience of anyone who has tried to reason about complex web state from blurry or lossy screenshots. (인류학)
The crucial limit is that better sight is not better proof. A model can now see more of the interface, keep more of the state in memory, and describe the flow more accurately. That improves hypothesis quality. It does not eliminate the need for an external verifier that can replay actions, confirm permissions, and distinguish “interesting UI artifact” from “security finding with reliable reachability.” In practice, Claude 4.7’s visual strength is most valuable when you use it to create smaller, better verification steps, not when you treat a convincing UI interpretation as a finished conclusion. (인류학)
Claude 4.7 in hypothesis generation and test-path design
This is the part of the workflow where Claude 4.7 may save the most time per hour for experienced testers. A seasoned pentester usually does not need help inventing every test from scratch. They need help narrowing the search space without missing the weird edge path. Given a route, a middleware chain, a browser flow, a role model, and a few proxy artifacts, Claude can often tell you which assumptions deserve to be challenged first, which preconditions matter, and what the smallest non-destructive reproduction path might look like. That is not the same thing as discovering a novel exploit chain from pure intuition. It is often more valuable because it reduces unproductive thrashing. (펜리전트)
The reason this is a good fit for Claude 4.7 is that the task is half reasoning and half bookkeeping. You want the model to remember what it already saw, organize competing explanations, and sequence checks in a way that reveals the decisive evidence quickly. Anthropic’s release notes repeatedly emphasize long-horizon work, strong instruction-following, and more direct agentic behavior. Its launch post also says users report being able to hand off harder coding work with more confidence and that the model devises ways to verify its own outputs before reporting back. In security terms, that translates well to “turn this messy target into a bounded test plan.” (인류학)
The thing to resist is the jump from “better hypotheses” to “automatic proof.” Anthropic’s own cybersecurity messaging is careful here. When it launched Claude Code Security, it described a multi-stage verification process where Claude re-examines findings, tries to prove or disprove them, assigns confidence, and still leaves human approval as the final gate. That is a good mental model for offensive work too. Even when the model is right about what deserves attention, it should not also be the sole judge of whether a finding is confirmed, materially exploitable, or severe enough to escalate. Separate the planner from the verifier and the system becomes much more trustworthy. (인류학)
A practical way to use Claude 4.7 here is to demand specific outputs instead of generic “thoughts.” Ask for the narrow preconditions, the minimum reproducible path, the exact evidence that would confirm or falsify the hypothesis, and the smallest regression check that would fail if the bug returned. Those outputs are closer to the real unit of pentest work than “generate an exploit.” They are also easier to test independently. In other words, the best use of Claude 4.7 is often to make verification easier, not to make verification disappear. (펜리전트)
Claude 4.7 in patch review and remediation retesting
If you want the least controversial and most immediately useful offensive-security application of Claude 4.7, this is it. Security work does not end when a bug is found. In many teams, the most expensive part comes next: reading the patch, understanding what actually changed, spotting untouched side paths, generating regression checks, and deciding whether the remediation fixed the security property or merely changed the code shape. Those are exactly the kinds of tasks where long context, repository traversal, and careful instruction-following matter more than raw exploit creativity. (Claude API 문서)
CVE-2024-4577 is a good example of why this phase matters. NVD describes it as a PHP-CGI issue on Windows where, under certain code pages and with Apache plus PHP-CGI, Windows “Best-Fit” character replacement can cause PHP-CGI to misinterpret characters as PHP options, potentially exposing source code or enabling arbitrary PHP execution. The important lesson is not the exploit novelty. It is the precondition stack. This is not every PHP deployment. It depends on Windows, CGI mode, certain code pages, and affected version ranges. CISA added the issue to the Known Exploited Vulnerabilities catalog, so the operational pressure is real. But the answer for many security teams is not “write a custom exploit.” It is “quickly identify which assets actually match the preconditions, patch them, and retest the smallest possible path to confirm the risk is gone.” Claude 4.7 is well suited to help build and reason through that retest sequence. (NVD)
A model is especially useful here because patch validation often requires two kinds of reading at once. One is semantic: what did the vendor or maintainers intend to fix. The other is environmental: what does this target really look like in production. Claude 4.7 can help turn version notes, deployment assumptions, route behavior, and test artifacts into a specific retest checklist. What it should not do is guess that the risk is gone because the vendor changed a function name or because the explanation sounds plausible. A retest is still a retest. (인류학)
A minimal retest template for a known issue often looks more useful than a clever proof-of-concept. The example below is intentionally plain. It forces the tester to nail the environmental conditions before they spend energy on a live check. That is exactly the kind of discipline Claude 4.7 can improve when used as a planning and documentation layer.
Retest checklist for a known issue
1. Confirm product and exact deployed version
2. Confirm the required operating mode or feature flag
3. Confirm whether the vulnerable code path is externally reachable
4. Reproduce the smallest safe indicator of the issue
5. Capture the evidence that proves the indicator is real
6. Apply the patch or mitigation
7. Re-run the same indicator check
8. Add one side-path regression check the patch could have missed
9. Document residual risk, if any
That looks simple because good retesting often is simple once the thinking is clean. Claude 4.7’s role is to make the thinking clean faster. It is not to replace the evidence step that makes the retest worth trusting. (csrc.nist.gov)
Claude 4.7 in evidence synthesis and final reporting
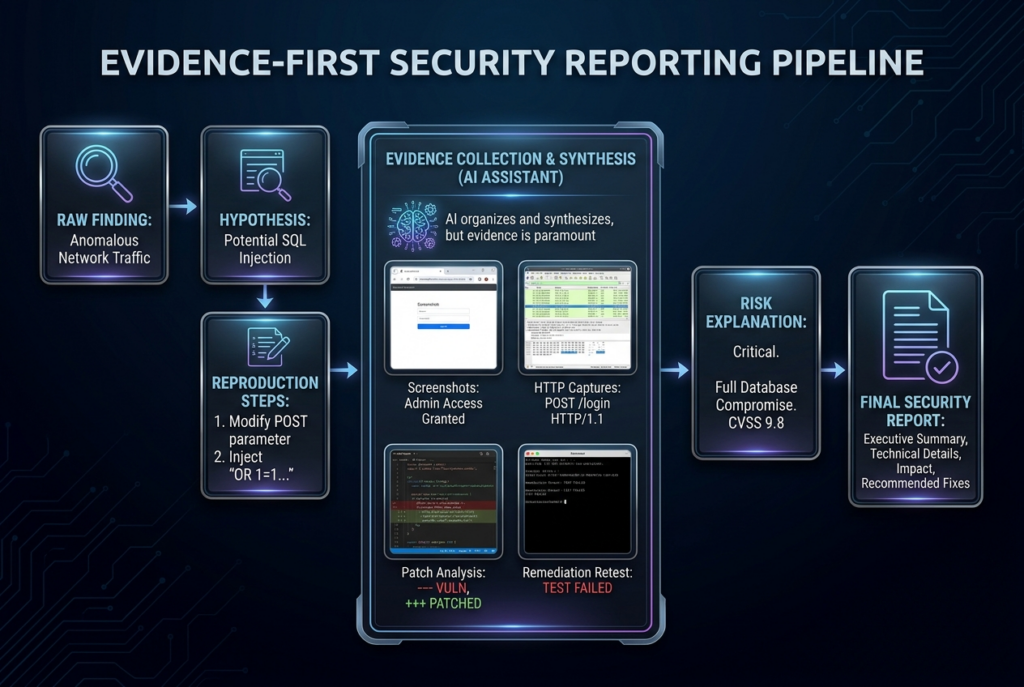
A strong model is wasted if the last mile is still a pile of screenshots and memory fragments. Reporting is one of the least glamorous parts of offensive security, but it is also where many AI systems quietly fail. A good report is not an eloquent summary. It is a reproducible package of scope, preconditions, smallest successful path, technical evidence, impact explanation, and remediation logic. NIST SP 800-115 explicitly places analysis and mitigation development in the testing lifecycle, and Anthropic’s own Claude Code Security materials emphasize verification, confidence ratings, and human approval rather than “AI found it, so trust it.” That is a good standard for reporting too. (csrc.nist.gov)
This is where Claude 4.7’s context and document strengths are especially practical. A model that can keep code, artifacts, browser observations, diff notes, and remediation reasoning in one thread can turn a messy engagement into a coherent narrative faster than most humans can do manually. That matters because many findings are not lost in testing. They are lost in translation between the tester who understands what happened and the engineer or security lead who has to act on it. A model that can reliably preserve that chain of evidence is not doing “marketing writing.” It is reducing failure in the handoff between discovery and remediation. (Claude Platform)
Teams that use Claude 4.7 this way often discover that the gap is not whether the model can write a polished paragraph. The gap is whether the workflow can preserve proof. That is the problem Penligent’s recent writing gets right when it talks about evidence-first pentest copilots and AI pentest reports: the challenge is not making AI produce a pretty deliverable, but keeping raw evidence, reproduction steps, screenshots, captures, and retest results tied tightly enough to the narrative that another engineer can independently verify the claim. That is a real engineering problem, not a copywriting problem. (펜리전트)
A simple rule helps here. Do not let Claude 4.7 generate a final finding unless the workflow already has four things: the narrow preconditions, the minimum successful reproduction path, the evidence that proves the behavior occurred, and a regression check that should fail if the issue returns. Without those four pieces, the result is still a research note, not a finding. The model may still help write it, but it has not earned the authority to close the loop. (펜리전트)
The matrix below summarizes the highest-value places for Claude 4.7 in a real authorized engagement. The left side is where the model is often useful. The right side is where humans, tools, or the environment still need to own the final truth. (csrc.nist.gov)
| Workflow phase | Where Claude 4.7 helps most | What it should not own | What must verify the result |
|---|---|---|---|
| Scoping support | Organizing scope docs, target maps, and assumptions | Final scope decisions | Engagement owner and written authorization |
| Recon and code review | Mapping flows, trust boundaries, and risky assumptions | Final attack selection | Tester judgment and target evidence |
| Screenshot and browser-state analysis | Explaining UI state and hidden flows | Declaring exploitability from visuals alone | Replayable state checks and browser evidence |
| Test-path design | Producing minimum reproduction paths and preconditions | Declaring a hypothesis proven | Proxy logs, runtime behavior, and controlled retests |
| Active validation | Narrowing the next action and expected indicator | Live proof of compromise without confirmation | External tools, verifiers, and human review |
| Patch review | Explaining diffs, side paths, and regression checks | Declaring remediation complete from code alone | Actual retest against the deployed or staging target |
| Reporting | Turning evidence into a coherent narrative | Inventing proof or impact | Artifacts, captures, screenshots, and regression output |
Where Claude 4.7 is still the wrong mental model
The easiest way to misuse Claude 4.7 is to think that a model strong enough to help with serious security work must therefore be close to replacing the whole job. Anthropic’s own public research argues against that simplification. In its Firefox work with Mozilla, the company says Claude Opus 4.6 was able to find previously unknown issues in the current Firefox codebase, including a use-after-free discovered after roughly twenty minutes of exploration. Anthropic says it eventually scanned nearly 6,000 C++ files and submitted 112 unique reports. That is important signal. It shows frontier models are materially useful at bug finding in mature, complex software. (인류학)
But Anthropic’s exploit write-up on CVE-2026-2796 is just as important because it explains the boundary instead of hiding it. The company says the exploit Claude wrote for that now-patched bug worked only inside a testing environment that intentionally removed some of the security features of modern web browsers, and that Opus 4.6 turned a vulnerability into an exploit in only two cases despite having hundreds of chances across dozens of bugs. That is not a small footnote. It is the difference between “this model is interesting for vulnerability research” and “this model is a reliable red-team operator against real, defended targets.” (red.anthropic.com)
That same boundary appears in much more ordinary work. Claude 4.7 should not decide what is in scope. It should not choose which accounts are safe to use. It should not decide whether a side effect is acceptable. It should not declare that a vendor patch is complete because the diff looks smart. Those are governance, evidence, and environmental questions. Anthropic’s own Claude Code security model assumes this separation. It requires explicit permission for sensitive actions, confines write access to the project scope, supports sandboxed bash, and describes multiple protections against prompt injection and command abuse. Those are the controls of a system built with the expectation that plausible next actions are not always acceptable next actions. Pentesting is full of exactly that problem. (Claude API 문서)
This is also why prompt injection and agent hijacking are not abstract safety topics that belong somewhere else. NIST’s work on agent hijacking says many current AI agents remain vulnerable to indirect prompt injection, in which malicious instructions are inserted into data that an agent ingests, causing it to take unintended actions. NIST’s 2026 RFI on agent security expands that warning to the deployment layer, calling out risks from adversarial data, insecure models, and harmful agent actions in connected systems. If you let Claude 4.7 touch untrusted repositories, attacker-controlled content, reflected browser material, or fetched web data during a security workflow, you are already operating inside that threat model. That does not make the model unusable. It makes permissions, sandboxing, isolation, and external verification non-negotiable. (NIST)
What real CVEs reveal about the boundary
CVE examples are useful here only if they clarify where the model helps and where it still needs an external truth source. The point is not to show off a bag of vulnerability trivia. It is to understand which parts of a real security workflow map naturally to a model like Claude 4.7 and which parts do not.
CVE-2026-2796 and the Firefox boundary
CVE-2026-2796 is a clean example because it sits right at the intersection of model capability and model limit. NVD describes it as a JIT miscompilation issue in Firefox’s JavaScript WebAssembly component that was fixed in Firefox 148 and Thunderbird 148. Anthropic’s exploit write-up uses it as a case study for how Claude Opus 4.6 wrote a proof-of-concept exploit in a controlled environment. Anthropic also says clearly that the exploit only worked in a testing environment with browser protections intentionally removed, not as a full-chain real-world browser escape. (NVD)
That case is relevant to Claude 4.7 because it shows what to learn from Anthropic’s public cyber research without overlearning the wrong lesson. The lesson is not “Claude can now just pop browsers.” The lesson is that frontier models are becoming very strong at reading complex codebases, isolating interesting bug patterns, and in some cases pushing further toward exploitation under controlled conditions. That makes them more useful for vulnerability discovery and triage than many security teams still assume. It does not mean a general-purpose, generally available model should be treated as a production-grade browser exploitation agent. (인류학)
For pentesters, the practical takeaway is that Claude 4.7 should be treated as a force multiplier in pre-proof work: bug pattern recognition, code-path narrowing, crash triage, hypothesis generation, and exploit precondition analysis. Once the job shifts to “prove this against the live target, under this auth state, with these protections still enabled,” the need for an external verifier becomes even more obvious, not less. (인류학)
CVE-2024-4577 and the value of precondition triage
CVE-2024-4577 is useful for a different reason. NVD says the issue affects certain Windows deployments using Apache and PHP-CGI, where Windows “Best-Fit” behavior can cause PHP-CGI to interpret characters as PHP options, enabling source disclosure or arbitrary PHP execution. CISA later added the issue to its Known Exploited Vulnerabilities catalog. This is exactly the kind of vulnerability where the hardest practical work in many enterprises is not inventing a payload. It is quickly separating matching assets from non-matching assets, understanding whether CGI mode is actually in use, confirming the relevant code pages, and validating that remediation truly removes the exploitable path. (NVD)
Claude 4.7 fits well into that kind of work because it can hold advisories, environment data, test notes, and version information together in one thread, then produce a narrow retest plan instead of a generic “scan for CVE” instruction. This is a good example of why the model often adds more value after disclosure than during the mythic exploit-generation stage. In real teams, someone still has to ask: which systems actually satisfy the preconditions, what is the least disruptive proof step, how do we write the regression check, and how do we explain residual exposure to operations. That is all high-context reasoning work. (Claude Platform)
CVE-2024-3400 and why live proof still belongs outside the model
CVE-2024-3400 is the opposite type of lesson. Palo Alto’s advisory and NVD describe it as a command injection issue arising from arbitrary file creation in the GlobalProtect feature of PAN-OS, allowing unauthenticated remote code execution with root privileges on affected firewalls under specific conditions. NVD also records CISA KEV actions and mitigation guidance, and a later CISA advisory on Iran-based cyber actors says those actors were likely probing for PAN-OS and GlobalProtect devices vulnerable to CVE-2024-3400. This is what an internet-facing, high-pressure, high-consequence case looks like. (security.paloaltonetworks.com)
Claude 4.7 can absolutely help around this kind of issue. It can summarize the vendor advisory, explain version ranges, help parse whether the environment matches the affected configuration, and structure emergency retesting and reporting. What it should not be allowed to do by default is improvise on live internet-facing infrastructure and then declare victory because the output looks plausible. Cases like PAN-OS are exactly where the environmental truth matters most: telemetry state, edge exposure, compensating controls, patch status, rate limits, and operational risk. A model can help the operator move faster. It does not replace the need for operator control. (security.paloaltonetworks.com)
CVE-2024-3094 and why long-context review matters
CVE-2024-3094, the xz backdoor, is not a web exploit case. It is useful here because it shows why “strong on large, weird, distributed context” is a security capability in its own right. NVD describes malicious code in upstream xz tarballs starting with version 5.6.0, where obfuscated build instructions caused the build process to extract a hidden object file that modified specific functions in liblzma and affected software linked against it. This is not the kind of issue you understand from one route handler or one screenshot. It lives in release artifacts, build steps, hidden files, and indirect trust relationships. (NVD)
That is the kind of problem where Claude 4.7’s long context can become genuinely useful for defenders and auditors: not because the model “solves supply chain security,” but because it can keep the release story, the build story, the dependency story, and the operational story together long enough to help a human ask better questions. Again, the model’s best role is structured reasoning across too much context, not magical proof by eloquence. (Claude Platform)
The Anthropic product surfaces that actually matter
Another source of confusion is treating “Claude” as one thing. It is not. The relevant Anthropic surfaces for security teams are materially different. If you want a chat assistant that can help brainstorm or summarize, Claude in general may be enough. If you want a practical engine for repo review, bounded commands, approvals, and patch reasoning, Claude Code matters much more. If you want to build your own agent harness with hooks, custom tools, permissions, sessions, and external verifiers, the Agent SDK matters. If you want long-running, cloud-hosted, stateful execution with event history and streamed observability, Claude Managed Agents matter. Those are not the same operating model. (Claude API 문서)
Claude Code is the most immediately relevant surface for many appsec and pentest-adjacent workflows because Anthropic’s documentation positions it around reading code, editing files, running commands, permissions, hooks, and a security model with explicit approvals and sandboxing. Its security documentation says bash is sandboxable, write access is restricted to the working scope, network requests require approval by default, risky commands like curl 그리고 wget are blocked by default in certain contexts, and prompt-injection safeguards include context-aware analysis and input sanitization. That is a meaningful control plane for security-assisted code and artifact work. (Claude API 문서)
The Agent SDK matters when you want the same core loop as Claude Code but need to program it yourself. Anthropic’s docs say the SDK gives you the same tools, agent loop, and context management that power Claude Code, including reading files, running commands, web search, editing code, and hooks such as PreToolUse, PostToolUse, SessionStart및 SessionEnd. That is precisely the level where a security team can insert custom validation, logging, deny rules, or tool wrappers instead of hoping a monolithic agent will behave itself. (Claude API 문서)
Managed Agents matter when the work stops looking like a shell session and starts looking like orchestration. Anthropic describes them as fully managed agent infrastructure with agents, environments, sessions, and event-based communication. The overview says they are best for long-running execution, stateful sessions, and secure containers with pre-installed packages and network access. The event stream docs say the whole communication model is event-based, with user events steering the session, session and agent events providing observability, and tool confirmation pauses that can require allow or deny decisions before a tool executes. That is much closer to how a serious pentest harness should behave than a raw chat loop is. (Claude Platform)
The surface you choose should depend on the job. For repo review and bounded local reasoning, Claude Code is often enough. For a custom verifier-backed workflow, the Agent SDK is better. For long-lived cloud execution with event history and steering, Managed Agents are the better fit. The real mistake is assuming that because all three use Claude, they imply the same security affordances. They do not. (Claude API 문서)
The table below condenses the practical differences into security terms instead of product-language abstraction. (Claude API 문서)
| Anthropic surface | Best fit in security work | Biggest strength | Biggest risk if misused | Most important control |
|---|---|---|---|---|
| General Claude chat | Brainstorming, writeups, advisory digestion | Fast reasoning with little setup | Mistaking plausible language for proof | Human review and external evidence |
| Claude Code | Repo review, diff review, bounded commands, local investigations | Permissions, hooks, sandboxing, practical dev workflow | Granting too many tools too early | Read-only first, explicit approvals |
| Agent SDK | Custom pentest copilots and verifier-backed workflows | Programmable hooks, tools, sessions, subagents | Building a powerful agent without strong policy gates | PreToolUse and PostToolUse controls |
| Managed Agents | Long-running cloud investigations and orchestrated tool flows | Stateful sessions, event history, tool confirmations | Assuming managed runtime means safe runtime | Event-driven approvals and observability |
| Computer use | Authenticated browser and desktop-state observation | Better visibility into UI-only state | Confusing visual success with security proof | Replayable verification and scoped environments |
Building a Claude 4.7 pentest workflow that does not lie to you
The most valuable design principle is separation of duties inside the harness. Do not let the same model hypothesize, execute, interpret, and approve its own work without an outside check. That architecture is efficient in demos and fragile in security work. A better pattern is planner, executor, verifier, and reporter. Claude 4.7 can sit in one or more of those roles, but the verifier should ideally be independent of the same free-form generation loop that created the hypothesis in the first place. Anthropic’s own public writing points toward that design. Claude Code Security uses multi-stage verification before a finding reaches an analyst, and Managed Agents pause for tool confirmations rather than assuming the agent should always continue. (인류학)
The second principle is read-only by default. Anthropic’s security docs say Claude Code starts with strict read-only permissions and requests explicit approval before additional actions. That is exactly right for offensive-security-adjacent work. If the model has not yet earned the right to act, do not let it act. Give it repo context, logs, screenshots, route definitions, and notes. Ask it to map flows, identify preconditions, and propose bounded tests. Then, and only then, decide whether a narrower execution phase should begin. You will get better test plans, fewer pointless commands, and fewer false positives born from premature action. (Claude API 문서)
The third principle is to treat permissions as part of the test methodology, not as UX friction. Anthropic documents hooks, permission modes, tool confirmations, and event-driven control. Those are not conveniences for enterprise admins. They are the mechanism by which you keep a smart model from collapsing the difference between “possible next step” and “allowed next step.” In a pentest harness, that means policy gates for network-affecting tools, separate lanes for read-only and state-changing actions, hard denials for out-of-scope targets, and audit trails for every escalated step. (Claude API 문서)
The fourth principle is to expect hostile inputs. NIST’s agent-hijacking work says current agents are vulnerable to indirect prompt injection, and Anthropic’s own security docs list prompt-injection protections such as explicit approvals, command blocklists, isolated context windows for web fetch, and trust verification. If your model ingests target-controlled code, HTML, tickets, emails, browser content, or shell output, you are already in the danger zone. That is why a pentest copilot should use sandboxing, isolate fetched content where possible, distrust arbitrary instructions embedded in artifacts, and require manual review for commands that reach outside the narrow task boundary. (NIST)
Many teams will discover at this point that Claude 4.7 behaves more like a reasoning engine than a complete offensive workflow. That is not a weakness; it is just the honest architecture. The missing pieces are usually scoped execution, proof collection, replayable validation, and evidence packaging. That is the gap Penligent’s recent English writing on Claude-oriented pentest copilots and Claude Code harness design keeps pointing to: once you move from repo understanding and test-path design into target-facing validation, you need more than a model. You need a harness that preserves approvals, artifacts, and proof. (펜리전트)
Hooks are one of the best places to enforce that discipline. Anthropic’s Agent SDK documentation shows hook support at key lifecycle points and demonstrates using hooks to log or transform behavior. In security work, the same mechanism can be used to deny risky tools by default, log file mutations, require human review before network effects, and annotate sessions with policy context. Even a small amount of hook logic is enough to turn “agentic helper” into “auditable assistant.” (Claude API 문서)
A simple pattern is enough to illustrate the point. The example below logs file edits and can be extended to block or flag risky tool classes before they run. The value is not the exact code. The value is the architecture: the model proposes, the hook inspects, and the workflow decides whether the proposed action belongs in the engagement. (Claude API 문서)
import asyncio
from datetime import datetime
from claude_agent_sdk import query, ClaudeAgentOptions, HookMatcher
async def log_or_block(input_data, tool_use_id, context):
tool_name = input_data.get("tool_name", "")
if tool_name in {"Bash", "WebFetch", "WebSearch"}:
# Replace this with your own approval or deny policy
print(f"[REVIEW NEEDED] {tool_name} at {datetime.now()}")
return {}
async def main():
async for message in query(
prompt="Review the auth flow and propose the next bounded validation step.",
options=ClaudeAgentOptions(
allowed_tools=["Read", "Glob", "Grep", "Bash"],
hooks={
"PreToolUse": [
HookMatcher(matcher="Bash|WebFetch|WebSearch", hooks=[log_or_block])
]
},
),
):
if hasattr(message, "result"):
print(message.result)
asyncio.run(main())
The fifth principle is to make the browser a source of evidence, not a substitute for a verifier. If Claude 4.7 sees that a hidden field appears, or that a UI branch is exposed to the wrong role, that is valuable. But the finding still needs a replayable, controlled confirmation path. Anthropic’s tools improve the model’s access to browser or desktop state. They do not change the burden of proof. A good harness converts what the model sees into the smallest check that another tool, tester, or environment can confirm independently. (Claude API 문서)
The sixth principle is to make reporting downstream from evidence, not downstream from eloquence. If the workflow cannot preserve artifacts, screenshots, captures, environment notes, and retest results, the final report will collapse into a polished version of uncertainty. In practice, that means the report generator should be the last consumer of a verified evidence chain, not the place where weak evidence gets rhetorically upgraded into certainty. Penligent’s reporting-oriented writing is useful here because it frames the deliverable correctly: not as “make AI output a PDF,” but as “make the evidence trail legible and reviewable.” (펜리전트)
Migration, cost, and operational caveats for security teams
Teams evaluating Claude 4.7 for security work should not wait until production to discover the migration friction. Anthropic’s migration guide is unusually explicit. Extended thinking budgets are removed in Opus 4.7. Non-default sampling parameters like temperature, top_p및 top_k will error. Assistant-message prefills must be removed. If your UI displays thinking, you need to opt in to summarized thinking display. And Anthropic recommends re-benchmarking end-to-end cost and latency under the updated tokenization. For teams with old red-team or appsec harnesses, that is not cosmetic. It can break real workflows. (Claude Platform)
The thinking change is especially important for security workloads because many of them are bimodal. Some tasks are easy, such as summarizing an advisory. Others are hard, such as reasoning across a repo, a patch, and a browser workflow to determine whether a security property still fails. Anthropic says adaptive thinking is the only supported “thinking on” mode in Opus 4.7, and its migration guidance recommends adaptive thinking with effort controls for autonomous multi-step agents, bug finding, and computer-use agents. Security teams should treat effort settings as a workload-specific tuning parameter, not a default they set once and forget. (Claude Platform)
The tokenizer change is just as important. Anthropic’s pricing page says Opus 4.7 may use up to 35 percent more tokens for the same fixed text. In security workflows, “same fixed text” often means long config files, IaC, repo snippets, stack traces, tickets, HTML, screenshots that drive vision tokens, and accumulated notes from earlier turns. Even if the base price per million tokens did not change, the total usage curve may. This is one reason task budgets are worth testing on long artifact-heavy runs: not because they solve cost, but because they give the model a visible incentive to prioritize instead of meandering across the full search space. (Claude Platform)
Surface choice also affects cost shape. Anthropic says Managed Agents are billed on tokens and session runtime, with runtime accruing only when the session is in running status. That is a different billing model from a simple Messages API loop and a better one for some long-lived orchestrations. But it also means security teams should benchmark the whole workflow, not just the model’s response quality. A repo-review loop, a browser-state loop, and a long-running session with tool confirmations will have very different economic profiles even if they all use the same underlying model. (Claude Platform)
The table below is the short version of what security teams should test before rolling Opus 4.7 into any serious workflow. (Claude Platform)
| Change or constraint | Why it matters in security work | Recommended test before rollout |
|---|---|---|
| Adaptive thinking only | Old harnesses using extended thinking will break | Re-run repo review, bug triage, and browser-state tasks with effort tuning |
| Non-default sampling params error | Old deterministic wrappers may fail unexpectedly | Remove legacy params and verify harness behavior |
| Assistant-message prefills removed | Some structured-security pipelines relied on prefills | Switch to structured outputs or format controls |
| New tokenizer | Long logs, diffs, and screenshot-heavy runs may cost more | Re-benchmark real artifact-heavy sessions |
| Task budgets | Can improve discipline in long loops but may also overconstrain work | Test several budgets on the same engagement-shaped task |
| CVP availability mismatch | Dual-use work may behave differently across surfaces | Confirm your chosen platform actually supports your policy path |
| ZDR not eligible for CVP | Privacy posture may conflict with cyber-use adjustment | Resolve the policy choice before deployment, not after blocks appear |
So should security teams use Claude 4.7
Yes, but not for the reason most hype posts imply.
Security teams should use Claude 4.7 where their bottleneck is understanding too much context too slowly. That includes codebase orientation, screenshot and browser-state analysis, trust-boundary mapping, patch review, remediation retesting, and evidence synthesis. Anthropic’s public documentation and research give real support for that claim: long context, stronger vision, agentic coding orientation, practical tool surfaces, managed sessions, explicit permissions, and security-specific workflow investments all point in the same direction. (인류학)
They should not use Claude 4.7 as though it were a drop-in replacement for the whole pentest or red-team engagement. Anthropic’s own cyber safeguards make that interpretation inaccurate at the product level, and its Firefox exploit case study makes it inaccurate at the capability level. The company is telling you, in plain language, that high-risk dual-use cyber work is sensitive enough to block by default and route through a verification program, and that even strong exploit results should be understood in the context of controlled environments and independent validation. That is not a reason to dismiss the model. It is a reason to assign it a mature role. (support.claude.com)
The most accurate sentence is probably this: Claude 4.7 is a strong pentest and red-team copilot when the job is to reduce uncertainty, compress context, design bounded checks, and transform evidence into action. It is a weak substitute for the parts of the job that still require authorization judgment, target truth, and independent proof. Teams that build around that distinction will get value quickly. Teams that ignore it will get polished output without enough truth behind it. (펜리전트)
추가 읽기 및 참조 링크
- 인류학, Introducing Claude Opus 4.7. (인류학)
- Anthropic Claude API Docs, What’s new in Claude Opus 4.7. (Claude Platform)
- Anthropic Claude API Docs, Migration guide. (Claude Platform)
- Anthropic Help Center, Real-time cyber safeguards on Claude. (support.claude.com)
- 인류학, Partnering with Mozilla to improve Firefox’s security. (인류학)
- Anthropic Red Team, Reverse engineering Claude’s CVE-2026-2796 exploit. (red.anthropic.com)
- 인류학, Making frontier cybersecurity capabilities available to defenders. (인류학)
- Anthropic Claude Code Docs, 보안. (Claude API 문서)
- Anthropic Claude Code Docs, Agent SDK overview. (Claude API 문서)
- Anthropic Claude API Docs, Claude Managed Agents overview, Get started, Session event stream및 Start a session. (Claude Platform)
- NIST, 정보 보안 테스트 및 평가에 대한 기술 가이드, SP 800-115. (csrc.nist.gov)
- NIST, Technical Blog: Strengthening AI Agent Hijacking Evaluations. (NIST)
- NIST, CAISI Issues Request for Information About Securing AI Agent Systems. (NIST)
- OWASP, Web Security Testing Guide. (owasp.org)
- NVD, CVE-2026-2796. (NVD)
- NVD, CVE-2024-4577. (NVD)
- CISA KEV, CVE-2024-4577. (cisa.gov)
- Palo Alto Networks advisory and NVD, CVE-2024-3400. (security.paloaltonetworks.com)
- CISA advisory on Iran-based actors probing PAN-OS vulnerable to CVE-2024-3400. (cisa.gov)
- NVD, CVE-2024-3094. (NVD)
- 펜테스트 코파일럿용 클로드 AI, 클로드 코드로 증거 우선 워크플로 구축하기. (펜리전트)
- Claude Code Harness for AI Pentesting. (펜리전트)
- 클로드 코드 보안 및 펜리전트, 화이트박스 결과에서 블랙박스 증명까지. (펜리전트)
- AI 펜테스트 보고서를 받는 방법. (펜리전트)
- Penligent homepage. (펜리전트)
