El anuncio del Mythos de Anthropic empujó a mucha gente hacia la pregunta equivocada. La versión ruidosa era: "¿Qué modelo es ahora el mejor hacker?". La versión más útil es más difícil y más operativa: ¿cuánto modelo necesitas en cada fase de una prueba de penetración, qué andamiaje tiene que existir a su alrededor, cómo verificas lo que dice, y qué estás comprando realmente por dólar cuando pasas de una señal candidata a un hallazgo defendible? Los propios materiales públicos de Anthropic describen un sistema, no un indicador mágico. El Proyecto Glasswing dice que Mythos Preview encontró miles de vulnerabilidades de día cero en todos los principales sistemas operativos y navegadores, y el escrito del Equipo Rojo de Anthropic describe un andamiaje simple pero real: lanzar un contenedor aislado, dejar que el modelo inspeccione el código y ejecute el objetivo, iterar con la depuración y producir un informe de errores con pasos de prueba de concepto. La respuesta de AISLE no negaba esa capacidad. Argumentaba que gran parte de lo que importa en ese pipeline ya está disponible para modelos más pequeños, más baratos y, en algunos casos, de peso abierto, una vez que el flujo de trabajo se estructura correctamente. (antropic.com)
Esta distinción es importante porque el "pentesting de IA" está empezando a utilizarse para casi cualquier cosa con un LLM conectado a un escáner. NIST SP 800-115 sigue definiendo las pruebas técnicas de seguridad en torno a la planificación, la ejecución, el análisis de los resultados y la estrategia de mitigación. La Guía de Pruebas de Seguridad Web de OWASP todavía trata las pruebas de seguridad como un marco disciplinado para evaluar aplicaciones y servicios web, no como una ráfaga de comentarios generados por modelos. El Top 10 de Seguridad API de OWASP todavía pone la Autorización a Nivel de Objeto Rota al frente de la lista porque las fallas duras en sistemas reales usualmente viven en relaciones de objetos, límites de roles, transiciones de estado, y lógica de negocios, no solo en cadenas de patrones coincidentes. Una vez que se restablece esa línea de base, el debate sobre Mythos se vuelve mucho más fácil de razonar. Una prueba de penetración no es un modelo de respuesta. Es un proceso acotado y probatorio que convierte la incertidumbre en prueba. (csrc.nist.gov)
La mejor contribución de AISLE al debate no es que "desacreditara" Mythos. Es que descompuso el proceso. La historia pública de Anthropic comprime de forma natural el escaneado, el reconocimiento de vulnerabilidades, el triaje, la evaluación de explotabilidad, la construcción de exploits y la corrección en una capacidad continua. AISLE argumenta que esta compresión es retóricamente conveniente pero operativamente engañosa. Desde su punto de vista, la ciberseguridad de IA es una pila de tareas diferentes con distintas propiedades de escalado: escaneado de amplio espectro, detección de vulnerabilidades, triaje y discriminación de falsos positivos, generación de parches y, en ocasiones, construcción de exploits. Su punto más importante es el que los equipos de seguridad deberían interiorizar: la función de producción para la seguridad de la IA no es solo inteligencia por token. También incluye tokens por dólar, tokens por segundo y la experiencia en seguridad integrada en el andamiaje que dirige, valida y limita el modelo. No es una corrección pequeña. Es la diferencia entre comprar una demo y construir una práctica. (AISLE)
El pentesting de IA sigue siendo un flujo de trabajo, no un modelo gigante
La forma más sólida de entender el pentesting de IA en 2026 es dejar de tratarlo como un concurso de razonamiento abstracto y empezar a tratarlo como un problema de diseño de flujos de trabajo. Un flujo de trabajo de seguridad real tiene que hacer varias cosas bien a la vez. Tiene que reducir el alcance sin perder el contexto importante. Tiene que conservar el estado a través de solicitudes, roles o sesiones. Tiene que distinguir un problema plausible de un problema reproducible. Debe conservar pruebas suficientes para que otro ingeniero pueda reproducir lo sucedido. Tiene que evitar exagerar el impacto cuando una condición no es realmente alcanzable. Y si el sistema está realizando una explotación o validación activa, tiene que hacer todo eso sin romper la disciplina de alcance o producir pruebas que no puedan sobrevivir a la revisión. Son requisitos de ingeniería antes que de modelo. (csrc.nist.gov)
Por este motivo, el reciente debate sobre las pruebas comparativas se está alejando silenciosamente de las "trivialidades de seguridad" estáticas para centrarse en tareas integrales. El benchmark CTI-REALM de Microsoft está explícitamente enmarcado en la ingeniería de detección del mundo real más que en preguntas y respuestas aisladas. Pone a prueba la lectura de inteligencia sobre amenazas, la exploración de telemetría, la iteración sobre KQL y lógica Sigma, y la validación de resultados frente a la verdad sobre el terreno. El ámbito exacto es la ingeniería de detección más que el pentesting, pero la lección estructural es la misma: un punto de referencia de seguridad se vuelve más útil a medida que se acerca al flujo de trabajo que los humanos tienen que llevar a cabo hasta el final. El futuro de la evaluación ofensiva se moverá probablemente en la misma dirección. La mejor evaluación no se limitará a preguntar si un modelo puede describir un fallo. Se preguntará si un sistema acotado puede encontrar el lugar adecuado para buscar, separar el ruido de la señal, probar la condición, preservar el rastro del artefacto y comunicar el resultado de una manera en la que otro ingeniero confíe. (Microsoft)
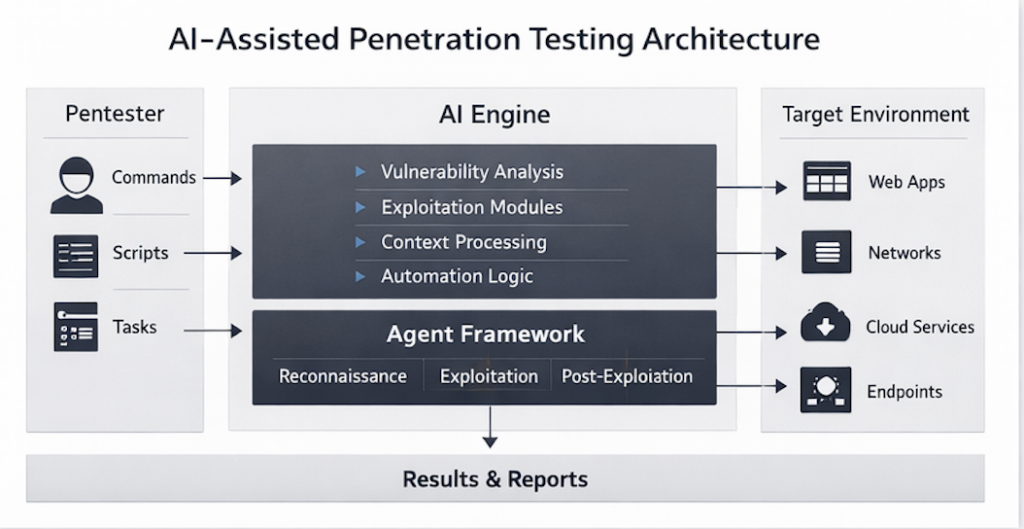
Por lo tanto, una arquitectura de pentesting de IA útil se parece menos a un monolito y más a un equipo de relevos. Un modelo rápido y barato a menudo puede hacer el trabajo de primera pasada de inventariar puntos finales, agrupar rutas, detectar patrones de estructura o identificar regiones de código que merezcan ser escaladas. Un modelo de razonamiento algo más sólido puede realizar el filtrado de falsos positivos, la clasificación de explotabilidad y la limpieza de hipótesis. El modelo más caro no debería ser el predeterminado para todo. Debe ser su nivel de escalado para los lugares donde el espacio de búsqueda es lo suficientemente estrecho y el valor esperado es lo suficientemente alto como para que valga la pena pagar por el razonamiento a nivel de frontera. Esta es la versión práctica de tu punto central: el objetivo no es alquilar el modelo más inteligente del mundo en cada paso. El objetivo es expresar la cantidad adecuada de inteligencia en la etapa adecuada con un flujo de trabajo que no desperdicie cobertura, dinero o atención del revisor. (AISLE)
La siguiente tabla sintetiza esa visión de canalización utilizando la descomposición de AISLE, el andamiaje revelado de Anthropic y el marco clásico de pentest del NIST y OWASP. (Rojo antrópico)
| Etapa de canalización | Qué hace realmente el sistema | Cuello de botella dominante | Los modelos pequeños o medianos suelen ser suficientes | Cuando un modelo de frontera se gana el pan | Barandilla de ingeniería no negociable |
|---|---|---|---|---|---|
| Reducción de activos y contextos | Trazar el objetivo y reducir el espacio de búsqueda | Cobertura y velocidad | Sí | Raramente | Límites del ámbito de aplicación y manifiestos de objetivos |
| Descubrimiento de candidatos | Destape de rutas o comportamientos de código sospechosos | Amplitud por dólar | Sí | Ocasionalmente | Registros reproducibles de lo examinado |
| Triaje y control de falsos positivos | Separar las cuestiones verosímiles de las reales | Precisión y contexto | A menudo | A veces | Puertas de pruebas antes de la promoción |
| Evaluación de la explotabilidad | Estimar si el impacto es real en este entorno | Razonamiento consciente del entorno | A veces | A menudo | Hipótesis medioambientales claras |
| Construcción de exploits | Transformar una condición en impacto laboral | Búsqueda restringida de horizonte largo | Menos a menudo | Con frecuencia | Controles de ejecución y aprobación aislados |
| Informes y repetición de pruebas | Traducir los resultados en algo en lo que otro ingeniero pueda confiar | Calidad y reproducibilidad de los artefactos | Sí | Raramente | Pasos de reproducción, deltas y prueba de repetición |
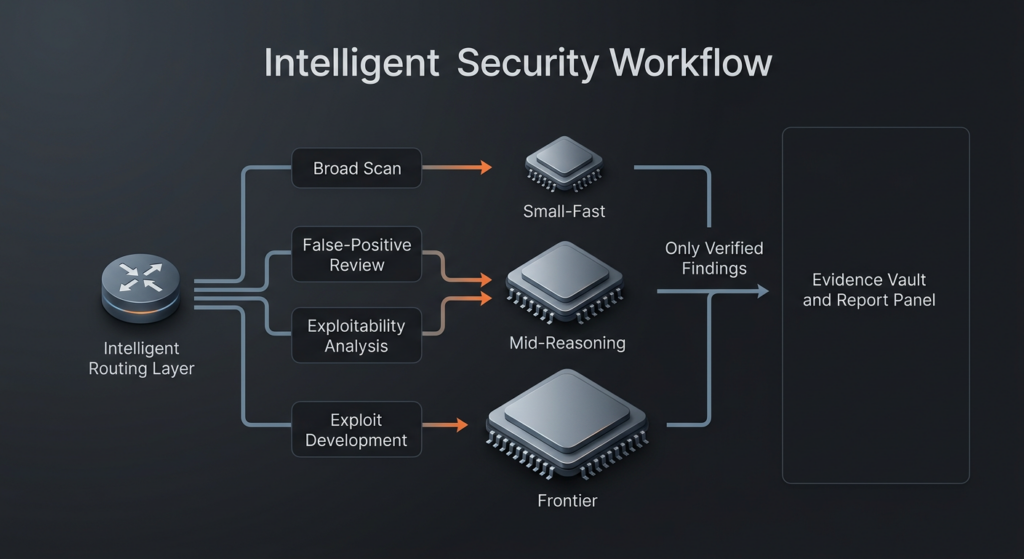
Los modelos pequeños ya importan más de lo que muchos quieren admitir
Los experimentos de AISLE son valiosos porque atacan la cuestión exactamente al nivel adecuado. La empresa no pretendía que los modelos pequeños pudieran reproducir de forma autónoma toda la tubería antrópica de extremo a extremo en grandes repositorios. Planteó una pregunta más estrecha: una vez aislado el código relevante, ¿qué parte del razonamiento público del escaparate Mythos pueden recuperar los modelos baratos o abiertos? Eso está mucho más cerca de la forma en que un sistema de descubrimiento bien construido realmente opera. Un buen andamiaje dedica tiempo a reducir el conjunto de candidatos. Para cuando le pides a un modelo que razone en serio, no deberías seguir lanzándole todo un código base y esperar que te inspire. (AISLE)
En la prueba de replicación NFS FreeBSD de AISLE, todos los modelos evaluados detectaron el desbordamiento. Eso incluyó GPT-OSS-20b, descrito como un modelo de 20B MoE con 3,6B parámetros activos, que según AISLE costó alrededor de $0,11 por millón de tokens y aún así razonó correctamente a una conclusión crítica de ejecución remota de código en la función aislada. En el caso de OpenBSD SACK, el campo se separó bruscamente. El modelo más pequeño no recuperó la cadena completa, pero un modelo abierto de 5,1 mil millones de activos sí lo hizo. La conclusión más general de la empresa fue que las clasificaciones se modificaron drásticamente en las distintas tareas, incluido un ejercicio de discriminación de falsos positivos de OWASP en el que los modelos abiertos más pequeños superaron a varios modelos de frontera. Se esté o no de acuerdo con todos los detalles de la metodología de AISLE, la macroseñal es difícil de ignorar: no hay un único modelo estable que sea el mejor en todas las tareas de seguridad, y la pendiente de la capacidad no es suave. (AISLE)
Este resultado no debería escandalizar a los pentesters experimentados. El trabajo de seguridad está lleno de dificultades desiguales. Un fallo de control de acceso oculto en un flujo de trabajo de tres roles con estado puede ser más difícil de validar que un problema de corrupción de memoria cuyo oráculo de fallo está limpio. Un parecido aburrido a una inyección SQL puede ser más difícil de clasificar correctamente que un desbordamiento de pila ruidoso pero real si este último tiene señales obvias de corrupción de memoria y el primero requiere un razonamiento sutil sobre cómo fluyen realmente los datos. Las tareas difieren tanto que una única etiqueta de "mejor modelo" suele ser menos informativa que una política de enrutamiento. La cuestión útil no es qué modelo gana la categoría. Es qué modelo gana esta etapa, con este presupuesto de contexto, con este validador, a este precio, con este requisito de latencia. (AISLE)
También hay aquí una cuestión básica de economía de búsqueda. Si el descubrimiento de candidatos y la revisión en primera instancia pueden realizarse de forma muy barata, un defensor puede permitirse una cobertura mucho más amplia. AISLE expone este argumento directamente: miles de detectives adecuados buscando ampliamente pueden superar a un detective brillante que tiene que adivinar dónde buscar. En la práctica, esto significa que un equipo de seguridad puede obtener señales más útiles saturando la primera fase con modelos baratos y reservando el razonamiento caro para los hallazgos que sobreviven a las puertas de pruebas. La idea parece anticlimática porque es más administrativa que mítica. También es la forma en que suelen triunfar los programas de seguridad maduros. No maximizan la brillantez en cada etapa. Maximizan el rendimiento sin perder la confianza. (AISLE)
El mito sigue siendo importante cuando el trabajo es duro
Nada de eso significa que los modelos de frontera se hayan vuelto irrelevantes. La propia evidencia de Anthropic sugiere que la brecha sigue siendo significativa en la parte más difícil de la pila. En su Red Team writeup, Anthropic dice que Mythos Preview está en una liga diferente de Opus 4.6 en el desarrollo autónomo de exploits. En una prueba comparativa derivada de vulnerabilidades encontradas previamente en el motor JavaScript de Firefox, Anthropic dice que Opus 4.6 produjo exploits que funcionaron sólo dos veces en varios cientos de intentos, mientras que Mythos Preview produjo 181 exploits que funcionaron y alcanzó el control de registro 29 veces adicionales. La empresa también afirma que Mythos Preview identificó y explotó de forma autónoma una vulnerabilidad de FreeBSD de hace 17 años, CVE-2026-4747, tras escanear cientos de archivos del kernel. No son ganancias triviales en el límite de la distribución. Son grandes deltas exactamente en la región donde la explotación pasa de "probablemente hay algo mal aquí" a "puedo hacer este movimiento". (Rojo antrópico)
Esto es importante porque la construcción de una hazaña es una habilidad diferente del reconocimiento de vulnerabilidades. A menudo exige una planificación a largo plazo, la adaptación a las limitaciones, la reutilización creativa de los bloques de construcción y la persistencia suficiente para repetir las estrategias fallidas. Muchos flujos de trabajo de seguridad nunca necesitan ese nivel de autonomía. Muchos casos de uso defensivo o de validación intensiva se detienen mucho antes de que la explotación se convierta en un arma. Pero si su flujo de trabajo necesita una generación profunda de exploits bajo restricciones, entonces la capacidad del modelo de frontera no es un detalle de marketing. Es la diferencia entre una condición candidata y una cadena de trabajo. La conclusión correcta no es que el modelo más potente sea innecesario. La conclusión correcta no es que el modelo más potente sea innecesario, sino que el modelo más potente debe colocarse allí donde su ventaja es realmente importante, en lugar de quemarlo en cada pasada de bajo valor. (Rojo antrópico)
La propia arquitectura de Anthropic insinúa la misma lección. La publicación pública del Equipo Rojo de la empresa no describe un escenario en el que Mythos crea errores espontáneamente de la nada. Describe un entorno de contenedores, acceso al código, experimentación iterativa, validación y generación de informes de errores. En otras palabras, incluso en la frontera, los mejores resultados del modelo aparecen cuando está incrustado dentro de una estructura que le da lugar, memoria, herramientas, retroalimentación, y una condición de éxito. Esto no es un punto débil de la afirmación. Es la cuestión. Cuanto más capaz sea el modelo, más valioso será el flujo de trabajo que lo rodea, porque el coste del fracaso sin restricciones aumenta con la capacidad. (Rojo antrópico)
El pentesting económico de la IA trata de conclusiones verificadas, no de teatro de pruebas comparativas
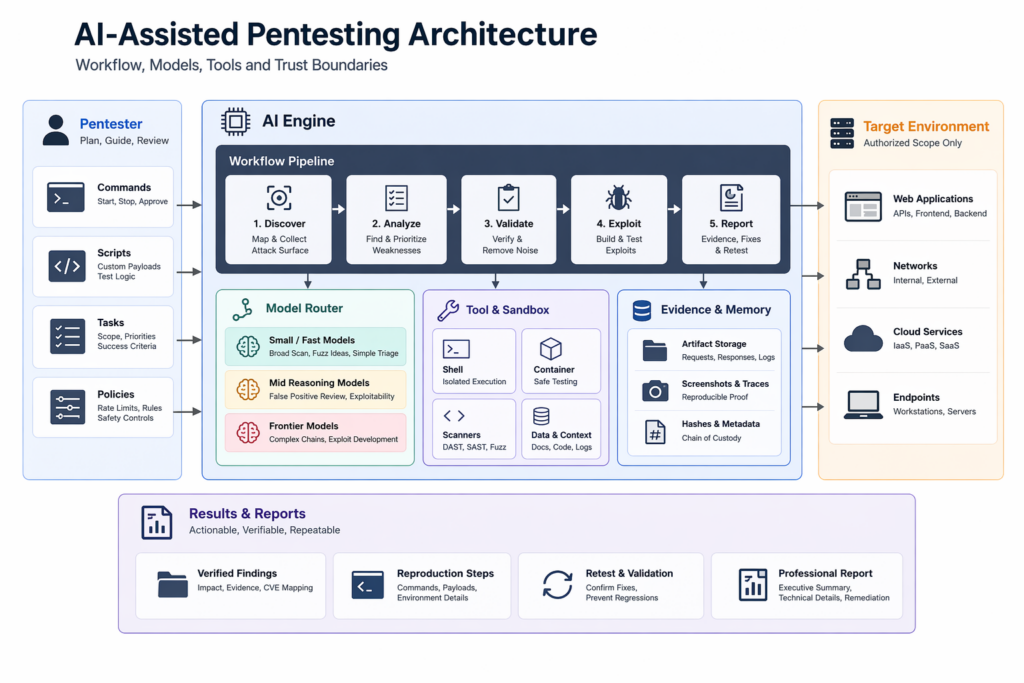
Los equipos de seguridad deberían desconfiar de cualquier discusión sobre precios que empiece y termine con el coste de los tokens. La verdadera unidad de cuenta en el pentesting no es el "coste por millón de tokens". Está más cerca del coste por hallazgo verificado, el coste por verdadero positivo retenido después de la revisión humana, el tiempo desde la señal inicial hasta la prueba reproducible y el coste de la atención del revisor quemada en el ruido. La definición del NIST ya apunta en esa dirección al incluir el análisis y la mitigación, no sólo la detección. En las operaciones de seguridad, un hallazgo que no puede sobrevivir a la repetición tiene un valor negativo. Consume atención, crea una deuda de información y puede degradar la confianza en todo el proceso. (csrc.nist.gov)
La página del Proyecto Glasswing de Anthropic dice que Mythos Preview estará disponible para los participantes a $25 por millón de tokens de entrada y a $125 por millón de tokens de salida tras el periodo de créditos de uso, con hasta $100 millones en créditos comprometidos durante el avance de la investigación. El informe de AISLE, por el contrario, destaca un coste de modelo activo de 3.600 millones de $0,11 por millón de tokens en una de sus tareas de replicación. Estas cifras no son perfectamente comparables, pero la dirección es suficientemente obvia sin forzar una falsa precisión: las diferencias de precio entre modelos son grandes, y eso importa en el momento en que se deja de pensar en demostraciones y se empieza a pensar en flujos de trabajo de producción sostenidos y repetidos. Un sistema que elige por defecto el modelo más caro en cada fase no es "serio" por definición. Puede que sólo sea antieconómico y esté mal encaminado. (antropic.com)
La mejor manera de pensar en el coste es preguntarse en qué cambia el resultado final si se gastan dólares en modelos de frontera. Si un modelo barato puede agrupar correctamente las rutas, identificar la superficie de ataque probable o rechazar falsos positivos obvios, entonces cada dólar que se gasta utilizando un modelo de frontera para repetir ese trabajo es un dólar que no se puede gastar en una validación más profunda, en intentos de explotación a más largo plazo, en pruebas de flujo autenticado o en volver a realizar pruebas después de las correcciones. Por lo tanto, una buena economía de pentesting se basa en la asignación de etapas. Una cobertura barata compra superficie. Con un razonamiento más sólido se adquiere claridad. El razonamiento fronterizo te compra intentos de avance en los que el espacio de búsqueda ya se ha comprimido lo suficiente como para que la inteligencia, y no la amplitud, sea el factor limitante. (AISLE)
La tabla siguiente es un cuadro de mando más útil para la economía del pentesting de IA que la diapositiva de referencia de cualquier proveedor. Es una síntesis del flujo de trabajo y de la lógica de fijación de precios reflejada en las fuentes anteriores. (csrc.nist.gov)
| Métrica | Por qué importa más que las puntuaciones brutas de los puntos de referencia | Distorsión común | Lo que debe preguntar un equipo disciplinado |
|---|---|---|---|
| Coste por hallazgo verificado | Aquí es donde la señal se convierte en valor defendible | Contar cada candidato como una victoria | Cuántos hallazgos sobreviven a la repetición y la revisión |
| Coste por verdadero positivo conservado tras el triaje | El ruido destruye la confianza de los críticos | Recuentos inflados de "problemas encontrados | ¿Cuál es la carga de rechazo de falsos positivos |
| Tiempo desde la señal hasta la prueba | La velocidad sólo importa si acaba en prueba | Medir sólo el tiempo de la primera hipótesis | ¿Cuánto falta para que haya un reproductor y un rastro de artefactos |
| Cobertura por dólar | Los modelos baratos pueden ampliar el espacio de búsqueda | Uso excesivo de modelos caros en etapas fáciles | Qué etapas están saturadas de cobertura de bajo coste |
| Tiempo de repetición de la prueba tras la corrección | El valor de seguridad sólo persiste si se verifican las correcciones | Notificación sin repetición de la prueba | ¿Qué tan rápido puede el flujo de trabajo confirmar una solución? |
| Minutos humanos por hallazgo promovido | El verdadero cuello de botella suele ser la atención del revisor | Ocultar el trabajo de limpieza de los analistas | Cuánto esfuerzo manual sigue requiriendo cada hallazgo verificado |
Casos reales demuestran por qué el flujo de trabajo vence a la mitología de los modelos
La brecha entre "comportamiento interesante del modelo" y "valor real del pentesting" se hace evidente cuando se observan las clases de vulnerabilidades reales. Lo importante no es que un LLM pueda narrarlas. Lo importante es si un sistema puede acotar correctamente el contexto, comprender la aplicabilidad, validar el impacto y preservar la prueba sin fabricar confianza. Los casos que se exponen a continuación son útiles porque ponen el acento en distintas partes del proceso. Algunos recompensan el razonamiento semántico. Otros recompensan el conocimiento del entorno. Algunos castigan a los equipos que confunden el conocimiento de CVE con el conocimiento de explotabilidad. Algunos no encajan bien con una mentalidad de escáner puro. Todos ellos llevan a la misma conclusión: la calidad del modelo es importante, pero el diseño del flujo de trabajo decide si esa calidad se convierte en un trabajo de seguridad fiable. (El proyecto FreeBSD)
CVE-2026-4747, FreeBSD RPCSEC_GSS y la diferencia entre detección y prueba
CVE-2026-4747 es el ejemplo más limpio porque aparece tanto en el escaparate de Anthropic como en el aviso oficial de FreeBSD. FreeBSD dice que el problema es un fallo de ejecución remota de código en la validación de paquetes RPCSEC_GSS que afecta a todas las versiones soportadas en el momento de la divulgación, y da crédito a "Nicholas Carlini usando Claude, Anthropic". El post del Equipo Rojo de Anthropic describe que Mythos Preview identificó y explotó el fallo de forma totalmente autónoma tras escanear cientos de archivos en el kernel, mientras que la réplica de AISLE argumenta que una vez aislada la función vulnerable y proporcionado el contexto arquitectónico relevante, incluso modelos más pequeños pueden reconocer el desbordamiento y razonar el impacto crítico. Ese es exactamente el tipo de caso que separa la búsqueda a escala de repositorio del razonamiento localizado de vulnerabilidades. No prueba que los modelos pequeños puedan hacer todo el trabajo. Demuestra que una parte importante de la "parte inteligente" es accesible mucho antes en la curva de capacidad del modelo de lo que mucha gente suponía. (El proyecto FreeBSD)
La lección operativa es aún más útil que la simbólica. CVE-2026-4747 no es sólo un titular porque esté asociado a la IA. Es importante porque se encuentra en la intersección del análisis de protocolos, el contexto del kernel, la gravedad del exploit y la validación. Un flujo de trabajo de pentesting que simplemente diga "posible desbordamiento en la ruta de autenticación" no es suficiente. Un flujo de trabajo serio tiene que preservar los supuestos del paquete, la región del código, el argumento de explotabilidad, el entorno exacto y los pasos de reproducción. Por eso la métrica de éxito correcta no es "el modelo encontró un fallo". Es "el sistema produjo un hallazgo que otro ingeniero puede parchear y en el que puede confiar". (csrc.nist.gov)
OpenBSD SACK, razonamiento sutil es donde el enrutamiento empieza a importar
El bug SACK de OpenBSD en el post de Anthropic es una mejor prueba de razonamiento sutil que el caso de FreeBSD. Anthropic lo describe como un fallo ya parcheado de hace 27 años en un sistema operativo conocido por su seguridad. La réplica de AISLE es útil porque hace explícita la dificultad subyacente: el problema no es un patrón de corrupción de memoria caricaturescamente obvio. Tiene que ver con la validación de límites inferiores, el comportamiento de desbordamiento con signo en macros de comparación de secuencias y una cadena que lleva a una condición de puntero nulo sólo bajo valores de paquete cuidadosamente elegidos. AISLE informa de que un modelo abierto 5.1B-activo recuperó la cadena pública completa mientras que varios otros modelos fallaron parte del razonamiento. Esto no es una vuelta de la victoria para los modelos pequeños. Es una lección de enrutamiento. Algunas etapas ya están comoditizadas. Otras siguen exigiendo un escalado selectivo. (Rojo antrópico)
La conclusión práctica para los pentesters es que los fallos sutiles son precisamente aquellos en los que un sistema debe ser conservador con los ascensos. Un modelo que dice con confianza "robusto ante tales escenarios" en una pasada y luego recupera una compleja cadena de exploits en otra familia de modelos es un recordatorio de que el consenso entre modelos no es lo mismo que la verdad. Para esta clase de problemas, el flujo de trabajo debe preservar las suposiciones de los paquetes, las condiciones de contorno y los artefactos de prueba ejecutables antes de que un hallazgo tenga autoridad. Cuanto más difícil sea la cadena de razonamiento, más sólida deberá ser la puerta de pruebas. (AISLE)
FFmpeg H.264, la semántica puede derrotar a la intuición de fuerza bruta
El ejemplo de Anthropic con FFmpeg es importante por otra razón. La compañía dice que Mythos Preview encontró una vulnerabilidad de 16 años en la ruta del decodificador H.264 que implicaba un desajuste entre un contador de rebanadas de 32 bits y una tabla de propiedad de 16 bits inicializada con un valor centinela. Antrópico enmarca el error como haber sobrevivido a un fuerte escrutinio en uno de los proyectos de medios de comunicación más a fondo probado en el mundo, incluyendo años de atención fuzzing. Tanto si se quiere hacer hincapié en la edad, la reputación de la base de código o el historial de pruebas, la lección de ingeniería es la misma: no todos los bugs de alto valor se parecen a los tipos de fallos que las estrategias de búsqueda tradicionales sacan a la superficie con facilidad. Algunos fallos viven en desajustes semánticos, suposiciones centinela y construcciones de estado raras que es perfectamente razonable pasar por alto si tu sistema se optimiza principalmente para firmas conocidas o reconocimiento de patrones poco profundos. (Rojo antrópico)
Eso convierte a FFmpeg en un argumento de peso para los flujos de trabajo mixtos. Los escáneres puros son débiles ante las trampas semánticas. Los agentes de razonamiento puro sin validadores son propensos al exceso de confianza. El sistema correcto acopla la exploración semántica con un validador lo suficientemente fuerte como para rechazar malas historias. En contextos de seguridad de memoria, esto puede ser un sanitizador o un oráculo de fallos. En contextos de aplicaciones web, puede ser un arnés de repetición y un modelo de estado que tenga en cuenta los privilegios. En contextos de API puede ser una repetición de transacciones diferenciada por roles a través de objetos. El patrón ganador no es "sustituir las herramientas por el lenguaje". Es "usar el lenguaje para guiar las herramientas hacia los experimentos correctos". (Rojo antrópico)
CVE-2024-3094, XZ y los límites del pentesting de IA basado en titulares
La puerta trasera XZ es un correctivo útil porque castiga el pensamiento simplista sobre vulnerabilidades. NVD describe código malicioso en los tarballs de xz a partir de la versión 5.6.0, con instrucciones de compilación extra que extraen un archivo de objeto oculto que modifica el comportamiento de liblzma durante la compilación. Este es un problema de la cadena de suministro y de los artefactos de publicación, no simplemente un problema de lectura de código dentro del repositorio. Un sistema que sólo escanea árboles de fuentes o banners de versiones puede fácilmente pasar por alto lo más importante. La verdadera lección es que la aplicabilidad puede depender de la ruta de publicación, el entorno de compilación, la integración de paquetes y el comportamiento de la distribución posterior. Este es exactamente el tipo de caso en el que la ayuda de la IA es tan buena como las pruebas y la procedencia que puede recuperar. (nvd.nist.gov)
Para el pentesting de IA, CVE-2024-3094 es una advertencia para no confundir la comprensión de noticias sobre vulnerabilidades con la validación operativa. Un modelo que puede explicar XZ elocuentemente no le ha ayudado a menos que el sistema pueda responder a preguntas más difíciles: ¿se introdujo realmente la versión afectada, consumió su ruta de construcción los artefactos alterados, qué versiones de paquetes cruzaron esa ruta, qué binarios enlazaron la biblioteca modificada y qué límite de confianza falló? En los casos de la cadena de suministro es donde más rápido se rompe el cuento de "el modelo más grande gana", porque el cuello de botella suele ser la procedencia, no la prosa. (nvd.nist.gov)
CVE-2024-6387, regreSSHion y la diferencia entre gravedad y viabilidad
NVD describe CVE-2024-6387 como una regresión de seguridad en el servidor de OpenSSH donde una condición de carrera en el manejo de señales puede permitir a un atacante remoto no autenticado desencadenar un comportamiento inseguro al fallar la autenticación dentro de un límite de tiempo. El punto importante para este artículo no es el debate sobre la explotabilidad en entornos específicos. Es que el flujo de trabajo tiene que razonar sobre el entorno, el tiempo, la exposición y la prioridad operativa real en lugar de detenerse en el "fallo remoto crítico". Muchos sistemas de seguridad de IA suenan persuasivos precisamente donde son menos útiles: pueden replantear la gravedad sin hacer el trabajo más difícil de razonar sobre la aplicabilidad. (nvd.nist.gov)
Esta es la razón por la que la clasificación de explotabilidad no debería delegarse a una sola pasada del texto del modelo. Un sistema útil debería preguntar si el servicio está orientado a Internet, si la versión afectada está expuesta en primer lugar, si los controles compensatorios cambian la ventana de ataque y cómo sería la condición de prueba esperada bajo una validación segura. Un modelo puede ayudar. Un flujo de trabajo tiene que decidir. Cuanto más maduro sea el equipo, menos impresionado debería estar por la reformulación fluida de la descripción del CVE y más interesado debería estar en lo que el sistema puede probar sobre este entorno. (csrc.nist.gov)
CVE-2024-3400 y CVE-2024-4577, la aplicabilidad no es opcional
La descripción de NVD de CVE-2024-3400 es directa: una inyección de comando resultante de la creación de archivos arbitrarios en GlobalProtect en versiones específicas de PAN-OS y configuraciones de características puede permitir la ejecución no autenticada de código raíz, mientras que Cloud NGFW, los dispositivos Panorama y Prisma Access no se ven afectados. CVE-2024-4577 está igualmente ligado a la configuración de una manera diferente: NVD dice que las versiones afectadas de PHP en Windows en modo CGI pueden malinterpretar caracteres bajo páginas de código específicas y permitir opciones PHP controladas por atacantes, con consecuencias de hasta ejecución de código arbitrario. Estos son ejemplos perfectos de por qué el pentesting de IA real no puede detenerse en la búsqueda de CVE. Tiene que responder a preguntas de configuración. ¿Está habilitada la función? ¿Está afectado el tipo de dispositivo? ¿Se utiliza el modo CGI? ¿Qué página de código está en juego? ¿Puede alcanzarse realmente la condición desde la ruta expuesta? (nvd.nist.gov)
No se trata de casos extremos. Son ejemplos ordinarios de por qué el medio del pentesting es más difícil que el frente. La parte delantera consiste en darse cuenta de la posibilidad. La parte intermedia consiste en separar la verdad del entorno del lenguaje genérico del riesgo. En ese punto intermedio es donde el flujo de trabajo, la recuperación, la conservación del estado y la recopilación de pruebas se ganan su sustento. También es donde los modelos pequeños o medianos pueden hacer a menudo un trabajo excelente si el sistema ya ha recopilado los datos medioambientales correctos. El cuello de botella no siempre es la profundidad del razonamiento abstracto. A veces se trata de si el flujo de trabajo se ha molestado siquiera en recopilar los hechos que hacen que una vulnerabilidad sea real. (csrc.nist.gov)
La tabla de casos que figura a continuación condensa el patrón. No pretende ser un catálogo, sino una ayuda para la toma de decisiones. (El proyecto FreeBSD)
| Caso | Por qué es importante | En qué se equivoca una mentalidad basada únicamente en modelos | Qué aporta un sistema que da prioridad al flujo de trabajo |
|---|---|---|---|
| CVE-2026-4747 FreeBSD RPCSEC_GSS | Ejemplo limpio de descubrimiento, gravedad y prueba | Confunde el razonamiento aislado con la autonomía de extremo a extremo | Aislamiento de funciones, contexto de paquetes, reproductor, rastro de artefactos |
| Error de SACK en OpenBSD | Pruebas de razonamiento sutil y lógica de explotación | Trata una explicación segura como la verdad fundamental | Validación en varios pasos y promoción conservadora |
| Fallo de FFmpeg H.264 | Demuestra que los errores semánticos pueden sobrevivir a pruebas intensivas | Sobreíndices en fallos compatibles con la firma | Razonamiento semántico vinculado a validadores |
| CVE-2024-3094 XZ | El contexto de la cadena de suministro supera al escaneado en origen | Supone que basta con una inspección | Procedencia, ruta de compilación, análisis de artefactos de publicación |
| CVE-2024-6387 regreSSHion | Gravedad no es lo mismo que prioridad operativa | Repite el lenguaje del CVE sin juicio de aplicabilidad | Validación en función de la exposición y el entorno |
| CVE-2024-3400 PAN-OS | Las características y el alcance del producto importan | Ignora los requisitos previos de configuración | Controles de aplicabilidad en función del producto |
| CVE-2024-4577 PHP-CGI | La configuración regional y el modo de ejecución son importantes | Trata la coincidencia de versión como prueba de explotabilidad | Validación en tiempo de ejecución y de páginas de código |
Construir el flujo de trabajo que haga útiles los modelos más pequeños
Un sistema de pentesting de IA realista empieza con límites, no con avisos. Antes de que cualquier modelo vea un objetivo, el sistema ya debe conocer los hosts autorizados, las clases de hosts prohibidos, la tasa máxima de solicitudes, las identidades y roles disponibles para pruebas autenticadas, las categorías de acciones que requieren aprobación explícita y los artefactos que deben conservarse para su posterior revisión. Los modelos se vuelven peligrosos sobre todo cuando no están integrados en políticas que sobrevivan a su fluidez momentánea. Un agente fuerte no es más seguro porque sea más fuerte. Es más seguro porque está delimitado con mayor precisión. Esto es tan cierto para un modelo de frontera como para uno barato. (csrc.nist.gov)
Un simple manifiesto de alcance no es glamuroso, pero es la diferencia entre un flujo de trabajo gobernado y una proeza. La estructura que se muestra a continuación no pretende ser un archivo de producción completo. Muestra el tipo mínimo de información que el flujo de trabajo debe formalizar antes de que cualquier agente comience las pruebas activas.
compromiso:
target_id: prod-api-2026-04
propietario: security-team@example.com
authorization_ticket: CHG-48219
hosts_permitidos:
- api.ejemplo.com
- auth.ejemplo.com
forbidden_hosts:
- payments.internal.example.com
- admin-vpn.ejemplo.com
identidades_permitidas:
- cliente_basico
- cliente_premium
- agente_soporte
acciones_prohibidas:
- borrado destructivo de datos
- restablecimiento de contraseñas para usuarios reales
- escalada de privilegios de producción fuera de la puerta de aprobación
límites_de_tasa:
max_rps: 3
ráfaga: 10
evidencia:
output_dir: findings/prod-api-2026-04
save_http: true
save_screenshots: true
save_terminal_logs: true
save_reproducers: true
escalado:
frontier_model_required_for:
- business_logic_chain
- sandbox_escape_attempt
- síntesis de exploits en varios pasos
Una vez que existen los límites, la primera etapa suele ser barata y amplia. Inventariar los puntos finales. Agrupar rutas similares. Extraer documentación y pistas sobre el marco. Comparar respuestas entre roles. Registrar tiempos, redireccionamientos, transiciones de cookies e identificadores de objetos. En los proyectos con mucho código, indexar el proyecto y clasificar las regiones probablemente críticas para la seguridad. En pruebas web dinámicas, mapear estados y transiciones. Esto es reducción del espacio de búsqueda. Es donde los modelos económicos y las herramientas deterministas funcionan bien juntos. Aún no estás pidiendo un gran avance. Estás comprando amplitud organizada. (AISLE)
En la segunda fase es donde muchos sistemas empiezan a malgastar el dinero. En lugar de dirigir cada punto sospechoso al modelo más grande disponible, un flujo de trabajo disciplinado plantea una pregunta más estrecha: ¿puede un modelo modesto más un validador resolver esto? Para el trabajo de seguridad de memoria, esto puede significar un desinfectante, un oráculo de fallos o un reproductor minimizado. Para el trabajo web y de API, puede significar una reproducción diferencial entre roles, identificadores de objetos o estados de flujo de trabajo. Para CVEs sensibles a la configuración, puede significar la captura del entorno antes de la escalada de hipótesis. Un modelo no debería promocionarse porque el fallo parezca grave. Debería promocionarse porque el validador dice que la incertidumbre está ahora limitada por la inteligencia en lugar de limitada por las pruebas. (Rojo antrópico)
La política de enrutamiento puede esbozarse como código. Una vez más, la cuestión no es la aplicación exacta. Se trata de que la elección del modelo se convierta en una decisión política vinculada a la calidad de las pruebas, y no en un valor predeterminado permanente vinculado al prestigio del vendedor.
def choose_model(stage, signal_strength, validator_confidence, complexity):
if stage in {"asset_mapping", "endpoint_clustering", "first_pass_review"}:
return "modelo_pequeño_rápido"
si etapa en {"triaje", "revisión_falsos_positivos"}:
if validator_confidence >= 0.8:
return "modelo_pequeño_o_medio"
return "modelo_medio_de_razonamiento"
if stage in {"exploitability_assessment", "business_logic_analysis"}:
si complejidad == "alta
return "modelo_frontera"
return "modelo_razonamiento_medio"
if stage in {"exploit_construction", "sandbox_escape", "multi_bug_chain"}:
return "modelo_frontera"
return "modelo_razonamiento_medio"
Aquí es también donde las narrativas de los productos más saludables de la categoría empiezan a parecerse. La página de inicio pública de Penligent no enmarca el trabajo como "pedir el mejor modelo y esperar". Pone en primer plano un flujo operativo de tres pasos: "Encontrar vulnerabilidades. Verificar hallazgos. Ejecutar exploits", y lo complementa con "Resultados que se pueden reproducir a partir de pruebas" y "Editar solicitudes, bloquear el alcance y personalizar las acciones para su entorno". Incluso si un comprador nunca toca ese producto, esas son las preguntas correctas que hay que hacer a cualquier plataforma en este espacio porque se corresponden con auténticos requisitos de ingeniería: pruebas antes que promoción, artefactos antes que reclamaciones y control del operador antes que teatro de autonomía. (penligent.ai)
La canalización de los artefactos es tan importante como el enrutador de modelos. Si un flujo de trabajo no conserva suficiente material en bruto para reproducir un hallazgo más tarde, entonces se está entrenando silenciosamente para reportar conjeturas como hechos. Esa es la forma más rápida de destruir la confianza en las pruebas asistidas por IA. El siguiente fragmento es intencionadamente aburrido. Por eso es útil.
TARGET_ID="prod-api-2026-04"
OUT="resultados/$TARGET_ID/candidato-017"
mkdir -p "$OUT"
cp scope.yaml "$OUT/"
cp target-map.json "$OUT/"
cp request.txt "$OUT/"
cp response.txt "$OUT/"
cp role-a-session.txt "$OUT/"
cp rol-b-session.txt "$OUT/"
cp payload.txt "$OUT/"
cp terminal.log "$OUT/"
cp screenshot.png "$OUT/"
cp reproductor.sh "$OUT/"
cp notas.md "$OUT/"
sha256sum "$OUT"/* > "$OUT/artifact_hashes.txt"
Las buenas pruebas de seguridad suelen ser aburridas antes de ser valiosas. El modelo puede ayudar a escribir notas, comparar trazas, explicar un fallo o sugerir la siguiente rama a probar. Pero el flujo de trabajo sigue necesitando datos del entorno, solicitudes sin procesar, resultados de la ejecución y una ruta de repetición. Esto no es anti-AI. Es la forma de evitar que la IA se convierta en un amplificador de confianza para afirmaciones no verificadas. (penligent.ai)
Informar es el último paso, no el primer resultado visible
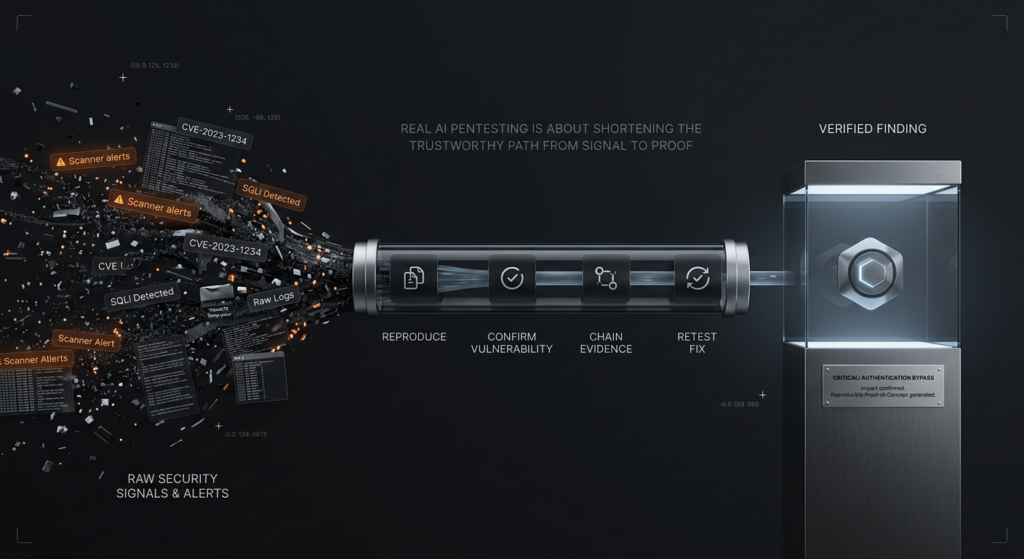
Uno de los hábitos más dañinos en las herramientas de seguridad de IA es generar informes pulidos antes de que el sistema se los haya ganado. El marco del NIST es útil en este caso porque sitúa el análisis y la mitigación dentro del proceso de prueba en lugar de después. Un informe no es el producto de un modelo de lenguaje inteligente. Es el envoltorio de un resultado verificado. Parece obvio, pero una parte sorprendente del mercado sigue equivocándose en la secuencia. Un sistema encuentra una pista, escribe una historia y deja que el propio informe convierta la incertidumbre en autoridad. Los pentesters deberían rechazar ese patrón. Los compradores deberían castigarlo. (csrc.nist.gov)
Una pauta mucho más saludable es definir una puerta de promoción. Un candidato no se convierte en un hallazgo verificado porque la explicación suene bien o la estimación CVSS parezca plausible. Se convierte en verificado cuando el flujo de trabajo tiene suficientes artefactos para reproducir el problema, suficiente contexto ambiental para apoyar la aplicabilidad, y suficiente evidencia para hacer que la remediación sea útil en lugar de especulativa. Una puerta mínima puede expresarse en lógica de políticas.
def promote_to_verified(candidate):
required = [
candidate.reproducer,
candidate.artifacts.http_or_binary_trace,
candidate.environment_notes,
candidate.impact_statement,
candidate.remediation_basis,
]
if not all(required):
return False, "missing required artifacts"
if candidate.finding_type == "access_control" and not candidate.role_differential_proof:
return False, "missing authorization differential evidence"
if candidate.finding_type == "memory_corruption" and not candidate.validator_signal:
return False, "missing crash or sanitizer validation"
if candidate.severity in {"critical", "high"} and not candidate.retest_plan:
return False, "missing retest criteria"
return True, "verified"
Este es el lugar donde la entrega del producto y la disciplina de ingeniería finalmente se encuentran. Las páginas de precios y productos de Penligent hacen hincapié en la exportación de informes con pasos de pruebas y reproducción, la reproducción de exploits con un solo clic con informes de cadena de pruebas y la entrega lista para auditoría de grado de equipo. El material público de Hacking Labs en torno a los informes de pentest de IA también enmarca el problema en probar lo que ocurrió más tarde, no sólo en generar un PDF más bonito ahora. Esta orientación es técnicamente saludable porque trata los informes como una expresión posterior de los artefactos en lugar de como un sustituto de los artefactos. Una vez más, la lección se generaliza más allá de cualquier proveedor: los sistemas en los que merece la pena confiar son los que pueden explicar cómo una afirmación se convierte en prueba. (penligent.ai)
Los modos de fallo que siguen atrapando a los equipos
El error más fácil es comprar el modelo más grande disponible y enrutar todo a través de él. Eso parece grave. A menudo produce la peor combinación de coste, latencia y fatiga del revisor. Las etapas fáciles se sobreaprovisionan. Las etapas difíciles siguen fallando porque el cuello de botella no era la inteligencia, sino la disciplina contextual o la falta de validadores. El equipo concluye entonces que el pentesting de IA "no funciona", cuando el verdadero problema era que trataba la calidad del modelo como un sustituto de la calidad del flujo de trabajo. El marco de AISLE en torno a los tokens por dólar, los tokens por segundo y la experiencia en seguridad integrada es un antídoto útil. En los procesos serios, la velocidad y la cobertura no son notas al margen. Forman parte de la ecuación de capacidad. (AISLE)
Un segundo error es confundir el aumento de escáneres con las pruebas de penetración. La guía de pruebas de OWASP sigue siendo amplia por una razón. Las pruebas reales incluyen mapeo, comportamiento autenticado, manejo de estado, comprobaciones de autorización y lógica de negocio. Un sistema que no puede preservar el contexto multi-rol o razonar sobre la propiedad de los objetos todavía puede ser útil, pero no está haciendo pentesting general en el sentido fuerte que la mayoría de los profesionales quieren decir. Esto es especialmente importante en el caso de las API, donde una autorización a nivel de objeto rota sigue siendo un riesgo importante porque los identificadores viajan a través de rutas, cabeceras, cargas útiles y estado de flujo de trabajo implícito. Un asistente de IA que no entienda ese terreno tenderá a producir un alto volumen de texto sobre seguridad y un bajo volumen de pruebas sobre riesgo. (owasp.org)
Un tercer error es tratar a los exploit demos como la totalidad del valor. Mythos se hizo famoso porque la construcción de exploits es vívida y aterradora, y los propios datos de Anthropic sugieren que la capacidad fronteriza en esta región es real. Pero muchas organizaciones no fracasan porque carezcan de un escritor de exploits perfectamente autónomo. Fracasan porque no pueden mantenerse al día con el triaje consciente del entorno, las pruebas de flujo de trabajo autenticado, la captura de pruebas reproducibles o la repetición de pruebas después de los parches. Los programas de seguridad suelen verse atascados por la conversión de la señal bruta en acción fiable. Por eso, los sistemas más potentes del mercado hacen cada vez más hincapié en los hallazgos verificados, la reproducibilidad y la calidad de la entrega. El temible exploit no es irrelevante. Simplemente no es el único cuello de botella, y a menudo no es el primero. (Rojo antrópico)
Un cuarto error es ignorar el control humano. Los sistemas agenticos más fuertes necesitan controles más estrictos, no más laxos. El marco público de Penligent en torno al alcance bloqueado y las acciones personalizables es saludable por la misma razón que lo es el andamiaje contenedorizado de Anthropic: el sistema sólo es útil en un entorno real si los operadores pueden restringir dónde actúa y cómo se promueven las acciones arriesgadas. La autonomía sin gobernanza no es madurez. Es confianza prestada. (Rojo antrópico)
Qué deben medir realmente los equipos
Llegados a este punto, las métricas adecuadas deberían parecer obvias, pero la mayoría de los equipos siguen sin instrumentarlas bien. Miden los problemas encontrados, los deltas de referencia o el tiempo medio de análisis y pasan por alto las variables que determinan si un programa de pentesting de IA es digno de confianza. Las métricas básicas deben medir la conversión de señal a prueba, la durabilidad de los hallazgos bajo revisión y el coste de esa conversión. Esas son las variables que revelan si el flujo de trabajo está aprendiendo realmente. (csrc.nist.gov)
| Métrica | Cómo es el bien | Lo que parece malo | Por qué es importante |
|---|---|---|---|
| Tasa de conversión de candidatos a verificados | Inferior pero estable y explicable | Elevado sobre el papel porque los candidatos se promocionan en exceso | Muestra si las puertas de pruebas son reales |
| Tiempo medio de reproducción | Previsiblemente escaso en clases repetibles | Largo y caótico a pesar de las impresionantes demostraciones | Mide la utilidad operativa |
| Minutos del revisor por hallazgo promovido | Disminuye con el tiempo | Carga de limpieza oculta para los analistas | Captura si la IA está comprimiendo el trabajo o exportándolo |
| Porcentaje de aprobados en los exámenes de recuperación | Elevado y bien documentado | Las conclusiones desaparecen en los informes atrasados | Indica si la entrega cierra el bucle |
| Modelo de gastos por etapa | La mayor parte del gasto se concentra en las etapas difíciles | La mayor parte del gasto se desperdicia en etapas fáciles | Revela si la política de rutas es sensata |
| Compartir hallazgos de lógica empresarial | Aumento de las pruebas de estado | Casi cero porque el flujo de trabajo nunca abandona el modo escáner | Indica si el sistema puede gestionar el riesgo real de la aplicación |
Por tanto, la pregunta de compra más importante en 2026 no es "¿Qué modelo utiliza?". Es "¿Cómo convierte su sistema una señal bruta en un hallazgo verificado, y qué artefactos existen en cada paso?". Una segunda pregunta de peso es "¿En qué gasta su costoso presupuesto de razonamiento?". Si un proveedor no puede responder a ninguna de las dos con especificidad, entonces probablemente tenga una historia modelo, no un flujo de trabajo de pentesting. Eso no significa que el producto sea inútil. Sólo significa que no deberías comprarlo como si resolviera el problema más difícil. (csrc.nist.gov)
AI pentesting después de Mythos significa enrutamiento, no culto
El mito importa. Los materiales públicos de Anthropic hacen que sea imposible descartarlo honestamente. El modelo parece haber empujado la frontera de forma significativa en el trabajo autónomo de exploits, y el Proyecto Glasswing no es un anuncio menor. Anthropic afirma que la iniciativa incluye importantes socios de lanzamiento, más de 40 organizaciones adicionales, grandes compromisos de créditos de uso y un plan explícito para estudiar cómo debe evolucionar la práctica de la seguridad en respuesta. No es una señal de juguete. Es un indicador de que los principales laboratorios creen que la ciberseguridad se ha convertido en uno de los dominios del mundo real más importantes para los modelos agénticos avanzados. (antropic.com)
AISLE es importante por la razón contraria, pero igualmente importante. Obliga a dejar de narrar la seguridad de la IA como si toda la capacidad llegara en un bloque indivisible. Sus resultados sugieren que partes significativas del proceso ya son accesibles a modelos más pequeños y baratos, especialmente una vez que se ha reducido la ruta del código relevante o el contexto de destino. También replantea el éxito en torno a la aceptación del mantenedor, la corrección de confianza y el diseño a nivel de sistema. Esto se acerca más a lo que realmente necesitan los equipos de seguridad que cualquier tabla clasificatoria abstracta de "mejor modelo cibernético". (AISLE)
La síntesis correcta no es el compromiso porque sí. Es más aguda que eso. Los modelos de frontera se están volviendo muy importantes en la parte superior de la pila, especialmente para la generación de exploits restringidos y el razonamiento de largo horizonte. Pero el verdadero foso en el pentesting de IA no es el modelo más grande por sí mismo. Es el camino más corto y fiable de la señal a la prueba. Ese camino se construye a partir del control del alcance, la reducción del contexto, el enrutamiento del modelo, los validadores, la conservación de artefactos, la disciplina de repetición de pruebas y la entrega que otro ingeniero puede verificar. Si se construye bien ese camino, los modelos más pequeños se vuelven sorprendentemente potentes. Si lo construyes mal, incluso el mejor modelo del mundo te dará en la mayoría de los casos una prosa cara. (Rojo antrópico)
Para los equipos que construyen o compran en esta categoría, esa es la verdadera lección post-Mythos. No preguntes sólo quién tiene más inteligencia. Pregunte quién sabe dónde gastarla, dónde restringirla y cómo demostrarlo. En 2026, eso es lo que separa una impresionante demostración de seguridad de un flujo de trabajo de seguridad que realmente puede vivir dentro de una organización de ingeniería. (csrc.nist.gov)
Para saber más
- Anthropic, Proyecto Glasswing. (antropic.com)
- Equipo Rojo de la Frontera Antrópica, avance de Claude Mythos. (Rojo antrópico)
- AISLE, Ciberseguridad de la IA después de Mythos, La frontera irregular. (AISLE)
- Microsoft, CTI-REALM benchmark y MSRC AI security work. (Microsoft)
- NIST SP 800-115, Guía técnica de pruebas y evaluación de la seguridad de la información. (csrc.nist.gov)
- Guía de pruebas de seguridad web de OWASP. (owasp.org)
- OWASP API Security Top 10 2023. (owasp.org)
- Aviso de FreeBSD para CVE-2026-4747. (El proyecto FreeBSD)
- Página de inicio de Penligent. (penligent.ai)
- Penligent, AI Pentest Tool, cómo será la verdadera ofensiva automatizada en 2026. (penligent.ai)
- Penligent, AI Pentester en 2026. (penligent.ai)
- Penligent, The 2026 Ultimate Guide to AI Penetration Testing. (penligent.ai)

