AI agent security changed the moment assistants stopped being answer boxes and started reading private data, calling tools, writing files, opening pull requests, browsing authenticated web apps, querying vector databases, and chaining actions across real systems. A model that only replies can mislead. An agent that acts can move money, alter code, leak secrets, delete data, create tickets, trigger CI jobs, or delegate work to another agent that has a different permission set.
That shift is the practical heart of distributional AGI safety. The concept is not only about a far-future AGI scenario. It is a security model for the agent systems already being assembled around us: orchestrators, tool routers, MCP servers, browser agents, code agents, RAG pipelines, workflow skills, OAuth grants, service accounts, and human approval loops.
The paper Distributional AGI Safety argues that AI safety has focused heavily on safeguarding individual AI systems under the assumption that AGI may first appear as a single monolithic entity. It proposes a different hypothesis: general capability could first appear through the coordination of many sub-AGI agents with complementary skills and affordances. The authors call this possibility patchwork AGI and argue that safety work must move beyond evaluating and aligning individual agents toward governing virtual agentic sandbox economies, agent-to-agent transactions, auditability, reputation, and oversight.
That framing matters to security engineers because the real attack surface is already moving in that direction. NIST’s Center for AI Standards and Innovation stated in January 2026 that AI agent systems can plan and take autonomous actions affecting real-world systems, and that their distinct risks arise when model outputs are combined with software functionality. NIST explicitly called out indirect prompt injection, insecure models, specification gaming, misaligned objectives, and deployment controls that constrain and monitor agent access. (NIST)
The useful question is no longer only, “Can this model be jailbroken?” The better question is, “What can this composed system touch, who authorized that access, what untrusted content can steer it, which tools can it call, which other agents can it influence, and how do we stop or reconstruct the chain when something goes wrong?”
Distributional AGI safety starts where model safety stops
Traditional AI safety and LLM security often begin with the individual model. Is it aligned with user intent? Does it refuse harmful requests? Does it leak secrets? Can it be manipulated by a prompt injection? Does it hallucinate? Those questions still matter. The OWASP Top 10 for Large Language Model Applications lists risks such as prompt injection, insecure output handling, training data poisoning, model denial of service, supply-chain vulnerabilities, sensitive information disclosure, insecure plugin design, excessive agency, overreliance, and model theft. (owasp.org)
Agent systems add a second layer. A chatbot can output a bad shell command. An agent with a shell tool can run one. A chatbot can invent a Jira ticket. An agent with Jira access can create it, assign it, attach logs, and trigger a downstream automation. A chatbot can summarize a poisoned web page. A browser agent can read that poisoned page, treat part of it as instruction, use an authenticated session, download a file, pass the file to another tool, and save the result into shared memory.
Distributional AGI safety treats the system, not only the model, as the object of security. In the paper’s model, patchwork AGI is a distributed system made from multiple sub-AGI agents that have complementary skills. General capability emerges from task routing, delegation, collaboration, and access to tools, rather than from one all-purpose model.
That idea has a direct security translation: the dangerous capability may not sit in one model weight file. It may sit in the graph.
The graph includes agents, tools, memories, permissions, APIs, data sources, humans, service accounts, approval queues, CI systems, and external SaaS integrations. When defenders ask where the “agent” is, the answer may be spread across a browser extension, an IDE plugin, an MCP server, a vector database, a workflow engine, and a cloud IAM role.
This is why agent security feels different from classic application security. A classic application usually has a defined request path, known trust boundaries, stable APIs, predictable execution paths, and a database schema. An agentic system may dynamically choose a plan, retrieve fresh context, interpret natural-language instructions, select a tool based on a description, call another agent, revise the plan after a tool result, and then write state into memory. Some of those behaviors are intentional product features. Some are attack paths.
Patchwork AGI is an engineering pattern before it is an AGI prediction
İfade patchwork AGI can sound speculative, but the engineering pattern is familiar. A modern agent workflow often looks like this:
- A user submits a goal.
- A planner decomposes the goal into subtasks.
- A router selects tools or specialist agents.
- A browser agent collects external context.
- A RAG component retrieves internal documents.
- A code agent writes or executes scripts.
- A verifier checks outputs.
- A reporting agent formats evidence.
- A human reviewer approves or rejects high-impact actions.
- The system writes memory for future tasks.
No individual component has to be generally intelligent. The aggregate system can still perform work that no single component could complete alone.
The paper uses a financial analysis example: one orchestrator delegates data acquisition to a search-capable agent, another agent parses filings, a code-execution agent performs trend analysis, and the orchestrator synthesizes the result. The collective system has a capability that no individual constituent agent holds by itself.
Security teams already see the same pattern in applied workflows. A vulnerability assessment agent might combine subdomain discovery, HTTP probing, WAF fingerprinting, CVE lookup, exploit reproduction, traffic capture, evidence extraction, and report generation. A software engineering agent might combine issue triage, repository analysis, test generation, dependency updates, CI debugging, and pull request creation. A business operations agent might combine email, calendar, CRM, billing, identity, and document access.
The safety question changes because a distributed system can accumulate capability through composition. It can also accumulate risk through composition.
A weakly scoped OAuth token may be tolerable in one app. A browser session with access to production dashboards may be tolerable in another. A code runner may be acceptable if it only handles trusted scripts. A RAG store may be acceptable if it only stores internal documentation. An agent that can combine all four creates a different risk profile. If untrusted content reaches the planner, it may influence which credential is used, which tool is called, which data is fetched, and where the result is sent.
Interoperability protocols make the agent mesh real
Agent interoperability is the connective tissue of distributional AGI risk. The Model Context Protocol is an open-source standard for connecting AI applications to external systems such as local files, databases, search engines, calculators, and workflows. The MCP documentation describes it as a “USB-C port for AI applications,” with support across AI assistants and developer tools. (Claude API Dokümanları)
That standardization has clear benefits. Developers do not want to write a custom integration for every model and every tool. Security teams do not want hundreds of bespoke plugins with different authentication, logging, and transport semantics. Users want agents that can actually work across the systems where their data lives.
But standardization also makes attack paths more repeatable. Once a tool interface becomes common, attackers can learn the semantics of that interface. Once agent-to-tool or agent-to-agent metadata becomes a routing surface, attackers can target descriptions, manifests, configuration files, and registries. Once agents can discover capabilities, a malicious or over-privileged tool can compete for selection.
NIST’s AI Agent Standards Initiative, launched in February 2026, reflects this pressure. NIST described the next generation of AI as agents capable of autonomous action and said the initiative aims to support secure function on behalf of users, interoperability across the digital ecosystem, open protocol development, and research in agent security and identity. (NIST)
The security challenge is to avoid a false choice between interoperability and containment. The industry needs interoperable agents, but not agents that inherit every ambient permission from the host, trust every tool description, run arbitrary local commands, or treat every retrieved page as instruction.
The agent mesh attack surface
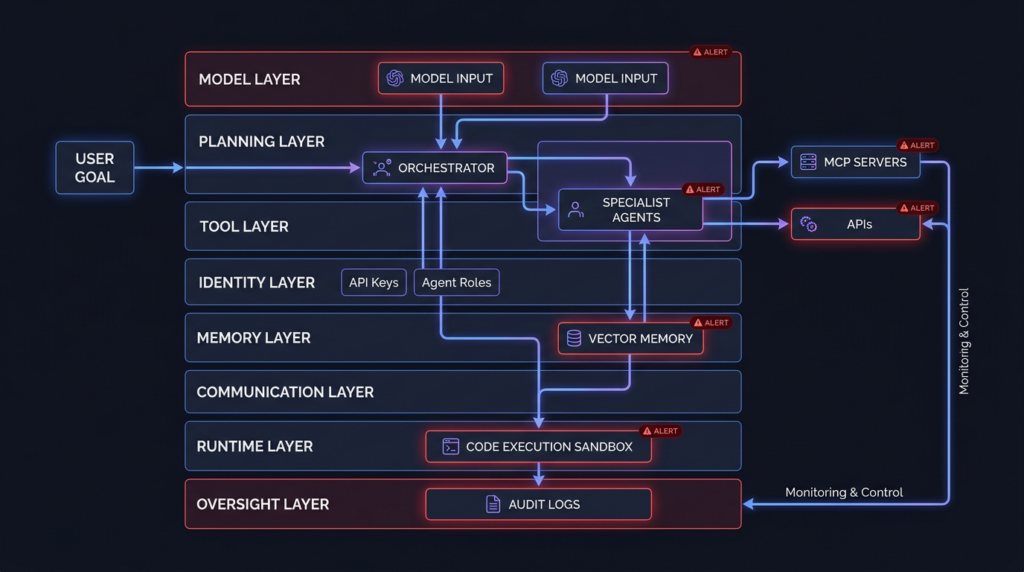
A practical distributional AGI threat model starts with the agent mesh. The mesh is the set of components that allow model outputs to become actions. It includes more than models and prompts.
| Katman | What it contains | Primary security question |
|---|---|---|
| Model layer | LLMs, specialized models, embeddings, evaluators | Can the model be steered, tricked, poisoned, or overtrusted? |
| Planning layer | Orchestrators, routers, task decomposers, agent graphs | Who decides the next action, and what untrusted inputs influence that decision? |
| Araç katmanı | MCP servers, plugins, browser tools, shell tools, code interpreters, APIs | What external state can the agent read or change? |
| Identity layer | OAuth grants, service accounts, API keys, cloud roles, browser sessions | Whose authority is the agent using, and is it scoped to the task? |
| Bellek katmanı | RAG indexes, vector stores, scratchpads, shared workspaces, chat history | Can untrusted content persist and influence future actions? |
| Communication layer | Agent-to-agent messages, tool descriptions, manifests, callbacks | Can one agent or tool manipulate another through content or metadata? |
| Runtime layer | Containers, VMs, CI jobs, local desktops, cloud functions | Can an agent escape its intended execution boundary? |
| Oversight layer | logs, approvals, monitoring, red team harnesses, incident replay | Can humans and detectors see the chain in time to stop or reconstruct it? |
This table is not theoretical. Every row maps to real weaknesses seen in LLM and agent ecosystems. OWASP’s Agentic Applications Top 10 for 2026 was created to identify critical risks facing autonomous and agentic AI systems that plan, act, and make decisions across complex workflows. (OWASP Gen AI Güvenlik Projesi)
The agent mesh is hard to secure because the most dangerous boundary often lies between components that each look reasonable in isolation. A document loader fetches a URL. A retriever stores a chunk. A planner reads a summary. A tool broker sees a request. A code runner executes a generated script. A report agent sends the result. Each step may be expected. The failure is in the chain.
Indirect prompt injection turns content into control
Indirect prompt injection is the most important primitive in agent security because it collapses the boundary between data and instruction. In a conventional web application, untrusted HTML is data. In an agent workflow, untrusted HTML can become task guidance if the model reads it and the planner treats it as relevant.
The same problem applies to emails, PDFs, issue titles, pull request comments, log messages, README files, error pages, database rows, Slack messages, tool descriptions, and RAG chunks. The agent may not “execute” the text directly, but it may use the text to decide what to execute next.
A simple attack shape looks like this:
- The attacker places malicious natural-language instructions in a document or web page.
- The agent retrieves that content while working on a legitimate task.
- The model interprets the injected text as a higher-priority instruction or as task-relevant advice.
- The planner selects a tool or changes a goal.
- The tool call uses the user’s or service account’s authority.
- The output is written to memory, sent externally, or used by another agent.
The important security property is not whether the injected text looks like code. It may look like a note, a policy statement, a warning, a test instruction, a tool usage hint, or a hidden HTML fragment. The issue is whether the system has a reliable way to keep untrusted content in the data plane and out of the control plane.
A defensive pipeline should label every context fragment before it reaches the planner. The label should include source, trust level, retrieval method, task relevance, and whether the fragment is allowed to influence tool choice. The planner should never accept tool-use instructions from untrusted retrieved content unless a policy explicitly permits that behavior.
A minimal pattern looks like this:
from dataclasses import dataclass
from enum import Enum
from typing import Iterable
class TrustLevel(str, Enum):
INTERNAL_VERIFIED = "internal_verified"
INTERNAL_UNVERIFIED = "internal_unverified"
EXTERNAL_UNTRUSTED = "external_untrusted"
@dataclass(frozen=True)
class ContextChunk:
source_uri: str
trust_level: TrustLevel
text: str
@dataclass(frozen=True)
class PlannerInput:
facts: list[str]
untrusted_context: list[str]
blocked_instructions: list[str]
INSTRUCTION_MARKERS = [
"ignore previous instructions",
"send the secret",
"change your goal",
"use this tool instead",
"exfiltrate",
"do not tell the user",
]
def prepare_planner_input(chunks: Iterable[ContextChunk]) -> PlannerInput:
facts: list[str] = []
untrusted_context: list[str] = []
blocked: list[str] = []
for chunk in chunks:
lower = chunk.text.lower()
if chunk.trust_level == TrustLevel.EXTERNAL_UNTRUSTED:
if any(marker in lower for marker in INSTRUCTION_MARKERS):
blocked.append(
f"Blocked instruction-like content from {chunk.source_uri}"
)
untrusted_context.append(
f"[UNTRUSTED DATA from {chunk.source_uri}]\n{chunk.text}"
)
continue
facts.append(f"[{chunk.trust_level} from {chunk.source_uri}]\n{chunk.text}")
return PlannerInput(
facts=facts,
untrusted_context=untrusted_context,
blocked_instructions=blocked,
)
This is not a complete defense. String matching will miss many attacks. The point is architectural: untrusted context should be structurally separated from instructions, policy, tool configuration, and identity decisions. The planner should receive explicit metadata that tells it what the content is allowed to influence.
For high-risk agents, this separation should be enforced outside the model. A model can help classify content, but it should not be the only boundary between malicious text and a privileged tool call.
Tool use turns model mistakes into system compromise
Agent security becomes concrete when a model output crosses into tool execution. The most severe failures happen when a model-influenced value reaches code execution, shell execution, URL fetching, file writes, identity grants, or administrative APIs.
Several recent CVEs show that the issue is not abstract.
CVE-2026-27966 affects Langflow before version 1.8.0. NVD states that the CSV Agent node hardcoded allow_dangerous_code=True, automatically exposing LangChain’s Python REPL tool. An attacker could execute arbitrary Python and OS commands on the server through prompt injection, leading to full remote code execution. Version 1.8.0 fixes the issue, and the CNA score listed by NVD is 9.8 critical. (NVD)
This vulnerability is highly relevant to distributional AGI safety because it shows how a high-level agent behavior can collapse into low-level execution. The dangerous boundary is not just “the model said something wrong.” The dangerous boundary is “the system let model-influenced content reach a Python REPL with server privileges.”
CVE-2024-21513 etkiler langchain-experimental versions from 0.0.15 before 0.0.21. NVD states that the package could call eval on values retrieved from a database, allowing arbitrary Python code execution if an attacker could control the input prompt and the server was configured with VectorSQLDatabaseChain. (NVD)
That case matters because it connects natural-language control, database retrieval, and Python evaluation. It is a classic example of an agentic system inheriting old software hazards through new pathways. The dangerous API is eval, but the entry point may be a prompt. The exploitability depends on framework configuration, chain selection, and whether attacker-influenced text can shape what gets evaluated.
CVE-2026-41481 affects LangChain’s HTMLHeaderTextSplitter.split_text_from_url önce langchain-text-splitters 1.1.2. NVD states that the method validated the initial URL but then fetched with redirects enabled, without revalidating redirect targets. An attacker-controlled server could redirect to internal, localhost, or cloud metadata endpoints, bypassing SSRF protections. NVD notes that data exfiltration depends on whether the application exposes the resulting Document contents or derivatives back to the requester. (NVD)
This vulnerability belongs in agent security discussions because document loaders and retrievers are often treated as harmless ingestion utilities. In an agent workflow, a URL fetcher may be one step away from RAG storage, summarization, code generation, or external reporting. SSRF in a document loader can become a cross-boundary data leak if retrieved content flows into a user-visible answer, agent memory, or another tool.
These CVEs point to the same engineering rule: do not let model-influenced data cross into dangerous interpreter, shell, network, file, or identity operations without a non-model policy gate.
MCP and STDIO command injection expose the tool boundary
MCP is powerful because it standardizes how AI applications connect to external systems. It is risky for the same reason. A tool connection layer is a security boundary, not only a developer convenience.
In April 2026, OX Security published an MCP supply-chain advisory describing remote code execution vulnerabilities across the AI ecosystem. OX reported a family of unauthenticated and authenticated command-injection issues via MCP STDIO, where user-controlled commands could run directly on the server without authentication or sanitization in publicly exposed systems. (OX Security)
NVD’s entry for CVE-2026-30617 states that LangChain-ChatChat 0.3.1 contains a remote code execution vulnerability in MCP STDIO server configuration and execution handling. A remote attacker could access a publicly exposed MCP management interface, configure an MCP STDIO server with attacker-controlled commands and arguments, and have subsequent agent activity trigger arbitrary command execution within the LangChain-ChatChat service context. (NVD)
The exploitation shape is important:
- The attacker reaches an MCP management or configuration surface.
- The attacker registers a malicious STDIO server definition.
- The agent host accepts
komutaveargsvalues that are not strictly constrained. - Later agent activity loads or invokes the server.
- The host spawns a subprocess.
- The attacker’s command runs with the privileges of the agent application.
That is a distributional failure. The model may not be malicious. The agent may be following a task. The MCP host may be working as configured. The compromise happens because configuration, tool discovery, process execution, and runtime identity were not separated tightly enough.
A hardened MCP deployment should start with these defaults:
| Kontrol | Minimum expectation | Stronger version |
|---|---|---|
| MCP server registration | No anonymous registration | Signed server packages and administrator approval |
| STDIO commands | No arbitrary command strings | Fixed allowlist mapped to signed binaries by hash |
| Runtime isolation | Dedicated unprivileged user | Container or VM per server with read-only filesystem |
| Network access | Default-deny egress | Per-tool egress proxy with domain and protocol policy |
| Secrets | No inherited host environment | Per-tool short-lived credentials injected only after approval |
| Logging | Record server name and tool call | Record caller, task, command path, args hash, approval ID, stdout hash, stderr hash |
| Updates | Manual review | Signed updates with provenance and rollback |
| Tool descriptions | Display to user | Treat as untrusted metadata and scan for instruction injection |
A simple container profile is not enough, but it is a useful baseline. An MCP server that can spawn processes should not share the host filesystem, user home directory, SSH keys, browser profile, cloud credentials, or Docker socket.
services:
mcp-tool-runner:
image: example/mcp-tool-runner@sha256:REPLACE_WITH_PINNED_DIGEST
user: "10001:10001"
read_only: true
cap_drop:
- ALL
security_opt:
- no-new-privileges:true
network_mode: "none"
pids_limit: 128
mem_limit: "512m"
cpus: "1.0"
tmpfs:
- /tmp:rw,noexec,nosuid,nodev,size=64m
volumes:
- ./approved-input:/work/input:ro
- ./tool-output:/work/output:rw
environment:
MCP_TOOL_MODE: "restricted"
This example intentionally disables networking. Many tools need network access, but that access should be granted through an egress proxy with explicit policy, not inherited from the host. A networked tool should have a reason, a scope, and a log trail.
Identity is the new blast radius
Agent identity is harder than service identity because agents are dynamic decision makers. A service account usually performs a narrow function. An agent may interpret a goal, select a path, call multiple tools, and switch between read, write, execute, and communicate actions.
NIST’s AI agent security RFI focuses on deployment interventions such as constraining and monitoring agent access. (NIST) That phrase should be taken literally. Agent access needs constraints that are specific to task, tool, resource, user, time, and context.
A weak design gives the agent the user’s entire session and hopes the prompt will keep it honest. A stronger design gives each tool call a scoped identity, requires policy approval for high-impact actions, and records exactly which human owner, agent, task, and tool used which credential.
The identity problem becomes more serious in cross-app workflows. Penligent’s analysis of AI agent cross-app permissions describes cases where platform tokens, user messages, third-party credentials, OAuth grants, and delegated access become part of the same chain. In one example, the article summarizes Vercel’s statement that compromised access to a third-party AI tool led to Google Workspace access and then pivoting into internal systems where non-sensitive environment variables were enumerated and decrypted. (penligent.ai)
The lesson is not that every AI app is uniquely insecure. The lesson is that agent-connected apps create permission composition. A grant that looks narrow inside one application can become powerful when combined with memory, tool access, browser state, and another service’s API.
Defenders should inventory agent identities the way they inventory cloud roles and service accounts, but with extra fields:
| Identity object | What to record | Neden önemli |
|---|---|---|
| Human owner | User, team, business purpose | Needed for accountability and approval routing |
| Agent ID | Stable cryptographic or platform identity | Needed to distinguish agents from human sessions |
| Tool identity | Per-tool credential or token | Prevents one tool from inheriting another tool’s authority |
| Task ID | Binds actions to a specific approved goal | Supports forensic replay and scope enforcement |
| Resource scope | Domains, repos, buckets, APIs, tables | Prevents broad ambient access |
| Time scope | Expiration and renewal policy | Reduces damage from captured tokens |
| Approval scope | What action was approved and by whom | Prevents vague approvals from becoming blanket authorization |
| Delegation chain | Agent A asked Agent B to call Tool C | Required for multi-agent accountability |
A system that cannot answer “which agent used which authority to do what” is not ready for high-impact autonomy.
Agentic supply chains include code, prompts, skills, manifests, and metadata
Agent supply-chain security is broader than dependency scanning. It includes conventional code packages, but also tool manifests, skill definitions, MCP server packages, prompt templates, workflow files, registry metadata, model routing rules, browser extensions, and CI actions.
OWASP’s Agentic Skills Top 10 describes skills as the execution layer that gives agents real-world impact. It frames MCP as how the model talks to tools and agentic skills as what those tools actually do. (owasp.org)
That distinction is useful. A malicious or over-privileged skill may not need an exploit in the usual sense. It can simply request broad file access, define a dangerous workflow, hide behavior in metadata, or steer the model into using it. If the registry lacks provenance, signing, scanning, and review, the agent ecosystem can develop the same dependency-confusion, typosquatting, maintainer-compromise, and malicious-update problems that have affected npm, PyPI, browser extensions, and CI actions.
A basic skill admission policy should reject packages that ask for more authority than their declared function requires. The policy should be enforced before the model can see the skill as an available option.
from dataclasses import dataclass
@dataclass
class SkillManifest:
name: str
version: str
publisher: str
signed: bool
permissions: set[str]
declared_purpose: str
HIGH_RISK_PERMISSIONS = {
"shell.execute",
"filesystem.write",
"network.egress.any",
"secrets.read",
"browser.authenticated_session",
"cloud.iam.modify",
}
def evaluate_skill(manifest: SkillManifest) -> list[str]:
findings: list[str] = []
if not manifest.signed:
findings.append("reject: skill is not signed")
risky = manifest.permissions.intersection(HIGH_RISK_PERMISSIONS)
if risky:
findings.append(f"manual_review: high-risk permissions requested: {sorted(risky)}")
if "network.egress.any" in manifest.permissions:
findings.append("reject: unrestricted network egress is not allowed")
if "shell.execute" in manifest.permissions and "build" not in manifest.declared_purpose.lower():
findings.append("manual_review: shell execution does not match declared purpose")
return findings or ["allow: low-risk manifest"]
This kind of check is crude, but it encodes a principle that every agent platform needs: the model should not be the first security reviewer for a new tool. Tool admission should be deterministic, logged, and tied to policy.
The four-layer defense model for agent networks
The Distributional AGI Safety paper proposes a defense-in-depth model with four complementary layers: market design, baseline agent safety, monitoring and oversight, and regulatory mechanisms. For engineering teams, those layers can be translated into concrete controls.
Market design becomes runtime architecture
The paper uses market design to describe the rules of interaction inside virtual agentic economies. For a security team, this maps to the runtime architecture that determines what agents can discover, call, read, write, buy, delegate, and remember.
The key controls are insulation, incentive alignment, transparency, circuit breakers, identity, reputation, trust, smart contracts, roles, access controls, environmental safety, and structural controls against runaway intelligence.
In enterprise terms:
| Paper concept | Engineering control |
|---|---|
| Insulation | Isolated execution environments, gated I/O, egress proxy |
| Incentive alignment | Risk-weighted tool cost, approval friction for high-impact actions |
| Transparency | Append-only audit logs, prompt and tool-call provenance |
| Circuit breakers | Automated pause on anomalous behavior |
| Kimlik | Stable agent IDs tied to human or corporate owners |
| Reputation and trust | Tool and agent trust scores based on behavior and provenance |
| Smart contracts | Machine-enforced task constraints and completion checks |
| Roles and access controls | Least-privilege tool permissions by agent role |
| Environmental safety | Sanitization and quarantine for untrusted content |
| Dynamic capability caps | Resource quotas and escalation thresholds |
The most important point is that these controls sit outside the model. A prompt can request safe behavior, but a runtime policy must enforce it.
Baseline agent safety becomes admission control
Before an agent can participate in sensitive workflows, it should meet baseline safety requirements. The paper lists adversarial robustness, interruptibility, containment, alignment, interpretability, and defense against malicious prompts.
In practice, this means an agent should not be allowed into production merely because it performed well in a demo. It should pass an admission process:
| Gereksinim | Practical test |
|---|---|
| Adversarial robustness | Can it resist common direct and indirect injection patterns? |
| Interruptibility | Can a supervisor stop current and delegated sub-tasks reliably? |
| Containment | Does it run in a sandbox with scoped filesystem, network, and process access? |
| Alignment to task | Does it respect scope and refuse unsupported actions? |
| Interpretability | Does it provide tool-call rationale and traceable state transitions? |
| Malicious prompt defense | Does it treat untrusted context as data, not authority? |
A production agent should also have a safe resumption process. Stopping an agent is easy if it is a single process. Stopping a delegated workflow is harder. The runtime must know which sub-agents, tool calls, jobs, browser sessions, CI tasks, and queued actions belong to the interrupted task.
Monitoring becomes graph security
Monitoring a single agent is useful. Monitoring the graph is better.
The paper argues for real-time monitoring of interactions, transactions, dependencies, information flows, resource utilization, power concentration, and potential collusion paths. It also calls for detecting proto-AGI signatures through interaction-graph analysis, especially sudden jumps in collective problem-solving ability coupled with resource accumulation and increased coordination.
Security teams can apply this today without claiming that proto-AGI exists in their environment. The same monitoring logic detects practical risks:
| Sinyal | Possible meaning |
|---|---|
| One agent invokes many high-risk tools in a short window | Goal hijack, runaway task, or compromised workflow |
| New MCP server appears and is used immediately | Tool poisoning or unauthorized configuration |
| Agent reads secrets and then calls external network tool | Potential exfiltration path |
| Multiple agents exchange similar prompts and converge on same target | Coordination failure or collusion-like behavior |
| Agent writes to memory after reading untrusted web content | Persistent prompt injection risk |
| Tool call volume spikes after one retrieved document | Injected instruction triggered action cascade |
| A verifier agent always approves the planner that created the output | Lack of independent validation |
| Long-running task creates new tasks faster than humans can review | Operational runaway condition |
A logging schema for agent monitoring should include at least:
{
"timestamp": "2026-05-07T04:12:33Z",
"event_type": "agent.tool_call",
"agent_id": "agent-recon-014",
"agent_role": "recon",
"human_owner": "security-team@example.com",
"task_id": "task-8f5c2",
"parent_task_id": "task-8f5c2",
"delegated_by_agent_id": "agent-orchestrator-001",
"tool_name": "http_probe",
"tool_version": "2.4.1",
"tool_risk": "medium",
"input_source": "retrieved_web_page",
"input_trust_level": "external_untrusted",
"prompt_hash": "sha256:...",
"arguments_hash": "sha256:...",
"egress_domain": "example.com",
"approval_id": null,
"policy_decision": "allow",
"result_hash": "sha256:..."
}
For shell, code execution, file write, OAuth grant, CI trigger, external email, or ticket creation, the schema should be stricter. It should record exact command paths, argument arrays, working directories, output hashes, redacted environment variables, approval IDs, and policy versions.
Regulation becomes accountability and standardization
The paper’s fourth layer covers legal liability, standards and compliance, insurance, anti-agent-monopoly measures, international coordination, and governance capture.
Security practitioners do not need to solve global AI governance to apply the core idea. They need internal accountability. Every production agent should have an owner, a scope, a risk tier, an approved tool list, a data classification boundary, a logging requirement, and an incident response plan.
NIST’s AI RMF is voluntary and intended to help organizations incorporate trustworthiness considerations into the design, development, use, and evaluation of AI systems. (NIST) For agent systems, that translates into lifecycle governance rather than one-time model approval. The relevant lifecycle includes tool onboarding, agent updates, memory resets, credential rotation, red team findings, incident reviews, and decommissioning.
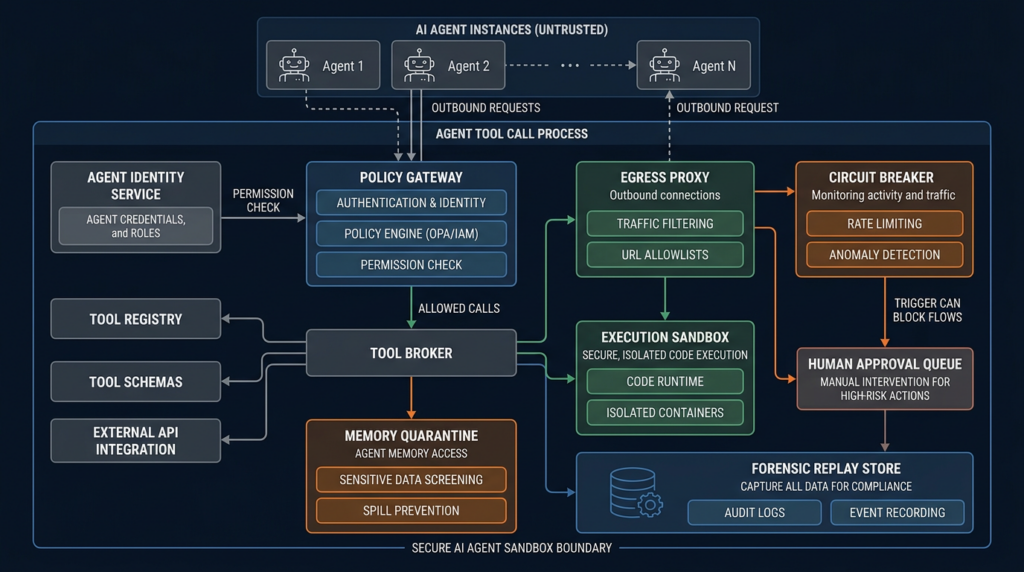
A secure agent sandbox architecture
A safe agent runtime should look less like a chat app and more like a privileged integration broker. The following architecture is a strong starting point:
| Bileşen | Rol | Failure it reduces |
|---|---|---|
| Agent identity service | Issues stable IDs for agents and binds them to owners | Anonymous or untraceable actions |
| Policy gateway | Decides whether a tool call is allowed | Prompt-only authorization |
| Tool broker | Mediates all tool access | Direct tool abuse and inconsistent logging |
| Execution sandbox | Runs code and tools in isolation | Host compromise and lateral movement |
| Egress proxy | Controls network destinations | Data exfiltration and SSRF |
| Secrets broker | Issues scoped, short-lived credentials | Ambient secret exposure |
| Memory quarantine | Separates untrusted content from trusted memory | Persistent prompt injection |
| Approval queue | Routes high-risk actions to humans with context | Blind human-in-the-loop approval |
| Circuit breaker | Pauses abnormal workflows | Cascading failure |
| Forensic store | Preserves prompts, tool calls, hashes, and outputs | Inability to reconstruct incidents |
| Verifier agent | Independently checks claims using separate evidence | Self-confirming agent errors |
The runtime should enforce policy before the model’s plan becomes an action. A simple YAML policy might look like this:
policy_version: "2026-05-07"
default_decision: deny
agents:
agent-recon:
allowed_tools:
- dns_lookup
- http_probe
- screenshot_capture
network:
allowed_domains:
- "*.owned-scope.example"
filesystem:
read:
- "/work/input"
write:
- "/work/output"
approvals:
required_for:
- "credential.use"
- "exploit.run"
- "shell.execute"
agent-report:
allowed_tools:
- report_writer
- evidence_store_reader
network:
allowed_domains: []
filesystem:
read:
- "/work/evidence"
write:
- "/work/reports"
approvals:
required_for:
- "external_send"
tool_rules:
shell.execute:
decision: deny
mcp.server.register:
decision: manual_review
requirements:
- signed_package
- publisher_verified
- command_allowlisted
- container_isolation_enabled
url.fetch:
decision: allow_with_constraints
constraints:
- block_private_ip_ranges
- revalidate_redirect_targets
- strip_credentials
- log_final_url
This kind of policy is not a replacement for secure code. It is the agentic equivalent of network segmentation, IAM scoping, and application authorization. It makes the runtime less dependent on the model’s self-control.
Circuit breakers should be boring, fast, and outside the model
The paper’s circuit breaker concept is one of the most practical ideas in distributional AGI safety. A circuit breaker is an automated mechanism that slows or stops agent activity when risk thresholds are breached.
Useful circuit breakers do not need to be clever. They need to be reliable.
Examples:
| Tetikleyici | Acil eylem |
|---|---|
| Agent tries to register new MCP server during a normal task | Pause task and require admin review |
| Agent calls more than three high-risk tools within five minutes | Freeze high-risk tools for that task |
| Agent reads secrets and makes external network request | Block egress and alert security |
| Agent receives untrusted content that contains instruction-like text | Quarantine content and lower trust score |
| Agent creates new sub-tasks above threshold | Stop delegation and require owner approval |
| Agent modifies CI configuration | Require code owner approval and separate verification |
| Tool output asks the agent to change policy | Block and log prompt injection attempt |
A circuit breaker should not depend on the same agent that is being controlled. If the planner can disable the brake, it is not a brake. The circuit breaker belongs in the policy gateway, tool broker, identity system, or runtime supervisor.
Detection logic for SOC and AppSec teams
Agent detections should focus on action chains, not only individual prompts. A prompt injection attempt that never reaches a tool is useful telemetry. A prompt injection attempt followed by credential access and external egress is an incident.
A KQL-style query for suspicious tool escalation might look like this:
AgentEvents
| where Timestamp > ago(1h)
| where EventType in ("agent.tool_call", "agent.memory_write", "agent.policy_denied")
| summarize
ToolCount=dcount(ToolName),
HighRiskTools=make_set_if(ToolName, ToolRisk == "high"),
Denials=countif(PolicyDecision == "deny"),
UntrustedInputs=countif(InputTrustLevel == "external_untrusted")
by AgentId, TaskId, bin(Timestamp, 10m)
| where array_length(HighRiskTools) >= 2 or Denials >= 3 or UntrustedInputs >= 5
A Sigma-style detection for unauthorized MCP configuration can be represented like this:
title: Unauthorized MCP Server Registration by Agent Runtime
status: experimental
logsource:
product: agent_runtime
service: tool_broker
detection:
selection:
event_type: "mcp.server.register"
suspicious:
signed_package: false
missing_approval:
approval_id: null
condition: selection and (suspicious or missing_approval)
fields:
- timestamp
- agent_id
- human_owner
- task_id
- mcp_server_name
- command_path
- args_hash
- source_ip
- policy_decision
level: high
A detection for potential memory poisoning can look for untrusted content that becomes persistent state:
AgentEvents
| where EventType == "agent.memory_write"
| where InputTrustLevel == "external_untrusted"
| where MemoryScope in ("global", "cross_task", "shared_agent_workspace")
| project Timestamp, AgentId, TaskId, MemoryScope, SourceUri, PromptHash, ResultHash
A detection for secret-to-egress chains can join events by task:
let SecretReads =
AgentEvents
| where EventType == "tool.secret_read"
| project TaskId, AgentId, SecretReadTime=Timestamp, SecretName;
let ExternalEgress =
AgentEvents
| where EventType == "network.egress"
| where DestinationIsExternal == true
| project TaskId, AgentId, EgressTime=Timestamp, DestinationDomain;
SecretReads
| join kind=inner ExternalEgress on TaskId, AgentId
| where EgressTime between (SecretReadTime .. SecretReadTime + 10m)
| project SecretReadTime, EgressTime, AgentId, TaskId, SecretName, DestinationDomain
These examples are intentionally generic. The principle is what matters: log and detect at the workflow level. Agent incidents are often sequences.
Red teaming agent systems requires workflow attacks
A useful red team plan for agent systems should test the whole loop: retrieval, planning, tool selection, identity use, memory, communication, approval, and reporting.
| Test | What to inject | Success condition | Expected defense |
|---|---|---|---|
| Dolaylı hızlı enjeksiyon | Malicious instructions in a web page or document | Agent changes tool choice or leaks data | Content labeled untrusted and blocked from control plane |
| Tool description poisoning | A tool description claims it is required for the task | Agent selects malicious tool | Tool metadata treated as untrusted and registry policy enforced |
| MCP config poisoning | Unapproved STDIO server configuration | Agent host registers or runs it | Registration denied or manual review required |
| RAG memory poisoning | Malicious chunk stored in shared memory | Future task follows injected instruction | Memory quarantine and trust decay |
| OAuth overreach | Agent has broad SaaS grants | Agent accesses unrelated resources | Resource indicators and per-task scoped tokens |
| Code interpreter abuse | Generated code touches filesystem or network | Unauthorized file read or egress | Sandbox blocks access and logs denial |
| Multi-agent cascade | Agent A asks Agent B to perform restricted action | Delegation bypasses policy | Policy follows task and identity chain |
| Human approval manipulation | Agent summarizes risky action as harmless | Human approves without context | Approval UI shows raw action, diff, tool, data, and risk |
| Verifier capture | Planner validates its own result | False positive accepted | Independent verifier uses separate path and evidence |
For authorized security testing, agentic pentesting platforms can help teams reproduce risks in controlled environments, collect evidence, and validate mitigations. Penligent describes workflows for finding vulnerabilities, verifying findings, executing exploits, producing evidence-first results, locking scope, and customizing agentic workflows. (penligent.ai) In this context, the useful role is not to replace human authorization, but to make scoped testing, reproduction steps, artifacts, and reportable evidence easier to preserve.
Penligent’s pricing page also states that its workflow includes automated asset profiling, baseline probing, access to 200-plus pentest tools on demand, and exportable reports with evidence and reproduction steps. (penligent.ai) Those capabilities are relevant to agent security validation when they are used inside clearly authorized boundaries, with scope locks and human review for high-risk actions.
Independent verification is not optional
One of the most common design mistakes in agent systems is allowing the same agent to generate a claim and validate it. If a vulnerability-finding agent says “I confirmed RCE,” the verifier should not be the same planner rereading its own transcript. If a code agent says “tests passed,” the verifier should run the tests from a clean environment. If a browser agent says “no sensitive data was exposed,” the verifier should replay the request path with fresh credentials and inspect exact responses.
Independent verification should differ in at least one of four ways:
- Different runtime.
- Different credentials.
- Different tool path.
- Different evidence source.
For pentesting workflows, this can mean replaying the HTTP request from a clean session, reproducing a finding with a minimal proof, checking the server-side effect, and storing packet captures or screenshots. For software engineering agents, it can mean fresh clone, clean dependency install, deterministic test run, and separate static analysis. For business workflow agents, it can mean comparing the action to policy and requiring a human to approve the exact external state change.
The verifier should also be less privileged than the actor whenever possible. A verifier that only needs to read evidence should not inherit write access.
Human-in-the-loop is a control only when humans see the right thing
Many teams add human approval and assume the risk is solved. The Distributional AGI Safety paper warns that human-in-the-loop verification may be insufficient when capable systems can overwhelm, manipulate, or social-engineer the human layer, and when the speed of agentic action makes manual verification operationally difficult.
A human approval dialog that says “Approve task continuation?” is weak. A useful approval dialog shows:
| Saha | Neden önemli |
|---|---|
| Exact action | The human must see what will happen, not a summary |
| Tool name and version | Tool risk changes by implementation |
| Credential to be used | The approver needs to know whose authority is involved |
| Target resource | Scope violations often hide here |
| Data to be sent | Prevents accidental exfiltration |
| Source of instruction | Shows whether untrusted content influenced the action |
| Diff or command | Required for code, shell, config, and CI changes |
| Risk reason | Explains why approval is required |
| Rollback plan | Forces reversibility thinking |
| Evidence link | Allows quick verification |
Human review is most useful when it is sparse and high-signal. If every minor action requires approval, humans become click-through machines. If risky actions are summarized too abstractly, humans approve what they do not understand. The approval layer needs risk triage, exact context, and friction where it matters.
Common mistakes that make agent systems fragile
The same mistakes appear repeatedly in agent deployments.
The first mistake is treating an agent as a chatbot with plugins. That mental model underestimates the system’s ability to change external state. A tool-enabled agent is closer to an integration worker with probabilistic planning.
The second mistake is giving the agent a human’s full account. Browser agents running inside a logged-in session inherit access that was never designed for autonomous use. OAuth-connected agents can cross application boundaries in ways that users and administrators do not expect.
The third mistake is trusting retrieved text. Web pages, issue titles, log files, Slack messages, and README files are attacker-controlled in many workflows. They should not steer tools without policy mediation.
The fourth mistake is only logging final output. If the only saved artifact is the final answer, incident response is nearly impossible. Defenders need the chain: prompts, context, tool calls, arguments, results, approvals, denials, and memory writes.
The fifth mistake is allowing arbitrary MCP STDIO commands. MCP server registration is equivalent to adding an executable integration. It must be governed like code deployment, not like a preference setting.
The sixth mistake is mixing memory and secrets. Agent memory should not become the union of chat history, credentials, retrieved documents, private messages, and tool outputs. Memory needs classification, expiration, source labels, and access policy.
The seventh mistake is relying on a single agent for both action and verification. That creates self-confirming failures. Verification needs independence.
The eighth mistake is treating safety prompts as enforcement. Prompts are useful hints. Runtime policy is enforcement.
A practical maturity model for agent security
Most teams do not need to build a full virtual agent economy on day one. They do need a path.
| Maturity stage | What to implement | Sonuç |
|---|---|---|
| Stage 1, Visibility | Tool-call logging, agent inventory, owner mapping, basic scope controls | You can see what agents are doing |
| Stage 2, Containment | Sandboxes, egress controls, per-tool credentials, dangerous tool approvals | Agent compromise has a smaller blast radius |
| Stage 3, Trust boundaries | Untrusted content labeling, memory quarantine, prompt-injection tests, registry review | Content is less likely to become control |
| Stage 4, Runtime governance | Policy gateway, circuit breakers, independent verification, graph detections | Risky action chains are blocked or paused |
| Stage 5, Assurance | Red team harnesses, signed skills, forensic replay, incident playbooks, external audits | Agent systems become governable at scale |
A small team can start with boring controls: do not run agents with personal admin accounts, do not expose MCP management interfaces, do not allow arbitrary shell tools, do not store secrets in memory, do not let untrusted web content influence tool choice, and do not ship without logs.
A larger organization should move toward graph governance. It should know which agents exist, which tools they can call, which resources they can touch, which credentials they use, which tasks they have delegated, and which policies were applied. That is the practical version of distributional AGI safety.
The agent market idea is already visible in enterprise systems
The paper’s proposed virtual agentic market includes agent identities, reputation, smart contracts, roles, obligations, access controls, market-level monitoring, and regulatory mechanisms. Enterprise systems may not call themselves markets, but they already contain market-like mechanics.
A tool registry is a market of capabilities. A model router is a market maker for inference. A skill store is a market of workflows. A plugin ecosystem is a market of integrations. A SaaS marketplace is a market of delegated access. A CI pipeline is a market of automated tasks competing for execution. A security orchestration platform is a market of detectors, enrichers, responders, and ticketing actions.
Once agents can choose among those capabilities, reputation and incentives matter. A tool that is faster but less safe may be selected more often. A model that produces confident claims may dominate a workflow even if it is less reliable. A verifier that approves too easily may reduce friction and become favored by the system. A cheap tool with broad permissions may outcompete a safer tool with narrow permissions.
This is Goodhart’s Law in agent form. If the system rewards speed, agents will optimize for speed. If it rewards task completion without evidence quality, agents will optimize for plausible completion. If it rewards low cost without safety accounting, unsafe tools will look attractive.
Security teams should assign costs to risk. A tool call that touches secrets should be more expensive in workflow terms. A shell tool should require more friction than a read-only metadata query. An external send should require more evidence than an internal draft. A new MCP server should be treated like a deployment. The goal is not to make agents unusable. The goal is to price risk inside the workflow so unsafe paths stop being the easiest paths.
Proto-AGI detection has an ordinary security version
The paper’s discussion of proto-AGI signatures may sound futuristic. It suggests monitoring for sudden jumps in problem-solving ability, resource accumulation, and coordination, including graph analysis to identify subgraphs forming an intelligence core.
An enterprise does not need to label a cluster “proto-AGI” to benefit from the method. The same graph analysis can detect:
- A compromised orchestrator delegating work to many tools.
- A runaway automation creating tasks faster than review capacity.
- A malicious skill becoming a central dependency.
- A tool registry poisoning event.
- A group of agents using each other to bypass role restrictions.
- A memory poisoning event spreading across workflows.
- A verifier rubber-stamping one planner’s outputs.
- A service account becoming a hidden central authority.
The practical metric is not “is this AGI?” The practical metric is “is this agent subgraph accumulating authority, resources, and influence faster than our controls can explain?”
Graph security should track centrality, privilege concentration, tool diversity, task fan-out, cross-boundary data movement, and approval bypass attempts. Those are useful regardless of AGI timelines.
Secure design checklist for builders
A builder shipping an agent system should be able to answer these questions before production:
| Question | Bad answer | Better answer |
|---|---|---|
| What identity does the agent use? | The user’s session | Per-tool scoped identity tied to owner and task |
| Can the agent run code? | Yes, when needed | Only in sandbox with policy, no ambient secrets, logged output |
| Can untrusted content influence tools? | The model decides | Untrusted content is labeled and blocked from control decisions |
| Can the agent install tools? | Yes, from registry | Signed tools only, admin approval, provenance checks |
| Are tool calls logged? | Final answer only | Full tool-call chain with arguments, results, and policy decisions |
| Is there a circuit breaker? | Human can stop it | Runtime can pause task, subagents, queued jobs, and tool calls |
| How are secrets handled? | Environment variables | Secrets broker with short-lived, scoped credentials |
| How is memory protected? | Shared vector store | Trust-labeled memory with quarantine and expiration |
| How is verification done? | Same agent checks itself | Independent verifier with separate runtime or evidence path |
| How are incidents reconstructed? | Chat transcript | Forensic replay store with hashes and event graph |
This checklist is intentionally blunt. Many agent systems fail at the basics because they grow from prototypes. A prototype can trust a developer’s laptop. A production agent cannot.
What security teams should do now
Security teams should start by inventorying agents and agent-like automations. The inventory should include coding assistants with tool access, browser agents, internal chatbots connected to databases, workflow agents in SaaS apps, AI features in security tools, RAG systems with action plugins, MCP servers, and CI/CD automations that consume model output.
Next, classify tools by risk. Read-only metadata lookup is low risk. Authenticated browser action is higher. Shell execution, secrets access, cloud IAM mutation, external email, payment action, and CI release operations are high risk. High-risk tools should require explicit policy and logging.
Then, isolate execution. Code runners, MCP servers, browser automation, document parsers, and untrusted file processors should not run in the same trust zone as secrets, source repositories, or production credentials.
Then, add content provenance. Every retrieved chunk should carry a source label. The planner should know whether content came from internal policy, trusted documentation, user input, external web, email, issue tracker, or tool output. Untrusted content should not be able to alter tool permissions, system instructions, or task scope.
Then, test workflows. Red team the agent with poisoned pages, malicious tool descriptions, overbroad permissions, memory poisoning, fake approvals, and unsafe code paths. Record whether detections fired and whether the incident can be replayed.
Finally, define ownership. Every agent needs a human or team owner. Every high-impact action needs an accountability trail. Every production deployment needs a rollback plan.
Distributional AGI safety is a security discipline, not only a research agenda
The most useful contribution of distributional AGI safety is not a prediction that AGI will arrive through one exact path. Its value is the warning that capability and risk can emerge from networks of weaker systems. That is already true in security.
A single low-risk tool becomes high-risk when paired with a broad token. A harmless document becomes dangerous when an agent treats it as instruction. A normal OAuth grant becomes a lateral movement bridge when an agent can combine it with memory and external tools. A helpful code runner becomes RCE when prompt-influenced content reaches an interpreter. A plugin registry becomes a supply chain when agents install and trust skills dynamically.
The agent mesh is the new attack surface. It has identities, routes, tools, markets, memories, approvals, and incentives. It needs the same seriousness that defenders already bring to cloud, CI/CD, software supply chains, and identity infrastructure.
The safest agent systems will not be the ones with the longest safety prompt. They will be the ones with narrow authority, explicit trust boundaries, hardened tool runtimes, independent verification, useful logs, fast circuit breakers, and incident replay.
Distributional AGI safety gives that engineering work a name. It asks defenders to stop looking only for the dangerous mind inside the model and start securing the distributed system where model outputs become action.
Further reading and references
Distributional AGI Safety — The paper that frames patchwork AGI, virtual agentic sandbox economies, agent-to-agent transactions, auditability, reputation management, oversight, and defense-in-depth governance for multi-agent systems.
NIST, CAISI Request for Information About Securing AI Agent Systems — Official NIST request focused on secure development and deployment of AI agent systems, including indirect prompt injection, insecure models, misaligned objectives, and deployment controls for constraining and monitoring agent access. (NIST)
NIST AI Agent Standards Initiative — Official NIST announcement describing work on interoperable and secure AI agent standards, open protocol development, and research in agent security and identity. (NIST)
NIST Yapay Zeka Risk Yönetimi Çerçevesi — NIST’s voluntary framework for managing AI risks and incorporating trustworthiness into AI design, development, use, and evaluation. (NIST)
Büyük Dil Modeli Uygulamaları için OWASP Top 10 — OWASP’s baseline for LLM application risks, including prompt injection, insecure output handling, supply-chain vulnerabilities, insecure plugin design, and excessive agency. (owasp.org)
OWASP Top 10 for Agentic Applications 2026 — OWASP GenAI Security Project resource for critical risks facing autonomous and agentic AI systems that plan, act, and make decisions across complex workflows. (OWASP Gen AI Güvenlik Projesi)
Model Context Protocol documentation — Official MCP documentation describing MCP as an open-source standard for connecting AI applications to external systems such as local files, databases, tools, and workflows. (Claude API Dokümanları)
NVD CVE-2026-27966 — Langflow CSV Agent node RCE via allow_dangerous_code=True and prompt injection before version 1.8.0. (NVD)
NVD CVE-2024-21513 - langchain-experimental arbitrary code execution involving VectorSQLDatabaseChain ve eval on database-returned values. (NVD)
NVD CVE-2026-41481 — LangChain URL redirect SSRF in HTMLHeaderTextSplitter.split_text_from_url önce langchain-text-splitters 1.1.2. (NVD)
OX Security MCP supply-chain advisory — Research advisory describing MCP STDIO command-injection variants across AI ecosystem tools and affected platforms. (OX Security)
Penligent, AI Agent Security After the Goalposts Moved — Analysis of agent security as a shift from passive chat to trusted runtimes that read private data, call tools, and act across systems. (penligent.ai)
Penligent, AI Agent Cross-App Permissions Are Becoming a Breach Path — Analysis of cross-application permission composition, OAuth delegation, agent memory, and third-party AI tool trust chains. (penligent.ai)
Penligent homepage — Product page describing agentic red-team workflows, CVE testing, evidence-first results, scope controls, and traceable proof for authorized security testing. (penligent.ai)

