The easiest way to misunderstand AI agent security is to keep treating it like an access-control problem inside a single application.
That model is already breaking in public.
In February 2026, Wiz disclosed that Moltbook, a social network for AI agents, exposed a misconfigured Supabase database with full read and write access. The exposure included 1.5 million API authentication tokens, 35,000 email addresses, and private messages between agents. Wiz said some of those messages also contained third-party credentials, including API keys, and that Moltbook secured the issue within hours after disclosure. (wiz.io)
In April 2026, Vercel disclosed a different kind of failure. According to Vercel’s bulletin, the incident began with the compromise of Context.ai, a third-party AI tool used by a Vercel employee. Vercel said the attacker used that access to take over the employee’s individual Google Workspace account, then pivoted into Vercel systems and enumerated and decrypted non-sensitive environment variables for a limited subset of customers. Context’s own security statement confirms that its legacy consumer AI Office Suite included a feature that let AI agents perform actions across external applications, that some OAuth tokens were compromised in the incident, and that one of those tokens was used to access Vercel’s Google Workspace. (Vercel)
Those incidents do not share the same root cause. Moltbook was, at bottom, a storage and exposure failure. Vercel and Context involved a third-party AI tool, OAuth trust, and lateral movement into a corporate environment. But they rhyme in exactly the place modern security teams are least prepared to monitor: the effective permission surface created when an agent, connector, OAuth app, MCP server, or tool chain bridges multiple systems at once. (wiz.io)
The Hacker News recently framed that class of problem as a “toxic combination,” meaning a permission breakdown between two or more applications bridged by an AI agent, integration, or OAuth grant that no single application owner ever intended to authorize as one coherent risk surface. That phrasing is useful, even if it is not a formal standard term, because it captures the structural shift clearly: the dangerous unit is no longer the app. It is the chain. (The Hacker News)
That shift matters because AI agents do not merely “have access.” They plan, retrieve, transform, hand off, call tools, and push output into other systems. The resulting security problem is not just whether a grant exists, but what happens when several grants combine across systems, with natural-language context flowing through the middle. OpenAI’s prompt-injection guidance makes the same point in different words: the practical goal is not perfect detection of malicious input, but designing systems so that the impact of manipulation is constrained even if some attacks succeed. (OpenAI)
That is the frame for the rest of this piece. The question is not whether AI agents need permissions. Of course they do. The real question is how ordinary-looking permissions across OAuth, MCP, skills, local tools, SaaS connectors, and downstream APIs quietly become breach paths.
Why AI Agent Cross-App Permissions Break Single-App Security Reviews
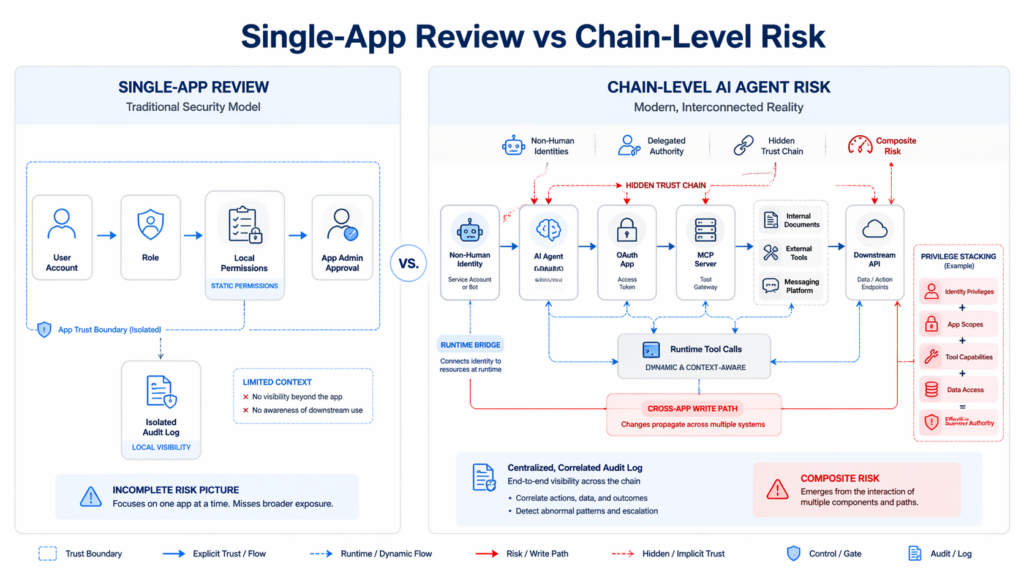
Most enterprise security processes still evaluate access one application at a time. That is reasonable if identities are mostly human, permissions are mostly static, and integrations are cataloged before they ever run.
Agent systems violate all three assumptions.
The Cloud Security Alliance’s State of SaaS Security report says 46% of organizations struggle to monitor non-human identities, and 56% report concern about overprivileged API access in SaaS-to-SaaS integrations. The same report says many organizations still rely on fragmented controls such as vendor-native tools and manual audits, which leave critical gaps across modern SaaS environments. (cloudsecurityalliance.org)
That gap widens as soon as an agent becomes the bridge between systems. A bot with read access in one app and write access in another is not just “a bot with two grants.” It is a data movement path. An IDE assistant that can read repository content and post to a messaging tool is not just “two approved integrations.” It is a cross-context execution surface. An AI office tool that can act inside Google Workspace on behalf of a user is not just “productivity automation.” It is delegated authority with persistence. (The Hacker News)
The Model Context Protocol documents reflect the same change in architecture. The authorization material says MCP servers use OAuth 2.1-style authorization flows to protect sensitive resources and operations, while the specification requires clients to include a resource parameter and requires servers to validate that tokens were specifically issued for their use. In other words, the protocol itself assumes that the recipient, target resource, and delegation boundary matter. That is exactly what single-app reviews tend to flatten away. (modelcontextprotocol.io)
Traditional IAM language also starts to lose precision here. “Who has access” is no longer enough. You need to ask at least four harder questions: what can the agent read, what can it write, what external tools can it invoke, and what new destinations become reachable when those actions are chained together. CSA’s 2025 publication on Agentic AI IAM makes the same argument directly, saying traditional IAM protocols built for static applications and human users cannot keep up with autonomy, ephemerality, and delegation patterns in agentic environments. (cloudsecurityalliance.org)
The table below shows why this is more than a vocabulary shift.
| Review question | Single-app review | Chain-level review | Why the difference matters |
|---|---|---|---|
| Who has access | Focuses on users, service accounts, and app-local roles | Includes bots, AI agents, MCP servers, OAuth apps, skills, and subagents | Non-human identities often hold the most operational reach in agent workflows (cloudsecurityalliance.org) |
| What can they do | Evaluates scopes or roles inside one application | Evaluates the composite effect of scopes across apps and tools | Read in one app plus write in another can create exfiltration or tampering paths (The Hacker News) |
| How was access granted | Looks at provisioning and app-level approval | Looks at runtime bridges formed by OAuth consent, MCP installation, or skill loading | The chain often forms after the last formal review completed (The Hacker News) |
| What logs are relevant | Login events, role changes, app admin actions | Tool calls, model messages, MCP sessions, OAuth grants, egress, secret reads, environment-variable access | You cannot see a chain from one logging plane alone (OpenAI Geliştiricileri) |
| What breaks the model | Usually a bad role, exposed key, or missing MFA | Often a bridge, token misuse, prompt injection, or scope combination | Agents turn acceptable local permissions into unacceptable global effects (OpenAI) |
The critical point is not that single-app review is useless. It is that it answers the wrong unit of risk. It governs approvals inside boxes. The attacker is walking across the lines between them.
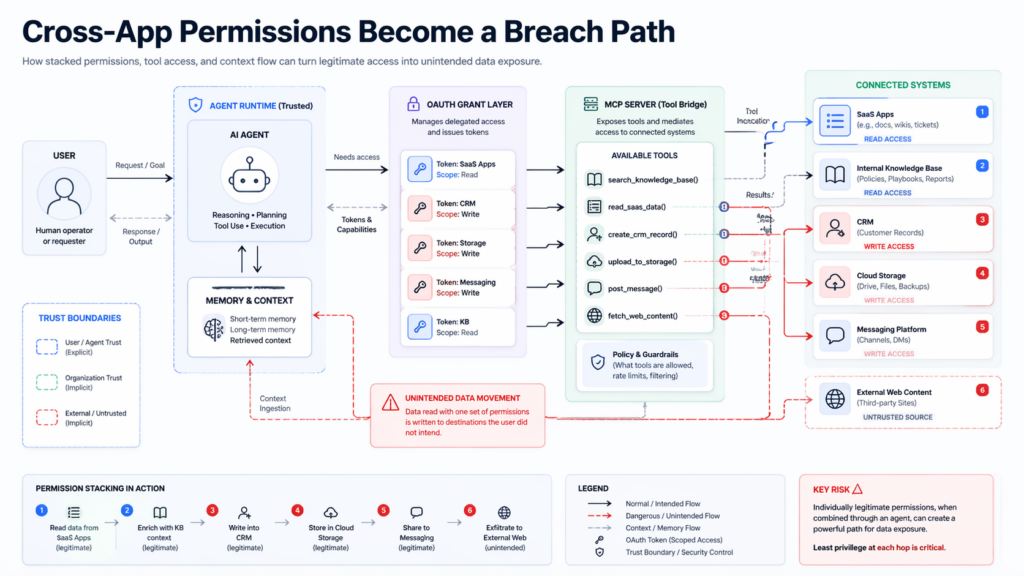
How Cross-App Permissions Become Toxic Combinations
The Hacker News article that popularized the “toxic combination” framing described the shape clearly: an AI agent, integration, or MCP server bridges two or more applications through OAuth grants, API scopes, or tool-use chains, and each side looks acceptable on its own because the bridge itself is what no one reviewed. Its example was an IDE connector that can post code snippets into Slack. The Slack admin approves the bot. The IDE admin approves the outbound connection. What no one reviews is the trust relationship between source editing and business messaging once both are live. (The Hacker News)
That example is powerful because it captures four distinct layers of risk.
The first is delegation. Someone gave the agent or connector a legitimate grant. No exploit is required for that initial step. Vercel’s incident makes the danger of this plain: Context’s AI Office Suite was explicitly intended to let AI agents perform Google Workspace actions such as writing emails or creating documents on the grantee’s behalf. The dangerous thing was not that such a feature existed. The dangerous thing was what followed once those delegated tokens were stolen and reused in another context. (Bağlam)
The second is composition. The effective permission surface is the sum of multiple edges, not a single scope. Reco’s April 2026 writing on agent-to-agent trust chains makes this exact point: per-user or per-application review stops working when the effective scope is determined by the composition of the chain. A read-only agent connected downstream to a public-facing channel becomes a data exposure vector, even if every hop looks benign in isolation. (reco.ai)
The third is confused deputy behavior. AWS defines the confused deputy problem as a situation where an entity that does not itself have permission to perform an action coerces a more privileged entity to perform it instead. The MCP security best-practices guide explicitly warns about confused deputy risks for MCP proxy servers that connect to third-party APIs, and it says proper per-client consent and related controls are required to prevent them. (docs.aws.amazon.com)
The fourth is yürütme. Once an agent can invoke tools, move data, or write into another application, the problem stops being just “access.” It becomes action. OpenAI’s prompt-injection material describes the same shift: as AI tools gain the ability to browse the web, help with research, and access user data in other apps, prompt injection becomes dangerous because it can trick the system into unintended action, not merely unintended text. (OpenAI)
To make this concrete, imagine an internal research assistant with the following perfectly plausible configuration:
- Read access to a private document store
- Search access to the web
- An MCP server that can call a CRM or ticketing system
- A messaging connector that can post summaries to Slack
- An email action capable of sending follow-ups
- Long-lived memory about recent user tasks
None of those grants is automatically reckless. But together they create an execution chain that can ingest untrusted content, retrieve sensitive internal data, generate transformed output, and publish or send it elsewhere. That is the real unit of risk.
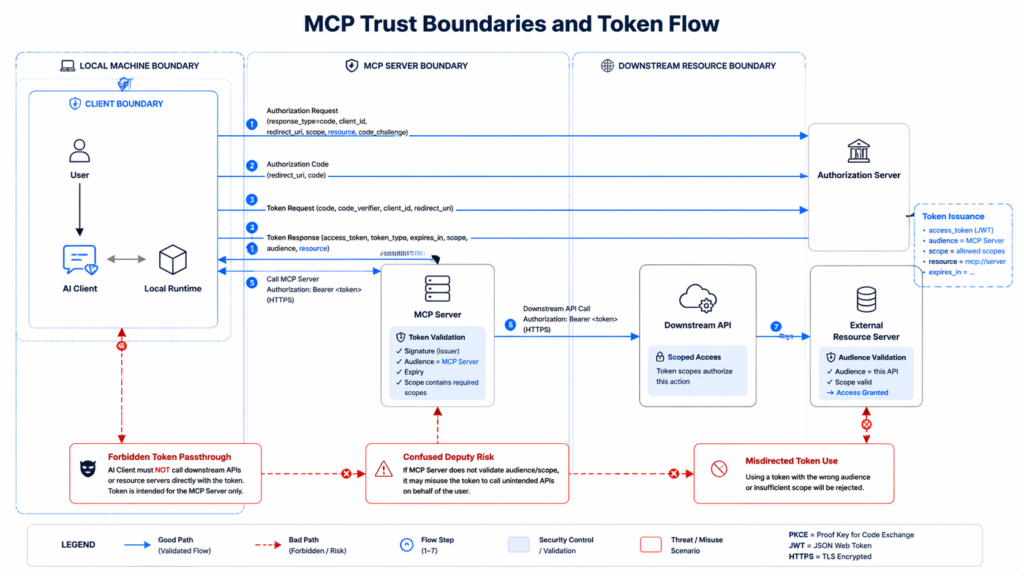
This is why the MCP specification bans token passthrough. The security guide calls token passthrough an anti-pattern in which an MCP server accepts tokens from a client without validating that they were issued for the MCP server, then forwards them to downstream APIs. The authorization specification is even more direct: if a server both accepts tokens with incorrect audiences and forwards them unmodified to downstream services, it can create the confused deputy problem. MCP servers must only accept tokens specifically intended for themselves. (modelcontextprotocol.io)
The lesson is broader than MCP. Every agent bridge should be treated like a security boundary with its own identity, own recipient validation, own audit trail, and own output restrictions. When organizations skip that discipline, “integration” quietly becomes “attack path.”
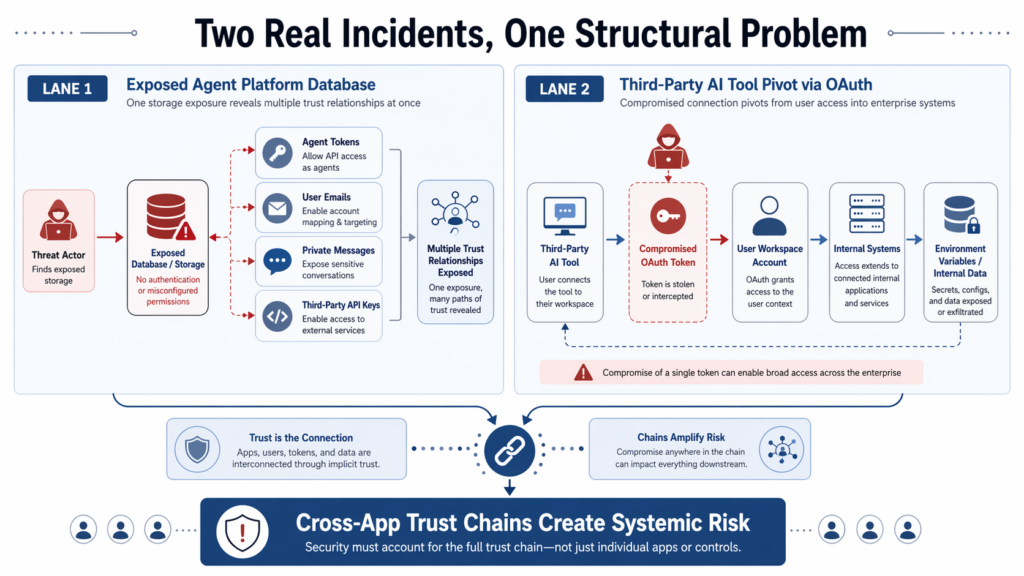
The Moltbook Exposure and the Vercel Context Incident Show Two Sides of the Same Security Shift
It is tempting to read Moltbook as an immature startup story and Vercel as a supply-chain story, then file them into separate mental drawers. That is the wrong lesson.
Moltbook shows what happens when an agent platform stores too much of the chain in one place. Wiz found a misconfigured Supabase database with read and write exposure to platform data, including agent API authentication tokens, email addresses, and private messages. Some private messages contained third-party credentials. That means identity material for the platform and identity material for outside services ended up co-located with conversational context. In a system built for agents, that is not merely sensitive data concentration. It is chain concentration. (wiz.io)
The Hacker News summary sharpened the structural point further. It described Moltbook’s agents as sitting on the bridge, carrying credentials for their host platform and for outside services their users had wired them into, in a place where neither platform owner had full line of sight. That is a vivid description of cross-app permission composition: one compromise did not just expose “user data.” It exposed the connective tissue between multiple systems. (The Hacker News)
Vercel and Context show the same pattern from the opposite direction. Here the dangerous concentration was not a database table but a trust chain. Context says its AI Office Suite consumer product let AI agents perform actions across external applications through another third-party service. It later learned that OAuth tokens belonging to some users were compromised during an incident in its AWS environment, and that one of those tokens was used to access Vercel’s Google Workspace. Vercel says that access then let the attacker pivot into internal systems and enumerate and decrypt non-sensitive environment variables. (Bağlam)
That sequence matters because the attacker did not need to exploit Vercel’s public-facing edge first. They rode an already-authorized relationship. Trend Micro’s analysis describes the incident as an OAuth supply-chain compromise and emphasizes the same structural point: trust relationships created by OAuth can become lateral movement paths that bypass traditional perimeter thinking. That is Trend’s framing, not Vercel’s own formal terminology, but it is a fair synthesis of the confirmed chain. (Trend Micro)
The difference between the two incidents is operationally important:
| Incident | Initial failure | Bridge element | What crossed the boundary | What defenders likely lacked | Operational lesson |
|---|---|---|---|---|---|
| Moltbook | Misconfigured database exposure | Agent platform holding both internal and external credential material | Platform tokens, user emails, agent messages, third-party credentials | Separation between platform identity, agent context, and downstream secrets | Do not let one storage plane become the union of identity, memory, and downstream access (wiz.io) |
| Vercel and Context | Compromised third-party AI tool and stolen OAuth tokens | Google Workspace OAuth delegation from a Vercel employee to Context AI Office Suite | Workspace access, then Vercel internal access and customer environment-variable exposure | Strong constraints on third-party AI app grants and continuous validation of delegated access | Treat OAuth-connected AI tools as part of your attack surface, not as harmless productivity add-ons (Vercel) |
What ties the cases together is not vendor immaturity or attacker novelty. It is a new security center of gravity. We used to ask, “Is this app secure?” The more relevant question now is, “What can this app, this token, this tool, or this agent do when combined with the others already in play?”
Why MCP Expands AI Agent Cross-App Permissions Risk
MCP deserves special attention because it turns abstract risk into a technical implementation problem.
The MCP authorization tutorial says secure authorization for MCP servers follows OAuth 2.1 conventions and uses the authorization code flow with PKCE to protect sensitive resources and operations. The specification further says clients must use the resource parameter to explicitly specify the target resource and that servers must validate that the token was actually issued for them. These requirements are not paperwork. They are core defenses against privilege confusion in multi-hop systems. (modelcontextprotocol.io)
The security best-practices guide then fills in the rest of the threat model.
It explicitly warns about token passthrough, calling it an anti-pattern. It says MCP servers must not accept tokens not explicitly issued for the MCP server and must not forward tokens downstream as though validation had already happened. It also documents SSRF risk during OAuth metadata discovery, where a malicious MCP server can influence URLs fetched by a client. And it documents local MCP server compromise, including the risk of malicious startup commands, insecure localhost services reached through DNS rebinding, and arbitrary code execution with the same privileges as the MCP client. (modelcontextprotocol.io)
That last point is one of the most underappreciated in the whole agent ecosystem.
People often talk about MCP as if it were mainly a way to “let the model use tools.” The local-server sections of the official security guide make clear that this is incomplete. A local MCP server is a process running on the user’s machine. It may have direct access to files, network, and local resources. The guide says one-click local MCP configuration must show the exact command to be executed, warn that it runs code on the user’s system, and execute such commands in a sandbox with minimal privileges. It further recommends restricted file-system and network access, and says local servers that run over HTTP should require authorization or use IPC mechanisms with restricted access. (modelcontextprotocol.io)
This is not merely “hardening advice.” It is a statement about the boundary itself. Once the model becomes the dispatcher for processes, tools, and external connections, the security question shifts from model output quality to execution governance. CSA’s secure MCP implementation primer says exactly that in more formal language: because the LLM can autonomously decide to call tools that execute code and interact with data, failure to secure the MCP implementation can lead to severe consequences including data breaches, system compromise, and financial loss. It then maps MCP to the MAESTRO framework and highlights MCP-specific threats such as tool misuse, goal manipulation, weak input validation, poor logging, resource hijacking, environment-variable exposure, and supply-chain attacks in the framework layer. (cloudsecurityalliance.org)
That is why scope design becomes a first-order security control.
The MCP security guide includes a dedicated scope-minimization section and recommends a progressive least-privilege model with a minimal initial scope set, incremental elevation when privileged actions are first attempted, and tolerance for reduced-scope tokens. The point is not just to be tidy. Broad scopes make token compromise more damaging, make revocation harder, and blur the audit trail. (modelcontextprotocol.io)
This is where MCP and general OAuth security thinking meet. RFC 9700, the current Best Current Practice for OAuth 2.0 security, says it updates and extends older OAuth guidance based on broader application and newly discovered threats. It also explicitly warns that the implicit grant and related response types are vulnerable to access-token leakage and replay, recommending that clients should not use the implicit grant unless those vectors are mitigated. In agent systems, where tokens may be carried across bridges and through intermediaries, old convenience patterns age badly. (datatracker.ietf.org)
The practical takeaway is simple: MCP is not dangerous because it exists. It is dangerous when teams treat it as a transparent pipe instead of a delegated execution boundary.
Prompt Injection Turns Cross-App Permissions Into Execution Problems
Prompt injection is often described as a model-safety issue. In agentic systems, that description is too narrow.
OpenAI’s November 2025 explanation of prompt injections says the problem emerged as AI products moved beyond a conversation between one user and one AI and started incorporating content from many sources, including the internet. The attack works because a third party can smuggle instructions into the conversation context and trick the model into doing something the user did not ask for. When the system can act across connected apps, the consequences move from bad answers to data exposure and unintended actions. (OpenAI)
The deeper engineering version of the same point appears in OpenAI’s March 2026 post on designing agents to resist prompt injection. That post says the goal should not be limited to detecting malicious input. It should be designing systems so that the impact of manipulation is constrained even if the manipulation succeeds. That is exactly the right mindset for cross-app permission risk. In a connected agent, the question is not whether you can perfectly classify every malicious webpage, file, or tool response. The question is whether one successful manipulation can reach a dangerous action. (OpenAI)
OpenAI’s deep-research documentation becomes strikingly concrete here. It says prompt injection can be smuggled through web pages, file-search results, or MCP search results. It warns that if the model obeys those instructions it may send private data to an external destination. It also says no automated filter can catch every case, and recommends concrete controls: connect only trusted MCP servers, upload only trusted files to vector stores, log and review tool calls and model messages, stage workflows so public-web research and private-data access happen in separate calls, validate tool arguments with schemas or regexes, and review returned links before opening or passing them onward. (OpenAI Geliştiricileri)
That guidance matters because cross-app permissions amplify prompt injection in at least three ways.
First, prompt injection can alter destination selection. An agent with legitimate write capability may be tricked into sending data to a new sink.
Second, prompt injection can alter parameter selection. A tool that is safe under ordinary arguments may become dangerous under unexpected ones.
Third, prompt injection can alter handoff behavior. One subagent or tool call can poison the context handed to the next, producing a chain whose local actions all look plausible.
Anthropic’s Claude Code engineering posts supply another missing piece: the human control plane is fragile. Its March 2026 article on auto mode says Claude Code users approve 93% of permission prompts. Anthropic’s point is not that human approval is worthless, but that repeated approval leads to fatigue, and fatigue weakens the safety value of each prompt. The article describes auto mode as an attempt to reduce that fatigue while still blocking dangerous actions, and it even notes that a benign subagent at delegation time can be compromised mid-run by prompt injection in content it reads. (anthropic.com)
Anthropic’s October 2025 sandboxing article pushes the lesson further. It says sandboxing can reduce permission prompts by 84% in internal usage and explains that real safety comes from two hard boundaries: file-system isolation and network isolation. The article explicitly says both are necessary. Without network isolation, a compromised agent could exfiltrate sensitive files such as SSH keys. Without file-system isolation, a compromised agent could escape the sandbox and gain network access. (anthropic.com)
This is the right way to think about connected AI systems. Prompt injection is not just a failure to ignore malicious text. It is a way of steering delegated authority. Once you see it that way, the defense stack changes. You stop relying on “recognize bad inputs” and start asking which actions, destinations, scopes, and bridges remain possible after the model has been fooled.
OWASP’s latest LLM guidance reinforces this. LLM01 for 2025 says prompt injection affects how models process prompts, can influence critical decisions, and is not fully mitigated by techniques such as RAG or fine-tuning. OWASP’s Agentic Skills Top 10 then moves one layer down and says skills are the execution layer that gives agents real-world impact, recommending verified publishers, code signing, pinned versions, isolated runtimes, network restrictions, inventory, approval workflows, and audit logging. That is exactly the control pattern needed once prompt injection can reach connected tools. (OWASP Gen AI Güvenlik Projesi)
The CVEs That Make AI Agent Cross-App Permissions a Practical Security Issue
The fastest way to make this topic vague is to talk about “agent risk” in the abstract. The fastest way to ground it again is to read the vulnerability records.
These CVEs do not all describe the same bug class. That is why they are useful. Together they show how many different layers can fail once models, tools, local runtimes, HTTP transports, and downstream systems are wired together.
CVE-2025-66416 and CVE-2025-66414, DNS Rebinding Against Local HTTP MCP Servers
NVD says the MCP Python SDK, before version 1.23.0, and the official TypeScript SDK, before version 1.24.0, did not enable DNS rebinding protection by default for HTTP-based MCP servers in certain configurations. In the affected cases, a malicious website could exploit DNS rebinding to bypass same-origin protections and send requests to a local MCP server, potentially invoking tools or accessing resources exposed by that server on behalf of the user. The advisories note that stdio transport is not affected and that running unauthenticated local HTTP MCP servers is not recommended. (nvd.nist.gov)
Why this matters for cross-app permissions is straightforward. A local MCP server is often the bridge between the model and valuable local or network-reachable capabilities. If a malicious webpage can drive that bridge, the problem is no longer “a browser issue” or “a local dev issue.” It becomes delegated tool execution triggered from outside the user’s intended workflow. That is exactly the kind of chain most organizations do not inventory well.
The fix is equally instructive. Upgrade to fixed versions, avoid unauthenticated local HTTP transports when possible, prefer stdio for local-only use, and treat local MCP services as sensitive execution surfaces that require both transport-level and runtime-level containment. (nvd.nist.gov)
CVE-2026-39884, Argument Injection in mcp-server-kubernetes
NVD says versions 3.4.0 and earlier of mcp-server-kubernetes contain an argument-injection vulnerability in the port_forward tool. The issue arises because a kubectl command is built through string concatenation using user-controlled input and then naively split on spaces before being passed to spawn(). NVD notes that user-controlled fields such as namespace, resource type, resource name, local port, and target port can therefore introduce arbitrary kubectl flags. (nvd.nist.gov)
This CVE matters because it is the clearest possible demonstration that tool use is not safe just because the tool is “legitimate.” The tool is Kubernetes administration. The user-facing action is port forwarding. The actual failure is command construction. That is what makes agent security hard in practice: the model may produce normal-looking parameters for a tool whose implementation does not robustly treat parameters as data.
In a cross-app permission setting, that means an agent may be authorized to reach infrastructure, but the real danger emerges only when a prompt-controlled parameter crosses into a fragile implementation. That is why output validation and per-tool argument schemas matter as much as access control. (nvd.nist.gov)
CVE-2026-39974, SSRF in n8n-MCP
NVD says that before version 2.47.4, n8n-mcp allowed an authenticated SSRF in certain multi-tenant HTTP deployments. A caller with a valid AUTH_TOKEN could make the server send HTTP requests to arbitrary URLs supplied through multi-tenant headers, and response bodies were reflected back through JSON-RPC. NVD specifically notes that affected deployments could expose cloud metadata endpoints, internal network services, and other hosts reachable by the server. Single-tenant stdio deployments and HTTP deployments without the multi-tenant headers are not affected. (nvd.nist.gov)
This is a classic example of why “authenticated” does not mean “safe.” The attack still requires a valid token. But once a token holder can make the bridge fetch arbitrary URLs and return the contents, the bridge becomes a reconnaissance and secret-retrieval surface. In practical terms, that means a seemingly narrow documentation or automation bridge can become a cross-boundary read primitive.
For defenders, the lesson is to separate who is authenticated from what the authenticated party can cause the server to fetch, and to restrict egress, metadata access, and multi-tenant header semantics aggressively. (nvd.nist.gov)
CVE-2026-39885, SSRF and Local File Read in FrontMCP
NVD says that before version 2.3.0, FrontMCP’s mcp-from-openapi library dereferenced $ref values in OpenAPI specifications without URL restrictions or custom resolvers. A malicious OpenAPI document could therefore cause the library to fetch internal addresses, cloud metadata endpoints, or local files during initialization, enabling SSRF and local file read. (nvd.nist.gov)
This is important because it shows that the dangerous bridge can form even before runtime tool invocation. Initialization logic, spec loading, schema dereferencing, and “helpful” automation features can all create cross-boundary read behavior. In other words, not every bridge is an explicit tool call. Some are hidden in setup.
That should change how teams review agent toolchains. You do not just inspect the tools that are called after the model starts planning. You inspect the parsers, registries, importers, loaders, metadata discovery flows, and update paths that make those tools available in the first place. (nvd.nist.gov)
CVE-2026-40159, Environment Leakage Through Spawned MCP Processes in PraisonAI
NVD says that before version 4.5.128, PraisonAI’s MCP integration allowed spawning background servers via stdio using user-supplied command strings, and that the implementation forwarded the entire parent process environment to the spawned subprocess. (nvd.nist.gov)
That is relevant because many teams still assume that the security boundary is mostly about what command gets executed. Sometimes the more consequential question is what context follows the command. If the child process inherits environment variables wholesale, secrets and privileged configuration may travel into places the operator never intended.
This is cross-app permission risk in a pure form. The dangerous bridge is not a token sent over OAuth. It is ambient authority bleeding into a child process because convenience won over least privilege.
What These CVEs Add Up To
The table below summarizes the pattern.
| CVE | Affected component | Exploit preconditions | Why it matters for cross-app permissions | Fix or mitigation |
|---|---|---|---|---|
| CVE-2025-66416 | MCP Python SDK | Local HTTP MCP server, no auth, affected transport, no DNS rebinding protection | A malicious website can drive a local bridge and invoke tools on behalf of the user | Upgrade to 1.23.0+, avoid unauthenticated local HTTP where possible, prefer stdio for local-only use (nvd.nist.gov) |
| CVE-2025-66414 | MCP TypeScript SDK | Same class of conditions in the official TS SDK | Same cross-boundary local-tool execution risk in TS ecosystems | Upgrade to 1.24.0+, enable protections, avoid insecure local HTTP deployment (nvd.nist.gov) |
| CVE-2026-39884 | mcp-server-kubernetes | User-controlled tool parameters reaching fragile command construction | Natural-language tool use becomes infrastructure command injection | Upgrade past 3.4.0 and enforce strict parameter handling with array-based execution patterns (nvd.nist.gov) |
| CVE-2026-39974 | n8n-mcp | Valid auth token in affected multi-tenant HTTP setup | An authenticated bridge becomes an SSRF and metadata-reading primitive | Upgrade to 2.47.4, restrict egress, review multi-tenant header handling and token sharing (nvd.nist.gov) |
| CVE-2026-39885 | FrontMCP | Processing untrusted OpenAPI specs during initialization | Initialization itself becomes a cross-boundary fetch and file-read surface | Upgrade to 2.3.0 and constrain URL resolution and local-file dereferencing (nvd.nist.gov) |
| CVE-2026-40159 | PraisonAI MCP integration | Spawned subprocesses using user-supplied command strings and inherited environment | Ambient authority and secrets can leak into child bridges | Upgrade to 4.5.128+ and minimize inherited environment for spawned processes (nvd.nist.gov) |
The important pattern is not “MCP is broken.” The pattern is that agent bridges fail at many layers: transport, scope design, startup commands, argument construction, metadata loading, subprocess boundaries, and egress. That is why any serious review of AI agent cross-app permissions has to be system-level.
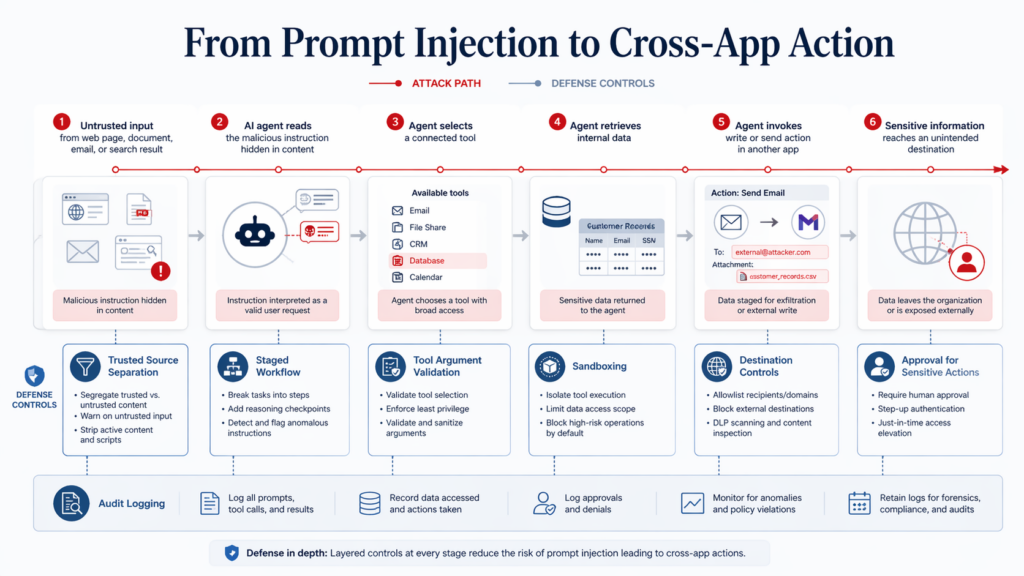
How to Threat-Model AI Agent Cross-App Permissions Instead of Just Listing Integrations
Threat modeling for agent systems has to start with a different mental unit.
CSA’s MAESTRO framework was built specifically for agentic AI because older threat-modeling approaches do not naturally capture multi-agent interactions, tool chains, autonomy, and shifting trust relationships. CSA’s public material describes MAESTRO as a layered framework for agentic AI, and its secure MCP implementation primer uses the framework to map threats across server, host, client, deployment, observability, security controls, and the broader agent ecosystem. (cloudsecurityalliance.org)
That is a useful starting point because chain-level security failures usually span multiple layers at once. A single toxic combination often includes all of the following:
- An identity layer problem, because a bot, agent, or OAuth app is holding delegated authority
- A tool layer problem, because the model can trigger useful actions
- A context layer problem, because the model is reading from untrusted or mixed-trust inputs
- An infrastructure layer problem, because the runtime has network or file-system reach it does not need
- An observability layer problem, because the bridge is not fully logged or attributed
- A governance layer problem, because no one approved the composition as one risk surface
CSA’s Agentic AI IAM publication adds a second important idea: traditional identity protocols such as OAuth 2.1, SAML, and OIDC were not designed for the autonomy, ephemerality, and delegation patterns common in multi-agent systems. That does not mean you stop using them. It means you stop assuming they fully solve the identity problem once the system can act at machine speed and pass tasks across tools and agents. (cloudsecurityalliance.org)
In practice, that means your asset inventory should not stop at “these are the agents we have.” It should record the bridges that matter.
Here is a minimal illustrative inventory object for a non-human identity that spans applications:
{
"identity_id": "agent-sales-research-01",
"owner": "sales-platform-security",
"type": "ai_agent",
"connected_apps": [
"google-workspace",
"slack",
"crm",
"internal-docs"
],
"grants": [
{"app": "google-workspace", "scope": "read:docs"},
{"app": "slack", "scope": "write:messages"},
{"app": "crm", "scope": "read:accounts"},
{"app": "internal-docs", "scope": "search"}
],
"execution_surfaces": [
"mcp_server",
"web_search",
"skill_runtime"
],
"allowed_destinations": [
"slack.company.example",
"crm.company.example"
],
"data_classes_seen": [
"customer_pii",
"sales_forecast",
"internal_notes"
],
"review_date": "2026-04-23",
"last_scope_change": "2026-04-20"
}
This matters because inventory is only useful if it captures composite risk. “AI agent exists” is weak metadata. “AI agent can search internal docs, read Google Docs, and write to Slack” is operational metadata.
Graph thinking helps here because chain risk is often easiest to see as a path problem. An illustrative Cypher-style query for toxic combinations might look like this:
MATCH p =
(src:DataStore {classification: "sensitive"})<-[:CAN_READ]-
(id:Identity)-[:USES]->(bridge:Bridge)
-[:CAN_WRITE|CAN_POST|CAN_SEND*1..2]->
(sink:Destination {egress: true})
WHERE id.kind IN ["ai_agent", "oauth_app", "mcp_server", "skill"]
RETURN id.name, bridge.name, src.name, sink.name, p
The point of a query like this is not that every team needs Neo4j. The point is that you need to ask path-shaped questions. Can a non-human identity read sensitive data and then write outside the original trust domain within one or two hops? That is the modern equivalent of “Who is local admin?” It is a boring question until it becomes the post-mortem.
Policy should also be composition-aware. A simple approval rule can block some of the most dangerous bridges before they ever go live:
package agent.approvals
deny[msg] {
input.identity.kind == "ai_agent"
some r
some w
r := input.requested_scopes[_]
w := input.existing_scopes[_]
r.effect == "write"
w.effect == "read"
r.app != w.app
w.data_class == "sensitive"
msg := sprintf(
"deny new write scope %s in %s because %s already has read-sensitive access in %s",) }
That does not solve everything. It does solve one frequent failure mode: adding a write grant in a second application without evaluating the read-sensitive grants the same identity already holds elsewhere.
Teams that validate these chains in practice usually discover that policy and runtime drift apart quickly. This is one place where continuous adversarial validation becomes useful. Penligent’s own Hacking Labs material frames the problem as post-authentication execution governance and argues that after you add a new MCP server, widen a tool scope, or change memory handling, you need continuous validation of whether dangerous actions are still blocked. That aligns with the broader engineering point here: inventory and policy are necessary, but they are not enough if the bridge can be re-shaped by a runtime change. (penligent.ai)
What Defenders Need to Log if They Actually Want to See the Chain
One reason chain-level compromise is hard to detect is that no single log source tells the whole story.
OpenAI’s deep-research guidance says developers should log and review tool calls and model messages, especially when those calls go to third-party endpoints. The MCP security best-practices guide emphasizes inbound request verification, strong session handling, URL validation during metadata discovery, restricted local-server startup, and scope minimization. Anthropic’s security engineering around Claude Code emphasizes that once an agent has autonomy, hard boundaries such as file-system and network isolation matter more than endless permission prompts. Together, those documents imply a practical logging and control model even if none of them publishes the same “checklist” in one place. (OpenAI Geliştiricileri)
The useful logging planes are these:
| Logging plane | What to capture | Neden önemli |
|---|---|---|
| IdP and OAuth audit | New app grants, changed scopes, consent timestamps, token audience, resource target | Shows when a bridge is created or widened |
| MCP server logs | Session creation, inbound auth verification, tool names, argument validation failures, upstream API calls | Reveals whether the bridge is being driven in expected ways |
| Model and orchestrator traces | Prompts, tool-selection rationale, subagent handoffs, denials, retries | Helps distinguish normal planning from manipulated execution |
| Runtime sandbox logs | File access, blocked writes, domain requests, newly requested destinations | Surfaces egress and local-access drift |
| Application audit logs | Slack posts, CRM writes, doc exports, email sends, environment-variable reads, secret retrievals | Shows the downstream effect of delegated action |
| Network egress | New domains, metadata endpoint access, internal service reachability from bridge components | Critical for SSRF and exfiltration visibility |
| Registry and installation events | Skill installs, MCP config changes, version changes, startup commands | Many chains begin at install or update time |
If you only collect login events, you will mostly see humans. If you only collect app audit logs, you will see effects but not the orchestrating chain. If you only collect orchestrator traces, you may miss what the downstream APIs actually did. Chain visibility comes from correlation.
A good working rule is that every action by a non-human identity should be attributable along four dimensions: who initiated it, on whose behalf it ran, what bridge executed it, and where the result went. When one of those is missing, you do not really have an audit trail. You have fragments.
A second rule is that you need explicit destination awareness. OpenAI’s guidance warns that links returned from results can themselves become exfiltration channels if sensitive context is accidentally embedded into URLs. Anthropic’s sandboxing guidance stresses domain-level network restriction for the same reason. In a connected agent, destination is not a detail. It is part of the authorization decision. (OpenAI Geliştiricileri)
Hardening AI Agent Cross-App Permissions Without Killing Useful Automation
The right response to all of this is not to ban agents. It is to stop shipping them with invisible trust chains.
A realistic hardening program starts with OAuth basics. RFC 9700 says the implicit grant is vulnerable to token leakage and replay and should not be used unless those risks are mitigated. MCP’s authorization guidance points teams toward authorization-code-style flows with PKCE and explicit resource targeting. If your connected agent stack still uses legacy convenience patterns for delegated access, fix those before you add another layer of automation. (datatracker.ietf.org)
Then bind tokens tightly to recipients and intended resources. MCP is explicit here: servers must validate that tokens were issued for them, and token passthrough is forbidden. In practice, this means a bridge should never be allowed to act as a transparent courier of somebody else’s token. If it needs to talk to an upstream service, it should do so with a separate token obtained in its own role as a client to that service. (modelcontextprotocol.io)
Next, narrow the runtime. Anthropic’s sandboxing work is especially useful because it avoids vague “secure your agent” language and instead says what the boundary should be: file-system isolation plus network isolation. That translates cleanly into agent hardening for other environments as well. Connected agents should not have ambient access to the whole host, unrestricted outbound network access, or unconstrained ability to start arbitrary subprocesses. (anthropic.com)
Then separate phases of work. OpenAI’s deep-research guidance suggests staging workflows so public web research happens first and private MCP access happens in a second call with no web access. This is one of the most practical controls in the whole agent-security space because it breaks a common exfiltration shape: untrusted input arriving in the same context that also has authority to read secrets or act in private systems. (OpenAI Geliştiricileri)
Scope design matters just as much. The MCP security guide recommends a progressive least-privilege model with minimal initial scopes and targeted elevation when privileged actions are actually needed. That is superior to up-front “allow all” grants for two reasons. First, it shrinks what a stolen token can do. Second, it preserves cleaner audit semantics because privilege changes become visible events rather than hidden assumptions. Context’s statement about at least one employee enabling “allow all” Google Workspace permissions is a concrete reminder of how broad delegation changes blast radius. (modelcontextprotocol.io)
You also need stronger installation discipline for skills and connectors. OWASP’s Agentic Skills Top 10 recommends verified publishers with code signing, automated scanning, permission review before installation, version pinning, isolated runtimes, network restrictions, and comprehensive audit logging. That is not bureaucracy. It is a recognition that the execution layer in agents is itself a supply chain. (owasp.org)
Finally, stop treating agent review as a one-time approval. Continuous change is the default condition of these systems. New MCP servers get added. Old servers gain new scopes. Skills update. Memory behavior changes. Subagents appear. Context sources expand. The effect is cumulative. Penligent’s published writing on agent security in production makes this point well: once your agent is a production system, you need continuous validation, especially after adding a new MCP server, widening a tool scope, or changing memory storage. In practical terms, that means repeatedly testing whether your supposed controls still hold when the chain changes. (penligent.ai)
For teams already running agentic workflows in sensitive environments, the best program usually looks like this:
First, build and maintain an inventory of every non-human identity, every bridge, every skill, every local server, and every external destination.
Second, model composite scope rather than local scope.
Third, isolate file system and network by default.
Fourth, use recipient-bound tokens and avoid passthrough.
Fifth, separate public and private phases of agent work.
Sixth, pin and verify skills and connectors.
Seventh, continuously validate that dangerous paths remain blocked after every meaningful change. (modelcontextprotocol.io)
That is not a slogan. It is an operating model.
The Real Security Boundary Has Moved
The old boundary was the application.
The new boundary is the execution chain that connects the model, the context, the bridge, the token, the tool, and the destination.
Moltbook made that visible by co-locating platform identity, agent context, and third-party credential material in one exposed place. Vercel and Context made it visible by showing how a third-party AI tool’s delegated OAuth reach could become a pivot into an enterprise environment. The official MCP documents make it visible in protocol language by banning token passthrough, requiring resource targeting, and documenting confused deputy, SSRF, session hijacking, local-server compromise, and scope-minimization failures as first-class concerns. OpenAI and Anthropic make it visible from the system-engineering side by saying, in effect, that prompt injection will remain hard, human approvals fatigue quickly, and the only durable answer is to constrain what connected systems can do when something goes wrong. (wiz.io)
The next high-impact incident in this category may not look like a spectacular zero-day. It may look like an agent doing exactly what it was allowed to do, across exactly the apps it was allowed to touch, until someone finally notices that the chain itself should never have existed.
That is why AI agent cross-app permissions deserve to be treated as a breach path, not a feature checklist.
Further Reading and References
For the primary incident evidence, read Wiz on the Moltbook exposure, Vercel’s April 2026 security bulletin, Context’s incident response statement, and The Hacker News coverage that popularized the toxic-combination framing. (wiz.io)
For protocol and authorization details, read the official MCP Security Best Practices guide, the MCP authorization tutorial and specification, and RFC 9700 on OAuth 2.0 security best current practice. (modelcontextprotocol.io)
For prompt-injection and execution-boundary thinking, read OpenAI’s “Understanding prompt injections,” “Designing AI agents to resist prompt injection,” and the deep-research security guidance, plus Anthropic’s engineering posts on Claude Code auto mode and sandboxing. (OpenAI)
For frameworks and governance, read CSA’s State of SaaS Security report, the MAESTRO threat-modeling material, the CSA Agentic AI IAM publication, OWASP LLM01 on prompt injection, and the OWASP Agentic Skills Top 10. (cloudsecurityalliance.org)
For vulnerability records, review NVD entries for CVE-2025-66416, CVE-2025-66414, CVE-2026-39884, CVE-2026-39974, CVE-2026-39885, and CVE-2026-40159. (nvd.nist.gov)
For related Penligent reading that is genuinely close to this topic, see “AI Agent Security Beyond IAM, Why the Real Risk Starts After Authentication,” “Agentic AI Security in Production — MCP Security, Memory Poisoning, Tool Misuse, and the New Execution Boundary,” “Anthropic MCP Vulnerability, 7000 Servers, and the Case for Continuous Red Teaming,” and the Penligent homepage for the broader product context. (penligent.ai)

