Fragnesia CVE-2026-46300 is a Linux kernel local privilege escalation issue in the XFRM ESP-in-TCP attack surface. The practical risk is simple: a low-privileged local user can move from “I can run code” to “I can become root” by corrupting page-cache memory associated with read-only files. V12’s public write-up describes Fragnesia as a Dirty Frag family issue that abuses a logic bug in Linux XFRM ESP-in-TCP to achieve arbitrary byte writes into the kernel page cache without requiring a race condition. (GitHub)
That wording matters. Fragnesia is not a remote unauthenticated network bug by itself. It does not let a random internet user root a Linux server just because the server is online. It matters after initial access: a compromised web service account, a malicious CI job, an untrusted container workload, a stolen SSH credential, a browser sandbox escape, a shared shell account, or an AI agent runner that executes user-provided code. On those systems, local privilege escalation is often the difference between a contained incident and full host compromise.
The highest-priority targets are not every laptop in the same order. They are shared Linux hosts, CI runners, Kubernetes worker nodes, multi-tenant container platforms, developer jump boxes, research servers, sandboxed execution platforms, and any Linux machine where untrusted or semi-trusted users can execute local code. Ubuntu marks CVE-2026-46300 as High priority and summarizes the reason as “Trivial local privilege escalation,” while listing the issue as published on May 13, 2026. (Ubuntu)
Several facts are still moving. NVD’s public page may lag behind vendor and distribution tracking; when checked, the NVD page for CVE-2026-46300 showed “CVE ID Not Found,” while Ubuntu, AlmaLinux, Debian, SUSE, AWS, CloudLinux, Wiz, and V12 had already published or linked advisories, status pages, or technical notes. (NVD) That does not mean the issue is fake. It means defenders should not wait for one database to finish enrichment before checking their own Linux fleet.
The facts that matter first
| Fact | Current best-known status | Por qué es importante |
|---|---|---|
| CVE | CVE-2026-46300 | Multiple vendors and distributions track Fragnesia under this ID, even while some CVE database metadata may lag. |
| Common name | Fragnesia | The name comes from the kernel “forgetting” that a fragment is shared during coalescing, according to V12. (GitHub) |
| Clase de vulnerabilidad | Linux kernel local privilege escalation | Attackers need local code execution first, but the post-compromise impact can be full root. |
| Core subsystem | XFRM ESP-in-TCP, socket buffers, shared page fragments | The bug crosses networking, crypto, memory ownership, and page cache behavior. |
| Main primitive | Controlled writes into page-cache-backed read-only files | Disk hashes may remain clean while the in-memory cached file content is corrupted. |
| Public exploit status | Public PoC exists | V12 published a PoC and technical explanation, so defenders should assume exploit knowledge is available. (GitHub) |
| Race condition | Not required in the public description | V12 and Wiz both describe the primitive as deterministic rather than race-dependent. (GitHub) |
| Immediate fix | Vendor kernel update, reboot, or confirmed livepatch | Mitigations reduce exposure, but patching the kernel is the durable fix. |
| Temporary mitigation | Disable or denylist unnecessary ESP and rxrpc modules where compatible | Wiz and CloudLinux recommend disabling esp4, esp6y rxrpc when patches are not yet deployed and the functionality is not required. (wiz.io) |
| Highest-risk environments | Shared hosts, CI runners, Kubernetes nodes, untrusted execution platforms | These systems already give attackers the local code execution prerequisite. |
There is also a severity-scoring nuance. V12’s public write-up says Fragnesia received a CVSS score of 7.8, while SUSE lists CVSS v3.1 8.8 and CVSS v4.0 8.6 for its assessment. (GitHub) That discrepancy is not unusual when vendors apply their own product context, scoring vectors, or scope interpretation. Treat the operational question as more important than the decimal: can an untrusted local user run code on this kernel, and can the vulnerable path be reached?
Why Fragnesia is more dangerous than a normal local bug
Many teams instinctively down-rank local privilege escalation because the attacker already needs access. That habit fails in modern infrastructure. Local code execution is not rare; it is built into many workflows.
CI platforms execute pull requests. Build farms compile third-party code. Kubernetes clusters run containers from multiple teams. Notebook platforms run user-submitted Python. Browser automation sandboxes execute untrusted pages. AI coding agents and task runners may execute generated shell commands. Shared hosting gives many users a shell on the same kernel. In all of those environments, “local only” is not a small boundary. It is the exact boundary attackers want to cross.
Fragnesia is especially uncomfortable because it belongs to a recent cluster of Linux page-cache corruption and shared-fragment bugs. AlmaLinux described it as a separate bug from Dirty Frag that lives in the same surface and chains through the same modules, namely esp4, esp6y rxrpc. AlmaLinux’s post states that skb_try_coalesce() failed to propagate the SKBFL_SHARED_FRAG marker when transferring paged fragments between buffers, allowing XFRM ESP-in-TCP processing to perform in-place AES-GCM decryption over page-cache pages. (AlmaLinux OS)
CloudLinux’s explanation is even more direct: when a TCP socket transitions into espintcp ULP mode after data has already been spliced from a file into the receive queue, the kernel can treat queued file pages as ESP ciphertext and decrypt them in place. With control over the IV nonce, the attacker can turn that operation into a deterministic one-byte write into the page cache per trigger invocation. (CloudLinux Blog)
The public proof-of-concept targets /usr/bin/su, but defenders should not reduce the bug to “the su bug.” Help Net Security reported Microsoft’s observation that attackers are not constrained to that binary and may modify any file readable by the user, including sensitive files such as /etc/passwd. (Ayuda a la seguridad de la red) The exact exploit path may vary, but the defensive model is consistent: a read-only file becomes mutable in memory, and the filesystem on disk may not show the change.
The page cache is the real trust boundary
The key to understanding Fragnesia is the Linux page cache. Linux does not read every byte from disk every time a process opens a file. It caches file content in memory so later reads and executions can reuse it. That cache is normally transparent and safe. If a file is read-only on disk, the kernel should not let an unprivileged user rewrite the memory pages that represent that file.
Page-cache corruption breaks that mental model. The attacker does not necessarily write to the file with open, escriba ao pwrite. The attacker abuses a kernel path that treats a page-cache-backed page as a writable buffer. The file can remain unchanged on disk, while the cached bytes used by later reads or executions are altered in memory.
That is why ordinary integrity checks can be misleading. A package manager query may say /usr/bin/su is intact. A disk hash may match the vendor package. A filesystem monitor may see no ordinary file write. Yet a process executing the cached version of the file may consume corrupted bytes.
This is not unique to Fragnesia. Dirty Pipe, CVE-2022-0847, made the same broad lesson famous: page-cache-backed data can become dangerous when an optimized kernel path loses the boundary between a reference to file data and writable process-controlled data. Copy Fail CVE-2026-31431 carried the same operational warning in a different subsystem. Penligent’s earlier Copy Fail write-up framed the issue as a Linux local privilege escalation where AF_ALG, splice(), and AEAD behavior could place controlled bytes into the page cache of a readable file. (penligent.ai)
Fragnesia moves the danger into the networking and IPsec surface. The common pattern is not “crypto is broken” or “networking is broken.” The common pattern is that high-performance kernel paths often avoid copying data. That makes performance better, but it also makes provenance critical. If a subsystem forgets that a buffer is backed by a shared file page, a later in-place operation can become a write primitive.
What actually goes wrong in the kernel
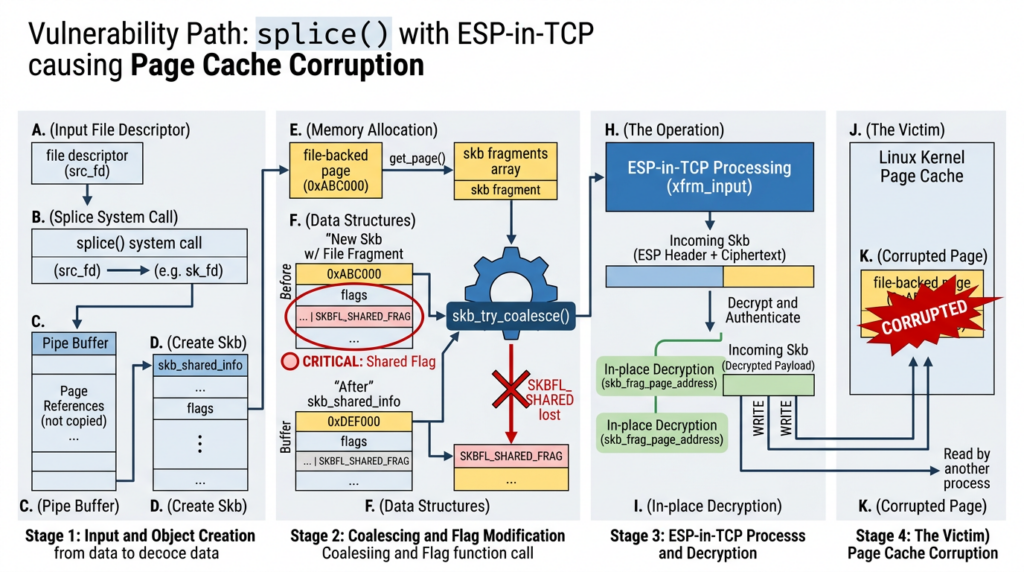
At a high level, Fragnesia is a shared-fragment bookkeeping failure. Linux networking uses sk_buff, often shortened to skb, to represent packet data. Packet data can be linear, or it can be stored in paged fragments. Those fragments may point to memory that is externally owned or backed by page-cache pages.
The kernel has markers to track when fragments are shared. One of those markers is SKBFL_SHARED_FRAG. The upstream patch posted to the netdev mailing list says skb_try_coalesce() can attach paged fragments from one skb to another. If the source skb has SKBFL_SHARED_FRAG set, the destination skb can contain the same externally owned or page-cache-backed fragments, but the marker was lost. The patch explains that this breaks the invariant relied on by later in-place writers, especially ESP input logic that checks skb_has_shared_frag() before deciding whether it can skip copy-on-write. (lists.openwall.net)
That is the root of the bug. The kernel later sees an skb and believes it does not contain shared page fragments. Because the marker was dropped during coalescing, ESP processing can decide it is safe to decrypt in place. If those fragments are actually page-cache-backed file pages, in-place decryption writes into cached file content.
Wiz describes the vulnerable path as a scenario where file-backed pages are spliced into a TCP receive queue before the socket transitions into espintcp ULP mode. Once ESP processing is enabled, the kernel decrypts queued data in place, producing controlled corruption of the underlying page cache through AES-GCM keystream manipulation. (wiz.io)
The important defender-level model looks like this:
| Kernel behavior | Security meaning |
|---|---|
splice() can move file-backed pages into a data path without copying file contents into a new userspace buffer | The receiving subsystem may handle memory whose origin still matters |
| skb coalescing can combine fragments for efficiency | Metadata must remain correct after the merge |
SKBFL_SHARED_FRAG indicates that fragment ownership is not ordinary writable skb memory | Losing this flag can make later code trust a buffer it should copy first |
| ESP-in-TCP can perform decryption over skb data | If it decrypts in place over a shared page, crypto output becomes page-cache corruption |
| AES-GCM keystream is controllable enough in the described setup to choose byte-level effects | A tiny write primitive can be repeated until a useful payload is staged |
| Disk file remains unchanged | Disk-only integrity checks are not enough after suspected exploitation |
This is why Fragnesia CVE-2026-46300 should be treated as a boundary failure, not a generic “kernel memory bug.” The core failure is that a page-cache-backed file fragment crosses into a path that later behaves as if it owns writable packet memory.
The exploit chain from a defender’s view
The public exploit details are already available, but production defenders do not need to run them to understand their exposure. The safer way to reason about Fragnesia is as a sequence of preconditions and signals.
| Escenario | Gol del atacante | Defender signal | Qué verificar |
|---|---|---|---|
| Initial foothold | Run low-privileged code locally | Web shell, CI job, container command, SSH session, user shell, agent task runner | Which users and workloads can execute arbitrary commands |
| Namespace setup | Gain capabilities in a restricted namespace | unshare, clone, clone3, setns, unusual network namespace creation | Whether unprivileged user namespaces are enabled and needed |
| XFRM setup | Reach ESP-in-TCP processing | Netlink XFRM activity, ESP modules, TCP ULP manipulation | Whether esp4, esp6, rxrpc, and ESP-in-TCP support are present or loadable |
| Page-cache corruption | Write controlled bytes into cached file pages | Hard to observe directly, but may correlate with unusual syscall sequences | Whether suspicious behavior occurred before patch or mitigation |
| Privilege transition | Execute a corrupted cached file to become root | Unexpected /usr/bin/su, shell spawn, setuid binary execution, root process from odd parent | Whether root shells, persistence, or credential access followed |
| Cleanup or persistence | Hide traces or retain access | Reboot, drop_caches, new keys, cron jobs, systemd services, container escape artifacts | Whether secrets and host state must be rotated or rebuilt |
The strongest signal is not one syscall. It is the cluster. A benign system may use namespaces. A legitimate IPsec deployment may load ESP modules. A normal admin may run su. A suspicious sequence combines untrusted local code execution, namespace creation, XFRM or ESP activity, page-cache-sensitive behavior, and a sudden setuid-root execution path.
Why the public PoC changes the patch window
The presence of public PoC material changes defender behavior even when no confirmed exploitation is known. The Hacker News reported that a PoC had been released by V12 and cited Microsoft as saying no in-the-wild exploitation had been observed at that time, while urging users to apply patches and consider Dirty Frag mitigations if patching was not possible. (Noticias Hacker) Help Net Security similarly noted that Microsoft analysts had not seen evidence of in-the-wild exploitation at the time of reporting. (Ayuda a la seguridad de la red)
That “at the time” qualifier matters. A local privilege escalation with a public proof-of-concept becomes useful to many attackers quickly because it does not need to be the first step in the intrusion. It can be dropped into existing playbooks. Any actor who already has a low-privileged shell can test whether the host is vulnerable. For CI runners and shared compute, the attacker may not even need to compromise a service first; submitting a job or running code may be the intended platform behavior.
Public exploit availability should push Fragnesia into emergency triage for systems that meet three conditions:
| Condición | Why it raises priority |
|---|---|
| Untrusted or semi-trusted users can execute local code | The attack prerequisite is already satisfied |
| The vulnerable kernel path is present or loadable | The exploit path may be reachable |
| The host contains valuable credentials, build secrets, production access, or other tenants | Root compromise has high blast radius |
A single-user Linux desktop used only by a careful owner still needs a patched kernel, but it is not the same emergency as a shared CI runner executing arbitrary pull requests.
Fragnesia, Dirty Frag, Copy Fail, and Dirty Pipe
Fragnesia is easier to understand when placed next to related Linux page-cache and shared-fragment bugs.
| Issue | Main subsystem | Primitivo | Attack prerequisite | Por qué es importante |
|---|---|---|---|---|
| Dirty Pipe, CVE-2022-0847 | Pipe buffer and page cache behavior | Write to page-cache-backed read-only files | Local code execution | Showed how a small kernel bookkeeping failure can make read-only file data mutable in memory. |
| Copy Fail, CVE-2026-31431 | Linux crypto subsystem, AF_ALG, authencesn, splice() | Controlled page-cache write | Local code execution | Demonstrated a deterministic local-to-root path through crypto and zero-copy file handling. Microsoft described it as a Linux kernel crypto-subsystem bug that could corrupt cached readable files, including setuid binaries. (Microsoft) |
| Dirty Frag, CVE-2026-43284 and CVE-2026-43500 | ESP/XFRM and rxrpc | Page-cache corruption chain | Local code execution | AlmaLinux described Dirty Frag as chaining two kernel bugs, one covering IPsec ESP and one covering rxrpc. (AlmaLinux OS) |
| Fragnesia, CVE-2026-46300 | XFRM ESP-in-TCP, skb coalescing | Byte-level page-cache corruption | Local code execution | A separate bug in the same attack surface, caused by losing shared-frag metadata during skb coalescing. (AlmaLinux OS) |
The shared lesson is that “read-only” must remain true across every kernel subsystem that receives a reference to file-backed memory. When a subsystem preserves a pointer to a page instead of copying its contents, it also inherits the obligation to preserve ownership semantics. Dirty Pipe, Copy Fail, Dirty Frag, and Fragnesia all punish failures in that obligation.
Fragnesia is not just another named vulnerability. It is part of a pattern in which performance-oriented data paths become privilege boundaries. splice(), skb coalescing, scatter-gather buffers, ESP processing, and in-place crypto all exist for good reasons. The problem appears when one path assumes it owns a writable buffer while the buffer is actually a file-backed page shared with the VFS page cache.
Affected systems and vendor status are not uniform
One easy mistake is to ask, “Is Linux affected?” The useful question is more specific: which distribution, which kernel build, which modules, which config, which mitigations, and which workloads?
Ubuntu lists the issue as High priority and shows several Ubuntu kernel package tracks as “Needs evaluation” on its CVE page. (Ubuntu) Debian’s tracker listed multiple Debian releases and kernel packages as vulnerable, with unstable shown as unfixed when the tracker page was checked. (Debian Security Tracker) SUSE’s CVE page rated the issue important and showed a long product matrix with many affected products and some released or in-progress states, depending on product line. (SUSE)
AWS is an important counterexample. Amazon’s security bulletin says Amazon Linux does not provide the espintcp module used by the proof-of-concept and is not affected, while also stating that AWS would include a correctness patch to the core networking code as defense in depth. (Amazon Web Services, Inc.) That is exactly the kind of vendor-specific nuance defenders need. A generic scanner label is not enough.
CloudLinux stated that Fragnesia is a separate bug from Dirty Frag, but in the same XFRM/ESP class, and that the immediate mitigation is identical. It also described KernelCare livepatch status and how to verify patch metadata with kcarectl --patch-info | grep CVE-2026-46300 once metadata is finalized. (CloudLinux Blog) AlmaLinux published test builds for AL8, AL9, and AL10, then refreshed those test builds after additional upstream patches landed on the netdev list. (AlmaLinux OS)
That variability should shape your remediation plan. Do not copy a fixed version from another distribution and assume it applies to your fleet. For each kernel family, check the vendor’s advisory, installed package version, running kernel version, and whether the machine has actually rebooted into the fixed kernel.
Priority order for real environments
| Medio ambiente | Risk level | Por qué | Acción inmediata |
|---|---|---|---|
| Public CI runners executing untrusted pull requests | Crítica | Running attacker-controlled code is normal workflow | Patch or isolate immediately, rotate runner secrets, rebuild nodes after suspicious jobs |
| Multi-tenant Kubernetes worker nodes | Crítica | Containers share the host kernel, and local LPE can become node compromise | Patch nodes, drain and reboot, enforce seccomp, remove privileged workloads |
| Shared hosting and shell servers | Crítica | Many users share one kernel | Patch, restrict local shells, disable unnecessary ESP modules, review root transitions |
| AI agent sandboxes and code execution workers | Alta | Generated or user-provided code may run locally | Isolate node pools, patch fast, log command execution and namespace creation |
| Notebook and data science platforms | Alta | Users often execute arbitrary Python, shell commands, and packages | Patch, restrict namespaces, isolate tenants, rotate accessible tokens |
| Developer jump hosts | Alta | Many users, SSH access, credentials nearby | Patch, monitor setuid execution, reduce interactive access |
| Single-tenant production servers with no local users | Medio | Requires prior code execution, but web RCE or service compromise can provide it | Patch in expedited window, verify no foothold exists |
| Single-user workstation | Medium to low | Risk depends on whether untrusted code is run locally | Patch promptly, avoid running unknown PoCs or scripts |
The right prioritization question is not “Is it internet-facing?” It is “Who can run local code on this kernel?” That includes containers and job runners, not only Unix user accounts.
Safe exposure checks without running an exploit
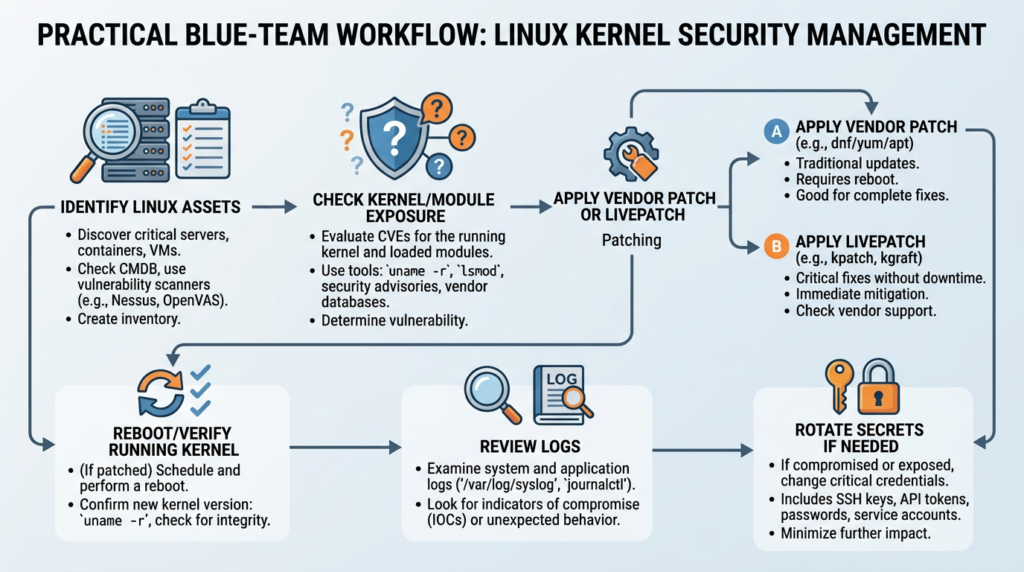
Defenders do not need to run the public PoC on production systems. In fact, they should not. A page-cache corruption exploit can alter in-memory behavior of privileged binaries, and cleanup is easy to mishandle.
Start with passive checks.
uname -a
cat /etc/os-release
Check whether relevant modules are loaded.
lsmod | egrep '^(esp4|esp6|rxrpc|espintcp)'
Check whether relevant modules may exist on disk.
find /lib/modules/"$(uname -r)" -type f \
| egrep '/(esp4|esp6|rxrpc|espintcp)\.ko(\.xz|\.zst|\.gz)?$'
Check common kernel config flags. File paths vary by distribution.
grep -E 'CONFIG_XFRM|CONFIG_INET_ESP|CONFIG_IPV6_ESP|CONFIG_INET_ESPINTCP|CONFIG_RXKAD' \
/boot/config-"$(uname -r)" 2>/dev/null || true
Check installed kernel packages on Debian and Ubuntu systems.
dpkg -l 'linux-image*' 'linux-modules*' 2>/dev/null | awk '/^ii/ {print $2, $3}'
Check installed kernel packages on RHEL-like systems.
rpm -qa 'kernel*' | sort
Check whether the running kernel is the newly installed kernel after patching.
uname -r
ls -lt /boot/vmlinuz-* | head
The key mistake is installing a patched kernel package and forgetting the reboot. If your live kernel is still the vulnerable version, your package database may look better than your actual risk.
For CloudLinux or systems using KernelCare, use vendor-specific verification. CloudLinux recommends checking KernelCare patch information for CVE-2026-46300 once patch metadata is finalized. (CloudLinux Blog)
kcarectl --patch-info | grep -i 'CVE-2026-46300\|fragnesia' || true
kcarectl --info | grep -i 'kpatch-build-time' || true
A safe validation workflow should produce an evidence record: hostname, kernel version, package version, running kernel, module status, vendor advisory status, mitigation status, reboot status, and residual exposure. In authorized environments, AI-assisted validation platforms can help turn that evidence into a repeatable workflow rather than a one-off spreadsheet. Penligent’s AI pentesting workflow is relevant here when teams need to organize CVE summaries, asset context, validation steps, evidence, and reporting in one place, while its Copy Fail coverage provides a closely related example of page-cache-based Linux local privilege escalation analysis. (penligent.ai)
Temporary mitigation when patching cannot happen immediately
Patch first when possible. A workaround should not become the long-term control. But production systems often need a bridge between disclosure and reboot.
Wiz recommends applying vendor kernel patches as they become available, and until patches are deployed, disabling vulnerable modules for Fragnesia and Dirty Frag if they are not required. (wiz.io) CloudLinux gives the same immediate mitigation family and notes that Fragnesia’s immediate mitigation is identical to Dirty Frag’s because the issues sit in the same XFRM/ESP class. (CloudLinux Blog)
A defensive denylist can look like this:
sudo modprobe -r esp4 esp6 rxrpc 2>/dev/null || true
cat <<'EOF' | sudo tee /etc/modprobe.d/fragnesia-xfrm.conf
install esp4 /bin/false
install esp6 /bin/false
install rxrpc /bin/false
EOF
sudo depmod -a
Verify the denylist behavior.
for mod in esp4 esp6 rxrpc; do
echo "Checking $mod"
modprobe -n -v "$mod" 2>&1
done
This mitigation is only appropriate if the system does not depend on the disabled functionality. IPsec, VPN, transport security, cluster services, and some specialized workloads may break if you disable the wrong modules. Test before broad deployment, especially on network appliances, VPN gateways, security monitoring systems, or clusters with unusual kernel networking dependencies.
For Ubuntu-like environments, restricting unprivileged user namespaces can reduce exposure to the public path. Wiz says AppArmor restrictions on unprivileged user namespaces, such as Ubuntu defaults, may serve as a partial mitigation that requires additional bypasses, but it is not a replacement for patching. (wiz.io) V12’s write-up also notes Ubuntu’s AppArmor restriction and frames bypassing it as outside the scope of the vulnerability. (GitHub)
A temporary setting may look like this on systems where workloads tolerate it:
sudo sysctl -w kernel.apparmor_restrict_unprivileged_userns=1
cat <<'EOF' | sudo tee /etc/sysctl.d/99-restrict-unprivileged-userns.conf
kernel.apparmor_restrict_unprivileged_userns=1
EOF
Do not assume this knob exists or behaves identically on every distribution. Verify with your vendor documentation and test application compatibility.
Kubernetes and container risk
Containers do not have their own kernel. Namespace and cgroup isolation are important, but they do not make the kernel disappear. A kernel local privilege escalation can become a node-level incident when a containerized workload can reach the vulnerable path.
Fragnesia is especially relevant to Kubernetes and CI systems because those environments frequently run code from many trust zones on the same kernel. A tenant container, build job, or plugin that starts as a low-privileged process may gain host-level power if the kernel can be exploited.
Baseline hardening does not fix Fragnesia, but it can reduce the number of workloads that can reach dangerous primitives. Start with the obvious controls:
apiVersion: v1
kind: Pod
metadata:
name: baseline-seccomp-example
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
containers:
- name: app
image: example/app:stable
securityContext:
allowPrivilegeEscalation: false
privileged: false
runAsNonRoot: true
capabilities:
drop:
- ALL
That manifest is not a Fragnesia patch. It is a baseline. The real controls are patched worker kernels, node pool isolation, removal of privileged containers, rejection of unnecessary hostPath mounts, RuntimeDefault seccomp, reduced Linux capabilities, and fast rebuild of nodes that ran untrusted code before the patch.
For CI runners, assume secrets are the blast-radius multiplier. If a runner could have been exploited, rotate tokens reachable from that runner: cloud credentials, package registry tokens, deployment keys, SSH private keys, CI variables, signing keys, and service-account tokens. A local root bug on a build host is not just a host problem. It can become a software supply chain problem.
Detection logic that does not depend on file hashes
Fragnesia-style attacks challenge disk-centric detection. A clean disk hash does not prove the in-memory cached version of a file was never corrupted. Detection should focus on behavior, preconditions, and post-exploitation effects.
Useful signals include:
| Señal | Por qué es importante | Noise level | Response |
|---|---|---|---|
| Untrusted user creates user or network namespace | Public descriptions rely on namespace setup to obtain capabilities in an isolated namespace | Medio | Correlate with workload identity and parent process |
| XFRM netlink manipulation by unexpected process | ESP security association setup is part of the described path | Low to medium | Investigate process tree and user context |
| Unexpected ESP or rxrpc module loading | The temporary mitigation targets these modules | Medio | Confirm business need and patch state |
setsockopt activity involving TCP ULP by unusual local process | ESP-in-TCP path is relevant to Fragnesia | Low to medium | Correlate with namespace and module events |
Abnormal /usr/bin/su ejecución | Public PoC targets su to trigger root shell | Medio | Look at parent process, user, TTY, session, and subsequent commands |
| Non-root process rapidly spawning root shell | Possible privilege escalation outcome | Bajo | Treat as high severity |
| Cache clearing or reboot after suspicious local execution | Could be benign admin behavior or cleanup | Medio | Preserve logs and timeline |
| New root persistence | Expected attacker follow-up after local root | Bajo | Incident response, not simple patching |
Auditd can help on traditional servers, though high-volume systems need careful tuning.
# Namespace-related syscalls
sudo auditctl -a always,exit -F arch=b64 -S unshare,setns,clone,clone3 -k namespace-creation
# Watch execution of common setuid transition binaries
sudo auditctl -w /usr/bin/su -p x -k su-exec
sudo auditctl -w /usr/bin/sudo -p x -k sudo-exec
sudo auditctl -w /usr/bin/pkexec -p x -k pkexec-exec
# Watch manual cache dropping
sudo auditctl -w /proc/sys/vm/drop_caches -p w -k drop-caches
These rules will not prove Fragnesia exploitation by themselves. They create timeline anchors. The best investigation comes from correlating auditd, EDR, shell history, process telemetry, container runtime logs, Kubernetes audit logs, kernel logs, CI job logs, and identity events.
For Kubernetes, look for workloads that should never create namespaces, manipulate networking, or run setuid binaries. Also review admission logs for privileged pods, host networking, host PID namespace, broad capabilities, and hostPath mounts.
Incident response after suspected exploitation
If a vulnerable host may have been exploited before patching, do not stop at “install update.” A page-cache LPE is a privilege transition. Treat it as potential root compromise.
A practical response sequence:
- Isolate the host from untrusted workloads and external control paths.
- Preserve volatile evidence before rebooting when feasible.
- Record running kernel, loaded modules, process tree, logged-in users, container list, and active network connections.
- Collect audit logs, auth logs, shell history, CI job logs, Kubernetes events, and EDR timeline.
- Check recent executions of
su,sudo,pkexec, shells, compilers, and unknown binaries. - Look for root persistence: new users, SSH keys, cron jobs, systemd units, LD preload tricks, kernel modules, suspicious containers, and modified startup scripts.
- Patch the kernel and reboot into the fixed version, or apply a verified livepatch.
- Clear page cache or reboot if page-cache corruption is suspected.
- Rotate credentials reachable from the host.
- Rebuild high-risk nodes from a trusted image rather than trusting in-place cleanup.
CloudLinux warns that applying the mitigation alone is not enough on systems that may have been targeted before mitigation, because the exploit can modify legitimate system binaries in page cache as part of gaining root; after mitigating, defenders should force a reload from disk by dropping page cache or rebooting. Help Net Security quoted that warning in its Fragnesia coverage. (Ayuda a la seguridad de la red)
Use this command only when you understand its operational impact:
sudo sh -c 'sync; echo 3 > /proc/sys/vm/drop_caches'
A reboot is often cleaner, especially after patching. But neither cache dropping nor rebooting proves the host was not compromised. If the attacker obtained root, they may have added persistence, stolen credentials, or moved laterally.
Common mistakes
The first mistake is treating Fragnesia as a remote exposure problem only. A server that is not directly internet-facing can still be high risk if CI jobs, containers, plugins, data science notebooks, or internal users run code on it.
The second mistake is trusting disk hashes after suspected page-cache corruption. Disk hashes are still useful, but they do not answer the page-cache question.
The third mistake is installing a patched kernel package without rebooting. The vulnerable kernel remains active until the system boots into the fixed version or receives a confirmed livepatch.
The fourth mistake is assuming Dirty Frag patches automatically fix Fragnesia. The Hacker News reported V12’s statement that Fragnesia is a separate ESP/XFRM bug with its own patch, although the mitigation is similar to Dirty Frag’s. (Noticias Hacker)
The fifth mistake is disabling modules without checking business impact. Some environments use IPsec or related networking features intentionally. A rushed mitigation can break production traffic.
The sixth mistake is running public PoC code in production to “check quickly.” A successful run may alter page-cache contents and leave privileged binaries in a dangerous in-memory state until eviction or reboot. V12’s write-up includes a cleanup warning because the targeted cached binary can remain modified after exploitation. (GitHub)
Practical patch checklist
Use a checklist that separates asset discovery, exposure, remediation, and proof.
| Paso | Evidence to collect | Pass condition |
|---|---|---|
| Identify systems | Hostname, owner, OS, kernel, role | Every Linux host is mapped to an owner and workload type |
| Prioritize | Local code execution risk, tenant model, secrets present | CI, Kubernetes, shared hosts, and sandboxes are first |
| Check vendor status | Ubuntu, Debian, SUSE, RHEL-like, CloudLinux, AWS, or other vendor advisory | Correct advisory used for that kernel family |
| Check running kernel | uname -r | Running kernel matches fixed version or verified livepatch |
| Check module exposure | lsmod, module path, config flags | Unneeded modules disabled where patch is delayed |
| Apply patch | Package update or livepatch | Patch installed successfully |
| Reboot or verify livepatch | Boot time, uname -r, livepatch metadata | Vulnerable kernel no longer running |
| Review suspicious activity | Auth logs, audit logs, EDR, CI logs, container logs | No unexplained root transition or persistence |
| Rotate secrets if needed | CI tokens, cloud keys, SSH keys, registry tokens | Secrets exposed to risky nodes are rotated |
| Document closure | Evidence bundle, residual risk, exception owner | Remediation is auditable |
PREGUNTAS FRECUENTES
Is Fragnesia remotely exploitable by itself?
- No. The known Fragnesia CVE-2026-46300 path is a local privilege escalation.
- The attacker needs some way to run code locally first, such as a shell, CI job, container workload, compromised service account, or sandboxed execution environment.
- The risk is still serious because many real systems intentionally run untrusted or semi-trusted code.
- Treat it as a post-compromise root escalation issue, not as a standalone remote RCE.
What makes CVE-2026-46300 different from Dirty Frag?
- Fragnesia is a separate bug, not just a rebrand of Dirty Frag.
- It sits in the same broad XFRM/ESP and page-fragment attack surface.
- Dirty Frag mitigations that disable the same unused modules may reduce exposure to the public Fragnesia path.
- A Dirty Frag patch alone should not be assumed to fix Fragnesia unless your vendor explicitly says your kernel contains the Fragnesia fix.
Why can disk hashes look clean after page-cache corruption?
- The attack corrupts cached file pages in memory.
- The on-disk file may remain unchanged.
- Package verification and disk checksums can still match the vendor package.
- Runtime behavior can still be compromised while the corrupted cached page remains active.
- After suspected exploitation, investigate behavior and root activity, not only file integrity.
Are containers affected by Fragnesia?
- Containers share the host kernel.
- A vulnerable host kernel can expose multiple containers on the same node.
- Risk is highest when containers run untrusted code, have broad capabilities, use privileged mode, or run on shared worker nodes.
- Patch worker nodes, isolate untrusted workloads, enforce RuntimeDefault seccomp, and remove privileged containers where possible.
Does disabling esp4, esp6, and rxrpc fully fix the issue?
- No. It is a temporary mitigation for systems that do not need those modules.
- The durable fix is a vendor kernel patch or verified livepatch.
- Disabling modules may break IPsec or other legitimate workloads.
- If the host may already have been exploited, mitigation alone is not enough; investigate and consider reboot, cache clearing, credential rotation, and rebuild.
What should defenders check first?
- Check the running kernel with
uname -r. - Check the vendor advisory for that exact distribution and kernel family.
- Check whether the host runs untrusted local code.
- Check whether relevant ESP, XFRM, or rxrpc functionality is loaded or available.
- Check whether the host has been rebooted into the fixed kernel after package updates.
- Check auth and process logs for suspicious local-to-root transitions.
Should security teams run the public PoC in production?
- No.
- A successful exploit can alter page-cache contents and affect privileged binary execution.
- Run exploit validation only in an isolated lab that matches the target kernel and distribution.
- Production validation should rely on kernel version, vendor advisory mapping, module exposure, configuration review, and controlled defensive telemetry.
- If exploit reproduction is required for assurance, use an authorized test environment and preserve clear evidence boundaries.
Para saber más
V12’s Fragnesia disclosure is the primary public technical source for the vulnerability mechanism, naming, affected-version guidance, and proof-of-concept context. (GitHub)
The netdev patch thread is worth reading because it shows the actual kernel invariant failure: skb_try_coalesce() did not preserve the shared-frag marker during paged-fragment transfer. (lists.openwall.net)
Wiz’s technical note gives a concise defender-readable explanation of XFRM ESP-in-TCP, file-backed pages, namespace use, and recommended mitigations. (wiz.io)
AlmaLinux’s Fragnesia advisory is useful for downstream kernel status, mitigation context, and how enterprise distributions handled patched test builds. (AlmaLinux OS)
CloudLinux’s advisory is useful for operational mitigation, livepatch status, and verification commands for KernelCare-managed systems. (CloudLinux Blog)
Closing judgment
Fragnesia CVE-2026-46300 is not dangerous because it has a memorable name. It is dangerous because it turns a subtle kernel ownership mistake into a root path for attackers who already have local code execution. The affected boundary is not just a module or a single binary. It is the trust relationship between file-backed memory, socket buffers, shared fragments, and in-place processing.
Defenders should prioritize systems where local code execution is normal: CI, containers, shared Linux, automation workers, notebook platforms, and agent sandboxes. Patch the kernel, reboot or verify livepatch status, disable unnecessary vulnerable modules only as a temporary bridge, and investigate any suspicious root transition as a real incident. The lesson from Fragnesia, Dirty Frag, and Copy Fail is the same: when the kernel forgets where a page came from, a few bytes can be enough to own the box.