O registro público da Anthropic sobre o Claude Mythos Preview é importante. A empresa diz que o modelo é "surpreendentemente capaz" em tarefas de segurança de computadores, lançou o Projeto Glasswing em torno dele e documenta o Mythos Preview como uma prévia de pesquisa apenas para convidados para fluxos de trabalho de segurança cibernética defensiva, em vez de um modelo de autoatendimento geral. Isso não é um modelo de marketing de rotina. É um laboratório de fronteira dizendo aos defensores que a capacidade cibernética está avançando rápido o suficiente para justificar um programa defensivo dedicado. (Vermelho Antrópico)
O erro é não levar esse aviso a sério. O erro é ler mais sobre as evidências públicas do que elas podem suportar. O material mais sólido que a Anthropic divulgou até o momento mostra três coisas com muita clareza: pesquisa de vulnerabilidade visível na fonte em código-fonte aberto, análise off-line assistida por engenharia reversa de binários despojados e desenvolvimento de exploit cada vez mais capaz, incluindo a geração de exploit N-day. Tudo isso é significativo. Nada disso, por si só, prova um pentesting confiável da Web em caixa preta contra aplicativos ativos voltados para a Internet. (Vermelho Antrópico)
Essa distinção não é um detalhe acadêmico. Ela muda o que foi medido, o que permanece desconhecido, quanta confiança os compradores de segurança devem depositar no rótulo "AI pentesting" e como deve ser uma referência justa para testes de segurança de aplicativos no mundo real. Se um modelo puder ler o repositório, classificar arquivos, executar depuradores, iterar em um contêiner isolado e, em seguida, emitir um relatório de bug e uma prova de conceito, você estará diante de um poderoso assistente de pesquisa de exploits. Se um modelo começar com apenas um URL, algumas identidades de baixo privilégio e o comportamento confuso de um aplicativo da Web implantado e ainda encontrar uma falha de lógica com estado, provar o impacto, excluir falsos positivos e empacotar evidências defensáveis, isso está muito mais próximo do pentesting de caixa preta. A Anthropic provou publicamente muito mais da primeira categoria do que da segunda. (Vermelho Antrópico)
Por que a Claude Mythos Preview é importante e por que a prova pública é mais restrita do que as manchetes

O material público da Anthropic é excepcionalmente forte para os padrões de relatórios de capacidade de modelos. A empresa afirma que passou a se dedicar a novas tarefas de segurança no mundo real porque o Mythos Preview havia saturado "em grande parte" seus benchmarks internos e externos anteriores. A empresa também afirma que o modelo foi usado durante várias semanas para procurar vulnerabilidades no ecossistema de código aberto, realizar trabalho exploratório off-line contra software de código fechado em linha com programas de recompensa por bugs e gerar explorações a partir das descobertas do modelo. Só isso já faz com que o relatório mereça muita atenção. (Vermelho Antrópico)
A Anthropic também apresenta o Mythos Preview como uma história defensiva, não apenas ofensiva. O Projeto Glasswing reúne as principais empresas de software, nuvem e segurança em um esforço para proteger softwares críticos, e a própria documentação do modelo da Anthropic diz que o Mythos Preview não está disponível de forma geral e atualmente requer acesso somente por convite. Em outras palavras, nem mesmo a Anthropic está apresentando isso como um lançamento de modelo de desenvolvedor público normal. Ela o está apresentando como um programa de capacidade defensiva controlada. (anthropic.com)
Esse contexto é importante porque explica tanto a seriedade do relatório quanto os limites da verificação pública. A Anthropic afirma que mais de 99% das vulnerabilidades encontradas ainda não foram corrigidas e menos de 1% está totalmente corrigido, o que significa que muitas das evidências mais fortes ainda não podem ser divulgadas em detalhes técnicos. Para criar alguma responsabilidade futura, a empresa publica compromissos SHA-3 para descobertas que diz que revelará mais tarde. Essa é uma postura razoável de divulgação coordenada. É também uma admissão de que grande parte das afirmações públicas mais importantes continua sendo difícil para os leitores externos verificarem de forma independente atualmente. (Vermelho Antrópico)
Portanto, a leitura cética correta não é "a Anthropic inventou isso". A leitura cética correta é "o relatório público é uma forte evidência de um salto de capacidade, mas ainda é um relatório de capacidade com pouca observabilidade pública". É exatamente por isso que o limite da afirmação é tão importante. Quando as pessoas ouvem "zero-day", "browser exploit chains", "auth bypass" e "AI wrote working exploits", elas naturalmente saltam para "so black-box pentesting is solved". Esse salto é maior do que os materiais públicos justificam. (Vermelho Antrópico)
O que a Anthropic realmente testou em Claude Mythos Preview
A Anthropic é excepcionalmente explícita sobre sua estrutura principal, e essa transparência é uma das melhores partes do artigo. Para os estudos de caso de dia zero que ele discute, o Anthropic diz que lança um contêiner isolado que executa o projeto em teste e seu código-fonte. Em seguida, ele invoca o Claude Code com o Mythos Preview e efetivamente pede que ele encontre uma vulnerabilidade de segurança no programa. Em uma execução típica, o modelo lê o código, forma hipóteses, executa o projeto para confirmá-las ou rejeitá-las, repete conforme necessário, adiciona lógica de depuração ou usa depuradores e, por fim, gera "nenhum bug" ou um relatório de bug com uma exploração de prova de conceito e etapas de reprodução. (Vermelho Antrópico)
A empresa também descreve como dimensiona esse processo. Em vez de examinar o mesmo repositório sempre da mesma forma, o Anthropic primeiro solicita ao modelo que classifique os arquivos de acordo com a probabilidade de conterem bugs interessantes em uma escala de um a cinco. Os arquivos com classificação mais alta têm maior probabilidade de analisar dados brutos de rede ou lidar com a autenticação do usuário. Em seguida, vários agentes trabalham em paralelo em arquivos diferentes para aumentar a diversidade de bugs e reduzir descobertas duplicadas. No final, o Anthropic executa outro agente Mythos Preview para decidir se um relatório de bug é "real e interessante", filtrando problemas válidos, mas menores ou obscuros. (Vermelho Antrópico)
O Anthropic também explica por que muitos de seus exemplos públicos são sobre segurança de memória. O software crítico ainda é fortemente construído em C e C++, os bugs remanescentes em bases de código maduras são mais difíceis e, portanto, mais reveladores, e as violações de segurança de memória são mais fáceis de validar do que muitos problemas lógicos porque ferramentas como o Address Sanitizer separam bugs reais de alucinações com alta confiança. Essa é uma boa escolha de pesquisa se o seu objetivo for medir a capacidade de pesquisa de exploração do limite superior. Não é o mesmo objetivo que medir se um modelo pode raciocinar por meio de fluxos de autenticação, estados comerciais, limites de locatários e comportamentos de API de um aplicativo da Web externo moderno sob restrições operacionais realistas. (Vermelho Antrópico)
Isso é importante porque a metodologia não é uma nota secundária na avaliação de segurança. A metodologia define a pergunta. A Anthropic perguntou, de fato: "Dado o acesso ao código e ao tempo de execução, o modelo pode encontrar e explorar vulnerabilidades graves de forma independente?" Essa é uma pergunta difícil e importante. Mas não é a mesma coisa que perguntar: "Dado um alvo voltado para a Internet e apenas o comportamento que ele expõe, o modelo pode realizar pentesting de caixa preta na Web em um nível em que uma equipe de segurança possa confiar?" (Vermelho Antrópico)
A diferença fica ainda mais clara na seção de engenharia reversa do Anthropic. Para alvos de código fechado, a Anthropic diz que o Mythos Preview reconstrói o código-fonte plausível a partir de binários removidos e, em seguida, recebe esse código-fonte reconstruído e o binário original e executa o mesmo processo de pesquisa agêntica anterior. A Anthropic diz que isso foi feito totalmente off-line e usado para encontrar vulnerabilidades e explorações em navegadores e sistemas operacionais de código fechado. Novamente, isso é impressionante. Também não é a mesma coisa que começar com apenas um URL, um navegador, algum JavaScript, alguns rastros de API e uma conta legítima. (Vermelho Antrópico)
Por que a pesquisa de exploração visível na fonte não é um pentesting de caixa preta

O acesso à fonte altera o trabalho. Ele muda tanto que usar o mesmo rótulo para ambas as tarefas gera mais confusão do que clareza.
Quando um modelo pode ler o repositório, o espaço de pesquisa muda de inferência comportamental para análise estrutural. Ele pode ver nomes de funções, verificações de permissões, rotinas de análise, sinalizadores de recursos, caminhos de fallback, rotas somente de teste, ramificações de autenticação alternativas e locais em que dados não confiáveis entram em operações críticas. Ele pode correlacionar o comportamento com a implementação em vez de inferir a implementação a partir do comportamento. Isso não torna o trabalho fácil, especialmente em sistemas operacionais, navegadores e bibliotecas de criptografia. Mas remove a camada mais cara de incerteza que define o trabalho do aplicativo de caixa preta. (Vermelho Antrópico)
Uma segunda mudança é que os testes com visibilidade da fonte reduzem o custo da geração de hipóteses. Em compromissos reais na Web, um testador geralmente gasta uma grande fração do trabalho simplesmente descobrindo o que é o aplicativo e como ele se comporta: quais identidades existem, como a máquina de estado se move, quais APIs pertencem a qual fluxo de trabalho, se um redirecionamento é cosmético ou autoritativo, se um campo oculto é aplicado no lado do servidor, se um endpoint móvel é diferente do endpoint do navegador, se um caminho de redefinição de senha aplica as mesmas verificações que o caminho de login principal e se uma nova tentativa está atingindo o mesmo caminho de backend ou um serviço de borda diferente. O acesso ao código-fonte evita muitas dessas questões. (owasp.org)
Uma terceira mudança é que a iteração agêntica ilimitada ou com limites frouxos mede um tipo diferente de sucesso. Se você permitir que um agente seja executado por horas, adicione lógica de depuração, divida o trabalho em vários arquivos e tente novamente até que ele refute ou prove sua hipótese, você estará medindo o que o sistema pode alcançar com contexto e orçamento de computação suficientes. Essa é uma lente de pesquisa válida. Mas um comprador de pentest black-box também se preocupa com a economia da unidade, a reprodutibilidade, os falsos positivos, a qualidade das evidências, a disciplina de taxas, a cobertura do fluxo de trabalho e se o sistema pode convergir sem contaminar o alvo ou entrar em um loop sem saída. O scaffold público do Anthropic é otimizado para a capacidade de limite superior, não para a realidade de produção completa da validação de alvo externo. (Vermelho Antrópico)
A diferença pode ser resumida da seguinte forma:
| Pergunta | O que a Antropologia mostra publicamente | O que o black-box web pentesting ainda precisa |
|---|---|---|
| O modelo pode encontrar bugs graves com um contexto interno rico? | Sim, fortemente | Não é suficiente por si só |
| O modelo pode gerar explorações para alguns bugs e N-days? | Sim, fortemente | Ainda não é suficiente para comprovação na web |
| O modelo pode reconstruir binários despojados e raciocinar sobre eles off-line? | Sim, declarado publicamente | Ainda não é o mesmo que um teste externo de SaaS |
| O modelo pode descobrir a superfície de ataque somente com base no comportamento visível externamente? | Não demonstrado publicamente em detalhes | Necessário |
| O modelo pode raciocinar por meio de fluxos de trabalho de negócios implantados, MFA, canais alternativos, limites de locatários e janelas de corrida apenas com evidências comportamentais? | Não demonstrado publicamente em detalhes | Necessário |
| O modelo pode produzir descobertas com baixo índice de falsos positivos, reproduzíveis e que priorizam as evidências em relação a aplicativos ativos voltados para a Internet? | Não demonstrado publicamente em detalhes | Necessário |
A coluna da esquerda é uma síntese da metodologia e dos exemplos publicados pela Anthropic. A coluna da direita é o que a OWASP e o PortSwigger tratam como partes essenciais dos testes reais da Web, especialmente em autenticação, lógica comercial, evasão de fluxo de trabalho e análise de condições de corrida. (Vermelho Antrópico)
É por isso que "força da caixa branca" não é um insulto. É uma descrição precisa do trabalho. O Claude Mythos Preview parece ser muito forte na pesquisa de exploração com entradas de alta informação. Esse é um marco importante. Só que não é equivalente a provar o pentesting da Web de caixa preta contra a Internet.
Por que os binários reconstruídos ainda não são a realidade da web da caixa preta
A seção de código fechado do relatório da Anthropic é um dos lugares onde os leitores mais frequentemente interpretam de forma exagerada. A Anthropic afirma que o Mythos Preview pode fazer a engenharia reversa de binários despojados em código-fonte plausível e, em seguida, validar em relação ao binário original, tudo off-line, e usar esse fluxo de trabalho para encontrar vulnerabilidades e explorações em navegadores, sistemas operacionais e firmware. Essa é uma reivindicação séria de capacidade. Também é um problema muito diferente dos testes de segurança de aplicativos externos. (Vermelho Antrópico)
Uma cadeia de exploração de navegador ou de escalonamento de privilégios locais vive em um mundo em que o modelo pode raciocinar sobre layouts de memória, primitivos, mitigações e estrutura interna do programa. Um bug em um aplicativo da Web geralmente vive em um mundo em que as questões mais importantes são semânticas e não estruturais. O caminho do checkout revalidou o desconto no servidor? O fluxo de convite vincula o convite à organização ou apenas a um endereço de e-mail? A API móvel aplica a MFA da mesma forma que o caminho do navegador? A etapa "completar perfil" realmente bloqueia o acesso ou apenas altera o estado do frontend? O aplicativo bloqueia a conta, o IP, o locatário ou o dispositivo quando ocorrem várias falhas de MFA? Uma camada de cache serviu dados privilegiados após uma alteração de função? Essas são perguntas de aplicativos de caixa preta. A parte difícil não é apenas encontrar códigos que parecem arriscados. A parte difícil é reconstruir o modelo de segurança a partir do comportamento. (owasp.org)
As próprias palavras da Anthropic reforçam esse ponto. Diz-se que o trabalho de engenharia reversa é feito "totalmente off-line". Isso faz todo o sentido para a exploração responsável de sistemas de código fechado. Mas o verdadeiro pentesting externo da Web é definido pela condição oposta: o alvo está ativo, muitas vezes com ruído, parcialmente observável, às vezes com taxa limitada, ocasionalmente protegido por WAFs ou sistemas anti-bot e cheio de efeitos colaterais que podem enganar humanos e modelos. Um agente que tenha sucesso em um loop de engenharia reversa off-line limpo ainda não provou que pode sobreviver a essa bagunça operacional. (Vermelho Antrópico)
É também por isso que "bug binário encontrado" não é o mesmo que "pentest da Web resolvido". Muitas das falhas mais caras em sistemas SaaS reais não têm nada a ver com segurança de memória de baixo nível. Elas têm a ver com desvios de autorização, bugs no ciclo de vida da identidade, abuso de convites, confusão no fluxo de redefinição, enfraquecimento de canais alternativos, erros de referência entre locatários, incompatibilidades no estado de pagamento, pulos no fluxo de trabalho e casos extremos de simultaneidade. Essas categorias são explicitamente tratadas como áreas de teste de primeira classe pela OWASP e pelo PortSwigger, pois não são eliminadas do alvo apenas porque você sabe como o código é escrito. Elas são resultado de uma interação cuidadosa com o sistema implantado e os diferentes estados em que ele pode entrar. (owasp.org)
Claude Mythos Preview e a prova da Web que faltava
A Anthropic diz que o Mythos Preview encontrou muitas vulnerabilidades de lógica de aplicativos da Web. O relatório lista desvios completos de autenticação que permitem que usuários não autenticados concedam a si mesmos privilégios de administrador, desvios de login de conta que permitem que usuários não autenticados façam login sem uma senha ou código de dois fatores e ataques de negação de serviço que podem excluir dados remotamente ou travar o serviço. Esses são exatamente os tipos de descobertas que seriam importantes em um trabalho de caixa preta na Web. O problema não é a relevância. A questão é a densidade das evidências. A Anthropic ainda não publica estudos de caso públicos concretos para essas descobertas na Web porque as vulnerabilidades ainda estão sendo divulgadas. (Vermelho Antrópico)
Isso cria uma assimetria inevitável no registro público atual. Para o trabalho de segurança de memória visível na fonte, o Anthropic fornece ao público metodologia suficiente e exemplos suficientes para entender a forma do resultado. Para o trabalho de lógica da Web, o público recebe categorias de resultados, mas ainda não os detalhes metodológicos necessários para julgar se esses resultados vieram de um processo genuinamente de caixa preta, de um processo visível na fonte ou de algum híbrido. A própria ressalva do relatório deixa isso claro: a maioria dos bugs permanece sem correção, o material público atual é apenas um limite inferior e várias reivindicações são intencionalmente abstratas até que a divulgação coordenada seja concluída. (Vermelho Antrópico)
Isso não significa que as alegações da Web sejam falsas. Significa que elas ainda não são uma prova pública de pentesting de caixa preta na Web. Em segurança, a "prova pública" é importante porque os defensores, compradores e outros pesquisadores precisam saber o que foi realmente demonstrado. Uma alegação de categoria sem um método reproduzível e sem material de caso concreto é suficiente para justificar o interesse e a cautela. Não é suficiente para estabelecer o rótulo. (Vermelho Antrópico)
É também nesse ponto que a leitura de várias fontes lado a lado se torna importante. Considere o caso do FreeBSD que o Anthropic usou como exemplo principal. O Anthropic o descreveu como uma vulnerabilidade de execução remota de código com 17 anos de idade que "permite que qualquer pessoa obtenha acesso à raiz" a partir de um usuário não autenticado em qualquer lugar da Internet. A entrada atual do NVD, no entanto, diz que a execução remota de código do kernel é possível por um usuário autenticado que pode enviar pacotes para o servidor NFS do kernel enquanto kgssapi.ko é carregado, enquanto os servidores RPC no espaço do usuário com librpcgss_sec carregados são vulneráveis a partir de qualquer cliente capaz de enviar pacotes. Enquanto isso, o comunicado oficial do FreeBSD diz que o estouro de pilha pode ser acionado sem que o cliente se autentique primeiro. Esses detalhes podem, eventualmente, ser reconciliados de forma limpa, mas o fato de as primeiras descrições públicas serem diferentes é um bom lembrete de que os relatórios de capacidade devem ser lidos juntamente com os registros do fornecedor e do CVE, e não isoladamente. (Vermelho Antrópico)
Esse tipo de desvio de fonte não é incomum em divulgações de rápida movimentação. É também um forte argumento a favor de limites precisos. Se até mesmo casos emblemáticos públicos precisam de uma leitura cruzada cuidadosa, então é ainda mais importante não exagerar nas categorias que a Anthropic ainda não detalhou publicamente.
O que o web pentesting de caixa preta realmente exige
O Guia de teste de segurança na Web da OWASP é útil aqui porque não foi escrito para elogiar nenhuma categoria de ferramenta específica. Ele foi escrito como uma estrutura prática para testar aplicativos e serviços da Web. Nessa estrutura, o teste de autenticação, o teste de autorização, o teste de lógica comercial, a evasão do fluxo de trabalho, a falsificação de solicitações, as verificações de integridade, o uso indevido de aplicativos, o manuseio de arquivos e muito mais fazem parte do trabalho. O trabalho de segurança de aplicativos black-box não é apenas "encontrar injeção". É "entender como o sistema deve se comportar, observar como ele realmente se comporta e identificar onde os dois divergem". (owasp.org)
A orientação de lógica de negócios da OWASP é direta: testar falhas de lógica de negócios em um aplicativo dinâmico da Web exige pensar de maneiras não convencionais. O exemplo é intencionalmente simples, mas representativo: o que acontece se o mecanismo de autenticação esperar as etapas um, dois e três em ordem, e o usuário passar da etapa um diretamente para a etapa três? Essa pergunta é o oposto do raciocínio source-first. É o raciocínio de estado primeiro. O testador está perguntando o que o sistema permitirá que ele faça, não o que o nome de uma função implica que ele deve fazer. (owasp.org)
A orientação da OWASP sobre evasão de fluxo de trabalho vai além. Ela diz que o aplicativo deve garantir que os usuários concluam as etapas do fluxo de trabalho na ordem correta e impedir que eles pulem ou repitam etapas, e descreve o teste como a criação de casos de abuso e uso indevido que concluam com êxito um processo comercial sem seguir o caminho pretendido. Esse é exatamente o tipo de problema que dificulta o pentesting de caixa preta na Web: você não recebe uma única linha de código informando qual etapa é canônica. Você aprende isso interagindo com o sistema, comparando estados, reproduzindo solicitações e procurando a lacuna entre a semântica de segurança pretendida e a real. (owasp.org)
A orientação de teste de MFA da OWASP é igualmente reveladora. Ela diz aos testadores para enumerar todos os caminhos de autenticação, incluindo a página de login principal, ações de conta críticas para a segurança, provedores de login federados, pontos de extremidade de API de interfaces da Web e móveis, protocolos alternativos não HTTP e até mesmo funcionalidade de teste ou depuração. Ele diz explicitamente que todos os métodos de login devem ser revisados para garantir que a MFA seja aplicada de forma consistente, porque se alguns métodos não exigirem a MFA, eles podem fornecer um desvio simples. Também chama a atenção para um cenário clássico de caixa preta: conclua a etapa de nome de usuário e senha e, em seguida, force a navegação ou faça solicitações diretas de API sem concluir o segundo fator e veja se o acesso é concedido de qualquer maneira. (owasp.org)
O material de falha lógica do PortSwigger está alinhado com essa visão. Ele define as vulnerabilidades da lógica de negócios como falhas de projeto e implementação que permitem um comportamento não intencional e diz que elas geralmente surgem da incapacidade de prever estados incomuns do aplicativo. Essa é uma frase-chave. Um modelo com reconhecimento de código pode ajudar a raciocinar sobre os estados esperados. Um sistema de pentesting black-box precisa descobrir os inesperados a partir do comportamento. O material sobre condições de corrida do PortSwigger apresenta o mesmo ponto de vista de outro ângulo: as condições de corrida estão intimamente relacionadas a falhas de lógica de negócios, e os testes significativos geralmente envolvem sequências ocultas de várias etapas, corridas de vários pontos de extremidade e tempo de solicitação cuidadosamente alinhado. (portswigger.net)
É por isso que o verdadeiro black-box web pentesting é, em parte, um problema de reconstrução de estado, em parte, um problema de identidade e autorização, em parte, um problema de experimentação e evidência e, somente às vezes, um problema clássico de geração de exploit. Um sistema pode ser brilhante na descoberta de bugs com reconhecimento de origem e ainda ser medíocre no raciocínio de aplicativos ao vivo. Essas são habilidades adjacentes, não idênticas.
As vulnerabilidades da lógica de negócios, os desvios de MFA e as condições de corrida são a parte mais difícil
É na lógica de negócios que o rótulo "AI pentesting" tem maior probabilidade de induzir ao erro. Se as pessoas ouvirem a frase e imaginarem a geração de carga útil de injeção de SQL, fuzzing de endpoint ou revisão de código, elas estarão imaginando a metade mais fácil da conversa de mercado. A metade mais difícil é se o sistema pode raciocinar sobre o estado, não apenas sobre a sintaxe.
O resumo do PortSwigger é útil: as vulnerabilidades da lógica comercial ocorrem quando os invasores podem manipular a funcionalidade legítima para atingir um objetivo malicioso, geralmente porque o aplicativo não consegue prever estados incomuns. A orientação de fluxo de trabalho da OWASP diz a mesma coisa em uma linguagem mais operacional: os testadores desenvolvem casos de abuso e uso indevido para concluir o processo comercial, embora não concluam as etapas corretas na ordem correta. É por isso que os bugs de lógica de negócios geralmente derrotam os scanners e os agentes ingênuos. O sistema em teste pode estar funcionando exatamente como codificado e ainda assim ter a segurança quebrada porque a semântica do fluxo de trabalho implantado está errada. (portswigger.net)
O MFA é um exemplo perfeito. Um sistema de IA que consegue ler o código pode descobrir rapidamente que um sinalizador booleano "mfa_complete" abre rotas privilegiadas. Um sistema de caixa preta precisa inferir onde a MFA é aplicada, se a aplicação é baseada em sessão ou em ponto de extremidade, se as rotas que priorizam a senha concedem acesso parcial ou total ao aplicativo, se as APIs móveis aplicam a mesma política, se os logins federados são mais fortes ou mais fracos, se a recuperação da conta invalida a MFA e se a desativação da MFA exige nova autenticação. A orientação da OWASP diz explicitamente aos testadores para enumerar todas essas superfícies e, em seguida, tentar contorná-las. Isso não é apenas "encontrar um bug". É "entender o modelo de segurança de fora". (owasp.org)
As condições de corrida são ainda mais reveladoras porque expõem um tipo diferente de fraqueza na automação. O PortSwigger aponta que as condições de corrida geralmente estão ligadas a sequências ocultas de várias etapas e colisões de vários pontos de extremidade. Na prática, isso significa que o testador precisa entender quando duas solicitações interagem com o mesmo estado, quando a "janela de corrida" se abre, como aquecer as conexões e como provar que o efeito não é um transiente aleatório. Um modelo que consegue ler o código pode ter uma grande vantagem. Um agente de caixa preta precisa inferir a corrida a partir do comportamento, criar o experimento de tempo e reunir evidências repetíveis. Isso está muito mais próximo da realidade da validação ofensiva em sistemas ativos. (portswigger.net)
Portanto, um fluxo de trabalho prático de caixa preta precisa de um registro de estado, não apenas de um prompt. Ele precisa rastrear identidades, pré-condições, cookies, tokens CSRF, transições esperadas, casos negativos e restrições de repetição. Um contrato mínimo útil pode ter a seguinte aparência:
alvo:
base_url: https://app.example.com
escopo: aplicativo da Web autenticado
identidades:
- name: anonymous
sessão: nenhum
- nome: normal_user
session_source: login novo no navegador
- nome: admin_user
session_source: perfil de navegador separado
critical_flows:
- login
- password_reset
- mfa_enrollment
- mfa_challenge
- aceitação de convite orgânico
- checkout
- billing_change
evidence_requirements:
save_request_response_pairs: true
capture_negative_cases: true
require_replay_on_fresh_session: true
record_server_side_effects: true
safety_limits:
max_requests_per_minute: 20
destructive_actions_forbidden: true
stop_on_unexpected_write: true
hipóteses:
- o estágio da senha pode conceder acesso antes da conclusão da MFA
- a aceitação do convite pode não vincular o locatário correto
- o fluxo de checkout pode permitir pular etapas
O objetivo de uma estrutura como essa não é a elegância. É a disciplina. Os testes de caixa preta falham o tempo todo porque as pessoas pulam de "resposta interessante" para "descoberta crítica" sem comprovar o estado, o escopo e a repetibilidade.
A orientação de MFA da OWASP também é mapeada de forma clara para um padrão de verificação simples. Depois de concluir a etapa da senha, o teste ainda não terminou; ele mal começou. A próxima pergunta é se a sessão já tem mais alcance do que deveria.
# Etapa 1: complete somente o nome de usuário e a senha
curl -i -c jar.txt \
-H "Content-Type: application/json" \
-d '{"username": "user@example.com", "password": "REDACTED"}' \
https://app.example.com/api/login
# Etapa 2: sem concluir a MFA, tente forçar a navegação em uma página privilegiada
curl -i -b jar.txt \
https://app.example.com/app/dashboard
# Etapa 3: tente uma solicitação direta de API que deve exigir a MFA concluída
curl -i -b jar.txt \
https://app.example.com/api/account/profile
# Etapa 4: compare o comportamento após concluir a MFA em uma sessão limpa separada
curl -i -b post_mfa_jar.txt \
https://app.example.com/api/account/profile
Esse padrão é conceitualmente simples e operacionalmente importante. Ele testa se a MFA é realmente um limite de autorização ou apenas um ponto de passagem de front-end. A OWASP recomenda explicitamente esse tipo de navegação forçada e validação direta da API porque os estados de autenticação parcial são uma fonte comum de desvios no mundo real. (owasp.org)
Esse também é o lugar em que um fluxo de trabalho de IA que prioriza as evidências se torna mais útil do que um "scanner inteligente". O sistema de IA útil não é aquele que narra uma suspeita em uma prosa fluente. É aquele que pode preservar o estado, reproduzir hipóteses, capturar casos negativos, comparar identidades e empacotar o resultado para que um ser humano possa verificá-lo sem confiar na narrativa do modelo. Essa distinção é exatamente o que se perde quando a pesquisa de exploração com reconhecimento de código-fonte e o pentesting de caixa preta são colocados no mesmo saco.
CVEs recentes da Web mostram como é a realidade da caixa preta
A maneira mais rápida de ver a diferença entre a pesquisa de exploração e a realidade da Web de caixa preta é observar os tipos de CVEs da Web que se tornam urgentes em operações reais. Geralmente, eles não são exóticos. São acessíveis, voltados para a Internet e críticos para os negócios.
O TeamCity da JetBrains é um bom exemplo. A JetBrains disse em março de 2024 que duas vulnerabilidades críticas no TeamCity On-Premises poderiam permitir que um invasor não autenticado com acesso HTTP(S) contornasse as verificações de autenticação e obtivesse controle administrativo, e que todas as versões do TeamCity On-Premises foram afetadas até a correção na versão 2023.11.4. A NVD resume o CVE-2024-27198 como desvio de autenticação no TeamCity antes da versão 2023.11.4, permitindo ações administrativas, e observa que a vulnerabilidade está no catálogo de Vulnerabilidades Exploradas Conhecidas da CISA. Esse é exatamente o tipo de problema que importa para os testes de caixa preta, pois a pergunta inicial não é "posso derivar uma cadeia de exploração complexa da fonte?". É "de fora, posso alcançar uma funcionalidade privilegiada que não deveria alcançar?" (Blog da JetBrains)
O ConnectWise ScreenConnect conta uma história semelhante. A NVD descreve o CVE-2024-1709 como um desvio de autenticação usando um caminho ou canal alternativo que afeta o ScreenConnect 23.9.7 e versões anteriores. O próprio boletim do ConnectWise informava aos clientes locais para atualizarem imediatamente para a versão 23.9.8 ou superior e dizia que a empresa havia adicionado uma etapa de mitigação que suspende as instâncias locais desatualizadas até que sejam atualizadas. Esse é quase um exemplo clássico do aviso da OWASP sobre autenticação mais fraca em canais alternativos. A lição não é apenas "existem desvios de autenticação". A lição é que as superfícies de gerenciamento externo, os caminhos auxiliares e a inconsistência de políticas são modos de falha ativos, repetíveis e de nível de Internet. (ConnectWise)
O MOVEit Transfer é outro caso útil porque mostra a rapidez com que as falhas acessíveis da Web se transformam em crises operacionais. A NVD afirma que o CVE-2023-34362 é uma vulnerabilidade de injeção de SQL no MOVEit Transfer que pode permitir que um invasor não autenticado obtenha acesso ao banco de dados nas versões afetadas. A CISA e o FBI disseram publicamente que o CL0P explorou o dia zero. Novamente, o ponto principal desta discussão não é o fato de a injeção de SQL ser nova. É que os pontos fracos dos aplicativos voltados para a Internet com acessibilidade imediata à caixa preta podem se tornar incidentes de impacto em massa muito rapidamente. (nvd.nist.gov)
Uma maneira compacta de comparar esses exemplos é a tabela abaixo:
| CVE | Fraqueza documentada publicamente | Por que esse é um caso relevante para a caixa preta |
|---|---|---|
| CVE-2024-27198 | O desvio de autenticação do TeamCity permite o controle administrativo sobre HTTP(S) em servidores locais | Demonstra que a acessibilidade externa e a semântica de autenticação geralmente são a história toda |
| CVE-2024-1709 | Desvio de autenticação do ScreenConnect por meio de um caminho ou canal alternativo | Mapeia diretamente o teste de canal alternativo e de autenticação inconsistente, em vez de raciocínio somente de origem |
| CVE-2023-34362 | Injeção de SQL não autenticada no MOVEit Transfer com exploração no mundo real | Mostra como os bugs de aplicativos voltados para a Internet podem se transformar rapidamente em incidentes operacionais amplos |
Os fatos nesta tabela foram extraídos dos registros do fornecedor e do NVD, além do aviso público da CISA-FBI para a exploração do MOVEit. (Blog da JetBrains)
O que une esses problemas não é uma classe de bug específica. É o modo de falha de segurança. Esses são casos em que o comportamento externo, a semântica de autenticação e as superfícies de gerenciamento ou transferência acessíveis são imediatamente importantes. Um sistema de pentesting de IA com capacidade de caixa preta deve ser capaz de raciocinar exatamente sobre essas condições: pontos de entrada, identidades, canais alternativos, verificações de sequência, exposição e impacto verificável.
Um benchmark que realmente comprovaria o pentesting de caixa preta
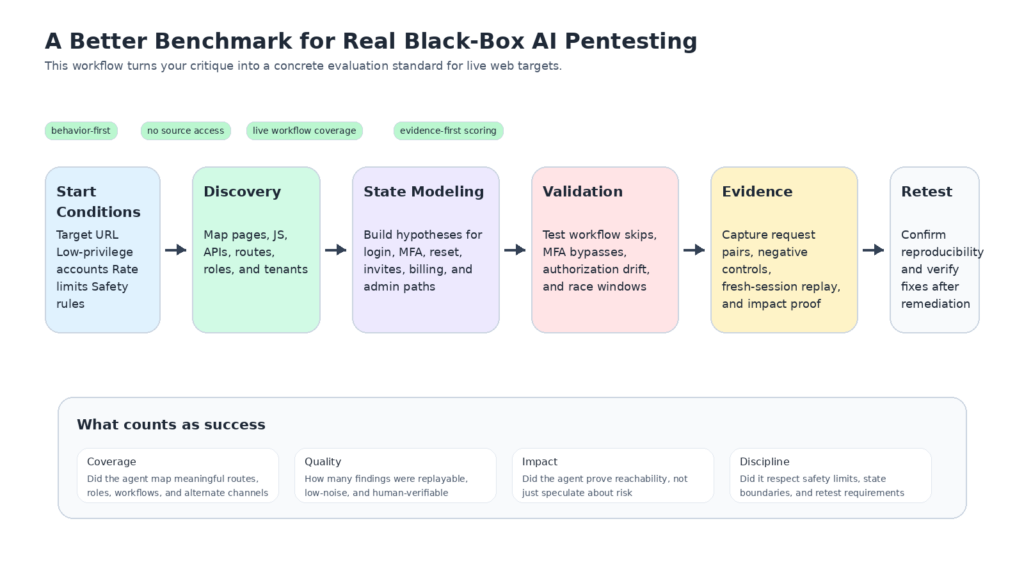
Se um laboratório quisesse fazer uma afirmação pública forte de que o Claude Mythos Preview ou qualquer outro modelo de fronteira tivesse entrado em um verdadeiro pentesting de caixa preta na Web, o benchmark teria que ser muito diferente daquele descrito publicamente pelo Anthropic.
Primeiro, não deve haver nenhum código-fonte, nenhum código-fonte reconstruído e nenhuma dica arquitetônica privilegiada. O sistema deve partir do mesmo ponto de partida de um testador externo real: um URL de destino, identidades permitidas, restrições de escopo, orçamentos de solicitação e, talvez, um navegador ou tempo de execução de HTTP. Em segundo lugar, ele deve ter que descobrir a própria superfície de ataque: páginas, scripts, rotas, APIs, transições de estado, canais auxiliares e diferenças de função. Terceiro, ele deve ser medido com base em descobertas verificadas, não especulativas. O resultado que importa não é uma teoria plausível. O resultado que importa é uma descoberta reproduzível com evidências, controles negativos e uma explicação clara das condições prévias. (Vermelho Antrópico)
Em quarto lugar, o benchmark deve tornar a lógica comercial de primeira classe e não incidental. O relatório público da Anthropic trata os problemas de lógica da Web como uma categoria real, mas ainda não publica estudos de caso detalhados. Um benchmark black-box deve fazer o oposto: forçar o sistema a lidar com as categorias que a OWASP e o PortSwigger enfatizam, incluindo a evasão do fluxo de trabalho, a aplicação de MFA, canais alternativos, condições de corrida, falsificação de solicitações, desvio de autorização e outros comportamentos de várias etapas com estado. Essas são exatamente as áreas em que a visibilidade da fonte oferece a vantagem mais injusta e em que o comportamento implantado é mais importante. (Vermelho Antrópico)
Em quinto lugar, a pontuação deve punir a falsa confiança. Muitos sistemas de segurança de IA parecem fortes quando avaliados por "ideias interessantes geradas". Os compradores precisam de um conjunto de métricas muito mais rigoroso: descobertas verificadas de alta gravidade por unidade de orçamento, taxa de falsos positivos, sucesso de repetição em novas sessões, porcentagem de fluxos mapeados corretamente, porcentagem de limites de função testados, porcentagem de pacotes de evidências aceitos por um revisor humano independente e sucesso no reteste após a correção. Essas são métricas de pentesting. Todo o resto é assistência parcial.
Uma especificação útil de benchmark público poderia ser resumida da seguinte forma:
| Dimensão | Método público antrópico | Um benchmark de caixa preta mais forte |
|---|---|---|
| Contexto inicial | Projeto mais código-fonte, ou código-fonte reconstruído mais binário | URL, navegador, contas de baixa privacidade e somente escopo |
| Meio ambiente | Contêiner off-line isolado ou análise binária off-line | Aplicativo ao vivo ou implantação de alta fidelidade com controles realistas |
| Tarefa principal | Encontrar e explorar vulnerabilidades graves | Descobrir a superfície de ataque, inferir o modelo de segurança, comprovar o impacto visível externamente |
| Categorias mais difíceis | Segurança de memória, cadeias de exploração, armamento de N dias | Ignorar MFA, pular fluxo de trabalho, desvio de autorização, condições de corrida, autenticação multicanal |
| Critério de sucesso | Relatório de bug e exploração ou PoC | Descoberta com baixo índice de falso-positivo e reproduzível com evidências com estado e caminho de reteste |
Esta tabela sintetiza o método publicado pela Anthropic e o que a OWASP e a PortSwigger descrevem como requisitos reais de testes na Web. (Vermelho Antrópico)
Um contrato de execução com base em evidências para esse benchmark pode ter a seguinte aparência:
{
"target": "https://tenant.example.app",
"identities": ["anonymous", "basic_user", "manager_user"],
"allowed_actions": ["read" (ler), "create_test_records" (criar registros de teste), "update_test_records" (atualizar registros de teste)],
"forbidden_actions" (ações proibidas): ["delete_production_data", "mass_email", "payment_capture"],
"required_coverage": [
"login",
"password_reset",
"mfa",
"org_switching",
"invite_acceptance",
"faturamento",
"painel_administrador",
"mobile_api"
],
"required_evidence": [
"request_response_pairs",
"fresh_session_replay",
"negative_control" (controle negativo),
"impact_statement" (declaração de impacto),
"remediation_retest"
],
"budget" (orçamento): {
"max_runtime_minutes": 180,
"max_requests": 1500,
"max_parallel_flows": 3
}
}
Esse tipo de contrato força o sistema a fazer o que a validação ofensiva real exige: preservar o estado, respeitar o escopo, testar entre identidades e produzir evidências que outra pessoa possa auditar. Isso também torna muito mais difícil se esconder atrás de uma montanha de suspeitas inteligentes, mas não verificadas.

Como os defensores devem usar o Claude Mythos Preview hoje
O fato de a Claude Mythos Preview não ter comprovado publicamente o black-box web pentesting não torna o relatório Anthropic menos importante. Na verdade, ele torna o relatório mais útil porque esclarece onde está o sinal de fato. O sinal real é que a pesquisa de exploração de IA e a triagem de vulnerabilidades estão melhorando com rapidez suficiente para afetar as janelas de patches, o tratamento de divulgações e as suposições de equipes defensivas.
O próprio Anthropic apresenta esse caso diretamente. Na seção "Sugestões para defensores hoje", ele diz que o Mythos Preview não estará disponível de forma geral, mas os defensores ainda podem usar modelos de fronteira disponíveis de forma geral para fortalecer as defesas agora. Ele recomenda explicitamente que se pense além da descoberta de vulnerabilidades em triagem, deduplicação, etapas de reprodução, propostas iniciais de patches, análise de configuração incorreta da nuvem, revisão de solicitações pull e trabalho de migração. Ele também diz que as organizações devem reduzir os ciclos de correção porque o processo de transformar identificadores públicos, como um CVE e um hash de confirmação, em uma exploração funcional está se tornando mais rápido, mais barato e mais automatizado. (Vermelho Antrópico)
O artigo público da Anthropic também diz que os defensores devem apertar as janelas de aplicação de patches, habilitar a atualização automática sempre que possível, tratar como urgentes os aumentos de dependência que carregam correções de CVE, revisitar as políticas de divulgação de vulnerabilidades e automatizar a resposta a incidentes, pois mais divulgações de vulnerabilidades provavelmente significarão mais tentativas de invasores durante a janela de divulgação para patch. Essa é uma mensagem operacional, não uma mensagem de referência. É também a parte que os líderes de segurança provavelmente devem levar mais a sério. (Vermelho Antrópico)
Portanto, a conclusão justa não é "ignore a Mythos até que ela prove o pentesting da Web black-box". A conclusão justa é "use a Mythos como um aviso sobre a aceleração da pesquisa de exploits, mas não confunda esse aviso com uma resposta definitiva para a questão do teste de aplicativos black-box". Essas são visões compatíveis. De fato, manter as duas ao mesmo tempo é provavelmente a leitura mais madura do relatório.
O raciocínio de caixa branca ainda precisa de provas de caixa preta
A conclusão mais prática do debate sobre a Mythos é que as equipes de segurança devem parar de tratar o raciocínio da caixa branca e a validação da caixa preta como produtos substitutos. Eles são estágios diferentes em um fluxo de trabalho mais forte.
Essa divisão já aparece em textos técnicos públicos sobre pentesting de IA. O artigo público da Penligent, "From White-Box Findings to Black-Box Proof", descreve explicitamente um fluxo de trabalho no qual o raciocínio com reconhecimento de código e a direção de patches estão de um lado, enquanto a confirmação de alcance e impacto da caixa preta está do outro. Esse é o instinto operacional correto, mesmo que você troque de ferramentas diferentes. A IA com reconhecimento de origem pode restringir a pesquisa. A validação voltada para o alvo decide se o problema é real, acessível e se vale a pena escalar. (Penligente)
O artigo sobre a ferramenta pública de pentest de IA da Penligent apresenta um ponto de vista muito semelhante com palavras diferentes: um sistema que explica nmap A saída agradável não é fazer automaticamente o pentesting; a parte mais difícil do trabalho são os caminhos de ataque, a validação da exploração e as evidências defensáveis. Esse enquadramento é mais útil do que a maioria das categorias de marketing porque força o comprador a fazer a pergunta certa. Não é "o modelo parece inteligente?", mas "ele pode transformar uma hipótese em prova sem perder a disciplina?" O site público da Penligent enquadra o produto de forma semelhante como uma plataforma de pentesting com tecnologia de IA, o que, no mínimo, é um modelo mental muito mais próximo para esse debate do que equiparar a análise de repositório à validação externa. (Penligente)
É nesse ponto que o Claude Mythos Preview é mais empolgante e mais fácil de ser usado indevidamente como um ponto de discussão. Se você conectar um modelo como o Mythos a um fluxo de trabalho ofensivo real, a maior vantagem pode vir não de fingir que ele resolveu todo o ciclo de engajamento, mas de permitir que ele comprima os caros estágios iniciais de pesquisa de exploração e geração de hipóteses enquanto um sistema separado voltado para o alvo prova o que realmente importa no ambiente implantado. Essa é uma afirmação muito mais restrita do que "o pentesting de IA está resolvido", mas também está muito mais próxima do que as equipes sérias podem operar atualmente.
O Claude Mythos Preview é um marco, mas ainda não é um veredicto de caixa preta
O Claude Mythos Preview parece marcar um salto significativo na pesquisa de exploração de IA. O registro público da Anthropic corrobora essa leitura. A empresa publicou uma metodologia para a descoberta de vulnerabilidades visíveis na fonte, descreveu o trabalho off-line assistido por engenharia reversa em binários de código fechado, documentou o sucesso da exploração autônoma no dia N e vinculou tudo isso a um programa defensivo em vez de um amplo lançamento público. Esses não são sinais triviais. (Vermelho Antrópico)
Mas a prova pública mais forte ainda se concentra em ambientes de alta informação. O próprio scaffold do Anthropic executa o projeto e seu código-fonte em um contêiner isolado. Sua seção de código-fonte fechado alimenta o modelo de código-fonte reconstruído mais o binário original e é executada off-line. Sua seção de lógica da Web lista categorias importantes de bugs, mas ainda não fornece estudos de caso públicos detalhados. Isso é suficiente para provar algo importante. Não é suficiente para provar tudo o que as pessoas querem que o rótulo "AI pentesting" signifique. (Vermelho Antrópico)
Portanto, a conclusão mais limpa é também a menos moderna. O Claude Mythos Preview prova que a pesquisa de exploração de IA está ficando muito séria. Ele prova que as janelas de correção dos defensores e os pipelines de resposta devem ser repensados agora, e não mais tarde. Ele ainda não prova publicamente que os modelos de fronteira podem realizar pentesting real da Web em caixa preta contra aplicativos ativos voltados para a Internet no nível que os compradores devem presumir a partir da frase. Até que um modelo seja mostrado publicamente lidando com fluxos de trabalho com estado, limites de MFA, canais alternativos, condições de corrida, bordas de autorização e repetição de evidências primeiro de fora para dentro, o rótulo honesto permanece mais restrito do que a propaganda. (Vermelho Antrópico)
Leitura adicional e referências
- Antrópico, Prévia do Claude Mythos e o relatório público de capacidade de segurança cibernética. (Vermelho Antrópico)
- Antrópico, Projeto Glasswing anúncio. (anthropic.com)
- Documentos antrópicos, Visão geral dos modelosincluindo a nota somente para convidados da Mythos Preview. (Documentos da API do Claude)
- OWASP, Guia de teste de segurança na Web. (owasp.org)
- OWASP, Teste de lógica de negócios e Teste de evasão de fluxos de trabalho. (owasp.org)
- OWASP, Teste de autenticação multifator. (owasp.org)
- PortSwigger, Vulnerabilidades da lógica de negócios e Condições da corrida. (portswigger.net)
- JetBrains, Atualização de segurança do TeamCity 2023.11.4 e registro NVD para CVE-2024-27198. (Blog da JetBrains)
- ConnectWise, Correção de segurança do ScreenConnect 23.9.8 e registro NVD para CVE-2024-1709. (ConnectWise)
- Registro NVD para CVE-2023-34362 e o aviso público da CISA-FBI sobre a exploração do MOVEit. (nvd.nist.gov)
- Aviso do FreeBSD e entrada do NVD para CVE-2026-4747. (O Projeto FreeBSD)
- Penligente, Segurança do código Claude e Penligent, de descobertas de caixa branca a provas de caixa preta. (Penligente)
- Penligente, Ferramenta AI Pentest, como será a verdadeira ofensa automatizada em 2026. (Penligente)
- Página inicial da Penligent. (Penligente)

