In 2025, Andreas Happe and Jürgen Cito from TU Wien published“On the Surprising Efficacy of LLMs for Penetration‑Testing”, revealing a startling reality: Large Language Models (LLMs) can match—and sometimes surpass—human experts in key pentesting tasks such as pattern recognition, attack‑chain construction, and navigating uncertainty in dynamic environments, all while offering cost‑effective scalability.
Against the backdrop of escalating cyber threats, severe talent shortages, and increasingly complex enterprise infrastructure, this marks a new era: a shift from command‑line‑driven “black magic” to AI‑powered security testing. With AI embedded into the offensive security toolkit, organizations can cut test cycles from days to hours, turning advanced pentesting skills into a security infrastructure accessible to everyone.

How LLMs Are Applied in Penetration Testing?
“Empirical evidence from “On the Surprising Efficacy of LLMs for Penetration‑Testing” suggests that the operational characteristics of Large Language Models align unusually well with the real‑world practices of penetration testers. One frequently cited factor is the prevalence of technological monocultures within enterprise infrastructure. Such homogeneity allows LLMs to leverage their exceptional pattern‑matching capabilities to identify recurring security misconfigurations and vulnerability signatures that mirror examples embedded in their training corpora. As a result, models can formulate attack strategies that map directly onto known exploit paths, minimizing the exploratory overhead typically required by human testers.
Another significant advantage lies in the ability of LLMs to manage uncertainty within dynamic and state‑changing target environments. In multi‑step penetration exercises, the model continually synthesizes observed conditions — such as service responses, authentication behaviors, or partial error states — into an evolving “world‑view.” This representation informs subsequent decision‑making, enabling the model to pivot between tactics fluidly and discard irrelevant or outdated assumptions without the rigid procedural constraints that burden rule‑based systems.
LLMs also deliver cost‑efficiency and scalability benefits. Off‑the‑shelf general‑purpose models have already demonstrated proficiency in complex offensive security tasks, reducing the need for resource‑intensive training of domain‑specific systems. Even where additional contextual knowledge is required, techniques such as in‑context learning and Retrieval‑Augmented Generation (RAG) can extend capabilities without retraining from scratch, accelerating deployment into diverse organizational settings. Importantly, this flexibility extends beyond academic testbeds into production‑grade scenarios.
Finally, automation integrated within LLM‑driven workflows enhances productivity by closing the traditional gap between detection and remediation. The model is capable of validating the authenticity of initial findings, filtering false positives caused by transient network conditions or tool limitations, and applying context‑aware prioritization that directs remediation efforts to the most impactful vulnerabilities first. Such an end‑to‑end flow — from reconnaissance through validation to actionable reporting — compresses operational timelines from days to hours, while maintaining a level of transparency in reasoning and methodology conducive to audit and regulatory review.
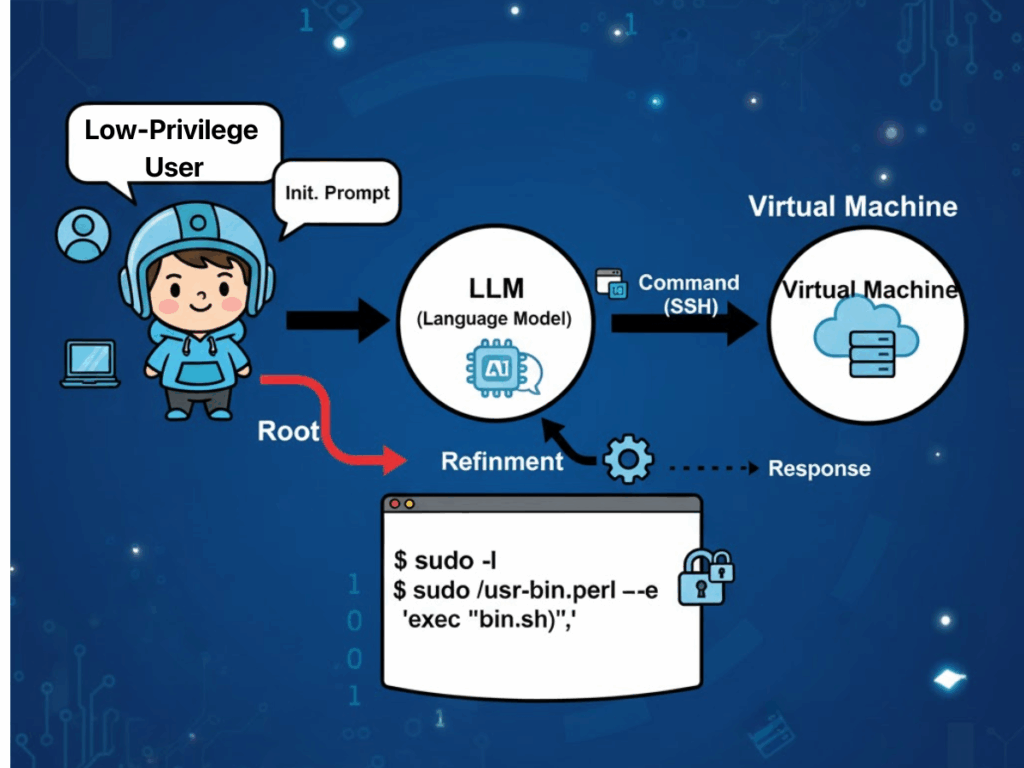
Challenges of LLM‑Based Pentesting
These advantages, however, must be weighed against notable challenges that emerge in operational contexts.
Reliability Issues and Security Risks
Stability and reproducibility remain problematic: subtle differences between model versions can lead to divergences in tool usage or attack sequencing. Under identical conditions, multiple runs may produce entirely different attack chains, undermining result consistency and complicating validation. In dynamic tests, while adaptive strategy is a strength, insufficiently constrained models can drift from the intended task scope, executing irrelevant or even unsafe actions if guardrails are not enforced.
Cost and Energy Burden
Resource consumption presents another constraint. High‑capacity reasoning models demand significantly greater computational power, with energy usage reported at up to seventy times that of smaller, task‑specific models. For organizations planning sustained or large‑scale autonomous pentesting deployments, this translates into meaningful operational costs and environmental impact. Automation itself is double‑edged: a model’s prioritization logic might overlook lower‑priority findings that nonetheless pose significant latent risks, necessitating the presence of skilled human oversight to catch such omissions.
Privacy and Digital Sovereignty
Privacy and compliance concerns remain acute, particularly when cloud inference is used. Input data such as configuration files, proprietary code segments, or environment details may be transmitted to third‑party providers via API, raising the specter of cross‑border data transfer violations. Multinational enterprises must balance the productivity benefits of LLM integration with the reality of divergent regional compliance laws.
Ambiguous Accountability
Finally, accountability is unresolved — should AI‑driven testing inadvertently disrupt production systems or cause data loss, the current legal landscape offers no definitive attribution of responsibility, exposing organizations to contractual, regulatory, and reputational risk.
Penligent.ai: The AI Red‑Teaming Revolution
Penligent.ai emerges as a specialized response to many of these hurdles. Described as the world’s first Agentic AI Hacker, it moves beyond the roles of standalone scanners or rigid automation scripts by interpreting natural‑language directives, decomposing complex objectives into executable sub‑tasks, selecting from an integrated library of over two hundred industry‑standard security tools, and coordinating them intelligently to produce validated, prioritized vulnerability lists accompanied by remediation guidance.
Transparency is baked into its workflow: users can observe each reasoning step, see exactly which tool was invoked, and understand why certain conclusions were drawn and what action will follow. This design bolsters trust and facilitates audits, making Penligent not merely a tool but a collaborative red‑team partner that scales from individual use to enterprise deployment. By embedding compliance‑aware logic aligned with frameworks such as NIST TEVV and OWASP’s Generative AI Red‑Teaming guidelines, it bridges the gap between automation potential and regulated practice.
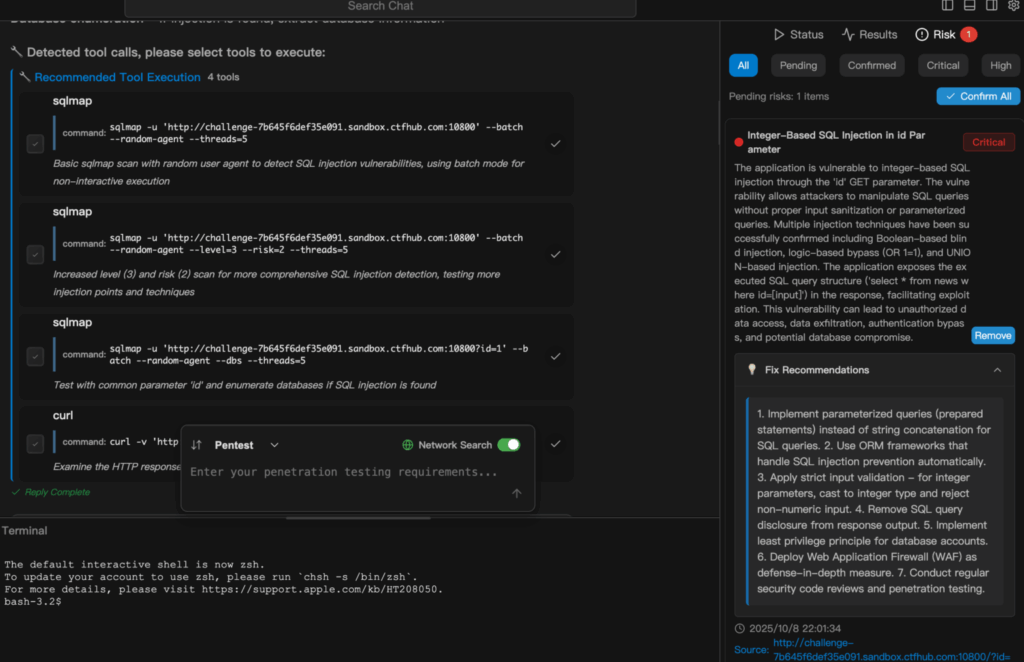
Example Demonstration
The following excerpt outlines how Penligent.ai transitions from a simple natural‑language task to a fully executed and reported security test. Here’s an example of running an SQL injection scan in Penligent.
Conclusion
From the academic validation of capabilities in “On the Surprising Efficacy of LLMs for Penetration‑Testing” to the operational refinement embodied in Penligent.ai, the trajectory of AI‑enabled offensive security is clear: the tools are maturing from proof‑of‑concept into production‑ready platforms. For cybersecurity professionals, penetration testers, and AI security enthusiasts, this is less an incremental improvement than a shift in the underlying paradigm. By reducing cycle time, lowering entry barriers, enhancing transparency, and integrating compliance from the outset, Penligent.ai exemplifies how intelligent automation can help both human experts and non‑specialists defend — and test — the systems on which modern business depends.
The challenge now lies not in proving that these systems work, but in deploying them responsibly: ensuring stability and reproducibility, curbing misuse, safeguarding privacy, and establishing accountability. Done right, AI‑driven pentesting may well become not just a competitive advantage, but a foundational component of the security posture in an era where threats evolve faster than ever before.

