Die Phrase KI-Assistent für das rote Team Das klingt präzise, bis man versucht, einen zu kaufen, zu bauen oder ihm in einem tatsächlichen Einsatz zu vertrauen.
In der Praxis wird die Bezeichnung auf mindestens vier verschiedene Dinge angewandt. Manchmal ist damit ein Sicherheits-Chatbot gemeint, der ein CVE erklären oder einen Burp-Workflow vorschlagen kann. Manchmal ist damit ein Copilot gemeint, der Protokolle liest und nächste Schritte vorschlägt, während ein Mensch die eigentlichen Tests durchführt. Manchmal bedeutet es einen Agenten, der einen Browser bedienen, HTTP-Anfragen abspielen, Code untersuchen und Tools aufrufen kann. Manchmal handelt es sich um eine umfassendere Validierungsplattform, die Erkundung, Hypothesenbildung, Verifizierung und Berichterstellung miteinander verknüpfen kann. Wenn man diese Bereiche in einer Kategorie zusammenfasst, wird der Teil ausgeblendet, auf den es bei der offensiven Arbeit am meisten ankommt: ob das System dazu beitragen kann, dass reproduzierbare Beweise unter expliziten Zwängenund nicht nur plausibler Text. NIST definiert Penetrationstests nach wie vor als eingeschränkte Sicherheitstests, bei denen versucht wird, Sicherheitsfunktionen zu umgehen, und SP 800-115 verankert technische Tests nach wie vor in der Planung, Ausführung, Analyse und Schadensbegrenzung und nicht in freien Experimenten. Das externe Red-Teaming-Papier von OpenAI definiert KI-Red-Teaming ähnlich als strukturierte Anstrengung, um Fehler und Schwachstellen in einem KI-System zu finden, und nicht als einen vom Systemverhalten losgelösten Schnelligkeitswettbewerb. (csrc.nist.gov)
Diese Unterscheidung ist jetzt noch wichtiger, weil die Risikooberfläche nicht mehr darin besteht, dass das Modell etwas Seltsames gesagt hat. Das KI-Red-Team von Google bringt es auf den Punkt: Viele der wichtigen Sicherheitsprobleme treten erst dann auf, wenn ein Modell in Produkte integriert wird und die Möglichkeit erhält, zu handeln oder auf sensible Informationen zuzugreifen. Anthropic vertritt einen ähnlichen Standpunkt für browserfähige Agenten, bei denen jede Seite, jedes eingebettete Dokument und jede Aktionsoberfläche zu einem potenziellen Injektionspfad wird. Die offizielle Dokumentation zum Model Context Protocol macht dieselbe Verschiebung aus einem anderen Blickwinkel sichtbar: Sobald ein Assistent mit Tools, OAuth-Flows, APIs von Drittanbietern, lokalen Diensten und externen Ressourcen interagieren kann, hört das Problem auf, sich nur auf das Verhalten des Modells zu beschränken und wird zu einem Problem der gesamten Sicherheitsarchitektur. (Google Wolke)
Ein nützlicher KI-Assistent für das rote Team ist also nicht "ein LLM für Hacker". Er ist ein Assistent für von Menschen überwachte offensive Tests das die Organisation, Ausführung, Verifizierung und Dokumentation von Teilen eines autorisierten Auftrags innerhalb einer begrenzten Kontrollebene unterstützt. Die Kontrollebene ist ebenso wichtig wie das Modell. Sie definiert Umfang, Identitäten, Genehmigungsregeln, Werkzeugberechtigungen, Nachweisanforderungen und Bereinigungserwartungen. Ohne sie ist der Assistent in der Regel entweder zu schwach, um von Bedeutung zu sein, oder zu gefährlich, um ihm zu vertrauen. (csrc.nist.gov)
KI-Red-Team-Assistent, Assistent, Kopilot, Agent oder Plattform
Bevor man sich über Produktaussagen oder technische Entscheidungen streitet, ist es hilfreich, die Hauptkategorien zu unterscheiden.
| Kategorie | Typische Fähigkeiten | Was sie in der Regel nicht zuverlässig leisten kann | Hauptausfallmodus |
|---|---|---|---|
| Sicherheits-Chatbot | Konzepte erläutern, Protokolle zusammenfassen, Befehle entwerfen, CVEs diskutieren | Aufrechterhaltung des Einsatzstatus, Überprüfung der Verwertbarkeit, Sicherung von Beweisen, sicheres Operieren an lebenden Zielen | Produziert sicheren Text, der sich wie ein Beweis anfühlt |
| Pentest-Kopilot | Befehle vorschlagen, Befunde analysieren, bei der Triage von Scannerausgaben helfen, Notizen machen | Durchsetzung des Geltungsbereichs, unabhängige Validierung der Auswirkungen, End-to-End-Kontrolle der Instrumente | Wird wie ein Operator statt wie ein Berater behandelt |
| KI-Assistent für das rote Team | Verfolgen von Hypothesen, Aufrufen eingeschränkter Tools, Wiederholung von Anfragen, Unterstützung der Browservalidierung, Sammeln von Beweisen, Unterstützung von Wiederholungstests | Sicherer Betrieb ohne harte Grenzen, Improvisation bei fehlenden Kontrollen, Ersetzen der menschlichen Beurteilung von Auswirkungen | Scope Drift, Missbrauch von Injektionswerkzeugen, Falschmeldungen, die als Befunde dargestellt werden |
| Autonome Validierungsplattform | Koordinierung von mehrstufigen Arbeitsabläufen, Aufrechterhaltung des Gedächtnisses, Wiederholung von Tests in großem Umfang, Erstellung von Beweisbündeln und Berichten | Autorisierung, Governance oder menschliche Überprüfung auf magische Weise lösen | Übermäßige Autonomie und versteckte Annahmen werden zu einem systemischen Risiko |
Dies ist keine semantische Übung. Es ändert die Art und Weise, wie Sie das System bewerten, welche Berechtigungen Sie ihm geben und wie der Erfolg aussieht. In den öffentlichen Unterlagen zu Security Copilot von Microsoft wird ein Agent als halbautonome oder autonome Recheneinheit definiert, die Bedingungen wahrnehmen, Entscheidungen treffen und verbundene Tools verwenden kann. Außerdem wird zwischen statischer und dynamischer Werkzeugauswahl unterschieden, und diese Unterscheidung ist bei offensiven Arbeitsabläufen direkt relevant: Ein System, das nur eine festgelegte Reihe von Werkzeugen innerhalb eines definierten Laufs aufrufen kann, ist viel einfacher zu verstehen als ein System, das sein Werkzeuguniversum während des Laufs dynamisch erweitern kann. In den FAQ zu den Agenten von Microsoft wird auch betont, dass Administratoren die Identität des Agenten und die rollenbasierte Zugriffskontrolle festlegen, was eine gute Grunderinnerung daran ist, dass jeder Assistent, der sinnvolle Arbeit leistet, einen expliziten Sicherheitsprinzipal und keine implizite Vertrauensblase benötigt. (Microsoft Lernen)
Der Unterschied zwischen "Assistent" und "Agent" ist beim Red Teaming noch wichtiger als bei der Blue Team Automation. Auf der defensiven Seite kann ein Agent oft auf Arbeitsabläufe wie Triage, Anreicherung oder Empfehlung beschränkt sein. Bei der offensiven Arbeit kann dasselbe Muster Netzwerkzugriff, authentifizierte Sitzungen, Browser-Aktionen, das Lesen lokaler Dateien oder die Ausführung von Befehlen bedeuten. Das bedeutet, dass ein KI-Red-Team-Assistent das Workflow-Bewusstsein eines Agenten, aber die Betriebsdisziplin eines regulierten Test-Harnischs benötigt. Wenn Sie ihn wie ein besseres Chat-Fenster behandeln, werden Sie ihn entweder zu wenig nutzen oder die Kontrolle über ihn verlieren. (Microsoft Lernen)
Was sich ändert, wenn das Modell handeln kann
Der Hauptfehler in vielen Gesprächen über KI-Sicherheit besteht darin, dass das Modell isoliert betrachtet wird, während das Drumherum außer Acht gelassen wird. Das Red-Team-Papier von OpenAI definiert KI-Systeme ausdrücklich als ein oder mehrere Modelle, die mit zusätzlichen Komponenten wie Dateneingaben, Hardware, Software und Schnittstellen integriert sind. Das ist die richtige Analyseeinheit für einen Red-Team-Assistenten. Ein Modell ohne Hilfsmittel kann immer noch Anweisungen weitergeben oder halluzinieren. Ein Modell mit einem Browser, lokalem Dateisystemzugriff, Shell-Ausführung und ein paar MCP-Servern kann Verzweigungen löschen, Geheimnisse hochladen, authentifizierte Aktionen nachspielen oder seine eigenen nachgelagerten Überlegungen vergiften. (cdn.openai.com)
Laut Googles AI Red Team ist das Risiko von Soforteinspeisungen gestiegen, da sich Agenten von der einfachen Beantwortung von Fragen zu komplexen, mehrstufigen Arbeitsabläufen entwickelt haben, die gleichzeitig sensible Daten erfassen und kritische Aktionen durchführen. Anthropic sagt, dass Browser-Agenten eine große Angriffsfläche haben, weil jede Webseite, jedes eingebettete Dokument und jedes dynamische Skript ein potenzieller Injektionsvektor ist und weil Browser-Agenten viele verschiedene Aktionen wie Navigation, Ausfüllen von Formularen und Downloads durchführen können. Der OWASP-Leitfaden zu Prompt Injection enthält einen wichtigen Hinweis für alle, die hoffen, dass Abrufen oder Feinabstimmung das Problem lösen: Weder RAG noch Feinabstimmung mindern die Schwachstellen von Prompt Injection vollständig. (Google Wolke)
Die Veränderung ist nicht nur technischer Natur. Sie ist operationell. Ein statischer Scanner versagt auf bekannte Weise: unvollständige Abdeckung, verrauschte Signaturen, unzureichender Kontext. Ein aktiver Assistent versagt auf komplexe Weise. Er kann eine Scope-Notiz falsch lesen, nicht vertrauenswürdige Anweisungen von einer Seite übernehmen, ein unsicheres Werkzeug wählen, eine zustandsverändernde Aktion durchführen und dann das Ergebnis so beschreiben, dass es intern kohärent klingt. Aus diesem Grund ist die Frage, wie intelligent das Modell ist, zweitrangig. Die primäre Frage ist, ob das System gezwungen werden kann, sich wie ein eingeschränktes Testinstrument anstelle eines Allzweckoperators zu verhalten. (Google Wolke)
Ein Bedrohungsmodell für einen KI-Red-Team-Assistenten
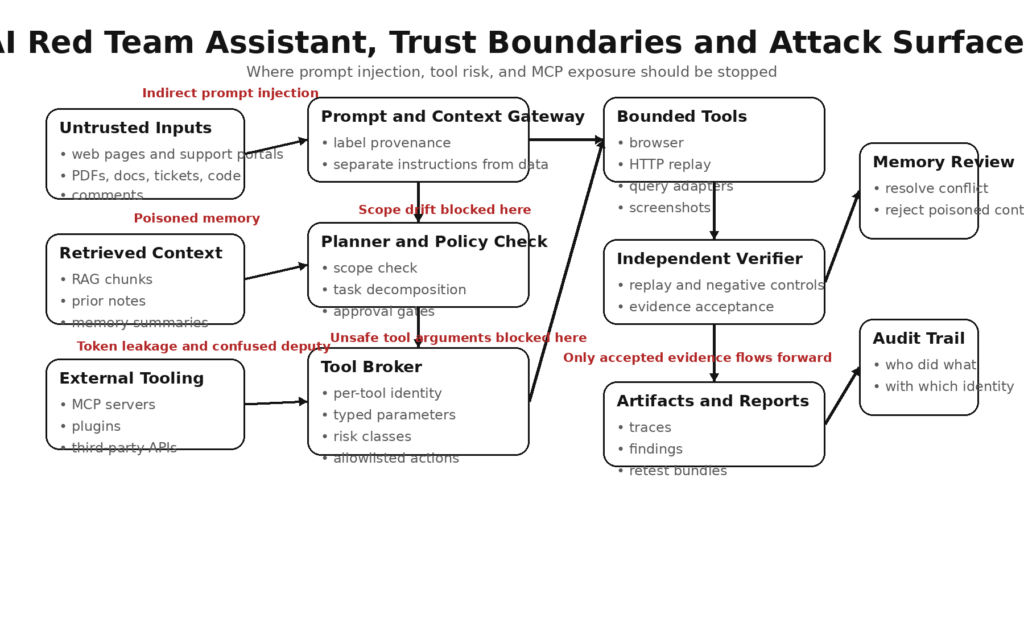
Wenn Sie verstehen wollen, wo diese Systeme versagen, modellieren Sie den Assistenten als eine Kette mit sechs Angriffsflächen: Eingaben, Speicher, Werkzeuge, Protokolle, Umgebung und Ausgaben.
Eingaben
Zu den Eingaben gehören direkte Benutzeraufforderungen, Issue Tickets, interne Notizen, API-Dokumentation, PDFs, HTML, RAG-Kontext, E-Mails, Commit Diffs und Scanner-Ausgaben. Jedes dieser Elemente kann Anweisungen, irreführende Artefakte, versteckten Text oder gegnerisches Framing enthalten. Der Bericht von Unit 42 über webbasierte indirekte Prompt Injection ist hier wichtig, weil er zeigt, dass dies nicht mehr nur eine Laborkuriosität ist. Ihr Bericht beschreibt versteckte oder manipulierte Anweisungen, die in gutartigen Webinhalten, Kommentaren, Metadaten oder benutzergenerierten Texten eingebettet sind und später von LLM-basierten Tools bei normalen Aufgaben wie der Zusammenfassung oder Inhaltsanalyse verwendet werden. Sie berichten auch, dass sie in der freien Wildbahn mehrere unterschiedliche Techniken beobachtet haben und nicht nur ein einziges Spielzeugbeispiel. (Referat 42)
Speicher
Der Speicher klingt hilfreich, bis er zu einem Kontaminationskanal wird. In einem Speicher können sich falsche Annahmen, zu vertrauenswürdiges Benutzerfeedback, bösartige Zusammenfassungen oder von Angreifern kontrollierter Kontext ansammeln, der später als vertrauenswürdiger Betriebszustand behandelt wird. In den öffentlichen FAQ von Microsoft für Security Copilot-Agenten wird darauf hingewiesen, dass Benutzer Feedback einreichen können, das im Speicher abgelegt wird, und dass sie das Feedback auf Mehrdeutigkeit und Konflikte überprüfen sollten. Dies ist eine milde produktsprachliche Version einer schwerwiegenderen Sicherheitstatsache: Persistenter Speicher ist ein weiterer Ort, an dem Injektionen und Vergiftungen über eine einzelne Runde hinaus überleben können. (Microsoft Lernen)
Werkzeuge
Zu den Tools gehören Shells, Browser, HTTP-Clients, SQL- oder KQL-Abfrageadapter, Bildschirmschreiber, lokale Dateisysteme, Paketmanager, Git-Operationen und externe APIs. Das Risiko besteht nicht nur bei gefährlichen Tools. Sichere Tools werden gefährlich, wenn sie mit unsicheren Anweisungen oder hochwertigen Anmeldeinformationen verbunden sind. Ein Browser im Nur-Lese-Modus ist eine Sache. Ein Browser, der sich bei einer Verwaltungskonsole in der Produktion authentifizieren und durch Workflow-Entscheidungen klicken kann, ist eine andere. Ein Abfragetool kann für die Sammlung von Beweisen nützlich sein, aber die unsichere Handhabung von Parametern verwandelt es in eine Angriffsfläche. (Anthropisch)
Protokolle und Integrationen
Model Context Protocol, Plugin-Frameworks, Proxy-Server, OAuth-Bridges und Agent-SDKs bieten eine weitere Angriffsfläche. Die MCP-eigene Sicherheitsdokumentation warnt vor Problemen mit verwirrten Stellvertretern, schlechter Isolierung von Einwilligungen und Fehlern bei der Handhabung von Token. Dies sind genau die Arten von Problemen, die einen Assistenten von einem "Modell mit einem Werkzeug" in einen "schlecht isolierten Identitätsbroker mit Systemzugang" verwandeln. (Modell-Kontext-Protokoll)
Umwelt und Identität
Die Umgebung umfasst Containergrenzen, CI-Runner, Localhost-Dienste, SSH-Schlüssel, Cookies, API-Schlüssel und Cloud-Rollen. Teams gehen oft davon aus, dass lokal gleichbedeutend mit sicher ist, aber aktuelle CVEs im MCP-Ökosystem zeigen das Gegenteil. Wenn ein HTTP-basierter lokaler Server nicht über einen DNS-Rebinding-Schutz oder eine ordnungsgemäße Authentifizierung verfügt, kann eine bösartige Seite Dienste erreichen, von denen die Entwickler dachten, sie seien für das Web unsichtbar. (GitHub)
Outputs und nachgelagerte Maßnahmen
Die Ergebnisse sind nicht harmlos. Ein generierter Bericht kann falsche Schlussfolgerungen enthalten. Ein Vorschlag zur Abhilfe kann zu einer Fehlkonfiguration werden. Eine Pull-Anfrage kann eine Hintertür enthalten. Eine "sichere Zusammenfassung" kann eine vergiftete Anweisung enthalten, die später wieder konsumiert wird. Mit anderen Worten: Die Ausgabefläche des Assistenten kann zur Eingabefläche des nächsten Systems werden. Aus diesem Grund sind Beweise und Wiederholung wichtiger als Eloquenz. (csrc.nist.gov)
Das Bedrohungsmodell lässt sich in kompakter Form wie folgt darstellen:
| Oberfläche | Häufiges Scheitern | Echte Konsequenz | Priorität der Kontrolle |
|---|---|---|---|
| Benutzer- und Inhaltseingaben | Aufforderungsinjektion, versteckte Anweisungen, falscher Kontext | Unsichere Werkzeugwahl, Leckagen, falsch priorisierte Tests | Hoch |
| Speicher und Zusammenfassungen | Anhaltende Vergiftung, veraltete Annahmen | Wiederholte schlechte Handlungen und falsche Erkenntnisse | Hoch |
| Werkzeuge | Zu weitreichende Berechtigungen, schlechte Handhabung von Parametern | Befehlsausführung, Datenmissbrauch, Zustandsänderungen | Kritisch |
| MCP und Plugins | Token-Missbrauch, Zustimmungs-Verwirrung, Localhost-Exposition | Unbefugter API-Zugriff, Exfiltration, Proxy-Missbrauch | Kritisch |
| Umwelt | Übermäßige lokale oder Cloud-Privilegien | Kompromittierung von Hosts, Diebstahl von Anmeldeinformationen, zerstörerische Aktionen | Kritisch |
| Ausgänge | Ungeprüfte Schlussfolgerungen, vergiftete Artefakte | Schlechte Berichte, falsches Vertrauen, unsichere Folgemaßnahmen | Hoch |
Dies ist auch der Punkt, an dem viele Evaluierungen scheitern. Die Teams fragen, ob das Modell Nutzlasten erzeugen oder eine Kette zusammenfassen kann. Sie fragen nicht, ob der Assistent seine Beschränkungen beibehalten kann, nachdem er einen feindseligen Problemkommentar gelesen hat, ob er Beweise von Spekulationen unterscheiden kann oder ob er einen gefährlichen Pfad ablehnt, wenn ein angeschlossenes Tool diesen Pfad verfügbar macht. Das sind die Fragen, die darüber entscheiden, ob das System überhaupt in ein Verfahren gehört. (Google Wolke)
Was ein brauchbarer Assistent braucht, Umfang, Identität, Nachweis und Überprüfung
Ein seriöser KI-Red-Team-Assistent wird nicht durch das Aufsetzen einer Hülle auf ein Modell erstellt. Er wird gebaut, indem man dem Modell eine ein diszipliniertes Arbeitsumfeld.
Der Anwendungsbereich kommt zuerst
Die Automatisierung von Red Teams wird in dem Moment rücksichtslos, in dem der Umfang zu kurz kommt. Die NIST-Definitionen für Penetrationstests betonen spezifische Einschränkungen, und SP 800-115 legt den Rahmen für technische Tests auf die Planung vor der Ausführung. Ein Arbeitsassistent beginnt daher mit einem maschinenlesbaren Umfang: autorisierte Hosts, Testidentitäten, verbotene Aktionen, Ratenbeschränkungen, genehmigte Zeiten, Richtlinien für zerstörerische Aktionen, Anforderungen an die Datenverarbeitung und Regeln für die Aufbewahrung von Ergebnissen. Wenn der Geltungsbereich nur in menschlicher Prosa existiert, wird der Assistent ihn schließlich verletzen. (csrc.nist.gov)
Hier ist ein Muster zur Veranschaulichung:
Engagement:
name: "staging-multitenant-api-q2"
Bereich:
Domains:
- "staging.api.example.test"
ip_ranges:
- "203.0.113.0/28"
forbidden:
- "production"
- "kunden_daten_export"
- "credential_rotation"
Identitäten:
- Name: "Mieter_ein_Leser"
Berechtigungen: ["read_only"]
- Name: "Mieter_b_Leser"
permissions: ["read_only"]
Werkzeuge:
allow:
- "http_replay"
- "browser_readonly"
- "bildschirmfoto"
- "diff_responses"
- "grep_logs"
verweigern:
- "shell_exec"
- "git_push"
- "paket_install"
- "external_webhook"
Genehmigungen:
require_human_for:
- "state_changing_http"
- "credential_export"
- "externes_netz"
- "beliebiges_neues_Werkzeug"
Beweise:
require:
- "request_trace"
- "antwort_spur"
- "zeitstempel"
- "identität_kontext"
- "replay_result"
Der Sinn einer solchen Politik ist nicht die Bürokratie. Es geht darum, das Engagement in eine eingeschränkte Laufzeit zu verwandeln, so dass der Assistent seinen eigenen Betriebsbereich nicht unbemerkt ausweiten kann. Diese Entscheidung steht im Einklang mit Microsofts Unterscheidung zwischen statischer und dynamischer Werkzeugauswahl und mit MCPs Betonung der ausdrücklichen Zustimmung des Benutzers und der Werkzeugsicherheit. (Microsoft Lernen)
Das geringste Privileg muss real sein, nicht rhetorisch
Least Privilege klingt selbstverständlich, bis man sieht, wie viele Assistentenprototypen mit weitreichendem lokalem Dateisystemzugriff, in den Prozess geladenen Umgebungsvariablen, an leistungsstarke Benutzerkonten gebundenen Browsersitzungen und Tooladaptern, die alles erben, was der Host erreichen kann, ausgeführt werden. In der öffentlichen Dokumentation von Microsoft für Security Copilot-Agenten wird betont, dass Administratoren die Identität des Agenten und RBAC zuweisen. Das Sicherheitsmaterial von MCP warnt vor schlampigen Autorisierungsmustern und Token-Missbrauch. Dies sind keine Lektionen, die nur für Verteidiger gelten. In einem offensiven Assistenten muss jede Identität einen Zweck haben, und jeder Zweck muss enger gefasst sein als das vollständige Konto des menschlichen Bedieners. (Microsoft Lernen)
Das bedeutet separate Identitäten für das Lesen eines Wikis, die Wiedergabe von HTTP-Anfragen, die Aufnahme von Screenshots oder die Abfrage von Staging-Protokollen. Es bedeutet kurzlebige Anmeldeinformationen statt statischer Token. Es bedeutet, dass lokale Tools keine Cloud-Geheimnisse erben sollten, nur weil die Workstation sie zufällig hat. Es bedeutet, dass es keinen zweideutigen "Operator-Modus" geben sollte, in dem das Modell alles tun kann, was der Host tun kann. (Modell-Kontext-Protokoll)
Planer, Ausführender und Überprüfer müssen getrennte Rollen sein
Einer der häufigsten Fehler bei der Entwicklung von Agenten besteht darin, dass ein und dasselbe Modell Hypothesen aufstellt, ausführt, interpretiert und seine eigene Arbeit genehmigt. Das ist bei Demos effizient und bei echten Tests gefährlich. In dem OpenAI-Papier über externes Red Teaming wird argumentiert, dass Red Teaming eine Komponente eines umfassenderen Evaluierungsportfolios ist und den Anstoß für systematischere Evaluierungen geben kann. Die Methodik von AISI geht noch weiter in eine praktische Richtung, indem sie die Arbeit in Planung und Vorbereitung, Durchführung von Angriffen und Berichterstattung mit Verbesserungsplänen unterteilt. Diese Struktur ist nützlich, weil sie eine Trennung der Funktionen und nicht eine einzige allwissende Schleife impliziert. (cdn.openai.com)
Bei einem KI-Red-Team-Assistenten schlägt der Planer einen begrenzten Testauftrag vor. Der Ausführende führt eine erlaubte Aktion aus. Der Verifizierer fragt, ob die Beweise die Behauptung tatsächlich unterstützen. Der Reporter bündelt Artefakte, Kontext und Vorbehalte. Diese Rollen können immer noch modellgestützt sein, aber sie sollten nicht zu einer ungeprüften Erzählmaschine verschmolzen werden.
Ein minimales Überprüfungsmuster kann wie folgt ausgedrückt werden:
def accept_finding(f):
return all([
f.scope_check_passed,
f.primary_trace ist nicht None,
f.replay_trace ist nicht None,
f.identity_context ist nicht None,
f.negative_control_passed,
f.side_effects_documented,
f.impact_statement_is_supported
])
Das sieht einfach aus, weil es einfach sein sollte. Eine Feststellung wird nicht akzeptiert, weil das Modell überzeugend klingt. Er wird akzeptiert, weil das Beweisbündel die Messlatte übersteigt. Diese Denkweise trägt auch dazu bei, die halluzinierte Inflation des Schweregrads zu begrenzen, die einer der schnellsten Wege ist, das Vertrauen in KI-gestützte Tests zu zerstören. (csrc.nist.gov)
Protokolle müssen Artefakte sein, keine nachträglichen Überlegungen
Google betont in der Diskussion über sein KI-Red-Team strenge Einsatzregeln, keine echten Kundendaten bei Übungen und eine detaillierte Protokollierung der Aktivitäten. Das ist die richtige Vorgabe. Ein offensiver Assistent sollte Aufforderungen, Tool-Inputs, Tool-Outputs, Genehmigungen, die verwendete Identität, das betroffene Scope-Objekt und Evidenz-Hashes aufzeichnen. Ohne diese haben Sie keinen Assistenten, den Sie überprüfen können; Sie haben einen stochastischen Geschichtengenerator, der an Seiteneffekte gebunden ist. (Google Wolke)
Verifizierung muss Nicht-Determinismus berücksichtigen
Die herkömmliche Exploit-Verifizierung setzt ein gewisses Maß an Stabilität voraus. KI-verknüpftes Verhalten ist oft weniger stabil. In der praktischen Methodik von AISI wird darauf hingewiesen, dass Angriffssignaturen wiederholt werden sollten, da das Systemverhalten probabilistisch und nicht deterministisch sein kann. Die von Anthropic veröffentlichte Arbeit zur Abwehr von Browser-Prompt-Injection verwendet die Erfolgsrate von Angriffen bei wiederholten Versuchen und nicht eine einmalige Pass/Fail-Methode. Das sagt Ihnen etwas Wichtiges: Der Assistent sollte eine einmalige Antwortanomalie nicht zu einem bestätigten Befund erheben, ohne Wiederholungen, Kontrollvergleiche und konsistente Beweise. (Japan AISI)
Prompt Injection ist kein Chatbot-Bug, sondern ein Assistenten-Betriebsrisiko
Der Begriff "Prompt Injection" wird so oft diskutiert, dass er abstrakt zu klingen beginnt. Bei einem KI-Red-Team-Assistenten ist sie überhaupt nicht abstrakt. Sie ist oft der kürzeste Weg von "hilfreicher Automatisierung" zu "unsicherem delegiertem Verhalten".
OWASP definiert Prompt Injection als eine Schwachstelle, bei der Benutzer-Prompts das Verhalten oder die Ausgaben des Modells auf unbeabsichtigte Weise verändern, und weist ausdrücklich darauf hin, dass solche Anweisungen nicht für den Menschen sichtbar sein müssen, wenn sie vom Modell geparst werden. OWASP stellt auch fest, dass RAG und Feinabstimmung das Problem nicht vollständig entschärfen. Das ist wichtig, weil viele Assistenten als "unternehmenssicher" vermarktet werden, nur weil sie aus genehmigten Dokumenten lesen oder sich auf die Abfrage und nicht auf einen offenen Chat verlassen. Wenn diese Dokumente, Kommentare oder Seiten von einem Angreifer beeinflusst werden können, beseitigt die Abrufgrenze nicht die Injektionsgrenze. (OWASP Gen AI Sicherheitsprojekt)
Indirekte Prompt-Injektion ist für Assistenten besonders relevant, da Assistenten Inhalte als Teil des Arbeitsablaufs und nicht nur als Konversation konsumieren. Referat 42 beschreibt webbasierte indirekte Prompt Injection als manipulierte Anweisungen, die in gutartige Inhalte eingebettet sind, die ein LLM später bei Routineaufgaben verarbeitet. Sie beschreiben auch die beobachteten Angriffsabsichten, einschließlich der Umgehung von Überprüfungen, Phishing-Promotion, Datenlecks, Prompt-Lecks und nicht autorisierte Aktionen. Selbst wenn eine spezifische Kampagne nicht zu einer bestätigten Kompromittierung führt, ist das Bedrohungsmodell bereits realistisch genug, um für jeden von Bedeutung zu sein, der einen Handlungsassistenten entwickelt oder verwendet. (Referat 42)
Die Arbeit von Anthropic zur Browserabwehr macht das gleiche Risiko konkret. Ein browserfähiger Agent sieht eine große Menge an nicht vertrauenswürdigem Material und hat viele Möglichkeiten, darauf zu reagieren. Das Problem ist nicht auf exotische HTML-Tricks beschränkt. Eine normale Webseite, ein Support-Ticket oder eine Problembeschreibung kann zu einer Befehlsquelle werden, wenn der Assistent nicht in der Lage ist, aufgabenrelevante Daten von den Anweisungen des Angreifers zu trennen. Aus diesem Grund ist die Verwendung von Browsern nicht nur eine "bequemere Eingabe". Es ist eine Erweiterung der Angriffsfläche. (Anthropisch)
Dies hat direkte Auswirkungen auf offensive Testabläufe. Red Teams lesen ständig nicht vertrauenswürdige Inhalte: Dokumentationen von Bug Bounty-Programmen, offengelegte Repos, Changelogs, Help Center, durchgesickerte Konfigurationsfragmente, öffentliche Issue Tracker, Testkonten, interne Wikis während autorisierter Bewertungen und zielgesteuerte Anwendungsantworten. Ein Assistent, der diese nicht als gegnerische Eingaben behandeln kann, ist nicht sicher genug, um in den Arbeitsablauf integriert zu werden. (Google Wolke)
Das richtige Ziel besteht nicht darin, so zu tun, als ob die sofortige Injektion abgeschafft werden könnte. Es geht darum, den Assistenten so zu gestalten, dass Injektionen nirgendwo gefährlich landen können. Das bedeutet: Nur-Lese-Vorgaben, hochgradig reibende Grenzen um zustandsverändernde Werkzeuge, Nachverfolgung der Provenienz von Prompts, Inhaltskennzeichnung, Kontextkompartimentierung und Output-Verifizierung, die nicht auf die eigene Zusammenfassung des Modells über das, was gerade passiert ist, vertraut. (Anthropisch)
MCP, lokale Tools und der falsche Komfort von localhost
Wenn Prompt Injection das meistdiskutierte Problem bei der Sicherheit von Assistenten ist, dann ist die Integrationssicherheit im MCP-Stil das am meisten unterschätzte Problem.
MCP ist ein offenes Protokoll zur Verbindung von LLM-Anwendungen mit externen Daten und Werkzeugen. Die offizielle Dokumentation des Protokolls erörtert sowohl Komfortfunktionen als auch die damit verbundenen Sicherheitsaspekte, einschließlich Datenschutz, Benutzerzustimmung, Werkzeugsicherheit und speziellerer Probleme wie verwirrtes Stellvertreterverhalten. Das Dokument über bewährte Sicherheitspraktiken warnt davor, dass schlecht konzipierte MCP-Proxyserver es böswilligen Clients ermöglichen können, eine Autorisierung ohne ordnungsgemäße Zustimmung des Benutzers zu erhalten, insbesondere wenn gemeinsam genutzte statische Client-IDs, dynamische Registrierung und Zustimmungs-Cookies schlecht kombiniert werden. (Modell-Kontext-Protokoll)
Das ist für einen KI-Red-Team-Assistenten von Bedeutung, weil MCP die Vertrauensgrenze in zweierlei Hinsicht verändert.
Erstens wird dadurch die Vorstellung normalisiert, dass ein Modell über ein gemeinsames Protokoll mit vielen Werkzeugen kommunizieren kann. Das ist operationell nützlich und sicherheitsrelevant zugleich. Es erhöht die Anzahl der möglichen Aktionspfade und die Chance, dass ein sicher aussehender Tool-Aufruf ein leistungsfähiges Backend über einen Proxy erreichen kann, den der Anwender nicht vollständig versteht. (Modell-Kontext-Protokoll)
Zweitens ermutigt es die Entwickler, Dienste lokal auszuführen und davon auszugehen, dass Lokalität gleichbedeutend mit Sicherheit ist. Jüngste CVEs zeigen das Gegenteil. CVE-2026-34742 betraf das MCP Go SDK vor 1.4.0, da der DNS-Rebinding-Schutz für bestimmte HTTP-Handler standardmäßig deaktiviert war, was es einer bösartigen Website ermöglichte, einen MCP-Server mit lokalem Host zu erreichen, wenn keine anderen Schutzmaßnahmen vorhanden waren. Ähnliche DNS-Rebinding-Probleme wurden für das Python MCP SDK vor 1.23.0 und das TypeScript SDK vor 1.24.0 aufgedeckt. Die Lektion ist umfassender als eine einzelne Sprache: Wenn Ihr Assistent HTTP-basierte lokale Dienste offenlegt, wird der Browser Teil Ihrer Angriffsfläche, ob Sie das wollen oder nicht. (GitHub)
Das gleiche Muster zeigt sich bei Fehlern im Umgang mit Token. In den MCP-Sicherheitsrichtlinien wird Token-Passthrough ausdrücklich als Anti-Pattern bezeichnet, da es die Berechtigungsgrenzen und die Client-Isolierung untergraben kann. Ein Red-Team-Assistent, der Benutzertoken erbt, sie an andere Server weitergibt oder sie über Kontexte hinweg gemeinsam nutzt, kann betrieblich bequem und architektonisch unsolide sein. Das Ergebnis kann eine nicht autorisierte API-Nutzung sein, die wie legitimer Assistentenverkehr aussieht. (Modell-Kontext-Protokoll)
Für Praktiker sind die Mindestfragen einfach zu beantworten. Erhält jeder Kunde eine isolierte Zustimmung? Sind die Token auf eine bestimmte Zielgruppe beschränkt und kurzlebig? Beinhaltet die Exposition des lokalen Hosts Schutzmaßnahmen gegen DNS-Rebinding? Sind die Tools nach Risiko kategorisiert und nicht als allgemeine "Fähigkeiten" in einen Topf geworfen? Kann der Betreiber sehen, mit welcher Identität jedes Tool aufgerufen wurde? Wenn die Antwort vage ausfällt, ist die Integrationsebene nicht ausgereift genug für eine ernsthafte offensive Arbeit. (Modell-Kontext-Protokoll)
Echte CVEs, die direkt auf Designfehler von Assistenten zurückzuführen sind
Der einfachste Weg, um handfeste Behauptungen zur KI-Sicherheit zu durchschauen, ist ein Blick auf die tatsächlichen Schwachstellenklassen im Zusammenhang mit Agenten, MCP-Integrationen und mit Tools verbundenen Programmierumgebungen. Das interessante Muster ist, dass die wichtigsten Schwachstellen selten isoliert betrachtet "das Modell wurde geknackt" sind. In der Regel handelt es sich um Fehler bei Konfigurationsvertrauen, Identitätstrennung, lokale Exposition oder unsichere Tool-Vermittlung.
| CVE | Komponente | Art der Schwachstelle | Warum es für KI-Assistenten von Bedeutung ist |
|---|---|---|---|
| CVE-2025-53098 | Roo-Code | Ausführungspfad von der Eingabeaufforderung zur Konfiguration zum Befehl | Zeigt, wie ein Modell veranlasst werden kann, unsichere Konfigurationen zu schreiben, die später mit Zustimmung des Benutzers ausgeführt werden |
| CVE-2025-34072 | Veralteter anthropischer Slack MCP Server | Exfiltration sensibler Daten durch automatische Entfaltung von Links | Zeigt, wie Nachrichtenvorschauen und externe Links Daten, auf die der Assistent zugreifen kann, preisgeben können |
| CVE-2026-34742 | MCP Go SDK | DNS-Rebinding-Schutz bei bestimmten HTTP-Pfaden standardmäßig deaktiviert | Zeigt, dass localhost Teil der Web-Angriffsfläche ist, wenn es über HTTP zugänglich ist |
| CVE-2025-66416 | MCP Python SDK | Fehlender Standardschutz für DNS-Wiederanbindung | Dieselbe Lektion in einer anderen Laufzeit |
| CVE-2025-66414 | MCP TypeScript SDK | Fehlender Standardschutz für DNS-Wiederanbindung | Dieselbe Lektion in einer anderen Laufzeit |
| CVE-2026-33980 | Azure Data Explorer MCP-Server | KQL-Einspritzung in Werkzeug-Handlern | Zeigt, dass Abfragetools zu Backend-Injektionsflächen werden können, wenn die Parameter nicht sicher vermittelt werden |
CVE-2025-53098, Roo Code und die Gefahr, dass Prompts das Vertrauen umschreiben
Der GitHub-Hinweis zu CVE-2025-53098 beschreibt ein Problem in Roo Code, bei dem auf Projektebene .roo/mcp.json Konfiguration verwendet werden, um eine beliebige Befehlsausführung zu erreichen. In dem Advisory wird eine plausible Kette erläutert: Eine bösartige Eingabeaufforderung kann den Agenten dazu veranlassen, einen manipulierten Befehl in die Konfiguration zu schreiben, und wenn der Benutzer die Dateiänderungen automatisch genehmigt hat, kann eine beliebige Befehlsausführung folgen. Dies ist keine exotische LLM-Schwäche. Es handelt sich um eine klassische Grenzverletzung, bei der promptsgesteuerte Inhalte ausführbares Vertrauensmaterial verändern dürfen. (GitHub)
Für einen KI-Red-Team-Assistenten ist dies eine wichtige Vorsichtsmaßnahme. Viele offensive Arbeitsabläufe beinhalten rechtmäßig Konfigurationsdateien, Runbooks, Aufgabenmanifeste oder lokale Kabelbaumdefinitionen. Wenn das Modell diese Dateien als Teil eines "hilfreichen" Workflows umschreiben kann, dann wird die Konfiguration Teil der Code-Ausführungskette. Die Lösung besteht nicht nur darin, eine Produktversion zu patchen. Die allgemeine Abhilfemaßnahme besteht darin, Richtlinien und Konfigurationen als geschützte Güter zu behandeln: Trennen Sie die Bearbeitungsberechtigungen von den Laufzeitberechtigungen, verlangen Sie eine menschliche Überprüfung für ausführbare Konfigurationsänderungen und lassen Sie niemals zu, dass von Assistenten generierte Konfigurationen ohne Validierung zu einem vertrauenswürdigen Laufzeitzustand werden. (GitHub)
CVE-2025-34072, Slack MCP Link Entfaltung und versteckte Exfil Pfade
CVE-2025-34072 betraf einen veralteten Anthropic Slack MCP Server und beinhaltete die Exfiltration sensibler Daten durch automatisch entfaltete, von Angreifern erstellte Links. Das ist wichtig, weil viele Assistenten-Bereitstellungen Chat-Systeme, Ticket-Systeme oder Kollaborationsplattformen berühren, bei denen "Vorschau dieses Links" harmlos erscheint. In Wirklichkeit haben die Vorschau- und Anreicherungspfade oft Zugriff auf kontextbezogene Daten oder Geheimnisse, die der ursprüngliche Angreifer niemals erhalten sollte. (GitHub)
Die Lektion für einen Red-Team-Assistenten ist, dass die Unterscheidung zwischen einer "Tool-Aktion" und einer "Komfortfunktion im Hintergrund" oft falsch ist. Die Entfaltung von Links, die Zusammenfassung von Inhalten, die Extraktion von Metadaten und die automatische Anreicherung können allesamt zu Exfiltrationsflächen werden, wenn sie auf von Angreifern kontrollierte Inhalte angewendet werden. Die Abhilfemaßnahmen zielen darauf ab, die automatische Anreicherung bei nicht vertrauenswürdigen Eingaben zu deaktivieren, die für die Nachrichtenintegration verwendeten Token zu isolieren und eine explizite Vermittlungsschicht zwischen externen Inhalten und dem für den Assistenten sichtbaren Kontext zu verlangen. (GitHub)
CVE-2026-34742, localhost ist nicht eine freie Vertrauensgrenze
Die Offenlegung von CVE-2026-34742 im MCP Go SDK ist nützlich, weil sie eine hartnäckige Fehlannahme widerlegt: "Es lauscht nur auf localhost, also ist es in Ordnung." Vor den korrigierten Versionen war der DNS-Rebinding-Schutz in bestimmten HTTP-basierten Handlern standardmäßig deaktiviert, wodurch bösartige Websites unter den richtigen Bedingungen lokale MCP-Dienste erreichen konnten. Ähnliche Standard-Schutzlücken wurden später für die Python- und TypeScript-SDKs dokumentiert. (GitHub)
Für einen KI-Red-Team-Assistenten bedeutet dies, dass eine rein lokale Nutzung des Tools nicht ausreicht. Wenn der Assistent auch einen Browser bedient, Webinhalte liest oder den Host mit einer normalen Browsersitzung teilt, wird die Grenze zwischen lokal und remote dünner, als Teams erwarten. Zu den wirksamen Abhilfemaßnahmen gehören DNS-Rebinding-Verteidigungsmaßnahmen, obligatorische Authentifizierung selbst bei lokalen Diensten, strenge Herkunftsprüfungen, Firewalls auf Host-Ebene und die Weigerung, hochwirksame Tools über allgemeines HTTP freizugeben, wenn engere IPC-Optionen verfügbar sind. (Modell-Kontext-Protokoll)
CVE-2026-33980, Query Mediation ist Teil der Werkzeugsicherheit
CVE-2026-33980 betraf einen Azure Data Explorer MCP-Server durch KQL-Injektion in Tool-Handlern, bei denen benutzergesteuerte Eingaben unsicher interpoliert wurden. Dies ist ein nützliches Beispiel, weil es zeigt, wie eine scheinbar passive "Datenabruf"-Funktion zu einer Ausführungsoberfläche wird, wenn die Vermittlungsschicht schwach ist. Ein Assistent braucht keinen Shell-Zugang, um Schaden anzurichten. Wenn er Backend-Abfragen gegen sensible Datenspeicher beeinflussen kann, reicht das schon aus. (GitHub)
Die allgemeine Lehre ist, dass es bei der Sicherheit von Werkzeugen nicht nur darum geht, welches Werkzeug aufrufbar ist. Es geht auch um wie Argumente übersetzt werden in das Backend-System. Ein sicherer Assistent sollte typisierte Parameter, zulassungspflichtige Operationen, vorbereitete Abfragen, sofern das Backend diese unterstützt, und verifizierungsseitige Prüfungen bevorzugen, die zwischen "erwarteter Datensatz abgerufen" und "Assistent hat eine umfassende Sondierungsabfrage synthetisiert, weil sie hilfreich klang." (Modell-Kontext-Protokoll)
Diese CVEs zeigen auch eine breitere Wahrheit auf. Bei der Sicherheit von Assistenten konzentrieren sich die scharfen Kanten um den Kabelbaum und die Adapter. Deshalb ist es irreführend, ein System als sicher zu vermarkten, nur weil das Basismodell ein gutes Ablehnungsverhalten aufweist. Die entscheidende Frage ist, ob der gesamte Weg von der Eingabeaufforderung über das Werkzeug und die Umgebung bis hin zum Artefakt als sichere Pipeline konzipiert wurde. (cdn.openai.com)
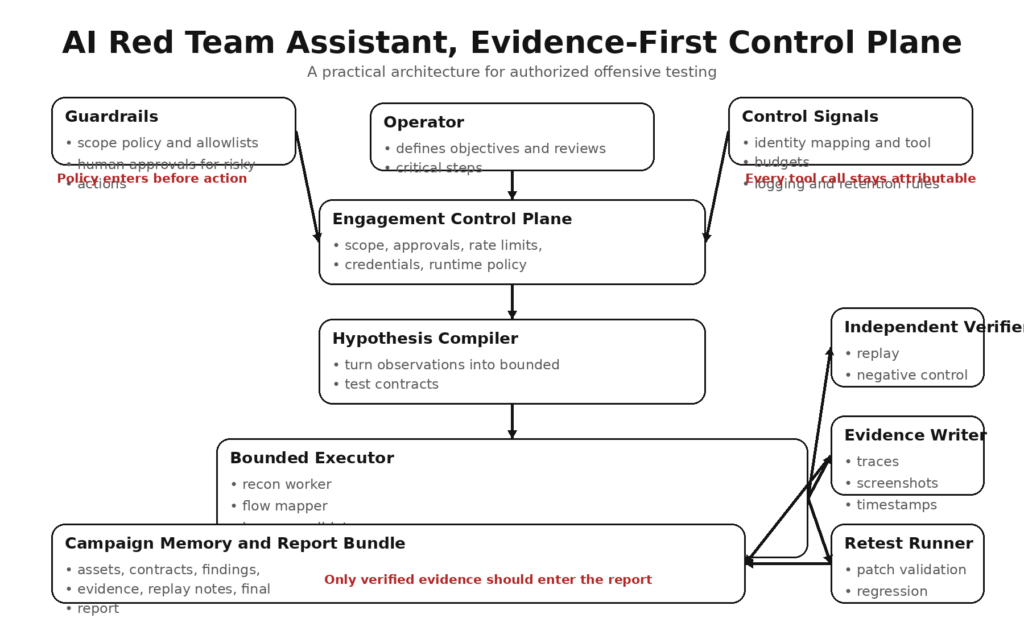
Eine praktische Architektur für autorisierte offensive Tests

Eine praktikable Architektur für einen KI-Assistenten für das rote Team sieht weniger wie ein Chatbot und mehr wie ein eingeschränkter Prüfstand aus.
1. Einschaltkontrollebene
Diese Schicht ist für die Autorisierung, den Umfang, die Zeitplanung, den Werkzeugbestand, die Identitäten, die Ratenkontrolle, die Protokollierungsregeln und die Richtlinien für destruktive Aktionen zuständig. Sie sollte der einzige Ort sein, an dem der Assistent erfährt, was er tun darf. Dieses Design steht im Einklang mit der Prozessorientierung in NIST SP 800-115 und mit dem umfassenderen Governance- und Risikomanagementrahmen im Generative AI Profile von NIST. (csrc.nist.gov)
2. Hypothesen-Compiler
Der Assistent sollte nicht direkt von Beobachtungen zu Aktionen übergehen. Er sollte zunächst Beobachtungen in begrenzte Testverträge umwandeln. Ein Vertrag könnte lauten: "Vergleich des Objektlesezugriffs für zwei schreibgeschützte Identitäten mit einem Staging-API-Endpunkt unter Verwendung von Replay-Only-Tools, Beibehaltung von Anfrage-/Antwortspuren, keine Zustandsänderungen." An dieser Stelle verwandelt das System lärmende Erkundungen in etwas Testbares und Überprüfbares. Die AISI-Methodik ist hier nützlich, weil sie die Angriffsplanung als disziplinierte Phase und nicht als improvisierte Fortsetzung der Aufklärung behandelt. (Japan AISI)
3. Begrenzter Vollstrecker
Der Executor führt den Vertrag nur mit den angegebenen Tools und Identitäten aus. Er entscheidet nicht, dass er plötzlich eine Paketinstallation, einen neuen Netzwerkzugang oder eine zusätzliche Integration benötigt, nur weil das Modell neugierig geworden ist. Statische Werkzeugsätze sind leichter zu prüfen als dynamische Erweiterungen. Wenn eine dynamische Erweiterung notwendig ist, sollte sie mit ausdrücklicher Genehmigung erfolgen. Microsofts Leitfaden für Agentenkomponenten ist hier von Bedeutung, da er die Sicherheits- und Vorhersagevorteile fester Werkzeugsätze hervorhebt. (Microsoft Lernen)
4. Unabhängige Prüfstelle
Der Prüfer fragt nicht: "Hat das Modell gedacht, dass das funktioniert?" Er fragt: "Kann dies unter den gleichen Bedingungen und mit dem gleichen Anspruch wiederholt werden?" Die Arbeit von OpenAI im Bereich Red Teaming betont, dass Red Teaming als Grundlage für breitere, wiederholbare Bewertungen dienen sollte und nicht als alleiniges Maß für das Systemrisiko. Ein Verifizierer in offensiven Arbeitsabläufen erfüllt dieselbe Funktion, indem er Beweise durch eine engere Akzeptanzschleuse zwingt. (cdn.openai.com)
5. Verfasser von Nachweisen
Jede sinnvolle Aktion sollte ein Bündel hinterlassen: Zeitstempel, Eingabeaufforderungen oder Aufgaben-IDs, Tool-Aufrufe, verwendete Identität, Anfrage- und Antwortspuren, ggf. Screenshots, negative Kontrollen, Wiederholungsergebnisse und Bereinigungshinweise. Das KI-Red-Team von Google spricht von detaillierten Aktivitätsprotokollen und Angriffsberichten. Offensivassistenten sollten etwas Ähnliches produzieren, aber mit ausreichender technischer Präzision, damit ein anderer Ingenieur den Weg nachvollziehen kann. (Google Wolke)
6. Läufer erneut testen
Die Ergebnisse verschlechtern sich schnell, wenn sie nach einem Patch oder einer Umgebungsänderung nicht erneut validiert werden können. Ein Assistent, der dabei hilft, wiederholbare Tests zu erstellen, ist viel wertvoller als ein Assistent, der dramatische, einmalige Protokolle erstellt. Der öffentliche Leitfaden von Promptfoo ist in diesem Zusammenhang nützlich, da er Red Teaming als systematisches Sondieren betrachtet, das über viele Tests und Iterationen, einschließlich CI-ähnlicher Workflows, wiederholt und gemessen werden kann. (Promptfoo)
In der Praxis interessieren sich die Teams, die diese Kategorie bewerten, in der Regel weniger dafür, ob das Modell beeindruckend klingt, sondern eher dafür, ob der Arbeitsablauf kontrollierbar ist. Die öffentlichen Penligent-Materialien sind in dieser Hinsicht bemerkenswert, da sie den Schwerpunkt eher auf bedienergesteuerte agenturische Arbeitsabläufe, editierbare Eingabeaufforderungen und auf den Handlungsspielraum bezogene Grenzen legen als auf reines Autonomie-Theater. Das ist die richtige Richtung für diese Systemklasse: Offensivassistenz sollte sich eher wie ein straff verwaltetes Gurtzeug anfühlen als ein uneingeschränkter Operator. (penligent.ai)
Was der Assistent während eines Engagements tatsächlich tun sollte
Ein guter KI-Red-Team-Assistent hilft am meisten in den Teilen einer Bewertung, die strukturiert, repetitiv und nachweisintensiv sind.
Aufklärungsorganisation
Der Assistent kann Beobachtungen aus Dokumenten, Routen, APIs und Antwortmustern zu prüfbaren Angriffshypothesen zusammenfassen. Das wichtige Wort ist prüfbar. Es sollte aus "interessant" nicht "angreifbar" werden. Sie sollte aus "Diese beiden Rollen scheinen unterschiedliche Filter für dieselbe Objektfamilie zu erhalten" machen "Vergleichen Sie die Autorisierung auf Objektebene unter diesen Identitäten mit Hilfe von Replay-Only-Anfragen." (csrc.nist.gov)
Authentifiziertes Flow Mapping
Assistenten sind nützlich bei der Verfolgung zustandsabhängiger Anwendungsflüsse: Sitzungserfassung, CSRF-Token-Behandlung, mehrstufige Formulare, Rollenänderungen, Feature-Flags und Objektreferenzen. Hier versagen einfache Chatsysteme in der Regel, weil sie den Status verlieren und zu stark verallgemeinern. Ein beschränkter Assistent kann stattdessen einen Aufgabenbaum führen, bereinigte Ablaufkontrollpunkte speichern und dem Bediener bei der Entscheidung helfen, welche Übergänge einen Test wert sind. (penligent.ai)
Kontrolliertes Abspielen und Vergleichen
Der Assistent ist besonders wertvoll, wenn er risikoarme Anfragen über mehrere Identitäten hinweg wiederholen, Ergebnisse diffundieren und Artefakte aufbewahren kann. Dies unterstützt klassische Autorisierungstests, Business-Logic-Tests und Regressionstests, ohne dem System unbegrenzte Freiheit zu gewähren. Der Schlüssel liegt darin, die Werkzeugebene eng zu halten und die Anforderungen an den Nachweis streng zu formulieren. (csrc.nist.gov)
Verpackung von Beweismitteln
Die meiste Mühe bei echten Einsätzen besteht nicht darin, eine Idee zu entdecken. Es geht darum, die Idee zu beweisen, sie klar zu dokumentieren und genügend Kontext für erneute Tests zu erhalten. Ein Assistent, der Spuren, Screenshots, Objektidentifikatoren, Rollenkontext, Zeitstempel, Hinweise auf Auswirkungen und Abhilfemaßnahmen in einem stabilen Format zusammenstellen kann, ist wirklich nützlich. Ein Assistent, der nur auffällige Zusammenfassungen erstellen kann, ist es nicht. (csrc.nist.gov)
Wiederholungsprüfung nach der Sanierung
Dies ist einer der besten Anwendungsfälle für KI-Hilfe, da das Zielverhalten eng gefasst ist und die Akzeptanzkriterien konkret sind. Der Assistent kann frühere Vergleiche erneut durchführen, bestätigen, dass sich negative Kontrollen immer noch ordnungsgemäß verhalten, und das Evidenzbündel aktualisieren. Dies steht im Einklang mit der weiter gefassten Idee aus den Materialien von OpenAI und AISI, dass die Erkenntnisse aus dem Red Teaming in eine wiederholbare Bewertung einfließen sollten, anstatt in einer einmaligen Sitzung gefangen zu bleiben. (cdn.openai.com)
Die Unterscheidung zwischen "Vorschlag" und "verifizierter Feststellung" ist hier wichtig. In Penligents öffentlichem Schreiben über KI-Pentest-Copiloten und Evidence-First-Kabelbäume wird diese Unterscheidung ausdrücklich gemacht, und sie ist ein hilfreicher Weg, um jedes Tool in dieser Kategorie zu bewerten. Wenn ein Anbieter Ihnen nicht zeigen kann, wie aus Vorschlägen bestätigte Ergebnisse unter eingeschränkter Ausführung und Wiedergabe werden, haben Sie es wahrscheinlich mit einer intelligenten Schnittstelle zu tun und nicht mit einem Assistenten, der echten Tests standhalten kann. (penligent.ai)
Beispiel, ein autorisierter Multi-Tenant-Zugangskontrolltest
Am sichersten lässt sich der Arbeitsablauf anhand eines synthetischen, aber realistischen Beispiels erklären.
Angenommen, ein autorisierter Einsatz in einer Staging-Umgebung für eine mandantenfähige SaaS-Anwendung. Das Ziel ist eng gefasst: Es soll überprüft werden, ob Nur-Lese-Benutzer von Mandant A über einen API-Endpunkt auf Objekt-Metadaten zugreifen können, die zu Mandant B gehören. Es handelt sich um eine Staging-Umgebung, die Identitäten sind genehmigt, und die Richtlinie verbietet zustandsändernde Aktionen oder Massenaufzählungen. Dieser Aufbau spiegelt den Schwerpunkt des NIST auf Tests unter expliziten Einschränkungen wider. (csrc.nist.gov)
Die Aufgabe des Assistenten besteht nicht darin, "die App zu hacken". Seine Aufgabe besteht darin, Beobachtungen in eine sichere Testsequenz umzuwandeln. Er erhält die OpenAPI-Beschreibung, einige erfasste Basisanforderungen von jeder Rolle und die Engagement-Richtlinie. Er stellt fest, dass Objektreferenzen UUID-ähnlich sind, das Antwortschema Tenant-Scoped-Metadaten enthält und dieselbe Ressourcenfamilie von beiden Identitäten unter verschiedenen Listenansichten erreicht werden kann. Sie schlägt einen Nur-Lese-Vergleichsvertrag anstelle eines offenen Aufzählungsplans vor. (Japan AISI)
Ein menschlicher Prüfer genehmigt den Vertrag, da er innerhalb des Geltungsbereichs bleibt und nur Wiedergabewerkzeuge verwendet. Der Executor führt dann einen minimalen Satz von Anfragen aus: einen bekannt guten Lesezugriff von Mandant A auf ein Objekt, das A gehört, einen bekannt guten Lesezugriff von Mandant B auf ein Objekt, das B gehört, und eine mandantenübergreifende Wiedergabe, die dieselbe Pfadstruktur, aber keine Schreibvorgänge, kein Parameter-Fuzzing und kein Volumen verwendet. Der Verifizierer prüft dann, ob die mandantenübergreifende Wiedergabe einen Autorisierungsfehler, eine teilweise Offenlegung oder eine vollständige Objektantwort ergab. Er führt auch eine Negativkontrolle mit einem eindeutig nicht existierenden Objektverweis durch, um eine Umgehung der Autorisierung von einer inkonsistenten Fehlerbehandlung zu unterscheiden. (csrc.nist.gov)
Ein Beispiel für einen Replay-Block könnte folgendermaßen aussehen:
GET /api/v1/documents/9b3d3c8f-tenant-b-object HTTP/1.1
Host: staging.api.example.test
Autorisierung: Bearer TENANT_A_READER_TOKEN
Akzeptieren: application/json
X-Trace-Mode: replay
Der Assistent sollte nicht von sich aus entscheiden, dass eine überraschende Antwort eine Schwachstelle beweist. Stattdessen prüft der Überprüfer die Konsistenz. Ist das gleiche Ergebnis zweimal aufgetreten? Trat es nur unter einer Identität auf? Gehörte das Objekt eindeutig dem anderen Mandanten? Enthielt die Antwort sensible Felder oder nur öffentliche Metadaten? Gab es ein Caching-Artefakt oder ein veraltetes Proxy-Verhalten, das das Ergebnis erklären könnte? Dies sind die Fragen, die Beweise von Aufregung unterscheiden. (Japan AISI)
Wenn der Befund zutrifft, sollte das Berichtsbündel die Baseline-Traces, die mandantenübergreifende Wiedergabe, die Negativkontrolle, die verwendeten Identitäten, Zeitstempel, die genauen Akzeptanzkriterien und eine knappe Aussage zu den Auswirkungen enthalten. Etwas wie "mandantenübergreifende Offenlegung von Metadaten mit Lesezugriff für Dokumentobjekte unter Endpunkt X bestätigt" ist viel besser als "kritischer Ausfall der Mandantenisolierung", es sei denn, die Beweise unterstützen eine stärkere Behauptung. Der Assistent kann bei der Erstellung des Berichts behilflich sein, aber die Aussage über den Schweregrad muss immer noch von einem Menschen überprüft werden. (csrc.nist.gov)
Dieses Beispiel ist absichtlich bescheiden, und genau das ist der Punkt. Ein KI-Assistent für das rote Team verdient Vertrauen, indem er mit begrenzter, überprüfbarer Verifizierungsarbeit hilft. Wenn er dies nicht gut kann, sollte man ihm keine größere Autonomie zutrauen. (Microsoft Lernen)
Warum die Automatisierung in den wichtigsten Momenten lügt
Die Automatisierung ist großartig bei der Produktion von Bewegung. Weniger zuverlässig ist sie bei der Erstellung von Beweisen.
In dem Papier von OpenAI wird ausdrücklich darauf hingewiesen, dass Red Teaming nur ein Teil eines umfassenderen Bewertungs- und Steuerungskonzepts ist und keine eigenständige Garantie darstellt. Im praktischen Leitfaden von AISI werden wiederholte Angriffe und eine strukturierte Berichterstattung als notwendig erachtet, da einzelne Beobachtungen nicht ausreichen. Der Leitfaden von Promptfoo betont die systematische Untersuchung und messbare Ergebnisse über viele Durchläufe hinweg. Zusammengenommen weisen diese Quellen auf dieselbe Lektion hin: Offensive KI-Automatisierung wird Sie am ehesten in die Irre führen, wenn das System unsichere Signale in eindeutige Schlussfolgerungen umwandeln darf. (cdn.openai.com)
Hier sind die häufigsten Fehlerarten:
Ein Scanner-Treffer wird zu einem "Exploit-Pfad", weil der Assistent erklären kann, warum er wichtig sein könnte. Ein Browser-Artefakt wird zu einem "bestätigten Datenzugriff", weil das Modell den Zustand der Seite sicher beschreibt. Eine einmalige anomale Reaktion wird zu einer stabilen Schwachstelle, weil der Assistent für eine entschlossene Sprache belohnt wird. Eine generierte Schweregradeinstufung übertrifft die Beweise. Ein Abhilfemaßnahmenvorschlag wird als vertrauenswürdig eingestuft, obwohl der Assistent die Grundursache nie überprüft hat. (csrc.nist.gov)
Dies ist auch der Punkt, an dem sehr leistungsfähige Sprachmodelle die Dinge verschlimmern können. Stärkere Argumentation kann ungestützte Erzählungen kohärenter klingen lassen. Das bedeutet nicht, dass Modelle nutzlos sind. Es bedeutet, dass die Akzeptanzgrenze nicht-sprachlich bleiben muss: Spuren, Kontrollen, Wiederholungen und klare Umfangskontrollen. Die Menschen brauchen den Assistenten nicht, um klug zu klingen. Sie brauchen ihn, um die Arbeit zu organisieren, ohne Gewissheit zu produzieren. (cdn.openai.com)
Open-Source-Tools wie Garak, Promptfoo und Counterfit von Microsoft sind gerade deshalb nützlich, weil sie diese Messphilosophie auf unterschiedliche Weise verstärken. Promptfoo legt den Schwerpunkt auf automatisiertes Sondieren von Gegnern und die Bewertung des Verhaltens von KI-Anwendungen. Garak präsentiert sich als ein LLM-Schwachstellen-Scanner. Counterfit automatisiert die Sicherheitsprüfung von KI-Systemen und wendet ML-Techniken für Angreifer an. Keines dieser Tools ersetzt auf magische Weise die Validierung auf Systemebene, aber zusammen veranschaulichen sie die richtige Gewohnheit: Verwenden Sie die Automatisierung, um die Abdeckung und Regression zu erweitern, nicht um auf Beweisanforderungen zu verzichten. (Promptfoo)
Die Sicht eines Verteidigers, was blaue Teams und Plattformbetreiber protokollieren und kontrollieren sollten
Die blauen Teams müssen nicht raten, wie sie diese Systeme bewerten sollen. Die gleichen Eigenschaften, die einen Assistenten für rote Teams nützlich machen, machen ihn für Verteidiger beobachtbar.
Das NIST-Profil für generative KI ist hilfreich, weil es Sicherheit, Datenschutz und andere Risiken als Lebenszyklusbelange behandelt, die durch Governance-, Mapping-, Mess- und Managementfunktionen verwaltet werden müssen. Das SAIF von Google betrachtet die KI-Sicherheit in ähnlicher Weise als eine Erweiterung der bestehenden Sicherheitsgrundlagen, der Erkennung, der Reaktion und der automatisierten Abwehrmaßnahmen. Diese Dokumente sind nicht spezifisch für offensive Assistenten, aber die Kontrollen lassen sich gut übersetzen. (nvlpubs.nist.gov)
Ein Plattformteam, das einen KI-Red-Team-Assistenten beaufsichtigt, sollte mindestens die folgenden Telemetrieklassen erfassen:
| Klasse Telemetrie | Warum das wichtig ist |
|---|---|
| Metadaten zu Aufforderungen und Aufgaben | Rekonstruieren Sie die Absicht des Betreibers und identifizieren Sie die Injektionsquellen |
| Prüfpfad für Werkzeuganrufe | Sehen Sie sich an, was tatsächlich passiert ist, nicht was der Assistent später behauptet hat |
| Zuordnung von Identitäten und Berechtigungsnachweisen | Jede Aktion mit dem genauen Konto oder Token verknüpfen |
| Herkunft der Inhalte | Unterscheidung zwischen vertrauenswürdiger Dokumentation und nicht vertrauenswürdigen Web- oder Benutzerinhalten |
| Zulassungsereignisse | Überprüfung, ob risikobehaftete Grenzen umgangen oder überstrapaziert wurden |
| Artefakt-Hashes für Beweise | Wahrung der Integrität von Screenshots, Spuren und Berichtspaketen |
| Speicheränderungen | Erkennung von Vergiftungen, Konflikten und veralteten Annahmen, die in einen dauerhaften Zustand übergehen |
Microsofts öffentliches Material zum Security Copilot-Agenten enthält auch einen wertvollen operativen Hinweis: Selbst bei einem defensiven Produkt werden die Benutzer aufgefordert, die Entscheidungen des Agenten zu überprüfen, bevor sie handeln, und das gespeicherte Feedback muss aufgrund von Unklarheiten und Konflikten beachtet werden. Das sollte die Toleranz gegenüber offensiven Produkten, die Autonomie nach dem Motto "Einstellen und Vergessen" behaupten, verringern. Wenn eine Plattform, die Microsoft selbst als vorschauwürdig bezeichnet, immer noch menschliche Überprüfung und Gedächtnishygiene erwartet, sollte ein KI-Assistent für das rote Team nicht weniger Kontrolle versprechen, während er gefährlichere Aufgaben übernimmt. (Microsoft Lernen)
Die Verteidiger sollten auch im Voraus entscheiden, welche Aktionen einen harten Stopp auslösen. Beispiele hierfür sind jeder Versuch, Anmeldeinformationen zu exportieren, jeder nicht genehmigte externe Netzwerkaufruf, jede Änderung an der Konfiguration ausführbarer Dateien, jeder Zugriff auf Systeme mit Produktionskennzeichnung und jede Erweiterung des Werkzeugsatzes über die aktuelle Eingriffsrichtlinie hinaus. Dies sind keine Sicherheitsvorkehrungen auf Modellebene. Es handelt sich um Sicherheitsvorkehrungen auf der Steuerungsebene, die leichter zu verstehen sind. (Modell-Kontext-Protokoll)
Kaufen oder bauen, die entscheidenden Fragen
Wenn Sie einen Anbieter oder einen internen Prototyp evaluieren, gibt es eine kurze Liste technischer Fragen, die seriöse Systeme von Demo-Systemen unterscheiden.
- Kann der Assistent maschinenlesbare Geltungsbereiche erzwingen, oder liest er nur Geltungsbereiche in natürlicher Sprache.
- Werden Werkzeuge statisch deklariert, dynamisch hinzugefügt oder beides.
- Können risikoreiche Aktionen die ausdrückliche Zustimmung von Menschen erfordern.
- Gibt es einen separaten Überprüfungspfad, oder genehmigt dasselbe Modell seine eigenen Ergebnisse.
- Welche Beweisartefakte sind zwingend erforderlich, bevor ein Befund akzeptiert wird.
- Wie geht das System mit nicht vertrauenswürdigen Webinhalten, Ausgabetexten, PDFs oder RAG-Ergebnissen um?
- Gibt es ein Gedächtnis, und wenn ja, wie wird eine Vergiftung oder Unklarheit überprüft?
- Unter welchen Identitäten laufen die Werkzeuge, und wie eng sind diese Identitäten?
- Wenn MCP involviert ist, wie werden Zustimmung, Token-Isolation und Localhost-Exposition kontrolliert.
- Können die Ergebnisse nach der Behebung wiedergegeben werden.
- Kann der Betreiber zwischen Vorschlägen und gesicherten Erkenntnissen unterscheiden?
- Sind die Protokolle vollständig genug, dass ein anderer Ingenieur den Lauf rekonstruieren kann? (Microsoft Lernen)
Eine schwache Antwort auf eine dieser Fragen disqualifiziert ein System nicht unbedingt. Eine schwache Antwort auf mehrere Fragen bedeutet jedoch in der Regel, dass das Produkt eher auf eine flüssige Demo als auf die Integrität des Engagements optimiert ist. Dieser Kompromiss mag für Recherchen oder Notizen akzeptabel sein. Für ein Tool, das den Anspruch erhebt, echte offensive Tests zu unterstützen, ist er nicht akzeptabel. (csrc.nist.gov)
Was der Begriff in Zukunft bedeuten sollte
Die Phrase KI-Assistent für das rote Team ist es wert, beibehalten zu werden, aber nur, wenn es etwas strengeres bedeutet als "Sicherheits-Chatbot mit Tool-Zugang".
Ein echter Assistent dieser Kategorie sollte mit expliziter Autorisierung arbeiten, mit eingeschränkten Identitäten laufen, nicht vertrauenswürdige Inhalte konsumieren, ohne ihnen blind zu gehorchen, die Planung von der Ausführung und Verifizierung trennen, Artefakte standardmäßig aufbewahren und wiederholbare Beweise als wichtiger erachten als eloquente Erzählungen. Das Modell ist wichtig, aber der Harness ist noch wichtiger. Die öffentlichen Materialien von OpenAI und AISI weisen beide auf Struktur, Wiederholbarkeit und mehrstufige Evaluierung hin, statt auf Improvisation. Die öffentliche Arbeit von Google und Anthropic macht deutlich, dass die wirklichen Risiken in der Integrationsoberfläche und der Handlungsfähigkeit liegen. Die Sicherheitsrichtlinien von MCP machen deutlich, dass die Protokoll- und Adapterschicht nicht als ein Implementierungsdetail behandelt werden kann. (cdn.openai.com)
Das ist der Standard, den man anwenden sollte, egal ob man ein Produkt kauft, ein internes System aufbaut oder versucht, die jüngste Welle von Behauptungen über "agentische Sicherheit" zu verstehen. Wenn der Assistent nicht in der Lage ist, begrenzte Aktionen, saubere Beweise und überprüfbares Verhalten zu liefern, ist er nicht bereit für ein echtes Engagement. Er ist immer noch nur eine überzeugende Schnittstelle. (csrc.nist.gov)
Weiterführende Literatur und Referenzen
- Microsoft AI Red Team, Überblick und Planungsgrundsätze für das Red Teaming von KI-Systemen. (Microsoft Lernen)
- OpenAI, Der Ansatz von OpenAI für externes Red Teaming. (cdn.openai.com)
- NIST SP 800-115, Technischer Leitfaden für die Prüfung und Bewertung der Informationssicherheit. (csrc.nist.gov)
- NIST, Rahmen für das Risikomanagement im Bereich der künstlichen Intelligenz, Profil der generativen künstlichen Intelligenz. (nvlpubs.nist.gov)
- Google, Das sichere KI-Framework von Google, SAIF. (Sicherheitszentrum)
- Google Cloud, Wie Google es macht: Aufbau eines effektiven KI-Red-Teams. (Google Wolke)
- OWASP, LLM01 Prompt Injektion. (OWASP Gen AI Sicherheitsprojekt)
- OWASP, Top 10 der Agentikanwendungen für 2026. (OWASP Gen AI Sicherheitsprojekt)
- Modell-Kontext-Protokoll, Spezifikation und Bewährte Sicherheitspraktiken. (Modell-Kontext-Protokoll)
- Anthropisch, Abschwächung des Risikos von Prompt-Injektionen bei der Browser-Nutzung. (Anthropisch)
- Anthropisch, Claude Code Auto Mode, ein sicherer Weg, Berechtigungen zu überspringen. (Anthropisch)
- Einheit 42, Täuschung von KI-Agenten, Web-basierte indirekte Prompt-Injektion in freier Wildbahn beobachtet. (Referat 42)
- Promptfoo, LLM Leitfaden für Red Teaming. (Promptfoo)
- Garak, Open-Source-LLM-Schwachstellen-Scanner. (Garak)
- Counterfit, Open-Source-Automatisierung für Sicherheitstests von KI-Systemen. (Microsoft)
- AI Pentest Tool, wie eine echte automatisierte Offensive im Jahr 2026 aussehen wird. (penligent.ai)
- AI Pentest Copilot, von intelligenten Vorschlägen bis zu verifizierten Befunden. (penligent.ai)
- Claude Code Harness für AI Pentesting. (penligent.ai)

