Anthropic’s Mythos announcement pushed a lot of people toward the wrong question. The loud version was, “Which model is now the best hacker?” The more useful version is harder and more operational: how much model do you need at each stage of a penetration test, what scaffolding has to exist around it, how do you verify what it says, and what are you actually buying per dollar when you move from a candidate signal to a defensible finding? Anthropic’s own public materials describe a system, not a magic prompt. Project Glasswing says Mythos Preview found thousands of zero-day vulnerabilities across every major operating system and browser, and Anthropic’s Red Team writeup describes a simple but real scaffold: launch an isolated container, let the model inspect code and run the target, iterate with debugging, and produce a bug report with proof-of-concept steps. AISLE’s reply did not deny that capability. It argued that much of what matters in that pipeline is already available to smaller, cheaper, and in some cases open-weight models once the workflow is structured correctly. (anthropic.com)
That distinction matters because “AI pentesting” is starting to get used for almost anything with an LLM attached to a scanner. NIST SP 800-115 still defines technical security testing around planning, execution, analysis of findings, and mitigation strategy. OWASP’s Web Security Testing Guide still treats security testing as a disciplined framework for assessing web applications and services, not a burst of model-generated commentary. OWASP’s API Security Top 10 still puts Broken Object Level Authorization at the front of the list because the hard failures in real systems usually live in object relationships, role boundaries, state transitions, and business logic, not just in pattern-matched strings. Once that baseline is restored, the Mythos debate becomes much easier to reason about. A penetration test is not a model answer. It is a bounded, evidence-bearing process that turns uncertainty into proof. (csrc.nist.gov)
AISLE’s best contribution to the discussion is not that it “debunked” Mythos. It is that it decomposed the pipeline. Anthropic’s public story naturally compresses scanning, vulnerability recognition, triage, exploitability assessment, exploit construction, and remediation into one continuous capability. AISLE argues that this compression is rhetorically convenient but operationally misleading. In its framing, AI cybersecurity is a stack of different tasks with different scaling properties: broad-spectrum scanning, vulnerability detection, triage and false-positive discrimination, patch generation, and sometimes exploit construction. Its further point is the one security teams should internalize: the production function for AI security is not just intelligence per token. It also includes tokens per dollar, tokens per second, and the security expertise embedded in the scaffold that routes, validates, and constrains the model. That is not a small correction. It is the difference between buying a demo and building a practice. (AISLE)
AI pentesting is still a workflow, not a giant model
The strongest way to understand AI pentesting in 2026 is to stop treating it as an abstract reasoning contest and start treating it as a workflow design problem. A real security workflow has to do several things well at once. It has to narrow scope without losing important context. It has to retain state across requests, roles, or sessions. It has to distinguish a plausible issue from a reproducible issue. It has to preserve enough evidence that another engineer can replay what happened. It has to avoid overstating impact when a condition is not actually reachable. And if the system is doing active exploitation or validation, it has to do all of that without breaking scope discipline or producing evidence that cannot survive review. Those are engineering requirements before they are model requirements. (csrc.nist.gov)
That is why the recent benchmark conversation is quietly moving away from static “security trivia” and toward end-to-end tasks. Microsoft’s CTI-REALM benchmark is explicitly framed around real-world detection engineering rather than isolated Q and A. It tests reading threat intelligence, exploring telemetry, iterating on KQL and Sigma logic, and validating results against ground truth. The exact domain is detection engineering rather than pentesting, but the structural lesson is the same: a security benchmark becomes more useful as it gets closer to the workflow that humans actually have to carry to completion. The future of offensive evaluation will likely move in the same direction. The best evaluation will not simply ask whether a model can describe a bug. It will ask whether a bounded system can find the right place to look, separate noise from signal, prove the condition, preserve the artifact trail, and communicate the result in a way another engineer trusts. (マイクロソフト)
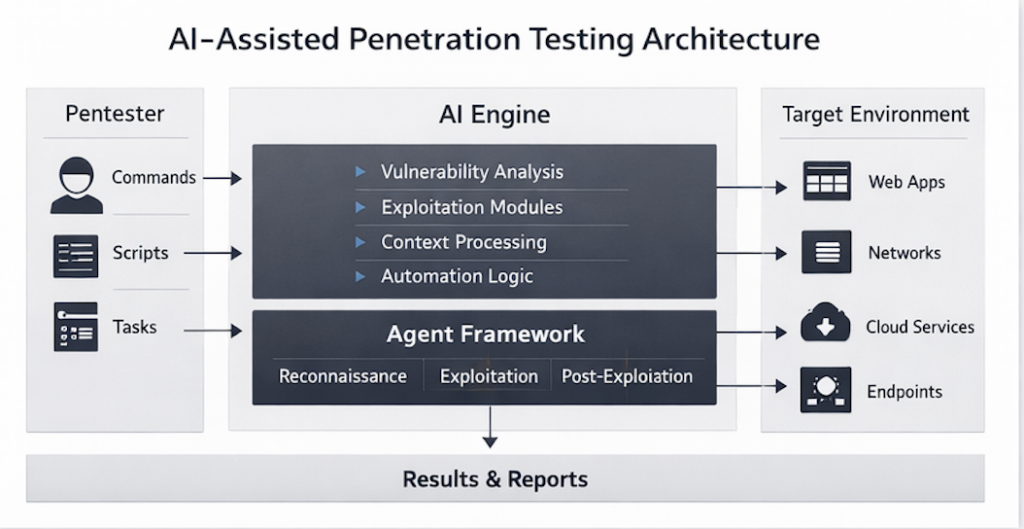
A useful AI pentesting architecture therefore looks less like a monolith and more like a relay team. A fast and cheap model can often do the first-pass work of inventorying endpoints, clustering routes, spotting framework patterns, or identifying code regions that are worth escalation. A somewhat stronger reasoning model can do false-positive filtering, exploitability ranking, and hypothesis cleanup. The most expensive model should not be your default for everything. It should be your escalation tier for the places where the search space is narrow enough and the expected value is high enough that frontier-level reasoning is worth paying for. That is the practical version of your core point: the goal is not to rent the smartest model in the world on every step. The goal is to express the right amount of intelligence at the right stage under a workflow that does not waste coverage, money, or reviewer attention. (AISLE)
The table below synthesizes that pipeline view using AISLE’s decomposition, Anthropic’s disclosed scaffold, and the classical pentest framing from NIST and OWASP. (Anthropic Red)
| Pipeline stage | What the system is really doing | Dominant bottleneck | Small or mid models often suffice | When a frontier model earns its keep | Non-negotiable engineering guardrail |
|---|---|---|---|---|---|
| Asset and context reduction | Mapping the target and shrinking the search space | Coverage and speed | はい | Rarely | Hard scope boundaries and target manifests |
| Candidate discovery | Surfacing suspicious code paths, routes, or behaviors | Breadth per dollar | はい | Occasionally | Replayable logs of what was examined |
| Triage and false-positive control | Separating plausible issues from real issues | Precision and context | Often | Sometimes | Evidence gates before promotion |
| Exploitability assessment | Estimating whether impact is real in this environment | Environment-aware reasoning | Sometimes | Often | Clear environmental assumptions |
| Exploit construction | Turning a condition into working impact | Long-horizon constrained search | Less often | Frequently | Isolated execution and approval controls |
| Reporting and retest | Translating findings into something another engineer can trust | Artifact quality and reproducibility | はい | Rarely | Reproduction steps, deltas, and retest proof |
Small models already matter more than many people want to admit
AISLE’s experiments are valuable because they attack the issue at exactly the right level. The company did not claim that small models can autonomously reproduce the entire Anthropic pipeline end to end on large repositories. It asked a narrower question: once the relevant code is isolated, how much of the public Mythos showcase reasoning can cheap or open models recover? That is much closer to the way a well-built discovery system actually operates. A good scaffold spends time narrowing the candidate set. By the time you are asking a model to reason seriously, you should not still be throwing an entire codebase at it and hoping for inspiration. (AISLE)
On AISLE’s FreeBSD NFS replication test, every model it evaluated detected the overflow. That included GPT-OSS-20b, described as a 20B MoE model with 3.6B active parameters, which AISLE says cost about $0.11 per million tokens and still correctly reasoned to a critical remote code execution conclusion in the isolated function. On the OpenBSD SACK case, the field separated sharply. The smaller model did not recover the full chain, but a 5.1B-active open model did. The company’s broader takeaway was that rankings reshuffled dramatically across tasks, including an OWASP false-positive discrimination exercise where smaller open models outperformed several frontier models. Whether or not one agrees with every detail of AISLE’s methodology, the macro signal is hard to ignore: there is no stable single best model across all security tasks, and the slope of capability is not smooth. (AISLE)
That result should not shock experienced pentesters. Security work is full of uneven difficulty. An access-control flaw hidden in a stateful three-role workflow can be harder to validate than a memory corruption issue whose crash oracle is clean. A boring SQL injection lookalike may be harder to triage correctly than a noisy but real stack overflow if the latter has obvious memory corruption signals and the former requires subtle reasoning about how data actually flows. Tasks differ so much that a single “best model” label is often less informative than a routing policy. The useful question is not which model wins the category. It is which model wins this stage, under this context budget, with this validator, at this price, under this latency requirement. (AISLE)
There is also a basic search-economics point here. If candidate discovery and first-pass review can be run very cheaply, a defender can afford much wider coverage. AISLE makes this argument directly: thousands of adequate detectives searching broadly can outperform one brilliant detective who has to guess where to look. In practice that means a security team may get more useful signal from saturating the early pipeline with inexpensive models and reserving expensive reasoning for the findings that survive evidence gates. The idea feels anti-climactic because it is managerial rather than mythic. It is also how mature security programs usually win. They do not maximize brilliance at every stage. They maximize throughput without losing trust. (AISLE)
Mythos still matters where the work gets hard
None of that means frontier models have become irrelevant. Anthropic’s own evidence suggests that the gap is still meaningful in the hardest part of the stack. In its Red Team writeup, Anthropic says Mythos Preview is in a different league from Opus 4.6 on autonomous exploit development. On a benchmark derived from previously found Firefox JavaScript engine vulnerabilities, Anthropic says Opus 4.6 produced working exploits only twice in several hundred attempts, while Mythos Preview produced 181 working exploits and reached register control 29 additional times. The company also states that Mythos Preview autonomously identified and exploited a 17-year-old FreeBSD vulnerability, CVE-2026-4747, after scanning hundreds of files in the kernel. Those are not trivial gains at the edge of the distribution. They are large deltas in exactly the region where exploitation turns from “there is probably something wrong here” into “I can make this move.” (Anthropic Red)
That matters because exploit construction is a different skill from vulnerability recognition. It often demands longer horizon planning, adaptation to constraints, creative reuse of building blocks, and enough persistence to iterate through failed strategies. Many security workflows never need that level of autonomy. Plenty of defensive or validation-heavy use cases stop well before fully weaponized exploitation. But if your workflow does need deep exploit generation under constraints, then frontier-model capability is not a marketing detail. It is the difference between a candidate condition and a working chain. The right conclusion is not that the strongest model is unnecessary. It is that the strongest model should be placed where its edge actually compounds, rather than burned on every low-value pass. (Anthropic Red)
Anthropic’s own architecture hints at the same lesson. The company’s public Red Team post does not describe a scenario where Mythos spontaneously dreams up bugs from nowhere. It describes a containerized environment, code access, iterative experimentation, validation, and bug-report generation. In other words, even at the frontier, the model’s best results appear when it is embedded inside a structure that gives it place, memory, tools, feedback, and a success condition. That is not a weakness in the claim. It is the point. The more capable the model becomes, the more valuable the surrounding workflow becomes, because the cost of unconstrained failure rises with capability. (Anthropic Red)
AI pentesting economics are about verified findings, not benchmark theater
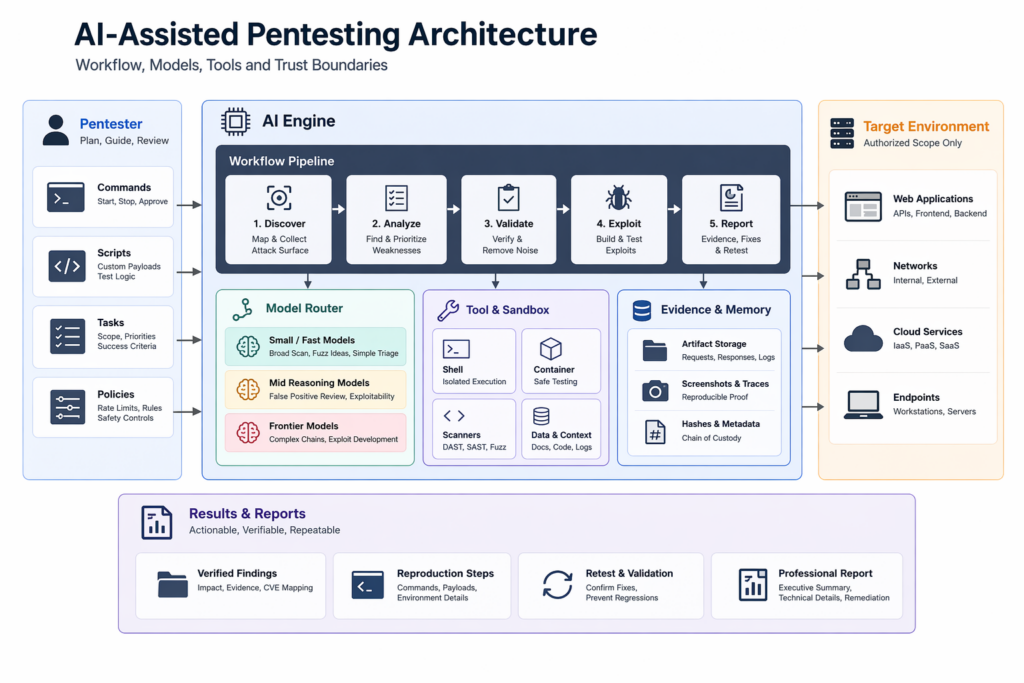
Security teams should be very suspicious of any pricing discussion that starts and ends with token cost. The real unit of account in pentesting is not “cost per million tokens.” It is closer to cost per verified finding, cost per retained true positive after human review, time from initial signal to reproducible proof, and cost of reviewer attention burned on noise. NIST’s definition already points in that direction by including analysis and mitigation, not just detection. In security operations, a finding that cannot survive replay has negative value. It consumes attention, creates reporting debt, and can degrade trust in the whole pipeline. (csrc.nist.gov)
Anthropic’s Project Glasswing page says Mythos Preview will be available to participants at $25 per million input tokens and $125 per million output tokens after the usage-credit period, with up to $100 million in credits committed during the research preview. AISLE’s writeup, by contrast, highlights a 3.6B-active model cost of $0.11 per million tokens on one of its replication tasks. Those numbers are not perfectly apples to apples, but the directional point is obvious enough without forcing a false precision: the price differences across models are large, and that matters the moment you stop thinking in demos and start thinking in sustained, repeated, production workflows. A system that defaults to the most expensive model on every stage is not “serious” by definition. It may just be uneconomical and badly routed. (anthropic.com)
The better way to think about cost is to ask where spending frontier-model dollars changes the final outcome. If a cheap model can correctly cluster routes, identify likely attack surface, or reject obvious false positives, then every dollar you spend using a frontier model to repeat that work is a dollar you cannot spend on deeper validation, longer-horizon exploit attempts, authenticated flow testing, or retesting after fixes. Good pentesting economics are therefore about stage allocation. Cheap coverage buys you surface area. Stronger reasoning buys you clarity. Frontier reasoning buys you breakthrough attempts where the search space has already been compressed enough that intelligence, not breadth, is the limiting factor. (AISLE)
The table below is a more useful dashboard for AI pentesting economics than any vendor’s benchmark slide. It is a synthesis of the workflow and pricing logic reflected in the sources above. (csrc.nist.gov)
| メートル | Why it matters more than raw benchmark scores | Common distortion | What a disciplined team should ask |
|---|---|---|---|
| Cost per verified finding | This is where signal becomes defensible value | Counting every candidate as a win | How many findings survive replay and review |
| Cost per true positive kept after triage | Noise destroys reviewer trust | Inflated “issues found” counts | What is the false-positive rejection burden |
| Time from signal to proof | Speed only matters if it ends in evidence | Measuring only first hypothesis time | How long until there is a reproducer and artifact trail |
| Coverage per dollar | Cheap models can widen search space | Overusing expensive models on easy stages | Which stages are saturated with low-cost coverage |
| Retest time after remediation | Security value persists only if fixes are verified | Reporting without retest | How fast can the workflow confirm a fix |
| Human minutes per promoted finding | The true bottleneck is usually reviewer attention | Hiding analyst cleanup labor | How much manual effort each verified finding still requires |
Real cases show why workflow beats model mythology
The gap between “interesting model behavior” and “real pentesting value” becomes obvious when you look at actual vulnerability classes. The important thing is not that an LLM can narrate them. The important thing is whether a system can correctly narrow context, understand applicability, validate impact, and preserve proof without fabricating confidence. The cases below are useful because they stress different parts of the pipeline. Some reward semantic reasoning. Some reward environmental awareness. Some punish teams that confuse CVE knowledge with exploitability knowledge. Some are bad fits for a pure scanner mindset. All of them push toward the same conclusion: model quality matters, but workflow design decides whether that quality becomes reliable security work. (The FreeBSD Project)
CVE-2026-4747, FreeBSD RPCSEC_GSS and the difference between detection and proof
CVE-2026-4747 is the cleanest example because it appears in both Anthropic’s showcase and the official FreeBSD advisory. FreeBSD says the issue is a remote code execution flaw in RPCSEC_GSS packet validation affecting all supported versions at disclosure, and credits “Nicholas Carlini using Claude, Anthropic.” Anthropic’s Red Team post describes Mythos Preview as having fully autonomously identified and exploited the bug after scanning hundreds of files in the kernel, while AISLE’s replication argues that once the vulnerable function is isolated and the relevant architectural context is provided, even smaller models can recognize the overflow and reason to critical impact. That is exactly the kind of case that separates repo-scale search from localized vulnerability reasoning. It does not prove that small models can do the whole job. It proves that a major chunk of the “smart part” becomes accessible much earlier in the model-capability curve than many people assumed. (The FreeBSD Project)
The operational lesson is even more useful than the symbolic one. CVE-2026-4747 is not just a headline because it was AI-associated. It matters because it sits at the intersection of protocol parsing, kernel context, exploit severity, and validation. A pentesting workflow that merely says “possible overflow in authentication path” is not enough. A serious workflow has to preserve the packet assumptions, the code region, the exploitability argument, the exact environment, and the reproduction steps. That is why the right success metric is not “the model found a bug.” It is “the system produced a finding another engineer can patch and trust.” (csrc.nist.gov)
OpenBSD SACK, subtle reasoning is where routing starts to matter
The OpenBSD SACK bug in Anthropic’s post is a better test of subtle reasoning than the FreeBSD case. Anthropic describes it as a now-patched 27-year-old bug in an operating system known for security. AISLE’s replication is useful because it makes the underlying difficulty explicit: the issue is not a cartoonishly obvious memory corruption pattern. It involves lower-bound validation, signed overflow behavior in sequence comparison macros, and a chain that leads to a null pointer condition only under carefully chosen packet values. AISLE reports that a 5.1B-active open model recovered the full public chain while several other models failed part of the reasoning. That is not a victory lap for small models. It is a routing lesson. Some stages are already commoditized. Others still demand selective escalation. (Anthropic Red)
The practical takeaway for pentesters is that subtle bugs are precisely where a system should be conservative with promotions. A model that confidently says “robust to such scenarios” on one pass and then recovers a complex exploit chain on another model family is a reminder that consensus across models is not the same thing as truth. For this class of issue, the workflow must preserve packet assumptions, boundary conditions, and executable proof artifacts before a finding becomes authoritative. The harder the reasoning chain, the stronger the evidence gate needs to be. (AISLE)
FFmpeg H.264, semantics can defeat brute-force intuition
Anthropic’s FFmpeg example matters for a different reason. The company says Mythos Preview found a 16-year-old vulnerability in the H.264 decoder path involving a mismatch between a 32-bit slice counter and a 16-bit ownership table initialized with a sentinel value. Anthropic frames the bug as having survived heavy scrutiny in one of the most thoroughly tested media projects in the world, including years of fuzzing attention. Whether one wants to emphasize the age, the codebase reputation, or the testing history, the engineering lesson is the same: not all high-value bugs look like the kinds of faults traditional search strategies surface easily. Some failures live in semantic mismatches, sentinel assumptions, and rare state constructions that are perfectly reasonable to miss if your system mostly optimizes for known signatures or shallow pattern recognition. (Anthropic Red)
That makes FFmpeg a strong argument for mixed workflows. Pure scanners are weak on semantic traps. Pure reasoning agents without validators are prone to overconfidence. The right system couples semantic exploration with a validator strong enough to reject bad stories. In memory-safety contexts that may be a sanitizer or crash oracle. In web application contexts it may be a replay harness and a privilege-aware state model. In API contexts it may be role-differentiated transaction replay across objects. The winning pattern is not “replace tools with language.” It is “use language to guide tools toward the right experiments.” (Anthropic Red)
CVE-2024-3094, XZ and the limits of headline-driven AI pentesting
The XZ backdoor is a useful corrective because it punishes simplistic vulnerability thinking. NVD describes malicious code in upstream xz tarballs beginning with version 5.6.0, with extra build instructions extracting a hidden object file that modified liblzma behavior during the build. That is a supply-chain and release-artifact problem, not merely an in-repo code-reading problem. A system that only scans source trees or version banners can easily miss the thing that matters most. The real lesson is that applicability can depend on release path, build environment, package integration, and downstream distribution behavior. That is exactly the kind of case where AI assistance is only as good as the evidence and provenance it can retrieve. (nvd.nist.gov)
For AI pentesting, CVE-2024-3094 is a warning against confusing vulnerability news comprehension with operational validation. A model that can explain XZ eloquently has not helped you unless the system can answer harder questions: was the affected release actually introduced, did your build path consume the tampered artifacts, what package versions crossed that path, what binaries linked the modified library, and what trust boundary failed. Supply-chain cases are where the “largest model wins” story breaks down fastest, because the bottleneck is often provenance, not prose. (nvd.nist.gov)
CVE-2024-6387, regreSSHion and the difference between severity and practicality
NVD describes CVE-2024-6387 as a security regression in OpenSSH’s server where a race condition in signal handling may allow an unauthenticated remote attacker to trigger unsafe behavior by failing authentication within a time limit. The important point for this article is not the exploitability debate around specific environments. It is that the workflow has to reason about environment, timing, exposure, and actual operational priority rather than stopping at “critical remote bug.” Many AI security systems sound persuasive precisely where they are least useful: they can restate severity without doing the harder job of applicability reasoning. (nvd.nist.gov)
This is why exploitability ranking should not be delegated to a single pass of model text. A useful system should ask whether the service is internet-facing, whether the affected version is exposed in the first place, whether compensating controls change the attack window, and what the expected proof condition would look like under safe validation. A model can assist. A workflow has to decide. The more mature the team, the less impressed it should be by fluent restatement of the CVE description and the more interested it should be in what the system can prove about this environment. (csrc.nist.gov)
CVE-2024-3400 and CVE-2024-4577, applicability is not optional
NVD’s description of CVE-2024-3400 is direct: a command injection resulting from arbitrary file creation in GlobalProtect on specific PAN-OS versions and feature configurations may enable unauthenticated root code execution, while Cloud NGFW, Panorama appliances, and Prisma Access are not impacted. CVE-2024-4577 is equally configuration-bound in a different way: NVD says affected PHP versions on Windows in CGI mode can misinterpret characters under specific code pages and allow attacker-controlled PHP options, with consequences up to arbitrary code execution. Those are perfect examples of why real AI pentesting cannot stop at CVE lookup. It has to answer configuration questions. Is the feature enabled? Is the appliance type affected? Is CGI mode in use? What code page is in play? Can the condition actually be reached from the exposed path? (nvd.nist.gov)
These are not edge cases. They are ordinary examples of why the middle of pentesting is harder than the front. The front is noticing the possibility. The middle is sorting environment truth from generic risk language. That middle is where workflow, retrieval, state retention, and evidence collection earn their keep. It is also where small or mid-sized models can often do excellent work if the system has already gathered the right environmental facts. The bottleneck is not always abstract reasoning depth. Sometimes it is whether the workflow even bothered to collect the facts that make a vulnerability real. (csrc.nist.gov)
The case table below condenses the pattern. It is meant as a decision aid rather than a catalog. (The FreeBSD Project)
| Case | Why it matters here | What a model-only mindset gets wrong | What a workflow-first system has to add |
|---|---|---|---|
| CVE-2026-4747 FreeBSD RPCSEC_GSS | Clean example of discovery, severity, and proof | Confuses isolated reasoning with end-to-end autonomy | Function isolation, packet context, reproducer, artifact trail |
| OpenBSD SACK bug | Tests subtle reasoning and exploitability logic | Treats one confident explanation as ground truth | Multi-step validation and conservative promotion |
| FFmpeg H.264 flaw | Shows semantic bugs can survive heavy testing | Overindexes on signature-friendly faults | Semantic reasoning tied to validators |
| CVE-2024-3094 XZ | Supply-chain context beats source-only scanning | Assumes repo inspection is enough | Provenance, build path, release artifact analysis |
| CVE-2024-6387 regreSSHion | Severity is not the same as operational priority | Repeats CVE language without applicability judgment | Exposure and environment-aware validation |
| CVE-2024-3400 PAN-OS | Feature and product scope matter | Ignores configuration prerequisites | Product-aware applicability checks |
| CVE-2024-4577 PHP-CGI | Locale and runtime mode matter | Treats version match as exploitability proof | Runtime and code-page validation |
Building the workflow that makes smaller models useful
A realistic AI pentesting system starts with boundaries, not prompts. Before any model sees a target, the system should already know the authorized hosts, the forbidden host classes, the maximum request rate, the identities and roles available for authenticated testing, the categories of actions that require explicit approval, and the artifacts that must be preserved for later review. Models become dangerous mostly when they are not embedded in policies that outlive their momentary fluency. A strong agent is not safer because it is stronger. It is safer because it is more precisely bounded. That is as true for a frontier model as it is for a cheap one. (csrc.nist.gov)
A simple scope manifest is not glamorous, but it is the difference between a governed workflow and a stunt. The structure below is not meant to be a complete production file. It shows the minimum sort of information the workflow should formalize before any agent begins active testing.
engagement:
target_id: prod-api-2026-04
owner: security-team@example.com
authorization_ticket: CHG-48219
allowed_hosts:
- api.example.com
- auth.example.com
forbidden_hosts:
- payments.internal.example.com
- admin-vpn.example.com
allowed_identities:
- customer_basic
- customer_premium
- support_agent
prohibited_actions:
- destructive data deletion
- password resets for real users
- production privilege escalation outside approval gate
rate_limits:
max_rps: 3
burst: 10
evidence:
output_dir: findings/prod-api-2026-04
save_http: true
save_screenshots: true
save_terminal_logs: true
save_reproducers: true
escalation:
frontier_model_required_for:
- business_logic_chain
- sandbox_escape_attempt
- multi-step exploit synthesis
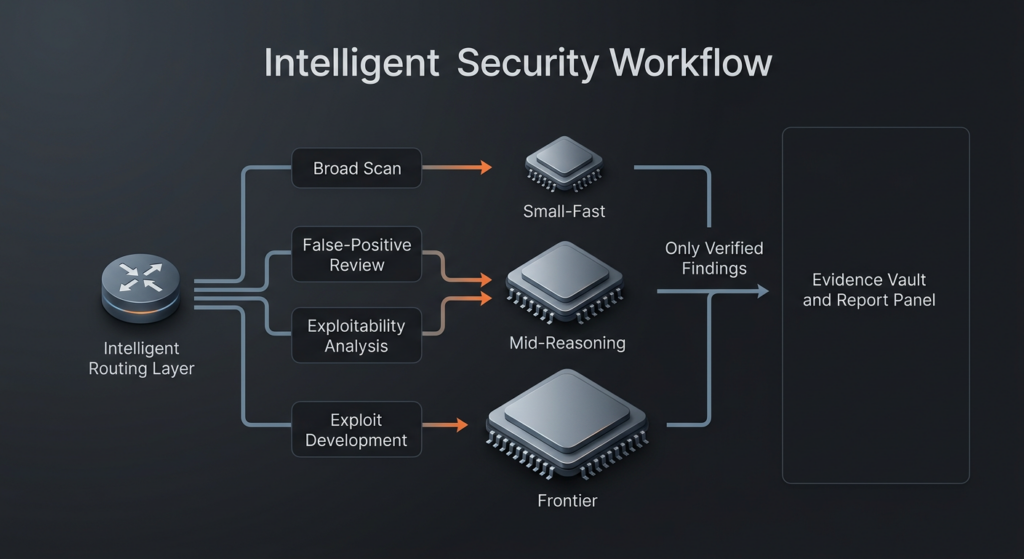
Once boundaries exist, the first stage should usually be cheap and broad. Inventory endpoints. Cluster similar routes. Pull documentation and framework hints. Compare responses across roles. Record timing, redirects, cookie transitions, and object identifiers. In code-heavy engagements, index the project and rank likely security-critical regions. In dynamic web tests, map states and transitions. That is search-space reduction. It is where inexpensive models and deterministic tools work together well. You are not asking for a breakthrough yet. You are buying organized breadth. (AISLE)
The second stage is where many systems start wasting money. Instead of routing every suspicious point to the largest model available, a disciplined workflow asks a narrower question: can a modest model plus a validator settle this? For memory-safety work, that may mean a sanitizer, crash oracle, or minimized reproducer. For web and API work, it may mean differential replay between roles, object identifiers, or workflow states. For config-sensitive CVEs, it may mean environment capture before hypothesis escalation. A model should not be promoted because the bug sounds severe. It should be promoted because the validator says the uncertainty is now intelligence-limited rather than evidence-limited. (Anthropic Red)
The routing policy can be sketched as code. Again, the point is not the exact implementation. The point is that model choice becomes a policy decision attached to evidence quality, not a permanent default attached to vendor prestige.
def choose_model(stage, signal_strength, validator_confidence, complexity):
if stage in {"asset_mapping", "endpoint_clustering", "first_pass_review"}:
return "small_fast_model"
if stage in {"triage", "false_positive_review"}:
if validator_confidence >= 0.8:
return "small_or_mid_model"
return "mid_reasoning_model"
if stage in {"exploitability_assessment", "business_logic_analysis"}:
if complexity == "high":
return "frontier_model"
return "mid_reasoning_model"
if stage in {"exploit_construction", "sandbox_escape", "multi_bug_chain"}:
return "frontier_model"
return "mid_reasoning_model"
This is also where the healthiest product narratives in the category start to look similar. Penligent’s public homepage does not frame the work as “ask the best model and hope.” It foregrounds a three-step operational flow, “Find Vulnerabilities. Verify Findings. Execute Exploits,” and pairs that with “Evidence-First Results You Can Reproduce” and “Edit prompts, lock scope, and customize actions for your environment.” Even if a buyer never touches that product, those are the right questions to ask of any platform in this space because they map to genuine engineering requirements: proof before promotion, artifacts before claims, and operator control before autonomy theater. (ペンリジェント・アイ)
The artifact pipeline matters just as much as the model router. If a workflow does not preserve enough raw material to replay a finding later, then it is quietly training itself to report guesses as facts. That is the fastest way to destroy trust in AI-assisted testing. The shell fragment below is intentionally boring. That is why it is useful.
TARGET_ID="prod-api-2026-04"
OUT="findings/$TARGET_ID/candidate-017"
mkdir -p "$OUT"
cp scope.yaml "$OUT/"
cp target-map.json "$OUT/"
cp request.txt "$OUT/"
cp response.txt "$OUT/"
cp role-a-session.txt "$OUT/"
cp role-b-session.txt "$OUT/"
cp payload.txt "$OUT/"
cp terminal.log "$OUT/"
cp screenshot.png "$OUT/"
cp reproducer.sh "$OUT/"
cp notes.md "$OUT/"
sha256sum "$OUT"/* > "$OUT/artifact_hashes.txt"
Good security evidence is often boring before it becomes valuable. The model can help write notes, compare traces, explain a crash, or suggest the next branch to test. But the workflow still needs environmental facts, raw requests, execution output, and a replay path. That is not anti-AI. It is how you keep AI from becoming a confidence amplifier for unverified claims. (ペンリジェント・アイ)
Reporting is the last step, not the first visible output
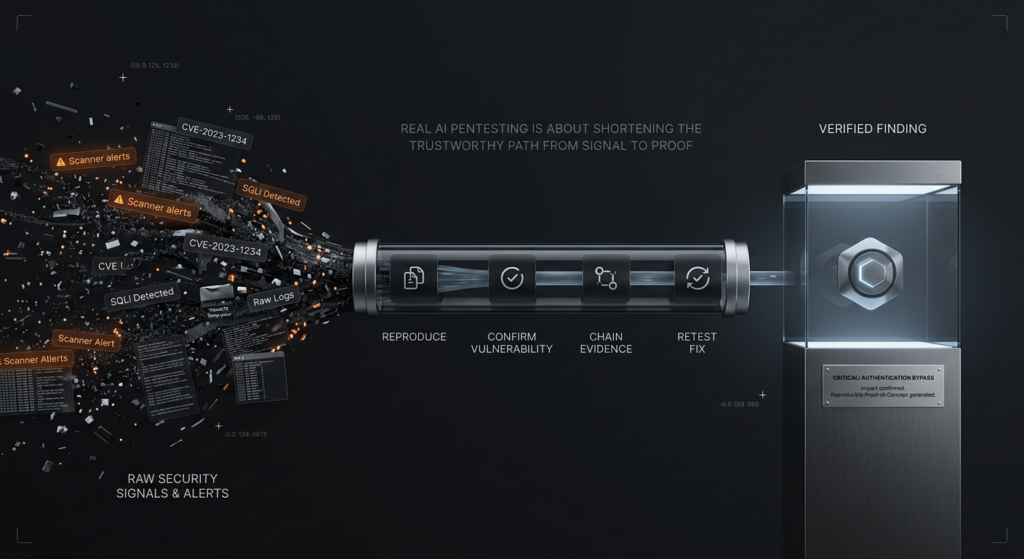
One of the most damaging habits in AI security tooling is generating polished reports before the system has earned them. NIST’s framing is useful here because it places analysis and mitigation inside the testing process rather than after it. A report is not the product of a clever language model. It is the packaging of a verified result. That sounds obvious, but a surprising amount of the market still gets the sequence wrong. A system finds a hint, writes a story, and lets the report itself launder uncertainty into authority. Pentesters should refuse that pattern. Buyers should punish it. (csrc.nist.gov)
A much healthier pattern is to define a promotion gate. A candidate does not become a verified finding because the explanation sounds good or the CVSS estimate sounds plausible. It becomes verified when the workflow has enough artifacts to replay the issue, enough environmental context to support applicability, and enough evidence to make remediation useful rather than speculative. A minimal gate can be expressed in policy logic.
def promote_to_verified(candidate):
required = [
candidate.reproducer,
candidate.artifacts.http_or_binary_trace,
candidate.environment_notes,
candidate.impact_statement,
candidate.remediation_basis,
]
if not all(required):
return False, "missing required artifacts"
if candidate.finding_type == "access_control" and not candidate.role_differential_proof:
return False, "missing authorization differential evidence"
if candidate.finding_type == "memory_corruption" and not candidate.validator_signal:
return False, "missing crash or sanitizer validation"
if candidate.severity in {"critical", "high"} and not candidate.retest_plan:
return False, "missing retest criteria"
return True, "verified"
This is the place where product delivery and engineering discipline finally meet. Penligent’s pricing and product pages emphasize report export with evidence and reproduction steps, one-click exploit reproduction with evidence-chain reporting, and team-grade audit-ready delivery. The public Hacking Labs material around AI pentest reports also frames the problem as proving what happened later, not just generating a prettier PDF now. That orientation is technically healthy because it treats reporting as a downstream expression of artifacts rather than as a substitute for artifacts. Again, the lesson generalizes beyond any one vendor: the systems worth trusting are the ones that can tell you how a claim becomes evidence. (ペンリジェント・アイ)
The failure modes that still trap teams
The easiest mistake is to buy the biggest model available and route everything through it. That feels serious. It often produces the worst combination of cost, latency, and reviewer fatigue. Easy stages get over-provisioned. Hard stages still fail because the bottleneck was not intelligence but context discipline or missing validators. The team then concludes that AI pentesting “doesn’t work,” when the real problem was that it treated model quality as a substitute for workflow quality. AISLE’s framing around tokens per dollar, tokens per second, and embedded security expertise is a useful antidote. In serious pipelines, speed and coverage are not side notes. They are part of the capability equation. (AISLE)
A second mistake is to confuse scanner augmentation with penetration testing. OWASP’s testing guidance remains broad for a reason. Real testing includes mapping, authenticated behavior, state handling, authorization checks, and business logic. A system that cannot preserve multi-role context or reason about object ownership can still be useful, but it is not doing general pentesting in the strong sense most practitioners mean. This is especially important for APIs, where Broken Object Level Authorization remains a top risk because identifiers travel through routes, headers, payloads, and implied workflow state. An AI assistant that does not understand that terrain will tend to produce a high volume of text about security and a low volume of evidence about risk. (owasp.org)
A third mistake is to treat exploit demos as the whole of value. Mythos became famous because exploit construction is vivid and scary, and Anthropic’s own data suggests that frontier capability in this region is real. But many organizations do not fail because they lacked a perfectly autonomous exploit writer. They fail because they cannot keep up with environment-aware triage, authenticated workflow testing, reproducible evidence capture, or retesting after patches. Security programs are usually bottlenecked by the conversion of raw signal into trusted action. That is why the strongest systems in the market increasingly emphasize verified findings, replayability, and delivery quality. The scary exploit is not irrelevant. It is just not the only bottleneck, and often not the first one. (Anthropic Red)
A fourth mistake is to ignore human override. Stronger agentic systems need tighter controls, not looser ones. Penligent’s public framing around locked scope and customizable actions is healthy for the same reason Anthropic’s containerized scaffold is healthy: the system is only useful in a real environment if operators can constrain where it acts and how risky actions are promoted. Autonomy without governance is not maturity. It is borrowed confidence. (Anthropic Red)
What teams should actually measure
By this point, the right metrics should feel obvious, but most teams still do not instrument them well. They measure issues found, benchmark deltas, or average analysis time and miss the variables that determine whether an AI pentesting program becomes trustworthy. The core metrics should measure conversion from signal to proof, durability of findings under review, and cost of that conversion. Those are the variables that reveal whether the workflow is actually learning. (csrc.nist.gov)
| メートル | What good looks like | What bad looks like | なぜそれが重要なのか |
|---|---|---|---|
| Candidate to verified conversion rate | Lower but stable and explainable | High on paper because candidates are over-promoted | Shows whether evidence gates are real |
| Mean time to reproducer | Predictably short on repeatable classes | Long and chaotic despite impressive demos | Measures operational usefulness |
| Reviewer minutes per promoted finding | Declining over time | Hidden cleanup burden on analysts | Captures whether AI is compressing work or exporting it |
| Retest success rate after remediation | High and well-documented | Findings disappear into reporting backlog | Tells you whether delivery closes the loop |
| Model spend by stage | Most spend concentrated on hard stages | Most spend wasted on easy stages | Reveals whether routing policy is sane |
| Business-logic finding share | Rising as stateful testing improves | Near zero because workflow never leaves scanner mode | Indicates whether the system can handle real application risk |
The strongest buying question in 2026 is therefore not “Which model do you use?” It is “How does your system turn a raw signal into a verified finding, and what artifacts exist at every step?” A second strong question is “Where do you spend your expensive reasoning budget?” If a vendor cannot answer either one with specificity, then it probably has a model story, not a pentesting workflow. That does not make the product useless. It just means you should not buy it as if it were solving the harder problem. (csrc.nist.gov)
AI pentesting after Mythos means routing, not worship
Mythos matters. Anthropic’s public materials make that impossible to dismiss honestly. The model appears to have pushed the frontier meaningfully on autonomous exploit work, and Project Glasswing is not a minor announcement. Anthropic says the initiative includes major launch partners, over 40 additional organizations, large usage-credit commitments, and an explicit plan to study how security practice should evolve in response. That is not a toy signal. It is a marker that the leading labs believe cybersecurity has become one of the most important real-world domains for advanced agentic models. (anthropic.com)
AISLE matters for the opposite but equally important reason. It forces the field to stop narrating AI security as if all of the capability arrives in one indivisible block. Its results suggest that significant parts of the pipeline are already accessible to smaller and cheaper models, especially once the relevant code path or target context has been narrowed. It also reframes success around maintainer acceptance, trusted remediation, and system-level design. That is closer to what security teams actually need than any abstract “best cyber model” leaderboard. (AISLE)
The right synthesis is not compromise for its own sake. It is sharper than that. Frontier models are becoming very important at the top of the stack, especially for constrained exploit generation and long-horizon reasoning. But the real moat in AI pentesting is not the biggest model by itself. It is the shortest trustworthy path from signal to proof. That path is built from scope control, context reduction, model routing, validators, artifact preservation, retest discipline, and delivery that another engineer can verify. If you build that path well, smaller models become surprisingly powerful. If you build it badly, even the best model in the world will mostly give you expensive prose. (Anthropic Red)
For teams building or buying in this category, that is the real post-Mythos lesson. Do not ask only who has the most intelligence. Ask who knows where to spend it, where to constrain it, and how to prove it. In 2026, that is what separates an impressive security demo from a security workflow that can actually live inside an engineering organization. (csrc.nist.gov)
Further reading
- Anthropic, Project Glasswing. (anthropic.com)
- Anthropic Frontier Red Team, Claude Mythos Preview. (Anthropic Red)
- AISLE, AI Cybersecurity After Mythos, The Jagged Frontier. (AISLE)
- Microsoft, CTI-REALM benchmark and MSRC AI security work. (マイクロソフト)
- NIST SP 800-115, Technical Guide to Information Security Testing and Assessment. (csrc.nist.gov)
- OWASP Web Security Testing Guide. (owasp.org)
- OWASP API Security Top 10 2023. (owasp.org)
- FreeBSD advisory for CVE-2026-4747. (The FreeBSD Project)
- Penligent homepage. (ペンリジェント・アイ)
- Penligent, AI Pentest Tool, What Real Automated Offense Looks Like in 2026. (ペンリジェント・アイ)
- Penligent, AI Pentester in 2026. (ペンリジェント・アイ)
- Penligent, The 2026 Ultimate Guide to AI Penetration Testing. (ペンリジェント・アイ)

