Choosing between Gemma 4 and Qwen for AI pentesting is not really a benchmark problem. It is a workflow problem. A penetration-testing system does not succeed because a model sounds sharper in chat. It succeeds because it can keep state across messy evidence, propose useful next actions, stay inside scope, and avoid turning tool use into a new attack surface. That is exactly why the PentestGPT paper still matters: its core finding was not that LLMs could fully replace a tester, but that they could help meaningfully on specific sub-tasks, while the overall workflow still needed modular design to reduce context loss and preserve the shape of an engagement. (USENIX)
That framing immediately changes how Gemma 4 and Qwen should be compared. Gemma 4’s official materials emphasize long context, native function calling, native support for the sistem role, configurable thinking, and multimodal understanding that explicitly includes document and PDF parsing plus screen and UI understanding. Qwen’s official materials, by contrast, spread the story across the model family and the agent stack: Qwen3 offers dense and MoE variants, thinking and non-thinking modes, long context, and vendor-claimed strength on tool use; Qwen-Agent layers in Function Calling, MCP, Code Interpreter, BrowserQwen, and a built-in tool-call parser; Qwen Code extends that further into a terminal-first agent with built-in tools and subagents. Those are not the same kind of strengths, and pretending they are the same leads to shallow conclusions. (Google AI for Developers)
So the useful question is narrower and more honest. If you are building an AI pentesting workflow that treats the model as a governed local reasoning core, which family maps better to that role? And if you are building a tool-heavy, terminal-friendly, agentic execution layer, which family gives you more off-the-shelf surface area without hiding the new risk you are introducing? Once the question is framed that way, Gemma 4 and Qwen stop looking like direct substitutes and start looking like two different ways to assemble the middle of an offensive-security system. That distinction matters for buyers, builders, and researchers alike. (Penligent)
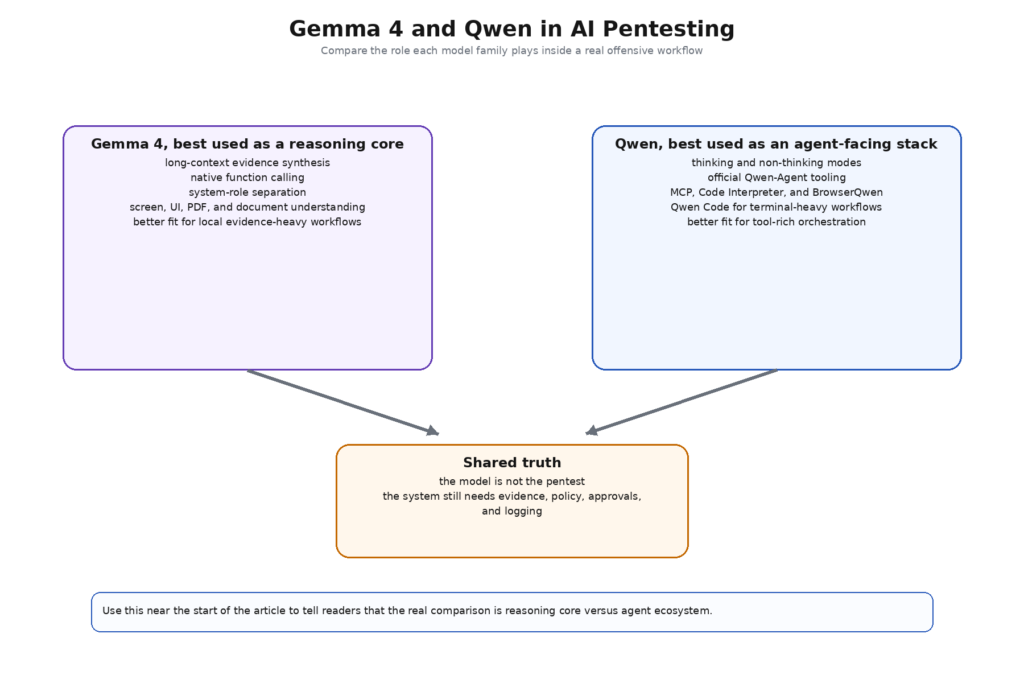
Gemma 4 vs Qwen for AI Pentesting starts with a fair comparison
The first mistake in this space is comparing one vendor’s base model to another vendor’s entire ecosystem. For a fair discussion, the cleanest model-to-model comparison is Gemma 4 31B against Qwen3 32B, with Qwen3 30B-A3B as the more agent-leaning open MoE-style alternative in the same family. Google’s Gemma 4 model card lists a dense 31B model and a 26B A4B MoE model, both with 256K context. The official Qwen3 repository lists dense 32B plus 30B-A3B and 235B-A22B MoE variants, and it describes the family as supporting seamless switching between thinking and non-thinking modes. (Google AI for Developers)
The second mistake is hiding multimodality inside a language-model comparison. Gemma 4 31B natively supports text and image input as part of the same model family, and Google’s model card explicitly lists document and PDF parsing, screen and UI understanding, OCR, and chart comprehension among core capabilities. Qwen can absolutely compete on multimodal work, but the official way to do that is usually not plain Qwen3. It is Qwen3-VL or Qwen3.5-class multimodal models. Qwen3-VL’s own repository describes it as the strongest vision-language model in the Qwen series to date, with a visual-agent orientation, native 256K context, and 1M context extension via YaRN. That means the “Gemma 4 vs Qwen” answer changes depending on whether you mean Qwen3 language models or the broader Qwen multimodal and agent stack. (Google AI for Developers)
The third mistake is assuming pentesting should care most about vendor benchmark tables. It should not. Vendor benchmark tables are good at telling you how a vendor wants its model family to be understood. They are not good at telling you how the model will behave when given screenshots from an admin portal, a partially authenticated browser trace, some JavaScript-extracted routes, a role-diff matrix, and a requirement not to exceed scope or trigger destructive actions. Pentesting is a systems problem. The model matters, but only inside the control plane wrapped around it. That is the same lesson public pentest-AI writing keeps returning to: the durable question is not “which model explains nmap output best,” but “which system can move from raw signal to verified finding without losing control.” (Penligent)
A fair comparison therefore has four layers. First comes the model itself: context length, reasoning mode, input types, and core inference behavior. Second comes the tool surface: function calling, parser support, agent frameworks, and terminal integration. Third comes the guardrail surface: how easy it is to keep policy, scope, and execution separate from the model. Fourth comes the operational surface: how easily the model and its tooling can be deployed locally, governed, audited, and kept out of the wrong network path. Once you compare Gemma 4 and Qwen at those four layers, the choice becomes much less ideological and much more practical. (Google AI for Developers)
The official capability surface that matters in AI pentesting
Before talking about which model is better, it is worth looking at what Google and Qwen actually document publicly, because the safest conclusions usually come from the boring parts of the docs, not from launch-day hype. Google’s Gemma 4 materials say the 31B dense and 26B A4B medium models support 256K context, configurable thinking, multimodal input, function calling, and native support for the sistem role. Google also documents the 31B model’s approximate inference memory requirements at 58.3 GB in BF16, 30.4 GB in 8-bit, and 17.4 GB in Q4_0, while warning that context and software overhead are extra. Qwen’s official Qwen3 repository documents dense and MoE models from 0.6B up through 32B, 30B-A3B, and 235B-A22B, plus switching between thinking and non-thinking modes and long-context handling that the repo describes as 256K, extendable to 1 million tokens. (Google AI for Developers)
What matters for pentesting is not only whether those features exist, but what kind of work they make easier. Long context is valuable when a model needs to reason over evidence bundles. Native function calling is valuable when the model should request bounded actions instead of printing arbitrary command strings. Native support for the sistem role matters because a pentest control plane benefits from a hard separation between policy instructions and target evidence. Multimodal input matters if your workflow includes screenshots, internal PDFs, and UI-heavy applications. Thinking and non-thinking modes matter because offensive workflows contain both reasoning-heavy phases and fast repetitive phases. The danger is that different model families expose these strengths in very different shapes. Gemma 4 pushes more of them into the same family interface. Qwen pushes more of them into a broader ecosystem of model family plus official agent stack. (Google AI for Developers)
| Capability area | Gemma 4 official surface | Qwen official surface | Why it matters in AI pentesting | Kaynak |
|---|---|---|---|---|
| Core context window | Up to 256K on 31B and 26B A4B | 256K long-context understanding, extendable to 1M in Qwen3 repo language | Longer investigations need more room for recon, traces, notes, and role diffs | (Google AI for Developers) |
| Reasoning mode | Configurable thinking mode across Gemma 4 | Thinking and non-thinking modes, with explicit switching controls | Pentest flows alternate between deep analysis and lighter operational turns | (Google AI for Developers) |
| Function and tool use | Native function calling, plus explicit Google warning that execution must be validated externally | Qwen3 emphasizes tool usage, and Qwen-Agent adds native multi-step tool calling and parsing | Tool use is useful only when it is structured and controlled | (Google AI for Developers) |
| Multimodal path | Gemma 4 31B supports text and image input in the same family, including UI and PDF understanding | Qwen’s multimodal story lives mainly in Qwen3-VL and related families | Screenshot-heavy application testing changes what “better model” means | (Google AI for Developers) |
| Agent framework | No single official Gemma-first agent framework comparable to Qwen-Agent | Qwen-Agent officially supports MCP, Code Interpreter, BrowserQwen, and custom tools | Stronger official tooling can speed up agentic prototypes | (Qwen) |
| Terminal agent story | Function calling exists, but terminal tooling is not the main public story | Qwen Code is a terminal-first open-source agent for Qwen models | Repo review, scripting, and tool-heavy workflows often live in the terminal | (GitHub) |
Even that table can mislead if read too casually. The fact that Qwen has a broader official tooling surface does not automatically make it better for AI pentesting. It means Qwen is easier to position as a model family inside an agent stack. The fact that Gemma 4 puts multimodality, system-role support, function calling, and local deployability into a single documented family does not automatically make it stronger overall. It means Gemma is easier to position as a controlled local reasoning layer. Those are different system-design choices, and a pentesting team can reasonably prefer one or the other based on where the most expensive part of its workflow lives. (Google AI for Developers)
Gemma 4 maps naturally to local pentest reasoning
Gemma 4’s strongest case in offensive security is not that it is the most agentic open model on paper. It is that Google’s own documentation makes it unusually easy to use it as a local reasoning core without pretending that the model itself should own execution. Google documents long context, system-role support, function calling, and a set of multimodal capabilities that line up almost suspiciously well with real pentest evidence: document and PDF parsing, UI and screen understanding, OCR, and chart comprehension. Google’s function-calling guide also states the most important guardrail plainly: a Gemma model cannot execute code on its own, and any generated code must be run and validated by the application with safeguards in place. That is exactly the right mental model for offensive security. (Google AI for Developers)
Why does that matter? Because the hardest middle section of pentesting is usually not exploitation syntax. It is evidence interpretation. It is reading a client bundle and deciding whether /api/v1/admin/export is probably reachable only from a privileged role or whether the client is masking a weaker server-side boundary. It is comparing screenshots of two user roles and deciding whether a hidden control is worth a read-only validation step. It is taking an authenticated replay diff and recognizing that the same business object is exposing different field sets under different roles in a way that suggests broken object-level authorization. A model that can keep more of that evidence in active context and reason over UI clues, text traces, and extracted routes inside one interface is genuinely useful. (Google AI for Developers)
Gemma 4 also benefits from a cleaner story about local control. Google’s model docs place the 31B and 26B A4B models in consumer GPU and workstation territory, while the smaller models are explicitly described as on-device friendly. The published memory table makes clear that 31B is not a casual laptop toy, but it is still a model family you can reason about inside a private deployment plan rather than only as a hosted API dependency. That matters when the evidence includes internal screenshots, raw traces, partially redacted reports, or design artifacts that teams do not want moving through more systems than necessary. In a pentest program, local inference is rarely about ideology. It is usually about evidence control. (Google AI for Developers)
There is another subtle advantage in Gemma 4’s prompt and role structure. Google’s prompt-formatting docs show explicit control tokens for sistem, userve model turns, plus separate agentic and reasoning control tokens. That matters in a guarded pentest architecture because policy, scope, and approval rules should not live in the same textual soup as the target evidence. Security teams often talk about this problem as prompt hygiene, but the deeper issue is authority separation. A model that is easier to keep inside a structured conversation boundary is easier to wrap in a safer control plane. Gemma 4 is not unique in supporting roles, but Google’s documentation puts that capability right next to reasoning and tool control instead of treating it as an implementation footnote. (Google AI for Developers)
The practical result is that Gemma 4 feels like a model family that wants to sit behind a normalization layer. Evidence comes in from collectors, gets turned into structured records, lands inside a long-context prompt or retrieval frame, and the model returns hypotheses, rankings, and action requests rather than commands. That is exactly how a serious AI pentesting workflow should behave. Public Penligent writing on AI pentesters uses almost the same framing when it defines an AI pentester as a governed system that shrinks the distance between raw signal and verified finding rather than as a toy chatbot or autonomous exploit bot. That is the most useful place to put Gemma 4 in the stack. (Penligent)
This does not mean Gemma 4 is obviously better at every pentesting task. It means the family’s documented shape aligns very well with a security architecture in which the model is powerful but not sovereign. That is a big distinction. In many offensive programs, the hardest problem is not “how do I make the model do more.” It is “how do I make the model do only the right amount, while still being useful.” Gemma 4’s public design and documentation make that discipline easier to argue for. (Google AI for Developers)
Qwen maps naturally to a tool-heavy agent stack
Qwen’s strongest case in AI pentesting sits somewhere else. If Gemma 4 feels like a clean local reasoning core, Qwen feels like an ecosystem that has already decided tool use is part of the product story. The Qwen3 repository describes the family as supporting seamless switching between thinking and non-thinking modes, dense and MoE models, 256K long-context understanding extendable to 1 million tokens, and expertise in agent capabilities with external tool integration in both thinking and unthinking modes. That is already a more overtly agent-facing posture than what Google says about Gemma 4. (GitHub)
Then the official ecosystem takes over. Qwen-Agent’s documentation lists native support for parallel and multi-step tool calling, MCP integration, Code Interpreter, web search and extraction, custom tools, context management, and a browser-oriented assistant called BrowserQwen. The Qwen Code repository extends that into a terminal-first open-source agent optimized for Qwen models, with built-in tools, subagents, IDE integration, and a workflow designed for people who live in command lines and codebases. This is not a minor difference. For teams whose pentest workflow already depends on scripting, repo review, lab automation, terminal controllers, or custom tool registries, Qwen’s official stack reduces the amount of glue they need to write before the system looks like an agent instead of a chat wrapper. (Qwen)
That matters because a surprising amount of AI pentesting work is not web-page reasoning. It is workbench reasoning. You are reading code, extracting routes, triaging large artifacts, transforming evidence, writing helper scripts, or orchestrating repeated validation steps. Qwen Code is not a pentesting framework, and it would be irresponsible to market it that way. But it is a strong example of why Qwen feels more natural once a workflow becomes terminal-heavy. It is officially described as an open-source AI agent for the terminal, optimized for Qwen series models, with rich built-in tools, subagents, and a “Claude Code-like” experience. That is exactly the kind of surface area security teams often end up repurposing for engineering-heavy offensive tasks. (GitHub)
The thinking and non-thinking split also has genuine operational value. Offensive workflows are heterogeneous. Some steps want deep reasoning: attack-path ranking, auth-flow interpretation, root-cause explanation. Other steps want speed and structure: classify this endpoint, rewrite this request template, summarize this trace, generate this report skeleton, or reformat these artifacts. Qwen3’s official repo documents two ways to control this behavior: tokenizer-level enable_thinking=False ve /think veya /no_think instructions in the system or user message. That makes Qwen attractive for teams that want one family to cover both “think hard” and “move fast” turns inside one orchestration layer. (GitHub)
There is, however, a catch that matters more in security than in ordinary developer tooling. The richer the tool surface, the harder the boundary problem becomes. Qwen-Agent explicitly ships a code_interpreter tool that executes Python code. It explicitly supports MCP integration. It explicitly supports external tools and custom tools. That power is useful. It is also a reminder that a Qwen-centered AI pentesting stack is likely to accumulate a wider execution surface faster than a Gemma-centered reasoning stack. In other words, the thing that makes Qwen easier to adopt for agentic automation is also the thing that makes governance more urgent. (Qwen)
Qwen’s own docs even surface a small but telling engineering footnote. In its Qwen3 repository, the serving notes for SGLang warn that request preprocessing can drop reasoning_content, which may make multi-step tool use with Qwen3 thinking models suboptimal, and the project recommends a workaround while fixes are in progress. That is not a scandal. It is something better: a realistic reminder that agentic quality in production depends on the whole serving path, not only on the model checkpoint. Security teams should read that sort of note as carefully as they read benchmark tables, because in offensive automation, plumbing quality often decides whether a capability survives contact with the real stack. (GitHub)
So Qwen is not “better for AI pentesting” in a universal sense. It is better if your definition of the problem already includes a real agent framework, terminal integration, code-interpreter-like capabilities, MCP connectivity, and multi-tool orchestration. If that is the stack you intend to build, Qwen gives you more official building blocks. The cost is that you now own a broader and more dangerous control surface. In pentesting, that is never a footnote. It is the story. (Qwen)
Multimodal evidence changes the comparison more than most model reviews admit
A lot of model comparisons still treat multimodality as a consumer feature. In AI pentesting, it is not. Screenshot-heavy and document-heavy workflows are common, and they are often exactly where LLM assistance becomes useful. Think about the actual evidence an offensive team handles: screenshots of admin portals, billing consoles, internal dashboards, moderation queues, export screens, feature-flag UIs, role-specific flows, architecture PDFs, and long support or implementation documents. A model that can reason across those inputs directly changes what “AI pentesting” can mean. (Google AI for Developers)
This is where Gemma 4 becomes unusually attractive. Google’s model card explicitly lists document and PDF parsing, screen and UI understanding, OCR, and variable-resolution image processing as core image-understanding capabilities. That means the same family that handles long text reasoning and function calling can also consume screenshots and documents in the same model lane. For teams building a local evidence-centric workflow, that is a big simplification. You do not need a separate multimodal family just to classify whether a screenshot looks like an internal export console, a staff-only moderation view, or a regular user dashboard with cosmetic differences. (Google AI for Developers)
Qwen can absolutely answer this challenge, but the answer usually comes through a different model line. Qwen3-VL’s repository describes a full visual-agent story, including GUI operation, stronger agent interaction capabilities, native 256K context, and document parsing features. If a team is willing to expand the “Qwen” side of the comparison from Qwen3 language models to Qwen3-VL plus Qwen-Agent, then the multimodal gap narrows a lot and may disappear for some workflows. But that becomes a different systems decision than “Gemma 4 31B vs Qwen3 32B.” It becomes “one family where multimodality is already part of the comparison” versus “a broader family where multimodality lives in a dedicated adjacent branch.” That is a meaningful architectural difference. (GitHub)
In pentesting terms, the distinction shows up in how messy the evidence pipeline becomes. If the model is going to inspect screenshots, PDFs, and UI state all the time, it is operationally easier when the reasoning model and the visual reasoning path are the same family and the same guardrail story. If the team already runs a more modular agent stack, splitting language reasoning from vision reasoning may be fine or even desirable. But the decision should be made consciously. Too many “best model for pentesting” discussions hide this complexity by praising a model’s screenshots or UI performance without saying whether that required a different model family or extra agent scaffolding. (Google AI for Developers)
This matters in real offensive work because multimodal evidence is often the shortest path to a correct next step. A backend export button visible only to one role may matter more than ten generic vulnerability summaries. A single PDF describing internal workflow approvals may matter more than a week of vague threat-model chat. A side-by-side screenshot of a basic user and a billing admin may reveal a privilege gradient worth testing before any HTTP replay happens. If the model cannot ingest that evidence naturally, human effort rises. If it can ingest it, but only through a separate subsystem with looser guardrails, system risk rises. The “best” choice depends on which of those two costs hurts more in your environment. (Penligent)
This is one place where the public Penligent framing is useful even if you ignore the product itself. Its recent writing on AI pentesters and pentest AI tools keeps returning to the same operational point: the hard problem is not polished summarization. It is turning diverse, stateful evidence into validated findings inside a controlled workflow. Multimodal evidence belongs squarely in that problem. Teams that treat it as a side feature will design worse comparisons and worse systems. (Penligent)
Tool use and guardrails change the threat model before they improve the workflow
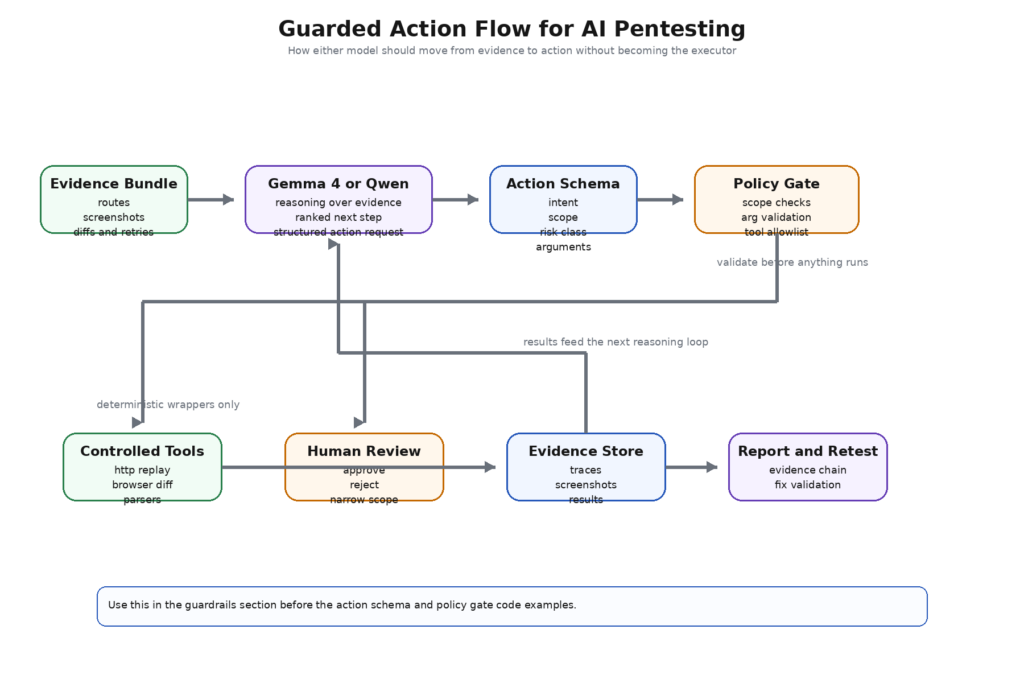
The moment a model stops being a reader and starts becoming a requester of actions, the threat model changes. OWASP’s Top 10 for LLM applications keeps prompt injection, insecure output handling, insecure plugin design, and excessive agency as separate categories because modern AI systems fail in exactly those ways. The GenAI Red Teaming Guide makes the same point from another angle: a serious evaluation has to look at the model, the implementation, the infrastructure, and the runtime behavior together. In pentesting, that warning lands even harder because the system is intentionally pointed at hostile or semi-hostile input, and because its tools are often more privileged than ordinary application helpers. (OWASP)
That is why the right architecture for either Gemma 4 or Qwen is not “model writes commands and tools run them.” The right architecture is “model emits structured action requests, policy evaluates them, operator approves where needed, and only then do deterministic wrappers execute.” Google’s own Gemma function-calling guide explicitly says the model cannot execute code on its own and that generated code must be validated before execution. That sentence should be read as an architectural principle, not a usage note. Qwen-Agent’s richer tool surface makes the same principle even more important, precisely because it includes things like Code Interpreter and MCP connectivity out of the box. (Google AI for Developers)
In practice, a safe action contract looks boring. That is good. The model should return typed fields like niyet, target_scope, risk_class, required_tool, arguments, evidence_basisve needs_approval. It should not return raw Bash or PowerShell for direct execution. It should not interpolate uncontrolled arguments into shell strings. It should not silently decide that a state-changing operation counts as “read-only.” A pentest control plane wants the model to behave like a planner and classifier, not like a root shell with better English. That is true whether the model is Gemma 4, Qwen, or anything else. (Google AI for Developers)
Here is the kind of action object that keeps a model useful without making it sovereign:
{
"intent": "verify_object_level_authorization",
"target_scope": {
"project_id": "acme-b2b-portal",
"asset": "app.target.example",
"route_group": "/api/v1/invoices"
},
"risk_class": "credentialed_read_only_replay",
"required_tool": "http_replay_runner",
"arguments": {
"method": "GET",
"candidate_object_ids": ["inv_1042", "inv_1043", "inv_1044"],
"role_profiles": ["basic_user", "billing_admin"]
},
"evidence_basis": [
"bundle_extract:/api/v1/invoices/{invoice_id}",
"ui_screenshot:billing_export_screen",
"response_diff:role_matrix_02"
],
"needs_approval": true
}
That schema is useful because it narrows the model’s responsibility. The model is responsible for describing what kind of check is warranted, under what scope, and on what evidence basis. The control plane is responsible for deciding whether the requested tool is allowed, whether the arguments are safe, whether the action fits the declared risk class, and whether an operator must approve it. Security teams that skip that separation usually rediscover the same problem under a different name: the model said something plausible, another system trusted it too much, and a dangerous tool became the real vulnerability. That is not an “AI bug.” It is an architecture bug. (OWASP)
A simple policy gate makes the distinction concrete:
ALLOWED_TOOLS = {
"passive_recon_runner",
"http_replay_runner",
"screenshot_diff_runner",
"js_endpoint_mapper",
"report_writer",
}
RISK_CLASSES = {
"passive": {"approval": False, "state_change": False},
"credentialed_read_only_replay": {"approval": True, "state_change": False},
"ui_navigation_only": {"approval": True, "state_change": False},
"state_modifying": {"approval": True, "state_change": True},
"prohibited": {"approval": True, "state_change": True},
}
def validate_action(action, allowed_assets):
asset = action["target_scope"]["asset"]
if asset not in allowed_assets:
return False, "asset outside scope"
tool = action["required_tool"]
if tool not in ALLOWED_TOOLS:
return False, "tool not allowed"
risk_class = action["risk_class"]
if risk_class not in RISK_CLASSES:
return False, "unknown risk class"
if risk_class == "prohibited":
return False, "blocked by policy"
return True, "allowed"
def dispatch(action):
# Deterministic wrapper, no raw shell interpolation
return f"queued:{action['required_tool']}"
This kind of wrapper is not glamorous, but it is what makes AI pentesting defensible. Public Penligent material on agentic security and AI pentesters has the same underlying thesis even when it is not talking about any specific model family: the path from raw signal to action has to be governed, reviewable, and evidence-backed. That is the right lens for comparing Gemma 4 and Qwen. The question is not who can call more tools. It is who fits more cleanly into the control model you can actually defend. (Penligent)
Recent CVEs explain the real difference better than vendor benchmarks do
Security teams should pay close attention to recent CVEs in agent frameworks and tool-execution layers because they reveal where model choice stops mattering and system design starts mattering a lot. These are not abstract safety debates. They are production failures that show what happens when natural-language systems get too close to privileged execution.
The most direct example is CVE-2026-27966 in Langflow. NVD describes a remote code execution flaw in the CSV Agent node prior to version 1.8.0. The issue was that the node hardcoded allow_dangerous_code=True, which automatically exposed LangChain’s Python REPL tool. That turned prompt injection into arbitrary Python and operating-system command execution. It is hard to imagine a better demonstration of why “stronger tool use” is not a free win in AI pentesting. If your stack makes it easy for a model to reach a general code-execution primitive, then a content-level manipulation problem can quickly become a server compromise problem. (NVD)
The lesson for the Gemma 4 versus Qwen comparison is not “Qwen is risky” or “Gemma is safe.” The lesson is that a Qwen-centered stack, because it gives you more official agent tooling and more immediate paths to code execution and MCP integration, will usually let you build a more capable agent faster. It will also let you build a more dangerous one faster. A Gemma-centered stack, because it nudges you more naturally toward external validation and controlled function-calling patterns, often makes it easier to keep the model on the reasoning side of the line. Whether that is an advantage depends on what you need, but it is absolutely a design tradeoff, not a matter of taste. (Google AI for Developers)
The second instructive case is CVE-2025-53355 içinde mcp-server-kubernetes. NVD says the MCP server used unsanitized input parameters inside a child_process.execSync call, enabling command injection and potential remote code execution, with a fix in version 2.5.0. That is the exact kind of bug that matters to AI pentesting architects because it is not really about Kubernetes at all. It is about the agent boundary. The moment a model can pass arguments into a tool wrapper that reaches a shell or a high-privilege API, every parameter becomes part of the attack surface. If you choose a richer tool-use ecosystem, this is the class of mistake you must be prepared to design against. (NVD)
The third case, CVE-2025-66414, moves the warning into local developer workflows. NVD says the official TypeScript SDK for MCP did not enable DNS rebinding protection by default for HTTP-based servers prior to version 1.24.0. If an unauthenticated HTTP MCP server ran on localhost without rebinding protection, a malicious website could exploit DNS rebinding to bypass browser same-origin restrictions and send requests to that local MCP server. This case matters because “local” is often used as a synonym for “safe” in AI tooling. It is not. Local inference and local tooling are valuable, but once they are network-exposed in the wrong way, they become just another reachable service with unusually interesting powers. (NVD)
The fourth case, CVE-2025-67511, hits even closer to the offensive-security use case. NVD describes a command-injection flaw in the Cybersecurity AI framework’s run_ssh_command_with_credentials() function, available to AI agents in versions 0.5.9 and below. Only password and command inputs were escaped, while username, host, and port remained injectable, and the issue had no fix at publication time. This is exactly what happens when an AI-oriented security tool exposes powerful actions through poorly bounded interfaces. The model is not the only security problem. The “helpful” tool around it becomes the vulnerability. (NVD)
| CVE | Affected area | What broke | Why it matters for Gemma 4 vs Qwen in AI pentesting | Kaynak |
|---|---|---|---|---|
| CVE-2026-27966 | Langflow CSV Agent | Prompt injection reached Python REPL because dangerous code execution was enabled | Richer agent tooling can collapse content-level manipulation into RCE if execution boundaries are loose | (NVD) |
| CVE-2025-53355 | mcp-server-kubernetes | Unsanitized parameters in execSync enabled command injection | Strong tool ecosystems demand strict argument validation and no shell interpolation | (NVD) |
| CVE-2025-66414 | MCP TypeScript SDK | DNS rebinding protection disabled by default for HTTP-based localhost MCP servers | Local agent tooling is not inherently safe when exposed through weak local network assumptions | (NVD) |
| CVE-2025-67511 | Cybersecurity AI framework | SSH helper exposed injectable fields to AI agent execution | Security-specific agent tooling can become a privileged injection sink if wrappers are careless | (NVD) |
These CVEs also help explain a subtle but important conclusion. If you are choosing a model family for AI pentesting, you should not ask only “which one reasons better.” You should ask “which one makes it easier for my team to keep reasoning and execution properly separated.” In many environments, that question will point toward Gemma 4 as a cleaner local reasoning core. In other environments, the team may still choose Qwen because the productivity gains from its official agent ecosystem are worth the extra governance cost. The correct answer is contextual, but the cost side of the tradeoff is no longer theoretical. CVE records have already started writing it down for us. (NVD)
A fair AI pentesting harness matters more than a benchmark screenshot
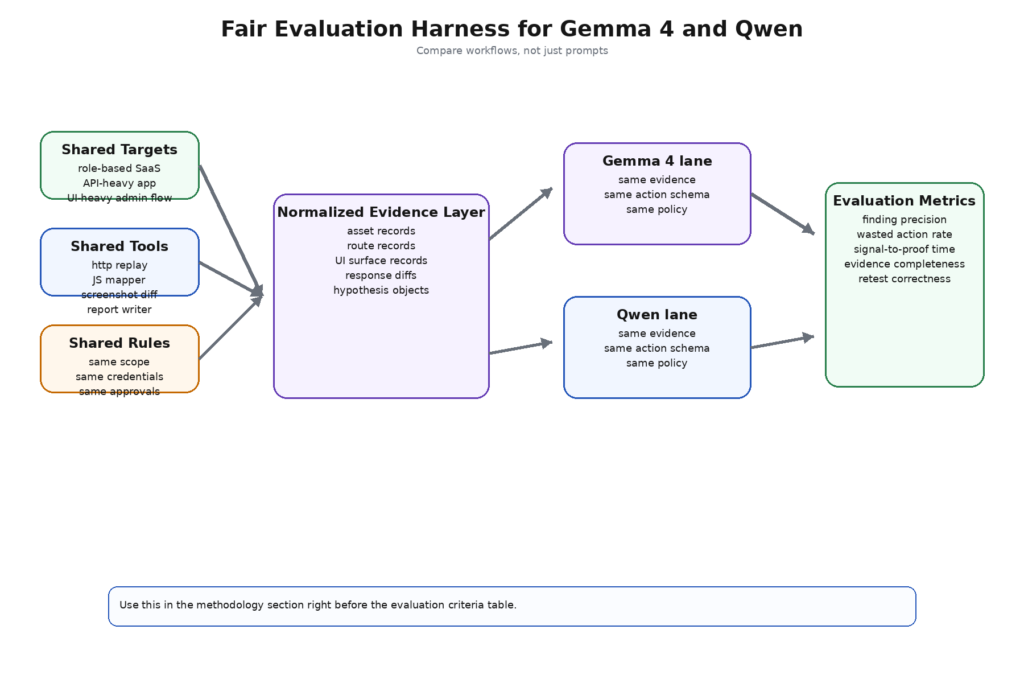
The way to compare Gemma 4 and Qwen in practice is not to ask them both for a clever payload and declare a winner. A serious evaluation needs a workload that looks like offensive work instead of like a prompt demo. The benchmark categories that matter are not “general chat,” “coding,” or “reasoning” in the abstract. They are the recurring sub-problems inside a pentest workflow.
The first category is recon synthesis. Can the model take passive scan output, route extraction, header metadata, screenshots, notes, and prior retries, then identify the small number of paths most likely to matter? This is where long context and evidence normalization matter more than raw model eloquence. A good result is not a longer list of ideas. It is a shorter, more defensible list. PentestGPT’s modular design was built precisely because free-form end-to-end state is hard for LLMs to preserve. That remains the correct mental model for comparing these systems. (USENIX)
The second category is authenticated flow reasoning. Can the model compare role behavior across browser and API evidence and infer which differences look like product design versus authorization failure? This matters because many valuable findings in real applications are not syntax bugs. They are trust-boundary bugs. That kind of reasoning needs more than code generation. It needs state retention and business-object interpretation.
The third category is tool selection and action proposal. Once the model has a hypothesis, does it request the right next action? A good model should propose a narrow, evidence-backed validation step. A weak one will say something generic like “try SQL injection,” “test IDOR,” or “inspect the API further.” The goal is not maximum creativity. It is high signal in the next investigative move.
The fourth category is long-context retention. Can the model remember what was already tried, what failed, which auth state mattered, and what evidence really supported the current hypothesis? This is where PentestGPT’s context-loss warning still bites, and where long context becomes valuable only if the surrounding evidence system is disciplined. (USENIX)
The fifth category is multimodal evidence handling. If screenshots, PDFs, or UI-heavy products are part of the workflow, can the model classify privileged surfaces and role differences without collapsing into vague description? Here Gemma 4’s in-family multimodal support is a structural advantage. Qwen can close the gap if the comparison expands to Qwen3-VL, but that changes the system shape and the model scope, so the test harness has to say so explicitly. (Google AI for Developers)
The sixth category is reporting and retesting quality. Can the model preserve the difference between observation, hypothesis, action, and conclusion? A polished but overconfident finding is worse than a blunt but reproducible one. Pentest systems gain value when they make evidence easier to reuse in retests, not when they make prose easier to admire.
A reasonable harness therefore evaluates not only model outputs, but workflow quality:
| Metrik | What it measures | Why it matters more than generic LLM benchmarks |
|---|---|---|
| Finding precision | How often a proposed path becomes a verified issue | Pentesting is about proof, not imagination |
| Wasted action rate | How many model-suggested actions are rejected, redundant, or blocked | A good model should reduce operator drag, not increase it |
| Signal-to-proof time | Time from first weak clue to verified or rejected hypothesis | The goal is faster, cleaner investigation loops |
| Kanıt bütünlüğü | Whether another engineer can reproduce the result from stored artifacts | Security work must survive handoff and retest |
| Approval burden | How much human review is needed per useful action | Guardrails must be workable, not ceremonial |
| Context efficiency | Whether the model uses active context well without drowning in noise | Long context is only useful if the prompt stays meaningful |
| Retest correctness | Whether the model can tell a fixed issue from a moved or partial issue | Retesting is one of the highest-value uses of AI assistance |
A useful evaluation harness also needs a strict configuration layer. Same target class, same tool wrappers, same evidence schema, same approval rules, same operator policy, same rate limits, same credential boundaries. If Gemma 4 gets screenshots and Qwen does not, the result is meaningless. If Qwen gets Qwen-Agent and Gemma gets only raw chat prompts, the result is meaningless. If one model is allowed to emit direct execution strings and the other must emit typed actions, the result is worse than meaningless because it teaches the wrong lesson. (OWASP Gen AI Güvenlik Projesi)
A minimal harness config can look like this:
project: ai-pentest-model-comparison
targets:
- class: role-based-saas-webapp
- class: api-heavy-b2b-portal
tools:
- passive_recon_runner
- js_endpoint_mapper
- http_replay_runner
- screenshot_diff_runner
- report_writer
evidence_schema:
- asset_record
- route_record
- ui_surface_record
- response_diff_record
- hypothesis_record
approval_rules:
passive: auto
credentialed_read_only_replay: human_review
state_modifying: blocked
metrics:
- finding_precision
- wasted_action_rate
- signal_to_proof_time
- evidence_completeness
- retest_correctness
That sort of harness is not as fun as a benchmark leaderboard, but it answers the right question. It tells you whether the model family fits the offensive workflow you actually run. For security teams, that is a much more important result than knowing which vendor scored higher on a vendor-selected reasoning benchmark. (USENIX)
Gemma 4 versus Qwen is really local reasoning versus broader agent surface
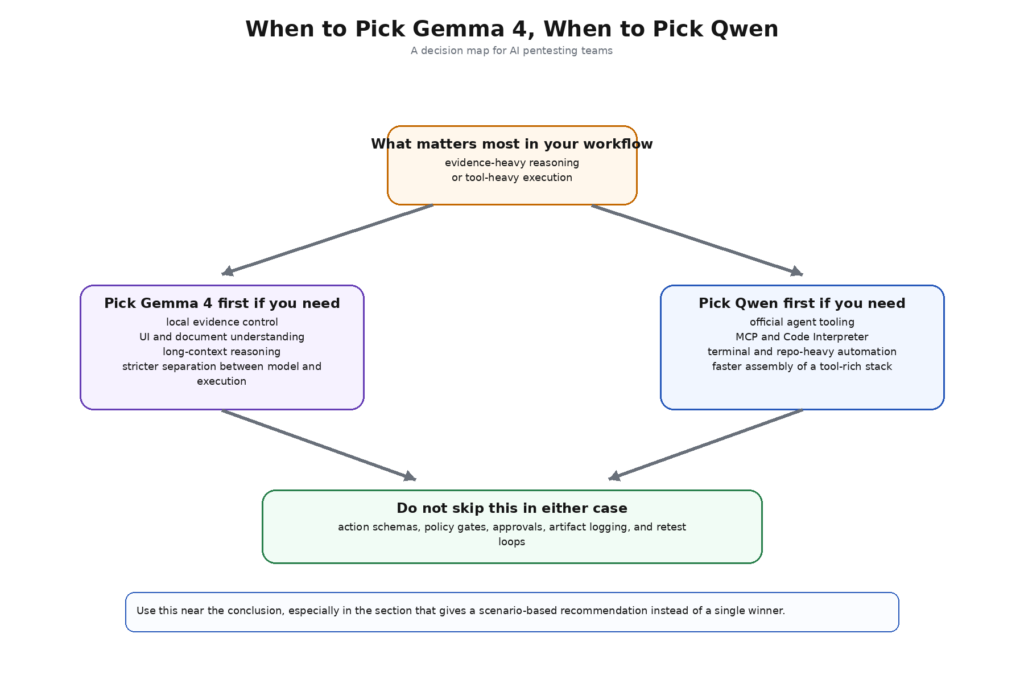
Once the comparison is grounded in workflow, the tradeoff becomes clearer. Gemma 4 is easier to recommend when the team wants one local family to reason across text, screenshots, PDFs, and structured tool requests inside a guarded workflow. Google’s own docs make it easy to describe the model that way: 256K context on the larger models, built-in thinking, native function calling, explicit support for the sistem role, and image understanding that includes UI and document parsing. If the team’s biggest bottleneck is the human effort required to read evidence and decide what deserves validation, Gemma 4 is a very natural fit. (Google AI for Developers)
Qwen is easier to recommend when the team’s biggest bottleneck is not evidence interpretation but agent plumbing. If the desired stack includes MCP, code execution, browser-oriented assistants, terminal agents, local OpenAI-compatible serving, and the ability to swap between thinking and non-thinking turns inside one family and framework, Qwen gives you more official parts to work with. That makes Qwen a compelling choice for teams that already have strong execution governance and want to move faster on orchestration. It also makes Qwen the more dangerous default for teams that do not yet have that governance. (Qwen)
There is also a third, less obvious scenario. Some teams do not really want to build the control plane themselves. They want AI pentesting, but they want it as a workflow with evidence capture, authenticated testing, report generation, retesting, and reviewable boundaries already in place. Public Penligent material describes exactly that kind of governed offensive workflow rather than a generic chat assistant. Whether a team buys or builds, the requirement is the same: the model has to be only one layer of the system. If that idea sounds disappointingly unglamorous, it is probably a sign the design is maturing. (Penligent)
The biggest practical mistake is forcing one answer across all three scenarios. A local evidence-heavy workflow, a terminal-heavy agentic workflow, and a multimodal GUI-heavy workflow are not the same thing. Gemma 4 tends to win the first one more cleanly. Qwen tends to win the second one more cleanly. The third one depends on whether the Qwen side is allowed to expand into Qwen3-VL. Once you say that out loud, most of the false certainty around “best model for AI pentesting” disappears. (Google AI for Developers)
Common mistakes when teams compare Gemma 4 and Qwen for security work
The first mistake is comparing a model to an ecosystem. Gemma 4 31B is a model-family choice. “Qwen” often becomes shorthand for Qwen3, Qwen-Agent, Qwen Code, and sometimes Qwen3-VL all at once. That makes Qwen look stronger or weaker depending on what gets quietly bundled into the comparison. A fair article needs to say what layer is under test every time. (Google AI for Developers)
The second mistake is treating screenshots as a side feature. In many pentest workflows, screenshots are not cosmetic evidence. They are the shortest route to finding privilege differences, dangerous export paths, hidden actions, and administrative workflows. A comparison that ignores multimodal evidence is often really just comparing two models for note-taking. (Google AI for Developers)
The third mistake is rewarding aggressive tool use instead of safe tool use. A model that requests more actions is not necessarily a better pentest model. It may simply be a worse-governed one. The relevant question is whether those actions are scoped, justified, and reproducible.
The fourth mistake is confusing local deployment with low risk. Recent MCP and agent-tool CVEs are enough to prove otherwise. A local service that is reachable, under-authenticated, or poorly wrapped is still an attack surface, whether it runs on localhost or not. (NVD)
The fifth mistake is letting the model write the report as if confidence were evidence. The best security writing is still evidence writing. AI helps when it preserves the chain from observation to action to conclusion. It hurts when it compresses that chain into persuasive text that hides uncertainty.
The final answer is not a single winner
If the question is which family is easier to use as a guarded local reasoning core for AI pentesting, the better answer is Gemma 4, especially Gemma 4 31B. The official feature set lines up unusually well with what evidence-heavy offensive workflows actually need: long context, native function calling, sistem-role support, UI and PDF understanding, and an explicit vendor warning that execution must remain outside the model and inside validated application logic. That is a healthy shape for security work. (Google AI for Developers)
If the question is which family is easier to use as a broader open agent stack with official tooling for function calling, MCP, code execution, terminal workflows, and browser assistance, the better answer is Qwen. The combination of Qwen3, Qwen-Agent, and Qwen Code gives builders more official components for agentic execution than Gemma currently does. That is a real strength, not a cosmetic one. It also means the team must treat tool misuse, execution boundary design, and local-service hardening as first-class work items rather than as later polishing. (Qwen)
If the question is which side is better for multimodal pentesting with screenshots and document-heavy evidence, the answer is more conditional. Gemma 4 makes that story simpler if you want one family that already includes those capabilities in the same model line. Qwen can absolutely compete if the comparison expands to Qwen3-VL, but that is a different systems choice than plain Qwen3 plus agent tooling. The honest answer is not “Gemma wins” or “Qwen wins.” The honest answer is “decide first whether you are choosing a model, an agent ecosystem, or a multimodal security workbench.” (Google AI for Developers)
That is the real verdict. Gemma 4 is the cleaner choice for teams that want a governed local model to think, compare, rank, and explain. Qwen is the cleaner choice for teams that want the wider official agent surface and are prepared to own the sharper security edges that come with it. In AI pentesting, that is often the most honest kind of winner you can name. (Penligent)
Further reading
Google AI for Developers, Gemma 4 model card ve Gemma 4 model overview, for context length, multimodal capabilities, system-role support, and memory requirements. (Google AI for Developers)
Google AI for Developers, Function calling with Gemma 4 ve Gemma 4 Prompt Formatting, for the execution warning and the role plus control-token design. (Google AI for Developers)
Google AI for Developers and Google Open Source Blog, Gemma releases ve Gemma 4 under Apache 2.0, for release timing and licensing context. (Google AI for Developers)
Qwen official repositories and docs, Qwen3, Qwen-Agentve Qwen Code, for model-family scope, thinking and non-thinking controls, MCP, Code Interpreter, and terminal-agent workflows. (GitHub)
Qwen official multimodal materials, Qwen3-VL, if your AI pentesting workflow depends heavily on screenshot, GUI, or document understanding. (GitHub)
USENIX Security 2024, PentestGPT, for the most useful public research framing on where LLMs help inside penetration testing and why modular design matters. (USENIX)
OWASP, Top 10 for Large Language Model Applications ve GenAI Red Teaming Guide, for prompt injection, insecure output handling, excessive agency, and whole-system evaluation. (OWASP)
NIST and MITRE, AI 100-2 Adversarial Machine Learning ve MITRE ATLAS, for AI threat modeling and system-level security language. (NIST Bilgisayar Güvenliği Kaynak Merkezi)
NVD records for CVE-2026-27966, CVE-2025-53355, CVE-2025-66414ve CVE-2025-67511, because agent and tool boundaries are already failing in the wild. (NVD)
Penligent Hacking Labs, AI Pentester in 2026, Agentic AI Security in Production, Pentest AI Tools in 2026, AI Pentest Tool, What Real Automated Offense Looks Like in 2026ve Best AI Model for Pentesting, for workflow-centric perspectives closely related to this topic. (Penligent)

