Why the center of gravity is shifting local
Cloud LLMs remain remarkable, yet red-team reality is unforgiving: rate limits arrive mid-engagement, pricing reshuffles break planning models, and regional policy shifts disrupt evidence collection. For teams that live and die by reproducibility, forensics, and clean audit trails, those uncertainties are not a nuance—they are operational risk. In parallel, regulated environments in healthcare, finance, and the public sector increasingly prefer that sensitive data never leaves controlled networks, which pushes model execution toward laptops, workstations, and private clusters. That shift is visible in the open: reports track the rise of “shadow AI,” with a large share of employees acknowledging unsanctioned AI use that risks data exposure; the takeaway for security is simple—own your inference path or someone else will. (Cybernews)
A second force is transparency. Open-source small models—7B to 13B parameters, quantized, pruned, and tuned—are becoming “good enough” for a large portion of triage, PoC generation, and scripting assistance, while remaining auditable at the weight and prompt-template level. Combine that with near-zero marginal cost per run and sub-second local latency on commodity GPUs, and you get an experimentation loop that is both faster and easier to govern than a remote black-box endpoint. The local-first route also minimizes the blast radius of upstream outages and policy changes that would otherwise stall a test window. Yet “local” is not automatically “safe”: recent scans found hundreds of self-hosted LLM endpoints, including Ollama, exposed on the public internet—reminding us that basic access control and network isolation still matter. (TechRadar)
Sources: Cybernews on shadow-AI prevalence and risks; TechRadar and Cisco Talos on exposed Ollama servers. (TechRadar)
Defining pentestai in practice
pentestai is Penligent’s working definition for AI-assisted penetration testing: a method and workflow where local, open-source small LLMs orchestrate your existing toolchain—Burp, SQLMap, Nuclei, GHunt—while capturing commands, parameters, artifacts, and reproduction steps as a permanent evidence trail. The model is not the “actor”; it is the collaborator that proposes commands, synthesizes PoCs, and reasons over scanner output under human supervision. In a hybrid posture, long-chain reasoning or ultra-long context tasks can escalate to cloud models, but verification and initial evidence collection stay on hardware you control.
The case for “local + open small LLMs”
A local-first posture maps cleanly to privacy and compliance controls because data remains inside the device boundary and your audit system of record. The approach aligns with control families familiar to security leaders—access enforcement, auditing, and data minimization—codified in frameworks such as NIST SP 800-53. Moreover, open weights allow external review, supply-chain verification, and deterministic reproduction of findings across teams and time. When cloud throttles, fails, or changes terms, your red team does not go dark; it continues on the workstation next to you. The caveat: treat your local model runtime as a sensitive service—authenticate it, segment it, and never expose it directly to the internet. (NIST Computer Security Resource Center)
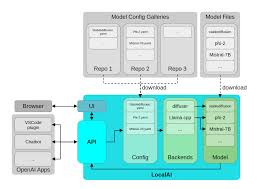
A reference stack for pentestai
Local does not mean monolithic. It means thoughtfully staged capacity where each rung carries a specific testing role, and the whole ladder can hand off to the cloud for complexity, scale, or context window when warranted.
| Tier | Typical hardware | Model/runtime | Primary role | Notes |
|---|---|---|---|---|
| Lightweight prototype | MacBook class | Ollama running 7B–13B quantized models | Prompt→command synthesis, small PoCs, log triage | Portable, private, low latency. (Ollama) |
| Budget lab | GTX 1070 / iGPU | GGUF with llama.cpp or LM Studio | Air-gapped drills, offline automation | Stable even on older GPUs/iGPUs. (huggingface.co) |
| High-end workstation | RTX 4090 (24GB) | Multi-agent orchestration + fuzz loops | Large asset sets, parallel validation | High concurrency, short feedback cycles. (NVIDIA) |
| Edge & mobile | Apple devices + Core ML | On-device inference | Field sampling in regulated sites | Zero cloud exposure for PHI/PII. (Apple Developer) |
In this architecture, Ollama simplifies local model management and API access, GGUF provides an efficient, portable format optimized for CPU/GPU inference, RTX 4090 class systems unlock aggressive fuzzing and multi-agent flows, and Core ML keeps sensitive data on device while leveraging Apple’s Neural Engine. (Ollama)
What changes in day-to-day testing
For Web/API targets, pentestai accelerates the loop from OSINT and parameter discovery to hypothesis generation and templated checks. Candidate IDORs, mis-scoped authorization rules, or rate-limit bypasses can be turned into verifiable Nuclei templates with prompts and a small parsing scaffold, while access-control and injection risks align cleanly with OWASP Top 10 and ASVS guidance you already use for reporting. (OWASP Foundation)
In credentials and federation work, models help compose and validate test plans for OAuth 2.0 and OpenID Connect flows: state, nonce, audience, and token lifetimes cease to be tribal knowledge and become checklist items with scripts attached. The benefit is not a “magic exploit” but a rigorous, repeatable way to audit assumptions, log each attempt, and preserve artifacts for review. (datatracker.ietf.org)
For LLM security—prompt injection, exfiltration, jailbreaks, and policy bypass—local models are doubly useful: they simulate adversarial inputs and reason about defense-in-depth without sending your prompts, system instructions, or sanitized corpora outside your perimeter. That is both a data-governance and a speed win. Meanwhile, the industry’s misconfigured LLM endpoints are a cautionary tale: if you self-host, lock it down. (TechRadar)
A minimal local chain: model-assisted Nuclei verification
# Use a local 7B–13B model via Ollama to synthesize a Nuclei template+command.
prompt='Generate a Nuclei template to probe for a basic IDOR at /api/v1/user?id=... .
Return only valid YAML and a one-line nuclei command to run it.'
curl -s http://localhost:11434/api/generate \
-d '{"model":"llama3.1:8b-instruct-q4","prompt":"'"$prompt"'", "stream": false}' \
| jq -r '.response' > gen.txt
# Extract YAML and run it, then hash artifacts into an audit log.
awk '/^id: /,/^$/' gen.txt > templates/idor.yaml
nuclei -t templates/idor.yaml -u https://target.example.com -o evidence/idor.out
sha256sum templates/idor.yaml evidence/idor.out >> audit.log
This is not “let the model hack.” It is human-directed automation with tight scope, captured evidence, and deterministic reproduction.
Governance that actually holds up in audits
Local-first does not excuse weak process. Treat prompts as versioned assets, run unit-level tests for safety and determinism, and enforce RBAC on your orchestration layer. Map your controls to NIST SP 800-53 families so your reviewers recognize them: access control (AC), audit and accountability (AU), configuration management (CM), and system and information integrity (SI). Keep the model runtime in a private segment, require auth, and log all invocations—including prompt text, tool calls, and hashes of generated artifacts. And because most Web/API findings eventually land in executive reports, tie your language and severity to OWASP to minimize rewrite cycles with AppSec and compliance. (NIST Computer Security Resource Center)
When to escalate to cloud and why hybrid is honest
There are legitimate reasons to use hosted models: extremely long contexts, multi-stage reasoning across heterogeneous corpora, or stringent availability SLAs for production pipelines. A defensible policy is “local for verification, cloud for scale,” with explicit data-handling rules and redaction baked in. It acknowledges the reality that some problems exceed the practical limits of local hardware while keeping the sensitive core of your tests within your audit boundary.
Where Penligent fits if you need a productized path
Penligent operationalizes pentestai into an evidence-first workflow: natural-language instructions are transformed into executable tool chains; findings are validated and logged with parameters and artifacts; and reports align with frameworks your stakeholders already trust, such as OWASP Top 10 and NIST SP 800-53. Deployments support Ollama for local management, GGUF models for efficient inference, and Core ML for on-device testing where zero cloud exposure is a compliance requirement. The result is an “always-on” red team posture that survives vendor rate limits, policy changes, and network partitions without losing auditability. (Ollama)
Practical reading and anchors your team already uses
If your testing spans auth and identity, keep the OAuth 2.0 and OpenID Connect specs close; if you escalate to cloud, ensure your evidence still maps to the same reporting spine. For web risk framing, point product managers and engineering leadership to OWASP Top 10 primers so remediation cycles are shorter and less adversarial. And if you pursue the workstation route, profile an RTX 4090 class system for parallel fuzzing and agent orchestration; if you stay mobile or in the clinic, use Core ML and its toolchain to keep regulated data on device. (datatracker.ietf.org)
Sources
- Shadow-AI prevalence and workplace risk (Cybernews; TechRadar summary of the same survey). (Cybernews)
- Exposed local LLM endpoints, including Ollama (TechRadar; Cisco Talos blog). (TechRadar)
- OWASP Top 10 (official). (OWASP Foundation)
- NIST SP 800-53 Rev. 5 (official HTML and PDF). (NIST Computer Security Resource Center)
- OAuth 2.0 (RFC 6749) and OpenID Connect Core 1.0. (datatracker.ietf.org)
- Ollama and GGUF references; Core ML docs; NVIDIA RTX 4090 product page. (Ollama)
Authoritative links to keep handy:
OWASP Top 10 · NIST SP 800-53 Rev. 5 · RFC 6749 OAuth 2.0 · OpenID Connect Core 1.0 · Ollama · GGUF overview · Core ML docs · GeForce RTX 4090

