O Claude Code é mais fácil de ser mal interpretado quando as pessoas o tratam como uma caixa de prompt melhor com acesso ao shell. O próprio material público do Anthropic descreve algo mais específico. Um harness, ou andaime, é o sistema que permite que um modelo atue como um agente, processando entradas, orquestrando chamadas de ferramentas, gerenciando o contexto e retornando resultados. A Anthropic deixa explícito que, ao avaliar um agente, você está avaliando o harness e o modelo juntos, e não o modelo isoladamente. Seu Agent SDK é estruturado da mesma forma: O Claude Code como uma biblioteca programável com as mesmas ferramentas, loop de agente e gerenciamento de contexto que potencializam o próprio Claude Code. (Antrópica)
Essa distinção é mais importante na segurança ofensiva do que em quase qualquer outro domínio de aplicativo. O teste de penetração não é um problema de bate-papo. É um problema de planejamento, um problema de gerenciamento de estado, um problema de verificação, um problema de relatório e um problema de segurança ao mesmo tempo. O NIST SP 800-115 define teste técnico como um processo que inclui planejamento, realização de testes, análise de resultados e desenvolvimento de estratégias de atenuação. O Guia de Testes de Segurança na Web da OWASP ainda trata os testes na Web como uma disciplina ampla que abrange coleta de informações, autenticação, autorização, gerenciamento de sessões, validação de entrada, lógica comercial e testes de API. O Guia de testes de IA da OWASP, publicado no final de 2025, estende essa mentalidade aos testes de confiabilidade para sistemas de IA. (NIST CSRC)
O artigo do PentestGPT apresentou o mesmo argumento do lado da pesquisa. Seus autores descobriram que os modelos de linguagem grandes geralmente eram bons em subtarefas, como usar ferramentas de segurança, interpretar resultados e propor as próximas ações, mas tinham dificuldades para manter todo o contexto de teste ao longo do tempo. A resposta deles não foi um prompt mais longo. Foi uma arquitetura tripartite com módulos separados para raciocínio, geração e análise, projetada especificamente para atenuar a perda de contexto. (arXiv)
É nesse ponto que a ideia do chicote do Claude Code se torna útil para o pentesting de IA. A lição mais importante não é o fato de um agente de codificação poder executar comandos. Muitos sistemas podem executar comandos. A lição é que o comportamento sério do agente vem do sistema circundante: a camada de planejamento, o limite da ferramenta, o modelo de aprovação, os artefatos de transferência, o verificador e a cadeia de evidências. O próprio trabalho de longo prazo da Anthropic com o arreio deixa isso claro. Suas publicações públicas de engenharia descrevem o desvio de contexto, a "ansiedade de contexto", as transferências estruturadas, as funções de planejador-gerador-avaliador, os contratos de sprint e o valor de um avaliador separado que é mais cético do que o gerador. (Antrópica)
Se você levar isso para o pentesting, a pergunta muda. Ela deixa de ser "O Claude Code pode fazer pentesting?" e passa a ser "Como seria um arnês de pentesting se pegasse emprestadas as ideias certas do Claude Code e as adaptasse ao trabalho de segurança voltado para o alvo e que prioriza as evidências?" Essa é a arquitetura que vale a pena construir.
Do estímulo ao andaime
A maneira mais rápida de explicar a mudança é a seguinte: um prompt solicita um comportamento, enquanto um chicote regula o comportamento.
Em uma configuração de pentest de IA ingênua, o modelo recebe um alvo, talvez algumas ferramentas e uma instrução vaga como "encontrar vulnerabilidades". Às vezes, isso funciona para tarefas de brinquedo. Em um compromisso real, geralmente produz um dos quatro resultados ruins. O primeiro é o tool thrash, em que o modelo continua invocando o reconhecimento em nível superficial sem convergir para uma hipótese concreta. O segundo é o estado frágil, em que o modelo esquece o que importava três chamadas de ferramenta atrás. O terceiro é a inflação narrativa, em que "isso parece vulnerável" é registrado como uma descoberta confirmada. O quarto é o desvio inseguro, em que o sistema expande o escopo ou executa ações que nunca foram explicitamente autorizadas. As descobertas de benchmark do PentestGPT sobre perda de contexto e a redação pública do Anthropic sobre agentes de longa duração apontam para o mesmo modo de falha central: o problema não é apenas a qualidade do raciocínio, mas se o sistema em torno do modelo preserva a direção e o controle. (arXiv)
A orientação de melhores práticas da Anthropic é notavelmente direta aqui. Ela diz que a coisa mais importante que você pode fazer é dar ao Claude uma maneira de verificar seu trabalho. Sem critérios claros de sucesso, você se torna o único ciclo de feedback. No código, isso significa testes, capturas de tela ou resultados esperados. No pentesting, a tradução é mais forte: sessões novas, solicitações reproduzíveis, alterações de função, validação do estado do navegador e captura de artefatos. Um agente de pentest que não pode verificar suas próprias afirmações não é um testador autônomo. Ele é um gerador de hipóteses com uma quantidade perigosa de confiança. (Cláudio)
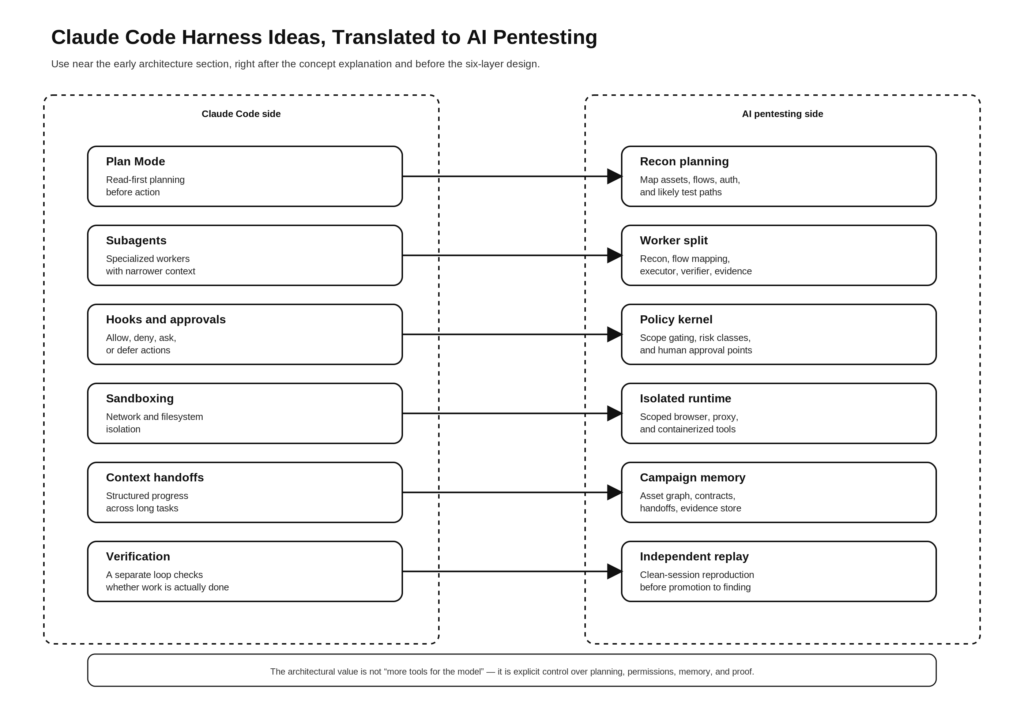
O Claude Code também expõe um padrão de design que os engenheiros de segurança devem usar quase que literalmente: use um planejamento seguro e orientado à leitura desde o início e, em seguida, aumente apenas quando tiver um motivo limitado para fazê-lo. O Plan Mode nos documentos públicos é explicitamente projetado para análise somente de leitura e coleta de requisitos antes que qualquer alteração seja feita. Em uma tradução de pentest, isso se torna o planejamento recon-first: rastrear, mapear, agrupar, correlacionar e decidir o que merece uma verificação ativa antes de tentar qualquer ação de mudança de estado. (Documentos da API do Claude)
A mesma lógica se aplica aos subagentes. Os documentos do Anthropic descrevem os subagentes personalizados como assistentes especializados com seus próprios prompts, seu próprio acesso a ferramentas e suas próprias janelas de contexto. Isso não é apenas uma conveniência de codificação. É um bom modelo mental para pentesting de IA, porque o reconhecimento, a compreensão do fluxo de negócios, a validação de exploração e os relatórios não são o mesmo trabalho e não devem compartilhar permissões ou contexto idênticos. (Documentos da API do Claude)
Portanto, o chicote de fios abaixo não é um clone do Claude Code. Ele é uma tradução.
O que as primitivas públicas do Claude Code se tornam no pentesting de IA
O mapeamento é simples quando o formato da tarefa está claro.
| Claude Código primitivo | O que isso significa no Código Claude | Tradução de pentesting de IA |
|---|---|---|
| Modo de planejamento | Análise somente leitura antes das edições | Reconhecimento somente de leitura, mapeamento de ativos e planejamento de metas |
| Subagentes | Assistentes especializados com funções distintas e acesso a ferramentas | Funcionário de reconhecimento, mapeador de fluxo, executor, verificador, redator de evidências |
| Ganchos PreToolUse e PermissionRequest | Controles de política antes da execução da ferramenta | Gatekeeper em tempo de execução para escopo, classe de risco, taxa e aprovação |
| Sandboxing | Isolamento do sistema de arquivos e da rede para uma autonomia mais segura | Executor de teste contido, listas de permissões de domínio, controles de saída, navegador e proxy isolados |
| Compactação de contexto e transferências | Continuidade de tarefas longas apesar dos limites do contexto | Memória de campanha, resumos de sessão, compromissos retomáveis |
| Dê ao Claude uma maneira de verificar seu trabalho | Os testes e os resultados esperados aumentam a confiabilidade | Repetição, difusão, confirmação de várias sessões, evidência reproduzível |
| Modo automático negar e continuar | Se for bloqueado, recupere-se e tente um caminho mais seguro | Se um teste ativo for negado, volte para a validação passiva ou de menor risco |
Esta é uma síntese, mas cada linha está fundamentada no material público da Anthropic. Seus documentos e publicações de engenharia descrevem o Modo Plano como análise somente de leitura, subagentes como contextos especializados, ganchos como pontos de controle do tipo "permitir-denunciar-pedir-deferir", sandboxing como isolamento do sistema de arquivos e da rede, chicotes de longa duração como sistemas multiagentes estruturados com handoffs e verificação como a melhoria de maior alavancagem para a confiabilidade do agente. (Documentos da API do Claude)
O restante deste artigo desenvolve a versão pentest dessa tabela.
Por que o pentesting de IA precisa de mais do que um modelo
Um teste de penetração é uma das piores tarefas possíveis para um agente único em movimento livre. O alvo muda sob observação. O estado de autenticação é importante. A lógica comercial é importante. As suposições ambientais são importantes. Um "sucesso" pode ser falso se só funcionar em uma sessão poluída, só funcionar com cookies de administrador já presentes, só funcionar contra um artefato de CDN ou só aparecer porque o agente interpretou uma resposta ruidosa como prova.
O OWASP WSTG continua sendo útil aqui porque força o testador a pensar em categorias de ataque amplas, em vez de pensar em ataques isolados do scanner. O AI Testing Guide estende essa disciplina aos sistemas de IA, tratando a avaliação como um teste de confiança prático e estruturado, em vez de uma verificação de vibração. O PentestGPT segue na mesma direção a partir de outro ângulo: o progresso real vem da decomposição do trabalho e da manutenção de uma representação do estado. (OWASP)
O trabalho de longa duração da Anthropic sobre arreios acrescenta uma lição complementar. A arquitetura do planejador-gerador-avaliador melhorou os resultados porque os agentes não faziam todos a mesma coisa. O planejador expandiu os prompts curtos em especificações mais completas. O gerador construiu de forma incremental. O avaliador usou a interação direta com o aplicativo em execução e aplicou limites rígidos. Antes de cada sprint, o gerador e o avaliador negociavam um contrato sobre o significado de "feito". Esse padrão exato é quase embaraçosamente adequado ao pentesting. (Antrópica)
Em termos de pentesting, a tradução é óbvia. O planejador se torna um compilador de hipóteses. O gerador se torna um trabalhador de execução. O avaliador se torna um verificador independente. O contrato de sprint torna-se um contrato de ataque. O sistema de compactação e transferência se torna uma memória de campanha. O resultado não é um "pentesting mais agêntico" em termos abstratos. É um sistema que pode passar do sinal à prova sem converter discretamente suposições em descobertas.
As seis camadas de um chicote de pentesting de IA
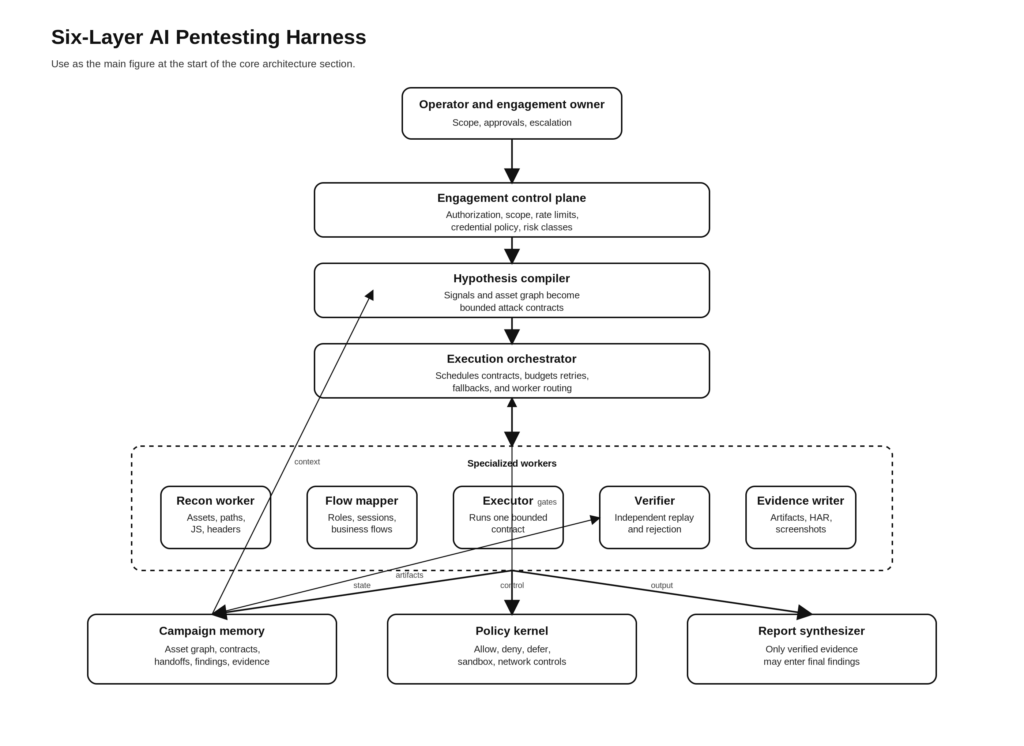
A arquitetura a seguir é o projeto que eu criaria se o objetivo fosse pegar emprestadas as ideias mais fortes do Claude Code e adaptá-las ao pentesting de IA autorizado e baseado em evidências.
Camada um, plano de controle de engajamento
O arreio começa antes da primeira chamada de ferramenta. Ele começa com o próprio engajamento.
O NIST SP 800-115 enfatiza o planejamento como parte dos testes técnicos, e não como papelada fora do sistema. A estrutura de agentes de confiança da Anthropic diz praticamente a mesma coisa em outro vocabulário: manter os humanos no controle, especialmente antes de ações de alto risco, e tratar a autonomia como algo que deve ser limitado. O código Claude é descrito como somente leitura por padrão e com aprovação para modificar sistemas. Para o pentesting, essa mesma lógica deve ser codificada em um manifesto de compromisso legível por máquina que o tempo de execução consome a cada turno. (NIST CSRC)
Um plano de controle de engajamento adequado inclui escopo, janelas de autorização, categorias de teste, ações não permitidas, orçamentos de tráfego, rótulos de destino, limites de credenciais, restrições de navegador, roteamento de proxy e regras de retenção de evidências. Ele também precisa de uma classificação das ações por risco. Leituras passivas e coleta de metadados são uma classe. A enumeração ativa de baixo impacto é outra. Ações de mudança de estado, uso de credenciais, uploads de arquivos ou qualquer validação semelhante a uma exploração devem ficar atrás de portas separadas. O plano de controle é onde o "pentest autorizado" deixa de ser uma frase em um prompt e começa a se tornar uma política de tempo de execução.
Um manifesto mínimo pode ser assim:
engajamento:
id: acme-web-2026-q2
authorized_by: security-team
window_start: 2026-04-10T09:00:00Z
window_end: 2026-04-17T23:00:00Z
escopo:
domains:
- app.example.com
- api.example.com
exclude_paths:
- /payments/live/*
- /admin/billing/*
allowed_identities:
- anonymous
- low_priv_user
forbidden_targets:
- thirdparty.example.net
- *.internal.example.com
tempo de execução:
max_rps: 2
browser_allowed: true
upload_tests_allowed: false
credential_rotation_required: true
network_allowlist:
- app.example.com
- api.example.com
- auth.example.com
risk_policy:
passive_recon: auto
low_impact_validation: auto
state_changing_actions: human_approval
exploit_like_execution: proibido
external_callbacks: proibido
relatórios:
capture_har: true
capture_screenshots: true
redact_secrets: true
Esse exemplo é simples, mas o ponto arquitetônico é maior. Um agente de pentest nunca deveria ter que inferir o escopo do compromisso apenas com base no inglês. O plano de controle deve ser analisado em decisões difíceis de tempo de execução. O modelo de ganchos da Anthropic é uma inspiração útil aqui porque formaliza os pontos de decisão antes da execução da ferramenta, enquanto sua estrutura de segurança insiste que os humanos mantenham o controle antes de ações de alto risco. (Documentos da API do Claude)
Camada dois, compilador de hipóteses e contratos de sprint
A próxima camada traduz as observações em trabalho limitado.
O arnês de aplicativos de longa duração da Claude Code usava um planejador para expandir prompts breves em especificações de produto mais completas e, em seguida, usava a negociação gerador-avaliador para decidir o que contava como um sprint concluído. No pentesting, o equivalente não é um plano de recursos. É uma hipótese de ataque com condições de teste explícitas. (Antrópica)
Isso é importante porque o teste de penetração não é apenas a execução de ferramentas. É o gerenciamento de hipóteses. Um testador vê um comportamento, forma uma teoria, pergunta o que teria de ser verdade para que essa teoria fosse importante e, em seguida, projeta uma verificação. O chicote deve tornar isso explícito. Em vez de dizer ao modelo "test auth", o sistema deve criar um contrato como: "Esse alvo parece aceitar identificadores de objetos controlados pelo usuário em três pontos de extremidade. Teste se a autorização é aplicada no lado do servidor nas transições de função, usando apenas credenciais de baixo privilégio, sem alterar os registros protegidos." Esse é um trabalho que o modelo pode executar. "Encontrar algo interessante" não é.
Um contrato de ataque prático tem pelo menos esses campos:
{
"contract_id": "idor-orders-001",
"target": "",
"goal" (objetivo): "Verificar se a autorização em nível de objeto é aplicada nas funções de usuário",
"preconditions": [
"Duas contas de baixo privilégio com acesso a diferentes conjuntos de pedidos",
"Sessão limpa para cada repetição"
],
"allowed_actions": [
"Solicitações GET",
"Navegação do navegador",
"Reinicialização de sessão",
"Difusão de resposta"
],
"forbidden_actions": [
"Modificação de registro",
"Enumeração em massa",
"Chamadas de retorno externas"
],
"success_signals": [
"Acesso entre contas a dados de pedidos protegidos",
"Reprodução estável em duas sessões limpas"
],
"failure_signals": [
"Negação de autorização consistente",
"O comportamento só aparece no estado de sessão poluída"
],
"required_evidence": [
"Par de solicitação e resposta",
"Mapeamento de função",
"Transcrição da repetição",
"Captura de tela se visível no navegador"
],
"risk_class": "medium" (médio),
"budget" (orçamento): {
"max_requests": 20,
"max_duration_seconds": 600
},
"exit_condition": "Verified or rejected with reasons" (Verificado ou rejeitado com motivos)
}
O contrato faz duas coisas ao mesmo tempo. Ele restringe o espaço de pesquisa e eleva o nível de evidência. O relatório público da Anthropic observa que o gerador e o avaliador negociaram um contrato de sprint antes do início do trabalho, precisamente porque o avaliador precisava de uma definição testável de concluído. A mesma disciplina é ainda mais valiosa em segurança, onde "feito" é perigosamente fácil de falsificar. (Antrópica)
Camada três, trabalhadores especializados em execução
Os subagentes são uma das ideias mais transferíveis da pilha do Claude Code. A Anthropic os descreve como assistentes especializados para fluxos de trabalho específicos de tarefas e gerenciamento de contexto aprimorado. Isso deve soar imediatamente verdadeiro para qualquer pessoa que tenha feito um pentesting real. Reconhecimento, mapeamento de fluxo de autenticação, validação de exploração e elaboração de relatórios são tarefas diferentes. Eles não devem compartilhar os mesmos prompts, ferramentas ou autoridade. (Documentos da API do Claude)
Um chicote de pentest maduro deve separar, no mínimo, cinco funções de execução.
O primeiro é um trabalhador de reconhecimento. Seu trabalho é descobrir e normalizar a área de superfície: hosts, caminhos, endpoints, parâmetros, rotas JavaScript, variantes de login, cabeçalhos, armazenamentos de objetos, superfícies de administração e dependências de terceiros. Ele deve usar bastante as ferramentas, mas com poucos privilégios. Não deve ser permitido "validar" descobertas no sentido de relatório.
O segundo é um mapeador de fluxo. Esse trabalhador está mais próximo de um analista de modelagem de ameaças do que de um scanner. Ele transforma listas de endpoints em comportamentos. Quais são as identidades existentes? Onde estão as transições? Quais ações têm estado? Que tipos de objetos aparecem no tráfego do navegador? Quais campos ocultos moldam as decisões do fluxo de trabalho? O resultado não é uma alegação de vulnerabilidade. É um gráfico estruturado do comportamento comercial.
O terceiro é um executor de hipóteses. Esse é o trabalhador que realmente executa verificações ativas limitadas com base em um contrato. Ele deve obter apenas as ferramentas e as permissões exigidas por esse contrato. Nada mais. A documentação pública do Anthropic sobre subagentes, permissões e ganchos dá grande suporte a esse estilo de delegação limitada: use contextos especializados e restrinja o acesso às ferramentas ao que cada unidade realmente precisa. (Documentos da API do Claude)
O quarto é um verificador. Esse trabalhador não deve ser a mesma entidade que executou a verificação inicial. O trabalho de longa duração da Anthropic sobre arreios é especialmente útil aqui porque argumenta que a autoavaliação é fraca e que um avaliador separado é mais fácil de ajustar em direção ao ceticismo. Para o pentesting, esse princípio não é uma otimização. É um requisito de validade. (Antrópica)
O quinto é um gravador de evidências. Seu trabalho é converter o rastreamento bruto em artefatos que outro engenheiro possa reproduzir. Isso significa pares de solicitação-resposta, trechos de HAR, capturas de tela, notas de ambiente, atribuições de função, casos negativos e notas de limpeza. Se o seu arreio mescla esse trabalhador com o executor, a captura de evidências tende a se tornar seletiva e confusa.
Você pode acrescentar mais funções posteriormente, mas essas cinco são suficientes para criar uma separação saudável de tarefas.
Camada quatro, loops de verificadores independentes
Essa é a camada que decide se o sistema é um chicote de pentest ou uma máquina de contar histórias.
A página de práticas recomendadas da Anthropic diz que critérios claros de verificação são a melhoria de maior alavancagem que você pode fazer. Seu sistema de gerenciamento de aplicativos de longa duração levou isso a sério, dando ao avaliador acesso ao Playwright e limites rígidos. O avaliador poderia reprovar um sprint se qualquer critério importante não fosse atendido. Em segurança, o equivalente é simples de descrever e difícil de falsificar: uma descoberta não está completa até que um verificador independente possa reproduzir o comportamento relevante em condições controladas. (Cláudio)
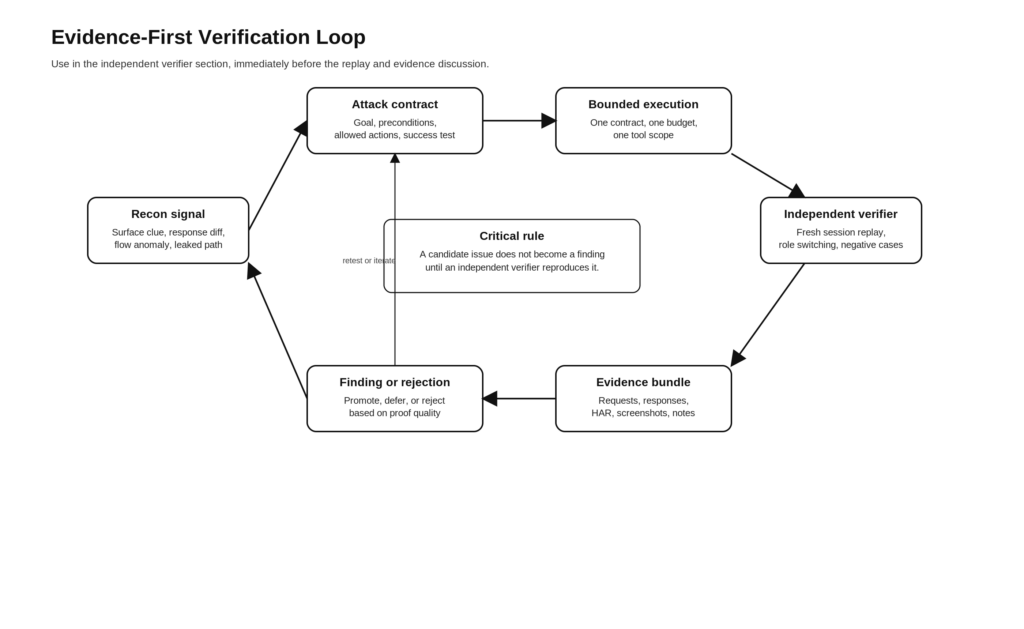
Para testes da Web e de API, um verificador independente geralmente precisa fazer uma combinação dos seguintes itens:
- Reinicie a sessão e reproduza a partir do estado limpo.
- Troque de papéis ou identidades e compare o comportamento.
- Confirme se o resultado não é causado pelo estado do cliente em cache ou por cookies poluídos.
- Confirme se o resultado não é um problema transitório de upstream, um artefato de proxy ou uma anomalia de WAF.
- Capture casos negativos para que o relatório possa explicar o que não é o problema.
- Capture evidências suficientes para que um ser humano possa reproduzi-las sem confiar na narração do modelo.
Um pequeno andaime de repetição pode ter a seguinte aparência:
from dataclasses import dataclass
from typing import List, Dict
@dataclass
class ReplayCase:
name: str
session_profile: str
request_spec: Dict
expected_signal: str
Classe de dados
class VerificationResult:
nome_do_caso: str
observed_signal: str
correspondido: bool
artifacts: List[str]
notas: str
def run_verification(cases: List[ReplayCase], runner) -> List[VerificationResult]:
results = []
for case in cases:
runner.reset_session(case.session_profile)
response = runner.send(case.request_spec)
observed = runner.classify_signal(response)
artefatos = []
artifacts.append(runner.save_request_response(case.name, response))
se runner.browser_visible(response):
artifacts.append(runner.save_screenshot(case.name))
results.append(
VerificationResult(
case_name=case.name,
observed_signal=observed,
matched=(observed == case.expected_signal),
artifacts=artifacts,
notes=runner.explain_difference(case.expected_signal, observed)
)
)
retornar resultados
O código é intencionalmente simples. O ponto importante é o procedimento. A verificação é uma passagem separada, não uma reflexão posterior. O próprio texto público da Anthropic sobre agentes confiáveis também reforça o lado do controle: os agentes são valiosos porque podem agir, mas os humanos devem permanecer no controle antes de decisões ou ações de alto risco. Um controle de pentest deve tratar a promoção de "problema candidato" para "descoberta relatável" como uma dessas transições de alto risco. (Antrópica)
Esse também é o ponto em que uma plataforma ofensiva nativa de fluxo de trabalho se torna mais fácil de justificar do que uma pilha de ferramentas conectadas ad hoc. Os materiais públicos da Penligent continuam retornando ao mesmo padrão: sinal não é suficiente, e um fluxo de trabalho útil é aquele que transforma descobertas em impacto verificado, preserva uma cadeia de provas e empacota o resultado em relatórios editáveis. Sua página inicial enfatiza o bloqueio de escopo, as ações personalizáveis, a execução guiada do sinal à prova e os relatórios, enquanto as postagens técnicas recentes enfatizam os testes adaptativos, o estado preservado e as descobertas verificadas em vez de suposições narradas. Independentemente de uma equipe usar essa plataforma específica ou não, o princípio operacional está exatamente correto: o relatório deve ser o fim da cadeia de evidências, não o substituto dela. (Penligente)
Camada cinco, memória persistente e handoffs
Um dos pontos fortes e discretos do trabalho de longa duração da Anthropic sobre arreios é que ele trata o estado como um problema de engenharia de primeira classe. Suas postagens descrevem duas técnicas relacionadas. Uma delas é a compactação de contexto, que mantém uma sessão em andamento ao encurtar o histórico. A outra é a redefinição de contexto mais a transferência estruturada, que fornece a um novo agente um estado de artefato suficiente para continuar trabalhando de forma coerente. Eles observam que a compactação por si só nem sempre resolve o desvio e que as transferências estruturadas podem ser essenciais. (Antrópica)
Isso se encaixa quase perfeitamente no pentesting. Um compromisso real raramente é um único loop ininterrupto. Os alvos mudam. As sessões expiram. Os operadores param e retomam. As credenciais mudam. Portanto, um aproveitamento significativo precisa de uma memória persistente e estruturada que seja mais rica do que o histórico do bate-papo.
No mínimo, o modelo de memória deve conter:
- um manifesto de engajamento,
- um gráfico de ativos,
- uma lista de contratos e seus status,
- um registro de localização,
- um depósito de provas,
- uma transferência de progresso,
- e um registro de resumo da sessão.
Um layout de diretório simples geralmente é suficiente:
campanha/
engagement.yaml
ativos/
asset_graph.json
rotas.json
identidades.json
contratos/
001-auth-flow.json
002-idor-orders.json
findings/
candidatos.jsonl
verificados.jsonl
rejected.jsonl
provas/
002-idor-orders/
replay_case_a.har
replay_case_b.har
navegador.png
notes.md
progresso/
handoff.md
latest_summary.json
sessões/
2026-04-11T0100Z.jsonl
2026-04-11T0900Z.jsonl
A principal escolha de design é que o modelo nunca precisa reconstruir toda a campanha a partir da memória prosaica. Em vez disso, o arnês lhe dá um estado tipado. Essa é exatamente a lição que o PentestGPT apontou com sua Árvore de Tarefas de Pentesting e exatamente o tipo de fluxo de artefato estruturado no qual o Anthropic se baseou em um trabalho de longa duração. (arXiv)
Essa camada também é importante para a auditabilidade. Um revisor humano deve ser capaz de responder a perguntas simples sem pedir que o modelo se lembre de nada. Quais hipóteses foram testadas e rejeitadas? Quais foram promovidas? Quais foram bloqueadas pela política? Quais ainda precisam de aprovação humana? Quais identidades foram usadas? Quais conjuntos de evidências estão completos? Se a resposta a essas perguntas existir apenas em uma transcrição de agente, o chicote ainda não está maduro.
Camada seis, kernel de política e controles de tempo de execução
O modelo de segurança pública do Claude Code é um dos motivos mais claros pelos quais ele é útil como referência arquitetônica. O Anthropic não apresenta o uso de ferramentas apenas como uma questão de confiança. Ele apresenta o uso de ferramentas como algo regido por aprovações, hooks, sandboxing e políticas. A documentação dos hooks diz que o PreToolUse pode permitir, negar, solicitar ou adiar chamadas de ferramentas e pode até modificar a entrada da ferramenta antes da execução. A referência dos hooks também avisa que os hooks de comando são executados com todas as permissões do usuário do sistema. A postagem sobre sandboxing é igualmente clara quanto ao fato de que o sandboxing eficaz exige tanto o isolamento do sistema de arquivos quanto o isolamento da rede. Sem o isolamento da rede, um agente comprometido pode exfiltrar arquivos confidenciais; sem o isolamento do sistema de arquivos, ele pode escapar e recuperar o acesso à rede. (Documentos da API do Claude)
Para o pentesting, isso significa que o harness precisa de um núcleo de política que fique fora do modelo e tome as decisões finais sobre o que pode acontecer. Um padrão útil é classificar as ações em quatro grupos.
As ações automáticas são de baixo risco, leituras dentro do escopo e sondas limitadas.
As ações controladas por aprovação são verificações ativas que podem mudar de estado ou criar ruído.
As ações diferidas são verificações legítimas que precisam que um ser humano responda primeiro a uma pergunta, como, por exemplo, se um teste de upload de baixo impacto é aceitável para esse alvo.
Ações proibidas são tudo o que está fora do envelope autorizado.
Um pequeno arquivo de política pode expressar isso de forma clara:
políticas:
- name: passive-read
match:
tool: [Read, WebFetch, BrowserNavigate]
escopo_alvo: in_scope
classe_de_ação: passive
decisão: allow
- nome: low-impact-api-validation
match:
tool: [HttpRequest]
method: [GET, HEAD]
escopo_alvo: in_scope
rate_limit_ok: true
decisão: allow
- nome: state-changing-checks
match:
tool: [HttpRequest, BrowserAction]
method: [POST, PUT, PATCH, DELETE]
escopo_alvo: in_scope
decisão: deferir
question: "Essa ação pode alterar o estado do aplicativo. Aprova?"
- nome: external-callbacks
match:
destination_scope: external
decisão: negar
motivo: "A infraestrutura de retorno de chamada fora do escopo está bloqueada"
- nome: exploit-like-execution
match:
action_class: exploit_validation
decisão: deny
motivo: "A execução de estilo de exploração está fora deste perfil de compromisso"
É aqui que a ideia de "negar e continuar" da Anthropic se torna valiosa. Sua descrição pública do modo automático diz que, quando o classificador bloqueia uma ação, o Claude não deve simplesmente parar; ele deve se recuperar e tentar um caminho mais seguro onde houver um. Em um chicote de pentest, isso significa que uma ação destrutiva negada deve acionar um fallback para confirmação passiva, análise de caminho de código, comparação de funções ou escalonamento humano em vez de uma parada total. (Antrópica)
O núcleo da política também precisa entender o risco específico do MCP. A orientação oficial de segurança do MCP é excepcionalmente relevante para as equipes de segurança porque não fala em termos vagos. Ela menciona questões confusas de deputy, token passthrough, SSRF, sequestro de sessão, comprometimento do servidor MCP local e minimização do escopo como superfícies de ataque reais. A especificação de autorização do MCP também exige a validação do público e rejeita explicitamente os padrões de uso indevido de tokens que obscureceriam os limites de segurança entre os serviços. (Modelo de protocolo de contexto)
Um chicote de pentest que se conecta às ferramentas MCP, mas não valida independentemente os públicos dos tokens, não impõe a minimização do escopo e não separa as credenciais upstream e downstream, está sendo construído sobre areia.
Por que as metas devem ser tratadas como entradas adversárias
O maior erro que as pessoas cometem com o pentesting autêntico é presumir que o alvo é a única coisa a ser testada. Na realidade, tudo o que toca o chicote pode se tornar uma superfície de ataque.
A pesquisa de injeção de prompt de navegador da Anthropic diz isso claramente. Quando um agente navega na Internet, cada página é um possível vetor de ataque. A injeção imediata continua sendo um grande desafio não resolvido, especialmente porque os agentes realizam ações no mundo real, e a Anthropic diz explicitamente que o problema não está resolvido mesmo com defesas aprimoradas. O material GenAI da OWASP diz o mesmo em termos mais gerais: a injeção imediata pode expor dados confidenciais, conceder acesso não autorizado a funções, executar comandos em sistemas conectados e manipular a tomada de decisões. A injeção indireta de prompt é especialmente relevante quando o modelo consome dados externos, como páginas, documentos ou arquivos. (Antrópica)
Isso tem uma implicação direta no pentesting de IA. O corpo da resposta de destino não é apenas dados. Um pacote JavaScript, um nó DOM, um PDF, um campo de comentário ou uma página de documentação podem conter instruções projetadas para orientar o modelo. O mesmo pode acontecer com um repositório, um arquivo de leitura, um arquivo de saída de ferramenta ou uma resposta de API simulada. Portanto, o harness deve tratar o alvo como uma entrada adversária em todas as camadas.
Isso muda a forma como você projeta os operadores. O recon worker não deve ter permissão para reinterpretar o conteúdo arbitrário da página como instruções confiáveis. O mapeador de fluxo deve separar as observações extraídas das diretivas do agente. O verificador não deve confiar nos comentários fornecidos pelo executor. O escritor de evidências deve anotar a origem dos artefatos e se eles foram gerados a partir de fontes confiáveis ou não confiáveis. A injeção de prompt não é um caso de borda opcional. Ela faz parte do modelo normal de ameaças para testes com agentes. (Antrópica)
Ele também muda a forma como você pensa sobre as ferramentas. O guia de segurança do MCP não discute apenas os tokens. Ele menciona o comprometimento do servidor local e a minimização do escopo porque o plano da ferramenta faz parte da superfície de ataque. A documentação de hooks do Anthropic adverte de forma semelhante que os hooks de comando são executados com as permissões completas do usuário. Quando você combina acesso à ferramenta, execução de comando, acesso ao navegador, memória e configuração local do repositório, a antiga linha entre "dados" e "execução" começa a se dissolver. (Modelo de protocolo de contexto)
Uma maneira útil de raciocinar sobre isso é modelar quatro classes de entrada.
| Classe de entrada | Exemplos | Risco primário | Controle necessário |
|---|---|---|---|
| Instruções confiáveis | Manifesto de engajamento, aprovações do operador, regras de política | Autorização excessivamente ampla ou política obsoleta | Política versionada, revisão, controle de alterações |
| Contexto interno semiconfiável | Anotações, resumos de entrega, evidências anteriores | Envenenamento de memória, suposições obsoletas | Esquemas estruturados, tags de proveniência, expiração |
| Conteúdo de destino não confiável | HTML, JS, documentos, PDFs, respostas de API | Injeção indireta, direcionamento incorreto, prova falsa | Rotulagem de entrada, análise em sandbox, nenhuma instrução implícita a seguir |
| Conteúdo do plano da ferramenta | Saídas de MCP, entradas de gancho, configuração de repositório, scripts locais | Execução de comandos, roubo de tokens, delegado confuso, SSRF | Listas de permissão de ferramentas, validação de público, isolamento de contêineres, modelo de confiança de repositório |
A tabela é uma síntese, mas segue os padrões de ameaças documentados pela Anthropic, pela OWASP e pela própria orientação oficial de segurança da MCP. (Antrópica)
Os CVEs que tornam essa arquitetura não opcional
O design de alto nível torna-se muito menos abstrato quando você observa o que já aconteceu em sistemas de agentes adjacentes.
Langflow CVE-2025-3248 e o mito dos pontos de extremidade auxiliares inofensivos
A NVD descreve o CVE-2025-3248 como um problema de injeção de código nas versões do Langflow anteriores à 1.3.0. O ponto de extremidade vulnerável era /api/v1/validate/codee a falha permitia que um invasor remoto não autenticado enviasse solicitações criadas que executavam códigos arbitrários. Posteriormente, a CISA adicionou o problema ao seu fluxo de trabalho de Vulnerabilidades Exploradas Conhecidas. (NVD)
Por que isso é importante para um artigo sobre arreios de pentest? Porque é um exemplo claro de uma falha que muitas equipes ainda subestimam. Os produtos de fluxo de trabalho de IA geralmente contêm caminhos de "ajuda" ou de "validação" que parecem funções de suporte em vez de superfícies de execução essenciais. Na prática, a coisa chamada validação pode ser exatamente o local onde ocorre a execução insegura. Um arquiteto de arreios deve aprender duas lições com isso. Em primeiro lugar, os recursos auxiliares internos devem ser modelados em termos de ameaças como limites de execução, não como recursos de conveniência. Em segundo lugar, a política e a verificação devem abranger os pontos de extremidade de suporte de forma tão agressiva quanto os óbvios. (NVD)
Para os defensores, a história da mitigação é igualmente instrutiva. O NVD aponta para versões corrigidas e referências de fornecedores. No nível da arquitetura, o reparo não é apenas "adicionar autenticação". É também "parar de presumir que os recursos de validação de código podem processar com segurança entradas controladas por invasores". Essa é uma correção de projeto, não apenas um patch. (NVD)
Langflow CVE-2026-33017 e o perigo das correções parciais
O problema posterior do Langflow é ainda mais revelador. O NVD descreve o CVE-2026-33017 como uma falha de execução remota de código não autenticada em versões anteriores à 1.9.0. O ponto de extremidade vulnerável, POST /api/v1/build_public_tmp/{flow_id}/flowO sistema de fluxo de dados do usuário, que era intencionalmente não autenticado para fluxos públicos, mas aceitava dados de fluxo controlados por invasores contendo código Python arbitrário em definições de nó e os passava para exec() com zero sandboxing. A NVD observa explicitamente que esse problema é diferente do CVE-2025-3248. Não foi o mesmo bug que ressurgiu no mesmo endpoint. Foi o modelo de execução mais amplo que apareceu em outro lugar. A NVD também registra que a falha entrou no Catálogo de Vulnerabilidades Exploradas Conhecidas da CISA em março de 2026. (NVD)
Esse é exatamente o tipo de lição com a qual os criadores de chicotes de pentest de IA devem se preocupar. Um sistema pode corrigir um ponto de extremidade perigoso e ainda manter o padrão subjacente em outro lugar. Se o seu harness tiver vários caminhos de código que possam transformar dados não confiáveis em invocações de ferramentas, ações do navegador ou comandos do shell, não basta corrigir uma superfície. Você precisa de um limite arquitetônico. Na linguagem da Anthropic, isso significa sandboxing real e camadas de permissão. Na linguagem do pentest-harness, isso significa um núcleo de política fora do modelo e um tempo de execução que nunca trata as superfícies "públicas" ou "auxiliares" como sendo automaticamente de baixo risco. (Antrópica)
Problemas de configuração em nível de repositório do Claude Code e o novo limite de execução
O caso de advertência mais relevante para o próprio Claude Code veio da Check Point Research em fevereiro de 2026. O artigo diz que as configurações de projetos mal-intencionados podem abusar de ganchos, integrações de MCP e variáveis de ambiente para obter execução remota de código e roubo de credenciais de API quando os usuários clonam e abrem repositórios não confiáveis. Seu resumo afirma que os problemas foram corrigidos antes da publicação, mas a lição arquitetônica é maior do que a correção. Eles argumentam que os arquivos de configuração em nível de repositório se tornaram uma camada de execução ativa em vez de metadados operacionais inofensivos. A Check Point associou essa pesquisa ao CVE-2025-59536 e ao CVE-2026-21852. (Pesquisa da Check Point)
Essa descoberta se alinha desconfortavelmente bem com a própria documentação do Anthropic. A referência dos hooks diz que os hooks de comando são executados com as permissões completas do usuário do sistema. A postagem sobre sandboxing diz que a proteção eficaz requer isolamento do sistema de arquivos e da rede. Se juntarmos essas informações, é difícil não perceber a implicação: quando uma ferramenta agêntica puder ler arquivos, executar comandos, conectar ferramentas e carregar a configuração local do projeto, o conteúdo do repositório se tornará parte do limite de execução. (Documentos da API do Claude)
Para o pentesting de IA, isso é importante por dois motivos. Primeiro, seu harness frequentemente interage com alvos não confiáveis, repositórios não confiáveis, documentos não confiáveis ou conteúdo de navegador não confiável. Em segundo lugar, as equipes de pentesting são especialmente propensas a conectar scripts locais, integrações de proxy, servidores MCP e automação específica do projeto. Isso significa que um harness mal projetado pode ser atacado pelo próprio ecossistema que está sendo usado para testar outros. Se você pegar emprestada uma lição do caso do Claude Code, que seja esta: a configuração faz parte do tempo de execução. Modele as ameaças dessa forma.
O que esses casos significam na prática
Os três casos acima apontam para uma conclusão comum. O risco em sistemas agênticos não é apenas o fato de o modelo raciocinar mal. O risco é que um caminho de execução em algum lugar do harness aceite entradas não confiáveis como se fossem seguras para serem executadas, autorizadas ou confiáveis. O risco é que um caminho de execução em algum lugar do chicote aceite uma entrada não confiável como se fosse seguro executar, seguro autorizar ou seguro confiar.
É por isso que o design de seis camadas não é uma cerimônia. O plano de engajamento evita o excesso acidental. O compilador de hipóteses restringe a execução. A especialização do trabalhador reduz a disseminação de privilégios. O verificador suprime as provas falsas. A memória persistente impede que a perda de estado se torne um desvio narrativo. O núcleo da política mantém o plano da ferramenta sob controle externo. Sem essas camadas, você está apostando a integridade de um fluxo de trabalho de pentest em um modelo que se mantém coerente e benevolente sob condições adversas. O registro público já diz que isso não é suficiente. (NVD)
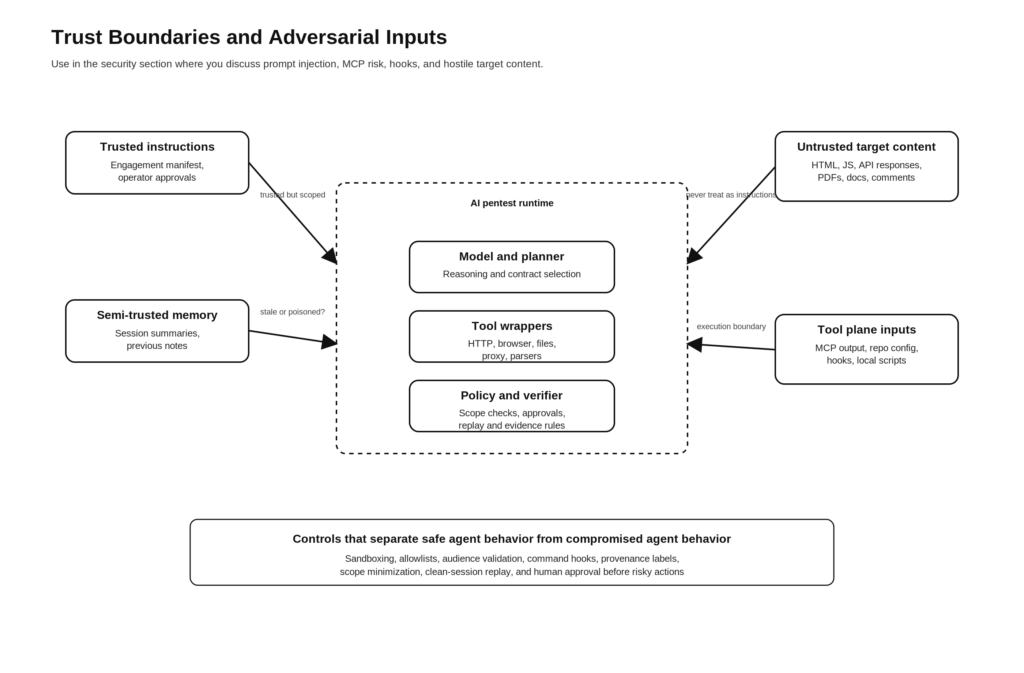
Arquitetura de referência para um conjunto de pentest de IA que prioriza as evidências
O sistema completo pode ser representado de forma compacta:
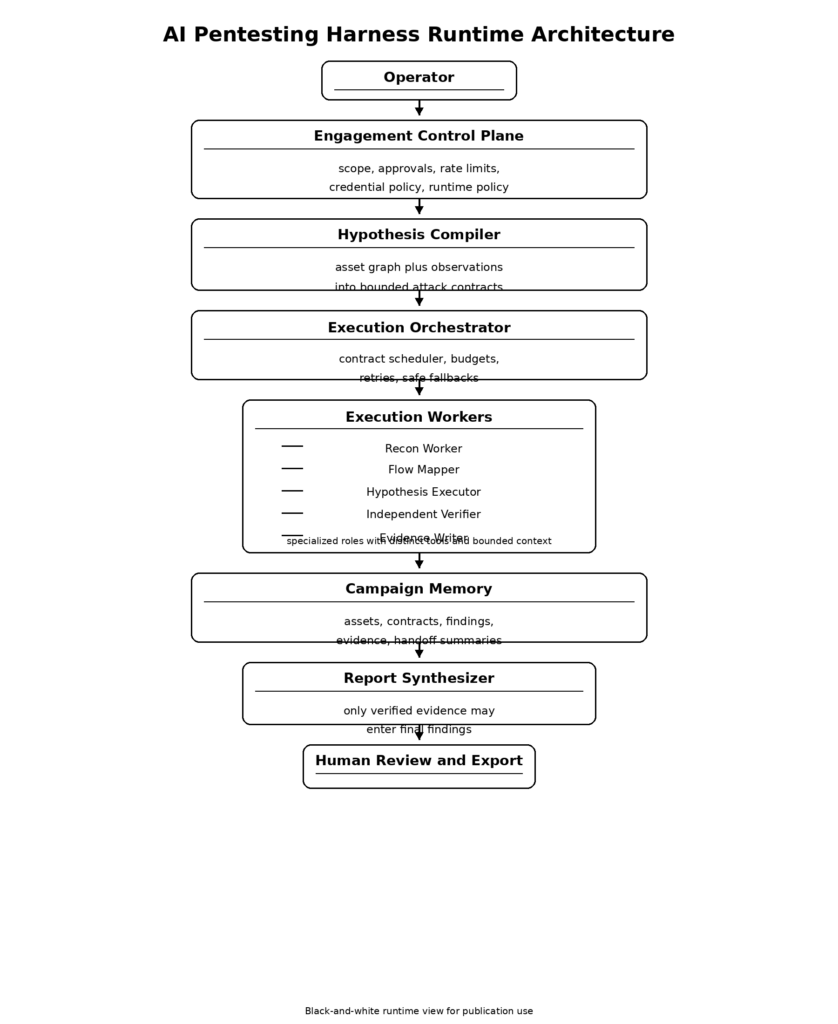
Há dois motivos pelos quais esse formato funciona.
A primeira é que ela corresponde à forma como os testes reais se desenvolvem. O reconhecimento produz possibilidades. A análise de fluxo transforma as possibilidades em ideias de ataque. A execução testa uma ideia limitada de cada vez. A verificação decide se o resultado merece confiança. O relatório só acontece depois disso. O NIST SP 800-115 e o OWASP WSTG são documentos muito diferentes, mas ambos reforçam que o teste é um processo, e não uma única fase do resultado da ferramenta. (NIST CSRC)
A segunda é que ela corresponde às observações públicas da Anthropic sobre os agentes. As tarefas longas melhoram quando o trabalho é decomposto, quando os artefatos de transferência preservam o estado e quando um avaliador cético fica fora do gerador. Assistentes especializados melhoram o gerenciamento do contexto. Os critérios de verificação melhoram os resultados. Sandboxing e limites de política tornam a autonomia mais segura. (Antrópica)
Uma primeira versão forte desse sistema não precisa de exploração autônoma. Ela precisa de uma progressão disciplinada. O equipamento mínimo viável deve ser capaz de:
- escopo e política de ingestão,
- criar um gráfico de ativos,
- compilar um contrato de cada vez,
- executar verificações limitadas,
- reproduzi-los de forma independente,
- evidências persistentes,
- e exportar um artefato reportável.
Isso é suficiente para provar a arquitetura antes de adicionar um comportamento mais ousado.
Modelo de dados, gráfico de ativos, contrato de ataque, pacote de evidências
A escolha de engenharia mais importante nesse tipo de sistema é parar de centralizar tudo no bate-papo de forma livre e começar a centralizar tudo nos objetos de dados.
O primeiro objeto é o gráfico de ativos. Não se trata apenas de uma lista de URLs. É um gráfico de domínios, endpoints, parâmetros, cookies, cabeçalhos, identidades, funções, rotas JavaScript, armazenamentos de objetos, superfícies de administração e transições observadas entre eles. Sua finalidade não é apenas a visualização. É fornecer ao harness um modelo utilizável por máquina de onde podem existir limites de confiança e bordas de ataque.
Um esquema simplificado pode ter a seguinte aparência:
from dataclasses import dataclass, field
from typing import List, Dict
classe de dados
class AssetNode:
id: str
tipo: str
labels: List[str]
atributos: Dict[str, str] = field(default_factory=dict)
@classe de dados
classe AssetEdge:
source: str
destino: str
relação: str
evidence_refs: List[str] = field(default_factory=list)
O segundo objeto é o contrato de ataque. Essa é a unidade de trabalho e a unidade de avaliação. Ele deve ser durável, digitado, resumível e auditável. Se o sistema não puder informar qual contrato está executando, o que significa sucesso e quais evidências são necessárias, ele ainda está operando como um agente de conversação e não como um chicote de pentest.
O terceiro objeto é o conjunto de evidências. É a partir dele que uma descoberta relatável é construída. Não é um parágrafo. Não é um resumo. Um conjunto.
{
"finding_id": "idor-orders-001",
"status": "verified" (verificado),
"severity_candidate": "alto",
"contracts": ["idor-orders-001"],
"artifacts" (artefatos): {
"requests": ["req-1.json", "req-2.json"],
"respostas": ["res-1.json", "res-2.json"],
"screenshots": ["browser-1.png"],
"har": ["session-a.har"],
"logs": ["verifier-notes.md"]
},
"reproduction" (reprodução): {
"identities" (identidades): ["user_a", "user_b"],
"steps" (etapas): [
"Fazer login como usuário_a",
"Capturar ID do pedido",
"Login como usuário_b",
"Repetir GET em relação ao id do pedido do usuário_a"
],
"negative_case": "ID aleatório inexistente retorna 404"
},
"confidence" (confiança): "high" (alta),
"review_required": true
}
É aqui que outra observação contida sobre o produto se encaixa naturalmente. O material recente da Penligent sobre a Claude como copiloto de pentest faz uma observação com a qual é fácil concordar, mesmo que você remova totalmente a marca: um sistema sólido deve enfatizar relatórios editáveis, material de prova de conceito reproduzível e descobertas verificadas em vez de narração de IA não verificável. As plataformas públicas de pentest nativas de fluxo de trabalho que centralizam esses resultados estão mirando no lado certo do problema. A parte difícil não é fazer com que um modelo pareça inteligente. É fazer com que o fluxo de trabalho preserve a verdade o suficiente para que outra pessoa possa executá-lo novamente. (Penligente)
Padrões de implementação e código
A lógica central do orquestrador não precisa ser misteriosa. Ela só precisa ser disciplinada.
Um loop mínimo pode funcionar da seguinte forma:
def run_campaign(campaign):
while True:
contract = campaign.next_ready_contract()
se o contrato for None:
break
if not campaign.policy.allows(contract):
campaign.defer(contract, reason="policy gate")
continuar
execution_result = campaign.executor.run(contract)
se execution_result.status == "rejected":
campaign.record_rejection(contract, execution_result)
continuar
verification_result = campaign.verifier.run(contract, execution_result)
se verification_result.status == "verified":
bundle = campaign.evidence_writer.build_bundle(
contrato, resultado_da_execução, resultado_da_verificação
)
campaign.promote_finding(contract, bundle)
elif verification_result.status == "needs_review":
campaign.queue_human_review(contract, verification_result)
caso contrário:
campaign.record_rejection(contract, verification_result)
campaign.write_handoff()
O que importa não é a sintaxe. É a estrutura. O loop força cada candidato a passar pela mesma progressão: programar, política, executar, verificar, persistir. Esse padrão é a tradução de segurança ofensiva do loop gerador-avaliador da Anthropic e sua ênfase nos critérios de verificação. (Antrópica)
O verificador também pode impor a disciplina de repetição com a geração explícita de casos:
def build_replay_cases(contract, candidate):
cases = []
for identity in contract["required_identities"]:
cases.append({
"name": f"{contract['contract_id']}-{identity}-clean",
"session_profile": identity,
"request_spec": candidate["request_spec"],
"expected_signal": candidato["expected_signal"]
})
se contract.get("negative_case"):
cases.append({
"name": f"{contract['contract_id']}-negative",
"session_profile": contract["negative_case"]["identity"],
"request_spec": contract["negative_case"]["request_spec"],
"expected_signal": contract["negative_case"]["expected_signal"]
})
retornar casos
Um verificador com reconhecimento de navegador pode adicionar instantâneos do DOM ou capturas de tela como evidência de suporte, o que é conceitualmente semelhante à forma como o avaliador do Anthropic usou o Playwright para inspecionar o aplicativo em execução, em vez de confiar apenas na saída estática. (Antrópica)
Por fim, o mecanismo de política pode ficar atrás de invólucros de ferramentas em vez de ficar dentro de prompts:
def guarded_http_request(policy, request):
decision = policy.evaluate_http(request)
se decision.kind == "deny":
raise PermissionError(decision.reason)
se decision.kind == "defer":
raise RuntimeError("Aprovação humana necessária")
return send_http(request)
Essa única opção é mais importante do que parece. Se o modelo puder apenas "prometer" respeitar o escopo, mas o tempo de execução não puder aplicá-lo, o chicote será frágil por construção.
Avaliar o chicote, não apenas o modelo
O artigo "Demystifying evals for AI agents", da Anthropic, aborda o assunto diretamente: quando você avalia um agente, você avalia o equipamento e o modelo trabalhando juntos. Essa também deve ser uma premissa fundamental para o pentesting de IA. (Antrópica)
A pergunta de avaliação errada é: "O modelo sugeriu o próximo passo correto?" As perguntas de avaliação corretas estão mais próximas disso:
| Métrico | Por que é importante |
|---|---|
| Taxa de conclusão do contrato | Mostra se o chicote pode converter observações em unidades de teste acabadas |
| Taxa de aprovação na verificação | Mede quantas questões de candidatos sobrevivem à repetição independente |
| Taxa de supressão de falso-positivo | Mostra se o verificador está fazendo um trabalho real |
| Completude das evidências | Mede se as descobertas são realmente reportáveis |
| Taxa de violação da política | Revela comportamento inseguro ou fora do escopo |
| Taxa de escalonamento humano | Ajuda a calibrar a autonomia versus a supervisão |
| Taxa de sucesso do currículo | Testa se campanhas longas sobrevivem à interrupção |
| Precisão do reteste do patch | Mede se o sistema pode validar correções sem desvios |
A tabela é arquitetônica e não de origem, mas decorre diretamente da estrutura de avaliação da Anthropic e do que padrões como o NIST SP 800-115 e o OWASP WSTG esperam de um trabalho de teste real. Um sistema que obtém muitos acertos de candidatos, mas produz evidências fracas e violações frequentes de políticas não é melhor do que um sistema mais lento com menos descobertas, mais limpas e reproduzíveis. (Antrópica)
A metodologia de benchmark do PentestGPT também é útil aqui porque não reduziu o desempenho a um resultado final de exploração binária. O documento enfatiza o progresso das subtarefas e a realização progressiva. Esse é um bom instinto para a avaliação de arreios. Uma campanha deve receber crédito pelo mapeamento preciso de ativos, pela rejeição correta de hipóteses e pelo tratamento fiel de casos negativos, e não apenas pelos momentos de "exploit encontrado". (arXiv)
Modos de falha comuns
A maioria dos sistemas de pentest de IA não falha porque o modelo é muito fraco. Eles falham porque a arquitetura permite que a coisa errada conte como sucesso.
Uma falha comum é permitir que o mesmo trabalhador execute e valide. O trabalho público da Anthropic em arreios de longa duração diz que os avaliadores separados são mais fáceis de se sintonizar com o ceticismo do que os geradores. No pentesting, a combinação dessas funções é um convite para aumentar a confiança. (Antrópica)
Outra falha é tratar a memória como política. A estrutura de agente confiável da Anthropic enfatiza que os humanos devem manter o controle e que as permissões são importantes. A memória ajuda na continuidade, mas não impõe o escopo. Se o seu único controle de escopo for uma nota que o modelo leu anteriormente, você não tem controle de escopo. (Antrópica)
Uma terceira falha é conceder acesso amplo ao shell ou à rede muito cedo. O próprio material de sandboxing do Anthropic é explícito quanto à importância do isolamento do sistema de arquivos e da rede. Os documentos dos hooks são igualmente explícitos quanto ao fato de os hooks de comando serem executados com as permissões completas do usuário do sistema. Se um harness de pentest começar com um shell totalmente privilegiado e um caminho de rede global, ele estará a uma entrada comprometida de se tornar parte do problema. (Antrópica)
Uma quarta falha é escrever relatórios a partir da narração do agente em vez de pacotes de evidências. Esse é o caminho mais curto para falsos positivos que parecem profissionais. Quanto mais polido for o modelo de linguagem, mais perigoso isso se torna, porque o relatório parece certo, mesmo quando a prova subjacente é fraca.
Uma quinta falha é acreditar que a injeção imediata é um problema principalmente para chatbots de consumidores ou assistentes de navegador. A pesquisa de uso de navegador da Anthropic e o material de injeção imediata da OWASP dizem o contrário. Qualquer sistema que consuma conteúdo não confiável e possa realizar ações em ferramentas conectadas está no escopo. Um controle de pentest de IA vive exatamente nesse mundo. (Antrópica)
Como é um modelo operacional maduro
Um arnês de teste de IA maduro não tenta apagar o ser humano. Ele muda onde o ser humano é mais importante.
A estrutura de agentes de confiança pública da Anthropic define isso como manter os humanos no controle e, ao mesmo tempo, permitir a autonomia do agente. Isso mapeia claramente o pentesting. O ser humano não deve ter que copiar manualmente cada cabeçalho em cada solicitação de repetição. O ser humano deve decidir qual classe de ação de risco é aceitável, o que conta como um resultado reportável e quando um resultado candidato é importante o suficiente para ser escalado. (Antrópica)
Na prática, um modelo operacional maduro geralmente tem a seguinte aparência.
O operador aprova o manifesto e o conjunto de metas.
O harness faz o reconhecimento somente de leitura e cria um primeiro gráfico de ativos.
O compilador de hipóteses gera contratos limitados.
Os executores executam verificações de baixo risco automaticamente.
O verificador promove apenas resultados reproduzíveis de forma independente.
Os testes de maior risco são adiados para aprovação do operador.
Os conjuntos de evidências, e não a narração, alimentam o relatório.
Após a correção, os mesmos contratos são reproduzidos para testes de regressão.
Esse modelo operacional também facilita a combinação de ferramentas em vez de escolher um campo. O Claude Code, de acordo com os próprios documentos da Anthropic, é uma bancada de trabalho governada e forte para raciocínio com reconhecimento de repo, ferramentas locais e fluxos de trabalho de subagentes flexíveis. Os sistemas de pentest nativos do fluxo de trabalho, incluindo o Penligent em seus materiais públicos, são otimizados em torno da verificação voltada para o alvo, preservação de provas e empacotamento de relatórios. A postura madura não é confundir esses trabalhos. É entender onde cada um pertence. (Documentos da API do Claude)
Fechando o ciclo
A contribuição mais útil do Claude Code para o pentesting de IA não é um conjunto de comandos. É uma maneira de pensar nos agentes como sistemas.
O trabalho de aproveitamento público do Anthropic diz que as tarefas longas melhoram quando o contexto é gerenciado deliberadamente, o trabalho é decomposto, os avaliadores são separados e o sucesso é vinculado a testes concretos. O PentestGPT afirma que o pentesting automatizado melhora quando a perda de contexto é tratada como um problema de design e não como um problema de prontidão. O NIST e a OWASP nos lembram que o teste de segurança é um processo disciplinado com planejamento, execução, análise e relatório, e não uma sequência inteligente de suposições. CVEs reais no Langflow e pesquisas reais sobre a superfície de execução em nível de repositório do próprio Claude Code mostram o que acontece quando os sistemas agênticos obscurecem a linha entre conveniência e controle. (Antrópica)
Portanto, a ambição certa não é "fazer o modelo parecer mais autônomo". A ambição certa é criar um dispositivo que possa manter o estado, preservar o escopo, separar o planejamento da ação, separar a ação da validação e separar a evidência da narração.
Essa é a diferença entre uma IA que ajuda no pentesting e um fluxo de trabalho de pentesting em que se pode realmente confiar.
Leitura adicional e referências
- Anthropic, Arreios eficazes para agentes de longa duração. (Antrópica)
- Anthropic, design de chicote para desenvolvimento de aplicativos de longa duração. (Antrópica)
- Anthropic, Desmistificando as provas para agentes de IA. (Antrópica)
- Anthropic, visão geral do SDK do agente. (Documentos da API do Claude)
- Anthropic, Práticas recomendadas para o código Claude. (Cláudio)
- Anthropic, Criar subagentes personalizados. (Documentos da API do Claude)
- Antrópico, referência de Hooks. (Documentos da API do Claude)
- Anthropic, Beyond permission prompts, tornando o Claude Code mais seguro e autônomo. (Antrópica)
- Anthropic, Claude Code modo automático, uma maneira mais segura de ignorar permissões. (Antrópica)
- Anthropic, Mitigating the risk of prompt injections in browser use. (Antrópica)
- PentestGPT, apresentação da USENIX Security 2024. (USENIX)
- Documento PentestGPT, versão HTML do arXiv. (arXiv)
- NIST SP 800-115, Guia técnico para testes e avaliações de segurança da informação. (NIST CSRC)
- Guia de teste de segurança na Web da OWASP. (OWASP)
- Guia de teste de IA da OWASP. (OWASP)
- Iniciativa de segurança agêntica da OWASP e os 10 principais aplicativos agênticos de 2026. (Projeto de segurança de IA da OWASP Gen)
- Injeção de prompt do OWASP LLM01. (Projeto de segurança de IA da OWASP Gen)
- Protocolo de contexto de modelo, práticas recomendadas de segurança. (Modelo de protocolo de contexto)
- Protocolo de contexto de modelo, especificação de autorização. (Modelo de protocolo de contexto)
- NVD, CVE-2025-3248. (NVD)
- NVD, CVE-2026-33017. (NVD)
- Aviso do Langflow GitHub para CVE-2026-33017. (GitHub)
- Check Point Research, Caught in the Hook, RCE e API Token Exfiltration por meio de arquivos de projeto do Claude Code. (Pesquisa da Check Point)
- Check Point Research, resumo das falhas do Código Claude. (Blog da Check Point)
- Ferramenta AI Pentest, como será a verdadeira ofensa automatizada em 2026. (Penligente)
- AI Pentest Copilot, de sugestões inteligentes a descobertas verificadas. (Penligente)
- Claude AI para Pentest Copilot, Criando um fluxo de trabalho que prioriza as evidências com o código Claude. (Penligente)
- Claude Code for Pentesting vs Penligent, onde um agente de codificação pára e um fluxo de trabalho de pentest começa. (Penligente)
- Claude Code Security and Penligent, From White-Box Findings to Black-Box Proof (Segurança do código Claude e Penligent, de descobertas de caixa branca a provas de caixa preta). (Penligente)
- Página inicial da Penligent. (Penligente)

