The most useful question in offensive AI right now is not whether models can help with penetration testing. They can. The harder question is whether the economics work. If the answer were already yes at internet scale, the public internet would look different: more constant autonomous probing, more cheap target-specific exploit chaining, and more persistent low-cost compromise attempts against ordinary organizations rather than only high-value targets. That is not what the evidence suggests. The current reality is narrower and more interesting. AI pentesting already makes financial sense for bounded, high-value, repeatable work. It does not yet make economic sense as a universal substitute for cheap mass exploitation. (openai.com)
That distinction starts with what penetration testing actually is. NIST does not describe pentesting as asking an LLM what might be wrong. It describes penetration testing as security testing in which evaluators mimic real-world attacks to identify ways to circumvent the security features of an application, system, or network. In practice, real tests often combine multiple weaknesses to gain more access than any one issue would allow. That is why the cost question matters so much. A scanner summary is cheap. A credible attempt to model an attacker, pressure a real system, verify impact, and preserve evidence is not. (owasp.org)
The right headline, then, is not that AI pentesting is too expensive to matter. The right headline is that AI pentesting is already economically viable where the target is valuable enough, the workflow is structured enough, and the output needs to be verified enough. The same economics look much worse when the task is broad, unauthenticated, noisy, and highly variable. That is the line between a defensible enterprise workflow and the fantasy of an agent that cheaply hacks the whole internet while you sleep. (USENIX)
AI pentesting economics start with what vendors are charging
The easiest way to see that agentic work is not cheap is to look at what the model vendors themselves are doing. OpenAI’s current pricing materials list higher-paid tiers for heavier, more persistent usage, and its API pricing clearly separates model inference from tools such as web search and containers. Anthropic’s current pricing presents Max tiers at higher monthly price points and separately positions Claude Managed Agents for long-running asynchronous work. Those are not the prices or product boundaries of a commodity chat product. They are pricing signals for users expected to run longer, denser, more tool-heavy workloads. (openai.com)
Anthropic is even more explicit on the developer side. Its Claude Code cost guidance says average usage is about six dollars per developer per day, that ninety percent of daily costs stay below twelve dollars, and that team usage often lands around one hundred to two hundred dollars per developer per month with Sonnet-class usage patterns. In other words, one of the strongest public signals in the market is not that agents are basically free now. It is that agents already create a recognizable operating bill even in a mainstream coding use case. (IntuitionLabs)
The API side tells the same story in more granular form. OpenAI’s public pricing page currently lists GPT-5.4 mini at seventy-five cents per million input tokens and four dollars fifty per million output tokens, while web search and container usage are separately billed. Anthropic’s pricing page lists Claude Sonnet 4.6 at three dollars per million input tokens and fifteen dollars per million output tokens on standard pricing, and notes that Managed Agents sessions are billed at model rates while web search inside sessions is also charged separately. Anthropic also exposes one-million-token context support on selected models at standard pricing, which is convenient but also a reminder that long context is a real cost surface, not free memory. (openai.com)
That pricing structure matters for security work because security work is unusually good at turning one useful response into many chained responses with tools. A real pentest run does not stop after one good idea. It expands into enumeration, follow-up prompts, tool output interpretation, payload adjustment, authentication handling, exploit validation, evidence capture, and reporting. Agentic security workflows are therefore much closer to coding agents and research agents than to ordinary chat. The unit economics should be judged accordingly. (platform.claude.com)
AI pentesting cost is not one number, it is a stack
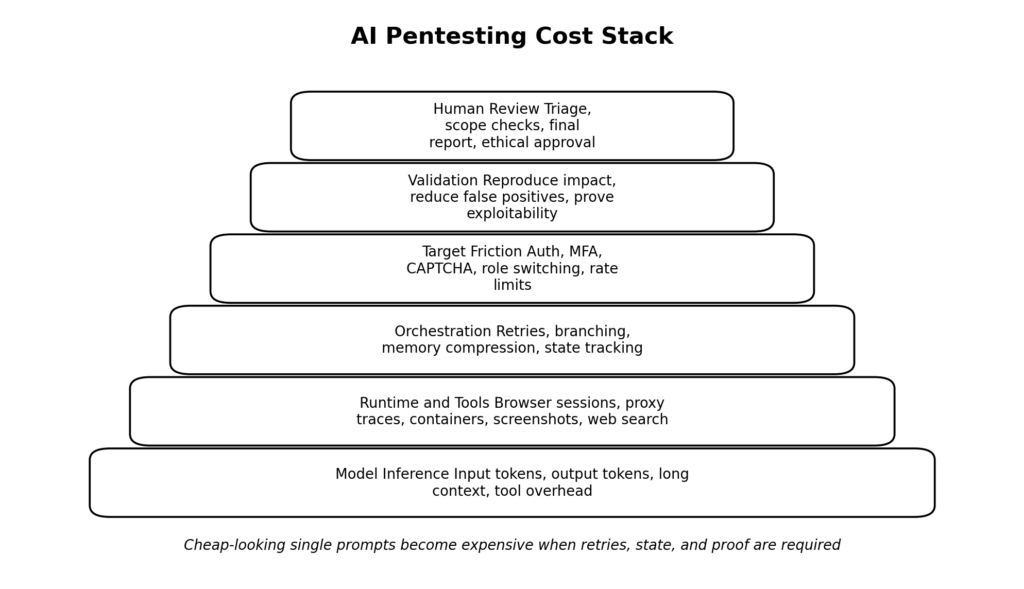
Most people ask what AI pentesting costs as if there were a single number. There is not. What exists instead is a layered cost stack, and the difference between a profitable workflow and an unprofitable one is usually determined by which layers dominate.
| Cost layer | What you are really paying for | Why it grows faster than expected |
|---|---|---|
| Model inference | Input tokens, output tokens, long context, vision input | Recon is noisy, tool output is verbose, retries compound history |
| Tool and runtime | Web search, shell sessions, containers, browser automation | Every useful action creates more state, logs, screenshots, and artifacts |
| Orchestration | Reflection loops, branching, summarization, memory compression | Failure recovery and exploration multiply calls |
| Target access | Accounts, seeded data, MFA handling, safe test setup | Authenticated testing is often more expensive than exploit logic |
| Validación | Reproducing impact, reducing false positives, proving exploitability | Most candidate findings die here |
| Human review | Triage, scope enforcement, final write-up, ethical guardrails | Customers and bounty programs still want proof, not vibes |
The crucial mistake is to price only the first row. If all you count is model inference, some AI pentesting workloads look astonishingly cheap. If you count the whole stack, especially retries and human review, the economics change fast. That is consistent with how both OpenAI and Anthropic expose pricing: they do not package everything into a magical flat rate for serious agentic work. They meter the expensive parts because those parts are real. (openai.com)
The floor is cheap, the full workflow is not
At a purely mechanical level, modern model pricing can make a single text-heavy turn look trivial. With OpenAI’s current GPT-5.4 mini rates, even fairly large prompts can still look inexpensive in raw token terms. Anthropic’s raw API rates tell a similar story at small scale: one careful pass over a target’s documentation, response samples, and JavaScript files may cost very little relative to the potential value of a good lead. (openai.com)
But pentesting rarely behaves like a single well-shaped prompt. It behaves like a tree. The model asks for more endpoints. The proxy output is larger than expected. A login flow breaks and needs a different sequence. A candidate BOLA turns out to be a cache issue. The exploit works only under one role. The report needs a clean proof path. The agent re-reads prior state because the task branch drifted. Each of those events adds cost. The direct token bill may still be manageable, but the workflow bill rises because each branch also consumes human attention, wall-clock time, and confidence. That is the point where cheap inference stops being the relevant metric. (USENIX)
A cost model that ignores branch failure is especially misleading in security work. Large language models are good at compressing messy evidence into plausible next steps. They are much less reliable at knowing early and with confidence whether a branch is worth pursuing. Security testing therefore suffers from a brutal form of hidden spend: many branches produce articulate but economically useless work. (USENIX)
A small calculator is more honest than a slogan
A simple estimator makes the problem easier to see. This is not a benchmark and it is not a vendor quote. It is a practical budgeting model for a single agentic pentest run.
def estimate_ai_pentest_run(
input_mtok,
output_mtok,
model_in_usd_per_mtok,
model_out_usd_per_mtok,
web_search_calls=0,
web_search_usd_per_call=0.01,
container_sessions=0,
container_usd_per_session=0.03,
retry_multiplier=1.0,
human_review_hours=0.0,
reviewer_hourly_usd=0.0,
):
model_cost = (input_mtok * model_in_usd_per_mtok) + (output_mtok * model_out_usd_per_mtok)
tool_cost = (web_search_calls * web_search_usd_per_call) + (container_sessions * container_usd_per_session)
automation_cost = (model_cost + tool_cost) * retry_multiplier
human_cost = human_review_hours * reviewer_hourly_usd
total_cost = automation_cost + human_cost
return {
"model_cost_usd": round(model_cost, 2),
"tool_cost_usd": round(tool_cost, 2),
"automation_cost_after_retries_usd": round(automation_cost, 2),
"human_review_cost_usd": round(human_cost, 2),
"total_cost_usd": round(total_cost, 2),
}
example = estimate_ai_pentest_run(
input_mtok=1.8,
output_mtok=0.25,
model_in_usd_per_mtok=0.75,
model_out_usd_per_mtok=4.50,
web_search_calls=12,
container_sessions=10,
retry_multiplier=2.3,
human_review_hours=1.5,
reviewer_hourly_usd=125,
)
print(example)
The useful thing about a calculator like this is not the exact output. It is the discipline it forces. Once you add retries, tool calls, and human review, the dominant cost may no longer be the model at all. That insight matches the direction of current vendor pricing: OpenAI charges separately for tools such as web search and containers, and Anthropic separately exposes model usage, tool overhead, Managed Agents billing, and average Claude Code operating costs. (openai.com)
Now compare two practical cases. In a lightweight public-web recon task, the model may read some HTML, a handful of JavaScript files, and perhaps a public OpenAPI description. That can be very inexpensive. In an authenticated SaaS test with role switching, CSRF tokens, object ID permutations, screenshots, repeated proxy traces, and validation attempts, the same workflow can cost an order of magnitude more before the report is even fit for submission. The difference is not that the second target is harder in the abstract. The difference is that the second target imposes more state, more friction, and more places to fail. (USENIX)
Why AI bug bounty math is harsher than enterprise math
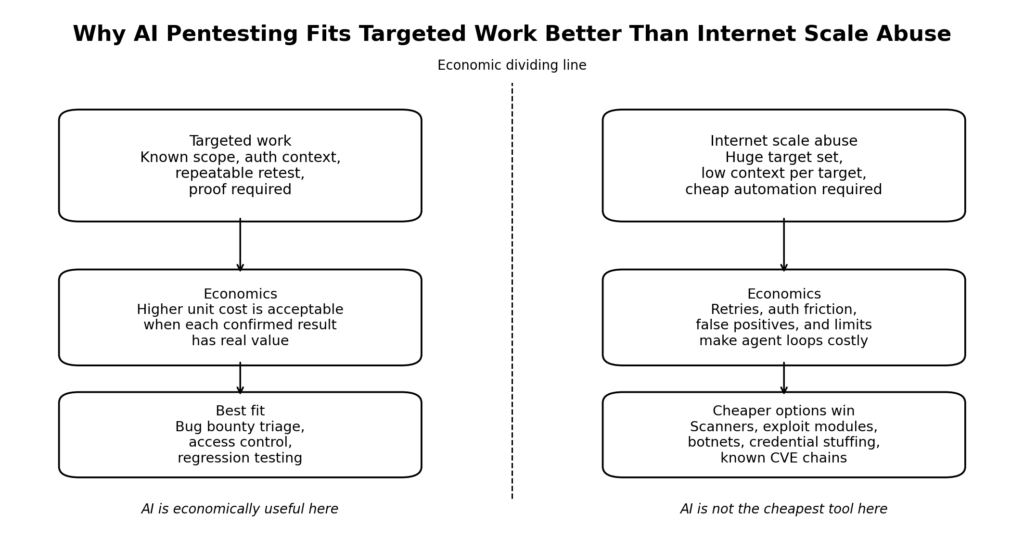
Enterprise buyers and bug bounty researchers solve different equations. An enterprise team cares about whether AI shortens time to verified risk, increases coverage, reduces false positives, or lowers the amount of senior attention required per engagement. A solo bug bounty hunter cares about expected payout minus time, tooling, and failure costs. The same agent can look attractive in the first equation and mediocre in the second.
The evidence from hacker platforms already points toward a human-augmented model rather than a fully autonomous one. Bugcrowd’s 2026 material says AI adoption among hackers reached eighty-two percent and frames the change as human-augmented intelligence rather than human replacement. HackerOne’s 2025 Hacker-Powered Security Report says it is built on more than 580,000 validated vulnerabilities, eighty-one million dollars in payouts that year, and insights from 1,950 enterprise programs, while also reporting two-hundred-ten percent growth in valid AI vulnerability reports and a five-hundred-forty percent increase in prompt injection as an attack vector. AI is not hypothetical in hacker workflows anymore. It is operational. But the public data describes augmentation and surface expansion more than full replacement of human judgment. (Bugcrowd)
Bugcrowd’s own 2026 reporting makes the same point more directly. AI is increasingly useful for common issues, repetitive triage, and broader coverage, but the most valuable attack paths still depend heavily on understanding how the target actually works. That is almost a direct description of where bug bounty economics split. Low-context, high-volume tasks are the place where automation helps the most. High-context, high-payoff, target-specific chains are exactly where the remaining human advantage is hardest to remove. (Bugcrowd)
That is why AI can improve a bounty workflow and still leave the final ROI ambiguous. If AI helps you audit more JavaScript, organize endpoints, draft a better proof, and summarize impact more clearly, that is real value. If it also leads you through ten confident dead ends on a stateful target before you abandon the path, the value can evaporate. In bug bounty, the hidden failure cost is not theoretical. It is the difference between a clean submission and a lost day.
Where AI already pays off for bug bounty hunters
The highest-return AI use cases in bug bounty are not the ones that look most autonomous in a demo. They are the ones that remove expensive context switching from work the researcher still understands.
Bugcrowd’s 2026 report and related materials describe AI helping with reporting quality, broader coverage, and more output for the same budget. That is consistent with how many researchers actually use it. AI helps parse large JavaScript bundles, cluster repeated endpoint patterns, summarize business logic, explain unusual headers, generate payload variants, or polish a vulnerability narrative so the program team can reproduce it faster. Those are not glamorous tasks, but they are exactly where solo hunters lose time. When AI compresses that loop, it can increase throughput without pretending to guarantee discoveries. (Bugcrowd)
The product signals from PortSwigger point in the same direction. Burp AI documentation emphasizes that the user remains in control, that the features do not run unless explicitly activated, and that AI is being used to enhance tasks such as access-control validation, login-sequence generation, and issue exploration. What is notable is what Burp AI does not promise. It does not promise an unsupervised agent that replaces the tester. It promises faster validation, fewer dead ends, and less manual friction inside a tool the tester already trusts. That is exactly what economically rational AI in bug bounty looks like today. (owasp.org)
That product posture is not caution for its own sake. It is an economic admission. If a mature AppSec vendor believed that cheap, general, autonomous exploitation was already the dominant value path, its public messaging would look different. Instead, the value proposition centers on false-positive reduction, workflow continuity, and operator-controlled automation. Those are the places where the cost-to-signal ratio is already good. (owasp.org)
Why false positives are more expensive than token bills
The central economic problem in AI pentesting is not price per token. It is price per validated finding.
A security workflow can tolerate a lot of cheap inference. It cannot tolerate endless cheap inference that does not converge. Every candidate issue that dies late is costly. It consumed target context, agent time, and reviewer attention. In bug bounty it may also consume scarce emotional energy. A workflow that keeps you productively curious is worth more than one that produces articulate nonsense with great confidence.
That is one reason access control remains such a revealing category. OWASP’s current Top 10 keeps Broken Access Control at the top, and the OWASP API Security Top 10 continues to lead with Broken Object Level Authorization. These are exactly the kinds of flaws that are easy to describe and often hard to prove at scale because they require authenticated state, user-role comparison, and careful understanding of object scope. PortSwigger’s AI-related materials also stress the difficulty of reducing false positives in access-control testing. That is an unusually honest description of where the economics break: access-control bugs are valuable, common, and painful, so reducing false positives there has real monetary value. (owasp.org)
The implication is bigger than access control. Any vulnerability class that is easy to enumerate but expensive to validate will become a battleground for AI economics. Whoever reduces the cost of proving or disproving candidate impact wins, even if the underlying model is not dramatically better.
Traditional mass exploitation is still cheaper than agentic internet-scale hacking
This is the part many discussions miss. The internet is not under constant agentic attack partly because a huge share of profitable mass exploitation never needed expensive agentic reasoning in the first place.
When a vulnerability is remotely reachable, standardized, easy to fingerprint, and easy to trigger with limited context, the cheapest offensive path is usually not a reflective AI agent. It is a thin scanner, a deterministic check, an exploit module, a credential stuffing rig, or a botnet. The economics of mass exploitation reward repeatability, not elegance. That is why old-fashioned automation still matters so much.
A few recent high-impact CVEs make the difference obvious.
Log4Shell shows what cheap internet-scale exploitation looks like
NVD describes CVE-2021-44228, Log4Shell, as a flaw in Log4j 2 where attacker-controlled log messages or log parameters can lead to arbitrary code execution through JNDI lookups. The NVD record notes that this behavior was disabled by default in version 2.15.0 and fully removed in 2.16.0. Older releases could be mitigated by disabling lookups or removing the JndiLookup class. Economically, Log4Shell was nearly perfect for mass exploitation: internet-wide, standardized, easy to test for, and devastating when present. An attacker did not need a long-running agent to understand whether a target was worth a second look. A cheap payload, broad scanning, and existing exploit infrastructure already fit the business model. (nvd.nist.gov)
That distinction matters. When people imagine AI hacking the whole internet, they often imagine AI replacing all automation. In practice, the cheapest and fastest offensive workflow for a Log4Shell-class bug was already available without expensive agent loops. AI might help prioritize, summarize, or adapt payloads, but it was not required to make the attack economically viable. (nvd.nist.gov)
MOVEit shows how unauthenticated external bugs industrialize quickly
NVD describes CVE-2023-34362 in Progress MOVEit Transfer as a SQL injection flaw in the web application that could allow an unauthenticated attacker to access the database, infer structure and contents, and execute SQL statements that alter or delete database elements. Public records and advisories tied the flaw to real-world exploitation. Again, the economics are the point. MOVEit did not become a major incident class because attackers had a magical autonomous reasoning engine. It became one because the vulnerability was high-value, unauthenticated, internet-facing, and standard enough to weaponize. Once that is true, the cheapest offense is not a costly general agent. It is focused industrialization around one exploit path. (nvd.nist.gov)
ScreenConnect is another reminder that external management planes are special
NVD describes CVE-2024-1709 as an authentication bypass in ConnectWise ScreenConnect 23.9.7 and earlier that may allow direct access to confidential information or critical systems. From an economic perspective, management interfaces compress attacker decision-making. If the surface is exposed and the flaw is severe, the expected value per successful attempt is high. That kind of target does not require a sophisticated general agent to be attractive. It requires a quick way to find exposed instances and test a known path. (nvd.nist.gov)
This is where many AI offense conversations go off track. The existence of stronger agents does not erase the economic dominance of conventional automation against standardized, high-payoff, internet-facing vulnerabilities.
The Ivanti chain shows why standardized exploit chains beat freeform agent reasoning
NVD describes CVE-2023-46805 as an authentication bypass in Ivanti Connect Secure and Ivanti Policy Secure that lets a remote attacker access restricted resources by bypassing control checks. In the same vulnerability cluster, command-execution flaws such as CVE-2024-21887 made chaining even more dangerous. Economically, this is a near-perfect example of why standardized exploit chains remain cheaper than freeform agentic offense. Once the chain is known, the work is not understand this company’s business logic from scratch. The work is find exposed devices, validate versions, execute chain, move on. Even if AI helps package the chain or explain it, the margin comes from standardization and repetition. (nvd.nist.gov)
That is why the internet is not waiting for a universal pentest agent to become dangerous. The most profitable corners of offensive automation already had a path. AI becomes most economically attractive when the problem is not already reducible to a known exploit pattern.
AI pentesting makes the most sense where context is expensive and reuse is possible
The strongest current use case for AI pentesting is not mass exploitation. It is expensive context handling.
That includes authenticated application mapping, organizing large proxy traces, interpreting noisy results, generating targeted follow-up checks, validating likely access-control issues, retesting after fixes, and converting raw observations into reproducible evidence. These are tasks where human expertise still matters, but the human’s time is the expensive part. If AI reduces that time without collapsing reliability, the economics can work even when the raw token bill is non-trivial.
This is also where the original PentestGPT research still matters. The USENIX Security 2024 paper introduced a framework built around multiple self-interacting modules to mitigate context loss and improve automated pentesting sub-tasks. More recent research such as Shell or Nothing sharpened the reality check by reporting that existing systems still struggle to obtain system shells under realistic conditions, while also showing that better memory and exploit-handling systems can reduce execution time and financial cost. The trend line is clear. AI is real. The value is real. The hard part is not getting the model to sound like a pentester. The hard part is getting the whole system to converge on verified impact without spending too much money or too much reviewer attention along the way. (USENIX)
AI pentesting economics are best in bounded workflows
The most profitable AI pentesting workflows today tend to share three features. They are bounded, they are reusable, and they are proof-oriented.
| Workflow type | Why the economics work | Why the economics break |
|---|---|---|
| Authenticated mapping and role comparison | High-value human time is saved and context can be reused across many checks | Breaks if login and account setup dominate the job |
| Access-control and BOLA verification | AI can cluster object patterns and help reduce false positives | Breaks if the agent cannot maintain consistent role state |
| Retesting after fixes | The target and exploit path are already known | Breaks if remediation changed the app more than expected |
| Evidence packaging and report drafting | AI compresses writing, screenshots, notes, and reproduction steps | Breaks if the underlying finding was never truly validated |
| Broad unauthenticated scanning | Cheap if treated as recon only | Breaks when people mistake recon for pentesting |
| Internet-wide autonomous compromise | Rarely worth it compared with simpler automation | Breaks on cost, rate limits, false positives, and target variability |
NIST’s definition of pentesting and OWASP’s continuing emphasis on access control make these bounded workflows especially important. Penetration testing is about active attempts to defeat security controls and often relies on combinations of issues. Broken access control and object-level authorization remain central because they sit right at the boundary where automation is useful but proof still matters. That boundary is where AI can produce real economic leverage. (owasp.org)
A governed AI pentesting workflow is also where product design starts to matter more than model marketing. Penligent’s public English materials repeatedly frame an AI pentester as a governed system that shrinks the distance between raw signal and verified finding. That framing is economically important because the expensive part of security work is rarely the first hypothesis. It is the path from noisy hint to defensible evidence. (Penligente)
The same idea shows up on Penligent’s public product pages in a different form: operator-controlled workflows, scope control, and human-in-the-loop execution rather than blind autonomy. Whether a team uses Penligent or not, that design direction is telling. The financially valuable product is not the one that promises to hack anything. It is the one that helps a human tester prove what matters faster, with tighter control over scope and actions. (Penligente)
The hidden tax on autonomous hacking
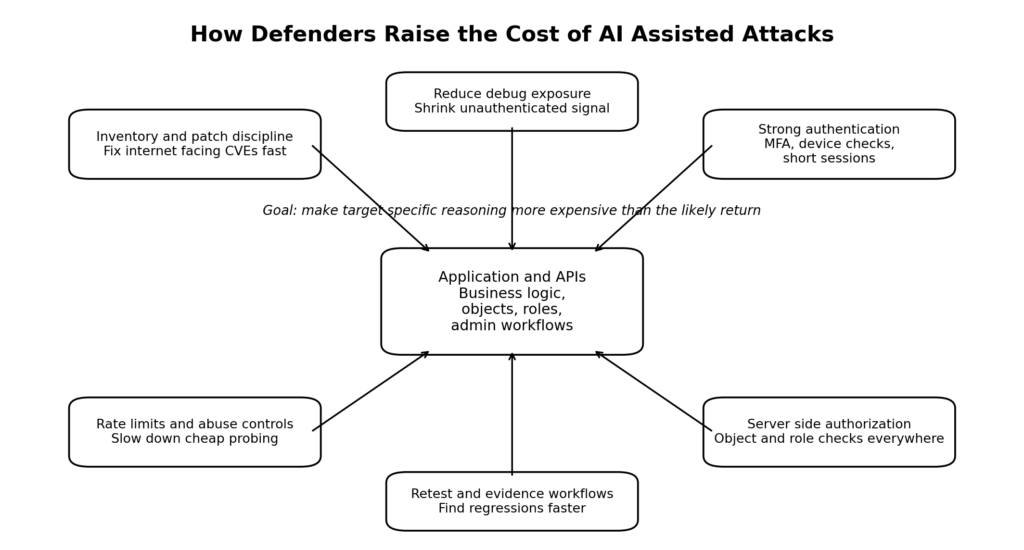
Even if model prices fell tomorrow, autonomous hacking would still carry hidden taxes that do not show up in a flat per-token comparison.
The first tax is branching. Security work rarely moves in a straight line. Every unknown parameter, alternate role, hidden API, or strange state transition creates another branch. A branch is not just another completion. It is another chance to reload context, reissue tool calls, gather artifacts, and later explain why the branch mattered or did not. The economic damage from branches is amplified by the fact that many of them fail late.
The second tax is target friction. MFA, CAPTCHA, device binding, short session lifetimes, signed requests, rate limits, and anti-bot controls all push the attacker away from a cheap generic loop and toward more expensive per-target adaptation. That is one reason the OWASP API Security Top 10 is helpful through an economics lens. BOLA is often easy to spot but still needs correct state and object handling to validate. Unrestricted resource consumption and sensitive business flows are both reminders that the structure of the target affects the economics of abuse. (owasp.org)
The third tax is provider friction in hosted environments. Anthropic’s current rate-limit documentation says Claude API usage is governed by both spend limits and rate limits, and its Managed Agents documentation exposes separate request ceilings for create and read operations. That does not make abuse impossible, and serious attackers can self-host or spread usage. But it does mean hosted agent infrastructure is not frictionless. The platform itself imposes economic and operational guardrails. (platform.claude.com)
A reasonable engineering inference follows from that. Hosted frontier-model agents are currently a poor fit for indiscriminate internet-scale abuse because they combine non-zero per-run cost with external rate and spend controls. Open-weight and self-hosted models remove some of those controls, but then the operator pays elsewhere: GPU time, infrastructure, integration effort, model quality, and tool reliability. The bill moves. It does not disappear.
A budget guardrail is a security control, not just a finance control
The strongest AI pentesting teams increasingly treat budget policy as part of execution policy. That is not just a finance concern. It is also a quality concern, because a workflow that is allowed to burn through endless branches is often a workflow that has not learned when to stop.
run_policy:
scope_lock: true
max_input_tokens_per_run: 2500000
max_output_tokens_per_run: 400000
max_web_search_calls: 20
max_container_sessions: 12
max_retry_depth: 3
max_parallel_branches: 4
require_human_review_for:
- privilege_escalation
- state_changing_actions
- external_callbacks
- destructive_tests
stop_conditions:
- repeated_non_deterministic_results
- unresolved_authentication_drift
- confidence_below_threshold
- cost_per_validated_finding_exceeds_budget
The logic behind a policy like this lines up with the broader market evidence. OpenAI and Anthropic both separately price model usage and tools. Anthropic separately documents spend limits and Managed Agents rate limits. PortSwigger’s AI security tooling keeps the operator in control and makes activation explicit. Mature products in this space keep converging on the same lesson: tighter control over tool use is not a restriction on value. It is often what protects value. (openai.com)
What defenders should do with this economic reality
The defensive takeaway is not that AI offense is overhyped. The defensive takeaway is optimize for the attacks that are becoming cheaper, and raise cost everywhere else.
Start with the surfaces that are already cheap to exploit at scale. Internet-facing management planes, file-transfer appliances, VPN gateways, widely deployed libraries, and externally reachable admin flows are where standardized automation wins. The CVE examples above are not historical curiosities. They are a map of what defenders keep underestimating. If a flaw is remotely reachable, high-value, and repeatable, assume attackers do not need an expensive general agent to monetize it. (nvd.nist.gov)
Then look at the targets where AI does help. Broken access control, BOLA, authenticated API misuse, sensitive business flows, and permission drift are all hard enough to resist naive automation and common enough to justify structured AI-assisted testing. OWASP’s current materials make that plain. Broken Access Control remains the top category in the OWASP Top 10, and the API Security Top 10 still leads with BOLA because object identifiers are easy for attackers to manipulate and easy for developers to under-protect. If AI helps attackers and defenders reason faster about those conditions, verification speed becomes part of the security advantage. (owasp.org)
That is why verified retesting matters so much. Security teams do not only need more findings. They need fewer ambiguous findings, faster confirmation of real impact, and cheaper regression testing after changes. A workflow that can replay an attack path, prove whether the bug still exists, and preserve evidence will usually beat a workflow that simply generates more prose about possible issues.
From a design standpoint, the best defensive moves often increase attacker-specific context requirements. Stronger role separation, shorter-lived sessions, better object authorization checks, cleaner asset inventories, reduced debug exposure, scoped admin functions, and meaningful rate limits all increase the amount of target-specific reasoning an attacker must perform. That does not make attacks impossible. It makes them less economical.
The market signal from AI security data is not comfort, it is compression
HackerOne’s report showing rapid growth in valid AI vulnerability reports should not be read as proof that all offensive work is becoming autonomous. It should be read as proof that the attack surface is expanding and that the distance between research and submission is shrinking. Bugcrowd’s 2026 reporting says AI already helps researchers cover more ground and produce better reports for the same budget. Those are compression signals. More work is being done per unit of human effort. That is strategically important even if no one has built a cheap, universal hacking machine. (HackerOne)
This is also why the public debate often feels confused. One side says AI offense is overrated because it does not autonomously hack everything. The other says AI offense is underrated because it already makes researchers faster. Both are partly right. The mistake is treating those as the same claim. AI does not yet cheaply generalize to the whole internet, and AI already changes the economics of high-value validation. Both can be true at the same time.
The next few years will not look like free autonomous chaos
The most plausible near-term future is not free autonomous chaos. It is more targeted, more economic, and more structured than that.
Research is clearly moving. Shell or Nothing reports that current systems still struggle to obtain shells under realistic conditions, but also that better agent architecture can reduce time and financial cost and work on laptop-scale deployments. Vendor products are moving toward first-class agent infrastructure, richer tool use, longer contexts, and higher paid capacity. Security tooling is moving toward AI-assisted validation rather than AI theater. Those trends do not point to a world where AI is irrelevant. They point to a world where the margin is in system design, verification discipline, and cost control. (arXiv)
That is why the most important offensive-security question is economic, not mystical. Can the system convert expensive context into verified signal cheaply enough to justify continued use? For high-value, bounded workflows, the answer is already yes often enough to matter. For indiscriminate internet-scale autonomous compromise, the answer is still no often enough to matter just as much.
The practical consequence is straightforward. Defenders should worry less about a sci-fi vision of free AI hacking everything everywhere and more about a very real shift already underway: AI is making it cheaper to turn messy reconnaissance into plausible attack paths, cheaper to validate likely security findings, cheaper to retest after changes, and cheaper to package evidence into actionable output. That is more than enough to change the balance of security work.

